Spaces:
Configuration error


MiniCPM-V是面向图文理解的端侧多模态大模型系列。该系列模型接受图像和文本输入,并提供高质量的文本输出。自2024年2月以来,我们共发布了4个版本模型,旨在实现领先的性能和高效的部署,目前该系列最值得关注的模型包括:
MiniCPM-Llama3-V 2.5:🔥🔥🔥 MiniCPM-V系列的最新、性能最佳模型。总参数量8B,多模态综合性能超越 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等商用闭源模型,OCR 能力及指令跟随能力进一步提升,并支持超过30种语言的多模态交互。通过系统使用模型量化、CPU、NPU、编译优化等高效推理技术,MiniCPM-Llama3-V 2.5 可以实现高效的终端设备部署。
MiniCPM-V 2.0:MiniCPM-V系列的最轻量级模型。总参数量2B,多模态综合性能超越 Yi-VL 34B、CogVLM-Chat 17B、Qwen-VL-Chat 10B 等更大参数规模的模型,可接受 180 万像素的任意长宽比图像输入,实现了和 Gemini Pro 相近的场景文字识别能力以及和 GPT-4V 相匹的低幻觉率。
更新日志
📌 置顶
- [2024.05.28] 💥 MiniCPM-Llama3-V 2.5 现在在 llama.cpp 和 ollama 中完全支持其功能!请拉取最新的 llama.cpp 和 ollama 代码。我们还发布了各种大小的 GGUF 版本,请点击这里查看。ollama 使用的 FAQ 将在一天内发布,敬请关注!
- [2024.05.28] 💫 我们现在支持 MiniCPM-Llama3-V 2.5 的 LoRA 微调,更多内存使用统计信息可以在这里找到。
- [2024.05.23] 🔍 我们添加了Phi-3-vision-128k-instruct 与 MiniCPM-Llama3-V 2.5的全面对比,包括基准测试评估、多语言能力和推理效率 🌟📊🌍🚀。点击这里查看详细信息。
- [2024.05.23] 🔥🔥🔥 MiniCPM-V 在 GitHub Trending 和 Hugging Face Trending 上登顶!MiniCPM-Llama3-V 2.5 Demo 被 Hugging Face 的 Gradio 官方账户推荐,欢迎点击这里体验!
- [2024.05.25] MiniCPM-Llama3-V 2.5 支持流式输出和自定义系统提示词了,欢迎试用!
- [2024.05.24] 我们开源了 MiniCPM-Llama3-V 2.5 gguf,支持 llama.cpp 推理!实现端侧 6-8 tokens/s 的流畅解码,欢迎试用!
- [2024.05.20] 我们开源了 MiniCPM-Llama3-V 2.5,增强了 OCR 能力,支持 30 多种语言,并首次在端侧实现了 GPT-4V 级的多模态能力!我们提供了高效推理和简易微调的支持,欢迎试用!
- [2024.04.23] 我们增加了对 vLLM 的支持,欢迎体验!
- [2024.04.18] 我们在 HuggingFace Space 新增了 MiniCPM-V 2.0 的 demo,欢迎体验!
- [2024.04.17] MiniCPM-V 2.0 现在支持用户部署本地 WebUI Demo 了,欢迎试用!
- [2024.04.15] MiniCPM-V 2.0 现在可以通过 SWIFT 框架 微调 了,支持流式输出!
- [2024.04.12] 我们开源了 MiniCPM-V 2.0,该模型刷新了 OCRBench 开源模型最佳成绩,在场景文字识别能力上比肩 Gemini Pro,同时还在综合了 11 个主流多模态大模型评测基准的 OpenCompass 榜单上超过了 Qwen-VL-Chat 10B、CogVLM-Chat 17B 和 Yi-VL 34B 等更大参数规模的模型!点击这里查看 MiniCPM-V 2.0 技术博客。
- [2024.03.14] MiniCPM-V 现在支持 SWIFT 框架下的微调了,感谢 Jintao 的贡献!
- [2024.03.01] MiniCPM-V 现在支持在 Mac 电脑上进行部署!
- [2024.02.01] 我们开源了 MiniCPM-V 和 OmniLMM-12B,分别可以支持高效的端侧部署和同规模领先的多模态能力!
目录
MiniCPM-Llama3-V 2.5
MiniCPM-Llama3-V 2.5 是 MiniCPM-V 系列的最新版本模型,基于 SigLip-400M 和 Llama3-8B-Instruct 构建,共 8B 参数量,相较于 MiniCPM-V 2.0 性能取得较大幅度提升。MiniCPM-Llama3-V 2.5 值得关注的特点包括:
🔥 领先的性能。 MiniCPM-Llama3-V 2.5 在综合了 11 个主流多模态大模型评测基准的 OpenCompass 榜单上平均得分 65.1,以 8B 量级的大小超过了 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等主流商用闭源多模态大模型,大幅超越基于Llama 3构建的其他多模态大模型。
💪 优秀的 OCR 能力。 MiniCPM-Llama3-V 2.5 可接受 180 万像素的任意宽高比图像输入,OCRBench 得分达到 725,超越 GPT-4o、GPT-4V、Gemini Pro、Qwen-VL-Max 等商用闭源模型,达到最佳水平。基于近期用户反馈建议,MiniCPM-Llama3-V 2.5 增强了全文 OCR 信息提取、表格图像转 markdown 等高频实用能力,并且进一步加强了指令跟随、复杂推理能力,带来更好的多模态交互体感。
🏆 可信行为。 借助最新的 RLAIF-V 对齐技术(RLHF-V [CVPR'24]系列的最新技术),MiniCPM-Llama3-V 2.5 具有更加可信的多模态行为,在 Object HalBench 的幻觉率降低到了 **10.3%**,显著低于 GPT-4V-1106 (13.6%),达到开源社区最佳水平。数据集已发布。
🌏 多语言支持。 得益于 Llama 3 强大的多语言能力和 VisCPM 的跨语言泛化技术,MiniCPM-Llama3-V 2.5 在中英双语多模态能力的基础上,仅通过少量翻译的多模态数据的指令微调,高效泛化支持了德语、法语、西班牙语、意大利语、韩语等 30+ 种语言的多模态能力,并表现出了良好的多语言多模态对话性能。查看所有支持语言
🚀 高效部署。 MiniCPM-Llama3-V 2.5 较为系统地通过模型量化、CPU、NPU、编译优化等高效加速技术,实现高效的终端设备部署。对于高通芯片的移动手机,我们首次将 NPU 加速框架 QNN 整合进了 llama.cpp。经过系统优化后,MiniCPM-Llama3-V 2.5 实现了多模态大模型端侧语言解码速度 3 倍加速、图像编码 150 倍加速的巨大提升。
💫 易于使用。 MiniCPM-Llama3-V 2.5 可以通过多种方式轻松使用:(1)llama.cpp 和 ollama 支持在本地设备上进行高效的 CPU 推理;(2)提供 16 种尺寸的 GGUF 格式量化模型;(3)仅需 2 张 V100 GPU 即可进行高效的 LoRA 微调;( 4)支持流式输出;(5)快速搭建 Gradio 和 Streamlit 本地 WebUI demo;( 6.)HuggingFace Spaces 交互式 demo。
性能评估
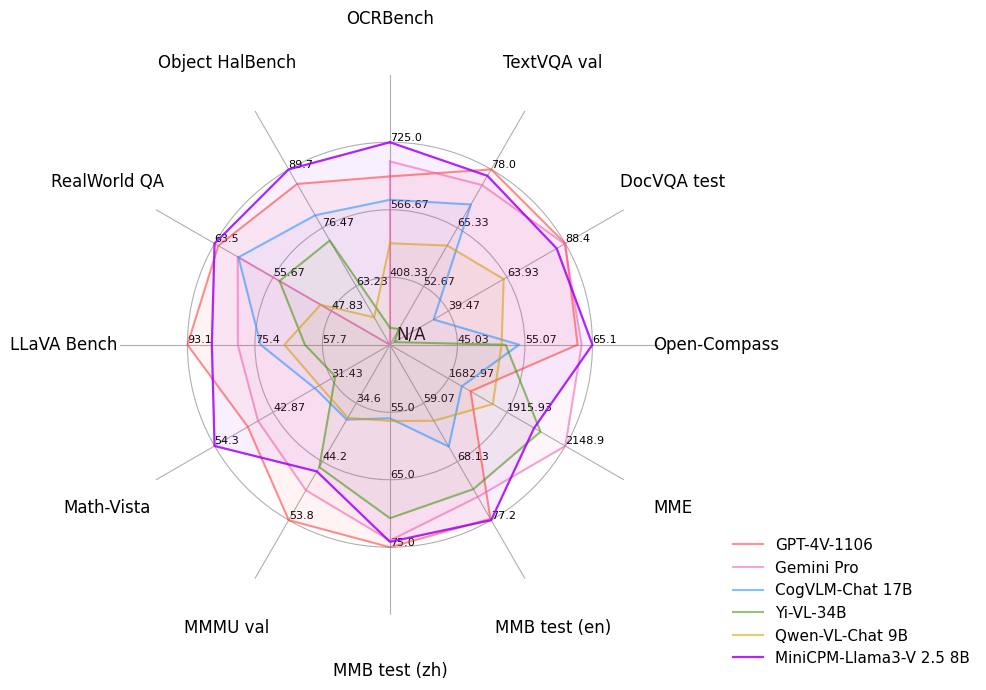
TextVQA, DocVQA, OCRBench, OpenCompass MultiModal Avg Score, MME, MMBench, MMMU, MathVista, LLaVA Bench, RealWorld QA, Object HalBench上的详细评测结果。
| Model | Size | OCRBench | TextVQA val | DocVQA test | Open-Compass | MME | MMB test (en) | MMB test (cn) | MMMU val | Math-Vista | LLaVA Bench | RealWorld QA | Object HalBench |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary | |||||||||||||
| Gemini Pro | - | 680 | 74.6 | 88.1 | 62.9 | 2148.9 | 73.6 | 74.3 | 48.9 | 45.8 | 79.9 | 60.4 | - |
| GPT-4V (2023.11.06) | - | 645 | 78.0 | 88.4 | 63.5 | 1771.5 | 77.0 | 74.4 | 53.8 | 47.8 | 93.1 | 63.0 | 86.4 |
| Open-source | |||||||||||||
| Mini-Gemini | 2.2B | - | 56.2 | 34.2* | - | 1653.0 | - | - | 31.7 | - | - | - | - |
| Qwen-VL-Chat | 9.6B | 488 | 61.5 | 62.6 | 51.6 | 1860.0 | 61.8 | 56.3 | 37.0 | 33.8 | 67.7 | 49.3 | 56.2 |
| DeepSeek-VL-7B | 7.3B | 435 | 64.7* | 47.0* | 54.6 | 1765.4 | 73.8 | 71.4 | 38.3 | 36.8 | 77.8 | 54.2 | - |
| Yi-VL-34B | 34B | 290 | 43.4* | 16.9* | 52.2 | 2050.2 | 72.4 | 70.7 | 45.1 | 30.7 | 62.3 | 54.8 | 79.3 |
| CogVLM-Chat | 17.4B | 590 | 70.4 | 33.3* | 54.2 | 1736.6 | 65.8 | 55.9 | 37.3 | 34.7 | 73.9 | 60.3 | 73.6 |
| TextMonkey | 9.7B | 558 | 64.3 | 66.7 | - | - | - | - | - | - | - | - | - |
| Idefics2 | 8.0B | - | 73.0 | 74.0 | 57.2 | 1847.6 | 75.7 | 68.6 | 45.2 | 52.2 | 49.1 | 60.7 | - |
| Bunny-LLama-3-8B | 8.4B | - | - | - | 54.3 | 1920.3 | 77.0 | 73.9 | 41.3 | 31.5 | 61.2 | 58.8 | - |
| LLaVA-NeXT Llama-3-8B | 8.4B | - | - | - | - | 1971.5 | - | - | 41.7 | - | 80.1 | 60.0 | - |
| Phi-3-vision-128k-instruct | 4.2B | 639* | 70.9 | - | - | 1537.5* | - | - | 40.4 | 44.5 | 64.2* | 58.8* | - |
| MiniCPM-V 1.0 | 2.8B | 366 | 60.6 | 38.2 | 47.5 | 1650.2 | 64.1 | 62.6 | 38.3 | 28.9 | 51.3 | 51.2 | 78.4 |
| MiniCPM-V 2.0 | 2.8B | 605 | 74.1 | 71.9 | 54.5 | 1808.6 | 69.1 | 66.5 | 38.2 | 38.7 | 69.2 | 55.8 | 85.5 |
| MiniCPM-Llama3-V 2.5 | 8.5B | 725 | 76.6 | 84.8 | 65.1 | 2024.6 | 77.2 | 74.2 | 45.8 | 54.3 | 86.7 | 63.5 | 89.7 |
多语言LLaVA Bench评测结果
典型示例

我们将 MiniCPM-Llama3-V 2.5 部署在小米 14 Pro 上,并录制了以下演示视频。



MiniCPM-V 2.0
查看 MiniCPM-V 2.0 的详细信息
MiniCPM-V 2.0可以高效部署到终端设备。该模型基于 SigLip-400M 和 MiniCPM-2.4B构建,通过perceiver resampler连接。其特点包括:
🔥 优秀的性能。
MiniCPM-V 2.0 在多个测试基准(如 OCRBench, TextVQA, MME, MMB, MathVista 等)中实现了 7B 以下模型的最佳性能。在综合了 11 个主流多模态大模型评测基准的 OpenCompass 榜单上超过了 Qwen-VL-Chat 9.6B、CogVLM-Chat 17.4B 和 Yi-VL 34B 等更大参数规模的模型。MiniCPM-V 2.0 还展现出领先的 OCR 能力,在场景文字识别能力上接近 Gemini Pro,OCRBench 得分达到开源模型第一。
🏆 可信行为。
多模态大模型深受幻觉问题困扰,模型经常生成和图像中的事实不符的文本。MiniCPM-V 2.0 是 第一个通过多模态 RLHF 对齐的端侧多模态大模型(借助 RLHF-V [CVPR'24] 系列技术)。该模型在 Object HalBench 达到和 GPT-4V 相仿的性能。
🌟 高清图像高效编码。
MiniCPM-V 2.0 可以接受 180 万像素的任意长宽比图像输入(基于最新的LLaVA-UHD 技术),这使得模型可以感知到小物体、密集文字等更加细粒度的视觉信息。
⚡️ 高效部署。
MiniCPM-V 2.0 可以高效部署在大多数消费级显卡和个人电脑上,包括移动手机等终端设备。在视觉编码方面,我们通过perceiver resampler将图像表示压缩为更少的 token。这使得 MiniCPM-V 2.0 即便是面对高分辨率图像,也能占用较低的存储并展现优秀的推理速度。
🙌 双语支持。
MiniCPM-V 2.0 提供领先的中英双语多模态能力支持。 该能力通过 VisCPM [ICLR'24] 论文中提出的多模态能力的跨语言泛化技术实现。
典型示例

我们将 MiniCPM-V 2.0 部署在小米 14 Pro 上,并录制了以下演示视频,未经任何视频剪辑。


历史版本模型
Online Demo
欢迎通过以下链接使用我们的网页端推理服务: MiniCPM-Llama3-V 2.5 | MiniCPM-V 2.0.
安装
- 克隆我们的仓库并跳转到相应目录
git clone https://github.com/OpenBMB/MiniCPM-V.git
cd MiniCPM-V
- 创建 conda 环境
conda create -n MiniCPMV python=3.10 -y
conda activate MiniCPMV
- 安装依赖
pip install -r requirements.txt
推理
模型库
| 模型 | 设备 | 资源 | 简介 | 下载链接 |
|---|---|---|---|---|
| MiniCPM-Llama3-V 2.5 | GPU | 19 GB | 最新版本,提供最佳的端侧多模态理解能力。 | 🤗 |
| MiniCPM-Llama3-V 2.5 gguf | CPU | 5 GB | gguf 版本,更低的内存占用和更高的推理效率。 | 🤗 |
| MiniCPM-Llama3-V 2.5 int4 | GPU | 8 GB | int4量化版,更低显存占用。 | 🤗 |
| MiniCPM-V 2.0 | GPU | 8 GB | 轻量级版本,平衡计算开销和多模态理解能力。 | 🤗 |
| MiniCPM-V 1.0 | GPU | 7 GB | 最轻量版本, 提供最快的推理速度。 | 🤗 |
更多历史版本模型
多轮对话
请参考以下代码进行推理。

from chat import MiniCPMVChat, img2base64
import torch
import json
torch.manual_seed(0)
chat_model = MiniCPMVChat('openbmb/MiniCPM-Llama3-V-2_5')
im_64 = img2base64('./assets/airplane.jpeg')
# First round chat
msgs = [{"role": "user", "content": "Tell me the model of this aircraft."}]
inputs = {"image": im_64, "question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
# Second round chat
# pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": answer})
msgs.append({"role": "user", "content": "Introduce something about Airbus A380."})
inputs = {"image": im_64, "question": json.dumps(msgs)}
answer = chat_model.chat(inputs)
print(answer)
可以得到以下输出:
"The aircraft in the image is an Airbus A380, which can be identified by its large size, double-deck structure, and the distinctive shape of its wings and engines. The A380 is a wide-body aircraft known for being the world's largest passenger airliner, designed for long-haul flights. It has four engines, which are characteristic of large commercial aircraft. The registration number on the aircraft can also provide specific information about the model if looked up in an aviation database."
"The Airbus A380 is a double-deck, wide-body, four-engine jet airliner made by Airbus. It is the world's largest passenger airliner and is known for its long-haul capabilities. The aircraft was developed to improve efficiency and comfort for passengers traveling over long distances. It has two full-length passenger decks, which can accommodate more passengers than a typical single-aisle airplane. The A380 has been operated by airlines such as Lufthansa, Singapore Airlines, and Emirates, among others. It is widely recognized for its unique design and significant impact on the aviation industry."
Mac 推理
点击查看 MiniCPM-Llama3-V 2.5 / MiniCPM-V 2.0 基于Mac MPS运行 (Apple silicon 或 AMD GPUs)的示例。
# test.py Need more than 16GB memory to run.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True, low_cpu_mem_usage=True)
model = model.to(device='mps')
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True)
model.eval()
image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
question = 'Where is this photo taken?'
msgs = [{'role': 'user', 'content': question}]
answer, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True
)
print(answer)
运行:
PYTORCH_ENABLE_MPS_FALLBACK=1 python test.py
手机端部署
MiniCPM-V 2.0 可运行在Android手机上,点击2.0安装apk使用; MiniCPM-Llama3-V 2.5 将很快推出,敬请期待。
本地WebUI Demo部署
点击查看本地WebUI demo 在 NVIDIA GPU、Mac等不同设备部署方法
pip install -r requirements.txt
# For NVIDIA GPUs, run:
python web_demo_2.5.py --device cuda
# For Mac with MPS (Apple silicon or AMD GPUs), run:
PYTORCH_ENABLE_MPS_FALLBACK=1 python web_demo_2.5.py --device mps
llama.cpp 部署
MiniCPM-Llama3-V 2.5 现在支持llama.cpp啦! 用法请参考我们的fork llama.cpp, 在手机上可以支持 6~8 token/s 的流畅推理(测试环境:Xiaomi 14 pro + Snapdragon 8 Gen 3)。
vLLM 部署
点击查看 vLLM 部署运行的方法
由于我们对 vLLM 提交的 PR 还在 review 中,因此目前我们 fork 了一个 vLLM 仓库以供测试使用。- 首先克隆我们 fork 的 vLLM 库:
git clone https://github.com/OpenBMB/vllm.git
- 安装 vLLM 库:
cd vllm
pip install -e .
- 安装 timm 库:
pip install timm=0.9.10
- 测试运行示例程序:
python examples/minicpmv_example.py
微调
简易微调
我们支持使用 Huggingface Transformers 库简易地微调 MiniCPM-V 2.0 和 MiniCPM-Llama3-V 2.5 模型。
使用 SWIFT 框架
我们支持使用 SWIFT 框架微调 MiniCPM-V 系列模型。SWIFT 支持近 200 种大语言模型和多模态大模型的训练、推理、评测和部署。支持 PEFT 提供的轻量训练方案和完整的 Adapters 库支持的最新训练技术如 NEFTune、LoRA+、LLaMA-PRO 等。
参考文档:MiniCPM-V 1.0,MiniCPM-V 2.0
未来计划
- 支持 MiniCPM-V 系列模型微调
- 实时多模态交互代码开源
模型协议
本仓库中代码依照 Apache-2.0 协议开源
本项目中模型权重的使用遵循 “通用模型许可协议-来源说明-宣传限制-商业授权”。
本项目中模型权重对学术研究完全开放。
如需将模型用于商业用途,请联系 cpm@modelbest.cn 来获取书面授权,登记后可以免费商业使用。
声明
作为多模态大模型,MiniCPM-V 系列模型(包括 OmniLMM)通过学习大量的多模态数据来生成内容,但它无法理解、表达个人观点或价值判断,它所输出的任何内容都不代表模型开发者的观点和立场。
因此用户在使用本项目的系列模型生成的内容时,应自行负责对其进行评估和验证。如果由于使用本项目的系列开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
机构
本项目由以下机构共同开发:



其他多模态项目
👏 欢迎了解我们更多的多模态项目:
VisCPM | RLHF-V | LLaVA-UHD | RLAIF-V
🌟 Star History

引用
如果您觉得我们模型/代码/论文有帮助,请给我们 ⭐ 和 引用 📝,感谢!
@article{yu2023rlhf,
title={Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback},
author={Yu, Tianyu and Yao, Yuan and Zhang, Haoye and He, Taiwen and Han, Yifeng and Cui, Ganqu and Hu, Jinyi and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong and others},
journal={arXiv preprint arXiv:2312.00849},
year={2023}
}
@article{viscpm,
title={Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages},
author={Jinyi Hu and Yuan Yao and Chongyi Wang and Shan Wang and Yinxu Pan and Qianyu Chen and Tianyu Yu and Hanghao Wu and Yue Zhao and Haoye Zhang and Xu Han and Yankai Lin and Jiao Xue and Dahai Li and Zhiyuan Liu and Maosong Sun},
journal={arXiv preprint arXiv:2308.12038},
year={2023}
}
@article{xu2024llava-uhd,
title={{LLaVA-UHD}: an LMM Perceiving Any Aspect Ratio and High-Resolution Images},
author={Xu, Ruyi and Yao, Yuan and Guo, Zonghao and Cui, Junbo and Ni, Zanlin and Ge, Chunjiang and Chua, Tat-Seng and Liu, Zhiyuan and Huang, Gao},
journal={arXiv preprint arXiv:2403.11703},
year={2024}
}
@article{yu2024rlaifv,
title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness},
author={Yu, Tianyu and Zhang, Haoye and Yao, Yuan and Dang, Yunkai and Chen, Da and Lu, Xiaoman and Cui, Ganqu and He, Taiwen and Liu, Zhiyuan and Chua, Tat-Seng and Sun, Maosong},
journal={arXiv preprint arXiv:2405.17220},
year={2024}
}