
metadata
license: llama2
library_name: transformers
Bitnet-LLama-70M
Inspired from Bitnet-LLama-70M is a 70M parameter model trained using the method described in The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits.
It was trained on the subset of the HuggingFaceTB/cosmopedia dataset. This is just a small experiment to try out BitNet. Bitnet-LLama-70M was trained for 2 epochs on Colab T4.
This model is just an experiment and you might not get good results while chatting with it due to smaller model size and less training.
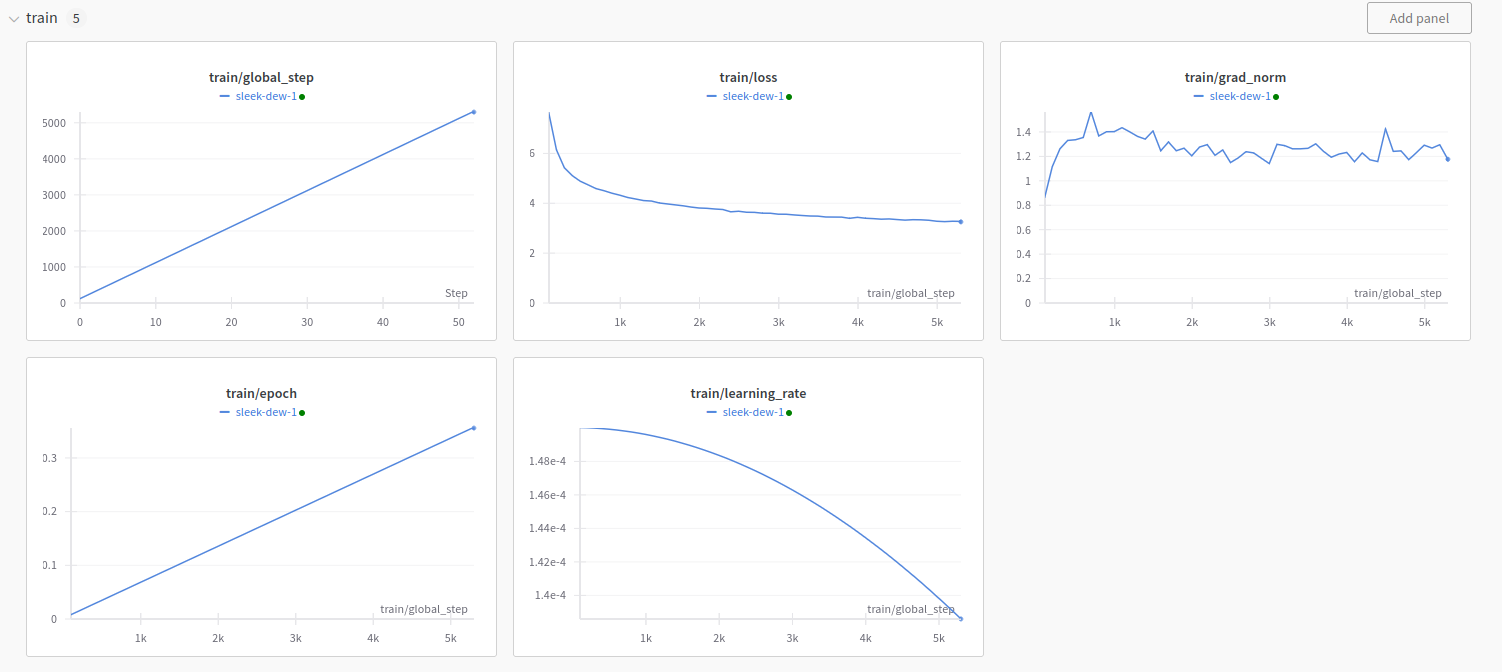
Wandb training report is as follows:
Load a pretrained BitNet model
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.models.llama.modeling_llama import *
model = "nijil-k/Bitnet-1.58b-Nous-Llama2-70M"
tokenizer = AutoTokenizer.from_pretrained(model)
model = AutoModelForCausalLM.from_pretrained(model)
def convert_to_bitnet(model, copy_weights):
for name, module in model.named_modules():
# Replace linear layers with BitNet
if isinstance(module, LlamaSdpaAttention) or isinstance(module, LlamaMLP):
for child_name, child_module in module.named_children():
if isinstance(child_module, nn.Linear):
bitlinear = BitLinear(child_module.in_features, child_module.out_features, child_module.bias is not None).to(device="cuda:0")
if copy_weights:
bitlinear.weight = child_module.weight
if child_module.bias is not None:
bitlinear.bias = child_module.bias
setattr(module, child_name, bitlinear)
# Remove redundant input_layernorms
elif isinstance(module, LlamaDecoderLayer):
for child_name, child_module in module.named_children():
if isinstance(child_module, LlamaRMSNorm) and child_name == "input_layernorm":
setattr(module, child_name, nn.Identity().to(device="cuda:0"))
convert_to_bitnet(model, copy_weights=True)
model.to(device="cuda:0")
prompt = "What is Machine Learning?"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generate_ids = model.generate(inputs.input_ids, max_length=100)
tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]