
nomic-embed-text-v1.5: Resizable Production Embeddings with Matryoshka Representation Learning
nomic-embed-text-v1.5 is an improvement upon Nomic Embed that utilizes Matryoshka Representation Learning which gives developers the flexibility to trade off the embedding size for a negligible reduction in performance.
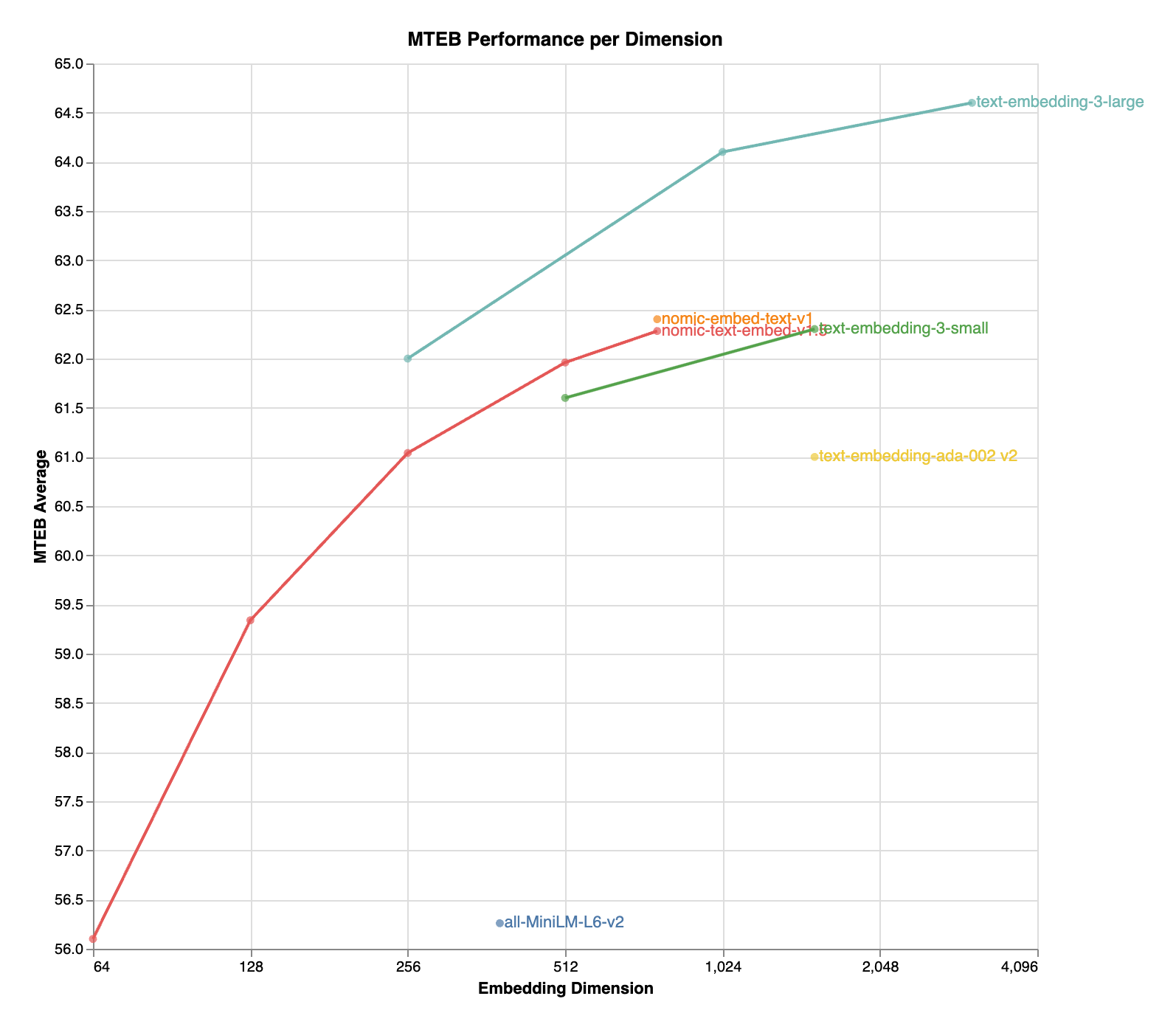
| Name | SeqLen | Dimension | MTEB |
|---|---|---|---|
| nomic-embed-text-v1 | 8192 | 768 | 62.39 |
| nomic-embed-text-v1.5 | 8192 | 768 | 62.28 |
| nomic-embed-text-v1.5 | 8192 | 512 | 61.96 |
| nomic-embed-text-v1.5 | 8192 | 256 | 61.04 |
| nomic-embed-text-v1.5 | 8192 | 128 | 59.34 |
| nomic-embed-text-v1.5 | 8192 | 64 | 56.10 |
Hosted Inference API
The easiest way to get started with Nomic Embed is through the Nomic Embedding API.
Generating embeddings with the nomic Python client is as easy as
from nomic import embed
output = embed.text(
texts=['Nomic Embedding API', '#keepAIOpen'],
model='nomic-embed-text-v1.5',
task_type='search_document',
dimensionality=256,
)
print(output)
For more information, see the API reference
Data Visualization
Click the Nomic Atlas map below to visualize a 5M sample of our contrastive pretraining data!

Training Details
We train our embedder using a multi-stage training pipeline. Starting from a long-context BERT model, the first unsupervised contrastive stage trains on a dataset generated from weakly related text pairs, such as question-answer pairs from forums like StackExchange and Quora, title-body pairs from Amazon reviews, and summarizations from news articles.
In the second finetuning stage, higher quality labeled datasets such as search queries and answers from web searches are leveraged. Data curation and hard-example mining is crucial in this stage.
For more details, see the Nomic Embed Technical Report and corresponding blog post.
Training data to train the models is released in its entirety. For more details, see the contrastors repository
Usage
Note nomic-embed-text requires prefixes! We support the prefixes [search_query, search_document, classification, clustering].
For retrieval applications, you should prepend search_document for all your documents and search_query for your queries.
Sentence Transformers
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
matryoshka_dim = 512
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
embeddings = model.encode(sentences, convert_to_tensor=True)
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)
Transformers
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?']
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1.5', trust_remote_code=True, safe_serialization=True)
model.eval()
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
+ matryoshka_dim = 512
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
+ embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
+ embeddings = embeddings[:, :matryoshka_dim]
embeddings = F.normalize(embeddings, p=2, dim=1)
print(embeddings)
The model natively supports scaling of the sequence length past 2048 tokens. To do so,
- tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
+ tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased', model_max_length=8192)
- model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1', trust_remote_code=True)
+ model = AutoModel.from_pretrained('nomic-ai/nomic-embed-text-v1', trust_remote_code=True, rotary_scaling_factor=2)
Transformers.js
import { pipeline, layer_norm } from '@xenova/transformers';
// Create a feature extraction pipeline
const extractor = await pipeline('feature-extraction', 'nomic-ai/nomic-embed-text-v1.5', {
quantized: false, // Comment out this line to use the quantized version
});
// Define sentences
const texts = ['search_query: What is TSNE?', 'search_query: Who is Laurens van der Maaten?'];
// Compute sentence embeddings
let embeddings = await extractor(texts, { pooling: 'mean' });
console.log(embeddings); // Tensor of shape [2, 768]
const matryoshka_dim = 512;
embeddings = layer_norm(embeddings, [embeddings.dims[1]])
.slice(null, [0, matryoshka_dim])
.normalize(2, -1);
console.log(embeddings.tolist());
Join the Nomic Community
- Nomic: https://nomic.ai
- Discord: https://discord.gg/myY5YDR8z8
- Twitter: https://twitter.com/nomic_ai
Citation
If you find the model, dataset, or training code useful, please cite our work
@misc{nussbaum2024nomic,
title={Nomic Embed: Training a Reproducible Long Context Text Embedder},
author={Zach Nussbaum and John X. Morris and Brandon Duderstadt and Andriy Mulyar},
year={2024},
eprint={2402.01613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 30
Spaces using lightbird-ai/nomic 2
Evaluation results
- accuracy on MTEB AmazonCounterfactualClassification (en)test set self-reported75.209
- ap on MTEB AmazonCounterfactualClassification (en)test set self-reported38.576
- f1 on MTEB AmazonCounterfactualClassification (en)test set self-reported69.356
- accuracy on MTEB AmazonPolarityClassificationtest set self-reported91.814
- ap on MTEB AmazonPolarityClassificationtest set self-reported88.652
- f1 on MTEB AmazonPolarityClassificationtest set self-reported91.804
- accuracy on MTEB AmazonReviewsClassification (en)test set self-reported47.162
- f1 on MTEB AmazonReviewsClassification (en)test set self-reported46.593
- map_at_1 on MTEB ArguAnatest set self-reported24.253
- map_at_10 on MTEB ArguAnatest set self-reported38.962