
Context length schedule and performance

Hey,
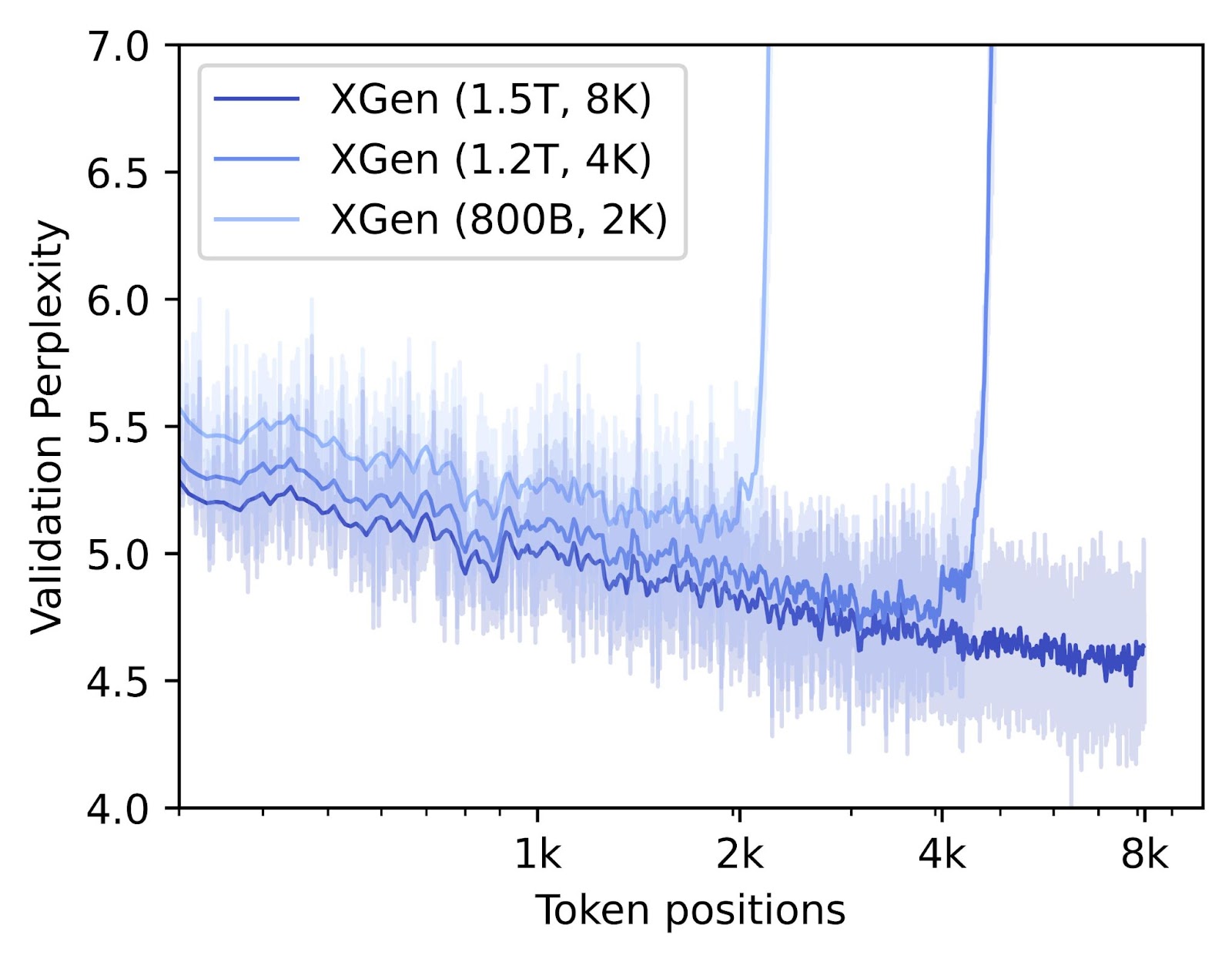
I’m looking at your chart showing incredible performance improvement greatly extending the context length with a smaller portion of training at the end.
It’s quite notable most of the gains are in the untrained context lengths.
It looks to me like steadily increasing the context length throughout training could possibly flatline the chart, these relative gains are so big.
Has anyone tried training on steadily increasing context lengths?

Hey,
I’m looking at your chart showing incredible performance improvement greatly extending the context length with a smaller portion of training at the end.
It’s quite notable most of the gains are in the untrained context lengths.
It looks to me like steadily increasing the context length throughout training could possibly flatline the chart, these relative gains are so big.
Has anyone tried training on steadily increasing context lengths?
Yes, this is a good idea. One of the examples is Xgen long sequence models: https://blog.salesforceairesearch.com/xgen/, they trained with 2k, 4k and 8k sequence lengths. One downside: you need to perform more granular experiments on the smaller scale to find the best combination. Hope that helps!
| xgen | btlm |
|---|---|
 |
 |
The XGen chart does not give the appearance of transferring to untrained context lengths the way the BTLM chart does. It's notable they trained for more tokens on the shorter contexts, and plotted against a logarithmic context length axis.
It still seems very few instances of increasing the context length. Has anyone tried ramping up the context length one token at a time during training, with ALiBi? Or is there a reason if not?