
Vietnamese Self-Supervised Learning Wav2Vec2 model
Model
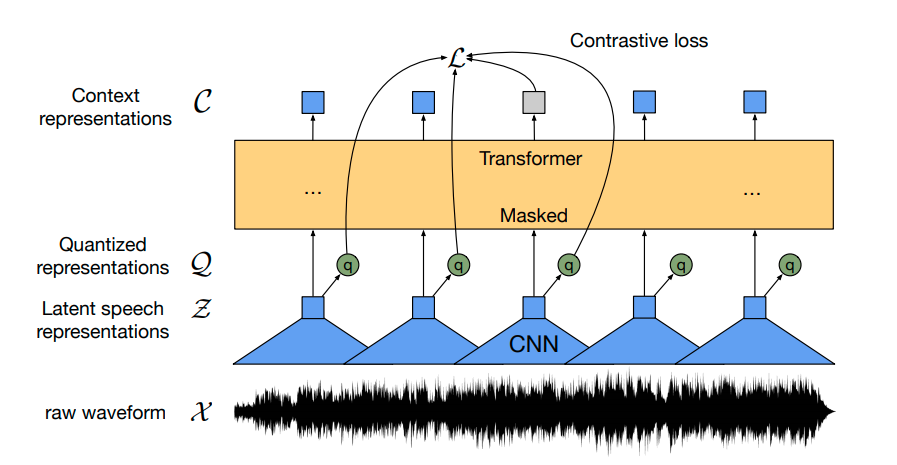
We use wav2vec2 architecture for doing Self-Supervised learning
Data
Our self-supervised model is pre-trained on a massive audio set of 13k hours of Vietnamese youtube audio, which includes:
- Clean audio
- Noise audio
- Conversation
- Multi-gender and dialects
Download
We have already upload our pre-trained model to the Huggingface. The base model trained 35 epochs and the large model trained 20 epochs in about 30 days using TPU V3-8.
- Based version ~ 95M params
- Large version ~ 317M params
Usage
from transformers import Wav2Vec2ForPreTraining, Wav2Vec2Processor
model_name = 'nguyenvulebinh/wav2vec2-base-vi'
# model_name = 'nguyenvulebinh/wav2vec2-large-vi'
model = Wav2Vec2ForPreTraining.from_pretrained(model_name)
processor = Wav2Vec2Processor.from_pretrained(model_name)
Since our model has the same architecture as the English wav2vec2 version, you can use this notebook for more information on how to fine-tune the model.
Finetuned version
VLSP 2020 ASR dataset
Benchmark WER result on VLSP T1 testset:
| base model | large model | |
|---|---|---|
| without LM | 8.66 | 6.90 |
| with 5-grams LM | 6.53 | 5.32 |
Usage
#pytorch
#!pip install transformers==4.20.0
#!pip install https://github.com/kpu/kenlm/archive/master.zip
#!pip install pyctcdecode==0.4.0
from transformers.file_utils import cached_path, hf_bucket_url
from importlib.machinery import SourceFileLoader
from transformers import Wav2Vec2ProcessorWithLM
from IPython.lib.display import Audio
import torchaudio
import torch
# Load model & processor
model_name = "nguyenvulebinh/wav2vec2-base-vi-vlsp2020"
# model_name = "nguyenvulebinh/wav2vec2-large-vi-vlsp2020"
model = SourceFileLoader("model", cached_path(hf_bucket_url(model_name,filename="model_handling.py"))).load_module().Wav2Vec2ForCTC.from_pretrained(model_name)
processor = Wav2Vec2ProcessorWithLM.from_pretrained(model_name)
# Load an example audio (16k)
audio, sample_rate = torchaudio.load(cached_path(hf_bucket_url(model_name, filename="t2_0000006682.wav")))
input_data = processor.feature_extractor(audio[0], sampling_rate=16000, return_tensors='pt')
# Infer
output = model(**input_data)
# Output transcript without LM
print(processor.tokenizer.decode(output.logits.argmax(dim=-1)[0].detach().cpu().numpy()))
# Output transcript with LM
print(processor.decode(output.logits.cpu().detach().numpy()[0], beam_width=100).text)
Acknowledgment
- We would like to thank the Google TPU Research Cloud (TRC) program and Soonson Kwon (Google ML Ecosystem programs Lead) for their support.
- Special thanks to my colleagues at VietAI and VAIS for their advice.
Contact
nguyenvulebinh@gmail.com / binh@vietai.org

- Downloads last month
- 186
Inference Providers
NEW
This model is not currently available via any of the supported third-party Inference Providers, and
HF Inference API was unable to determine this model’s pipeline type.