Spaces:
Running

Running

metadata
title: README
emoji: 🐢
colorFrom: purple
colorTo: gray
sdk: static
pinned: false
Intel and Hugging Face are building powerful optimization tools to accelerate training and inference with Transformers.

Learn more about Hugging Face collaboration with Intel AI
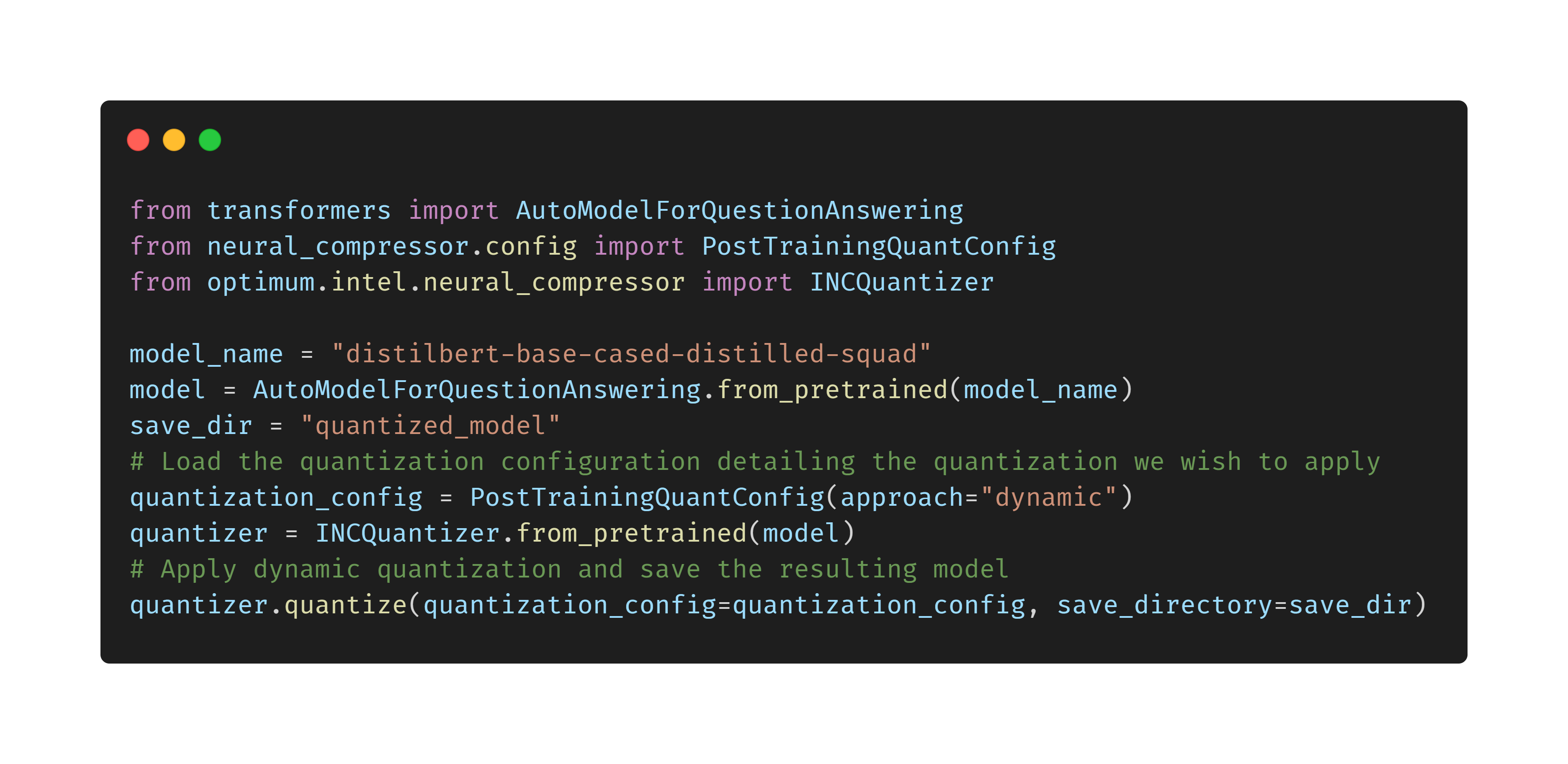
Quantize Transformers with Intel® Neural Compressor and Optimum

Quantizing 7B LLM on Intel CPU
Intel optimizes the most widely adopted and innovative AI software tools, frameworks, and libraries for Intel® architecture. Whether you are computing locally or deploying AI applications on a massive scale, your organization can achieve peak performance with AI software optimized for Intel® Xeon® Scalable platforms.
Intel’s engineering collaboration with Hugging Face offers state-of-the-art hardware and software acceleration to train, fine-tune and predict with Transformers.
Useful Resources: