

language: en
tags:
- speech quantization
license: mit
datasets:
- LibriTTS
Highlights
This model is used for speech codec or quantization on English utterances.
- Lower frame rate, 25 token/s for each quantizer
- Achieving higher codec quality under low band widths
- Training with structured dropout, enabling various band widths during inference with a single model
- Quantizing a raw speech waveform into a sequence of discrete tokens
FunCodec model
This model is trained with FunCodec, an open-source toolkits for speech quantization (codec) from the Damo academy, Alibaba Group. This repository provides a pre-trained model on the LibriTTS corpus. It can be applied to low-band-width speech communication, speech quantization, zero-shot speech synthesis and other academic research topics. Compared with EnCodec and SoundStream, the following improved techniques are utilized to train the model, resulting in higher codec quality and ViSQOL scores under the same band width:
- The magnitude spectrum loss is employed to enhance the middle and high frequency signals
- Structured dropout is employed to smooth the code space, as well as enable various band widths in a single model
- Codes are initialized by k-means clusters rather than random values
- Codebooks are maintained with exponential moving average and dead-code-elimination mechanism, resulting in high utilization factor for codebooks.
Model description
This model is a variational autoencoder that uses residual vector quantisation (RVQ) to obtain several parallel sequences of discrete latent representations. Here is an overview of FunCodec models.
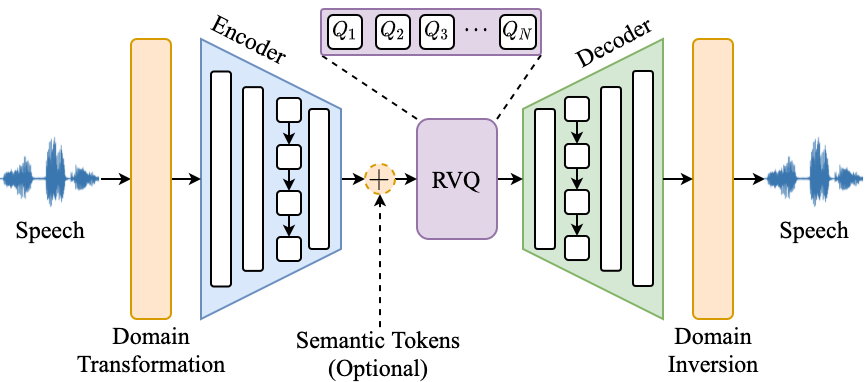
In general, FunCodec models consist of five modules: a domain transformation module, an encoder, a RVQ module, a decoder and a domain inversion module.
- Domain Transformation:transfer signals into time domain, short-time frequency domain, magnitude-angle domain or magnitude-phase domain.
- Encoder:encode signals into compact representations with stacked convolutional and LSTM layers.
- Semantic tokens (Optional): augment encoder outputs with semantic tokens to enhance the content information, not used in this model.
- RVQ:quantize the representations into parallel sequences of discrete tokens with cascaded vector quantizers.
- Decoder:decode quantized embeddings into different signal domains the same as inputs.
- Domain Inversion:re-synthesize perceptible waveforms from different domains.
More details can be found at:
- Paper: FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec
- Codebase: FunCodec
Intended uses & sceneries
Inference with FunCodec
You can extract codecs and reconstruct them back to waveforms with FunCodec repository.
FunCodec installation
# Install Pytorch GPU (version >= 1.12.0):
conda install pytorch==1.12.0
# for other versions, please refer: https://pytorch.org/get-started/locally
# Download codebase:
git clone https://github.com/alibaba-damo-academy/FunCodec.git
# Install FunCodec codebase:
cd FunCodec
pip install --editable ./
Codec extraction
# Enter the example directory
cd egs/LibriTTS/codec
# Specify the model name
model_name="audio_codec-encodec-en-libritts-16k-nq32ds640-pytorch"
# Download the model
git lfs install
git clone https://huggingface.co/alibaba-damo/${model_name}
mkdir exp
mv ${model_name} exp/$model_name
# Extracting codec within the input file "input_wav.scp" and the codecs are saved under "outputs/codecs"
bash encoding_decoding.sh --stage 1 --batch_size 16 --num_workers 4 --gpu_devices "0,1" \
--model_dir exp/${model_name} --bit_width 16000 --file_sampling_rate 16000 \
--wav_scp input_wav.scp --out_dir outputs/codecs
# input_wav.scp has the following format:
# uttid1 path/to/file1.wav
# uttid2 path/to/file2.wav
# ...
Reconstruct waveforms from codecs
# Reconstruct waveforms into "outputs/recon_wavs"
bash encoding_decoding.sh --stage 2 --batch_size 16 --num_workers 4 --gpu_devices "0,1" \
--model_dir exp/${model_name} --bit_width 16000 --file_sampling_rate 16000 \
--wav_scp outputs/codecs/codecs.txt --out_dir outputs/recon_wavs
# codecs.txt is the output of stage 1, which has the following format:
# uttid1 [[[1, 2, 3, ...],[2, 3, 4, ...], ...]]
# uttid2 [[[9, 7, 5, ...],[3, 1, 2, ...], ...]]
# ...
Inference with Huggingface Transformers
Inference with Huggingface transformers package is under development.
Application sceneries
Running environment
- Currently, the model only passed the tests on Linux-x86_64. Mac and Windows systems are not tested.
Intended using sceneries
- This model is suitable for academic usages
- Speech quantization, codec and tokenization for English utterances
Evaluation results
Training configuration
- Feature info: raw waveform input
- Train info: Adam, lr 3e-4, batch_size 32, 2 gpu(Tesla V100), acc_grad 1, 300000 steps, speech_max_length 51200
- Loss info: L1, L2, discriminative loss
- Model info: SEANet, Conv, LSTM
- Train config: config.yaml
- Model size: 57.83 M parameters
Experimental Results
Test set: LibriTTS-test, ViSQOL scores
| testset | 50 tk/s | 100 tk/s | 200 tk/s | 400 tk/s |
|---|---|---|---|---|
| LibriTTS | 3.64 | 3.94 | 4.16 | 4.29 |
Limitations and bias
- Not very robust to background noises and reverberation
BibTeX entry and citation info
@misc{du2023funcodec,
title={FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec},
author={Zhihao Du, Shiliang Zhang, Kai Hu, Siqi Zheng},
year={2023},
eprint={2309.07405},
archivePrefix={arXiv},
primaryClass={cs.Sound}
}