

Or4cl3/1nsfw
Text Generation
•
Updated
•
5
![]()

In this work, we introduce ORCA, a publicly available benchmark for Arabic language understanding evaluation. ORCA is carefully constructed to cover diverse Arabic varieties and a wide range of challenging Arabic understanding tasks exploiting 60 different datasets across seven NLU task clusters. To measure current progress in Arabic NLU, we use ORCA to offer a comprehensive comparison between 18 multilingual and Arabic language models.
We arrange ORCA, into seven NLU task clusters. These are (1) sentence classification, (2) structured prediction (3) semantic textual similarity and paraphrase, (4) text classification, (5) natural language inference, (6) word sense disambiguation, and (7) question answering.
| Task | Variation | Metric | Reference |
|---|---|---|---|
| ANS Stance | MSA | Macro F1 | (Khouja, 2020) |
| Baly Stance | MSA | Macro F1 | (Balyet al., 2018) |
| XLNI | MSA | Macro F1 | (Conneau et al., 2018) |
| Task | Variation | Metric | Reference |
|---|---|---|---|
| Question Answering | MSA | Macro F1 | (Abdul-Mageed et al., 2020a) |
| Task | Variation | Metric | Reference |
|---|---|---|---|
| Emotion Regression | MSA | Spearman Correlation | (Saif et al., 2018) |
| MQ2Q | MSA | Macro F1 | (Seelawi al., 2019) |
| STS | MSA | Macro F1 | (Cer et al., 2017) |
| Task | Variation | Metric | Reference |
|---|---|---|---|
| Aqmar NER | MSA | Macro F1 | (Mohit, 2012) |
| Arabic NER Corpus | MSA | Macro F1 | (Benajiba and Rosso, 2007) |
| Dialect Part Of Speech | DA | Macro F1 | (Darwish et al., 2018) |
| MSA Part Of Speech | MSA | Macro F1 | (Liang et al., 2020) |
| Task | Variation | Metric | Reference |
|---|---|---|---|
| Topic | MSA | Macro F1 | (Abbas et al.,2011), (Chouigui et al.,2017), (Saad, 2010). |
| Task | Variation | Metric | Reference |
|---|---|---|---|
| Word Sense Disambiguation | MSA | Macro F1 | (El-Razzaz, 2021) |
To obtain access to the ORCA benchmark on Huggingface, follow the following steps:
Login on your Haggingface account
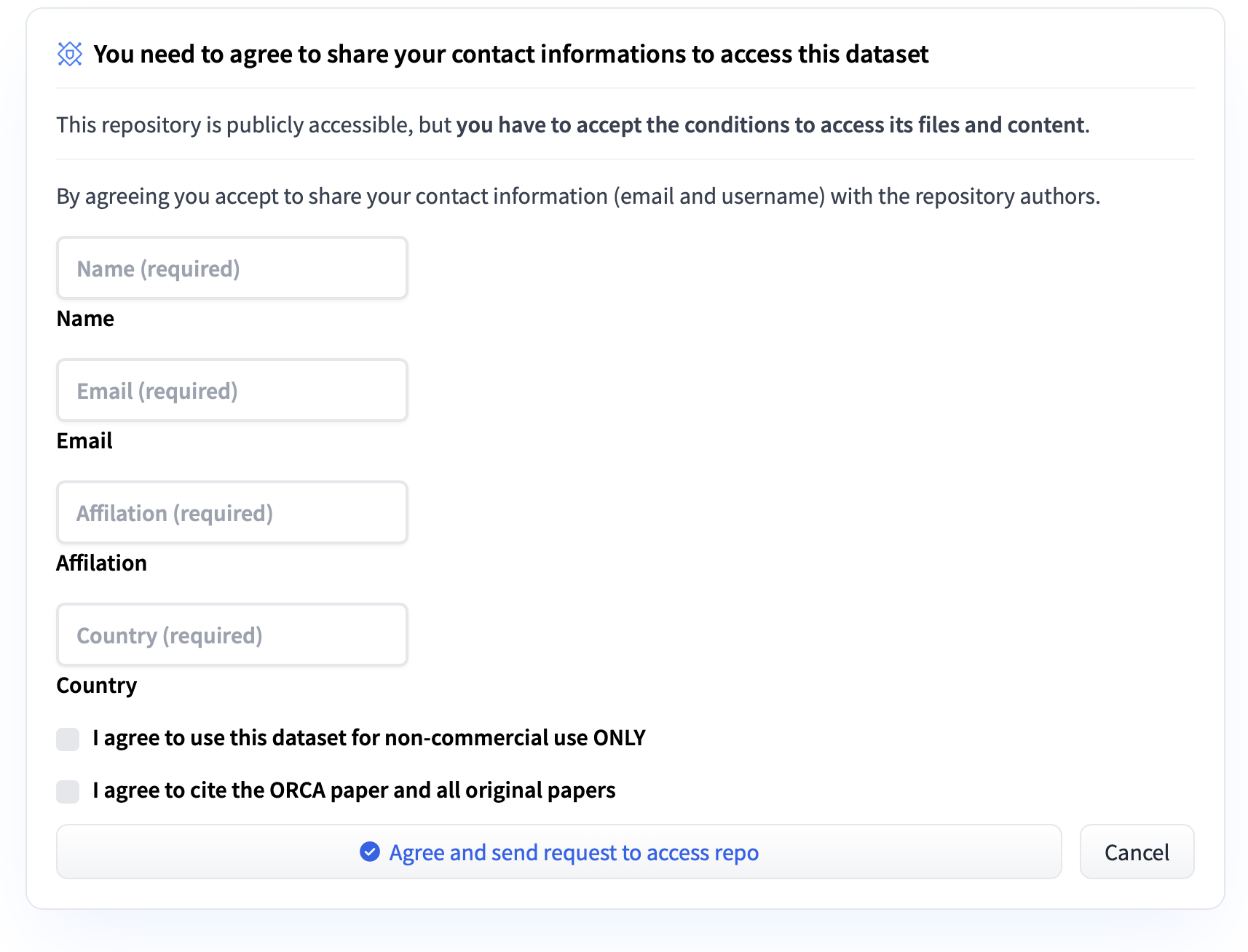
Request access
pip install datasets transformers seqeval
You can get/manage your access tokens in your settings.
export HUGGINGFACE_TOKEN=""
huggingface-cli login --token $HUGGINGFACE_TOKEN
We provide a Google Colab Notebook that includes instructions for fine-tuning any model on ORCA tasks. ![]()
We design a public leaderboard for scoring PLMs on ORCA. Our leaderboard is interactive and offers rich meta-data about the various datasets involved as well as the language models we evaluate.
You can evalute your models using ORCA leaderboard: https://orca.dlnlp.ai
If you use ORCA for your scientific publication, or if you find the resources in this repository useful, please cite our paper as follows:
@inproceedings{elmadany-etal-2023-orca,
title = "{ORCA}: A Challenging Benchmark for {A}rabic Language Understanding",
author = "Elmadany, AbdelRahim and
Nagoudi, ElMoatez Billah and
Abdul-Mageed, Muhammad",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.609",
pages = "9559--9586",
}
We gratefully acknowledge support from the Natural Sciences and Engineering Research Council of Canada, the Social Sciences and Humanities Research Council of Canada, Canadian Foundation for Innovation, ComputeCanada and UBC ARC-Sockeye. We also thank the Google TensorFlow Research Cloud (TFRC) program for providing us with free TPU access.