Spaces:
Runtime error


title: MimicMotion
emoji: 🤸♀️
colorFrom: blue
colorTo: purple
sdk: gradio
sdk_version: 4.39.0
app_file: app.py
pinned: false
suggested_hardware: a10g-large
MimicMotion
MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance
Yuang Zhang1,2, Jiaxi Gu1, Li-Wen Wang1, Han Wang1,2, Junqi Cheng1, Yuefeng Zhu1, Fangyuan Zou1
[1Tencent; 2Shanghai Jiao Tong University]






Highlights: rich details, good temporal smoothness, and long video length.
Overview
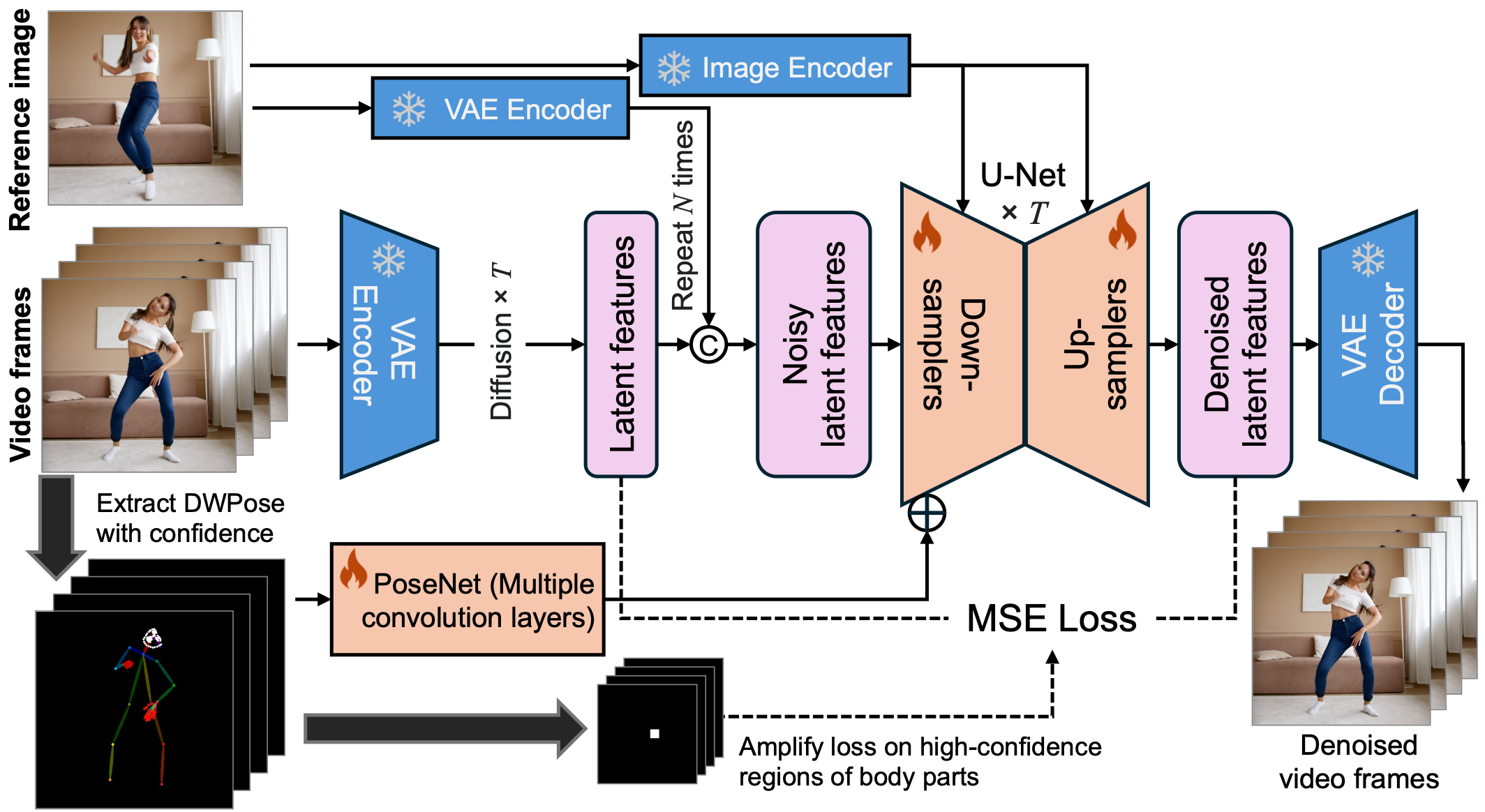
An overview of the framework of MimicMotion.
In recent years, generative artificial intelligence has achieved significant advancements in the field of image generation, spawning a variety of applications. However, video generation still faces considerable challenges in various aspects such as controllability, video length, and richness of details, which hinder the application and popularization of this technology. In this work, we propose a controllable video generation framework, dubbed MimicMotion, which can generate high-quality videos of arbitrary length with any motion guidance. Comparing with previous methods, our approach has several highlights. Firstly, with confidence-aware pose guidance, temporal smoothness can be achieved so model robustness can be enhanced with large-scale training data. Secondly, regional loss amplification based on pose confidence significantly eases the distortion of image significantly. Lastly, for generating long smooth videos, a progressive latent fusion strategy is proposed. By this means, videos of arbitrary length can be generated with acceptable resource consumption. With extensive experiments and user studies, MimicMotion demonstrates significant improvements over previous approaches in multiple aspects.
Quickstart
Environment setup
Recommend python 3+ with torch 2.x are validated with an Nvidia V100 GPU. Follow the command below to install all the dependencies of python:
conda env create -f environment.yaml
conda activate mimicmotion
Download weights
Please download weights manually as follows:
cd MimicMotions/
mkdir models
- Download SVD model: stabilityai/stable-video-diffusion-img2vid-xt-1-1
git lfs install git clone https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1 mkdir -p models/SVD mv stable-video-diffusion-img2vid-xt-1-1 models/SVD/ - Download DWPose pretrained model: dwpose
git lfs install git clone https://huggingface.co/yzd-v/DWPose mv DWPose models/ - Download the pre-trained checkpoint of MimicMotion from Huggingface
curl -o models/MimicMotion.pth https://huggingface.co/ixaac/MimicMotion/resolve/main/MimicMotion.pth
Finally, all the weights should be organized in models as follows
models/
├── DWPose
│ ├── dw-ll_ucoco_384.onnx
│ └── yolox_l.onnx
├── SVD
│ └──stable-video-diffusion-img2vid-xt-1-1
└── MimicMotion.pth
Model inference
We provide the inference script.
python inference.py --inference_config configs/test.yaml
Citation
@article{mimicmotion2024,
title={MimicMotion: High-Quality Human Motion Video Generation with Confidence-aware Pose Guidance},
author={Yuang Zhang and Jiaxi Gu and Li-Wen Wang and Han Wang and Junqi Cheng and Yuefeng Zhu and Fangyuan Zou},
journal={arXiv preprint arXiv:2406.19680},
year={2024}
}