
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.26B
| node_id
stringlengths 18
32
| number
int64 1
4.44k
| title
stringlengths 1
276
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
sequence | created_at
int64 1,587B
1,654B
| updated_at
int64 1,587B
1,654B
| closed_at
int64 1,587B
1,654B
⌀ | author_association
stringclasses 3
values | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 1
value | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/1690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1690/comments | https://api.github.com/repos/huggingface/datasets/issues/1690/events | https://github.com/huggingface/datasets/pull/1690 | 779,441,631 | MDExOlB1bGxSZXF1ZXN0NTQ5NDEwOTgw | 1,690 | Fast start up | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,873,673,000 | 1,609,942,859,000 | 1,609,942,858,000 | MEMBER | null | Currently if optional dependencies such as tensorflow, torch, apache_beam, faiss and elasticsearch are installed, then it takes a long time to do `import datasets` since it imports all of these heavy dependencies.
To make a fast start up for `datasets` I changed that so that they are not imported when `datasets` is being imported. On my side it changed the import time of `datasets` from 5sec to 0.5sec, which is enjoyable.
To be able to check if optional dependencies are available without importing them I'm using `importlib_metadata`, which is part of the standard lib in python>=3.8 and was backported. The difference with `importlib` is that it also enables to get the versions of the libraries without importing them.
I added this dependency in `setup.py`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1690/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 3,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1690/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1690",
"html_url": "https://github.com/huggingface/datasets/pull/1690",
"diff_url": "https://github.com/huggingface/datasets/pull/1690.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1690.patch",
"merged_at": 1609942858000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1689/comments | https://api.github.com/repos/huggingface/datasets/issues/1689/events | https://github.com/huggingface/datasets/pull/1689 | 779,107,313 | MDExOlB1bGxSZXF1ZXN0NTQ5MTEwMDgw | 1,689 | Fix ade_corpus_v2 config names | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,857,208,000 | 1,609,858,509,000 | 1,609,858,508,000 | MEMBER | null | There are currently some typos in the config names of the `ade_corpus_v2` dataset, I fixed them:
- Ade_corpos_v2_classificaion -> Ade_corpus_v2_classification
- Ade_corpos_v2_drug_ade_relation -> Ade_corpus_v2_drug_ade_relation
- Ade_corpos_v2_drug_dosage_relation -> Ade_corpus_v2_drug_dosage_relation | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1689/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1689/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1689",
"html_url": "https://github.com/huggingface/datasets/pull/1689",
"diff_url": "https://github.com/huggingface/datasets/pull/1689.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1689.patch",
"merged_at": 1609858508000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1688 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1688/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1688/comments | https://api.github.com/repos/huggingface/datasets/issues/1688/events | https://github.com/huggingface/datasets/pull/1688 | 779,029,685 | MDExOlB1bGxSZXF1ZXN0NTQ5MDM5ODg0 | 1,688 | Fix DaNE last example | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,853,377,000 | 1,609,855,215,000 | 1,609,855,213,000 | MEMBER | null | The last example from the DaNE dataset is empty.
Fix #1686 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1688/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1688/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1688",
"html_url": "https://github.com/huggingface/datasets/pull/1688",
"diff_url": "https://github.com/huggingface/datasets/pull/1688.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1688.patch",
"merged_at": 1609855213000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1687 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1687/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1687/comments | https://api.github.com/repos/huggingface/datasets/issues/1687/events | https://github.com/huggingface/datasets/issues/1687 | 779,004,894 | MDU6SXNzdWU3NzkwMDQ4OTQ= | 1,687 | Question: Shouldn't .info be a part of DatasetDict? | {
"login": "KennethEnevoldsen",
"id": 23721977,
"node_id": "MDQ6VXNlcjIzNzIxOTc3",
"avatar_url": "https://avatars.githubusercontent.com/u/23721977?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KennethEnevoldsen",
"html_url": "https://github.com/KennethEnevoldsen",
"followers_url": "https://api.github.com/users/KennethEnevoldsen/followers",
"following_url": "https://api.github.com/users/KennethEnevoldsen/following{/other_user}",
"gists_url": "https://api.github.com/users/KennethEnevoldsen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KennethEnevoldsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KennethEnevoldsen/subscriptions",
"organizations_url": "https://api.github.com/users/KennethEnevoldsen/orgs",
"repos_url": "https://api.github.com/users/KennethEnevoldsen/repos",
"events_url": "https://api.github.com/users/KennethEnevoldsen/events{/privacy}",
"received_events_url": "https://api.github.com/users/KennethEnevoldsen/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"We could do something. There is a part of `.info` which is split specific (cache files, split instructions) but maybe if could be made to work.",
"Yes this was kinda the idea I was going for. DatasetDict.info would be the shared info amongs the datasets (maybe even some info on how they differ). "
] | 1,609,852,121,000 | 1,610,014,686,000 | null | CONTRIBUTOR | null | Currently, only `Dataset` contains the .info or .features, but as many datasets contains standard splits (train, test) and thus the underlying information is the same (or at least should be) across the datasets.
For instance:
```
>>> ds = datasets.load_dataset("conll2002", "es")
>>> ds.info
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'DatasetDict' object has no attribute 'info'
```
I could imagine that this wouldn't work for datasets dicts which hold entirely different datasets (multimodal datasets), but it seems odd that splits of the same dataset is treated the same as what is essentially different datasets.
Intuitively it would also make sense that if a dataset is supplied via. the load_dataset that is have a common .info which covers the entire dataset.
It is entirely possible that I am missing another perspective | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1687/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1687/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1686 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1686/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1686/comments | https://api.github.com/repos/huggingface/datasets/issues/1686/events | https://github.com/huggingface/datasets/issues/1686 | 778,921,684 | MDU6SXNzdWU3Nzg5MjE2ODQ= | 1,686 | Dataset Error: DaNE contains empty samples at the end | {
"login": "KennethEnevoldsen",
"id": 23721977,
"node_id": "MDQ6VXNlcjIzNzIxOTc3",
"avatar_url": "https://avatars.githubusercontent.com/u/23721977?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KennethEnevoldsen",
"html_url": "https://github.com/KennethEnevoldsen",
"followers_url": "https://api.github.com/users/KennethEnevoldsen/followers",
"following_url": "https://api.github.com/users/KennethEnevoldsen/following{/other_user}",
"gists_url": "https://api.github.com/users/KennethEnevoldsen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KennethEnevoldsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KennethEnevoldsen/subscriptions",
"organizations_url": "https://api.github.com/users/KennethEnevoldsen/orgs",
"repos_url": "https://api.github.com/users/KennethEnevoldsen/repos",
"events_url": "https://api.github.com/users/KennethEnevoldsen/events{/privacy}",
"received_events_url": "https://api.github.com/users/KennethEnevoldsen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for reporting, I opened a PR to fix that",
"One the PR is merged the fix will be available in the next release of `datasets`.\r\n\r\nIf you don't want to wait the next release you can still load the script from the master branch with\r\n\r\n```python\r\nload_dataset(\"dane\", script_version=\"master\")\r\n```",
"If you have other questions feel free to reopen :) "
] | 1,609,847,666,000 | 1,609,855,269,000 | 1,609,855,213,000 | CONTRIBUTOR | null | The dataset DaNE, contains empty samples at the end. It is naturally easy to remove using a filter but should probably not be there, to begin with as it can cause errors.
```python
>>> import datasets
[...]
>>> dataset = datasets.load_dataset("dane")
[...]
>>> dataset["test"][-1]
{'dep_ids': [], 'dep_labels': [], 'lemmas': [], 'morph_tags': [], 'ner_tags': [], 'pos_tags': [], 'sent_id': '', 'text': '', 'tok_ids': [], 'tokens': []}
>>> dataset["train"][-1]
{'dep_ids': [], 'dep_labels': [], 'lemmas': [], 'morph_tags': [], 'ner_tags': [], 'pos_tags': [], 'sent_id': '', 'text': '', 'tok_ids': [], 'tokens': []}
```
Best,
Kenneth | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1686/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1686/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1685/comments | https://api.github.com/repos/huggingface/datasets/issues/1685/events | https://github.com/huggingface/datasets/pull/1685 | 778,914,431 | MDExOlB1bGxSZXF1ZXN0NTQ4OTM1MzY2 | 1,685 | Update README.md of covid-tweets-japanese | {
"login": "forest1988",
"id": 2755894,
"node_id": "MDQ6VXNlcjI3NTU4OTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2755894?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/forest1988",
"html_url": "https://github.com/forest1988",
"followers_url": "https://api.github.com/users/forest1988/followers",
"following_url": "https://api.github.com/users/forest1988/following{/other_user}",
"gists_url": "https://api.github.com/users/forest1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/forest1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/forest1988/subscriptions",
"organizations_url": "https://api.github.com/users/forest1988/orgs",
"repos_url": "https://api.github.com/users/forest1988/repos",
"events_url": "https://api.github.com/users/forest1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/forest1988/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thanks for reviewing and merging!"
] | 1,609,847,247,000 | 1,609,928,832,000 | 1,609,925,470,000 | CONTRIBUTOR | null | Update README.md of covid-tweets-japanese added by PR https://github.com/huggingface/datasets/pull/1367 and https://github.com/huggingface/datasets/pull/1402.
- Update "Data Splits" to be more precise that no information is provided for now.
- old: [More Information Needed]
- new: No information about data splits is provided for now.
- The automatic generation of links seemed not working properly, so I added a space before and after the URL to make the links work correctly. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1685/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1685/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1685",
"html_url": "https://github.com/huggingface/datasets/pull/1685",
"diff_url": "https://github.com/huggingface/datasets/pull/1685.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1685.patch",
"merged_at": 1609925470000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1684 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1684/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1684/comments | https://api.github.com/repos/huggingface/datasets/issues/1684/events | https://github.com/huggingface/datasets/pull/1684 | 778,356,196 | MDExOlB1bGxSZXF1ZXN0NTQ4NDU3NDY1 | 1,684 | Add CANER Corpus | {
"login": "KMFODA",
"id": 35491698,
"node_id": "MDQ6VXNlcjM1NDkxNjk4",
"avatar_url": "https://avatars.githubusercontent.com/u/35491698?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KMFODA",
"html_url": "https://github.com/KMFODA",
"followers_url": "https://api.github.com/users/KMFODA/followers",
"following_url": "https://api.github.com/users/KMFODA/following{/other_user}",
"gists_url": "https://api.github.com/users/KMFODA/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KMFODA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KMFODA/subscriptions",
"organizations_url": "https://api.github.com/users/KMFODA/orgs",
"repos_url": "https://api.github.com/users/KMFODA/repos",
"events_url": "https://api.github.com/users/KMFODA/events{/privacy}",
"received_events_url": "https://api.github.com/users/KMFODA/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,793,351,000 | 1,611,565,760,000 | 1,611,565,760,000 | CONTRIBUTOR | null | What does this PR do?
Adds the following dataset:
https://github.com/RamziSalah/Classical-Arabic-Named-Entity-Recognition-Corpus
Who can review?
@lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1684/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1684/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1684",
"html_url": "https://github.com/huggingface/datasets/pull/1684",
"diff_url": "https://github.com/huggingface/datasets/pull/1684.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1684.patch",
"merged_at": 1611565760000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1683 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1683/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1683/comments | https://api.github.com/repos/huggingface/datasets/issues/1683/events | https://github.com/huggingface/datasets/issues/1683 | 778,287,612 | MDU6SXNzdWU3NzgyODc2MTI= | 1,683 | `ArrowInvalid` occurs while running `Dataset.map()` function for DPRContext | {
"login": "abarbosa94",
"id": 6608232,
"node_id": "MDQ6VXNlcjY2MDgyMzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/6608232?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abarbosa94",
"html_url": "https://github.com/abarbosa94",
"followers_url": "https://api.github.com/users/abarbosa94/followers",
"following_url": "https://api.github.com/users/abarbosa94/following{/other_user}",
"gists_url": "https://api.github.com/users/abarbosa94/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abarbosa94/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abarbosa94/subscriptions",
"organizations_url": "https://api.github.com/users/abarbosa94/orgs",
"repos_url": "https://api.github.com/users/abarbosa94/repos",
"events_url": "https://api.github.com/users/abarbosa94/events{/privacy}",
"received_events_url": "https://api.github.com/users/abarbosa94/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Looks like the mapping function returns a dictionary with a 768-dim array in the `embeddings` field. Since the map is batched, we actually expect the `embeddings` field to be an array of shape (batch_size, 768) to have one embedding per example in the batch.\r\n\r\nTo fix that can you try to remove one of the `[0]` ? In my opinion you only need one of them, not two.",
"It makes sense :D\r\n\r\nIt seems to work! Thanks a lot :))\r\n\r\nClosing the issue"
] | 1,609,786,073,000 | 1,609,787,085,000 | 1,609,787,085,000 | CONTRIBUTOR | null | It seems to fail the final batch ):
steps to reproduce:
```
from datasets import load_dataset
from elasticsearch import Elasticsearch
import torch
from transformers import file_utils, set_seed
from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast
MAX_SEQ_LENGTH = 256
ctx_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base", cache_dir="../datasets/")
ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(
"facebook/dpr-ctx_encoder-single-nq-base",
cache_dir="..datasets/"
)
dataset = load_dataset('text',
data_files='data/raw/ARC_Corpus.txt',
cache_dir='../datasets')
torch.set_grad_enabled(False)
ds_with_embeddings = dataset.map(
lambda example: {
'embeddings': ctx_encoder(
**ctx_tokenizer(
example["text"],
padding='max_length',
truncation=True,
max_length=MAX_SEQ_LENGTH,
return_tensors="pt"
)
)[0][0].numpy(),
},
batched=True,
load_from_cache_file=False,
batch_size=1000
)
```
ARC Corpus can be obtained from [here](https://ai2-datasets.s3-us-west-2.amazonaws.com/arc/ARC-V1-Feb2018.zip)
And then the error:
```
---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
<ipython-input-13-67d139bb2ed3> in <module>
14 batched=True,
15 load_from_cache_file=False,
---> 16 batch_size=1000
17 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/dataset_dict.py in map(self, function, with_indices, input_columns, batched, batch_size, remove_columns, keep_in_memory, load_from_cache_file, cache_file_names, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc)
301 num_proc=num_proc,
302 )
--> 303 for k, dataset in self.items()
304 }
305 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/dataset_dict.py in <dictcomp>(.0)
301 num_proc=num_proc,
302 )
--> 303 for k, dataset in self.items()
304 }
305 )
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in map(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, num_proc, suffix_template, new_fingerprint)
1257 fn_kwargs=fn_kwargs,
1258 new_fingerprint=new_fingerprint,
-> 1259 update_data=update_data,
1260 )
1261 else:
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
155 }
156 # apply actual function
--> 157 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
158 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
159 # re-apply format to the output
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
161 # Call actual function
162
--> 163 out = func(self, *args, **kwargs)
164
165 # Update fingerprint of in-place transforms + update in-place history of transforms
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_dataset.py in _map_single(self, function, with_indices, input_columns, batched, batch_size, drop_last_batch, remove_columns, keep_in_memory, load_from_cache_file, cache_file_name, writer_batch_size, features, disable_nullable, fn_kwargs, new_fingerprint, rank, offset, update_data)
1526 if update_data:
1527 batch = cast_to_python_objects(batch)
-> 1528 writer.write_batch(batch)
1529 if update_data:
1530 writer.finalize() # close_stream=bool(buf_writer is None)) # We only close if we are writing in a file
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/datasets/arrow_writer.py in write_batch(self, batch_examples, writer_batch_size)
276 typed_sequence = TypedSequence(batch_examples[col], type=col_type, try_type=col_try_type)
277 typed_sequence_examples[col] = typed_sequence
--> 278 pa_table = pa.Table.from_pydict(typed_sequence_examples)
279 self.write_table(pa_table)
280
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.from_pydict()
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.from_arrays()
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.validate()
~/.cache/pypoetry/virtualenvs/masters-utTTC0p8-py3.7/lib/python3.7/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Column 1 named text expected length 768 but got length 1000
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1683/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1683/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1682 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1682/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1682/comments | https://api.github.com/repos/huggingface/datasets/issues/1682/events | https://github.com/huggingface/datasets/pull/1682 | 778,268,156 | MDExOlB1bGxSZXF1ZXN0NTQ4Mzg1NTk1 | 1,682 | Don't use xlrd for xlsx files | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,783,910,000 | 1,609,783,994,000 | 1,609,783,993,000 | MEMBER | null | Since the latest release of `xlrd` (2.0), the support for xlsx files stopped.
Therefore we needed to use something else.
A good alternative is `openpyxl` which has also an integration with pandas si we can still call `pd.read_excel`.
I left the unused import of `openpyxl` in the dataset scripts to show users that this is a required dependency to use the scripts.
I tested the different datasets using `datasets-cli test` and the tests are successful (no missing examples). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1682/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1682/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1682",
"html_url": "https://github.com/huggingface/datasets/pull/1682",
"diff_url": "https://github.com/huggingface/datasets/pull/1682.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1682.patch",
"merged_at": 1609783993000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1681 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1681/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1681/comments | https://api.github.com/repos/huggingface/datasets/issues/1681/events | https://github.com/huggingface/datasets/issues/1681 | 777,644,163 | MDU6SXNzdWU3Nzc2NDQxNjM= | 1,681 | Dataset "dane" missing | {
"login": "KennethEnevoldsen",
"id": 23721977,
"node_id": "MDQ6VXNlcjIzNzIxOTc3",
"avatar_url": "https://avatars.githubusercontent.com/u/23721977?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/KennethEnevoldsen",
"html_url": "https://github.com/KennethEnevoldsen",
"followers_url": "https://api.github.com/users/KennethEnevoldsen/followers",
"following_url": "https://api.github.com/users/KennethEnevoldsen/following{/other_user}",
"gists_url": "https://api.github.com/users/KennethEnevoldsen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/KennethEnevoldsen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/KennethEnevoldsen/subscriptions",
"organizations_url": "https://api.github.com/users/KennethEnevoldsen/orgs",
"repos_url": "https://api.github.com/users/KennethEnevoldsen/repos",
"events_url": "https://api.github.com/users/KennethEnevoldsen/events{/privacy}",
"received_events_url": "https://api.github.com/users/KennethEnevoldsen/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @KennethEnevoldsen ,\r\nI think the issue might be that this dataset was added during the community sprint and has not been released yet. It will be available with the v2 of datasets.\r\nFor now, you should be able to load the datasets after installing the latest (master) version of datasets using pip:\r\npip install git+https://github.com/huggingface/datasets.git@master",
"The `dane` dataset was added recently, that's why it wasn't available yet. We did an intermediate release today just before the v2.0.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `dane` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"dane\")\r\n```",
"Thanks. Solved the problem."
] | 1,609,682,583,000 | 1,609,835,735,000 | 1,609,835,713,000 | CONTRIBUTOR | null | the `dane` dataset appear to be missing in the latest version (1.1.3).
```python
>>> import datasets
>>> datasets.__version__
'1.1.3'
>>> "dane" in datasets.list_datasets()
True
```
As we can see it should be present, but doesn't seem to be findable when using `load_dataset`.
```python
>>> datasets.load_dataset("dane")
Traceback (most recent call last):
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 300, in cached_path
output_path = get_from_cache(
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dane/dane.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 300, in cached_path
output_path = get_from_cache(
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dane/dane.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/load.py", line 588, in load_dataset
module_path, hash = prepare_module(
File "/home/kenneth/.Envs/EDP/lib/python3.8/site-packages/datasets/load.py", line 280, in prepare_module
raise FileNotFoundError(
FileNotFoundError: Couldn't find file locally at dane/dane.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dane/dane.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dane/dane.py
```
This issue might be relevant to @ophelielacroix from the Alexandra Institut whom created the data. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1681/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1681/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1680 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1680/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1680/comments | https://api.github.com/repos/huggingface/datasets/issues/1680/events | https://github.com/huggingface/datasets/pull/1680 | 777,623,053 | MDExOlB1bGxSZXF1ZXN0NTQ3ODY4MjEw | 1,680 | added TurkishProductReviews dataset | {
"login": "basakbuluz",
"id": 41359672,
"node_id": "MDQ6VXNlcjQxMzU5Njcy",
"avatar_url": "https://avatars.githubusercontent.com/u/41359672?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/basakbuluz",
"html_url": "https://github.com/basakbuluz",
"followers_url": "https://api.github.com/users/basakbuluz/followers",
"following_url": "https://api.github.com/users/basakbuluz/following{/other_user}",
"gists_url": "https://api.github.com/users/basakbuluz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/basakbuluz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/basakbuluz/subscriptions",
"organizations_url": "https://api.github.com/users/basakbuluz/orgs",
"repos_url": "https://api.github.com/users/basakbuluz/repos",
"events_url": "https://api.github.com/users/basakbuluz/events{/privacy}",
"received_events_url": "https://api.github.com/users/basakbuluz/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq, can you please review this PR?",
"Thanks for the suggestions. Updates were made and dataset_infos.json file was created again."
] | 1,609,674,779,000 | 1,609,784,135,000 | 1,609,784,135,000 | CONTRIBUTOR | null | This PR added **Turkish Product Reviews Dataset contains 235.165 product reviews collected online. There are 220.284 positive, 14881 negative reviews**.
- **Repository:** [turkish-text-data](https://github.com/fthbrmnby/turkish-text-data)
- **Point of Contact:** Fatih Barmanbay - @fthbrmnby | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1680/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1680/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1680",
"html_url": "https://github.com/huggingface/datasets/pull/1680",
"diff_url": "https://github.com/huggingface/datasets/pull/1680.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1680.patch",
"merged_at": 1609784135000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1679 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1679/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1679/comments | https://api.github.com/repos/huggingface/datasets/issues/1679/events | https://github.com/huggingface/datasets/issues/1679 | 777,587,792 | MDU6SXNzdWU3Nzc1ODc3OTI= | 1,679 | Can't import cc100 dataset | {
"login": "alighofrani95",
"id": 14968123,
"node_id": "MDQ6VXNlcjE0OTY4MTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/14968123?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alighofrani95",
"html_url": "https://github.com/alighofrani95",
"followers_url": "https://api.github.com/users/alighofrani95/followers",
"following_url": "https://api.github.com/users/alighofrani95/following{/other_user}",
"gists_url": "https://api.github.com/users/alighofrani95/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alighofrani95/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alighofrani95/subscriptions",
"organizations_url": "https://api.github.com/users/alighofrani95/orgs",
"repos_url": "https://api.github.com/users/alighofrani95/repos",
"events_url": "https://api.github.com/users/alighofrani95/events{/privacy}",
"received_events_url": "https://api.github.com/users/alighofrani95/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"cc100 was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `cc100` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nlang = \"en\"\r\ndataset = load_dataset(\"cc100\", lang=lang, split=\"train\")\r\n```"
] | 1,609,657,976,000 | 1,609,785,698,000 | null | NONE | null | There is some issue to import cc100 dataset.
```
from datasets import load_dataset
dataset = load_dataset("cc100")
```
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/cc100/cc100.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/cc100/cc100.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
280 raise FileNotFoundError(
281 "Couldn't find file locally at {}, or remotely at {} or {}".format(
--> 282 combined_path, github_file_path, file_path
283 )
284 )
FileNotFoundError: Couldn't find file locally at cc100/cc100.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/cc100/cc100.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/cc100/cc100.py | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1679/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1679/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1678/comments | https://api.github.com/repos/huggingface/datasets/issues/1678/events | https://github.com/huggingface/datasets/pull/1678 | 777,567,920 | MDExOlB1bGxSZXF1ZXN0NTQ3ODI4MTMy | 1,678 | Switchboard Dialog Act Corpus added under `datasets/swda` | {
"login": "gmihaila",
"id": 22454783,
"node_id": "MDQ6VXNlcjIyNDU0Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/22454783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gmihaila",
"html_url": "https://github.com/gmihaila",
"followers_url": "https://api.github.com/users/gmihaila/followers",
"following_url": "https://api.github.com/users/gmihaila/following{/other_user}",
"gists_url": "https://api.github.com/users/gmihaila/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gmihaila/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gmihaila/subscriptions",
"organizations_url": "https://api.github.com/users/gmihaila/orgs",
"repos_url": "https://api.github.com/users/gmihaila/repos",
"events_url": "https://api.github.com/users/gmihaila/events{/privacy}",
"received_events_url": "https://api.github.com/users/gmihaila/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq Thank you for your detailed comments! I fixed everything you suggested.\r\n\r\nPlease let me know if I'm missing anything else.",
"It looks like the Transcript and Utterance objects are missing, maybe we can mention it in the README ? Or just add them ? @gmihaila @bhavitvyamalik ",
"Hi @lhoestq,\r\nI'm working on this to add the full dataset",
"> It looks like the Transcript and Utterance objects are missing, maybe we can mention it in the README ? Or just add them ? @gmihaila @bhavitvyamalik\r\n\r\n@lhoestq Any info on how to add them?",
"@gmihaila, instead of using the current repo you should look into [this](https://github.com/cgpotts/swda). You can use the `csv` files uploaded in this repo (`swda.zip`) to access other fields and include them in this dataset. It has one dependency too, `swda.py`, you can download that separately and include it in your dataset's folder to be imported while reading the `csv` files.\r\n\r\nAlmost all the attributes of `Transcript` and `Utterance` objects are of the type str, int, or list. As far as `trees` attribute is concerned in utterance object you can simply parse it as string and user can maybe later convert it to nltk.tree object",
"@bhavitvyamalik Thank you for the clarification! \r\n\r\nI didn't use [that](https://github.com/cgpotts/swda) because it doesn't have the splits. I think in combination with [what I used](https://github.com/NathanDuran/Switchboard-Corpus) would help.\r\n\r\nLet me know if I can help! I can make those changes if you don't have the time.",
"I'm a bit busy for the next 2 weeks. I'll be able to complete it by end of January only. Maybe you can start with it and I'll help you?\r\nAlso, I looked into the official train/val/test splits and not all the files are there in the repo I used so I think either we'll have to skip them or put all of that into just train",
"Yes, I can start working on it and ask you to do a code review.\r\n\r\nYes, not all files are there. I'll try to find papers that have the correct and full splits, if not, I'll do like you suggested.\r\n\r\nThank you again for your help @bhavitvyamalik !"
] | 1,609,646,021,000 | 1,610,129,361,000 | 1,609,841,195,000 | CONTRIBUTOR | null | Switchboard Dialog Act Corpus
Intro:
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
Details:
[homepage](http://compprag.christopherpotts.net/swda.html)
[repo](https://github.com/NathanDuran/Switchboard-Corpus/raw/master/swda_data/)
I believe this is an important dataset to have since there is no dataset related to dialogue act added.
I didn't find any formatting for pull request. I hope all this information is enough.
For any support please contact me. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1678/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1678/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1678",
"html_url": "https://github.com/huggingface/datasets/pull/1678",
"diff_url": "https://github.com/huggingface/datasets/pull/1678.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1678.patch",
"merged_at": 1609841195000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1677/comments | https://api.github.com/repos/huggingface/datasets/issues/1677/events | https://github.com/huggingface/datasets/pull/1677 | 777,553,383 | MDExOlB1bGxSZXF1ZXN0NTQ3ODE3ODI1 | 1,677 | Switchboard Dialog Act Corpus added under `datasets/swda` | {
"login": "gmihaila",
"id": 22454783,
"node_id": "MDQ6VXNlcjIyNDU0Nzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/22454783?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gmihaila",
"html_url": "https://github.com/gmihaila",
"followers_url": "https://api.github.com/users/gmihaila/followers",
"following_url": "https://api.github.com/users/gmihaila/following{/other_user}",
"gists_url": "https://api.github.com/users/gmihaila/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gmihaila/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gmihaila/subscriptions",
"organizations_url": "https://api.github.com/users/gmihaila/orgs",
"repos_url": "https://api.github.com/users/gmihaila/repos",
"events_url": "https://api.github.com/users/gmihaila/events{/privacy}",
"received_events_url": "https://api.github.com/users/gmihaila/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Need to fix code formatting."
] | 1,609,636,602,000 | 1,609,642,557,000 | 1,609,642,556,000 | CONTRIBUTOR | null | Pleased to announced that I added my first dataset **Switchboard Dialog Act Corpus**.
I think this is an important datasets to be added since it is the only one related to dialogue act classification.
Hope the pull request is ok. Wasn't able to see any special formatting for the pull request form.
The Switchboard Dialog Act Corpus (SwDA) extends the Switchboard-1 Telephone Speech Corpus, Release 2,
with turn/utterance-level dialog-act tags. The tags summarize syntactic, semantic, and pragmatic information
about the associated turn. The SwDA project was undertaken at UC Boulder in the late 1990s.
[webpage](http://compprag.christopherpotts.net/swda.html)
[repo](https://github.com/NathanDuran/Switchboard-Corpus/raw/master/swda_data/)
Please contact me for any support!
All tests passed and followed all steps in the contribution guide!
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1677/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1677/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1677",
"html_url": "https://github.com/huggingface/datasets/pull/1677",
"diff_url": "https://github.com/huggingface/datasets/pull/1677.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1677.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1676 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1676/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1676/comments | https://api.github.com/repos/huggingface/datasets/issues/1676/events | https://github.com/huggingface/datasets/pull/1676 | 777,477,645 | MDExOlB1bGxSZXF1ZXN0NTQ3NzY1OTY3 | 1,676 | new version of Ted Talks IWSLT (WIT3) | {
"login": "skyprince999",
"id": 9033954,
"node_id": "MDQ6VXNlcjkwMzM5NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9033954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyprince999",
"html_url": "https://github.com/skyprince999",
"followers_url": "https://api.github.com/users/skyprince999/followers",
"following_url": "https://api.github.com/users/skyprince999/following{/other_user}",
"gists_url": "https://api.github.com/users/skyprince999/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyprince999/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyprince999/subscriptions",
"organizations_url": "https://api.github.com/users/skyprince999/orgs",
"repos_url": "https://api.github.com/users/skyprince999/repos",
"events_url": "https://api.github.com/users/skyprince999/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyprince999/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"> Nice thank you ! Actually as it is a translation dataset we should probably have one configuration = one language pair no ?\r\n> \r\n> Could you use the same trick for this dataset ?\r\n\r\nI was looking for this input, infact I had written a long post on the Slack channel,...(_but unfortunately due to the holidays didn;t get a respones_). Initially I had tried with language pairs and then with specific language configs. \r\n\r\nI'll have a look at the `opus-gnomes` dataset\r\n",
"Oh sorry I must have missed your message then :/\r\nI was off a few days during the holidays\r\n\r\nHopefully this trick can enable the use of any language pair (+ year ?) combination and also simplify a lot the dummy data creation since it will only require a few configs.",
"Updated it as per the comments. But couldn't figure out why the dummy tests are failing >> \r\n```\r\n$RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_ted_talks_iwslt\r\n.....\r\n....\r\ntests/test_dataset_common.py:198: in check_load_dataset\r\n self.parent.assertTrue(len(dataset[split]) > 0)\r\nE AssertionError: False is not true\r\n```"
] | 1,609,601,403,000 | 1,610,619,019,000 | 1,610,619,019,000 | CONTRIBUTOR | null | In the previous iteration #1608 I had used language pairs. Which created 21,582 configs (109*108) !!!
Now, TED talks in _each language_ is a separate config. So it's more cleaner with _just 109 configs_ (one for each language). Dummy files were created manually.
Locally I was able to clear the `python datasets-cli test datasets/......` . Which created the `dataset_info.json` file . The test for the dummy files was also cleared. However couldn't figure out how to specify the local data folder for the real dataset
**Note: that this requires manual download of the dataset.**
**Note2: The high number of _Files changed (112)_ is because of the large number of dummy files/configs!** | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1676/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1676/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1676",
"html_url": "https://github.com/huggingface/datasets/pull/1676",
"diff_url": "https://github.com/huggingface/datasets/pull/1676.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1676.patch",
"merged_at": 1610619019000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1675/comments | https://api.github.com/repos/huggingface/datasets/issues/1675/events | https://github.com/huggingface/datasets/issues/1675 | 777,367,320 | MDU6SXNzdWU3NzczNjczMjA= | 1,675 | Add the 800GB Pile dataset? | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null | [
"The pile dataset would be very nice.\r\nBenchmarks show that pile trained models achieve better results than most of actually trained models",
"The pile can very easily be added and adapted using this [tfds implementation](https://github.com/EleutherAI/The-Pile/blob/master/the_pile/tfds_pile.py) from the repo. \r\n\r\nHowever, the question is whether you'd be ok with 800GB+ cached in your local disk, since the tfds implementation was designed to offload the storage to Google Cloud Storage.",
"With the dataset streaming feature (see #2375) it will be more convenient to play with such big datasets :)\r\nI'm currently adding C4 (see #2511 ) but I can probably start working on this afterwards",
"Hi folks! Just wanted to follow up on this -- would be really nice to get the Pile on HF Datasets... unclear if it would be easy to also add partitions of the Pile subject to the original 22 datasets used, but that would be nice too!",
"Hi folks, thanks to some awesome work by @lhoestq and @albertvillanova you can now stream the Pile as follows:\r\n\r\n```python\r\n# Install master branch of `datasets`\r\npip install git+https://github.com/huggingface/datasets.git#egg=datasets[streaming]\r\npip install zstandard\r\n\r\nfrom datasets import load_dataset\r\n\r\ndset = load_dataset(\"json\", data_files=\"https://the-eye.eu/public/AI/pile/train/00.jsonl.zst\", streaming=True, split=\"train\")\r\nnext(iter(dset))\r\n# {'meta': {'pile_set_name': 'Pile-CC'},\r\n# 'text': 'It is done, and submitted. You can play “Survival of the Tastiest” on Android, and on the web ... '}\r\n```\r\n\r\nNext step is to add the Pile as a \"canonical\" dataset that can be streamed without specifying the file names explicitly :)",
"> Hi folks! Just wanted to follow up on this -- would be really nice to get the Pile on HF Datasets... unclear if it would be easy to also add partitions of the Pile subject to the original 22 datasets used, but that would be nice too!\r\n\r\nHi @siddk thanks to a tip from @richarddwang it seems we can access some of the partitions that EleutherAI created for the Pile [here](https://the-eye.eu/public/AI/pile_preliminary_components/). What's missing are links to the preprocessed versions of pre-existing datasets like DeepMind Mathematics and OpenSubtitles, but worst case we do the processing ourselves and host these components on the Hub.\r\n\r\nMy current idea is that we could provide 23 configs: one for each of the 22 datasets and an `all` config that links to the train / dev / test splits that EleutherAI released [here](https://the-eye.eu/public/AI/pile/), e.g.\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\n# Load a single component\r\nyoutube_subtitles = load_dataset(\"the_pile\", \"youtube_subtitles\")\r\n# Load the train / dev / test splits of the whole corpus\r\ndset = load_dataset(\"the_pile\", \"all\")\r\n```\r\n\r\nIdeally we'd like everything to be compatible with the streaming API and there's ongoing work by @albertvillanova to make this happen for the various compression algorithms.\r\n\r\ncc @lhoestq ",
"Ah I just saw that @lhoestq is already thinking about the specifying of one or more subsets in [this PR](https://github.com/huggingface/datasets/pull/2817#issuecomment-901874049) :)"
] | 1,609,541,892,000 | 1,638,372,547,000 | 1,638,372,547,000 | MEMBER | null | ## Adding a Dataset
- **Name:** The Pile
- **Description:** The Pile is a 825 GiB diverse, open source language modelling data set that consists of 22 smaller, high-quality datasets combined together. See [here](https://twitter.com/nabla_theta/status/1345130408170541056?s=20) for the Twitter announcement
- **Paper:** https://pile.eleuther.ai/paper.pdf
- **Data:** https://pile.eleuther.ai/
- **Motivation:** Enables hardcore (GPT-3 scale!) language modelling
## Remarks
Given the extreme size of this dataset, I'm not sure how feasible this will be to include in `datasets` 🤯 . I'm also unsure how many `datasets` users are pretraining LMs, so the usage of this dataset may not warrant the effort to integrate it.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1675/reactions",
"total_count": 12,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 1,
"heart": 0,
"rocket": 5,
"eyes": 2
} | https://api.github.com/repos/huggingface/datasets/issues/1675/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1674/comments | https://api.github.com/repos/huggingface/datasets/issues/1674/events | https://github.com/huggingface/datasets/issues/1674 | 777,321,840 | MDU6SXNzdWU3NzczMjE4NDA= | 1,674 | dutch_social can't be loaded | {
"login": "koenvandenberge",
"id": 10134844,
"node_id": "MDQ6VXNlcjEwMTM0ODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/10134844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/koenvandenberge",
"html_url": "https://github.com/koenvandenberge",
"followers_url": "https://api.github.com/users/koenvandenberge/followers",
"following_url": "https://api.github.com/users/koenvandenberge/following{/other_user}",
"gists_url": "https://api.github.com/users/koenvandenberge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/koenvandenberge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koenvandenberge/subscriptions",
"organizations_url": "https://api.github.com/users/koenvandenberge/orgs",
"repos_url": "https://api.github.com/users/koenvandenberge/repos",
"events_url": "https://api.github.com/users/koenvandenberge/events{/privacy}",
"received_events_url": "https://api.github.com/users/koenvandenberge/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"exactly the same issue in some other datasets.\r\nDid you find any solution??\r\n",
"Hi @koenvandenberge and @alighofrani95!\r\nThe datasets you're experiencing issues with were most likely added recently to the `datasets` library, meaning they have not been released yet. They will be released with the v2 of the library.\r\nMeanwhile, you can still load the datasets using one of the techniques described in this issue: #1641 \r\nLet me know if this helps!",
"Maybe we should do a small release on Monday in the meantime @lhoestq ?",
"Yes sure !",
"I just did the release :)\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `dutch_social` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"dutch_social\")\r\n```",
"@lhoestq could you also shed light on the Hindi Wikipedia Dataset for issue number #1673. Will this also be available in the new release that you committed recently?",
"The issue is different for this one, let me give more details in the issue",
"Okay. Could you comment on the #1673 thread? Actually @thomwolf had commented that if i use datasets library from source, it would allow me to download the Hindi Wikipedia Dataset but even the version 1.1.3 gave me the same issue. The details are there in the issue #1673 thread."
] | 1,609,522,628,000 | 1,609,841,821,000 | null | NONE | null | Hi all,
I'm trying to import the `dutch_social` dataset described [here](https://huggingface.co/datasets/dutch_social).
However, the code that should load the data doesn't seem to be working, in particular because the corresponding files can't be found at the provided links.
```
(base) Koens-MacBook-Pro:~ koenvandenberge$ python
Python 3.7.4 (default, Aug 13 2019, 15:17:50)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from datasets import load_dataset
dataset = load_dataset(
'dutch_social')
>>> dataset = load_dataset(
... 'dutch_social')
Traceback (most recent call last):
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dutch_social/dutch_social.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dutch_social/dutch_social.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/koenvandenberge/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 282, in prepare_module
combined_path, github_file_path, file_path
FileNotFoundError: Couldn't find file locally at dutch_social/dutch_social.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/dutch_social/dutch_social.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/dutch_social/dutch_social.py
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1674/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1674/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1673 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1673/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1673/comments | https://api.github.com/repos/huggingface/datasets/issues/1673/events | https://github.com/huggingface/datasets/issues/1673 | 777,263,651 | MDU6SXNzdWU3NzcyNjM2NTE= | 1,673 | Unable to Download Hindi Wikipedia Dataset | {
"login": "aditya3498",
"id": 30871963,
"node_id": "MDQ6VXNlcjMwODcxOTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/30871963?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aditya3498",
"html_url": "https://github.com/aditya3498",
"followers_url": "https://api.github.com/users/aditya3498/followers",
"following_url": "https://api.github.com/users/aditya3498/following{/other_user}",
"gists_url": "https://api.github.com/users/aditya3498/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aditya3498/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aditya3498/subscriptions",
"organizations_url": "https://api.github.com/users/aditya3498/orgs",
"repos_url": "https://api.github.com/users/aditya3498/repos",
"events_url": "https://api.github.com/users/aditya3498/events{/privacy}",
"received_events_url": "https://api.github.com/users/aditya3498/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Currently this dataset is only available when the library is installed from source since it was added after the last release.\r\n\r\nWe pin the dataset version with the library version so that people can have a reproducible dataset and processing when pinning the library.\r\n\r\nWe'll see if we can provide access to newer datasets with a warning that they are newer than your library version, that would help in cases like yours.",
"So for now, should i try and install the library from source and then try out the same piece of code? Will it work then, considering both the versions will match then?",
"Yes",
"Hey, so i tried installing the library from source using the commands : **git clone https://github.com/huggingface/datasets**, **cd datasets** and then **pip3 install -e .**. But i still am facing the same error that file is not found. Please advise.\r\n\r\nThe Datasets library version now is 1.1.3 by installing from source as compared to the earlier 1.0.3 that i had loaded using pip command but I am still getting same error\r\n\r\n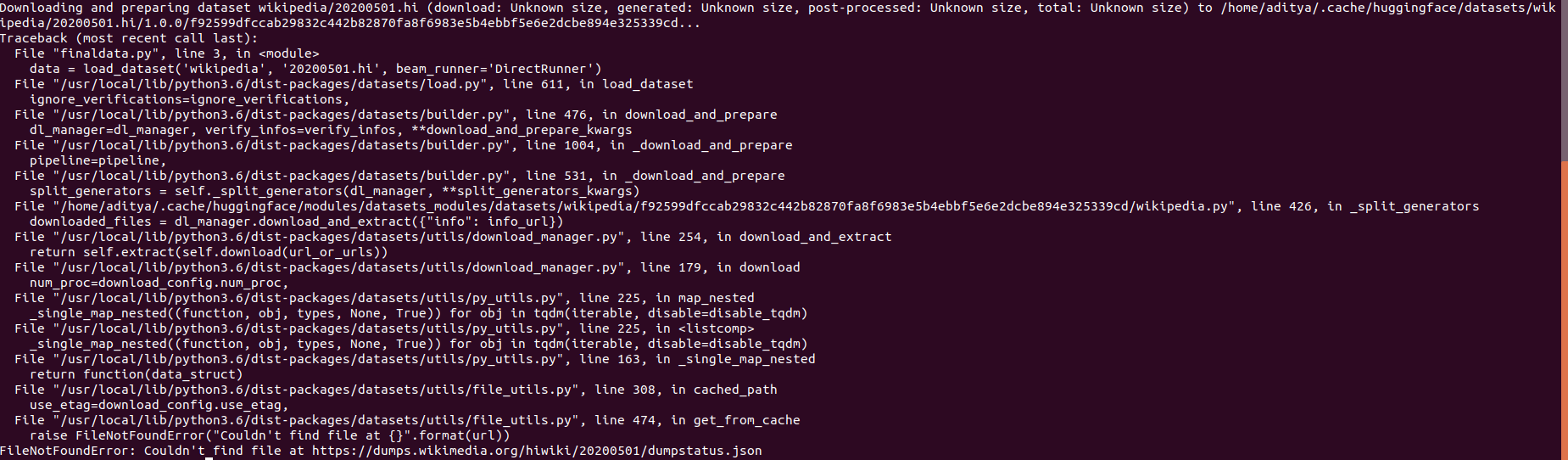\r\n",
"Looks like the wikipedia dump for hindi at the date of 05/05/2020 is not available anymore.\r\nYou can try to load a more recent version of wikipedia\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nd = load_dataset(\"wikipedia\", language=\"hi\", date=\"20210101\", split=\"train\", beam_runner=\"DirectRunner\")\r\n```",
"Okay, thank you so much"
] | 1,609,498,373,000 | 1,609,842,132,000 | 1,609,842,132,000 | NONE | null | I used the Dataset Library in Python to load the wikipedia dataset with the Hindi Config 20200501.hi along with something called beam_runner='DirectRunner' and it keeps giving me the error that the file is not found. I have attached the screenshot of the error and the code both. Please help me to understand how to resolve this issue.


| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1673/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1673/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1672/comments | https://api.github.com/repos/huggingface/datasets/issues/1672/events | https://github.com/huggingface/datasets/issues/1672 | 777,258,941 | MDU6SXNzdWU3NzcyNTg5NDE= | 1,672 | load_dataset hang on file_lock | {
"login": "tomacai",
"id": 69860107,
"node_id": "MDQ6VXNlcjY5ODYwMTA3",
"avatar_url": "https://avatars.githubusercontent.com/u/69860107?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tomacai",
"html_url": "https://github.com/tomacai",
"followers_url": "https://api.github.com/users/tomacai/followers",
"following_url": "https://api.github.com/users/tomacai/following{/other_user}",
"gists_url": "https://api.github.com/users/tomacai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tomacai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tomacai/subscriptions",
"organizations_url": "https://api.github.com/users/tomacai/orgs",
"repos_url": "https://api.github.com/users/tomacai/repos",
"events_url": "https://api.github.com/users/tomacai/events{/privacy}",
"received_events_url": "https://api.github.com/users/tomacai/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Can you try to upgrade to a more recent version of datasets?",
"Thank, upgrading to 1.1.3 resolved the issue.",
"Having the same issue with `datasets 1.1.3` of `1.5.0` (both tracebacks look the same) and `kilt_wikipedia`, Ubuntu 20.04\r\n\r\n```py\r\nIn [1]: from datasets import load_dataset \r\n\r\nIn [2]: wikipedia = load_dataset('kilt_wikipedia')['full'] \r\nDownloading: 7.37kB [00:00, 2.74MB/s] \r\nDownloading: 3.33kB [00:00, 1.44MB/s] \r\n^C---------------------------------------------------------------------------\r\nOSError Traceback (most recent call last)\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/utils/filelock.py in _acquire(self)\r\n 380 try:\r\n--> 381 fcntl.flock(fd, fcntl.LOCK_EX | fcntl.LOCK_NB)\r\n 382 except (IOError, OSError):\r\n\r\nOSError: [Errno 37] No locks available\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nKeyboardInterrupt Traceback (most recent call last)\r\n<ipython-input-2-f412d3d46ec9> in <module>\r\n----> 1 wikipedia = load_dataset('kilt_wikipedia')['full']\r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, sav\r\ne_infos, script_version, **config_kwargs)\r\n 601 hash=hash,\r\n 602 features=features,\r\n--> 603 **config_kwargs,\r\n 604 )\r\n 605 \r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/builder.py in __init__(self, *args, **kwargs)\r\n 841 def __init__(self, *args, **kwargs):\r\n 842 self._writer_batch_size = kwargs.pop(\"writer_batch_size\", self._writer_batch_size)\r\n--> 843 super(GeneratorBasedBuilder, self).__init__(*args, **kwargs)\r\n 844 \r\n 845 @abc.abstractmethod\r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/builder.py in __init__(self, cache_dir, name, hash, features, **config_kwargs)\r\n 174 os.makedirs(self._cache_dir_root, exist_ok=True)\r\n 175 lock_path = os.path.join(self._cache_dir_root, self._cache_dir.replace(os.sep, \"_\") + \".lock\")\r\n--> 176 with FileLock(lock_path):\r\n 177 if os.path.exists(self._cache_dir): # check if data exist\r\n 178 if len(os.listdir(self._cache_dir)) > 0:\r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/utils/filelock.py in __enter__(self)\r\n 312 \r\n 313 def __enter__(self):\r\n--> 314 self.acquire()\r\n 315 return self\r\n 316 \r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/utils/filelock.py in acquire(self, timeout, poll_intervall)\r\n 261 if not self.is_locked:\r\n 262 logger().debug(\"Attempting to acquire lock %s on %s\", lock_id, lock_filename)\r\n--> 263 self._acquire()\r\n 264 \r\n 265 if self.is_locked:\r\n\r\n~/anaconda3/envs/transformers2/lib/python3.7/site-packages/datasets/utils/filelock.py in _acquire(self)\r\n 379 \r\n 380 try:\r\n--> 381 fcntl.flock(fd, fcntl.LOCK_EX | fcntl.LOCK_NB)\r\n 382 except (IOError, OSError):\r\n 383 os.close(fd)\r\n\r\nKeyboardInterrupt: \r\n\r\n```"
] | 1,609,496,707,000 | 1,617,207,853,000 | 1,609,501,656,000 | NONE | null | I am trying to load the squad dataset. Fails on Windows 10 but succeeds in Colab.
Transformers: 3.3.1
Datasets: 1.0.2
Windows 10 (also tested in WSL)
```
datasets.logging.set_verbosity_debug()
datasets.
train_dataset = load_dataset('squad', split='train')
valid_dataset = load_dataset('squad', split='validation')
train_dataset.features
```
```
https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py not found in cache or force_download set to True, downloading to C:\Users\simpl\.cache\huggingface\datasets\tmpzj_o_6u7
Downloading:
5.24k/? [00:00<00:00, 134kB/s]
storing https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py in cache at C:\Users\simpl\.cache\huggingface\datasets\f6877c8d2e01e8fcb60dc101be28b54a7522feac756deb9ac5c39c6d8ebef1ce.85f43de978b9b25921cb78d7a2f2b350c04acdbaedb9ecb5f7101cd7c0950e68.py
creating metadata file for C:\Users\simpl\.cache\huggingface\datasets\f6877c8d2e01e8fcb60dc101be28b54a7522feac756deb9ac5c39c6d8ebef1ce.85f43de978b9b25921cb78d7a2f2b350c04acdbaedb9ecb5f7101cd7c0950e68.py
Checking C:\Users\simpl\.cache\huggingface\datasets\f6877c8d2e01e8fcb60dc101be28b54a7522feac756deb9ac5c39c6d8ebef1ce.85f43de978b9b25921cb78d7a2f2b350c04acdbaedb9ecb5f7101cd7c0950e68.py for additional imports.
Found main folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py at C:\Users\simpl\.cache\huggingface\modules\datasets_modules\datasets\squad
Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py at C:\Users\simpl\.cache\huggingface\modules\datasets_modules\datasets\squad\1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41
Found script file from https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py to C:\Users\simpl\.cache\huggingface\modules\datasets_modules\datasets\squad\1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41\squad.py
Couldn't find dataset infos file at https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad\dataset_infos.json
Found metadata file for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/squad.py at C:\Users\simpl\.cache\huggingface\modules\datasets_modules\datasets\squad\1244d044b266a5e4dbd4174d23cb995eead372fbca31a03edc3f8a132787af41\squad.json
No config specified, defaulting to first: squad/plain_text
```
Interrupting the jupyter kernel we are in a file lock.
In Google Colab the download is ok. In contrast to a local run in colab dataset_infos.json is downloaded
```
https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/squad/dataset_infos.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/datasets/tmptl9ha_ad
Downloading:
2.19k/? [00:00<00:00, 26.2kB/s]
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1672/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1672/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1671/comments | https://api.github.com/repos/huggingface/datasets/issues/1671/events | https://github.com/huggingface/datasets/issues/1671 | 776,652,193 | MDU6SXNzdWU3NzY2NTIxOTM= | 1,671 | connection issue | {
"login": "rabeehkarimimahabadi",
"id": 73364383,
"node_id": "MDQ6VXNlcjczMzY0Mzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehkarimimahabadi",
"html_url": "https://github.com/rabeehkarimimahabadi",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehkarimimahabadi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehkarimimahabadi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehkarimimahabadi/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehkarimimahabadi/orgs",
"repos_url": "https://api.github.com/users/rabeehkarimimahabadi/repos",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehkarimimahabadi/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Also, mayjor issue for me is the format issue, even if I go through changing the whole code to use load_from_disk, then if I do \r\n\r\nd = datasets.load_from_disk(\"imdb\")\r\nd = d[\"train\"][:10] => the format of this is no more in datasets format\r\nthis is different from you call load_datasets(\"train[10]\")\r\n\r\ncould you tell me how I can make the two datastes the same format @lhoestq \r\n\r\n",
"> `\r\nrequests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/glue/glue.py (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7ff6d6c60a20>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)'))`\r\n\r\nDo you have an internet connection on the machine ? Is there a proxy that might block requests to aws ?\r\n\r\n> I tried to do read the data, save it to a path and then set HF_HOME, which does not work and this is still not reading from the old set path, could you assist me how to save the datasets in a path, and let dataset library read from this path to avoid connection issue. thanks\r\n\r\nHF_HOME is used to specify the directory for the cache files of this library.\r\nYou can use save_to_disk and load_from_disk without changing the HF_HOME:\r\n```python\r\nimdb = datasets.load_dataset(\"imdb\")\r\nimdb.save_to_disk(\"/idiap/temp/rkarimi/hf_datasets/imdb\")\r\nimdb = datasets.load_from_disk(\"/idiap/temp/rkarimi/hf_datasets/imdb\")\r\n```\r\n\r\n> could you tell me how I can make the two datastes the same format\r\n\r\nIndeed they returns different things:\r\n- `load_dataset` returns a `Dataset` object if the split is specified, or a `DatasetDict` if no split is given. Therefore `load_datasets(\"imdb\", split=\"train[10]\")` returns a `Dataset` object containing 10 elements.\r\n- doing `d[\"train\"][:10]` on a DatasetDict \"d\" gets the train split `d[\"train\"]` as a `Dataset` object and then gets the first 10 elements as a dictionary"
] | 1,609,365,380,000 | 1,609,754,391,000 | null | NONE | null | Hi
I am getting this connection issue, resulting in large failure on cloud, @lhoestq I appreciate your help on this.
If I want to keep the codes the same, so not using save_to_disk, load_from_disk, but save the datastes in the way load_dataset reads from and copy the files in the same folder the datasets library reads from, could you assist me how this can be done, thanks
I tried to do read the data, save it to a path and then set HF_HOME, which does not work and this is still not reading from the old set path, could you assist me how to save the datasets in a path, and let dataset library read from this path to avoid connection issue. thanks
```
imdb = datasets.load_dataset("imdb")
imdb.save_to_disk("/idiap/temp/rkarimi/hf_datasets/imdb")
>>> os.environ["HF_HOME"]="/idiap/temp/rkarimi/hf_datasets/"
>>> imdb = datasets.load_dataset("imdb")
Reusing dataset imdb (/idiap/temp/rkarimi/cache_home_2/datasets/imdb/plain_text/1.0.0/90099cb476936b753383ba2ae6ab2eae419b2e87f71cd5189cb9c8e5814d12a3)
```
I tried afterwards to set HF_HOME in bash, this makes it read from it, but it cannot let dataset library load from the saved path and still downloading data. could you tell me how to fix this issue @lhoestq thanks
Also this is on cloud, so I save them in a path, copy it to "another machine" to load the data
### Error stack
```
Traceback (most recent call last):
File "./finetune_t5_trainer.py", line 344, in <module>
main()
File "./finetune_t5_trainer.py", line 232, in main
for task in data_args.eval_tasks} if training_args.do_test else None
File "./finetune_t5_trainer.py", line 232, in <dictcomp>
for task in data_args.eval_tasks} if training_args.do_test else None
File "/workdir/seq2seq/data/tasks.py", line 136, in get_dataset
split = self.get_sampled_split(split, n_obs)
File "/workdir/seq2seq/data/tasks.py", line 64, in get_sampled_split
dataset = self.load_dataset(split)
File "/workdir/seq2seq/data/tasks.py", line 454, in load_dataset
split=split, script_version="master")
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 263, in prepare_module
head_hf_s3(path, filename=name, dataset=dataset)
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 200, in head_hf_s3
return http_head(hf_bucket_url(identifier=identifier, filename=filename, use_cdn=use_cdn, dataset=dataset))
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 403, in http_head
url, proxies=proxies, headers=headers, cookies=cookies, allow_redirects=allow_redirects, timeout=timeout
File "/usr/local/lib/python3.6/dist-packages/requests/api.py", line 104, in head
return request('head', url, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/requests/api.py", line 61, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/requests/sessions.py", line 542, in request
resp = self.send(prep, **send_kwargs)
File "/usr/local/lib/python3.6/dist-packages/requests/sessions.py", line 655, in send
r = adapter.send(request, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/requests/adapters.py", line 504, in send
raise ConnectTimeout(e, request=request)
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='s3.amazonaws.com', port=443): Max retries exceeded with url: /datasets.huggingface.co/datasets/datasets/glue/glue.py (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7ff6d6c60a20>, 'Connection to s3.amazonaws.com timed out. (connect timeout=10)'))
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1671/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1671/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1670/comments | https://api.github.com/repos/huggingface/datasets/issues/1670/events | https://github.com/huggingface/datasets/issues/1670 | 776,608,579 | MDU6SXNzdWU3NzY2MDg1Nzk= | 1,670 | wiki_dpr pre-processing performance | {
"login": "dbarnhart",
"id": 753898,
"node_id": "MDQ6VXNlcjc1Mzg5OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/753898?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dbarnhart",
"html_url": "https://github.com/dbarnhart",
"followers_url": "https://api.github.com/users/dbarnhart/followers",
"following_url": "https://api.github.com/users/dbarnhart/following{/other_user}",
"gists_url": "https://api.github.com/users/dbarnhart/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dbarnhart/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dbarnhart/subscriptions",
"organizations_url": "https://api.github.com/users/dbarnhart/orgs",
"repos_url": "https://api.github.com/users/dbarnhart/repos",
"events_url": "https://api.github.com/users/dbarnhart/events{/privacy}",
"received_events_url": "https://api.github.com/users/dbarnhart/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 2067401494,
"node_id": "MDU6TGFiZWwyMDY3NDAxNDk0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/Dataset%20discussion",
"name": "Dataset discussion",
"color": "72f99f",
"default": false,
"description": "Discussions on the datasets"
}
] | open | false | null | [] | null | [
"Hi ! And thanks for the tips :) \r\n\r\nIndeed currently `wiki_dpr` takes some time to be processed.\r\nMultiprocessing for dataset generation is definitely going to speed up things.\r\n\r\nRegarding the index note that for the default configurations, the index is downloaded instead of being built, which avoid spending time on constructing the index. However in other cases it would be awesome to make the construction faster.\r\n\r\nAny contribution that can help things faster are welcome. In particular in you have some code that can build a wiki_dpr IVF PQ index in a sharded GPU setup and would like to share it, we can add it to an `examples` folder. In particular since faiss is becoming the library of reference for dataset indexing for tasks like Open Domain Question Answering.\r\n\r\n",
"I'd be happy to contribute something when I get the time, probably adding multiprocessing and / or cython support to wiki_dpr. I've written cythonized apache beam code before as well.\r\n\r\nFor sharded index building, I used the FAISS example code for indexing 1 billion vectors as a start. I'm sure you're aware that the documentation isn't great, but the source code is fairly easy to follow.",
"Nice thanks ! That would be awesome to make its construction faster :) "
] | 1,609,357,303,000 | 1,611,826,896,000 | null | NONE | null | I've been working with wiki_dpr and noticed that the dataset processing is seriously impaired in performance [1]. It takes about 12h to process the entire dataset. Most of this time is simply loading and processing the data, but the actual indexing is also quite slow (3h).
I won't repeat the concerns around multiprocessing as they are addressed in other issues (#786), but this is the first obvious thing to do. Using cython to speed up the text manipulation may be also help. Loading and processing a dataset of this size in under 15 minutes does not seem unreasonable on a modern multi-core machine. I have hit such targets myself on similar tasks. Would love to see this improve.
The other issue is that it takes 3h to construct the FAISS index. If only we could use GPUs with HNSW, but we can't. My sharded GPU indexing code can build an IVF + PQ index in 10 minutes on 20 million vectors. Still, 3h seems slow even for the CPU.
It looks like HF is adding only 1000 vectors at a time by default [2], whereas the faiss benchmarks adds 1 million vectors at a time (effectively) [3]. It's possible the runtime could be reduced with a larger batch. Also, it looks like project dependencies ultimately use OpenBLAS, but this is known to have issues when combined with OpenMP, which HNSW does [3]. A workaround is to set the environment variable `OMP_WAIT_POLICY=PASSIVE` via `os.environ` or similar.
References:
[1] https://github.com/huggingface/datasets/blob/master/datasets/wiki_dpr/wiki_dpr.py
[2] https://github.com/huggingface/datasets/blob/master/src/datasets/search.py
[3] https://github.com/facebookresearch/faiss/blob/master/benchs/bench_hnsw.py
[4] https://github.com/facebookresearch/faiss/issues/422 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1670/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1670/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1669/comments | https://api.github.com/repos/huggingface/datasets/issues/1669/events | https://github.com/huggingface/datasets/issues/1669 | 776,608,386 | MDU6SXNzdWU3NzY2MDgzODY= | 1,669 | wiki_dpr dataset pre-processesing performance | {
"login": "dbarnhart",
"id": 753898,
"node_id": "MDQ6VXNlcjc1Mzg5OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/753898?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dbarnhart",
"html_url": "https://github.com/dbarnhart",
"followers_url": "https://api.github.com/users/dbarnhart/followers",
"following_url": "https://api.github.com/users/dbarnhart/following{/other_user}",
"gists_url": "https://api.github.com/users/dbarnhart/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dbarnhart/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dbarnhart/subscriptions",
"organizations_url": "https://api.github.com/users/dbarnhart/orgs",
"repos_url": "https://api.github.com/users/dbarnhart/repos",
"events_url": "https://api.github.com/users/dbarnhart/events{/privacy}",
"received_events_url": "https://api.github.com/users/dbarnhart/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Sorry, double posted."
] | 1,609,357,269,000 | 1,609,357,345,000 | 1,609,357,345,000 | NONE | null | I've been working with wiki_dpr and noticed that the dataset processing is seriously impaired in performance [1]. It takes about 12h to process the entire dataset. Most of this time is simply loading and processing the data, but the actual indexing is also quite slow (3h).
I won't repeat the concerns around multiprocessing as they are addressed in other issues (#786), but this is the first obvious thing to do. Using cython to speed up the text manipulation may be also help. Loading and processing a dataset of this size in under 15 minutes does not seem unreasonable on a modern multi-core machine. I have hit such targets myself on similar tasks. Would love to see this improve.
The other issue is that it takes 3h to construct the FAISS index. If only we could use GPUs with HNSW, but we can't. My sharded GPU indexing code can build an IVF + PQ index in 10 minutes on 20 million vectors. Still, 3h seems slow even for the CPU.
It looks like HF is adding only 1000 vectors at a time by default [2], whereas the faiss benchmarks adds 1 million vectors at a time (effectively) [3]. It's possible the runtime could be reduced with a larger batch. Also, it looks like project dependencies ultimately use OpenBLAS, but this is known to have issues when combined with OpenMP, which HNSW does [3]. A workaround is to set the environment variable `OMP_WAIT_POLICY=PASSIVE` via `os.environ` or similar.
References:
[1] https://github.com/huggingface/datasets/blob/master/datasets/wiki_dpr/wiki_dpr.py
[2] https://github.com/huggingface/datasets/blob/master/src/datasets/search.py
[3] https://github.com/facebookresearch/faiss/blob/master/benchs/bench_hnsw.py
[4] https://github.com/facebookresearch/faiss/issues/422 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1669/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1669/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1668/comments | https://api.github.com/repos/huggingface/datasets/issues/1668/events | https://github.com/huggingface/datasets/pull/1668 | 776,552,854 | MDExOlB1bGxSZXF1ZXN0NTQ3MDIxODI0 | 1,668 | xed_en_fi dataset Cleanup | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,348,278,000 | 1,609,348,964,000 | 1,609,348,963,000 | MEMBER | null | Fix ClassLabel feature type and minor mistakes in the dataset card | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1668/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1668/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1668",
"html_url": "https://github.com/huggingface/datasets/pull/1668",
"diff_url": "https://github.com/huggingface/datasets/pull/1668.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1668.patch",
"merged_at": 1609348963000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1667 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1667/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1667/comments | https://api.github.com/repos/huggingface/datasets/issues/1667/events | https://github.com/huggingface/datasets/pull/1667 | 776,446,658 | MDExOlB1bGxSZXF1ZXN0NTQ2OTM4MjAy | 1,667 | Fix NER metric example in Overview notebook | {
"login": "jungwhank",
"id": 53588015,
"node_id": "MDQ6VXNlcjUzNTg4MDE1",
"avatar_url": "https://avatars.githubusercontent.com/u/53588015?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jungwhank",
"html_url": "https://github.com/jungwhank",
"followers_url": "https://api.github.com/users/jungwhank/followers",
"following_url": "https://api.github.com/users/jungwhank/following{/other_user}",
"gists_url": "https://api.github.com/users/jungwhank/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jungwhank/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jungwhank/subscriptions",
"organizations_url": "https://api.github.com/users/jungwhank/orgs",
"repos_url": "https://api.github.com/users/jungwhank/repos",
"events_url": "https://api.github.com/users/jungwhank/events{/privacy}",
"received_events_url": "https://api.github.com/users/jungwhank/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,333,519,000 | 1,609,377,128,000 | 1,609,348,911,000 | CONTRIBUTOR | null | Fix errors in `NER metric example` section in `Overview.ipynb`.
```
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-37-ee559b166e25> in <module>()
----> 1 ner_metric = load_metric('seqeval')
2 references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
3 predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
4 ner_metric.compute(predictions, references)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
340 if needs_to_be_installed:
341 raise ImportError(
--> 342 f"To be able to use this {module_type}, you need to install the following dependencies"
343 f"{[lib_name for lib_name, lib_path in needs_to_be_installed]} using 'pip install "
344 f"{' '.join([lib_path for lib_name, lib_path in needs_to_be_installed])}' for instance'"
ImportError: To be able to use this metric, you need to install the following dependencies['seqeval'] using 'pip install seqeval' for instance'
```
```
ValueError Traceback (most recent call last)
<ipython-input-39-ee559b166e25> in <module>()
2 references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
3 predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
----> 4 ner_metric.compute(predictions, references)
/usr/local/lib/python3.6/dist-packages/datasets/metric.py in compute(self, *args, **kwargs)
378 """
379 if args:
--> 380 raise ValueError("Please call `compute` using keyword arguments.")
381
382 predictions = kwargs.pop("predictions", None)
ValueError: Please call `compute` using keyword arguments.
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1667/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1667/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1667",
"html_url": "https://github.com/huggingface/datasets/pull/1667",
"diff_url": "https://github.com/huggingface/datasets/pull/1667.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1667.patch",
"merged_at": 1609348911000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1666/comments | https://api.github.com/repos/huggingface/datasets/issues/1666/events | https://github.com/huggingface/datasets/pull/1666 | 776,432,006 | MDExOlB1bGxSZXF1ZXN0NTQ2OTI2MzQw | 1,666 | Add language to dataset card for Makhzan dataset. | {
"login": "arkhalid",
"id": 14899066,
"node_id": "MDQ6VXNlcjE0ODk5MDY2",
"avatar_url": "https://avatars.githubusercontent.com/u/14899066?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arkhalid",
"html_url": "https://github.com/arkhalid",
"followers_url": "https://api.github.com/users/arkhalid/followers",
"following_url": "https://api.github.com/users/arkhalid/following{/other_user}",
"gists_url": "https://api.github.com/users/arkhalid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arkhalid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arkhalid/subscriptions",
"organizations_url": "https://api.github.com/users/arkhalid/orgs",
"repos_url": "https://api.github.com/users/arkhalid/repos",
"events_url": "https://api.github.com/users/arkhalid/events{/privacy}",
"received_events_url": "https://api.github.com/users/arkhalid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,331,152,000 | 1,609,348,835,000 | 1,609,348,835,000 | CONTRIBUTOR | null | Add language to dataset card. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1666/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1666/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1666",
"html_url": "https://github.com/huggingface/datasets/pull/1666",
"diff_url": "https://github.com/huggingface/datasets/pull/1666.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1666.patch",
"merged_at": 1609348835000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1665/comments | https://api.github.com/repos/huggingface/datasets/issues/1665/events | https://github.com/huggingface/datasets/pull/1665 | 776,431,087 | MDExOlB1bGxSZXF1ZXN0NTQ2OTI1NTgw | 1,665 | Add language to dataset card for Counter dataset. | {
"login": "arkhalid",
"id": 14899066,
"node_id": "MDQ6VXNlcjE0ODk5MDY2",
"avatar_url": "https://avatars.githubusercontent.com/u/14899066?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arkhalid",
"html_url": "https://github.com/arkhalid",
"followers_url": "https://api.github.com/users/arkhalid/followers",
"following_url": "https://api.github.com/users/arkhalid/following{/other_user}",
"gists_url": "https://api.github.com/users/arkhalid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arkhalid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arkhalid/subscriptions",
"organizations_url": "https://api.github.com/users/arkhalid/orgs",
"repos_url": "https://api.github.com/users/arkhalid/repos",
"events_url": "https://api.github.com/users/arkhalid/events{/privacy}",
"received_events_url": "https://api.github.com/users/arkhalid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,331,000,000 | 1,609,348,820,000 | 1,609,348,820,000 | CONTRIBUTOR | null | Add language. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1665/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1665/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1665",
"html_url": "https://github.com/huggingface/datasets/pull/1665",
"diff_url": "https://github.com/huggingface/datasets/pull/1665.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1665.patch",
"merged_at": 1609348820000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1664 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1664/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1664/comments | https://api.github.com/repos/huggingface/datasets/issues/1664/events | https://github.com/huggingface/datasets/pull/1664 | 775,956,441 | MDExOlB1bGxSZXF1ZXN0NTQ2NTM1NDcy | 1,664 | removed \n in labels | {
"login": "bhavitvyamalik",
"id": 19718818,
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhavitvyamalik",
"html_url": "https://github.com/bhavitvyamalik",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
"gists_url": "https://api.github.com/users/bhavitvyamalik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhavitvyamalik/subscriptions",
"organizations_url": "https://api.github.com/users/bhavitvyamalik/orgs",
"repos_url": "https://api.github.com/users/bhavitvyamalik/repos",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhavitvyamalik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,256,503,000 | 1,609,348,729,000 | 1,609,348,729,000 | CONTRIBUTOR | null | updated social_i_qa labels as per #1633 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1664/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1664/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1664",
"html_url": "https://github.com/huggingface/datasets/pull/1664",
"diff_url": "https://github.com/huggingface/datasets/pull/1664.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1664.patch",
"merged_at": 1609348729000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1663/comments | https://api.github.com/repos/huggingface/datasets/issues/1663/events | https://github.com/huggingface/datasets/pull/1663 | 775,914,320 | MDExOlB1bGxSZXF1ZXN0NTQ2NTAzMjg5 | 1,663 | update saving and loading methods for faiss index so to accept path l… | {
"login": "tslott",
"id": 11614798,
"node_id": "MDQ6VXNlcjExNjE0Nzk4",
"avatar_url": "https://avatars.githubusercontent.com/u/11614798?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tslott",
"html_url": "https://github.com/tslott",
"followers_url": "https://api.github.com/users/tslott/followers",
"following_url": "https://api.github.com/users/tslott/following{/other_user}",
"gists_url": "https://api.github.com/users/tslott/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tslott/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tslott/subscriptions",
"organizations_url": "https://api.github.com/users/tslott/orgs",
"repos_url": "https://api.github.com/users/tslott/repos",
"events_url": "https://api.github.com/users/tslott/events{/privacy}",
"received_events_url": "https://api.github.com/users/tslott/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Seems ok for me, what do you think @lhoestq ?"
] | 1,609,251,337,000 | 1,610,962,043,000 | 1,610,962,043,000 | CONTRIBUTOR | null | - Update saving and loading methods for faiss index so to accept path like objects from pathlib
The current code only supports using a string type to save and load a faiss index. This change makes it possible to use a string type OR a Path from [pathlib](https://docs.python.org/3/library/pathlib.html). The codes becomes a more intuitive this way I think. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1663/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1663/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1663",
"html_url": "https://github.com/huggingface/datasets/pull/1663",
"diff_url": "https://github.com/huggingface/datasets/pull/1663.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1663.patch",
"merged_at": 1610962043000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1662 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1662/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1662/comments | https://api.github.com/repos/huggingface/datasets/issues/1662/events | https://github.com/huggingface/datasets/issues/1662 | 775,890,154 | MDU6SXNzdWU3NzU4OTAxNTQ= | 1,662 | Arrow file is too large when saving vector data | {
"login": "weiwangthu",
"id": 22360336,
"node_id": "MDQ6VXNlcjIyMzYwMzM2",
"avatar_url": "https://avatars.githubusercontent.com/u/22360336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/weiwangthu",
"html_url": "https://github.com/weiwangthu",
"followers_url": "https://api.github.com/users/weiwangthu/followers",
"following_url": "https://api.github.com/users/weiwangthu/following{/other_user}",
"gists_url": "https://api.github.com/users/weiwangthu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/weiwangthu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/weiwangthu/subscriptions",
"organizations_url": "https://api.github.com/users/weiwangthu/orgs",
"repos_url": "https://api.github.com/users/weiwangthu/repos",
"events_url": "https://api.github.com/users/weiwangthu/events{/privacy}",
"received_events_url": "https://api.github.com/users/weiwangthu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi !\r\nThe arrow file size is due to the embeddings. Indeed if they're stored as float32 then the total size of the embeddings is\r\n\r\n20 000 000 vectors * 768 dimensions * 4 bytes per dimension ~= 60GB\r\n\r\nIf you want to reduce the size you can consider using quantization for example, or maybe using dimension reduction techniques.\r\n",
"Thanks for your reply @lhoestq.\r\nI want to save original embedding for these sentences for subsequent calculations. So does arrow have a way to save in a compressed format to reduce the size of the file?",
"Arrow doesn't have compression since it is designed to have no serialization overhead",
"I see. Thank you."
] | 1,609,248,192,000 | 1,611,238,359,000 | 1,611,238,359,000 | NONE | null | I computed the sentence embedding of each sentence of bookcorpus data using bert base and saved them to disk. I used 20M sentences and the obtained arrow file is about 59GB while the original text file is only about 1.3GB. Are there any ways to reduce the size of the arrow file? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1662/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1662/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1661/comments | https://api.github.com/repos/huggingface/datasets/issues/1661/events | https://github.com/huggingface/datasets/pull/1661 | 775,840,801 | MDExOlB1bGxSZXF1ZXN0NTQ2NDQzNjYx | 1,661 | updated dataset cards | {
"login": "Nilanshrajput",
"id": 28673745,
"node_id": "MDQ6VXNlcjI4NjczNzQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/28673745?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nilanshrajput",
"html_url": "https://github.com/Nilanshrajput",
"followers_url": "https://api.github.com/users/Nilanshrajput/followers",
"following_url": "https://api.github.com/users/Nilanshrajput/following{/other_user}",
"gists_url": "https://api.github.com/users/Nilanshrajput/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nilanshrajput/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nilanshrajput/subscriptions",
"organizations_url": "https://api.github.com/users/Nilanshrajput/orgs",
"repos_url": "https://api.github.com/users/Nilanshrajput/repos",
"events_url": "https://api.github.com/users/Nilanshrajput/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nilanshrajput/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,240,840,000 | 1,609,348,516,000 | 1,609,348,516,000 | CONTRIBUTOR | null | added dataset instance in the card. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1661/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1661/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1661",
"html_url": "https://github.com/huggingface/datasets/pull/1661",
"diff_url": "https://github.com/huggingface/datasets/pull/1661.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1661.patch",
"merged_at": 1609348516000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1660/comments | https://api.github.com/repos/huggingface/datasets/issues/1660/events | https://github.com/huggingface/datasets/pull/1660 | 775,831,423 | MDExOlB1bGxSZXF1ZXN0NTQ2NDM2MDg1 | 1,660 | add dataset info | {
"login": "harshalmittal4",
"id": 24206326,
"node_id": "MDQ6VXNlcjI0MjA2MzI2",
"avatar_url": "https://avatars.githubusercontent.com/u/24206326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/harshalmittal4",
"html_url": "https://github.com/harshalmittal4",
"followers_url": "https://api.github.com/users/harshalmittal4/followers",
"following_url": "https://api.github.com/users/harshalmittal4/following{/other_user}",
"gists_url": "https://api.github.com/users/harshalmittal4/gists{/gist_id}",
"starred_url": "https://api.github.com/users/harshalmittal4/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harshalmittal4/subscriptions",
"organizations_url": "https://api.github.com/users/harshalmittal4/orgs",
"repos_url": "https://api.github.com/users/harshalmittal4/repos",
"events_url": "https://api.github.com/users/harshalmittal4/events{/privacy}",
"received_events_url": "https://api.github.com/users/harshalmittal4/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,239,499,000 | 1,609,347,870,000 | 1,609,347,870,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1660/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1660/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1660",
"html_url": "https://github.com/huggingface/datasets/pull/1660",
"diff_url": "https://github.com/huggingface/datasets/pull/1660.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1660.patch",
"merged_at": 1609347870000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1659/comments | https://api.github.com/repos/huggingface/datasets/issues/1659/events | https://github.com/huggingface/datasets/pull/1659 | 775,831,288 | MDExOlB1bGxSZXF1ZXN0NTQ2NDM1OTcy | 1,659 | update dataset info | {
"login": "harshalmittal4",
"id": 24206326,
"node_id": "MDQ6VXNlcjI0MjA2MzI2",
"avatar_url": "https://avatars.githubusercontent.com/u/24206326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/harshalmittal4",
"html_url": "https://github.com/harshalmittal4",
"followers_url": "https://api.github.com/users/harshalmittal4/followers",
"following_url": "https://api.github.com/users/harshalmittal4/following{/other_user}",
"gists_url": "https://api.github.com/users/harshalmittal4/gists{/gist_id}",
"starred_url": "https://api.github.com/users/harshalmittal4/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harshalmittal4/subscriptions",
"organizations_url": "https://api.github.com/users/harshalmittal4/orgs",
"repos_url": "https://api.github.com/users/harshalmittal4/repos",
"events_url": "https://api.github.com/users/harshalmittal4/events{/privacy}",
"received_events_url": "https://api.github.com/users/harshalmittal4/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,239,481,000 | 1,609,347,307,000 | 1,609,347,307,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1659/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1659/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1659",
"html_url": "https://github.com/huggingface/datasets/pull/1659",
"diff_url": "https://github.com/huggingface/datasets/pull/1659.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1659.patch",
"merged_at": 1609347307000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1658/comments | https://api.github.com/repos/huggingface/datasets/issues/1658/events | https://github.com/huggingface/datasets/pull/1658 | 775,651,085 | MDExOlB1bGxSZXF1ZXN0NTQ2Mjg4Njg4 | 1,658 | brwac dataset: add instances and data splits info | {
"login": "jonatasgrosman",
"id": 5097052,
"node_id": "MDQ6VXNlcjUwOTcwNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonatasgrosman",
"html_url": "https://github.com/jonatasgrosman",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
"gists_url": "https://api.github.com/users/jonatasgrosman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonatasgrosman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonatasgrosman/subscriptions",
"organizations_url": "https://api.github.com/users/jonatasgrosman/orgs",
"repos_url": "https://api.github.com/users/jonatasgrosman/repos",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonatasgrosman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,205,085,000 | 1,609,347,266,000 | 1,609,347,266,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1658/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1658/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1658",
"html_url": "https://github.com/huggingface/datasets/pull/1658",
"diff_url": "https://github.com/huggingface/datasets/pull/1658.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1658.patch",
"merged_at": 1609347266000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1657 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1657/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1657/comments | https://api.github.com/repos/huggingface/datasets/issues/1657/events | https://github.com/huggingface/datasets/pull/1657 | 775,647,000 | MDExOlB1bGxSZXF1ZXN0NTQ2Mjg1NjU2 | 1,657 | mac_morpho dataset: add data splits info | {
"login": "jonatasgrosman",
"id": 5097052,
"node_id": "MDQ6VXNlcjUwOTcwNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonatasgrosman",
"html_url": "https://github.com/jonatasgrosman",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
"gists_url": "https://api.github.com/users/jonatasgrosman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonatasgrosman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonatasgrosman/subscriptions",
"organizations_url": "https://api.github.com/users/jonatasgrosman/orgs",
"repos_url": "https://api.github.com/users/jonatasgrosman/repos",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonatasgrosman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,203,921,000 | 1,609,347,084,000 | 1,609,347,084,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1657/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1657/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1657",
"html_url": "https://github.com/huggingface/datasets/pull/1657",
"diff_url": "https://github.com/huggingface/datasets/pull/1657.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1657.patch",
"merged_at": 1609347084000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1656 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1656/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1656/comments | https://api.github.com/repos/huggingface/datasets/issues/1656/events | https://github.com/huggingface/datasets/pull/1656 | 775,645,356 | MDExOlB1bGxSZXF1ZXN0NTQ2Mjg0NDI3 | 1,656 | assin 2 dataset: add instances and data splits info | {
"login": "jonatasgrosman",
"id": 5097052,
"node_id": "MDQ6VXNlcjUwOTcwNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonatasgrosman",
"html_url": "https://github.com/jonatasgrosman",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
"gists_url": "https://api.github.com/users/jonatasgrosman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonatasgrosman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonatasgrosman/subscriptions",
"organizations_url": "https://api.github.com/users/jonatasgrosman/orgs",
"repos_url": "https://api.github.com/users/jonatasgrosman/repos",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonatasgrosman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,203,471,000 | 1,609,347,056,000 | 1,609,347,056,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1656/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1656/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1656",
"html_url": "https://github.com/huggingface/datasets/pull/1656",
"diff_url": "https://github.com/huggingface/datasets/pull/1656.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1656.patch",
"merged_at": 1609347056000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1655/comments | https://api.github.com/repos/huggingface/datasets/issues/1655/events | https://github.com/huggingface/datasets/pull/1655 | 775,643,418 | MDExOlB1bGxSZXF1ZXN0NTQ2MjgyOTM4 | 1,655 | assin dataset: add instances and data splits info | {
"login": "jonatasgrosman",
"id": 5097052,
"node_id": "MDQ6VXNlcjUwOTcwNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonatasgrosman",
"html_url": "https://github.com/jonatasgrosman",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
"gists_url": "https://api.github.com/users/jonatasgrosman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonatasgrosman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonatasgrosman/subscriptions",
"organizations_url": "https://api.github.com/users/jonatasgrosman/orgs",
"repos_url": "https://api.github.com/users/jonatasgrosman/repos",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonatasgrosman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,202,876,000 | 1,609,347,023,000 | 1,609,347,023,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1655/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1655/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1655",
"html_url": "https://github.com/huggingface/datasets/pull/1655",
"diff_url": "https://github.com/huggingface/datasets/pull/1655.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1655.patch",
"merged_at": 1609347022000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1654/comments | https://api.github.com/repos/huggingface/datasets/issues/1654/events | https://github.com/huggingface/datasets/pull/1654 | 775,640,729 | MDExOlB1bGxSZXF1ZXN0NTQ2MjgwODIy | 1,654 | lener_br dataset: add instances and data splits info | {
"login": "jonatasgrosman",
"id": 5097052,
"node_id": "MDQ6VXNlcjUwOTcwNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonatasgrosman",
"html_url": "https://github.com/jonatasgrosman",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
"gists_url": "https://api.github.com/users/jonatasgrosman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonatasgrosman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonatasgrosman/subscriptions",
"organizations_url": "https://api.github.com/users/jonatasgrosman/orgs",
"repos_url": "https://api.github.com/users/jonatasgrosman/repos",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonatasgrosman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,202,112,000 | 1,609,346,972,000 | 1,609,346,972,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1654/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1654/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1654",
"html_url": "https://github.com/huggingface/datasets/pull/1654",
"diff_url": "https://github.com/huggingface/datasets/pull/1654.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1654.patch",
"merged_at": 1609346972000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1653/comments | https://api.github.com/repos/huggingface/datasets/issues/1653/events | https://github.com/huggingface/datasets/pull/1653 | 775,632,945 | MDExOlB1bGxSZXF1ZXN0NTQ2Mjc0Njc0 | 1,653 | harem dataset: add data splits info | {
"login": "jonatasgrosman",
"id": 5097052,
"node_id": "MDQ6VXNlcjUwOTcwNTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5097052?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jonatasgrosman",
"html_url": "https://github.com/jonatasgrosman",
"followers_url": "https://api.github.com/users/jonatasgrosman/followers",
"following_url": "https://api.github.com/users/jonatasgrosman/following{/other_user}",
"gists_url": "https://api.github.com/users/jonatasgrosman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jonatasgrosman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jonatasgrosman/subscriptions",
"organizations_url": "https://api.github.com/users/jonatasgrosman/orgs",
"repos_url": "https://api.github.com/users/jonatasgrosman/repos",
"events_url": "https://api.github.com/users/jonatasgrosman/events{/privacy}",
"received_events_url": "https://api.github.com/users/jonatasgrosman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,199,900,000 | 1,609,346,943,000 | 1,609,346,943,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1653/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1653/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1653",
"html_url": "https://github.com/huggingface/datasets/pull/1653",
"diff_url": "https://github.com/huggingface/datasets/pull/1653.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1653.patch",
"merged_at": 1609346943000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1652 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1652/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1652/comments | https://api.github.com/repos/huggingface/datasets/issues/1652/events | https://github.com/huggingface/datasets/pull/1652 | 775,571,813 | MDExOlB1bGxSZXF1ZXN0NTQ2MjI1NTM1 | 1,652 | Update dataset cards from previous sprint | {
"login": "j-chim",
"id": 22435209,
"node_id": "MDQ6VXNlcjIyNDM1MjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/22435209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/j-chim",
"html_url": "https://github.com/j-chim",
"followers_url": "https://api.github.com/users/j-chim/followers",
"following_url": "https://api.github.com/users/j-chim/following{/other_user}",
"gists_url": "https://api.github.com/users/j-chim/gists{/gist_id}",
"starred_url": "https://api.github.com/users/j-chim/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/j-chim/subscriptions",
"organizations_url": "https://api.github.com/users/j-chim/orgs",
"repos_url": "https://api.github.com/users/j-chim/repos",
"events_url": "https://api.github.com/users/j-chim/events{/privacy}",
"received_events_url": "https://api.github.com/users/j-chim/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,186,847,000 | 1,609,346,884,000 | 1,609,346,884,000 | CONTRIBUTOR | null | This PR updates the dataset cards/readmes for the 4 approved PRs I submitted in the previous sprint. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1652/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1652/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1652",
"html_url": "https://github.com/huggingface/datasets/pull/1652",
"diff_url": "https://github.com/huggingface/datasets/pull/1652.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1652.patch",
"merged_at": 1609346884000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1651/comments | https://api.github.com/repos/huggingface/datasets/issues/1651/events | https://github.com/huggingface/datasets/pull/1651 | 775,554,319 | MDExOlB1bGxSZXF1ZXN0NTQ2MjExMjQw | 1,651 | Add twi wordsim353 | {
"login": "dadelani",
"id": 23586676,
"node_id": "MDQ6VXNlcjIzNTg2Njc2",
"avatar_url": "https://avatars.githubusercontent.com/u/23586676?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dadelani",
"html_url": "https://github.com/dadelani",
"followers_url": "https://api.github.com/users/dadelani/followers",
"following_url": "https://api.github.com/users/dadelani/following{/other_user}",
"gists_url": "https://api.github.com/users/dadelani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dadelani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dadelani/subscriptions",
"organizations_url": "https://api.github.com/users/dadelani/orgs",
"repos_url": "https://api.github.com/users/dadelani/repos",
"events_url": "https://api.github.com/users/dadelani/events{/privacy}",
"received_events_url": "https://api.github.com/users/dadelani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Well actually it looks like it was already added in #1428 \r\n\r\nMaybe we can close this one ? Or you wanted to make changes to this dataset ?",
"Thank you, it's just a modification of Readme. I added the missing citation.",
"Indeed thanks"
] | 1,609,183,915,000 | 1,609,753,179,000 | 1,609,753,178,000 | CONTRIBUTOR | null | Added the citation information to the README file | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1651/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1651/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1651",
"html_url": "https://github.com/huggingface/datasets/pull/1651",
"diff_url": "https://github.com/huggingface/datasets/pull/1651.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1651.patch",
"merged_at": 1609753178000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1650/comments | https://api.github.com/repos/huggingface/datasets/issues/1650/events | https://github.com/huggingface/datasets/pull/1650 | 775,545,912 | MDExOlB1bGxSZXF1ZXN0NTQ2MjA0MzYy | 1,650 | Update README.md | {
"login": "MisbahKhan789",
"id": 15351802,
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MisbahKhan789",
"html_url": "https://github.com/MisbahKhan789",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,182,545,000 | 1,609,238,594,000 | 1,609,238,594,000 | CONTRIBUTOR | null | added dataset summary | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1650/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1650/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1650",
"html_url": "https://github.com/huggingface/datasets/pull/1650",
"diff_url": "https://github.com/huggingface/datasets/pull/1650.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1650.patch",
"merged_at": 1609238594000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1649/comments | https://api.github.com/repos/huggingface/datasets/issues/1649/events | https://github.com/huggingface/datasets/pull/1649 | 775,544,487 | MDExOlB1bGxSZXF1ZXN0NTQ2MjAzMjE1 | 1,649 | Update README.md | {
"login": "MisbahKhan789",
"id": 15351802,
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MisbahKhan789",
"html_url": "https://github.com/MisbahKhan789",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,182,300,000 | 1,609,239,058,000 | 1,609,238,583,000 | CONTRIBUTOR | null | Added information in the dataset card | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1649/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1649/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1649",
"html_url": "https://github.com/huggingface/datasets/pull/1649",
"diff_url": "https://github.com/huggingface/datasets/pull/1649.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1649.patch",
"merged_at": 1609238583000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1648/comments | https://api.github.com/repos/huggingface/datasets/issues/1648/events | https://github.com/huggingface/datasets/pull/1648 | 775,542,360 | MDExOlB1bGxSZXF1ZXN0NTQ2MjAxNTQ0 | 1,648 | Update README.md | {
"login": "MisbahKhan789",
"id": 15351802,
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MisbahKhan789",
"html_url": "https://github.com/MisbahKhan789",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,181,946,000 | 1,609,238,354,000 | 1,609,238,354,000 | CONTRIBUTOR | null | added dataset summary | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1648/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1648/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1648",
"html_url": "https://github.com/huggingface/datasets/pull/1648",
"diff_url": "https://github.com/huggingface/datasets/pull/1648.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1648.patch",
"merged_at": 1609238354000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1647/comments | https://api.github.com/repos/huggingface/datasets/issues/1647/events | https://github.com/huggingface/datasets/issues/1647 | 775,525,799 | MDU6SXNzdWU3NzU1MjU3OTk= | 1,647 | NarrativeQA fails to load with `load_dataset` | {
"login": "eric-mitchell",
"id": 56408839,
"node_id": "MDQ6VXNlcjU2NDA4ODM5",
"avatar_url": "https://avatars.githubusercontent.com/u/56408839?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eric-mitchell",
"html_url": "https://github.com/eric-mitchell",
"followers_url": "https://api.github.com/users/eric-mitchell/followers",
"following_url": "https://api.github.com/users/eric-mitchell/following{/other_user}",
"gists_url": "https://api.github.com/users/eric-mitchell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eric-mitchell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eric-mitchell/subscriptions",
"organizations_url": "https://api.github.com/users/eric-mitchell/orgs",
"repos_url": "https://api.github.com/users/eric-mitchell/repos",
"events_url": "https://api.github.com/users/eric-mitchell/events{/privacy}",
"received_events_url": "https://api.github.com/users/eric-mitchell/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @eric-mitchell,\r\nI think the issue might be that this dataset was added during the community sprint and has not been released yet. It will be available with the v2 of `datasets`.\r\nFor now, you should be able to load the datasets after installing the latest (master) version of `datasets` using pip:\r\n`pip install git+https://github.com/huggingface/datasets.git@master`",
"@bhavitvyamalik Great, thanks for this! Confirmed that the problem is resolved on master at [cbbda53](https://github.com/huggingface/datasets/commit/cbbda53ac1520b01f0f67ed6017003936c41ec59).",
"Update: HuggingFace did an intermediate release yesterday just before the v2.0.\r\n\r\nTo load it you can just update `datasets`\r\n\r\n`pip install --upgrade datasets`"
] | 1,609,179,369,000 | 1,609,848,308,000 | 1,609,696,685,000 | NONE | null | When loading the NarrativeQA dataset with `load_dataset('narrativeqa')` as given in the documentation [here](https://huggingface.co/datasets/narrativeqa), I receive a cascade of exceptions, ending with
FileNotFoundError: Couldn't find file locally at narrativeqa/narrativeqa.py, or remotely at
https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/narrativeqa/narrativeqa.py or
https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/narrativeqa/narrativeqa.py
Workaround: manually copy the `narrativeqa.py` builder into my local directory with
curl https://raw.githubusercontent.com/huggingface/datasets/master/datasets/narrativeqa/narrativeqa.py -o narrativeqa.py
and load the dataset as `load_dataset('narrativeqa.py')` everything works fine. I'm on datasets v1.1.3 using Python 3.6.10. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1647/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1647/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1646/comments | https://api.github.com/repos/huggingface/datasets/issues/1646/events | https://github.com/huggingface/datasets/pull/1646 | 775,499,344 | MDExOlB1bGxSZXF1ZXN0NTQ2MTY4MTk3 | 1,646 | Add missing homepage in some dataset cards | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,175,388,000 | 1,609,769,337,000 | 1,609,769,336,000 | MEMBER | null | In some dataset cards the homepage field in the `Dataset Description` section was missing/empty | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1646/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1646/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1646",
"html_url": "https://github.com/huggingface/datasets/pull/1646",
"diff_url": "https://github.com/huggingface/datasets/pull/1646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1646.patch",
"merged_at": 1609769336000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1645/comments | https://api.github.com/repos/huggingface/datasets/issues/1645/events | https://github.com/huggingface/datasets/pull/1645 | 775,473,106 | MDExOlB1bGxSZXF1ZXN0NTQ2MTQ4OTUx | 1,645 | Rename "part-of-speech-tagging" tag in some dataset cards | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,171,749,000 | 1,610,014,094,000 | 1,610,014,093,000 | MEMBER | null | `part-of-speech-tagging` was not part of the tagging taxonomy under `structure-prediction` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1645/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1645",
"html_url": "https://github.com/huggingface/datasets/pull/1645",
"diff_url": "https://github.com/huggingface/datasets/pull/1645.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1645.patch",
"merged_at": 1610014093000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1644/comments | https://api.github.com/repos/huggingface/datasets/issues/1644/events | https://github.com/huggingface/datasets/issues/1644 | 775,375,880 | MDU6SXNzdWU3NzUzNzU4ODA= | 1,644 | HoVeR dataset fails to load | {
"login": "urikz",
"id": 1473778,
"node_id": "MDQ6VXNlcjE0NzM3Nzg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1473778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/urikz",
"html_url": "https://github.com/urikz",
"followers_url": "https://api.github.com/users/urikz/followers",
"following_url": "https://api.github.com/users/urikz/following{/other_user}",
"gists_url": "https://api.github.com/users/urikz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/urikz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/urikz/subscriptions",
"organizations_url": "https://api.github.com/users/urikz/orgs",
"repos_url": "https://api.github.com/users/urikz/repos",
"events_url": "https://api.github.com/users/urikz/events{/privacy}",
"received_events_url": "https://api.github.com/users/urikz/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hover was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `hover` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"hover\")\r\n```"
] | 1,609,158,427,000 | 1,609,785,991,000 | null | NONE | null | Hi! I'm getting an error when trying to load **HoVeR** dataset. Another one (**SQuAD**) does work for me. I'm using the latest (1.1.3) version of the library.
Steps to reproduce the error:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("hover")
Traceback (most recent call last):
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/hover/hover.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/hover/hover.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/Users/urikz/anaconda/envs/mentionmemory/lib/python3.7/site-packages/datasets/load.py", line 282, in prepare_module
combined_path, github_file_path, file_path
FileNotFoundError: Couldn't find file locally at hover/hover.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/hover/hover.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/hover/hover.py
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1644/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1644/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1643/comments | https://api.github.com/repos/huggingface/datasets/issues/1643/events | https://github.com/huggingface/datasets/issues/1643 | 775,280,046 | MDU6SXNzdWU3NzUyODAwNDY= | 1,643 | Dataset social_bias_frames 404 | {
"login": "atemate",
"id": 7501517,
"node_id": "MDQ6VXNlcjc1MDE1MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7501517?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/atemate",
"html_url": "https://github.com/atemate",
"followers_url": "https://api.github.com/users/atemate/followers",
"following_url": "https://api.github.com/users/atemate/following{/other_user}",
"gists_url": "https://api.github.com/users/atemate/gists{/gist_id}",
"starred_url": "https://api.github.com/users/atemate/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/atemate/subscriptions",
"organizations_url": "https://api.github.com/users/atemate/orgs",
"repos_url": "https://api.github.com/users/atemate/repos",
"events_url": "https://api.github.com/users/atemate/events{/privacy}",
"received_events_url": "https://api.github.com/users/atemate/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I see, master is already fixed in https://github.com/huggingface/datasets/commit/9e058f098a0919efd03a136b9b9c3dec5076f626"
] | 1,609,144,534,000 | 1,609,144,687,000 | 1,609,144,687,000 | NONE | null | ```
>>> from datasets import load_dataset
>>> dataset = load_dataset("social_bias_frames")
...
Downloading and preparing dataset social_bias_frames/default
...
~/.pyenv/versions/3.7.6/lib/python3.7/site-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag)
484 )
485 elif response is not None and response.status_code == 404:
--> 486 raise FileNotFoundError("Couldn't find file at {}".format(url))
487 raise ConnectionError("Couldn't reach {}".format(url))
488
FileNotFoundError: Couldn't find file at https://homes.cs.washington.edu/~msap/social-bias-frames/SocialBiasFrames_v2.tgz
```
[Here](https://homes.cs.washington.edu/~msap/social-bias-frames/) we find button `Download data` with the correct URL for the data: https://homes.cs.washington.edu/~msap/social-bias-frames/SBIC.v2.tgz | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1643/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1643/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1642/comments | https://api.github.com/repos/huggingface/datasets/issues/1642/events | https://github.com/huggingface/datasets/pull/1642 | 775,159,568 | MDExOlB1bGxSZXF1ZXN0NTQ1ODk1MzY1 | 1,642 | Ollie dataset | {
"login": "ontocord",
"id": 8900094,
"node_id": "MDQ6VXNlcjg5MDAwOTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8900094?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ontocord",
"html_url": "https://github.com/ontocord",
"followers_url": "https://api.github.com/users/ontocord/followers",
"following_url": "https://api.github.com/users/ontocord/following{/other_user}",
"gists_url": "https://api.github.com/users/ontocord/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ontocord/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ontocord/subscriptions",
"organizations_url": "https://api.github.com/users/ontocord/orgs",
"repos_url": "https://api.github.com/users/ontocord/repos",
"events_url": "https://api.github.com/users/ontocord/events{/privacy}",
"received_events_url": "https://api.github.com/users/ontocord/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,123,417,000 | 1,609,767,325,000 | 1,609,767,324,000 | CONTRIBUTOR | null | This is the dataset used to train the Ollie open information extraction algorithm. It has over 21M sentences. See http://knowitall.github.io/ollie/ for more details. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1642/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1642/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1642",
"html_url": "https://github.com/huggingface/datasets/pull/1642",
"diff_url": "https://github.com/huggingface/datasets/pull/1642.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1642.patch",
"merged_at": 1609767324000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1641/comments | https://api.github.com/repos/huggingface/datasets/issues/1641/events | https://github.com/huggingface/datasets/issues/1641 | 775,110,872 | MDU6SXNzdWU3NzUxMTA4NzI= | 1,641 | muchocine dataset cannot be dowloaded | {
"login": "mrm8488",
"id": 3653789,
"node_id": "MDQ6VXNlcjM2NTM3ODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3653789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mrm8488",
"html_url": "https://github.com/mrm8488",
"followers_url": "https://api.github.com/users/mrm8488/followers",
"following_url": "https://api.github.com/users/mrm8488/following{/other_user}",
"gists_url": "https://api.github.com/users/mrm8488/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mrm8488/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrm8488/subscriptions",
"organizations_url": "https://api.github.com/users/mrm8488/orgs",
"repos_url": "https://api.github.com/users/mrm8488/repos",
"events_url": "https://api.github.com/users/mrm8488/events{/privacy}",
"received_events_url": "https://api.github.com/users/mrm8488/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | null | [] | null | [
"I have encountered the same error with `v1.0.1` and `v1.0.2` on both Windows and Linux environments. However, cloning the repo and using the path to the dataset's root directory worked for me. Even after having the dataset cached - passing the path is the only way (for now) to load the dataset.\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"squad\") # Works\r\ndataset = load_dataset(\"code_search_net\", \"python\") # Error\r\ndataset = load_dataset(\"covid_qa_deepset\") # Error\r\n\r\npath = \"/huggingface/datasets/datasets/{}/\"\r\ndataset = load_dataset(path.format(\"code_search_net\"), \"python\") # Works\r\ndataset = load_dataset(path.format(\"covid_qa_deepset\")) # Works\r\n```\r\n\r\n",
"Hi @mrm8488 and @amoux!\r\n The datasets you are trying to load have been added to the library during the community sprint for v2 last month. They will be available with the v2 release!\r\nFor now, there are still a couple of solutions to load the datasets:\r\n1. As suggested by @amoux, you can clone the git repo and pass the local path to the script\r\n2. You can also install the latest (master) version of `datasets` using pip: `pip install git+https://github.com/huggingface/datasets.git@master`",
"If you don't want to clone entire `datasets` repo, just download the `muchocine` directory and pass the local path to the directory. Cheers!",
"Muchocine was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `muchocine` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"muchocine\", split=\"train\")\r\n```",
"Thanks @lhoestq "
] | 1,609,104,388,000 | 1,627,967,249,000 | 1,627,967,249,000 | CONTRIBUTOR | null | ```python
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
267 try:
--> 268 local_path = cached_path(file_path, download_config=download_config)
269 except FileNotFoundError:
7 frames
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/muchocine/muchocine.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/muchocine/muchocine.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
281 raise FileNotFoundError(
282 "Couldn't find file locally at {}, or remotely at {} or {}".format(
--> 283 combined_path, github_file_path, file_path
284 )
285 )
FileNotFoundError: Couldn't find file locally at muchocine/muchocine.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.0.2/datasets/muchocine/muchocine.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/muchocine/muchocine.py
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1641/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1641/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1640/comments | https://api.github.com/repos/huggingface/datasets/issues/1640/events | https://github.com/huggingface/datasets/pull/1640 | 774,921,836 | MDExOlB1bGxSZXF1ZXN0NTQ1NzI2NzY4 | 1,640 | Fix "'BertTokenizerFast' object has no attribute 'max_len'" | {
"login": "mflis",
"id": 15031715,
"node_id": "MDQ6VXNlcjE1MDMxNzE1",
"avatar_url": "https://avatars.githubusercontent.com/u/15031715?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mflis",
"html_url": "https://github.com/mflis",
"followers_url": "https://api.github.com/users/mflis/followers",
"following_url": "https://api.github.com/users/mflis/following{/other_user}",
"gists_url": "https://api.github.com/users/mflis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mflis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mflis/subscriptions",
"organizations_url": "https://api.github.com/users/mflis/orgs",
"repos_url": "https://api.github.com/users/mflis/repos",
"events_url": "https://api.github.com/users/mflis/events{/privacy}",
"received_events_url": "https://api.github.com/users/mflis/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,609,010,741,000 | 1,609,176,395,000 | 1,609,176,395,000 | CONTRIBUTOR | null | Tensorflow 2.3.0 gives:
FutureWarning: The `max_len` attribute has been deprecated and will be removed in a future version, use `model_max_length` instead.
Tensorflow 2.4.0 gives:
AttributeError 'BertTokenizerFast' object has no attribute 'max_len' | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1640/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1640/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1640",
"html_url": "https://github.com/huggingface/datasets/pull/1640",
"diff_url": "https://github.com/huggingface/datasets/pull/1640.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1640.patch",
"merged_at": 1609176395000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1639/comments | https://api.github.com/repos/huggingface/datasets/issues/1639/events | https://github.com/huggingface/datasets/issues/1639 | 774,903,472 | MDU6SXNzdWU3NzQ5MDM0NzI= | 1,639 | bug with sst2 in glue | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Maybe you can use nltk's treebank detokenizer ?\r\n```python\r\nfrom nltk.tokenize.treebank import TreebankWordDetokenizer\r\n\r\nTreebankWordDetokenizer().detokenize(\"it 's a charming and often affecting journey . \".split())\r\n# \"it's a charming and often affecting journey.\"\r\n```",
"I am looking for alternative file URL here instead of adding extra processing code: https://github.com/huggingface/datasets/blob/171f2bba9dd8b92006b13cf076a5bf31d67d3e69/datasets/glue/glue.py#L174",
"I don't know if there exists a detokenized version somewhere. Even the version on kaggle is tokenized"
] | 1,609,001,843,000 | 1,630,076,603,000 | null | NONE | null | Hi
I am getting very low accuracy on SST2 I investigate this and observe that for this dataset sentences are tokenized, while this is correct for the other datasets in GLUE, please see below.
Is there any alternatives I could get untokenized sentences? I am unfortunately under time pressure to report some results on this dataset. thank you for your help. @lhoestq
```
>>> a = datasets.load_dataset('glue', 'sst2', split="validation", script_version="master")
Reusing dataset glue (/julia/datasets/glue/sst2/1.0.0/7c99657241149a24692c402a5c3f34d4c9f1df5ac2e4c3759fadea38f6cb29c4)
>>> a[:10]
{'idx': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9], 'label': [1, 0, 1, 1, 0, 1, 0, 0, 1, 0], 'sentence': ["it 's a charming and often affecting journey . ", 'unflinchingly bleak and desperate ', 'allows us to hope that nolan is poised to embark a major career as a commercial yet inventive filmmaker . ', "the acting , costumes , music , cinematography and sound are all astounding given the production 's austere locales . ", "it 's slow -- very , very slow . ", 'although laced with humor and a few fanciful touches , the film is a refreshingly serious look at young women . ', 'a sometimes tedious film . ', "or doing last year 's taxes with your ex-wife . ", "you do n't have to know about music to appreciate the film 's easygoing blend of comedy and romance . ", "in exactly 89 minutes , most of which passed as slowly as if i 'd been sitting naked on an igloo , formula 51 sank from quirky to jerky to utter turkey . "]}
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1639/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1638/comments | https://api.github.com/repos/huggingface/datasets/issues/1638/events | https://github.com/huggingface/datasets/pull/1638 | 774,869,184 | MDExOlB1bGxSZXF1ZXN0NTQ1Njg5ODQ5 | 1,638 | Add id_puisi dataset | {
"login": "ilhamfp",
"id": 31740013,
"node_id": "MDQ6VXNlcjMxNzQwMDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/31740013?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ilhamfp",
"html_url": "https://github.com/ilhamfp",
"followers_url": "https://api.github.com/users/ilhamfp/followers",
"following_url": "https://api.github.com/users/ilhamfp/following{/other_user}",
"gists_url": "https://api.github.com/users/ilhamfp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ilhamfp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ilhamfp/subscriptions",
"organizations_url": "https://api.github.com/users/ilhamfp/orgs",
"repos_url": "https://api.github.com/users/ilhamfp/repos",
"events_url": "https://api.github.com/users/ilhamfp/events{/privacy}",
"received_events_url": "https://api.github.com/users/ilhamfp/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,986,515,000 | 1,609,346,057,000 | 1,609,346,057,000 | CONTRIBUTOR | null | Puisi (poem) is an Indonesian poetic form. The dataset contains 7223 Indonesian puisi with its title and author. :) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1638/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1638/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1638",
"html_url": "https://github.com/huggingface/datasets/pull/1638",
"diff_url": "https://github.com/huggingface/datasets/pull/1638.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1638.patch",
"merged_at": 1609346057000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1637/comments | https://api.github.com/repos/huggingface/datasets/issues/1637/events | https://github.com/huggingface/datasets/pull/1637 | 774,710,014 | MDExOlB1bGxSZXF1ZXN0NTQ1NTc1NTMw | 1,637 | Added `pn_summary` dataset | {
"login": "m3hrdadfi",
"id": 2601833,
"node_id": "MDQ6VXNlcjI2MDE4MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/2601833?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/m3hrdadfi",
"html_url": "https://github.com/m3hrdadfi",
"followers_url": "https://api.github.com/users/m3hrdadfi/followers",
"following_url": "https://api.github.com/users/m3hrdadfi/following{/other_user}",
"gists_url": "https://api.github.com/users/m3hrdadfi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/m3hrdadfi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/m3hrdadfi/subscriptions",
"organizations_url": "https://api.github.com/users/m3hrdadfi/orgs",
"repos_url": "https://api.github.com/users/m3hrdadfi/repos",
"events_url": "https://api.github.com/users/m3hrdadfi/events{/privacy}",
"received_events_url": "https://api.github.com/users/m3hrdadfi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"As always, I got stuck in the correct order of imports 😅\r\n@lhoestq, It's finished!",
"@lhoestq, It's done! Is there anything else that needs changes?"
] | 1,608,894,084,000 | 1,609,767,799,000 | 1,609,767,799,000 | CONTRIBUTOR | null | #1635
You did a great job with the fluent procedure regarding adding a dataset. I took the chance to add the dataset on my own. Thank you for your awesome job, and I hope this dataset found the researchers happy, specifically those interested in Persian Language (Farsi)! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1637/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1637/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1637",
"html_url": "https://github.com/huggingface/datasets/pull/1637",
"diff_url": "https://github.com/huggingface/datasets/pull/1637.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1637.patch",
"merged_at": 1609767799000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1636/comments | https://api.github.com/repos/huggingface/datasets/issues/1636/events | https://github.com/huggingface/datasets/issues/1636 | 774,574,378 | MDU6SXNzdWU3NzQ1NzQzNzg= | 1,636 | winogrande cannot be dowloaded | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"I have same issue for other datasets (`myanmar_news` in my case).\r\n\r\nA version of `datasets` runs correctly on my local machine (**without GPU**) which looking for the dataset at \r\n```\r\nhttps://raw.githubusercontent.com/huggingface/datasets/master/datasets/myanmar_news/myanmar_news.py\r\n```\r\n\r\nMeanwhile, other version runs on Colab (**with GPU**) failed to download the dataset. It try to find the dataset at `1.1.3` instead of `master` . If I disable GPU on my Colab, the code can load the dataset without any problem.\r\n\r\nMaybe there is some version missmatch with the GPU and CPU version of code for these datasets?",
"It looks like they're two different issues\r\n\r\n----------\r\n\r\nFirst for `myanmar_news`: \r\n\r\nIt must come from the way you installed `datasets`.\r\nIf you install `datasets` from source, then the `myanmar_news` script will be loaded from `master`.\r\nHowever if you install from `pip` it will get it using the version of the lib (here `1.1.3`) and `myanmar_news` is not available in `1.1.3`.\r\n\r\nThe difference between your GPU and CPU executions must be the environment, one seems to have installed `datasets` from source and not the other.\r\n\r\n----------\r\n\r\nThen for `winogrande`:\r\n\r\nThe errors says that the url https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/winogrande/winogrande.py is not reachable.\r\nHowever it works fine on my side.\r\n\r\nDoes your machine have an internet connection ? Are connections to github blocked by some sort of proxy ?\r\nCan you also try again in case github had issues when you tried the first time ?\r\n"
] | 1,608,848,902,000 | 1,609,163,629,000 | null | NONE | null | Hi,
I am getting this error when trying to run the codes on the cloud. Thank you for any suggestion and help on this @lhoestq
```
File "./finetune_trainer.py", line 318, in <module>
main()
File "./finetune_trainer.py", line 148, in main
for task in data_args.tasks]
File "./finetune_trainer.py", line 148, in <listcomp>
for task in data_args.tasks]
File "/workdir/seq2seq/data/tasks.py", line 65, in get_dataset
dataset = self.load_dataset(split=split)
File "/workdir/seq2seq/data/tasks.py", line 466, in load_dataset
return datasets.load_dataset('winogrande', 'winogrande_l', split=split)
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 487, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/winogrande/winogrande.py
yo/0 I1224 14:17:46.419031 31226 main shadow.py:122 > Traceback (most recent call last):
File "/usr/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.6/dist-packages/torch/distributed/launch.py", line 260, in <module>
main()
File "/usr/local/lib/python3.6/dist-packages/torch/distributed/launch.py", line 256, in main
cmd=cmd)
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1636/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1636/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1635/comments | https://api.github.com/repos/huggingface/datasets/issues/1635/events | https://github.com/huggingface/datasets/issues/1635 | 774,524,492 | MDU6SXNzdWU3NzQ1MjQ0OTI= | 1,635 | Persian Abstractive/Extractive Text Summarization | {
"login": "m3hrdadfi",
"id": 2601833,
"node_id": "MDQ6VXNlcjI2MDE4MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/2601833?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/m3hrdadfi",
"html_url": "https://github.com/m3hrdadfi",
"followers_url": "https://api.github.com/users/m3hrdadfi/followers",
"following_url": "https://api.github.com/users/m3hrdadfi/following{/other_user}",
"gists_url": "https://api.github.com/users/m3hrdadfi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/m3hrdadfi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/m3hrdadfi/subscriptions",
"organizations_url": "https://api.github.com/users/m3hrdadfi/orgs",
"repos_url": "https://api.github.com/users/m3hrdadfi/repos",
"events_url": "https://api.github.com/users/m3hrdadfi/events{/privacy}",
"received_events_url": "https://api.github.com/users/m3hrdadfi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [] | 1,608,832,032,000 | 1,609,773,064,000 | 1,609,773,064,000 | CONTRIBUTOR | null | Assembling datasets tailored to different tasks and languages is a precious target. This would be great to have this dataset included.
## Adding a Dataset
- **Name:** *pn-summary*
- **Description:** *A well-structured summarization dataset for the Persian language consists of 93,207 records. It is prepared for Abstractive/Extractive tasks (like cnn_dailymail for English). It can also be used in other scopes like Text Generation, Title Generation, and News Category Classification.*
- **Paper:** *https://arxiv.org/abs/2012.11204*
- **Data:** *https://github.com/hooshvare/pn-summary/#download*
- **Motivation:** *It is the first Persian abstractive/extractive Text summarization dataset (like cnn_dailymail for English)!*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1635/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1635/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1634/comments | https://api.github.com/repos/huggingface/datasets/issues/1634/events | https://github.com/huggingface/datasets/issues/1634 | 774,487,934 | MDU6SXNzdWU3NzQ0ODc5MzQ= | 1,634 | Inspecting datasets per category | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"That's interesting, can you tell me what you think would be useful to access to inspect a dataset?\r\n\r\nYou can filter them in the hub with the search by the way: https://huggingface.co/datasets have you seen it?",
"Hi @thomwolf \r\nthank you, I was not aware of this, I was looking into the data viewer linked into readme page. \r\n\r\nThis is exactly what I was looking for, but this does not work currently, please see the attached \r\nI am selecting to see all nli datasets in english and it retrieves none. thanks\r\n\r\n\r\n\r\n\r\n\r\n",
"I see 4 results for NLI in English but indeed some are not tagged yet and missing (GLUE), we will focus on that in January (cc @yjernite): https://huggingface.co/datasets?filter=task_ids:natural-language-inference,languages:en"
] | 1,608,823,594,000 | 1,610,098,084,000 | null | NONE | null | Hi
Is there a way I could get all NLI datasets/all QA datasets to get some understanding of available datasets per category? this is hard for me to inspect the datasets one by one in the webpage, thanks for the suggestions @lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1634/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1634/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1633/comments | https://api.github.com/repos/huggingface/datasets/issues/1633/events | https://github.com/huggingface/datasets/issues/1633 | 774,422,603 | MDU6SXNzdWU3NzQ0MjI2MDM= | 1,633 | social_i_qa wrong format of labels | {
"login": "ghost",
"id": 10137,
"node_id": "MDQ6VXNlcjEwMTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/10137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ghost",
"html_url": "https://github.com/ghost",
"followers_url": "https://api.github.com/users/ghost/followers",
"following_url": "https://api.github.com/users/ghost/following{/other_user}",
"gists_url": "https://api.github.com/users/ghost/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ghost/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ghost/subscriptions",
"organizations_url": "https://api.github.com/users/ghost/orgs",
"repos_url": "https://api.github.com/users/ghost/repos",
"events_url": "https://api.github.com/users/ghost/events{/privacy}",
"received_events_url": "https://api.github.com/users/ghost/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"@lhoestq, should I raise a PR for this? Just a minor change while reading labels text file",
"Sure feel free to open a PR thanks !"
] | 1,608,815,514,000 | 1,609,348,729,000 | 1,609,348,729,000 | NONE | null | Hi,
there is extra "\n" in labels of social_i_qa datasets, no big deal, but I was wondering if you could remove it to make it consistent.
so label is 'label': '1\n', not '1'
thanks
```
>>> import datasets
>>> from datasets import load_dataset
>>> dataset = load_dataset(
... 'social_i_qa')
cahce dir /julia/cache/datasets
Downloading: 4.72kB [00:00, 3.52MB/s]
cahce dir /julia/cache/datasets
Downloading: 2.19kB [00:00, 1.81MB/s]
Using custom data configuration default
Reusing dataset social_i_qa (/julia/datasets/social_i_qa/default/0.1.0/4a4190cc2d2482d43416c2167c0c5dccdd769d4482e84893614bd069e5c3ba06)
>>> dataset['train'][0]
{'answerA': 'like attending', 'answerB': 'like staying home', 'answerC': 'a good friend to have', 'context': 'Cameron decided to have a barbecue and gathered her friends together.', 'label': '1\n', 'question': 'How would Others feel as a result?'}
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1633/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1633/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1632/comments | https://api.github.com/repos/huggingface/datasets/issues/1632/events | https://github.com/huggingface/datasets/issues/1632 | 774,388,625 | MDU6SXNzdWU3NzQzODg2MjU= | 1,632 | SICK dataset | {
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [] | 1,608,813,614,000 | 1,612,540,165,000 | 1,612,540,165,000 | CONTRIBUTOR | null | Hi, this would be great to have this dataset included. I might be missing something, but I could not find it in the list of already included datasets. Thank you.
## Adding a Dataset
- **Name:** SICK
- **Description:** SICK consists of about 10,000 English sentence pairs that include many examples of the lexical, syntactic, and semantic phenomena.
- **Paper:** https://www.aclweb.org/anthology/L14-1314/
- **Data:** http://marcobaroni.org/composes/sick.html
- **Motivation:** This dataset is well-known in the NLP community used for recognizing entailment between sentences.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1632/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1632/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1631/comments | https://api.github.com/repos/huggingface/datasets/issues/1631/events | https://github.com/huggingface/datasets/pull/1631 | 774,349,222 | MDExOlB1bGxSZXF1ZXN0NTQ1Mjc5MTE2 | 1,631 | Update README.md | {
"login": "savasy",
"id": 6584825,
"node_id": "MDQ6VXNlcjY1ODQ4MjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6584825?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/savasy",
"html_url": "https://github.com/savasy",
"followers_url": "https://api.github.com/users/savasy/followers",
"following_url": "https://api.github.com/users/savasy/following{/other_user}",
"gists_url": "https://api.github.com/users/savasy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/savasy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/savasy/subscriptions",
"organizations_url": "https://api.github.com/users/savasy/orgs",
"repos_url": "https://api.github.com/users/savasy/repos",
"events_url": "https://api.github.com/users/savasy/events{/privacy}",
"received_events_url": "https://api.github.com/users/savasy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,810,352,000 | 1,609,176,941,000 | 1,609,175,764,000 | CONTRIBUTOR | null | I made small change for citation | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1631/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1631/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1631",
"html_url": "https://github.com/huggingface/datasets/pull/1631",
"diff_url": "https://github.com/huggingface/datasets/pull/1631.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1631.patch",
"merged_at": 1609175764000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1630/comments | https://api.github.com/repos/huggingface/datasets/issues/1630/events | https://github.com/huggingface/datasets/issues/1630 | 774,332,129 | MDU6SXNzdWU3NzQzMzIxMjk= | 1,630 | Adding UKP Argument Aspect Similarity Corpus | {
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"Adding a link to the guide on adding a dataset if someone want to give it a try: https://github.com/huggingface/datasets#add-a-new-dataset-to-the-hub\r\n\r\nwe should add this guide to the issue template @lhoestq ",
"thanks @thomwolf , this is added now. The template is correct, sorry my mistake not to include it. "
] | 1,608,807,691,000 | 1,608,809,418,000 | null | CONTRIBUTOR | null | Hi, this would be great to have this dataset included.
## Adding a Dataset
- **Name:** UKP Argument Aspect Similarity Corpus
- **Description:** The UKP Argument Aspect Similarity Corpus (UKP ASPECT) includes 3,595 sentence pairs over 28 controversial topics. Each sentence pair was annotated via crowdsourcing as either “high similarity”, “some similarity”, “no similarity” or “not related” with respect to the topic.
- **Paper:** https://www.aclweb.org/anthology/P19-1054/
- **Data:** https://tudatalib.ulb.tu-darmstadt.de/handle/tudatalib/1998
- **Motivation:** this is one of the datasets currently used frequently in recent adapter papers like https://arxiv.org/pdf/2005.00247.pdf
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Thank you | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1630/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1630/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1629/comments | https://api.github.com/repos/huggingface/datasets/issues/1629/events | https://github.com/huggingface/datasets/pull/1629 | 774,255,716 | MDExOlB1bGxSZXF1ZXN0NTQ1MjAwNTQ3 | 1,629 | add wongnai_reviews test set labels | {
"login": "cstorm125",
"id": 15519308,
"node_id": "MDQ6VXNlcjE1NTE5MzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/15519308?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cstorm125",
"html_url": "https://github.com/cstorm125",
"followers_url": "https://api.github.com/users/cstorm125/followers",
"following_url": "https://api.github.com/users/cstorm125/following{/other_user}",
"gists_url": "https://api.github.com/users/cstorm125/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cstorm125/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cstorm125/subscriptions",
"organizations_url": "https://api.github.com/users/cstorm125/orgs",
"repos_url": "https://api.github.com/users/cstorm125/repos",
"events_url": "https://api.github.com/users/cstorm125/events{/privacy}",
"received_events_url": "https://api.github.com/users/cstorm125/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,796,951,000 | 1,609,176,219,000 | 1,609,176,219,000 | CONTRIBUTOR | null | - add test set labels provided by @ekapolc
- refactor `star_rating` to a `datasets.features.ClassLabel` field | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1629/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1629/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1629",
"html_url": "https://github.com/huggingface/datasets/pull/1629",
"diff_url": "https://github.com/huggingface/datasets/pull/1629.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1629.patch",
"merged_at": 1609176219000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1628/comments | https://api.github.com/repos/huggingface/datasets/issues/1628/events | https://github.com/huggingface/datasets/pull/1628 | 774,091,411 | MDExOlB1bGxSZXF1ZXN0NTQ1MDY5NTAy | 1,628 | made suggested changes to hate-speech-and-offensive-language | {
"login": "MisbahKhan789",
"id": 15351802,
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MisbahKhan789",
"html_url": "https://github.com/MisbahKhan789",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,765,932,000 | 1,609,150,280,000 | 1,609,150,280,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1628/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1628/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1628",
"html_url": "https://github.com/huggingface/datasets/pull/1628",
"diff_url": "https://github.com/huggingface/datasets/pull/1628.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1628.patch",
"merged_at": 1609150280000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1627/comments | https://api.github.com/repos/huggingface/datasets/issues/1627/events | https://github.com/huggingface/datasets/issues/1627 | 773,960,255 | MDU6SXNzdWU3NzM5NjAyNTU= | 1,627 | `Dataset.map` disable progress bar | {
"login": "Nickil21",
"id": 8767964,
"node_id": "MDQ6VXNlcjg3Njc5NjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8767964?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nickil21",
"html_url": "https://github.com/Nickil21",
"followers_url": "https://api.github.com/users/Nickil21/followers",
"following_url": "https://api.github.com/users/Nickil21/following{/other_user}",
"gists_url": "https://api.github.com/users/Nickil21/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nickil21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nickil21/subscriptions",
"organizations_url": "https://api.github.com/users/Nickil21/orgs",
"repos_url": "https://api.github.com/users/Nickil21/repos",
"events_url": "https://api.github.com/users/Nickil21/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nickil21/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Progress bar can be disabled like this:\r\n```python\r\nfrom datasets.utils.logging import set_verbosity_error\r\nset_verbosity_error()\r\n```\r\n\r\nThere is this line in `Dataset.map`:\r\n```python\r\nnot_verbose = bool(logger.getEffectiveLevel() > WARNING)\r\n```\r\n\r\nSo any logging level higher than `WARNING` turns off the progress bar."
