Hugging Face
Models
Datasets
Spaces
Posts
Docs
Enterprise
Pricing
Log In
Sign Up
sp-uhh
/
speech-enhancement-sgmse
like
9
Follow
Signal Processing Group at University of Hamburg
4
Audio-to-Audio
PyTorch
5 datasets
English
speech-enhancement
dereverberation
diffusion-models
generative-models
audio-processing
arxiv:
2406.06185
arxiv:
2409.10753
License:
mit
Model card
Files
Files and versions
Community
c4644b2
speech-enhancement-sgmse
2 contributors
History:
29 commits
Shokoufehhh
Upload config.yaml
c4644b2
verified
3 months ago
logs
Upload 40 files
4 months ago
preprocessing
Upload 40 files
4 months ago
pretrained_checkpoints
Upload ears_reverb.ckpt
3 months ago
sgmse
Upload 40 files
4 months ago
.gitattributes
Safe
1.52 kB
initial commit
4 months ago
.gitignore
Safe
5.52 kB
Upload 40 files
4 months ago
LICENSE
Safe
1.1 kB
Upload 40 files
4 months ago
README.md
Safe
9.41 kB
Update README.md
3 months ago
app.py
Safe
148 Bytes
Added app.py for audio-to-audio interface
3 months ago
calc_metrics.py
Safe
3.16 kB
Upload 40 files
4 months ago
config.yaml
Safe
2.84 kB
Upload config.yaml
3 months ago
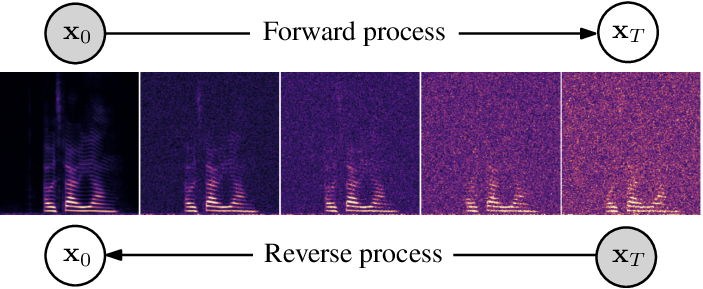
diffusion_process.png
Safe
244 kB
Upload 40 files
4 months ago
enhancement.py
Safe
3.15 kB
Upload 40 files
4 months ago
requirements.txt
Safe
240 Bytes
Upload 40 files
4 months ago
requirements_version.txt
Safe
397 Bytes
Upload 40 files
4 months ago
train.py
Safe
4.74 kB
Upload 40 files
4 months ago


{kind=link}
{kind=link}