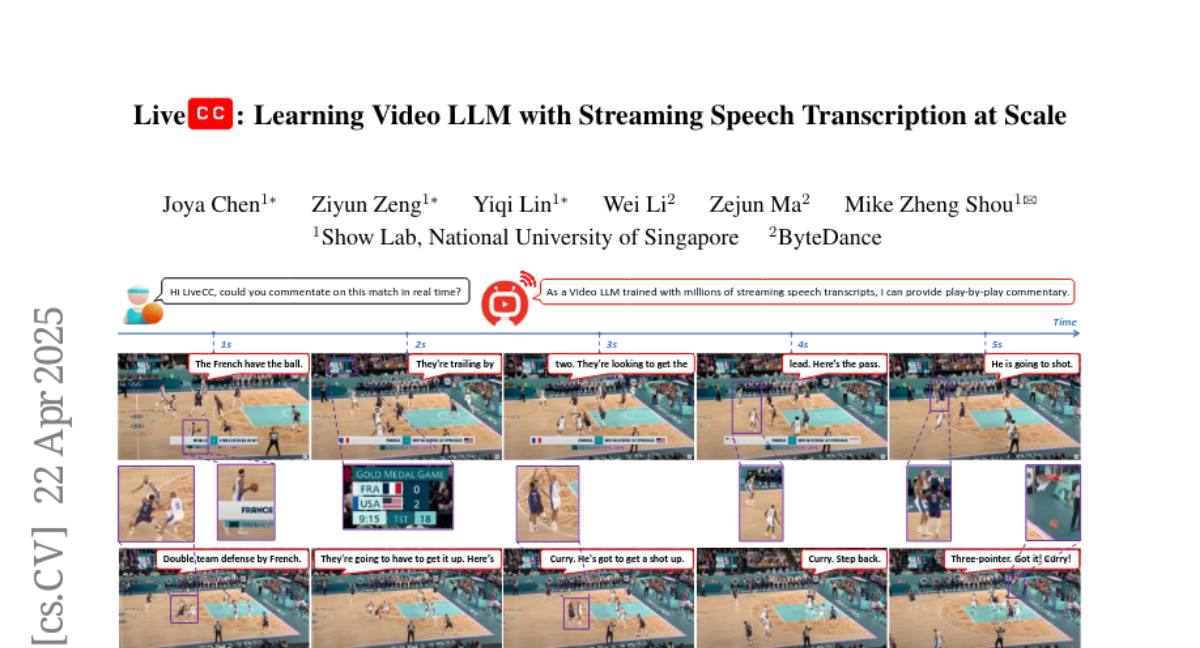
Learning Video LLM with Streaming Speech Transcription at Scale (CVPR 2025)
Joya Chen
chenjoya
AI & ML interests
Video LLM
Recent Activity
upvoted a paper about 2 months ago
Mixture-of-Depths Attention upvoted a paper about 2 months ago
Anatomy of a Lie: A Multi-Stage Diagnostic Framework for Tracing Hallucinations in Vision-Language Models upvoted a paper about 2 months ago
Beyond Language Modeling: An Exploration of Multimodal PretrainingOrganizations