Spaces:
Runtime error

Runtime error

We introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction! By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences.
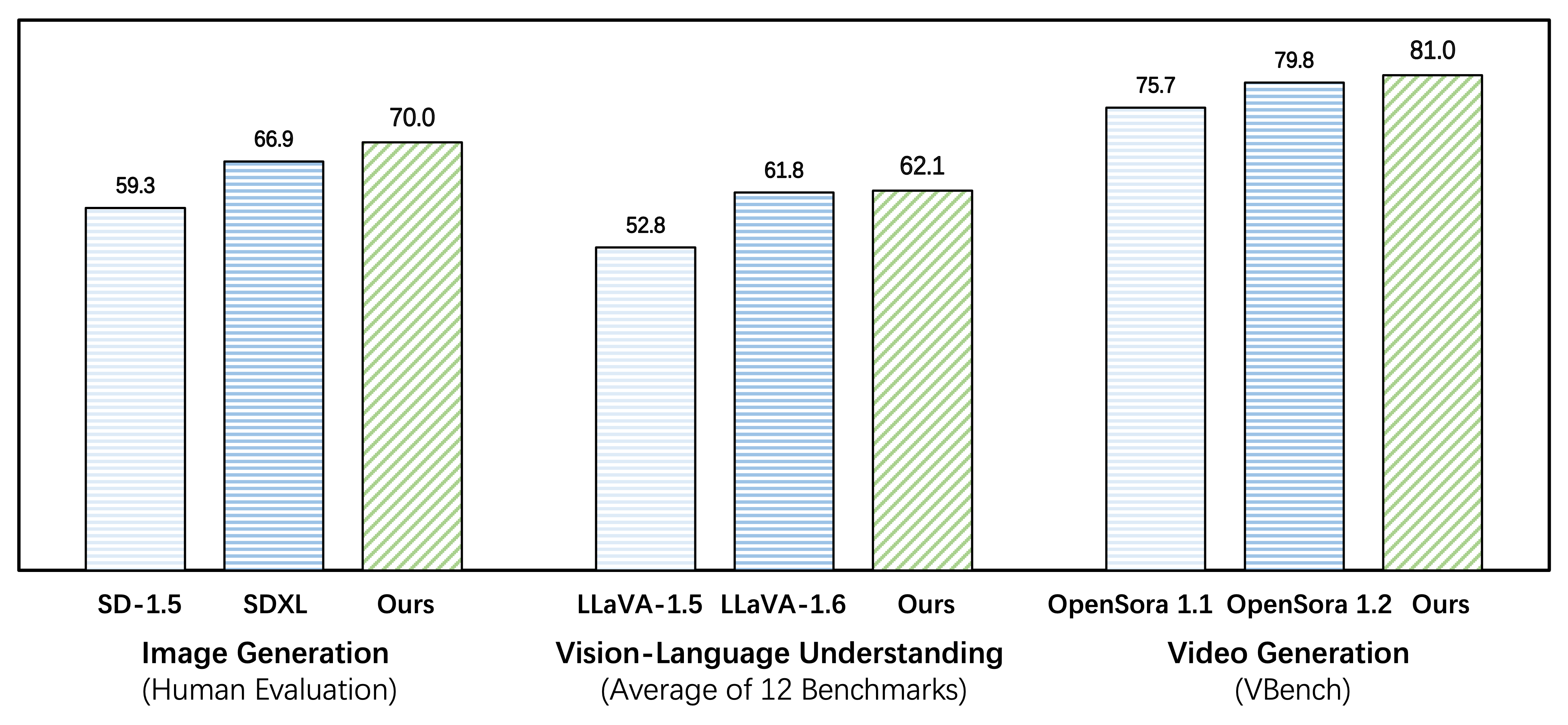
Emu3 excels in both generation and perception
Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship open models such as SDXL, LLaVA-1.6 and OpenSora-1.2, while eliminating the need for diffusion or compositional architectures.
Highlights
- Emu3 is capable of generating high-quality images following the text input, by simply predicting the next vision token. The model naturally supports flexible resolutions and styles.
- Emu3 shows strong vision-language understanding capabilities to see the physical world and provides coherent text responses. Notably, this capability is achieved without depending on a CLIP and a pretrained LLM.
- Emu3 simply generates a video causally by predicting the next token in a video sequence, unlike the video diffusion model as in Sora. With a video in context, Emu3 can also naturally extend the video and predict what will happen next.
TODO
- Release model weights of tokenizer, Emu3-Chat and Emu3-Gen
- Release the inference code.
- Release the evaluation code.
- Release training scripts for pretrain, sft and dpo.
Setup
Clone this repository and install required packages:
git clone https://github.com/baaivision/Emu3
cd Emu3
pip install -r requirements.txt
Model Weights
Quickstart
Use 🤗Transformers to run Emu3-Gen for image generation
from PIL import Image
from transformers import AutoTokenizer, AutoModel, AutoImageProcessor, AutoModelForCausalLM
from transformers.generation.configuration_utils import GenerationConfig
from transformers.generation import LogitsProcessorList, PrefixConstrainedLogitsProcessor, UnbatchedClassifierFreeGuidanceLogitsProcessor
import torch
from emu3.mllm.processing_emu3 import Emu3Processor
# model path
EMU_HUB = "BAAI/Emu3-Gen"
VQ_HUB = "BAAI/Emu3-VisionTokenizer"
# prepare model and processor
model = AutoModelForCausalLM.from_pretrained(
EMU_HUB,
device_map="cuda:0",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(EMU_HUB, trust_remote_code=True)
image_processor = AutoImageProcessor.from_pretrained(VQ_HUB, trust_remote_code=True)
image_tokenizer = AutoModel.from_pretrained(VQ_HUB, device_map="cuda:0", trust_remote_code=True).eval()
processor = Emu3Processor(image_processor, image_tokenizer, tokenizer)
# prepare input
POSITIVE_PROMPT = " masterpiece, film grained, best quality."
NEGATIVE_PROMPT = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry."
classifier_free_guidance = 3.0
prompt = "a portrait of young girl."
prompt += POSITIVE_PROMPT
kwargs = dict(
mode='G',
ratio="1:1",
image_area=model.config.image_area,
return_tensors="pt",
)
pos_inputs = processor(text=prompt, **kwargs)
neg_inputs = processor(text=NEGATIVE_PROMPT, **kwargs)
# prepare hyper parameters
GENERATION_CONFIG = GenerationConfig(
use_cache=True,
eos_token_id=model.config.eos_token_id,
pad_token_id=model.config.pad_token_id,
max_new_tokens=40960,
do_sample=True,
top_k=2048,
)
h, w = pos_inputs.image_size[0]
constrained_fn = processor.build_prefix_constrained_fn(h, w)
logits_processor = LogitsProcessorList([
UnbatchedClassifierFreeGuidanceLogitsProcessor(
classifier_free_guidance,
model,
unconditional_ids=neg_inputs.input_ids.to("cuda:0"),
),
PrefixConstrainedLogitsProcessor(
constrained_fn ,
num_beams=1,
),
])
# generate
outputs = model.generate(
pos_inputs.input_ids.to("cuda:0"),
GENERATION_CONFIG,
logits_processor=logits_processor
)
mm_list = processor.decode(outputs[0])
for idx, im in enumerate(mm_list):
if not isinstance(im, Image.Image):
continue
im.save(f"result_{idx}.png")
Use 🤗Transformers to run Emu3-Chat for vision-language understanding
from PIL import Image
from transformers import AutoTokenizer, AutoModel, AutoImageProcessor, AutoModelForCausalLM
from transformers.generation.configuration_utils import GenerationConfig
import torch
from emu3.mllm.processing_emu3 import Emu3Processor
# model path
EMU_HUB = "BAAI/Emu3-Chat"
VQ_HUB = "BAAI/Emu3-VisionTokenier"
# prepare model and processor
model = AutoModelForCausalLM.from_pretrained(
EMU_HUB,
device_map="cuda:0",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(EMU_HUB, trust_remote_code=True)
image_processor = AutoImageProcessor.from_pretrained(VQ_HUB, trust_remote_code=True)
image_tokenizer = AutoModel.from_pretrained(VQ_HUB, device_map="cuda:0", trust_remote_code=True).eval()
processor = Emu3Processor(image_processor, image_tokenizer, tokenizer)
# prepare input
text = "Please describe the image"
image = Image.open("assets/demo.png")
inputs = processor(
text=text,
image=image,
mode='U',
padding_side="left",
padding="longest",
return_tensors="pt",
)
# prepare hyper parameters
GENERATION_CONFIG = GenerationConfig(pad_token_id=tokenizer.pad_token_id, bos_token_id=tokenizer.bos_token_id, eos_token_id=tokenizer.eos_token_id)
# generate
outputs = model.generate(
inputs.input_ids.to("cuda:0"),
GENERATION_CONFIG,
max_new_tokens=320,
)
outputs = outputs[:, inputs.input_ids.shape[-1]:]
print(processor.batch_decode(outputs, skip_special_tokens=True)[0])
Acknowledgement
We thank the great work from Emu Series, QWen2-VL and MoVQGAN