
SigLIP
Collection
Contrastive (sigmoid) image-text models from https://arxiv.org/abs/2303.15343
•
10 items
•
Updated
•
63
SigLIP model pre-trained on WebLi at resolution 224x224. It was introduced in the paper Sigmoid Loss for Language Image Pre-Training by Zhai et al. and first released in this repository.
Disclaimer: The team releasing SigLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
SigLIP is CLIP, a multimodal model, with a better loss function. The sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. This allows further scaling up the batch size, while also performing better at smaller batch sizes.
A TLDR of SigLIP by one of the authors can be found here.
You can use the raw model for tasks like zero-shot image classification and image-text retrieval. See the model hub to look for other versions on a task that interests you.
Here is how to use this model to perform zero-shot image classification:
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a photo of 2 cats", "a photo of 2 dogs"]
inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image) # these are the probabilities
print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
Alternatively, one can leverage the pipeline API which abstracts away the complexity for the user:
from transformers import pipeline
from PIL import Image
import requests
# load pipe
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
print(outputs)
For more code examples, we refer to the documentation.
SigLIP is pre-trained on the English image-text pairs of the WebLI dataset (Chen et al., 2023).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
Texts are tokenized and padded to the same length (64 tokens).
The model was trained on 16 TPU-v4 chips for three days.
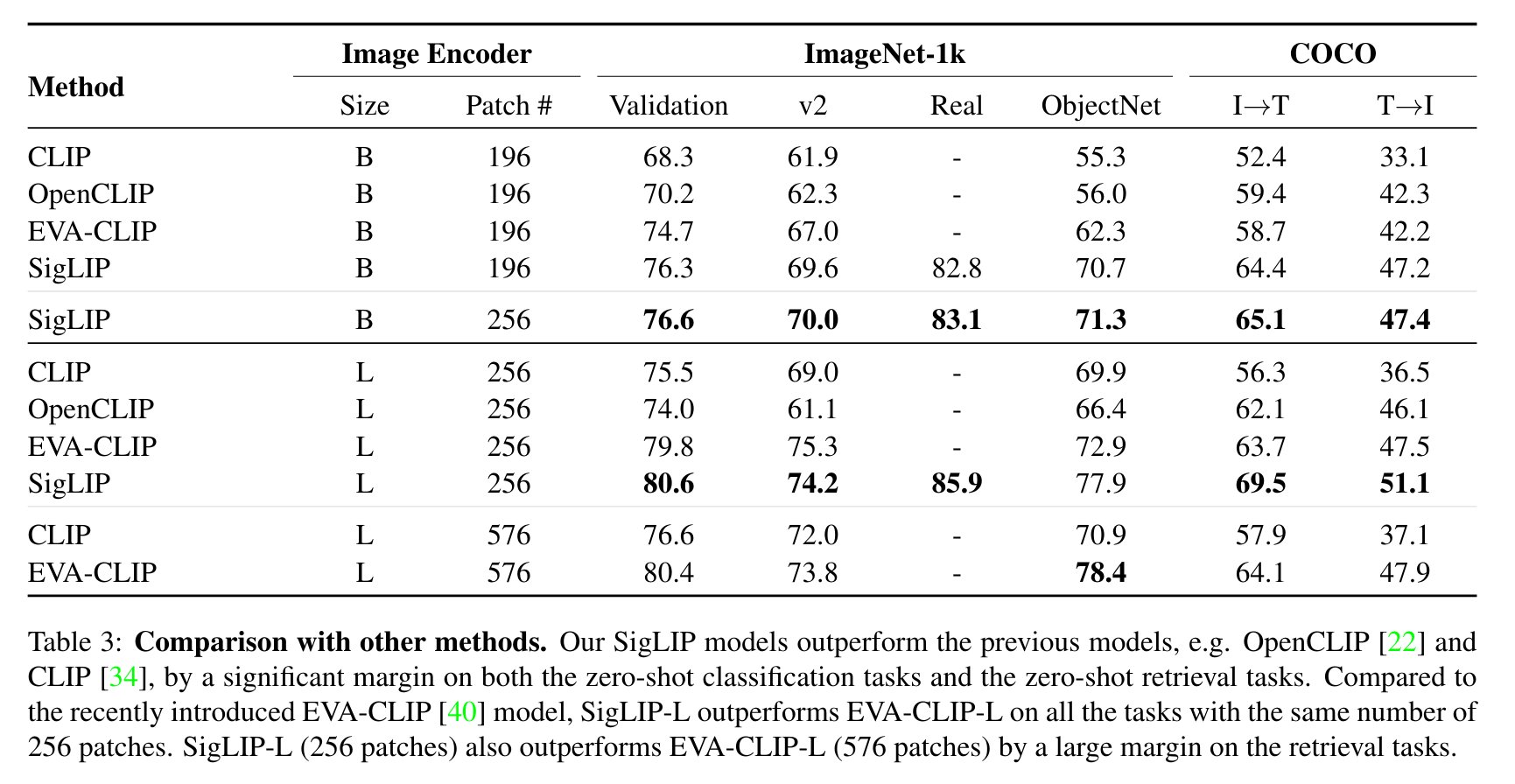
Evaluation of SigLIP compared to CLIP is shown below (taken from the paper).
@misc{zhai2023sigmoid,
title={Sigmoid Loss for Language Image Pre-Training},
author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},
year={2023},
eprint={2303.15343},
archivePrefix={arXiv},
primaryClass={cs.CV}
}