
aya-expanse-8b-awq-4bit
This repository contains a quantized version of the CohereForAI/aya-expanse-8b model using the AWQ method in 4-bit precision.
Model Summary
- Quantized Model: kevinbazira/aya-expanse-8b-awq-4bit
- Quantization Method: AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
- AWQ Version: GEMM
- Precision: 4-bit
- Original Model: CohereForAI/aya-expanse-8b
How to Use the Quantized Model
1. Install the necessary packages
Before using the quantized model, please ensure your environment has:
2. Run inference
Load and use the quantized model as shown below in Python:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, AwqConfig
# Set up device
device = torch.device('cuda:1') # Remember to use the correct device here
# Load model and tokenizer
model_name = "kevinbazira/aya-expanse-8b-awq-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_name)
quantization_config = AwqConfig(version="exllama")
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map={"": device.index},
quantization_config=quantization_config
)
# Prepare input
# https://huggingface.co/docs/transformers/en/pad_truncation
input_text = "Add your prompt here."
inputs = tokenizer(input_text, return_tensors="pt", truncation=True, padding="max_length", max_length=64)
inputs = {key: value.to(device) for key, value in inputs.items()}
# Perform text generation
# https://huggingface.co/docs/transformers/en/main_classes/text_generation
outputs = model.generate(
**inputs,
num_return_sequences=1,
min_new_tokens=64,
max_new_tokens=64,
do_sample=False,
use_cache=True,
num_beams=1
)
# Decode and print the output
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
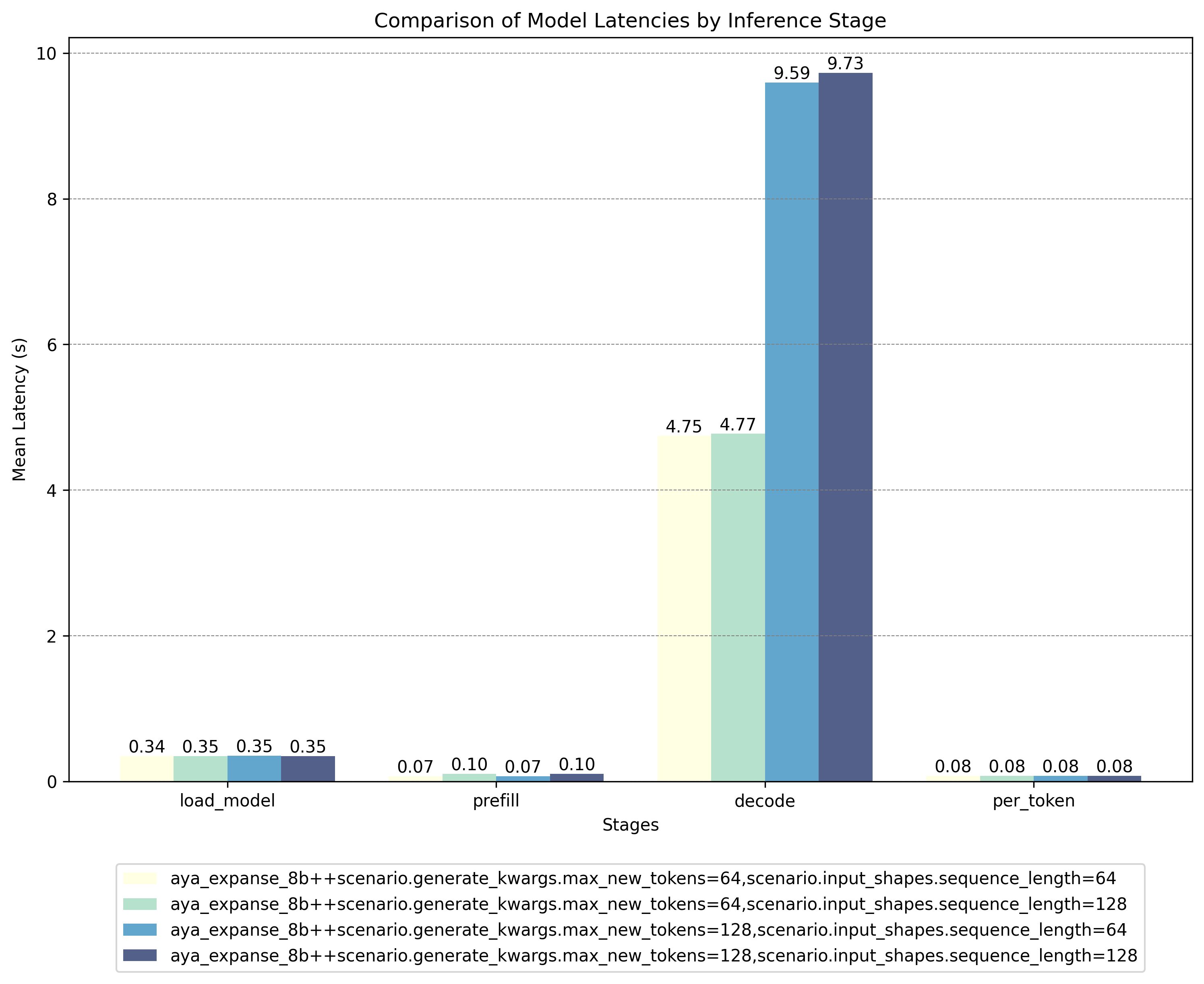
Benchmark Results
To evaluate the performance of the quantized model, we run benchmarks using the Hugging Face Optimum Benchmark tool on an AMD MI200 GPU with ROCm 6.1 and below are the results:
Unquantized Model Results:
AWQ Quantized Model Results:
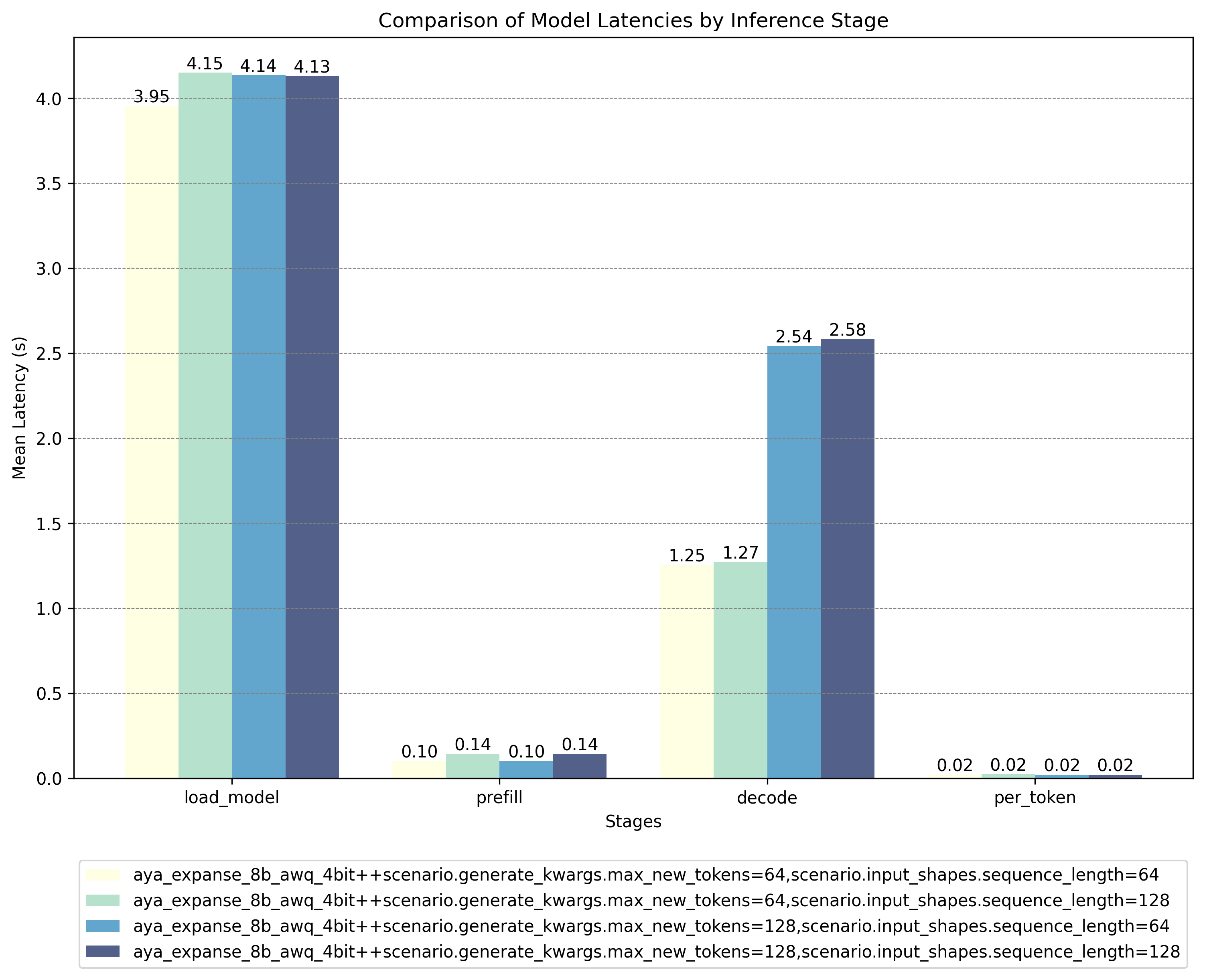
These results show that the AWQ quantized model offers significant speed advantages during critical inference stages (decode and per-token), outweighing the higher latencies encountered during the load and prefill phases. For deployment scenarios where inference speed is paramount, you can preload the quantized model to eliminate initial latency concerns.
More Information
- Original Model: For details about the original model's architecture, training dataset, and performance, please visit the CohereForAI aya-expanse-8b model card.
- Support or inquiries: If you run into any issues or have questions about the quantized model, feel free to reach me via email:
contact@kevinbazira.com. I'll be happy to help!
- Downloads last month
- 54
Model tree for kevinbazira/aya-expanse-8b-awq-4bit
Base model
CohereForAI/aya-expanse-8b