Spaces:
Running

Running
Merve Noyan
commited on
Commit
•
57cd770
1
Parent(s):
a93f663
additions
Browse files- pages/.DS_Store +0 -0
- pages/18_Florence-2.py +8 -3
- pages/21_Llava-NeXT-Interleave.py +7 -3
- pages/22_Chameleon.py +10 -4
- pages/24_SAMv2.py +8 -5
- pages/25_UDOP.py +81 -0
- pages/26_MiniGemini.py +77 -0
- pages/27_ColPali.py +93 -0
- pages/ColPali/image_1.png +0 -0
- pages/ColPali/image_2.jpeg +0 -0
- pages/ColPali/image_3.png +0 -0
- pages/ColPali/image_4.jpeg +0 -0
- pages/ColPali/image_5.png +0 -0
- pages/MiniGemini/image_1.jpeg +0 -0
- pages/MiniGemini/image_2.jpeg +0 -0
- pages/MiniGemini/image_3.jpeg +0 -0
- pages/MiniGemini/image_4.jpeg +0 -0
- pages/MiniGemini/image_5.jpeg +0 -0
- pages/MiniGemini/image_6.png +0 -0
- pages/UDOP/image_1.jpeg +0 -0
- pages/UDOP/image_2.png +0 -0
- pages/UDOP/image_3.jpeg +0 -0
- pages/UDOP/image_4.jpeg +0 -0
- pages/UDOP/image_5.jpeg +0 -0
pages/.DS_Store
ADDED
|
Binary file (10.2 kB). View file
|
|
|
pages/18_Florence-2.py
CHANGED
|
@@ -58,10 +58,15 @@ st.image("pages/Florence-2/image_6.jpg", use_column_width=True)
|
|
| 58 |
st.markdown(""" """)
|
| 59 |
|
| 60 |
st.info("""
|
| 61 |
-
|
| 62 |
-
|
|
|
|
| 63 |
by Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan (2023)
|
| 64 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 65 |
|
| 66 |
st.markdown(""" """)
|
| 67 |
st.markdown(""" """)
|
|
|
|
| 58 |
st.markdown(""" """)
|
| 59 |
|
| 60 |
st.info("""
|
| 61 |
+
Resources:
|
| 62 |
+
|
| 63 |
+
- [Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks](https://arxiv.org/abs/2311.06242)
|
| 64 |
by Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan (2023)
|
| 65 |
+
|
| 66 |
+
- [Hugging Face blog post](https://huggingface.co/blog/finetune-florence2)
|
| 67 |
+
|
| 68 |
+
- [All the fine-tuned Florence-2 models](https://huggingface.co/models?search=florence-2)
|
| 69 |
+
""", icon="📚")
|
| 70 |
|
| 71 |
st.markdown(""" """)
|
| 72 |
st.markdown(""" """)
|
pages/21_Llava-NeXT-Interleave.py
CHANGED
|
@@ -66,10 +66,14 @@ st.image("pages/Llava-NeXT-Interleave/image_6.jpg", use_column_width=True)
|
|
| 66 |
st.markdown(""" """)
|
| 67 |
|
| 68 |
st.info("""
|
| 69 |
-
|
| 70 |
-
|
|
|
|
| 71 |
by Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, Chunyuan Li (2024)
|
| 72 |
-
[GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT/blob/inference/docs/LLaVA-NeXT-Interleave.md)
|
|
|
|
|
|
|
|
|
|
| 73 |
|
| 74 |
st.markdown(""" """)
|
| 75 |
st.markdown(""" """)
|
|
|
|
| 66 |
st.markdown(""" """)
|
| 67 |
|
| 68 |
st.info("""
|
| 69 |
+
Resources:
|
| 70 |
+
|
| 71 |
+
- [LLaVA-NeXT: Tackling Multi-image, Video, and 3D in Large Multimodal Models](https://llava-vl.github.io/blog/2024-06-16-llava-next-interleave/)
|
| 72 |
by Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, Chunyuan Li (2024)
|
| 73 |
+
[GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT/blob/inference/docs/LLaVA-NeXT-Interleave.md)
|
| 74 |
+
- [Transformers Documentation](https://huggingface.co/docs/transformers/en/model_doc/llava)
|
| 75 |
+
- [Demo](https://huggingface.co/spaces/merve/llava-next-interleave)
|
| 76 |
+
""", icon="📚")
|
| 77 |
|
| 78 |
st.markdown(""" """)
|
| 79 |
st.markdown(""" """)
|
pages/22_Chameleon.py
CHANGED
|
@@ -67,11 +67,17 @@ st.image("pages/Chameleon/image_6.jpg", use_column_width=True)
|
|
| 67 |
st.markdown(""" """)
|
| 68 |
|
| 69 |
st.info("""
|
| 70 |
-
|
| 71 |
-
|
|
|
|
| 72 |
by Chameleon Team (2024)
|
| 73 |
-
|
| 74 |
-
[
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 75 |
|
| 76 |
st.markdown(""" """)
|
| 77 |
st.markdown(""" """)
|
|
|
|
| 67 |
st.markdown(""" """)
|
| 68 |
|
| 69 |
st.info("""
|
| 70 |
+
Resources:
|
| 71 |
+
|
| 72 |
+
- [Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://arxiv.org/abs/2405.09818)
|
| 73 |
by Chameleon Team (2024)
|
| 74 |
+
|
| 75 |
+
- [GitHub](https://github.com/facebookresearch/chameleon)
|
| 76 |
+
|
| 77 |
+
- [Hugging Face documentation](https://huggingface.co/docs/transformers/model_doc/chameleon)
|
| 78 |
+
|
| 79 |
+
- [Demo](https://huggingface.co/spaces/merve/chameleon-7b)
|
| 80 |
+
""", icon="📚")
|
| 81 |
|
| 82 |
st.markdown(""" """)
|
| 83 |
st.markdown(""" """)
|
pages/24_SAMv2.py
CHANGED
|
@@ -67,11 +67,14 @@ st.image("pages/SAMv2/image_4.jpg", use_column_width=True)
|
|
| 67 |
st.markdown(""" """)
|
| 68 |
|
| 69 |
st.info("""
|
| 70 |
-
|
| 71 |
-
|
|
|
|
| 72 |
by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer (2024)
|
| 73 |
-
|
| 74 |
-
[
|
|
|
|
|
|
|
| 75 |
|
| 76 |
st.markdown(""" """)
|
| 77 |
st.markdown(""" """)
|
|
@@ -85,4 +88,4 @@ with col2:
|
|
| 85 |
switch_page("Home")
|
| 86 |
with col3:
|
| 87 |
if st.button('Next paper', use_container_width=True):
|
| 88 |
-
switch_page("
|
|
|
|
| 67 |
st.markdown(""" """)
|
| 68 |
|
| 69 |
st.info("""
|
| 70 |
+
Resources:
|
| 71 |
+
|
| 72 |
+
- [SAM 2: Segment Anything in Images and Videos]()
|
| 73 |
by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer (2024)
|
| 74 |
+
|
| 75 |
+
- [GitHub](https://github.com/facebookresearch/segment-anything-2)
|
| 76 |
+
|
| 77 |
+
- [Model and Demos Collection](https://huggingface.co/collections/merve/sam2-66ac9deac6fca3bc5482fe30)""", icon="📚")
|
| 78 |
|
| 79 |
st.markdown(""" """)
|
| 80 |
st.markdown(""" """)
|
|
|
|
| 88 |
switch_page("Home")
|
| 89 |
with col3:
|
| 90 |
if st.button('Next paper', use_container_width=True):
|
| 91 |
+
switch_page("UDOP")
|
pages/25_UDOP.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("SAMv2")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://x.com/mervenoyann/status/1767200350530859321) (Mar 11, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""New foundation model on document understanding and generation in transformers 🤩
|
| 10 |
+
UDOP by MSFT is a bleeding-edge model that is capable of many tasks, including question answering, document editing and more! 🤯
|
| 11 |
+
Check out the [demo](https://huggingface.co/spaces/merve/UDOP).
|
| 12 |
+
Technical details 🧶""")
|
| 13 |
+
st.markdown(""" """)
|
| 14 |
+
|
| 15 |
+
st.image("pages/UDOP/image_1.jpeg", use_column_width=True)
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.markdown("""
|
| 19 |
+
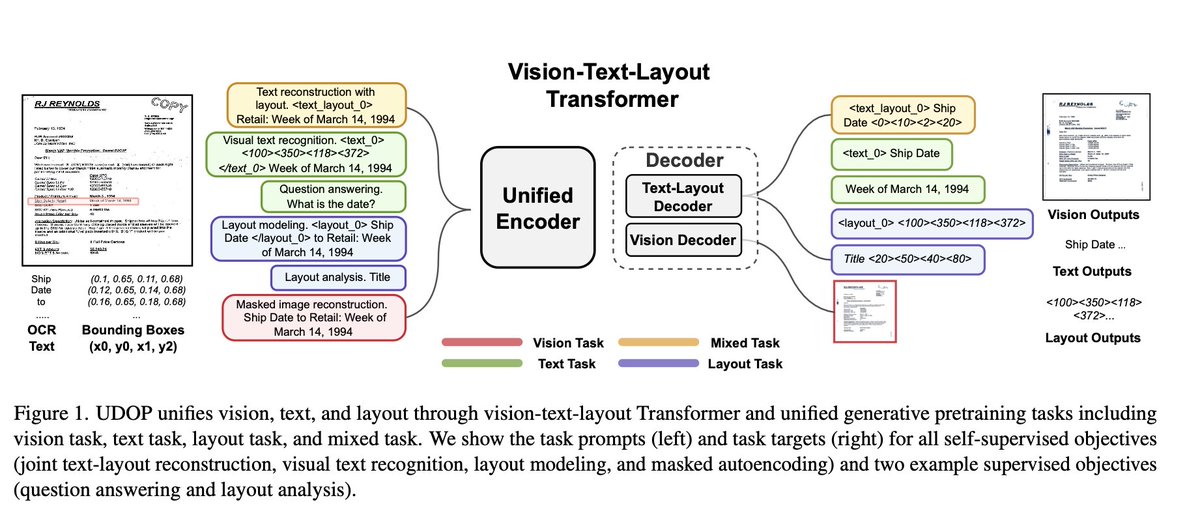
UDOP is a model that combines vision, text and layout. 📝
|
| 20 |
+
This model is very interesting because the input representation truly captures the nature of the document modality: text, where the text is, and the layout of the document matters!""")
|
| 21 |
+
st.markdown(""" """)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
st.markdown("""
|
| 25 |
+
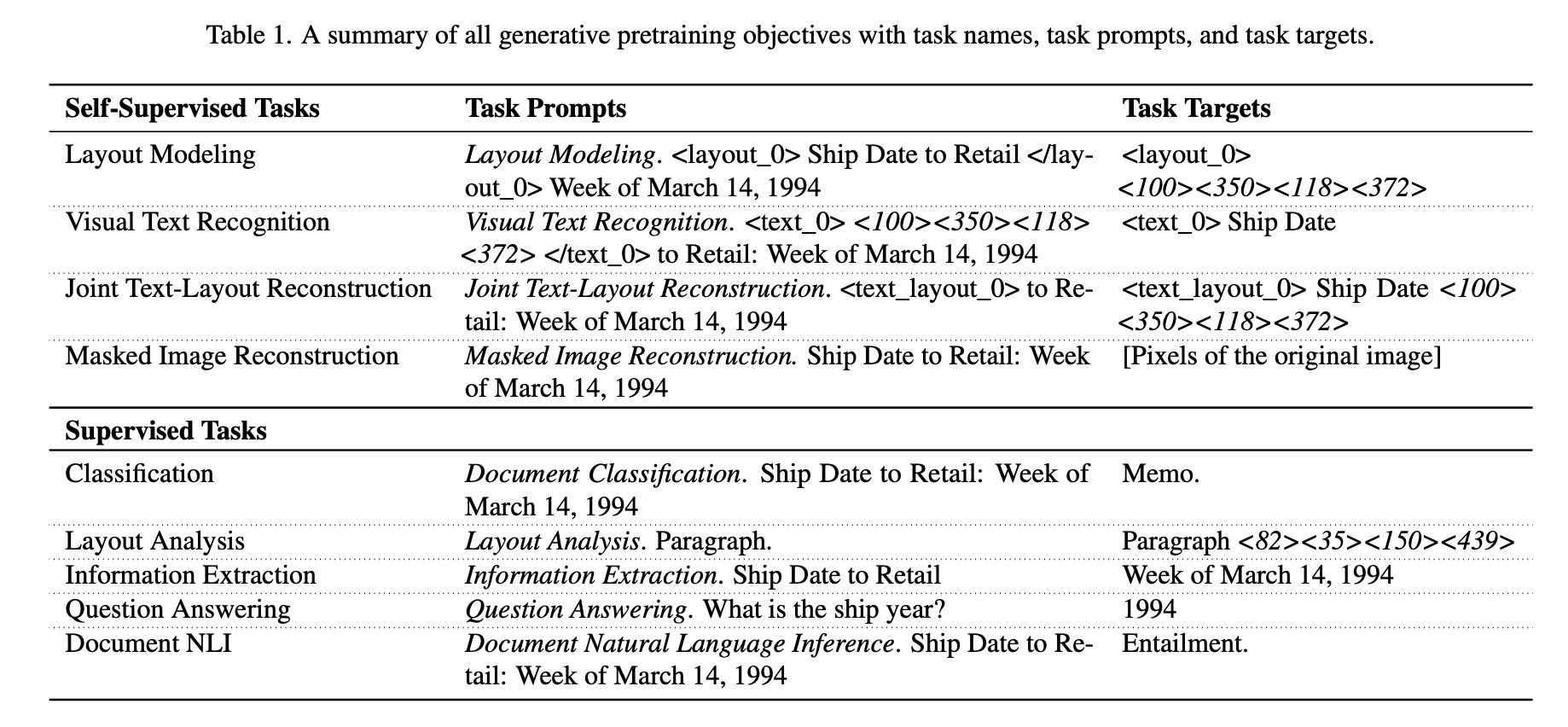
If you know T5, it resembles that: it's pre-trained on both self-supervised and supervised objectives over text, image and layout.
|
| 26 |
+
To switch between tasks, one simply needs to change the task specific prompt at the beginning, e.g. for QA, one prepends with Question answering.""")
|
| 27 |
+
st.markdown(""" """)
|
| 28 |
+
|
| 29 |
+
st.image("pages/UDOP/image_2.png", use_column_width=True)
|
| 30 |
+
st.markdown(""" """)
|
| 31 |
+
|
| 32 |
+
st.markdown("""
|
| 33 |
+
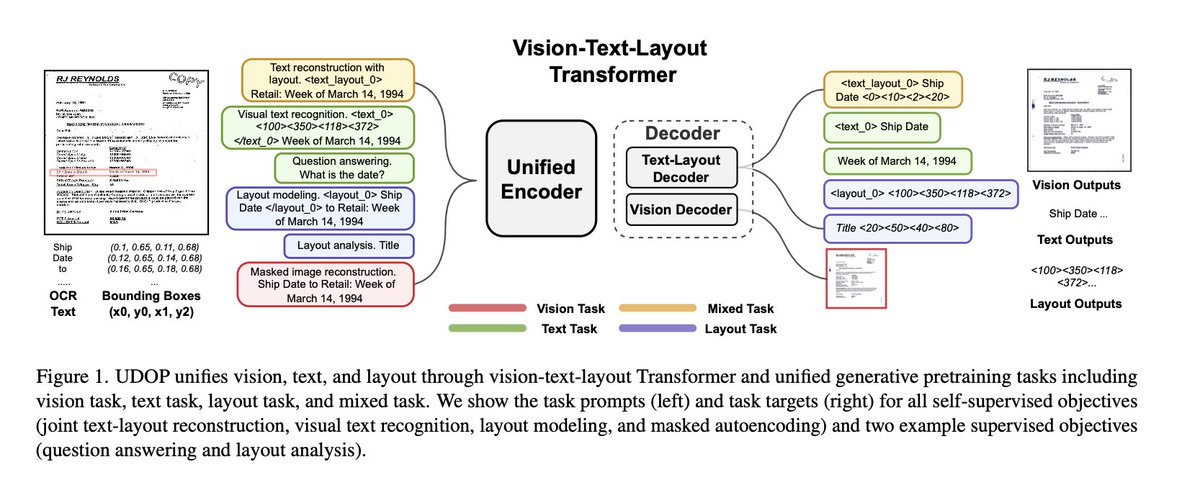
As for the architecture, it's like T5, except it has a single encoder that takes in text, image and layout, and two decoders (text-layout and vision decoders) combined into one.
|
| 34 |
+
The vision decoder is a masked autoencoder (thus the capabilities of document editing).
|
| 35 |
+
""")
|
| 36 |
+
st.image("pages/UDOP/image_3.jpeg", use_column_width=True)
|
| 37 |
+
st.markdown(""" """)
|
| 38 |
+
|
| 39 |
+
st.image("pages/UDOP/image_3.jpeg", use_column_width=True)
|
| 40 |
+
st.markdown(""" """)
|
| 41 |
+
|
| 42 |
+
st.markdown("""
|
| 43 |
+
For me, the most interesting capability is document reconstruction, document editing and layout re-arrangement (see below 👇 ) this decoder isn't released though because it could be used maliciously to fake document editing.
|
| 44 |
+
""")
|
| 45 |
+
st.markdown(""" """)
|
| 46 |
+
|
| 47 |
+
st.image("pages/UDOP/image_4.jpeg", use_column_width=True)
|
| 48 |
+
st.markdown(""" """)
|
| 49 |
+
|
| 50 |
+
st.markdown("""
|
| 51 |
+
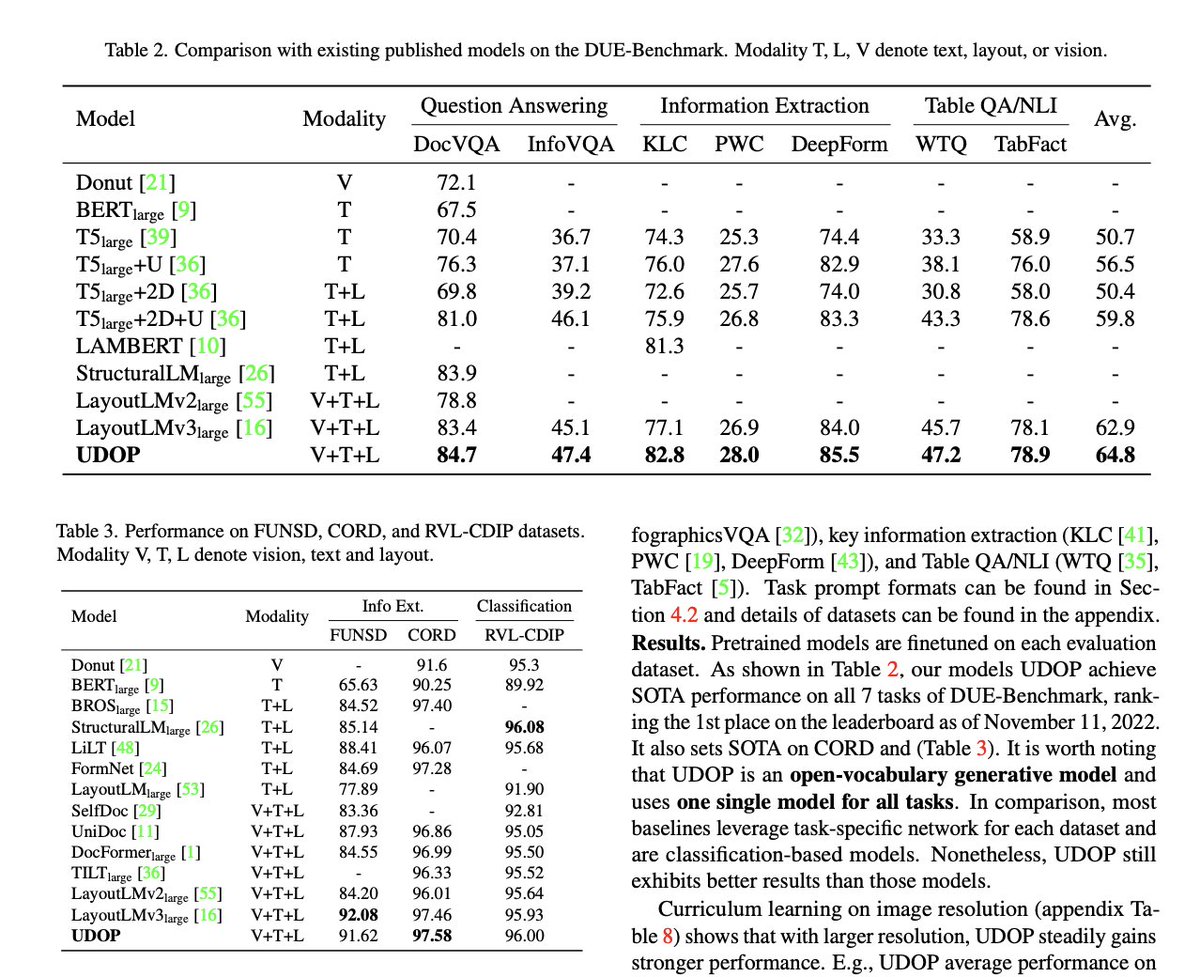
Overall, the model performs very well on document understanding benchmark (DUE) and also information extraction (FUNSD, CORD) and classification (RVL-CDIP) for vision, text, layout modalities 👇
|
| 52 |
+
""")
|
| 53 |
+
st.markdown(""" """)
|
| 54 |
+
|
| 55 |
+
st.image("pages/UDOP/image_5.jpeg", use_column_width=True)
|
| 56 |
+
st.markdown(""" """)
|
| 57 |
+
|
| 58 |
+
st.info("""
|
| 59 |
+
Resources:
|
| 60 |
+
- [Unifying Vision, Text, and Layout for Universal Document Processing](https://arxiv.org/abs/2212.02623)
|
| 61 |
+
Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal (2022)