] | 1,608,746,022,000 | 1,609,012,656,000 | 1,609,012,637,000 | NONE | null | I can't find anything to turn off the `tqdm` progress bars while running a preprocessing function using `Dataset.map`. I want to do akin to `disable_tqdm=True` in the case of `transformers`. Is there something like that? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1627/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1627/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1626/comments | https://api.github.com/repos/huggingface/datasets/issues/1626/events | https://github.com/huggingface/datasets/pull/1626 | 773,840,368 | MDExOlB1bGxSZXF1ZXN0NTQ0ODYxMDE4 | 1,626 | Fix dataset_dict.shuffle with single seed | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,734,016,000 | 1,609,754,404,000 | 1,609,754,403,000 | MEMBER | null | Fix #1610
I added support for single integer used in `DatasetDict.shuffle`. Previously only a dictionary of seed was allowed.
Moreover I added the missing `seed` parameter. Previously only `seeds` was allowed. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1626/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1626/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1626",
"html_url": "https://github.com/huggingface/datasets/pull/1626",
"diff_url": "https://github.com/huggingface/datasets/pull/1626.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1626.patch",
"merged_at": 1609754403000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1625/comments | https://api.github.com/repos/huggingface/datasets/issues/1625/events | https://github.com/huggingface/datasets/pull/1625 | 773,771,596 | MDExOlB1bGxSZXF1ZXN0NTQ0Nzk4MDM1 | 1,625 | Fixed bug in the shape property | {
"login": "noaonoszko",
"id": 47183162,
"node_id": "MDQ6VXNlcjQ3MTgzMTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/47183162?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/noaonoszko",
"html_url": "https://github.com/noaonoszko",
"followers_url": "https://api.github.com/users/noaonoszko/followers",
"following_url": "https://api.github.com/users/noaonoszko/following{/other_user}",
"gists_url": "https://api.github.com/users/noaonoszko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/noaonoszko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/noaonoszko/subscriptions",
"organizations_url": "https://api.github.com/users/noaonoszko/orgs",
"repos_url": "https://api.github.com/users/noaonoszko/repos",
"events_url": "https://api.github.com/users/noaonoszko/events{/privacy}",
"received_events_url": "https://api.github.com/users/noaonoszko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,730,401,000 | 1,609,629,772,000 | 1,608,732,793,000 | CONTRIBUTOR | null | Fix to the bug reported in issue #1622. Just replaced `return tuple(self._indices.num_rows, self._data.num_columns)` by `return (self._indices.num_rows, self._data.num_columns)`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1625/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1625/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1625",
"html_url": "https://github.com/huggingface/datasets/pull/1625",
"diff_url": "https://github.com/huggingface/datasets/pull/1625.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1625.patch",
"merged_at": 1608732793000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1624 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1624/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1624/comments | https://api.github.com/repos/huggingface/datasets/issues/1624/events | https://github.com/huggingface/datasets/issues/1624 | 773,669,700 | MDU6SXNzdWU3NzM2Njk3MDA= | 1,624 | Cannot download ade_corpus_v2 | {
"login": "him1411",
"id": 20259310,
"node_id": "MDQ6VXNlcjIwMjU5MzEw",
"avatar_url": "https://avatars.githubusercontent.com/u/20259310?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/him1411",
"html_url": "https://github.com/him1411",
"followers_url": "https://api.github.com/users/him1411/followers",
"following_url": "https://api.github.com/users/him1411/following{/other_user}",
"gists_url": "https://api.github.com/users/him1411/gists{/gist_id}",
"starred_url": "https://api.github.com/users/him1411/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/him1411/subscriptions",
"organizations_url": "https://api.github.com/users/him1411/orgs",
"repos_url": "https://api.github.com/users/him1411/repos",
"events_url": "https://api.github.com/users/him1411/events{/privacy}",
"received_events_url": "https://api.github.com/users/him1411/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @him1411, the dataset you are trying to load has been added during the community sprint and has not been released yet. It will be available with the v2 of `datasets`.\r\nFor now, you should be able to load the datasets after installing the latest (master) version of `datasets` using pip:\r\n`pip install git+https://github.com/huggingface/datasets.git@master`",
"`ade_corpus_v2` was added recently, that's why it wasn't available yet.\r\n\r\nTo load it you can just update `datasets`\r\n```\r\npip install --upgrade datasets\r\n```\r\n\r\nand then you can load `ade_corpus_v2` with\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"ade_corpus_v2\", \"Ade_corpos_v2_drug_ade_relation\")\r\n```\r\n\r\n(looks like there is a typo in the configuration name, we'll fix it for the v2.0 release of `datasets` soon)"
] | 1,608,721,094,000 | 1,627,967,334,000 | 1,627,967,334,000 | NONE | null | I tried this to get the dataset following this url : https://huggingface.co/datasets/ade_corpus_v2
but received this error :
`Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/ade_corpus_v2/ade_corpus_v2.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 278, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 486, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/ade_corpus_v2/ade_corpus_v2.py
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/opt/anaconda3/lib/python3.7/site-packages/datasets/load.py", line 282, in prepare_module
combined_path, github_file_path, file_path
FileNotFoundError: Couldn't find file locally at ade_corpus_v2/ade_corpus_v2.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/ade_corpus_v2/ade_corpus_v2.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/ade_corpus_v2/ade_corpus_v2.py`
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1624/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1624/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1623/comments | https://api.github.com/repos/huggingface/datasets/issues/1623/events | https://github.com/huggingface/datasets/pull/1623 | 772,950,710 | MDExOlB1bGxSZXF1ZXN0NTQ0MTI2ODQ4 | 1,623 | Add CLIMATE-FEVER dataset | {
"login": "tdiggelm",
"id": 1658969,
"node_id": "MDQ6VXNlcjE2NTg5Njk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1658969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tdiggelm",
"html_url": "https://github.com/tdiggelm",
"followers_url": "https://api.github.com/users/tdiggelm/followers",
"following_url": "https://api.github.com/users/tdiggelm/following{/other_user}",
"gists_url": "https://api.github.com/users/tdiggelm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tdiggelm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tdiggelm/subscriptions",
"organizations_url": "https://api.github.com/users/tdiggelm/orgs",
"repos_url": "https://api.github.com/users/tdiggelm/repos",
"events_url": "https://api.github.com/users/tdiggelm/events{/privacy}",
"received_events_url": "https://api.github.com/users/tdiggelm/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thank you @lhoestq for your comments! 😄 I added your suggested changes, ran the tests and regenerated `dataset_infos.json` and `dummy_data`."
] | 1,608,644,045,000 | 1,608,659,633,000 | 1,608,659,633,000 | CONTRIBUTOR | null | As suggested by @SBrandeis , fresh PR that adds CLIMATE-FEVER. Replaces PR #1579.
---
A dataset adopting the FEVER methodology that consists of 1,535 real-world claims regarding climate-change collected on the internet. Each claim is accompanied by five manually annotated evidence sentences retrieved from the English Wikipedia that support, refute or do not give enough information to validate the claim totalling in 7,675 claim-evidence pairs. The dataset features challenging claims that relate multiple facets and disputed cases of claims where both supporting and refuting evidence are present.
More information can be found at:
* Homepage: http://climatefever.ai
* Paper: https://arxiv.org/abs/2012.00614 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1623/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1623",
"html_url": "https://github.com/huggingface/datasets/pull/1623",
"diff_url": "https://github.com/huggingface/datasets/pull/1623.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1623.patch",
"merged_at": 1608659633000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1622/comments | https://api.github.com/repos/huggingface/datasets/issues/1622/events | https://github.com/huggingface/datasets/issues/1622 | 772,940,768 | MDU6SXNzdWU3NzI5NDA3Njg= | 1,622 | Can't call shape on the output of select() | {
"login": "noaonoszko",
"id": 47183162,
"node_id": "MDQ6VXNlcjQ3MTgzMTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/47183162?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/noaonoszko",
"html_url": "https://github.com/noaonoszko",
"followers_url": "https://api.github.com/users/noaonoszko/followers",
"following_url": "https://api.github.com/users/noaonoszko/following{/other_user}",
"gists_url": "https://api.github.com/users/noaonoszko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/noaonoszko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/noaonoszko/subscriptions",
"organizations_url": "https://api.github.com/users/noaonoszko/orgs",
"repos_url": "https://api.github.com/users/noaonoszko/repos",
"events_url": "https://api.github.com/users/noaonoszko/events{/privacy}",
"received_events_url": "https://api.github.com/users/noaonoszko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Indeed that's a typo, do you want to open a PR to fix it?",
"Yes, created a PR"
] | 1,608,643,120,000 | 1,608,730,633,000 | 1,608,730,632,000 | CONTRIBUTOR | null | I get the error `TypeError: tuple expected at most 1 argument, got 2` when calling `shape` on the output of `select()`.
It's line 531 in shape in arrow_dataset.py that causes the problem:
``return tuple(self._indices.num_rows, self._data.num_columns)``
This makes sense, since `tuple(num1, num2)` is not a valid call.
Full code to reproduce:
```python
dataset = load_dataset("cnn_dailymail", "3.0.0")
train_set = dataset["train"]
t = train_set.select(range(10))
print(t.shape) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1622/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1622/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1621/comments | https://api.github.com/repos/huggingface/datasets/issues/1621/events | https://github.com/huggingface/datasets/pull/1621 | 772,940,417 | MDExOlB1bGxSZXF1ZXN0NTQ0MTE4MTAz | 1,621 | updated dutch_social.py for loading jsonl (lines instead of list) files | {
"login": "skyprince999",
"id": 9033954,
"node_id": "MDQ6VXNlcjkwMzM5NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9033954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyprince999",
"html_url": "https://github.com/skyprince999",
"followers_url": "https://api.github.com/users/skyprince999/followers",
"following_url": "https://api.github.com/users/skyprince999/following{/other_user}",
"gists_url": "https://api.github.com/users/skyprince999/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyprince999/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyprince999/subscriptions",
"organizations_url": "https://api.github.com/users/skyprince999/orgs",
"repos_url": "https://api.github.com/users/skyprince999/repos",
"events_url": "https://api.github.com/users/skyprince999/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyprince999/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,643,091,000 | 1,608,724,311,000 | 1,608,724,311,000 | CONTRIBUTOR | null | the data_loader is modified to load files on the fly. Earlier it was reading the entire file and then processing the records
Pls refer to previous PR #1321 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1621/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1621/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1621",
"html_url": "https://github.com/huggingface/datasets/pull/1621",
"diff_url": "https://github.com/huggingface/datasets/pull/1621.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1621.patch",
"merged_at": 1608724311000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1620/comments | https://api.github.com/repos/huggingface/datasets/issues/1620/events | https://github.com/huggingface/datasets/pull/1620 | 772,620,056 | MDExOlB1bGxSZXF1ZXN0NTQzODUxNTY3 | 1,620 | Adding myPOS2017 dataset | {
"login": "hungluumfc",
"id": 69781878,
"node_id": "MDQ6VXNlcjY5NzgxODc4",
"avatar_url": "https://avatars.githubusercontent.com/u/69781878?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hungluumfc",
"html_url": "https://github.com/hungluumfc",
"followers_url": "https://api.github.com/users/hungluumfc/followers",
"following_url": "https://api.github.com/users/hungluumfc/following{/other_user}",
"gists_url": "https://api.github.com/users/hungluumfc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hungluumfc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hungluumfc/subscriptions",
"organizations_url": "https://api.github.com/users/hungluumfc/orgs",
"repos_url": "https://api.github.com/users/hungluumfc/repos",
"events_url": "https://api.github.com/users/hungluumfc/events{/privacy}",
"received_events_url": "https://api.github.com/users/hungluumfc/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"I've updated the code and Readme to reflect your comments.\r\nThank you very much,",
"looks like this PR includes changes about many other files than the ones for myPOS2017\r\n\r\nCould you open another branch and another PR please ?\r\n(or fix this branch)",
"Hi @hungluumfc ! Have you had a chance to fix this PR so that it only includes the changes for `mypos` ? \r\n\r\nFeel free to ping me if you have questions or if I can help :) "
] | 1,608,609,895,000 | 1,611,915,817,000 | null | NONE | null | myPOS Corpus (Myanmar Part-of-Speech Corpus) for Myanmar language NLP Research and Developments | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1620/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1620/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1620",
"html_url": "https://github.com/huggingface/datasets/pull/1620",
"diff_url": "https://github.com/huggingface/datasets/pull/1620.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1620.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1619/comments | https://api.github.com/repos/huggingface/datasets/issues/1619/events | https://github.com/huggingface/datasets/pull/1619 | 772,508,558 | MDExOlB1bGxSZXF1ZXN0NTQzNzYyMTUw | 1,619 | data loader for reading comprehension task | {
"login": "songfeng",
"id": 2062185,
"node_id": "MDQ6VXNlcjIwNjIxODU=",
"avatar_url": "https://avatars.githubusercontent.com/u/2062185?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/songfeng",
"html_url": "https://github.com/songfeng",
"followers_url": "https://api.github.com/users/songfeng/followers",
"following_url": "https://api.github.com/users/songfeng/following{/other_user}",
"gists_url": "https://api.github.com/users/songfeng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/songfeng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/songfeng/subscriptions",
"organizations_url": "https://api.github.com/users/songfeng/orgs",
"repos_url": "https://api.github.com/users/songfeng/repos",
"events_url": "https://api.github.com/users/songfeng/events{/privacy}",
"received_events_url": "https://api.github.com/users/songfeng/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Thank you for all the feedback! I have updated the dummy data with a zip under 30KB, which needs to include at least one data instance from both document domain and dialog domain. Please let me know if it is still too big. Thanks!",
"Thank you again for the feedback! I am not too sure what the preferable style for data instance in readme, but still added my edits. Thanks!"
] | 1,608,590,434,000 | 1,609,151,573,000 | 1,609,151,573,000 | CONTRIBUTOR | null | added doc2dial data loader and dummy data for reading comprehension task. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1619/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1619",
"html_url": "https://github.com/huggingface/datasets/pull/1619",
"diff_url": "https://github.com/huggingface/datasets/pull/1619.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1619.patch",
"merged_at": 1609151573000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1618/comments | https://api.github.com/repos/huggingface/datasets/issues/1618/events | https://github.com/huggingface/datasets/issues/1618 | 772,248,730 | MDU6SXNzdWU3NzIyNDg3MzA= | 1,618 | Can't filter language:EN on https://huggingface.co/datasets | {
"login": "davidefiocco",
"id": 4547987,
"node_id": "MDQ6VXNlcjQ1NDc5ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4547987?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidefiocco",
"html_url": "https://github.com/davidefiocco",
"followers_url": "https://api.github.com/users/davidefiocco/followers",
"following_url": "https://api.github.com/users/davidefiocco/following{/other_user}",
"gists_url": "https://api.github.com/users/davidefiocco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/davidefiocco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/davidefiocco/subscriptions",
"organizations_url": "https://api.github.com/users/davidefiocco/orgs",
"repos_url": "https://api.github.com/users/davidefiocco/repos",
"events_url": "https://api.github.com/users/davidefiocco/events{/privacy}",
"received_events_url": "https://api.github.com/users/davidefiocco/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"cc'ing @mapmeld ",
"Full language list is now deployed to https://huggingface.co/datasets ! Recommend close",
"Cool @mapmeld ! My 2 cents (for a next iteration), it would be cool to have a small search widget in the filter dropdown as you have a ton of languages now here! Closing this in the meantime."
] | 1,608,564,203,000 | 1,608,657,420,000 | 1,608,657,369,000 | NONE | null | When visiting https://huggingface.co/datasets, I don't see an obvious way to filter only English datasets. This is unexpected for me, am I missing something? I'd expect English to be selectable in the language widget. This problem reproduced on Mozilla Firefox and MS Edge:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1618/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1617/comments | https://api.github.com/repos/huggingface/datasets/issues/1617/events | https://github.com/huggingface/datasets/pull/1617 | 772,084,764 | MDExOlB1bGxSZXF1ZXN0NTQzNDE5MTM5 | 1,617 | cifar10 initial commit | {
"login": "czabo",
"id": 75574105,
"node_id": "MDQ6VXNlcjc1NTc0MTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/75574105?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/czabo",
"html_url": "https://github.com/czabo",
"followers_url": "https://api.github.com/users/czabo/followers",
"following_url": "https://api.github.com/users/czabo/following{/other_user}",
"gists_url": "https://api.github.com/users/czabo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/czabo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/czabo/subscriptions",
"organizations_url": "https://api.github.com/users/czabo/orgs",
"repos_url": "https://api.github.com/users/czabo/repos",
"events_url": "https://api.github.com/users/czabo/events{/privacy}",
"received_events_url": "https://api.github.com/users/czabo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Yee a Computer Vision dataset!",
"Yep, the first one ! Thank @czabo "
] | 1,608,549,530,000 | 1,608,632,285,000 | 1,608,631,888,000 | CONTRIBUTOR | null | CIFAR-10 dataset. Didn't add the tagging since there are no vision related tags. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1617/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1617/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1617",
"html_url": "https://github.com/huggingface/datasets/pull/1617",
"diff_url": "https://github.com/huggingface/datasets/pull/1617.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1617.patch",
"merged_at": 1608631888000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1616/comments | https://api.github.com/repos/huggingface/datasets/issues/1616/events | https://github.com/huggingface/datasets/pull/1616 | 772,074,229 | MDExOlB1bGxSZXF1ZXN0NTQzNDEwNDc1 | 1,616 | added TurkishMovieSentiment dataset | {
"login": "yavuzKomecoglu",
"id": 5150963,
"node_id": "MDQ6VXNlcjUxNTA5NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5150963?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yavuzKomecoglu",
"html_url": "https://github.com/yavuzKomecoglu",
"followers_url": "https://api.github.com/users/yavuzKomecoglu/followers",
"following_url": "https://api.github.com/users/yavuzKomecoglu/following{/other_user}",
"gists_url": "https://api.github.com/users/yavuzKomecoglu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yavuzKomecoglu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yavuzKomecoglu/subscriptions",
"organizations_url": "https://api.github.com/users/yavuzKomecoglu/orgs",
"repos_url": "https://api.github.com/users/yavuzKomecoglu/repos",
"events_url": "https://api.github.com/users/yavuzKomecoglu/events{/privacy}",
"received_events_url": "https://api.github.com/users/yavuzKomecoglu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"> I just generated the dataset_infos.json file\r\n> \r\n> Thanks for adding this one !\r\n\r\nThank you very much for your support."
] | 1,608,548,596,000 | 1,608,793,721,000 | 1,608,742,206,000 | CONTRIBUTOR | null | This PR adds the **TurkishMovieSentiment: This dataset contains turkish movie reviews.**
- **Homepage:** [https://www.kaggle.com/mustfkeskin/turkish-movie-sentiment-analysis-dataset/tasks](https://www.kaggle.com/mustfkeskin/turkish-movie-sentiment-analysis-dataset/tasks)
- **Point of Contact:** [Mustafa Keskin](https://www.linkedin.com/in/mustfkeskin/) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1616/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1616/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1616",
"html_url": "https://github.com/huggingface/datasets/pull/1616",
"diff_url": "https://github.com/huggingface/datasets/pull/1616.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1616.patch",
"merged_at": 1608742206000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1615/comments | https://api.github.com/repos/huggingface/datasets/issues/1615/events | https://github.com/huggingface/datasets/issues/1615 | 771,641,088 | MDU6SXNzdWU3NzE2NDEwODg= | 1,615 | Bug: Can't download TriviaQA with `load_dataset` - custom `cache_dir` | {
"login": "SapirWeissbuch",
"id": 44585792,
"node_id": "MDQ6VXNlcjQ0NTg1Nzky",
"avatar_url": "https://avatars.githubusercontent.com/u/44585792?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SapirWeissbuch",
"html_url": "https://github.com/SapirWeissbuch",
"followers_url": "https://api.github.com/users/SapirWeissbuch/followers",
"following_url": "https://api.github.com/users/SapirWeissbuch/following{/other_user}",
"gists_url": "https://api.github.com/users/SapirWeissbuch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SapirWeissbuch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SapirWeissbuch/subscriptions",
"organizations_url": "https://api.github.com/users/SapirWeissbuch/orgs",
"repos_url": "https://api.github.com/users/SapirWeissbuch/repos",
"events_url": "https://api.github.com/users/SapirWeissbuch/events{/privacy}",
"received_events_url": "https://api.github.com/users/SapirWeissbuch/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Hi @SapirWeissbuch,\r\nWhen you are saying it freezes, at that time it is unzipping the file from the zip file it downloaded. Since it's a very heavy file it'll take some time. It was taking ~11GB after unzipping when it started reading examples for me. Hope that helps!\r\n\r\n",
"Hi @bhavitvyamalik \r\nThanks for the reply!\r\nActually I let it run for 30 minutes before I killed the process. In this time, 30GB were extracted (much more than 11GB), I checked the size of the destination directory.\r\n\r\nWhat version of Datasets are you using?\r\n",
"I'm using datasets version: 1.1.3. I think you should drop `cache_dir` and use only\r\n`dataset = datasets.load_dataset(\"trivia_qa\", \"rc\")`\r\n\r\nTried that on colab and it's working there too\r\n\r\n",
"Train, Validation, and Test splits contain 138384, 18669, and 17210 samples respectively. It takes some time to read the samples. Even in your colab notebook it was reading the samples before you killed the process. Let me know if it works now!",
"Hi, it works on colab but it still doesn't work on my computer, same problem as before - overly large and long extraction process.\r\nI have to use a custom 'cache_dir' because I don't have any space left in my home directory where it is defaulted, maybe this could be the issue?",
"I tried running this again - More details of the problem:\r\nCode:\r\n```\r\ndatasets.load_dataset(\"trivia_qa\", \"rc\", cache_dir=\"/path/to/cache\")\r\n```\r\n\r\nThe output:\r\n```\r\nDownloading and preparing dataset trivia_qa/rc (download: 2.48 GiB, generated: 14.92 GiB, post-processed: Unknown size, total: 17.40 GiB) to path/to/cache/trivia_qa/rc/1.1.0/e734e28133f4d9a353af322aa52b9f266f6f27cbf2f072690a1694e577546b0d... \r\nDownloading: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.67G/2.67G [03:38<00:00, 12.2MB/s]\r\n\r\n```\r\nThe process continues (no progress bar is visible).\r\nI tried `du -sh .` in `path/to/cache`, and the size keeps increasing, reached 35G before I killed the process.\r\n\r\nGoogle Colab with custom `cache_dir` has same issue.\r\nhttps://colab.research.google.com/drive/1nn1Lw02GhfGFylzbS2j6yksGjPo7kkN-?usp=sharing#scrollTo=2G2O0AeNIXan",
"1) You can clear the huggingface folder in your `.cache` directory to use default directory for datasets. Speed of extraction and loading of samples depends a lot on your machine's configurations too.\r\n\r\n2) I tried on colab `dataset = datasets.load_dataset(\"trivia_qa\", \"rc\", cache_dir = \"./datasets\")`. After memory usage reached around 42GB (starting from 32GB used already), the dataset was loaded in the memory. Even Your colab notebook shows \r\n\r\nwhich means it's loaded now.",
"Facing the same issue.\r\nI am able to download datasets without `cache_dir`, however, when I specify the `cache_dir`, the process hangs indefinitely after partial download. \r\nTried for `data = load_dataset(\"cnn_dailymail\", \"3.0.0\")`",
"Hi @ashutoshml,\r\nI tried this and it worked for me:\r\n`data = load_dataset(\"cnn_dailymail\", \"3.0.0\", cache_dir=\"./dummy\")`\r\n\r\nI'm using datasets==1.8.0. It took around 3-4 mins for dataset to unpack and start loading examples.",
"Ok. I waited for 20-30 mins, and it still is stuck.\r\nI am using datasets==1.8.0.\r\n\r\nIs there anyway to check what is happening? like a` --verbose` flag?\r\n\r\n\r\n"
] | 1,608,485,258,000 | 1,624,626,693,000 | null | NONE | null | Hello,
I'm having issue downloading TriviaQA dataset with `load_dataset`.
## Environment info
- `datasets` version: 1.1.3
- Platform: Linux-4.19.129-aufs-1-x86_64-with-debian-10.1
- Python version: 3.7.3
## The code I'm running:
```python
import datasets
dataset = datasets.load_dataset("trivia_qa", "rc", cache_dir = "./datasets")
```
## The output:
1. Download begins:
```
Downloading and preparing dataset trivia_qa/rc (download: 2.48 GiB, generated: 14.92 GiB, post-processed: Unknown size, total: 17.40 GiB) to /cs/labs/gabis/sapirweissbuch/tr
ivia_qa/rc/1.1.0/e734e28133f4d9a353af322aa52b9f266f6f27cbf2f072690a1694e577546b0d...
Downloading: 17%|███████████████████▉ | 446M/2.67G [00:37<04:45, 7.77MB/s]
```
2. 100% is reached
3. It got stuck here for about an hour, and added additional 30G of data to "./datasets" directory. I killed the process eventually.
A similar issue can be observed in Google Colab:
https://colab.research.google.com/drive/1nn1Lw02GhfGFylzbS2j6yksGjPo7kkN-?usp=sharing
## Expected behaviour:
The dataset "TriviaQA" should be successfully downloaded.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1615/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1615/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1613/comments | https://api.github.com/repos/huggingface/datasets/issues/1613/events | https://github.com/huggingface/datasets/pull/1613 | 771,577,050 | MDExOlB1bGxSZXF1ZXN0NTQzMDYwNzEx | 1,613 | Add id_clickbait | {
"login": "cahya-wirawan",
"id": 7669893,
"node_id": "MDQ6VXNlcjc2Njk4OTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7669893?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cahya-wirawan",
"html_url": "https://github.com/cahya-wirawan",
"followers_url": "https://api.github.com/users/cahya-wirawan/followers",
"following_url": "https://api.github.com/users/cahya-wirawan/following{/other_user}",
"gists_url": "https://api.github.com/users/cahya-wirawan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cahya-wirawan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cahya-wirawan/subscriptions",
"organizations_url": "https://api.github.com/users/cahya-wirawan/orgs",
"repos_url": "https://api.github.com/users/cahya-wirawan/repos",
"events_url": "https://api.github.com/users/cahya-wirawan/events{/privacy}",
"received_events_url": "https://api.github.com/users/cahya-wirawan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,467,089,000 | 1,608,659,127,000 | 1,608,659,127,000 | CONTRIBUTOR | null | This is the CLICK-ID dataset, a collection of annotated clickbait Indonesian news headlines that was collected from 12 local online news | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1613/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1613/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1613",
"html_url": "https://github.com/huggingface/datasets/pull/1613",
"diff_url": "https://github.com/huggingface/datasets/pull/1613.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1613.patch",
"merged_at": 1608659127000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1612/comments | https://api.github.com/repos/huggingface/datasets/issues/1612/events | https://github.com/huggingface/datasets/pull/1612 | 771,558,160 | MDExOlB1bGxSZXF1ZXN0NTQzMDQ3NjQ1 | 1,612 | Adding wiki asp dataset as new PR | {
"login": "katnoria",
"id": 7674948,
"node_id": "MDQ6VXNlcjc2NzQ5NDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/7674948?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/katnoria",
"html_url": "https://github.com/katnoria",
"followers_url": "https://api.github.com/users/katnoria/followers",
"following_url": "https://api.github.com/users/katnoria/following{/other_user}",
"gists_url": "https://api.github.com/users/katnoria/gists{/gist_id}",
"starred_url": "https://api.github.com/users/katnoria/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/katnoria/subscriptions",
"organizations_url": "https://api.github.com/users/katnoria/orgs",
"repos_url": "https://api.github.com/users/katnoria/repos",
"events_url": "https://api.github.com/users/katnoria/events{/privacy}",
"received_events_url": "https://api.github.com/users/katnoria/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,459,908,000 | 1,608,560,013,000 | 1,608,560,013,000 | CONTRIBUTOR | null | Hi @lhoestq, Adding wiki asp as new branch because #1539 has other commits. This version has dummy data for each domain <20/30KB. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1612/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1612/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1612",
"html_url": "https://github.com/huggingface/datasets/pull/1612",
"diff_url": "https://github.com/huggingface/datasets/pull/1612.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1612.patch",
"merged_at": 1608560013000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1611/comments | https://api.github.com/repos/huggingface/datasets/issues/1611/events | https://github.com/huggingface/datasets/issues/1611 | 771,486,456 | MDU6SXNzdWU3NzE0ODY0NTY= | 1,611 | shuffle with torch generator | {
"login": "rabeehkarimimahabadi",
"id": 73364383,
"node_id": "MDQ6VXNlcjczMzY0Mzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehkarimimahabadi",
"html_url": "https://github.com/rabeehkarimimahabadi",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehkarimimahabadi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehkarimimahabadi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehkarimimahabadi/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehkarimimahabadi/orgs",
"repos_url": "https://api.github.com/users/rabeehkarimimahabadi/repos",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehkarimimahabadi/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Is there a way one can convert the two generator? not sure overall what alternatives I could have to shuffle the datasets with a torch generator, thanks ",
"@lhoestq let me please expalin in more details, maybe you could help me suggesting an alternative to solve the issue for now, I have multiple large datasets using huggingface library, then I need to define a distributed sampler on top of it, for this I need to shard the datasets and give each shard to each core, but before sharding I need to shuffle the dataset, if you are familiar with distributed sampler in pytorch, this needs to be done based on seed+epoch generator to make it consistent across the cores they do it through defining a torch generator, I was wondering if you could tell me how I can shuffle the data for now, I am unfortunately blocked by this and have a limited time left, and I greatly appreciate your help on this. thanks ",
"@lhoestq Is there a way I could shuffle the datasets from this library with a custom defined shuffle function? thanks for your help on this. ",
"Right now the shuffle method only accepts the `seed` (optional int) or `generator` (optional `np.random.Generator`) parameters.\r\n\r\nHere is a suggestion to shuffle the data using your own shuffle method using `select`.\r\n`select` can be used to re-order the dataset samples or simply pick a few ones if you want.\r\nIt's what is used under the hood when you call `dataset.shuffle`.\r\n\r\nTo use `select` you must have the list of re-ordered indices of your samples.\r\n\r\nLet's say you have a `shuffle` methods that you want to use. Then you can first build your shuffled list of indices:\r\n```python\r\nshuffled_indices = shuffle(range(len(dataset)))\r\n```\r\n\r\nThen you can shuffle your dataset using the shuffled indices with \r\n```python\r\nshuffled_dataset = dataset.select(shuffled_indices)\r\n```\r\n\r\nHope that helps",
"thank you @lhoestq thank you very much for responding to my question, this greatly helped me and remove the blocking for continuing my work, thanks. ",
"@lhoestq could you confirm the method proposed does not bring the whole data into memory? thanks ",
"Yes the dataset is not loaded into memory",
"great. thanks a lot."
] | 1,608,425,834,000 | 1,654,097,413,000 | 1,654,097,413,000 | NONE | null | Hi
I need to shuffle mutliple large datasets with `generator = torch.Generator()` for a distributed sampler which needs to make sure datasets are consistent across different cores, for this, this is really necessary for me to use torch generator, based on documentation this generator is not supported with datasets, I really need to make shuffle work with this generator and I was wondering what I can do about this issue, thanks for your help
@lhoestq | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1611/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1610/comments | https://api.github.com/repos/huggingface/datasets/issues/1610/events | https://github.com/huggingface/datasets/issues/1610 | 771,453,599 | MDU6SXNzdWU3NzE0NTM1OTk= | 1,610 | shuffle does not accept seed | {
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi, did you check the doc on `shuffle`?\r\nhttps://huggingface.co/docs/datasets/package_reference/main_classes.html?datasets.Dataset.shuffle#datasets.Dataset.shuffle",
"Hi Thomas\r\nthanks for reponse, yes, I did checked it, but this does not work for me please see \r\n\r\n```\r\n(internship) rkarimi@italix17:/idiap/user/rkarimi/dev$ python \r\nPython 3.7.9 (default, Aug 31 2020, 12:42:55) \r\n[GCC 7.3.0] :: Anaconda, Inc. on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import datasets \r\n2020-12-20 01:48:50.766004: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory\r\n2020-12-20 01:48:50.766029: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\n>>> data = datasets.load_dataset(\"scitail\", \"snli_format\")\r\ncahce dir /idiap/temp/rkarimi/cache_home_1/datasets\r\ncahce dir /idiap/temp/rkarimi/cache_home_1/datasets\r\nReusing dataset scitail (/idiap/temp/rkarimi/cache_home_1/datasets/scitail/snli_format/1.1.0/fd8ccdfc3134ce86eb4ef10ba7f21ee2a125c946e26bb1dd3625fe74f48d3b90)\r\n>>> data.shuffle(seed=2)\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nTypeError: shuffle() got an unexpected keyword argument 'seed'\r\n\r\n```\r\n\r\ndatasets version\r\n`datasets 1.1.2 <pip>\r\n`\r\n",
"Thanks for reporting ! \r\n\r\nIndeed it looks like an issue with `suffle` on `DatasetDict`. We're going to fix that.\r\nIn the meantime you can shuffle each split (train, validation, test) separately:\r\n```python\r\nshuffled_train_dataset = data[\"train\"].shuffle(seed=42)\r\n```\r\n"
] | 1,608,411,579,000 | 1,609,754,403,000 | 1,609,754,403,000 | CONTRIBUTOR | null | Hi
I need to shuffle the dataset, but this needs to be based on epoch+seed to be consistent across the cores, when I pass seed to shuffle, this does not accept seed, could you assist me with this? thanks @lhoestq
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1610/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1610/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1609/comments | https://api.github.com/repos/huggingface/datasets/issues/1609/events | https://github.com/huggingface/datasets/issues/1609 | 771,421,881 | MDU6SXNzdWU3NzE0MjE4ODE= | 1,609 | Not able to use 'jigsaw_toxicity_pred' dataset | {
"login": "jassimran",
"id": 7424133,
"node_id": "MDQ6VXNlcjc0MjQxMzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7424133?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jassimran",
"html_url": "https://github.com/jassimran",
"followers_url": "https://api.github.com/users/jassimran/followers",
"following_url": "https://api.github.com/users/jassimran/following{/other_user}",
"gists_url": "https://api.github.com/users/jassimran/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jassimran/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jassimran/subscriptions",
"organizations_url": "https://api.github.com/users/jassimran/orgs",
"repos_url": "https://api.github.com/users/jassimran/repos",
"events_url": "https://api.github.com/users/jassimran/events{/privacy}",
"received_events_url": "https://api.github.com/users/jassimran/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi @jassimran,\r\nThe `jigsaw_toxicity_pred` dataset has not been released yet, it will be available with version 2 of `datasets`, coming soon.\r\nYou can still access it by installing the master (unreleased) version of datasets directly :\r\n`pip install git+https://github.com/huggingface/datasets.git@master`\r\nPlease let me know if this helps",
"Thanks.That works for now."
] | 1,608,399,348,000 | 1,608,655,344,000 | 1,608,655,343,000 | NONE | null | When trying to use jigsaw_toxicity_pred dataset, like this in a [colab](https://colab.research.google.com/drive/1LwO2A5M2X5dvhkAFYE4D2CUT3WUdWnkn?usp=sharing):
```
from datasets import list_datasets, list_metrics, load_dataset, load_metric
ds = load_dataset("jigsaw_toxicity_pred")
```
I see below error:
> FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
FileNotFoundError: Couldn't find file at https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py
During handling of the above exception, another exception occurred:
FileNotFoundError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/datasets/load.py in prepare_module(path, script_version, download_config, download_mode, dataset, force_local_path, **download_kwargs)
280 raise FileNotFoundError(
281 "Couldn't find file locally at {}, or remotely at {} or {}".format(
--> 282 combined_path, github_file_path, file_path
283 )
284 )
FileNotFoundError: Couldn't find file locally at jigsaw_toxicity_pred/jigsaw_toxicity_pred.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.3/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/jigsaw_toxicity_pred/jigsaw_toxicity_pred.py | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1609/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1609/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1608/comments | https://api.github.com/repos/huggingface/datasets/issues/1608/events | https://github.com/huggingface/datasets/pull/1608 | 771,329,434 | MDExOlB1bGxSZXF1ZXN0NTQyODkyMTQ4 | 1,608 | adding ted_talks_iwslt | {
"login": "skyprince999",
"id": 9033954,
"node_id": "MDQ6VXNlcjkwMzM5NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9033954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyprince999",
"html_url": "https://github.com/skyprince999",
"followers_url": "https://api.github.com/users/skyprince999/followers",
"following_url": "https://api.github.com/users/skyprince999/following{/other_user}",
"gists_url": "https://api.github.com/users/skyprince999/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyprince999/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyprince999/subscriptions",
"organizations_url": "https://api.github.com/users/skyprince999/orgs",
"repos_url": "https://api.github.com/users/skyprince999/repos",
"events_url": "https://api.github.com/users/skyprince999/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyprince999/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Closing this with reference to the new approach #1676 "
] | 1,608,363,401,000 | 1,609,602,252,000 | 1,609,602,251,000 | CONTRIBUTOR | null | UPDATE2: (2nd Jan) Wrote a long writeup on the slack channel. I don't think this approach is correct. Basically this created language pairs (109*108)
Running the `pytest `went for more than 40+ hours and it was still running!
So working on a different approach, such that the number of configs = number of languages. Will make a new pull request with that.
UPDATE: This requires manual download dataset
This is a draft version | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1608/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1608",
"html_url": "https://github.com/huggingface/datasets/pull/1608",
"diff_url": "https://github.com/huggingface/datasets/pull/1608.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1608.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1607/comments | https://api.github.com/repos/huggingface/datasets/issues/1607/events | https://github.com/huggingface/datasets/pull/1607 | 771,325,852 | MDExOlB1bGxSZXF1ZXN0NTQyODg5OTky | 1,607 | modified tweets hate speech detection | {
"login": "darshan-gandhi",
"id": 44197177,
"node_id": "MDQ6VXNlcjQ0MTk3MTc3",
"avatar_url": "https://avatars.githubusercontent.com/u/44197177?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/darshan-gandhi",
"html_url": "https://github.com/darshan-gandhi",
"followers_url": "https://api.github.com/users/darshan-gandhi/followers",
"following_url": "https://api.github.com/users/darshan-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/darshan-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/darshan-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/darshan-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/darshan-gandhi/orgs",
"repos_url": "https://api.github.com/users/darshan-gandhi/repos",
"events_url": "https://api.github.com/users/darshan-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/darshan-gandhi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,362,020,000 | 1,608,566,928,000 | 1,608,566,928,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1607/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1607",
"html_url": "https://github.com/huggingface/datasets/pull/1607",
"diff_url": "https://github.com/huggingface/datasets/pull/1607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1607.patch",
"merged_at": 1608566928000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1606/comments | https://api.github.com/repos/huggingface/datasets/issues/1606/events | https://github.com/huggingface/datasets/pull/1606 | 771,116,455 | MDExOlB1bGxSZXF1ZXN0NTQyNzMwNTEw | 1,606 | added Semantic Scholar Open Research Corpus | {
"login": "bhavitvyamalik",
"id": 19718818,
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhavitvyamalik",
"html_url": "https://github.com/bhavitvyamalik",
"followers_url": "https://api.github.com/users/bhavitvyamalik/followers",
"following_url": "https://api.github.com/users/bhavitvyamalik/following{/other_user}",
"gists_url": "https://api.github.com/users/bhavitvyamalik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhavitvyamalik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhavitvyamalik/subscriptions",
"organizations_url": "https://api.github.com/users/bhavitvyamalik/orgs",
"repos_url": "https://api.github.com/users/bhavitvyamalik/repos",
"events_url": "https://api.github.com/users/bhavitvyamalik/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhavitvyamalik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I think we’ll need complete dataset_infos.json to create YAML tags. I ran the script again with 100 files after going through your comments and it was occupying ~16 GB space. So in total it should take ~960GB and I don’t have this much memory available with me. Also, I'll have to download the whole dataset for generating dummy data, right?"
] | 1,608,319,284,000 | 1,612,344,659,000 | 1,612,344,659,000 | CONTRIBUTOR | null | I picked up this dataset [Semantic Scholar Open Research Corpus](https://allenai.org/data/s2orc) but it contains 6000 files to be downloaded. I tried the current code with 100 files and it worked fine (took ~15GB space). For 6000 files it would occupy ~900GB space which I don’t have. Can someone from the HF team with that much of disk space help me with generate dataset_infos and dummy_data? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1606/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1606/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1606",
"html_url": "https://github.com/huggingface/datasets/pull/1606",
"diff_url": "https://github.com/huggingface/datasets/pull/1606.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1606.patch",
"merged_at": 1612344659000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1605/comments | https://api.github.com/repos/huggingface/datasets/issues/1605/events | https://github.com/huggingface/datasets/issues/1605 | 770,979,620 | MDU6SXNzdWU3NzA5Nzk2MjA= | 1,605 | Navigation version breaking | {
"login": "mttk",
"id": 3007947,
"node_id": "MDQ6VXNlcjMwMDc5NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/3007947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mttk",
"html_url": "https://github.com/mttk",
"followers_url": "https://api.github.com/users/mttk/followers",
"following_url": "https://api.github.com/users/mttk/following{/other_user}",
"gists_url": "https://api.github.com/users/mttk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mttk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mttk/subscriptions",
"organizations_url": "https://api.github.com/users/mttk/orgs",
"repos_url": "https://api.github.com/users/mttk/repos",
"events_url": "https://api.github.com/users/mttk/events{/privacy}",
"received_events_url": "https://api.github.com/users/mttk/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [] | 1,608,305,784,000 | 1,608,306,112,000 | null | NONE | null | Hi,
when navigating docs (Chrome, Ubuntu) (e.g. on this page: https://huggingface.co/docs/datasets/loading_metrics.html#using-a-custom-metric-script) the version control dropdown has the wrong string displayed as the current version:

**Edit:** this actually happens _only_ if you open a link to a concrete subsection.
IMO, the best way to fix this without getting too deep into the intricacies of retrieving version numbers from the URL would be to change [this](https://github.com/huggingface/datasets/blob/master/docs/source/_static/js/custom.js#L112) line to:
```
let label = (version in versionMapping) ? version : stableVersion
```
which delegates the check to the (already maintained) keys of the version mapping dictionary & should be more robust. There's a similar ternary expression [here](https://github.com/huggingface/datasets/blob/master/docs/source/_static/js/custom.js#L97) which should also fail in this case.
I'd also suggest swapping this [block](https://github.com/huggingface/datasets/blob/master/docs/source/_static/js/custom.js#L80-L90) to `string.contains(version) for version in versionMapping` which might be more robust. I'd add a PR myself but I'm by no means competent in JS :)
I also have a side question wrt. docs versioning: I'm trying to make docs for a project which are versioned alike to your dropdown versioning. I was wondering how do you handle storage of multiple doc versions on your server? Do you update what `https://huggingface.co/docs/datasets` points to for every stable release & manually create new folders for each released version?
So far I'm building & publishing (scping) the docs to the server with a github action which works well for a single version, but would ideally need to reorder the public files triggered on a new release. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1605/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1604/comments | https://api.github.com/repos/huggingface/datasets/issues/1604/events | https://github.com/huggingface/datasets/issues/1604 | 770,862,112 | MDU6SXNzdWU3NzA4NjIxMTI= | 1,604 | Add tests for the download functions ? | {
"login": "SBrandeis",
"id": 33657802,
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SBrandeis",
"html_url": "https://github.com/SBrandeis",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 1,608,295,765,000 | 1,608,295,765,000 | null | CONTRIBUTOR | null | AFAIK the download functions in `DownloadManager` are not tested yet. It could be good to add some to ensure behavior is as expected. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1604/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1604/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1603/comments | https://api.github.com/repos/huggingface/datasets/issues/1603/events | https://github.com/huggingface/datasets/pull/1603 | 770,857,221 | MDExOlB1bGxSZXF1ZXN0NTQyNTIwNDkx | 1,603 | Add retries to HTTP requests | {
"login": "SBrandeis",
"id": 33657802,
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SBrandeis",
"html_url": "https://github.com/SBrandeis",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"merging this one then :) "
] | 1,608,295,291,000 | 1,608,651,247,000 | 1,608,651,247,000 | CONTRIBUTOR | null | ## What does this PR do ?
Adding retries to HTTP GET & HEAD requests, when they fail with a `ConnectTimeout` exception.
The "canonical" way to do this is to use [urllib's Retry class](https://urllib3.readthedocs.io/en/latest/reference/urllib3.util.html#urllib3.util.Retry) and wrap it in a [HttpAdapter](https://requests.readthedocs.io/en/master/api/#requests.adapters.HTTPAdapter). Seems a bit overkill to me, plus it forces us to use the `requests.Session` object. I prefer this simpler implementation. I'm open to remarks and suggestions @lhoestq @yjernite
Fixes #1102 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1603/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1603/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1603",
"html_url": "https://github.com/huggingface/datasets/pull/1603",
"diff_url": "https://github.com/huggingface/datasets/pull/1603.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1603.patch",
"merged_at": 1608651246000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1602/comments | https://api.github.com/repos/huggingface/datasets/issues/1602/events | https://github.com/huggingface/datasets/pull/1602 | 770,841,810 | MDExOlB1bGxSZXF1ZXN0NTQyNTA4NTM4 | 1,602 | second update of id_newspapers_2018 | {
"login": "cahya-wirawan",
"id": 7669893,
"node_id": "MDQ6VXNlcjc2Njk4OTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7669893?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cahya-wirawan",
"html_url": "https://github.com/cahya-wirawan",
"followers_url": "https://api.github.com/users/cahya-wirawan/followers",
"following_url": "https://api.github.com/users/cahya-wirawan/following{/other_user}",
"gists_url": "https://api.github.com/users/cahya-wirawan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cahya-wirawan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cahya-wirawan/subscriptions",
"organizations_url": "https://api.github.com/users/cahya-wirawan/orgs",
"repos_url": "https://api.github.com/users/cahya-wirawan/repos",
"events_url": "https://api.github.com/users/cahya-wirawan/events{/privacy}",
"received_events_url": "https://api.github.com/users/cahya-wirawan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,293,797,000 | 1,608,633,675,000 | 1,608,633,674,000 | CONTRIBUTOR | null | The feature "url" is currently set wrongly to data["date"], this PR fix it to data["url"].
I added also an additional POC. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1602/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1602/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1602",
"html_url": "https://github.com/huggingface/datasets/pull/1602",
"diff_url": "https://github.com/huggingface/datasets/pull/1602.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1602.patch",
"merged_at": 1608633674000
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1601/comments | https://api.github.com/repos/huggingface/datasets/issues/1601/events | https://github.com/huggingface/datasets/pull/1601 | 770,758,914 | MDExOlB1bGxSZXF1ZXN0NTQyNDQzNDE3 | 1,601 | second update of the id_newspapers_2018 | {
"login": "cahya-wirawan",
"id": 7669893,
"node_id": "MDQ6VXNlcjc2Njk4OTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/7669893?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cahya-wirawan",
"html_url": "https://github.com/cahya-wirawan",
"followers_url": "https://api.github.com/users/cahya-wirawan/followers",
"following_url": "https://api.github.com/users/cahya-wirawan/following{/other_user}",
"gists_url": "https://api.github.com/users/cahya-wirawan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cahya-wirawan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cahya-wirawan/subscriptions",
"organizations_url": "https://api.github.com/users/cahya-wirawan/orgs",
"repos_url": "https://api.github.com/users/cahya-wirawan/repos",
"events_url": "https://api.github.com/users/cahya-wirawan/events{/privacy}",
"received_events_url": "https://api.github.com/users/cahya-wirawan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"I close this PR, since it based on 1 week old repo. And I will create a new one"
] | 1,608,286,220,000 | 1,608,293,731,000 | 1,608,293,731,000 | CONTRIBUTOR | null | The feature "url" is currently set wrongly to data["date"], this PR fix it to data["url"].
