OPT
Overview
The OPT model was proposed in Open Pre-trained Transformer Language Models by Meta AI. OPT is a series of open-sourced large causal language models which perform similar in performance to GPT3.
The abstract from the paper is the following:
Large language models, which are often trained for hundreds of thousands of compute days, have shown remarkable capabilities for zero- and few-shot learning. Given their computational cost, these models are difficult to replicate without significant capital. For the few that are available through APIs, no access is granted to the full model weights, making them difficult to study. We present Open Pre-trained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters, which we aim to fully and responsibly share with interested researchers. We show that OPT-175B is comparable to GPT-3, while requiring only 1/7th the carbon footprint to develop. We are also releasing our logbook detailing the infrastructure challenges we faced, along with code for experimenting with all of the released models.
This model was contributed by Arthur Zucker, Younes Belkada, and Patrick Von Platen. The original code can be found here.
Tips:
- OPT has the same architecture as
BartDecoder. - Contrary to GPT2, OPT adds the EOS token
</s>to the beginning of every prompt.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with OPT. If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we will review it. The resource should ideally demonstrate something new instead of duplicating an existing resource.
- A notebook on fine-tuning OPT with PEFT, bitsandbytes, and Transformers. 🌎
- A blog post on decoding strategies with OPT.
- Causal language modeling chapter of the 🤗 Hugging Face Course.
- OPTForCausalLM is supported by this causal language modeling example script and notebook.
- TFOPTForCausalLM is supported by this causal language modeling example script and notebook.
- FlaxOPTForCausalLM is supported by this causal language modeling example script.
- Text classification task guide
- OPTForSequenceClassification is supported by this example script and notebook.
- OPTForQuestionAnswering is supported by this question answering example script and notebook.
- Question answering chapter of the 🤗 Hugging Face Course.
⚡️ Inference
- A blog post on How 🤗 Accelerate runs very large models thanks to PyTorch with OPT.
Combining OPT and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16“)
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> from transformers import OPTForCausalLM, GPT2Tokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
"Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
"there?")
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'</s>A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'Expected speedups
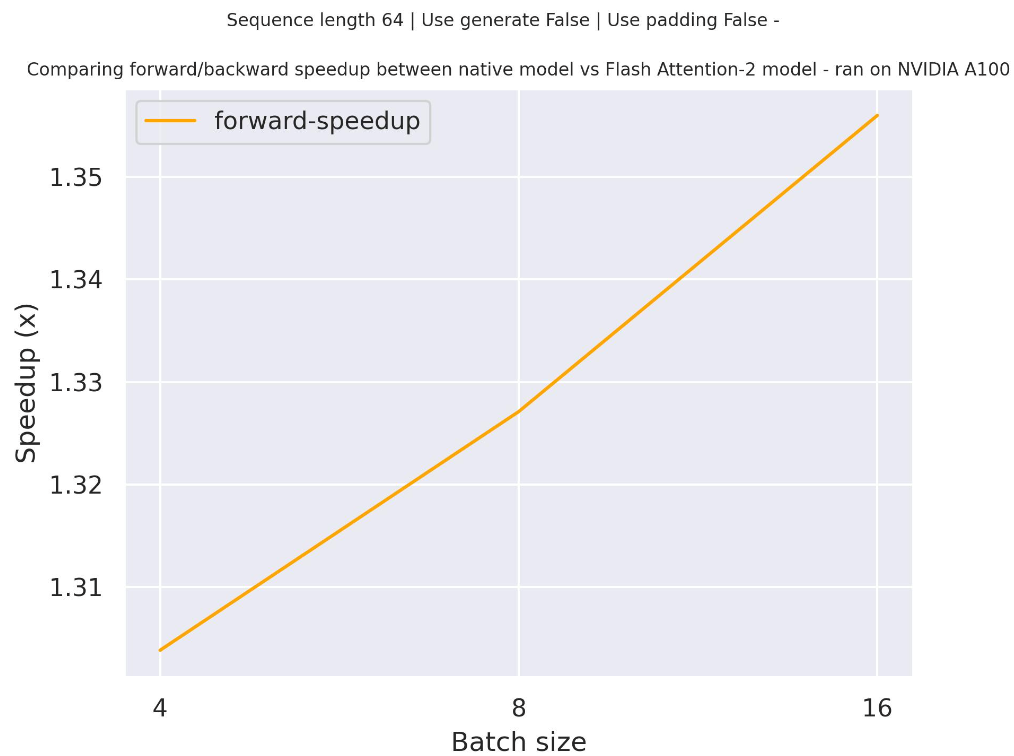
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using facebook/opt-2.7b checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
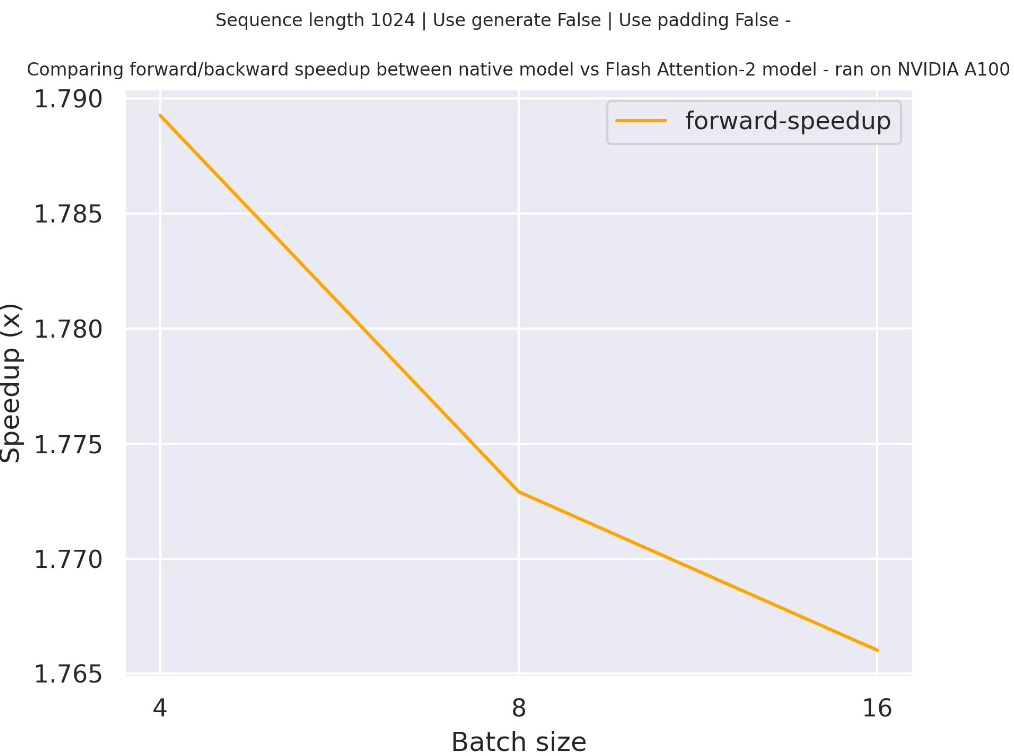
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using facebook/opt-350m checkpoint and the Flash Attention 2 version of the model using two different sequence lengths.
Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of torch.nn.functional. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
official documentation
or the GPU Inference
page for more information.
SDPA is used by default for torch>=2.1.1 when an implementation is available, but you may also set
attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used.
from transformers import OPTForCausalLM
model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="sdpa")
...For the best speedups, we recommend loading the model in half-precision (e.g. torch.float16 or torch.bfloat16).
On a local benchmark (L40S-45GB, PyTorch 2.4.0, OS Debian GNU/Linux 11) using float16 with
facebook/opt-350m, we saw the
following speedups during training and inference.
Training
| batch_size | seq_len | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | sdpa peak mem (MB) | Mem saving (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 0.047 | 0.037 | 26.360 | 1474.611 | 1474.32 | 0.019 |
| 1 | 256 | 0.046 | 0.037 | 24.335 | 1498.541 | 1499.49 | -0.063 |
| 1 | 512 | 0.046 | 0.037 | 24.959 | 1973.544 | 1551.35 | 27.215 |
| 1 | 1024 | 0.062 | 0.038 | 65.135 | 4867.113 | 1698.35 | 186.578 |
| 1 | 2048 | 0.230 | 0.039 | 483.933 | 15662.224 | 2715.75 | 476.718 |
| 2 | 128 | 0.045 | 0.037 | 20.455 | 1498.164 | 1499.49 | -0.089 |
| 2 | 256 | 0.046 | 0.037 | 24.027 | 1569.367 | 1551.35 | 1.161 |
| 2 | 512 | 0.045 | 0.037 | 20.965 | 3257.074 | 1698.35 | 91.778 |
| 2 | 1024 | 0.122 | 0.038 | 225.958 | 9054.405 | 2715.75 | 233.403 |
| 2 | 2048 | 0.464 | 0.067 | 593.646 | 30572.058 | 4750.55 | 543.548 |
| 4 | 128 | 0.045 | 0.037 | 21.918 | 1549.448 | 1551.35 | -0.123 |
| 4 | 256 | 0.044 | 0.038 | 18.084 | 2451.768 | 1698.35 | 44.361 |
| 4 | 512 | 0.069 | 0.037 | 84.421 | 5833.180 | 2715.75 | 114.791 |
| 4 | 1024 | 0.262 | 0.062 | 319.475 | 17427.842 | 4750.55 | 266.860 |
| 4 | 2048 | OOM | 0.062 | Eager OOM | OOM | 4750.55 | Eager OOM |
| 8 | 128 | 0.044 | 0.037 | 18.436 | 2049.115 | 1697.78 | 20.694 |
| 8 | 256 | 0.048 | 0.036 | 32.887 | 4222.567 | 2715.75 | 55.484 |
| 8 | 512 | 0.153 | 0.06 | 154.862 | 10985.391 | 4750.55 | 131.245 |
| 8 | 1024 | 0.526 | 0.122 | 330.697 | 34175.763 | 8821.18 | 287.428 |
| 8 | 2048 | OOM | 0.122 | Eager OOM | OOM | 8821.18 | Eager OOM |
Inference
| batch_size | seq_len | Per token latency eager (ms) | Per token latency SDPA (ms) | Speedup (%) | Mem eager (MB) | Mem BT (MB) | Mem saved (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 11.634 | 8.647 | 34.546 | 717.676 | 717.674 | 0 |
| 1 | 256 | 11.593 | 8.86 | 30.851 | 742.852 | 742.845 | 0.001 |
| 1 | 512 | 11.515 | 8.816 | 30.614 | 798.232 | 799.593 | -0.17 |
| 1 | 1024 | 11.556 | 8.915 | 29.628 | 917.265 | 895.538 | 2.426 |
| 2 | 128 | 12.724 | 11.002 | 15.659 | 762.434 | 762.431 | 0 |
| 2 | 256 | 12.704 | 11.063 | 14.83 | 816.809 | 816.733 | 0.009 |
| 2 | 512 | 12.757 | 10.947 | 16.535 | 917.383 | 918.339 | -0.104 |
| 2 | 1024 | 13.018 | 11.018 | 18.147 | 1162.65 | 1114.81 | 4.291 |
| 4 | 128 | 12.739 | 10.959 | 16.243 | 856.335 | 856.483 | -0.017 |
| 4 | 256 | 12.718 | 10.837 | 17.355 | 957.298 | 957.674 | -0.039 |
| 4 | 512 | 12.813 | 10.822 | 18.393 | 1158.44 | 1158.45 | -0.001 |
| 4 | 1024 | 13.416 | 11.06 | 21.301 | 1653.42 | 1557.19 | 6.18 |
| 8 | 128 | 12.763 | 10.891 | 17.193 | 1036.13 | 1036.51 | -0.036 |
| 8 | 256 | 12.89 | 11.104 | 16.085 | 1236.98 | 1236.87 | 0.01 |
| 8 | 512 | 13.327 | 10.939 | 21.836 | 1642.29 | 1641.78 | 0.031 |
| 8 | 1024 | 15.181 | 11.175 | 35.848 | 2634.98 | 2443.35 | 7.843 |
OPTConfig
class transformers.OPTConfig
< source >( vocab_size = 50272 hidden_size = 768 num_hidden_layers = 12 ffn_dim = 3072 max_position_embeddings = 2048 do_layer_norm_before = True _remove_final_layer_norm = False word_embed_proj_dim = None dropout = 0.1 attention_dropout = 0.0 num_attention_heads = 12 activation_function = 'relu' layerdrop = 0.0 init_std = 0.02 use_cache = True pad_token_id = 1 bos_token_id = 2 eos_token_id = 2 enable_bias = True layer_norm_elementwise_affine = True **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 50272) — Vocabulary size of the OPT model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling OPTModel - hidden_size (
int, optional, defaults to 768) — Dimensionality of the layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of decoder layers. - ffn_dim (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (often named feed-forward) layer in decoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer decoder. - activation_function (
strorfunction, optional, defaults to"relu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","silu"and"gelu_new"are supported. - max_position_embeddings (
int, optional, defaults to 2048) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - do_layer_norm_before (
bool, optional, defaults toTrue) — Whether to perform layer normalization before the attention block. - word_embed_proj_dim (
int, optional) —word_embed_proj_dimcan be set to down-project word embeddings, e.g.opt-350m. Defaults tohidden_size. - dropout (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - layerdrop (
float, optional, defaults to 0.0) — The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more details. - init_std (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). - enable_bias (
bool, optional, defaults toTrue) — Whether or not if the linear layers in the attention blocks should use the bias term. - layer_norm_elementwise_affine (
bool, optional, defaults toTrue) — Whether or not if the layer norms should have learnable parameters.
This is the configuration class to store the configuration of a OPTModel. It is used to instantiate a OPT model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the OPT facebook/opt-350m architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import OPTConfig, OPTModel
>>> # Initializing a OPT facebook/opt-large style configuration
>>> configuration = OPTConfig()
>>> # Initializing a model (with random weights) from the facebook/opt-large style configuration
>>> model = OPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configOPTModel
class transformers.OPTModel
< source >( config: OPTConfig )
Parameters
- config (OPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare OPT Model outputting raw hidden-states without any specific head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.List[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.BaseModelOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. for padding use -1.
Returns
transformers.modeling_outputs.BaseModelOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (OPTConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and optionally ifconfig.is_encoder_decoder=True2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
config.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The OPTModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, OPTModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = OPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateOPTForCausalLM
forward
< source >( input_ids: LongTensor = None attention_mask: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.List[torch.FloatTensor]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.CausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.Tensorof shape(num_hidden_layers, num_attention_heads), optional) — Mask to nullify selected heads of the attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head). The two additional tensors are only required when the model is used as a decoder in a Sequence to Sequence model.Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. for padding use -1.
Returns
transformers.modeling_outputs.CausalLMOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.CausalLMOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (OPTConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head))Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Example:
>>> from transformers import AutoTokenizer, OPTForCausalLM
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = "Hey, are you conscious? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you conscious? Can you talk to me?\nI'm not conscious. I'm just a little bit of a weirdo."OPTForSequenceClassification
class transformers.OPTForSequenceClassification
< source >( config: OPTConfig )
Parameters
- config (OPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The OPT Model transformer with a sequence classification head on top (linear layer).
OPTForSequenceClassification uses the last token in order to do the classification, as other causal models (e.g. GPT-2) do.
