
license: llama3.2
datasets:
- BAAI/Infinity-Instruct
base_model:
- meta-llama/Llama-3.2-1B-Instruct
Model Overview
This weight is a fine-tuned version of Llama-3.2-1B-Instruct using the LLM-Neo method. Usage is identical to the original Llama-3.2-1B-Instruct model.
Training Details
The training process employs the LLM-Neo method. The dataset is derived from a mixed sample of BAAI/Infinity-Instruct, specifically the 0625 and 7M subsets, with a total of 10k instruction samples. The KD (knowledge distillation) model used is Llama-3.1-8B-Instruct, with the following hyperparameters:
- Learning Rate: 1e-4
- Epochs: 1
- KD Ratio: 0.9
- Rank: 128
Model Performance Evaluation
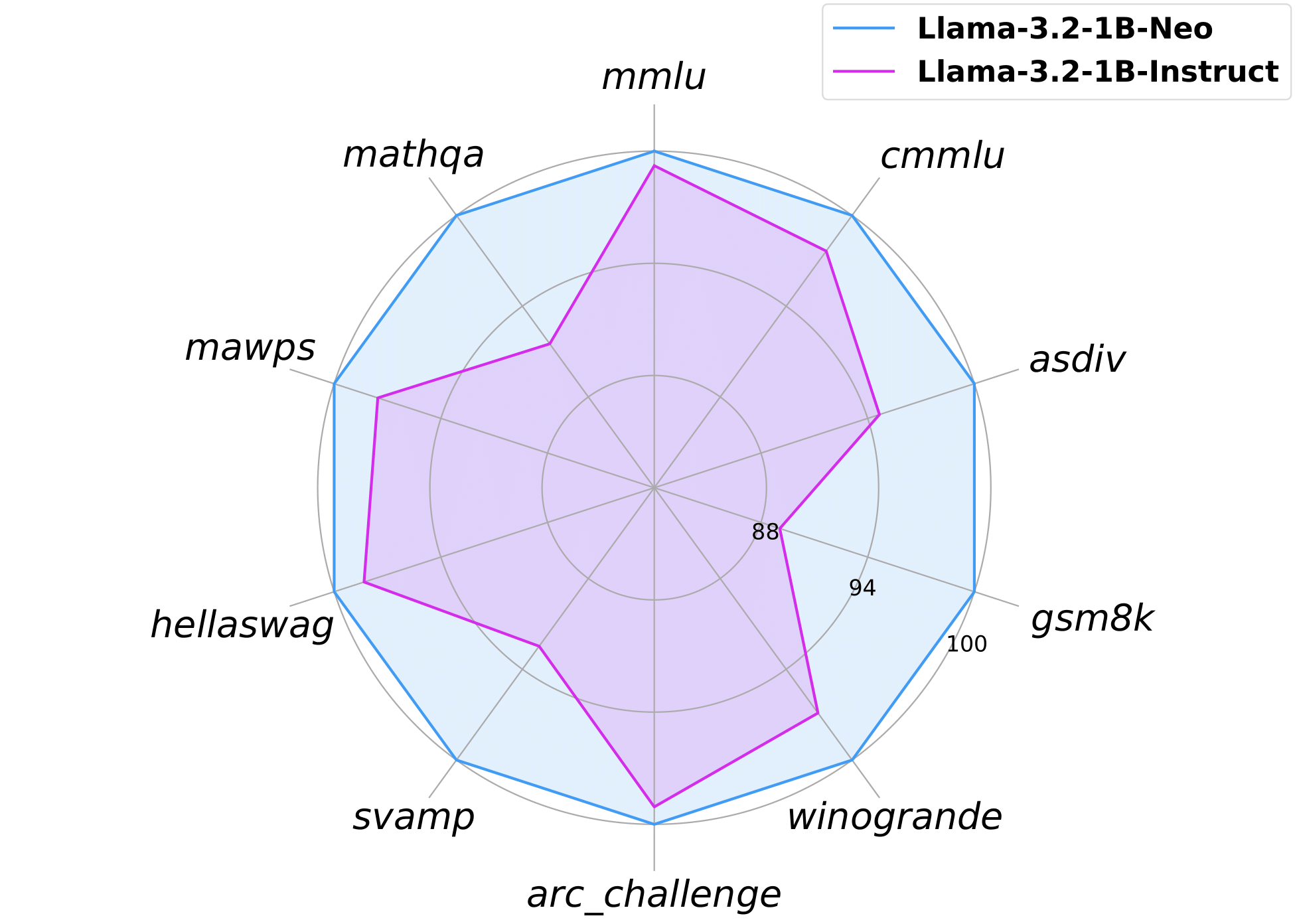
The evaluation of this model is divided into two parts: results from lm-evaluation-harness and math-evaluation-harness frameworks.
Note: The results are influenced by the specific benchmark versions and testing hardware/software configurations. Therefore, the reported metrics should be interpreted as relative performance within a given setup.
Part 1: lm-evaluation-harness results
In this part, the model was evaluated on several widely-used benchmark datasets, covering reasoning, commonsense, mathematics, and language understanding tasks. Below is a detailed comparison of the performance metrics between Llama-3.2-1B-Instruct and the current model:
| Dataset | Llama-3.2-1B-Instruct | Llama-3.2-1B-Instruct-Neo |
|---|---|---|
| ARC Challenge | 36.09 | 36.43 |
| ARC Easy | 68.52 | 67.51 |
| CEval | 39.45 | 39.67 |
| CMMLU | 35.62 | 36.48 |
| MMLU | 45.91 | 46.27 |
| HellaSwag | 45.07 | 45.84 |
| OpenBookQA | 24.40 | 25.40 |
| PIQA | 73.88 | 74.32 |
| Winogrande | 59.27 | 61.17 |
The results demonstrate that the current model outperforms Llama-3.2-1B-Instruct in several tasks, especially in reasoning tasks (e.g., Winogrande) and commonsense tasks (e.g., PIQA).
Part 2: math-evaluation-harness results
In this part, the model was evaluated specifically on mathematical reasoning and related tasks, focusing on its ability to handle complex mathematical problems.
| Dataset | Llama-3.2-1B-Instruct | Llama-3.2-1B-Instruct-Neo |
|---|---|---|
| GSM8K | 35.00 | 39.30 |
| Minerva Math | 14.80 | 22.80 |
| SVAMP | 50.40 | 54.50 |
| ASDiv | 67.40 | 71.20 |
| MAWPS | 83.50 | 85.60 |
| TabMWP | 41.90 | 35.40 |
| MathQ | 44.20 | 48.30 |
| MMLU-STEM | 37.90 | 38.90 |
The mathematical evaluation highlights significant improvements of the current model in handling complex problems, with notable progress on datasets such as Minerva Math and GSM8K.
Summary
- Strengths: The current model demonstrates notable improvements over Llama-3.2-1B-Instruct across multiple benchmark tasks, particularly in reasoning and mathematical problem-solving.
- Future Directions: Further optimization in logical reasoning tasks (e.g., TabMWP) and continued enhancements in general language and mathematical adaptability.