
filename
stringlengths 7
56
| text
stringlengths 257
90.2k
⌀ |
|---|---|
perf_train_cpu_many.md |
# Efficient Training on Multiple CPUs
When training on a single CPU is too slow, we can use multiple CPUs. This guide focuses on PyTorch-based DDP enabling distributed CPU training efficiently.
## Intel® oneCCL Bindings for PyTorch
[Intel® oneCCL](https://github.com/oneapi-src/oneCCL) (collective communications library) is a library for efficient distributed deep learning training implementing such collectives like allreduce, allgather, alltoall. For more information on oneCCL, please refer to the [oneCCL documentation](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html) and [oneCCL specification](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html).
Module `oneccl_bindings_for_pytorch` (`torch_ccl` before version 1.12) implements PyTorch C10D ProcessGroup API and can be dynamically loaded as external ProcessGroup and only works on Linux platform now
Check more detailed information for [oneccl_bind_pt](https://github.com/intel/torch-ccl).
### Intel® oneCCL Bindings for PyTorch installation:
Wheel files are available for the following Python versions:
| Extension Version | Python 3.6 | Python 3.7 | Python 3.8 | Python 3.9 | Python 3.10 |
| :---------------: | :--------: | :--------: | :--------: | :--------: | :---------: |
| 1.13.0 | | √ | √ | √ | √ |
| 1.12.100 | | √ | √ | √ | √ |
| 1.12.0 | | √ | √ | √ | √ |
| 1.11.0 | | √ | √ | √ | √ |
| 1.10.0 | √ | √ | √ | √ | |
pip install oneccl_bind_pt=={pytorch_version} -f https://developer.intel.com/ipex-whl-stable-cpu
where `{pytorch_version}` should be your PyTorch version, for instance 1.13.0.
Check more approaches for [oneccl_bind_pt installation](https://github.com/intel/torch-ccl).
Versions of oneCCL and PyTorch must match.
oneccl_bindings_for_pytorch 1.12.0 prebuilt wheel does not work with PyTorch 1.12.1 (it is for PyTorch 1.12.0)
PyTorch 1.12.1 should work with oneccl_bindings_for_pytorch 1.12.100
## Intel® MPI library
Use this standards-based MPI implementation to deliver flexible, efficient, scalable cluster messaging on Intel® architecture. This component is part of the Intel® oneAPI HPC Toolkit.
oneccl_bindings_for_pytorch is installed along with the MPI tool set. Need to source the environment before using it.
for Intel® oneCCL >= 1.12.0
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
for Intel® oneCCL whose version < 1.12.0
torch_ccl_path=$(python -c "import torch; import torch_ccl; import os; print(os.path.abspath(os.path.dirname(torch_ccl.__file__)))")
source $torch_ccl_path/env/setvars.sh
#### IPEX installation:
IPEX provides performance optimizations for CPU training with both Float32 and BFloat16, you could refer [single CPU section](./perf_train_cpu).
The following "Usage in Trainer" takes mpirun in Intel® MPI library as an example.
## Usage in Trainer
To enable multi CPU distributed training in the Trainer with the ccl backend, users should add **`--ddp_backend ccl`** in the command arguments.
Let's see an example with the [question-answering example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
The following command enables training with 2 processes on one Xeon node, with one process running per one socket. The variables OMP_NUM_THREADS/CCL_WORKER_COUNT can be tuned for optimal performance.
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=127.0.0.1
mpirun -n 2 -genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex
The following command enables training with a total of four processes on two Xeons (node0 and node1, taking node0 as the main process), ppn (processes per node) is set to 2, with one process running per one socket. The variables OMP_NUM_THREADS/CCL_WORKER_COUNT can be tuned for optimal performance.
In node0, you need to create a configuration file which contains the IP addresses of each node (for example hostfile) and pass that configuration file path as an argument.
```shell script
cat hostfile
xxx.xxx.xxx.xxx #node0 ip
xxx.xxx.xxx.xxx #node1 ip
Now, run the following command in node0 and **4DDP** will be enabled in node0 and node1 with BF16 auto mixed precision:
```shell script
export CCL_WORKER_COUNT=1
export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
mpirun -f hostfile -n 4 -ppn 2 \
-genv OMP_NUM_THREADS=23 \
python3 run_qa.py \
--model_name_or_path bert-large-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/ \
--no_cuda \
--ddp_backend ccl \
--use_ipex \
--bf16
|
bertology.md |
# BERTology
There is a growing field of study concerned with investigating the inner working of large-scale transformers like BERT
(that some call "BERTology"). Some good examples of this field are:
- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
https://arxiv.org/abs/1905.05950
- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
Manning: https://arxiv.org/abs/1906.04341
- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
In order to help this new field develop, we have included a few additional features in the BERT/GPT/GPT-2 models to
help people access the inner representations, mainly adapted from the great work of Paul Michel
(https://arxiv.org/abs/1905.10650):
- accessing all the hidden-states of BERT/GPT/GPT-2,
- accessing all the attention weights for each head of BERT/GPT/GPT-2,
- retrieving heads output values and gradients to be able to compute head importance score and prune head as explained
in https://arxiv.org/abs/1905.10650.
To help you understand and use these features, we have added a specific example script: [bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py) while extract information and prune a model pre-trained on
GLUE.
|
training.md |
# Fine-tune a pretrained model
[[open-in-colab]]
There are significant benefits to using a pretrained model. It reduces computation costs, your carbon footprint, and allows you to use state-of-the-art models without having to train one from scratch. 🤗 Transformers provides access to thousands of pretrained models for a wide range of tasks. When you use a pretrained model, you train it on a dataset specific to your task. This is known as fine-tuning, an incredibly powerful training technique. In this tutorial, you will fine-tune a pretrained model with a deep learning framework of your choice:
* Fine-tune a pretrained model with 🤗 Transformers [`Trainer`].
* Fine-tune a pretrained model in TensorFlow with Keras.
* Fine-tune a pretrained model in native PyTorch.
## Prepare a dataset
Before you can fine-tune a pretrained model, download a dataset and prepare it for training. The previous tutorial showed you how to process data for training, and now you get an opportunity to put those skills to the test!
Begin by loading the [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full) dataset:
>>> from datasets import load_dataset
>>> dataset = load_dataset("yelp_review_full")
>>> dataset["train"][100]
{'label': 0,
'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularlythat takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
As you now know, you need a tokenizer to process the text and include a padding and truncation strategy to handle any variable sequence lengths. To process your dataset in one step, use 🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process#map) method to apply a preprocessing function over the entire dataset:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
>>> def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
If you like, you can create a smaller subset of the full dataset to fine-tune on to reduce the time it takes:
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
## Train
At this point, you should follow the section corresponding to the framework you want to use. You can use the links
in the right sidebar to jump to the one you want - and if you want to hide all of the content for a given framework,
just use the button at the top-right of that framework's block!
## Train with PyTorch Trainer
🤗 Transformers provides a [`Trainer`] class optimized for training 🤗 Transformers models, making it easier to start training without manually writing your own training loop. The [`Trainer`] API supports a wide range of training options and features such as logging, gradient accumulation, and mixed precision.
Start by loading your model and specify the number of expected labels. From the Yelp Review [dataset card](https://huggingface.co/datasets/yelp_review_full#data-fields), you know there are five labels:
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
You will see a warning about some of the pretrained weights not being used and some weights being randomly
initialized. Don't worry, this is completely normal! The pretrained head of the BERT model is discarded, and replaced with a randomly initialized classification head. You will fine-tune this new model head on your sequence classification task, transferring the knowledge of the pretrained model to it.
### Training hyperparameters
Next, create a [`TrainingArguments`] class which contains all the hyperparameters you can tune as well as flags for activating different training options. For this tutorial you can start with the default training [hyperparameters](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments), but feel free to experiment with these to find your optimal settings.
Specify where to save the checkpoints from your training:
>>> from transformers import TrainingArguments
>>> training_args = TrainingArguments(output_dir="test_trainer")
### Evaluate
[`Trainer`] does not automatically evaluate model performance during training. You'll need to pass [`Trainer`] a function to compute and report metrics. The [🤗 Evaluate](https://huggingface.co/docs/evaluate/index) library provides a simple [`accuracy`](https://huggingface.co/spaces/evaluate-metric/accuracy) function you can load with the [`evaluate.load`] (see this [quicktour](https://huggingface.co/docs/evaluate/a_quick_tour) for more information) function:
>>> import numpy as np
>>> import evaluate
>>> metric = evaluate.load("accuracy")
Call [`~evaluate.compute`] on `metric` to calculate the accuracy of your predictions. Before passing your predictions to `compute`, you need to convert the logits to predictions (remember all 🤗 Transformers models return logits):
>>> def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
If you'd like to monitor your evaluation metrics during fine-tuning, specify the `evaluation_strategy` parameter in your training arguments to report the evaluation metric at the end of each epoch:
>>> from transformers import TrainingArguments, Trainer
>>> training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch")
### Trainer
Create a [`Trainer`] object with your model, training arguments, training and test datasets, and evaluation function:
>>> trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
Then fine-tune your model by calling [`~transformers.Trainer.train`]:
>>> trainer.train()
## Train a TensorFlow model with Keras
You can also train 🤗 Transformers models in TensorFlow with the Keras API!
### Loading data for Keras
When you want to train a 🤗 Transformers model with the Keras API, you need to convert your dataset to a format that
Keras understands. If your dataset is small, you can just convert the whole thing to NumPy arrays and pass it to Keras.
Let's try that first before we do anything more complicated.
First, load a dataset. We'll use the CoLA dataset from the [GLUE benchmark](https://huggingface.co/datasets/glue),
since it's a simple binary text classification task, and just take the training split for now.
from datasets import load_dataset
dataset = load_dataset("glue", "cola")
dataset = dataset["train"] # Just take the training split for now
Next, load a tokenizer and tokenize the data as NumPy arrays. Note that the labels are already a list of 0 and 1s,
so we can just convert that directly to a NumPy array without tokenization!
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_data = tokenizer(dataset["sentence"], return_tensors="np", padding=True)
# Tokenizer returns a BatchEncoding, but we convert that to a dict for Keras
tokenized_data = dict(tokenized_data)
labels = np.array(dataset["label"]) # Label is already an array of 0 and 1
Finally, load, [`compile`](https://keras.io/api/models/model_training_apis/#compile-method), and [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) the model. Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
from transformers import TFAutoModelForSequenceClassification
from tensorflow.keras.optimizers import Adam
# Load and compile our model
model = TFAutoModelForSequenceClassification.from_pretrained("bert-base-cased")
# Lower learning rates are often better for fine-tuning transformers
model.compile(optimizer=Adam(3e-5)) # No loss argument!
model.fit(tokenized_data, labels)
You don't have to pass a loss argument to your models when you `compile()` them! Hugging Face models automatically
choose a loss that is appropriate for their task and model architecture if this argument is left blank. You can always
override this by specifying a loss yourself if you want to!
This approach works great for smaller datasets, but for larger datasets, you might find it starts to become a problem. Why?
Because the tokenized array and labels would have to be fully loaded into memory, and because NumPy doesn’t handle
“jagged” arrays, so every tokenized sample would have to be padded to the length of the longest sample in the whole
dataset. That’s going to make your array even bigger, and all those padding tokens will slow down training too!
### Loading data as a tf.data.Dataset
If you want to avoid slowing down training, you can load your data as a `tf.data.Dataset` instead. Although you can write your own
`tf.data` pipeline if you want, we have two convenience methods for doing this:
- [`~TFPreTrainedModel.prepare_tf_dataset`]: This is the method we recommend in most cases. Because it is a method
on your model, it can inspect the model to automatically figure out which columns are usable as model inputs, and
discard the others to make a simpler, more performant dataset.
- [`~datasets.Dataset.to_tf_dataset`]: This method is more low-level, and is useful when you want to exactly control how
your dataset is created, by specifying exactly which `columns` and `label_cols` to include.
Before you can use [`~TFPreTrainedModel.prepare_tf_dataset`], you will need to add the tokenizer outputs to your dataset as columns, as shown in
the following code sample:
def tokenize_dataset(data):
# Keys of the returned dictionary will be added to the dataset as columns
return tokenizer(data["text"])
dataset = dataset.map(tokenize_dataset)
Remember that Hugging Face datasets are stored on disk by default, so this will not inflate your memory usage! Once the
columns have been added, you can stream batches from the dataset and add padding to each batch, which greatly
reduces the number of padding tokens compared to padding the entire dataset.
>>> tf_dataset = model.prepare_tf_dataset(dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer)
Note that in the code sample above, you need to pass the tokenizer to `prepare_tf_dataset` so it can correctly pad batches as they're loaded.
If all the samples in your dataset are the same length and no padding is necessary, you can skip this argument.
If you need to do something more complex than just padding samples (e.g. corrupting tokens for masked language
modelling), you can use the `collate_fn` argument instead to pass a function that will be called to transform the
list of samples into a batch and apply any preprocessing you want. See our
[examples](https://github.com/huggingface/transformers/tree/main/examples) or
[notebooks](https://huggingface.co/docs/transformers/notebooks) to see this approach in action.
Once you've created a `tf.data.Dataset`, you can compile and fit the model as before:
model.compile(optimizer=Adam(3e-5)) # No loss argument!
model.fit(tf_dataset)
## Train in native PyTorch
[`Trainer`] takes care of the training loop and allows you to fine-tune a model in a single line of code. For users who prefer to write their own training loop, you can also fine-tune a 🤗 Transformers model in native PyTorch.
At this point, you may need to restart your notebook or execute the following code to free some memory:
del model
del trainer
torch.cuda.empty_cache()
Next, manually postprocess `tokenized_dataset` to prepare it for training.
1. Remove the `text` column because the model does not accept raw text as an input:
>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
2. Rename the `label` column to `labels` because the model expects the argument to be named `labels`:
>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
3. Set the format of the dataset to return PyTorch tensors instead of lists:
>>> tokenized_datasets.set_format("torch")
Then create a smaller subset of the dataset as previously shown to speed up the fine-tuning:
>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
### DataLoader
Create a `DataLoader` for your training and test datasets so you can iterate over batches of data:
>>> from torch.utils.data import DataLoader
>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
Load your model with the number of expected labels:
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
### Optimizer and learning rate scheduler
Create an optimizer and learning rate scheduler to fine-tune the model. Let's use the [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) optimizer from PyTorch:
>>> from torch.optim import AdamW
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
Create the default learning rate scheduler from [`Trainer`]:
>>> from transformers import get_scheduler
>>> num_epochs = 3
>>> num_training_steps = num_epochs * len(train_dataloader)
>>> lr_scheduler = get_scheduler(
name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
)
Lastly, specify `device` to use a GPU if you have access to one. Otherwise, training on a CPU may take several hours instead of a couple of minutes.
>>> import torch
>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
>>> model.to(device)
Get free access to a cloud GPU if you don't have one with a hosted notebook like [Colaboratory](https://colab.research.google.com/) or [SageMaker StudioLab](https://studiolab.sagemaker.aws/).
Great, now you are ready to train! 🥳
### Training loop
To keep track of your training progress, use the [tqdm](https://tqdm.github.io/) library to add a progress bar over the number of training steps:
>>> from tqdm.auto import tqdm
>>> progress_bar = tqdm(range(num_training_steps))
>>> model.train()
>>> for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
### Evaluate
Just like how you added an evaluation function to [`Trainer`], you need to do the same when you write your own training loop. But instead of calculating and reporting the metric at the end of each epoch, this time you'll accumulate all the batches with [`~evaluate.add_batch`] and calculate the metric at the very end.
>>> import evaluate
>>> metric = evaluate.load("accuracy")
>>> model.eval()
>>> for batch in eval_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
>>> metric.compute()
## Additional resources
For more fine-tuning examples, refer to:
- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) includes scripts
to train common NLP tasks in PyTorch and TensorFlow.
- [🤗 Transformers Notebooks](notebooks) contains various notebooks on how to fine-tune a model for specific tasks in PyTorch and TensorFlow.
|
tf_xla.md |
# XLA Integration for TensorFlow Models
[[open-in-colab]]
Accelerated Linear Algebra, dubbed XLA, is a compiler for accelerating the runtime of TensorFlow Models. From the [official documentation](https://www.tensorflow.org/xla):
XLA (Accelerated Linear Algebra) is a domain-specific compiler for linear algebra that can accelerate TensorFlow models with potentially no source code changes.
Using XLA in TensorFlow is simple – it comes packaged inside the `tensorflow` library, and it can be triggered with the `jit_compile` argument in any graph-creating function such as [`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs). When using Keras methods like `fit()` and `predict()`, you can enable XLA simply by passing the `jit_compile` argument to `model.compile()`. However, XLA is not limited to these methods - it can also be used to accelerate any arbitrary `tf.function`.
Several TensorFlow methods in 🤗 Transformers have been rewritten to be XLA-compatible, including text generation for models such as [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2), [T5](https://huggingface.co/docs/transformers/model_doc/t5) and [OPT](https://huggingface.co/docs/transformers/model_doc/opt), as well as speech processing for models such as [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper).
While the exact amount of speed-up is very much model-dependent, for TensorFlow text generation models inside 🤗 Transformers, we noticed a speed-up of ~100x. This document will explain how you can use XLA for these models to get the maximum amount of performance. We’ll also provide links to additional resources if you’re interested to learn more about the benchmarks and our design philosophy behind the XLA integration.
## Running TF functions with XLA
Let us consider the following model in TensorFlow:
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)
The above model accepts inputs having a dimension of `(10, )`. We can use the model for running a forward pass like so:
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)
In order to run the forward pass with an XLA-compiled function, we’d need to do:
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
The default `call()` function of the `model` is used for compiling the XLA graph. But if there’s any other model function you want to compile into XLA that’s also possible with:
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
## Running a TF text generation model with XLA from 🤗 Transformers
To enable XLA-accelerated generation within 🤗 Transformers, you need to have a recent version of `transformers` installed. You can install it by running:
```bash
pip install transformers --upgrade
And then you can run the following code:
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
As you can notice, enabling XLA on `generate()` is just a single line of code. The rest of the code remains unchanged. However, there are a couple of gotchas in the above code snippet that are specific to XLA. You need to be aware of those to realize the speed-ups that XLA can bring in. We discuss these in the following section.
## Gotchas to be aware of
When you are executing an XLA-enabled function (like `xla_generate()` above) for the first time, it will internally try to infer the computation graph, which is time-consuming. This process is known as [“tracing”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing).
You might notice that the generation time is not fast. Successive calls of `xla_generate()` (or any other XLA-enabled function) won’t have to infer the computation graph, given the inputs to the function follow the same shape with which the computation graph was initially built. While this is not a problem for modalities with fixed input shapes (e.g., images), you must pay attention if you are working with variable input shape modalities (e.g., text).
To ensure `xla_generate()` always operates with the same input shapes, you can specify the `padding` arguments when calling the tokenizer.
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
This way, you can ensure that the inputs to `xla_generate()` will always receive inputs with the shape it was traced with and thus leading to speed-ups in the generation time. You can verify this with the code below:
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="left", pad_token="")
model = TFAutoModelForCausalLM.from_pretrained("gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
On a Tesla T4 GPU, you can expect the outputs like so:
```bash
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms
The first call to `xla_generate()` is time-consuming because of tracing, but the successive calls are orders of magnitude faster. Keep in mind that any change in the generation options at any point with trigger re-tracing and thus leading to slow-downs in the generation time.
We didn’t cover all the text generation options 🤗 Transformers provides in this document. We encourage you to read the documentation for advanced use cases.
## Additional Resources
Here, we leave you with some additional resources if you want to delve deeper into XLA in 🤗 Transformers and in general.
* [This Colab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb) provides an interactive demonstration if you want to fiddle with the XLA-compatible encoder-decoder (like [T5](https://huggingface.co/docs/transformers/model_doc/t5)) and decoder-only (like [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)) text generation models.
* [This blog post](https://huggingface.co/blog/tf-xla-generate) provides an overview of the comparison benchmarks for XLA-compatible models along with a friendly introduction to XLA in TensorFlow.
* [This blog post](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) discusses our design philosophy behind adding XLA support to the TensorFlow models in 🤗 Transformers.
* Recommended posts for learning more about XLA and TensorFlow graphs in general:
* [XLA: Optimizing Compiler for Machine Learning](https://www.tensorflow.org/xla)
* [Introduction to graphs and tf.function](https://www.tensorflow.org/guide/intro_to_graphs)
* [Better performance with tf.function](https://www.tensorflow.org/guide/function) |
run_scripts.md |
# Train with a script
Along with the 🤗 Transformers [notebooks](./noteboks/README), there are also example scripts demonstrating how to train a model for a task with [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), or [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
You will also find scripts we've used in our [research projects](https://github.com/huggingface/transformers/tree/main/examples/research_projects) and [legacy examples](https://github.com/huggingface/transformers/tree/main/examples/legacy) which are mostly community contributed. These scripts are not actively maintained and require a specific version of 🤗 Transformers that will most likely be incompatible with the latest version of the library.
The example scripts are not expected to work out-of-the-box on every problem, and you may need to adapt the script to the problem you're trying to solve. To help you with this, most of the scripts fully expose how data is preprocessed, allowing you to edit it as necessary for your use case.
For any feature you'd like to implement in an example script, please discuss it on the [forum](https://discuss.huggingface.co/) or in an [issue](https://github.com/huggingface/transformers/issues) before submitting a Pull Request. While we welcome bug fixes, it is unlikely we will merge a Pull Request that adds more functionality at the cost of readability.
This guide will show you how to run an example summarization training script in [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). All examples are expected to work with both frameworks unless otherwise specified.
## Setup
To successfully run the latest version of the example scripts, you have to **install 🤗 Transformers from source** in a new virtual environment:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
For older versions of the example scripts, click on the toggle below:
Examples for older versions of 🤗 Transformers
v4.5.1
v4.4.2
v4.3.3
v4.2.2
v4.1.1
v4.0.1
v3.5.1
v3.4.0
v3.3.1
v3.2.0
v3.1.0
v3.0.2
v2.11.0
v2.10.0
v2.9.1
v2.8.0
v2.7.0
v2.6.0
v2.5.1
v2.4.0
v2.3.0
v2.2.0
v2.1.1
v2.0.0
v1.2.0
v1.1.0
v1.0.0
Then switch your current clone of 🤗 Transformers to a specific version, like v3.5.1 for example:
```bash
git checkout tags/v3.5.1
After you've setup the correct library version, navigate to the example folder of your choice and install the example specific requirements:
```bash
pip install -r requirements.txt
## Run a script
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset with the [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
The example script downloads and preprocesses a dataset from the 🤗 [Datasets](https://huggingface.co/docs/datasets/) library. Then the script fine-tunes a dataset using Keras on an architecture that supports summarization. The following example shows how to fine-tune [T5-small](https://huggingface.co/t5-small) on the [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) dataset. The T5 model requires an additional `source_prefix` argument due to how it was trained. This prompt lets T5 know this is a summarization task.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
## Distributed training and mixed precision
The [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) supports distributed training and mixed precision, which means you can also use it in a script. To enable both of these features:
- Add the `fp16` argument to enable mixed precision.
- Set the number of GPUs to use with the `nproc_per_node` argument.
```bash
python -m torch.distributed.launch \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
TensorFlow scripts utilize a [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) for distributed training, and you don't need to add any additional arguments to the training script. The TensorFlow script will use multiple GPUs by default if they are available.
## Run a script on a TPU
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. PyTorch supports TPUs with the [XLA](https://www.tensorflow.org/xla) deep learning compiler (see [here](https://github.com/pytorch/xla/blob/master/README.md) for more details). To use a TPU, launch the `xla_spawn.py` script and use the `num_cores` argument to set the number of TPU cores you want to use.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. TensorFlow scripts utilize a [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) for training on TPUs. To use a TPU, pass the name of the TPU resource to the `tpu` argument.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
## Run a script with 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) is a PyTorch-only library that offers a unified method for training a model on several types of setups (CPU-only, multiple GPUs, TPUs) while maintaining complete visibility into the PyTorch training loop. Make sure you have 🤗 Accelerate installed if you don't already have it:
> Note: As Accelerate is rapidly developing, the git version of accelerate must be installed to run the scripts
```bash
pip install git+https://github.com/huggingface/accelerate
Instead of the `run_summarization.py` script, you need to use the `run_summarization_no_trainer.py` script. 🤗 Accelerate supported scripts will have a `task_no_trainer.py` file in the folder. Begin by running the following command to create and save a configuration file:
```bash
accelerate config
Test your setup to make sure it is configured correctly:
```bash
accelerate test
Now you are ready to launch the training:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
## Use a custom dataset
The summarization script supports custom datasets as long as they are a CSV or JSON Line file. When you use your own dataset, you need to specify several additional arguments:
- `train_file` and `validation_file` specify the path to your training and validation files.
- `text_column` is the input text to summarize.