I added also an additional POC. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1601/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1601",
"html_url": "https://github.com/huggingface/datasets/pull/1601",
"diff_url": "https://github.com/huggingface/datasets/pull/1601.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1601.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1600/comments | https://api.github.com/repos/huggingface/datasets/issues/1600/events | https://github.com/huggingface/datasets/issues/1600 | 770,582,960 | MDU6SXNzdWU3NzA1ODI5NjA= | 1,600 | AttributeError: 'DatasetDict' object has no attribute 'train_test_split' | {
"login": "david-waterworth",
"id": 5028974,
"node_id": "MDQ6VXNlcjUwMjg5NzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david-waterworth",
"html_url": "https://github.com/david-waterworth",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user}",
"gists_url": "https://api.github.com/users/david-waterworth/gists{/gist_id}",
"starred_url": "https://api.github.com/users/david-waterworth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david-waterworth/subscriptions",
"organizations_url": "https://api.github.com/users/david-waterworth/orgs",
"repos_url": "https://api.github.com/users/david-waterworth/repos",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"received_events_url": "https://api.github.com/users/david-waterworth/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892912,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question",
"name": "question",
"color": "d876e3",
"default": true,
"description": "Further information is requested"
}
] | closed | false | null | [] | null | [
"Hi @david-waterworth!\r\n\r\nAs indicated in the error message, `load_dataset(\"csv\")` returns a `DatasetDict` object, which is mapping of `str` to `Dataset` objects. I believe in this case the behavior is to return a `train` split with all the data.\r\n`train_test_split` is a method of the `Dataset` object, so you will need to do something like this:\r\n```python\r\ndataset_dict = load_dataset(`'csv', data_files='data.txt')\r\ndataset = dataset_dict['split name, eg train']\r\ndataset.train_test_split(test_size=0.1)\r\n```\r\n\r\nPlease let me know if this helps. 🙂 ",
"Thanks, that's working - the same issue also tripped me up with training. \r\n\r\nI also agree https://github.com/huggingface/datasets/issues/767 would be a useful addition. ",
"Closing this now",
"> ```python\r\n> dataset_dict = load_dataset(`'csv', data_files='data.txt')\r\n> dataset = dataset_dict['split name, eg train']\r\n> dataset.train_test_split(test_size=0.1)\r\n> ```\r\n\r\nI am getting error like\r\nKeyError: 'split name, eg train'\r\nCould you please tell me how to solve this?",
"dataset = load_dataset('csv', data_files=['files/datasets/dataset.csv'])\r\ndataset = dataset['train']\r\ndataset = dataset.train_test_split(test_size=0.1)"
] | 1,608,269,830,000 | 1,623,756,346,000 | 1,608,536,338,000 | NONE | null | The following code fails with "'DatasetDict' object has no attribute 'train_test_split'" - am I doing something wrong?
```
from datasets import load_dataset
dataset = load_dataset('csv', data_files='data.txt')
dataset = dataset.train_test_split(test_size=0.1)
```
> AttributeError: 'DatasetDict' object has no attribute 'train_test_split' | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1600/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1599/comments | https://api.github.com/repos/huggingface/datasets/issues/1599/events | https://github.com/huggingface/datasets/pull/1599 | 770,431,389 | MDExOlB1bGxSZXF1ZXN0NTQyMTgwMzI4 | 1,599 | add Korean Sarcasm Dataset | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,245,396,000 | 1,631,897,672,000 | 1,608,744,359,000 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1599/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1599/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1599",
"html_url": "https://github.com/huggingface/datasets/pull/1599",
"diff_url": "https://github.com/huggingface/datasets/pull/1599.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1599.patch",
"merged_at": 1608744359000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1598/comments | https://api.github.com/repos/huggingface/datasets/issues/1598/events | https://github.com/huggingface/datasets/pull/1598 | 770,332,440 | MDExOlB1bGxSZXF1ZXN0NTQyMDk2NTM4 | 1,598 | made suggested changes in fake-news-english | {
"login": "MisbahKhan789",
"id": 15351802,
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MisbahKhan789",
"html_url": "https://github.com/MisbahKhan789",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,235,589,000 | 1,608,284,638,000 | 1,608,284,637,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1598/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1598/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1598",
"html_url": "https://github.com/huggingface/datasets/pull/1598",
"diff_url": "https://github.com/huggingface/datasets/pull/1598.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1598.patch",
"merged_at": 1608284637000
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1597/comments | https://api.github.com/repos/huggingface/datasets/issues/1597/events | https://github.com/huggingface/datasets/pull/1597 | 770,276,140 | MDExOlB1bGxSZXF1ZXN0NTQyMDUwMTc5 | 1,597 | adding hate-speech-and-offensive-language | {
"login": "MisbahKhan789",
"id": 15351802,
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MisbahKhan789",
"html_url": "https://github.com/MisbahKhan789",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"made suggested changes and opened PR https://github.com/huggingface/datasets/pull/1628"
] | 1,608,230,115,000 | 1,608,766,037,000 | 1,608,766,036,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1597/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1597/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1597",
"html_url": "https://github.com/huggingface/datasets/pull/1597",
"diff_url": "https://github.com/huggingface/datasets/pull/1597.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1597.patch",
"merged_at": null
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1596/comments | https://api.github.com/repos/huggingface/datasets/issues/1596/events | https://github.com/huggingface/datasets/pull/1596 | 770,260,531 | MDExOlB1bGxSZXF1ZXN0NTQyMDM3NTU0 | 1,596 | made suggested changes to hate-speech-and-offensive-language | {
"login": "MisbahKhan789",
"id": 15351802,
"node_id": "MDQ6VXNlcjE1MzUxODAy",
"avatar_url": "https://avatars.githubusercontent.com/u/15351802?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MisbahKhan789",
"html_url": "https://github.com/MisbahKhan789",
"followers_url": "https://api.github.com/users/MisbahKhan789/followers",
"following_url": "https://api.github.com/users/MisbahKhan789/following{/other_user}",
"gists_url": "https://api.github.com/users/MisbahKhan789/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MisbahKhan789/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MisbahKhan789/subscriptions",
"organizations_url": "https://api.github.com/users/MisbahKhan789/orgs",
"repos_url": "https://api.github.com/users/MisbahKhan789/repos",
"events_url": "https://api.github.com/users/MisbahKhan789/events{/privacy}",
"received_events_url": "https://api.github.com/users/MisbahKhan789/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 1,608,228,566,000 | 1,608,230,162,000 | 1,608,230,153,000 | CONTRIBUTOR | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1596/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1596",
"html_url": "https://github.com/huggingface/datasets/pull/1596",
"diff_url": "https://github.com/huggingface/datasets/pull/1596.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1596.patch",
"merged_at": null
} | true |
|
https://api.github.com/repos/huggingface/datasets/issues/1595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1595/comments | https://api.github.com/repos/huggingface/datasets/issues/1595/events | https://github.com/huggingface/datasets/pull/1595 | 770,153,693 | MDExOlB1bGxSZXF1ZXN0NTQxOTUwNDk4 | 1,595 | Logiqa en | {
"login": "aclifton314",
"id": 53267795,
"node_id": "MDQ6VXNlcjUzMjY3Nzk1",
"avatar_url": "https://avatars.githubusercontent.com/u/53267795?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aclifton314",
"html_url": "https://github.com/aclifton314",
"followers_url": "https://api.github.com/users/aclifton314/followers",
"following_url": "https://api.github.com/users/aclifton314/following{/other_user}",
"gists_url": "https://api.github.com/users/aclifton314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aclifton314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aclifton314/subscriptions",
"organizations_url": "https://api.github.com/users/aclifton314/orgs",
"repos_url": "https://api.github.com/users/aclifton314/repos",
"events_url": "https://api.github.com/users/aclifton314/events{/privacy}",
"received_events_url": "https://api.github.com/users/aclifton314/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"I'm getting an error when I try to create the dummy data:\r\n```python\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ python datasets-cli dummy_data ./datasets/logiqa_en/ --auto_generate \r\n2021-01-07 10:50:12.024791: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory\r\n2021-01-07 10:50:12.024814: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\nUsing custom data configuration default\r\nCouldn't generate dummy file 'datasets/dummy/1.1.0/dummy_data/master.zip/LogiQA-dataset-master/README.md'. Ignore that if this file is not useful for dummy data.\r\nDummy data generation done but dummy data test failed since splits ['train', 'test', 'validation'] have 0 examples for config 'default''.\r\nAutomatic dummy data generation failed for some configs of './datasets/logiqa_en/'\r\n```",
"Hi ! Sorry for the delay\r\n\r\nTo fix your issue for the dummy data you must increase the number of lines that will be kept to generate the dummy files. By default it's 5, and as you need at least 8 lines here to yield one example you must increase this.\r\n\r\nYou can increase the number of lines to 32 for example by doing\r\n```\r\ndatasets-cli dummy_data ./datasets/logica_en --auto_generate --n_lines 32\r\n```\r\n\r\nAlso it looks like there are changes about other datasets in this PR (imppres). Can you fix that ? You may need to create another branch and another PR.",
"To fix the branch issue, I went ahead and made a backup of the dataset then deleted my local copy of my fork of `datasets`. I then followed the [detailed guide](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md) from the beginning to reclone the fork and start a new branch. \r\n\r\nHowever, when it came time to create the dummy data I got the following error:\r\n```python\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ datasets-cli dummy_data ./datasets/logiqa_en --auto_generate --n_lines 32\r\n2021-02-03 11:23:23.145885: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory\r\n2021-02-03 11:23:23.145914: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\nUsing custom data configuration default\r\nCouldn't generate dummy file 'datasets/logiqa_en/dummy/1.1.0/dummy_data/master.zip/LogiQA-dataset-master/README.md'. Ignore that if this file is not useful for dummy data.\r\nTraceback (most recent call last):\r\n File \"/home/aclifton/anaconda3/bin/datasets-cli\", line 36, in <module>\r\n service.run()\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/commands/dummy_data.py\", line 317, in run\r\n keep_uncompressed=self._keep_uncompressed,\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/commands/dummy_data.py\", line 355, in _autogenerate_dummy_data\r\n dataset_builder._prepare_split(split_generator)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/builder.py\", line 905, in _prepare_split\r\n example = self.info.features.encode_example(record)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 799, in encode_example\r\n return encode_nested_example(self, example)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 710, in encode_nested_example\r\n (k, encode_nested_example(sub_schema, sub_obj)) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 710, in <genexpr>\r\n (k, encode_nested_example(sub_schema, sub_obj)) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 737, in encode_nested_example\r\n return schema.encode_example(obj)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 522, in encode_example\r\n example_data = self.str2int(example_data)\r\n File \"/home/aclifton/anaconda3/lib/python3.7/site-packages/datasets/features.py\", line 481, in str2int\r\n output.append(self._str2int[str(value)])\r\nKeyError: \"Some Cantonese don't like chili, so some southerners don't like chili.\"\r\n```",
"Hi ! The error happens when the script is verifying that the generated dummy data work fine with the dataset script.\r\nApparently it fails because the text `\"Some Cantonese don't like chili, so some southerners don't like chili.\"` was given in a field that is a ClassLabel feature (probably the `answer` field), while it actually expects \"a\", \"b\", \"c\" or \"d\". Can you fix the script so that it returns the expected labels for this field instead of the text ?\r\n\r\nAlso it would be awesome to rename this field `answerKey` instead of `answer` to have the same column names as the other multiple-choice-QA datasets in the library :) ",
"Ok getting closer! I got the dummy data to work. However I am now getting the following error:\r\n```python\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ RUN_SLOW=1 pytest tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_logiqa_en\r\n===================================================================== test session starts ======================================================================\r\nplatform linux -- Python 3.7.6, pytest-5.3.5, py-1.8.1, pluggy-0.13.1\r\nrootdir: /home/aclifton/data/hf_datasets_sprint/datasets\r\nplugins: astropy-header-0.1.2, xdist-2.1.0, doctestplus-0.5.0, forked-1.3.0, hypothesis-5.5.4, arraydiff-0.3, remotedata-0.3.2, openfiles-0.4.0\r\ncollected 0 items / 1 error \r\n\r\n============================================================================ ERRORS ============================================================================\r\n________________________________________________________ ERROR collecting tests/test_dataset_common.py _________________________________________________________\r\nImportError while importing test module '/home/aclifton/data/hf_datasets_sprint/datasets/tests/test_dataset_common.py'.\r\nHint: make sure your test modules/packages have valid Python names.\r\nTraceback:\r\ntests/test_dataset_common.py:42: in <module>\r\n from datasets.packaged_modules import _PACKAGED_DATASETS_MODULES\r\nE ModuleNotFoundError: No module named 'datasets.packaged_modules'\r\n----------------------------------------------------------------------- Captured stderr ------------------------------------------------------------------------\r\n2021-02-10 11:06:14.345510: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory\r\n2021-02-10 11:06:14.345551: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\n======================================================================= warnings summary =======================================================================\r\n/home/aclifton/anaconda3/lib/python3.7/site-packages/tensorflow/python/autograph/utils/testing.py:21\r\n /home/aclifton/anaconda3/lib/python3.7/site-packages/tensorflow/python/autograph/utils/testing.py:21: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses\r\n import imp\r\n\r\n/home/aclifton/anaconda3/lib/python3.7/site-packages/apache_beam/typehints/typehints.py:693\r\n /home/aclifton/anaconda3/lib/python3.7/site-packages/apache_beam/typehints/typehints.py:693: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working\r\n if not isinstance(type_params, collections.Iterable):\r\n\r\n/home/aclifton/anaconda3/lib/python3.7/site-packages/apache_beam/typehints/typehints.py:532\r\n /home/aclifton/anaconda3/lib/python3.7/site-packages/apache_beam/typehints/typehints.py:532: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working\r\n if not isinstance(type_params, (collections.Sequence, set)):\r\n\r\n/home/aclifton/anaconda3/lib/python3.7/site-packages/elasticsearch/compat.py:38\r\n /home/aclifton/anaconda3/lib/python3.7/site-packages/elasticsearch/compat.py:38: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working\r\n from collections import Mapping\r\n\r\n-- Docs: https://docs.pytest.org/en/latest/warnings.html\r\n================================================================= 4 warnings, 1 error in 2.74s =================================================================\r\nERROR: not found: /home/aclifton/data/hf_datasets_sprint/datasets/tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_logiqa_en\r\n(no name '/home/aclifton/data/hf_datasets_sprint/datasets/tests/test_dataset_common.py::LocalDatasetTest::test_load_real_dataset_logiqa_en' in any of [<Module test_dataset_common.py>])\r\n\r\n```",
"Hi ! It looks like the version of `datasets` that is installed in your environment doesn't match the version of `datasets` you're using for the tests. Can you try uninstalling datasets and reinstall it again ?\r\n```\r\npip uninstall datasets -y\r\npip install -e .\r\n```",
"Closer still!\r\n```python\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ git commit\r\n[logiqa_en 2664fe7f] fixed several issues with logiqa_en.\r\n 4 files changed, 324 insertions(+)\r\n create mode 100644 datasets/logiqa_en/README.md\r\n create mode 100644 datasets/logiqa_en/dataset_infos.json\r\n create mode 100644 datasets/logiqa_en/dummy/1.1.0/dummy_data.zip\r\n create mode 100644 datasets/logiqa_en/logiqa_en.py\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ git fetch upstream\r\nremote: Enumerating objects: 1, done.\r\nremote: Counting objects: 100% (1/1), done.\r\nremote: Total 1 (delta 0), reused 0 (delta 0), pack-reused 0\r\nUnpacking objects: 100% (1/1), 590 bytes | 590.00 KiB/s, done.\r\nFrom https://github.com/huggingface/datasets\r\n 6e114a0c..318b09eb master -> upstream/master\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ git rebase upstream/master \r\nerror: cannot rebase: You have unstaged changes.\r\nerror: Please commit or stash them.\r\naclifton@pop-os:~/data/hf_datasets_sprint/datasets$ git push -u origin logiqa_en\r\nUsername for 'https://github.com': aclifton314\r\nPassword for 'https://aclifton314@github.com': \r\nTo https://github.com/aclifton314/datasets\r\n ! [rejected] logiqa_en -> logiqa_en (non-fast-forward)\r\nerror: failed to push some refs to 'https://github.com/aclifton314/datasets'\r\nhint: Updates were rejected because the tip of your current branch is behind\r\nhint: its remote counterpart. Integrate the remote changes (e.g.\r\nhint: 'git pull ...') before pushing again.\r\nhint: See the 'Note about fast-forwards' in 'git push --help' for details.\r\n```"
] | 1,608,219,720,000 | 1,612,981,992,000 | null | CONTRIBUTOR | null | logiqa in english. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1595/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1595/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1595",
"html_url": "https://github.com/huggingface/datasets/pull/1595",
"diff_url": "https://github.com/huggingface/datasets/pull/1595.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1595.patch",
"merged_at": null
} | true |
https://api.github.com/repos/huggingface/datasets/issues/1594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1594/comments | https://api.github.com/repos/huggingface/datasets/issues/1594/events | https://github.com/huggingface/datasets/issues/1594 | 769,747,767 | MDU6SXNzdWU3Njk3NDc3Njc= | 1,594 | connection error | {
"login": "rabeehkarimimahabadi",
"id": 73364383,
"node_id": "MDQ6VXNlcjczMzY0Mzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/73364383?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehkarimimahabadi",
"html_url": "https://github.com/rabeehkarimimahabadi",
"followers_url": "https://api.github.com/users/rabeehkarimimahabadi/followers",
"following_url": "https://api.github.com/users/rabeehkarimimahabadi/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehkarimimahabadi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehkarimimahabadi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehkarimimahabadi/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehkarimimahabadi/orgs",
"repos_url": "https://api.github.com/users/rabeehkarimimahabadi/repos",
"events_url": "https://api.github.com/users/rabeehkarimimahabadi/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehkarimimahabadi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"This happen quite often when they are too many concurrent requests to github.\r\n\r\ni can understand it’s a bit cumbersome to handle on the user side. Maybe we should try a few times in the lib (eg with timeout) before failing, what do you think @lhoestq ?",
"Yes currently there's no retry afaik. We should add retries",
"Retries were added in #1603 :) \r\nIt will be available in the next release",
"Hi @lhoestq thank you for the modification, I will use`script_version=\"master\"` for now :), to my experience, also setting timeout to a larger number like 3*60 which I normally use helps a lot on this.\r\n"
] | 1,608,196,714,000 | 1,654,097,622,000 | 1,654,097,621,000 | NONE | null | Hi
I am hitting to this error, thanks
```
> Traceback (most recent call last):
File "finetune_t5_trainer.py", line 379, in <module>
main()
File "finetune_t5_trainer.py", line 208, in main
if training_args.do_eval or training_args.evaluation_strategy != EvaluationStrategy.NO
File "finetune_t5_trainer.py", line 207, in <dictcomp>
for task in data_args.eval_tasks}
File "/workdir/seq2seq/data/tasks.py", line 70, in get_dataset
dataset = self.load_dataset(split=split)
File "/workdir/seq2seq/data/tasks.py", line 66, in load_dataset
return datasets.load_dataset(self.task.name, split=split, script_version="master")
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 589, in load_dataset
path, script_version=script_version, download_config=download_config, download_mode=download_mode, dataset=True
File "/usr/local/lib/python3.6/dist-packages/datasets/load.py", line 267, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 308, in cached_path
use_etag=download_config.use_etag,
File "/usr/local/lib/python3.6/dist-packages/datasets/utils/file_utils.py", line 487, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/master/datasets/boolq/boolq.py
el/0 I1217 01:11:33.898849 354161 main shadow.py:210 Current job status: FINISHED
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1594/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1593/comments | https://api.github.com/repos/huggingface/datasets/issues/1593/events | https://github.com/huggingface/datasets/issues/1593 | 769,611,386 | MDU6SXNzdWU3Njk2MTEzODY= | 1,593 | Access to key in DatasetDict map | {
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Indeed that would be cool\r\n\r\nAlso FYI right now the easiest way to do this is\r\n```python\r\ndataset_dict[\"train\"] = dataset_dict[\"train\"].map(my_transform_for_the_train_set)\r\ndataset_dict[\"test\"] = dataset_dict[\"test\"].map(my_transform_for_the_test_set)\r\n```"
] | 1,608,188,540,000 | 1,610,534,283,000 | null | NONE | null | It is possible that we want to do different things in the `map` function (and possibly other functions too) of a `DatasetDict`, depending on the key. I understand that `DatasetDict.map` is a really thin wrapper of `Dataset.map`, so it is easy to directly implement this functionality in the client code. Still, it'd be nice if there can be a flag, similar to `with_indices`, that allows the callable to know the key inside `DatasetDict`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1593/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1593/timeline | null | null | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1591/comments | https://api.github.com/repos/huggingface/datasets/issues/1591/events | https://github.com/huggingface/datasets/issues/1591 | 769,383,714 | MDU6SXNzdWU3NjkzODM3MTQ= | 1,591 | IWSLT-17 Link Broken | {
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate",
"name": "duplicate",
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | null | [] | null | [
"Sorry, this is a duplicate of #1287. Not sure why it didn't come up when I searched `iwslt` in the issues list.",
"Closing this since its a duplicate"
] | 1,608,166,002,000 | 1,608,278,796,000 | 1,608,278,728,000 | NONE | null | ```
FileNotFoundError: Couldn't find file at https://wit3.fbk.eu/archive/2017-01-trnmted//texts/DeEnItNlRo/DeEnItNlRo/DeEnItNlRo-DeEnItNlRo.tgz
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1591/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1590/comments | https://api.github.com/repos/huggingface/datasets/issues/1590/events | https://github.com/huggingface/datasets/issues/1590 | 769,242,858 | MDU6SXNzdWU3NjkyNDI4NTg= | 1,590 | Add helper to resolve namespace collision | {
"login": "jramapuram",
"id": 8204807,
"node_id": "MDQ6VXNlcjgyMDQ4MDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8204807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jramapuram",
"html_url": "https://github.com/jramapuram",
"followers_url": "https://api.github.com/users/jramapuram/followers",
"following_url": "https://api.github.com/users/jramapuram/following{/other_user}",
"gists_url": "https://api.github.com/users/jramapuram/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jramapuram/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jramapuram/subscriptions",
"organizations_url": "https://api.github.com/users/jramapuram/orgs",
"repos_url": "https://api.github.com/users/jramapuram/repos",
"events_url": "https://api.github.com/users/jramapuram/events{/privacy}",
"received_events_url": "https://api.github.com/users/jramapuram/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Do you have an example?",
"I was thinking about using something like [importlib](https://docs.python.org/3/library/importlib.html#importing-a-source-file-directly) to over-ride the collision. \r\n\r\n**Reason requested**: I use the [following template](https://github.com/jramapuram/ml_base/) repo where I house all my datasets as a submodule.",
"Alternatively huggingface could consider some submodule type structure like:\r\n\r\n`import huggingface.datasets`\r\n`import huggingface.transformers`\r\n\r\n`datasets` is a very common module in ML and should be an end-user decision and not scope all of python ¯\\_(ツ)_/¯ \r\n",
"That's a interesting option indeed. We'll think about it.",
"It also wasn't initially obvious to me that the samples which contain `import datasets` were in fact importing a huggingface library (in fact all the huggingface imports are very generic - transformers, tokenizers, datasets...)"
] | 1,608,149,844,000 | 1,654,097,524,000 | 1,654,097,524,000 | NONE | null | Many projects use a module called `datasets`, however this is incompatible with huggingface datasets. It would be great if there if there was some helper or similar function to resolve such a common conflict. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1590/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1590/timeline | null | completed | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/1589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1589/comments | https://api.github.com/repos/huggingface/datasets/issues/1589/events | https://github.com/huggingface/datasets/pull/1589 | 769,187,141 | MDExOlB1bGxSZXF1ZXN0NTQxMzcwMTM0 | 1,589 | Update doc2dial.py | {
"login": "songfeng",
"id": 2062185,
"node_id": "MDQ6VXNlcjIwNjIxODU=",
"avatar_url": "https://avatars.githubusercontent.com/u/2062185?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/songfeng",
"html_url": "https://github.com/songfeng",
"followers_url": "https://api.github.com/users/songfeng/followers",
"following_url": "https://api.github.com/users/songfeng/following{/other_user}",
"gists_url": "https://api.github.com/users/songfeng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/songfeng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/songfeng/subscriptions",
"organizations_url": "https://api.github.com/users/songfeng/orgs",
"repos_url": "https://api.github.com/users/songfeng/repos",
"events_url": "https://api.github.com/users/songfeng/events{/privacy}",
"received_events_url": "https://api.github.com/users/songfeng/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | [
"Thanks for adding the `doc2dial_rc` config :) \r\n\r\nIt looks like you're missing the dummy data for this config though. Could you add them please ?\r\nAlso to fix the CI you'll need to format the code with `make style`"
] | 1,608,144,656,000 | 1,608,571,111,000 | null | CONTRIBUTOR | null | Added data loader for machine reading comprehension tasks proposed in the Doc2Dial EMNLP 2020 paper. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/1589/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/1589/timeline | null | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1589",
"html_url": "https://github.com/huggingface/datasets/pull/1589",
"diff_url": "https://github.com/huggingface/datasets/pull/1589.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/1589.patch",
"merged_at": null
} | true |