|
| 62 |
+
|
| 63 |
+
- [GitHub](https://github.com/microsoft/UDOP)
|
| 64 |
+
|
| 65 |
+
- [Hugging Face Models](https://huggingface.co/microsoft/udop-large)
|
| 66 |
+
|
| 67 |
+
- [Hugging Face documentation](https://huggingface.co/docs/transformers/en/model_doc/udop)""", icon="📚")
|
| 68 |
+
|
| 69 |
+
st.markdown(""" """)
|
| 70 |
+
st.markdown(""" """)
|
| 71 |
+
st.markdown(""" """)
|
| 72 |
+
col1, col2, col3 = st.columns(3)
|
| 73 |
+
with col1:
|
| 74 |
+
if st.button('Previous paper', use_container_width=True):
|
| 75 |
+
switch_page("SAMv2")
|
| 76 |
+
with col2:
|
| 77 |
+
if st.button('Home', use_container_width=True):
|
| 78 |
+
switch_page("Home")
|
| 79 |
+
with col3:
|
| 80 |
+
if st.button('Next paper', use_container_width=True):
|
| 81 |
+
switch_page("MiniGemini")
|
pages/26_MiniGemini.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("MiniGemini")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://x.com/mervenoyann/status/1783864388249694520) (April 26, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""
|
| 10 |
+
MiniGemini is the coolest VLM, let's explain 🧶
|
| 11 |
+
""")
|
| 12 |
+
st.markdown(""" """)
|
| 13 |
+
|
| 14 |
+
st.image("pages/MiniGemini/image_1.jpeg", use_column_width=True)
|
| 15 |
+
st.markdown(""" """)
|
| 16 |
+
|
| 17 |
+
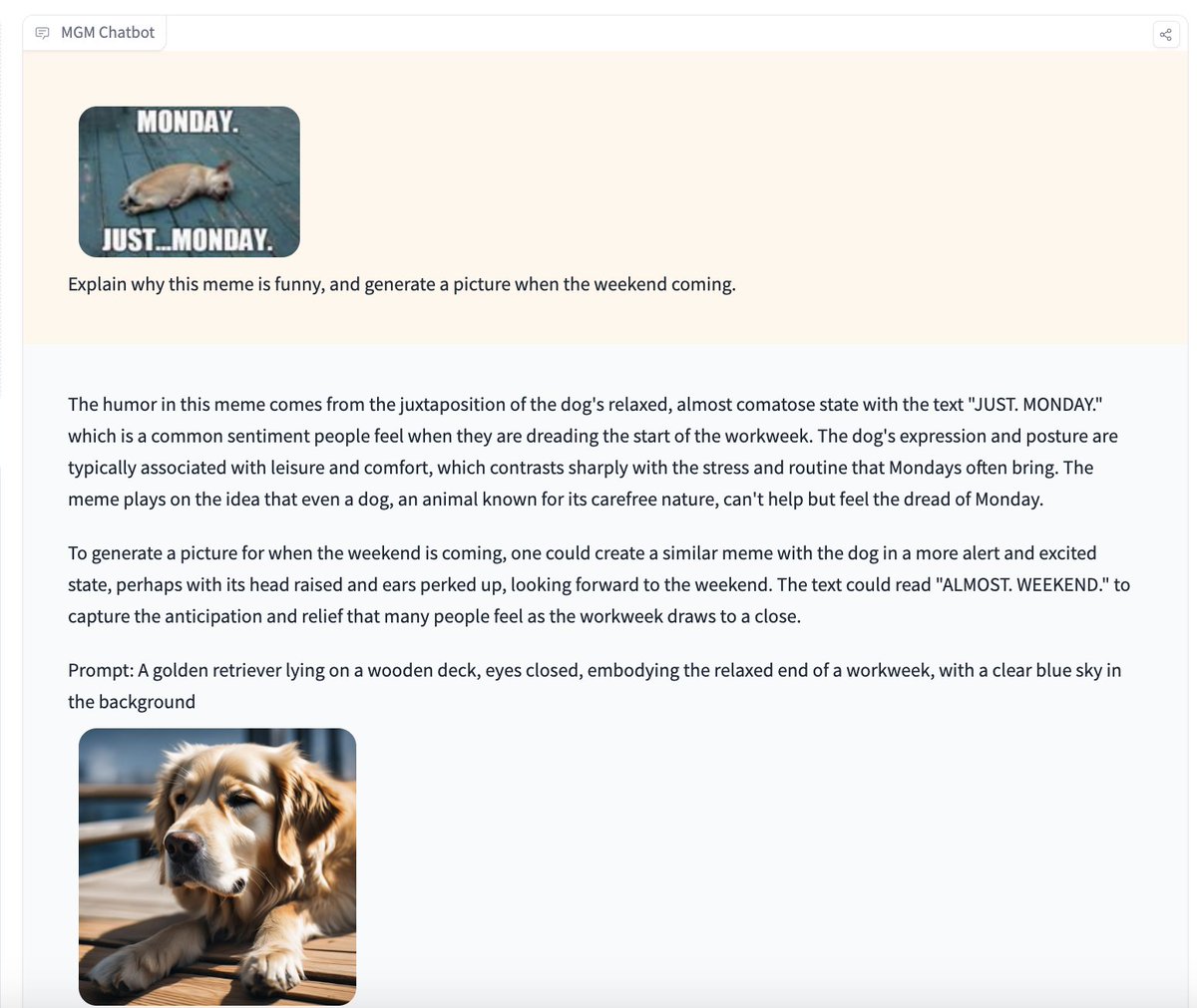
st.markdown("""MiniGemini is a vision language model that understands both image and text and also generates text and an image that goes best with the context! 🤯
|
| 18 |
+
""")
|
| 19 |
+
st.markdown(""" """)
|
| 20 |
+
|
| 21 |
+
st.image("pages/MiniGemini/image_2.jpeg", use_column_width=True)
|
| 22 |
+
st.markdown(""" """)
|
| 23 |
+
|
| 24 |
+
st.markdown("""
|
| 25 |
+
This model has two image encoders (one CNN and one ViT) in parallel to capture the details in the images
|
| 26 |
+
I saw the same design in DocOwl 1.5
|
| 27 |
+
then it has a decoder to output text and also a prompt to be sent to SDXL for image generation (which works very well!)""")
|
| 28 |
+
st.markdown(""" """)
|
| 29 |
+
|
| 30 |
+
st.image("pages/MiniGemini/image_3.jpeg", use_column_width=True)
|
| 31 |
+
st.markdown(""" """)
|
| 32 |
+
|
| 33 |
+
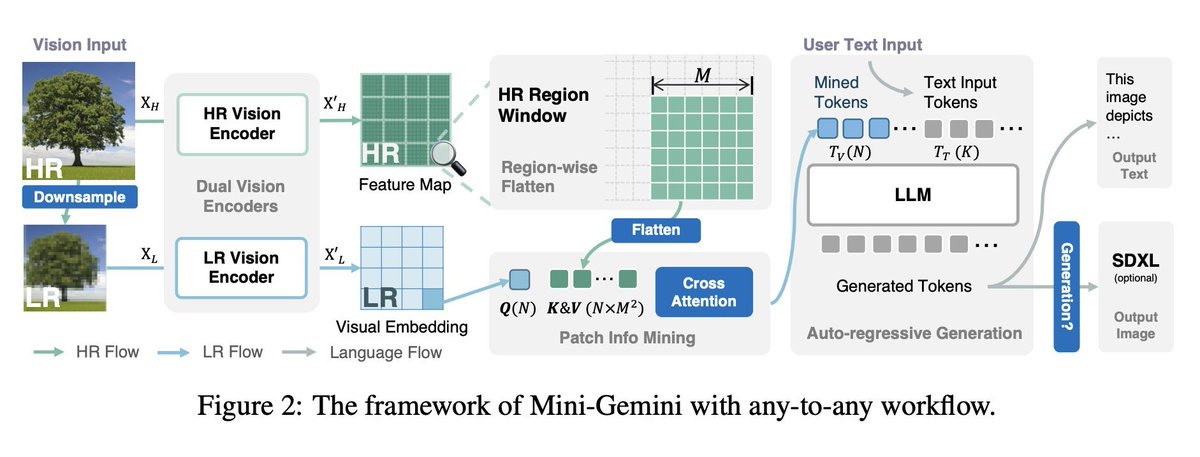
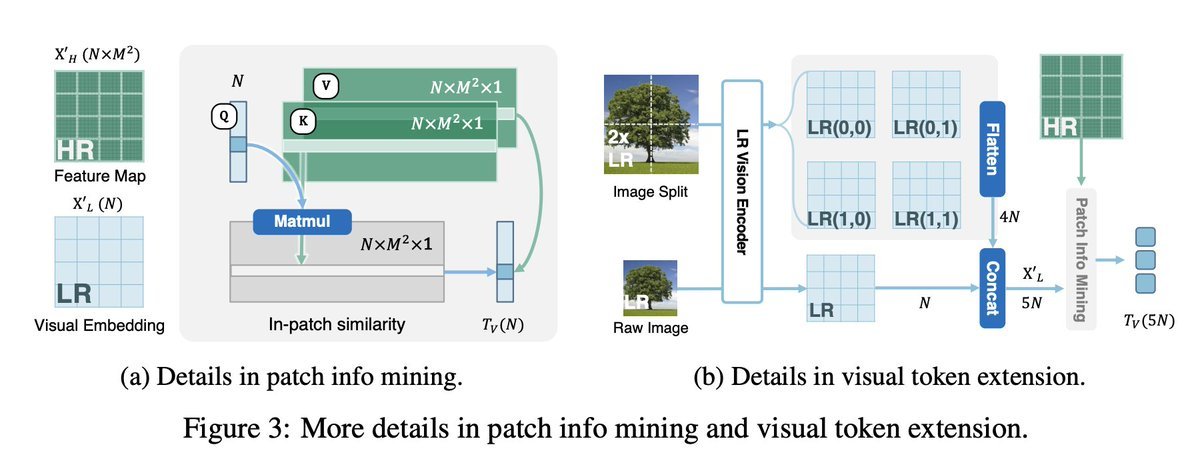
st.markdown("""They adopt CLIP's ViT for low resolution visual embedding encoder and a CNN-based one for high resolution image encoding (precisely a pre-trained ConvNeXt)
|
| 34 |
+
""")
|
| 35 |
+
st.markdown(""" """)
|
| 36 |
+
|
| 37 |
+
st.image("pages/MiniGemini/image_4.jpeg", use_column_width=True)
|
| 38 |
+
st.markdown(""" """)
|
| 39 |
+
|
| 40 |
+
st.markdown("""Thanks to the second encoder it can grasp details in images, which also comes in handy for e.g. document tasks (but see below the examples are mindblowing IMO)
|
| 41 |
+
""")
|
| 42 |
+
st.markdown(""" """)
|
| 43 |
+
|
| 44 |
+
st.image("pages/MiniGemini/image_5.jpeg", use_column_width=True)
|
| 45 |
+
st.markdown(""" """)
|
| 46 |
+
|
| 47 |
+
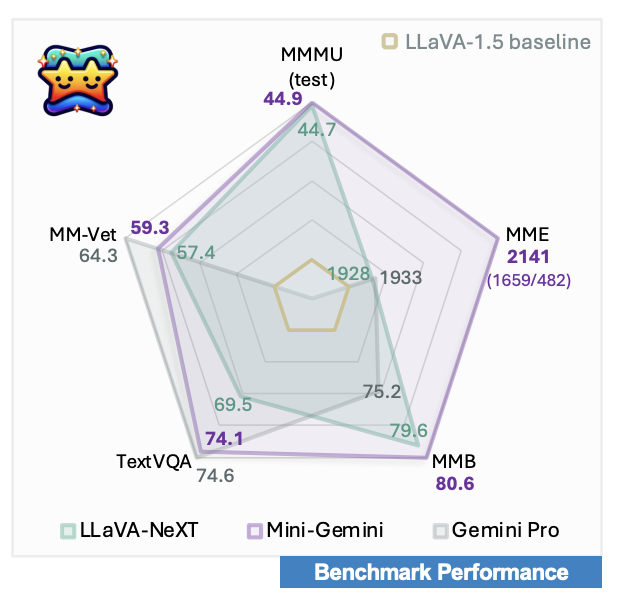
st.markdown("""According to their reporting the model performs very well across many benchmarks compared to LLaVA 1.5 and Gemini Pro
|
| 48 |
+
""")
|
| 49 |
+
st.markdown(""" """)
|
| 50 |
+
|
| 51 |
+
st.image("pages/MiniGemini/image_6.png", use_column_width=True)
|
| 52 |
+
st.markdown(""" """)
|
| 53 |
+
|
| 54 |
+
st.info("""
|
| 55 |
+
Resources:
|
| 56 |
+
|
| 57 |
+
- [Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models](https://huggingface.co/papers/2403.18814)
|
| 58 |
+
by Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, Jiaya Jia
|
| 59 |
+
(2024)
|
| 60 |
+
|
| 61 |
+
- [GitHub](https://github.com/dvlab-research/MGM)
