A newer version of the Streamlit SDK is available:
1.41.1
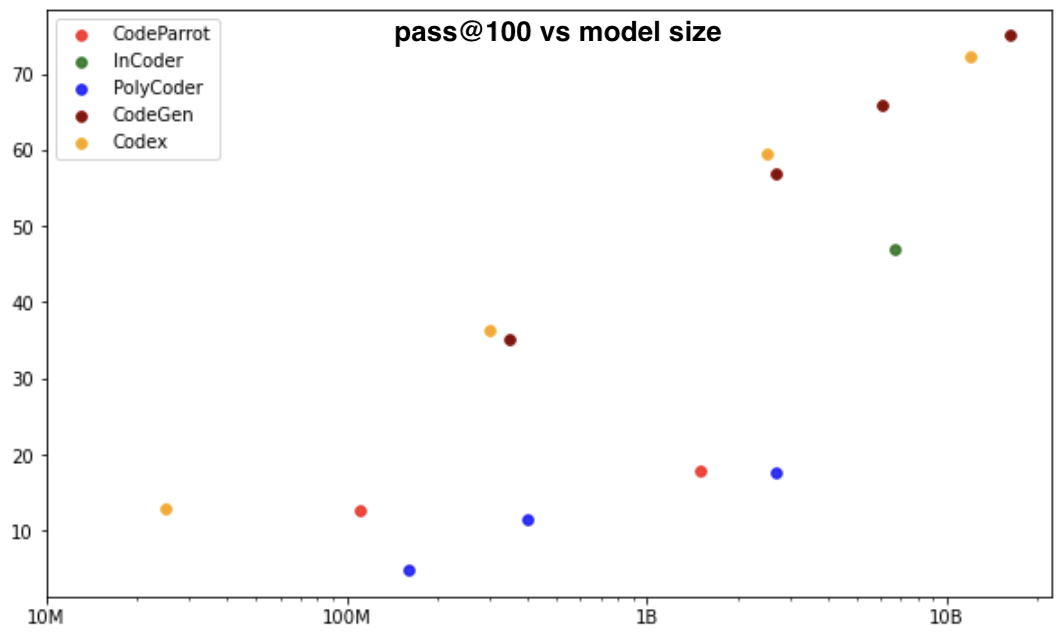
A natural way to evaluate code programs is to see if they pass unit tests, it is the idea behind the pass@k metric, a popular evaluation framework for code generation models, on HumanEval dataset, which was introduced in Codex paper. The dataset includes 164 handwritten programming problems. In the pass@k metric, k code samples are generated per problem, and a problem is considered solved if any sample passes the unit tests and the total fraction of problems solved is reported. In most papers, 200 candidate program completions are sampled, and pass@1, pass@10, and pass@100 are computed using an unbiased sampling estimator.
This plot shows the pass@100 by model size, for CodeParrot, InCoder, PolyCoder, CodeGen and Codex (not open-source):