
File size: 6,987 Bytes
b978278 1eff428 b978278 e2f4b59 b978278 0061667 b978278 83e6173 b978278 a5cc7ee 15377ab a5cc7ee b978278 d9ca473 08c365b d9ca473 08c365b d9ca473 3e5e38a 97ad2f1 3e5e38a d9ca473 b978278 d9ca473 b978278 d9ca473 b978278 e2f4b59 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 |
---
base_model:
- arcee-ai/Virtuoso-Small
- rombodawg/Rombos-LLM-V2.6-Qwen-14b
- sometimesanotion/Qwentinuum-14B-v013
- sometimesanotion/Lamarck-14B-v0.3
- EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2
- allura-org/TQ2.5-14B-Sugarquill-v1
- oxyapi/oxy-1-small
- v000000/Qwen2.5-Lumen-14B
- sthenno-com/miscii-14b-1225
- underwoods/medius-erebus-magnum-14b
- huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
language:
- en
metrics:
- accuracy
- code_eval
pipeline_tag: text-generation
---
Vimarckoso is a reasoning-focused part of the [Lamarck](https://huggingface.co/sometimesanotion/Lamarck-14B-v0.4-Qwenvergence) project. It began with a [recipe](https://huggingface.co/sometimesanotion/Qwen2.5-14B-Vimarckoso) based on [Wernicke](https://huggingface.co/CultriX/Qwen2.5-14B-Wernicke), and then I set out to boost instruction following without any great loss to reasoning. The results surpassed my expectations.
As of this writing, with [open-llm-leaderboard](https://huggingface.co/open-llm-leaderboard) catching up on rankings, Vimarckoso v3 should join Arcee AI's [Virtuoso-Small](https://huggingface.co/arcee-ai/Virtuoso-Small), Sthenno's [miscii-14b-1225](https://huggingface.co/sthenno-com/miscii-14b-1225) and Cultrix's [Qwen2.5-14B-Brocav3](https://huggingface.co/CultriX/Qwen2.5-14B-Brocav3) at the top of the 14B parameter text generation LLM category on this site. As the recipe below will show, their models are strong contributors to Vimarckoso. Congratulations to everyone whose work went into this!
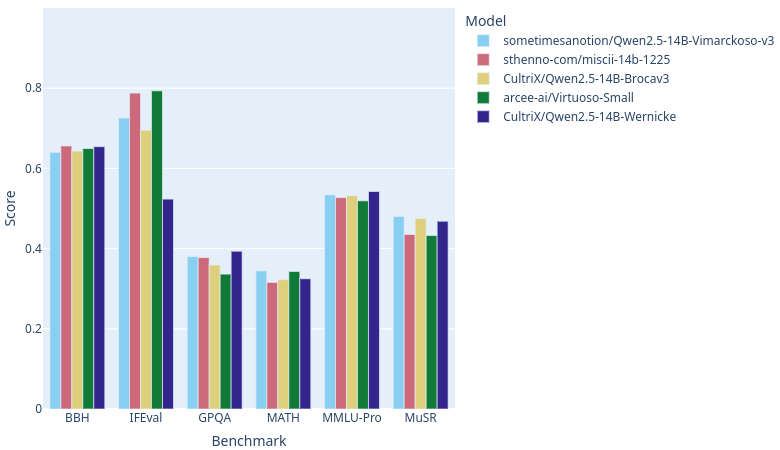
Wernicke and Vimarckoso both inherit very strong reasoning, and hence high GPQA and MUSR scores, from [EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2](https://huggingface.co/EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2). Prose quality gets a boost from models blended in [Qwenvergence-14B-v6-Prose](https://huggingface.co/Qwenvergence-14B-v6-Prose), and instruction following gets healed after the merges thanks to LoRAs based on [huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2](https://huggingface.co/huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2).
---
### Configuration
The following YAML configuration was used to produce this model:
```yaml
name: Qwenvergence-14B-v6-Prose-model_stock
merge_method: model_stock
base_model: Qwen/Qwen2.5-14B
tokenizer_source: huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2
parameters:
int8_mask: true
normalize: true
rescale: false
models:
- model: arcee-ai/Virtuoso-Small
- model: sometimesanotion/Lamarck-14B-v0.3
- model: EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2
- model: allura-org/TQ2.5-14B-Sugarquill-v1
- model: oxyapi/oxy-1-small
- model: v000000/Qwen2.5-Lumen-14B
- model: sthenno-com/miscii-14b-1225
- model: sthenno-com/miscii-14b-1225
- model: underwoods/medius-erebus-magnum-14b
- model: huihui-ai/Qwen2.5-14B-Instruct-abliterated-v2
dtype: float32
out_dtype: bfloat16
---
# Nifty TIES to allow a series of LoRA exchange among the above models
---
name: Qwenvergence-14B-v6-Prose
merge_method: ties
base_model: Qwen/Qwen2.5-14B
tokenizer_source: base
parameters:
density: 1.00
weight: 1.00
int8_mask: true
normalize: true
rescale: false
dtype: float32
out_dtype: bfloat16
models:
- model: sometimesanotion/Qwenvergence-14B-v6-Prose-slerp
parameters:
density: 1.00
weight: 1.00
---
# The last stable version of the Qwentinuum project which used successive breadcrumbs and SLERP merges to boost IFEval, merged back into Qwenvergence
name: Qwentinuum-14B-v6-Prose-slerp
merge_method: slerp
base_model: sometimesanotion/Qwenvergence-14B-v6-Prose
tokenizer_source: sometimesanotion/Qwenvergence-14B-v6-Prose
dtype: bfloat16
out_dtype: bfloat16
parameters:
int8_mask: true
normalize: true
rescale: false
parameters:
t:
- value: 0.40
slices:
- sources:
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
layer_range: [ 0, 8 ]
- model: sometimesanotion/Qwentinuum-14B-v6
layer_range: [ 0, 8 ]
- sources:
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
layer_range: [ 8, 16 ]
- model: sometimesanotion/Qwentinuum-14B-v6
layer_range: [ 8, 16 ]
- sources:
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
layer_range: [ 16, 24 ]
- model: sometimesanotion/Qwentinuum-14B-v6
layer_range: [ 16, 24 ]
- sources:
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
layer_range: [ 24, 32 ]
- model: sometimesanotion/Qwentinuum-14B-v6
layer_range: [ 24, 32 ]
- sources:
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
layer_range: [ 32, 40 ]
- model: sometimesanotion/Qwentinuum-14B-v6
layer_range: [ 32, 40 ]
- sources:
- model: sometimesanotion/Qwenvergence-14B-v6-Prose
layer_range: [ 40, 48 ]
- model: sometimesanotion/Qwentinuum-14B-v6
layer_range: [ 40, 48 ]
---
name: Qwen2.5-14B-Vimarckoso-v3-model_stock
merge_method: model_stock
base_model: sometimesanotion/Base-Qwenvergence
tokenizer_source: sometimesanotion/Abliterate-Qwenvergence
dtype: bfloat16
out_dtype: bfloat16
parameters:
int8_mask: true
normalize: true
rescale: false
# With this many models, it's good to pre-merge some LoRAs from Abliterate-Qwenvergence, with their ranks indicated in the suffixes.
models:
- model: EVA-UNIT-01/EVA-Qwen2.5-14B-v0.2-qv512
- model: arcee-ai/Virtuoso-Small-qv128
- model: v000000/Qwen2.5-Lumen-14B-qv256
- model: VAGOsolutions/SauerkrautLM-v2-14b-DPO-qv256
- model: rombodawg/Rombos-LLM-V2.6-Qwen-14b
- model: sometimesanotion/Qwentinuum-14B-v013
- model: sometimesanotion/Abliterate-Qwenvergence
---
name: Qwen2.5-14B-Vimarckoso-v3-slerp
merge_method: slerp
base_model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-model_stock
tokenizer_source: base
dtype: float32
out_dtype: bfloat16
parameters:
t:
- value: 0.20
slices:
- sources:
- model: sometimesanotion/Qwen2.5-14B-Vimarckoso-v3-model_stock
layer_range: [ 0, 48 ]
- model: sometimesanotion/Qwentinuum-14B-v6-Prose+sometimesanotion/Qwenvergence-Abliterate-256
layer_range: [ 0, 48 ]
``` |