|
| 62 |
+
|
| 63 |
+
- [Link to Model Repository](https://huggingface.co/YanweiLi/MGM-13B-HD)""", icon="📚")
|
| 64 |
+
|
| 65 |
+
st.markdown(""" """)
|
| 66 |
+
st.markdown(""" """)
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
col1, col2, col3 = st.columns(3)
|
| 69 |
+
with col1:
|
| 70 |
+
if st.button('Previous paper', use_container_width=True):
|
| 71 |
+
switch_page("UDOP")
|
| 72 |
+
with col2:
|
| 73 |
+
if st.button('Home', use_container_width=True):
|
| 74 |
+
switch_page("Home")
|
| 75 |
+
with col3:
|
| 76 |
+
if st.button('Next paper', use_container_width=True):
|
| 77 |
+
switch_page("ColPali")
|
pages/27_ColPali.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from streamlit_extras.switch_page_button import switch_page
|
| 3 |
+
|
| 4 |
+
st.title("ColPali")
|
| 5 |
+
|
| 6 |
+
st.success("""[Original tweet](https://x.com/mervenoyann/status/1811003265858912670) (Jul 10, 2024)""", icon="ℹ️")
|
| 7 |
+
st.markdown(""" """)
|
| 8 |
+
|
| 9 |
+
st.markdown("""
|
| 10 |
+
Forget any document retrievers, use ColPali 💥💥
|
| 11 |
+
|
| 12 |
+
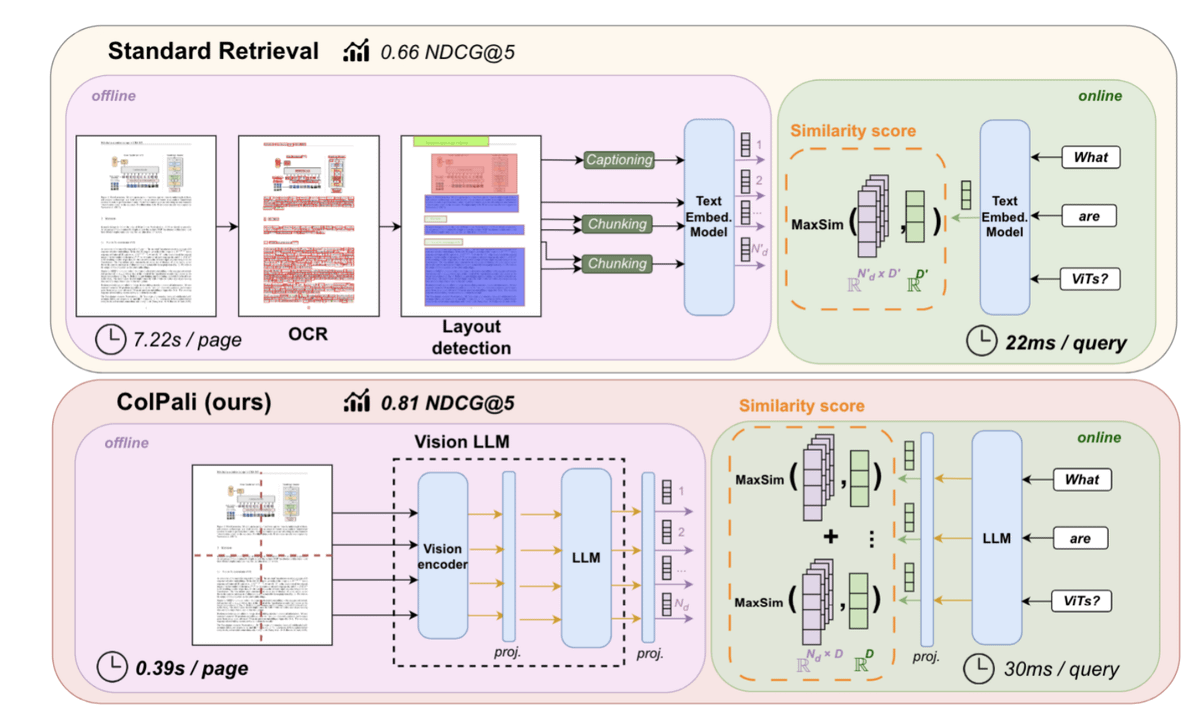
Document retrieval is done through OCR + layout detection, but it's overkill and doesn't work well! 🤓
|
| 13 |
+
|
| 14 |
+
ColPali uses a vision language model, which is better in doc understanding 📑
|
| 15 |
+
""")
|
| 16 |
+
st.markdown(""" """)
|
| 17 |
+
|
| 18 |
+
st.image("pages/ColPali/image_1.png", use_column_width=True)
|
| 19 |
+
st.markdown(""" """)
|
| 20 |
+
|
| 21 |
+
st.markdown("""
|
| 22 |
+
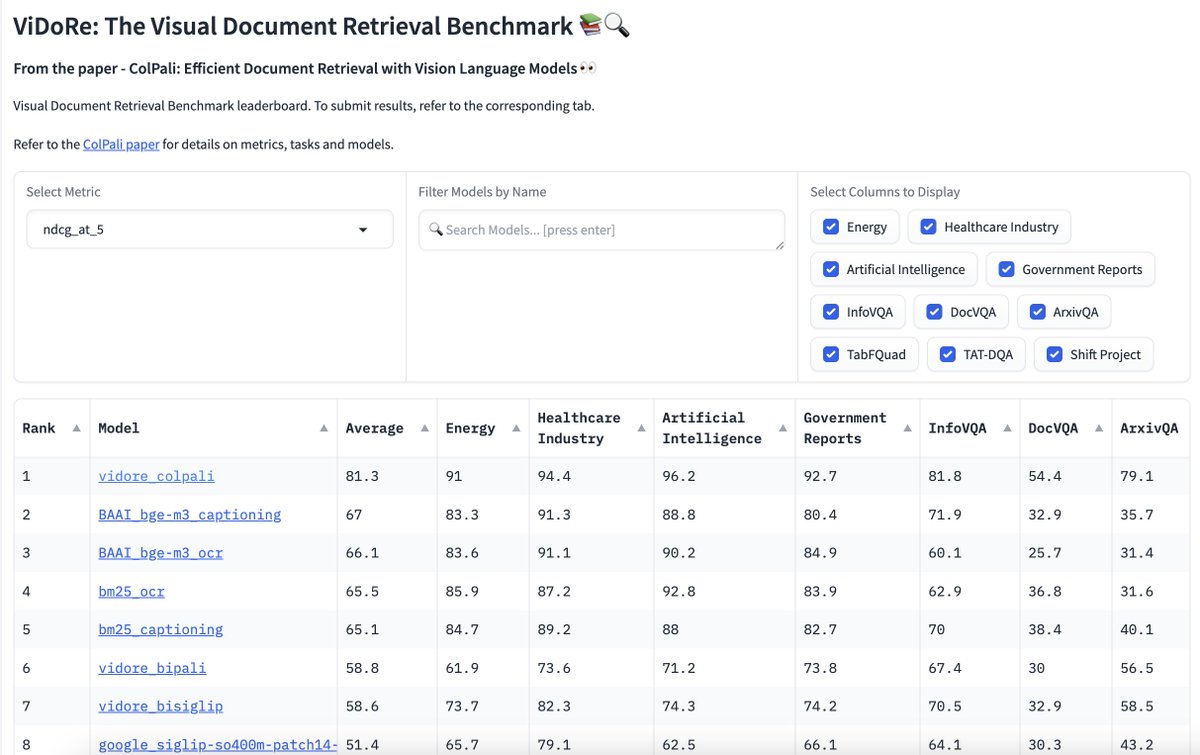
Check out [ColPali model](https://huggingface.co/vidore/colpali) (mit license!)
