

Arcee Spark
Arcee Spark is a powerful 7B parameter language model that punches well above its weight class. Initialized from Qwen2, this model underwent a sophisticated training process:
- Fine-tuned on 1.8 million samples
- Merged with Qwen2-7B-Instruct using Arcee's mergekit
- Further refined using Direct Preference Optimization (DPO)
This meticulous process results in exceptional performance, with Arcee Spark achieving the highest score on MT-Bench for models of its size, outperforming even GPT-3.5 on many tasks.
Key Features
- 7B parameters
- State-of-the-art performance for its size
- Initialized from Qwen2
- Advanced training process including fine-tuning, merging, and DPO
- Highest MT-Bench score in the 7B class
- Outperforms GPT-3.5 on many tasks
- Has a context length of 128k tokens, making it ideal for tasks requiring many conversation turns or working with large amounts of text.
Business Use Cases
Arcee Spark offers a compelling solution for businesses looking to leverage advanced AI capabilities without the hefty computational requirements of larger models. Its unique combination of small size and high performance makes it ideal for:
Real-time applications: Deploy Arcee Spark for chatbots, customer service automation, and interactive systems where low latency is crucial.
Edge computing: Run sophisticated AI tasks on edge devices or in resource-constrained environments.
Cost-effective scaling: Implement advanced language AI across your organization without breaking the bank on infrastructure or API costs.
Rapid prototyping: Quickly develop and iterate on AI-powered features and products.
On-premise deployment: Easily host Arcee Spark on local infrastructure for enhanced data privacy and security.
Performance and Efficiency
Arcee Spark demonstrates that bigger isn't always better in the world of language models. By leveraging advanced training techniques and architectural optimizations, it delivers:
- Speed: Blazing fast inference times, often 10-100x faster than larger models.
- Efficiency: Significantly lower computational requirements, reducing both costs and environmental impact.
- Flexibility: Easy to fine-tune or adapt for specific domains or tasks.
Despite its compact size, Arcee Spark offers deep reasoning capabilities, making it suitable for a wide range of complex tasks including:
- Advanced text generation
- Detailed question answering
- Nuanced sentiment analysis
- Complex problem-solving
