Spaces:
Running
on
Zero

LLaVA (based on Llama 2 LLM, Preview)
NOTE: This is a technical preview. We are still running hyperparameter search, and will release the final model soon. If you'd like to contribute to this, please contact us.
:llama: -Introduction- Llama 2 is an open-source LLM released by Meta AI today (July 18, 2023). Compared with its early version Llama 1, Llama 2 is more favored in stronger language performance, longer context window, and importantly commercially usable! While Llama 2 is changing the LLM market landscape in the language space, its multimodal ability remains unknown. We quickly develop the LLaVA variant based on the latest Llama 2 checkpoints, and release it to the community for the public use.
You need to apply for and download the latest Llama 2 checkpoints to start your own training (apply here)
Training
Please checkout pretrain.sh, finetune.sh, finetune_lora.sh.
LLaVA (based on Llama 2), What is different?
:volcano: How is the new LLaVA based on Llama 2 different from Llama 1? The comparisons of the training process are described:
- Pre-training. The pre-trained base LLM is changed from Llama 1 to Llama 2
- Language instruction-tuning. The previous LLaVA model starts with Vicuna, which is instruct tuned on ShareGPT data from Llama 1; The new LLaVA model starts with Llama 2 Chat, which is an instruct tuned checkpoint on dialogue data from Llama 2.
- Multimodal instruction-tuning. The same LLaVA-Lighting process is applied.
Results
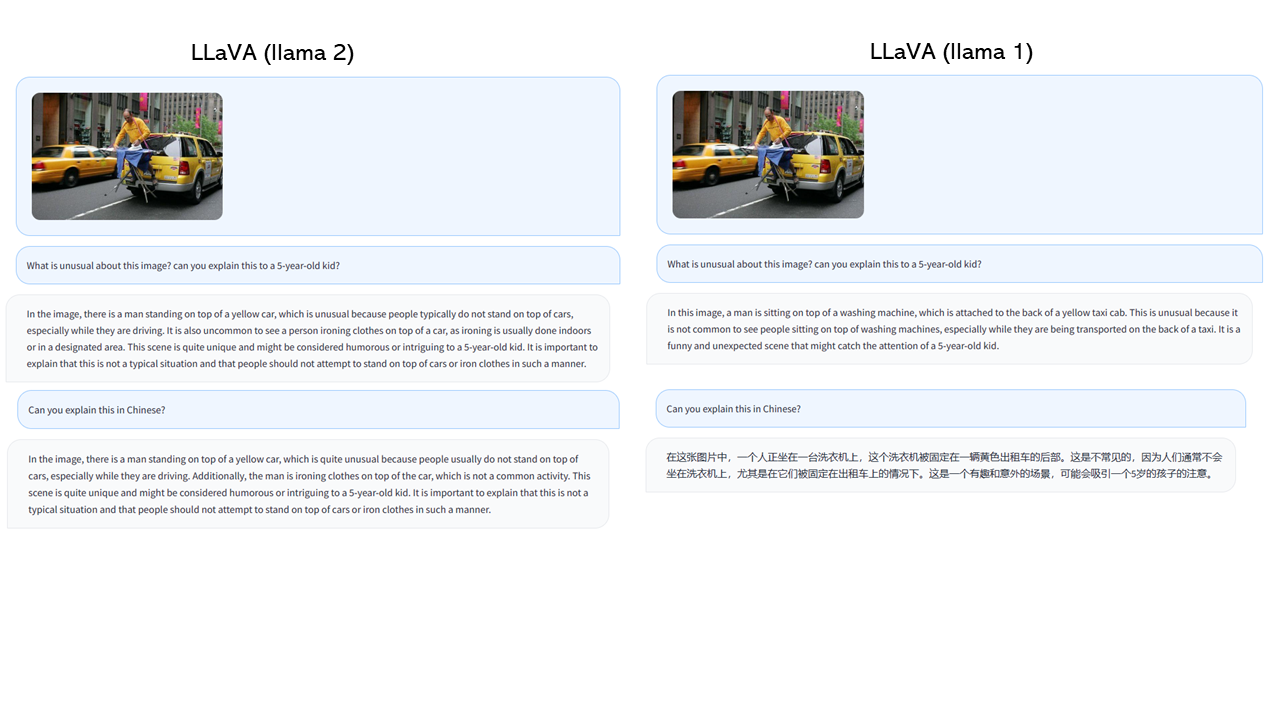
- Llama 2 is better at following the instructions of role playing; Llama 2 fails in following the instructions of translation
- The quantitative evaluation on LLaVA-Bench demonstrates on-par performance between Llama 2 and Llama 1 in LLaVA's multimodal chat ability.