- `summary_column` is the target text to output.
A summarization script using a custom dataset would look like this:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
## Test a script
It is often a good idea to run your script on a smaller number of dataset examples to ensure everything works as expected before committing to an entire dataset which may take hours to complete. Use the following arguments to truncate the dataset to a maximum number of samples:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
Not all example scripts support the `max_predict_samples` argument. If you aren't sure whether your script supports this argument, add the `-h` argument to check:
```bash
examples/pytorch/summarization/run_summarization.py -h
## Resume training from checkpoint
Another helpful option to enable is resuming training from a previous checkpoint. This will ensure you can pick up where you left off without starting over if your training gets interrupted. There are two methods to resume training from a checkpoint.
The first method uses the `output_dir previous_output_dir` argument to resume training from the latest checkpoint stored in `output_dir`. In this case, you should remove `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
The second method uses the `resume_from_checkpoint path_to_specific_checkpoint` argument to resume training from a specific checkpoint folder.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
## Share your model
All scripts can upload your final model to the [Model Hub](https://huggingface.co/models). Make sure you are logged into Hugging Face before you begin:
```bash
huggingface-cli login
Then add the `push_to_hub` argument to the script. This argument will create a repository with your Hugging Face username and the folder name specified in `output_dir`.
To give your repository a specific name, use the `push_to_hub_model_id` argument to add it. The repository will be automatically listed under your namespace.
The following example shows how to upload a model with a specific repository name:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
``` |
generation_strategies.md |
# Text generation strategies
Text generation is essential to many NLP tasks, such as open-ended text generation, summarization, translation, and
more. It also plays a role in a variety of mixed-modality applications that have text as an output like speech-to-text
and vision-to-text. Some of the models that can generate text include
GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper.
Check out a few examples that use [`~transformers.generation_utils.GenerationMixin.generate`] method to produce
text outputs for different tasks:
* [Text summarization](./tasks/summarization#inference)
* [Image captioning](./model_doc/git#transformers.GitForCausalLM.forward.example)
* [Audio transcription](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
Note that the inputs to the generate method depend on the model's modality. They are returned by the model's preprocessor
class, such as AutoTokenizer or AutoProcessor. If a model's preprocessor creates more than one kind of input, pass all
the inputs to generate(). You can learn more about the individual model's preprocessor in the corresponding model's documentation.
The process of selecting output tokens to generate text is known as decoding, and you can customize the decoding strategy
that the `generate()` method will use. Modifying a decoding strategy does not change the values of any trainable parameters.
However, it can have a noticeable impact on the quality of the generated output. It can help reduce repetition in the text
and make it more coherent.
This guide describes:
* default generation configuration
* common decoding strategies and their main parameters
* saving and sharing custom generation configurations with your fine-tuned model on 🤗 Hub
## Default text generation configuration
A decoding strategy for a model is defined in its generation configuration. When using pre-trained models for inference
within a [`pipeline`], the models call the `PreTrainedModel.generate()` method that applies a default generation
configuration under the hood. The default configuration is also used when no custom configuration has been saved with
the model.
When you load a model explicitly, you can inspect the generation configuration that comes with it through
`model.generation_config`:
thon
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256,
}
Printing out the `model.generation_config` reveals only the values that are different from the default generation
configuration, and does not list any of the default values.
The default generation configuration limits the size of the output combined with the input prompt to a maximum of 20
tokens to avoid running into resource limitations. The default decoding strategy is greedy search, which is the simplest decoding strategy that picks a token with the highest probability as the next token. For many tasks
and small output sizes this works well. However, when used to generate longer outputs, greedy search can start
producing highly repetitive results.
## Customize text generation
You can override any `generation_config` by passing the parameters and their values directly to the [`generate`] method:
thon
>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
Even if the default decoding strategy mostly works for your task, you can still tweak a few things. Some of the
commonly adjusted parameters include:
- `max_new_tokens`: the maximum number of tokens to generate. In other words, the size of the output sequence, not
including the tokens in the prompt. As an alternative to using the output's length as a stopping criteria, you can choose
to stop generation whenever the full generation exceeds some amount of time. To learn more, check [`StoppingCriteria`].
- `num_beams`: by specifying a number of beams higher than 1, you are effectively switching from greedy search to
beam search. This strategy evaluates several hypotheses at each time step and eventually chooses the hypothesis that
has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with a lower probability initial tokens and would've been ignored by the greedy search.
- `do_sample`: if set to `True`, this parameter enables decoding strategies such as multinomial sampling, beam-search
multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability
distribution over the entire vocabulary with various strategy-specific adjustments.
- `num_return_sequences`: the number of sequence candidates to return for each input. This option is only available for
the decoding strategies that support multiple sequence candidates, e.g. variations of beam search and sampling. Decoding
strategies like greedy search and contrastive search return a single output sequence.
## Save a custom decoding strategy with your model
If you would like to share your fine-tuned model with a specific generation configuration, you can:
* Create a [`GenerationConfig`] class instance
* Specify the decoding strategy parameters
* Save your generation configuration with [`GenerationConfig.save_pretrained`], making sure to leave its `config_file_name` argument empty
* Set `push_to_hub` to `True` to upload your config to the model's repo
thon
>>> from transformers import AutoModelForCausalLM, GenerationConfig
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
>>> generation_config = GenerationConfig(
max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
)
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
You can also store several generation configurations in a single directory, making use of the `config_file_name`
argument in [`GenerationConfig.save_pretrained`]. You can later instantiate them with [`GenerationConfig.from_pretrained`]. This is useful if you want to
store several generation configurations for a single model (e.g. one for creative text generation with sampling, and
one for summarization with beam search). You must have the right Hub permissions to add configuration files to a model.
thon
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("t5-small")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
>>> translation_generation_config = GenerationConfig(
num_beams=4,
early_stopping=True,
decoder_start_token_id=0,
eos_token_id=model.config.eos_token_id,
pad_token=model.config.pad_token_id,
)
>>> # Tip: add `push_to_hub=True` to push to the Hub
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
>>> # You could then use the named generation config file to parameterize generation
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
>>> outputs = model.generate(**inputs, generation_config=generation_config)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Les fichiers de configuration sont faciles à utiliser!']
## Streaming
The `generate()` supports streaming, through its `streamer` input. The `streamer` input is compatible with any instance
from a class that has the following methods: `put()` and `end()`. Internally, `put()` is used to push new tokens and
`end()` is used to flag the end of text generation.
The API for the streamer classes is still under development and may change in the future.
In practice, you can craft your own streaming class for all sorts of purposes! We also have basic streaming classes
ready for you to use. For example, you can use the [`TextStreamer`] class to stream the output of `generate()` into
your screen, one word at a time:
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
>>> tok = AutoTokenizer.from_pretrained("gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("gpt2")
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
>>> streamer = TextStreamer(tok)
>>> # Despite returning the usual output, the streamer will also print the generated text to stdout.
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
## Decoding strategies
Certain combinations of the `generate()` parameters, and ultimately `generation_config`, can be used to enable specific
decoding strategies. If you are new to this concept, we recommend reading [this blog post that illustrates how common decoding strategies work](https://huggingface.co/blog/how-to-generate).
Here, we'll show some of the parameters that control the decoding strategies and illustrate how you can use them.
### Greedy Search
[`generate`] uses greedy search decoding by default so you don't have to pass any parameters to enable it. This means the parameters `num_beams` is set to 1 and `do_sample=False`.
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "I look forward to"
>>> checkpoint = "distilgpt2"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
### Contrastive search
The contrastive search decoding strategy was proposed in the 2022 paper [A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417).
It demonstrates superior results for generating non-repetitive yet coherent long outputs. To learn how contrastive search
works, check out [this blog post](https://huggingface.co/blog/introducing-csearch).
The two main parameters that enable and control the behavior of contrastive search are `penalty_alpha` and `top_k`:
thon
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Hugging Face Company is"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
in the business and our customer service is second to none.\n\nIf you have any questions about our
products or services, feel free to contact us at any time. We look forward to hearing from you!']
### Multinomial sampling
As opposed to greedy search that always chooses a token with the highest probability as the
next token, multinomial sampling (also called ancestral sampling) randomly selects the next token based on the probability distribution over the entire
vocabulary given by the model. Every token with a non-zero probability has a chance of being selected, thus reducing the
risk of repetition.
To enable multinomial sampling set `do_sample=True` and `num_beams=1`.
thon
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> set_seed(0) # For reproducibility
>>> checkpoint = "gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Today was an amazing day because"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
that\'s a terrible feeling."']
### Beam-search decoding
Unlike greedy search, beam-search decoding keeps several hypotheses at each time step and eventually chooses
the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability
sequences that start with lower probability initial tokens and would've been ignored by the greedy search.
To enable this decoding strategy, specify the `num_beams` (aka number of hypotheses to keep track of) that is greater than 1.
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "It is astonishing how one can"
>>> checkpoint = "gpt2-medium"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
### Beam-search multinomial sampling
As the name implies, this decoding strategy combines beam search with multinomial sampling. You need to specify
the `num_beams` greater than 1, and set `do_sample=True` to use this decoding strategy.
thon
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
>>> set_seed(0) # For reproducibility
>>> prompt = "translate English to German: The house is wonderful."
>>> checkpoint = "t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Das Haus ist wunderbar.'
### Diverse beam search decoding
The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
set of beam sequences to choose from. To learn how it works, refer to [Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models](https://arxiv.org/pdf/1610.02424.pdf).
This approach has three main parameters: `num_beams`, `num_beam_groups`, and `diversity_penalty`.
The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
thon
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> checkpoint = "google/pegasus-xsum"
>>> prompt = (
"The Permaculture Design Principles are a set of universal design principles "
"that can be applied to any location, climate and culture, and they allow us to design "
"the most efficient and sustainable human habitation and food production systems. "
"Permaculture is a design system that encompasses a wide variety of disciplines, such "
"as ecology, landscape design, environmental science and energy conservation, and the "
"Permaculture design principles are drawn from these various disciplines. Each individual "
"design principle itself embodies a complete conceptual framework based on sound "
"scientific principles. When we bring all these separate principles together, we can "
"create a design system that both looks at whole systems, the parts that these systems "
"consist of, and how those parts interact with each other to create a complex, dynamic, "
"living system. Each design principle serves as a tool that allows us to integrate all "
"the separate parts of a design, referred to as elements, into a functional, synergistic, "
"whole system, where the elements harmoniously interact and work together in the most "
"efficient way possible."
)
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
culture, and they allow us to design the'
This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
[`generate`] method, which gives you even further control over the [`generate`] method's behavior.
For the complete list of the available parameters, refer to the [API documentation](./main_classes/text_generation.md).
### Assisted Decoding
Assisted decoding is a modification of the decoding strategies above that uses an assistant model with the same
tokenizer (ideally a much smaller model) to greedily generate a few candidate tokens. The main model then validates
the candidate tokens in a single forward pass, which speeds up the decoding process. Currently, only greedy search
and sampling are supported with assisted decoding, and doesn't support batched inputs. To learn more about assisted
decoding, check [this blog post](https://huggingface.co/blog/assisted-generation).
To enable assisted decoding, set the `assistant_model` argument with a model.
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
When using assisted decoding with sampling methods, you can use the `temperature` argument to control the randomness
just like in multinomial sampling. However, in assisted decoding, reducing the temperature will help improving latency.
thon
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> set_seed(42) # For reproducibility
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are going to the same party. It is a small party, in a small']
|
multilingual.md |
# Multilingual models for inference
[[open-in-colab]]
There are several multilingual models in 🤗 Transformers, and their inference usage differs from monolingual models. Not *all* multilingual model usage is different though. Some models, like [bert-base-multilingual-uncased](https://huggingface.co/bert-base-multilingual-uncased), can be used just like a monolingual model. This guide will show you how to use multilingual models whose usage differs for inference.
## XLM
XLM has ten different checkpoints, only one of which is monolingual. The nine remaining model checkpoints can be split into two categories: the checkpoints that use language embeddings and those that don't.
### XLM with language embeddings
The following XLM models use language embeddings to specify the language used at inference:
- `xlm-mlm-ende-1024` (Masked language modeling, English-German)
- `xlm-mlm-enfr-1024` (Masked language modeling, English-French)
- `xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
- `xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
- `xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
- `xlm-clm-enfr-1024` (Causal language modeling, English-French)
- `xlm-clm-ende-1024` (Causal language modeling, English-German)
Language embeddings are represented as a tensor of the same shape as the `input_ids` passed to the model. The values in these tensors depend on the language used and are identified by the tokenizer's `lang2id` and `id2lang` attributes.
In this example, load the `xlm-clm-enfr-1024` checkpoint (Causal language modeling, English-French):
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("xlm-clm-enfr-1024")
The `lang2id` attribute of the tokenizer displays this model's languages and their ids:
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
Next, create an example input:
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
Set the language id as `"en"` and use it to define the language embedding. The language embedding is a tensor filled with `0` since that is the language id for English. This tensor should be the same size as `input_ids`.
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, , 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
Now you can pass the `input_ids` and language embedding to the model:
>>> outputs = model(input_ids, langs=langs)
The [run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) script can generate text with language embeddings using the `xlm-clm` checkpoints.
### XLM without language embeddings
The following XLM models do not require language embeddings during inference:
- `xlm-mlm-17-1280` (Masked language modeling, 17 languages)
- `xlm-mlm-100-1280` (Masked language modeling, 100 languages)
These models are used for generic sentence representations, unlike the previous XLM checkpoints.
## BERT
The following BERT models can be used for multilingual tasks:
- `bert-base-multilingual-uncased` (Masked language modeling + Next sentence prediction, 102 languages)
- `bert-base-multilingual-cased` (Masked language modeling + Next sentence prediction, 104 languages)
These models do not require language embeddings during inference. They should identify the language from the
context and infer accordingly.
## XLM-RoBERTa
The following XLM-RoBERTa models can be used for multilingual tasks:
- `xlm-roberta-base` (Masked language modeling, 100 languages)
- `xlm-roberta-large` (Masked language modeling, 100 languages)
XLM-RoBERTa was trained on 2.5TB of newly created and cleaned CommonCrawl data in 100 languages. It provides strong gains over previously released multilingual models like mBERT or XLM on downstream tasks like classification, sequence labeling, and question answering.
## M2M100
The following M2M100 models can be used for multilingual translation:
- `facebook/m2m100_418M` (Translation)
- `facebook/m2m100_1.2B` (Translation)
In this example, load the `facebook/m2m100_418M` checkpoint to translate from Chinese to English. You can set the source language in the tokenizer:
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
Tokenize the text:
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
M2M100 forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
## MBart
The following MBart models can be used for multilingual translation:
- `facebook/mbart-large-50-one-to-many-mmt` (One-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-many-mmt` (Many-to-many multilingual machine translation, 50 languages)
- `facebook/mbart-large-50-many-to-one-mmt` (Many-to-one multilingual machine translation, 50 languages)
- `facebook/mbart-large-50` (Multilingual translation, 50 languages)
- `facebook/mbart-large-cc25`
In this example, load the `facebook/mbart-large-50-many-to-many-mmt` checkpoint to translate Finnish to English. You can set the source language in the tokenizer:
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
Tokenize the text:
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
MBart forces the target language id as the first generated token to translate to the target language. Set the `forced_bos_token_id` to `en` in the `generate` method to translate to English:
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
If you are using the `facebook/mbart-large-50-many-to-one-mmt` checkpoint, you don't need to force the target language id as the first generated token otherwise the usage is the same.
|
community.md |
# Community
This page regroups resources around 🤗 Transformers developed by the community.
## Community resources:
| Resource | Description | Author |
|:----------|:-------------|------:|
| [Hugging Face Transformers Glossary Flashcards](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | A set of flashcards based on the [Transformers Docs Glossary](glossary) that has been put into a form which can be easily learned/revised using [Anki ](https://apps.ankiweb.net/) an open source, cross platform app specifically designed for long term knowledge retention. See this [Introductory video on how to use the flashcards](https://www.youtube.com/watch?v=Dji_h7PILrw). | [Darigov Research](https://www.darigovresearch.com/) |
## Community notebooks:
| Notebook | Description | Author | |
|:----------|:-------------|:-------------|------:|
| [Fine-tune a pre-trained Transformer to generate lyrics](https://github.com/AlekseyKorshuk/huggingartists) | How to generate lyrics in the style of your favorite artist by fine-tuning a GPT-2 model | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
| [Train T5 in Tensorflow 2 ](https://github.com/snapthat/TF-T5-text-to-text) | How to train T5 for any task using Tensorflow 2. This notebook demonstrates a Question & Answer task implemented in Tensorflow 2 using SQUAD | [Muhammad Harris](https://github.com/HarrisDePerceptron) |[](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
| [Train T5 on TPU](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | How to train T5 on SQUAD with Transformers and Nlp | [Suraj Patil](https://github.com/patil-suraj) |[](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
| [Fine-tune T5 for Classification and Multiple Choice](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | How to fine-tune T5 for classification and multiple choice tasks using a text-to-text format with PyTorch Lightning | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
| [Fine-tune DialoGPT on New Datasets and Languages](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | How to fine-tune the DialoGPT model on a new dataset for open-dialog conversational chatbots | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
| [Long Sequence Modeling with Reformer](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | How to train on sequences as long as 500,000 tokens with Reformer | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
| [Fine-tune BART for Summarization](https://github.com/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) | How to fine-tune BART for summarization with fastai using blurr | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) |
| [Fine-tune a pre-trained Transformer on anyone's tweets](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | How to generate tweets in the style of your favorite Twitter account by fine-tuning a GPT-2 model | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
| [Optimize 🤗 Hugging Face models with Weights & Biases](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | A complete tutorial showcasing W&B integration with Hugging Face | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
| [Pretrain Longformer](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | How to build a "long" version of existing pretrained models | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
| [Fine-tune Longformer for QA](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | How to fine-tune longformer model for QA task | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
| [Evaluate Model with 🤗nlp](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | How to evaluate longformer on TriviaQA with `nlp` | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
| [Fine-tune T5 for Sentiment Span Extraction](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | How to fine-tune T5 for sentiment span extraction using a text-to-text format with PyTorch Lightning | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
| [Fine-tune DistilBert for Multiclass Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | How to fine-tune DistilBert for multiclass classification with PyTorch | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
|[Fine-tune BERT for Multi-label Classification](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|How to fine-tune BERT for multi-label classification using PyTorch|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
|[Fine-tune T5 for Summarization](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|How to fine-tune T5 for summarization in PyTorch and track experiments with WandB|[Abhishek Kumar Mishra](https://github.com/abhimishra91) |[](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|
|[Speed up Fine-Tuning in Transformers with Dynamic Padding / Bucketing](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)|How to speed up fine-tuning by a factor of 2 using dynamic padding / bucketing|[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
|[Pretrain Reformer for Masked Language Modeling](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| How to train a Reformer model with bi-directional self-attention layers | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
|[Expand and Fine Tune Sci-BERT](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| How to increase vocabulary of a pretrained SciBERT model from AllenAI on the CORD dataset and pipeline it. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
|[Fine Tune BlenderBotSmall for Summarization using the Trainer API](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| How to fine-tune BlenderBotSmall for summarization on a custom dataset, using the Trainer API. | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
|[Fine-tune Electra and interpret with Integrated Gradients](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | How to fine-tune Electra for sentiment analysis and interpret predictions with Captum Integrated Gradients | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
|[fine-tune a non-English GPT-2 Model with Trainer class](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | How to fine-tune a non-English GPT-2 Model with Trainer class | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
|[Fine-tune a DistilBERT Model for Multi Label Classification task](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | How to fine-tune a DistilBERT Model for Multi Label Classification task | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
|[Fine-tune ALBERT for sentence-pair classification](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) | How to fine-tune an ALBERT model or another BERT-based model for the sentence-pair classification task | [Nadir El Manouzi](https://github.com/NadirEM) | [](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
|[Fine-tune Roberta for sentiment analysis](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) | How to fine-tune a Roberta model for sentiment analysis | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
|[Evaluating Question Generation Models](https://github.com/flexudy-pipe/qugeev) | How accurate are the answers to questions generated by your seq2seq transformer model? | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
|[Classify text with DistilBERT and Tensorflow](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | How to fine-tune DistilBERT for text classification in TensorFlow | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
|[Leverage BERT for Encoder-Decoder Summarization on CNN/Dailymail](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | How to warm-start a *EncoderDecoderModel* with a *bert-base-uncased* checkpoint for summarization on CNN/Dailymail | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
|[Leverage RoBERTa for Encoder-Decoder Summarization on BBC XSum](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | How to warm-start a shared *EncoderDecoderModel* with a *roberta-base* checkpoint for summarization on BBC/XSum | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
|[Fine-tune TAPAS on Sequential Question Answering (SQA)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | How to fine-tune *TapasForQuestionAnswering* with a *tapas-base* checkpoint on the Sequential Question Answering (SQA) dataset | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
|[Evaluate TAPAS on Table Fact Checking (TabFact)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | How to evaluate a fine-tuned *TapasForSequenceClassification* with a *tapas-base-finetuned-tabfact* checkpoint using a combination of the 🤗 datasets and 🤗 transformers libraries | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
|[Fine-tuning mBART for translation](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | How to fine-tune mBART using Seq2SeqTrainer for Hindi to English translation | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
|[Fine-tune LayoutLM on FUNSD (a form understanding dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | How to fine-tune *LayoutLMForTokenClassification* on the FUNSD dataset for information extraction from scanned documents | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
|[Fine-Tune DistilGPT2 and Generate Text](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | How to fine-tune DistilGPT2 and generate text | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
|[Fine-Tune LED on up to 8K tokens](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | How to fine-tune LED on pubmed for long-range summarization | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
|[Evaluate LED on Arxiv](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | How to effectively evaluate LED on long-range summarization | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
|[Fine-tune LayoutLM on RVL-CDIP (a document image classification dataset)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | How to fine-tune *LayoutLMForSequenceClassification* on the RVL-CDIP dataset for scanned document classification | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
|[Wav2Vec2 CTC decoding with GPT2 adjustment](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | How to decode CTC sequence with language model adjustment | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)|
|[Fine-tune BART for summarization in two languages with Trainer class](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | How to fine-tune BART for summarization in two languages with Trainer class | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
|[Evaluate Big Bird on Trivia QA](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | How to evaluate BigBird on long document question answering on Trivia QA | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
| [Create video captions using Wav2Vec2](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | How to create YouTube captions from any video by transcribing the audio with Wav2Vec | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
| [Fine-tune the Vision Transformer on CIFAR-10 using PyTorch Lightning](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | How to fine-tune the Vision Transformer (ViT) on CIFAR-10 using HuggingFace Transformers, Datasets and PyTorch Lightning | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
| [Fine-tune the Vision Transformer on CIFAR-10 using the 🤗 Trainer](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | How to fine-tune the Vision Transformer (ViT) on CIFAR-10 using HuggingFace Transformers, Datasets and the 🤗 Trainer | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
| [Evaluate LUKE on Open Entity, an entity typing dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | How to evaluate *LukeForEntityClassification* on the Open Entity dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
| [Evaluate LUKE on TACRED, a relation extraction dataset](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | How to evaluate *LukeForEntityPairClassification* on the TACRED dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
| [Evaluate LUKE on CoNLL-2003, an important NER benchmark](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | How to evaluate *LukeForEntitySpanClassification* on the CoNLL-2003 dataset | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
| [Evaluate BigBird-Pegasus on PubMed dataset](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | How to evaluate *BigBirdPegasusForConditionalGeneration* on PubMed dataset | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
| [Speech Emotion Classification with Wav2Vec2](https://github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) | How to leverage a pretrained Wav2Vec2 model for Emotion Classification on the MEGA dataset | [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
| [Detect objects in an image with DETR](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | How to use a trained *DetrForObjectDetection* model to detect objects in an image and visualize attention | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
| [Fine-tune DETR on a custom object detection dataset](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | How to fine-tune *DetrForObjectDetection* on a custom object detection dataset | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
| [Finetune T5 for Named Entity Recognition](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | How to fine-tune *T5* on a Named Entity Recognition Task | [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
|
task_summary.md |
# What 🤗 Transformers can do
🤗 Transformers is a library of pretrained state-of-the-art models for natural language processing (NLP), computer vision, and audio and speech processing tasks. Not only does the library contain Transformer models, but it also has non-Transformer models like modern convolutional networks for computer vision tasks. If you look at some of the most popular consumer products today, like smartphones, apps, and televisions, odds are that some kind of deep learning technology is behind it. Want to remove a background object from a picture taken by your smartphone? This is an example of a panoptic segmentation task (don't worry if you don't know what this means yet, we'll describe it in the following sections!).
This page provides an overview of the different speech and audio, computer vision, and NLP tasks that can be solved with the 🤗 Transformers library in just three lines of code!
## Audio
Audio and speech processing tasks are a little different from the other modalities mainly because audio as an input is a continuous signal. Unlike text, a raw audio waveform can't be neatly split into discrete chunks the way a sentence can be divided into words. To get around this, the raw audio signal is typically sampled at regular intervals. If you take more samples within an interval, the sampling rate is higher, and the audio more closely resembles the original audio source.
Previous approaches preprocessed the audio to extract useful features from it. It is now more common to start audio and speech processing tasks by directly feeding the raw audio waveform to a feature encoder to extract an audio representation. This simplifies the preprocessing step and allows the model to learn the most essential features.
### Audio classification
Audio classification is a task that labels audio data from a predefined set of classes. It is a broad category with many specific applications, some of which include:
* acoustic scene classification: label audio with a scene label ("office", "beach", "stadium")
* acoustic event detection: label audio with a sound event label ("car horn", "whale calling", "glass breaking")
* tagging: label audio containing multiple sounds (birdsongs, speaker identification in a meeting)
* music classification: label music with a genre label ("metal", "hip-hop", "country")
>>> from transformers import pipeline
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4532, 'label': 'hap'},
{'score': 0.3622, 'label': 'sad'},
{'score': 0.0943, 'label': 'neu'},
{'score': 0.0903, 'label': 'ang'}]
### Automatic speech recognition
Automatic speech recognition (ASR) transcribes speech into text. It is one of the most common audio tasks due partly to speech being such a natural form of human communication. Today, ASR systems are embedded in "smart" technology products like speakers, phones, and cars. We can ask our virtual assistants to play music, set reminders, and tell us the weather.
But one of the key challenges Transformer architectures have helped with is in low-resource languages. By pretraining on large amounts of speech data, finetuning the model on only one hour of labeled speech data in a low-resource language can still produce high-quality results compared to previous ASR systems trained on 100x more labeled data.
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
## Computer vision
One of the first and earliest successful computer vision tasks was recognizing images of zip code numbers using a [convolutional neural network (CNN)](glossary#convolution). An image is composed of pixels, and each pixel has a numerical value. This makes it easy to represent an image as a matrix of pixel values. Each particular combination of pixel values describes the colors of an image.
Two general ways computer vision tasks can be solved are:
1. Use convolutions to learn the hierarchical features of an image from low-level features to high-level abstract things.
2. Split an image into patches and use a Transformer to gradually learn how each image patch is related to each other to form an image. Unlike the bottom-up approach favored by a CNN, this is kind of like starting out with a blurry image and then gradually bringing it into focus.
### Image classification
Image classification labels an entire image from a predefined set of classes. Like most classification tasks, there are many practical use cases for image classification, some of which include:
* healthcare: label medical images to detect disease or monitor patient health
* environment: label satellite images to monitor deforestation, inform wildland management or detect wildfires
* agriculture: label images of crops to monitor plant health or satellite images for land use monitoring
* ecology: label images of animal or plant species to monitor wildlife populations or track endangered species
>>> from transformers import pipeline
>>> classifier = pipeline(task="image-classification")
>>> preds = classifier(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.4335, 'label': 'lynx, catamount'}
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
{'score': 0.0239, 'label': 'Egyptian cat'}
{'score': 0.0229, 'label': 'tiger cat'}
### Object detection
Unlike image classification, object detection identifies multiple objects within an image and the objects' positions in an image (defined by the bounding box). Some example applications of object detection include:
* self-driving vehicles: detect everyday traffic objects such as other vehicles, pedestrians, and traffic lights
* remote sensing: disaster monitoring, urban planning, and weather forecasting
* defect detection: detect cracks or structural damage in buildings, and manufacturing defects
>>> from transformers import pipeline
>>> detector = pipeline(task="object-detection")
>>> preds = detector(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
>>> preds
[{'score': 0.9865,
'label': 'cat',
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
### Image segmentation
Image segmentation is a pixel-level task that assigns every pixel in an image to a class. It differs from object detection, which uses bounding boxes to label and predict objects in an image because segmentation is more granular. Segmentation can detect objects at a pixel-level. There are several types of image segmentation:
* instance segmentation: in addition to labeling the class of an object, it also labels each distinct instance of an object ("dog-1", "dog-2")
* panoptic segmentation: a combination of semantic and instance segmentation; it labels each pixel with a semantic class **and** each distinct instance of an object
Segmentation tasks are helpful in self-driving vehicles to create a pixel-level map of the world around them so they can navigate safely around pedestrians and other vehicles. It is also useful for medical imaging, where the task's finer granularity can help identify abnormal cells or organ features. Image segmentation can also be used in ecommerce to virtually try on clothes or create augmented reality experiences by overlaying objects in the real world through your camera.
>>> from transformers import pipeline
>>> segmenter = pipeline(task="image-segmentation")
>>> preds = segmenter(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.9879, 'label': 'LABEL_184'}
{'score': 0.9973, 'label': 'snow'}
{'score': 0.9972, 'label': 'cat'}
### Depth estimation
Depth estimation predicts the distance of each pixel in an image from the camera. This computer vision task is especially important for scene understanding and reconstruction. For example, in self-driving cars, vehicles need to understand how far objects like pedestrians, traffic signs, and other vehicles are to avoid obstacles and collisions. Depth information is also helpful for constructing 3D representations from 2D images and can be used to create high-quality 3D representations of biological structures or buildings.
There are two approaches to depth estimation:
* stereo: depths are estimated by comparing two images of the same image from slightly different angles
* monocular: depths are estimated from a single image
>>> from transformers import pipeline
>>> depth_estimator = pipeline(task="depth-estimation")
>>> preds = depth_estimator(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
)
## Natural language processing
NLP tasks are among the most common types of tasks because text is such a natural way for us to communicate. To get text into a format recognized by a model, it needs to be tokenized. This means dividing a sequence of text into separate words or subwords (tokens) and then converting these tokens into numbers. As a result, you can represent a sequence of text as a sequence of numbers, and once you have a sequence of numbers, it can be input into a model to solve all sorts of NLP tasks!
### Text classification
Like classification tasks in any modality, text classification labels a sequence of text (it can be sentence-level, a paragraph, or a document) from a predefined set of classes. There are many practical applications for text classification, some of which include:
* sentiment analysis: label text according to some polarity like `positive` or `negative` which can inform and support decision-making in fields like politics, finance, and marketing
* content classification: label text according to some topic to help organize and filter information in news and social media feeds (`weather`, `sports`, `finance`, etc.)
>>> from transformers import pipeline
>>> classifier = pipeline(task="sentiment-analysis")
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.9991, 'label': 'POSITIVE'}]
### Token classification
In any NLP task, text is preprocessed by separating the sequence of text into individual words or subwords. These are known as [tokens](/glossary#token). Token classification assigns each token a label from a predefined set of classes.
Two common types of token classification are:
* named entity recognition (NER): label a token according to an entity category like organization, person, location or date. NER is especially popular in biomedical settings, where it can label genes, proteins, and drug names.
* part-of-speech tagging (POS): label a token according to its part-of-speech like noun, verb, or adjective. POS is useful for helping translation systems understand how two identical words are grammatically different (bank as a noun versus bank as a verb).
>>> from transformers import pipeline
>>> classifier = pipeline(task="ner")
>>> preds = classifier("Hugging Face is a French company based in New York City.")
>>> preds = [
{
"entity": pred["entity"],
"score": round(pred["score"], 4),
"index": pred["index"],
"word": pred["word"],
"start": pred["start"],
"end": pred["end"],
}
for pred in preds
]
>>> print(*preds, sep="\n")
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
### Question answering
Question answering is another token-level task that returns an answer to a question, sometimes with context (open-domain) and other times without context (closed-domain). This task happens whenever we ask a virtual assistant something like whether a restaurant is open. It can also provide customer or technical support and help search engines retrieve the relevant information you're asking for.
There are two common types of question answering:
* extractive: given a question and some context, the answer is a span of text from the context the model must extract
* abstractive: given a question and some context, the answer is generated from the context; this approach is handled by the [`Text2TextGenerationPipeline`] instead of the [`QuestionAnsweringPipeline`] shown below
>>> from transformers import pipeline
>>> question_answerer = pipeline(task="question-answering")
>>> preds = question_answerer(
question="What is the name of the repository?",
context="The name of the repository is huggingface/transformers",
)
>>> print(
f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
)
score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
### Summarization
Summarization creates a shorter version of a text from a longer one while trying to preserve most of the meaning of the original document. Summarization is a sequence-to-sequence task; it outputs a shorter text sequence than the input. There are a lot of long-form documents that can be summarized to help readers quickly understand the main points. Legislative bills, legal and financial documents, patents, and scientific papers are a few examples of documents that could be summarized to save readers time and serve as a reading aid.
Like question answering, there are two types of summarization:
* extractive: identify and extract the most important sentences from the original text
* abstractive: generate the target summary (which may include new words not in the input document) from the original text; the [`SummarizationPipeline`] uses the abstractive approach
>>> from transformers import pipeline
>>> summarizer = pipeline(task="summarization")
>>> summarizer(
"In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
)
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
### Translation
Translation converts a sequence of text in one language to another. It is important in helping people from different backgrounds communicate with each other, help translate content to reach wider audiences, and even be a learning tool to help people learn a new language. Along with summarization, translation is a sequence-to-sequence task, meaning the model receives an input sequence and returns a target output sequence.
In the early days, translation models were mostly monolingual, but recently, there has been increasing interest in multilingual models that can translate between many pairs of languages.
>>> from transformers import pipeline
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
>>> translator = pipeline(task="translation", model="t5-small")
>>> translator(text)
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
### Language modeling
Language modeling is a task that predicts a word in a sequence of text. It has become a very popular NLP task because a pretrained language model can be finetuned for many other downstream tasks. Lately, there has been a lot of interest in large language models (LLMs) which demonstrate zero- or few-shot learning. This means the model can solve tasks it wasn't explicitly trained to do! Language models can be used to generate fluent and convincing text, though you need to be careful since the text may not always be accurate.
There are two types of language modeling:
* causal: the model's objective is to predict the next token in a sequence, and future tokens are masked
>>> from transformers import pipeline
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
>>> generator = pipeline(task="text-generation")
>>> generator(prompt) # doctest: +SKIP
* masked: the model's objective is to predict a masked token in a sequence with full access to the tokens in the sequence
>>> text = "Hugging Face is a community-based open-source for machine learning."
>>> fill_mask = pipeline(task="fill-mask")
>>> preds = fill_mask(text, top_k=1)
>>> preds = [
{
"score": round(pred["score"], 4),
"token": pred["token"],
"token_str": pred["token_str"],
"sequence": pred["sequence"],
}
for pred in preds
]
>>> preds
[{'score': 0.2236,
'token': 1761,
'token_str': ' platform',
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
## Multimodal
Multimodal tasks require a model to process multiple data modalities (text, image, audio, video) to solve a particular problem. Image captioning is an example of a multimodal task where the model takes an image as input and outputs a sequence of text describing the image or some properties of the image.
Although multimodal models work with different data types or modalities, internally, the preprocessing steps help the model convert all the data types into embeddings (vectors or list of numbers that holds meaningful information about the data). For a task like image captioning, the model learns relationships between image embeddings and text embeddings.
### Document question answering
Document question answering is a task that answers natural language questions from a document. Unlike a token-level question answering task which takes text as input, document question answering takes an image of a document as input along with a question about the document and returns an answer. Document question answering can be used to parse structured documents and extract key information from it. In the example below, the total amount and change due can be extracted from a receipt.
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/2/image/image.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
>>> preds = doc_question_answerer(
question="What is the total amount?",
image=image,
)
>>> preds
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
Hopefully, this page has given you some more background information about all the types of tasks in each modality and the practical importance of each one. In the next [section](tasks_explained), you'll learn **how** 🤗 Transformers work to solve these tasks. |
chat_templating.md |
# Templates for Chat Models
## Introduction
An increasingly common use case for LLMs is **chat**. In a chat context, rather than continuing a single string
of text (as is the case with a standard language model), the model instead continues a conversation that consists
of one or more **messages**, each of which includes a **role**, like "user" or "assistant", as well as message text.
Much like tokenization, different models expect very different input formats for chat. This is the reason we added
**chat templates** as a feature. Chat templates are part of the tokenizer. They specify how to convert conversations,
represented as lists of messages, into a single tokenizable string in the format that the model expects.
Let's make this concrete with a quick example using the `BlenderBot` model. BlenderBot has an extremely simple default
template, which mostly just adds whitespace between rounds of dialogue:
thon
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!"
Notice how the entire chat is condensed into a single string. If we use `tokenize=True`, which is the default setting,
that string will also be tokenized for us. To see a more complex template in action, though, let's use the
`mistralai/Mistral-7B-Instruct-v0.1` model.
thon
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
>>> chat = [
{"role": "user", "content": "Hello, how are you?"},
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
{"role": "user", "content": "I'd like to show off how chat templating works!"},
]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
"[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today? [INST] I'd like to show off how chat templating works! [/INST]"
Note that this time, the tokenizer has added the control tokens [INST] and [/INST] to indicate the start and end of
user messages (but not assistant messages!). Mistral-instruct was trained with these tokens, but BlenderBot was not.
## How do I use chat templates?
As you can see in the example above, chat templates are easy to use. Simply build a list of messages, with `role`
and `content` keys, and then pass it to the [`~PreTrainedTokenizer.apply_chat_template`] method. Once you do that,
you'll get output that's ready to go! When using chat templates as input for model generation, it's also a good idea
to use `add_generation_prompt=True` to add a [generation prompt](#what-are-generation-prompts).
Here's an example of preparing input for `model.generate()`, using the `Zephyr` assistant model:
thon
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
This will yield a string in the input format that Zephyr expects.
```text
<|system|>
You are a friendly chatbot who always responds in the style of a pirate
<|user|>
How many helicopters can a human eat in one sitting?
<|assistant|>
Now that our input is formatted correctly for Zephyr, we can use the model to generate a response to the user's question:
thon
outputs = model.generate(tokenized_chat, max_new_tokens=128)
print(tokenizer.decode(outputs[0]))
This will yield:
```text
<|system|>
You are a friendly chatbot who always responds in the style of a pirate
<|user|>
How many helicopters can a human eat in one sitting?
<|assistant|>
Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
Arr, 'twas easy after all!
## Is there an automated pipeline for chat?
Yes, there is: [`ConversationalPipeline`]. This pipeline is designed to make it easy to use chat models. Let's try
the `Zephyr` example again, but this time using the pipeline:
thon
from transformers import pipeline
pipe = pipeline("conversational", "HuggingFaceH4/zephyr-7b-beta")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
print(pipe(messages))
```text
Conversation id: 76d886a0-74bd-454e-9804-0467041a63dc
system: You are a friendly chatbot who always responds in the style of a pirate
user: How many helicopters can a human eat in one sitting?
assistant: Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
[`ConversationalPipeline`] will take care of all the details of tokenization and calling `apply_chat_template` for you -
once the model has a chat template, all you need to do is initialize the pipeline and pass it the list of messages!
## What are "generation prompts"?
You may have noticed that the `apply_chat_template` method has an `add_generation_prompt` argument. This argument tells
the template to add tokens that indicate the start of a bot response. For example, consider the following chat:
thon
messages = [
{"role": "user", "content": "Hi there!"},
{"role": "assistant", "content": "Nice to meet you!"},
{"role": "user", "content": "Can I ask a question?"}
]
Here's what this will look like without a generation prompt, using the ChatML template we saw in the Zephyr example:
thon
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
"""
And here's what it looks like **with** a generation prompt:
thon
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
<|im_start|>assistant
"""
Note that this time, we've added the tokens that indicate the start of a bot response. This ensures that when the model
generates text it will write a bot response instead of doing something unexpected, like continuing the user's
message. Remember, chat models are still just language models - they're trained to continue text, and chat is just a
special kind of text to them! You need to guide them with the appropriate control tokens so they know what they're
supposed to be doing.
Not all models require generation prompts. Some models, like BlenderBot and LLaMA, don't have any
special tokens before bot responses. In these cases, the `add_generation_prompt` argument will have no effect. The exact
effect that `add_generation_prompt` has will depend on the template being used.
## Can I use chat templates in training?
Yes! We recommend that you apply the chat template as a preprocessing step for your dataset. After this, you
can simply continue like any other language model training task. When training, you should usually set
`add_generation_prompt=False`, because the added tokens to prompt an assistant response will not be helpful during
training. Let's see an example:
thon
from transformers import AutoTokenizer
from datasets import Dataset
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
chat1 = [
{"role": "user", "content": "Which is bigger, the moon or the sun?"},
{"role": "assistant", "content": "The sun."}
]
chat2 = [
{"role": "user", "content": "Which is bigger, a virus or a bacterium?"},
{"role": "assistant", "content": "A bacterium."}
]
dataset = Dataset.from_dict({"chat": [chat1, chat2]})
dataset = dataset.map(lambda x: {"formatted_chat": tokenizer.apply_chat_template(x["chat"], tokenize=False, add_generation_prompt=False)})
print(dataset['formatted_chat'][0])
And we get:
```text
<|user|>
Which is bigger, the moon or the sun?
<|assistant|>
The sun.
From here, just continue training like you would with a standard language modelling task, using the `formatted_chat` column.
## Advanced: How do chat templates work?
The chat template for a model is stored on the `tokenizer.chat_template` attribute. If no chat template is set, the
default template for that model class is used instead. Let's take a look at the template for `BlenderBot`:
thon
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> tokenizer.default_chat_template
"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
That's kind of intimidating. Let's add some newlines and indentation to make it more readable. Note that the first
newline after each block as well as any preceding whitespace before a block are ignored by default, using the
Jinja `trim_blocks` and `lstrip_blocks` flags. However, be cautious - although leading whitespace on each
line is stripped, spaces between blocks on the same line are not. We strongly recommend checking that your template
isn't printing extra spaces where it shouldn't be!
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ ' ' }}
{% endif %}
{{ message['content'] }}
{% if not loop.last %}
{{ ' ' }}
{% endif %}
{% endfor %}
{{ eos_token }}
If you've never seen one of these before, this is a [Jinja template](https://jinja.palletsprojects.com/en/3.1.x/templates/).
Jinja is a templating language that allows you to write simple code that generates text. In many ways, the code and
syntax resembles Python. In pure Python, this template would look something like this:
thon
for idx, message in enumerate(messages):
if message['role'] == 'user':
print(' ')
print(message['content'])
if not idx == len(messages) - 1: # Check for the last message in the conversation
print(' ')
print(eos_token)
Effectively, the template does three things:
1. For each message, if the message is a user message, add a blank space before it, otherwise print nothing.
2. Add the message content
3. If the message is not the last message, add two spaces after it. After the final message, print the EOS token.
This is a pretty simple template - it doesn't add any control tokens, and it doesn't support "system" messages, which
are a common way to give the model directives about how it should behave in the subsequent conversation.
But Jinja gives you a lot of flexibility to do those things! Let's see a Jinja template that can format inputs
similarly to the way LLaMA formats them (note that the real LLaMA template includes handling for default system
messages and slightly different system message handling in general - don't use this one in your actual code!)
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<>\\n' + message['content'] + '\\n<>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ ' ' + message['content'] + ' ' + eos_token }}
{% endif %}
{% endfor %}
Hopefully if you stare at this for a little bit you can see what this template is doing - it adds specific tokens based
on the "role" of each message, which represents who sent it. User, assistant and system messages are clearly
distinguishable to the model because of the tokens they're wrapped in.
## Advanced: Adding and editing chat templates
### How do I create a chat template?
Simple, just write a jinja template and set `tokenizer.chat_template`. You may find it easier to start with an
existing template from another model and simply edit it for your needs! For example, we could take the LLaMA template
above and add "[ASST]" and "[/ASST]" to assistant messages:
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<>\\n' + message['content'].strip() + '\\n<>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
{% endif %}
{% endfor %}
Now, simply set the `tokenizer.chat_template` attribute. Next time you use [`~PreTrainedTokenizer.apply_chat_template`], it will
use your new template! This attribute will be saved in the `tokenizer_config.json` file, so you can use
[`~utils.PushToHubMixin.push_to_hub`] to upload your new template to the Hub and make sure everyone's using the right
template for your model!
thon
template = tokenizer.chat_template
template = template.replace("SYS", "SYSTEM") # Change the system token
tokenizer.chat_template = template # Set the new template
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
The method [`~PreTrainedTokenizer.apply_chat_template`] which uses your chat template is called by the [`ConversationalPipeline`] class, so
once you set the correct chat template, your model will automatically become compatible with [`ConversationalPipeline`].
### What are "default" templates?
Before the introduction of chat templates, chat handling was hardcoded at the model class level. For backwards
compatibility, we have retained this class-specific handling as default templates, also set at the class level. If a
model does not have a chat template set, but there is a default template for its model class, the `ConversationalPipeline`
class and methods like `apply_chat_template` will use the class template instead. You can find out what the default
template for your tokenizer is by checking the `tokenizer.default_chat_template` attribute.
This is something we do purely for backward compatibility reasons, to avoid breaking any existing workflows. Even when
the class template is appropriate for your model, we strongly recommend overriding the default template by
setting the `chat_template` attribute explicitly to make it clear to users that your model has been correctly configured
for chat, and to future-proof in case the default templates are ever altered or deprecated.
### What template should I use?
When setting the template for a model that's already been trained for chat, you should ensure that the template
exactly matches the message formatting that the model saw during training, or else you will probably experience
performance degradation. This is true even if you're training the model further - you will probably get the best
performance if you keep the chat tokens constant. This is very analogous to tokenization - you generally get the
best performance for inference or fine-tuning when you precisely match the tokenization used during training.
If you're training a model from scratch, or fine-tuning a base language model for chat, on the other hand,
you have a lot of freedom to choose an appropriate template! LLMs are smart enough to learn to handle lots of different
input formats. Our default template for models that don't have a class-specific template follows the
[ChatML format](https://github.com/openai/openai-python/blob/main/chatml.md), and this is a good, flexible choice for many use-cases. It looks like this:
{% for message in messages %}
{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
{% endfor %}
If you like this one, here it is in one-liner form, ready to copy into your code. The one-liner also includes
handy support for "generation prompts" - see the next section for more!
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
This template wraps each message in `<|im_start|>` and `<|im_end|>` tokens, and simply writes the role as a string, which
allows for flexibility in the roles you train with. The output looks like this:
```text
<|im_start|>system
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I'm doing great!<|im_end|>
The "user", "system" and "assistant" roles are the standard for chat, and we recommend using them when it makes sense,
particularly if you want your model to operate well with [`ConversationalPipeline`]. However, you are not limited
to these roles - templating is extremely flexible, and any string can be a role.
### I want to add some chat templates! How should I get started?
If you have any chat models, you should set their `tokenizer.chat_template` attribute and test it using
[`~PreTrainedTokenizer.apply_chat_template`], then push the updated tokenizer to the Hub. This applies even if you're
not the model owner - if you're using a model with an empty chat template, or one that's still using the default class
template, please open a [pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions) to the model repository so that this attribute can be set properly!
Once the attribute is set, that's it, you're done! `tokenizer.apply_chat_template` will now work correctly for that
model, which means it is also automatically supported in places like `ConversationalPipeline`!
By ensuring that models have this attribute, we can make sure that the whole community gets to use the full power of
open-source models. Formatting mismatches have been haunting the field and silently harming performance for too long -
it's time to put an end to them!
## Advanced: Template writing tips
If you're unfamiliar with Jinja, we generally find that the easiest way to write a chat template is to first
write a short Python script that formats messages the way you want, and then convert that script into a template.
Remember that the template handler will receive the conversation history as a variable called `messages`. Each
message is a dictionary with two keys, `role` and `content`. You will be able to access `messages` in your template
just like you can in Python, which means you can loop over it with `{% for message in messages %}` or access
individual messages with, for example, `{{ messages[0] }}`.
You can also use the following tips to convert your code to Jinja:
### For loops
For loops in Jinja look like this:
{% for message in messages %}
{{ message['content'] }}
{% endfor %}
Note that whatever's inside the {{ expression block }} will be printed to the output. You can use operators like
`+` to combine strings inside expression blocks.
### If statements
If statements in Jinja look like this:
{% if message['role'] == 'user' %}
{{ message['content'] }}
{% endif %}
Note how where Python uses whitespace to mark the beginnings and ends of `for` and `if` blocks, Jinja requires you
to explicitly end them with `{% endfor %}` and `{% endif %}`.