- Code generation and analysis
Model Availability
- Quants: Arcee Spark GGUF
- FP32: For those looking to squeeze every bit of performance out of the model, we offer an FP32 version that scores slightly higher on all benchmarks.
Benchmarks and Evaluations


MT-Bench
########## First turn ##########
score
model turn
arcee-spark 1 8.777778
########## Second turn ##########
score
model turn
arcee-spark 2 8.164634
########## Average ##########
score
model
arcee-spark 8.469325
EQ-Bench
EQ-Bench: 71.4
TruthfulQA
| Task | Version | Metric | Value | Stderr | |
|---|---|---|---|---|---|
| truthfulqa_mc | 1 | mc1 | 0.4382 | ± | 0.0174 |
| mc2 | 0.6150 | ± | 0.0155 |
AGI-Eval
| Task | Version | Metric | Value | Stderr | |
|---|---|---|---|---|---|
| agieval_aqua_rat | 0 | acc | 0.3937 | ± | 0.0307 |
| acc_norm | 0.3937 | ± | 0.0307 | ||
| agieval_logiqa_en | 0 | acc | 0.4731 | ± | 0.0196 |
| acc_norm | 0.4854 | ± | 0.0196 | ||
| agieval_lsat_ar | 0 | acc | 0.2783 | ± | 0.0296 |
| acc_norm | 0.3000 | ± | 0.0303 | ||
| agieval_lsat_lr | 0 | acc | 0.5549 | ± | 0.0220 |
| acc_norm | 0.5451 | ± | 0.0221 | ||
| agieval_lsat_rc | 0 | acc | 0.6022 | ± | 0.0299 |
| acc_norm | 0.6208 | ± | 0.0296 | ||
| agieval_sat_en | 0 | acc | 0.8155 | ± | 0.0271 |
| acc_norm | 0.8107 | ± | 0.0274 | ||
| agieval_sat_en_without_passage | 0 | acc | 0.4806 | ± | 0.0349 |
| acc_norm | 0.4612 | ± | 0.0348 | ||
| agieval_sat_math | 0 | acc | 0.4909 | ± | 0.0338 |
| acc_norm | 0.4545 | ± | 0.0336 |
AGI-eval average: 51.11
GPT4All Evaluation
| Task | Version | Metric | Value | Stderr | |
|---|---|---|---|---|---|
| arc_challenge | 0 | acc | 0.5333 | ± | 0.0146 |
| acc_norm | 0.5640 | ± | 0.0145 | ||
| arc_easy | 0 | acc | 0.8131 | ± | 0.0080 |
| acc_norm | 0.7668 | ± | 0.0087 | ||
| boolq | 1 | acc | 0.8471 | ± | 0.0063 |
| hellaswag | 0 | acc | 0.6206 | ± | 0.0048 |
| acc_norm | 0.8118 | ± | 0.0039 | ||
| openbookqa | 0 | acc | 0.3560 | ± | 0.0214 |
| acc_norm | 0.4600 | ± | 0.0223 | ||
| piqa | 0 | acc | 0.7987 | ± | 0.0094 |
| acc_norm | 0.8030 | ± | 0.0093 | ||
| winogrande | 0 | acc | 0.7690 | ± | 0.0130 |
Gpt4al Average: 69.37
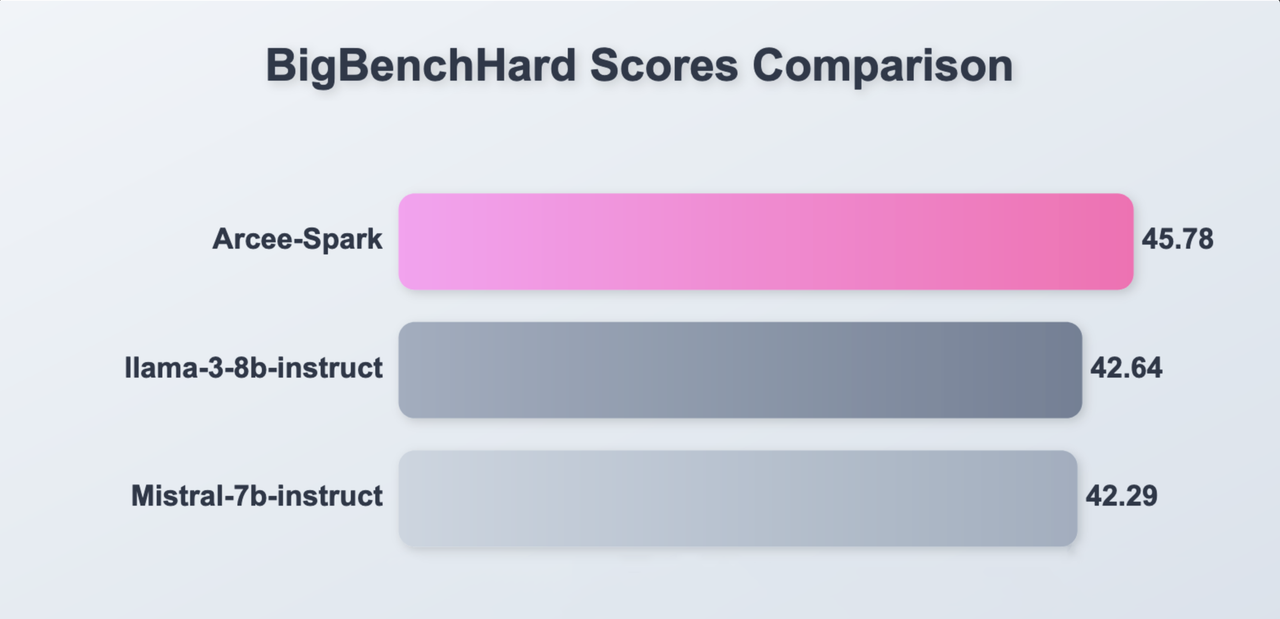
Big Bench Hard
| Task | Version | Metric | Value | Stderr | |
|---|---|---|---|---|---|
| bigbench_causal_judgement | 0 | multiple_choice_grade | 0.6053 | ± | 0.0356 |
| bigbench_date_understanding | 0 | multiple_choice_grade | 0.6450 | ± | 0.0249 |
| bigbench_disambiguation_qa | 0 | multiple_choice_grade | 0.5233 | ± | 0.0312 |
| bigbench_geometric_shapes | 0 | multiple_choice_grade | 0.2006 | ± | 0.0212 |
| exact_str_match | 0.0000 | ± | 0.0000 | ||
| bigbench_logical_deduction_five_objects | 0 | multiple_choice_grade | 0.2840 | ± | 0.0202 |
| bigbench_logical_deduction_seven_objects | 0 | multiple_choice_grade | 0.2429 | ± | 0.0162 |
| bigbench_logical_deduction_three_objects | 0 | multiple_choice_grade | 0.4367 | ± | 0.0287 |
| bigbench_movie_recommendation | 0 | multiple_choice_grade | 0.4720 | ± | 0.0223 |
| bigbench_navigate | 0 | multiple_choice_grade | 0.4980 | ± | 0.0158 |
| bigbench_reasoning_about_colored_objects | 0 | multiple_choice_grade | 0.5600 | ± | 0.0111 |
| bigbench_ruin_names | 0 | multiple_choice_grade | 0.4375 | ± | 0.0235 |
| bigbench_salient_translation_error_detection | 0 | multiple_choice_grade | 0.2685 | ± | 0.0140 |
| bigbench_snarks | 0 | multiple_choice_grade | 0.7348 | ± | 0.0329 |
| bigbench_sports_understanding | 0 | multiple_choice_grade | 0.6978 | ± | 0.0146 |
| bigbench_temporal_sequences | 0 | multiple_choice_grade | 0.4060 | ± | 0.0155 |
| bigbench_tracking_shuffled_objects_five_objects | 0 | multiple_choice_grade | 0.2072 | ± | 0.0115 |
| bigbench_tracking_shuffled_objects_seven_objects | 0 | multiple_choice_grade | 0.1406 | ± | 0.0083 |
| bigbench_tracking_shuffled_objects_three_objects | 0 | multiple_choice_grade | 0.4367 | ± | 0.0287 |
Big Bench average: 45.78
License
Arcee Spark is released under the Apache 2.0 license.
Acknowledgments
- The Qwen2 team for their foundational work
- The open-source AI community for their invaluable tools and datasets
- Our dedicated team of researchers and engineers who push the boundaries of what's possible with compact language models
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 25.54 |
| IFEval (0-Shot) | 56.21 |
| BBH (3-Shot) | 37.14 |
| MATH Lvl 5 (4-Shot) | 12.31 |
| GPQA (0-shot) | 7.61 |
| MuSR (0-shot) | 8.60 |
| MMLU-PRO (5-shot) | 31.36 |
- Downloads last month
- 189
Model tree for arcee-ai/Arcee-Spark
Space using arcee-ai/Arcee-Spark 1
Evaluation results
- strict accuracy on IFEval (0-Shot)Open LLM Leaderboard56.210
- normalized accuracy on BBH (3-Shot)Open LLM Leaderboard37.140
- exact match on MATH Lvl 5 (4-Shot)Open LLM Leaderboard12.310
- acc_norm on GPQA (0-shot)Open LLM Leaderboard7.610
- acc_norm on MuSR (0-shot)Open LLM Leaderboard8.600
- accuracy on MMLU-PRO (5-shot)test set Open LLM Leaderboard31.360