
license: apache-2.0
datasets:
- wchai/AuroraCap-trainset
base_model:
- lmsys/vicuna-7b-v1.5-16k
tags:
- caption
model-index:
- name: AuroraCap-7B
results:
- task:
type: video detailed caption
dataset:
type: VDC
name: VDC
metrics:
- type: Acc
value: 38.21
name: VDCScore
- type: Acc
value: 48.33
name: VDD
- type: cider
value: 9.51
- type: bleu
value: 30.9
name: bleu@1
- type: bleu
value: 4.06
name: bleu@4
- type: meteor
value: 19.09
- type: rouge
value: 21.58
name: rouge-l
- task:
type: video caption
dataset:
type: MSR-VTT
name: NSR-VTT
metrics:
- type: cider
value: 33.1
- type: bleu
value: 58.6
name: bleu@1
- type: bleu
value: 21
name: bleu@4
- type: meteor
value: 23.9
- type: rouge
value: 49.5
name: rouge-l
- task:
type: video caption
dataset:
type: VATEX
name: VATEX
metrics:
- type: cider
value: 33.8
- type: bleu
value: 57.1
name: bleu@1
- type: bleu
value: 18.4
name: bleu@4
- type: meteor
value: 19
- type: rouge
value: 40.8
name: rouge-l
- task:
type: video question anwering
dataset:
type: ActivityNet
name: ActivityNet
metrics:
- type: Acc
value: 61.8
- task:
type: video question anwering
dataset:
type: MSVD
name: MSVD
metrics:
- type: Acc
value: 62.6
- task:
type: video question anwering
dataset:
type: MSR-VTT
name: MSR-VTT
metrics:
- type: Acc
value: 43.5
- task:
type: video question anwering
dataset:
type: iVQA
name: iVQA
metrics:
- type: Acc
value: 55.2
pipeline_tag: video-text-to-text

Resources
- Website
- arXiv: Paper
- GitHub: Code
- Huggingface: AuroraCap Model
- Huggingface: VDC Benchmark
- Huggingface: Trainset
Features
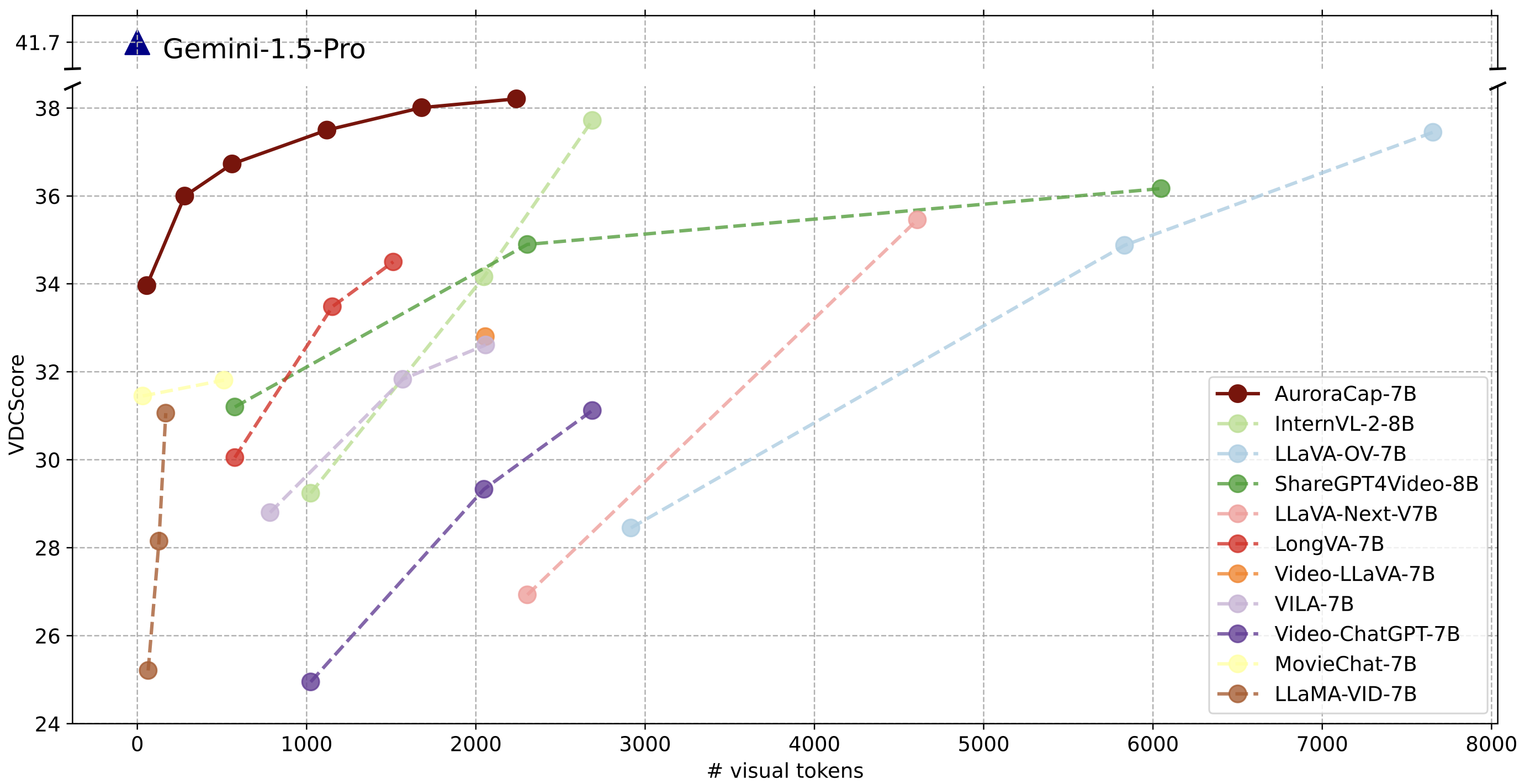
AuroraCap is a multimodal large language model for image and video captioning.
Quick Start
See Docs.
FAQ
Q: Can I only use token merging during inference?
A: No, our experiments show that token merging is also a way to accelerate training while maintaining similar performance. Additionally, besides auroracap, you can also use token merging on other llava-like models.
Q: Why do we provide both official LLaVA-format and Xtuner format weights for AuroraCap?
A: While Xtuner supports saving checkpoints in multiple formats, it currently only allows continued training with the Xtuner format. Therefore, we currently provide the model in the Xtuner format for both continued training and inference. In the future, we will provide the model in the official LLaVA format for both training and inference, enabling quicker SGLang deployment and integration with the transformers.
Citation
@article{chai2024auroracap,
title={AuroraCap: Efficient, Performant Video Detailed Captioning and a New Benchmark },
author={Wenhao Chai, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jeng-Neng Hwang, Saining Xie, Christopher D. Manning},
journal={arXiv preprint arXiv:2410.03051},
year={2024}
}