
VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving
Website | Paper | Video
Zilin Huang1,*, Zihao Sheng1,*, Yansong Qu2,†, Junwei You1, Sikai Chen1,✉
1University of Wisconsin-Madison, 2Purdue University
*Equally Contributing First Authors, ✉Corresponding Author
📢 News
- 2025.08: 🔥🔥 VLM-RL has been accepted to Transportation Research Part C: Emerging Technologies!
We will release the model weights on Hugging Face soon. Stay tuned!
💡 Highlights
🔥 To the best of our knowledge, VLM-RL is the first work in the autonomous driving field to unify VLMs with RL for end-to-end driving policy learning in the CARLA simulator.
🏁 VLM-RL outperforms state-of-the-art baselines, achieving a 10.5% reduction in collision rate, a 104.6% increase in route completion rate, and robust generalization to unseen driving scenarios.
| Route 1 | Route 2 | Route 3 | Route 4 | Route 5 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| Route 6 | Route 7 | Route 8 | Route 9 | Route 10 |
|---|---|---|---|---|
 |
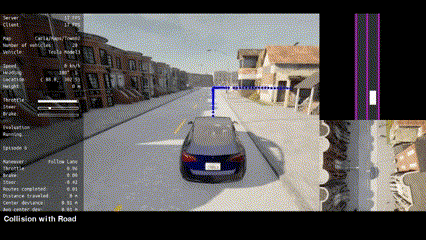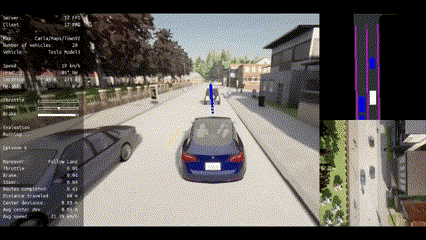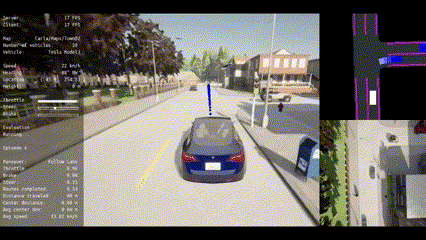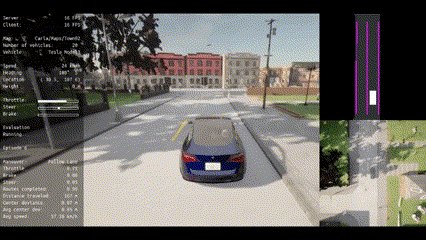 |
 |
 |
 |
📋 Table of Contents
🛠️ Getting Started
- Download and install
CARLA 0.9.13from the official release page. - Create a conda env and install the requirements:
# Clone the repo
git clone https://github.com/zihaosheng/VLM-RL.git
cd VLM-RL
# Create a conda env
conda create -y -n vlm-rl python=3.8
conda activate vlm-rl
# Install PyTorch
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
# Install the requirements
pip install -r requirements.txt
- Start a Carla server with the following command. You can ignore this if
start_carla=True
./CARLA_0.9.13/CarlaUE4.sh -quality_level=Low -benchmark -fps=15 -RenderOffScreen -prefernvidia -carla-world-port=2000
If start_carla=True, revise the CARLA_ROOT in carla_env/envs/carla_route_env.py to the path of your CARLA installation.
🚋 Training
Training VLM-RL
To reproduce the results in the paper, we provide the following training scripts:
python train.py --config=vlm_rl --start_carla --no_render --total_timesteps=1_000_000 --port=2000 --device=cuda:0
Note: On the first run, the script will automatically download the required OpenCLIP pre-trained model, which may take a few minutes. Please wait for the download to complete before the training begins.
To accelerate the training process, you can set up multiple CARLA servers running in parallel.
For example, to train the VLM-RL model with 3 CARLA servers on different GPUs, run the following commands in three separate terminals:
Terminal 1:
python train.py --config=vlm_rl --start_carla --no_render --total_timesteps=1_000_000 --port=2000 --device=cuda:0
Terminal 2:
python train.py --config=vlm_rl --start_carla --no_render --total_timesteps=1_000_000 --port=2005 --device=cuda:1
Terminal 3:
python train.py --config=vlm_rl --start_carla --no_render --total_timesteps=1_000_000 --port=2010 --device=cuda:2
To train the VLM-RL model with PPO, run:
python train.py --config=vlm_rl_ppo --start_carla --no_render --total_timesteps=1_000_000 --port=2000 --device=cuda:0
Training Baselines
To train baseline models, simply change the --config argument to the desired model. For example, to train the TIRL-SAC model, run:
python train.py --config=tirl_sac --start_carla --no_render --total_timesteps=1_000_000 --port=2000 --device=cuda:0
More baseline models can be found in the CONFIGS dictionary of config.py.
📊 Evaluation
To evaluate trained model checkpoints, run:
python run_eval.py
Note: that this command will first KILL all the existing CARLA servers and then start a new one. Try to avoid running this command while training is in progress.
👥 Contributors
Special thanks to the following contributors who have helped with this project:

Zihao Sheng |

Zilin Huang |

Yansong Qu |
Junwei You |
🎯 Citation
If you find VLM-RL useful for your research, please consider giving us a star 🌟 and citing our paper:
@article{huang2024vlmrl,
title={VLM-RL: A Unified Vision Language Models and Reinforcement Learning Framework for Safe Autonomous Driving},
author={Huang, Zilin and Sheng, Zihao and Qu, Yansong and You, Junwei and Chen, Sikai},
journal={arXiv preprint arXiv:2412.15544},
year={2024}
}
📚 Other Resources
Our team is actively working on research projects in the field of AI and autonomous driving. Here are a few of them you might find interesting: