
RecurrentGemma Model Card
Model Page: RecurrentGemma
This model card corresponds to the 9B base version of the RecurrentGemma model. You can also visit the model card of the 9B instruct model.
Resources and technical documentation:
Terms of Use: Terms
Authors: Google
Usage
Below we share some code snippets on how to get quickly started with running the model.
First, make sure to pip install transformers, then copy the snippet from the section that is relevant for your usecase.
Running the model on a single / multi GPU
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/recurrentgemma-9b")
model = AutoModelForCausalLM.from_pretrained("google/recurrentgemma-9b", device_map="auto")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
Model information
Model summary
Description
RecurrentGemma is a family of open language models built on a novel recurrent architecture developed at Google. Both pre-trained and instruction-tuned versions are available in English.
Like Gemma, RecurrentGemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. Because of its novel architecture, RecurrentGemma requires less memory than Gemma and achieves faster inference when generating long sequences.
Inputs and outputs
- Input: Text string (e.g., a question, a prompt, or a document to be summarized).
- Output: Generated English-language text in response to the input (e.g., an answer to the question, a summary of the document).
Citation
@article{recurrentgemma_2024,
title={RecurrentGemma},
url={},
DOI={},
publisher={Kaggle},
author={Griffin Team, Alexsandar Botev and Soham De and Samuel L Smith and Anushan Fernando and George-Christian Muraru and Ruba Haroun and Leonard Berrada et al.},
year={2024}
}
Model data
Training dataset and data processing
RecurrentGemma uses the same training data and data processing as used by the Gemma model family. A full description can be found on the Gemma model card.
Implementation information
Hardware and frameworks used during training
Like Gemma, RecurrentGemma was trained on TPUv5e, using JAX and ML Pathways.
Evaluation information
Benchmark results
Evaluation approach
These models were evaluated against a large collection of different datasets and metrics to cover different aspects of text generation:
Evaluation results
| Benchmark | Metric | RecurrentGemma 9B |
|---|---|---|
| MMLU | 5-shot, top-1 | 60.5 |
| HellaSwag | 0-shot | 80.4 |
| PIQA | 0-shot | 81.3 |
| SocialIQA | 0-shot | 52.3 |
| BoolQ | 0-shot | 80.3 |
| WinoGrande | partial score | 73.6 |
| CommonsenseQA | 7-shot | 73.2 |
| OpenBookQA | 51.8 | |
| ARC-e | 78.8 | |
| ARC-c | 52.0 | |
| TriviaQA | 5-shot | 70.5 |
| Natural Questions | 5-shot | 21.7 |
| HumanEval | pass@1 | 31.1 |
| MBPP | 3-shot | 42.0 |
| GSM8K | maj@1 | 42.6 |
| MATH | 4-shot | 23.8 |
| AGIEval | 39.3 | |
| BIG-Bench | 55.2 | |
| Average | 56.1 |
Inference speed results
RecurrentGemma provides improved sampling speeds, particularly for long sequences or large batch sizes. We compared the sampling speeds of RecurrentGemma-9B to Gemma-7B. Note that Gemma-7B uses Multi-Head Attention, and the speed improvements would be smaller when comparing against a transformer using Multi-Query Attention.
Throughput
We evaluated throughput, i.e., the maximum number of tokens produced per second by increasing the batch size, of RecurrentGemma-9B compared to Gemma-7B, using a prefill of 2K tokens.
