
Support Sanskrit
Browse files- README.md +21 -2
- ontology.png +0 -0
- wiktionary/wiktextract/extract.py +6 -1
README.md
CHANGED
|
@@ -9,6 +9,7 @@ language:
|
|
| 9 |
- ko
|
| 10 |
- peo
|
| 11 |
- akk
|
|
|
|
| 12 |
configs:
|
| 13 |
- config_name: Languages
|
| 14 |
data_files:
|
|
@@ -24,22 +25,27 @@ configs:
|
|
| 24 |
path: old-persian-wiktextract-data.jsonl
|
| 25 |
- split: Akkadian
|
| 26 |
path: akkadian-wiktextract-data.jsonl
|
|
|
|
|
|
|
| 27 |
- config_name: Graph
|
| 28 |
data_files:
|
| 29 |
- split: AllLanguage
|
| 30 |
path: word-definition-graph-data.jsonl
|
| 31 |
tags:
|
|
|
|
|
|
|
| 32 |
- Wiktionary
|
|
|
|
| 33 |
- German
|
| 34 |
- Latin
|
| 35 |
- Ancient Greek
|
| 36 |
- Korean
|
| 37 |
- Old Persian
|
| 38 |
- Akkadian
|
| 39 |
-
-
|
| 40 |
- Knowledge Graph
|
| 41 |
size_categories:
|
| 42 |
-
-
|
| 43 |
---
|
| 44 |
|
| 45 |
Wiktionary Data on Hugging Face Datasets
|
|
@@ -61,6 +67,7 @@ supports the following languages:
|
|
| 61 |
- __한국어__ - Korean
|
| 62 |
- __𐎠𐎼𐎹__ - [Old Persian](https://en.wikipedia.org/wiki/Old_Persian_cuneiform)
|
| 63 |
- __𒀝𒅗𒁺𒌑(𒌝)__ - [Akkadian](https://en.wikipedia.org/wiki/Akkadian_language)
|
|
|
|
| 64 |
|
| 65 |
[wiktionary-data]() was originally a sub-module of [wilhelm-graphdb](https://github.com/QubitPi/wilhelm-graphdb). While
|
| 66 |
the dataset it's getting bigger, I noticed a wave of more exciting potentials this dataset can bring about that
|
|
@@ -84,11 +91,23 @@ There are __two__ data subsets:
|
|
| 84 |
- `Korean`
|
| 85 |
- `OldPersian`
|
| 86 |
- `Akkadian`
|
|
|
|
| 87 |
|
| 88 |
2. __Graph__ subset that is useful for constructing knowledge graphs:
|
| 89 |
|
| 90 |
- `AllLanguage`: all the languages in a giant graph
|
| 91 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 92 |
Development
|
| 93 |
-----------
|
| 94 |
|
|
|
|
| 9 |
- ko
|
| 10 |
- peo
|
| 11 |
- akk
|
| 12 |
+
- sa
|
| 13 |
configs:
|
| 14 |
- config_name: Languages
