
File size: 4,743 Bytes
92f8b29 625ca7a 92f8b29 75541c5 1f62fcf 5420f56 92f8b29 b33f910 92f8b29 625ca7a 92f8b29 936c3a2 92f8b29 0c2361d 92f8b29 b33f910 92f8b29 b5bc017 92f8b29 9bf6454 92f8b29 0c2361d 92f8b29 b1113d1 92f8b29 625ca7a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
---
license: apache-2.0
base_model: hustvl/yolos-small
tags:
- object-detection
- vision
- transformers.js
- transformers
widget:
- src: https://i.imgur.com/MjMfEMk.jpeg
example_title: Children
---
# Yolos-small-person
YOLOS model fine-tuned on COCO 2017 object detection (118k annotated images). It was introduced in the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Fang et al. and first released in [this repository](https://github.com/hustvl/YOLOS).
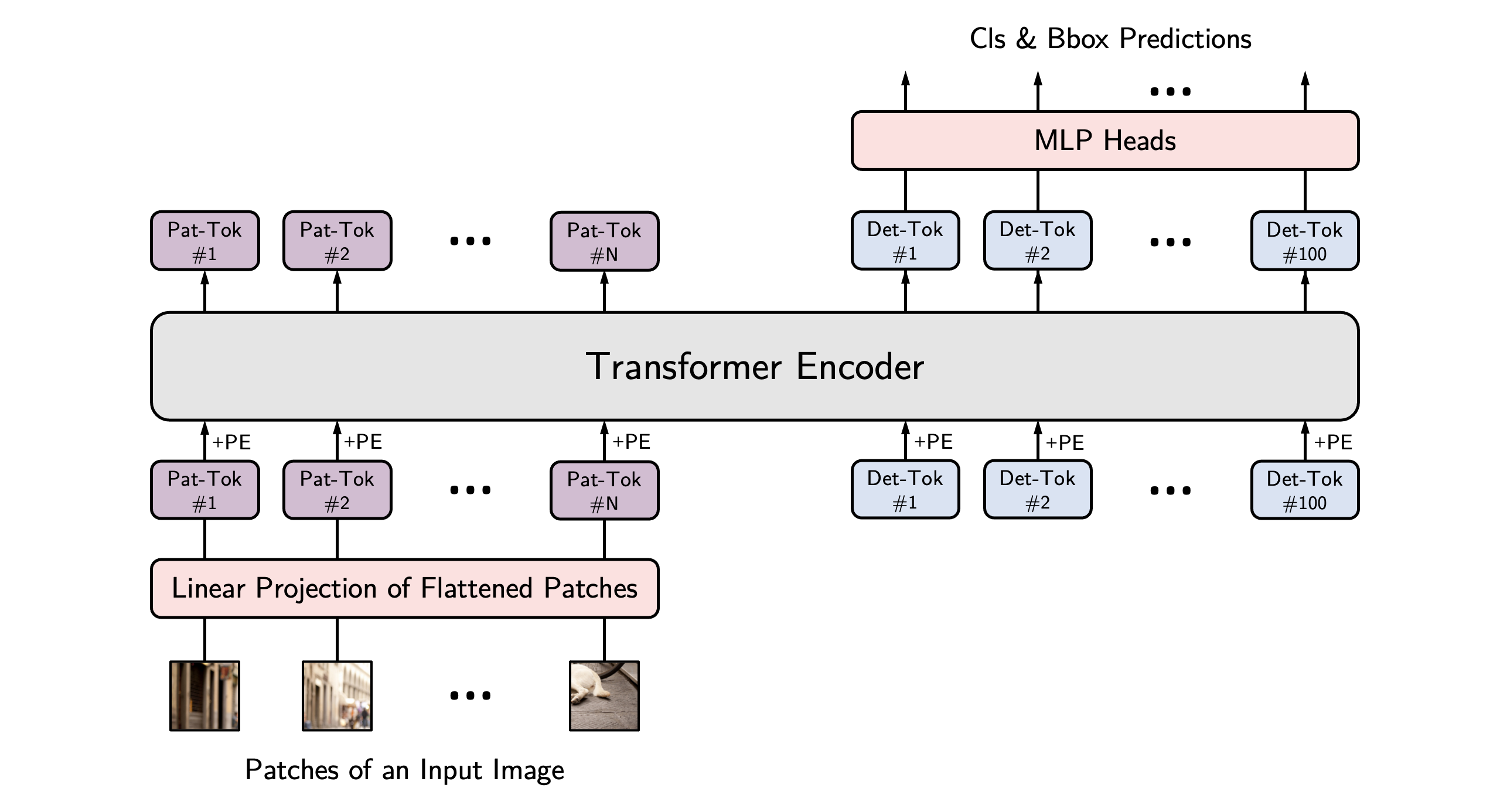
## Model description
This [hustvl/yolos-small](https://huggingface.co/hustvl/yolos-small) model has been finetuned on these two datasets[[1](https://universe.roboflow.com/new-workspace-phqon/object-detection-brcrx)][[2](https://universe.roboflow.com/tank-detect/person-dataset-kzsop)] (2604 samples) with the following results on the test set:
```
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.501
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.866
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.498
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.048
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.455
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.648
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.412
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.601
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.632
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.224
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.600
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.756
```
## How to use
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
import torch
from PIL import Image
import requests
url = "https://latestbollyholly.com/wp-content/uploads/2024/02/Jacob-Gooch.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("AdamCodd/yolos-small-person")
model = AutoModelForObjectDetection.from_pretrained("AdamCodd/yolos-small-person")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(outputs, threshold=0.7, target_sizes=target_sizes)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
```
Refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/yolos) for more code examples.
## Intended uses & limitations
This model is more of an experiment on a small scale and will need retraining on a more diverse dataset. This fine-tuned model performs best when detecting individuals who are relatively close to the viewpoint. As indicated by the metrics, it struggles to identify individuals farther away.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: AdamW with betas=(0.9,0.999) and epsilon=1e-08
- num_epochs: 5
- weight_decay: 1e-4
### Framework versions
- Transformers 4.37.0
- pycocotools 2.0.7
If you want to support me, you can [here](https://ko-fi.com/adamcodd).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-00666,
author = {Yuxin Fang and
Bencheng Liao and
Xinggang Wang and
Jiemin Fang and
Jiyang Qi and
Rui Wu and
Jianwei Niu and
Wenyu Liu},
title = {You Only Look at One Sequence: Rethinking Transformer in Vision through
Object Detection},
journal = {CoRR},
volume = {abs/2106.00666},
year = {2021},
url = {https://arxiv.org/abs/2106.00666},
eprinttype = {arXiv},
eprint = {2106.00666},
timestamp = {Fri, 29 Apr 2022 19:49:16 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-00666.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |