
Adding Conditional Control to Text-to-Image Diffusion Models
Paper
• 2302.05543 • Published
• 58
Controlnet v1.1 is the successor model of Controlnet v1.0 and was released in lllyasviel/ControlNet-v1-1 by Lvmin Zhang.
This checkpoint is a conversion of the original checkpoint into diffusers format.
It can be used in combination with Stable Diffusion, such as runwayml/stable-diffusion-v1-5.
For more details, please also have a look at the 🧨 Diffusers docs.
ControlNet is a neural network structure to control diffusion models by adding extra conditions.

This checkpoint corresponds to the ControlNet conditioned on openpose images.
Developed by: Lvmin Zhang, Maneesh Agrawala
Model type: Diffusion-based text-to-image generation model
Language(s): English
License: The CreativeML OpenRAIL M license is an Open RAIL M license, adapted from the work that BigScience and the RAIL Initiative are jointly carrying in the area of responsible AI licensing. See also the article about the BLOOM Open RAIL license on which our license is based.
Resources for more information: GitHub Repository, Paper.
Cite as:
@misc{zhang2023adding, title={Adding Conditional Control to Text-to-Image Diffusion Models}, author={Lvmin Zhang and Maneesh Agrawala}, year={2023}, eprint={2302.05543}, archivePrefix={arXiv}, primaryClass={cs.CV} }
Controlnet was proposed in Adding Conditional Control to Text-to-Image Diffusion Models by Lvmin Zhang, Maneesh Agrawala.
The abstract reads as follows:
We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.
It is recommended to use the checkpoint with Stable Diffusion v1-5 as the checkpoint has been trained on it. Experimentally, the checkpoint can be used with other diffusion models such as dreamboothed stable diffusion.
Note: If you want to process an image to create the auxiliary conditioning, external dependencies are required as shown below:
$ pip install controlnet_aux==0.3.0
diffusers and related packages:$ pip install diffusers transformers accelerate
import torch
import os
from huggingface_hub import HfApi
from pathlib import Path
from diffusers.utils import load_image
from PIL import Image
import numpy as np
from controlnet_aux import OpenposeDetector
from diffusers import (
ControlNetModel,
StableDiffusionControlNetPipeline,
UniPCMultistepScheduler,
)
checkpoint = "lllyasviel/control_v11p_sd15_openpose"
image = load_image(
"https://huggingface.co/lllyasviel/control_v11p_sd15_openpose/resolve/main/images/input.png"
)
prompt = "chef in the kitchen"
processor = OpenposeDetector.from_pretrained('lllyasviel/ControlNet')
control_image = processor(image, hand_and_face=True)
control_image.save("./images/control.png")
controlnet = ControlNetModel.from_pretrained(checkpoint, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=30, generator=generator, image=control_image).images[0]
image.save('images/image_out.png')



The authors released 14 different checkpoints, each trained with Stable Diffusion v1-5 on a different type of conditioning:
| Model Name | Control Image Overview | Control Image Example | Generated Image Example |
|---|---|---|---|
| lllyasviel/control_v11p_sd15_canny Trained with canny edge detection |
A monochrome image with white edges on a black background. |  |
 |
| lllyasviel/control_v11e_sd15_ip2p Trained with pixel to pixel instruction |
No condition . |  |
 |
| lllyasviel/control_v11p_sd15_inpaint Trained with image inpainting |
No condition. |  |
 |
| lllyasviel/control_v11p_sd15_mlsd Trained with multi-level line segment detection |
An image with annotated line segments. |  |
 |
| lllyasviel/control_v11f1p_sd15_depth Trained with depth estimation |
An image with depth information, usually represented as a grayscale image. |  |
 |
| lllyasviel/control_v11p_sd15_normalbae Trained with surface normal estimation |
An image with surface normal information, usually represented as a color-coded image. |  |
 |
| lllyasviel/control_v11p_sd15_seg Trained with image segmentation |
An image with segmented regions, usually represented as a color-coded image. |  |
 |
| lllyasviel/control_v11p_sd15_lineart Trained with line art generation |
An image with line art, usually black lines on a white background. |  |
 |
| lllyasviel/control_v11p_sd15s2_lineart_anime Trained with anime line art generation |
An image with anime-style line art. |  |
 |
| lllyasviel/control_v11p_sd15_openpose Trained with human pose estimation |
An image with human poses, usually represented as a set of keypoints or skeletons. | 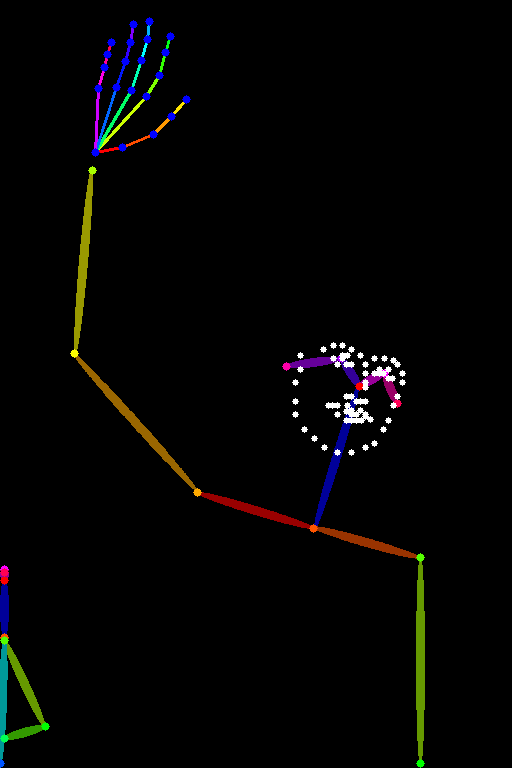 |
 |
| lllyasviel/control_v11p_sd15_scribble Trained with scribble-based image generation |
An image with scribbles, usually random or user-drawn strokes. |  |
 |
| lllyasviel/control_v11p_sd15_softedge Trained with soft edge image generation |
An image with soft edges, usually to create a more painterly or artistic effect. |  |
 |
| lllyasviel/control_v11e_sd15_shuffle Trained with image shuffling |
An image with shuffled patches or regions. |  |
 |
For more information, please also have a look at the Diffusers ControlNet Blog Post and have a look at the official docs.
Base model
runwayml/stable-diffusion-v1-5