
mGPT: Few-Shot Learners Go Multilingual
Paper
• 2204.07580 • Published
We introduce a family of autoregressive GPT-like models with 1.3 billion parameters trained on 61 languages from 25 language families using Wikipedia and Colossal Clean Crawled Corpus.
We reproduce the GPT-3 architecture using GPT-2 sources and the sparse attention mechanism, Deepspeed and Megatron frameworks allows us to effectively parallelize the training and inference steps. The resulting models show performance on par with the recently released XGLM models at the same time covering more languages and enhancing NLP possibilities for low resource languages.
The source code for the mGPT XL model is available on Github
mGPT: Few-Shot Learners Go Multilingual
@misc{https://doi.org/10.48550/arxiv.2204.07580,
doi = {10.48550/ARXIV.2204.07580},
url = {https://arxiv.org/abs/2204.07580},
author = {Shliazhko, Oleh and Fenogenova, Alena and Tikhonova, Maria and Mikhailov, Vladislav and Kozlova, Anastasia and Shavrina, Tatiana},
keywords = {Computation and Language (cs.CL), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences, I.2; I.2.7, 68-06, 68-04, 68T50, 68T01},
title = {mGPT: Few-Shot Learners Go Multilingual},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
Model supports 61 languages:
ISO codes:
ar he vi id jv ms tl lv lt eu ml ta te hy bn mr hi ur af da en de sv fr it pt ro es el os tg fa ja ka ko th bxr xal mn sw yo be bg ru uk pl my uz ba kk ky tt az cv tr tk tyv sax et fi hu
Languages:
Arabic, Hebrew, Vietnamese, Indonesian, Javanese, Malay, Tagalog, Latvian, Lithuanian, Basque, Malayalam, Tamil, Telugu, Armenian, Bengali, Marathi, Hindi, Urdu, Afrikaans, Danish, English, German, Swedish, French, Italian, Portuguese, Romanian, Spanish, Greek, Ossetian, Tajik, Persian, Japanese, Georgian, Korean, Thai, Buryat, Kalmyk, Mongolian, Swahili, Yoruba, Belarusian, Bulgarian, Russian, Ukrainian, Polish, Burmese, Uzbek, Bashkir, Kazakh, Kyrgyz, Tatar, Azerbaijani, Chuvash, Turkish, Turkmen, Tuvan, Yakut, Estonian, Finnish, Hungarian
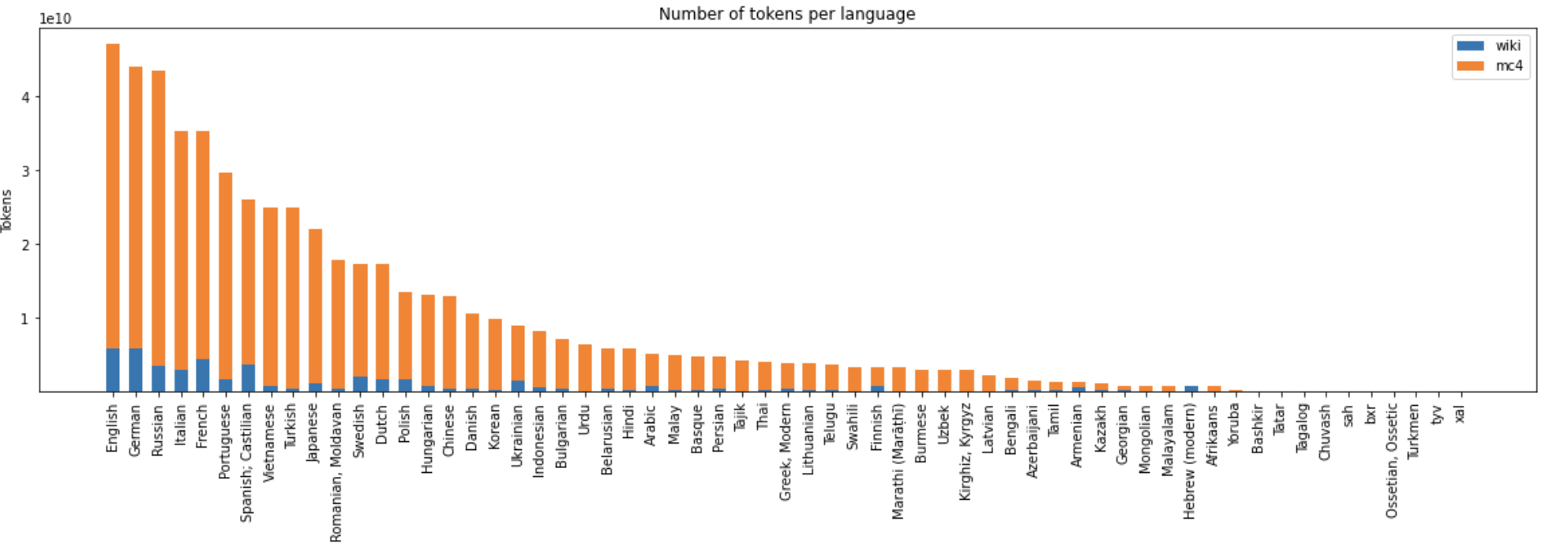 "General training corpus statistics"
"General training corpus statistics"
The model was trained with sequence length 512 using Megatron and Deepspeed libs by SberDevices team on a dataset of 600 GB of texts in 61 languages. The model has seen 440 billion BPE tokens in total.
Total training time was around 14 days on 256 Nvidia V100 GPUs.