|
| 23 |
+
Check out the [blog](https://huggingface.co/blog/manu/colpali)
|
| 24 |
+
|
| 25 |
+
The authors also released a new benchmark for document retrieval, [ViDoRe Leaderboard](https://huggingface.co/spaces/vidore/vidore-leaderboard), submit your model! """)
|
| 26 |
+
st.markdown(""" """)
|
| 27 |
+
|
| 28 |
+
st.image("pages/ColPali/image_2.jpeg", use_column_width=True)
|
| 29 |
+
st.markdown(""" """)
|
| 30 |
+
|
| 31 |
+
st.markdown("""
|
| 32 |
+
Regular document retrieval systems use OCR + layout detection + another model to retrieve information from documents, and then use output representations in applications like RAG 🥲
|
| 33 |
+
|
| 34 |
+
Meanwhile modern image encoders demonstrate out-of-the-box document understanding capabilities!""")
|
| 35 |
+
st.markdown(""" """)
|
| 36 |
+
|
| 37 |
+
st.markdown("""
|
| 38 |
+
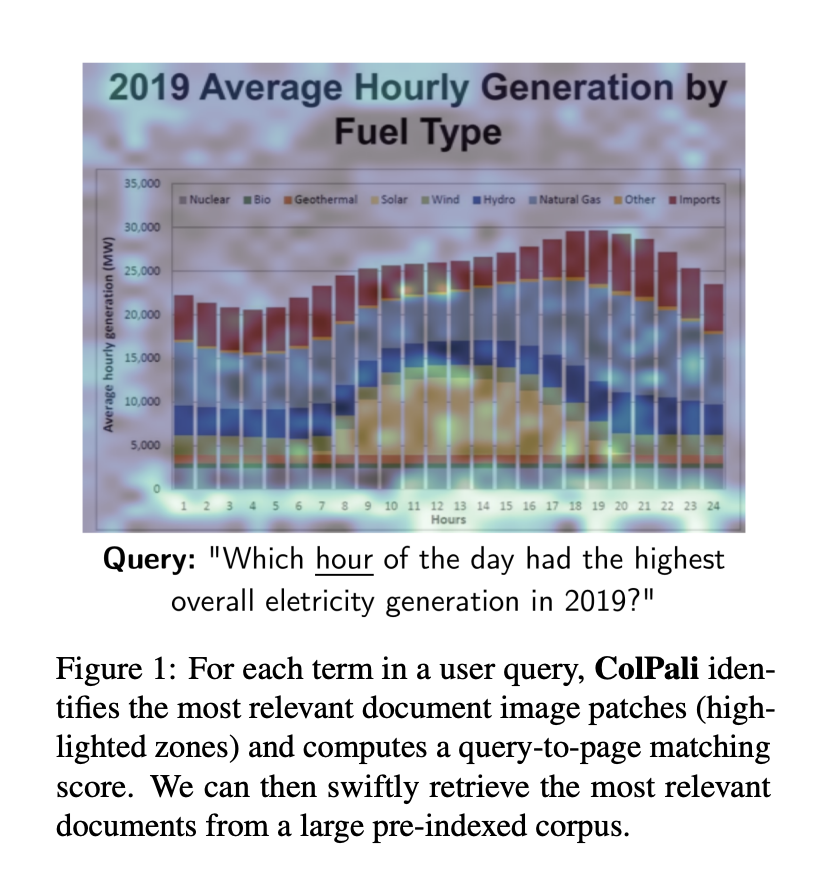
ColPali marries the idea of modern vision language models with retrieval 🤝
|
| 39 |
+
|
| 40 |
+
The authors apply contrastive fine-tuning to SigLIP on documents, and pool the outputs (they call it BiSigLip). Then they feed the patch embedding outputs to PaliGemma and create BiPali 🖇️
|
| 41 |
+
""")
|
| 42 |
+
st.markdown(""" """)
|
| 43 |
+
|
| 44 |
+
st.image("pages/ColPali/image_3.png", use_column_width=True)
|
| 45 |
+
st.markdown(""" """)
|
| 46 |
+
|
| 47 |
+
st.markdown("""
|
| 48 |
+
BiPali natively supports image patch embeddings to an LLM, which enables leveraging the ColBERT-like late interaction computations between text tokens and image patches (hence the name ColPali!) 🤩
|
| 49 |
+
""")
|
| 50 |
+
st.markdown(""" """)
|
| 51 |
+
|
| 52 |
+
st.markdown("""
|
| 53 |
+
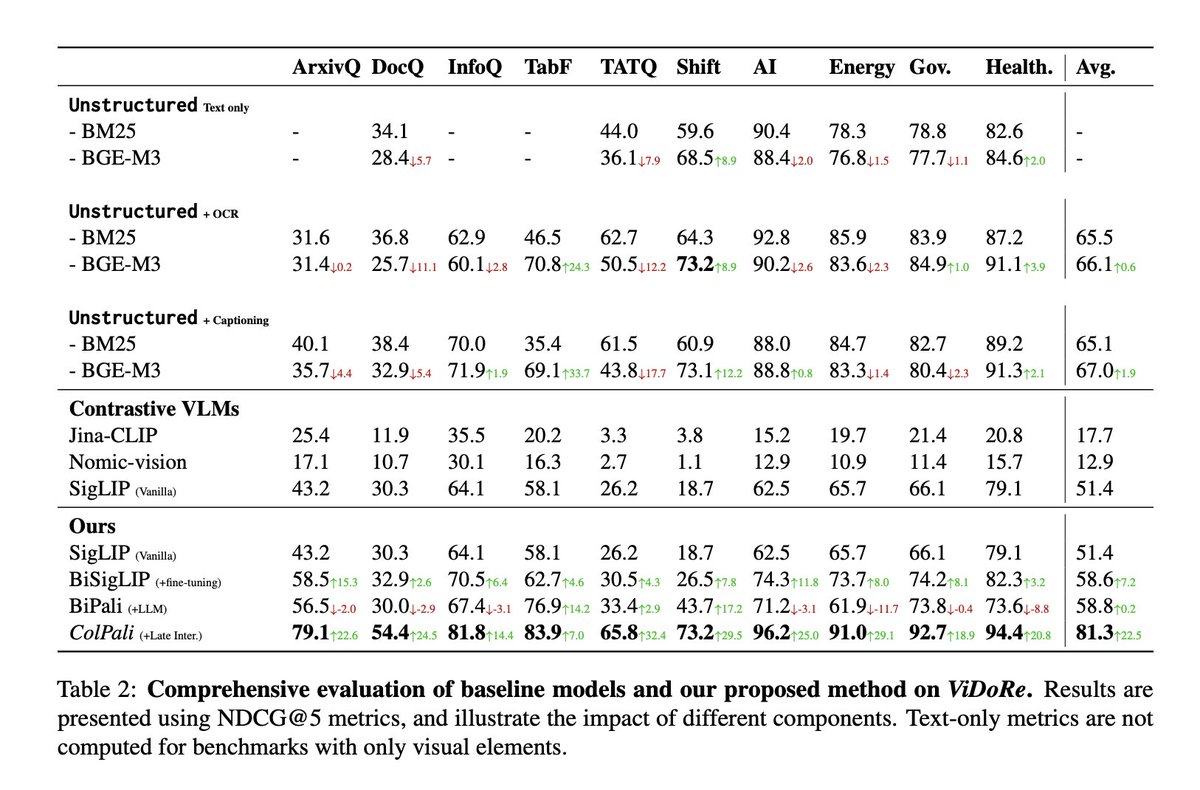
The authors created the ViDoRe benchmark by collecting PDF documents and generate queries from Claude-3 Sonnet.
|
| 54 |
+
|
| 55 |
+
See below how every model and ColPali performs on ViDoRe 👇🏻
|
| 56 |
+
""")
|
| 57 |
+
st.markdown(""" """)
|
| 58 |
+
|
| 59 |
+
st.image("pages/ColPali/image_4.jpeg", use_column_width=True)
|
| 60 |
+
st.markdown(""" """)
|
| 61 |
+
|
| 62 |
+
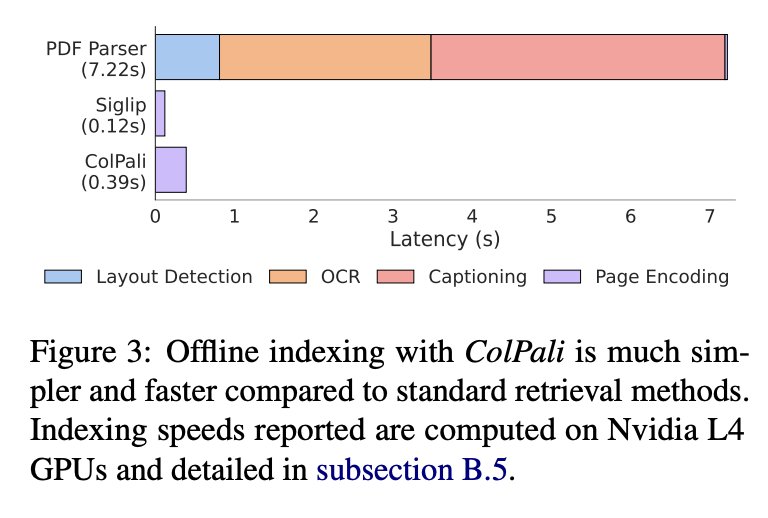
st.markdown("""Aside from performance improvements, ColPali is very fast for offline indexing as well!
|
| 63 |
+
""")
|
| 64 |
+
st.markdown(""" """)
|
| 65 |
+
|
| 66 |
+
st.image("pages/ColPali/image_5.png", use_column_width=True)
|
| 67 |
+
st.markdown(""" """)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
st.info("""
|
| 71 |
+
Resources:
|
| 72 |
+
- [ColPali: Efficient Document Retrieval with Vision Language Models](https://huggingface.co/papers/2407.01449)
|
| 73 |
+
by Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, Pierre Colombo (2024)
|
| 74 |
+
|
| 75 |
+
- [GitHub](https://github.com/illuin-tech/colpali)
|
| 76 |
+
|
| 77 |
+
- [Link to Models](https://huggingface.co/models?search=vidore)
|
| 78 |
+
|
| 79 |
+
- [Link to Leaderboard](https://huggingface.co/spaces/vidore/vidore-leaderboard)""", icon="📚")
|
| 80 |
+
|
| 81 |
+
st.markdown(""" """)
|
| 82 |
+
st.markdown(""" """)
|
| 83 |
+
st.markdown(""" """)
|
| 84 |
+
col1, col2, col3 = st.columns(3)
|
| 85 |
+
with col1:
|
| 86 |
+
if st.button('Previous paper', use_container_width=True):
|
| 87 |
+
switch_page("MiniGemini")
|
| 88 |
+
with col2:
|
| 89 |
+
if st.button('Home', use_container_width=True):
|
| 90 |
+
switch_page("Home")
|
| 91 |
+
with col3:
|
| 92 |
+
if st.button('Next paper', use_container_width=True):
|
| 93 |
+
switch_page("Home")
|
pages/ColPali/image_1.png
ADDED
|
pages/ColPali/image_2.jpeg
ADDED
|
pages/ColPali/image_3.png
ADDED
|
pages/ColPali/image_4.jpeg
ADDED
|
pages/ColPali/image_5.png
ADDED
|
pages/MiniGemini/image_1.jpeg
ADDED
|
pages/MiniGemini/image_2.jpeg
ADDED
|
pages/MiniGemini/image_3.jpeg
ADDED
|
pages/MiniGemini/image_4.jpeg
ADDED
|
pages/MiniGemini/image_5.jpeg
ADDED

|
pages/MiniGemini/image_6.png
ADDED
|
pages/UDOP/image_1.jpeg
ADDED
|
pages/UDOP/image_2.png
ADDED
|
pages/UDOP/image_3.jpeg
ADDED
|
pages/UDOP/image_4.jpeg
ADDED

|
pages/UDOP/image_5.jpeg
ADDED
|