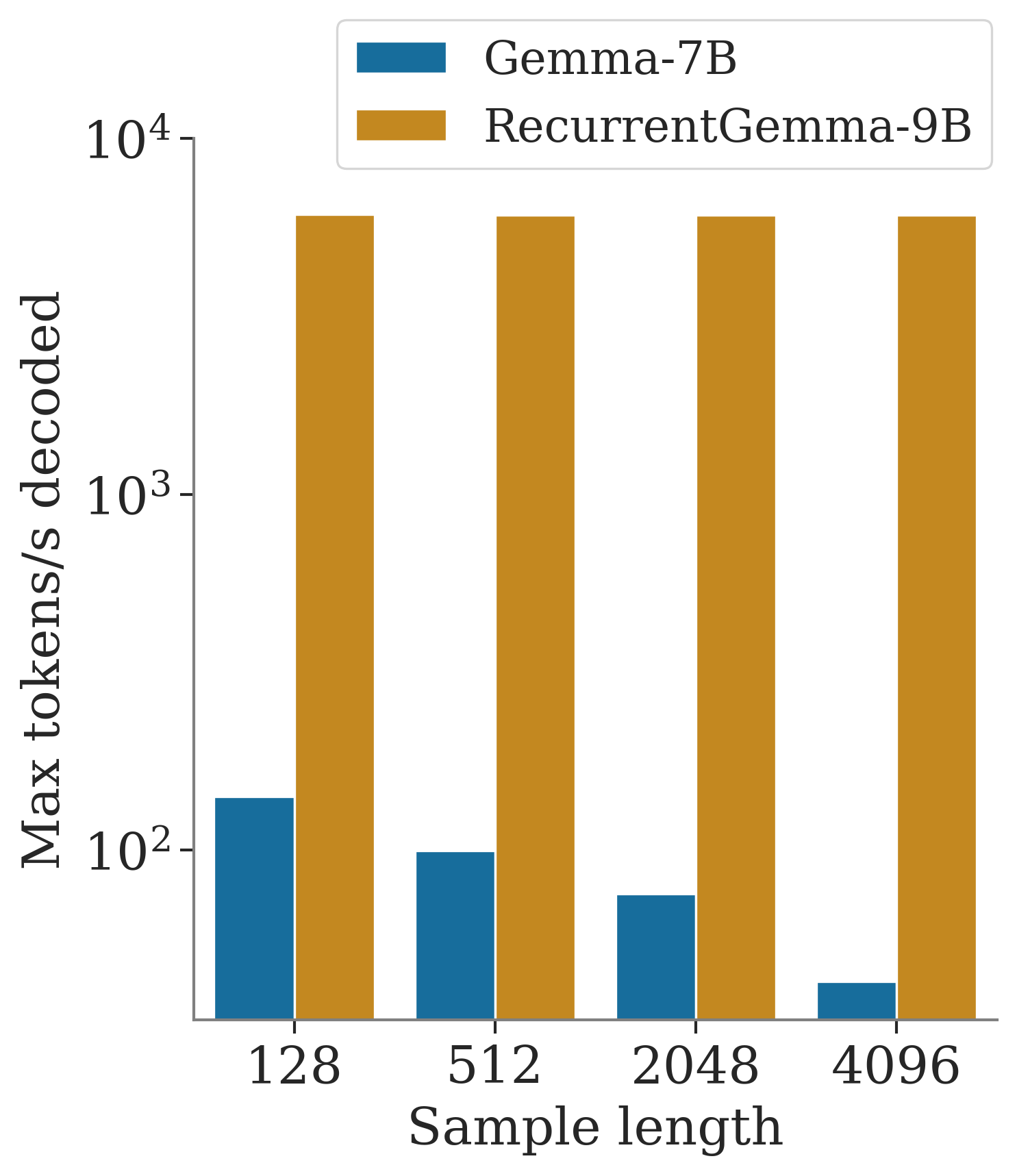
Latency
We also compared end-to-end speedups achieved by RecurrentGemma-9B over Gemma-7B when sampling a long sequence after a prefill of 4K tokens and using a batch size of 1.
| # Tokens Sampled | Gemma-7B (sec) | RecurrentGemma-9B (sec) | Improvement (%) |
|---|---|---|---|
| 128 | 3.1 | 2.8 | 9.2% |
| 256 | 5.9 | 5.4 | 9.7% |
| 512 | 11.6 | 10.5 | 10.7% |
| 1024 | 23.5 | 20.6 | 14.2% |
| 2048 | 48.2 | 40.9 | 17.7% |
| 4096 | 101.9 | 81.5 | 25.0% |
| 8192 | OOM | 162.8 | - |
| 16384 | OOM | 325.2 | - |
Ethics and safety
Ethics and safety evaluations
Evaluations approach
Our evaluation methods include structured evaluations and internal red-teaming testing of relevant content policies. Red-teaming was conducted by a number of different teams, each with different goals and human evaluation metrics. These models were evaluated against a number of different categories relevant to ethics and safety, including:
- Text-to-text content safety: Human evaluation on prompts covering safety policies including child sexual abuse and exploitation, harassment, violence and gore, and hate speech.
- Text-to-text representational harms: Benchmark against relevant academic datasets such as WinoBias and BBQ Dataset.
- Memorization: Automated evaluation of memorization of training data, including the risk of personally identifiable information exposure.
- Large-scale harm: Tests for “dangerous capabilities,” such as chemical, biological, radiological, and nuclear (CBRN) risks; as well as tests for persuasion and deception, cybersecurity, and autonomous replication.
Evaluation results
The results of ethics and safety evaluations are within acceptable thresholds for meeting internal policies for categories such as child safety, content safety, representational harms, memorization, large-scale harms. On top of robust internal evaluations, the results of well known safety benchmarks like BBQ, Winogender, Winobias, RealToxicity, and TruthfulQA are shown here.
| Benchmark | Metric | RecurrentGemma 9B | RecurrentGemma 9B IT |
|---|---|---|---|
| RealToxicity | avg | 10.3 | 8.8 |
| BOLD | 39.8 | 47.9 | |
| CrowS-Pairs | top-1 | 38.7 | 39.5 |
| BBQ Ambig | top-1 | 95.9 | 67.1 |
| BBQ Disambig | top-1 | 78.6 | 78.9 |
| Winogender | top-1 | 59.0 | 64.0 |
| TruthfulQA | 38.6 | 47.7 | |
| Winobias 1_2 | 61.5 | 60.6 | |
| Winobias 2_2 | 90.2 | 90.3 | |
| Toxigen | 58.8 | 64.5 |
Model usage and limitations
Known limitations
These models have certain limitations that users should be aware of:
- Training data
- The quality and diversity of the training data significantly influence the model's capabilities. Biases or gaps in the training data can lead to limitations in the model's responses.
- The scope of the training dataset determines the subject areas the model can handle effectively.
- Context and task complexity
- LLMs are better at tasks that can be framed with clear prompts and instructions. Open-ended or highly complex tasks might be challenging.
- A model's performance can be influenced by the amount of context provided (longer context generally leads to better outputs, up to a certain point).
- Language ambiguity and nuance
- Natural language is inherently complex. LLMs might struggle to grasp subtle nuances, sarcasm, or figurative language.
- Factual accuracy
- LLMs generate responses based on information they learned from their training datasets, but they are not knowledge bases. They may generate incorrect or outdated factual statements.
- Common sense
- LLMs rely on statistical patterns in language. They might lack the ability to apply common sense reasoning in certain situations.
Ethical considerations and risks
The development of large language models (LLMs) raises several ethical concerns. In creating an open model, we have carefully considered the following:
- Bias and fairness
- LLMs trained on large-scale, real-world text data can reflect socio-cultural biases embedded in the training material. These models underwent careful scrutiny, input data pre-processing described and posterior evaluations reported in this card.
- Misinformation and misuse
- LLMs can be misused to generate text that is false, misleading, or harmful.
- Guidelines are provided for responsible use with the model, see the Responsible Generative AI Toolkit.
- Transparency and accountability
- This model card summarizes details on the models' architecture, capabilities, limitations, and evaluation processes.
- A responsibly developed open model offers the opportunity to share innovation by making LLM technology accessible to developers and researchers across the AI ecosystem.
Risks Identified and Mitigations:
- Perpetuation of biases: It's encouraged to perform continuous monitoring (using evaluation metrics, human review) and the exploration of de-biasing techniques during model training, fine-tuning, and other use cases.
- Generation of harmful content: Mechanisms and guidelines for content safety are essential. Developers are encouraged to exercise caution and implement appropriate content safety safeguards based on their specific product policies and application use cases.
- Misuse for malicious purposes: Technical limitations and developer and end-user education can help mitigate against malicious applications of LLMs. Educational resources and reporting mechanisms for users to flag misuse are provided. Prohibited uses of Gemma models are outlined in our terms of use.
- Privacy violations: Models were trained on data filtered for removal of PII (Personally Identifiable Information). Developers are encouraged to adhere to privacy regulations with privacy-preserving techniques.
Intended usage
Application
Open Large Language Models (LLMs) have a wide range of applications across various industries and domains. The following list of potential uses is not comprehensive. The purpose of this list is to provide contextual information about the possible use-cases that the model creators considered as part of model training and development.
- Content creation and communication
- Text generation: These models can be used to generate creative text formats like poems, scripts, code, marketing copy, email drafts, etc.
- Chatbots and conversational AI: Power conversational interfaces for customer service, virtual assistants, or interactive applications.
- Text summarization: Generate concise summaries of a text corpus, research papers, or reports.
- Research and education
- Natural Language Processing (NLP) research: These models can serve as a foundation for researchers to experiment with NLP techniques, develop algorithms, and contribute to the advancement of the field.
- Language Learning Tools: Support interactive language learning experiences, aiding in grammar correction or providing writing practice.
- Knowledge Exploration: Assist researchers in exploring large bodies of text by generating summaries or answering questions about specific topics.
Benefits
At the time of release, this family of models provides high-performance open large language model implementations designed from the ground up for Responsible AI development compared to similarly sized models.
Using the benchmark evaluation metrics described in this document, these models have shown to provide superior performance to other, comparably-sized open model alternatives.
In particular, RecurrentGemma models achieve comparable performance to Gemma models but are faster during inference and require less memory, especially on long sequences.
- Downloads last month
- 9