### Special variables
Inside your template, you will have access to the list of `messages`, but you can also access several other special
variables. These include special tokens like `bos_token` and `eos_token`, as well as the `add_generation_prompt`
variable that we discussed above. You can also use the `loop` variable to access information about the current loop
iteration, for example using `{% if loop.last %}` to check if the current message is the last message in the
conversation. Here's an example that puts these ideas together to add a generation prompt at the end of the
conversation if add_generation_prompt is `True`:
{% if loop.last and add_generation_prompt %}
{{ bos_token + 'Assistant:\n' }}
{% endif %}
### Notes on whitespace
As much as possible, we've tried to get Jinja to ignore whitespace outside of {{ expressions }}. However, be aware
that Jinja is a general-purpose templating engine, and it may treat whitespace between blocks on the same line
as significant and print it to the output. We **strongly** recommend checking that your template isn't printing extra
spaces where it shouldn't be before you upload it! |
perf_torch_compile.md |
# Optimize inference using torch.compile()
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
## Benefits of torch.compile
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
`compile()` comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune` takes longer than `reduce-overhead` but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch` version 2.0.1.
## Benchmarking code
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
### Image Classification with ViT
thon
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
#### Object Detection with DETR
thon
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
#### Image Segmentation with Segformer
thon
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
Below you can find the list of the models we benchmarked.
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
Below you can find visualization of inference durations with and without `torch.compile()` and percentage improvements for each model in different hardware and batch sizes.
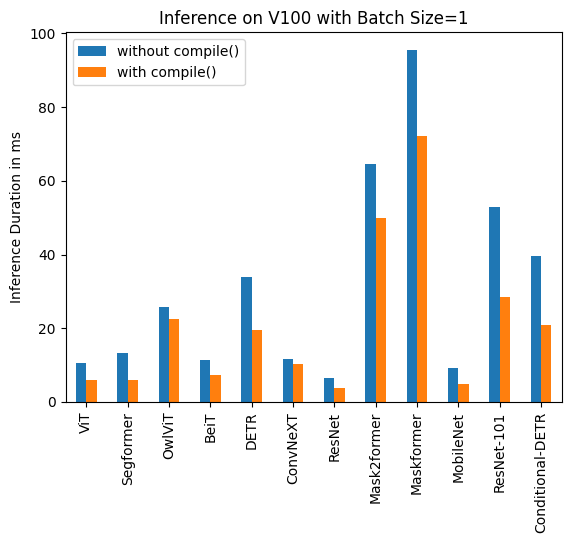
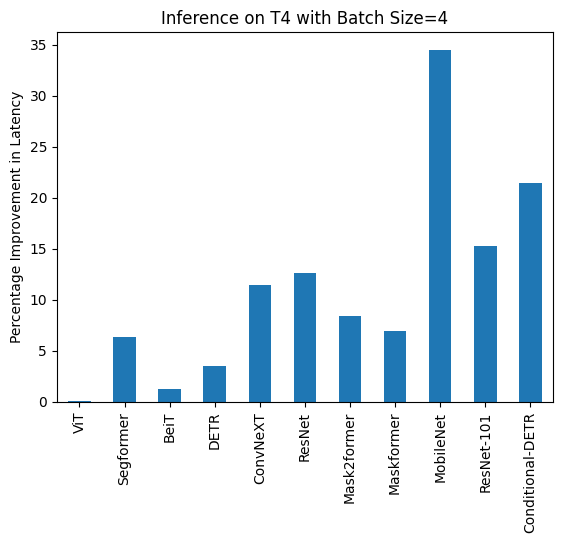
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## Reduce Overhead
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 - compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
hpo_train.md |
# Hyperparameter Search using Trainer API
🤗 Transformers provides a [`Trainer`] class optimized for training 🤗 Transformers models, making it easier to start training without manually writing your own training loop. The [`Trainer`] provides API for hyperparameter search. This doc shows how to enable it in example.
## Hyperparameter Search backend
[`Trainer`] supports four hyperparameter search backends currently:
[optuna](https://optuna.org/), [sigopt](https://sigopt.com/), [raytune](https://docs.ray.io/en/latest/tune/index.html) and [wandb](https://wandb.ai/site/sweeps).
you should install them before using them as the hyperparameter search backend
```bash
pip install optuna/sigopt/wandb/ray[tune]
## How to enable Hyperparameter search in example
Define the hyperparameter search space, different backends need different format.
For sigopt, see sigopt [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter), it's like following:
>>> def sigopt_hp_space(trial):
return [
{"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
{
"categorical_values": ["16", "32", "64", "128"],
"name": "per_device_train_batch_size",
"type": "categorical",
},
]
For optuna, see optuna [object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py), it's like following:
>>> def optuna_hp_space(trial):
return {
"learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
"per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
}
Optuna provides multi-objective HPO. You can pass `direction` in `hyperparameter_search` and define your own compute_objective to return multiple objective values. The Pareto Front (`List[BestRun]`) will be returned in hyperparameter_search, you should refer to the test case `TrainerHyperParameterMultiObjectOptunaIntegrationTest` in [test_trainer](https://github.com/huggingface/transformers/blob/main/tests/trainer/test_trainer.py). It's like following
>>> best_trials = trainer.hyperparameter_search(
direction=["minimize", "maximize"],
backend="optuna",
hp_space=optuna_hp_space,
n_trials=20,
compute_objective=compute_objective,
)
For raytune, see raytune [object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html), it's like following:
>>> def ray_hp_space(trial):
return {
"learning_rate": tune.loguniform(1e-6, 1e-4),
"per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
}
For wandb, see wandb [object_parameter](https://docs.wandb.ai/guides/sweeps/configuration), it's like following:
>>> def wandb_hp_space(trial):
return {
"method": "random",
"metric": {"name": "objective", "goal": "minimize"},
"parameters": {
"learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
"per_device_train_batch_size": {"values": [16, 32, 64, 128]},
},
}
Define a `model_init` function and pass it to the [`Trainer`], as an example:
>>> def model_init(trial):
return AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
Create a [`Trainer`] with your `model_init` function, training arguments, training and test datasets, and evaluation function:
>>> trainer = Trainer(
model=None,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
model_init=model_init,
data_collator=data_collator,
)
Call hyperparameter search, get the best trial parameters, backend could be `"optuna"`/`"sigopt"`/`"wandb"`/`"ray"`. direction can be`"minimize"` or `"maximize"`, which indicates whether to optimize greater or lower objective.
You could define your own compute_objective function, if not defined, the default compute_objective will be called, and the sum of eval metric like f1 is returned as objective value.
>>> best_trial = trainer.hyperparameter_search(
direction="maximize",
backend="optuna",
hp_space=optuna_hp_space,
n_trials=20,
compute_objective=compute_objective,
)
## Hyperparameter search For DDP finetune
Currently, Hyperparameter search for DDP is enabled for optuna and sigopt. Only the rank-zero process will generate the search trial and pass the argument to other ranks.
|
glossary.md |
# Glossary
This glossary defines general machine learning and 🤗 Transformers terms to help you better understand the
documentation.
## A
### attention mask
The attention mask is an optional argument used when batching sequences together.
This argument indicates to the model which tokens should be attended to, and which should not.
For example, consider these two sequences:
thon
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence_a = "This is a short sequence."
>>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
>>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
>>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
The encoded versions have different lengths:
thon
>>> len(encoded_sequence_a), len(encoded_sequence_b)
(8, 19)
Therefore, we can't put them together in the same tensor as-is. The first sequence needs to be padded up to the length
of the second one, or the second one needs to be truncated down to the length of the first one.
In the first case, the list of IDs will be extended by the padding indices. We can pass a list to the tokenizer and ask
it to pad like this:
thon
>>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
We can see that 0s have been added on the right of the first sentence to make it the same length as the second one:
thon
>>> padded_sequences["input_ids"]
[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
This can then be converted into a tensor in PyTorch or TensorFlow. The attention mask is a binary tensor indicating the
position of the padded indices so that the model does not attend to them. For the [`BertTokenizer`], `1` indicates a
value that should be attended to, while `0` indicates a padded value. This attention mask is in the dictionary returned
by the tokenizer under the key "attention_mask":
thon
>>> padded_sequences["attention_mask"]
[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
### autoencoding models
See [encoder models](#encoder-models) and [masked language modeling](#masked-language-modeling-mlm)
### autoregressive models
See [causal language modeling](#causal-language-modeling) and [decoder models](#decoder-models)
## B
### backbone
The backbone is the network (embeddings and layers) that outputs the raw hidden states or features. It is usually connected to a [head](#head) which accepts the features as its input to make a prediction. For example, [`ViTModel`] is a backbone without a specific head on top. Other models can also use [`VitModel`] as a backbone such as [DPT](model_doc/dpt).
## C
### causal language modeling
A pretraining task where the model reads the texts in order and has to predict the next word. It's usually done by
reading the whole sentence but using a mask inside the model to hide the future tokens at a certain timestep.
### channel
Color images are made up of some combination of values in three channels - red, green, and blue (RGB) - and grayscale images only have one channel. In 🤗 Transformers, the channel can be the first or last dimension of an image's tensor: [`n_channels`, `height`, `width`] or [`height`, `width`, `n_channels`].
### connectionist temporal classification (CTC)
An algorithm which allows a model to learn without knowing exactly how the input and output are aligned; CTC calculates the distribution of all possible outputs for a given input and chooses the most likely output from it. CTC is commonly used in speech recognition tasks because speech doesn't always cleanly align with the transcript for a variety of reasons such as a speaker's different speech rates.
### convolution
A type of layer in a neural network where the input matrix is multiplied element-wise by a smaller matrix (kernel or filter) and the values are summed up in a new matrix. This is known as a convolutional operation which is repeated over the entire input matrix. Each operation is applied to a different segment of the input matrix. Convolutional neural networks (CNNs) are commonly used in computer vision.
## D
### DataParallel (DP)
Parallelism technique for training on multiple GPUs where the same setup is replicated multiple times, with each instance
receiving a distinct data slice. The processing is done in parallel and all setups are synchronized at the end of each training step.
Learn more about how DataParallel works [here](perf_train_gpu_many#dataparallel-vs-distributeddataparallel).
### decoder input IDs
This input is specific to encoder-decoder models, and contains the input IDs that will be fed to the decoder. These
inputs should be used for sequence to sequence tasks, such as translation or summarization, and are usually built in a
way specific to each model.
Most encoder-decoder models (BART, T5) create their `decoder_input_ids` on their own from the `labels`. In such models,
passing the `labels` is the preferred way to handle training.
Please check each model's docs to see how they handle these input IDs for sequence to sequence training.
### decoder models
Also referred to as autoregressive models, decoder models involve a pretraining task (called causal language modeling) where the model reads the texts in order and has to predict the next word. It's usually done by
reading the whole sentence with a mask to hide future tokens at a certain timestep.
### deep learning (DL)
Machine learning algorithms which uses neural networks with several layers.
## E
### encoder models
Also known as autoencoding models, encoder models take an input (such as text or images) and transform them into a condensed numerical representation called an embedding. Oftentimes, encoder models are pretrained using techniques like [masked language modeling](#masked-language-modeling-mlm), which masks parts of the input sequence and forces the model to create more meaningful representations.
## F
### feature extraction
The process of selecting and transforming raw data into a set of features that are more informative and useful for machine learning algorithms. Some examples of feature extraction include transforming raw text into word embeddings and extracting important features such as edges or shapes from image/video data.
### feed forward chunking
In each residual attention block in transformers the self-attention layer is usually followed by 2 feed forward layers.
The intermediate embedding size of the feed forward layers is often bigger than the hidden size of the model (e.g., for
`bert-base-uncased`).
For an input of size `[batch_size, sequence_length]`, the memory required to store the intermediate feed forward
embeddings `[batch_size, sequence_length, config.intermediate_size]` can account for a large fraction of the memory
use. The authors of [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) noticed that since the
computation is independent of the `sequence_length` dimension, it is mathematically equivalent to compute the output
embeddings of both feed forward layers `[batch_size, config.hidden_size]_0, , [batch_size, config.hidden_size]_n`
individually and concat them afterward to `[batch_size, sequence_length, config.hidden_size]` with `n =
sequence_length`, which trades increased computation time against reduced memory use, but yields a mathematically
**equivalent** result.
For models employing the function [`apply_chunking_to_forward`], the `chunk_size` defines the number of output
embeddings that are computed in parallel and thus defines the trade-off between memory and time complexity. If
`chunk_size` is set to 0, no feed forward chunking is done.
### finetuned models
Finetuning is a form of transfer learning which involves taking a pretrained model, freezing its weights, and replacing the output layer with a newly added [model head](#head). The model head is trained on your target dataset.
See the [Fine-tune a pretrained model](https://huggingface.co/docs/transformers/training) tutorial for more details, and learn how to fine-tune models with 🤗 Transformers.
## H
### head
The model head refers to the last layer of a neural network that accepts the raw hidden states and projects them onto a different dimension. There is a different model head for each task. For example:
* [`GPT2ForSequenceClassification`] is a sequence classification head - a linear layer - on top of the base [`GPT2Model`].
* [`ViTForImageClassification`] is an image classification head - a linear layer on top of the final hidden state of the `CLS` token - on top of the base [`ViTModel`].
* [`Wav2Vec2ForCTC`] ia a language modeling head with [CTC](#connectionist-temporal-classification-(CTC)) on top of the base [`Wav2Vec2Model`].
## I
### image patch
Vision-based Transformers models split an image into smaller patches which are linearly embedded, and then passed as a sequence to the model. You can find the `patch_size` - or resolution - of the model in its configuration.
### inference
Inference is the process of evaluating a model on new data after training is complete. See the [Pipeline for inference](https://huggingface.co/docs/transformers/pipeline_tutorial) tutorial to learn how to perform inference with 🤗 Transformers.
### input IDs
The input ids are often the only required parameters to be passed to the model as input. They are token indices,
numerical representations of tokens building the sequences that will be used as input by the model.
Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
tokenizer, which is a [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) tokenizer:
thon
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence = "A Titan RTX has 24GB of VRAM"
The tokenizer takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
thon
>>> tokenized_sequence = tokenizer.tokenize(sequence)
The tokens are either words or subwords. Here for instance, "VRAM" wasn't in the model vocabulary, so it's been split
in "V", "RA" and "M". To indicate those tokens are not separate words but parts of the same word, a double-hash prefix
is added for "RA" and "M":
thon
>>> print(tokenized_sequence)
['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding
the sentence to the tokenizer, which leverages the Rust implementation of [🤗
Tokenizers](https://github.com/huggingface/tokenizers) for peak performance.
thon
>>> inputs = tokenizer(sequence)
The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly. The
token indices are under the key `input_ids`:
thon
>>> encoded_sequence = inputs["input_ids"]
>>> print(encoded_sequence)
[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
Note that the tokenizer automatically adds "special tokens" (if the associated model relies on them) which are special
IDs the model sometimes uses.
If we decode the previous sequence of ids,
thon
>>> decoded_sequence = tokenizer.decode(encoded_sequence)
we will see
thon
>>> print(decoded_sequence)
[CLS] A Titan RTX has 24GB of VRAM [SEP]
because this is the way a [`BertModel`] is going to expect its inputs.
## L
### labels
The labels are an optional argument which can be passed in order for the model to compute the loss itself. These labels
should be the expected prediction of the model: it will use the standard loss in order to compute the loss between its
predictions and the expected value (the label).
These labels are different according to the model head, for example:
- For sequence classification models, ([`BertForSequenceClassification`]), the model expects a tensor of dimension
`(batch_size)` with each value of the batch corresponding to the expected label of the entire sequence.
- For token classification models, ([`BertForTokenClassification`]), the model expects a tensor of dimension
`(batch_size, seq_length)` with each value corresponding to the expected label of each individual token.
- For masked language modeling, ([`BertForMaskedLM`]), the model expects a tensor of dimension `(batch_size,
seq_length)` with each value corresponding to the expected label of each individual token: the labels being the token
ID for the masked token, and values to be ignored for the rest (usually -100).
- For sequence to sequence tasks, ([`BartForConditionalGeneration`], [`MBartForConditionalGeneration`]), the model
expects a tensor of dimension `(batch_size, tgt_seq_length)` with each value corresponding to the target sequences
associated with each input sequence. During training, both BART and T5 will make the appropriate
`decoder_input_ids` and decoder attention masks internally. They usually do not need to be supplied. This does not
apply to models leveraging the Encoder-Decoder framework.
- For image classification models, ([`ViTForImageClassification`]), the model expects a tensor of dimension
`(batch_size)` with each value of the batch corresponding to the expected label of each individual image.
- For semantic segmentation models, ([`SegformerForSemanticSegmentation`]), the model expects a tensor of dimension
`(batch_size, height, width)` with each value of the batch corresponding to the expected label of each individual pixel.
- For object detection models, ([`DetrForObjectDetection`]), the model expects a list of dictionaries with a
`class_labels` and `boxes` key where each value of the batch corresponds to the expected label and number of bounding boxes of each individual image.
- For automatic speech recognition models, ([`Wav2Vec2ForCTC`]), the model expects a tensor of dimension `(batch_size,
target_length)` with each value corresponding to the expected label of each individual token.
Each model's labels may be different, so be sure to always check the documentation of each model for more information
about their specific labels!
The base models ([`BertModel`]) do not accept labels, as these are the base transformer models, simply outputting
features.
### large language models (LLM)
A generic term that refers to transformer language models (GPT-3, BLOOM, OPT) that were trained on a large quantity of data. These models also tend to have a large number of learnable parameters (e.g. 175 billion for GPT-3).
## M
### masked language modeling (MLM)
A pretraining task where the model sees a corrupted version of the texts, usually done by
masking some tokens randomly, and has to predict the original text.
### multimodal
A task that combines texts with another kind of inputs (for instance images).
## N
### Natural language generation (NLG)
All tasks related to generating text (for instance, [Write With Transformers](https://transformer.huggingface.co/), translation).
### Natural language processing (NLP)
A generic way to say "deal with texts".
### Natural language understanding (NLU)
All tasks related to understanding what is in a text (for instance classifying the
whole text, individual words).
## P
### pipeline
A pipeline in 🤗 Transformers is an abstraction referring to a series of steps that are executed in a specific order to preprocess and transform data and return a prediction from a model. Some example stages found in a pipeline might be data preprocessing, feature extraction, and normalization.
For more details, see [Pipelines for inference](https://huggingface.co/docs/transformers/pipeline_tutorial).
### PipelineParallel (PP)
Parallelism technique in which the model is split up vertically (layer-level) across multiple GPUs, so that only one or
several layers of the model are placed on a single GPU. Each GPU processes in parallel different stages of the pipeline
and working on a small chunk of the batch. Learn more about how PipelineParallel works [here](perf_train_gpu_many#from-naive-model-parallelism-to-pipeline-parallelism).
### pixel values
A tensor of the numerical representations of an image that is passed to a model. The pixel values have a shape of [`batch_size`, `num_channels`, `height`, `width`], and are generated from an image processor.
### pooling
An operation that reduces a matrix into a smaller matrix, either by taking the maximum or average of the pooled dimension(s). Pooling layers are commonly found between convolutional layers to downsample the feature representation.
### position IDs
Contrary to RNNs that have the position of each token embedded within them, transformers are unaware of the position of
each token. Therefore, the position IDs (`position_ids`) are used by the model to identify each token's position in the
list of tokens.
They are an optional parameter. If no `position_ids` are passed to the model, the IDs are automatically created as
absolute positional embeddings.
Absolute positional embeddings are selected in the range `[0, config.max_position_embeddings - 1]`. Some models use
other types of positional embeddings, such as sinusoidal position embeddings or relative position embeddings.
### preprocessing
The task of preparing raw data into a format that can be easily consumed by machine learning models. For example, text is typically preprocessed by tokenization. To gain a better idea of what preprocessing looks like for other input types, check out the [Preprocess](https://huggingface.co/docs/transformers/preprocessing) tutorial.
### pretrained model
A model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods involve a
self-supervised objective, which can be reading the text and trying to predict the next word (see [causal language
modeling](#causal-language-modeling)) or masking some words and trying to predict them (see [masked language
modeling](#masked-language-modeling-mlm)).
Speech and vision models have their own pretraining objectives. For example, Wav2Vec2 is a speech model pretrained on a contrastive task which requires the model to identify the "true" speech representation from a set of "false" speech representations. On the other hand, BEiT is a vision model pretrained on a masked image modeling task which masks some of the image patches and requires the model to predict the masked patches (similar to the masked language modeling objective).
## R
### recurrent neural network (RNN)
A type of model that uses a loop over a layer to process texts.
### representation learning
A subfield of machine learning which focuses on learning meaningful representations of raw data. Some examples of representation learning techniques include word embeddings, autoencoders, and Generative Adversarial Networks (GANs).
## S
### sampling rate
A measurement in hertz of the number of samples (the audio signal) taken per second. The sampling rate is a result of discretizing a continuous signal such as speech.
### self-attention
Each element of the input finds out which other elements of the input they should attend to.
### self-supervised learning
A category of machine learning techniques in which a model creates its own learning objective from unlabeled data. It differs from [unsupervised learning](#unsupervised-learning) and [supervised learning](#supervised-learning) in that the learning process is supervised, but not explicitly from the user.
One example of self-supervised learning is [masked language modeling](#masked-language-modeling-mlm), where a model is passed sentences with a proportion of its tokens removed and learns to predict the missing tokens.
### semi-supervised learning
A broad category of machine learning training techniques that leverages a small amount of labeled data with a larger quantity of unlabeled data to improve the accuracy of a model, unlike [supervised learning](#supervised-learning) and [unsupervised learning](#unsupervised-learning).
An example of a semi-supervised learning approach is "self-training", in which a model is trained on labeled data, and then used to make predictions on the unlabeled data. The portion of the unlabeled data that the model predicts with the most confidence gets added to the labeled dataset and used to retrain the model.
### sequence-to-sequence (seq2seq)
Models that generate a new sequence from an input, like translation models, or summarization models (such as
[Bart](model_doc/bart) or [T5](model_doc/t5)).
### Sharded DDP
Another name for the foundational [ZeRO](#zero-redundancy-optimizer--zero-) concept as used by various other implementations of ZeRO.
### stride
In [convolution](#convolution) or [pooling](#pooling), the stride refers to the distance the kernel is moved over a matrix. A stride of 1 means the kernel is moved one pixel over at a time, and a stride of 2 means the kernel is moved two pixels over at a time.
### supervised learning
A form of model training that directly uses labeled data to correct and instruct model performance. Data is fed into the model being trained, and its predictions are compared to the known labels. The model updates its weights based on how incorrect its predictions were, and the process is repeated to optimize model performance.
## T
### Tensor Parallelism (TP)
Parallelism technique for training on multiple GPUs in which each tensor is split up into multiple chunks, so instead of
having the whole tensor reside on a single GPU, each shard of the tensor resides on its designated GPU. Shards gets
processed separately and in parallel on different GPUs and the results are synced at the end of the processing step.
This is what is sometimes called horizontal parallelism, as the splitting happens on horizontal level.
Learn more about Tensor Parallelism [here](perf_train_gpu_many#tensor-parallelism).
### token
A part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords) or a
punctuation symbol.
### token Type IDs
Some models' purpose is to do classification on pairs of sentences or question answering.
These require two different sequences to be joined in a single "input_ids" entry, which usually is performed with the
help of special tokens, such as the classifier (`[CLS]`) and separator (`[SEP]`) tokens. For example, the BERT model
builds its two sequence input as such:
thon
>>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
We can use our tokenizer to automatically generate such a sentence by passing the two sequences to `tokenizer` as two
arguments (and not a list, like before) like this:
thon
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
>>> sequence_a = "HuggingFace is based in NYC"
>>> sequence_b = "Where is HuggingFace based?"
>>> encoded_dict = tokenizer(sequence_a, sequence_b)
>>> decoded = tokenizer.decode(encoded_dict["input_ids"])
which will return:
thon
>>> print(decoded)
[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
This is enough for some models to understand where one sequence ends and where another begins. However, other models,
such as BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying
the two types of sequence in the model.
The tokenizer returns this mask as the "token_type_ids" entry:
thon
>>> encoded_dict["token_type_ids"]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
The first sequence, the "context" used for the question, has all its tokens represented by a `0`, whereas the second
sequence, corresponding to the "question", has all its tokens represented by a `1`.
Some models, like [`XLNetModel`] use an additional token represented by a `2`.
### transfer learning
A technique that involves taking a pretrained model and adapting it to a dataset specific to your task. Instead of training a model from scratch, you can leverage knowledge obtained from an existing model as a starting point. This speeds up the learning process and reduces the amount of training data needed.
### transformer
Self-attention based deep learning model architecture.
## U
### unsupervised learning
A form of model training in which data provided to the model is not labeled. Unsupervised learning techniques leverage statistical information of the data distribution to find patterns useful for the task at hand.
## Z
### Zero Redundancy Optimizer (ZeRO)
Parallelism technique which performs sharding of the tensors somewhat similar to [TensorParallel](#tensorparallel--tp-),
except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need
to be modified. This method also supports various offloading techniques to compensate for limited GPU memory.
Learn more about ZeRO [here](perf_train_gpu_many#zero-data-parallelism). |
End of preview. Expand
in Dataset Viewer.
README.md exists but content is empty.
- Downloads last month
- 58