Spaces:
Running

Running

metadata
title: README
emoji: 👁
colorFrom: purple
colorTo: green
sdk: static
pinned: false
HuggingFaceTB
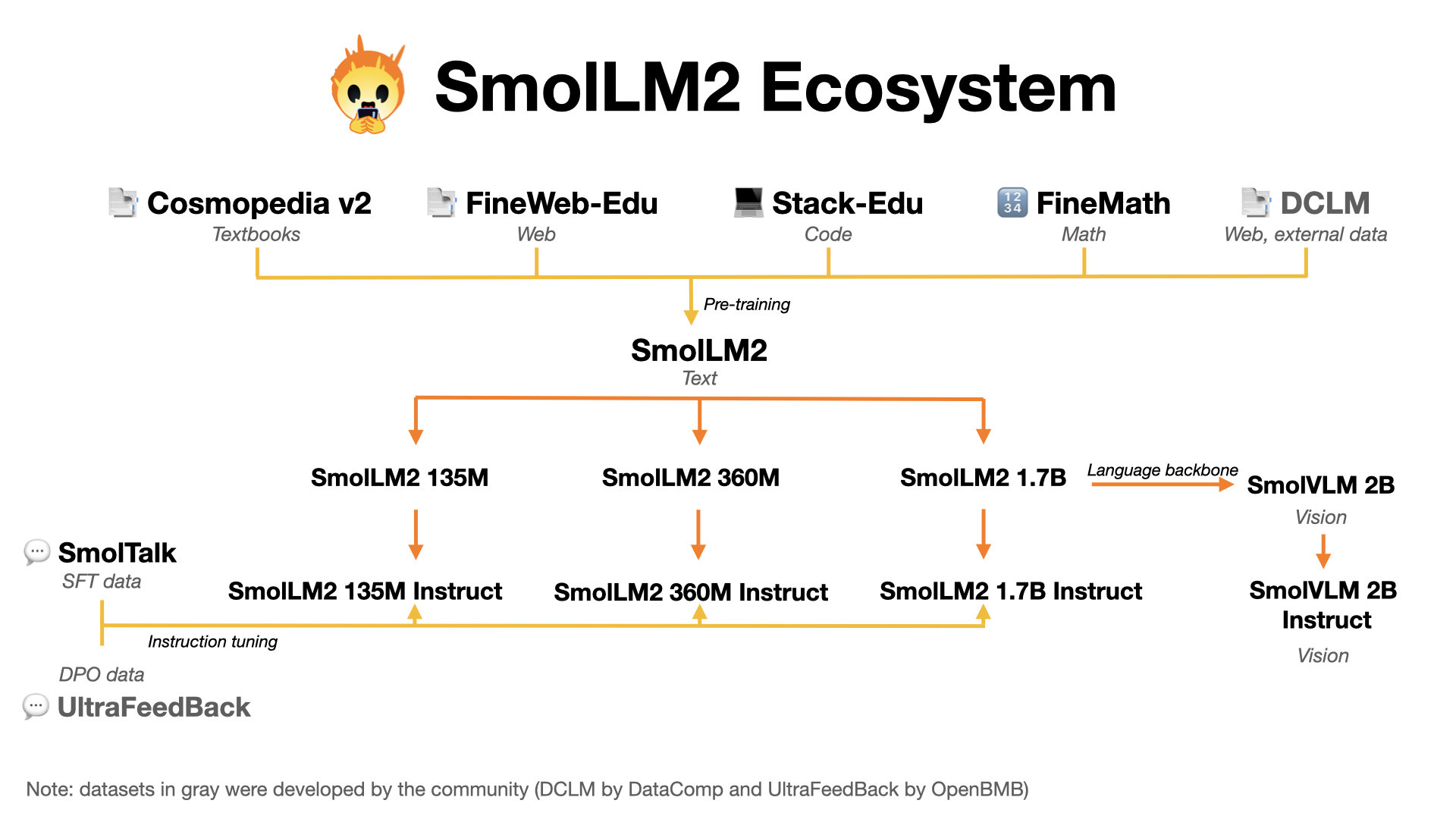
This is the home for smol models (SmolLM) and high quality pre-training datasets. We released:
- FineWeb-Edu: a filtered version of FineWeb dataset for educational content, paper available here.
- Cosmopedia: the largest open synthetic dataset, with 25B tokens and 30M samples. It contains synthetic textbooks, blog posts, and stories, posts generated by Mixtral. Blog post available here.
- Smollm-Corpus: the pre-training corpus of SmolLM: Cosmopedia v0.2, FineWeb-Edu dedup and Python-Edu. Blog post available here.
- SmolLM models and SmolLM2 models: a series of strong small models in three sizes: 135M, 360M and 1.7B
- SmolVLM: a 2 billion Vision Language Model (VLM) built for on-device inference. It uses SmolLM2-1.7B as a language backbone. Blog post available here.
News 🗞️
- SmolLM2: you can find our most capable model SmolLM2-1.7B here: https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct and our training and evaluation toolkit at: https://github.com/huggingface/smollm
- We released our SFT mix SmolTalk, a 1M samples synthetic dataset to improve instruction following, chat and reasoning: https://hf.co/datasets/HuggingFaceTB/smoltalk
- SmolVLM: a lightweight 2B Vision Language Model available here https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct