
Initial commit with model files
Browse files- README.md +498 -0
- config.json +24 -0
- config_sentence_transformers.json +10 -0
- config_setfit.json +8 -0
- model.safetensors +3 -0
- model_head.pkl +3 -0
- modules.json +20 -0
- sentence_bert_config.json +4 -0
- special_tokens_map.json +51 -0
- tokenizer.json +0 -0
- tokenizer_config.json +72 -0
- vocab.txt +0 -0
README.md
ADDED
|
@@ -0,0 +1,498 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: sentence-transformers/all-mpnet-base-v2
|
| 3 |
+
library_name: setfit
|
| 4 |
+
metrics:
|
| 5 |
+
- accuracy
|
| 6 |
+
pipeline_tag: text-classification
|
| 7 |
+
tags:
|
| 8 |
+
- setfit
|
| 9 |
+
- sentence-transformers
|
| 10 |
+
- text-classification
|
| 11 |
+
- generated_from_setfit_trainer
|
| 12 |
+
widget:
|
| 13 |
+
- text: "How to get single UnidirectionalSequenceRnnOp in tflite model ### Issue Type\r\
|
| 14 |
+
\n\r\nSupport\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\
|
| 15 |
+
\r\n2.8\r\n\r\n### Custom Code\r\n\r\nYes\r\n\r\n### OS Platform and Distribution\r\
|
| 16 |
+
\n\r\nUbuntu 18.04\r\n\r\nAccording to https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc\
|
| 17 |
+
\ there is `kUnidirectionalSequenceRnnOp` as a single operation in tflite, could\
|
| 18 |
+
\ you give a python code example - how can I get this? For example - this code\
|
| 19 |
+
\ for LSTM gives tflite with one UnidirectionalSequenceLSTM Op.\r\n```py\r\n#\
|
| 20 |
+
\ NOTE tested with TF 2.8.0\r\nimport tensorflow as tf\r\nimport numpy as np\r\
|
| 21 |
+
\n\r\nfrom tensorflow import keras\r\n\r\n\r\nmodel = keras.Sequential()\r\nshape\
|
| 22 |
+
\ = (4, 4)\r\n\r\nmodel.add(keras.layers.InputLayer(input_shape=shape, batch_size=1))\r\
|
| 23 |
+
\nmodel.add(keras.layers.LSTM(2, input_shape=shape))\r\n```\r\n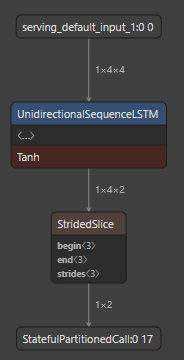\r\
|
| 24 |
+
\nHow can I do same for UnidirectionalSequenceRnn?"
|
| 25 |
+
- text: "[Feature Request] GELU activation with the Hexagon delegate **System information**\r\
|
| 26 |
+
\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04\r\n\
|
| 27 |
+
- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version\
|
| 28 |
+
\ (or github SHA if from source): 2.9.1\r\n\r\nI think I'd be able to implement\
|
| 29 |
+
\ this myself, but wanted to see if there was any interest in including this upstream.\
|
| 30 |
+
\ Most of this I'm writing out to make sure my own understanding is correct.\r\
|
| 31 |
+
\n\r\n### The problem\r\n\r\nI'd like to add support for the GELU op to the Hexagon\
|
| 32 |
+
\ Delegate. The motivation for this is mostly for use with [DistilBERT](https://huggingface.co/distilbert-base-multilingual-cased),\
|
| 33 |
+
\ which uses this activation function in its feedforward network layers. (Also\
|
| 34 |
+
\ used by BERT, GPT-3, RoBERTa, etc.)\r\n\r\nAdding this as a supported op for\
|
| 35 |
+
\ the Hexagon delegate would avoid creating a graph partition/transferring between\
|
| 36 |
+
\ DSP<-->CPU each time the GELU activation function is used.\r\n\r\n### How I'd\
|
| 37 |
+
\ implement this\r\n\r\nGELU in TF Lite is implemented as a lookup table when\
|
| 38 |
+
\ there are integer inputs ([here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/kernels/activations.cc#L120-L140)\
|
| 39 |
+
\ and [here](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/kernels/internal/reference/gelu.h#L37-L53)).\r\
|
| 40 |
+
\n\r\nThis same approach could be used for the Hexagon delegate, as it has int8/uint8\
|
| 41 |
+
\ data types and also supports lookup tables.\r\n\r\nI'd plan to do this by adding\
|
| 42 |
+
\ a new op builder in the delegate, populating a lookup table for each node as\
|
| 43 |
+
\ is currently done for the CPU version of the op, and then using the [Gather_8](https://source.codeaurora.org/quic/hexagon_nn/nnlib/tree/hexagon/ops/src/op_gather.c)\
|
| 44 |
+
\ nnlib library function to do the lookup.\r\n\r\n### Possible workaround\r\n\
|
| 45 |
+
\r\nA workaround I thought of:\r\n\r\nI'm going to try removing the [pattern matching](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/mlir/lite/transforms/optimize_patterns.td#L1034-L1095)\
|
| 46 |
+
\ for approximate GELU in MLIR, and then using the approximate version of GELU\
|
| 47 |
+
\ (so that using tanh and not Erf). This will probably be slower, but should\
|
| 48 |
+
\ let me keep execution on the DSP.\r\n\r\nSince this will then be tanh, addition,\
|
| 49 |
+
\ multiplication ops instead of GELU they should all be runnable by the DSP."
|
| 50 |
+
- text: "Data init API for TFLite Swift <details><summary>Click to expand!</summary>\
|
| 51 |
+
\ \n \n ### Issue Type\n\nFeature Request\n\n### Source\n\nsource\n\n### Tensorflow\
|
| 52 |
+
\ Version\n\n2.8+\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\
|
| 53 |
+
\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n\
|
| 54 |
+
_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\
|
| 55 |
+
\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and\
|
| 56 |
+
\ memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nThe current Swift\
|
| 57 |
+
\ API only has `init` functions from files on disk unlike the Java (Android) API\
|
| 58 |
+
\ which has a byte buffer initializer. It'd be convenient if the Swift API could\
|
| 59 |
+
\ initialize `Interpreters` from `Data`.\n```\n\n\n### Standalone code to reproduce\
|
| 60 |
+
\ the issue\n\n```shell\nNo code. This is a feature request\n```\n\n\n### Relevant\
|
| 61 |
+
\ log output\n\n_No response_</details>"
|
| 62 |
+
- text: "tf.distribute.MirroredStrategy for asynchronous training <details><summary>Click\
|
| 63 |
+
\ to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nFeature Request\r\n\r\n\
|
| 64 |
+
### Tensorflow Version\r\n\r\n2.8.1\r\n\r\n### Python version\r\n\r\n3.8.13\r\n\
|
| 65 |
+
\r\n### CUDA/cuDNN version\r\n\r\n11.8\r\n\r\n### Use Case\r\n\r\nI need to run\
|
| 66 |
+
\ multiple asynchronous copies of the same model on different slices of the dataset\
|
| 67 |
+
\ (e.g. with bootstrap sampling). There's no *good* way to do this in keras api\
|
| 68 |
+
\ that I'm aware of, although a couple of hacks exist. Would this use case be\
|
| 69 |
+
\ feasible with tf.distribute?\r\n\r\n### Feature Request\r\n\r\n`tf.distribute.MirroredStrategy`\
|
| 70 |
+
\ is a synchronous, data parallel strategy for distributed training across multiple\
|
| 71 |
+
\ devices on a single host worker.\r\n\r\nWould it be possible to modify this\
|
| 72 |
+
\ strategy to allow for asynchronous training of all model replicas, without computing\
|
| 73 |
+
\ the average gradient over all replicas to update weights? In this case each\
|
| 74 |
+
\ replica would need its own un-mirrored copy of model weights, and the update\
|
| 75 |
+
\ rule would depend only on the loss and gradients of each replica.\r\n\r\nThanks"
|
| 76 |
+
- text: "Build TensorFlow Lite for iOS failed!!!! Please go to Stack Overflow for\
|
| 77 |
+
\ help and support:\r\n\r\nhttps://stackoverflow.com/questions/tagged/tensorflow\r\
|
| 78 |
+
\n\r\nIf you open a GitHub issue, here is our policy:\r\n\r\n1. `bazel build --config=ios_arm64\
|
| 79 |
+
\ -c opt --cxxopt=--std=c++17 \\\\\r\n //tensorflow/lite/ios:TensorFlowLiteC_framework\r\
|
| 80 |
+
\n❯ bazel build --incompatible_run_shell_command_string=false --verbose_failures\
|
| 81 |
+
\ --config=ios_arm64 -c opt //tensorflow/lite/ios:TensorFlowLiteCMetal_framework\r\
|
| 82 |
+
\nINFO: Options provided by the client:\r\n Inherited 'common' options: --isatty=1\
|
| 83 |
+
\ --terminal_columns=170\r\nINFO: Reading rc options for 'build' from /Users/thao/Desktop/tensorflow/.bazelrc:\r\
|
| 84 |
+
\n Inherited 'common' options: --experimental_repo_remote_exec\r\nINFO: Reading\
|
| 85 |
+
\ rc options for 'build' from /Users/thao/Desktop/tensorflow/.bazelrc:\r\n 'build'\
|
| 86 |
+
\ options: --define framework_shared_object=true --define tsl_protobuf_header_only=true\
|
| 87 |
+
\ --define=use_fast_cpp_protos=true --define=allow_oversize_protos=true --spawn_strategy=standalone\
|
| 88 |
+
\ -c opt --announce_rc --define=grpc_no_ares=true --noincompatible_remove_legacy_whole_archive\
|
| 89 |
+
\ --enable_platform_specific_config --define=with_xla_support=true --config=short_logs\
|
| 90 |
+
\ --config=v2 --define=no_aws_support=true --define=no_hdfs_support=true --experimental_cc_shared_library\
|
| 91 |
+
\ --experimental_link_static_libraries_once=false\r\nINFO: Reading rc options\
|
| 92 |
+
\ for 'build' from /Users/thao/Desktop/tensorflow/.tf_configure.bazelrc:\r\n \
|
| 93 |
+
\ 'build' options: --action_env PYTHON_BIN_PATH=/Users/thao/miniforge3/bin/python\
|
| 94 |
+
\ --action_env PYTHON_LIB_PATH=/Users/thao/miniforge3/lib/python3.10/site-packages\
|
| 95 |
+
\ --python_path=/Users/thao/miniforge3/bin/python\r\nINFO: Reading rc options\
|
| 96 |
+
\ for 'build' from /Users/thao/Desktop/tensorflow/.bazelrc:\r\n 'build' options:\
|
| 97 |
+
\ --deleted_packages=tensorflow/compiler/mlir/tfrt,tensorflow/compiler/mlir/tfrt/benchmarks,tensorflow/compiler/mlir/tfrt/jit/python_binding,tensorflow/compiler/mlir/tfrt/jit/transforms,tensorflow/compiler/mlir/tfrt/python_tests,tensorflow/compiler/mlir/tfrt/tests,tensorflow/compiler/mlir/tfrt/tests/ir,tensorflow/compiler/mlir/tfrt/tests/analysis,tensorflow/compiler/mlir/tfrt/tests/jit,tensorflow/compiler/mlir/tfrt/tests/lhlo_to_tfrt,tensorflow/compiler/mlir/tfrt/tests/lhlo_to_jitrt,tensorflow/compiler/mlir/tfrt/tests/tf_to_corert,tensorflow/compiler/mlir/tfrt/tests/tf_to_tfrt_data,tensorflow/compiler/mlir/tfrt/tests/saved_model,tensorflow/compiler/mlir/tfrt/transforms/lhlo_gpu_to_tfrt_gpu,tensorflow/core/runtime_fallback,tensorflow/core/runtime_fallback/conversion,tensorflow/core/runtime_fallback/kernel,tensorflow/core/runtime_fallback/opdefs,tensorflow/core/runtime_fallback/runtime,tensorflow/core/runtime_fallback/util,tensorflow/core/tfrt/common,tensorflow/core/tfrt/eager,tensorflow/core/tfrt/eager/backends/cpu,tensorflow/core/tfrt/eager/backends/gpu,tensorflow/core/tfrt/eager/core_runtime,tensorflow/core/tfrt/eager/cpp_tests/core_runtime,tensorflow/core/tfrt/gpu,tensorflow/core/tfrt/run_handler_thread_pool,tensorflow/core/tfrt/runtime,tensorflow/core/tfrt/saved_model,tensorflow/core/tfrt/graph_executor,tensorflow/core/tfrt/saved_model/tests,tensorflow/core/tfrt/tpu,tensorflow/core/tfrt/utils\r\
|
| 98 |
+
\nINFO: Found applicable config definition build:short_logs in file /Users/thao/Desktop/tensorflow/.bazelrc:\
|
| 99 |
+
\ --output_filter=DONT_MATCH_ANYTHING\r\nINFO: Found applicable config definition\
|
| 100 |
+
\ build:v2 in file /Users/thao/Desktop/tensorflow/.bazelrc: --define=tf_api_version=2\
|
| 101 |
+
\ --action_env=TF2_BEHAVIOR=1\r\nINFO: Found applicable config definition build:ios_arm64\
|
| 102 |
+
\ in file /Users/thao/Desktop/tensorflow/.bazelrc: --config=ios --cpu=ios_arm64\r\
|
| 103 |
+
\nINFO: Found applicable config definition build:ios in file /Users/thao/Desktop/tensorflow/.bazelrc:\
|
| 104 |
+
\ --apple_platform_type=ios --apple_bitcode=embedded --copt=-fembed-bitcode --copt=-Wno-c++11-narrowing\
|
| 105 |
+
\ --noenable_platform_specific_config --copt=-w --cxxopt=-std=c++17 --host_cxxopt=-std=c++17\
|
| 106 |
+
\ --define=with_xla_support=false\r\nINFO: Build option --cxxopt has changed,\
|
| 107 |
+
\ discarding analysis cache.\r\nERROR: /private/var/tmp/_bazel_thao/26d40dc75f2c247e7283b353a9ab184f/external/local_config_cc/BUILD:48:19:\
|
| 108 |
+
\ in cc_toolchain_suite rule @local_config_cc//:toolchain: cc_toolchain_suite\
|
| 109 |
+
\ '@local_config_cc//:toolchain' does not contain a toolchain for cpu 'ios_arm64'\r\
|
| 110 |
+
\nERROR: /private/var/tmp/_bazel_thao/26d40dc75f2c247e7283b353a9ab184f/external/local_config_cc/BUILD:48:19:\
|
| 111 |
+
\ Analysis of target '@local_config_cc//:toolchain' failed\r\nERROR: Analysis\
|
| 112 |
+
\ of target '//tensorflow/lite/ios:TensorFlowLiteCMetal_framework' failed; build\
|
| 113 |
+
\ aborted: \r\nINFO: Elapsed time: 45.455s\r\nINFO: 0 processes.\r\nFAILED: Build\
|
| 114 |
+
\ did NOT complete successfully (66 packages loaded, 1118 targets configured)`\r\
|
| 115 |
+
\n\r\n**Here's why we have that policy**: TensorFlow developers respond to issues.\
|
| 116 |
+
\ We want to focus on work that benefits the whole community, e.g., fixing bugs\
|
| 117 |
+
\ and adding features. Support only helps individuals. GitHub also notifies thousands\
|
| 118 |
+
\ of people when issues are filed. We want them to see you communicating an interesting\
|
| 119 |
+
\ problem, rather than being redirected to Stack Overflow.\r\n\r\n------------------------\r\
|
| 120 |
+
\n\r\n### System information\r\nMacOS-M1Max : 13.3\r\nTensorflow:2.9.2\r\nPython:\
|
| 121 |
+
\ 3.10.0\r\n\r\n\r\n\r\n### Describe the problem\r\nDescribe the problem clearly\
|
| 122 |
+
\ here. Be sure to convey here why it's a bug in TensorFlow or a feature request.\r\
|
| 123 |
+
\n\r\n### Source code / logs\r\nInclude any logs or source code that would be\
|
| 124 |
+
\ helpful to diagnose the problem. If including tracebacks, please include the\
|
| 125 |
+
\ full traceback. Large logs and files should be attached. Try to provide a reproducible\
|
| 126 |
+
\ test case that is the bare minimum necessary to generate the problem.\r\n"
|
| 127 |
+
inference: true
|
| 128 |
+
---
|
| 129 |
+
|
| 130 |
+
# SetFit with sentence-transformers/all-mpnet-base-v2
|
| 131 |
+
|
| 132 |
+
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Text Classification. This SetFit model uses [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) as the Sentence Transformer embedding model. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
|
| 133 |
+
|
| 134 |
+
The model has been trained using an efficient few-shot learning technique that involves:
|
| 135 |
+
|
| 136 |
+
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
|
| 137 |
+
2. Training a classification head with features from the fine-tuned Sentence Transformer.
|
| 138 |
+
|
| 139 |
+
## Model Details
|
| 140 |
+
|
| 141 |
+
### Model Description
|
| 142 |
+
- **Model Type:** SetFit
|
| 143 |
+
- **Sentence Transformer body:** [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2)
|
| 144 |
+
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
|
| 145 |
+
- **Maximum Sequence Length:** 384 tokens
|
| 146 |
+
- **Number of Classes:** 3 classes
|
| 147 |
+
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
|
| 148 |
+
<!-- - **Language:** Unknown -->
|
| 149 |
+
<!-- - **License:** Unknown -->
|
| 150 |
+
|
| 151 |
+
### Model Sources
|
| 152 |
+
|
| 153 |
+
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
|
| 154 |
+
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
|
| 155 |
+
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
|
| 156 |
+
|
| 157 |
+
### Model Labels
|
| 158 |
+
| Label | Examples |
|
| 159 |
+
|:---------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
| 160 |
+
| question | <ul><li>"Parse output of `mobile_ssd_v2_float_coco.tflite` ### Issue type\n\nSupport\n\n### Have you reproduced the bug with TensorFlow Nightly?\n\nNo\n\n### Source\n\nsource\n\n### TensorFlow version\n\nv2.11.1\n\n### Custom code\n\nYes\n\n### OS platform and distribution\n\nLinux Ubuntu 20.04\n\n### Mobile device\n\nAndroid\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n6.2.0\n\n### GCC/compiler version\n\n12\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current behavior?\n\nI'm trying to use the model [mobile_ssd_v2_float_coco.tflite](https://storage.googleapis.com/download.tensorflow.org/models/tflite/gpu/mobile_ssd_v2_float_coco.tflite) on a C++ application, I'm able to execute the inference and get the results.\r\n\r\nBased on the Netron app I see that its output is:\r\n\r\n\r\nBut I couldn't find an example code showing how to parse this output.\r\n\r\nI tried to look into https://github.com/tensorflow/tensorflow/issues/29054 and https://github.com/tensorflow/tensorflow/issues/40298 but the output of the model is different from the one provided [here](https://storage.googleapis.com/download.tensorflow.org/models/tflite/gpu/mobile_ssd_v2_float_coco.tflite).\r\n\r\nDo you have any example code available in Java, Python, or even better in C++ to parse this model output?\n\n### Standalone code to reproduce the issue\n\n```shell\nNo example code is available to parse the output of mobile_ssd_v2_float_coco.tflite.\n```\n\n\n### Relevant log output\n\n_No response_"</li><li>'Tensorflow Lite library is crashing in WASM library at 3rd inference <details><summary>Click to expand!</summary> \r\n \r\n ### Issue Type\r\n\r\nSupport\r\n\r\n### Have you reproduced the bug with TF nightly?\r\n\r\nYes\r\n\r\n### Source\r\n\r\nsource\r\n\r\n### Tensorflow Version\r\n\r\n2.7.0\r\n\r\n### Custom Code\r\n\r\nYes\r\n\r\n### OS Platform and Distribution\r\n\r\nEmscripten, Ubuntu 18.04\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n_No response_\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\n```shell\r\nHello! I have C++ code that I want to deploy as WASM library and this code contains TFLite library. I have compiled TFLite library with XNNPack support using Emscripten toolchain quite easy, so no issue there. I have a leight-weight convolution+dense model that runs perfectly on Desktop, but I am starting having problems in the browser.\r\n\r\nIn 99% of cases I have an error on the third inference:\r\n\r\nUncaught RuntimeError: memory access out of bounds\r\n\r\nThrough some trivial debugging I have found out that the issue comes from _interpreter->Invoke() method. Does not matter if I put any input or not, I just need to call Invoke() three times and I have a crash.\r\n\r\nFirst thing first: I decided to add more memory to my WASM library by adding this line to CMake:\r\n\r\nSET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -s TOTAL_STACK=134217728 -s TOTAL_MEMORY=268435456")\r\nSET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -s TOTAL_STACK=134217728 -s TOTAL_MEMORY=268435456")\r\n\r\n128 MB and 256 MB in total for 1 MB model - I think this is more than enough. And on top of that, I am allowing Memory Growth. But unfortunately, I have exactly the same issue.\r\n\r\nI am beating on this problem for 2 weeks straight and at this stage I have no clue how to fix it. Also I have tried to set custom allocation using TfLiteCustomAllocation but in this case I have a crash on the very first inference. I guess I was not using it right, but unfortunately I couldn\'t find even one tutorial describing how to apply custom allocation in TFLite.\r\n\r\nI said that I have a crash in 99% of cases. There was one time when WASM library worked and inference worked as well. It happens just randomly once, and I couldn\'t reproduce it anymore.\r\n```\r\n\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```shell\r\nHere is the code that does TFLite inference\r\n\r\n\r\n#include <cstdlib>\r\n#include "tflite_model.h"\r\n#include <iostream>\r\n\r\n#include "tensorflow/lite/interpreter.h"\r\n#include "tensorflow/lite/util.h"\r\n\r\nnamespace tracker {\r\n\r\n#ifdef EMSCRIPTEN\r\n\tvoid TFLiteModel::init(std::stringstream& stream) {\r\n\r\n\t\tstd::string img_str = stream.str();\r\n\t\tstd::vector<char> img_model_data(img_str.size());\r\n\t\tstd::copy(img_str.begin(), img_str.end(), img_model_data.begin());\r\n\r\n\t\t_model = tflite::FlatBufferModel::BuildFromBuffer(img_str.data(), img_str.size());\r\n#else\r\n\tvoid TFLiteModel::init(const std::string& path) {\r\n\t\t_model = tflite::FlatBufferModel::BuildFromFile(path.c_str());\r\n\r\n#endif\r\n\r\n\t\ttflite::ops::builtin::BuiltinOpResolver resolver;\r\n\t\ttflite::InterpreterBuilder(*_model, resolver)(&_interpreter);\r\n\r\n\t\t_interpreter->AllocateTensors();\r\n\r\n\t\t/*for (int i = 0; i < _interpreter->tensors_size(); i++) {\r\n\t\t\tTfLiteTensor* tensor = _interpreter->tensor(i);\r\n\r\n\t\t\tif (tensor->allocation_type == kTfLiteArenaRw || tensor->allocation_type == kTfLiteArenaRwPersistent) {\r\n\r\n\t\t\t\tint aligned_bytes = tensor->bytes + (tflite::kDefaultTensorAlignment - tensor->bytes % tflite::kDefaultTensorAlignment) % tflite::kDefaultTensorAlignment;\r\n\r\n\t\t\t\tTfLiteCustomAllocation customAlloc;\r\n\t\t\t\tint result = posix_memalign(&customAlloc.data, tflite::kDefaultTensorAlignment, tensor->bytes);\r\n\t\t\t\tif (result != 0 || customAlloc.data == NULL) {\r\n\t\t\t\t\tstd::cout << "posix_memalign does not work!\\\\n";\r\n\t\t\t\t}\r\n\r\n\t\t\t\tTfLiteStatus st = _interpreter->SetCustomAllocationForTensor(i, customAlloc);\r\n\t\t\t\tstd::cout << "status = " << st << std::endl;\r\n\t\t\t\tif (tensor->bytes % tflite::kDefaultTensorAlignment != 0) {\r\n\t\t\t\t\tstd::cout << "bad! i " << i << ", size " << tensor->bytes << std::endl;\r\n\t\t\t\t}\r\n\t\t\t\t_allocations.push_back(customAlloc);\r\n\t\t\t}\r\n\t\t}\r\n\t\texit(0);*/\r\n\t}\r\n\r\n\tvoid TFLiteModel::forward(const cv::Mat& img_input, const std::vector<float>& lms_input) {\r\n\r\n\t\tfloat* model_in = _interpreter->typed_input_tensor<float>(0);\r\n\t\tstd::memcpy(model_in, img_input.data, img_input.total() * img_input.elemSize());\r\n\r\n\t\tfloat* lms_in = _interpreter->typed_input_tensor<float>(1);\r\n\t\tstd::memcpy(lms_in, lms_input.data(), sizeof(float) * lms_input.size());\r\n\t\t\r\n\t\t_interpreter->Invoke();\r\n\t}\r\n\r\n\tfloat* TFLiteModel::out() {\r\n\t\treturn _interpreter->typed_output_tensor<float>(0);\r\n\t}\r\n\r\n\tstd::vector<int> TFLiteModel::getOutputShape() const {\r\n\t\tTfLiteTensor* outtensor = _interpreter->output_tensor(0);\r\n\t\tTfLiteIntArray* dims = outtensor->dims;\r\n\r\n\t\tstd::vector<int> sh;\r\n\t\tfor (int i = 0; i < dims->size; i++) {\r\n\t\t\tsh.push_back(dims->data[i]);\r\n\t\t}\r\n\r\n\t\treturn sh;\r\n\t}\r\n}\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n_No response_</details>'</li><li>'error: \'tf.Conv2D\' op is neither a custom op nor a flex op ### 1. System information\r\n\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux Ubuntu 20.04\r\n- TensorFlow installation (pip package or built from source): pip package\r\n- TensorFlow library (version, if pip package or github SHA, if built from source): v2.10\r\n\r\n### 2. Code\r\nCode for conversion\r\n```\r\nconverter = tf.lite.TFLiteConverter.from_saved_model(f\'savedmodel/decoder\')\r\ntflite_model = converter.convert()\r\n\r\n# save the model\r\nwith open(f\'{name}.tflite\', \'wb\') as f:\r\n f.write(tflite_model)\r\n```\r\nCode for the model\r\n```\r\nlatent = keras.layers.Input((n_h, n_w, 4))\r\ndecoder = Decoder()\r\ndecoder = keras.models.Model(latent, decoder(latent))\r\n```\r\n```\r\nclass Decoder(keras.Sequential):\r\n def __init__(self):\r\n super().__init__(\r\n [\r\n keras.layers.Lambda(lambda x: 1 / 0.18215 * x),\r\n PaddedConv2D(4, 1),\r\n PaddedConv2D(512, 3, padding=1),\r\n ResnetBlock(512, 512),\r\n AttentionBlock(512),\r\n ResnetBlock(512, 512),\r\n ResnetBlock(512, 512),\r\n ResnetBlock(512, 512),\r\n ResnetBlock(512, 512),\r\n keras.layers.UpSampling2D(size=(2, 2)),\r\n PaddedConv2D(512, 3, padding=1),\r\n ResnetBlock(512, 512),\r\n ResnetBlock(512, 512),\r\n ResnetBlock(512, 512),\r\n keras.layers.UpSampling2D(size=(2, 2)),\r\n PaddedConv2D(512, 3, padding=1),\r\n ResnetBlock(512, 256),\r\n ResnetBlock(256, 256),\r\n ResnetBlock(256, 256),\r\n keras.layers.UpSampling2D(size=(2, 2)),\r\n PaddedConv2D(256, 3, padding=1),\r\n ResnetBlock(256, 128),\r\n ResnetBlock(128, 128),\r\n ResnetBlock(128, 128),\r\n tfa.layers.GroupNormalization(epsilon=1e-5),\r\n keras.layers.Activation("swish"),\r\n PaddedConv2D(3, 3, padding=1),\r\n ]\r\n )\r\n```\r\n\r\n### 3. Failure after conversion\r\nconversion fails\r\n\r\n\r\n### 5. (optional) Any other info / logs\r\n[error.log](https://github.com/tensorflow/tensorflow/files/10302790/error.log)\r\n```\r\nSome ops are not supported by the native TFLite runtime, you can enable TF kernels fallback using TF Select. See instructions: https://www.tensorflow.org/lite/guide/ops_select \r\nTF Select ops: Conv2D\r\nDetails:\r\n\ttf.Conv2D(tensor<?x?x?x?xf32>, tensor<1x1x512x512xf32>) -> (tensor<?x?x?x512xf32>) : {data_format = "NHWC", device = "", dilations = [1, 1, 1, 1], explicit_paddings = [], padding = "VALID", strides = [1, 1, 1, 1], use_cudnn_on_gpu = true}\r\n\ttf.Conv2D(tensor<?x?x?x?xf32>, tensor<3x3x128x128xf32>) -> (tensor<?x?x?x128xf32>) : {data_format = "NHWC", device = "", dilations = [1, 1, 1, 1], explicit_paddings = [], padding = "VALID", strides = [1, 1, 1, 1], use_cudnn_on_gpu = true}\r\n\ttf.Conv2D(tensor<?x?x?x?xf32>, tensor<3x3x128x3xf32>) -> (tensor<?x?x?x3xf32>) : {data_format = "NHWC", device = "", dilations = [1, 1, 1, 1], explicit_paddings = [], padding = "VALID", strides = [1, 1, 1, 1], use_cudnn_on_gpu = true}\r\n\ttf.Conv2D(tensor<?x?x?x?xf32>, tensor<3x3x256x128xf32>) -> (tensor<?x?x?x128xf32>) : {data_format = "NHWC", device = "", dilations = [1, 1, 1, 1], explicit_paddings = [], padding = "VALID", strides = [1, 1, 1, 1], use_cudnn_on_gpu = true}\r\n\ttf.Conv2D(tensor<?x?x?x?xf32>, tensor<3x3x256x256xf32>) -> (tensor<?x?x?x256xf32>) : {data_format = "NHWC", device = "", dilations = [1, 1, 1, 1], explicit_paddings = [], padding = "VALID", strides = [1, 1, 1, 1], use_cudnn_on_gpu = true}\r\n\ttf.Conv2D(tensor<?x?x?x?xf32>, tensor<3x3x512x256xf32>) -> (tensor<?x?x?x256xf32>) : {data_format = "NHWC", device = "", dilations = [1, 1, 1, 1], explicit_paddings = [], padding = "VALID", strides = [1, 1, 1, 1], use_cudnn_on_gpu = true}\r\n\ttf.Conv2D(tensor<?x?x?x?xf32>, tensor<3x3x512x512xf32>) -> (tensor<?x?x?x512xf32>) : {data_format = "NHWC", device = "", dilations = [1, 1, 1, 1], explicit_paddings = [], padding = "VALID", strides = [1, 1, 1, 1], use_cudnn_on_gpu = true}\r\n```\r\nAccording to the error message, I suspect that it can not recognize the input shape. But as you can see on the above code, input is specified for the functional API for `decoder` model. \r\n(FYI, The inference code is called with `predict_on_batch` method. I found out other model with `predict_on_batch` is converted successfully, but that model doesn\'t contain `conv2d` block inside. Can using `predict_on_batch` together with `conv2d` be a problem?)\r\n\r\n**I\'m sure `conv2d` is on the allowlist for TFLite operators. Any suggestions for this problem? Thank you.**'</li></ul> |
|
| 161 |
+
| feature | <ul><li>'tf.keras.optimizers.experimental.AdamW only support constant weight_decay <details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nFeature Request\n\n### Source\n\nsource\n\n### Tensorflow Version\n\n2.8\n\n### Custom Code\n\nNo\n\n### OS Platform and Distribution\n\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\ntf.keras.optimizers.experimental.AdamW only supports constant weight decay. But usually we want the weight_decay value to decay with learning rate schedule.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nThe legacy tfa.optimizers.AdamW supports callable weight_decay, which is much better.\n```\n\n\n### Relevant log output\n\n_No response_</details>'</li><li>'RFE tensorflow-aarch64==2.6.0 build ? **System information**\r\n TensorFlow version (you are using): 2.6.0\r\n- Are you willing to contribute it (Yes/No): Yes\r\n\r\n**Describe the feature and the current behavior/state.**\r\n\r\nBrainchip Akida AKD1000 SNN neuromorphic MetaTF SDK support 2.6.0 on x86_64. They claim support for aarch64, but when creating a virtualenv it fails on aarch64 due to lacking tensorflow-aarc64==2.6.0 build.\r\n\r\n**Will this change the current api? How?**\r\n\r\nNA\r\n\r\n**Who will benefit with this feature?**\r\n\r\nCustomer of Brainchip Akida who run on Arm64 platforms.\r\n\r\n**Any Other info.**\r\n\r\nhttps://doc.brainchipinc.com/installation.html\r\n\r\n\r\n'</li><li>"How to calculate 45 degree standing position of body from camera in swift (Pose estimation) <details><summary>Click to expand!</summary> \n \n ### Issue Type\n\nFeature Request\n\n### Source\n\nsource\n\n### Tensorflow Version\n\npod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['CoreML', 'Metal']\n\n### Custom Code\n\nYes\n\n### OS Platform and Distribution\n\n_No response_\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n_No response_\n\n### Bazel version\n\n_No response_\n\n### GCC/Compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current Behaviour?\n\n```shell\nHow to calculate 45 degree standing position of body from camera in swift.\n```\n\n\n### Standalone code to reproduce the issue\n\n```shell\nHow to calculate 45 degree standing position of body from camera in swift using the body keypoints. (Pose estimation)\n```\n\n\n### Relevant log output\n\n_No response_</details>"</li></ul> |
|
| 162 |
+
| bug | <ul><li>'Abort when running tensorflow.python.ops.gen_array_ops.depth_to_space ### Issue type\n\nBug\n\n### Have you reproduced the bug with TensorFlow Nightly?\n\nNo\n\n### Source\n\nbinary\n\n### TensorFlow version\n\n2.11.0\n\n### Custom code\n\nYes\n\n### OS platform and distribution\n\n22.04\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.9\n\n### Bazel version\n\n_No response_\n\n### GCC/compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\nnvidia-cudnn-cu11==8.6.0.163, cudatoolkit=11.8.0\n\n### GPU model and memory\n\n_No response_\n\n### Current behavior?\n\nDue to very large integer argument\n\n### Standalone code to reproduce the issue\n\n```shell\nimport tensorflow as tf\r\nimport os\r\nimport numpy as np\r\nfrom tensorflow.python.ops import gen_array_ops\r\ntry:\r\n arg_0_tensor = tf.random.uniform([3, 2, 3, 4], dtype=tf.float32)\r\n arg_0 = tf.identity(arg_0_tensor)\r\n arg_1 = 2147483647\r\n arg_2 = "NHWC"\r\n out = gen_array_ops.depth_to_space(arg_0,arg_1,arg_2,)\r\nexcept Exception as e:\r\n print("Error:"+str(e))\r\n\r\n```\n```\n\n\n### Relevant log output\n\n```shell\n023-08-13 00:23:53.644564: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.\r\n2023-08-13 00:23:54.491071: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.510564: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.510736: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.511051: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA\r\nTo enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\n2023-08-13 00:23:54.511595: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.511717: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.511830: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.572398: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.572634: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.572791: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:981] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\r\n2023-08-13 00:23:54.572916: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1613] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 153 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1660 Ti, pci bus id: 0000:01:00.0, compute capability: 7.5\r\n2023-08-13 00:23:54.594062: I tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:735] failed to allocate 153.88M (161349632 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory\r\n2023-08-13 00:23:54.594484: I tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:735] failed to allocate 138.49M (145214720 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory\r\n2023-08-13 00:23:54.600623: F tensorflow/core/framework/tensor_shape.cc:201] Non-OK-status: InitDims(dim_sizes) status: INVALID_ARGUMENT: Expected a non-negative size, got -2\r\nAborted\r\n\r\n```\n```\n'</li><li>"float8 (both e4m3fn and e5m2) missing from numbertype ### Issue Type\r\n\r\nBug\r\n\r\n### Have you reproduced the bug with TF nightly?\r\n\r\nNo\r\n\r\n### Source\r\n\r\nbinary\r\n\r\n### Tensorflow Version\r\n\r\n2.12.0\r\n\r\n### Custom Code\r\n\r\nYes\r\n\r\n### OS Platform and Distribution\r\n\r\nmacOS-13.2.1-arm64-arm-64bit\r\n\r\n### Mobile device\r\n\r\n_No response_\r\n\r\n### Python version\r\n\r\n3.9.6\r\n\r\n### Bazel version\r\n\r\n_No response_\r\n\r\n### GCC/Compiler version\r\n\r\n_No response_\r\n\r\n### CUDA/cuDNN version\r\n\r\n_No response_\r\n\r\n### GPU model and memory\r\n\r\n_No response_\r\n\r\n### Current Behaviour?\r\n\r\nFP8 datatypes are missing from `kNumberTypes` in `tensorflow/core/framework/types.h`, and also missing from `TF_CALL_FLOAT_TYPES(m)` in `tensorflow/core/framework/register_types.h`. This causes simple ops (like slice, transpose, split, etc.) to raise NotFoundError.\r\n\r\n### Standalone code to reproduce the issue\r\n\r\n```python\r\nimport tensorflow as tf\r\nfrom tensorflow.python.framework import dtypes\r\n\r\na = tf.constant([[1.2345678, 2.3456789, 3.4567891], [4.5678912, 5.6789123, 6.7891234]], dtype=dtypes.float16)\r\nprint(a)\r\n\r\na_fp8 = tf.cast(a, dtypes.float8_e4m3fn)\r\nprint(a_fp8)\r\n\r\nb = a_fp8[1:2] # tensorflow.python.framework.errors_impl.NotFoundError\r\nb = tf.transpose(a_fp8, [1, 0]) # tensorflow.python.framework.errors_impl.NotFoundError\r\n```\r\n\r\n\r\n### Relevant log output\r\n\r\n```\r\ntensorflow.python.framework.errors_impl.NotFoundError: Could not find device for node: {{node StridedSlice}} = StridedSlice[Index=DT_INT32, T=DT_FLOAT8_E4M3FN, begin_mask=0, ellipsis_mask=0, end_mask=0, new_axis_mask=0, shrink_axis_mask=0]\r\nAll kernels registered for op StridedSlice:\r\n device='XLA_CPU_JIT'; Index in [DT_INT32, DT_INT16, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT16, 930109355527764061, DT_HALF, DT_UINT32, DT_UINT64, DT_FLOAT8_E5M2, DT_FLOAT8_E4M3FN]\r\n device='CPU'; T in [DT_UINT64]\r\n device='CPU'; T in [DT_INT64]\r\n device='CPU'; T in [DT_UINT32]\r\n device='CPU'; T in [DT_UINT16]\r\n device='CPU'; T in [DT_INT16]\r\n device='CPU'; T in [DT_UINT8]\r\n device='CPU'; T in [DT_INT8]\r\n device='CPU'; T in [DT_INT32]\r\n device='CPU'; T in [DT_HALF]\r\n device='CPU'; T in [DT_BFLOAT16]\r\n device='CPU'; T in [DT_FLOAT]\r\n device='CPU'; T in [DT_DOUBLE]\r\n device='CPU'; T in [DT_COMPLEX64]\r\n device='CPU'; T in [DT_COMPLEX128]\r\n device='CPU'; T in [DT_BOOL]\r\n device='CPU'; T in [DT_STRING]\r\n device='CPU'; T in [DT_RESOURCE]\r\n device='CPU'; T in [DT_VARIANT]\r\n device='CPU'; T in [DT_QINT8]\r\n device='CPU'; T in [DT_QUINT8]\r\n device='CPU'; T in [DT_QINT32]\r\n device='DEFAULT'; T in [DT_INT32]\r\n [Op:StridedSlice] name: strided_slice/\r\n```\r\n\r\n```\r\ntensorflow.python.framework.errors_impl.NotFoundError: Could not find device for node: {{node Transpose}} = Transpose[T=DT_FLOAT8_E4M3FN, Tperm=DT_INT32]\r\nAll kernels registered for op Transpose:\r\n device='XLA_CPU_JIT'; Tperm in [DT_INT32, DT_INT64]; T in [DT_FLOAT, DT_DOUBLE, DT_INT32, DT_UINT8, DT_INT16, 930109355527764061, DT_HALF, DT_UINT32, DT_UINT64, DT_FLOAT8_E5M2, DT_FLOAT8_E4M3FN]\r\n device='CPU'; T in [DT_UINT64]\r\n device='CPU'; T in [DT_INT64]\r\n device='CPU'; T in [DT_UINT32]\r\n device='CPU'; T in [DT_UINT16]\r\n device='CPU'; T in [DT_INT16]\r\n device='CPU'; T in [DT_UINT8]\r\n device='CPU'; T in [DT_INT8]\r\n device='CPU'; T in [DT_INT32]\r\n device='CPU'; T in [DT_HALF]\r\n device='CPU'; T in [DT_BFLOAT16]\r\n device='CPU'; T in [DT_FLOAT]\r\n device='CPU'; T in [DT_DOUBLE]\r\n device='CPU'; T in [DT_COMPLEX64]\r\n device='CPU'; T in [DT_COMPLEX128]\r\n device='CPU'; T in [DT_BOOL]\r\n device='CPU'; T in [DT_STRING]\r\n device='CPU'; T in [DT_RESOURCE]\r\n device='CPU'; T in [DT_VARIANT]\r\n [Op:Transpose]\r\n```"</li><li>"My customized OP gives incorrect outputs on GPUs since `tf-nightly 2.13.0.dev20230413` ### Issue type\n\nBug\n\n### Have you reproduced the bug with TensorFlow Nightly?\n\nYes\n\n### Source\n\nbinary\n\n### TensorFlow version\n\n2.13\n\n### Custom code\n\nYes\n\n### OS platform and distribution\n\nfedora 36\n\n### Mobile device\n\n_No response_\n\n### Python version\n\n3.11.4\n\n### Bazel version\n\n_No response_\n\n### GCC/compiler version\n\n_No response_\n\n### CUDA/cuDNN version\n\n_No response_\n\n### GPU model and memory\n\n_No response_\n\n### Current behavior?\n\nI have a complex program based on TensorFlow with several customized OPs. These OPs were created following https://www.tensorflow.org/guide/create_op. Yesterday TF 2.13.0 was released, but after I upgraded to 2.13.0, I found that one of my customized OP gives incorrect results on GPUs and still has the correct outputs on CPUs.\r\n\r\nThen I tested many `tf-nightly` versions and found that `tf-nightly 2.13.0.dev20230412` works but `tf-nightly 2.13.0.dev20230413` fails. So the situation is shown in the following table:\r\n| version | CPU | GPU |\r\n| -------- | --------- | ----------- |\r\n| tensorflow 2.12.0 | Correct | Correct |\r\n| tensorflow 2.13.0 | Correct | Incorrect |\r\n| tf-nightly 2.13.0.dev20230412 | Correct | Correct |\r\n| tf-nightly 2.13.0.dev20230413 | Correct | Incorrect |\r\n\r\nI'd like to know what changed between April 12th and 13th related to the customized OPs. This can be a breaking change to downstream applications or an internal bug. Thanks!\r\n\r\nHere is a quick link for commits between April 12th and 13th:\r\nhttps://github.com/tensorflow/tensorflow/commits/master?before=525da8a93eca846e32e5c41eddc0496b25a2ef5b+770\r\n\n\n### Standalone code to reproduce the issue\n\n```shell\nIndeed, the reason is still unclear to me, so it is hard to create a minimal example.\r\n\r\nThe code of our customized OPs is https://github.com/deepmodeling/deepmd-kit/blob/37fd8d193362f91c925cf7c2f3a58b97dc921b27/source/op/prod_force_multi_device.cc#L49-L166\n```\n\n\n### Relevant log output\n\n_No response_"</li></ul> |
|
| 163 |
+
|
| 164 |
+
## Uses
|
| 165 |
+
|
| 166 |
+
### Direct Use for Inference
|
| 167 |
+
|
| 168 |
+
First install the SetFit library:
|
| 169 |
+
|
| 170 |
+
```bash
|
| 171 |
+
pip install setfit
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
Then you can load this model and run inference.
|
| 175 |
+
|
| 176 |
+
```python
|
| 177 |
+
from setfit import SetFitModel
|
| 178 |
+
|
| 179 |
+
# Download from the 🤗 Hub
|
| 180 |
+
model = SetFitModel.from_pretrained("setfit_model_id")
|
| 181 |
+
# Run inference
|
| 182 |
+
preds = model("Data init API for TFLite Swift <details><summary>Click to expand!</summary>
|
| 183 |
+
|
| 184 |
+
### Issue Type
|
| 185 |
+
|
| 186 |
+
Feature Request
|
| 187 |
+
|
| 188 |
+
### Source
|
| 189 |
+
|
| 190 |
+
source
|
| 191 |
+
|
| 192 |
+
### Tensorflow Version
|
| 193 |
+
|
| 194 |
+
2.8+
|
| 195 |
+
|
| 196 |
+
### Custom Code
|
| 197 |
+
|
| 198 |
+
No
|
| 199 |
+
|
| 200 |
+
### OS Platform and Distribution
|
| 201 |
+
|
| 202 |
+
_No response_
|
| 203 |
+
|
| 204 |
+
### Mobile device
|
| 205 |
+
|
| 206 |
+
_No response_
|
| 207 |
+
|
| 208 |
+
### Python version
|
| 209 |
+
|
| 210 |
+
_No response_
|
| 211 |
+
|
| 212 |
+
### Bazel version
|
| 213 |
+
|
| 214 |
+
_No response_
|
| 215 |
+
|
| 216 |
+
### GCC/Compiler version
|
| 217 |
+
|
| 218 |
+
_No response_
|
| 219 |
+
|
| 220 |
+
### CUDA/cuDNN version
|
| 221 |
+
|
| 222 |
+
_No response_
|
| 223 |
+
|
| 224 |
+
### GPU model and memory
|
| 225 |
+
|
| 226 |
+
_No response_
|
| 227 |
+
|
| 228 |
+
### Current Behaviour?
|
| 229 |
+
|
| 230 |
+
```shell
|
| 231 |
+
The current Swift API only has `init` functions from files on disk unlike the Java (Android) API which has a byte buffer initializer. It'd be convenient if the Swift API could initialize `Interpreters` from `Data`.
|
| 232 |
+
```
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
### Standalone code to reproduce the issue
|
| 236 |
+
|
| 237 |
+
```shell
|
| 238 |
+
No code. This is a feature request
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
### Relevant log output
|
| 243 |
+
|
| 244 |
+
_No response_</details>")
|
| 245 |
+
```
|
| 246 |
+
|
| 247 |
+
<!--
|
| 248 |
+
### Downstream Use
|
| 249 |
+
|
| 250 |
+
*List how someone could finetune this model on their own dataset.*
|
| 251 |
+
-->
|
| 252 |
+
|
| 253 |
+
<!--
|
| 254 |
+
### Out-of-Scope Use
|
| 255 |
+
|
| 256 |
+
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
|
| 257 |
+
-->
|
| 258 |
+
|
| 259 |
+
<!--
|
| 260 |
+
## Bias, Risks and Limitations
|
| 261 |
+
|
| 262 |
+
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
|
| 263 |
+
-->
|
| 264 |
+
|
| 265 |
+
<!--
|
| 266 |
+
### Recommendations
|
| 267 |
+
|
| 268 |
+
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
|
| 269 |
+
-->
|
| 270 |
+
|
| 271 |
+
## Training Details
|
| 272 |
+
|
| 273 |
+
### Training Set Metrics
|
| 274 |
+
| Training set | Min | Median | Max |
|
| 275 |
+
|:-------------|:----|:---------|:-----|
|
| 276 |
+
| Word count | 5 | 353.7433 | 6124 |
|
| 277 |
+
|
| 278 |
+
| Label | Training Sample Count |
|
| 279 |
+
|:---------|:----------------------|
|
| 280 |
+
| bug | 200 |
|
| 281 |
+
| feature | 200 |
|
| 282 |
+
| question | 200 |
|
| 283 |
+
|
| 284 |
+
### Training Hyperparameters
|
| 285 |
+
- batch_size: (16, 2)
|
| 286 |
+
- num_epochs: (1, 1)
|
| 287 |
+
- max_steps: -1
|
| 288 |
+
- sampling_strategy: oversampling
|
| 289 |
+
- num_iterations: 20
|
| 290 |
+
- body_learning_rate: (2e-05, 1e-05)
|
| 291 |
+
- head_learning_rate: 0.01
|
| 292 |
+
- loss: CosineSimilarityLoss
|
| 293 |
+
- distance_metric: cosine_distance
|
| 294 |
+
- margin: 0.25
|
| 295 |
+
- end_to_end: False
|
| 296 |
+
- use_amp: False
|
| 297 |
+
- warmup_proportion: 0.1
|
| 298 |
+
- seed: 42
|
| 299 |
+
- eval_max_steps: -1
|
| 300 |
+
- load_best_model_at_end: False
|
| 301 |
+
|
| 302 |
+
### Training Results
|
| 303 |
+
| Epoch | Step | Training Loss | Validation Loss |
|
| 304 |
+
|:------:|:----:|:-------------:|:---------------:|
|
| 305 |
+
| 0.0007 | 1 | 0.1719 | - |
|
| 306 |
+
| 0.0067 | 10 | 0.2869 | - |
|
| 307 |
+
| 0.0133 | 20 | 0.2513 | - |
|
| 308 |
+
| 0.02 | 30 | 0.1871 | - |
|
| 309 |
+
| 0.0267 | 40 | 0.2065 | - |
|
| 310 |
+
| 0.0333 | 50 | 0.2302 | - |
|
| 311 |
+
| 0.04 | 60 | 0.1645 | - |
|
| 312 |
+
| 0.0467 | 70 | 0.1887 | - |
|
| 313 |
+
| 0.0533 | 80 | 0.1376 | - |
|
| 314 |
+
| 0.06 | 90 | 0.1171 | - |
|
| 315 |
+
| 0.0667 | 100 | 0.1303 | - |
|
| 316 |
+
| 0.0733 | 110 | 0.121 | - |
|
| 317 |
+
| 0.08 | 120 | 0.1126 | - |
|
| 318 |
+
| 0.0867 | 130 | 0.1247 | - |
|
| 319 |
+
| 0.0933 | 140 | 0.1764 | - |
|
| 320 |
+
| 0.1 | 150 | 0.0401 | - |
|
| 321 |
+
| 0.1067 | 160 | 0.1571 | - |
|
| 322 |
+
| 0.1133 | 170 | 0.0186 | - |
|
| 323 |
+
| 0.12 | 180 | 0.0501 | - |
|
| 324 |
+
| 0.1267 | 190 | 0.1003 | - |
|
| 325 |
+
| 0.1333 | 200 | 0.0152 | - |
|
| 326 |
+
| 0.14 | 210 | 0.0784 | - |
|
| 327 |
+
| 0.1467 | 220 | 0.1423 | - |
|
| 328 |
+
| 0.1533 | 230 | 0.1313 | - |
|
| 329 |
+
| 0.16 | 240 | 0.0799 | - |
|
| 330 |
+
| 0.1667 | 250 | 0.0542 | - |
|
| 331 |
+
| 0.1733 | 260 | 0.0426 | - |
|
| 332 |
+
| 0.18 | 270 | 0.047 | - |
|
| 333 |
+
| 0.1867 | 280 | 0.0062 | - |
|
| 334 |
+
| 0.1933 | 290 | 0.0085 | - |
|
| 335 |
+
| 0.2 | 300 | 0.0625 | - |
|
| 336 |
+
| 0.2067 | 310 | 0.095 | - |
|
| 337 |
+
| 0.2133 | 320 | 0.0262 | - |
|
| 338 |
+
| 0.22 | 330 | 0.0029 | - |
|
| 339 |
+
| 0.2267 | 340 | 0.0097 | - |
|
| 340 |
+
| 0.2333 | 350 | 0.063 | - |
|
| 341 |
+
| 0.24 | 360 | 0.0059 | - |
|
| 342 |
+
| 0.2467 | 370 | 0.0016 | - |
|
| 343 |
+
| 0.2533 | 380 | 0.0025 | - |
|
| 344 |
+
| 0.26 | 390 | 0.0033 | - |
|
| 345 |
+
| 0.2667 | 400 | 0.0006 | - |
|
| 346 |
+
| 0.2733 | 410 | 0.0032 | - |
|
| 347 |
+
| 0.28 | 420 | 0.0045 | - |
|
| 348 |
+
| 0.2867 | 430 | 0.0013 | - |
|
| 349 |
+
| 0.2933 | 440 | 0.0011 | - |
|
| 350 |
+
| 0.3 | 450 | 0.001 | - |
|
| 351 |
+
| 0.3067 | 460 | 0.0044 | - |
|
| 352 |
+
| 0.3133 | 470 | 0.001 | - |
|
| 353 |
+
| 0.32 | 480 | 0.0009 | - |
|
| 354 |
+
| 0.3267 | 490 | 0.0004 | - |
|
| 355 |
+
| 0.3333 | 500 | 0.0006 | - |
|
| 356 |
+
| 0.34 | 510 | 0.001 | - |
|
| 357 |
+
| 0.3467 | 520 | 0.0003 | - |
|
| 358 |
+
| 0.3533 | 530 | 0.0008 | - |
|
| 359 |
+
| 0.36 | 540 | 0.0003 | - |
|
| 360 |
+
| 0.3667 | 550 | 0.0023 | - |
|
| 361 |
+
| 0.3733 | 560 | 0.0336 | - |
|
| 362 |
+
| 0.38 | 570 | 0.0004 | - |
|
| 363 |
+
| 0.3867 | 580 | 0.0003 | - |
|
| 364 |
+
| 0.3933 | 590 | 0.0006 | - |
|
| 365 |
+
| 0.4 | 600 | 0.0008 | - |
|
| 366 |
+
| 0.4067 | 610 | 0.0011 | - |
|
| 367 |
+
| 0.4133 | 620 | 0.0002 | - |
|
| 368 |
+
| 0.42 | 630 | 0.0004 | - |
|
| 369 |
+
| 0.4267 | 640 | 0.0005 | - |
|
| 370 |
+
| 0.4333 | 650 | 0.0601 | - |
|
| 371 |
+
| 0.44 | 660 | 0.0003 | - |
|
| 372 |
+
| 0.4467 | 670 | 0.0003 | - |
|
| 373 |
+
| 0.4533 | 680 | 0.0006 | - |
|
| 374 |
+
| 0.46 | 690 | 0.0005 | - |
|
| 375 |
+
| 0.4667 | 700 | 0.0003 | - |
|
| 376 |
+
| 0.4733 | 710 | 0.0006 | - |
|
| 377 |
+
| 0.48 | 720 | 0.0001 | - |
|
| 378 |
+
| 0.4867 | 730 | 0.0002 | - |
|
| 379 |
+
| 0.4933 | 740 | 0.0002 | - |
|
| 380 |
+
| 0.5 | 750 | 0.0002 | - |
|
| 381 |
+
| 0.5067 | 760 | 0.0002 | - |
|
| 382 |
+
| 0.5133 | 770 | 0.0016 | - |
|
| 383 |
+
| 0.52 | 780 | 0.0001 | - |
|
| 384 |
+
| 0.5267 | 790 | 0.0005 | - |
|
| 385 |
+
| 0.5333 | 800 | 0.0004 | - |
|
| 386 |
+
| 0.54 | 810 | 0.0039 | - |
|
| 387 |
+
| 0.5467 | 820 | 0.0031 | - |
|
| 388 |
+
| 0.5533 | 830 | 0.0008 | - |
|
| 389 |
+
| 0.56 | 840 | 0.0003 | - |
|
| 390 |
+
| 0.5667 | 850 | 0.0002 | - |
|
| 391 |
+
| 0.5733 | 860 | 0.0002 | - |
|
| 392 |
+
| 0.58 | 870 | 0.0002 | - |
|
| 393 |
+
| 0.5867 | 880 | 0.0001 | - |
|
| 394 |
+
| 0.5933 | 890 | 0.0004 | - |
|
| 395 |
+
| 0.6 | 900 | 0.0002 | - |
|
| 396 |
+
| 0.6067 | 910 | 0.0008 | - |
|
| 397 |
+
| 0.6133 | 920 | 0.0005 | - |
|
| 398 |
+
| 0.62 | 930 | 0.0005 | - |
|
| 399 |
+
| 0.6267 | 940 | 0.0002 | - |
|
| 400 |
+
| 0.6333 | 950 | 0.0001 | - |
|
| 401 |
+
| 0.64 | 960 | 0.0002 | - |
|
| 402 |
+
| 0.6467 | 970 | 0.0007 | - |
|
| 403 |
+
| 0.6533 | 980 | 0.0002 | - |
|
| 404 |
+
| 0.66 | 990 | 0.0002 | - |
|
| 405 |
+
| 0.6667 | 1000 | 0.0002 | - |
|
| 406 |
+
| 0.6733 | 1010 | 0.0002 | - |
|
| 407 |
+
| 0.68 | 1020 | 0.0002 | - |
|
| 408 |
+
| 0.6867 | 1030 | 0.0002 | - |
|
| 409 |
+
| 0.6933 | 1040 | 0.0004 | - |
|
| 410 |
+
| 0.7 | 1050 | 0.0076 | - |
|
| 411 |
+
| 0.7067 | 1060 | 0.0002 | - |
|
| 412 |
+
| 0.7133 | 1070 | 0.0002 | - |
|
| 413 |
+
| 0.72 | 1080 | 0.0001 | - |
|
| 414 |
+
| 0.7267 | 1090 | 0.0002 | - |
|
| 415 |
+
| 0.7333 | 1100 | 0.0001 | - |
|
| 416 |
+
| 0.74 | 1110 | 0.0365 | - |
|
| 417 |
+
| 0.7467 | 1120 | 0.0002 | - |
|
| 418 |
+
| 0.7533 | 1130 | 0.0002 | - |
|
| 419 |
+
| 0.76 | 1140 | 0.0003 | - |
|
| 420 |
+
| 0.7667 | 1150 | 0.0002 | - |
|
| 421 |
+
| 0.7733 | 1160 | 0.0002 | - |
|
| 422 |
+
| 0.78 | 1170 | 0.0004 | - |
|
| 423 |
+
| 0.7867 | 1180 | 0.0001 | - |
|
| 424 |
+
| 0.7933 | 1190 | 0.0001 | - |
|
| 425 |
+
| 0.8 | 1200 | 0.0001 | - |
|
| 426 |
+
| 0.8067 | 1210 | 0.0001 | - |
|
| 427 |
+
| 0.8133 | 1220 | 0.0002 | - |
|
| 428 |
+
| 0.82 | 1230 | 0.0002 | - |
|
| 429 |
+
| 0.8267 | 1240 | 0.0001 | - |
|
| 430 |
+
| 0.8333 | 1250 | 0.0001 | - |
|
| 431 |
+
| 0.84 | 1260 | 0.0002 | - |
|
| 432 |
+
| 0.8467 | 1270 | 0.0002 | - |
|
| 433 |
+
| 0.8533 | 1280 | 0.0 | - |
|
| 434 |
+
| 0.86 | 1290 | 0.0002 | - |
|
| 435 |
+
| 0.8667 | 1300 | 0.032 | - |
|
| 436 |
+
| 0.8733 | 1310 | 0.0001 | - |
|
| 437 |
+
| 0.88 | 1320 | 0.0001 | - |
|
| 438 |
+
| 0.8867 | 1330 | 0.0001 | - |
|
| 439 |
+
| 0.8933 | 1340 | 0.0003 | - |
|
| 440 |
+
| 0.9 | 1350 | 0.0001 | - |
|
| 441 |
+
| 0.9067 | 1360 | 0.0001 | - |
|
| 442 |
+
| 0.9133 | 1370 | 0.0001 | - |
|
| 443 |
+
| 0.92 | 1380 | 0.0001 | - |
|
| 444 |
+
| 0.9267 | 1390 | 0.0001 | - |
|
| 445 |
+
| 0.9333 | 1400 | 0.0001 | - |
|
| 446 |
+
| 0.94 | 1410 | 0.0001 | - |
|
| 447 |
+
| 0.9467 | 1420 | 0.0001 | - |
|
| 448 |
+
| 0.9533 | 1430 | 0.031 | - |
|
| 449 |
+
| 0.96 | 1440 | 0.0001 | - |
|
| 450 |
+
| 0.9667 | 1450 | 0.0003 | - |
|
| 451 |
+
| 0.9733 | 1460 | 0.0001 | - |
|
| 452 |
+
| 0.98 | 1470 | 0.0001 | - |
|
| 453 |
+
| 0.9867 | 1480 | 0.0001 | - |
|
| 454 |
+
| 0.9933 | 1490 | 0.0001 | - |
|
| 455 |
+
| 1.0 | 1500 | 0.0001 | - |
|
| 456 |
+
|
| 457 |
+
### Framework Versions
|
| 458 |
+
- Python: 3.10.12
|
| 459 |
+
- SetFit: 1.0.3
|
| 460 |
+
- Sentence Transformers: 3.0.1
|
| 461 |
+
- Transformers: 4.39.0
|
| 462 |
+
- PyTorch: 2.3.0+cu121
|
| 463 |
+
- Datasets: 2.20.0
|
| 464 |
+
- Tokenizers: 0.15.2
|
| 465 |
+
|
| 466 |
+
## Citation
|
| 467 |
+
|
| 468 |
+
### BibTeX
|
| 469 |
+
```bibtex
|
| 470 |
+
@article{https://doi.org/10.48550/arxiv.2209.11055,
|
| 471 |
+
doi = {10.48550/ARXIV.2209.11055},
|
| 472 |
+
url = {https://arxiv.org/abs/2209.11055},
|
| 473 |
+
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
|
| 474 |
+
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
|
| 475 |
+
title = {Efficient Few-Shot Learning Without Prompts},
|
| 476 |
+
publisher = {arXiv},
|
| 477 |
+
year = {2022},
|
| 478 |
+
copyright = {Creative Commons Attribution 4.0 International}
|
| 479 |
+
}
|
| 480 |
+
```
|
| 481 |
+
|
| 482 |
+
<!--
|
| 483 |
+
## Glossary
|
| 484 |
+
|
| 485 |
+
*Clearly define terms in order to be accessible across audiences.*
|
| 486 |
+
-->
|
| 487 |
+
|
| 488 |
+
<!--
|
| 489 |
+
## Model Card Authors
|
| 490 |
+
|
| 491 |
+
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
|
| 492 |
+
-->
|
| 493 |
+
|
| 494 |
+
<!--
|
| 495 |
+
## Model Card Contact
|
| 496 |
+
|
| 497 |
+
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
|
| 498 |
+
-->
|
config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "sentence-transformers/all-mpnet-base-v2",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MPNetModel"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "gelu",
|
| 10 |
+
"hidden_dropout_prob": 0.1,
|
| 11 |
+
"hidden_size": 768,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 3072,
|
| 14 |
+
"layer_norm_eps": 1e-05,
|
| 15 |
+
"max_position_embeddings": 514,
|
| 16 |
+
"model_type": "mpnet",
|
| 17 |
+
"num_attention_heads": 12,
|
| 18 |
+
"num_hidden_layers": 12,
|
| 19 |
+
"pad_token_id": 1,
|
| 20 |
+
"relative_attention_num_buckets": 32,
|
| 21 |
+
"torch_dtype": "float32",
|
| 22 |
+
"transformers_version": "4.39.0",
|
| 23 |
+
"vocab_size": 30527
|
| 24 |
+
}
|
config_sentence_transformers.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"__version__": {
|
| 3 |
+
"sentence_transformers": "3.0.1",
|
| 4 |
+
"transformers": "4.39.0",
|
| 5 |
+
"pytorch": "2.3.0+cu121"
|
| 6 |
+
},
|
| 7 |
+
"prompts": {},
|
| 8 |
+
"default_prompt_name": null,
|
| 9 |
+
"similarity_fn_name": null
|
| 10 |
+
}
|
config_setfit.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"normalize_embeddings": false,
|
| 3 |
+
"labels": [
|
| 4 |
+
"bug",
|
| 5 |
+
"feature",
|
| 6 |
+
"question"
|
| 7 |
+
]
|
| 8 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d632562f6d9ce2c446c4db10d918cb687c1ef97dce2e69433dd6f44fc41e41bc
|
| 3 |
+
size 437967672
|
model_head.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:21ca11af21df8e7306c0bfeb3270e8b571f8765a97a01abdd4d445c01d72b31c
|
| 3 |
+
size 19375
|
modules.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Pooling",
|
| 12 |
+
"type": "sentence_transformers.models.Pooling"
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"idx": 2,
|
| 16 |
+
"name": "2",
|
| 17 |
+
"path": "2_Normalize",
|
| 18 |
+
"type": "sentence_transformers.models.Normalize"
|
| 19 |
+
}
|
| 20 |
+
]
|
sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 384,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"cls_token": {
|
| 10 |
+
"content": "<s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"eos_token": {
|
| 17 |
+
"content": "</s>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"mask_token": {
|
| 24 |
+
"content": "<mask>",
|
| 25 |
+
"lstrip": true,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
},
|
| 30 |
+
"pad_token": {
|
| 31 |
+
"content": "<pad>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false
|
| 36 |
+
},
|
| 37 |
+
"sep_token": {
|
| 38 |
+
"content": "</s>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false
|
| 43 |
+
},
|
| 44 |
+
"unk_token": {
|
| 45 |
+
"content": "[UNK]",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false
|
| 50 |
+
}
|
| 51 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<s>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<pad>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"3": {
|
| 28 |
+
"content": "<unk>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": true,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"104": {
|
| 36 |
+
"content": "[UNK]",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"30526": {
|
| 44 |
+
"content": "<mask>",
|
| 45 |
+
"lstrip": true,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
}
|
| 51 |
+
},
|
| 52 |
+
"bos_token": "<s>",
|
| 53 |
+
"clean_up_tokenization_spaces": true,
|
| 54 |
+
"cls_token": "<s>",
|
| 55 |
+
"do_lower_case": true,
|
| 56 |
+
"eos_token": "</s>",
|
| 57 |
+
"mask_token": "<mask>",
|
| 58 |
+
"max_length": 128,
|
| 59 |
+
"model_max_length": 384,
|
| 60 |
+
"pad_to_multiple_of": null,
|
| 61 |
+
"pad_token": "<pad>",
|
| 62 |
+
"pad_token_type_id": 0,
|
| 63 |
+
"padding_side": "right",
|
| 64 |
+
"sep_token": "</s>",
|
| 65 |
+
"stride": 0,
|
| 66 |
+
"strip_accents": null,
|
| 67 |
+
"tokenize_chinese_chars": true,
|
| 68 |
+
"tokenizer_class": "MPNetTokenizer",
|
| 69 |
+
"truncation_side": "right",
|
| 70 |
+
"truncation_strategy": "longest_first",
|
| 71 |
+
"unk_token": "[UNK]"
|
| 72 |
+
}
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|