
metadata
license: cc0-1.0
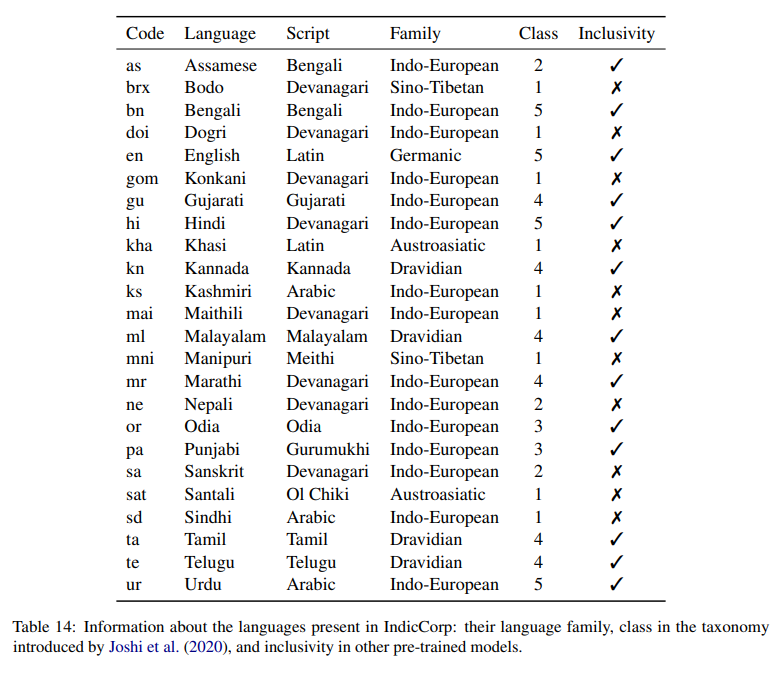
language:
- as
- brx
- bn
- doi
- en
- gom
- gu
- hi
- kha
- kn
- ks
- mai
- ml
- mni
- mr
- ne
- or
- pa
- sa
- sat
- sd
- ta
- te
- ur
task_categories:
- text-generation
IndicCorpv2
Github | Paper
Languages: 24
The largest collection of texts for Indic languages consisting of 20.9 billion tokens of which 14.4B tokens correspond to 23 Indic languages and 6.5B tokens of Indian English content curated from Indian websites.
Citation
@article{Doddapaneni2022towards,
title={Towards Leaving No Indic Language Behind: Building Monolingual Corpora, Benchmark and Models for Indic Languages},
author={Sumanth Doddapaneni and Rahul Aralikatte and Gowtham Ramesh and Shreyansh Goyal and Mitesh M. Khapra and Anoop Kunchukuttan and Pratyush Kumar},
journal={ArXiv},
year={2022},
volume={abs/2212.05409}
}