|
--- |
|
language: pt |
|
license: apache-2.0 |
|
tags: |
|
- generated_from_trainer |
|
- whisper-event |
|
datasets: |
|
- mozilla-foundation/common_voice_11_0 |
|
metrics: |
|
- wer |
|
model-index: |
|
- name: openai/whisper-medium |
|
results: |
|
- task: |
|
name: Automatic Speech Recognition |
|
type: automatic-speech-recognition |
|
dataset: |
|
name: mozilla-foundation/common_voice_11_0 |
|
type: mozilla-foundation/common_voice_11_0 |
|
config: pt |
|
split: test |
|
args: pt |
|
metrics: |
|
- name: Wer |
|
type: wer |
|
value: 6.598745817992301 |
|
--- |
|
|
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You |
|
should probably proofread and complete it, then remove this comment. --> |
|
|
|
# Portuguese Medium Whisper |
|
|
|
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the common_voice_11_0 dataset. |
|
It achieves the following results on the evaluation set: |
|
- Loss: 0.2628 |
|
- Wer: 6.5987 |
|
|
|
## Blog post |
|
|
|
All information about this model in this blog post: [Speech-to-Text & IA | Transcreva qualquer áudio para o português com o Whisper (OpenAI)... sem nenhum custo!](https://medium.com/@pierre_guillou/speech-to-text-ia-transcreva-qualquer-%C3%A1udio-para-o-portugu%C3%AAs-com-o-whisper-openai-sem-ad0c17384681). |
|
|
|
## New SOTA |
|
|
|
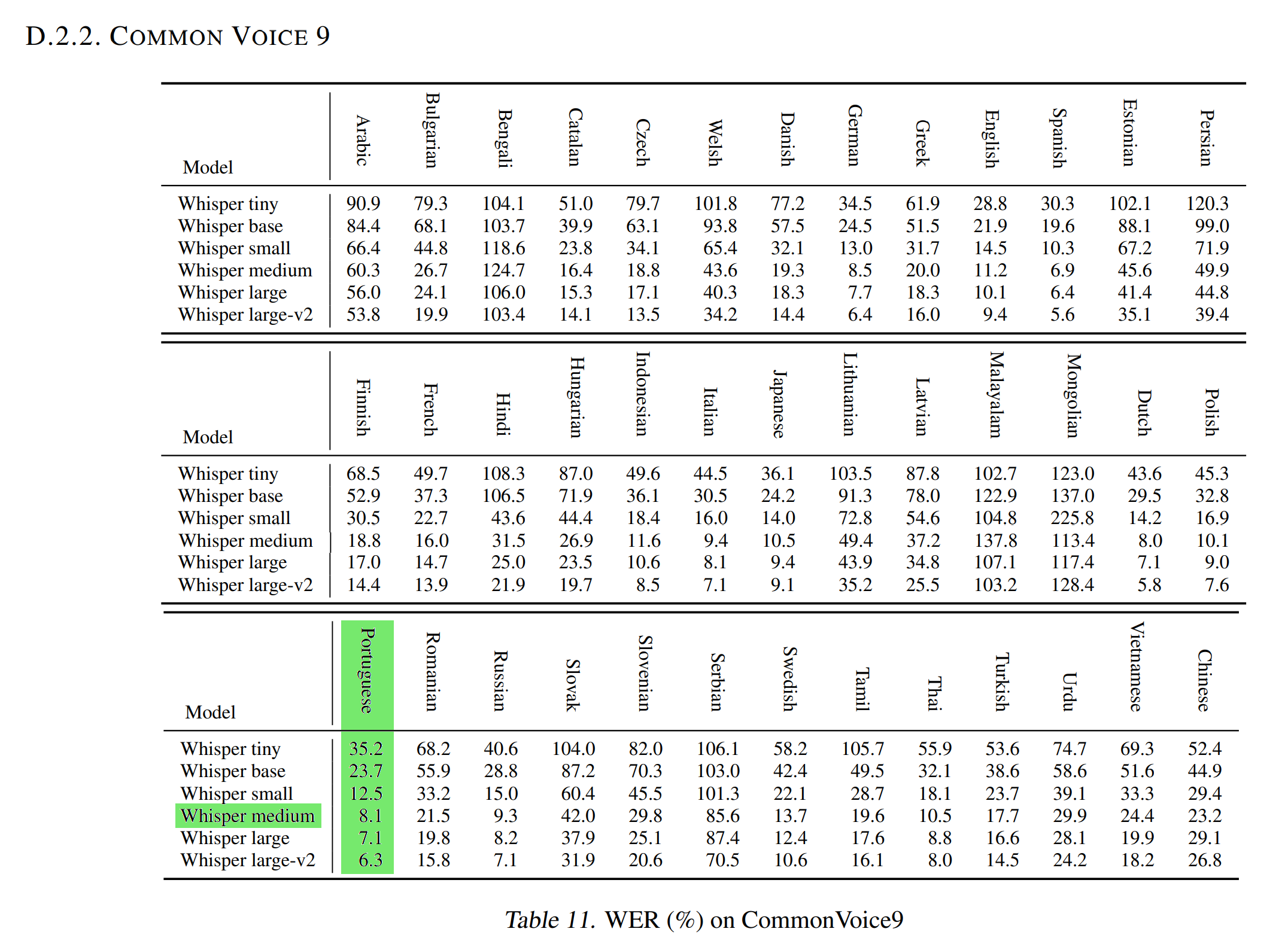
The Normalized WER in the [OpenAI Whisper article](https://cdn.openai.com/papers/whisper.pdf) with the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0) test dataset is 8.1. |
|
|
|
As this test dataset is similar to the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) test dataset used to evaluate our model (WER and WER Norm), it means that **our Portuguese Medium Whisper is better than the [Medium Whisper](https://huggingface.co/openai/whisper-medium) model at transcribing audios Portuguese in text** (and even better than the [Whisper Large](https://huggingface.co/openai/whisper-large) that has a WER Norm of 7.1!). |
|
|
|
 |
|
|
|
## Training procedure |
|
|
|
### Training hyperparameters |
|
|
|
The following hyperparameters were used during training: |
|
- learning_rate: 9e-06 |
|
- train_batch_size: 32 |
|
- eval_batch_size: 16 |
|
- seed: 42 |
|
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 |
|
- lr_scheduler_type: linear |
|
- lr_scheduler_warmup_steps: 500 |
|
- training_steps: 6000 |
|
- mixed_precision_training: Native AMP |
|
|
|
### Training results |
|
|
|
| Training Loss | Epoch | Step | Validation Loss | Wer | |
|
|:-------------:|:-----:|:----:|:---------------:|:------:| |
|
| 0.0333 | 2.07 | 1500 | 0.2073 | 6.9770 | |
|
| 0.0061 | 5.05 | 3000 | 0.2628 | 6.5987 | |
|
| 0.0007 | 8.03 | 4500 | 0.2960 | 6.6979 | |
|
| 0.0004 | 11.0 | 6000 | 0.3212 | 6.6794 | |
|
|
|
|
|
### Framework versions |
|
|
|
- Transformers 4.26.0.dev0 |
|
- Pytorch 1.13.0+cu117 |
|
- Datasets 2.7.1.dev0 |
|
- Tokenizers 0.13.2 |