|
| 15 |
data_files:
|
|
|
|
| 25 |
path: old-persian-wiktextract-data.jsonl
|
| 26 |
- split: Akkadian
|
| 27 |
path: akkadian-wiktextract-data.jsonl
|
| 28 |
+
- split: Sanskrit
|
| 29 |
+
path: sanskrit-wiktextract-data.jsonl
|
| 30 |
- config_name: Graph
|
| 31 |
data_files:
|
| 32 |
- split: AllLanguage
|
| 33 |
path: word-definition-graph-data.jsonl
|
| 34 |
tags:
|
| 35 |
+
- Natural Language Processing
|
| 36 |
+
- NLP
|
| 37 |
- Wiktionary
|
| 38 |
+
- Vocabulary
|
| 39 |
- German
|
| 40 |
- Latin
|
| 41 |
- Ancient Greek
|
| 42 |
- Korean
|
| 43 |
- Old Persian
|
| 44 |
- Akkadian
|
| 45 |
+
- Sanskrit
|
| 46 |
- Knowledge Graph
|
| 47 |
size_categories:
|
| 48 |
+
- 100M<n<1B
|
| 49 |
---
|
| 50 |
|
| 51 |
Wiktionary Data on Hugging Face Datasets
|
|
|
|
| 67 |
- __한국어__ - Korean
|
| 68 |
- __𐎠𐎼𐎹__ - [Old Persian](https://en.wikipedia.org/wiki/Old_Persian_cuneiform)
|
| 69 |
- __𒀝𒅗𒁺𒌑(𒌝)__ - [Akkadian](https://en.wikipedia.org/wiki/Akkadian_language)
|
| 70 |
+
- __संस्कृतम्__ - Sanskrit, or Classical Sanskrit
|
| 71 |
|
| 72 |
[wiktionary-data]() was originally a sub-module of [wilhelm-graphdb](https://github.com/QubitPi/wilhelm-graphdb). While
|
| 73 |
the dataset it's getting bigger, I noticed a wave of more exciting potentials this dataset can bring about that
|
|
|
|
| 91 |
- `Korean`
|
| 92 |
- `OldPersian`
|
| 93 |
- `Akkadian`
|
| 94 |
+
- `Sanskrit`
|
| 95 |
|
| 96 |
2. __Graph__ subset that is useful for constructing knowledge graphs:
|
| 97 |
|
| 98 |
- `AllLanguage`: all the languages in a giant graph
|
| 99 |
|
| 100 |
+
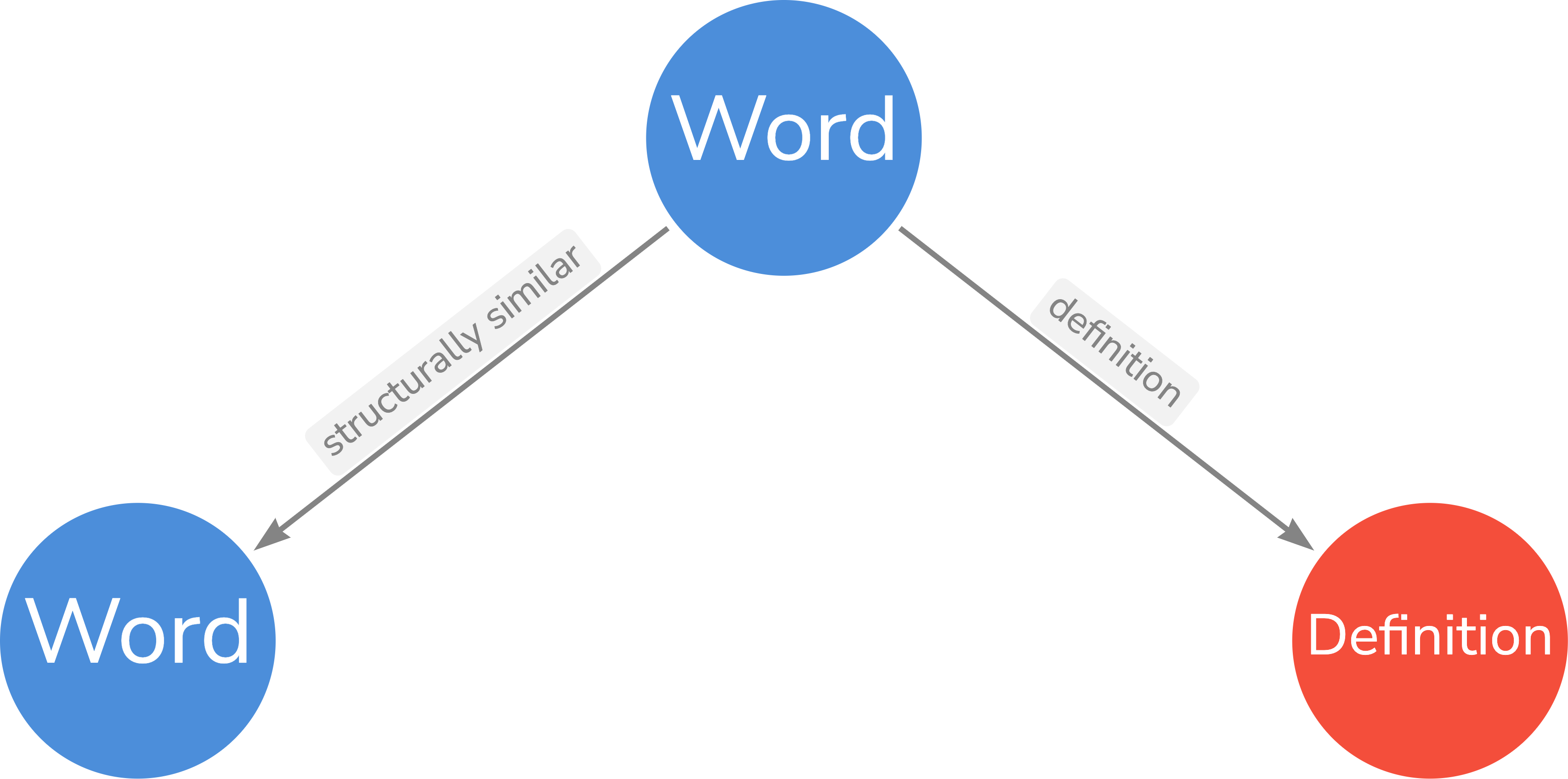
The _Graph_ data ontology is the following:
|
| 101 |
+
|
| 102 |
+
<div align="center">
|
| 103 |
+
<img src="ontology.png" size="50%" alt="Error loading ontology.png"/>
|
| 104 |
+
</div>
|
| 105 |
+
|
| 106 |
+
> [!TIP]
|
| 107 |
+
>
|
| 108 |
+
> Two words are structurally similar if and only if the two shares the same\