Since it does classification on the last token, it requires to know the position of the last token. If a
pad_token_id is defined in the configuration, it finds the last token that is not a padding token in each row. If
no pad_token_id is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
padding tokens when inputs_embeds are passed instead of input_ids, it does the same (take the last value in
each row of the batch).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. for padding use -1. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (OPTConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head))Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The OPTForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example of single-label classification:
>>> import torch
>>> from transformers import AutoTokenizer, OPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("ArthurZ/opt-350m-dummy-sc")
>>> model = OPTForSequenceClassification.from_pretrained("ArthurZ/opt-350m-dummy-sc")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
'LABEL_0'
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OPTForSequenceClassification.from_pretrained("ArthurZ/opt-350m-dummy-sc", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
1.71Example of multi-label classification:
>>> import torch
>>> from transformers import AutoTokenizer, OPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("ArthurZ/opt-350m-dummy-sc")
>>> model = OPTForSequenceClassification.from_pretrained("ArthurZ/opt-350m-dummy-sc", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OPTForSequenceClassification.from_pretrained(
... "ArthurZ/opt-350m-dummy-sc", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossOPTForQuestionAnswering
class transformers.OPTForQuestionAnswering
< source >( config: OPTConfig )
Parameters
- config (OPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The OPT Model transformer with a span classification head on top for extractive question-answering tasks like SQuAD
(a linear layers on top of the hidden-states output to compute span start logits and span end logits).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.Tensor]]] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None start_positions: typing.Optional[torch.LongTensor] = None end_positions: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. for padding use -1. - start_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the start of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss. - end_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the end of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss.
Returns
transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.QuestionAnsweringModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (OPTConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Total span extraction loss is the sum of a Cross-Entropy for the start and end positions. -
start_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-start scores (before SoftMax). -
end_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-end scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The OPTForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, OPTForQuestionAnswering
>>> import torch
>>> torch.manual_seed(4)
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> # note: we are loading a OPTForQuestionAnswering from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random
>>> model = OPTForQuestionAnswering.from_pretrained("facebook/opt-350m")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> answer_offset = len(tokenizer(question)[0])
>>> predict_answer_tokens = inputs.input_ids[
... 0, answer_offset + answer_start_index : answer_offset + answer_end_index + 1
... ]
>>> predicted = tokenizer.decode(predict_answer_tokens)
>>> predicted
' a nice puppet'TFOPTModel
class transformers.TFOPTModel
< source >( config: OPTConfig **kwargs )
Parameters
- config (OPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare TF OPT Model outputting raw hidden-states without any specific head on top. This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_idsonly and nothing else:model(input_ids) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_ids, attention_mask])ormodel([input_ids, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None inputs_embeds: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False **kwargs ) → transformers.modeling_tf_outputs.TFBaseModelOutputWithPast or tuple(tf.Tensor)
Parameters
- input_ids (
tf.Tensorof shape({0})) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
tf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
tf.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- past_key_values (
Tuple[Tuple[tf.Tensor]]of lengthconfig.n_layers) — contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding. Ifpast_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - use_cache (
bool, optional, defaults toTrue) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). Set toFalseduring training,Trueduring generation - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults toFalse) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation).
Returns
transformers.modeling_tf_outputs.TFBaseModelOutputWithPast or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFBaseModelOutputWithPast or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (OPTConfig) and inputs.
-
last_hidden_state (
tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. -
past_key_values (
List[tf.Tensor], optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — List oftf.Tensorof lengthconfig.n_layers, with each tensor of shape(2, batch_size, num_heads, sequence_length, embed_size_per_head)).Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFOPTModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, TFOPTModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = TFOPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFOPTForCausalLM
class transformers.TFOPTForCausalLM
< source >( config: OPTConfig **kwargs )
Parameters
- config (OPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The OPT Model transformer with a language modeling head on top.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_idsonly and nothing else:model(input_ids) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_ids, attention_mask])ormodel([input_ids, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_ids: TFModelInputType | None = None past_key_values: Optional[Tuple[Tuple[Union[np.ndarray, tf.Tensor]]]] = None attention_mask: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None labels: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False **kwargs ) → transformers.modeling_tf_outputs.TFCausalLMOutputWithPast or tuple(tf.Tensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- head_mask (
torch.Tensorof shape(num_hidden_layers, num_attention_heads), optional) — Mask to nullify selected heads of the attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head). The two additional tensors are only required when the model is used as a decoder in a Sequence to Sequence model.Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFCausalLMOutputWithPast or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (OPTConfig) and inputs.
-
loss (
tf.Tensorof shape(n,), optional, where n is the number of non-masked labels, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
List[tf.Tensor], optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — List oftf.Tensorof lengthconfig.n_layers, with each tensor of shape(2, batch_size, num_heads, sequence_length, embed_size_per_head)).Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast or tuple(tf.Tensor): A transformers.modeling_tf_outputs.TFCausalLMOutputWithPast or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (OPTConfig) and inputs.
-
loss (
tf.Tensorof shape(n,), optional, where n is the number of non-masked labels, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
List[tf.Tensor], optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — List oftf.Tensorof lengthconfig.n_layers, with each tensor of shape(2, batch_size, num_heads, sequence_length, embed_size_per_head)).Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Example:
>>> from transformers import AutoTokenizer, TFOPTForCausalLM
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = TFOPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> logits = outputs.logitsFlaxOPTModel
class transformers.FlaxOPTModel
< source >( config: OPTConfig input_shape: typing.Tuple[int] = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
__call__
< source >( input_ids: Array attention_mask: typing.Optional[jax.Array] = None position_ids: typing.Optional[jax.Array] = None params: dict = None past_key_values: dict = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None dropout_rng: <function PRNGKey at 0x7f50727b7640> = None deterministic: bool = True ) → transformers.modeling_flax_outputs.FlaxBaseModelOutput or tuple(torch.FloatTensor)
Returns
transformers.modeling_flax_outputs.FlaxBaseModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_flax_outputs.FlaxBaseModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (OPTConfig) and inputs.
-
last_hidden_state (
jnp.ndarrayof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Example:
>>> from transformers import AutoTokenizer, FlaxOPTModel
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = FlaxOPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateFlaxOPTForCausalLM
class transformers.FlaxOPTForCausalLM
< source >( config: OPTConfig input_shape: typing.Tuple[int] = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
Parameters
- config (OPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
- dtype (
jax.numpy.dtype, optional, defaults tojax.numpy.float32) — The data type of the computation. Can be one ofjax.numpy.float32,jax.numpy.float16(on GPUs) andjax.numpy.bfloat16(on TPUs).This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If specified all the computation will be performed with the given
dtype.Note that this only specifies the dtype of the computation and does not influence the dtype of model parameters.
If you wish to change the dtype of the model parameters, see to_fp16() and to_bf16().
OPT Model with a language modeling head on top (linear layer with weights tied to the input embeddings) e.g for autoregressive tasks.
This model inherits from FlaxPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a Flax Linen flax.nn.Module subclass. Use it as a regular Flax Module and refer to the Flax documentation for all matter related to general usage and behavior.
Finally, this model supports inherent JAX features such as:
__call__
< source >( input_ids: Array attention_mask: typing.Optional[jax.Array] = None position_ids: typing.Optional[jax.Array] = None params: dict = None past_key_values: dict = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None dropout_rng: <function PRNGKey at 0x7f50727b7640> = None deterministic: bool = True ) → transformers.modeling_flax_outputs.FlaxBaseModelOutput or tuple(torch.FloatTensor)
Returns
transformers.modeling_flax_outputs.FlaxBaseModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_flax_outputs.FlaxBaseModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (OPTConfig) and inputs.
-
last_hidden_state (
jnp.ndarrayof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(jnp.ndarray), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple ofjnp.ndarray(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(jnp.ndarray), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple ofjnp.ndarray(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Example:
>>> from transformers import AutoTokenizer, FlaxOPTForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = FlaxOPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]