

language:
- es
license: apache-2.0
library_name: transformers
tags:
- clickbait
- noticia
- spanish
- summary
- summarization
base_model: openchat/openchat-3.5-0106
datasets:
- somosnlp/NoticIA-it
metrics:
- rouge
pipeline_tag: text-generation
widget:
- example_title: Summary Example
messages:
- role: user
content: >-
Ahora eres una Inteligencia Artificial experta en desmontar titulares
sensacionalistas o clickbait. Tu tarea consiste en analizar noticias
con titulares sensacionalistas y generar un resumen de una sola frase
que revele la verdad detrás del titular.\nEste es el titular de la
noticia: Le compra un abrigo a su abuela de 97 años y la reacción de
esta es una fantasía\nEl titular plantea una pregunta o proporciona
información incompleta. Debes buscar en el cuerpo de la noticia una
frase que responda lo que se sugiere en el título. Siempre que puedas
cita el texto original, especialmente si se trata de una frase que
alguien ha dicho. Si citas una frase que alguien ha dicho, usa
comillas para indicar que es una cita. Usa siempre las mínimas
palabras posibles. No es necesario que la respuesta sea una oración
completa. Puede ser sólo el foco de la pregunta. Recuerda responder
siempre en Español.\nEste es el cuerpo de la noticia:\nLa usuaria de X
@Kokreta1 ha relatado la conversación que ha tenido con su abuela de
97 años cuando le ha dado el abrigo que le ha comprado para su
cumpleaños.\nTeniendo en cuenta la avanzada edad de la señora, la
tuitera le ha regalado una prenda acorde a sus años, algo con lo que
su yaya no ha estado de acuerdo.\nEl abrigo es de vieja, ha opinado la
mujer cuando lo ha visto. Os juro que soy muy fan. Mañana vamos las
dos (a por otro). Eso sí, la voy a llevar al Bershka, ha asegurado
entre risas la joven.\nSegún la propia cadena de ropa, la cual
pertenece a Inditex, su público se caracteriza por ser jóvenes
atrevidos, conocedores de las últimas tendencias e interesados en la
música, las redes sociales y las nuevas tecnologías, por lo que la
gente mayor no suele llevar este estilo.\nLa inusual personalidad de
la señora ha encantado a los usuarios de la red. Es por eso que el
relato ha acumulado más de 1.000 me gusta y cerca de 100 retuits,
además de una multitud de comentarios.\n
![]()
NoticIA-7B: Un Modelo para el Resumen de Artículos Clickbait en Español.
Definimos un artículo clickbait como un artículo que busca atraer la atención del lector a través de la curiosidad. Para ello, el titular plantea una pregunta o una afirmación incompleta, sansacionalista, exagerada o engañosa. La respuesta a la pregunta generada en el titular, no suele aparecer hasta el final del artículo, la cual es precedida por una gran cantidad de contenido irrelevante. El objetivo es que el usuario entre en la web a través del titular y después haga scroll hasta el final del artículo haciéndole ver la mayor cantidad de publicidad posible. Los artículos clickbait suelen ser de baja calidad y no aportan valor al lector, más allá de la curiosidad inicial. Este fenómeno hace socavar la confianza del público en las fuentes de noticias. Y afecta negativamente a los ingresos publicitarios de los creadores de contenidos legítimos, que podrían ver reducido su tráfico web.
Presentamos un modelo de 7B parámetros, entrenado con el dataset NoticIA. Este modelo es capaz de generar resúmenes concisos y de alta calidad de artículos con titulares clickbait.
Entrenamiento del Modelo
Para entrenar el modelo hemos desarrollado nuestra propia librería de entrenamiento y anotación: https://github.com/ikergarcia1996/NoticIA. Esta librería hace uso de 🤗 Transformers, 🤗 PEFT, Bitsandbytes y Deepspeed.
Para el hackathon hemos decidido entrenar un modelo de 7 Billones de parámetros, ya que, usando cuantificación de 4 bits, es posible ejecutar el modelo en hardware doméstico. Tras analizar el rendimiento de una gran cantidad de LLMs, nos hemos decantado por openchat-3.5-0106 debido a su gran rendimiento sin necesidad de ser preentrenado. Para perturbar lo mínimo posible el conocimiento previo del modelo que le permite obtener este rendimiento, hemos optado por usar la técnica de entrenamiento Low-Rank Adaptation (LoRA).
La configuración exacta de entrenamiento está disponible en: https://huggingface.co/somosnlp/NoticIA-7B/blob/main/openchat-3.5-0106_LoRA.yaml
Prompt
El prompt utilizado para el entrenamiento es el mismo definido explicado en https://huggingface.co/datasets/somosnlp/NoticIA-it. El prompt es convertido al template de chat específico de cada modelo.
Rendimiento
Como es habitual en las tareas de resumen, utilizamos la métrica de puntuación ROUGE para evaluar automáticamente los resúmenes producidos por los modelos. Nuestra métrica principal es ROUGE-1, que considera las palabras enteras como unidades básicas. Para calcular la puntuación ROUGE, ponemos en minúsculas ambos resúmenes y eliminamos los signos de puntuación. Además de la puntuación ROUGE, también tenemos en cuenta la longitud media de los resúmenes. Para nuestra tarea, pretendemos que los resúmenes sean concisos, un aspecto que la puntuación ROUGE no evalúa. Por lo tanto, al evaluar los modelos tenemos en cuenta tanto la puntuación ROUGE-1 como la longitud media de los resúmenes. Nuestro objetivo es encontrar un modelo que consiga la mayor puntuación ROUGE posible con la menor longitud de resumen posible, equilibrando calidad y brevedad.
Hemos realizado una evaluación incluyendo los mejores modelos de lenguaje entrenados para seguir instrucciones actuales, también hemos incluido el rendimiento obtenido por un anotador humano. El código para reproducir los resultados se encuentra en el siguiente enlace: https://github.com/ikergarcia1996/NoticIA
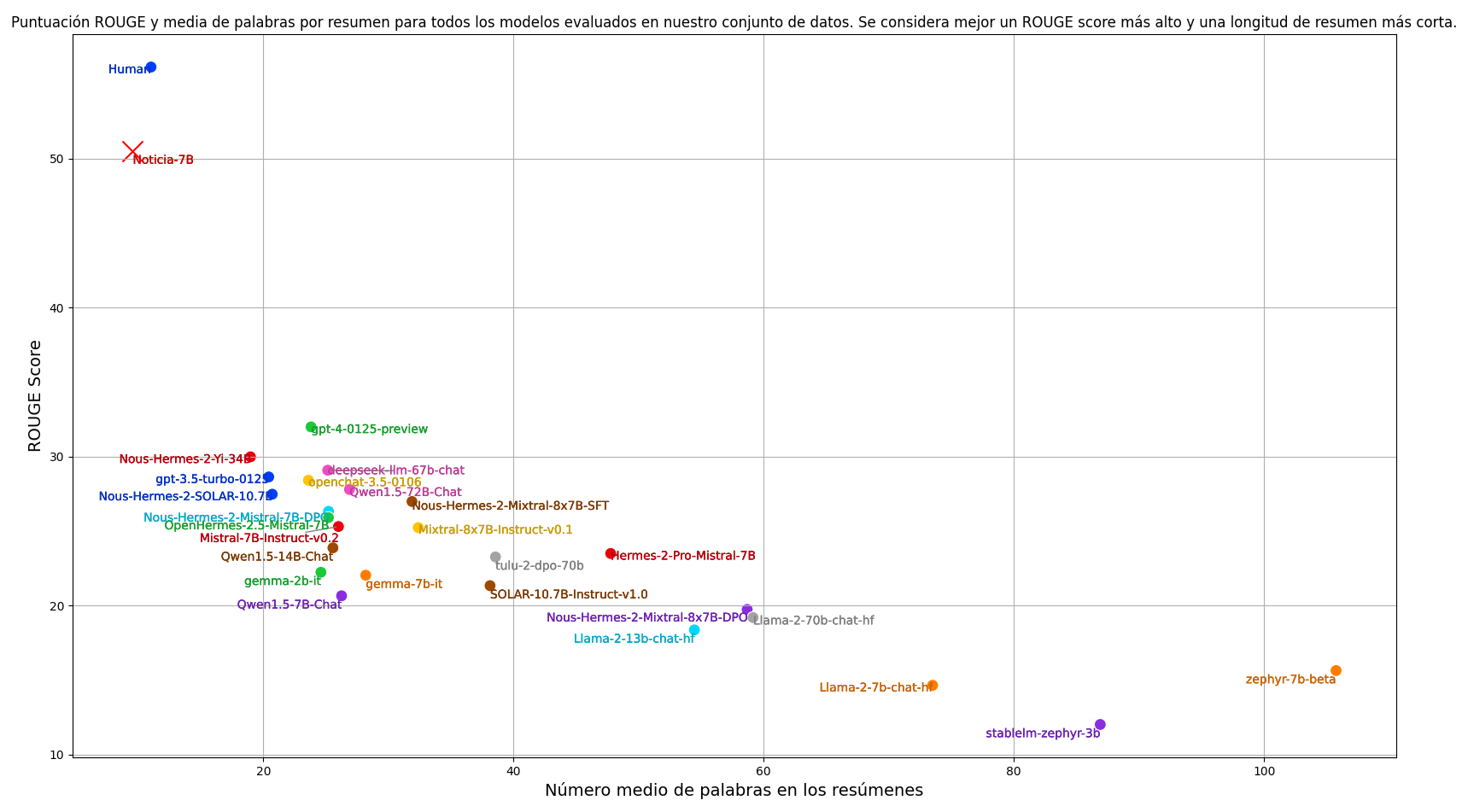
Tras el entrenamiento nuestro modelo adquire la capacidad de realizar resúmenes con una capacidad cercana a los humanos. Superando amplicamente a cualquier modelo en un setting zero-shot. Al mismo tiempo, el modelo produce resúmenes más concisos y cortos.
Demo
Una demo para probar nuestro modelo está disponible en el siguiente enlace: 🤗NoticIA-demo
Realizar un resumen de un artículo clickbait en la Web
El siguiente código muestra un ejemplo de como usar el modelo para generar un resumen a partir de la URL de un artículo clickbait.
import torch # pip install torch
from newspaper import Article #pip3 install newspaper3k
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
article_url ="https://www.huffingtonpost.es/virales/le-compra-abrigo-abuela-97nos-reaccion-fantasia.html"
article = Article(article_url)
article.download()
article.parse()
headline=article.title
body = article.text
def prompt(
headline: str,
body: str,
) -> str:
"""
Generate the prompt for the model.
Args:
headline (`str`):
The headline of the article.
body (`str`):
The body of the article.
Returns:
`str`: The formatted prompt.
"""
return (
f"Ahora eres una Inteligencia Artificial experta en desmontar titulares sensacionalistas o clickbait. "
f"Tu tarea consiste en analizar noticias con titulares sensacionalistas y "
f"generar un resumen de una sola frase que revele la verdad detrás del titular.\n"
f"Este es el titular de la noticia: {headline}\n"
f"El titular plantea una pregunta o proporciona información incompleta. "
f"Debes buscar en el cuerpo de la noticia una frase que responda lo que se sugiere en el título. "
f"Siempre que puedas cita el texto original, especialmente si se trata de una frase que alguien ha dicho. "
f"Si citas una frase que alguien ha dicho, usa comillas para indicar que es una cita. "
f"Usa siempre las mínimas palabras posibles. No es necesario que la respuesta sea una oración completa. "
f"Puede ser sólo el foco de la pregunta. "
f"Recuerda responder siempre en Español.\n"
f"Este es el cuerpo de la noticia:\n"
f"{body}\n"
)
prompt = prompt(headline=headline, body=body)
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto",quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
Realizar inferencia en el dataset NoticIA
El siguiente código muestra un ejemplo de como realizar una inferencia sobre un ejemplo de nuestro dataset.
import torch # pip install torch
from datasets import load_dataset # pip install datasets
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
dataset = load_dataset("somosnlp/NoticIA-it",split="test")
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": dataset[0]["pregunta"]}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
Usos del modelo
Este dataset ha sido entrenado para su uso en investigación científica. Si quieres hacer un uso comercial del modelo tendrás que tener el permiso expreso de los medios de los cuales han sido obtenidas las noticias usadas para entrenarlo. Prohibimos el uso de este modelo para realizar cualquier acción que pueda perjudicar la legitimidad o viabilidad económica de medios de comunicación legítimos y profesionales.
Model Description
- Author: Iker García-Ferrero
- Author Begoña Altuna
- Web Page: Github
- Language(s) (NLP): Spanish
Autores
Este modelo ha sido creado por Iker García-Ferrero y Begoña Altuna. Somos investigadores en PLN en la Universidad del País Vasco, dentro del grupo de investigación IXA y formamos parte de HiTZ, el Centro Vasco de Tecnología de la Lengua.