|
| 109 |
+
> [stem](https://en.wikipedia.org/wiki/Word_stem)
|
| 110 |
+
|
| 111 |
Development
|
| 112 |
-----------
|
| 113 |
|
ontology.png
ADDED
|
wiktionary/wiktextract/extract.py
CHANGED
|
@@ -44,7 +44,8 @@ def extract_data(wiktextract_data_path: str):
|
|
| 44 |
open("ancient-greek-wiktextract-data.jsonl", "w") as ancient_greek,
|
| 45 |
open("korean-wiktextract-data.jsonl", "w") as korean,
|
| 46 |
open("old-persian-wiktextract-data.jsonl", "w") as old_persian,
|
| 47 |
-
open("akkadian-wiktextract-data.jsonl", "w") as akkadian
|
|
|
|
| 48 |
):
|
| 49 |
for line in data:
|
| 50 |
vocabulary = json.loads(line)
|
|
@@ -81,6 +82,10 @@ def extract_data(wiktextract_data_path: str):
|
|
| 81 |
if vocabulary["lang"] == "Akkadian":
|
| 82 |
akkadian.write(json.dumps({"term": term, "part of speech": pos, "definitions": definitions, "audios": audios}))
|
| 83 |
akkadian.write("\n")
|
|
|
|
|
|
|
|
|
|
|
|
|
| 84 |
|
| 85 |
def extract_graph(wiktextract_data_path: str):
|
| 86 |
import json
|
|
|
|
| 44 |
open("ancient-greek-wiktextract-data.jsonl", "w") as ancient_greek,
|
| 45 |
open("korean-wiktextract-data.jsonl", "w") as korean,
|
| 46 |
open("old-persian-wiktextract-data.jsonl", "w") as old_persian,
|
| 47 |
+
open("akkadian-wiktextract-data.jsonl", "w") as akkadian,
|
| 48 |
+
open("sanskrit-wiktextract-data.jsonl", "w") as sanskrit
|
| 49 |
):
|
| 50 |
for line in data:
|
| 51 |
vocabulary = json.loads(line)
|
|
|
|
| 82 |
if vocabulary["lang"] == "Akkadian":
|
| 83 |
akkadian.write(json.dumps({"term": term, "part of speech": pos, "definitions": definitions, "audios": audios}))
|
| 84 |
akkadian.write("\n")
|
| 85 |
+
if vocabulary["lang"] == "Sanskrit":
|
| 86 |
+
sanskrit.write(json.dumps({"term": term, "part of speech": pos, "definitions": definitions, "audios": audios}))
|
| 87 |
+
sanskrit.write("\n")
|
| 88 |
+
|
| 89 |
|
| 90 |
def extract_graph(wiktextract_data_path: str):
|
| 91 |
import json
|