
library_name: transformers
license: apache-2.0
language:
- en
metrics:
- accuracy
pipeline_tag: image-classification
datasets:
- pcuenq/oxford-pets
Model Card for Model ID
Model Details
Model Description
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by: Mohammed Vasim
- Model type: Vision Transformer For Image Classification
- Finetuned from model [optional]: https://huggingface.co/google/vit-base-patch16-224
Model Sources [optional]
- Repository: https://huggingface.co/md-vasim/vit-base-patch16-224-finetuned-lora-oxford-pets
- Demo [optional]: https://md-vasim-vit-image-classification.hf.space/
Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale by Dosovitskiy et al. and first released in this repository. However, the weights were converted from the timm repository by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Model description
The pre-trained model is trained using LoRA method on custom dataset. The LoRA method is used to train the model with only trainable parameters.
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
What is LoRA
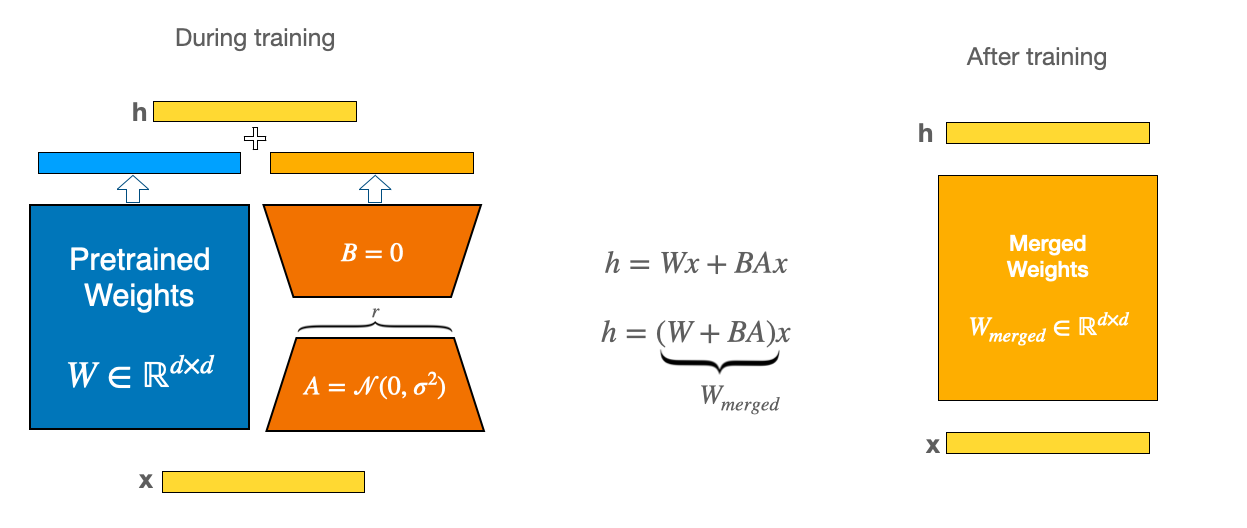
LoRA (Low-rank Optimization for Rapid Adaptation) is a parameter-efficient training method that utilizes low-rank decomposition to reduce the number of trainable parameters. Instead of updating the entire weight matrix, LoRA employs smaller matrices that adapt to new data while maintaining the original weight matrix.
To implement LoRA, we first freeze the pre-trained model weights and then insert trainable rank decomposition matrices into each layer of the transformer architecture. These matrices are much smaller than the original model weights and can capture the essential information for the adaptation. By multiplying the rank decomposition matrices with the frozen weights, we obtain a low-rank approximation of the adapted model weights. This way, we can reduce the number of trainable parameters by several orders of magnitude and also save GPU memory and inference time.
For example, let's suppose we have a pre-trained model with 100 million parameters and 50 layers, and we want to fine-tune the model. If we use LoRA, we can insert two rank decomposition matrices of size 100 x 10 and 10 x 100 into each layer of the model. By multiplying these matrices with the frozen weights, we can obtain a low-rank approximation of the adapted weights with only 2000 parameters per layer. This means that we can reduce the number of trainable parameters from 100 million to 2 million, which is a 50 times reduction. Moreover, we can also speed up the inference process by using the low-rank approximation instead of the original weights.
This approach offers several benefits:
- Reduced Trainable Parameters: LoRA significantly reduces the number of trainable parameters, leading to faster training and reduced memory consumption.
- Frozen Pre-trained Weights: The original weight matrix remains frozen, allowing it to be used as a foundation for multiple lightweight LoRA models. This facilitates efficient transfer learning and domain adaptation.
- Compatibility with Other Parameter-Efficient Methods: LoRA can be seamlessly integrated with other parameter-efficient techniques, such as knowledge distillation and pruning, further enhancing model efficiency.
- Comparable Performance: LoRA achieves performance comparable to fully fine-tuned models, demonstrating its effectiveness in preserving model accuracy despite reducing trainable parameters.
Let's examine the LoraConfig Parameters:
r: The rank of the update matrices, represented as an integer. Lower rank values result in smaller update matrices with fewer trainable parameters.target_modules: The modules (such as attention blocks) where the LoRA update matrices should be applied.alpha: The scaling factor for LoRA.layers_pattern: A pattern used to match layer names intarget_modulesiflayers_to_transformis specified. By default, Peft model will use a common layer pattern (layers, h, blocks, etc.). This pattern can also be used for exotic and custom models.rank_pattern: A mapping from layer names or regular expression expressions to ranks that differ from the default rank specified byr.alpha_pattern: A mapping from layer names or regular expression expressions to alphas that differ from the default alpha specified bylora_alpha.
Let's look at the components of the LoRA model:
- lora.Linear: LoRA adapts pre-trained models using a low-rank decomposition. It modifies the linear transformation layers (query, key, value) in the attention mechanism.
- base_layer: The original linear transformation.
- lora_dropout: Dropout applied to the LoRA parameters.
- lora_A: The matrix A in the low-rank decomposition.
- lora_B: The matrix B in the low-rank decomposition.
- lora_embedding_A/B: The learnable embeddings for LoRA.
Intended uses & limitations
You can use the raw model for image classification. See the model hub to look for fine-tuned versions on a task that interests you.
How to use
from transformers import ViTImageProcessor, ViTForImageClassification, AutoModelForImageClassification
from peft import PeftConfig, PeftModel
from PIL import Image
import requests
import torch
url = "https://huggingface.co/datasets/alanahmet/LoRA-pets-dataset/resolve/main/shiba_inu_136.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
repo_name = 'https://huggingface.co/md-vasim/vit-base-patch16-224-finetuned-lora-oxford-pets'
classes = ['chihuahua', 'newfoundland', 'english setter', 'Persian', 'yorkshire terrier', 'Maine Coon', 'boxer', 'leonberger', 'Birman', 'staffordshire bull terrier', 'Egyptian Mau', 'shiba inu', 'wheaten terrier', 'miniature pinscher', 'american pit bull terrier', 'Bombay', 'British Shorthair', 'german shorthaired', 'american bulldog', 'Abyssinian', 'great pyrenees', 'Siamese', 'Sphynx', 'english cocker spaniel', 'japanese chin', 'havanese', 'Russian Blue', 'saint bernard', 'samoyed', 'scottish terrier', 'keeshond', 'Bengal', 'Ragdoll', 'pomeranian', 'beagle', 'basset hound', 'pug']
label2id = {c:idx for idx,c in enumerate(classes)}
id2label = {idx:c for idx,c in enumerate(classes)}
config = PeftConfig.from_pretrained(repo_name)
model = AutoModelForImageClassification.from_pretrained(
config.base_model_name_or_path,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
)
# Load the Lora model
inference_model = PeftModel.from_pretrained(model, repo_name)
encoding = processor(image.convert("RGB"), return_tensors="pt")
with torch.no_grad():
outputs = inference_model(**encoding)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", inference_model.config.id2label[predicted_class_idx])
Training Arguments
batch_size = 128
args = TrainingArguments(
f"{model_checkpoint}-finetuned-lora-oxford-pets",
per_device_train_batch_size=batch_size,
learning_rate=5e-3,
num_train_epochs=5,
per_device_eval_batch_size=batch_size,
gradient_accumulation_steps=4,
logging_steps=10,
save_total_limit=2,
evaluation_strategy="epoch",
save_strategy="epoch",
metric_for_best_model="accuracy",
report_to='tensorboard',
fp16=True,
push_to_hub=True,
remove_unused_columns=False,
load_best_model_at_end=True,
)
For more code examples, we refer to the documentation.