

tags:
- medical
- biology
- chemistry
size_categories:
- n>1T
extra_gated_prompt: >-
I understand that this dataset contains articles grouped under three licensing
categories: Commercial Use Allowed (CC0, CC BY, CC BY-SA, CC BY-ND licenses),
Non-Commercial Use Only (CC BY-NC, CC BY-NC-SA, CC BY-NC-ND licenses), and
Other (no machine-readable Creative Commons license, no license, or a custom
license). I acknowledge that each individual data point in the dataset
specifies its corresponding license type, and I agree that it is my
responsibility to verify compliance with the licensing terms before using any
specific data point. I further agree to comply with the specific licensing
terms of each group when using the dataset in accordance to what is
established by the PubMed Central: PMC Open Acces Subset
extra_gated_fields:
I confirm that I have read and agree to the data usage agreement outlined above by checking this box: checkbox
I want to use this dataset for: text
Dataset Card for Dataset Name

Arxiv: Arxiv | Website: Biomedica | Training instructions: OpenCLIP | Tutorial: Google Colab
BIOMEDICA Dataset is a large-scale, deep-learning-ready biomedical dataset containing over 24M imagecaption pairs and 30M image-references from 6M unique open-source articles. Each data point is highly annotated with over 27 unique metadata fields, including article level information (e.g., license, publication title, date, PMID, keywords, MeSH terms) and coarse-grained image metadata (e.g., primary and secondary content labels and panel type) assigned via an unsupervised algorithm and human curation by a group of seven experts (clinicians and scientists).
BIOMEDIC\biomedica_webdataset is a serialized version of the BIOMEDICA dataset optimized for model development and formatted as a WebDataset for high-throughput streaming. This format provides 3x–10x higher I/O rates compared to random access memory.
Dataset Details
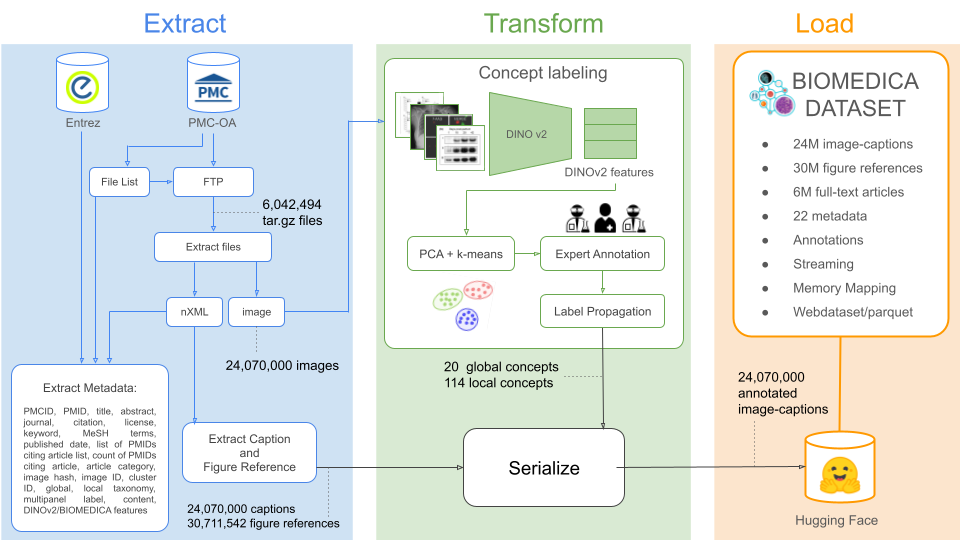
Dataset Description
- Curated by: Min Woo Sun and Alejandro Lozano
- Language(s) (NLP): English
- License: Varies depending on the dataset subset.
Dataset Sources
- Repository: https://github.com/minwoosun/biomedica-etl/tree/main
- Paper: https://arxiv.org/pdf/2501.07171
Acknowledgments
This research was supported by NIH grants (NIH#P30AG066515 to JJN), the Chan Zuckerberg Initiative Neurodegeneration Challenge Pairs Pilot Project to SYL (2020-221724, 5022), the Wu Tsai Knight Initiative Innovation grant (#KIG 102) to SYL, Hoffman-Yee Research Grant to SYL, the Arc Institute Graduate Fellowship to AL, the Stanford Data Science Graduate Research Fellowship MW, and the Quad Fellowship to JB. SYL is a Chan Zuckerberg Biohub – San Francisco Investigator.
We thank Daniel van Strien, Matthew Carrigan, and Omar Sanseviero from Hugging Face for their invaluable assistance with data upload and design planning on the Hugging Face platform.
Citation
@misc{lozano2025biomedicaopenbiomedicalimagecaption,
title={BIOMEDICA: An Open Biomedical Image-Caption Archive, Dataset, and Vision-Language Models Derived from Scientific Literature},
author={Alejandro Lozano and Min Woo Sun and James Burgess and Liangyu Chen and Jeffrey J Nirschl and Jeffrey Gu and Ivan Lopez and Josiah Aklilu and Austin Wolfgang Katzer and Collin Chiu and Anita Rau and Xiaohan Wang and Yuhui Zhang and Alfred Seunghoon Song and Robert Tibshirani and Serena Yeung-Levy},
year={2025},
eprint={2501.07171},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.07171},
}