

LongVA
🌐 Blog | 📃 Paper | 🤗 Hugging Face | 🎥 Demo
Long context capability can zero-shot transfer from language to vision.
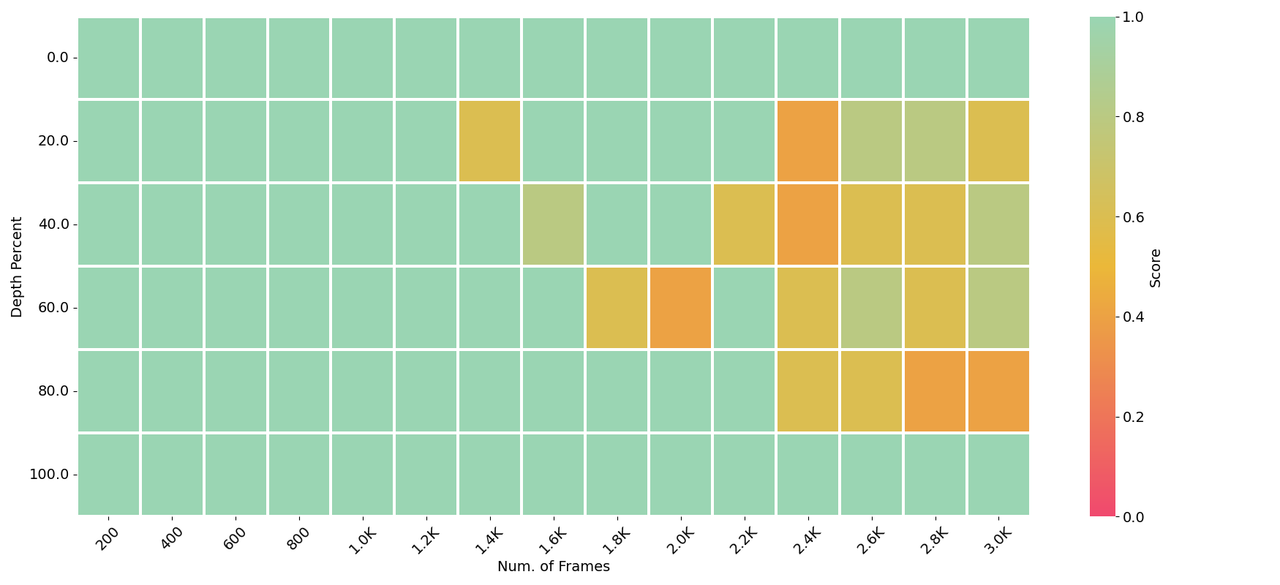
LongVA can process 2000 frames or over 200K visual tokens. It achieves state-of-the-art performance on Video-MME among 7B models.
Usage
First follow the instructions in our repo to install relevant packages.
from longva.model.builder import load_pretrained_model
from longva.mm_utils import tokenizer_image_token, process_images
from longva.constants import IMAGE_TOKEN_INDEX
from PIL import Image
from decord import VideoReader, cpu
import torch
import numpy as np
# fix seed
torch.manual_seed(0)
model_path = "lmms-lab/LongVA-7B-DPO"
image_path = "local_demo/assets/lmms-eval.png"
video_path = "local_demo/assets/dc_demo.mp4"
max_frames_num = 16 # you can change this to several thousands so long you GPU memory can handle it :)
gen_kwargs = {"do_sample": True, "temperature": 0.5, "top_p": None, "num_beams": 1, "use_cache": True, "max_new_tokens": 1024}
tokenizer, model, image_processor, _ = load_pretrained_model(model_path, None, "llava_qwen", device_map="cuda:0")
#image input
prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<image>\nDescribe the image in details.<|im_end|>\n<|im_start|>assistant\n"
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).to(model.device)
image = Image.open(image_path).convert("RGB")
images_tensor = process_images([image], image_processor, model.config).to(model.device, dtype=torch.float16)
with torch.inference_mode():
output_ids = model.generate(input_ids, images=images_tensor, image_sizes=[image.size], modalities=["image"], **gen_kwargs)
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
print(outputs)
print("-"*50)
#video input
prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<image>\nGive a detailed caption of the video as if I am blind.<|im_end|>\n<|im_start|>assistant\n"
input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors="pt").unsqueeze(0).to(model.device)
vr = VideoReader(video_path, ctx=cpu(0))
total_frame_num = len(vr)
uniform_sampled_frames = np.linspace(0, total_frame_num - 1, max_frames_num, dtype=int)
frame_idx = uniform_sampled_frames.tolist()
frames = vr.get_batch(frame_idx).asnumpy()
video_tensor = image_processor.preprocess(frames, return_tensors="pt")["pixel_values"].to(model.device, dtype=torch.float16)
with torch.inference_mode():
output_ids = model.generate(input_ids, images=[video_tensor], modalities=["video"], **gen_kwargs)
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
print(outputs)
License
This project utilizes certain datasets and checkpoints that are subject to their respective original licenses. Users must comply with all terms and conditions of these original licenses, including but not limited to the OpenAI Terms of Use for the dataset and the specific licenses for base language models (Qwen2 license). This project does not impose any additional constraints beyond those stipulated in the original licenses. Furthermore, users are reminded to ensure that their use of the dataset and checkpoints is in compliance with all applicable laws and regulations.