
license: apache-2.0
pretty_name: English Wiktionary Data in JSONL
language:
- en
- de
- la
- grc
- ko
- peo
- akk
- elx
- sa
configs:
- config_name: Wiktionary
data_files:
- split: German
path: german-wiktextract-data.jsonl
- split: Latin
path: latin-wiktextract-data.jsonl
- split: AncientGreek
path: ancient-greek-wiktextract-data.jsonl
- split: Korean
path: korean-wiktextract-data.jsonl
- split: OldPersian
path: old-persian-wiktextract-data.jsonl
- split: Akkadian
path: akkadian-wiktextract-data.jsonl
- split: Elamite
path: elamite-wiktextract-data.jsonl
- split: Sanskrit
path: sanskrit-wiktextract-data.jsonl
- config_name: Knowledge Graph
data_files:
- split: AllLanguage
path: word-definition-graph-data.jsonl
tags:
- Natural Language Processing
- NLP
- Wiktionary
- Vocabulary
- German
- Latin
- Ancient Greek
- Korean
- Old Persian
- Akkadian
- Elamite
- Sanskrit
- Knowledge Graph
size_categories:
- 100M<n<1B
Wiktionary Data on Hugging Face Datasets


![]()
wiktionary-data is a sub-data extraction of the English Wiktionary that currently supports the following languages:
- Deutsch - German
- Latinum - Latin
- Ἑλληνική - Ancient Greek
- 한국어 - Korean
- 𐎠𐎼𐎹 - Old Persian
- 𒀝𒅗𒁺𒌑(𒌝) - Akkadian
- Elamite
- संस्कृतम् - Sanskrit, or Classical Sanskrit
wiktionary-data was originally a sub-module of wilhelm-graphdb. While the dataset it's getting bigger, I noticed a wave of more exciting potentials this dataset can bring about that stretches beyond the scope of the containing project. Therefore I decided to promote it to a dedicated module; and here comes this repo.
The Wiktionary language data is available on 🤗 Hugging Face Datasets.
from datasets import load_dataset
dataset = load_dataset("QubitPi/wiktionary-data", split="German")
There are two data subsets:
Languages subset that contains the sub-data extraction of the following splits:
GermanLatinAncientGreekKoreanOldPersianAkkadianElamiteSanskrit
Graph subset that is useful for constructing knowledge graphs:
AllLanguage: all the languages in a giant graph
The Graph data ontology is the following:
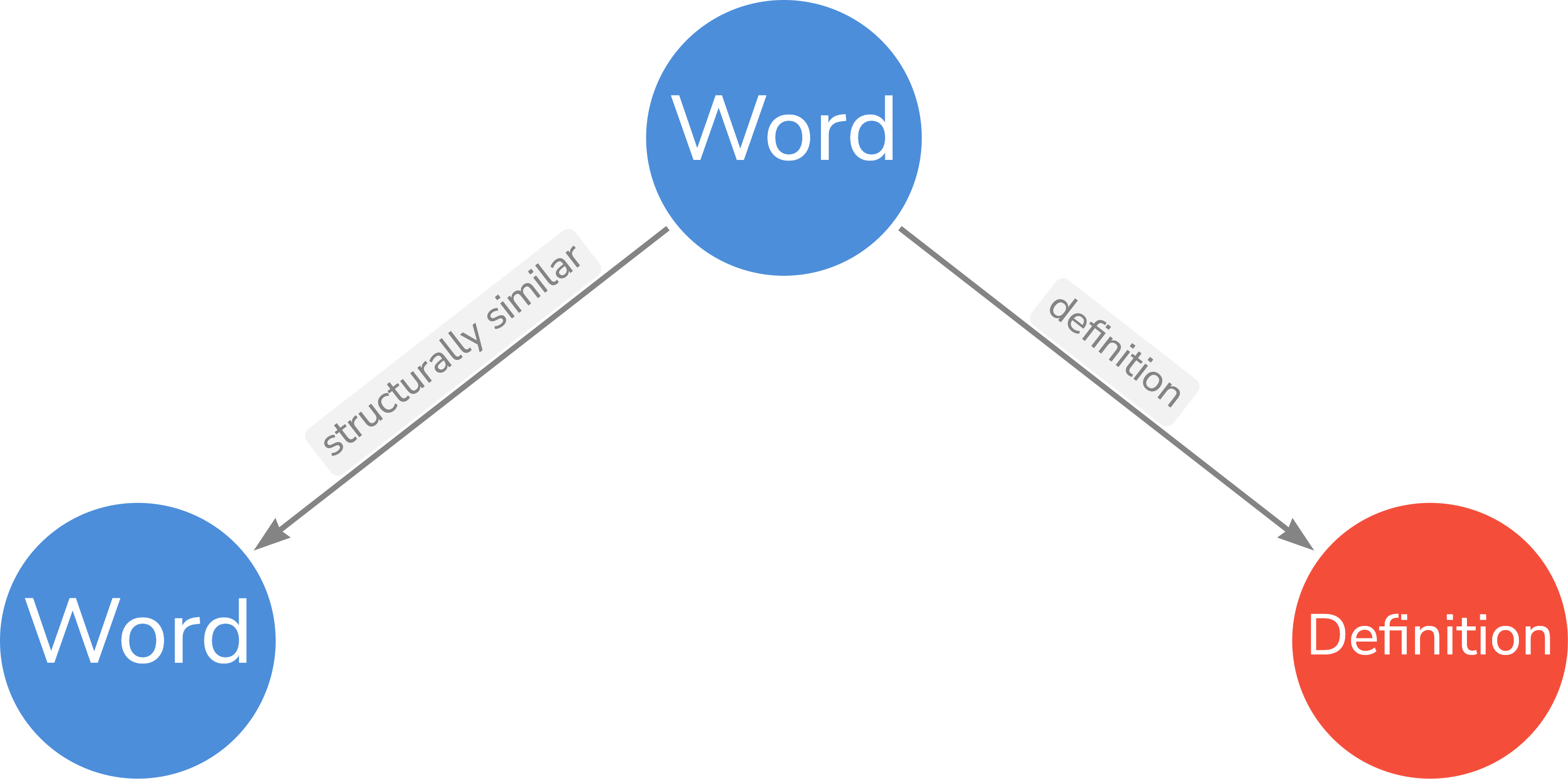
Two words are structurally similar if and only if the two shares the same stem
Development
Data Source
Although the original Wiktionary dump is available, parsing it from scratch involves rather complicated process. For example, acquiring the inflection data of most Indo-European languages on Wiktionary has already triggered some research-level efforts. We would probably do it in the future. At present, however, we would simply take the awesome works by tatuylonen which has already processed it and presented it in in JSONL format. wiktionary-data sources the data from raw Wiktextract data (JSONL, one object per line) option there.
Environment Setup
Get the source code:
git@github.com:QubitPi/wiktionary-data.git
cd wiktionary-data
It is strongly recommended to work in an isolated environment. Install virtualenv and create an isolated Python environment by
python3 -m pip install --user -U virtualenv
python3 -m virtualenv .venv
To activate this environment:
source .venv/bin/activate
or, on Windows
./venv\Scripts\activate
To deactivate this environment, use
deactivate
Installing Dependencies
pip3 install -r requirements.txt
License
The use and distribution terms for wiktionary-data are covered by the Apache License, Version 2.0.