
UniSpeech-Large-plus ITALIAN
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of Italian phonemes. When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
Paper: UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
Abstract In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
Usage
This is an speech model that has been fine-tuned on phoneme classification.
Inference
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
sample = next(iter(load_dataset("common_voice", "it", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# => 'm ɪ a n n o f a tː o ʊ n o f f ɛ r t a k e n o n p o t e v o p r ɔ p r i o r i f j ʊ t a r e'
# for "Mi hanno fatto un\'offerta che non potevo proprio rifiutare."
Evaluation
from datasets import load_dataset, load_metric
import datasets
import torch
from transformers import AutoModelForCTC, AutoProcessor
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
ds = load_dataset("mozilla-foundation/common_voice_3_0", "it", split="train+validation+test+other")
wer = load_metric("wer")
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
# taken from
# https://github.com/microsoft/UniSpeech/blob/main/UniSpeech/examples/unispeech/data/it/phonesMatches_reduced.json
with open("./testSeqs_uniform_new_version.text", "r") as f:
lines = f.readlines()
# retrieve ids model is evaluated on
ids = [x.split("\t")[0] for x in lines]
ds = ds.filter(lambda p: p.split("/")[-1].split(".")[0] in ids, input_columns=["path"])
ds = ds.cast_column("audio", datasets.Audio(sampling_rate=16_000))
def decode(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", sampling_rate=16_000)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, axis=-1)
batch["prediction"] = processor.batch_decode(pred_ids)
batch["target"] = processor.tokenizer.phonemize(batch["sentence"])
return batch
out = ds.map(decode, remove_columns=ds.column_names)
per = wer.compute(predictions=out["prediction"], references=out["target"])
print("per", per)
# -> should give per 0.06685252146070828 - compare to results below
Contribution
The model was contributed by cywang and patrickvonplaten.
License
The official license can be found here
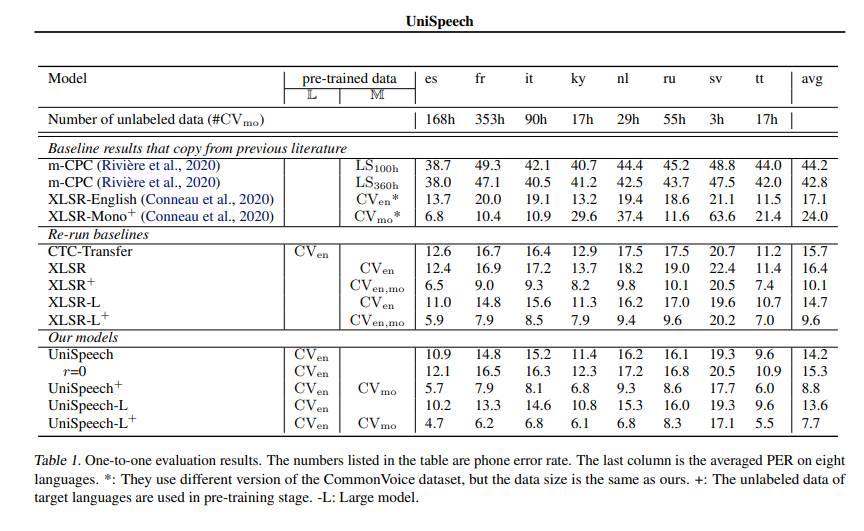
Official Results
See UniSpeeech-L^{+} - it:
- Downloads last month
- 61