
MoDE
Collection
Collection of pretrained MoDE Diffusion Policies. Variants include finetuned versions for all CALVIN benchmarks and LIBERO 90.
•
9 items
•
Updated
•
2
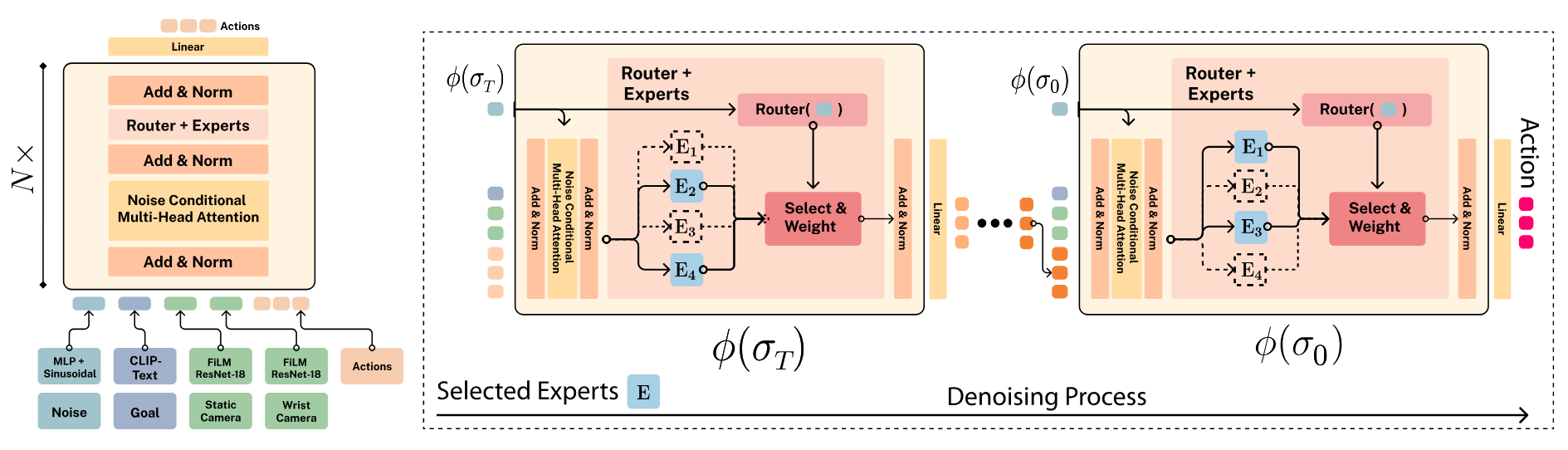
This model implements a Mixture of Diffusion Experts architecture for robotic manipulation, combining transformer-based backbone with noise-only expert routing. For faster inference, we can precache the chosen expert for each timestep to reduce computation time.
The model has been pretrained on a subset of OXE for 300k steps and finetuned for downstream tasks on the CALVIN/LIBERO dataset.
(B, T, 3, H, W) tensor(B, T, 3, H, W) tensor(B, T, 7) tensor representing delta EEF actionsCheck out our full model implementation on Github MoDE_Diffusion_Policy and follow the instructions in the readme to test the model on one of the environments.
obs = {
"rgb_obs": {
"rgb_static": static_image,
"rgb_gripper": gripper_image
}
}
goal = {"lang_text": "pick up the blue cube"}
action = model.step(obs, goal)
If you found the code usefull, please cite our work:
@misc{reuss2024efficient,
title={Efficient Diffusion Transformer Policies with Mixture of Expert Denoisers for Multitask Learning},
author={Moritz Reuss and Jyothish Pari and Pulkit Agrawal and Rudolf Lioutikov},
year={2024},
eprint={2412.12953},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
This model is released under the MIT license.
Unable to build the model tree, the base model loops to the model itself. Learn more.