



CoPaw-Flash
Collection
9 items • Updated
QwenPaw-Flash is a lightweight model deeply optimized for the QwenPaw autonomous agent scenario. Since its training phase, the model has been specifically refined for QwenPaw tasks, delivering enhanced agentic performance in tool invocation, command execution, memory management, and multi-step planning.
The core strength of QwenPaw-Flash stems from its native integration with the QwenPaw ecosystem. We have constructed extensive, high-quality agent trajectory data sampled from real QwenPaw environments, systematically enhancing the model's proficiency in high-frequency daily scenarios. Key features include:
QwenPaw-Flash-2B/4B/9B is fine-tuned from Qwen3.5-2B/4B/9B, sharing the same architectural parameters.
The complexity of QwenPaw's context engineering and tool usage poses heightened challenges for model evaluation. To address this, we have developed a dedicated benchmark tailored to the QwenPaw environment. This benchmark systematically evaluates model performance across five high-frequency usage scenarios, covering key operational dimensions.
Results indicate that QwenPaw-Flash delivers substantial improvements across multiple task categories, achieving performance comparable to leading flagship models—all while maintaining significantly lower resource requirements.
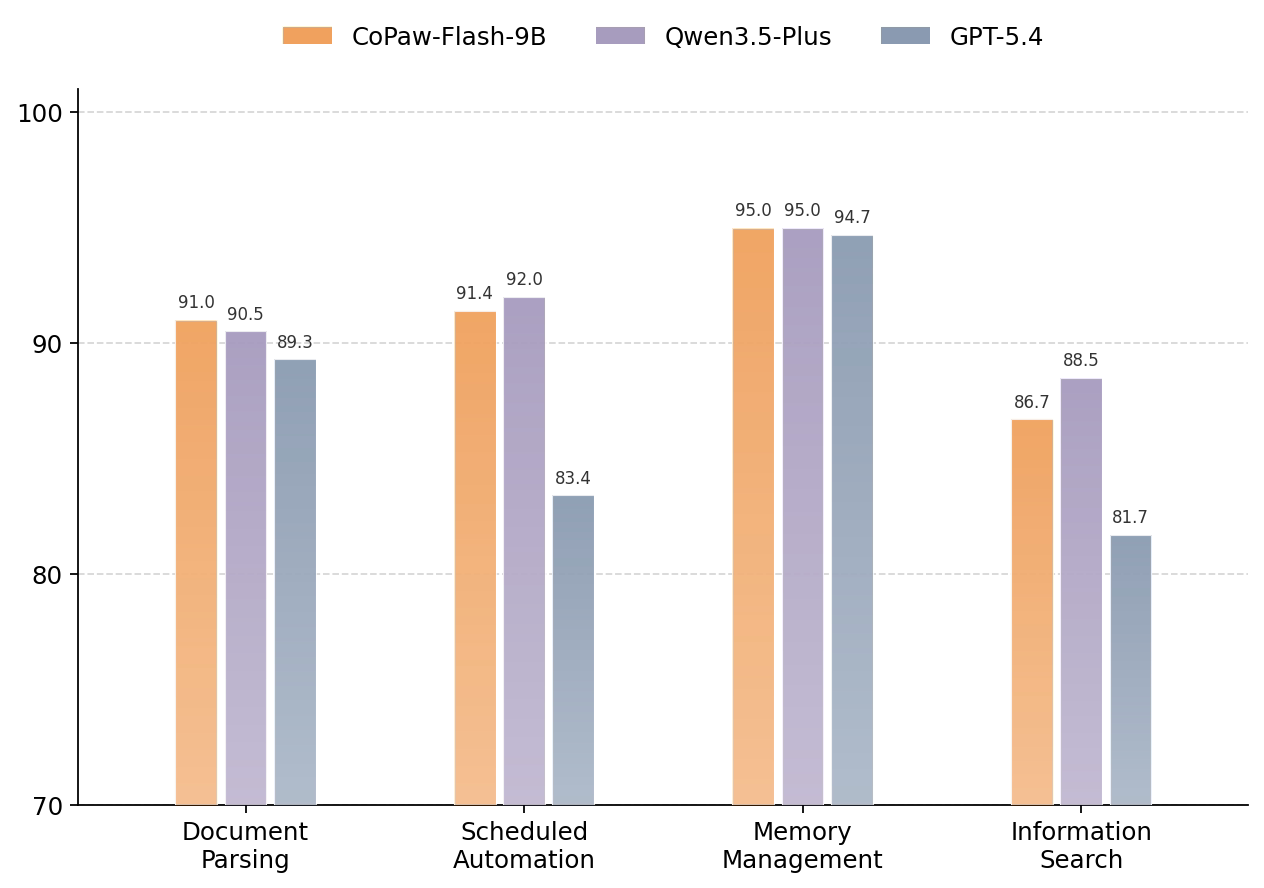
Figure 1: QwenPaw-Flash-9B compared with other models.
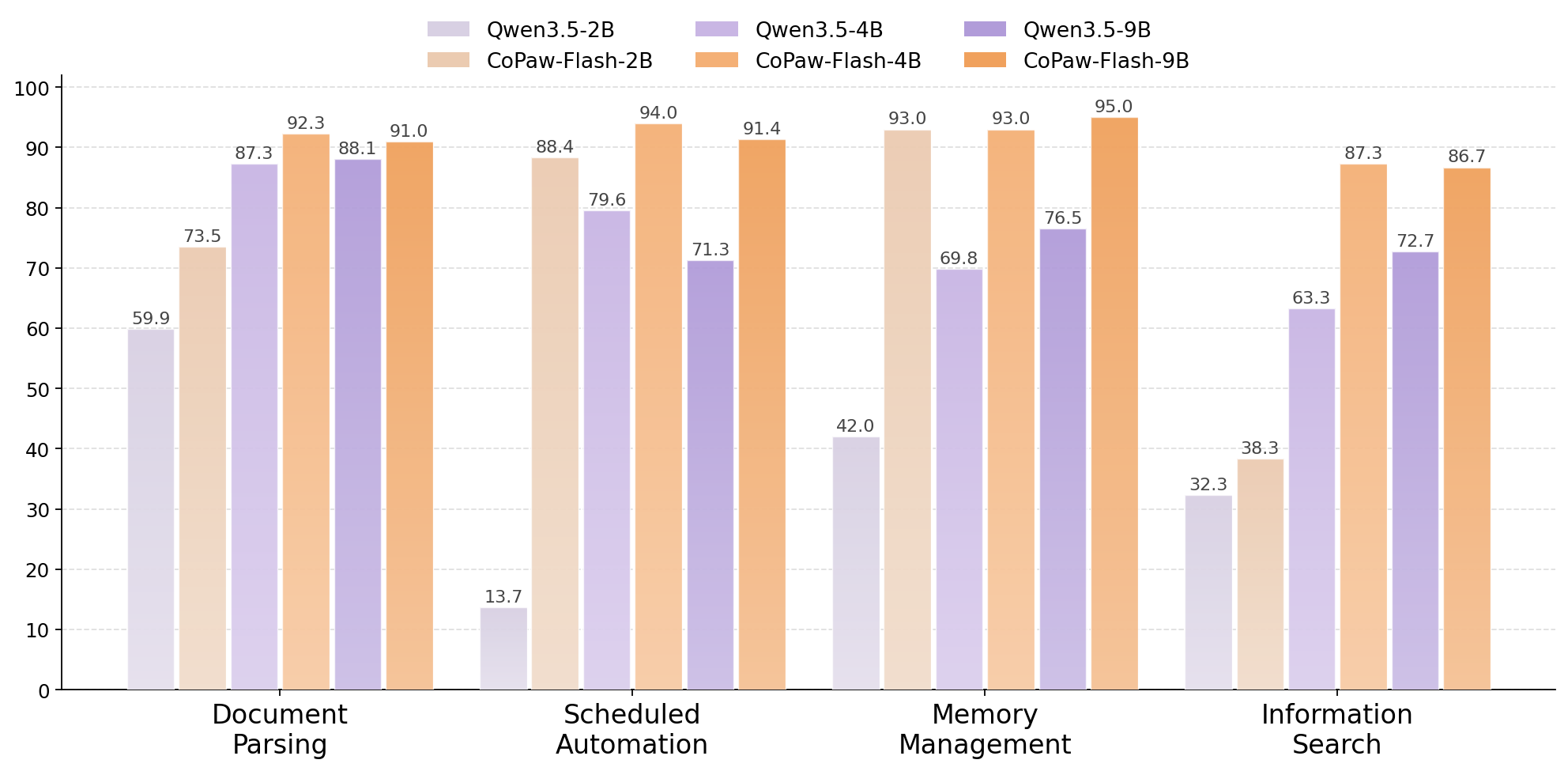
Figure 2: QwenPaw-Flash-2B/4B/9B compared with their respective baseline models.
QwenPaw-Flash can be served via APIs using popular inference frameworks. Below are example commands to launch OpenAI-compatible API servers for QwenPaw-Flash.
Check out Qwen llama.cpp documentation for more usage guide.
We advise you to clone llama.cpp and install it following the official guide. We follow the latest version of llama.cpp.
llama-server -m /path/to/.gguf
Once the server is running, you can access QwenPaw-Flash via standard HTTP requests or OpenAI-compatible SDKs.
Ensure the OpenAI Python SDK is installed and your environment variables are configured:
pip install -U openai
# Set the following accordingly
export OPENAI_BASE_URL="http://localhost:8000/v1"
export OPENAI_API_KEY="EMPTY"
The following Python script demonstrates how to interact with the model using the OpenAI SDK:
from openai import OpenAI
# Configured by environment variables
client = OpenAI()
messages = [
{"role": "user", "content": "Hello, QwenPaw!"},
]
chat_response = client.chat.completions.create(
model=<your_model_path>,
messages=messages,
max_tokens=81920,
temperature=1.0,
top_p=0.95,
presence_penalty=1.5,
extra_body={
"top_k": 20,
},
)
print("Chat response:", chat_response)
QwenPaw-Flash is developed by the AgentScope Team. If you would like to leave us a message, feel free to get in touch through the channels below.
We're not able to determine the quantization variants.